Python爬虫基础之Selenium详解
目录
- 1. Selenium简介
- 2. 为什么使用Selenium?
- 3. Selenium的安装
- 4. Selenium的使用
- 5. Selenium的元素定位
- 6. Selenium的交互
- 7. Chrome handless
- 参考文献
原文地址:https://program-park.top/2023/10/16/reptile_3/
本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关。
1. Selenium简介
Selenium 是一个用于 Web 应用程序测试的工具。最初是为网站自动化测试而开发的,可以直接运行在浏览器上,支持的浏览器包括 IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera 和 Edge 等。
爬虫中使用它是为了解决 requests 无法直接执行 JavaScript 代码的问题。Selenium 本质上是通过驱动浏览器,彻底模拟浏览器的操作,好比跳转、输入、点击、下拉等,来拿到网页渲染之后的结果。Selenium 是 Python 的一个第三方库,对外提供的接口能够操作浏览器,从而让浏览器完成自动化的操作。
2. 为什么使用Selenium?
Selenium 能模拟浏览器功能自动执行网页中的 JavaScript 代码,实现动态加载。
3. Selenium的安装
谷歌浏览器驱动下载地址:https://registry.npmmirror.com/binary.html?path=chromedriver/
查看自己谷歌浏览器的版本,我这里的版本是正式版本116.0.5845.188,驱动下载地址最新的只有114.0.5735.90,所以只能去官网的测试页面下载118.0.5993.70版本的驱动(https://googlechromelabs.github.io/chrome-for-testing/#stable,版本向下兼容),然后把下载的压缩包解压,将exe文件放入 PyCharm 项目的根目录下。
之后执行pip install selenium命令,安装 selenium 库。
4. Selenium的使用
from selenium import webdriver# 创建浏览器操作对象
path = 'chromedriver.exe'
browser= webdriver.Chrome(path)# 访问网站
url = 'https://www.baidu.com'browser.get(url)
# content = browser.page_source
# print(content)
需要注意的是,如果你的 selenium 是4.11.2以上的版本,不需要设置driver.exe的路径,selenium 可以自己处理浏览器的驱动程序,因此代码直接改为brower = webdriver.Chrome()即可。
运行代码,得到下面的效果:

5. Selenium的元素定位
自动化工具要做的就是模拟鼠标和键盘来操作点击、输入等等元素,但是操作这些元素的前提是找到它们,WebDriver 提供了很多元素定位的方法:
- 根据标签 id 获取元素:
from selenium import webdriver from selenium.webdriver.common.by import By# 创建浏览器操作对象 # path = 'chromedriver.exe' browser= webdriver.Chrome()# 访问网站 url = 'https://www.baidu.com' browser.get(url)button = browser.find_element(By.ID, 'su') # button = browser.find_elements(By.ID, 'su') print(button) - 根据标签 name 属性的值获取元素:
button = browser.find_element(By.NAME, 'wd') print(button) - 根据 Xpath 语句获取元素;
button = browser.find_element(By.XPATH, '//input[@id="su"]') print(button) - 根据标签名获取元素:
button = browser.find_elements(By.TAG_NAME, 'input') print(button) - 根据 bs4 语法获取元素:
button = browser.find_elements(By.CSS_SELECTOR, '#su') print(button) - 根据标签的文本获取元素(精确定位):
button = browser.find_elements(By.LINK_TEXT, '地图') print(button) - 根据标签的文本获取元素(模糊定位):
button = browser.find_elements(By.PARTIAL_LINK_TEXT, '地') print(button) - 根据 class 属性获取元素:
button = browser.find_element(By.CLASS_NAME, 'wrapper_new') print(button)
当我们定位到元素之后,自然就要考虑如何获取到元素的各种信息,selenium 给我们提供了获取元素不同信息的方法:
- 获取元素属性:
