Python 之 Pandas 分组操作详解和缺失数据处理
文章目录
- 一、groupby 分组操作详解
- 1. Groupby 的基本原理
- 2. agg 聚合操作
- 3. transform 转换值
- 4. apply
- 二、pandas 缺失数据处理
- 1. 缺失值类型
- 1.1 np.nan
- 1.2 None
- 1.3 NA 标量
- 2. 缺失值处理
- 2.1 查看缺失值的情形
- 2.2 缺失值的判断
- 2.3 删除缺失值
- 2.4 缺失值填充
- 在开始之前,我们需要先把 pandas、numpy 等一些必备的库导入。
import pandas as pd
import numpy as np
from datetime import datetime
一、groupby 分组操作详解
- 在数据分析中,我们经常会遇到这样的情况:根据某一列(或多列)标签把数据划分为不同的组别,然后再对其进行数据分析。
- 比如,某网站对注册用户的性别或者年龄等进行分组,从而研究出网站用户的画像(特点)。在 Pandas 中,要完成数据的分组操作,需要使用 groupby() 函数,它和 SQL 的 GROUP BY 操作非常相似。
- 在划分出来的组(group)上应用一些统计函数,从而达到数据分析的目的,比如对分组数据进行聚合、转换,或者过滤。这个过程主要包含以下三步:
- (1) 拆分(Spliting):表示对数据进行分组;
- (2) 应用(Applying):对分组数据应用聚合函数,进行相应计算;
- (3) 合并(Combining):最后汇总计算结果。
- 例如,我们模拟生成的 10 个样本数据,代码和数据如下:
company=["A","B","C"]
data=pd.DataFrame({"company":[company[x] for x in np.random.randint(0,len(company),10)],"salary":np.random.randint(5,50,10),"age":np.random.randint(15,50,10)}
)
data
#company salary age
#0 A 32 18
#1 A 30 29
#2 B 34 38
#3 C 44 37
#4 B 30 31
#5 C 28 19
#6 A 44 26
#7 A 6 34
#8 B 48 18
#9 A 37 33
1. Groupby 的基本原理
- 在 pandas 中,实现分组操作的代码很简单,仅需一行代码,在这里,将上面的数据集按照 company 字段进行划分:
group = data.groupby("company")
group
#<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001E9B57A3C88>
- 将上述代码输入 ipython 后,会得到一个 DataFrameGroupBy 对象。
- 那这个生成的 DataFrameGroupBy 是啥呢?对 data 进行了 groupby 后发生了什么?
- ipython 所返回的结果是其内存地址,并不利于直观地理解,为了看看 group 内部究竟是什么,这里把 group 转换成 list 的形式来看一看:
list(group)
#[('A',
# company salary age
# 0 A 32 18
# 1 A 30 29
# 6 A 44 26
# 7 A 6 34
# 9 A 37 33),
# ('B',
# company salary age
# 2 B 34 38
# 4 B 30 31
# 8 B 48 18),
# ('C',
# company salary age
# 3 C 44 37
# 5 C 28 19)]
– 转换成列表的形式后,可以看到,列表由三个元组组成,每个元组中,第一个元素是组别(这里是按照 company 进行分组,所以最后分为了 A,B,C),第二个元素的是对应组别下的 DataFrame,整个过程可以图解如下:
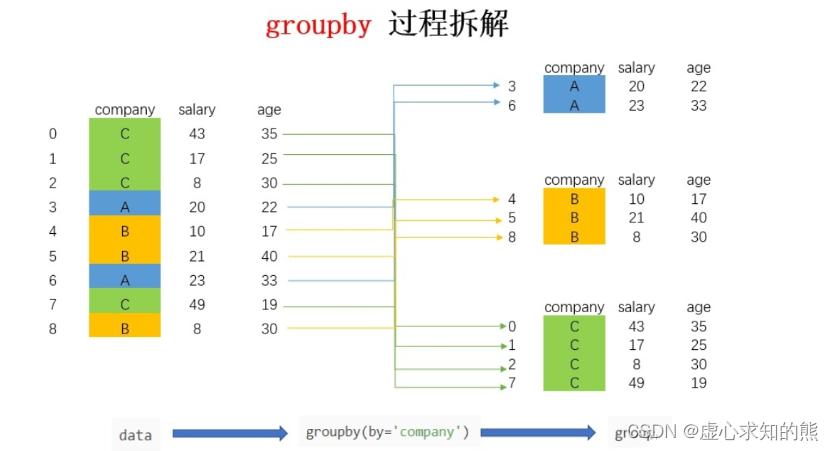
- 总结来说,groupby 的过程就是将原有的 DataFrame 按照 groupby 的字段(这里是 company),划分为若干个分组 DataFrame,被分为多少个组就有多少个分组 DataFrame。所以说,在 groupby 之后的一系列操作(如 agg、apply 等),均是基于子 DataFrame 的操作。
2. agg 聚合操作
- 聚合(Aggregation)操作是 groupby 后非常常见的操作,会写 SQL 的朋友对此应该是非常熟悉了。聚合操作可以用来求和、均值、最大值、最小值等,下面的表格列出了 Pandas 中常见的聚合操作。
| 函数 | 用途 |
|---|---|
| min | 最小值 |
| max | 最大值 |
