在 TensorFlow 中调试

如果调试是消除软件错误的过程,那么编程一定是添加错误的过程。Edsger
Dijkstra。来自 https://www.azquotes.com/quote/561997一、说明
在这篇文章中,我想谈谈 TensorFlow 中的调试。
在之前的一些帖子(此处、此处和此处)中,我向您介绍了我在 Mobileye(正式称为 Mobileye,英特尔公司)的团队如何使用TensorFlow、Amazon SageMaker和Amazon s3来训练我们的基于大量数据的深度神经网络。
二、关于调试
众所周知,程序调试是软件开发中不可或缺的一部分,调试所花费的时间常常超过编写原始程序所花费的时间。
调试是困难的,并且已经写了很多关于如何设计和实现程序以提高错误的再现性并简化根本原因分析过程的文章。
在机器学习中,由于机器学习算法固有的随机性,以及算法通常在远程计算机上的专用硬件加速器上运行,调试任务变得复杂。
由于使用符号执行(又名图形模式), TensorFlow 中的调试更加复杂,这提高了训练会话的运行时性能,但同时限制了自由读取图形中任意张量的能力,这是一种能力这对于调试很重要。
在这篇文章中,我将详细阐述调试 TensorFlow 训练程序的困难,并就如何解决这些困难提供一些建议。
出于法律目的,我想澄清的是,尽管我精心选择了副标题,但我不保证我在这里写的任何内容都会防止您失去理智。相反,我认为我几乎可以保证,无论我写了什么,您在调试 TensorFlow 程序时都可能会失去理智。但是,也许你会少一点失去理智。
在开始之前,我们先澄清一下讨论的范围。
三、调试类型
在本文中,调试是指识别代码或数据中导致训练课程突然中断的错误的艺术。
另一种调试超出了本文的范围,它指的是修复或调整不收敛的模型的任务,或者对某一类输入(例如车辆检测)产生不令人满意的预测的任务。无法识别粉色汽车的模型)。此过程可能涉及定义和评估模型指标、模型工件(例如梯度、激活和权重)的收集和统计分析、使用 TensorBoard 和 Amazon Sagemaker Debugger 等工具、超参数调整、重新架构或使用技术修改数据输入例如增强和增强。调整模型可能是一项极具挑战性、耗时且常常令人沮丧的任务。
错误类型:
在解决代码或数据中的错误领域内,我喜欢区分两类错误:错误和怪物错误。
我所说的错误是指相对容易重现的问题。错误的示例包括假设输入张量大小与训练数据不匹配的模型、尝试连接不匹配的张量或对无效数据类型执行 tf 操作。这些通常不依赖于特定的模型状态和数据,并且通常相对容易重现。它们不一定很容易修复,但与怪物错误相比,它们只是小孩子的游戏。
怪物错误是零星发生且不可预测的错误。仅在模型的特定状态、特定数据样本或模型状态和数据输入的特定组合上重现的错误可能会带来严重的挑战,并可能构成巨大的错误。
以下是基于真实事件的场景示例,肯定会导致血压升高:
现在是星期五下午,您的模型已经成功训练了几天。损失似乎正在很好地收敛,你开始想象在你选择的度假地点度过一个轻松的发布后周末假期。你回头看了一眼屏幕,发现突然之间,在没有任何警告的情况下,你的损失变成了 NaN。“当然”,你心里想,“这一定是由于一些完全随机的、瞬时的、宏观故障造成的”,然后你立即从最后一个有效的模型检查点恢复训练。又过了几个小时,这种事又发生了,然后又发生了。现在你开始恐慌,周末天堂的梦幻画面现在被需要解决一个怪物错误的诱人努力的想法所取代。
我们很快就会回到这个悲惨的例子。但首先,让我们勾选一些强制性的“调试”复选框。
四、Tensorflow 中的调试技巧
关于调试的艺术,更重要的是,开发可调试代码的艺术,人们已经投入了大量的精力。在本节中,我将提到一些与 TensorFlow 应用程序相关的技术。这个列表绝不是全面的。
4.1 保存模型检查点
这可能是我在这篇文章中要写的最重要的事情。请始终配置您的训练课程,以便定期保存模型的快照。
编程错误并不是训练失败的唯一原因......如果您在云中运行,您可能会遇到现场实例终止,或遇到内部服务器错误。如果您在本地运行,可能会发生断电,或者您的 GPU 可能会爆炸。如果您已经训练了几天,而没有存储中间检查点,则损坏可能会非常严重。如果你每小时保存一个检查点,那么你最多损失一个小时。TensorFlow 提供了用于存储检查点的实用程序,例如keras 模型检查点回调。您需要做的就是通过权衡存储检查点的开销和训练课程中意外故障的成本来决定捕获此类快照的频率。
4.2 接触者追踪
对于我为这一部分选择的标题,我向我的 Covid19 同行表示歉意,我无法抗拒。我所说的接触者追踪是指跟踪输入训练管道的训练数据的能力。
假设您的训练数据在 tfrecord 文件中分为 100,000 个,并且其中一个文件存在格式错误,导致程序崩溃或停止。缩小问题文件搜索范围的一种方法是记录输入管道的每个文件。一旦发生崩溃,您可以回顾日志以查看最近输入的文件是什么。正如我在之前的文章中提到的,我们使用 Amazon SageMaker 管道模式功能进行训练。管道模式的一个相当新的补充是管道模式服务器端日志,它记录正在输入管道的文件。
记录进入管道的数据可以帮助人们重现错误的能力,这将我们引向下一个要点。
4.3 (Ir) 再现性
