c++之二叉树【进阶版】
前言
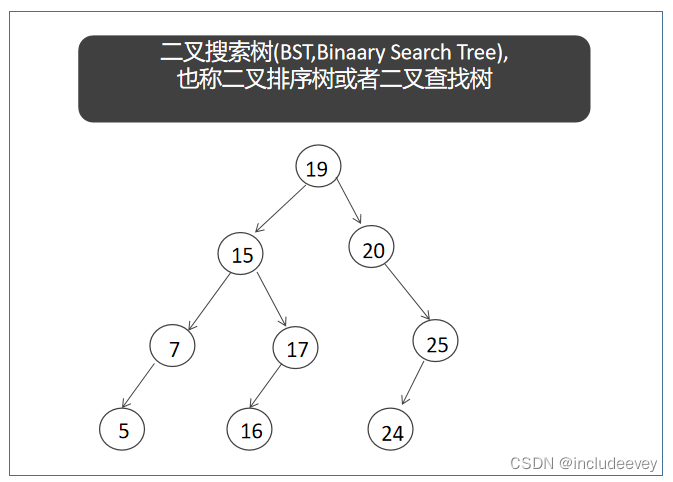
在c语言阶段的数据结构系列中已经学习过二叉树,但是这篇文章是二叉树的进阶版,因为首先就会讲到一种树形结构“二叉搜索树”,学习二叉搜索树的目标是为了更好的理解map和set的特性。二叉搜索树的特性就是左子树键值小于根,右子树键值大于根,所以二叉搜索树就天然的具有查找功能,有时二叉搜索树又叫二叉排序树或者二叉查找树。
目录
前言
Ⅰ、二叉搜索树概念
Ⅱ、二叉搜索树操作
Ⅲ、二叉搜索树的实现
Ⅳ、 二叉搜索树的应用
Ⅴ、二叉搜索树的性能分析
Ⅵ、二叉树进阶面试题
Ⅰ、二叉搜索树概念
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
●若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
●若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
●它的左右子树也分别为二叉搜索树
●它没有重复的键值
Ⅱ、二叉搜索树操作

int a[ ] = {8, 3, 1, 10, 6, 4, 7, 14, 13};
1. 二叉搜索树的查找
a、从根开始比较,查找,比根大则往右边走查找,比根小则往左边走查找。
b、最多查找高度次,走到到空,还没找到,这个值不存在。

2. 二叉搜索树的插入
插入的具体过程如下:
a. 树为空,则直接新增节点,赋值给root指针
b. 树不空,按二叉搜索树性质查找插入位置,插入新节点

1. 二叉搜索树的删除
首先查找元素是否在二叉搜索树中,如果不存在,则返回, 否则要删除的结点可能分下面四种情 况:
a. 要删除的结点无孩子结点
b. 要删除的结点只有左孩子结点
c. 要删除的结点只有右孩子结点
d. 要删除的结点有左、右孩子结点
看起来有待删除节点有4中情况,实际情况a可以与情况b或者c合并起来,因此真正的删除过程 如下:
●情况b:删除该结点且使被删除节点的双亲结点指向被删除节点的左孩子结点--直接删除
●情况c:删除该结点且使被删除节点的双亲结点指向被删除结点的右孩子结点--直接删除
●情况d:在它的右子树中寻找中序下的第一个结点(关键码最小),用它的值填补到被删除节点 中,再来处理该结点的删除问题--替换法删除
如图理解,情况a实质就是删除1,4,7,13可以直接删除。
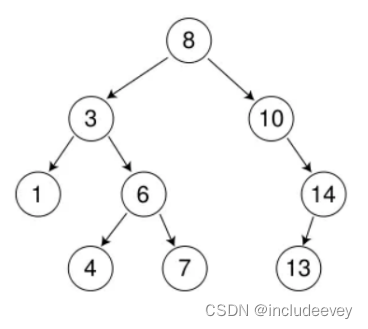
关于情况b,情况c,就需要详细探讨

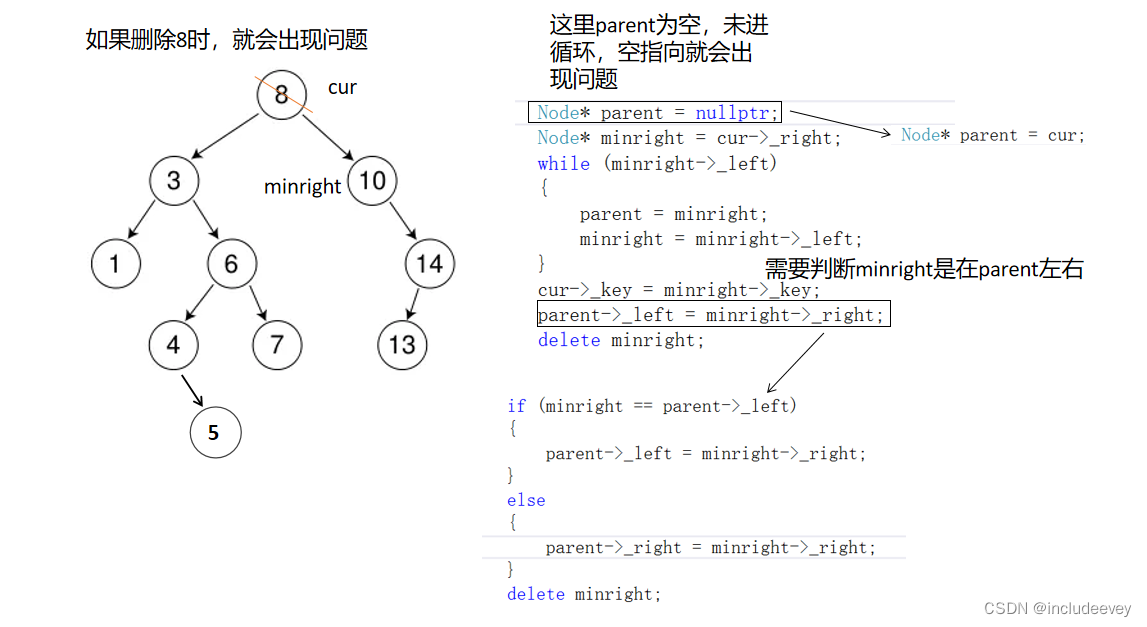
对于情况d是最难以理解的,这种情况就好比删除3和8,他们是需要替换法删除的场景,这种情况就需要找子树右边的最小值(minright),找到之后minright的key值与cur的key交换(赋值)后再判断后进行链接。