| sum | 求和 |
| mean | 均值 |
| median | 中位数 |
| std | 标准差 |
| var | 方差 |
| count | 计数 |
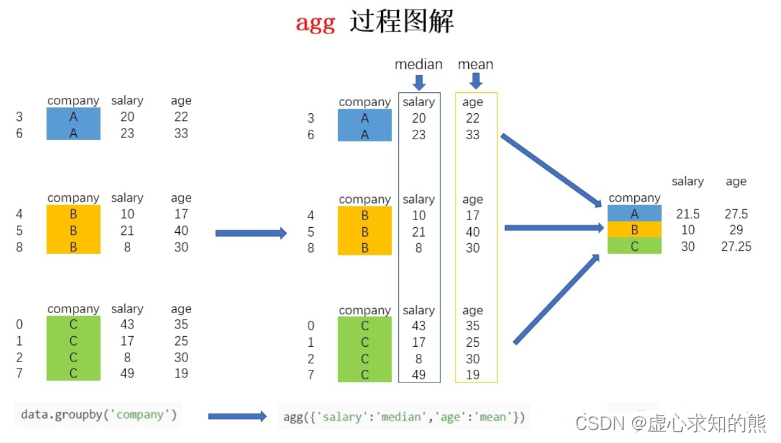
- 针对样例数据集,如果我们想求不同公司员工的平均年龄和平均薪水,可以按照下方的代码进行:
- 以 company 进行分组操作,聚合操作选择 mean 平均值。
data.groupby("company").agg('mean')
salary age
#company
#A 29.800000 28.0
#B 37.333333 29.0
#C 36.000000 28.0
- 如果想对针对不同的列求不同的值,比如要计算不同公司员工的平均年龄以及薪水的中位数,可以利用字典进行聚合操作的指定:
data.groupby('company').agg({'salary':'median','age':'mean'})
salary age
#company
#A 32 28
#B 34 29
#C 36 28
3. transform 转换值
- 在上面的 agg 中,我们学会了如何求不同公司员工的平均薪水,如果现在需要在原数据集中新增一列 avg_salary,代表员工所在的公司的平均薪水(相同公司的员工具有一样的平均薪水),该怎么实现呢?
- 如果按照正常的步骤来计算,需要先求得不同公司的平均薪水,然后按照员工和公司的对应关系填充到对应的位置,不用 transform 的话,需要使用 to_dict 将表格中的数据转换成字典格式。
avg_salary_dict= data.groupby('company')['salary'].mean().to_dict()
avg_salary_dict
#{'A': 29.8, 'B': 37.333333333333336, 'C': 36.0}
- map() 函数可以用于 Series 对象或 DataFrame 对象的一列,接收函数作为或字典对象作为参数,返回经过函数或字典映射处理后的值。
data['avg_salary'] = data['company'].map(avg_salary_dict)
data
#company salary age avg_salary
#0 A 32 18 29.800000
#1 A 30 29 29.800000
#2 B 34 38 37.333333
#3 C 44 37 36.000000
#4 B 30 31 37.333333
#5 C 28 19 36.000000
#6 A 44 26 29.800000
#7 A 6 34 29.800000
#8 B 48 18 37.333333
#9 A 37 33 29.800000
- 但是,如果我们使用 transform 的话,仅需要一行代码:
data['avg_salary1'] = data.groupby('company')['salary'].transform('mean')
data
#company salary age avg_salary avg_salary1
#0 A 32 18 29.800000 29.800000
#1 A 30 29 29.800000 29.800000
#2 B 34 38 37.333333 37.333333
#3 C 44 37 36.000000 36.000000
#4 B 30 31 37.333333 37.333333
#5 C 28 19 36.000000 36.000000
#6 A 44 26 29.800000 29.800000
#7 A 6 34 29.800000 29.800000
#8 B 48 18 37.333333 37.333333
#9 A 37 33 29.800000 29.800000
- 还是以图解的方式来看看进行 groupby 后 transform 的实现过程(为了更直观展示,图中加入了 company 列,实际按照上面的代码只有 salary 列):
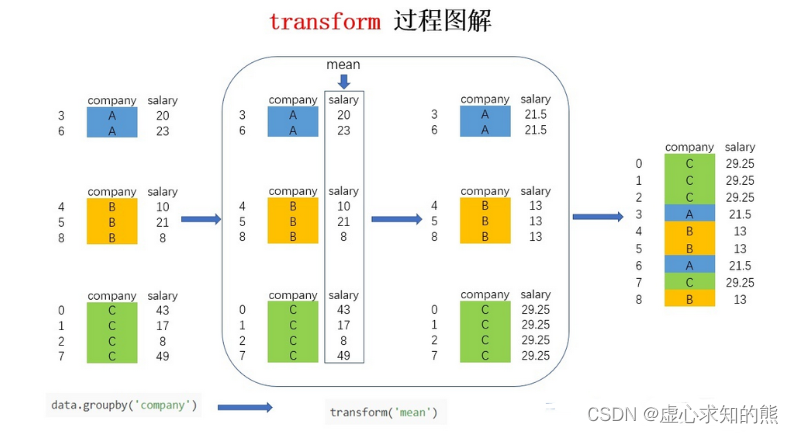
- 图中的大方框是 transform 和 agg 所不一样的地方,对 agg 而言,会计算得到 A,B,C 公司对应的均值并直接返回,但对 transform 而言,则会对每一条数据求得相应的结果,同一组内的样本会有相同的值,组内求完均值后会按照原索引的顺序返回结果。
4. apply
- 它相比 agg 和 transform 而言更加灵活,能够传入任意自定义的函数,实现复杂的数据操作。
- 对于 groupby 后的 apply,以分组后的子 DataFrame 作为参数传入指定函数的,基本操作单位是 DataFrame。
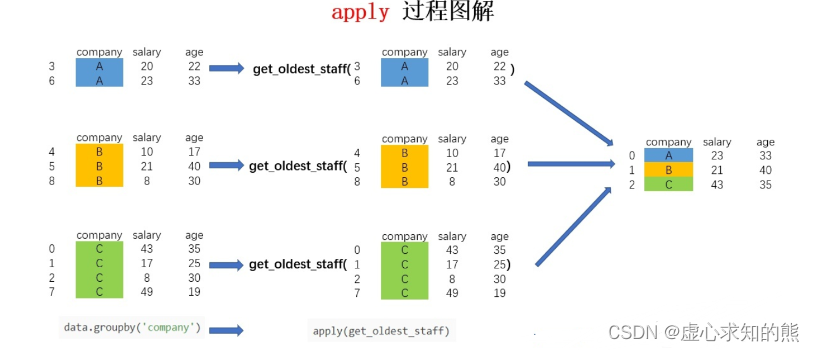
- 假设我现在需要获取各个公司年龄最大的员工的数据,该怎么实现呢?可以用以下代码实现:
