Dubbo 源码分析 – 集群容错之 Cluster
3.2.2 FailbackClusterInvoker
FailbackClusterInvoker 会在调用失败后,返回一个空结果给服务提供者。并通过定时任务对失败的调用进行重传,适合执行消息通知等操作。下面来看一下它的实现逻辑。
public class FailbackClusterInvoker<T> extends AbstractClusterInvoker<T> {private static final long RETRY_FAILED_PERIOD = 5 * 1000;private final ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(2,new NamedInternalThreadFactory("failback-cluster-timer", true));private final ConcurrentMap<Invocation, AbstractClusterInvoker<?>> failed = new ConcurrentHashMap<Invocation, AbstractClusterInvoker<?>>();private volatile ScheduledFuture<?> retryFuture;@Overrideprotected Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {try {checkInvokers(invokers, invocation);// 选择 InvokerInvoker<T> invoker = select(loadbalance, invocation, invokers, null);// 进行调用return invoker.invoke(invocation);} catch (Throwable e) {// 如果调用过程中发生异常,此时仅打印错误日志,不抛出异常logger.error("Failback to invoke method ...");// 记录调用信息addFailed(invocation, this);// 返回一个空结果给服务消费者return new RpcResult();}}private void addFailed(Invocation invocation, AbstractClusterInvoker<?> router) {if (retryFuture == null) {synchronized (this) {if (retryFuture == null) {// 创建定时任务,每隔5秒执行一次retryFuture = scheduledExecutorService.scheduleWithFixedDelay(new Runnable() {@Overridepublic void run() {try {// 对失败的调用进行重试retryFailed();} catch (Throwable t) {// 如果发生异常,仅打印异常日志,不抛出logger.error("Unexpected error occur at collect statistic", t);}}}, RETRY_FAILED_PERIOD, RETRY_FAILED_PERIOD, TimeUnit.MILLISECONDS);}}}// 添加 invocation 和 invoker 到 failed 中,// 这里的把 invoker 命名为 router,很奇怪,明显名不副实failed.put(invocation, router);}void retryFailed() {if (failed.size() == 0) {return;}// 遍历 failed,对失败的调用进行重试for (Map.Entry<Invocation, AbstractClusterInvoker<?>> entry : new HashMap<Invocation, AbstractClusterInvoker<?>>(failed).entrySet()) {Invocation invocation = entry.getKey();Invoker<?> invoker = entry.getValue();try {// 再次进行调用invoker.invoke(invocation);// 调用成功,则从 failed 中移除 invokerfailed.remove(invocation);} catch (Throwable e) {// 仅打印异常,不抛出logger.error("Failed retry to invoke method ...");}}}
}这个类主要由3个方法组成,首先是 doInvoker,该方法负责初次的远程调用。若远程调用失败,则通过 addFailed 方法将调用信息存入到 failed 中,等待定时重试。addFailed 在开始阶段会根据 retryFuture 为空与否,来决定是否开启定时任务。retryFailed 方法则是包含了失败重试的逻辑,该方法会对 failed 进行遍历,然后依次对 Invoker 进行调用。调用成功则将 Invoker 从 failed 中移除,调用失败则忽略失败原因。
以上就是 FailbackClusterInvoker 的执行逻辑,不是很复杂,继续往下看。
3.2.3 FailfastClusterInvoker
FailfastClusterInvoker 只会进行一次调用,失败后立即抛出异常。适用于幂等操作,比如新增记录。楼主日常开发中碰到过一次程序连续插入三条同样的记录问题,原因是新增记录过程中包含了一些耗时操作,导致接口超时。而我当时使用的是 Dubbo 默认的 Cluster Invoker,即 FailoverClusterInvoker。其会在调用失败后进行重试,所以导致插入服务提供者插入了3条同样的数据。如果当时考虑使用 FailfastClusterInvoker,就不会出现这种问题了。当然此时接口仍然会超时,所以更合理的做法是使用 Dubbo 异步特性。或者优化服务逻辑,避免超时。
其他的不多说了,下面直接看源码吧。
public class FailfastClusterInvoker<T> extends AbstractClusterInvoker<T> {@Overridepublic Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {checkInvokers(invokers, invocation);// 选择 InvokerInvoker<T> invoker = select(loadbalance, invocation, invokers, null);try {// 调用 Invokerreturn invoker.invoke(invocation);} catch (Throwable e) {if (e instanceof RpcException && ((RpcException) e).isBiz()) {// 抛出异常throw (RpcException) e;}// 抛出异常throw new RpcException(..., "Failfast invoke providers ...");}}
}上面代码比较简单了,首先是通过 select 方法选择 Invoker,然后进行远程调用。如果调用失败,则立即抛出异常。FailfastClusterInvoker 就先分析到这,下面分析 FailsafeClusterInvoker。
3.2.4 FailsafeClusterInvoker
FailsafeClusterInvoker 是一种失败安全的 Cluster Invoker。所谓的失败安全是指,当调用过程中出现异常时,FailsafeClusterInvoker 仅会打印异常,而不会抛出异常。Dubbo 官方给出的应用场景是写入审计日志等操作,这个场景我在日常开发中没遇到过,没发言权,就不多说了。下面直接分析源码。
public class FailsafeClusterInvoker<T> extends AbstractClusterInvoker<T> {@Overridepublic Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {try {checkInvokers(invokers, invocation);// 选择 InvokerInvoker<T> invoker = select(loadbalance, invocation, invokers, null);// 进行远程调用return invoker.invoke(invocation);} catch (Throwable e) {// 打印错误日志,但不抛出logger.error("Failsafe ignore exception: " + e.getMessage(), e);// 返回空结果忽略错误return new RpcResult();}}
