Flink1.14 SourceReader概念入门讲解与源码解析 (三)
目录
SourceReader 概念
SourceReader 源码方法
void start();
InputStatus pollNext(ReaderOutput output) throws Exception;
List snapshotState(long checkpointId);
CompletableFuture isAvailable();
void addSplits(List splits);
参考
SourceReader 概念
SourceReader是一个运行在Task Manager上的组件,主要是负责读取 SplitEnumerator 分配的source split。
SourceReader 提供了一个拉动式(pull-based)处理接口。Flink任务会在循环中不断调用 pollNext(ReaderOutput) 轮询来自 SourceReader 的记录。 pollNext(ReaderOutput) 方法的返回值指示 SourceReader 的状态。
- MORE_AVAILABLE - SourceReader 有可用的记录。
- NOTHING_AVAILABLE - SourceReader 现在没有可用的记录,但是将来可能会有记录可用。
- END_OF_INPUT - SourceReader 已经处理完所有记录,到达数据的尾部。这意味着 SourceReader 可以终止任务了。
pollNext(ReaderOutput) 会使用 ReaderOutput 作为参数,为了提高性能且在必要情况下, SourceReader 可以在一次 pollNext() 调用中返回多条记录。例如:有时外部系统的工作系统的工作粒度为块。而一个块可以包含多个记录,但是 source 只能在块的边界处设置 Checkpoint。在这种情况下, SourceReader 可以一次将一个块中的所有记录通过 ReaderOutput 发送至下游。
然而,除非有必要,SourceReader 的实现应该避免在一次 pollNext(ReaderOutput) 的调用中发送多个记录。这是因为对 SourceReader 轮询的任务线程工作在一个事件循环(event-loop)中,且不能阻塞。
在创建 SourceReader 时,相应的 SourceReaderContext 会提供给 Source,而 Source 则会将对应的上下文传递给 SourceReader 实例。 SourceReader 可以通过 SourceReaderContext 将 SourceEvent 传递给相应的 SplitEnumerator 。 Source 的一个典型设计模式是让 SourceReader 发送它们的本地信息给 SplitEnumerator,后者则会全局性地做出决定。
SourceReader API 是一个底层(low-level)API,允许用户自行处理分片,并使用自己的线程模型来获取和移交记录。为了帮助实现 SourceReader,Flink 提供了 SourceReaderBase 类,可以显著减少编写 SourceReader 所需要的工作量。
强烈建议连接器开发人员充分利用 SourceReaderBase 而不是从头开始编写 SourceReader。
这里简单说一下,如何通过 Source 创建 DataStream ,有两种方法(感觉上没啥区别):
- env.fromSource
- env.addSource
// fromSource 这个返回的是source
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Source mySource = new MySource(....);DataStream<Integer> stream = env.fromSource(mySource,WatermarkStrategy.noWatermarks(),// 无水标"MySourceName");
..// addSource 这个返回的是Source function
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<..> stream = env.addSource(new MySource(...));
SourceReader 源码方法
void start();
判断是否有splits了,如果当前没有已经分配的splits了就发送请求获取。
/** Start the reader. */void start();// FileSourceReader的实现@Overridepublic void start() {// we request a split only if we did not get splits during the checkpoint restoreif (getNumberOfCurrentlyAssignedSplits() == 0) {context.sendSplitRequest(); // 发送split的读取请求给SplitEnumerator,在handleSplitRequest方法中被调用}}InputStatus pollNext(ReaderOutput<T> output) throws Exception;
主要负责拉取下一个可读取的记录到SourceOutput,确保这个方法是非阻塞的,并且最好一次调用只输出一条数据。
/*** Poll the next available record into the {@link SourceOutput}.** <p>The implementation must make sure this method is non-blocking.** <p>Although the implementation can emit multiple records into the given SourceOutput, it is* recommended not doing so. Instead, emit one record into the SourceOutput and return a {@link* InputStatus#MORE_AVAILABLE} to let the caller thread know there are more records available.** @return The InputStatus of the SourceReader after the method invocation.*/InputStatus pollNext(ReaderOutput<T> output) throws Exception;// FileSourceReader读取数据的pollNext方法位于父类SourceReaderBase中
@Override
public InputStatus pollNext(ReaderOutput<T> output) throws Exception {// make sure we have a fetch we are working on, or move to the next// 获取当前从fetcher中读取到的一批split// RecordsWithSplitIds代表了从fetcher拉取到SourceReader的数据// RecordsWithSplitIds可以包含多个split,但是对于FileRecords而言,只代表一个splitRecordsWithSplitIds<E> recordsWithSplitId = this.currentFetch;if (recordsWithSplitId == null) {// 如果没有,获取下一批splitrecordsWithSplitId = getNextFetch(output);if (recordsWithSplitId == null) {// 如果还没有获取到,需要检查后续是否还会有数据到来。return trace(finishedOrAvailableLater());}}// we need to loop here, because we may have to go across splitswhile (true) {// Process one record.// 从split中获取下一条记录final E record = recordsWithSplitId.nextRecordFromSplit();if (record != null) {// emit the record.