def get_oldest_staff(x): df = x.sort_values(by = 'age',ascending=True) return df.iloc[-1,:]
oldest_staff = data.groupby('company',as_index=False).apply(get_oldest_staff)
oldest_staff
#company salary age avg_salary avg_salary1
#company
#A A 6 34 29.800000 29.800000
#B B 34 38 37.333333 37.333333
#C C 44 37 36.000000 36.000000
- 这样便得到了每个公司年龄最大的员工的数据,整个流程图解如下:
- 虽然说 apply 拥有更大的灵活性,但 apply 的运行效率会比 agg 和 transform 更慢。所以,groupby 之后能用 agg 和 transform 解决的问题还是优先使用这两个方法。
二、pandas 缺失数据处理
- 在一些数据分析业务中,数据缺失是我们经常遇见的问题,缺失值会导致数据质量的下降,从而影响模型预测的准确性, 这对于机器学习和数据挖掘影响尤为严重。因此妥善的处理缺失值能够使模型预测更为准确和有效。
- 稀疏数据,指的是在数据库或者数据集中存在大量缺失数据或者空值,我们把这样的数据集称为稀疏数据集。稀疏数据不是无效数据,只不过是信息不全而已,只要通过适当的方法就可以变废为宝。
- 稀疏数据的来源与产生原因有很多种,大致归为以下几种:
- (1) 由于调查不当产生的稀疏数据。
- (2) 由于天然限制产生的稀疏数据。
- (3) 文本挖掘中产生的稀疏数据。
1. 缺失值类型
- 在 pandas 中,缺失数据显示为 NaN。缺失值有 3 种表示方法:np.nan,None,pd.NA。
1.1 np.nan
- 缺失值有个特点,它不等于任何值,连自己都不相等。如果用 nan 和任何其它值比较都会返回 nan。
np.nan == np.nan
#False
- 也正由于这个特点,在数据集读入以后,不论列是什么类型的数据,默认的缺失值全为 np.nan。
- 因为 nan 在 Numpy 中的类型是浮点,因此整型列会转为浮点;而字符型由于无法转化为浮点型,只能归并为 object 类型(‘O’),原来是浮点型的则类型不变。
- 我们可以通过代码来观察 np.nan 的数据类型。
type(np.nan)
#float
- np.nan 可以将整型列转换为浮点型。
pd.Series([1,np.nan,3]).dtype
#dtype('float64')
- 除此之外,还要介绍一种针对时间序列的缺失值,它是单独存在的,用 NaT 表示,是 pandas 的内置类型,可以视为时间序列版的 np.nan,也是与自己不相等。
- 我们先生成最初的数据,三个 20220101。
s_time = pd.Series([pd.Timestamp('20220101')]*3)
s_time
#0 2022-01-01
#1 2022-01-01
#2 2022-01-01
#dtype: datetime64[ns]
- 将第三个 20220101 设置为 np.nan。
s_time[2] = np.nan
s_time
#0 2022-01-01
#1 2022-01-01
#2 NaT
#dtype: datetime64[ns]
1.2 None
- 还有一种就是 None,它要比 nan 好那么一点,因为它至少自己与自己相等。
None == None
#True
- 在传入数值类型后,会自动变为 np.nan。
pd.Series([1,None])
#0 1.0
#1 NaN
#dtype: float64
1.3 NA 标量
- pandas1.0 以后的版本中引入了一个专门表示缺失值的标量 pd.NA,它代表空整数、空布尔值、空字符。
- 对于不同数据类型采取不同的缺失值表示会很乱。pd.NA 就是为了统一而存在的。 pd.NA 的目标是提供一个缺失值指示器,可以在各种数据类型中一致使用(而不是 np.nan、None 或者 NaT 分情况使用)。
- 我们可以先生成初始数据。
s_new = pd.Series([1, 2], dtype="Int64")
s_new
#0 1
#1 2
#dtype: Int64
- 我们将第二个数设置为 pd.NA,发现整体的数据类型并没有发生改变。
s_new[1] = pd.NA
s_new
#0 1
#1 <NA>
#dtype: Int64
- 下面是 pd.NA 的一些常用算术运算和比较运算的示例:
# 加法
print("pd.NA + 1 :\t", pd.NA + 1)
# 乘法
print('"a" * pd.NA:\t', "a" * pd.NA)