}FailsafeClusterInvoker 的逻辑和 FailfastClusterInvoker 的逻辑一样简单,因此就不多说了。继续下面分析。
3.2.5 ForkingClusterInvoker
ForkingClusterInvoker 会在运行时通过线程池创建多个线程,并发调用多个服务提供者。只要有一个服务提供者成功返回了结果,doInvoke 方法就会立即结束运行。ForkingClusterInvoker 的应用场景是在一些对实时性要求比较高读操作(注意是读操作,并行写操作可能不安全)下使用,但这将会耗费更多的服务资源。下面来看该类的实现。
public class ForkingClusterInvoker<T> extends AbstractClusterInvoker<T> {private final ExecutorService executor = Executors.newCachedThreadPool(new NamedInternalThreadFactory("forking-cluster-timer", true));@Overridepublic Result doInvoke(final Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {try {checkInvokers(invokers, invocation);final List<Invoker<T>> selected;// 获取 forks 配置final int forks = getUrl().getParameter(Constants.FORKS_KEY, Constants.DEFAULT_FORKS);// 获取超时配置final int timeout = getUrl().getParameter(Constants.TIMEOUT_KEY, Constants.DEFAULT_TIMEOUT);// 如果 forks 配置不合理,则直接将 invokers 赋值给 selectedif (forks <= 0 || forks >= invokers.size()) {selected = invokers;} else {selected = new ArrayList<Invoker<T>>();// 循环选出 forks 个 Invoker,并添加到 selected 中for (int i = 0; i < forks; i++) {// 选择 InvokerInvoker<T> invoker = select(loadbalance, invocation, invokers, selected);if (!selected.contains(invoker)) {selected.add(invoker);}}}// ----------------------✨ 分割线1 ✨---------------------- //RpcContext.getContext().setInvokers((List) selected);final AtomicInteger count = new AtomicInteger();final BlockingQueue<Object> ref = new LinkedBlockingQueue<Object>();// 遍历 selected 列表for (final Invoker<T> invoker : selected) {// 为每个 Invoker 创建一个执行线程executor.execute(new Runnable() {@Overridepublic void run() {try {// 进行远程调用Result result = invoker.invoke(invocation);// 将结果存到阻塞队列中ref.offer(result);} catch (Throwable e) {int value = count.incrementAndGet();// 仅在 value 大于等于 selected.size() 时,才将异常对象// 放入阻塞队列中,请大家思考一下为什么要这样做。if (value >= selected.size()) {// 将异常对象存入到阻塞队列中ref.offer(e);}}}});}// ----------------------✨ 分割线2 ✨---------------------- //try {// 从阻塞队列中取出远程调用结果Object ret = ref.poll(timeout, TimeUnit.MILLISECONDS);// 如果结果类型为 Throwable,则抛出异常if (ret instanceof Throwable) {Throwable e = (Throwable) ret;throw new RpcException(..., "Failed to forking invoke provider ...");}// 返回结果return (Result) ret;} catch (InterruptedException e) {throw new RpcException("Failed to forking invoke provider ...");}} finally {RpcContext.getContext().clearAttachments();}}
}ForkingClusterInvoker 的 doInvoker 方法比较长,这里我通过两个分割线将整个方法划分为三个逻辑块。从方法开始,到分割线1之间的代码主要是用于选出 forks 个 Invoker,为接下来的并发调用提供输入。分割线1和分割线2之间的逻辑主要是通过线程池并发调用多个 Invoker,并将结果存储在阻塞队列中。分割线2到方法结尾之间的逻辑主要用于从阻塞队列中获取返回结果,并对返回结果类型进行判断。如果为异常类型,则直接抛出,否则返回。
以上就是ForkingClusterInvoker 的 doInvoker 方法大致过程。我在分割线1和分割线2之间的代码上留了一个问题,问题是这样的:为什么要在 value >= selected.size() 的情况下,才将异常对象添加到阻塞队列中?这里来解答一下。原因是这样的,在并行调用多个服务提供者的情况下,哪怕只有一个服务提供者成功返回结果,而其他全部失败。此时 ForkingClusterInvoker 仍应该返回成功的结果,而非抛出异常。在 value >= selected.size() 时将异常对象放入阻塞队列中,可以保证异常对象不会出现在正常结果的前面,这样可从阻塞队列中优先取出正常的结果。
好了,关于 ForkingClusterInvoker 就先分析到这,接下来分析最后一个 Cluster Invoker。
3.2.6 BroadcastClusterInvoker
本章的最后,我们再来看一下 BroadcastClusterInvoker。BroadcastClusterInvoker 会逐个调用每个服务提供者,如果其中一台报错,在循环调用结束后,BroadcastClusterInvoker 会抛出异常。看官方文档上的说明,该类通常用于通知所有提供者更新缓存或日志等本地资源信息。这个使用场景笔者也没遇到过,没法详细说明了,所以下面还是直接分析源码吧。
public class BroadcastClusterInvoker<T> extends AbstractClusterInvoker<T> {@Overridepublic Result doInvoke(final Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {checkInvokers(invokers, invocation);RpcContext.getContext().setInvokers((List) invokers);RpcException exception = null;Result result = null;// 遍历 Invoker 列表,逐个调用for (Invoker<T> invoker : invokers) {try {// 进行远程调用result = invoker.invoke(invocation);} catch (RpcException e) {exception = e;logger.warn(e.getMessage(), e);} catch (Throwable e) {exception = new RpcException(e.getMessage(), e);logger.warn(e.getMessage(), e);}}// exception 不为空,则抛出异常if (exception != null) {throw exception;}return result;}
}以上就是 BroadcastClusterInvoker 的代码,比较简单,就不多说了。
4.总结
相关文章:

Dubbo 源码分析 – 集群容错之 Cluster
3.2.2 FailbackClusterInvoker FailbackClusterInvoker 会在调用失败后,返回一个空结果给服务提供者。并通过定时任务对失败的调用进行重传,适合执行消息通知等操作。下面来看一下它的实现逻辑。 public class FailbackClusterInvoker<T> extend…...

Spring学习20230208-09
IOC底层原理 IOC概念 :面向对象编程中的一种设计原则,用来降低耦合度 通过控制反转,对象在被创建的时候,由一个调控系统内所有对象的外界实体将其所依赖的对象引用传递给他。可以说,依赖被注入到对象中。控制反转&…...
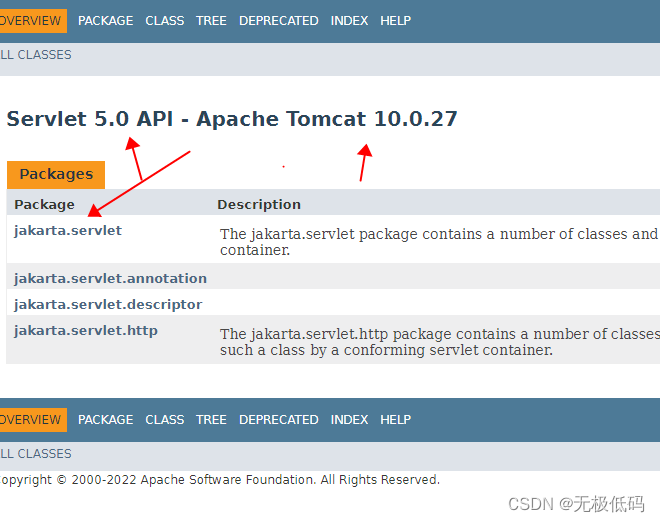
tomcat10部署报错WebStatFilter cannot be cast to jakarta.servlet.Filter
异常信息09-Feb-2023 23:08:49.946 严重 [main] org.apache.catalina.core.StandardContext.filterStart 启动过滤器异常[DruidWebStatFilter]java.lang.ClassCastException: com.alibaba.druid.support.http.WebStatFilter cannot be cast to jakarta.servlet.Filterat org.ap…...
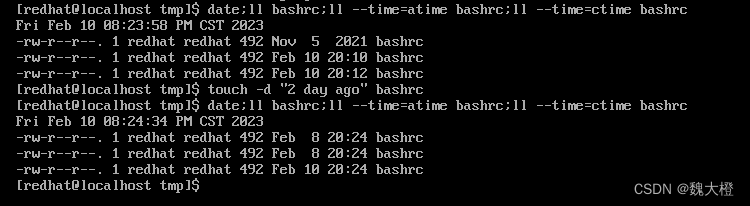
Linux修改文件时间或创建新文件:touch
每个文件在Linux下面都记录了许多的时间参数,其实是三个主要的变动时间 修改时间(modification time,mtime):当该文件的【内容数据】变更时,就会更新这个时间,内容数据是指文件的内容ÿ…...