from selenium import webdriver from selenium.webdriver.common.by import By# 创建浏览器操作对象 # path = 'chromedriver.exe' browser= webdriver.Chrome()# 访问网站 url = 'https://www.baidu.com' browser.get(url)button = browser.find_element(By.ID, 'su') print(input.get_attribute('class')) - 获取元素标签名:
input = browser.find_element(By.ID, 'su') print(input.tag_name) - 获取元素文本:
input = browser.find_element(By.ID, 'su') print(input.text) - 获取元素位置:
input = browser.find_element(By.ID, 'su') print(input.location) - 获取元素大小:
input = browser.find_element(By.ID, 'su') print(input.size)
6. Selenium的交互
页面交互指的是我们平时在浏览器上的各种操作,比如输入文本、点击链接、回车、下拉框等,下面就演示 selenium 是如何进行页面交互的。
- 输入文本:
from selenium import webdriver from selenium.webdriver.common.by import By import time# 创建浏览器操作对象 # path = 'chromedriver.exe' browser = webdriver.Chrome()# 访问网站 url = 'https://www.baidu.com' browser.get(url)# 定位输入框 input = browser.find_element(By.ID, 'kw') # 输入文本selenium input.send_keys('selenium') time.sleep(2)# 关闭浏览器 browser.close() - 点击:
from selenium import webdriver from selenium.webdriver.common.by import By import time# 创建浏览器操作对象 # path = 'chromedriver.exe' browser = webdriver.Chrome()# 访问网站 url = 'https://www.baidu.com' browser.get(url)# 定位输入框 input = browser.find_element(By.ID, 'kw') # 输入文本selenium input.send_keys('selenium') time.sleep(2)# 定位百度一下的按钮 button = browser.find_element(By.ID, 'su') # 点击按钮 button.click() time.sleep(2)# 关闭浏览器 browser.close() - 清除文本:
from selenium import webdriver from selenium.webdriver.common.by import By import time# 创建浏览器操作对象 # path = 'chromedriver.exe' browser = webdriver.Chrome()# 访问网站 url = 'https://www.baidu.com' browser.get(url)# 定位输入框 input = browser.find_element(By.ID, 'kw') # 输入文本selenium input.send_keys('selenium') time.sleep(2)# 清除selenium input.clear() time.sleep(2)# 关闭浏览器 browser.close() - 回车确认:
from selenium import webdriver from selenium.webdriver.common.by import By import time# 创建浏览器操作对象 # path = 'chromedriver.exe' browser = webdriver.Chrome()# 访问网站 url = 'https://www.baidu.com' browser.get(url)# 定位输入框 input = browser.find_element(By.ID, 'kw') # 输入文本selenium input.send_keys('selenium') time.sleep(2)# 回车查询 input.submit() time.sleep(2)# 关闭浏览器 browser.close() - 运行 JavaScript:
from selenium import webdriver from selenium.webdriver.common.by import By import time# 创建浏览器操作对象 # path = 'chromedriver.exe' browser = webdriver.Chrome()# 访问网站 url = 'https://www.baidu.com' browser.get(url)# 定位输入框 input = browser.find_element(By.ID, 'kw') # 输入文本selenium input.send_keys('selenium') time.sleep(2)# 回车查询 input.submit() time.sleep(2)# js代码 js_bottom = 'document.documentElement.scrollTop=100000' # 下拉进度条,页面滑动 browser.execute_script(js_bottom) time.sleep(2)# 关闭浏览器 browser.close() - 前进后退