# 以下两种其中结果为1
print("pd.NA ** 0 :\t", pd.NA ** 0)
print("1 ** pd.NA:\t", 1 ** pd.NA)##### 比较运算
print("pd.NA == pd.NA:\t", pd.NA == pd.NA)
print("pd.NA < 2.5:\t", pd.NA < 2.5)
print("np.add(pd.NA, 1):\t", np.add(pd.NA, 1))
2. 缺失值处理
- 对于缺失值一般有 2 种处理方式,要么删除,要么填充(用某个值代替缺失值)。 缺失值一般分 2 种,一种是某一列的数据缺失;另一种是整行数据都缺失,即一个空行。
- 本次所用到的 Excel 表格内容如下:
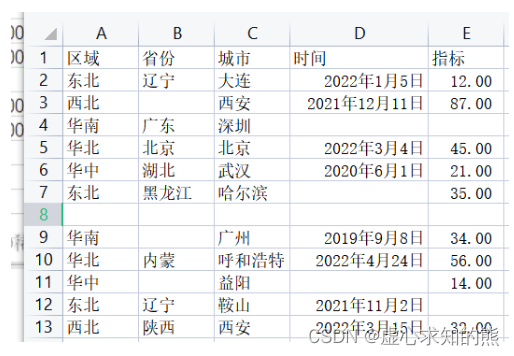
- 在最开始,我们先对 Excel 表格的内容进行读取。
df = pd.read_excel(r"data\data_test.xlsx")
- 从结果来看,每一列均有缺失值。这里特别注意,时间日期类型的数据缺失值用 NaT 表示,其他类型的都用 NaN 来表示。
2.1 查看缺失值的情形
我们可以使用 df.info() 来得知数据集各列的数据类型,是否为空值,内存占用情况。
df.info()
- 从结果来看,省份这一列是 8 non-null,说明省份这一列有 4 个 null 值。同理,时间这一列有 4 个缺失值,指标这一列有 3 个缺失值,城市这一列有 1 个缺失值,区域这一列有 1 个缺失值。
2.2 缺失值的判断
- 关于缺失值的判断,我们通过使用 isnull() 来判断具体的某个值是否是缺失值,如果是则返回 True,反之则为 False。
df.isnull()
2.3 删除缺失值
- 我们可以通过 dropna() 函数对缺失值进行删除,其语法模板如下:
df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
- 其中,axis:{0或’index’,1或’columns’},默认为 0 确定是否删除了包含缺少值的行或列。
- 0 或索引表示删除包含缺少值的行;1 或列表示删除包含缺少值的列。
- how:{‘any’,‘all’},默认为 any 确定是否从 DataFrame 中删除行或列,至少存在一个 NA 或所有 NA。
- any 表示如果存在任何 NA 值,请删除该行或列;all 表示如果所有值都是 NA,则删除该行或列。
- thresh: int 需要至少非 NA 值数据个数。
- subset 表示定义在哪些列中查找缺少的值。
- inplace 表示是否更改源数据。
- 我们先生成初始数据,用于后续的操作观察。
df = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],"toy": [np.nan, 'Batmobile', 'Bullwhip'],"born": [pd.NaT, pd.Timestamp("1940-04-25"), pd.NaT]})
df
#name toy born
#0 Alfred NaN NaT
#1 Batman Batmobile 1940-04-25
#2 Catwoman Bullwhip NaT
- 我们删除至少缺少一个元素的行(axis 默认是行,how 默认是删除至少存在一个)。
df.dropna()
#name toy born
#1 Batman Batmobile 1940-04-25
- 我们删除至少缺少一个元素的列。
df.dropna(axis='columns')
#name
#0 Alfred
#1 Batman
#2 Catwoman
- 我们删除缺少所有元素的行。
df.dropna(how='all')
#name toy born
#0 Alfred NaN NaT
#1 Batman Batmobile 1940-04-25
#2 Catwoman Bullwhip NaT
- 我们仅保留至少有 2 个非 NA 值的行。
df.dropna(thresh=2)
#name toy born
#1 Batman Batmobile 1940-04-25
#2 Catwoman Bullwhip NaT
- 我们定义在哪些列中查找缺少的值。
df.dropna(subset=['toy'])
#name toy born
#1 Batman Batmobile 1940-04-25
#2 Catwoman Bullwhip NaT
- 我们在同一个变量中保留操作数据(会对初始数据造成影响)。
df.dropna(inplace=True)
df
#name toy born
#1 Batman Batmobile 1940-04-25
2.4 缺失值填充
- 一般有用 0 填充,用平均值填充,用众数填充(大多数时候用这个),众数是指一组数据中出现次数最多的那个数据,一组数据可以有多个众数,也可以没有众数。