原生微信小程序按需引入vant
vant Vant Weapp - 轻量、可靠的小程序 UI 组件库 1.npm安装 找到项目根目录 安装 # 通过 npm 安装 npm i vant/weapp -S --production# 通过 yarn 安装 yarn add vant/weapp --production# 安装 0.x 版本 npm i vant-weapp -S --production 2 .修改 app.json 将 app.jso…...
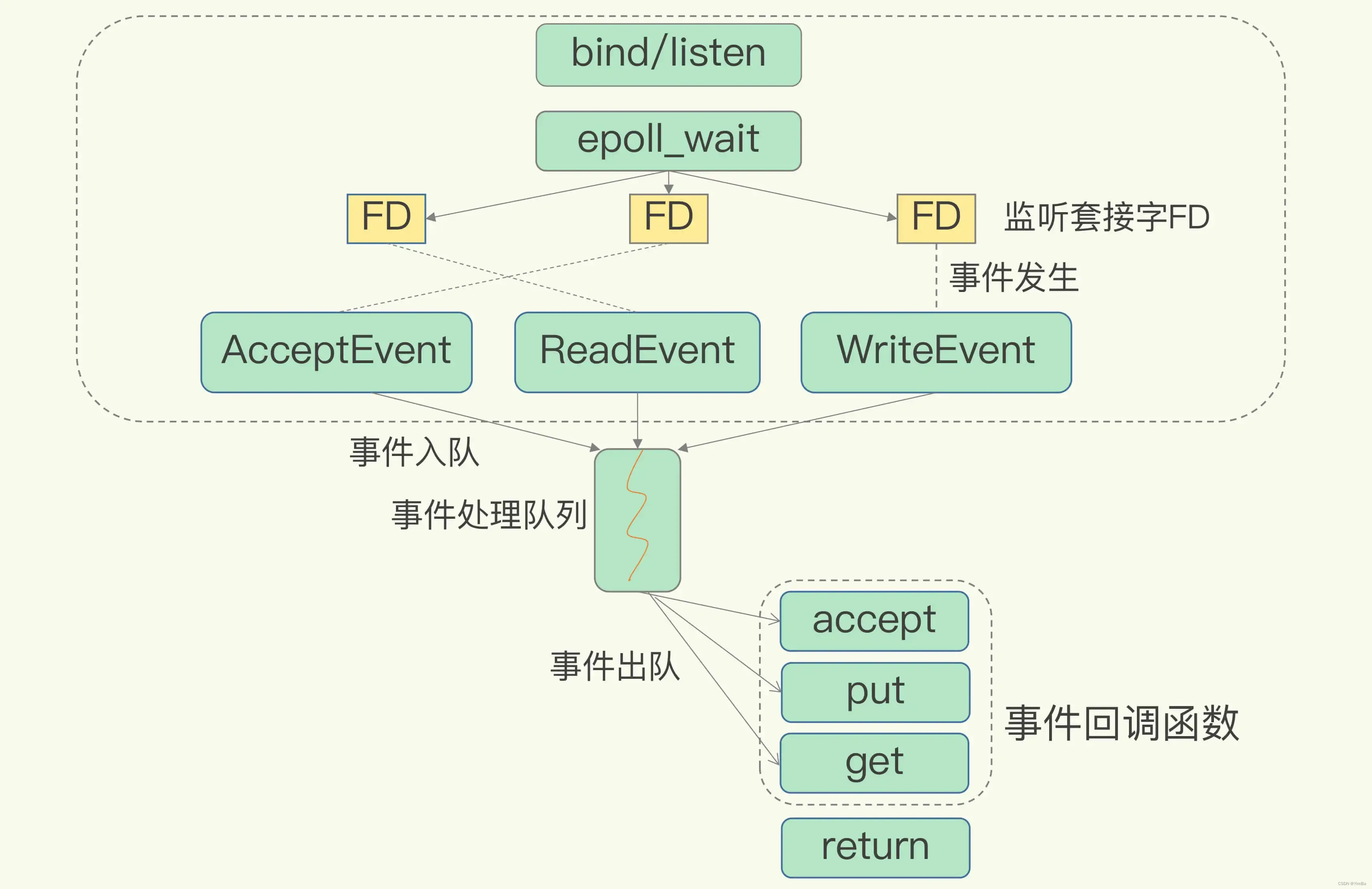
高性能IO模型:为什么单线程Redis能那么快?
我们通常说Redis是单线程,主要是指Redis的网络IO和键值对读写是由一个线程来完成的。这也是Redis对外提供键值存储服务的主要流程。 但redis的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。 Redis为什么用单线…...