重现错误的难易程度直接影响解决该错误的难易程度。我们总是希望编写代码以确保可重复性。这在 TensorFlow 程序中并不容易。机器学习应用通常依赖于随机变量的使用。我们随机初始化模型权重,随机增加数据,随机分片数据进行分布式训练,随机应用 dropout,在每个 epoch 之前对输入数据进行洗牌,然后在创建批次之前再次洗牌(使用 tf.dataset.shuffle) 。我们可以使用我们记录的伪随机种子来播种所有伪随机操作,但请记住,可能有许多不同的地方引入了随机化,并且跟踪所有这些很容易成为簿记噩梦。我无法告诉你有多少次我以为我已经删除了随机化的所有元素,结果却发现我错过了一个。此外,还有一些随机进程无法播种。如果您使用多个进程来导入训练数据,您可能无法控制数据记录实际输入的顺序(例如,如果在tf.data.Options () 中experimental_definistic 设置为 false )。当然,您可以在每个样本进入管道时对其进行记录,但这会带来很大的开销,而且可能令人望而却步。
最重要的是,虽然构建可重复的训练程序绝对是可能的,但我认为更明智的做法是接受非确定性,接受训练的不可重复性,并找到克服这种调试限制的方法。
4.4 模块化编程
创建可调试程序的关键技术是以模块化方式构建应用程序。应用于 TensorFlow 训练循环,这意味着能够分别测试训练管道的不同子集,例如数据集、损失函数、不同模型层和回调。这并不总是容易做到,因为一些训练模块(例如损失函数)非常依赖于其他模块。但还有很大的创作空间。例如,只需在应用数据集操作的子集的同时迭代数据集,就可以在输入管道上测试不同的函数。可以通过创建仅运行损失函数或回调的应用程序来测试损失函数或回调。人们可以通过用虚拟损失函数替换损失函数来中和损失函数。我喜欢构建具有多个输出点的模型,即能够轻松修改模型中的层数,以便测试不同层的影响。
在构建程序时,您对程序的模块化和可调试性考虑得越多,以后遭受的痛苦就越少。
4.5 热切执行
如果您是 TensorFlow 的常规用户,您可能遇到过“急切执行模式”、“图形模式”和“tf 函数限定符”等术语。您可能听说过一些(有些误导性的)说法,例如“在急切执行模式下调试是小菜一碟”,或“tensorflow 2 在急切执行模式下运行”。你可能和我一样,热衷于研究张量流源代码,试图理解不同的执行模式,结果却崩溃了,你的自尊心彻底崩溃了。为了充分了解它是如何工作的,我建议您参阅TensorFlow 文档,祝您好运。在这里,我们将仅提及与调试有关的要点。运行 TensorFlow 训练的最佳方式是在图形模式下运行。图模式是一种符号执行模式,这意味着我们无法任意访问图张量。用tf.function限定符包装的函数将在图形模式下运行。当您使用tf.keras.model.fit进行训练时,默认情况下,训练步骤以图形模式执行。当然,无法访问任意图张量使得图模式下的调试变得困难。在急切执行模式下,您可以访问任意张量,甚至可以使用调试器进行调试(前提是将断点放置在 model.call() 函数中的适当位置)。当然,当你在急切执行模式下运行时,你的训练会运行得慢得多。要将模型编程为在急切执行模式下进行训练,您需要调用 model.compile ()函数,并将 run_eagerly 标志设置为 true。
最重要的是,当您训练时,以图形模式运行,当您调试时,以急切执行模式运行。不幸的是,某些错误仅在图形模式下重现而不是在急切执行模式下重现的情况并不少见,这真是令人遗憾。此外,当您在本地环境中进行调试时,急切执行很有帮助,但在云中则不然。它通常在调试巨大的错误时不是很有用......除非您首先找到一种在本地环境中重现错误的方法(更多内容请参见下文)。
五、TensorFlow 日志记录和调试实用程序
尝试充分利用 TensorFlow 记录器。当您调试问题时,将记录器设置为信息最丰富的级别。
tf.debugging模块提供了一系列断言实用程序以及数字检查功能。特别是,tf.debugging.enable_check_numerics实用程序有助于查明有问题的函数。
tf.print函数可以打印任意图张量,它是一个附加实用程序,我发现它对于调试非常有用。
最后但并非最不重要的一点是,添加您自己的打印日志(在代码的非图形部分),以便更好地了解程序发生故障的位置。
5.1 解读 TensorFlow 错误消息
有时,您会很幸运地收到 TensorFlow 错误消息。不幸的是,并不总是立即清楚如何使用它们。我经常收到同事发来的电子邮件,其中包含神秘的 TensorFlow 消息,寻求帮助。当我看到消息时,例如:
tensorflow.python.framework.errors_impl.InvalidArgumentError: ConcatOp : Dimensions of inputs should match: shape[0] = [5,229376] vs. shape[2] = [3,1]或者
node DatasetToGraphV2 (defined at main.py:152) (1) Failed precondition: Failed to serialize the input pipeline graph: Conversion to GraphDef is not supported.或者
ValueError: slice index -1 of dimension 0 out of bounds. for 'loss/strided_slice' (op: 'StridedSlice') with input shapes: [0], [1], [1], [1] and with computed input tensors: input[1] = <-1>, input[2] = <0>, input[3] = <1>.我问自己(稍作修改以使帖子适合儿童)“我应该对此做什么?” 或者“为什么友善热爱的 TensorFlow 工程师不能给我更多的东西来使用?”。但我很快让自己平静下来(有时需要酒精饮料的帮助),然后说:“查姆,别这么被宠坏了。回去工作吧,庆幸你收到了任何消息。” 您应该做的第一件事是尝试在急切执行模式下和/或使用调试器重现错误。不幸的是,如上所述,这并不总是有帮助。
