C++位图,布隆过滤器
本期我们来学习位图,布隆过滤器等相关知识,以及模拟实现,需求前置知识
C++-哈希Hash-CSDN博客
C++-封装unordered_KLZUQ的博客-CSDN博客
目录
位图
布隆过滤器
海量数据面试题
全部代码
位图
我们先来看一道面试题
给 40 亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这 40 亿个数中。【腾讯】
这是一个查找在不在的问题,我们该如何解决呢?使用set可以吗?排序+二分查找可以吗?
如果但从效率来看,它们都是longN,但是都不行,40亿整数是160亿字节,换算下来大约是16G左右,内存是不会给我们开16G的,如果用set更恐怖,除了存整形,还要存各种附带的东西,left,right,parent,颜色等等,红黑树,哈希表这些都是有附带消耗的
这是一个在不在的问题,所以我们可以用0和1来表示存在,所以这里可以用比特位来标记,我们开2^32个比特位进行标记,这里和哈希的直接定址法一样,我们这里是开范围,而且2^32比特位是0.5G左右

此时我们来写需要的结构,我们用vector来实现,但是此时又有一个问题,什么类型的大小是一个比特位?没有,但是我们仔细回忆的话,位运算和位段都是可以实现一个比特位的

我们这里要实现两个接口,一个set一个reset,分别是将x映射的位置标记为1和0

一个int是32个比特位,假设此时x=80,我们首先要计算出x在第几个整形的位置,我们用x/32即可,在该整形的第几个位上面,我们可以用x%32,我们带入计算一下,80/32是2,刚好在第二个整形(从第0个开始),再用80%32是16,64+16是80,所以位置刚好是下标
这里还有一个问题,我们的机器其实是小端机
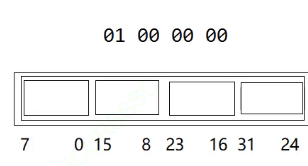
也就是说在内存中其实是这样的
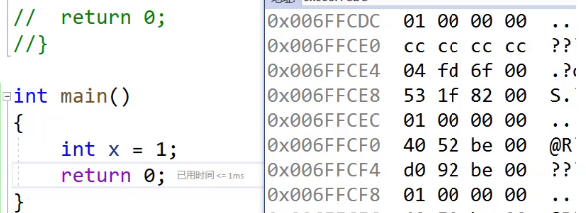
比如我们这里存了一个1,在内存中的存储就是这样的
//x映射的位置标记位1void set(size_t x){size_t i = x / 32;size_t j = x % 32;_a[i] |= (1<<j);}//x映射的位置标记位0void reset(size_t x){size_t i = x / 32;size_t j = x % 32;_a[i] &= (~(1 << j));}我们实现这两个函数,使用位运算就可以巧妙的解决问题
set我们让它的那个位置 | 上1,reset我们让那个位置&上~1(这里1用来移位,所以没有&0)
接下来我们要判断某个位置是0还是1
bool test(size_t x){size_t i = x / 32;size_t j = x % 32;return _a[i] & (1 << j);}我们&1即可,如果是0,返回则为假,是1返回真,注意这里是&,不是&=

我们再加上构造函数,开一下空间,这里向上取整
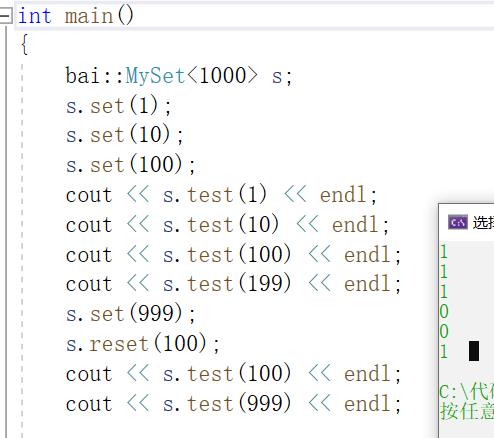
接着我们测试一下,没有问题
下面我们要来完成面试题,首先我们要开42亿的空间(不是40亿,题目说的是40亿个不重复,有可能比40亿大)
我们在这里写INT_MAX可以吗?不行,INT_MAX是21亿多

我们应该用这个,无符号的最大值
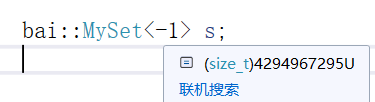
或者用更简单的办法,写个-1即可,因为这里是无符号,-1的补码是全1