但是通下面代码我们发现,这段代码删除8时就会发现root为nullptr,这样就出现错误了,还有一个问题就是minright可以是parent左右子树,所以关于删除的时候还需要判断是否parent的左右子树

Ⅲ、二叉搜索树的实现
二叉搜索树代码的实现,查找,插入是比较容易理解的,对于删除考虑的情况比较多。主要分三种情况,1.直接删除,2.左右子树为nullptr,交换删除,3.左右子树都不为nullptr,需要找minright替换key值后链接。
对于整个结构与我之前学习的二叉树基本一样,只是用到了c++,封装了节点(该节点中有左右节点和key值),通过模板实现不同参数的调用。
非递递归代码实现如下
#pragma once
#include <iostream>
#include <string>
using namespace std;namespace K
{template<class K>struct BSTreeNode{BSTreeNode<K>* _left;BSTreeNode<K>* _right;K _key;BSTreeNode(const K& key):_key(key), _left(nullptr), _right(nullptr){}};template<class K>class BSTree{typedef BSTreeNode<K> Node;public:BSTree():_root(nullptr){}BSTree(const BSTree<K> &t){_root = Copy(t._root);}BSTree<K>& operator=(BSTree<K> t){swap(_root, t._root);return *this;}~BSTree(){Destroy(_root);_root=nullptr;}bool Insert(const K& key){if (_root == nullptr){_root = new Node(key);return true;}Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{return false;}}cur = new Node(key);if (parent->_key < key){parent->_right = cur;}else{parent->_left = cur;}return true;}bool Erase(const K& key){Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{// 1、左为空// 2、右为空// 3、左右都不为空,替换删除if (cur->_left == nullptr){//if (parent == nullptr)if (cur == _root){_root = cur->_right;}else{if (parent->_left == cur){parent->_left = cur->_right;}else{parent->_right = cur->_right;}}delete cur;}else if (cur->_right == nullptr){//if (parent == nullptr)if (cur == _root){_root = cur->_left;}else{if (parent->_left == cur){parent->_left = cur->_left;}else{parent->_right = cur->_left;}}delete cur;}else{// 右子树的最小节点Node* parent = cur;Node* minRight = cur->_right;while (minRight->_left){parent = minRight;minRight = minRight->_left;}cur->_key = minRight->_key;if (minRight == parent->_left){parent->_left = minRight->_right;}else{parent->_right = minRight->_right;}delete minRight;}return true;}}return false;}void InOrder(){_InOrder(_root);cout << endl;}private:void Destroy(Node* root){if (root == nullptr)return;Destroy(root->_left);Destroy(root->_right);delete root;}Node* Copy(Node *root){if (root == nullptr)return nullptr;Node* newRoot = new Node(root->_key);newRoot->_left = Copy(root->_left);newRoot->_right = Copy(root->_right);return newRoot;}bool Find(const K& key){Node* cur = _root;while (cur){if (cur->_key < key)cur = cur->_right;else if (cur->_key > key)cur = cur->_left;elsereturn true;}return false;}void _InOrder(Node* root){if (root == nullptr)return;_InOrder(root->_left);cout << root->_key << " ";_InOrder(root->_right);}private:Node* _root = nullptr;};
}递归
这里递归主要讲解删除(Erase),相信大家之前对递归也是有所涉猎的。对于Erase的实现,开始也是通过递归查找key节点,还需要循环找到minright,然后通过(swap)交换key值和minright值,之后再通过递归(cur的子树)删除。下面我们就来深入分析递归删除,列如删除如图3。
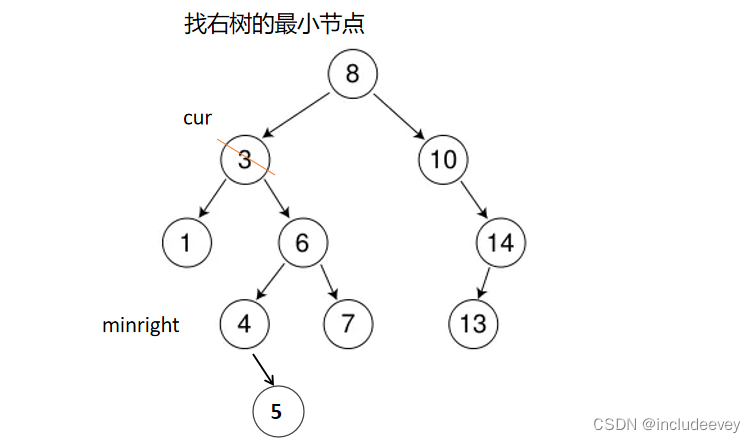
●1.先通过递归查找到删除节点

●2.如果是左右子树为nullptr,直接链接到根(root)

●3.这里如果删除的是3,就是通过上面步骤找到3为cur,然后判断出cur的左右子树都不为nullptr,这时就需要寻找minright,找到minright之后,swap交换(3,4),然后递归删除4节点的右子树的3。
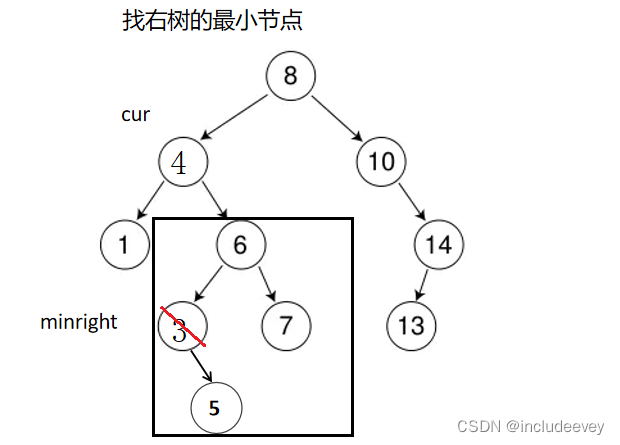