- 也可以向前填充(用缺失值的上一行对应字段的值填充,比如 D3 单元格缺失,那么就用 D2 单元格的值填充),或者向后填充(与向前填充对应)等方式。
- 其语法模板如下:
df.fillna(value=None,method=None,axis=None,inplace=False,limit=None,downcast=None)
- 其参数含义如下:
- value表示用于填充的值(例如 0),或者是一个 dict/Series/DataFrame 值,指定每个索引(对于一个系列)或列(对于一个数据帧)使用哪个值。不在 dict/Series/DataFrame 中的值将不会被填充。此值不能是列表。
- method 当中,ffill 表示将上一个有效观察值向前传播,bfill 表示将下一个有效观察值向后传播。
- axis 表示用于填充缺失值的轴。
- inplace 表示是否操作源数据。
- limit 表示要向前/向后填充的最大连续 NaN 值数。
- 我们先设定初始数据。
df = pd.DataFrame([[np.nan, 2, np.nan, 0],[3, 4, np.nan, 1],[np.nan, np.nan, np.nan, np.nan],
[np.nan, 3, np.nan, 4]],columns=list("ABCD"))
df
#A B C D
#0 NaN 2.0 NaN 0.0
#1 3.0 4.0 NaN 1.0
#2 NaN NaN NaN NaN
#3 NaN 3.0 NaN 4.0
- 我们可以将所有 NaN 元素替换为 0。
df.fillna(0)
#A B C D
#0 0.0 2.0 0.0 0.0
#1 3.0 4.0 0.0 1.0
#2 0.0 0.0 0.0 0.0
#3 0.0 3.0 0.0 4.0
- 我们可以向前或传播非空值。
df.fillna(method="ffill")
#A B C D
#0 NaN 2.0 NaN 0.0
#1 3.0 4.0 NaN 1.0
#2 3.0 4.0 NaN 1.0
#3 3.0 3.0 NaN 4.0
- 我们可以向后或传播非空值。
df.fillna(method="bfill")A B C D
#0 3.0 2.0 NaN 0.0
#1 3.0 4.0 NaN 1.0
#2 NaN 3.0 NaN 4.0
#3 NaN 3.0 NaN 4.0
- 我们将列 A、B、C 和 D 中的所有 NaN 元素分别替换为 0、1、2 和 3。
values = {"A": 0, "B": 1, "C": 2, "D": 3}
df.fillna(value=values)
#A B C D
#0 0.0 2.0 2.0 0.0
#1 3.0 4.0 2.0 1.0
#2 0.0 1.0 2.0 3.0
#3 0.0 3.0 2.0 4.0
- 我们可以只替换每列的第一个 NaN 元素。
df.fillna(0, limit=1)
#A B C D
#0 0.0 2.0 0.0 0.0
#1 3.0 4.0 NaN 1.0
#2 NaN 0.0 NaN 0.0
#3 NaN 3.0 NaN 4.0
- 当我们使用数据填充时,替换会沿着相同的列名和索引进行。对此,我们生成一个与初始数据具有部分相同的行标签和列标签的数据。
df2 = pd.DataFrame(np.random.rand(4,4), columns=list("ABCE"))
df2
#A B C E
#0 0.475937 0.169003 0.789308 0.772291
#1 0.554005 0.033041 0.732128 0.052256
#2 0.477042 0.375870 0.757475 0.794198
#3 0.912261 0.366646 0.730202 0.231903
- 我们用 df2 中的数据来填充 df1 中的空缺值。
df.fillna(value=df2)
# A B C D
#0 0.475937 2.00000 0.789308 0.0
#1 3.000000 4.00000 0.732128 1.0
#2 0.477042 0.37587 0.757475 NaN
#3 0.912261 3.00000 0.730202 4.0
- 这里需要注意的是,D 列不受影响,因为 df2 中不存在 D 列。
相关文章:
Python 之 Pandas 分组操作详解和缺失数据处理
文章目录一、groupby 分组操作详解1. Groupby 的基本原理2. agg 聚合操作3. transform 转换值4. apply二、pandas 缺失数据处理1. 缺失值类型1.1 np.nan1.2 None1.3 NA 标量2. 缺失值处理2.1 查看缺失值的情形2.2 缺失值的判断2.3 删除缺失值2.4 缺失值填充在开始之前ÿ…...

