【TensorFlow2 之013】TensorFlow-Lite

一、说明
在这篇文章中,我们将展示如何构建计算机视觉模型并准备将其部署在移动和嵌入式设备上。有了这些知识,您就可以真正将脚本部署到日常使用或移动应用程序中。
教程概述:
- 介绍
- 在 TensorFlow 中构建模型
- 将模型转换为 TensorFlow Lite
- 训练后量化
二、前提知识
上次,我们展示了如何使用迁移学习来提高模型性能。但是,当我们可以在智能手机或其他嵌入式设备上使用我们的模型时,为什么我们只使用我们的模型来预测计算机上猫或狗的图像呢?
TensorFlow Lite 是 TensorFlow 针对移动和嵌入式设备的轻量级解决方案。它使我们能够在移动设备上以低延迟快速运行机器学习模型,而无需访问服务器。
它可以通过 C++ API 在 Android 和 iOS 设备上使用,也可以与 Android 开发人员的 Java 包装器一起使用。
三、 在 TensorFlow 中构建模型
在开始使用 TensorFlow Lite 之前,我们需要训练一个模型。我们将使用台式计算机或云平台等更强大的机器从一组数据训练模型。然后,可以导出该模型并在移动设备上使用。
让我们首先准备训练数据集。我们将使用 wget .download 命令下载数据集。之后,我们需要解压缩它并合并训练和测试部分的路径。
import os
import wget
import zipfile wget.download("https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip")
100% [........................................................................] 68606236 / 68606236
Out[2]:
'cats_and_dogs_filtered.zip'
with zipfile.ZipFile("cats_and_dogs_filtered.zip","r") as zip_ref:zip_ref.extractall()base_dir = 'cats_and_dogs_filtered'train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
接下来,让我们导入所有必需的库并构建我们的模型。我们将使用一个名为MobileNetV2的预训练网络 ,该网络是在 ImageNet 数据集上进行训练的。之后,我们需要冻结预训练层并添加一个名为GlobalAveragePooling2D 的新层,然后是具有 sigmoid 激活函数的密集层。我们将使用图像数据生成器来迭代图像。
base_model = MobileNetV2(input_shape=(224, 224, 3),include_top=False,weights='imagenet')base_model.trainable = False
model = Sequential([base_model,GlobalAveragePooling2D(),Dense(1, activation='sigmoid')])
model.compile(loss='binary_crossentropy',optimizer=RMSprop(lr=0.001),metrics=['accuracy'])train_datagen = ImageDataGenerator(rescale=1./255)
val_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory(train_dir,target_size=(224, 224),batch_size=32,class_mode='binary')validation_generator = val_datagen.flow_from_directory(validation_dir,target_size=(224, 224),batch_size=32,class_mode='binary')
Found 2000 images belonging to 2 classes. Found 1000 images belonging to 2 classes.