from selenium import webdriver from selenium.webdriver.common.by import By import time# 创建浏览器操作对象 # path = 'chromedriver.exe' browser = webdriver.Chrome()# 访问网站 url = 'https://www.baidu.com' browser.get(url)# 定位输入框 input = browser.find_element(By.ID, 'kw') # 输入文本selenium input.send_keys('selenium') time.sleep(2)# 回车查询 input.submit() time.sleep(2)# js代码 js_bottom = 'document.documentElement.scrollTop=100000' # 页面滑动 browser.execute_script(js_bottom) time.sleep(2)# 定位下一页的按钮 next = browser.find_element(By.XPATH, '//a[@class="n"]') # 点击下一页 next.click() time.sleep(2)# 返回到上一页面 browser.back() time.sleep(2)# 前进到下一页 browser.forward() time.sleep(2)# 关闭浏览器 browser.close()
7. Chrome handless
在上面的测试过程中可以发现,虽然 selenium 简便好用,但是它的运行速度很慢,这是因为 selenium 是有界面的,需要执行前端 css 和 js 的渲染。那么下面就介绍一个无界面的浏览器,Chrome-handless 模式,运行效率要比真实的浏览器快很多,在 selenium 的基础上,支持页面元素查找、js 执行等,代码和 selenium 一致。
使用前提:
- Chrome
- Unix\Linux chrome >= 59
- Windows chrome >= 60
- Python >= 3.6
- Selenium >= 3.4.*
from selenium import webdriverdef share_browser():# headless自带配置,不需要再做额外的修改from selenium.webdriver.chrome.options import Options# 初始化chrome_options = Options()chrome_options.add_argument('‐‐headless')chrome_options.add_argument('‐‐disable‐gpu')# 谷歌浏览器的安装路径path = r'C:\Users\\AppData\Local\Google\Chrome\Application\chrome.exe'chrome_options.binary_location = pathbrowser = webdriver.Chrome(options=chrome_options)return browserbrowser = share_browser()
url = 'https://www.baidu.com'
browser.get(url)# 本地保存照片
browser.save_screenshot('baidu.png')
参考文献
【1】http://www.noobyard.com/article/p-boitcibx-g.html
【2】https://www.jb51.net/article/149145.htm
【3】https://zhuanlan.zhihu.com/p/462460461
【4】https://blog.csdn.net/weixin_67553250/article/details/127555724
【5】https://www.cnblogs.com/Summer-skr–blog/p/11491078.html
【6】https://www.bilibili.com/video/BV1Db4y1m7Ho?p=77
相关文章:
Python爬虫基础之Selenium详解
目录 1. Selenium简介2. 为什么使用Selenium?3. Selenium的安装4. Selenium的使用5. Selenium的元素定位6. Selenium的交互7. Chrome handless参考文献 原文地址:https://program-park.top/2023/10/16/reptile_3/ 本文章中所有内容仅供学习交流使用&…...
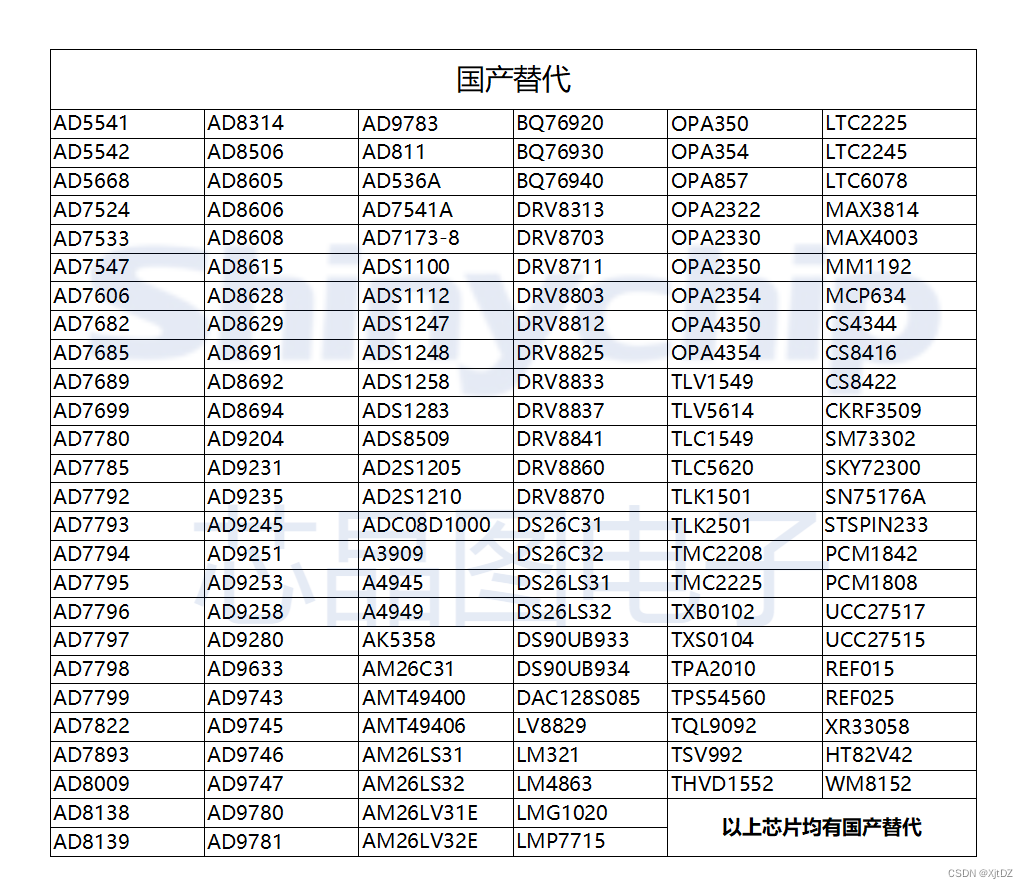
MS5228数模转换器可pin对pin兼容AD5628
MS5228/5248/5268 是一款 12/14/16bit 八通道输出的电压型 DAC,内部集成上电复位电路、可选内部基准、接口采用四线串口模式,最高工作频率可以到 40MHz,可以兼容 SPI、QSPI、DSP 接口和 Microwire 串口。可pin对pin兼容AD5628。输出接到一个 …...

