声音克隆,定制自己的声音,使用最新版Bert-VITS2的云端训练+推理记录
说明
- 本次训练服务器使用Google Colab T4 GPU
- Bert-VITS2库为:https://github.com/fishaudio/Bert-VITS2,其更新较为频繁,使用其2023.10.12的commit版本:
- 主要参考:B站诸多大佬视频,CSDN:https://blog.csdn.net/qq_51506262/article/details/133359555,
码云:https://gitee.com/Sake809/Bert-VITS2-Integration-package - 部署过程中出现诸多问题,对原版Bert-VITS2个别代码也有调整,调整后的代码已放码云:https://gitee.com/ajianoscgit/bert-vits2.git
- 本项目是确定可运行的,后续随着Bert-VITS2的持续更新,当前能稳定运行的代码后续可能会出问题。
环境准备
包括下载代码、下载模型等等步骤
下载项目
%cd /content/drive/MyDrive
# 这里是下载原仓库代码
#!git clone https://github.com/fishaudio/Bert-VITS2.git
# 这是下载码云调整后的代码
!git clone https://gitee.com/ajianoscgit/bert-vits2.git下载模型
这里只下载了中文语音的模型,在https://huggingface.co/hfl/chinese-roberta-wwm-ext-large/tree/main 下载即可,根据/content/drive/MyDrive/Bert-VITS2/bert/chinese-roberta-wwm-ext-large目录缺失的文件下载补全。
%cd /content/drive/MyDrive/Bert-VITS2/bert/chinese-roberta-wwm-ext-large
!wget https://huggingface.co/hfl/chinese-roberta-wwm-ext-large/resolve/main/flax_model.msgpack
!wget https://huggingface.co/hfl/chinese-roberta-wwm-ext-large/resolve/main/pytorch_model.bin
!wget https://huggingface.co/hfl/chinese-roberta-wwm-ext-large/resolve/main/tf_model.h5
下载底模文件:
底模文件使用b站大佬裁切好的底模,效果更好,https://www.bilibili.com/video/BV1hp4y1K78E
由于cloab无法直接下载到模型文件,只好先在站点下载完成之后再上传到谷歌云盘中,放在logs/base/目录下。
# 这是原版底模,使用1.1版b站大佬的底模替代!
%cd /content/drive/MyDrive/Bert-VITS2#!wget -P logs/base/ https://huggingface.co/Erythrocyte/bert-vits2_base_model/resolve/main/DUR_0.pth
#!wget -P logs/base/ https://huggingface.co/Erythrocyte/bert-vits2_base_model/resolve/main/D_0.pth
#!wget -P logs/base/ https://huggingface.co/Erythrocyte/bert-vits2_base_model/resolve/main/G_0.pth
编写数据预处理脚本
训练特定音色的模型时,需要首先将准备好的音频干声文件进行分割,将分割后的文件文本提取出来备用。
可以本地将这些文件先准备好,也可以服务器上制作,服务器上制作就用以下脚本实现。
以下脚本为实现此功能的相关脚本(该脚本根据csdn大佬的代码进行了调整,实现读取运行时参数和音频转写文本时汉字繁体转简体):
import os
from pathlib import Path
import librosa
from scipy.io import wavfile
import numpy as np
import whisper
import argparse
from langconv import *def split_long_audio(model, filepath, save_dir="short_dir", out_sr=44100)->str:'''将长音源wav文件分割为短音源文件,返回短音源文件存储路径path'''# 短音频文件存储路径save_dir=os.path.join(os.path.dirname(filepath),save_dir)if not os.path.exists(save_dir):os.makedirs(save_dir)#分割文件print(f'分割文件{filepath}...')result = model.transcribe(filepath, word_timestamps=True, task="transcribe", beam_size=5, best_of=5)segments = result['segments']wav, sr = librosa.load(filepath, sr=None, offset=0, duration=None, mono=True)wav, _ = librosa.effects.trim(wav, top_db=20)peak = np.abs(wav).max()if peak > 1.0:wav = 0.98 * wav / peakwav2 = librosa.resample(wav, orig_sr=sr, target_sr=out_sr)wav2 /= max(wav2.max(), -wav2.min())for i, seg in enumerate(segments):start_time = seg['start']end_time = seg['end']wav_seg = wav2[int(start_time * out_sr):int(end_time * out_sr)]wav_seg_name = f"{i}.wav" # 修改名字i+=1out_fpath = os.path.join(save_dir,wav_seg_name)wavfile.write(out_fpath, rate=out_sr, data=(wav_seg * np.iinfo(np.int16).max).astype(np.int16))return save_dirdef transcribe_one(audio_path): # 使用whisper语音识别# load audio and pad/trim it to fit 30 secondsaudio = whisper.load_audio(audio_path)audio = whisper.pad_or_trim(audio)# make log-Mel spectrogram and move to the same device as the modelmel = whisper.log_mel_spectrogram(audio).to(model.device)# detect the spoken language_, probs = model.detect_language(mel)lang = max(probs, key=probs.get)# decode the audiooptions = whisper.DecodingOptions(beam_size=5)result = whisper.decode(model, mel, options)#繁体转简体txt = result.texttxt = Converter('zh-hans').convert(txt)fileName = os.path.basename(audio_path)print(f'{fileName}:{lang}——>{txt}')return txtif __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('inputFilePath', type=str,help="干声源音频wav文件的全路径")parser.add_argument('listFileSavePath', type=str,help=".list文件存储全路径")parser.add_argument('--shortFilesPath', type=str, help="已经分割好了的短音频的存储目录全路径,用于当分割好之后再次运行时配置")opt = parser.parse_args()print(f'参数:{opt}')model = whisper.load_model("medium")#将长音源分割成短音源文件if not opt.shortFilesPath:save_dir = split_long_audio(model, opt.inputFilePath)else:save_dir = opt.shortFilesPath#为每个短音频文件提取文字内容,生成.lab文件和filelists目录下的.list文件if not os.path.exists(opt.listFileSavePath):file = open(opt.listFileSavePath, "w")file.close()print('提取文字内容...')files=os.listdir(save_dir)spk = os.path.basename(os.path.dirname(opt.inputFilePath))for file in files:if not file.endswith('.wav'):continuetext = transcribe_one(os.path.join(save_dir,file))with open(os.path.join(save_dir,f"{file}.lab"),'w') as f:f.write(text)with open(opt.listFileSavePath,'a', encoding="utf-8") as wf:wf.write(f"{os.path.join(save_dir,file)}|{spk}|ZH|{text}\n")print('音频预处理完成!')
安装依赖
#检查CUDA版本
import torch
print(torch.version.cuda)
print(torch.cuda.is_available())
#安装依赖
%cd /content/drive/MyDrive/Bert-VITS2!pip install wavfile
!pip install git+https://github.com/openai/whisper.git
!pip install -r requirements.txt
!pip install zhconv==1.4.3
!pip install zhtools==0.3.1
训练
音频预处理
- 音频需要自己录一段声音,1分钟以上,10分钟以内即可
- 音频使用Ultimate Vocal Remover工具去掉背景杂音,使其为一段纯音频的干声。Ultimate Vocal Remover工具使用见:https://github.com/Anjok07/ultimatevocalremovergui,作者封装了GUI,下载安装即可
- 提取好了的干声自行上传到项目的data目录下,data下需要新建一个名称目录,如zhangsan,文件结构如下:
Bert-VITS2
————data
——————zhangsan
————————ganshen.wav - 执行以下脚本,对音频预处理
%cd /content/drive/MyDrive/Bert-VITS2
!python 音频预处理脚本.py /content/drive/MyDrive/Bert-VITS2/data/zhangsan/ganshen.wav /content/drive/MyDrive/Bert-VITS2/filelists/zhangsan.list --shortFilesPath '/content/drive/MyDrive/Bert-VITS2/data/zhangsan/short_dir'
注意:音频预处理完成之后,要打开datalists目录下对应的list文件看看处理结果,把过分离奇的、错误明显的行直接删掉!
音频重采样
会在dataset下生成重采样后的音频,如果修改了源音频要进行二次训练,需要将原dataset下的文件删除。
%cd /content/drive/MyDrive/Bert-VITS2
!python resample.py --in_dir /content/drive/MyDrive/Bert-VITS2/data/zhangsan/short_dir
预处理.list文件
预处理完成会在filelists下生成.cleaned、train.list、val.list文件!
%cd /content/drive/MyDrive/Bert-VITS2
!python preprocess_text.py --transcription-path /content/drive/MyDrive/Bert-VITS2/filelists/zhangsan.list
生成pt文件
会在data/用户名/short_dir目录下生成对应视频文件的.bert.pt文件
%cd /content/drive/MyDrive/Bert-VITS2
!python bert_gen.py --num_processes 4
开始训练
注意1:开始训练前必须要先把data目录下本次训练的文件夹名字加到configs/config.json文件的spk2id下,并加一个id!!!这个案例中就是把“zhangsan”加到"标贝": 247,后面!
注意2:train_ms.py和data_utils.py有大量修改,支持多线程并行训练。但是T4服务器只有12G内存会爆仓,所以没有多线程的效果。
- 这里训练的总步数由config.json里面的epochs控制,一般设置为500左右就差不多了
- 训练生成的模型在logs目录下,其中DUR_x、D_x、G_x后面的数字都是一一对应的,程序断掉之后下次训练会继续在之前的步数上接着进行
%cd /content/drive/MyDrive/Bert-VITS2# -m:base,表示的logs/base/底模文件目录的base
!python train_ms.py -m base -c configs/config.json --cont
推理
- 有浏览器环境的,直接运行webui.py就可以开启界面操作推理
- 没有可视界面环境的,使用以下脚本进行命令行推理:
%cd /content/drive/MyDrive/Bert-VITS2
# -m:就是推理之后的模型路径
!python 命令行推理.py -m ./logs/base/G_8000.pth --text='你好啊你是谁呀' --speaker='zhangsan'
生成的音频文件自行下载下来即可播放。
相关文章:
声音克隆,定制自己的声音,使用最新版Bert-VITS2的云端训练+推理记录
说明 本次训练服务器使用Google Colab T4 GPUBert-VITS2库为:https://github.com/fishaudio/Bert-VITS2,其更新较为频繁,使用其2023.10.12的commit版本:主要参考:B站诸多大佬视频,CSDN:https://blog.csdn.…...