最后需要注意的一点是,递归就会调用_root,所以我们可以在类中先封装再调用。
非递归代码实现如下
namespace K
{template<class K>struct BSTreeNode{BSTreeNode<K>* _left;BSTreeNode<K>* _right;K _key;BSTreeNode(const K& key):_key(key), _left(nullptr), _right(nullptr){}};template<class K>class BSTree{typedef BSTreeNode<K> Node;public:BSTree():_root(nullptr){}BSTree(const BSTree<K> &t){_root = Copy(t._root);}BSTree<K>& operator=(BSTree<K> t){swap(_root, t._root);return *this;}~BSTree(){Destroy(_root);_root=nullptr;}void InOrder(){_InOrder(_root);cout << endl;}bool InsertR(const K& key){return _InsertR(_root,key);}bool FindR(const K& key){return _FindR(_root, key);}bool EraseR(const K& key){return _EraseR(_root, key);}private:void Destroy(Node* root){if (root == nullptr)return;Destroy(root->_left);Destroy(root->_right);delete root;}Node* Copy(Node *root){if (root == nullptr)return nullptr;Node* newRoot = new Node(root->_key);newRoot->_left = Copy(root->_left);newRoot->_right = Copy(root->_right);return newRoot;}bool _EraseR(Node*& root, const K& key){if (root == nullptr){return false;}if (root->_key < key){return _EraseR(root->_right, key);}else if (root->_key > key){return _EraseR(root->_left, key);}else{Node* del = root;if (root->_right == nullptr){root = root->_left;}else if (root->_left == nullptr){root = root->_right;}else{Node* minRight = root->_right;while (minRight->_left){minRight = minRight->_left;}swap(root->_key, minRight->_key);// 转换后在子树中去删除节点return _EraseR(root->_right, key);}delete del;return true;}}bool _InsertR(Node*& root, const K& key){if (root == nullptr){root = new Node(key);return true;}if (root->_key < key)return _InsertR(root->_right, key);else if (root->_key > key)return _InsertR(root->_left, key);elsereturn false;}bool _FindR(Node* root, const K& key){if (root == nullptr){return false;}if (root->_key < key){return _FindR(root->_right);}else if (root->_key> key){return _FindR(root->_left);}else{return true;}}
private:Node* _root = nullptr;};
}
Ⅳ、 二叉搜索树的应用
1. K模型:K模型即只有key作为关键码,结构中只需要存储Key即可,关键码即为需要搜索到的值。 比如:给一个单词word,判断该单词是否拼写正确,具体方式如下:
○以词库中所有单词集合中的每个单词作为key,构建一棵二叉搜索树
○在二叉搜索树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误。
2. KV模型:每一个关键码key,都有与之对应的值Value,即的键值对。该种方式在现实生活中非常常见:
○比如英汉词典就是英文与中文的对应关系,通过英文可以快速找到与其对应的中文,英文单词与其对应的中文就构成一种键值对;
○再比如统计单词次数,统计成功后,给定单词就可快速找到其出现的次数,单词与其出现次数就是就构成一种键值对。
改造二叉搜索树为KV结构如下
namespace KV