强化学习基础(2)—常用算法总结
目录 1.Value-Based 2. Policy-Based 参考文献 1.Value-Based Sarsa(State-action-reward-state’-action):是为了建立和优化状态-动作(state-action)的价值Q表格所建立的方法。首先初始化Q表格,根据当前的状态和动作与环境进行…...
Web攻防01-ASP应用相关漏洞-HTTP.SYSIIS短文件文件解析ACCESS注入
文章目录 ASP-默认安装-MDB数据库泄漏下载漏洞漏洞描述 ASP-中间件 HTTP.SYS(CVE-2015-1635)1、漏洞描述2、影响版本3、漏洞利用条件4、漏洞复现 ASP-中间件 IIS短文件漏洞1、漏洞描述2、漏洞成因:3、应用场景:4、利用工具:5、漏洞…...

入门小白拥有服务器的建议
学习网络知识 当我们拥有了一台服务器以后,需要提前准备学习一些网络、服务器、互联网方便的知识, 以备在后续学习工作中使用。 建议的网络知识学习清单: 1. 网络基础知识:包括网络拓扑结构、协议、IP地址、子网掩码、网关等基础概念。 2. 网络安全:包括网络攻击类型、防…...
Spring源码解析——事务增强器
正文 上一篇文章我们讲解了事务的Advisor是如何注册进Spring容器的,也讲解了Spring是如何将有配置事务的类配置上事务的,实际上也就是用了AOP那一套,也讲解了Advisor,pointcut验证流程,至此,事务的初始化工…...
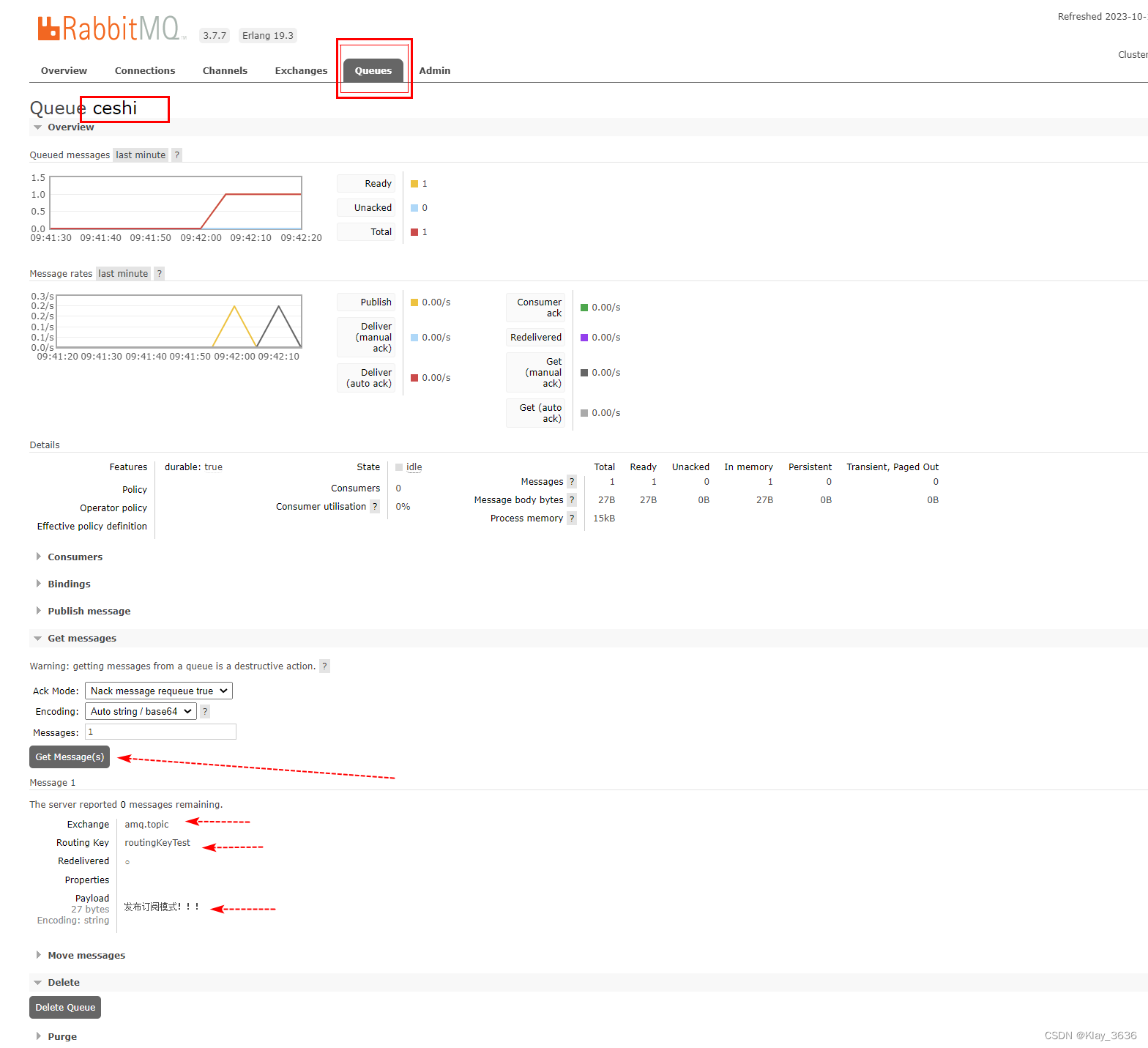