【人工智能 AI】什么是人工智能? What is Artificial Intelligence
目录 Introduction to Artificial Intelligence人工智能概论 What is Artificial Intelligence? 什么是人工智能?...

17、触发器
文章目录1 触发器概述2 触发器的创建2.1 创建触发器语法2.2 代码举例3 查看、删除触发器3.1 查看触发器3.2 删除触发器4 触发器的优缺点4.1 优点4.2 缺点4.3 注意点尚硅谷MySQL数据库教程-讲师:宋红康 我们缺乏的不是知识,而是学而不厌的态度 在实际开发…...

内核并发消杀器(KCSAN)技术分析
一、KCSAN介绍KCSAN(Kernel Concurrency Sanitizer)是一种动态竞态检测器,它依赖于编译时插装,并使用基于观察点的采样方法来检测竞态,其主要目的是检测数据竞争。KCSAN是一种检测LKMM(Linux内核内存一致性模型)定义的数据竞争(data race)的工…...

蓄水池抽样算法
蓄水池抽样,也称水塘抽样,是随机抽样算法的一种。基本抽样问题有一批数据(假设为一个数组,可以逐个读取),要从中随机抽取一个数字,求抽得的数字下标。常规的抽样方法是,先读取所有的…...

数据结构预算法之买股票最好时机动态规划(可买卖多次)
一.题目二.思路在动规五部曲中,这个区别主要是体现在递推公式上,其他都和上一篇文章思路是一样的。所以我们重点讲一讲递推公式。这里重申一下dp数组的含义:dp[i][0] 表示第i天持有股票所得现金。dp[i][1] 表示第i天不持有股票所得最多现金如…...
)
华为OD机试真题Java实现【蛇形矩阵】真题+解题思路+代码(20222023)
蛇形矩阵 蛇形矩阵是由1开始的自然数依次排列成的一个矩阵上三角形。 例如,当输入5时,应该输出的三角形为: 1 3 6 10 15 2 5 9 14 4 8 13 7 12 11请注意本题含有多组样例输入。 🔥🔥🔥🔥🔥👉👉👉👉👉👉 华为OD机试(Java)真题目录汇总 输入描述:…...
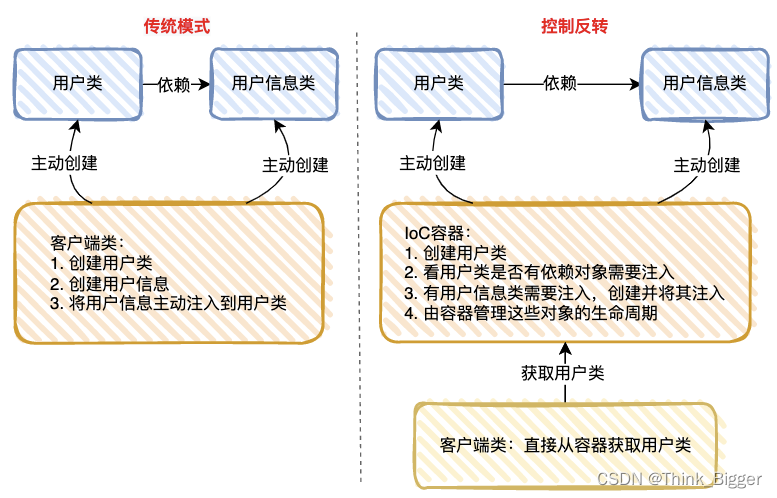
spring Bean的生命周期 IOC
文章目录 1. 基础知识1.1 什么是 IoC ?2. 扩展方法3. 源码入口1. 基础知识 1.1 什么是 IoC ? IoC,控制反转,想必大家都知道,所谓的控制反转,就是把 new 对象的权利交给容器,所有的对象都被容器控制,这就叫所谓的控制反转。 IoC 很好地体现了面向对象设计法则之一 —…...

