RocketMQ高性能核心原理与源码架构剖析
文章目录
- 一、源码环境搭建
- 主要功能模块
- 源码启动服务
- 启动nameServer
- 启动Broker
- 发送消息
- 消费消息
- 二、源码热身阶段
- NameServer的启动过程
- 关注重点
- 源码重点
- Broker服务启动过程
- 关注重点
- 源码重点
- Netty服务注册框架
- 关注重点
- 源码重点
- 关于RocketMQ的同步结果推送与异步结果推送
- Broker心跳注册管理
- 关注重点
- 源码重点
- 极简化的服务注册发现流程
- Producer发送消息过程
- 关注重点
- 源码重点
- Consumer拉取消息过程
- 关注重点
- 源码重点
- 广播模式与集群模式的Offset处理
- Consumer与MessageQueue建立绑定关系
- 顺序消费与并发消费
- 实际拉取消息还是通过PullMessageService完成的。
- 客户端负载均衡管理总结
- Producer负载均衡
- Consumer负载均衡
一、源码环境搭建
主要功能模块
RocketMQ的官方Git仓库地址:https://github.com/apache/rocketmq 可以用git把项目clone下来或者直接下载代码包。
也可以到RocketMQ的官方网站上下载指定版本的源码: http://rocketmq.apache.org/dowloading/releases/
源码下很多的功能模块,很容易让人迷失方向,我们只关注下几个最为重要的模块:
broker: Broker 模块(broke 启动进程)
client :消息客户端,包含消息生产者、消息消费者相关类
example: RocketMQ 例代码
namesrv:NameServer模块
store:消息存储模块
remoting:远程访问模块
源码启动服务
将源码导入IDEA后,需要先对源码进行编译。编译指令 clean install -Dmaven.test.skip=true
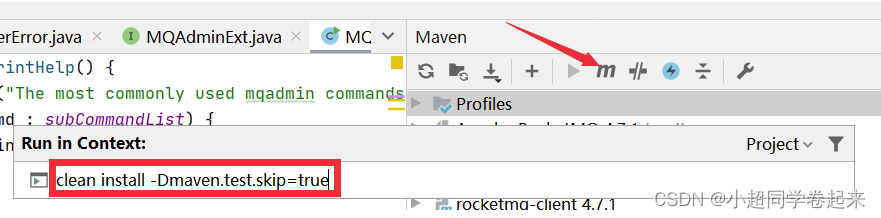
编译完成后就可以开始调试代码了。调试时需要按照以下步骤:
调试时,先在项目目录下创建一个conf目录,并从distribution拷贝broker.conf和logback_broker.xml和logback_namesrv.xml

启动nameServer
展开namesrv模块,运行NamesrvStartup类即可启动NameServer
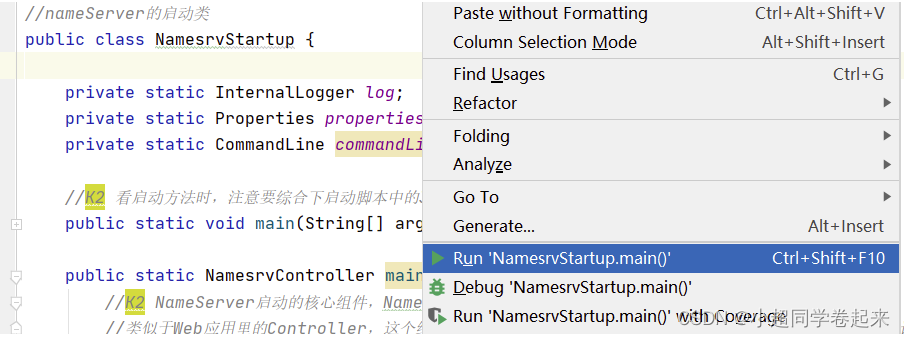
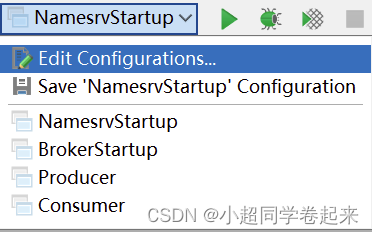
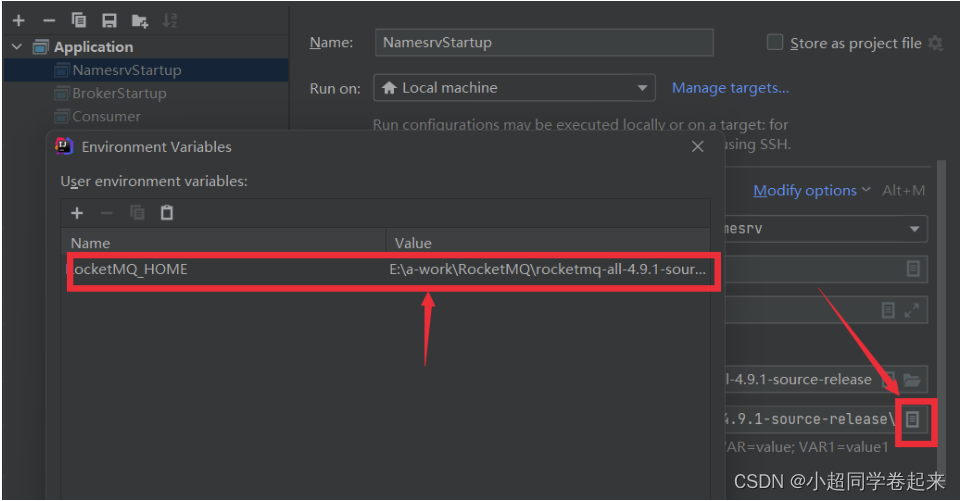
启动时,会报错,提示需要配置一个ROCKETMQ_HOME环境变量。这个环境变量我们可以在机器上配置,跟配置JAVA_HOME环境变量一样。也可以在IDEA的运行环境中配置。目录指向源码目录即可。
配置完成后,再次执行,看到以下日志内容,表示NameServer启动成功
The Name Server boot success. serializeType=JSON
启动Broker
启动Broker之前,我们需要先修改之前复制的broker.conf文件
brokerClusterName = DefaultCluster
brokerName = broker-a
brokerId = 0
deleteWhen = 04
fileReservedTime = 48
brokerRole = ASYNC_MASTER
flushDiskType = ASYNC_FLUSH# 自动创建Topic
autoCreateTopicEnable=true
# nameServ地址
namesrvAddr=127.0.0.1:9876
# 存储路径
storePathRootDir=E:\\RocketMQ\\data\\rocketmq\\dataDir
# commitLog路径
storePathCommitLog=E:\\RocketMQ\\data\\rocketmq\\dataDir\\commitlog
# 消息队列存储路径
storePathConsumeQueue=E:\\RocketMQ\\data\\rocketmq\\dataDir\\consumequeue
# 消息索引存储路径
storePathIndex=E:\\RocketMQ\\data\\rocketmq\\dataDir\\index
# checkpoint文件路径
storeCheckpoint=E:\\RocketMQ\\data\\rocketmq\\dataDir\\checkpoint
# abort文件存储路径
abortFile=E:\\RocketMQ\\data\\rocketmq\\dataDir\\abort
然后Broker的启动类是broker模块下的BrokerStartup。
启动Broker时,同样需要ROCETMQ_HOME环境变量,并且还需要配置一个-c 参数,指向broker.conf配置文件。
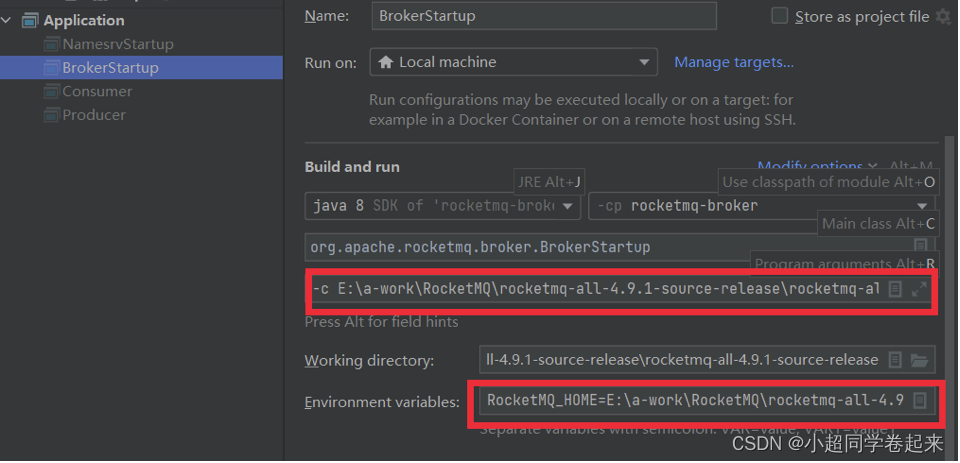
然后重新启动,即可启动Broker。
发送消息
在源码的example模块下,提供了非常详细的测试代码。例如我们启动example模块下的org.apache.rocketmq.example.quickstart.Producer类即可发送消息。
但是在测试源码中,需要指定NameServer地址。这个NameServer地址有两种指定方式,一种是配置一个NAMESRV_ADDR的环境变量。另一种是在源码中指定。我们可以在源码中加一行代码指定NameServer
producer.setNamesrvAddr(“127.0.0.1:9876”);
然后就可以发送消息了。
消费消息
我们可以使用同一模块下的org.apache.rocketmq.example.quickstart.Consumer类来消费消息。运行时同样需要指定NameServer地址