JAVA发送消息到RabbitMq
项目中,作为生产者自定义消息发送到RabbitMq。 1.引入rmq依赖 <!-- rabbitmq 依赖 --><dependency><groupId>com.rabbitmq</groupId><artifactId>amqp-client</artifactId><version>5.9.0</version></dependen…...
基本使用指南)
Python 函数(lambda 匿名函数、自定义函数、装饰器)基本使用指南
Python 函数 函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段 lambda 匿名函数 对于单行函数,使用 lambda 表达式可以省去定义函数的过程,让代码更加简洁; 对于不需要多次复用的函数&a…...

第五届芜湖机器人展,正运动助力智能装备“更快更准”更智能!
■展会名称: 第十一届中国(芜湖)科普产品博览交易会-第五届机器人展 ■展会日期 2023年10月21日-23日 ■展馆地点 中国ㆍ芜湖宜居国际博览中心B馆 ■展位号 B029 正运动技术,作为国内领先的运动控制企业,将于2023年10月21日参加芜湖机…...
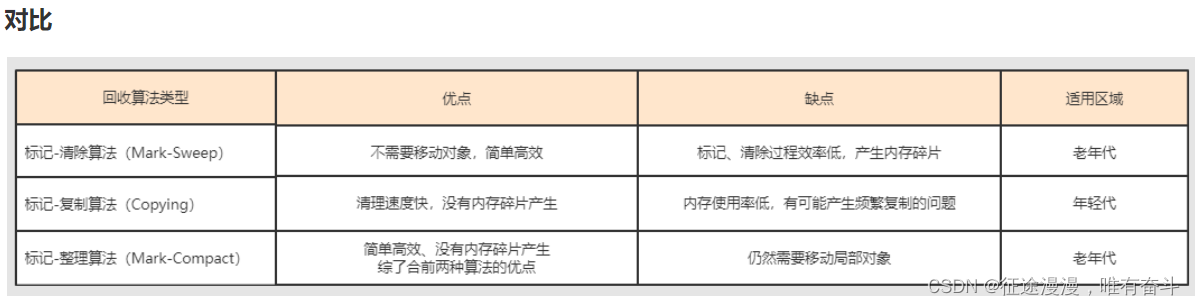
JVM八股文
1.JVM的内存结构? 2.OOM是什么,怎么排查? 3.请解释四种引用是什么意思有什么区别? 4.GC的回收算法有哪些? 5.怎么判断对象是否存活? 1.什么是JVM内存结构 jvm将虚拟机分为5大区域,程序计数器、…...