毫无疑问,上述消息并没有多大帮助。但不要绝望。有时,在一些调查工作的帮助下,您会找到可能引导您走向正确方向的线索。检查调用堆栈以查看它是否提供任何提示。如果消息包含形状大小,请尝试将它们与图形中可能具有相同形状的张量进行匹配。当然,还要上网搜索一下,看看其他人是否也遇到过类似的问题以及在什么场景下。不要绝望。
5.2 在本地环境中运行
当然,在本地环境中进行调试比在远程计算机或云中进行调试更容易。当您第一次创建模型时尤其如此。您的目标应该是在开始远程培训之前解决本地环境中尽可能多的问题。否则,您可能会浪费大量时间和金钱。
为了提高可重复性,您应该尝试使本地环境与远程环境尽可能相似。如果您在远程环境中使用 docker 镜像或虚拟环境,请尝试在本地使用相同的镜像。(如果您的远程训练在 Amazon SageMaker 上进行,您可以拉取所使用的 docker 镜像。)
当然,远程培训环境的某些要素可能无法在本地重现。例如,您可能遇到了仅在使用Amazon SageMaker 管道模式时才会重现的错误,该模式目前仅在云中运行时受支持。(在这种情况下,您可以考虑使用其他方法从 s3 访问数据。)
我希望我可以告诉您,这里描述的技术将解决您的所有问题。但可惜的是,事实并非如此。在下一节中,我们将回到上面说明的怪物错误场景,并介绍最后一项调试技术。
六、使用 TensorFlow 自定义训练循环进行调试
在我们上面描述的场景中,经过几天的训练,模型的特定状态和特定的训练批次样本的组合突然导致损失变为 NaN。
让我们评估一下如何使用上面的调试技术来调试这个问题。
- 如果我们仔细跟踪用于所有随机操作的种子,并且不存在不受控制的非确定性事件,理论上我们可以通过从头开始训练来重现该错误......但这需要几天的时间。
- 在本地环境或急切执行模式中进行复制可能需要数周时间。
- 我们可以从最近的检查点恢复,但只有当我们可以从完全相同的样本和所有伪随机生成器的完全相同的状态恢复时,我们才能够重现相同的模型状态和批次样本。
- 添加tf.prints会有帮助,但会带来巨大的开销
- 添加tf.debugging.enable_check_numerics对于查明失败的函数非常有帮助。如果函数中存在明显的错误,这可能就足够了。但它并不能让我们重现该错误。
理想情况下,我们能够在损失严重之前捕获输入和模型状态。然后,我们可以在受控(本地)环境中、在急切执行模式下并使用调试器重现该问题。
问题是我们不知道问题即将发生,直到它真正发生。当损失被报告为 NaN 时,模型已经使用 NaN 权重进行了更新,并且导致错误的批次样本已经被迭代。
我想提出的解决方案是自定义训练循环,以便我们在每一步记录当前样本,并且仅在梯度有效时更新模型权重。如果梯度无效,我们将停止训练并转储最后一批样本以及当前模型快照。这可以转移到您的本地环境,您可以在其中加载模型,并以急切执行模式输入捕获的数据样本,以便重现(并解决)错误。
我们稍后将讨论代码,但首先,简单介绍一下使用自定义训练循环的优缺点。
6.1 自定义训练循环与高级 API
关于是否编写自定义训练循环或依赖高级 API(例如tf.keras.model.fit ()),TensorFlow 用户之间存在着一个由来已久的争议。
定制训练循环的支持者预示着能够逐行控制训练的执行方式以及发挥创造力的自由。高级 API 的支持者称赞它提供的许多便利,最引人注目的是内置回调实用程序和分布式策略支持。使用高级 API 还可以确保您使用无错误且高度优化的训练循环实现。
从版本 2.2 开始,TensorFlow 引入了重写tf.keras.model类的train_step和make_train_function例程的功能。这使得人们能够引入某种程度的定制,同时继续享受 model.fit() 的便利。我们将演示如何重写这些函数,使我们能够捕获有问题的示例输入和模型状态以进行本地调试。
6.2 自定义捕获循环
在下面的代码块中,我们使用 train_step 和 make_train_functions 例程的自定义实现来扩展 tf.keras.models.Model 对象。为了充分理解该实现,我建议您将其与github 中例程的默认实现进行比较。您会注意到,我删除了与指标计算和策略支持相关的所有逻辑,以使代码更具可读性。需要注意的主要变化是:
- 在将梯度应用于模型权重之前,我们测试梯度是否为 NaN。仅当 NaN 不出现时,梯度才会应用于权重。否则,将向训练循环发送遇到错误的信号。信号的一个示例可以是将损耗设置为预定值,例如零或 NaN。
- 训练循环存储每一步的数据特征和标签(x 和 y)。请注意,为了做到这一点,我们已将数据集遍历(next(iterator) 调用)移至 @tf.function 范围之外。
- 该类有一个布尔“崩溃”标志,用于向主函数发出是否遇到错误的信号。