consumer.setNamesrvAddr(“192.168.232.128:9876”);
这样整个调试环境就搭建好了。
二、源码热身阶段
NameServer的启动过程
关注重点
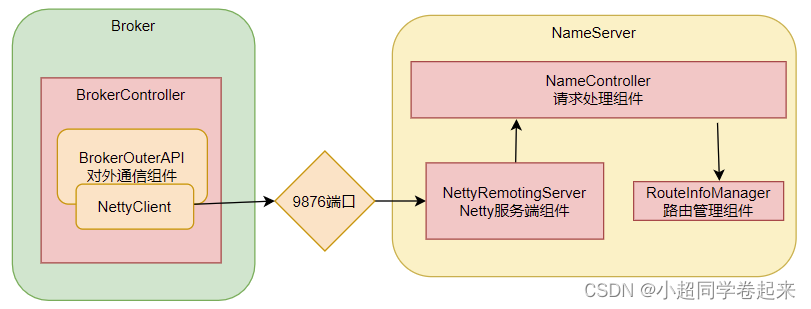
在RocketMQ集群中,实际记性消息存储、推送等核心功能点额是Broker。而NameServer的作用,其实和微服务中的注册中心非常类似,他只是提供了Broker端的服务注册与发现功能。
源码重点
NameServer的启动入口类是org.apache.rocketmq.namesrv.NamesrvStartup。其中的核心是构建并启动一个NamesrvController。这个Cotroller对象就跟MVC中的Controller是很类似的,都是响应客户端的请求。只不过,他响应的是基于Netty的客户端请求。
另外,他的实际启动过程,其实可以配合NameServer的启动脚本进行更深入的理解。
从NameServer启动和关闭这两个关键步骤,我们可以总结出NameServer的组件其实并不是很多,整个NameServer的结构是这样的;
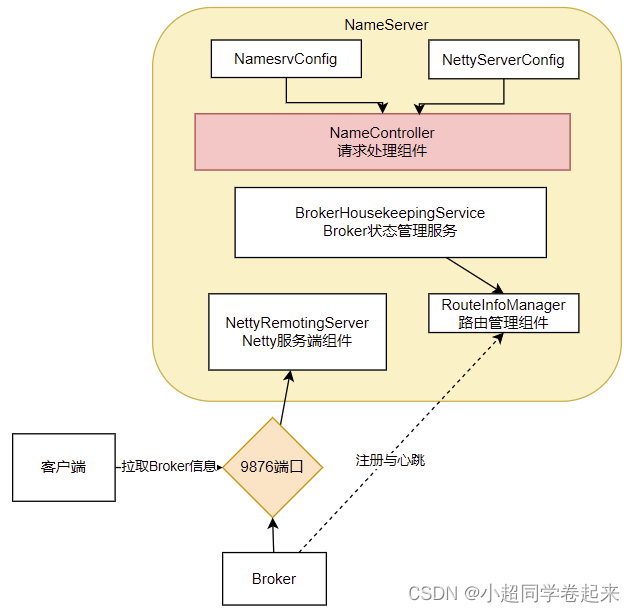
这两个配置类就可以用来指导如何优化Nameserver的配置。比如,如何调整nameserver的端口?自己试试从源码中找找答案。
从这里也能看出, RocketMQ的整体源码风格就是典型的MVC思想。Controller响应请求,Service处理业务,各种Table保存消息。
Broker服务启动过程
关注重点
Broker是整个RocketMQ的业务核心。所有消息存储、转发这些重要的业务都是Broker进行处理。
这里重点梳理Broker有哪些内部服务。这些内部服务将是整理Broker核心业务流程的起点。
源码重点
Broker启动的入口在BrokerStartup这个类,可以从他的main方法开始调试。
启动过程关键点:重点也是围绕一个BrokerController对象,先创建,然后再启动。
首先: 在BrokerStartup.createBrokerController方法中可以看到Broker的几个核心配置:
BrokerConfig : Broker服务配置
MessageStoreConfig : 消息存储配置。 这两个配置参数都可以在broker.conf文件中进行配置
NettyServerConfig :Netty服务端占用了10911端口。同样也可以在配置文件中覆盖。
NettyClientConfig : Broker既要作为Netty服务端,向客户端提供核心业务能力,又要作为Netty客户端,向NameServer注册心跳。
这些配置是我们了解如何优化 RocketMQ 使用的关键。
然后: 在BrokerController.start方法可以看到启动了一大堆Broker的核心服务,我们挑一些重要的
this.messageStore.start();//启动核心的消息存储组件this.remotingServer.start();
this.fastRemotingServer.start(); //启动两个Netty服务this.brokerOuterAPI.start();//启动客户端,往外发请求BrokerController.this.registerBrokerAll: //向NameServer注册心跳。this.brokerStatsManager.start();
this.brokerFastFailure.start();//这也是一些负责具体业务的功能组件
我们现在不需要了解这些核心组件的具体功能,只要有个大概,Broker中有一大堆的功能组件负责具体的业务。后面等到分析具体业务时再去深入每个服务的细节。
我们需要抽象出Broker的一个整体结构:
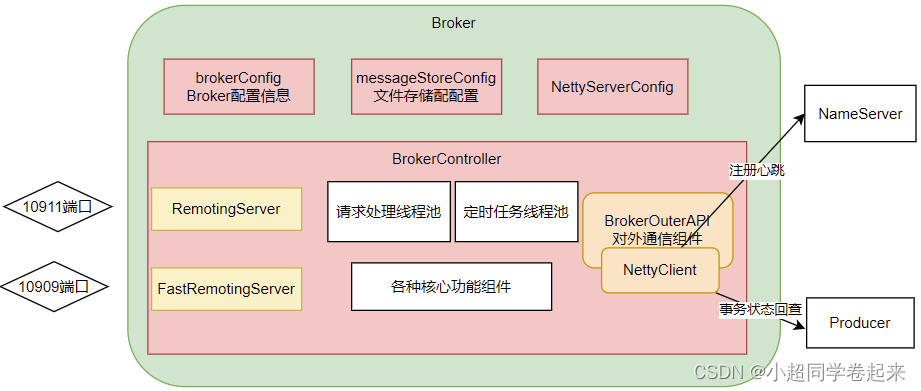
可以看到Broker启动了两个Netty服务,他们的功能基本差不多。实际上,在应用中,可以通过producer.setSendMessageWithVIPChannel(true),让少量比较重要的producer走VIP的通道。而在消费者端,也可以通过consumer.setVipChannelEnabled(true),让消费者支持VIP通道的数据。
Netty服务注册框架
关注重点
网络通信服务是构建分布式应用的基础,也是我们去理解RocketMQ底层业务的基础。这里就重点梳理RocketMQ的这个服务注册框架,理解各个业务进程之间是如何进行RPC远程通信的。
Netty的所有远程通信功能都由remoting模块实现。RemotingServer模块里包含了RPC的服务端RemotingServer以及客户端RemotingClient。在RocketMQ中,涉及到的远程服务非常多,在RocketMQ中,NameServer主要是RPC的服务端RemotingServer,Broker对于客户端来说,是RPC的服务端RemotingServer,而对于NameServer来说,又是RPC的客户端。各种Client是RPC的客户端RemotingClient。
需要理解的是,RocketMQ基于Netty保持客户端与服务端的长连接Channel。只要Channel是稳定的,那么即可以从客户端发请求到服务端,同样服务端也可以发请求到客户端。例如在事务消息场景中,就需要Broker多次主动向Producer发送请求确认事务的状态。所以,RemotingServer和RemotingClient都需要注册自己的服务。
源码重点
1、哪些组件需要Netty服务端?哪些组件需要Netty客户端? 比较好理解的,NameServer需要NettyServer。客户端,Producer和Consuer,需要NettyClient。Broker需要NettyServer响应客户端请求,需要NettyClient向NameServer注册心跳。但是有个问题, 事务消息的Producer也需要响应Broker的事务状态回查,他需要NettyServer吗?