history = model.fit(train_generator,epochs=6,validation_data=validation_generator,verbose=2)Train for 63 steps, validate for 32 steps Epoch 1/6 63/63 - 470s - loss: 0.3610 - accuracy: 0.8515 - val_loss: 0.1664 - val_accuracy: 0.9460 Epoch 2/6 63/63 - 139s - loss: 0.2055 - accuracy: 0.9210 - val_loss: 0.2065 - val_accuracy: 0.9150 Epoch 3/6 63/63 - 89s - loss: 0.1507 - accuracy: 0.9470 - val_loss: 0.1294 - val_accuracy: 0.9560 Epoch 4/6 63/63 - 81s - loss: 0.1342 - accuracy: 0.9510 - val_loss: 0.1733 - val_accuracy: 0.9350 Epoch 5/6 63/63 - 80s - loss: 0.1205 - accuracy: 0.9555 - val_loss: 0.1684 - val_accuracy: 0.9390 Epoch 6/6 63/63 - 82s - loss: 0.1079 - accuracy: 0.9620 - val_loss: 0.1418 - val_accuracy: 0.9450
四、 将模型转换为 TensorFlow Lite
在 TensorFlow 中训练深度神经网络后,我们可以将其转换为 TensorFlow Lite。
这里的想法是使用提供的 TensorFlow Lite 转换器来转换模型并生成 TensorFlow Lite FlatBuffer文件。此类文件的扩展名是.tflite。
可以直接从经过训练的 tf.keras 模型、保存的模型或具体的 TensorFlow 函数进行转换,这也是可能的。
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()open("converted_model.tflite", "wb").write(tflite_model)转换后,FlatBuffer 文件可以部署到客户端设备。在客户端设备上,它可以使用 TensorFlow Lite 解释器在本地运行。
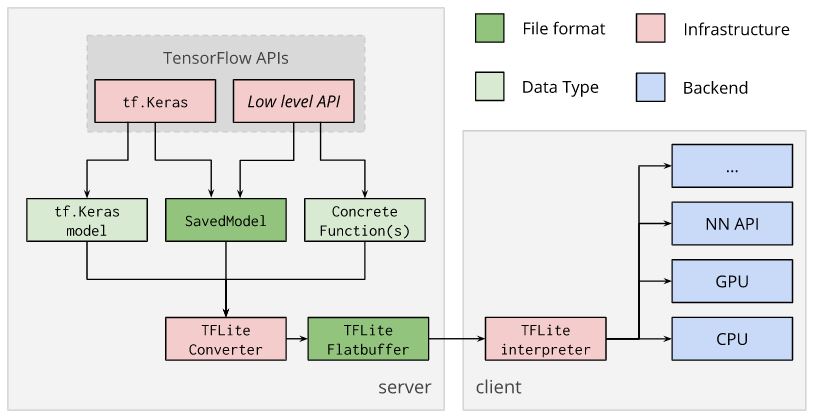
https://www.tensorflow.org/lite/convert
让我们看看如何使用TensorFlow Lite Interpreter直接从 Python 运行该模型。
interpreter = tf.lite.Interpreter(model_content=tflite_model)
interpreter.allocate_tensors()我们可以通过运行get_input_details和get_output_details函数来获取模型的输入和输出详细信息。我们还可以调整输入和输出的大小,这样我们就可以对整批图像进行预测。
input_details = interpreter.get_input_details()
output_details= interpreter.get_output_details()print("== Input details ==")
print("shape:", input_details[0]['shape'])
print("type:", input_details[0]['dtype'])
print("\n== Output details ==")
print("shape:", output_details[0]['shape'])
print("type:", output_details[0]['dtype'])== Input details == shape: [ 1 224 224 3] type: <class 'numpy.float32'>== Output details == shape: [1 1] type: <class 'numpy.float32'>
interpreter.resize_tensor_input(input_details[0]['index'], (32, 224, 224, 3))
interpreter.resize_tensor_input(output_details[0]['index'], (32, 5))
interpreter.allocate_tensors()input_details = interpreter.get_input_details()