详解cors跨域
文章目录同源策略cors基本概念cors跨域方式简单请求 simple request非简单请求- 预检请求CORS兼容情况CORS总结同源策略 在以前的一篇博客中有介绍,同源策略是一种安全机制,为了预防某些恶意的行为,限制浏览器从不同源文档和脚本进行交互的行…...
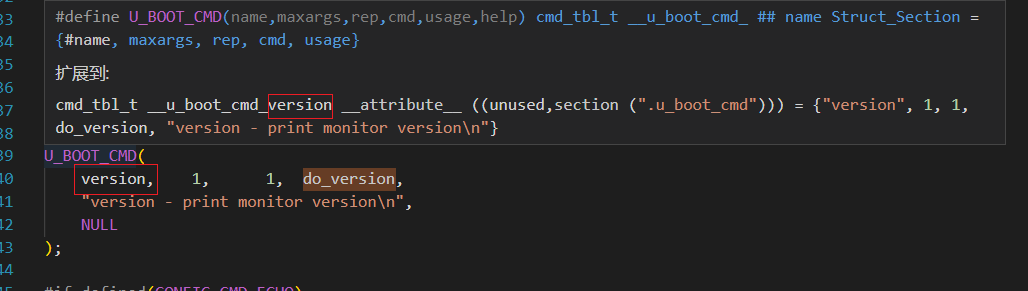
ARM uboot 源码分析7 - uboot的命令体系
一、uboot 命令体系基础 1、使用 uboot 命令 (1) uboot 启动后进入命令行环境下,在此输入命令按回车结束,uboot 会收取这个命令然后解析,然后执行。 2、uboot 命令体系实现代码在哪里 (1) uboot 命令体系的实现代码在 uboot/common/cmd_xx…...