NameServer不需要NettyClient,这也验证了之前介绍的NameServer之间不需要进行数据同步的说法。
2、所有的RPC请求数据都封账成RemotingCommand对象。而每个处理消息的服务逻辑,都会封装成一个NettyRequestProcessor对象。
3、服务端和客户端都维护一个processorTable,这是个HashMap。key是服务码requestCode,value是对应的运行单元 Pair<NettyRequestProcessor,ExecutorService>类型,包含了处理Processor和执行线程的线程池。具体的Processor,由业务系统自行注册。Broker服务注册见,BrokerController.registerProcessor(),客户端的服务注册见MQClientAPIImpl。NameServer则会注册一个大的DefaultRequestProcessor,统一处理所有服务。
4、请求类型分为REQUEST和RESPONSE。这是为了支持异步的RPC调用。NettyServer处理完请求后,可以先缓存到responseTable中,等NettyClient下次来获取,这样就不用阻塞Channel了,可以提升请求吞吐量。猜一猜Producer的同步请求的流程是什么样的?
5、重点理解remoting包中是如何实现全流程异步化。
整体RPC框架流程如下图:
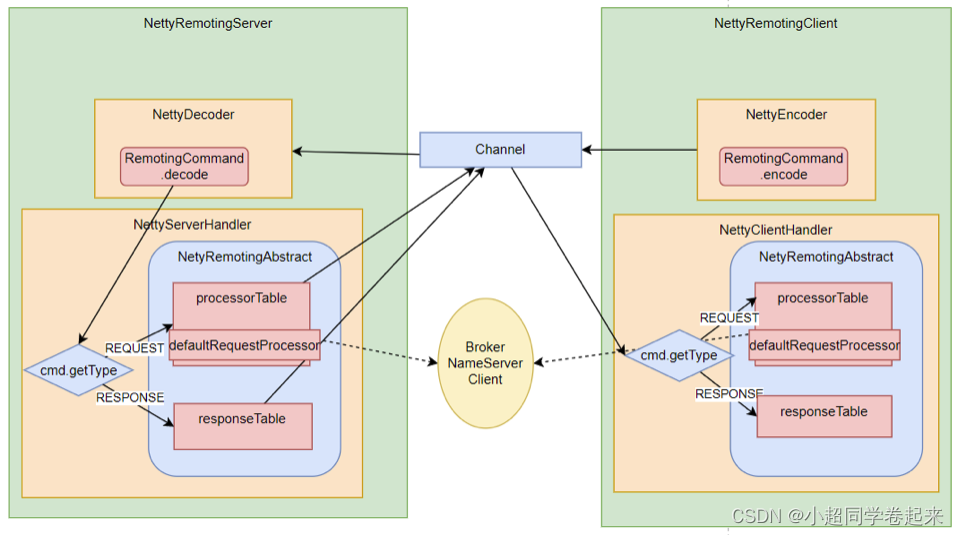
RocketMQ使用Netty框架提供了一套基于服务码的服务注册机制,让各种不同的组件都可以按照自己的需求,注册自己的服务方法。RocketMQ的这一套服务注册机制,是非常简洁使用的。在使用Netty进行其他相关应用开发时,都可以借鉴他的这一套服务注册机制。例如要开发一个大型的IM项目,要加减好友、发送文本,图片,甚至红包、维护群聊信息等等各种各样的请求,这些请求如何封装,就可以很好的参考这个框架。
关于RocketMQ的同步结果推送与异步结果推送
RocketMQ的RemotingServer服务端,会维护一个responseTable,这是一个线程同步的Map结构。 key为请求的ID,value是异步的消息结果。ConcurrentMap<Integer /* opaque */, ResponseFuture> 。
处理同步请求(NettyRemotingAbstract#invokeSyncImpl)时,处理的结果会存入responseTable,通过ResponseFuture提供一定的服务端异步处理支持,提升服务端的吞吐量。 请求返回后,立即从responseTable中移除请求记录。
实际上,同步也是通过异步实现的。
//org.apache.rocketmq.remoting.netty.ResponseFuture//发送消息后,通过countDownLatch阻塞当前线程,造成同步等待的效果。public RemotingCommand waitResponse(final long timeoutMillis) throws InterruptedException {this.countDownLatch.await(timeoutMillis, TimeUnit.MILLISECONDS);return this.responseCommand;}//等待异步获取到消息后,再通过countDownLatch释放当前线程。public void putResponse(final RemotingCommand responseCommand) {this.responseCommand = responseCommand;this.countDownLatch.countDown();}
处理异步请求(NettyRemotingAbstract#invokeAsyncImpl)时,处理的结果依然会存入responsTable,等待客户端后续再来请求结果。但是他保存的依然是一个ResponseFuture,也就是在客户端请求结果时再去获取真正的结果。 另外,在RemotingServer启动时,会启动一个定时的线程任务,不断扫描responseTable,将其中过期的response清除掉。
//org.apache.rocketmq.remoting.netty.NettyRemotingServer
this.timer.scheduleAtFixedRate(new TimerTask() {@Overridepublic void run() {try {NettyRemotingServer.this.scanResponseTable();} catch (Throwable e) {log.error("scanResponseTable exception", e);}}}, 1000 * 3, 1000);
Broker心跳注册管理
关注重点
Broker会在启动时向所有NameServer注册自己的服务信息,并且会定时往NameServer发送心跳信息。而NameServer会维护Broker的路由列表,并对路由表进行实时更新。这一轮就重点梳理这个过程。
源码重点
Broker启动后会立即发起向NameServer注册心跳。方法入口:BrokerController.this.registerBrokerAll。 然后启动一个定时任务,以10秒延迟,默认30秒的间隔持续向NameServer发送心跳。
NameServer内部会通过RouteInfoManager组件及时维护Broker信息。同时在NameServer启动时,会启动定时任务,扫描不活动的Broker。方法入口:NamesrvController.initialize方法。
极简化的服务注册发现流程
为什么RocketMQ要自己实现一个NameServer,而不用Zookeeper、Nacos这样现成的注册中心?