output_details= interpreter.get_output_details()print("== Input details ==")
print("shape:", input_details[0]['shape'])
print("type:", input_details[0]['dtype'])
print("\n== Output details ==")
print("shape:", output_details[0]['shape'])
print("type:", output_details[0]['dtype'])== Input details == shape: [ 32 224 224 3] type: <class 'numpy.float32'>== Output details == shape: [32 1] type: <class 'numpy.float32'>
接下来,我们可以生成一批图像,在我们的例子中为 32 个,因为这是之前图像数据生成器中使用的数量。
使用 TensorFlow Lite 进行预测的第一步是设置模型的输入,在我们的示例中是一批 32 张图像。设置输入张量后,我们可以调用invoke 命令来调用解释器。输出预测将通过调用get_tensor命令获得。
我们来对比一下 TensorFlow Lite 模型和 TensorFlow 模型的结果。它们应该是相同的。我们将使用np.testing.assert_almost_equal函数来完成此操作。如果结果在一定的小数位数内不相同,则会引发错误。
mage_batch, label_batch = next(iter(validation_generator))
interpreter.set_tensor(input_details[0]['index'], image_batch)
interpreter.invoke()
tflite_results = interpreter.get_tensor(output_details[0]['index'])tf_results = model.predict(image_batch)for tf_result, tflite_result in zip(tf_results, tflite_results):np.testing.assert_almost_equal(tf_result, tflite_result, decimal=5)到目前为止没有错误,所以它向我们表明此转换已成功完成。但这是有阶级概率的。让我们编写一个函数将其转换为类。该函数将执行与 TensorFlow 中内置函数相同的操作。此外,我们还将展示这些预测。红色将显示与主 TensorFlow 模型不同的预测,蓝色图像将显示两个模型做出相同的预测。作为标签,我们将显示 TensorFlow Lite 模型的预测。
def predict_classes(tf_model, tf_lite_interpreter, x):tf_lite_interpreter.set_tensor(input_details[0]['index'], x)tf_lite_interpreter.invoke()tflite_results = tf_lite_interpreter.get_tensor(output_details[0]['index'])tf_results = model.predict_classes(x)if tflite_results.shape[-1] > 1:tflite_results = tflite_results.argmax(axis=-1)else:tflite_results = (tflite_results > 0.5).astype('int32')plt.figure(figsize=(12,10))for n in range(32):plt.subplot(6,6,n+1)plt.subplots_adjust(hspace = 0.3)plt.imshow(image_batch[n])color = "blue" if tf_results[n] == tflite_results[n] else "red"plt.title(tflite_results[n], color=color)plt.axis('off')_ = plt.suptitle("Model predictions (blue: same, red: different)")predict_classes(model, interpreter, image_batch)
五、训练后量化
这非常简单,但某些模型并未针对在低功耗设备上运行进行优化。因此,为了解决这个问题,我们需要进行量化。
训练后量化是一种转换技术,可以减小模型大小,同时改善 CPU 和硬件加速器延迟,而模型精度几乎没有下降。
下表显示了三种技术及其优点,以及可以运行该技术的硬件。
| 技术 | 好处 | 硬件 |
|---|---|---|