// 如果获取到数据// 记录数量计数器加1numRecordsInCounter.inc(1);// 发送数据到Output// currentSplitOutput为当前split对应的下游output// currentSplitContext.state为reader的读取状态recordEmitter.emitRecord(record, currentSplitOutput, currentSplitContext.state);LOG.trace("Emitted record: {}", record);// We always emit MORE_AVAILABLE here, even though we do not strictly know whether// more is available. If nothing more is available, the next invocation will find// this out and return the correct status.// That means we emit the occasional 'false positive' for availability, but this// saves us doing checks for every record. Ultimately, this is cheaper.// 总是发送MORE_AVAILABLE// 如果真的没有可用数据,下次调用会返回正确的状态return trace(InputStatus.MORE_AVAILABLE);} else if (!moveToNextSplit(recordsWithSplitId, output)) {// 如果本次fetch的split已经全部被读取(本批没有更多的split),读取下一批数据// The fetch is done and we just discovered that and have not emitted anything, yet.// We need to move to the next fetch. As a shortcut, we call pollNext() here again,// rather than emitting nothing and waiting for the caller to call us again.return pollNext(output);}// else fall through the loop}
}getNextFetch方法获取下一批 split 。
@Nullable
private RecordsWithSplitIds<E> getNextFetch(final ReaderOutput<T> output) {// 检查fetcher是否有错误splitFetcherManager.checkErrors();LOG.trace("Getting next source data batch from queue");// elementsQueue中缓存了fetcher线程获取的split// 从这个队列中拿出一批splitfinal RecordsWithSplitIds<E> recordsWithSplitId = elementsQueue.poll();// 如果队列中没有数据,并且接下来这批split已被读取完毕,返回nullif (recordsWithSplitId == null || !moveToNextSplit(recordsWithSplitId, output)) {// No element available, set to available later if needed.return null;}// 更新当前的fetchcurrentFetch = recordsWithSplitId;return recordsWithSplitId;
}finishedOrAvailableLater 方法检查后续是否还有数据,返回对应的状态。
private InputStatus finishedOrAvailableLater() {// 检查所有的fetcher是否都已关闭final boolean allFetchersHaveShutdown = splitFetcherManager.maybeShutdownFinishedFetchers();// 如果reader不会再接收更多的split,或者所有的fetcher都已关闭// 返回NOTHING_AVAILABLE,将来可能会有记录可用。if (!(noMoreSplitsAssignment && allFetchersHaveShutdown)) {return InputStatus.NOTHING_AVAILABLE;}if (elementsQueue.isEmpty()) {// 如果缓存队列中没有数据,返回END_OF_INPUT// We may reach here because of exceptional split fetcher, check it.splitFetcherManager.checkErrors();return InputStatus.END_OF_INPUT;} else {// We can reach this case if we just processed all data from the queue and finished a// split,// and concurrently the fetcher finished another split, whose data is then in the queue.// 其他情况返回MORE_AVAILABLEreturn InputStatus.MORE_AVAILABLE;}
}moveToNextSplit 方法前往读取下一个split。
private boolean moveToNextSplit(RecordsWithSplitIds<E> recordsWithSplitIds, ReaderOutput<T> output) {// 获取下一个split的IDfinal String nextSplitId = recordsWithSplitIds.nextSplit();if (nextSplitId == null) {// 如果没获取到,则当前获取过程结束LOG.trace("Current fetch is finished.");finishCurrentFetch(recordsWithSplitIds, output);return false;}// 获取当前split上下文// Map<String, SplitContext<T, SplitStateT>> splitStates它保存了split ID和split的状态currentSplitContext = splitStates.get(nextSplitId);checkState(currentSplitContext != null, "Have records for a split that was not registered");// 获取当前split对应的output// SourceOperator在从SourceCoordinator获取到分片后会为每个分片创建一个OUtput,currentSplitOutput是当前分片的输出currentSplitOutput = currentSplitContext.getOrCreateSplitOutput(output);LOG.trace("Emitting records from fetch for split {}", nextSplitId);return true;
}List<SplitT> snapshotState(long checkpointId);
主要是负责创建 source 的 checkpoint 。
/*** Checkpoint on the state of the source.** @return the state of the source.*/List<SplitT> snapshotState(long checkpointId);public List<SplitT> snapshotState(long checkpointId) {List<SplitT> splits = new ArrayList();this.splitStates.forEach((id, context) -> {splits.add(this.toSplitType(id, context.state));});return splits;}CompletableFuture<Void> isAvailable();