首先,依赖外部组件会对产品的独立性形成侵入,不利于自己的版本演进。Kafka要抛弃Zookeeper就是一个先例。
另外,其实更重要的还是对业务的合理设计。NameServer之间不进行信息同步,而是依赖Broker端向所有NameServer同时发起注册。这让NameServer的服务可以非常轻量。如果可能,你可以与Nacos或Zookeeper的核心流程做下对比。
但是,要知道,这种极简的设计,其实是以牺牲数据一致性为代价的。Broker往多个NameServer同时发起注册,有可能部分NameServer注册成功,而部分NameServer注册失败了。这样,多个NameServer之间的数据是不一致的。作为注册中心,这是不可接受的。但是对于RocketMQ,这又变得可以接受了。因为客户端从NameServer上获得的,只要有一个正常运行的Broker就可以了,并不需要完整的Broker列表。
Producer发送消息过程
关注重点
首先:回顾下我们之前的Producer使用案例。
Producer有两种:
一种是普通发送者:DefaultMQProducer。只负责发送消息,发送完消息,就可以停止了。
另一种是事务消息发送者: TransactionMQProducer。支持事务消息机制。需要在事务消息过程中提供事务状态确认的服务,这就要求事务消息发送者虽然是一个客户端,但是也要完成整个事务消息的确认机制后才能退出。
事务消息机制后面将结合Broker进行整理分析。这一步暂不关注。我们只关注DefaultMQProducer的消息发送过程。
然后:整个Producer的使用流程,大致分为两个步骤:一是调用start方法,进行一大堆的准备工作。 二是各种send方法,进行消息发送。
那我们重点关注以下几个问题:
1、Producer启动过程中启动了哪些服务
2、Producer如何管理broker路由信息。 可以设想一下,如果Producer启动了之后,NameServer挂了,那么Producer还能不能发送消息?希望你先从源码中进行猜想,然后自己设计实验进行验证。
3、关于Producer的负载均衡。也就是Producer到底将消息发到哪个MessageQueue中。这里可以结合顺序消息机制来理解一下。消息中那个莫名奇妙的MessageSelector到底是如何工作的。
源码重点
1、Producer的核心启动流程
所有Producer的启动过程,最终都会调用到DefaultMQProducerImpl#start方法。在start方法中的通过一个mQClientFactory对象,启动生产者的一大堆重要服务。
这里其实就是一种设计模式,虽然有很多种不同的客户端,但是这些客户端的启动流程最终都是统一的,全是交由mQClientFactory对象来启动。而不同之处在于这些客户端在启动过程中,按照服务端的要求注册不同的信息。例如生产者注册到producerTable,消费者注册到consumerTable,管理控制端注册到adminExtTable
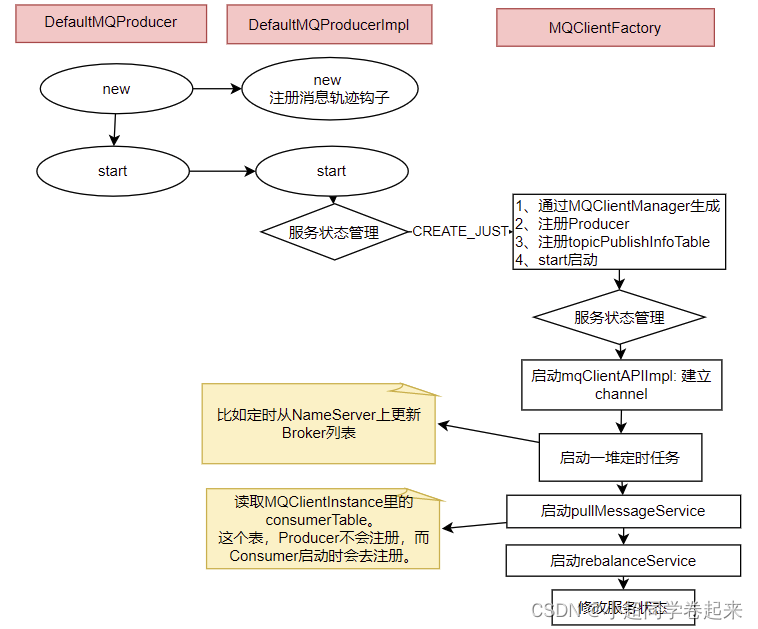
2、发送消息的核心流程
核心流程如下:
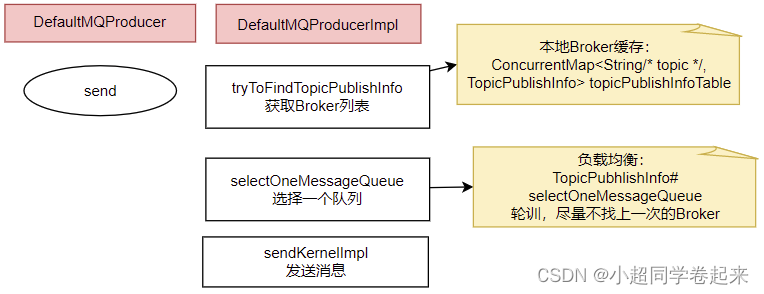
1、发送消息时,会维护一个本地的topicPublishInfoTable缓存,DefaultMQProducer会尽量保证这个缓存数据是最新的。但是,如果NameServer挂了,那么DefaultMQProducer还是会基于这个本地缓存去找Broker。只要能找到Broker,还是可以正常发送消息到Broker的。 --可以在生产者示例中,start后打一个断点,然后把NameServer停掉,这时,Producer还是可以发送消息的。
2、生产者如何找MessageQueue: 默认情况下,生产者是按照轮训的方式,依次轮训各个MessageQueue。但是如果某一次往一个Broker发送请求失败后,下一次就会跳过这个Broker。
//org.apache.rocketmq.client.impl.producer.TopicPublishInfo//如果进到这里lastBrokerName不为空,那么表示上一次向这个Broker发送消息是失败的,这时就尽量不要再往这个Broker发送消息了。public MessageQueue selectOneMessageQueue(final String lastBrokerName) {if (lastBrokerName == null) {return selectOneMessageQueue();} else {for (int i = 0; i < this.messageQueueList.size(); i++) {int index = this.sendWhichQueue.incrementAndGet();int pos = Math.abs(index) % this.messageQueueList.size();if (pos < 0)pos = 0;MessageQueue mq = this.messageQueueList.get(pos);if (!mq.getBrokerName().equals(lastBrokerName)) {return mq;}}return selectOneMessageQueue();}} 3、如果在发送消息时传了Selector,那么Producer就不会走这个负载均衡的逻辑,而是会使用Selector去寻找一个队列。 具体参见org.apache.rocketmq.client.impl.producer.DefaultMQProducerImpl#sendSelectImpl 方法。
Consumer拉取消息过程
关注重点
结合我们之前的示例,回顾下消费者这一块的几个重点问题:
消费者也是有两种,推模式消费者和拉模式消费者。优秀的MQ产品都会有一个高级的目标,就是要提升整个消息处理的性能。而要提升性能,服务端的优化手段往往不够直接,最为直接的优化手段就是对消费者进行优化。所以在RocketMQ中,整个消费者的业务逻辑是非常复杂的,甚至某种程度上来说,比服务端更复杂,所以,在这里我们重点关注用得最多的推模式的消费者。
消费者组之间有集群模式和广播模式两种消费模式。我们就要了解下这两种集群模式是如何做的逻辑封装。
然后我们关注下消费者端的负载均衡的原理。即消费者是如何绑定消费队列的,哪些消费策略到底是如何落地的。
最后我们来关注下在推模式的消费者中,MessageListenerConcurrently 和MessageListenerOrderly这两种消息监听器的处理逻辑到底有什么不同,为什么后者能保持消息顺序。
源码重点
Consumer的核心启动过程和Producer是一样的, 最终都是通过mQClientFactory对象启动。不过之间添加了一些注册信息。整体的启动过程如下:
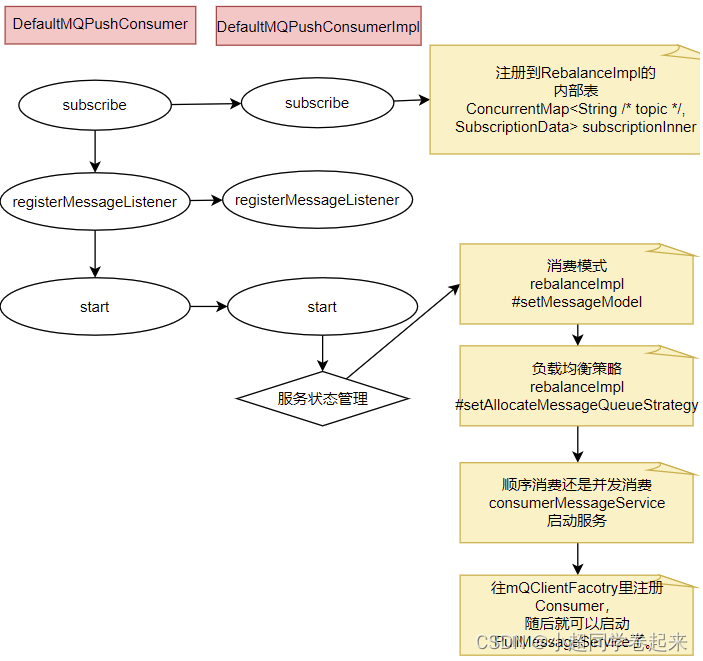
广播模式与集群模式的Offset处理
在DefaultMQPushConsumerImpl的start方法中,启动了非常多的核心服务。 比如,对于广播模式与集群模式的Offset处理