LeetCode讲解篇之198. 打家劫舍
LeetCode讲解篇之198. 打家劫舍 文章目录 LeetCode讲解篇之198. 打家劫舍题目描述题解思路题解代码 题目描述 题解思路 该问题可以通过递推来完成 递推公式: 前n间房的最大金额 max(前n-1间房的最大金额, 前n-2间房的最大金额第n-1间房的最…...
)
【下载共享文件】Java基于SMB协议 + JCIFS依赖下载Windows共享文件(亲测可用)
这篇文章,主要介绍如何使用JCIFS依赖库,基于SMB协议下载Windows共享文件。 目录 一、搭建Windows共享文件服务 1.1、创建共享文件目录 1.2、添加文件...

【评分卡实现】应用Python中的toad.ScoreCard函数实现评分卡
逻辑回归已经在各大银行和公司都实际运用于业务。之前的文章已经阐述了逻辑回归三部曲——逻辑回归和sigmod函数的由来、...
【数据结构】双链表的相关操作(声明结构体成员、初始化、判空、增、删、查)
双链表 双链表的特点声明双链表的结构体成员双链表的初始化带头结点的双链表初始化不带头结点的双链表初始化调用双链表的初始化 双链表的判空带头结点的双链表判空不带头结点的双链表判空 双链表的插入(按值插入)头插法建立双链表带头结点的头插法每次调…...
解析找不到msvcp140.dll的5个解决方法,快速修复dll丢失问题
在使用计算机过程中,我们也会遇到各种各样的问题。其中,找不到msvcp140.dll修复方法是一个非常普遍的问题。msvcp140.dll是一个动态链接库文件,它是Microsoft Visual C 2015 Redistributable的一部分。这个文件包含了许多用于运行C程序的函…...

代码管理工具 gitlab实战应用
系列文章目录 第一章 Java线程池技术应用 第二章 CountDownLatch和Semaphone的应用 第三章 Spring Cloud 简介 第四章 Spring Cloud Netflix 之 Eureka 第五章 Spring Cloud Netflix 之 Ribbon 第六章 Spring Cloud 之 OpenFeign 第七章 Spring Cloud 之 GateWay 第八章 Sprin…...
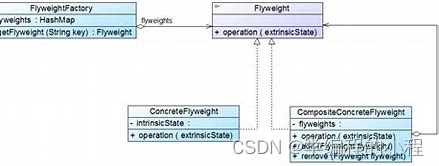
小谈设计模式(27)—享元模式
小谈设计模式(27)—享元模式 专栏介绍专栏地址专栏介绍 享元模式模式结构分析享元工厂(FlyweightFactory)享元接口(Flyweight)具体享元(ConcreteFlyweight)非共享具体享元࿰…...