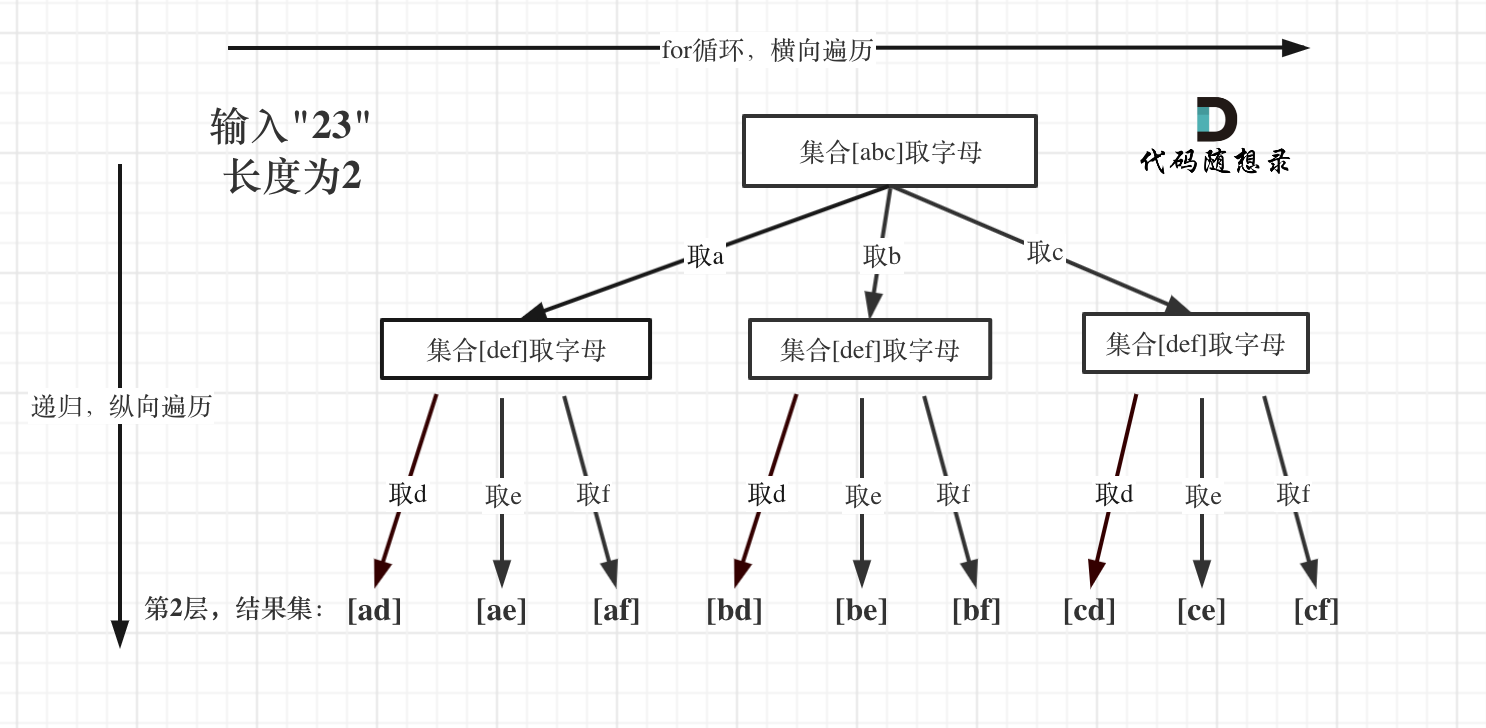
代码随想录算法训练营第二十四天丨 回溯算法part02
216.组合总和III 思路 本题就是在 [1,2,3,4,5,6,7,8,9] 这个集合中找到和为n的k个数的组合。 相对于77. 组合 (opens new window),无非就是多了一个限制,本题是要找到和为n的k个数的组合,而整个集合已经是固定的了[1,...,9]。 本题k相当于…...

【Python机器学习】零基础掌握AgglomerativeClustering聚类
如何解决城市规划问题? 城市规划者们面临一个复杂问题:如何合理地规划土地,使商业、居民、公园和其他设施互相便利,同时又不互相干扰?解决这个问题不仅需要对土地进行精准的分类,还要考虑到土地之间的相互关系。 借助层次聚类算法(Agglomerative Clustering),规划者…...