/*** Returns a future that signals that data is available from the reader.** <p>Once the future completes, the runtime will keep calling the {@link* #pollNext(ReaderOutput)} method until that methods returns a status other than {@link* InputStatus#MORE_AVAILABLE}. After that the, the runtime will again call this method to* obtain the next future. Once that completes, it will again call {@link* #pollNext(ReaderOutput)} and so on.** <p>The contract is the following: If the reader has data available, then all futures* previously returned by this method must eventually complete. Otherwise the source might stall* indefinitely.** <p>It is not a problem to have occasional "false positives", meaning to complete a future* even if no data is available. However, one should not use an "always complete" future in* cases no data is available, because that will result in busy waiting loops calling {@code* pollNext(...)} even though no data is available.** @return a future that will be completed once there is a record available to poll.*/// 创建一个future,表明reader中是否有数据可被读取// 一旦这个future进入completed状态,Flink一直调用pollNext(ReaderOutput)方法直到这个方法返回除InputStatus#MORE_AVAILABLE之外的内容// 在这之后,会再次调isAvailable方法获取下一个future。如果它completed,再次调用pollNext(ReaderOutput)。以此类推public CompletableFuture<Void> isAvailable() {return this.currentFetch != null ? FutureCompletingBlockingQueue.AVAILABLE : this.elementsQueue.getAvailabilityFuture();}void addSplits(List<SplitT> splits);
/*** Adds a list of splits for this reader to read. This method is called when the enumerator* assigns a split via {@link SplitEnumeratorContext#assignSplit(SourceSplit, int)} or {@link* SplitEnumeratorContext#assignSplits(SplitsAssignment)}.** @param splits The splits assigned by the split enumerator.*/// 添加一系列splits,以供reader读取。这个方法在SplitEnumeratorContext#assignSplit(SourceSplit, int)或者SplitEnumeratorContext#assignSplits(SplitsAssignment)中调用void addSplits(List<SplitT> splits);
其中,SourceReaderBase类的实现,fetcher的作用是从拉取split缓存到SourceReader中。
@Override
public void addSplits(List<SplitT> splits) {LOG.info("Adding split(s) to reader: {}", splits);// Initialize the state for each split.splits.forEach(s ->splitStates.put(s.splitId(), new SplitContext<>(s.splitId(), initializedState(s))));// Hand over the splits to the split fetcher to start fetch.splitFetcherManager.addSplits(splits);
}addSplits 方法将fetch任务交给 SplitFetcherManager 处理,它的 addSplits 方法如下:
@Override
public void addSplits(List<SplitT> splitsToAdd) {// 获取正在运行的fetcherSplitFetcher<E, SplitT> fetcher = getRunningFetcher();if (fetcher == null) {// 如果没有,创建出一个fetcherfetcher = createSplitFetcher();// Add the splits to the fetchers.// 将这个创建出的fetcher加入到running fetcher集合中fetcher.addSplits(splitsToAdd);// 启动这个fetcherstartFetcher(fetcher);} else {// 如果获取到了正在运行的fetcher,调用它的addSplits方法fetcher.addSplits(splitsToAdd);}
}最后我们查看SplitFetcher的addSplits方法:
public void addSplits(List<SplitT> splitsToAdd) {// 将任务包装成AddSplitTask,通过splitReader兼容不同格式数据的读取方式// 将封装好的任务加入到队列中enqueueTask(new AddSplitsTask<>(splitReader, splitsToAdd, assignedSplits));// 唤醒fetcher任务,使用SplitReader读取数据// Split读取数据并缓存到elementQueue的逻辑位于FetcherTask,不再具体分析wakeUp(true);
}参考
数据源 | Apache Flink
Flink 源码之新 Source 架构 - 简书
Flink新Source架构(下) - 知乎
相关文章:
)
Flink1.14 SourceReader概念入门讲解与源码解析 (三)
目录 SourceReader 概念 SourceReader 源码方法 void start(); InputStatus pollNext(ReaderOutput output) throws Exception; List snapshotState(long checkpointId); CompletableFuture isAvailable(); void addSplits(List splits); 参考 SourceReader 概念 Sour…...
PS运行中缺失d3dcompiler_47.dll问题的5个有效修复方法总结
在使用ps作图的时候,我们有时会遇到一些问题,其中之一就是“PS运行中缺失d3dcompiler_47.dll”的问题。这个问题可能会导致PS无法正常运行,“d3dcompiler_47.dll”。这是一个动态链接库文件,它是DirectX的一部分,主要负…...