手动写16进制也可以

另外位图在库里面也是有的

有各种接口,我们记住test,set和reset即可,其他的基本用不到
我们来看一些位图的应用
1. 给定 100 亿个整数,设计算法找到只出现一次的整数?2. 给两个文件,分别有 100 亿个整数,我们只有 1G 内存,如何找到两个文件交集?3. 位图应用变形: 1 个文件有 100 亿个 int , 1G 内存,设计算法找到出现次数不超过 2 次的所有整数
我们看第一个,100亿个整数,只出现一次
我们之前用1个位标记在不在,现在我们可以用2个位来表示状态,2个位可以表示出4种状态,我们用3种即可,00表示不在,01表示出现一次,10出现2次及以上,我们把位图改造一下即可解决
还有更省力的方法,我们用bitset来完成

开两个位图,第一个的第一位和第二个的第一位结合起来就是一个数的状态,依次类推

为了方便我们先把之前的myset改名和库里面一样的bitset
template<size_t N>class twobitset{public:void set(size_t x){//00 -> 01if (!_bs1.test(x) && !_bs2.test(x)){_bs2.set(x);}//01 -> 10else if(!_bs1.test(x) && _bs2.test(x)){_bs1.set(x);_bs2.reset(x);}// 本身是10代表出现2次及以上,就不变}bool is_once(size_t x){return !_bs1.test(x) && _bs2.test(x);}private:bitset<N> _bs1;bitset<N> _bs2;};我们实现一个towbitset,实现一个set接口,对于出现的数字,如果00就变为01,01就变为10,10不用变,然后提供一个isonce,判断出现一次的数
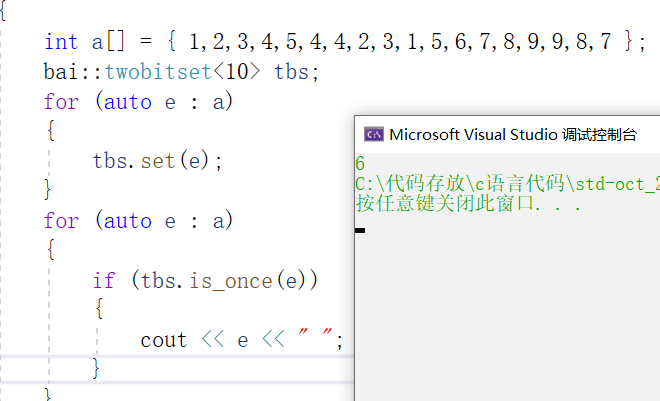
我们简单测试一下,没有问题
下面再看第二个问题,找两个文件的交集
![]()
我们把一个文件的所有值映射到位图,然后另一个文件来判断在不在可以吗?
可以,但是会有一些问题,比如第一个文件里有一个3,第二个文件里有3个3,那么这里得到的结果也是3个3,是需要进行去重的
我们来看更好的方法

我们把两个文件分别映射到两个位图,存在为1,不存在为0,然后对应的位置&一下即可,或者对应位置都为1的就是交集
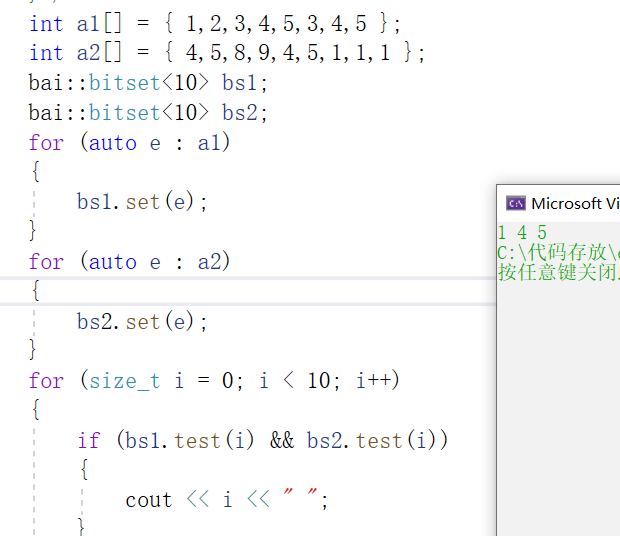
比如这样写
我们再看第三个问题