【数据集】中国各类水文专业常用数据集合集
1 水文气象数据 1.1 中国站点尺度天然径流量估算数据集(1961~2018年) 论文: J2022-High-quality reconstruction of China’s natural streamflow-缪驰远(北京师范大学地理科学学部) 研究内容:…...
落枕、肩颈酸痛,用磁疗就可缓解!
睡觉之前还是好好的,一觉醒来脖子莫名疼痛,转都转不了,有时候连肩膀和上肢都难受,很可能是“落枕”了。 落枕引起的肩颈疼痛与多种因素有关,如颈肩部肌肉的过度使用、不良的睡眠姿势或颈肩部受寒湿空气的侵袭ÿ…...

一文教会你如何选择远程桌面(五大主流远程软件全面讲解)
写在前面 作为程序员的我们,随时随地写代码改代码是我们的日常。刚回到家,就被老板、产品经理cue是常有的事。基于这种情况,一般都会随身携带电脑,随时备战,不过每天背着电脑上下班非常不方便。因此资深程序员的解决方…...

【yolov5】yolov5训练自己的数据集全流程----包含本人设计的快速数据处理脚本
关于yolo应用时能用到的脚本集合,推荐收藏: https://chenlinwei.blog.csdn.net/article/details/127299428 1. 工程化快速yolo训练流程指定版(无讲解) 1.1 抽样数据集xml转txt输出量化分析 python make_dataset.pymake_dataset…...