{template<class K, class V>struct BSTreeNode{BSTreeNode<K, V>* _left;BSTreeNode<K, V>* _right;K _key;V _value;BSTreeNode(const K& key, const V& value):_key(key), _value(value), _left(nullptr), _right(nullptr){}};template<class K, class V>class BSTree{typedef BSTreeNode<K, V> Node;public:bool Insert(const K& key, const V& value){if (_root == nullptr){_root = new Node(key, value);return true;}Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{return false;}}cur = new Node(key, value);if (parent->_key < key){parent->_right = cur;}else{parent->_left = cur;}return true;}Node* Find(const K& key){Node* cur = _root;while (cur){if (cur->_key < key){cur = cur->_right;}else if (cur->_key > key){cur = cur->_left;}else{return cur;}}return nullptr;}void Inorder(){_Inorder(_root);}void _Inorder(Node* root){if (root == nullptr)return;_Inorder(root->_left);cout << root->_key << ":" << root->_value << endl;_Inorder(root->_right);}private:Node* _root = nullptr;};
}测试1:通过英文查找中文,这个时候就用到KV搜索树,我们可以给树的key和value定义都为string类型,然后将信息插入到KV搜索树。最后通过查找key值,如果有就打印value即可。
void TestBSTree2()
{//词库中单词都放进这个搜索树中//key的搜索模型,判断在不在?//场景:检查单词拼写是否正确/车库出入系统/...//K::BSTree<string> dict;//Key/Value的搜索模型,通过Key查或者修改ValueKV::BSTree<string, string> dict;dict.Insert("sort", "排序");dict.Insert("string", "字符串");dict.Insert("left", "左边");dict.Insert("right", "右边");string str;while(cin >> str){KV::BSTreeNode<string, string>* ret = dict.Find(str); if (ret){cout << ret->_value << endl;}else{cout << "没有这个单词" << endl;}}}编译结果:sort 排序 left 左边 right 右边 hello 没有这个单词
测试2:统计水果出现的次数
void TestBSTree3()
{string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉" };KV::BSTree<string, int> countTree;for (auto e : arr){auto* ret = countTree.Find(e);if (ret == nullptr){countTree.Insert(e, 1);}else{ret->_value++;}}countTree.Inorder();
}Ⅴ、二叉搜索树的性能分析
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。 对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二 叉搜索树的深度的函数,即结点越深,则比较次数越多。
但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树:
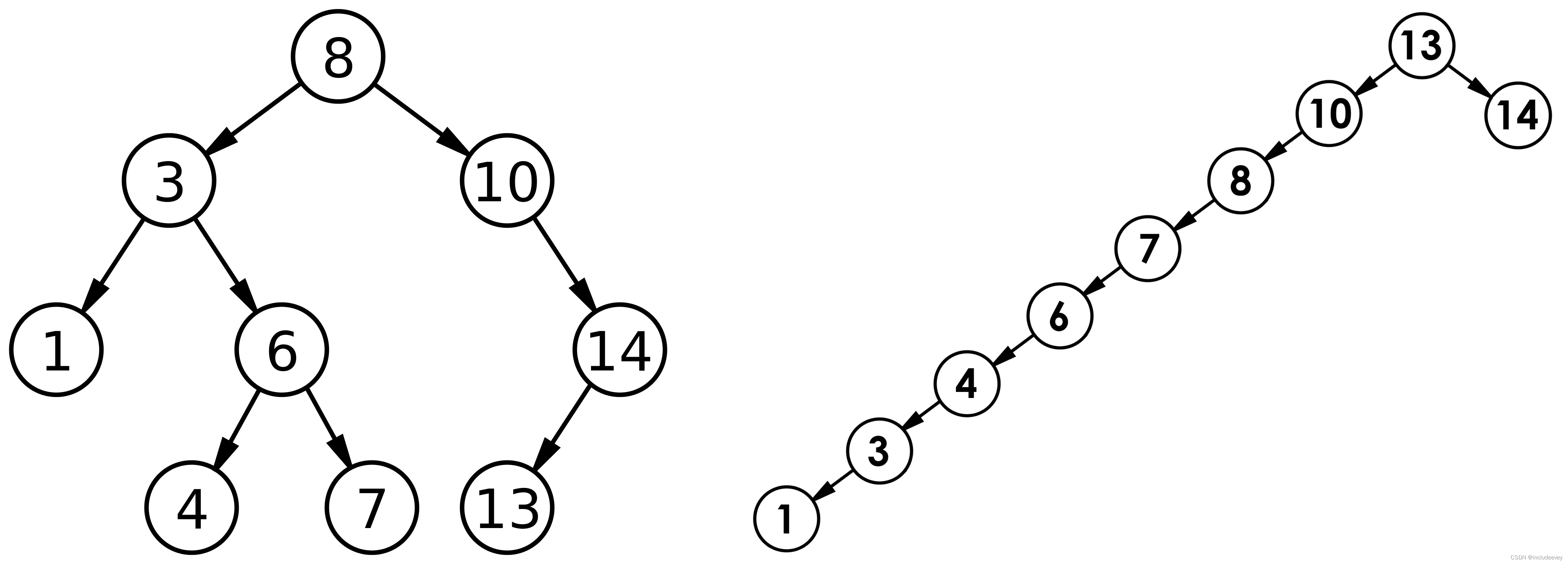
最优情况下,二叉搜索树为完全二叉树(或者接近完全二叉树),其平均比较次数为:$log_2 N$
最差情况下,二叉搜索树退化为单支树(或者类似单支),其平均比较次数为:$\frac{N}{2}$
问题:如果退化成单支树,二叉搜索树的性能就失去了。那能否进行改进,不论按照什么次序插 入关键码,二叉搜索树的性能都能达到最优?那么我们后续章节学习的AVL树和红黑树就可以上场了。
Ⅵ、二叉树进阶面试题
这些题目更适合使用C++完成,难度也更大一些
1. 二叉树创建字符串。OJ链接
2. 二叉树的分层遍历1。OJ链接
3. 二叉树的分层遍历2。OJ链接
4. 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先 。OJ链接
5. 二叉树搜索树转换成排序双向链表。OJ链接
6. 根据一棵树的前序遍历与中序遍历构造二叉树。 OJ链接
7. 根据一棵树的中序遍历与后序遍历构造二叉树。OJ链接
8. 二叉树的前序遍历,非递归迭代实现 。OJ链接
9. 二叉树中序遍历 ,非递归迭代实现。OJ链接
10. 二叉树的后序遍历 ,非递归迭代实现。OJ链接
相关文章:
c++之二叉树【进阶版】
前言 在c语言阶段的数据结构系列中已经学习过二叉树,但是这篇文章是二叉树的进阶版,因为首先就会讲到一种树形结构“二叉搜索树”,学习二叉搜索树的目标是为了更好的理解map和set的特性。二叉搜索树的特性就是左子树键值小于根,右…...
【数据库】 SQLServer
SQL Server 安装 配置 修改SQL Server默认的数据库文件保存路径_ 认识 master :是SQL Server中最重要的系统数据 库,存储SQL Server中的元数据。 Model:模板数据库,在创建新的数据库时,SQL Server 将会复制此数据…...