| 权重量化 | 缩小 4 倍,加速 2-3 倍,准确度提高 | 中央处理器 |
| 全整数量化 | 缩小 4 倍,加速 3 倍以上 | CPU、边缘TPU等 |
| Float16 量化 | 体积缩小 2 倍,具有潜在的 GPU 加速能力 | 中央处理器/图形处理器 |
让我们看看它是如何进行权重量化的,这是默认的。
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quant_model = converter.convert()open("converted_model.tflite", "wb").write(tflite_quant_model)interpreter = tf.lite.Interpreter(model_content=tflite_quant_model)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details= interpreter.get_output_details()interpreter.resize_tensor_input(input_details[0]['index'], (32, 224, 224, 3))
interpreter.resize_tensor_input(output_details[0]['index'], (32, 5))
interpreter.allocate_tensors()input_details = interpreter.get_input_details()
output_details= interpreter.get_output_details()
print("== Input details ==")
print("shape:", input_details[0]['shape'])
print("type:", input_details[0]['dtype'])
print("\n== Output details ==")
print("shape:", output_details[0]['shape'])
print("type:", output_details[0]['dtype'])== Input details == shape: [ 32 224 224 3] type: <class 'numpy.float32'>== Output details == shape: [32 1] type: <class 'numpy.float32'>
以下决策树可以帮助确定哪种训练后量化方法最适合您的用例。
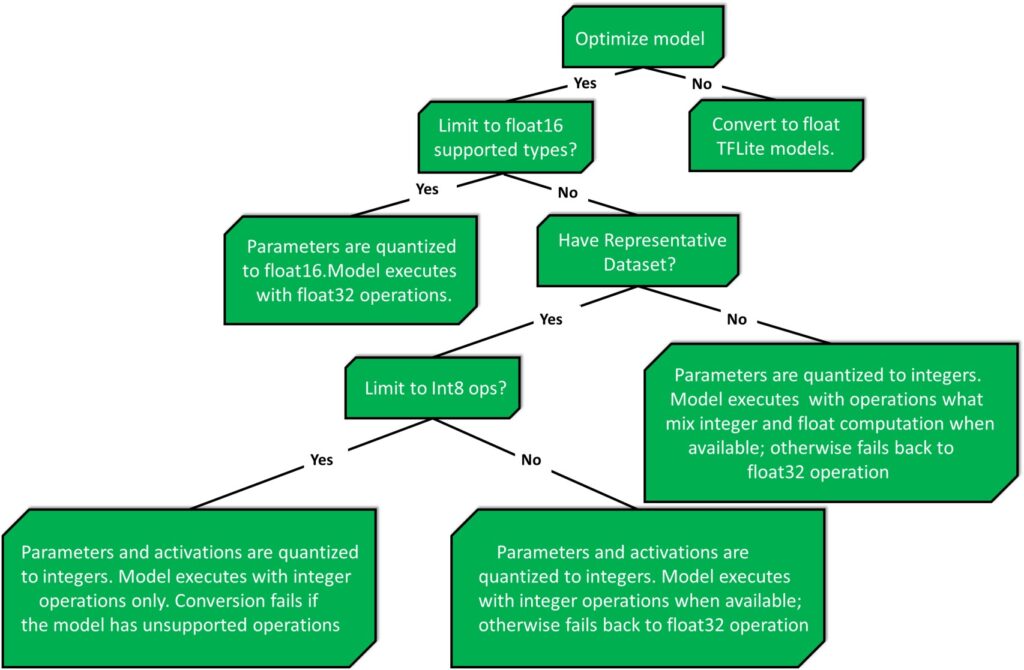
在我们的例子中,我们使用名为 MobileNetV2 的模型,该模型已经针对低功耗设备进行了优化。所以本例中的权重量化会降低模型精度。
和之前一样,让我们看看这次模型的表现如何。红色将显示与主 TensorFlow 模型不同的预测,蓝色图像将显示两个模型做出相同的预测。作为标签,我们将显示 TensorFlow Lite 模型的预测。
predict_classes(model, interpreter, image_batch)
六、总结
总而言之,在这篇文章中,我们讨论了从 TensorFlow 到 TensorFlow Lite 的转换以及低功耗设备的优化。在下一篇文章中,我们将展示如何在 TensorFlow 2.0 中实现 LeNet-5。
相关文章:
【TensorFlow2 之013】TensorFlow-Lite
一、说明 在这篇文章中,我们将展示如何构建计算机视觉模型并准备将其部署在移动和嵌入式设备上。有了这些知识,您就可以真正将脚本部署到日常使用或移动应用程序中。 教程概述: 介绍在 TensorFlow 中构建模型将模型转换为 TensorFlow Lite训练…...

Java基础--阳光总在风雨后,请相信彩虹
1、今日任务 JAVA SE-韩顺平视频教程–30p以上(今天得50p以上因为是基础)计算机基础八股记忆总结刷题(两题)可以先用python 1、SSM ssm->Spring(轻量级的文本开发框架)/SpringMVC(分层的w…...

高级网络调试技巧:使用Charles Proxy捕获和修改HTTP/HTTPS请求
今天我将与大家分享一种强大的网络调试技巧,那就是使用Charles Proxy来捕获和修改HTTP/HTTPS请求。如果您是一位开发人员或者网络调试爱好者,那么这个工具肯定对您有着很大的帮助。接下来,让我们一起来学习如何使用Charles Proxy进行高级网络…...
Discuz大气游戏风格模板/仿lol英雄联盟游戏DZ游戏模板GBK
Discuz大气游戏风格模板,lol英雄联盟游戏模板,DZ游戏娱乐模板GBK。模板名称:lol英雄联盟游戏(m0398_lol) 下载地址:https://bbs.csdn.net/topics/617408069...