if (this.defaultMQPushConsumer.getOffsetStore() != null) {this.offsetStore = this.defaultMQPushConsumer.getOffsetStore();} else {switch (this.defaultMQPushConsumer.getMessageModel()) {case BROADCASTING:this.offsetStore = new LocalFileOffsetStore(this.mQClientFactory, this.defaultMQPushConsumer.getConsumerGroup());break;case CLUSTERING:this.offsetStore = new RemoteBrokerOffsetStore(this.mQClientFactory, this.defaultMQPushConsumer.getConsumerGroup());break;default:break;}this.defaultMQPushConsumer.setOffsetStore(this.offsetStore);}this.offsetStore.load();
可以看到,广播模式是使用LocalFileOffsetStore,在Consumer本地保存Offset,而集群模式是使用RemoteBrokerOffsetStore,在Broker端远程保存offset。而这两种Offset的存储方式,最终都是通过维护本地的offsetTable缓存来管理Offset。
Consumer与MessageQueue建立绑定关系
start方法中还一个比较重要的东西是给rebalanceImpl设定了一个AllocateMessageQueueStrategy,用来给Consumer分配MessageQueue的。
this.rebalanceImpl.setMessageModel(this.defaultMQPushConsumer.getMessageModel());
//Consumer负载均衡策略
this.rebalanceImpl.setAllocateMessageQueueStrategy(this.defaultMQPushConsumer.getAllocateMessageQueueStrategy());
这个AllocateMessageQueueStrategy就是用来给Consumer和MessageQueue之间建立一种对应关系的。也就是说,只要Topic当中的MessageQueue以及同一个ConsumerGroup中的Consumer实例都没有变动,那么某一个Consumer实例只是消费固定的一个或多个MessageQueue上的消息,其他Consumer不会来抢这个Consumer对应的MessageQueue。
关于负载均衡机制,会在后面结合Producer的发送消息策略一起总结。不过这里,你可以想一下为什么要让一个MessageQueue只能由同一个ConsumerGroup中的一个Consumer实例来消费。
其实原因很简单,因为Broker需要按照ConsumerGroup管理每个MessageQueue上的Offset,如果一个MessageQueue上有多个同属一个ConsumerGroup的Consumer实例,他们的处理进度就会不一样。这样的话,Offset就乱套了。
顺序消费与并发消费
同样在start方法中,启动了consumerMessageService线程,进行消息拉取。
//Consumer中自行指定的回调函数。if (this.getMessageListenerInner() instanceof MessageListenerOrderly) {this.consumeOrderly = true;this.consumeMessageService =new ConsumeMessageOrderlyService(this, (MessageListenerOrderly) this.getMessageListenerInner());} else if (this.getMessageListenerInner() instanceof MessageListenerConcurrently) {this.consumeOrderly = false;this.consumeMessageService =new ConsumeMessageConcurrentlyService(this, (MessageListenerConcurrently) this.getMessageListenerInner());}
可以看到, Consumer通过registerMessageListener方法指定的回调函数,都被封装成了ConsumerMessageService的子实现类。
而对于这两个服务实现类的调用,会延续到DefaultMQPushConsumerImpl的pullCallback对象中。也就是Consumer每拉过来一批消息后,就向Broker提交下一个拉取消息的的请求。
这里也可以印证一个点,就是顺序消息,只对异步消费也就是推模式有效。同步消费的拉模式是无法进行顺序消费的。因为这个pullCallback对象,在拉模式的同步消费时,根本就没有往下传。
当然,这并不是说拉模式不能锁定队列进行顺序消费,拉模式在Consumer端应用就可以指定从哪个队列上拿消息。
PullCallback pullCallback = new PullCallback() {@Overridepublic void onSuccess(PullResult pullResult) {if (pullResult != null) {//...switch (pullResult.getPullStatus()) {case FOUND://...DefaultMQPushConsumerImpl.this.consumeMessageService.submitConsumeRequest(pullResult.getMsgFoundList(),processQueue,pullRequest.getMessageQueue(),dispatchToConsume);//... break;//...}}}
而这里提交的,实际上是一个ConsumeRequest线程。而提交的这个ConsumeRequest线程,在两个不同的ConsumerService中有不同的实现。
这其中,两者最为核心的区别在于ConsumerMessageOrderlyService是锁定了一个队列,处理完了之后,再消费下一个队列。
public void run() {// ....final Object objLock = messageQueueLock.fetchLockObject(this.messageQueue);synchronized (objLock) {//....}}
为什么给队列加个锁,就能保证顺序消费呢?结合顺序消息的实现机制理解一下。
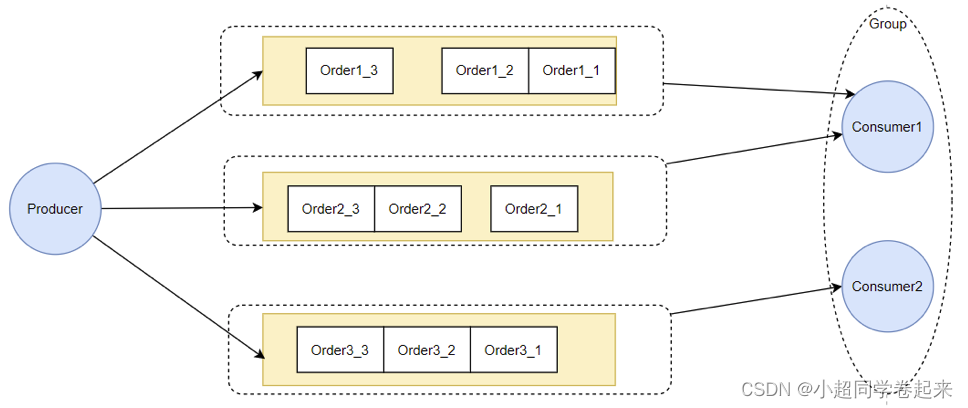
从源码中可以看到,Consumer提交请求时,都是往线程池里异步提交的请求。如果不加队列锁,那么就算Consumer提交针对同一个MessageQueue的拉取消息请求,这些请求都是异步执行,他们的返回顺序是乱的,无法进行控制。给队列加个锁之后,就保证了针对同一个队列的第二个请求,必须等第一个请求处理完了之后,释放了锁,才可以提交。这也是在异步情况下保证顺序的基础思路。