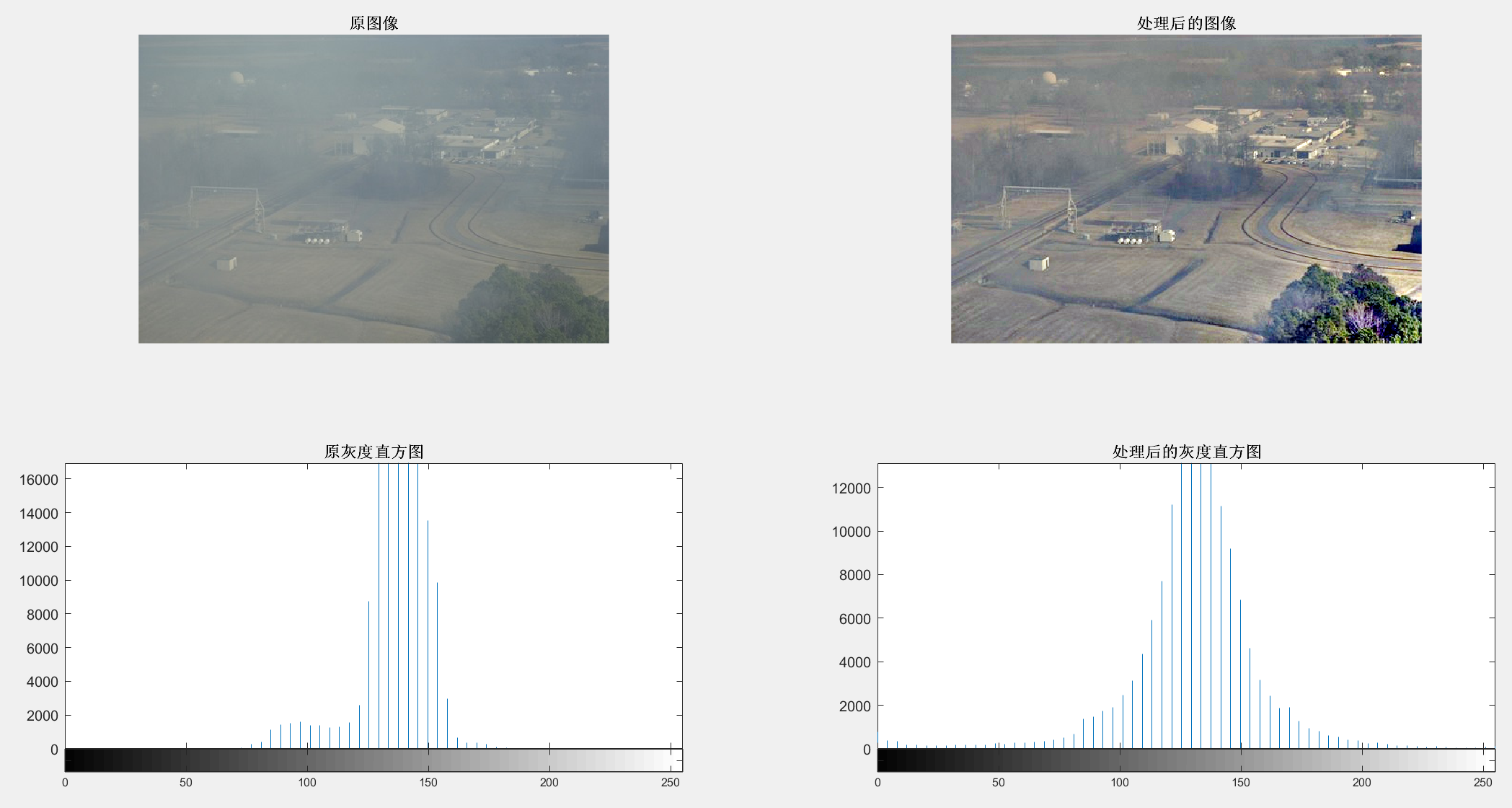
【MATLAB-Retinex图像增强算法的去雾技术】
续:【MATLAB-基于直方图优化的图像去雾技术】 【MATLAB-Retinex图像增强算法的去雾技术】 1 原图2 MATLAB实现代码3 结果图示 参考书籍:计算机视觉与深度学习实战:以MATLAB、Python为工具, 主编:刘衍琦, 詹福宇, 王德建…...