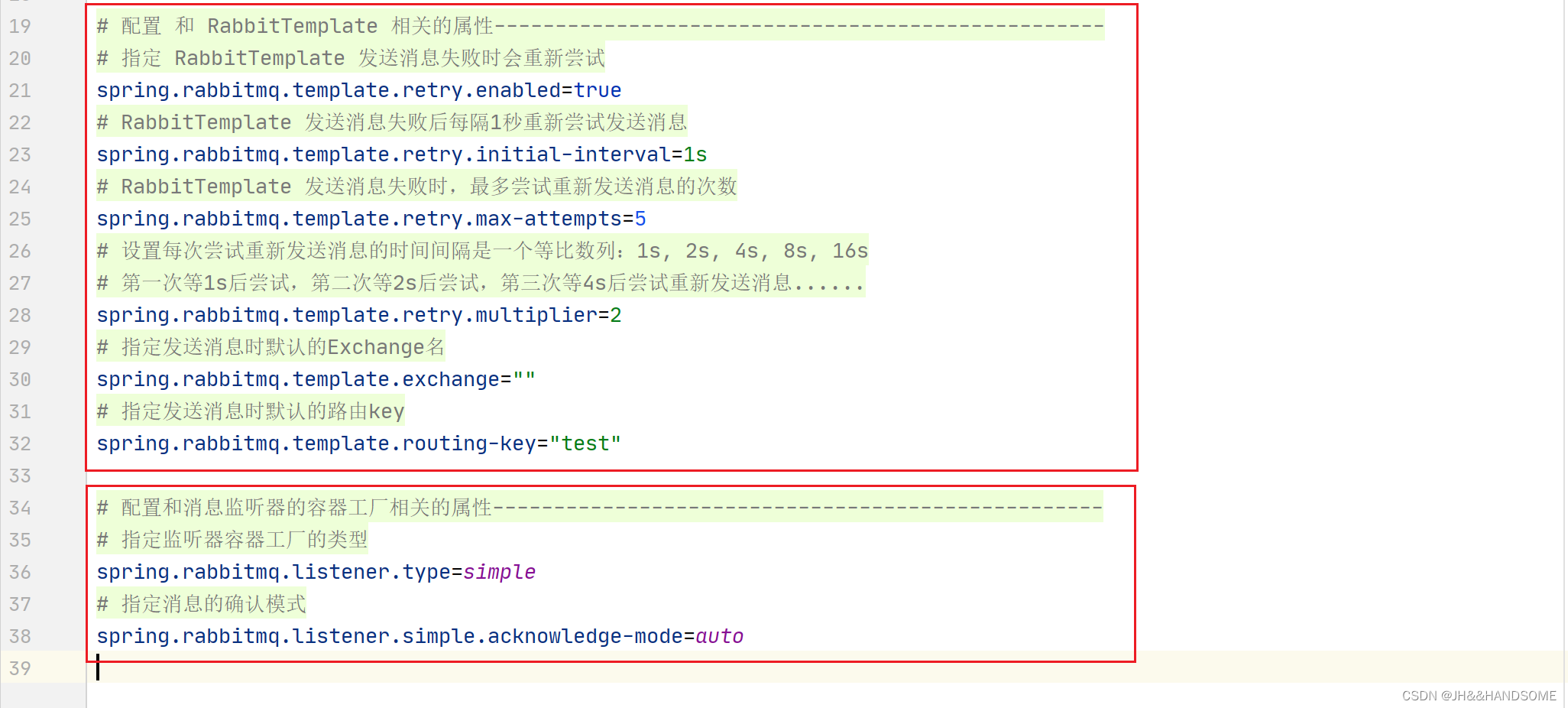
206、SpringBoot 整合 RabbitMQ 的自动配置类 和 对应的属性处理类 的知识点
目录 ★ Spring Boot 为 RabbitMQ 提供的自动配置▲ 自动配置类:RabbitAutoConfiguration▲ 属性处理类:RabbitProperties相关配置 ★ AmqpAdmin的方法★ AmqpTemplate的方法代码演示创建一个springboot的项目。application.properties 配置属性 ★ Spri…...
网络链接失败怀疑是服务器处于非正常状态?如何用本地电脑查看服务器是否正常?