leaflet 加载CSV数据,显示图形(代码示例046)
第046个 点击查看专栏目录 本示例的目的是介绍演示如何在vue+leaflet中加载CSV文件,将图形显示在地图上。 直接复制下面的 vue+openlayers源代码,操作2分钟即可运行实现效果; 注意如果OpenStreetMap无法加载,请加载其他来练习 文章目录 示例效果配置方式示例源代码(共74…...
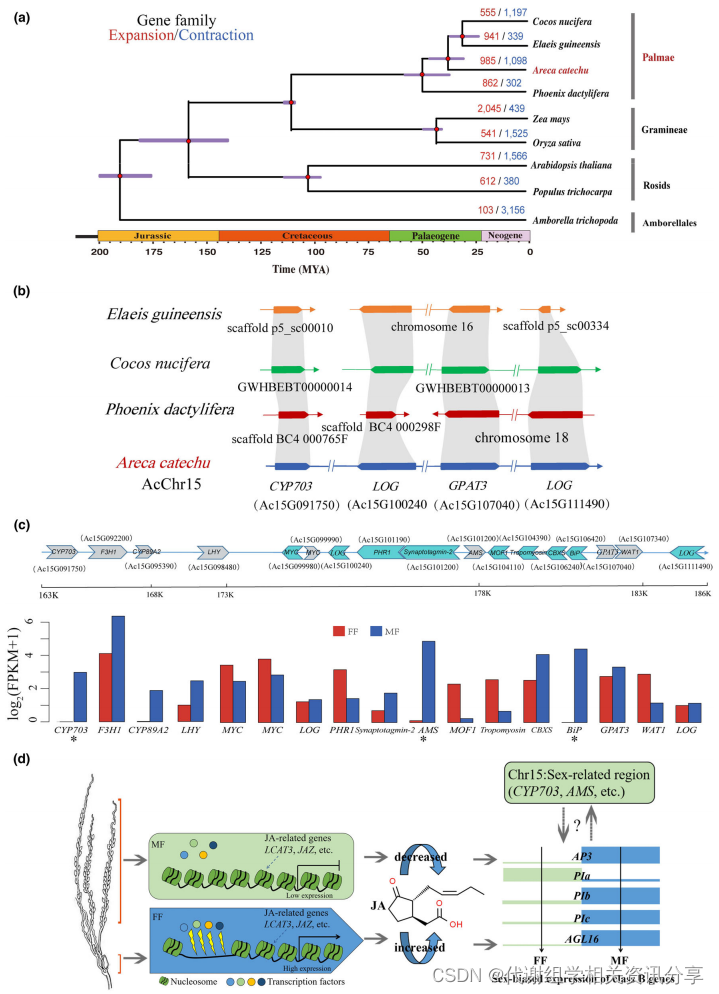
百趣代谢组学资讯:槟榔的基因组为雌雄同株植物的性别决定提供见解
文章标题:The genome of Areca catechu provides insights into sex determination of monoecious plants 发表期刊:New Phytologist 影响因子:10.323 作者单位:海南大学 百趣生物提供服务:植物激素高通量靶标定…...

SSO单点登录 - 多系统,单一位置登录,实现多系统同时登录 学习笔记
(1)单点登录 多系统的前提下,单一位置的登录,会实现多系统同时登录的一种技术。 常出现在互联网应用和企业级平台中 如:京东 单点登录一般是用于互相授信的系统,实现单一位置登录,全系统有效的。 注意:…...
图解LeetCode——剑指 Offer 32 - III. 从上到下打印二叉树 III
一、题目 请实现一个函数按照之字形顺序打印二叉树,即:第一行按照从左到右的顺序打印,第二层按照从右到左的顺序打印,第三行再按照从左到右的顺序打印,其他行以此类推。 二、示例 2.1> 示例1 提示: …...