使用 2 个 HSplitView 在 swiftUI 中创建一个 3 窗格界面
Pet*_*ter 8 嗯,我会的。在断断续续地挣扎了几个星期之后,在我问这个问题一个小时后,我似乎解决了它!只需将第二个 HSplitView 的 layoutPriority 设置为 1,并将中心视图也设置为 1。当你想到它时是有道理的࿱…...

【C++ 操作符重载:定制自己的运算符行为】
在C编程中,操作符重载是一项强大的特性,它允许程序员定制内置运算符的行为,使它们适用于用户自定义的数据类型。这篇博客将介绍什么是操作符重载,如何使用它,以及一些最佳实践。 什么是操作符重载? 操作符…...

Android Fragment 基本概念和基本使用
Android Fragment 基本概念和基本使用 一、基本概念 Fragment,简称碎片,是Android 3.0(API 11)提出的,为了兼容低版本,support-v4库中也开发了一套Fragment API,最低兼容Android 1.6。 过去s…...

xml schema中的all元素
说明 xml schema中的all元素表示其中的子元素可以按照任何顺序出现,每个元素可以出现0次或者1次。 https://www.w3.org/TR/xmlschema-1/#element-all maxOccurs的默认值是1,minOccurs 的默认值是1。 举例 <element name"TradePriceRequest&…...

Java8实战-总结42
Java8实战-总结42 用Optional取代null应用 Optional 的几种模式默认行为及解引用 Optional 对象两个 Optional 对象的组合使用 filter 剔除特定的值 用Optional取代null 应用 Optional 的几种模式 默认行为及解引用 Optional 对象 采用orElse方法读取这个变量的值࿰…...

实现日期间的运算——C++
😶🌫️Take your time ! 😶🌫️ 💥个人主页:🔥🔥🔥大魔王🔥🔥🔥 💥代码仓库:🔥🔥魔…...
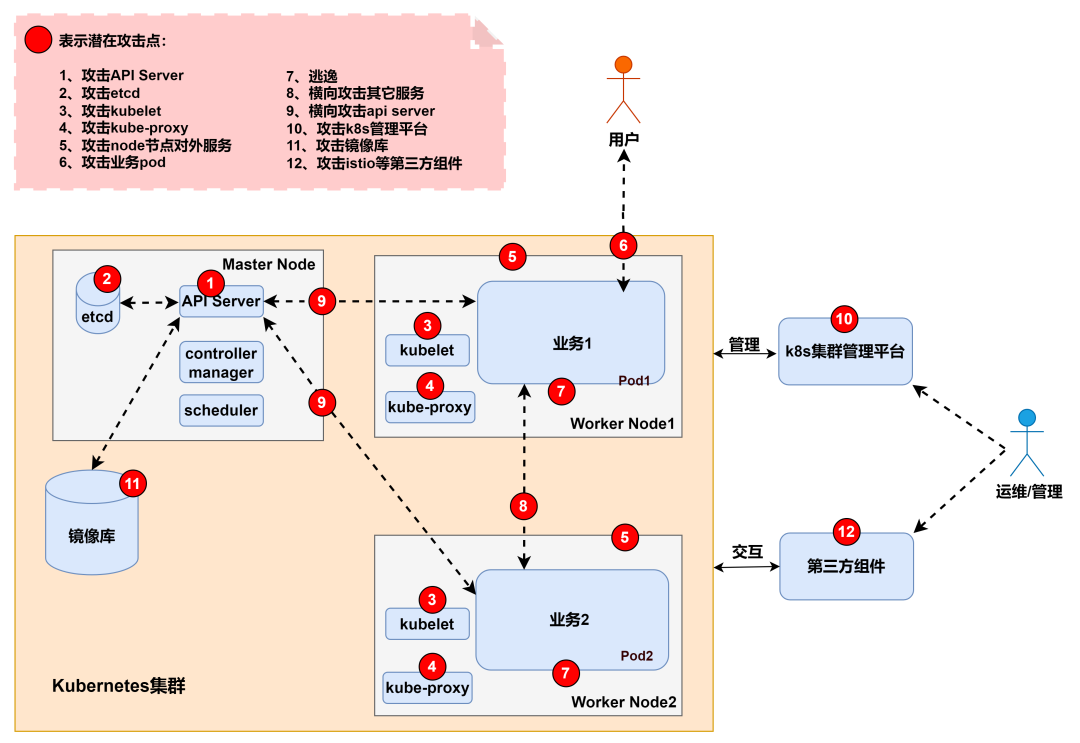
云上攻防-云原生篇K8s安全Config泄漏Etcd存储Dashboard鉴权Proxy暴露
文章目录 云原生-K8s安全-etcd未授权访问云原生-K8s安全-Dashboard未授权访问云原生-K8s安全-Configfile鉴权文件泄漏云原生-K8s安全-Kubectl Proxy不安全配置 云原生-K8s安全-etcd未授权访问 攻击2379端口:默认通过证书认证,主要存放节点的数据&#x…...