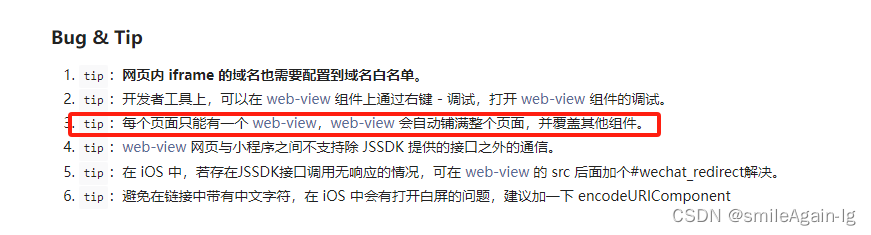
uniapp小程序中给web-view页面添加授权弹窗(使用cover-view组件覆盖实现该功能)
效果图: web-view是承载网页的容器。会自动铺满整个小程序页面,个人类型的小程序暂不支持使用。 再看下面一个提示: 每个页面只能有一个 web-view,web-view 会自动铺满整个页面,并覆盖其他组件。 也就是说,…...
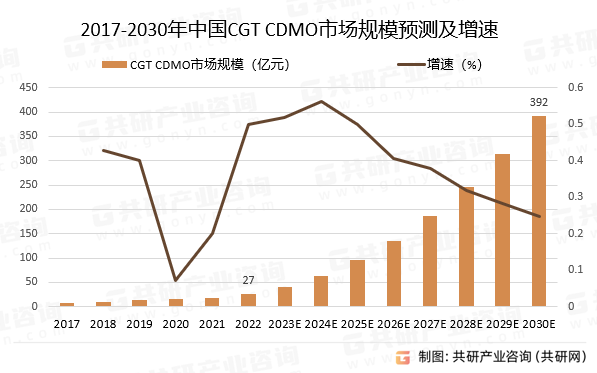
2023年全球及中国CGT CDMO市场发展现状分析:CGT 渗透率有效助力CGT CDMO快速发展[图]
与传统药物相比,CGT的外包服务更注重活体开发过程,如质粒、病毒、细胞的生产及纯化。标准化、规模化的工艺流程对最终制备的产品起到重要影响,是获取及制备能够满足临床需求的高质量CGT产品的关键。 CGT CDMO服务内容 资料来源:共…...

上抖音热搜榜需要做哪些准备?
要想在抖音上获得高曝光,首先需要了解抖音热搜榜的算法和规则。抖音热搜榜的排名主要取决于作品的点赞数、评论数、分享数和播放量。其中,播放量是影响排名的关键因素。因此,在创作作品时,要注重提高作品的播放量。此外࿰…...

LDA代码训练报错记录
1、AttributeError: ‘CountVectorizer‘ object has no attribute ‘get_feature_names‘ 代码内容: tf_feature_names tf_vectorizer.get_feature_names()报错信息 AttributeError: CountVectorizer object has no attribute get_feature_names报错解析&#…...

【吞噬星空】爽翻,徐欣喜提永恒之体,罗峰秒杀败类,阿特金磕头认错
Hello,小伙伴们,我是小郑继续为大家深度解析国漫资讯。 吞噬星空动画第89集终于更新了,阿特金三大巨头的好日子到头了,从他们对徐欣出手的那一刻,就已经有取死之道。如今罗峰强势回归,上演复仇戏码,让大家看…...

【c++】跟webrtc学状态改变
peerconn的状态看起来只是为了通知上层PeerConnectionState // See https://w3c.github.io/webrtc-pc/#dom-rtcpeerconnectionstateenum class PeerConnectionState {kNew,kConnecting,kConnected,kDisconnected,kFailed,kClosed,};static constexpr absl...