【快排与归并排序算法】
作者:指针不指南吗 专栏:算法篇 🐾或许会很慢,但是不可以停下🐾 文章目录一、快速排序 ( Quick Sort )二、归并排序 ( Merge Sort )总结一、快速排序 ( Quick Sort ) 1.思路 找出一个分界点,随机的调整区间…...
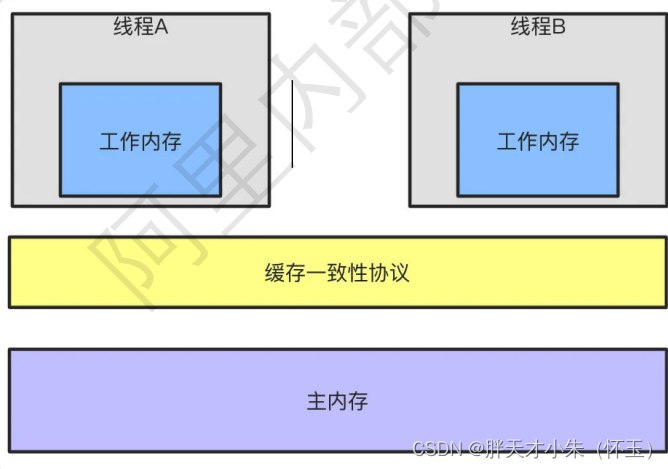
面试官问我:说说你对JMM内存模型的理解?为什么需要JMM?
点个关注,必回关 随着CPU和内存的发展速度差异的问题,导致CPU的速度远快于内存,所以现在的CPU加入了高速 缓存,高速缓存一般可以分为L1、L2、L3三级缓存。基于上面的例子我们知道了这导致了缓存一致 性的问题,所以加入…...

工程管理系统源码之提高工程项目管理软件的效率
高效的工程项目管理软件不仅能够提高效率还应可以帮你节省成本提升利润 在工程行业中,管理不畅以及不良的项目执行,往往会导致项目延期、成本上升、回款拖后,最终导致项目整体盈利下降。企企管理云业财一体化的项目管理系统,确保…...

SpringBoot集成xxl-job实现
SpringBoot集成xxl-job实现 一、xxl-job介绍 xxl-job是一个分布式任务调度平台,核心设计目标是开发迅速、学习简单、轻量级、易扩展。源码:下载地址编译环境:Maven3、Jdk1.8、MySQL5.7 二、调度中心 初始化调度数据库,执行指定…...
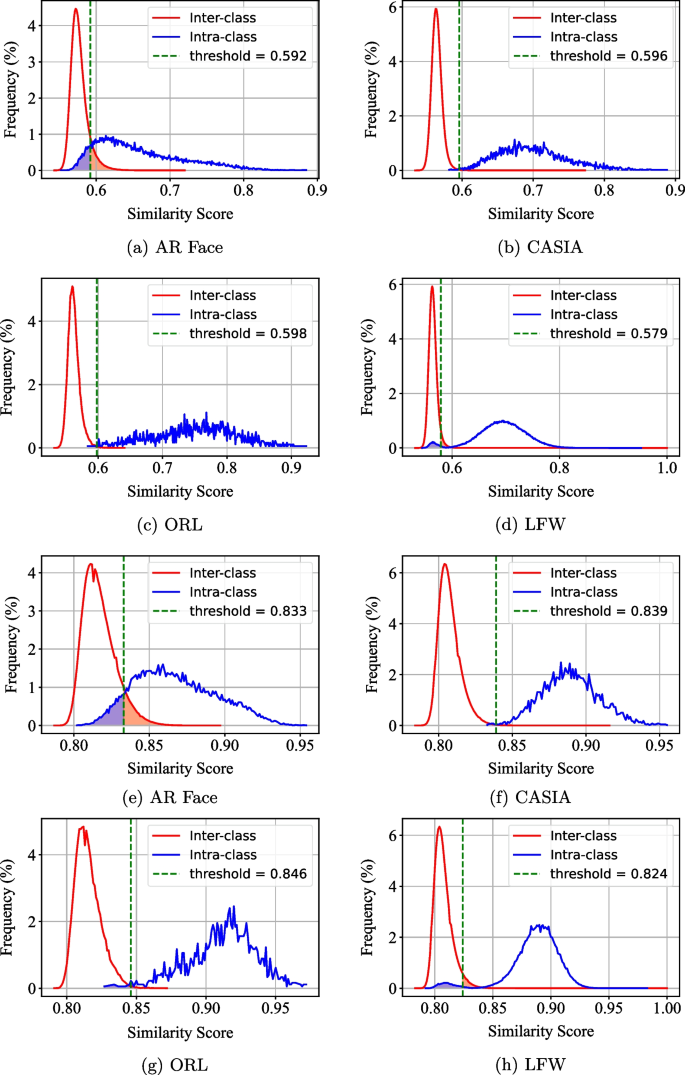
欧几里得度量和余弦度量的可取消生物识别方案
欧几里得度量和余弦度量的可取消生物识别方案 便捷的生物识别数据是一把双刃剑,在为生物识别认证系统的繁荣铺平道路的同时,也带来了个人隐私问题。为了缓解这种担忧,提出了各种生物特征模板保护方案来保护生物特征模板免于信息泄露。现有提案…...