ChatGPT 的工作原理学习 难以理解 需要先找个容易的课来跟下。
ChatGPT 的工作原理 传统搜超搜引擎原理:蜘蛛抓取和数据收集,用户交互查找。 ChatGPT 的工作原理:数据收集称为预训练,用户响应阶段称为推理。 ChatGPT是一种基于自然语言处理技术的人工智能模型,它的工作原理建立在…...
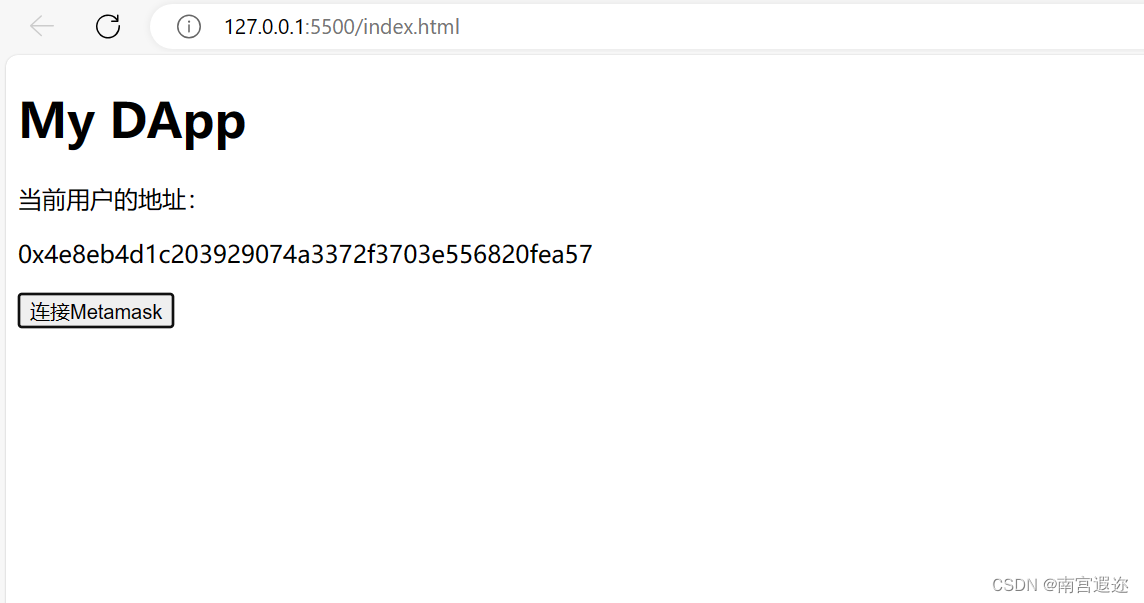
5.DApp-前端网页怎么连接MetaMask
题记 在前端网页连接metamask,以下是全部操作流程和代码。 编写index.html文件 index.html文件如下: <!DOCTYPE html> <html> <head> <title>My DApp</title> <!--导入用于检测Metamask提供者的JavaScript库--> &l…...
手机应用app打开游戏显示连接服务器失败是什么原因?排查解决方案?
亲爱的同学们,有时候我们在使用手机设备时,可能会遇到一个很头疼的问题——连接服务器失败。这个问题不仅让我们感到困扰,还影响到了我们的用户体验。那么,我们究竟能如何解决这个问题呢?今天,笔者就和大家…...

【Java学习之道】指引篇:从入门到入世
引言 你是否曾为找不到适合自己的Java学习之路而烦恼?是否想摆脱混乱的Java知识体系,找到一条从入门到精通的捷径?来《Java学习之道》吧,本专栏为你量身打造,让我们一起轻松踏上Java学习之旅! 第一章、Jav…...

pytorch_quantization安装
官方安装步骤: pip install nvidia-pyindex pip install pytorch-quantization直接安装pytorch-quantization会找不到,需要首先安装 nvidia-pyindex 包, nvidia-pyindex是一个 pip 源,用来连接英伟达的服务器下载需要的包。 如果…...
开源项目汇总
element-plus 人人开源 人人开源 多租户 若依 jeecg https://gitee.com/jeecg/jeecg?_fromgitee_search#https://gitee.com/link?targethttp%3A%2F%2Fidoc.jeecg.com jeeplus JeePlus快速开发平台 j2eefast Sa-Plus...