Linux 4.19 内核中 spinlock 概览
Linux内核中 spinlock相关数据结构和代码实现涉及的文件还是挺多的,这篇博客尝试从文件的角度来梳理一下 spinlock的相关数据结构和代码实现,适合想大概了解 Linux内核中 spinlock从上层 API到底层实现间的调用路径和传参变化,尤其适合了解 s…...
:基本概念TensorFlow的基本介绍,图,会话,会话中的run(),placeholder(),常见的报错)
TensorFlow 1.x学习(系列二 :1):基本概念TensorFlow的基本介绍,图,会话,会话中的run(),placeholder(),常见的报错
目录1.基本介绍2.图的结构3.会话,会话的run方法4.placeholder5.返回值异常写在前边的话:之前发布过一个关于TensorFlow1.x的转载系列,自己将基本的TensorFlow操作敲了一遍,但是仍然有很多地方理解的不够深入。所以重开一个系列&am…...
javaEE 初阶 — 关于 IPv4、IPv6 协议、NAT(网络地址转换)、动态分配 IP 地址 的介绍
文章目录1. IPv42. IPv63. NAT4. 动态分配 IP 地址1. IPv4 在互联网的世界中只有 0 和1 ,所以每个人都有一个由 0 和 1 组成的地址来让别人找到你。 这段由 0 和 1 组成的地址叫 IP 地址,这是互联网的基础资源,可以简单的理解为互联网的土地。…...
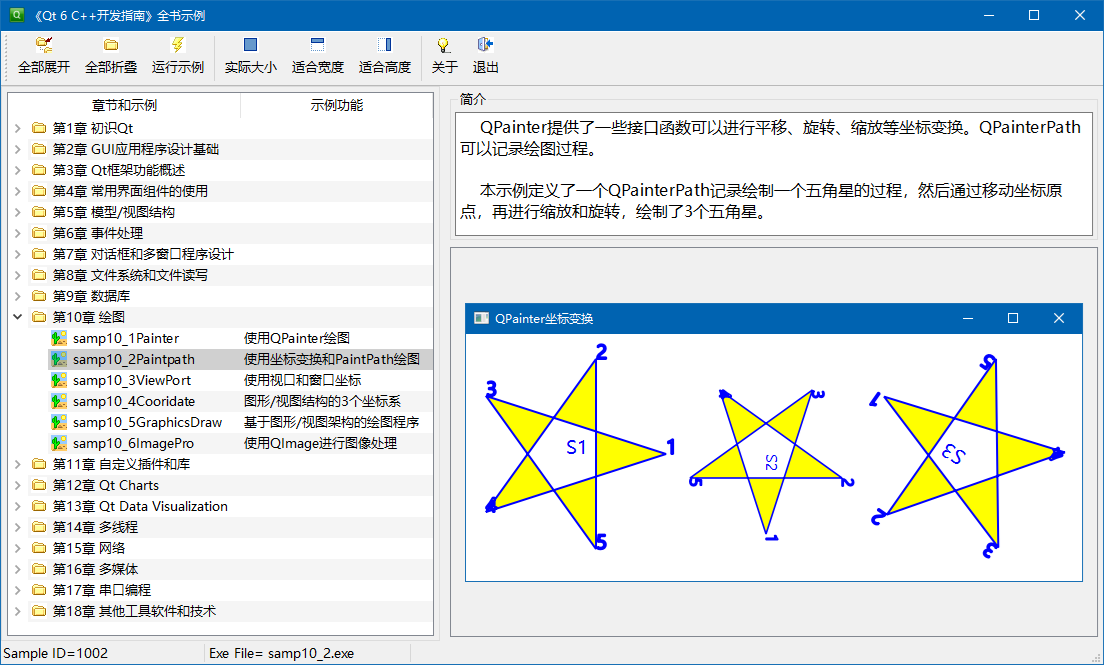
《Qt 6 C++开发指南》简介
我们编写的新书《Qt 6 C开发指南》在2月份终于正式发行销售了,这本书是对2018年5月出版的《Qt 5.9 C开发指南》的重磅升级。以下是本书前言的部分内容,算是对《Qt 6 C开发指南》的一个简介。1.编写本书的目的《Qt 5.9C开发指南》是我写的第一…...
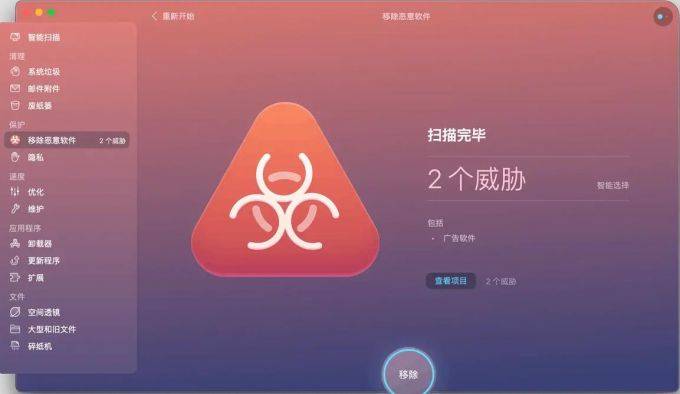
CleanMyMac是什么清理软件?及使用教程
你知道CleanMyMac是什么吗?它的字面意思为“清理我的Mac”,作为软件,那就是一款Mac清理工具,Mac OS X 系统下知名系统清理软件,是数以万计的Mac用户的选择。它可以流畅地与系统性能相结合,只需简单的步骤就…...