class CustomKerasModel(tf.keras.models.Model):def __init__(self, **kwargs):super(CustomKerasModel, self).__init__(**kwargs)# boolean flag that will signal to main function that # an error was encounteredself.crash = False@tf.functiondef train_step(self, data):x, y = datawith tf.GradientTape() as tape:y_pred = self(x, training=True) # Forward pass# Compute the loss value# (the loss function is configured in `compile()`)loss = self.compiled_loss(y, y_pred, regularization_losses=self.losses)# Compute gradientstrainable_vars = self.trainable_variablesgradients = tape.gradient(loss, trainable_vars)# concatenate the gradients into a single tensor for testingconcat_grads = tf.concat([tf.reshape(g,[-1]) for g in gradients],0)# In this example, we test for NaNs, # but we can include other testsif tf.reduce_any(tf.math.is_nan(concat_grads)):# if any of the gradients are NaN, send a signal to the # outer loop and halt the training. We choose to signal# to the outer loop by setting the loss to 0.return {'loss': 0.}else:# Update weightsself.optimizer.apply_gradients(zip(gradients, trainable_vars))return {'loss': loss}def make_train_function(self):if self.train_function is not None:return self.train_functiondef train_function(iterator):data = next(iterator)# records the current sampleself.x, self.y = datares = self.train_step(data)if res['loss'] == 0.:self.crash = Trueraise Exception()return resself.train_function = train_functionreturn self.train_functionif __name__ == '__main__':# train_ds = # inputs = # outputs =# optimizer =# loss = # epochs =# steps_per_epoch = model = CustomKerasModel(inputs=inputs, outputs=outputs)opt = tf.keras.optimizers.Adadelta(1.0)model.compile(loss=loss, optimizer=optimizer)try:model.fit(train_ds, epochs=epochs, steps_per_epoch=steps_per_epoch)except Exception as e:# check for signalif model.crash:model.save_weights('model_weights.ckpt')# pickle dump model.x and model.yfeatures_dict = {}for n, v in model.x.items():features_dict[n] = v.numpy()with open('features.pkl','wb') as f:pickle.dump(features_dict,f)labels_dict = {}for n, v in model.y.items():labels_dict[n] = v.numpy()with open('labels.pkl', 'wb') as f:pickle.dump(labels_dict, f)raise e值得注意的是,这种技术的训练运行时成本很小,这是因为以急切执行模式(而不是图形模式)从数据集中读取数据。(天下没有免费的午餐。)确切的成本取决于模型的大小;模型越大,这种变化就越小。您应该在自己的模型上评估此技术的开销,然后决定是否以及如何使用它。
七、概括
只要我们人类参与人工智能应用程序的开发,编程错误的普遍存在就一定会发生。设计代码时考虑到可调试性,并获取解决错误的工具和技术,可能会避免一些严重的折磨。
参考地址:
哈伊姆·兰德
相关文章:
在 TensorFlow 中调试
如果调试是消除软件错误的过程,那么编程一定是添加错误的过程。Edsger Dijkstra。来自 https://www.azquotes.com/quote/561997 一、说明 在这篇文章中,我想谈谈 TensorFlow 中的调试。 在之前的一些帖子(此处、此处和此处)中&…...

想要精通算法和SQL的成长之路 - 连续的子数组和
想要精通算法和SQL的成长之路 - 连续的子数组和 前言一. 连续的子数组和1.1 最原始的前缀和1.2 前缀和 哈希表 前言 想要精通算法和SQL的成长之路 - 系列导航 一. 连续的子数组和 原题链接 1.1 最原始的前缀和 如果这道题目,用前缀和来算,我们的思路…...