实际拉取消息还是通过PullMessageService完成的。
start方法中,相当于对很多消费者的服务进行初始化,包括指定一些服务的实现类,以及启动一些定时的任务线程,比如清理过期的请求缓存等。最后,会随着mQClientFactory组件的启动,启动一个PullMessageService。实际的消息拉取都交由PullMesasgeService进行。
所谓消息推模式,其实还是通过Consumer拉消息实现的。
//org.apache.rocketmq.client.impl.consumer.PullMessageServiceprivate void pullMessage(final PullRequest pullRequest) {final MQConsumerInner consumer = this.mQClientFactory.selectConsumer(pullRequest.getConsumerGroup());if (consumer != null) {DefaultMQPushConsumerImpl impl = (DefaultMQPushConsumerImpl) consumer;impl.pullMessage(pullRequest);} else {log.warn("No matched consumer for the PullRequest {}, drop it", pullRequest);}}
客户端负载均衡管理总结
从之前Producer发送消息的过程以及Conmer拉取消息的过程,我们可以抽象出RocketMQ中一个消息分配的管理模型。这个模型是我们在使用RocketMQ时,很重要的进行性能优化的依据。
Producer负载均衡
Producer发送消息时,默认会轮询目标Topic下的所有MessageQueue,并采用递增取模的方式往不同的MessageQueue上发送消息,以达到让消息平均落在不同的queue上的目的。而由于MessageQueue是分布在不同的Broker上的,所以消息也会发送到不同的broker上。
在之前源码中看到过,Producer轮训时,如果发现往某一个Broker上发送消息失败了,那么下一次会尽量避免再往同一个Broker上发送消息。但是,如果你的应用场景允许发送消息长延迟,也可以给Producer设定setSendLatencyFaultEnable(true)。这样对于某些Broker集群的网络不是很好的环境,可以提高消息发送成功的几率。
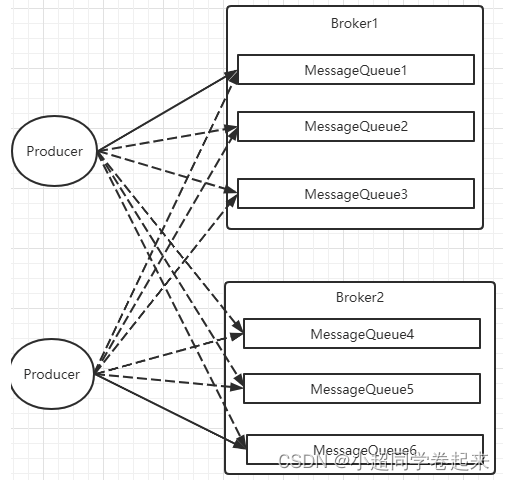
同时生产者在发送消息时,可以指定一个MessageQueueSelector。通过这个对象来将消息发送到自己指定的MessageQueue上。这样可以保证消息局部有序。
Consumer负载均衡
Consumer也是以MessageQueue为单位来进行负载均衡。分为集群模式和广播模式。
1、集群模式
在集群消费模式下,每条消息只需要投递到订阅这个topic的Consumer Group下的一个实例即可。RocketMQ采用主动拉取的方式拉取并消费消息,在拉取的时候需要明确指定拉取哪一条message queue。
而每当实例的数量有变更,都会触发一次所有实例的负载均衡,这时候会按照queue的数量和实例的数量平均分配queue给每个实例。
每次分配时,都会将MessageQueue和消费者ID进行排序后,再用不同的分配算法进行分配。内置的分配的算法共有六种,分别对应AllocateMessageQueueStrategy下的六种实现类,可以在consumer中直接set来指定。默认情况下使用的是最简单的平均分配策略。
AllocateMachineRoomNearby: 将同机房的Consumer和Broker优先分配在一起。
这个策略可以通过一个machineRoomResolver对象来定制Consumer和Broker的机房解析规则。然后还需要引入另外一个分配策略来对同机房的Broker和Consumer进行分配。一般也就用简单的平均分配策略或者轮询分配策略。
感觉这东西挺鸡肋的,直接给个属性指定机房不是挺好的吗。
源码中有测试代码AllocateMachineRoomNearByTest。
在示例中:Broker的机房指定方式: messageQueue.getBrokerName().split(“-”)[0],而Consumer的机房指定方式:clientID.split(“-”)[0]
clinetID的构建方式:见ClientConfig.buildMQClientId方法。按他的测试代码应该是要把clientIP指定为IDC1-CID-0这样的形式。
AllocateMessageQueueAveragely:平均分配。将所有MessageQueue平均分给每一个消费者
AllocateMessageQueueAveragelyByCircle: 轮询分配。轮流的给一个消费者分配一个MessageQueue。
AllocateMessageQueueByConfig: 不分配,直接指定一个messageQueue列表。类似于广播模式,直接指定所有队列。
AllocateMessageQueueByMachineRoom:按逻辑机房的概念进行分配。又是对BrokerName和ConsumerIdc有定制化的配置。
AllocateMessageQueueConsistentHash。源码中有测试代码AllocateMessageQueueConsitentHashTest。这个一致性哈希策略只需要指定一个虚拟节点数,是用的一个哈希环的算法,虚拟节点是为了让Hash数据在换上分布更为均匀。
最常用的就是平均分配和轮训分配了。例如平均分配时的分配情况是这样的:
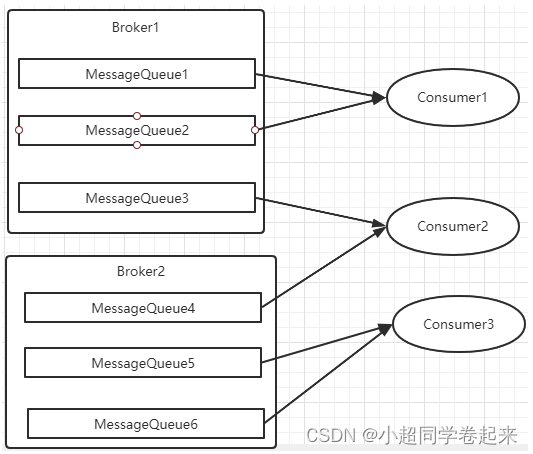
而轮训分配就不计算了,每次把一个队列分给下一个Consumer实例。
2、广播模式
广播模式下,每一条消息都会投递给订阅了Topic的所有消费者实例,所以也就没有消息分配这一说。而在实现上,就是在Consumer分配Queue时,所有Consumer都分到所有的Queue。
广播模式实现的关键是将消费者的消费偏移量不再保存到broker当中,而是保存到客户端当中,由客户端自行维护自己的消费偏移量。
相关文章:
RocketMQ高性能核心原理与源码架构剖析
文章目录 一、源码环境搭建主要功能模块源码启动服务启动nameServer启动Broker发送消息消费消息 二、源码热身阶段NameServer的启动过程关注重点源码重点 Broker服务启动过程关注重点源码重点 Netty服务注册框架关注重点源码重点关于RocketMQ的同步结果推送与异步结果推送 Brok…...
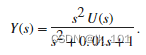
MATLAB中zp2tf函数用法
目录 语法 说明 示例 质点弹簧系统的传递函数 zp2tf函数的功能是将零极点增益滤波器参数转换为传递函数形式。。 语法 [b,a] zp2tf(z,p,k) 说明 [b, a] zp2tf(z, p, k) 将一个分解的传递函数表示方式转换。 将单输入/多输出(SIMO)系统的多输出…...