网络链接失败怀疑是服务器处于非正常状态?如何用本地电脑查看服务器是否正常? 网页会出现链接失败,可以实时用cdm大法,cdm可以更好的排查字节数据的返回,可以让我们更好的要检查服务器是否处于正常状态,接下…...

文件操作(打开关闭文件、文件顺序以及随机读写)
文章目录 写在前面1. 文件的打开与关闭1.1 文件指针1.2 文件的打开(fopen)与关闭(fclose)1.2.1 fopen函数1.2.2 fclose函数 2. 文件的顺序读写2.1. fgetc 和 fputc函数2.1.1 fputc函数2.1.2 fgetc函数 2.2 fgets 和 fputs函数2.2.1 fputs函数2.2.2 fgets函数 2.3 fscanf和fprin…...
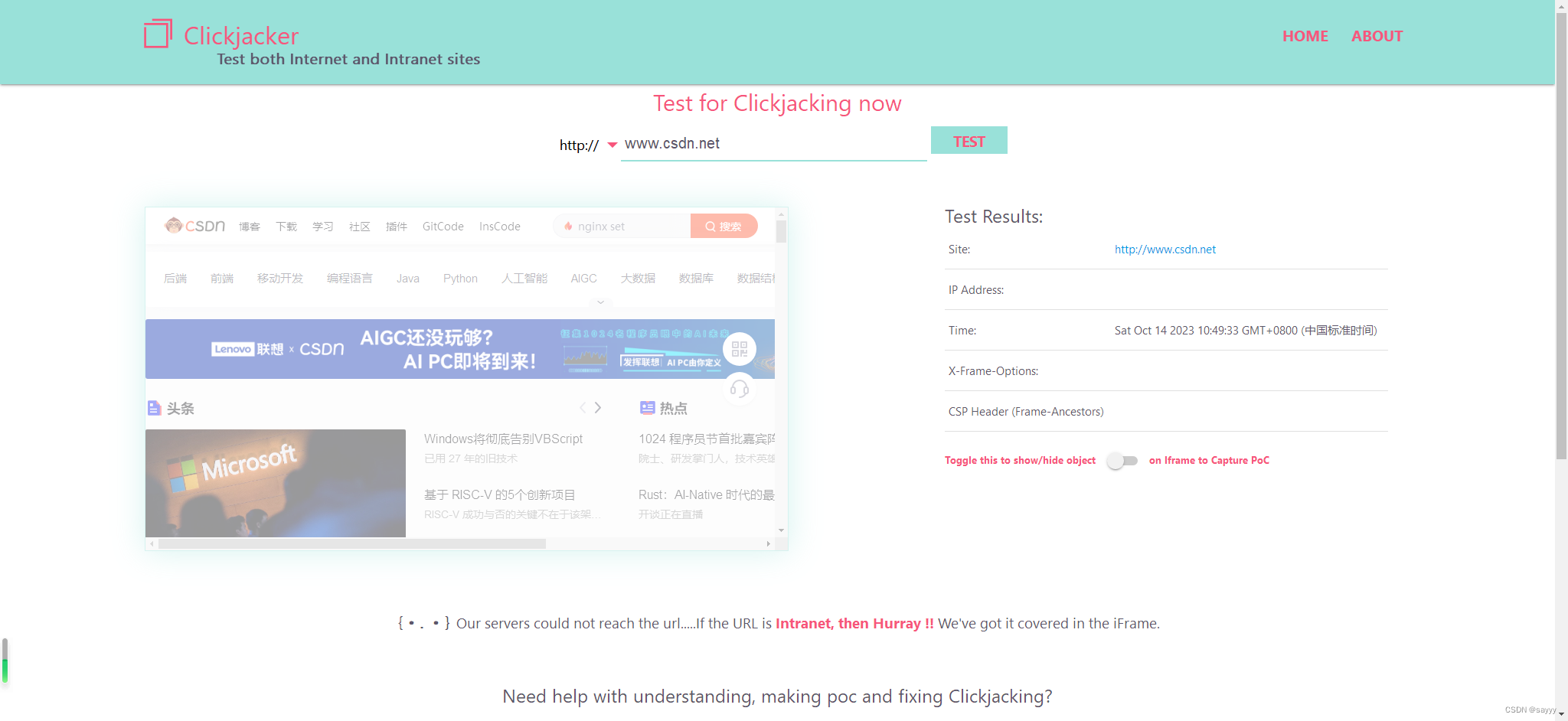
HTTP 响应头 X-Frame-Options
简介 X-Frame-Options HTTP 响应头用来给浏览器一个指示。该指示的作用为:是否允许页面在 <frame>, </iframe> 或者 <object> 中展现。 网站可以使用此功能,来确保自己网站的内容没有被嵌套到别人的网站中去,也从而避免了…...