不超过2次就是1次和2次,我们还是用2个位来表示,00表示0次,01表示1次,10表示2次,11表示2次以上,解决思路类似问题1
布隆过滤器
刚才的问题都是数字,如果是string呢?比如文件1和文件2找交集,里面都是字符串,比如“语文“,”数学“,”英语“这些
我们把这些字符串计算成对应成整形,映射到位图里,然后按刚才的思路走就行了,不过这样写会有一些问题,就是冲突,比如还有一个字符串”物理“,它和语文计算出的整形是一样的,映射到了同一个位置,是会受到影响的,就存在误判了
那有什么办法可以解决这个问题吗?
答案是不能,冲突是无法避免的,但是我们可以减少冲突
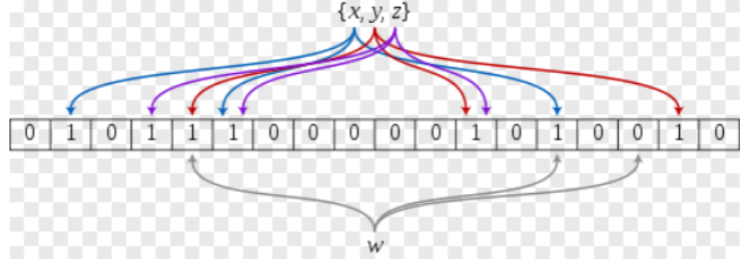
布隆过滤器是 由布隆( Burton Howard Bloom )在 1970 年提出的 一种紧凑型的、比较巧妙的 概 率型数据结构 ,特点是 高效地插入和查询,可以用来告诉你 “ 某样东西一定不存在或者可能存 在 ” ,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式 不仅可以提升查询效率,也 可以节省大量的内存空间 。
举个例子,你要和一个网友去面基,网友告诉你当天他穿的黑色裤子,背着白色的书包,在见面地点你一定不会认错吗?不一定,虽然提供了两个信息,但是还是会有冲突,所以我们只能提供更多的信息来降低冲突,但是不管提供多少信息,在人足够多的情况下还是可能认错
再回到我们的字符串,我们可以给一个字符串映射3个位置,虽然还可能会有认错,但是几率会低很多
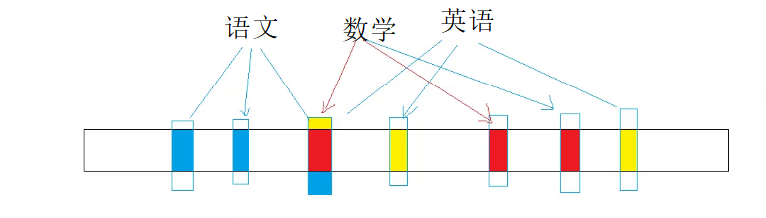
而且它们之间可能会有交叉

我们新添加一个物理,甚至可能会有两个位置和前面的元素冲突,但是只要不全冲突就行,容错率是大大提升的
应用场景:
不需要精确的场景,比如快速判断昵称是否注册过,我们就可以把所有昵称放到数据库里,我们可以接受百分之3到5的误判率,比如一个昵称没有被使用,但是却显示被使用了,对于用户来说其实是没什么问题的,换一个即可
假设我们需要精确,不容忍误判,我们可以这样玩,输入的不存在,就返回不存在,如果显示在,我们就去数据库再查一遍,以数据库的结果返回,这样可以减少不在的那些昵称要去查找的损耗,这里就是过滤器的作用,过滤掉了一些,降低数据库的负载压力,提高效率(为什么不全去数据库找?因为太慢了),这也是为什么他叫过滤器的原因
下面我们来对字符串实现过滤器,我们前面使用了字符串哈希算法,这里就需要用到它了,但是这里还有一个问题,会存在双重冲突的问题
第一个是两个字符串不同的,但转出来的整形是相同的,第二个是用除留余数法映射后可能回到相同的位置
基于这两个问题,布隆就想到了映射多个位置,所以就有了布隆过滤器
//BloomFilter.h
struct BKDRHash
{size_t operator()(const string& str){register size_t hash = 0;for (auto ch : str){hash = hash * 131 + ch;}return hash;}
};struct APHash
{size_t operator()(const string& str){register size_t hash = 0;size_t ch;for (size_t i = 0; i < str.size(); i++){size_t ch = str[i];if ((i & 1) == 0){hash ^= ((hash << 7) ^ ch ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));}}return hash;}};struct DJBHash
{size_t operator()(const string& str){register size_t hash = 5381;for (auto ch : str){hash += (hash << 5) + ch;}return hash;}
};template<size_t N,class K = string,class Hash1 = BKDRHash,class Hash2 = APHash,class Hash3 = DJBHash>
class BloomFilter
{
public:void Set(const K& key){size_t hash1 = Hash1()(key) % N;_bs.set(hash1);size_t hash2 = Hash2()(key) % N;_bs.set(hash2);size_t hash3 = Hash3()(key) % N;_bs.set(hash3);}bool Test(const K& key){size_t hash1 = Hash1()(key) % N;if (_bs.test(hash1) == false)return false;size_t hash2 = Hash2()(key) % N;if (_bs.test(hash2) == false)return false;size_t hash3 = Hash3()(key) % N;if (_bs.test(hash3) == false)return false;return true;//存在误判}
private:bitset<N> _bs;
};布隆过滤器实现起来就很简单了,我们借助库里面的bitset和三个字符串哈希算法来实现,然后我们将字符串哈希算法改为仿函数,我们只需要实现Set和Test即可