android.mk介绍
相对于Android的目前来说以前编译底层都使用Android.mk文件配置ndk,现在都使用Cmake这里我们着重介绍下Android.mk 最最基础的几个变量如下 # 定义模块当前路径 LOCAL_PATH : $(call my-dir) #清空当前环境变量 include $(CLEAR_VARS) # 生成libhell.so LOCAL_M…...
极光笔记 | 发送功能使用技巧分享
在全球化竞争激烈的商业环境中,高效的消息通知解决方案是企业成功的关键。EngageLab作为一家专注于海外市场的消息服务平台,为全球企业提供了一体化的消息通知解决方案。其中,EngageLab的国际邮件发送是其强大而灵活的产品服务之一。本文将与…...
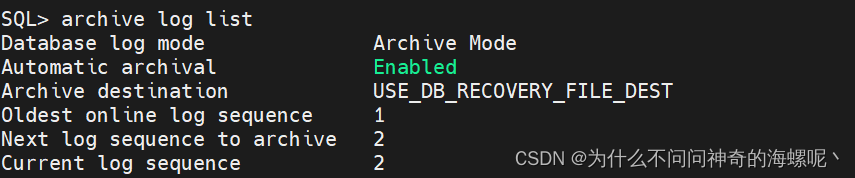
Oracle database 开启归档日志 archivelog
Oracle database 开启归档日志 archivelog 归档日志模式 (Archivelog Mode)。归档日志模式是一种数据库运行模式,它允许数据库将日志文件保存到归档日志目录中,以便在需要时进行恢复和还原操作。通过开启归档日志模式,可以提高数据库的可靠性…...

【学一点儿前端】ajax、axios和fetch的概念、区别和易混淆点
省流读法 ajax是js异步技术的术语,早期相关的api是xhr,它是一个术语。 fetch是es6新增的用于网络请求标准api,它是一个api。 axios是用于网络请求的第三方库,它是一个库。 1.Ajax 它的全称是:Asynchronous JavaScri…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...

TSN交换机正在重构工业网络,PROFINET和EtherCAT会被取代吗?
在工业自动化持续演进的今天,通信网络的角色正变得愈发关键。 2025年6月6日,为期三天的华南国际工业博览会在深圳国际会展中心(宝安)圆满落幕。作为国内工业通信领域的技术型企业,光路科技(Fiberroad&…...
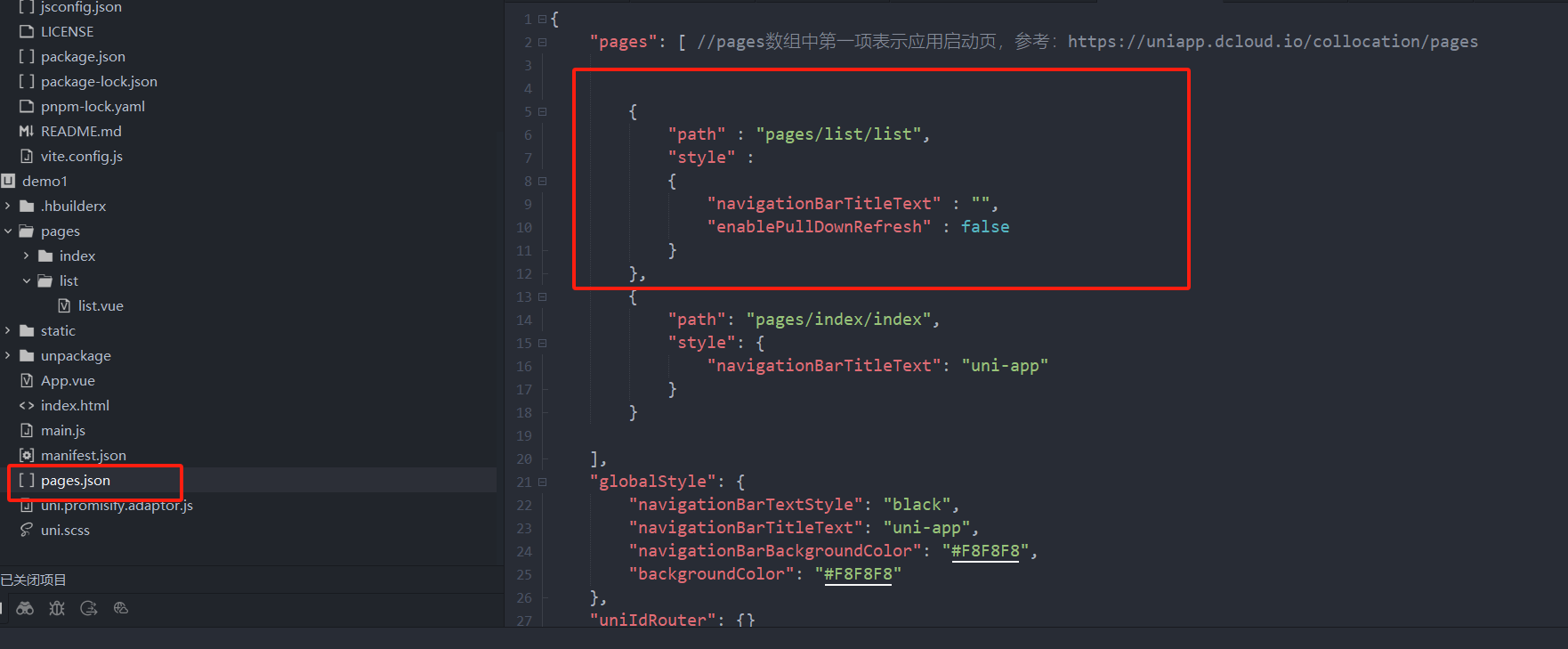
uniapp 小程序 学习(一)
利用Hbuilder 创建项目 运行到内置浏览器看效果 下载微信小程序 安装到Hbuilder 下载地址 :开发者工具默认安装 设置服务端口号 在Hbuilder中设置微信小程序 配置 找到运行设置,将微信开发者工具放入到Hbuilder中, 打开后出现 如下 bug 解…...