Linux小黑板(9):共享内存
"My poor lost soul"上章花了不少的篇幅讲了讲基于管道((匿名、命名))技术实现的进程间通信。进程为什么需要通信?目的是为了完成进程间的"协同",提高处理数据的能力、优化业务逻辑的实现等等,在linux中我们已经谈过了一个通信的大类…...
Detr源码解读(mmdetection)
Detr源码解读(mmdetection) 1、原理简要介绍 整体流程: 在给定一张输入图像后,1)特征向量提取: 首先经过ResNet提取图像的最后一层特征图F。注意此处仅仅用了一层特征图,是因为后续计算复杂度原因,另外&am…...
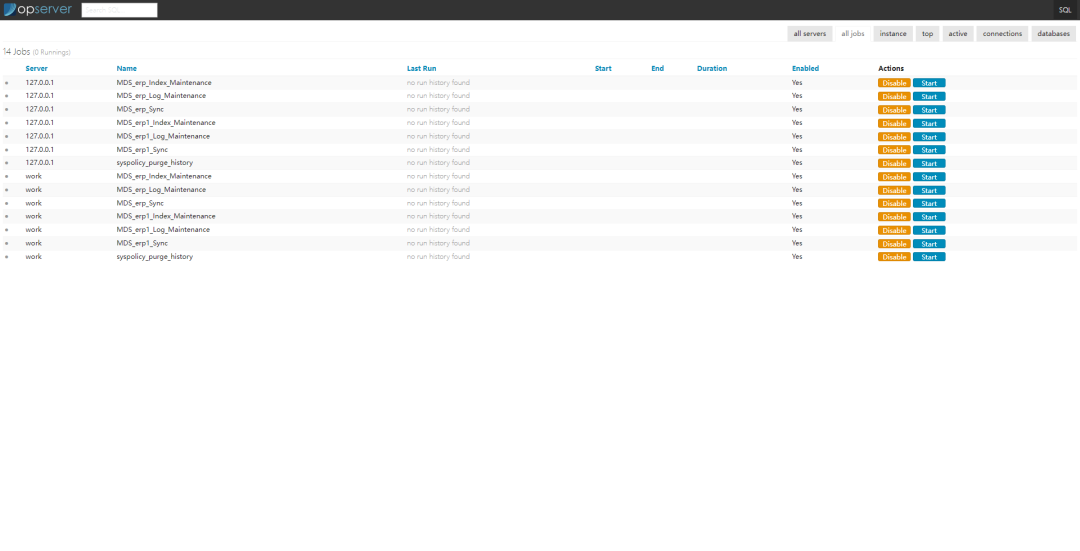
一个.Net Core开发的,撑起月6亿PV开源监控解决方案
更多开源项目请查看:一个专注推荐.Net开源项目的榜单 项目发布后,对于我们程序员来说,项目还不是真正的结束,保证项目的稳定运行也是非常重要的,而对于服务器的监控,就是保证稳定运行的手段之一。对数据库、…...
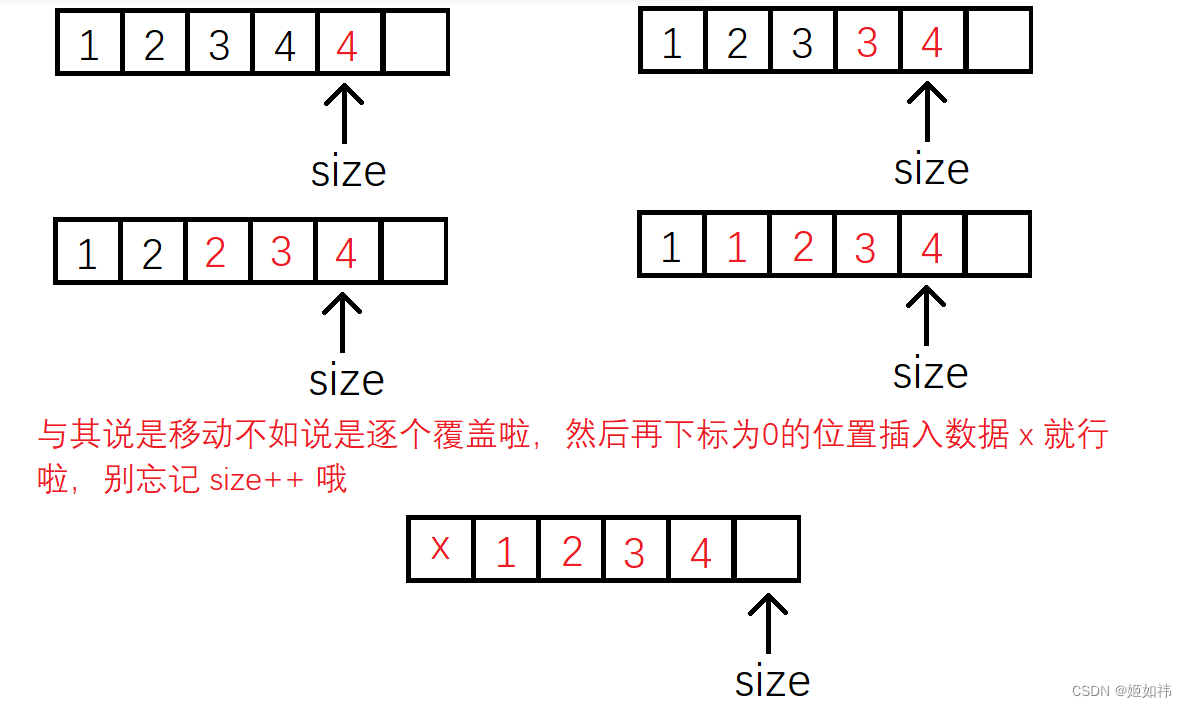
C语言数据结构初阶(2)----顺序表
目录 1. 顺序表的概念及结构 2. 动态顺序表的接口实现 2.1 SLInit(SL* ps) 的实现 2.2 SLDestory(SL* ps) 的实现 2.3 SLPrint(SL* ps) 的实现 2.4 SLCheckCapacity(SL* ps) 的实现 2.5 SLPushBack(SL* ps, SLDataType x) 的实现 2.6 SLPopBack(SL* ps) 的实现 2.7 SLP…...
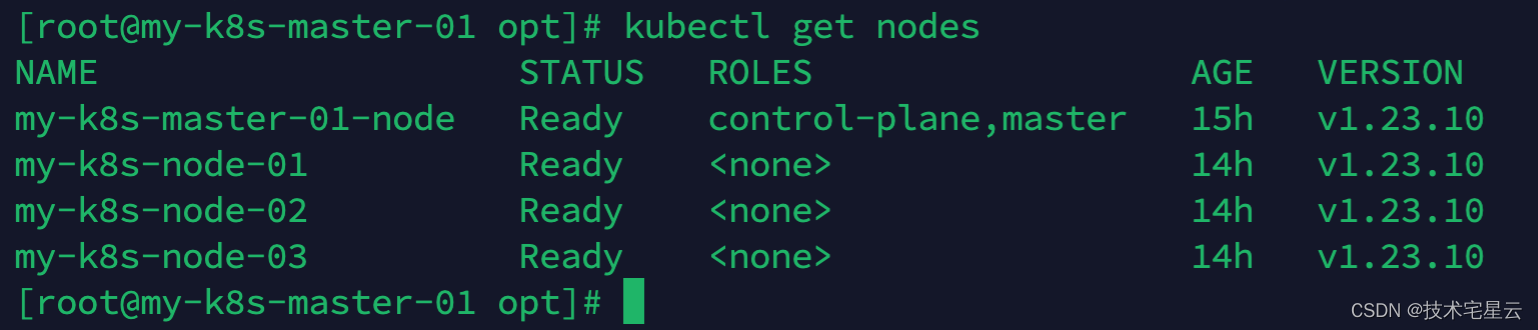
K8S常用命令速查手册
K8S常用命令速查手册一. K8S日常维护常用命令1.1 查看kubectl版本1.2 启动kubelet1.3 master节点执行查看所有的work-node节点列表1.4 查看所有的pod1.5 检查kubelet运行状态排查问题1.6 诊断某pod故障1.7 诊断kubelet故障方式一1.8 诊断kubelet故障方式二二. 端口策略相关2.1 …...