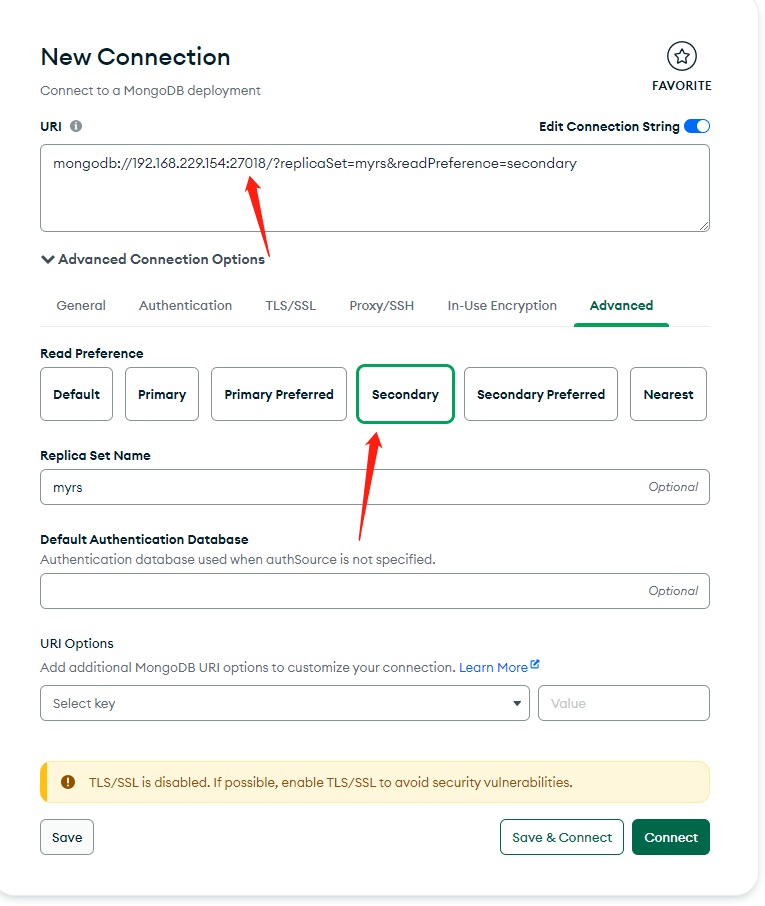
MongoDB 集群配置
一、副本集 Replica Sets 1.1 简介 MongoDB 中的副本集(Replica Set)是一组维护相同数据集的 mongod 服务。 副本集可提供冗余和高可用性,是所有生产部署的基础。 也可以说,副本集类似于有自动故障恢复功能的主从集群。通俗的讲就…...

random生成随机数的灵活运用
random返回的 [0,1) 之间的一个随即小数 思考:请写出获取 a-b 之间的一个随机整数,a,b均为整数,比如 a2 , b7 即返回一个数 x > [2,7]Math.random()*(b-a) 返回的就是 [0,b-a](int)(aMath.random()*(b-a1)) 》 (int)(2Math.random()*6) Ma…...

宏定义实现二进制数的奇偶位交换
思路分析 通过宏定义来实现二进制数的奇偶位交换,如果一个个遍历交换的话,那得算到猴年马月,这是我在网上看到的一个思路: 我们将每一位(整数在计算机里存储是4字节,32位)二进制数的奇数位保留…...