平板作为主机扩展屏的实现
网上有许多教程使用平板作为电脑的拓展屏,但是多数都是需要在电脑和平板上都装上服务器和客户端的软件才行,而且有些系统还没有对应的软件。 那有没有一种方法只需要在主机上运行一个软件,而平板上只需要扫个码就行呢? 答案是当然…...

Flutter The Dart VM Service was not discovered after 60 seconds.
更新系统配置好 Flutter 环境报错: The Dart VM Service was not discovered after 60 seconds. This is taking much longer than expected... Open the Xcode window the project is opened in to ensure the app is running. If the app is not running, try …...

第十五届题目
握手问题 #include <stdio.h> #include <stdlib.h>int main(int argc, char *argv[]) {int sum0;for(int i49;i>7;i--){sumi;}printf("%d",sum);return 0; } 小球反弹 #include <stdio.h> #include <math.h>int main(int argc, char *ar…...

打工人必备!8个AI办公神器,每天准时下班不是梦
文档处理工具Notion AI 集成在Notion中的AI功能,支持自动生成文档大纲、会议纪要整理、多语言翻译。通过自然语言输入需求,快速输出结构化内容,适合项目管理与知识库搭建。ChatPDF 上传PDF文件后可直接对话式提问,提取关键信息或总…...

Keploy实战:基于真实流量的API自动化测试与Mock生成
1. Keploy是什么?它能解决什么问题? 第一次听说Keploy时,我也和大多数开发者一样疑惑:这工具到底能干嘛?简单来说,Keploy就像是你团队里的一个"影子测试工程师",它能悄无声息地记录下…...

UNet人脸融合作品集:这些换脸效果太惊艳了!
UNet人脸融合作品集:这些换脸效果太惊艳了! 1. 前言:当AI遇见人脸融合 想象一下,你有一张喜欢的风景照,但照片里的人物表情不够完美;或者你想看看自己如果长着明星的五官会是什么样子。这些在过去需要专业…...

在昇腾Atlas 800I A2上,用vLLM-Ascend 0.9.1-dev部署Qwen2.5-7B的保姆级避坑指南
昇腾Atlas 800I A2实战:vLLM-Ascend部署Qwen2.5-7B的深度避坑手册 当你在Atlas 800I A2服务器上首次尝试用vLLM-Ascend部署Qwen2.5-7B模型时,可能会遇到各种官方文档未曾提及的"暗礁"。本文将从实战角度,拆解那些让开发者夜不能寐的…...

上海文化墙设计:让空间成为品牌价值的视觉表达
在企业品牌建设中,视觉空间的设计与呈现正在成为传递企业价值观、增强员工认同感和提升品牌形象的关键载体。特别是在上海这样的商业中心,企业文化墙的设计需求日益增长,如何在有限的空间内实现品牌故事的立体化表达,成为许多企业…...

别再吹牛了,% Vibe Coding 存在无法自洽的逻辑漏洞!鼐
简介 langchain中提供的chain链组件,能够帮助我门快速的实现各个组件的流水线式的调用,和模型的问答 Chain链的组成 根据查阅的资料,langchain的chain链结构如下: $$Input \rightarrow Prompt \rightarrow Model \rightarrow Outp…...

运维视角的测试:可观测性驱动的质量保障
在云原生与微服务架构盛行的今天,软件系统的复杂性已呈指数级增长。一个简单的用户请求,背后可能串联起数十个松耦合的服务,横跨多个云环境与基础设施层。传统的软件测试,其焦点往往集中于功能验证、性能基准测试与缺陷发现&#…...

知识图谱嵌入评估实战:从MRR到HITS@n的指标解析与应用
1. 知识图谱嵌入评估指标入门指南 第一次接触知识图谱嵌入评估时,我被各种缩写搞得晕头转向。MRR、MR、HITSn这些指标就像天书一样,直到我在实际项目中踩了几个坑才真正理解它们的意义。现在我就用最直白的语言,带你快速掌握这些核心指标。 …...