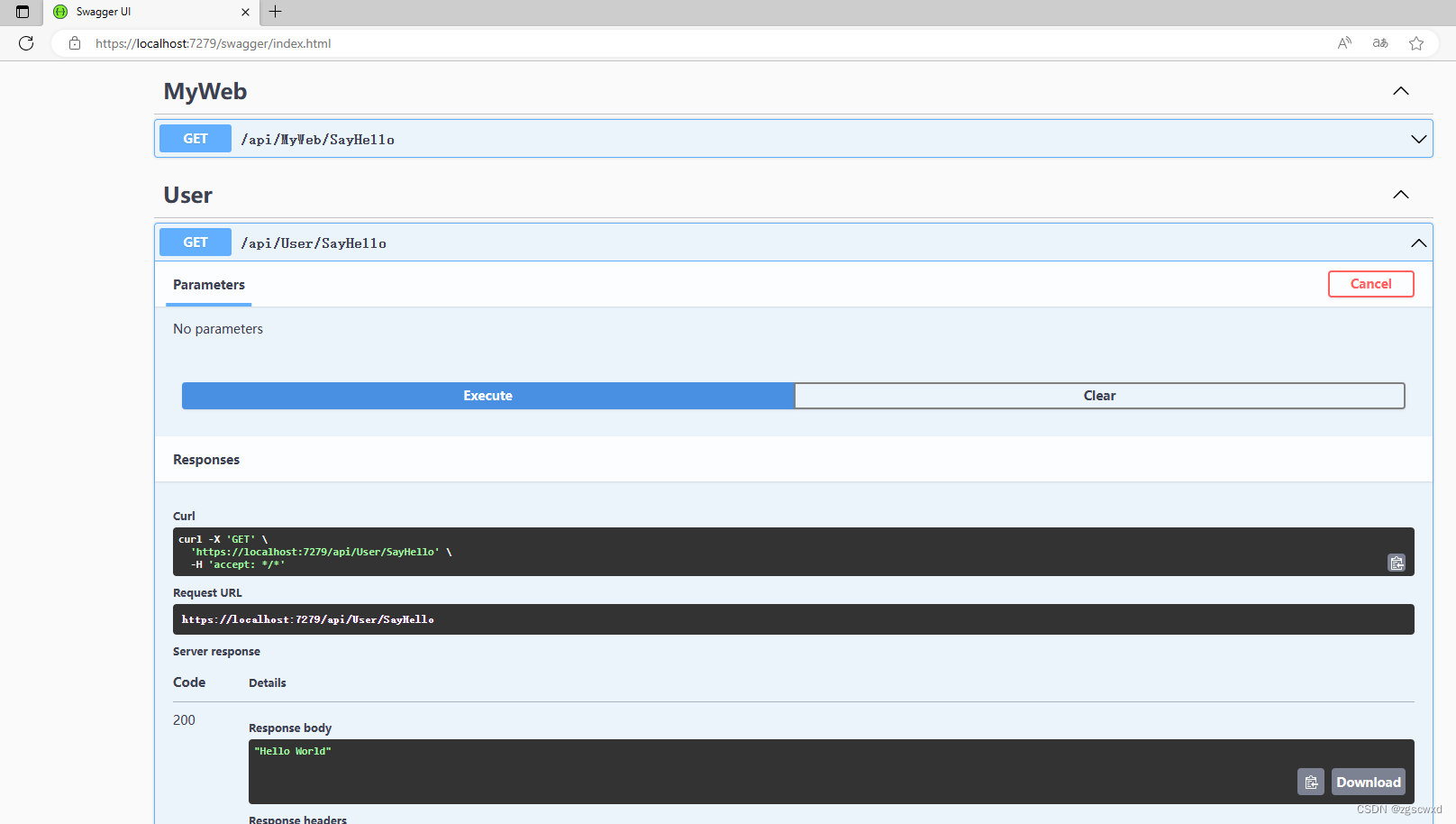
【入门】.Net Core 6 WebApi 项目搭建
一、创建项目 1.1.创建新项目:打开开发工具>创建新项目>搜索API>选择C#语言的ASP.NET Core Web API 1.2.配置新项目:**自定义项目信息以及存储路径 1.3.其他信息:这里框架必须选择.NET 6.0,其他配置默认勾选即可,也可以根…...

xtrabackup备份 脚本
1、全量备份在周末晚上22点执行备份,增量是周一到周六晚上22点执行 2、考虑到增量备份第一次是根据全量备份开始备份,后面都是根据上一次增量备份在增量脚本做了if判断,周日做一次目录清理 3、每周日晚上91点50清理目录 22点就在次备份&#…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

如何更改默认 Crontab 编辑器 ?
在 Linux 领域中,crontab 是您可能经常遇到的一个术语。这个实用程序在类 unix 操作系统上可用,用于调度在预定义时间和间隔自动执行的任务。这对管理员和高级用户非常有益,允许他们自动执行各种系统任务。 编辑 Crontab 文件通常使用文本编…...

Spring AI Chat Memory 实战指南:Local 与 JDBC 存储集成
一个面向 Java 开发者的 Sring-Ai 示例工程项目,该项目是一个 Spring AI 快速入门的样例工程项目,旨在通过一些小的案例展示 Spring AI 框架的核心功能和使用方法。 项目采用模块化设计,每个模块都专注于特定的功能领域,便于学习和…...