Linux系统下命令行安装MySQL5.6+详细步骤
1、因为想在腾讯云的服务器上创建自己的数据库,所以我在这里是通过使用Xshell 7来连接腾讯云的远程服务器; 2、Xshell 7与服务器连接好之后,就可以开始进行数据库的安装了(如果服务器曾经安装过数据库,得将之前安装的…...
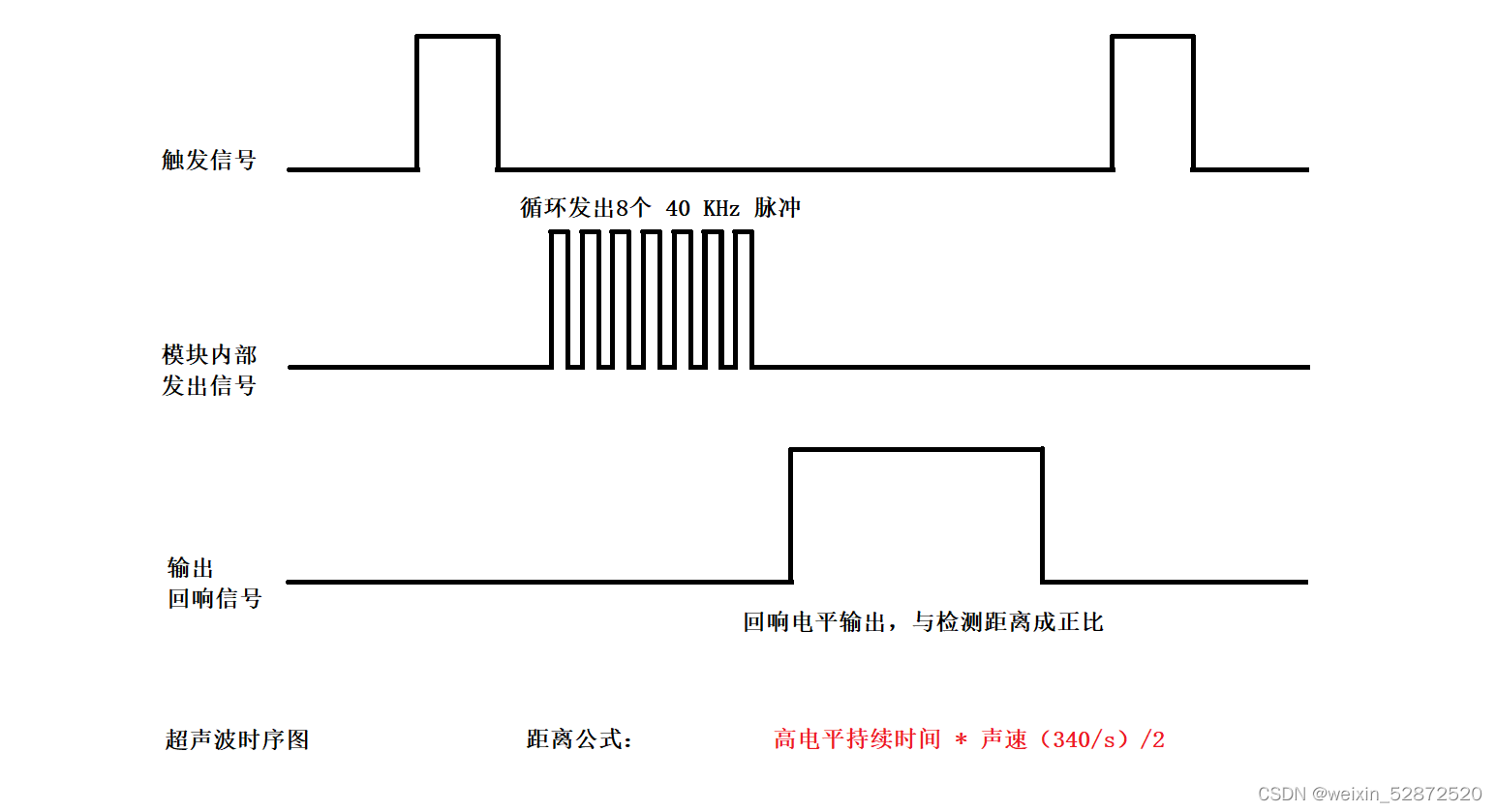
13.STM32超声波模块讲解与实战
目录 1.超声波模块讲解 2.超声波时序图 3.超声波测距步骤 4.项目实战 1.超声波模块讲解 超声波传感器模块上面通常有两个超声波元器件,一个用于发射,一个用于接收。电路板上有4个引脚:VCC GND Trig(触发)ÿ…...