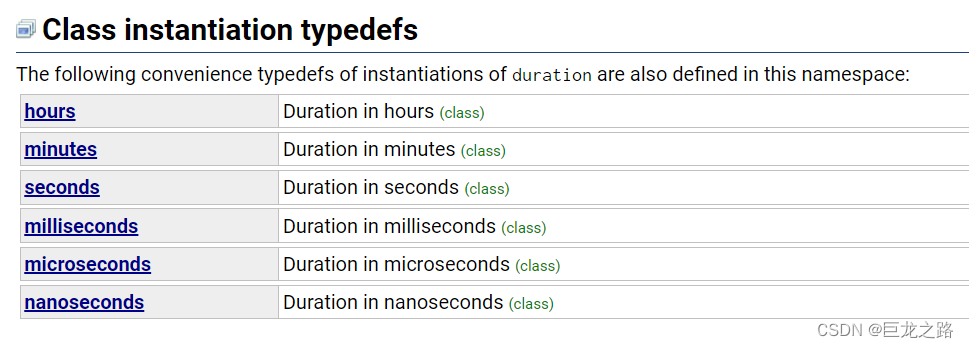
【C++】头文件chrono
2023年10月16日,周一晚上 当前我只是简单的了解了一下chrono 以后可能会深入了解chrono并更新文章 目录 功能原理头文件chrono中的一些类头文件chrono中的数据类型一个简单的示例程序小实验:证明a的效率比a高 功能 这个chrono头文件是用来处理时间的…...

Python学习六
前言:相信看到这篇文章的小伙伴都或多或少有一些编程基础,懂得一些linux的基本命令了吧,本篇文章将带领大家服务器如何部署一个使用django框架开发的一个网站进行云服务器端的部署。 文章使用到的的工具 Python:一种编程语言&…...

Springboot 集成 WebSocket
WebSocket是一种在单个TCP连接上进行全双工通信的协议。WebSocket使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。在WebSocket API中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接…...
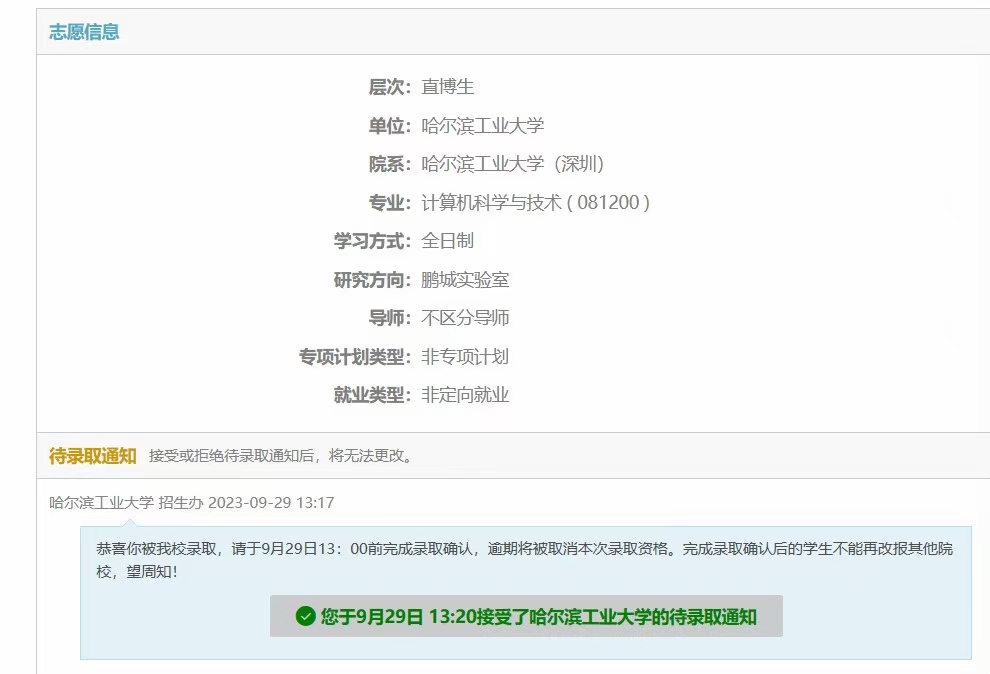
谨以此篇,纪念我2023年曲折的计算机保研之路
目录 阶段一:迷茫阶段二:准备个人意愿保研材料准备套磁老师5.1日 浙大线上编程测试5.8日 浙大线上面试 —— 一面5.17日 浙大线上面试——二面5.29日 实验室面试结果5.27日 南开线上面试6.20日 华师电话面试 阶段三:旅途北航CS(6.…...