我们简单测试一下,没有问题

我们还可以把hash123打印出来看一看

这里还是有一个冲突的,猪八戒的两个25
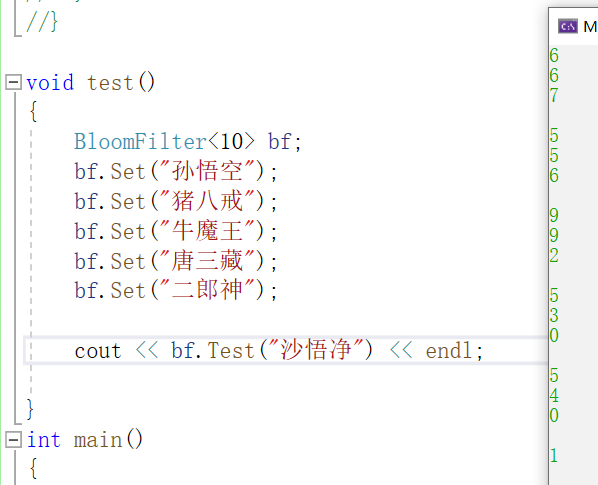
如果数据足够多,空间小的话冲突的概率就会很大,这里沙悟净就出现了误判
另外大家可以发现,我们这里是没有实现reset的,是不能实现的,举个例子,如果我们把上面的猪八戒reset了,5和6都会受影响,进而导致孙悟空和二郎神他们都会受影响,就不见了,所以一般不支持删除,删除一个值可能会影响其他值
如果想要强行支持删除,那要付出很大的代价,比如可以使用多个位标识一个值,使用引用计数
这里提供一篇知乎大佬写的布隆过滤器详解
详解布隆过滤器的原理,使用场景和注意事项 - 知乎 (zhihu.com)
建议大家看一看
下面我们来测试一下,我们set大量的值,然后再给其他大量的值,这些值里有一部分在过滤器里,一部分不在,我们来看看不在过滤器里的值会不会出现误判(也就是原本不在过滤器里的值显示出在)
void TestBloomFilter2()
{srand(time(0));const size_t N = 100000;BloomFilter<N * 4> bf;std::vector<std::string> v1;//std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";std::string url = "猪八戒";for (size_t i = 0; i < N; ++i){v1.push_back(url + std::to_string(i));}for (auto& str : v1){bf.Set(str);}// v2跟v1是相似字符串集(前缀一样),但是不一样std::vector<std::string> v2;for (size_t i = 0; i < N; ++i){std::string urlstr = url;urlstr += std::to_string(9999999 + i);v2.push_back(urlstr);}size_t n2 = 0;for (auto& str : v2){if (bf.Test(str)) // 误判{++n2;}}cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;// 不相似字符串集std::vector<std::string> v3;for (size_t i = 0; i < N; ++i){//string url = "zhihu.com";string url = "孙悟空";url += std::to_string(i + rand());v3.push_back(url);}size_t n3 = 0;for (auto& str : v3){if (bf.Test(str)){++n3;}}cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
}我们来看一看
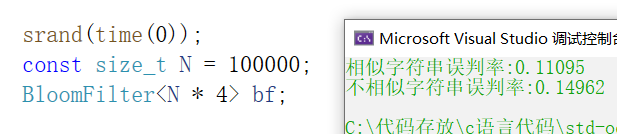