物理服务器与云服务器备份相同吗?
自从云计算兴起以来,服务器备份已经从两阶段的模拟操作演变为由云服务器备份软件执行的复杂的多个过程。但是支持物理服务器和虚拟服务器之间的备份相同吗?主要区别是什么?我们接下来将详细讨论这个问题。 物理服务器与云服务器备份的区别 如果您不熟悉虚拟服务器…...

【Linux】system V共享内存 | 消息队列 | 信号量
🌠 作者:阿亮joy. 🎆专栏:《学会Linux》 🎇 座右铭:每个优秀的人都有一段沉默的时光,那段时光是付出了很多努力却得不到结果的日子,我们把它叫做扎根 目录👉system V共…...

FSC的宣传许可 答疑
【FSC的宣传许可 答疑】问:已经采购了认证产品但没有贴FSC标签,是否可以申请宣传许可?答:不可以。要宣传您采用了FSC认证产品的前提条件之一是产品必须是认证且贴有标签的。如果产品没有贴标,则不可申请宣传许可。您的…...

Leetcode力扣秋招刷题路-0100
从0开始的秋招刷题路,记录下所刷每道题的题解,帮助自己回顾总结 100. 相同的树 给你两棵二叉树的根节点 p 和 q ,编写一个函数来检验这两棵树是否相同。 如果两个树在结构上相同,并且节点具有相同的值,则认为它们是…...

协作对象死锁及其解决方案
协作对象死锁及其解决方案 1.前言 在遇到转账等的需要保证线程安全的情况时,我们通常会使用加锁的方式来保证线程安全,但如果无法合理的使用锁,很可能导致死锁。或者有时我们使用线程池来进行资源的使用,如调用数据库࿰…...

良许也成为砖家啦~
大家好,我是良许。 没错,良许成为砖家啦,绝不是口嗨,有图有真相! 有人会说,咦,这明明是严宇啊,跟你良许有啥关系? 额。。老读者应该知道良许的来历—— 鄙人真名严宇&a…...

Java中的编程细节
前言: 学习过程中有不少时候遇到一些看似简单,做起来事倍功半的问题。我也想自己是个聪明人,学东西一听就懂,一学就会,马上就能灵活应用。但这种事不能强求,要么自己要看个十遍二十遍最后理清逻辑…...
 环境搭建)
Yolov8从pytorch到caffe (一) 环境搭建
Yolov8从pytorch到caffe (一) 环境搭建 1. 创建虚拟环境2. 安装pytorch与v8相关库3. 测试安装是否成功4. 测试推理图像在windows上配置YOLOv8的环境,训练自己的数据集并转换到caffemodel1. 创建虚拟环境 利用conda创建虚拟环境 conda create -n yolo python=3.8 -y 并进入ac…...
)
2023年CDGA考试-第16章-数据管理组织与角色期望(含答案)
2023年CDGA考试-第16章-数据管理组织与角色期望(含答案) 单选题 1.在定义任何新组织或尝试改进现有组织之前了解当前组织的哪些方面非常重要? A.企业文化、运营模式和人员 B.业务战略、技术战略、数据战略 C.工具、方法和流程 D.事业环境因素、组织过程资产,行动路线图 …...

Stream——集合数据按照某一字段排序
文章目录前言假设业务场景排序前的准备正序排序1、数据集合的判空 Optional.isPresent()2、使用sort排序3、将排序后的数据流转换为list你以为这样就完了?倒序排序前言 之前,针对Stream链式编程中的几个方法做了大致的说明。详情可以参考: J…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...

云原生周刊:k0s 成为 CNCF 沙箱项目
开源项目推荐 HAMi HAMi(原名 k8s‑vGPU‑scheduler)是一款 CNCF Sandbox 级别的开源 K8s 中间件,通过虚拟化 GPU/NPU 等异构设备并支持内存、计算核心时间片隔离及共享调度,为容器提供统一接口,实现细粒度资源配额…...