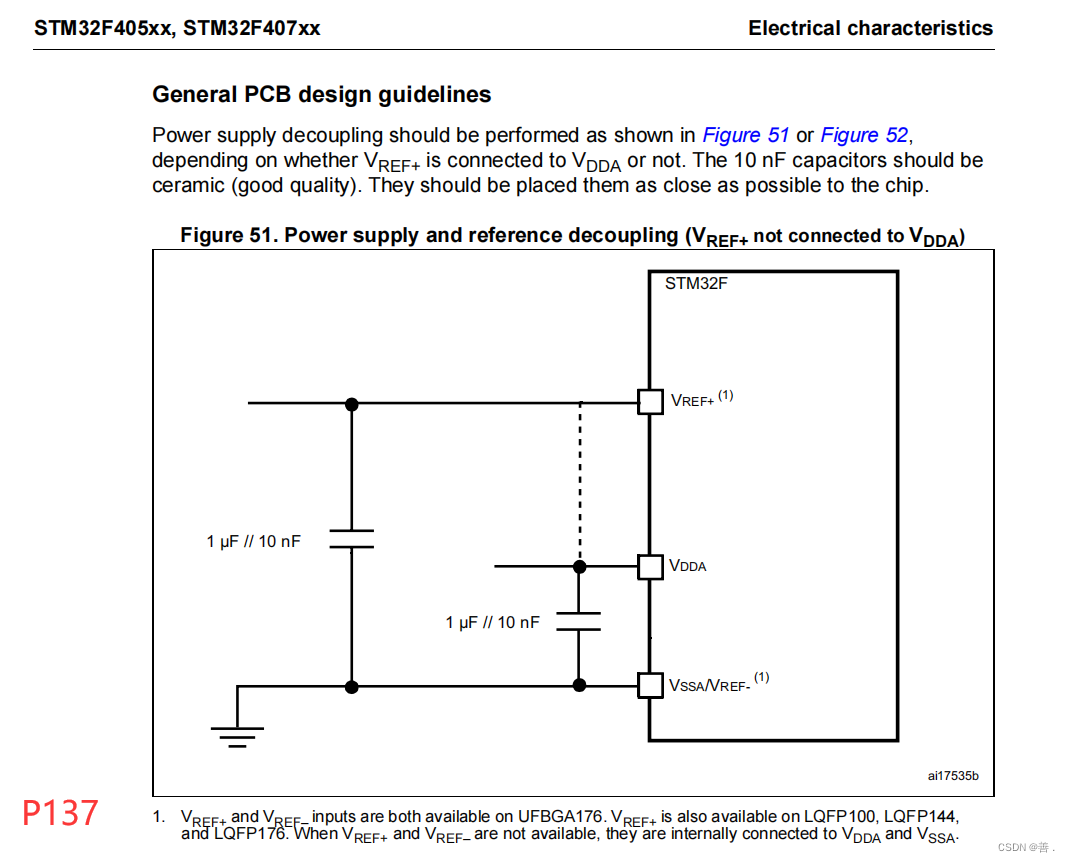
VSS、VDD、VBAT、VSSA
引言 在学习设计TM32时,发现芯片除了GPIO引脚外还会引出许多引脚,以STM32F407ZGT6为例除了GPIO引脚还会有以下引脚 如VSS、VDD、VBAT、VSSA、NRST、VREF、VDDA、VCAP_1、VCAP_2、PDR_ON这些引脚。他们有何作用,电路设计中应如何连接&#x…...

【Rust基础③】方法method、泛型与特征
文章目录 6 方法 Method6.1 定义方法self、&self 和 &mut self 6.2 自动引用和解引用6.3 关联函数 7 泛型和特征7.1 泛型 Generics7.1.1 结构体中使用泛型7.1.2 枚举中使用泛型7.1.3 方法中使用泛型为具体的泛型类型实现方法 7.1.4 const 泛型 7.2 特征 Trait7.2.1 为类…...
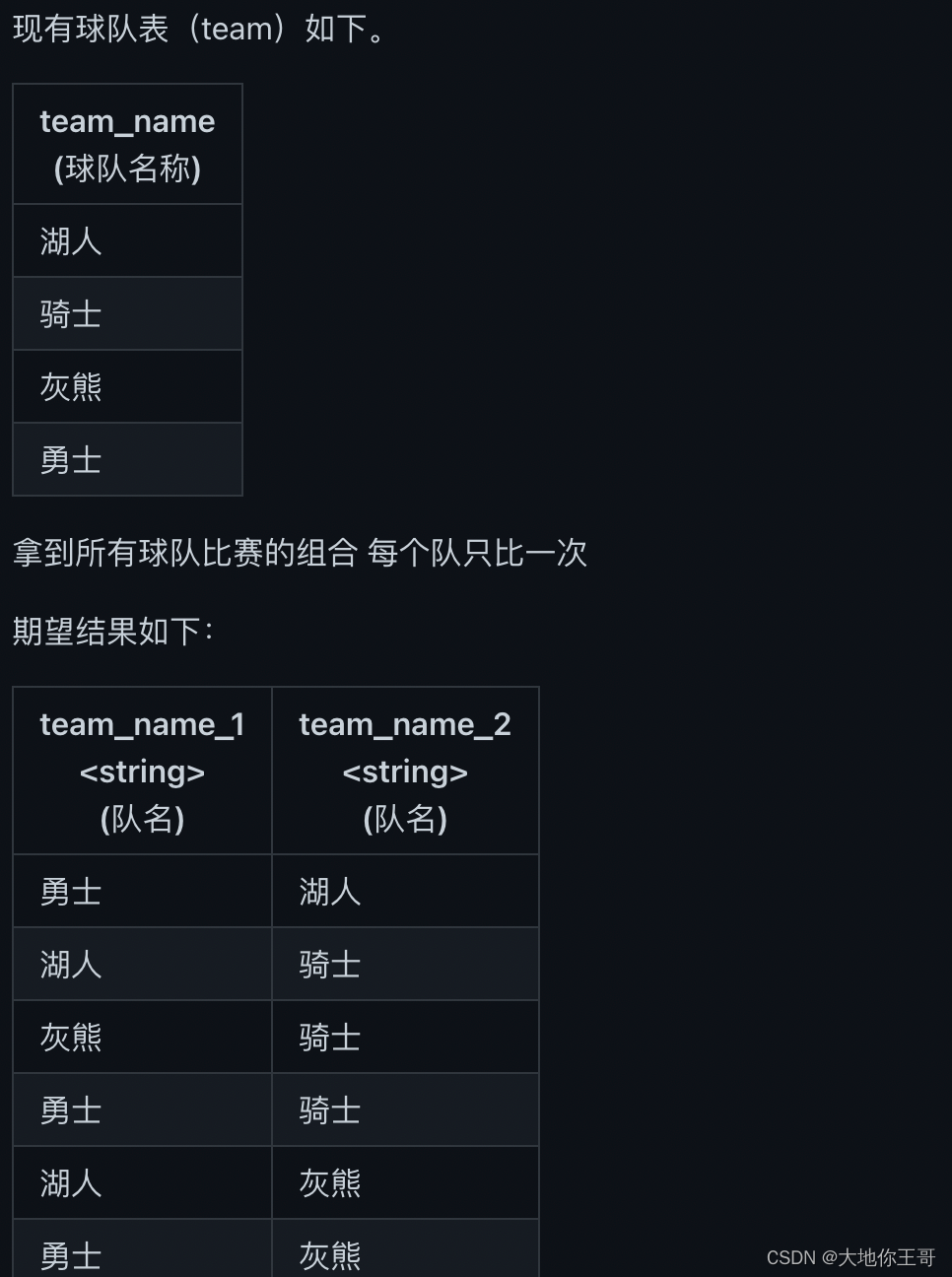
48.排列问题求解
思路分析:通过为每一队分配一个id,join条件要求t1.num < t2.num实现相同两队只比一次 代码实现: with t as (SELECT team_name,caseteam_nameWHEN 勇士 then 1WHEN 湖人 then 2WHEN 灰熊 then 3else 4end numFROM team )SELECT t1.team_…...

18.(开发工具篇Gitlab)Git如何回退到指定版本
首先: 使用git log命令查看提交历史,找到想要回退的版本的commit id. 使用git reset命令 第一步:git reset --hard 命令是强制回到某一个版本。执行后本地工程回退到该版本。 第二步:利用git push -f命令强制推到远程 如下所示: 优点:干净利落,回滚后完全回到最初状态…...
IDEA初始配置