tomcat指定使用的jdk版本
说明 有时候需要对tomcat配置指定的jdk版本号,此时,我们可以通过以下方式进行配置 设置方式 找到tomcat的bin目录中的setclasspath.bat。如果是linux系统则是setclasspath.sh set JAVA_HOMEC:\Program Files\Java\jdk8 set JRE_HOMEC:\Program Files…...
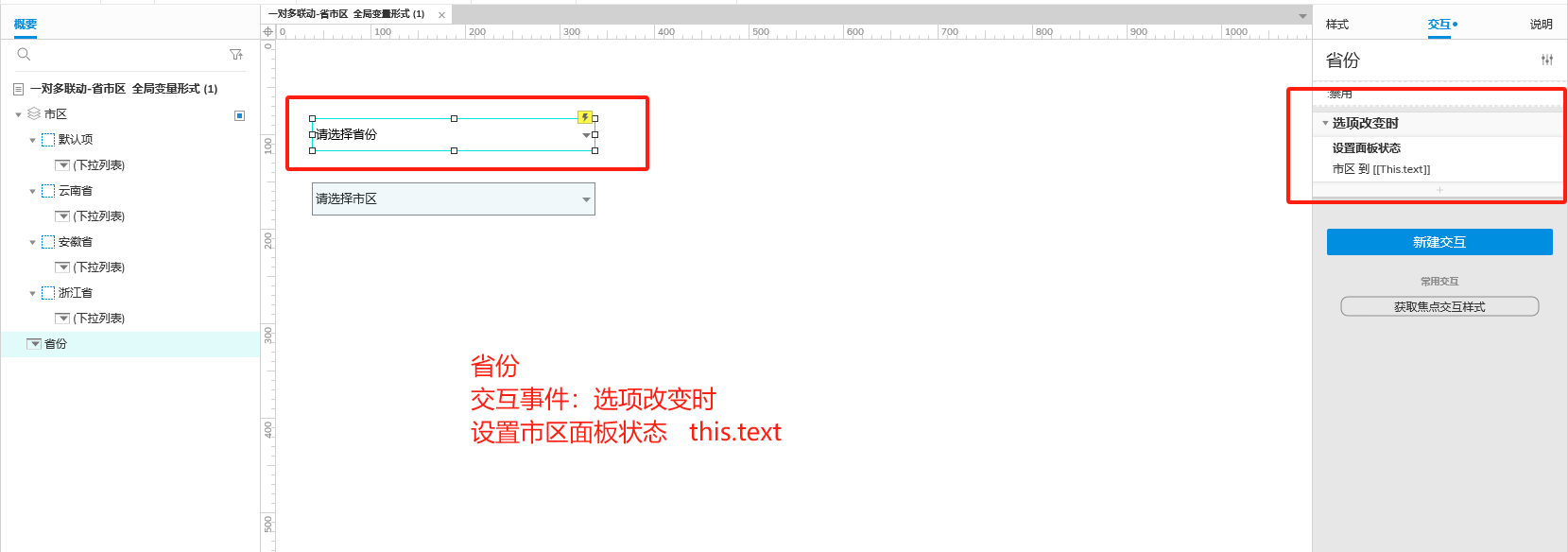
Axure 下拉框联动
实现选省、选完省之后选对应省份下的市区...