网络代理技术:隐私保护与安全加固的利器
随着数字化时代的不断演进,网络安全和个人隐私保护变得愈发重要。在这个背景下,网络代理技术崭露头角,成为网络工程师和普通用户的得力助手。本文将深入探讨Socks5代理、IP代理,以及它们在网络安全、爬虫开发和HTTP协议中的关键应…...
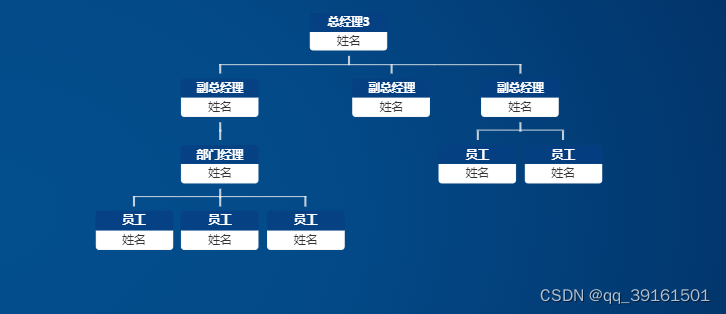
orgChart.js组织架构图
OrgChart.js是什么? 基于ES6的组织结构图插件。 特征 支持本地数据和远程数据(JSON)。 基于CSS3过渡的平滑扩展/折叠效果。 将图表对齐为4个方向。 允许用户通过拖放节点更改组织结构。 允许用户动态编辑组织图并将最终层次结构保存为…...

华纳云:SQL Server怎么批量导入和导出数据
在SQL Server中,您可以使用不同的方法来批量导入和导出数据,具体取决于您的需求和数据源。以下是一些常见的方法: 批量导入数据: 使用SQL Server Management Studio (SSMS) 导入向导: 打开SQL Server Management Stud…...
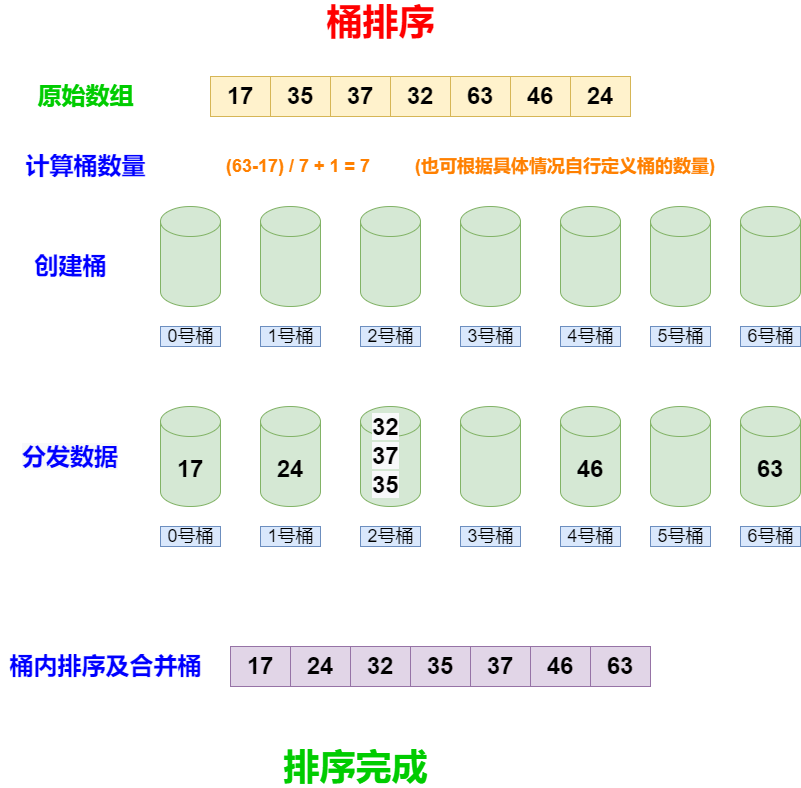
深入了解桶排序:原理、性能分析与 Java 实现
桶排序(Bucket Sort)是一种排序算法,通常用于将一组数据分割成有限数量的桶(或容器),然后对每个桶中的数据进行排序,最后将这些桶按顺序合并以得到排好序的数据集。 桶排序原理 确定桶的数量&am…...