1. 详细设置 安装完IDEA之后的简单配置。 1.1 如何打开详细配置界面 1、显示工具栏 2、选择详细配置菜单或按钮 1.2 系统设置 1、默认启动项目配置 启动IDEA时,默认自动打开上次开发的项目?还是自己选择? 如果去掉Reopen projects on …...

WM_COPYDATA传回返回值的一个方案
方案背景 适应场景,通过WM_COPYDATA进行进程间通信时,SendMessage不能返回自定义的数据,由此想到以下思路解决这个问题 A进程使用VirtualAlloc分配一块内存,通过某种方式将此地址以及A进程ID传给另一个进程B B进程使用OpenProce…...
【日常业务开发】接口性能优化
【日常业务开发】接口性能优化 缓存本地缓存分布式缓存 数据库分库分表SQL 优化 业务程序并行化异步化池化技术预先计算事务粒度批量读写锁的粒度尽快return上下文传递空间换时间集合空间大小 缓存 本地缓存 本地缓存,最大的优点是应用和cache同一个进程内部&…...
Android 10.0 禁止弹出系统simlock的锁卡弹窗功能实现
1.前言 在10.0的系统开发中,在一款产品中,需要实现simlock锁卡功能,在系统实现锁卡功能以后,在开机的过程中,或者是在插入sim卡 后,当系统检测到是禁用的sim卡后,就会弹出simlock锁卡弹窗,要求输入puk 解锁密码,功能需求禁用这个弹窗,所以就需要看是 哪里弹的,禁用…...
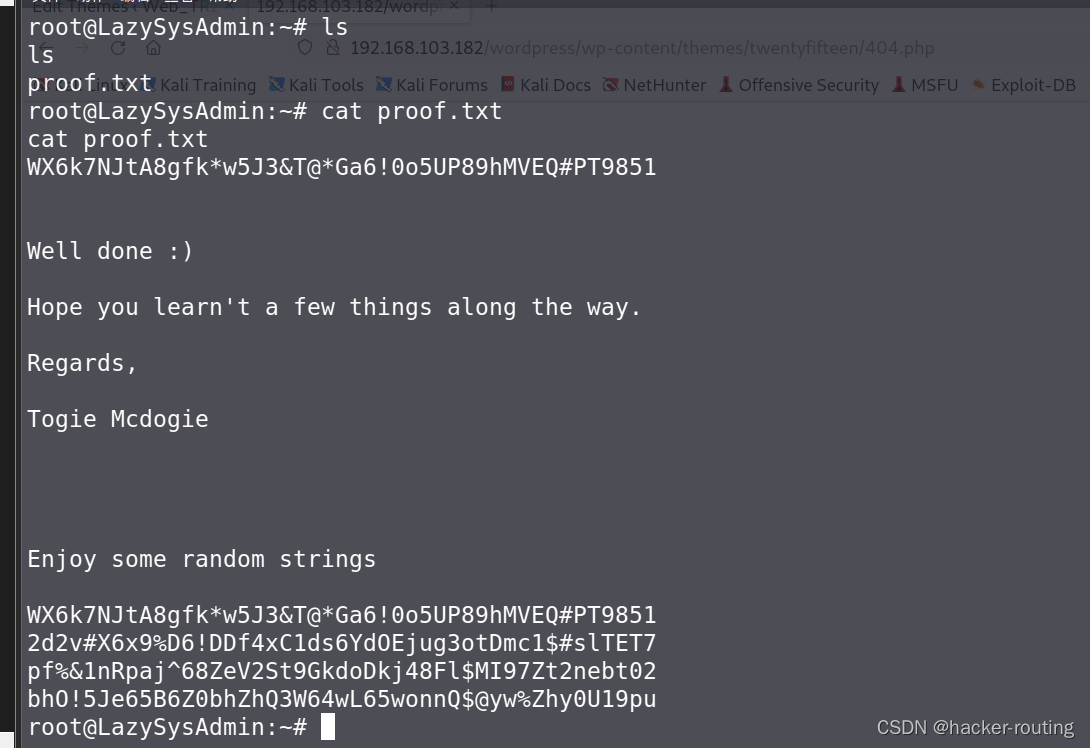
VulnHub lazysysadmin
一、信息收集 1.nmap扫描开发端口 开放了:22、80、445 访问80端口,没有发现什么有价值的信息 2.扫描共享文件 enum4linux--扫描共享文件 使用: enum4linux 192.168.103.182windows访问共享文件 \\192.168.103.182\文件夹名称信息收集&…...