解决:uniapp项目中调用小程序的chooseAddress() API失效
目录 问题描述 解决方案 问题描述 使用 Hbuilder X 编辑器和 uni-app 框架开发小程序项目,在调用小程序提供的 uni.chooseAddress() API实现选择收货地址的功能时,点击选择收货地址没有反应,获取不到用户收货地址,API失效了 …...
)
2023 项目组总结(待完善)
2023 项目组总结 目录概述需求: 设计思路实现思路分析1.JA项目2.XC项目3.XL 项目4.tydic 项目 总结 参考资料和推荐阅读 Survive by day and develop by night. talk for import biz , show your perfect code,full busy,skip hardness,make a better re…...

Chrome浏览器 键盘快捷键整理
名人说:莫听穿林打叶声,何妨吟啸且徐行。—— 苏轼《定风波莫听穿林打叶声》 本篇笔记整理:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 〇、前言一、常用快捷键二、分类型快捷键表(…...
【JAVA】集合与背后的逻辑框架,包装类,List,Map,Set,静态内部类
❤️ Author: 老九 ☕️ 个人博客:老九的CSDN博客 🙏 个人名言:不可控之事 乐观面对 😍 系列专栏: 文章目录 collectionCollection创建collection使用泛型collection方法 Map 接口Map的存储结构HashMap和Tr…...
mac电脑版数字图像处理软件:ACDSee Photo Studio 9最新 for Mac
ACDSee Photo Studio 9是一款由ACD Systems开发的功能强大的照片管理和编辑软件,专为Mac用户提供一站式解决方案,方便用户轻松浏览、管理和编辑照片。该软件提供了许多实用的工具和功能,包括高效的导入和排序工具、强大的编辑工具、智能组织和…...
酷开系统 | 酷开科技让你放肆嗨唱,聆听内心最真实的声音
在这个喧嚣的城市里,每个人都像是一座孤岛,漂浮在茫茫人海之中,我们总是忙于奔波在各种琐事之间,渐渐忘记了内心深处的声音,我们压抑自己的情感,害怕被误解、被批评,然而真正的我们,…...
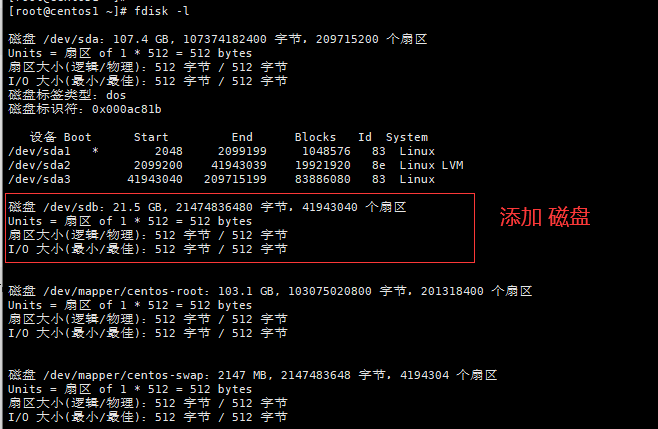
PC电脑 VMware安装的linux CentOs7如何扩容磁盘?
一、VM中进行扩容设置 必须要关闭当前CentOS,不然扩展按钮是灰色的。 输入值必须大于当前磁盘容量。然后点击扩展,等待扩展完成会提示一个弹框,点击确定,继续确定。 二、操作CentOS扩容——磁盘分区 第一步设置完成。那就启动 …...

redis极速的奥秘
文章目录 1.基于内存存储实现2.高效的数据结构3.合理的数据编码4.合理的线程模型5. 虚拟内存机制实现原理 1.基于内存存储实现 内存读写是比在磁盘快很多的,Redis 基于内存存储实现的数据库,相对于数据存在磁盘的 MySQL 数据库,省去磁盘 I/O…...

three.js之初识three.js
什么是three.js Three.js是一款运行在浏览器中的 3D 引擎(基于WebGL的API的封装) 什么是WebGL? WebGL(英语:Web Graphics Library)是一种3D绘图协议,这种绘图技术标准允许把JavaScript和Open…...

二维码智慧门牌管理系统:地址管理的现代革命
文章目录 前言一、标准地址的革新二、广泛的应用前景 前言 在科技不断发展和社会进步的背景下,高效、精准、智能的管理系统已经成为当今社会的迫切需求。传统的门牌管理系统在应对这一需求方面已显得力不从心,因此,二维码智慧门牌管理系统的…...
BricsCAD 23 for Mac:轻松驾驭CAD建模的强大工具
如果你正在寻找一款功能强大、操作简便的CAD建模软件,那么BricsCAD 23 for Mac绝对值得你考虑。这款软件将为你提供一套完整的2D和3D设计解决方案,让你在Mac上轻松创建、编辑和修改图形。 一、BricsCAD 23的功能特点 高效的2D和3D建模:Bric…...

如何利用Web应用防火墙应对未知威胁
网络安全是一个永恒的话题,尤其是在未知威胁不断涌现的情况下。Web应用防火墙(WAF)是企业网络安全防线的重要组成部分,能够帮助企业在面对未知威胁时采取有效的防护措施。本文将探讨如何利用Web应用防火墙应对未知的网络威胁。 一…...
四、多线程服务器
1.进程的缺陷和线程的优点 1.进程的缺陷 创建进程(复制)的工作本身会给操作系统带来相当沉重的负担。 而且,每个进程具有独立的内存空间,所以进程间通信的实现难度也会随之提高。 同时,上下文切换(Cont…...

基于vue实现滑块动画效果
主要实现:通过鼠标移移动、触摸元素、鼠标释放、离开元素事件来进行触发 创建了一个滑动盒子,其中包含一个滑块图片。通过鼠标按下或触摸开始事件,开始跟踪滑块的位置和鼠标/触摸位置之间的偏移量。然后,通过计算偏移量和起始时的…...

探寻蓝牙的未来:从蓝牙1.0到蓝牙5.4,如何引领无线连接革命?
►►►蓝牙名字的来源 这要源于一个小故事,公元940-985年,哈洛德布美塔特(Harald Blatand),后人称Harald Bluetooth,统一了整个丹麦。他的名字“Blatand”可能取自两个古老的丹麦词语。“bla”意思是黑皮肤的,而“tan…...
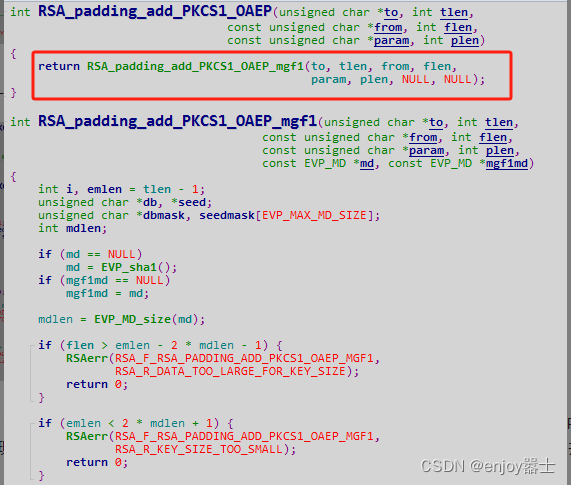
openssl 之 RSA加密数据设置OAEP SHA256填充方式
背景 如题 环境 openssl 1.1.1l c centos7.9 代码 /** 思路:填充方式自己写,不需要使用库提供的,然后加密时选择不填充的方式加密 关键代码 */ int padding_result RSA_padding_add_PKCS1_OAEP_mgf1(buf, padding_len, (unsigned char*…...

js将带标签的内容转为纯文本
背景:现需要将富文本的所有 html 标签全部删除得到纯文本 思路:创建临时DOM元素并获取其中的文本 创建一个临时 DOM 并给他赋值,然后我们使用 DOM 对象方法提取文本。 代码如下: convertToPlain( html){//新创建一个 divvar di…...