微店店铺所有商品数据接口,微店整店商品数据接口,微店店铺商品数据接口,微店API接口
微店店铺所有商品数据接口是一种允许开发者在其应用程序中调用微店店铺所有商品数据的API接口。利用这一接口,开发者可以获取微店店铺的所有商品信息,包括商品名称、价格、介绍、图片等。 其主要用途是帮助开发者进行各种业务场景的构建,例如…...

SSL证书能选择免费的吗?
当涉及到保护您的网站和您的用户的数据时,SSL证书是必不可少的。SSL证书是一种安全协议,用于加密在Web浏览器和服务器之间传输的数据,例如信用卡信息、登录凭据和个人身份信息。 但是,许多SSL证书都是付费的,这可能会…...

苹果macOS电脑版 植物大战僵尸游戏
植物大战僵尸是一款极富策略性的小游戏,充满趣味性和策略性。主题是植物与僵尸之间的战斗。玩家通过武装多种不同的植物,切换不同的功能,快速有效地把僵尸阻挡在入侵的道路上。不同的敌人,不同的玩法构成五种不同的游戏模式&#…...

【每日一题】ABC311G - One More Grid Task | 单调栈 | 简单
题目内容 原题链接 给定一个 n n n 行 m m m 列的矩阵,问权值最大的子矩阵的权值是多少。 对于一个矩阵,其权值定义为矩阵中的最小值 m i n v minv minv 乘上矩阵中所有元素的和。 数据范围 1 ≤ n , m ≤ 300 1\leq n,m \leq 300 1≤n,m≤300 1 ≤…...
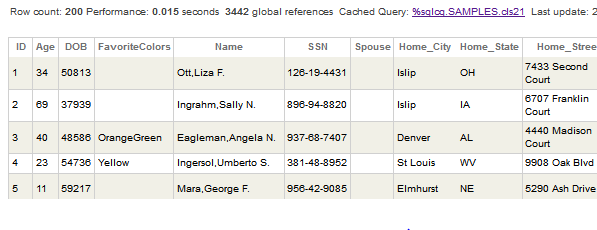
第五十六章 学习常用技能 - 执行 SQL 查询
文章目录 第五十六章 学习常用技能 - 执行 SQL 查询执行 SQL 查询检查对象属性 第五十六章 学习常用技能 - 执行 SQL 查询 执行 SQL 查询 要运行 SQL 查询,请在管理门户中执行以下操作: 选择系统资源管理器 > SQL。如果需要,请选择标题…...
2023年起重信号司索工(建筑特殊工种)证考试题库及起重信号司索工(建筑特殊工种)试题解析
题库来源:安全生产模拟考试一点通公众号小程序 2023年起重信号司索工(建筑特殊工种)证考试题库及起重信号司索工(建筑特殊工种)试题解析是安全生产模拟考试一点通结合(安监局)特种作业人员操作证考试大纲和(质检局)特…...
《华为战略管理法:DSTE实战体系》作者谢宁老师受邀为某电力上市集团提供两天的《成功的产品管理及产品经理》内训。
近日,《华为战略管理法:DSTE实战体系》作者谢宁老师受邀为某电力上市集团提供两天的《成功的产品管理及产品经理》内训。 谢宁老师作为华为培训管理部特聘资深讲师和顾问,也是畅销书《华为战略管理法:DSTE实战体系》、《智慧…...

finalshell连接虚拟机中的ubuntu
finalshell下载地址: https://www.finalshell.org/ubuntu设置root密码: sudo passwd rootubuntu关闭防火墙: sudo ufw disable安装ssh # sudo apt update #更新数据(可以不执行) # sudo apt upgrade #更新软件(可以不执行) sudo apt install open…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...

关于uniapp展示PDF的解决方案
在 UniApp 的 H5 环境中使用 pdf-vue3 组件可以实现完整的 PDF 预览功能。以下是详细实现步骤和注意事项: 一、安装依赖 安装 pdf-vue3 和 PDF.js 核心库: npm install pdf-vue3 pdfjs-dist二、基本使用示例 <template><view class"con…...

DiscuzX3.5发帖json api
参考文章:PHP实现独立Discuz站外发帖(直连操作数据库)_discuz 发帖api-CSDN博客 简单改造了一下,适配我自己的需求 有一个站点存在多个采集站,我想通过主站拿标题,采集站拿内容 使用到的sql如下 CREATE TABLE pre_forum_post_…...