ppt怎么压缩到10m以内?分享ppt缩小方法
在日常工作中,我们常常需要制作和分享PowerPoint演示文稿,然而,有时候文稿中的图片、视频等元素会导致文件过大,无法在电子邮件或其他平台上顺利传输。为了将PPT文件压缩到10M以内,我们可以使用一些专门的文件压缩工具…...
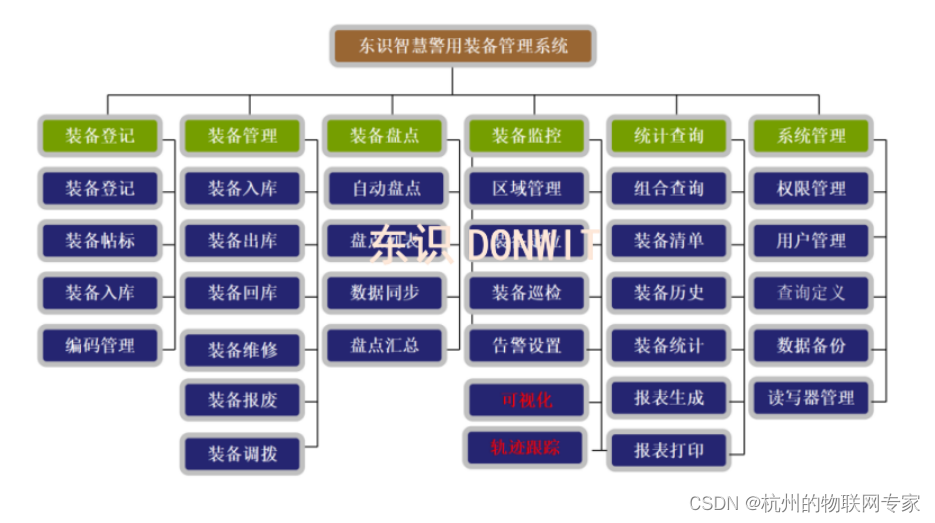
智能警用装备管理系统-科技赋能警务
警用物资装备管理系统(智装备DW-S304)是依托互云计算、大数据、RFID技术、数据库技术、AI、视频分析技术对警用装备进行统一管理、分析的信息化、智能化、规范化的系统。 (1)感知智能化 装备感知是整个方案的基础,本方…...

攻防千层饼
近年来,网络安全领域正在经历一场不断升级的攻防对抗,这场攻防已经不再局限于传统的攻击与防御模式,攻击者和防守者都已经越发熟练,对于传统攻防手法了如指掌。 在这个背景下,攻击者必须不断寻求创新的途径࿰…...

组件封装使用?
组件封装是指在软件开发中,将功能代码或数据封装成一个独立的、可重用的模块或组件。这种封装可以使得代码更加模块化、可维护性和可重用性。在许多编程语言和开发框架中,都有不同的方式来实现组件封装。 以下是一些常见的组件封装方法和技巧࿱…...
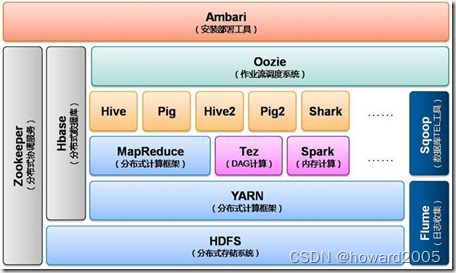
2.3 初探Hadoop世界
文章目录 零、学习目标一、导入新课二、新课讲解(一)Hadoop的前世今生1、Google处理大数据三大技术2、Hadoop如何诞生3、Hadoop主要发展历程 (二)Hadoop的优势1、扩容能力强2、成本低3、高效率4、可靠性5、高容错性 (三…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...