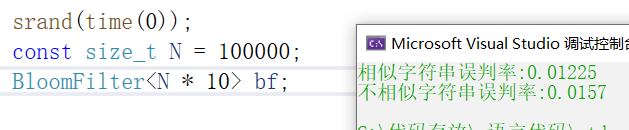
根据上面的测试结果来看,只要你舍得开空间,误判率是可以降低很多的,另外数据样本也是会有影响的,我们用了猪八戒这个字符串来测试,如果用上面很长的网址又是另一个结果,不过差别不会太大,而且只要我们把空间变大,误判率就会下降,一般推荐5到10倍左右
海量数据面试题
哈希切割给一个超过 100G 大小的 log file, log 中存着 IP 地址 , 设计算法找到出现次数最多的 IP 地址?与上题条件相同,如何找到 top K 的 IP ?如何直接用 Linux 系统命令实现?位图应用1. 给定 100 亿个整数,设计算法找到只出现一次的整数?2. 给两个文件,分别有 100 亿个整数,我们只有 1G 内存,如何找到两个文件交集?3. 位图应用变形: 1 个文件有 100 亿个 int , 1G 内存,设计算法找到出现次数不超过 2 次的所有整数布隆过滤器1. 给两个文件,分别有 100 亿个 query ,我们只有 1G 内存,如何找到两个文件交集?分别给出精确算法和近似算法2. 如何扩展 BloomFilter 使得它支持删除元素的操作
这些题我们讲过了部分,我们来看过滤器的1,要求给出精确算法,这里就需要用到哈希切分
假设平均一个query(查询)是30byte,100亿是3000亿字节,1G大约是10亿字节,也就是说一共是300G左右,而且还是两个这样的文件,现在我们只有1G内存
我们可以把文件切成一个一个的小文件,但是切成小文件后,交集该怎么找呢?一个一个的再去组合测试吗?这样太慢了
我们可以用哈希切分,比如我们把文件切成1000分,但不是平均切分,i = Hash(query) % 1000
i是多少,query就进入第i个小文件,两个文件都用这样的方式来处理
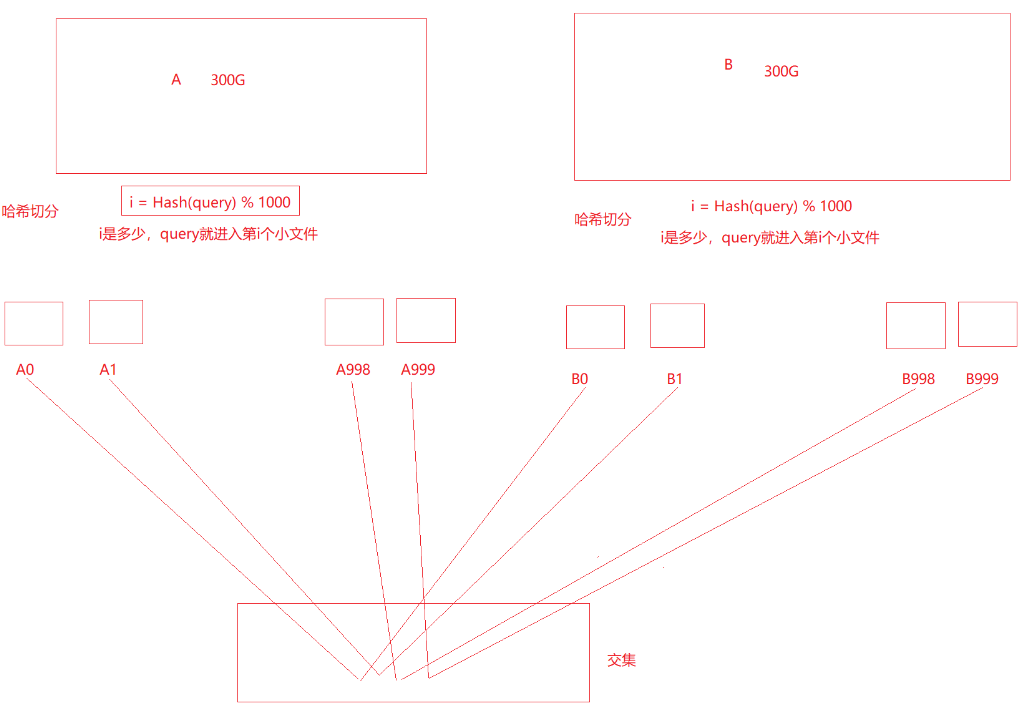
画出来大概就是这样,此时我们只需要对应编号的找即可,比如A0和B0找,A1和B1找即可
哈希切分的效果是,A和B中相同的query一定会分别进入Ai和Bi编号相同的小文件,比如一个query在文件A里经过hash,然后%1000,得到了500,那么如果B里面也有这个query,它也会经过一样的步骤,所以得到的i是相同的,进入小文件的编号也就是一样的,这里有点像哈希桶,同一个桶里就是冲突的,但是也有不冲突的,大多数的这种问题都是可以用哈希切分来解决
这里其实还有一个问题没有解决,找交集,是从Ai中读出来,然后放到set里,再从Bi中读取query,看在不在set,如果在,就是交集,就是可以找到Ai和Bi的交集,这里的切分,如果是平均切分就是一个文件300M,但我们是哈希切分,如果冲突太多,会导致某个Ai文件过大,甚至超过1G(别忘了set也要消耗内存),那该怎么办?
这里会有两个场景,比如Ai有5G,场景1,4G都是相同,1G是冲突,场景2,大多数是冲突
这里场景2我们可以换个哈希函数再次切分,一直切,是可以解决的,但是场景1不可以,相同的是切不开的,并且我们是无法区别到底是场景1还是场景2的
解决方案:1.先把Ai的query读到一个set,如果set的insert报错抛异常(bad_alloc),那么就说明大多数query是冲突,如果能全部读出来,insert到set里面,那么说明Ai中有大量相同的query(set自己可以去重)
2.如果抛异常,说明有大量冲突,我们换一个哈希函数,进行二次切分
我们再看下一个问题
![]()
这道题还可以扩展成出现次数最多的K个ip地址
同样的,我们还是使用哈希切分,比如我们切成300份,i = Hash(query) % 300
相同的ip一定会进入同一个小文件,之后我们用map分别统计每个小文件中ip出现的次数即可,出现次数最多的K个我们建小堆即可
全部代码
#pragma once
#include<vector>
using namespace std;
//bitset.h
namespace bai