【ELK 使用指南】ELK + Filebeat 分布式日志管理平台部署
ELK和EFLK 一、前言1.1 日志分析的作用1.2 需要收集的日志1.3 完整日志系统的基本特征 二、ELK概述2.1 ELK简介2.2 为什么要用ELK?2.3 ELK的组件 三、ELK组件详解3.1 Logstash3.1.1 简介3.1.2 Logstash命令常用选项3.1.3 Logstash 的输入和输出流3.1.4 Logstash配置文件 3.2 E…...
传输层 | UDP协议、TCP协议
之前讲过的http与https都是应用层协议,当应用层协议将报文构建好之后就要将报文往下层传输层进行传递,而传输层就是负责将数据能够从发送端传到接收端。 再谈端口号 端口号(port)标识了一个主机上进行通信的不同的应用程序,在TCP/IP协议中&…...

Webmin(CVE-2019-15107)远程命令执行漏洞复现
漏洞编号 CVE-2019-15107 webmin介绍 什么是webmin Webmin是目前功能最强大的基于Web的Unix系统管理工具。管理员通过浏览器访问Webmin的各种管理功能并完成相应的管理动作http://www.webmin.com/Webmin 是一个用 Perl 编写的基于浏览器的管理应用程序。是一个基于Web的界面…...
)
嵌入式实时操作系统的设计与开发 (前后台系统)
前后台结构 前后台系统也称为中断驱动系统,其软件结构的显著特点是运行的程序有前台和后台之分。 在后台,一组程序按照轮询方式访问CPU;在前台,当用户的请求到达时,首先向CPU触发中断,然后将该请求转交给后…...
Macos数字音乐库:Elsten Software Bliss for Mac
Elsten Software Bliss for Mac是一款优秀的音乐管理软件,它可以帮助用户自动化整理和标记数字音乐库,同时可以自动识别音乐信息并添加标签和元数据。 此外,Bliss还可以修复音乐库中的问题,例如重复的音乐文件和缺失的专辑封面等…...

基于SpringBoot的校园周边美食探索及分享平台的设计与实现
文章目录 项目介绍主要功能截图:登录注册个人信息管理后台首页轮播图管理美食鉴赏我的好友管理我的收藏管理用户管理部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给…...

GPT-4V的图片识别和分析能力
GPT-4V是OpenAI开发的大型语言模型,是GPT-4的升级版本。GPT-4V在以下几个方面进行了改进: 模型规模更大:GPT-4V的参数量达到了1.37T,是GPT-4的10倍。训练数据更丰富:GPT-4V的训练数据包括了1.56T的文本和代码数据。算…...

蓝桥杯(等差素数列,C++)
思路: 1、因为找的是长度为10,且公差最小的等差素数列,直接用枚举即可。 2、枚举用三重循环,第一重枚举首项,第二重枚举公差,第三重因为首项算一个,所以枚举九个等差素数。 代码:…...

Ceph 中的写入放大
新钛云服已累计为您分享769篇技术干货 介绍 Ceph 是一个开源的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。 Ceph 独一无二地在一个统一的系统中同时提供了对象、块、和文件存储功能。 Ceph 消除了对系统单一中心节点的依赖,实现了无中…...

铭豹扩展坞 USB转网口 突然无法识别解决方法
当 USB 转网口扩展坞在一台笔记本上无法识别,但在其他电脑上正常工作时,问题通常出在笔记本自身或其与扩展坞的兼容性上。以下是系统化的定位思路和排查步骤,帮助你快速找到故障原因: 背景: 一个M-pard(铭豹)扩展坞的网卡突然无法识别了,扩展出来的三个USB接口正常。…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...

Python+ZeroMQ实战:智能车辆状态监控与模拟模式自动切换
目录 关键点 技术实现1 技术实现2 摘要: 本文将介绍如何利用Python和ZeroMQ消息队列构建一个智能车辆状态监控系统。系统能够根据时间策略自动切换驾驶模式(自动驾驶、人工驾驶、远程驾驶、主动安全),并通过实时消息推送更新车…...