如何通过内网穿透实现远程连接NAS群晖drive并挂载电脑硬盘?
文章目录 前言1.群晖Synology Drive套件的安装1.1 安装Synology Drive套件1.2 设置Synology Drive套件1.3 局域网内电脑测试和使用 2.使用cpolar远程访问内网Synology Drive2.1 Cpolar云端设置2.2 Cpolar本地设置2.3 测试和使用 3. 结语 前言 群晖作为专业的数据存储中心&…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...
基于Springboot+Vue的办公管理系统
角色: 管理员、员工 技术: 后端: SpringBoot, Vue2, MySQL, Mybatis-Plus 前端: Vue2, Element-UI, Axios, Echarts, Vue-Router 核心功能: 该办公管理系统是一个综合性的企业内部管理平台,旨在提升企业运营效率和员工管理水…...
:工厂方法模式、单例模式和生成器模式)
上位机开发过程中的设计模式体会(1):工厂方法模式、单例模式和生成器模式
简介 在我的 QT/C 开发工作中,合理运用设计模式极大地提高了代码的可维护性和可扩展性。本文将分享我在实际项目中应用的三种创造型模式:工厂方法模式、单例模式和生成器模式。 1. 工厂模式 (Factory Pattern) 应用场景 在我的 QT 项目中曾经有一个需…...
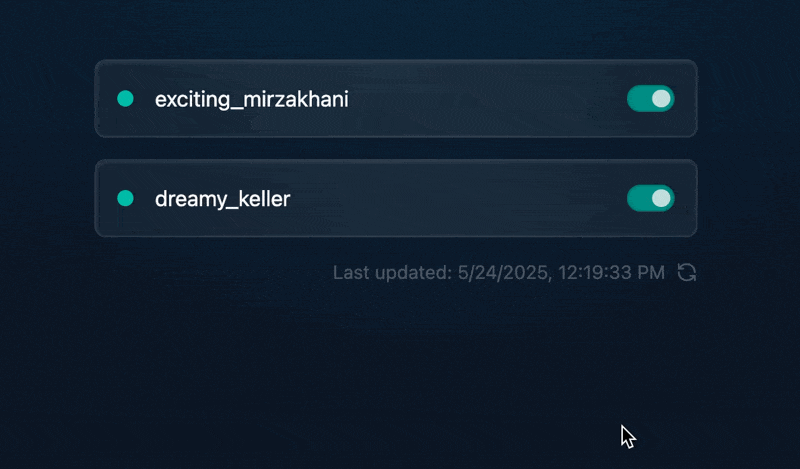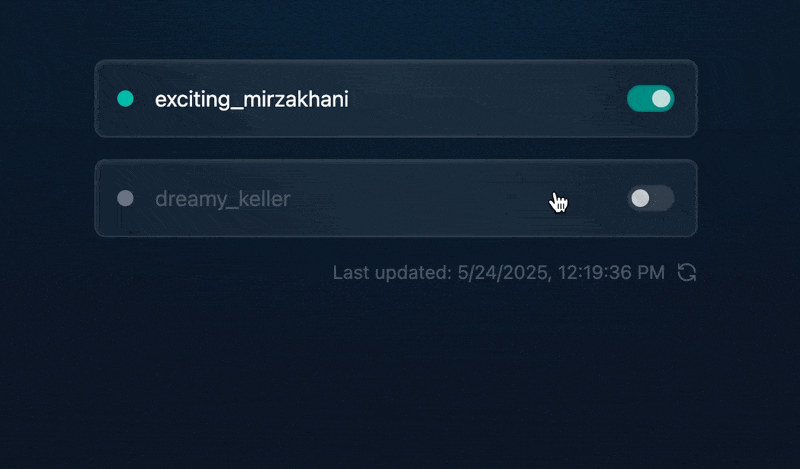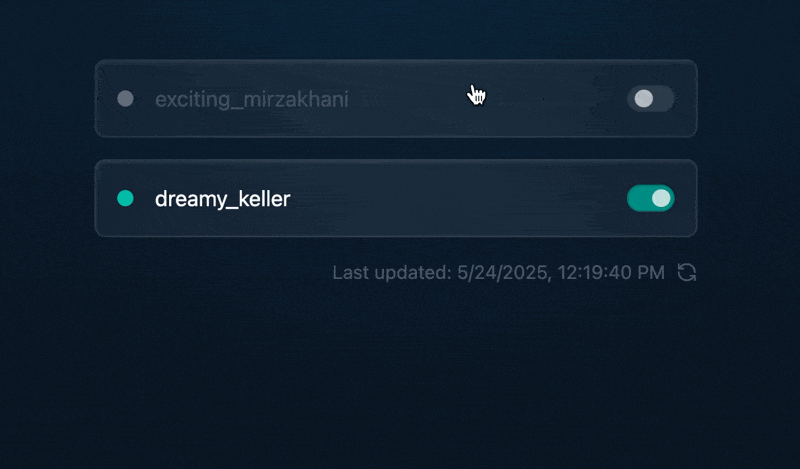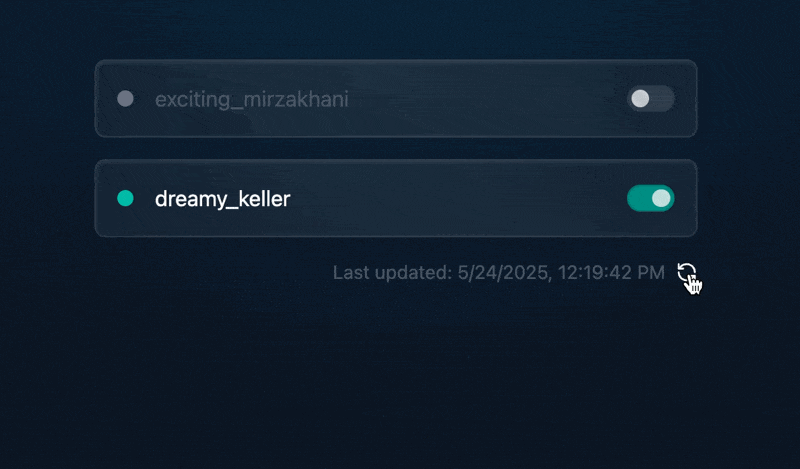
轻量级Docker管理工具Docker Switchboard
简介 什么是 Docker Switchboard ? Docker Switchboard 是一个轻量级的 Web 应用程序,用于管理 Docker 容器。它提供了一个干净、用户友好的界面来启动、停止和监控主机上运行的容器,使其成为本地开发、家庭实验室或小型服务器设置的理想选择…...
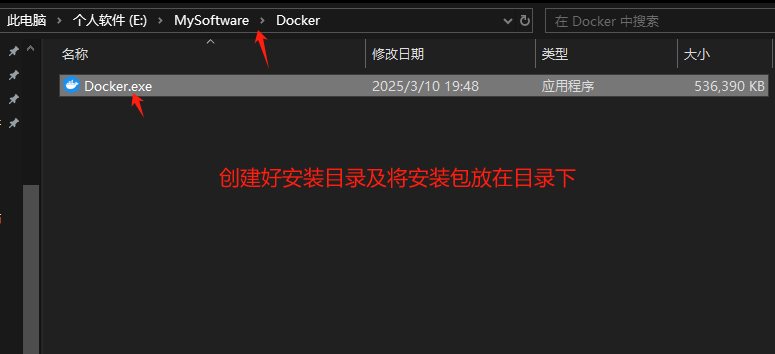
大模型——基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程
基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程 下载安装Docker Docker官网:https://www.docker.com/ 自定义Docker安装路径 Docker默认安装在C盘,大小大概2.9G,做这行最忌讳的就是安装软件全装C盘,所以我调整了下安装路径。 新建安装目录:E:\MyS…...