{template<size_t N>class bitset{public:bitset(){size_t num = N / 32 + 1;_a.resize(num);}//x映射的位置标记位1void set(size_t x){size_t i = x / 32;size_t j = x % 32;_a[i] |= (1<<j);}//x映射的位置标记位0void reset(size_t x){size_t i = x / 32;size_t j = x % 32;_a[i] &= (~(1 << j));}bool test(size_t x){size_t i = x / 32;size_t j = x % 32;return _a[i] & (1 << j);}private:vector<int> _a;};template<size_t N>class twobitset{public:void set(size_t x){//00 -> 01if (!_bs1.test(x) && !_bs2.test(x)){_bs2.set(x);}//01 -> 10else if(!_bs1.test(x) && _bs2.test(x)){_bs1.set(x);_bs2.reset(x);}// 本身是10代表出现2次及以上,就不变}bool is_once(size_t x){return !_bs1.test(x) && _bs2.test(x);}private:bitset<N> _bs1;bitset<N> _bs2;};
}#pragma once
#include<vector>
#include<iostream>
#include<bitset>
#include<string>
using namespace std;//BloomFilter.h
struct BKDRHash
{size_t operator()(const string& str){register size_t hash = 0;for (auto ch : str){hash = hash * 131 + ch;}return hash;}
};struct APHash
{size_t operator()(const string& str){register size_t hash = 0;size_t ch;for (size_t i = 0; i < str.size(); i++){size_t ch = str[i];if ((i & 1) == 0){hash ^= ((hash << 7) ^ ch ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));}}return hash;}};struct DJBHash
{size_t operator()(const string& str){register size_t hash = 5381;for (auto ch : str){hash += (hash << 5) + ch;}return hash;}
};template<size_t N,class K = string,class Hash1 = BKDRHash,class Hash2 = APHash,class Hash3 = DJBHash>
class BloomFilter
{
public:void Set(const K& key){size_t hash1 = Hash1()(key) % N;_bs.set(hash1);size_t hash2 = Hash2()(key) % N;_bs.set(hash2);size_t hash3 = Hash3()(key) % N;_bs.set(hash3);}bool Test(const K& key){size_t hash1 = Hash1()(key) % N;if (_bs.test(hash1) == false)return false;size_t hash2 = Hash2()(key) % N;if (_bs.test(hash2) == false)return false;size_t hash3 = Hash3()(key) % N;if (_bs.test(hash3) == false)return false;return true;//存在误判}
private:bitset<N> _bs;
};以上即为本期全部内容,希望大家可以有所收获
如有错误,还请指正
相关文章:

C++位图,布隆过滤器
本期我们来学习位图,布隆过滤器等相关知识,以及模拟实现,需求前置知识 C-哈希Hash-CSDN博客 C-封装unordered_KLZUQ的博客-CSDN博客 目录 位图 布隆过滤器 海量数据面试题 全部代码 位图 我们先来看一道面试题 给 40 亿个不重复的无符号…...

Python多种方法实现九九乘法表
你好,我是悦创。 九九乘法表是一种常见的算术学习工具,通常用于帮助学生记住乘法的基本运算。以下是使用Python实现九九乘法表的几种方法: 1. 使用两个嵌套循环 for i in range(1, 10):for j in range(1, i 1):print(f"{j}x{i}{i * …...

【力扣1876】长度为三且各字符不同的子字符串
👑专栏内容:力扣刷题⛪个人主页:子夜的星的主页💕座右铭:前路未远,步履不停 目录 一、题目描述二、题目分析 一、题目描述 题目链接:长度为三且各字符不同的子字符串 如果一个字符串不含有任何…...
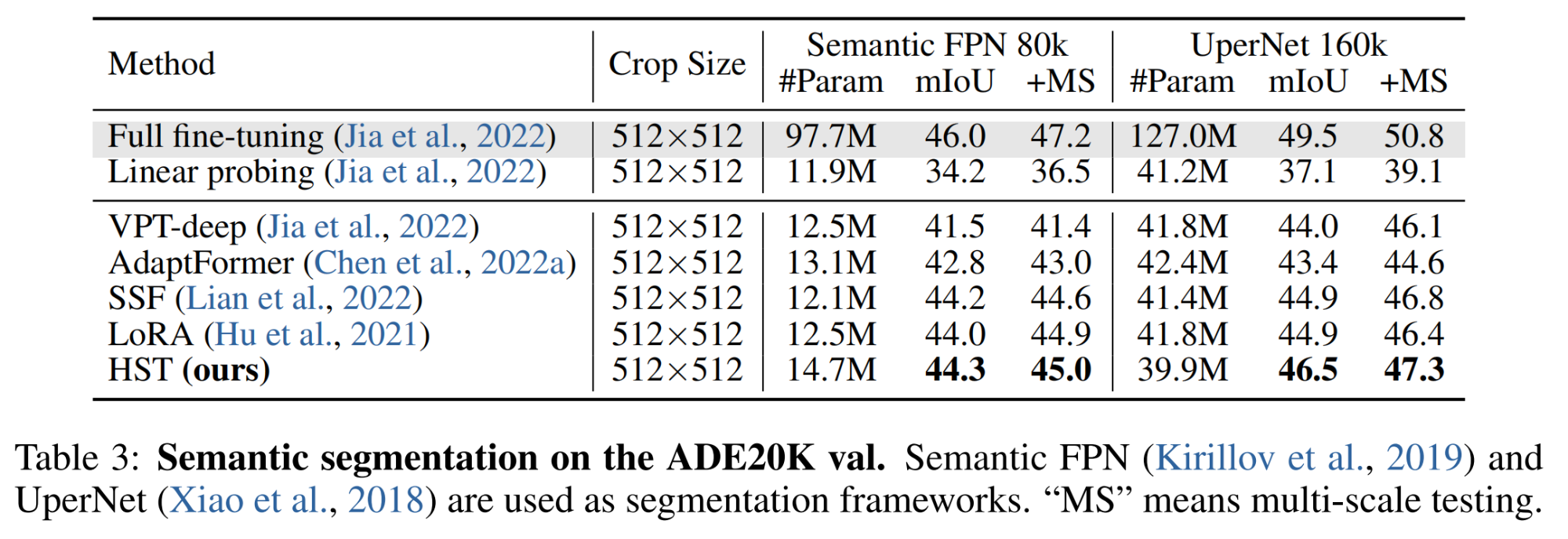
HSN:微调预训练ViT用于目标检测和语义分割,华南理工和阿里巴巴联合提出
今天跟大家分享华南理工大学和阿里巴巴联合提出的将ViT模型用于下游任务的高效微调方法HSN,该方法在迁移学习、目标检测、实例分割、语义分割等多个下游任务中表现优秀,性能接近甚至在某些任务上超越全参数微调。 论文标题:Hierarchical Side…...
机器学习的原理是什么?
训过小狗没? 没训过的话总见过吧? 你要能理解怎么训狗,就能非常轻易的理解机器学习的原理. 比如你想教小狗学习动作“坐下”一开始小狗根本不知道你在说什么。但是如果你每次都说坐下”然后帮助它坐下,并给它一块小零食作为奖励,经过多次…...

Java集合框架之ArrayList源码分析
文章目录 简介ArrayList底层数据结构初始化集合操作追加元素插入数据删除数据修改数据查找 扩容操作总结 简介 ArrayList是Java提供的线性集合,本篇笔记将从源码(java SE 17)的角度学习ArrayList: 什么是ArrayList?ArrayList底层数据结构是…...
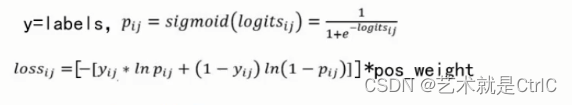
TensorFlow入门(二十、损失函数)
损失函数 损失函数用真实值与预测值的距离指导模型的收敛方向,是网络学习质量的关键。不管是什么样的网络结构,如果使用的损失函数不正确,最终训练出的模型一定是不正确的。常见的两类损失函数为:①均值平方差②交叉熵 均值平方差 均值平方差(Mean Squared Error,MSE),也称&qu…...

MySQL中死锁
数据库的死锁是指不同的事务在获取资源时相互等待,导致无法继续执行的一种情况。当发生死锁时,数据库会自动中断其中一个事务,以解除死锁。在数据库中,事务可以分为读事务和写事务。读事务只需要获取读锁,而写事务需要…...

【LeetCode刷题(数据结构)】:给定一个链表 每个节点包含一个额外增加的随机指针 该指针可以指向链表中的任何节点或空节点 要求返回这个链表的深度拷贝
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点 构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next…...

uniapp封装loading 的动画动态加载
实现效果 html代码 <view class"loadBox" v-if"loading"><img :src"logo" class"logo"> </view> css代码 .loadBox {width: 180rpx;min-height: 180rpx;border-radius: 50%;display: flex;align-items: center;j…...
Kopler.gl笔记:可视化功能总览
1 添加数据 2 添加图层 打开“数据层”菜单,开始可视化。 层(Layers)简单来说就是可以相互叠加的数据可视化。 3 添加过滤器 在地图上添加过滤器以限制显示的数据。过滤器必须基于数据集中的列。要创建新的过滤器,打开“过滤器…...

rust学习Cell、RefCell、OnceCell
背景 Rust 内存安全基于以下规则:给定一个对象 T,它只能具有以下之一: 对对象有多个不可变引用 (&T)(也称为别名 aliasing)对对象有一个可变引用 (&mut T)(也称为可变性 mutability)这是由 Rust 编译器强制执行的。然而,在某些情况下,该规则不够灵活(this r…...
基于SSM的摄影约拍系统
基于SSM的摄影约拍系统的设计与实现 开发语言:Java数据库:MySQL技术:SpringSpringMVCMyBatisJSP工具:IDEA/Ecilpse、Navicat、Maven 【主要功能】 前台系统:首页拍摄作品展示、摄影师展示、模特展示、文章信息、交流论…...
分析智能平台VMware Greenplum 7 正式发布!
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...
动态规划算法(3)--0-1背包、石子合并、数字三角形
目录 一、0-1背包 1、概述 2、暴力枚举法 3、动态规划 二、石子合并问题 1、概述 2、动态规划 3、环形石子怎么办? 三、数字三角形问题 1、概述 2、递归 3、线性规划 四、租用游艇问题 一、0-1背包 1、概述 0-1背包:给定多种物品和一个固定…...
Linux C/C++ 嗅探数据包并显示流量统计信息
嗅探数据包并显示流量统计信息是网络分析中的一种重要技术,常用于网络故障诊断、网络安全监控等方面。具体来说,嗅探器是一种可以捕获网络上传输的数据包,并将其展示给分析人员的软件工具。在嗅探器中,使用pcap库是一种常见的方法…...

Vitis导入自制IP导致无法构建Platform
怎么还有这种问题( 解决Vitis导入自制IP导致无法构建Platform – TaterLi 个人博客 Vitis报错:fatal error: xxx.h: No such file or directory._ly2lj的博客-CSDN博客 在指定位置黏入以上代码即可: INCLUDEFILES$(wildcard *.h) LIBSOUR…...

SQLAlchemy 使用封装实例
类封装 database.py #! /usr/bin/env python # -*- coding: utf-8 -*-import sys import json import logging from datetime import datetimefrom core.utils import classlock, parse_bool from core.config import (MYSQL_HOST,MYSQL_PORT,MYSQL_USER,MYSQL_PASS,MYSQL_DA…...

Android Framework通信:Binder
文章目录 前言一、Linux传统跨进程通信原理二、Android Binder跨进程通信原理1、动态内核可加载模块2、内存映射3、Binder IPC 实现原理 三、Android Binder IPC 通信模型1、Client/Server/ServiceManager/驱动Binder与路由器之间的角色关系 2、Binder通信过程3、Binder通信中的…...

如何用精准测试来搞垮团队?
测试行业每年会冒出来一些新鲜词:混沌工程、精准测试、AI测试…… 这些新概念、新技术让我们感到很焦虑,逼着自己去学习和了解这些新玩意,担心哪一天被淘汰掉。 以至于给我这样的错觉,当「回归测试」、「精准测试」这两个词摆在一…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

LangFlow技术架构分析
🔧 LangFlow 的可视化技术栈 前端节点编辑器 底层框架:基于 (一个现代化的 React 节点绘图库) 功能: 拖拽式构建 LangGraph 状态机 实时连线定义节点依赖关系 可视化调试循环和分支逻辑 与 LangGraph 的深…...
协议转换利器,profinet转ethercat网关的两大派系,各有千秋
随着工业以太网的发展,其高效、便捷、协议开放、易于冗余等诸多优点,被越来越多的工业现场所采用。西门子SIMATIC S7-1200/1500系列PLC集成有Profinet接口,具有实时性、开放性,使用TCP/IP和IT标准,符合基于工业以太网的…...
ubuntu22.04有线网络无法连接,图标也没了
今天突然无法有线网络无法连接任何设备,并且图标都没了 错误案例 往上一顿搜索,试了很多博客都不行,比如 Ubuntu22.04右上角网络图标消失 最后解决的办法 下载网卡驱动,重新安装 操作步骤 查看自己网卡的型号 lspci | gre…...

Linux 下 DMA 内存映射浅析
序 系统 I/O 设备驱动程序通常调用其特定子系统的接口为 DMA 分配内存,但最终会调到 DMA 子系统的dma_alloc_coherent()/dma_alloc_attrs() 等接口。 关于 dma_alloc_coherent 接口详细的代码讲解、调用流程,可以参考这篇文章,我觉得写的非常…...