逆向之Windows PE结构
写在前面 对于Windows PE文件结构,个人认为还是非常有必要掌握和了解的,不管是在做逆向分析、免杀、病毒分析,脱壳加壳都是有着非常重要的技能。但是PE文件的学习又是一个非常枯燥过程,希望本文可以帮你有一个了解。 PE文件结构…...

ACL是什么
目录 一、ACL是什么 二、ACL的使用:setacl与getacl 1)针对特定使用者的方式: 1. 创建acl_test1后设置其权限 2. 读取acl_test1的权限 2)针对特定群组的方式: 3)针对有效权限 mask 的设置方式…...
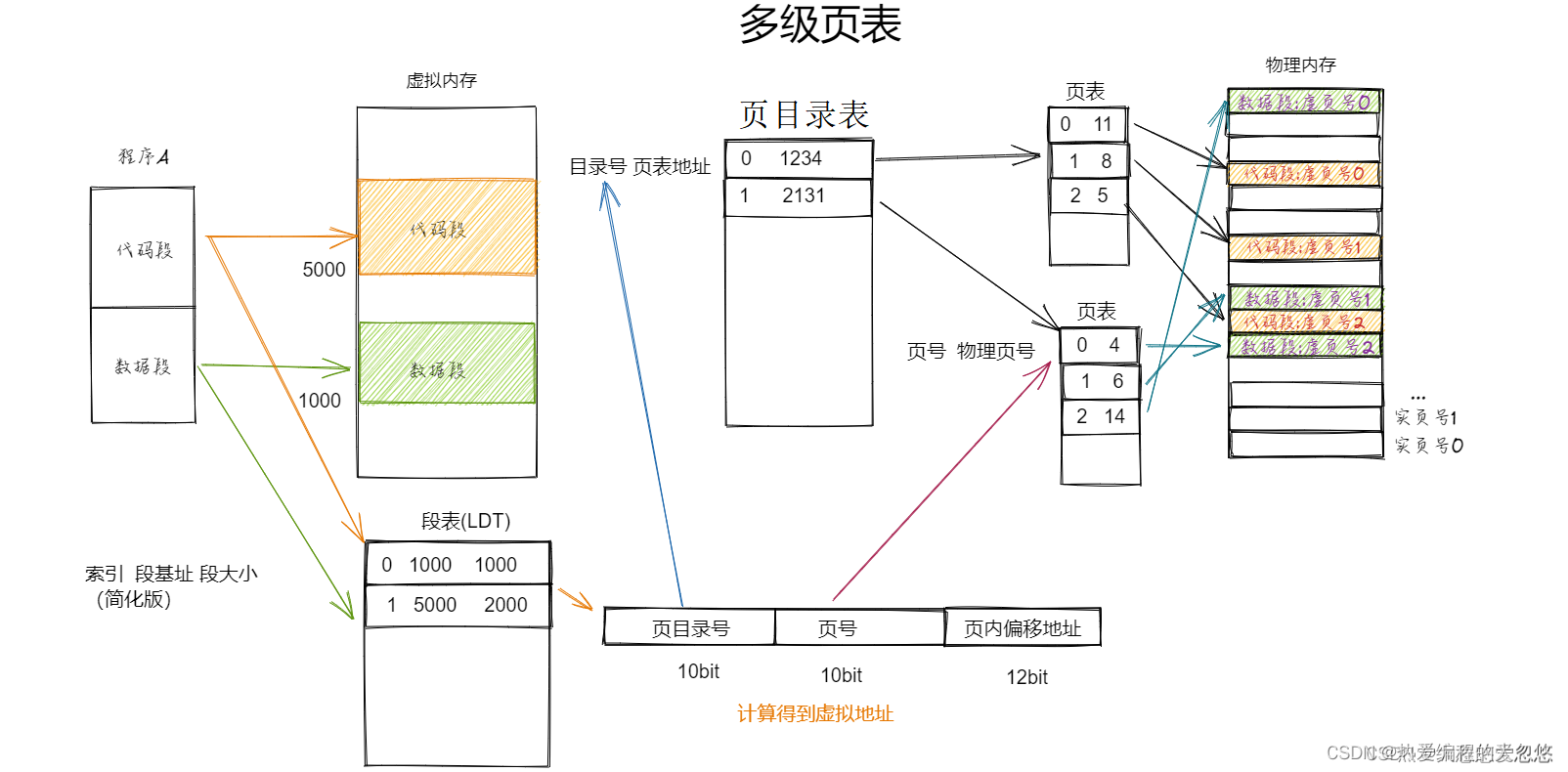
操作系统核心知识点整理--内存篇
操作系统核心知识点整理--内存篇按段对内存进行管理内存分区内存分页为什么需要多级页表TLB解决了多级页表什么样的缺陷?TLB缓存命中率高的原理是什么?段页结合: 为什么需要虚拟内存?虚拟地址到物理地址的转换过程段页式管理下程序如何载入内存?页面置…...
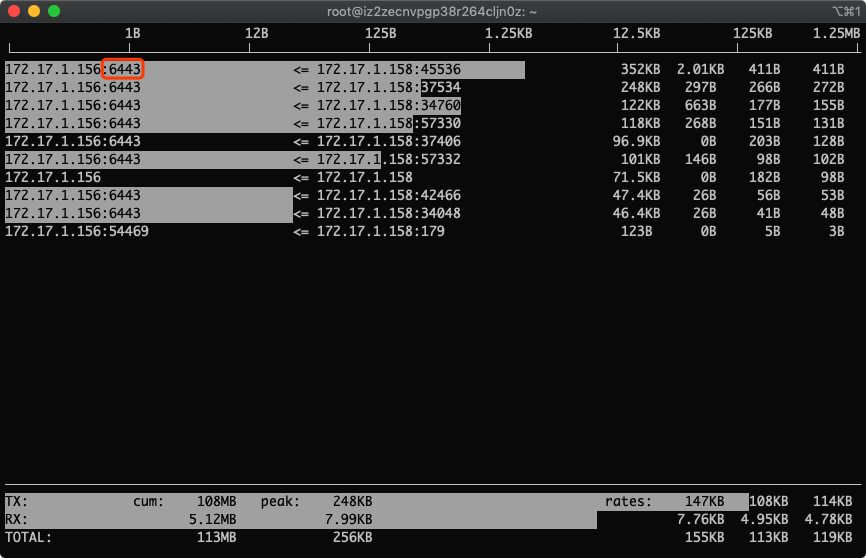
从零开始学习iftop流量监控(找出服务器耗费流量最多的ip和端口)
一、iftop是什么iftop是类似于top的实时流量监控工具。作用:监控网卡的实时流量(可以指定网段)、反向解析IP、显示端口信息等官网:http://www.ex-parrot.com/~pdw/iftop/二、界面说明>代表发送数据,< 代表接收数…...

第一篇博客------自我介绍篇
目录🔆自我介绍🔆学习目标🔆如何学习单片机Part 1 基础理论知识学习Part 2 单片机实践Part 3 单片机硬件设计🔆希望进入的公司🔆结束语🔆自我介绍 Hello!!!我是一名即已经步入大二的计算机小白。 --------…...
)
No suitable device found for this connection (device lo not available(网络突然出问题)
当执行 ifup ens33 出现错误:[rootlocalhost ~]# ifup ens33Error: Connection activation failed: No suitable device found for this connection (device lo not available because device is strictly unmanaged).1解决办法:[rootlocalhost ~]# chkc…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

Selenium常用函数介绍
目录 一,元素定位 1.1 cssSeector 1.2 xpath 二,操作测试对象 三,窗口 3.1 案例 3.2 窗口切换 3.3 窗口大小 3.4 屏幕截图 3.5 关闭窗口 四,弹窗 五,等待 六,导航 七,文件上传 …...

【JavaSE】多线程基础学习笔记
多线程基础 -线程相关概念 程序(Program) 是为完成特定任务、用某种语言编写的一组指令的集合简单的说:就是我们写的代码 进程 进程是指运行中的程序,比如我们使用QQ,就启动了一个进程,操作系统就会为该进程分配内存…...

uniapp 字符包含的相关方法
在uniapp中,如果你想检查一个字符串是否包含另一个子字符串,你可以使用JavaScript中的includes()方法或者indexOf()方法。这两种方法都可以达到目的,但它们在处理方式和返回值上有所不同。 使用includes()方法 includes()方法用于判断一个字…...

Ubuntu Cursor升级成v1.0
0. 当前版本低 使用当前 Cursor v0.50时 GitHub Copilot Chat 打不开,快捷键也不好用,当看到 Cursor 升级后,还是蛮高兴的 1. 下载 Cursor 下载地址:https://www.cursor.com/cn/downloads 点击下载 Linux (x64) ,…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...
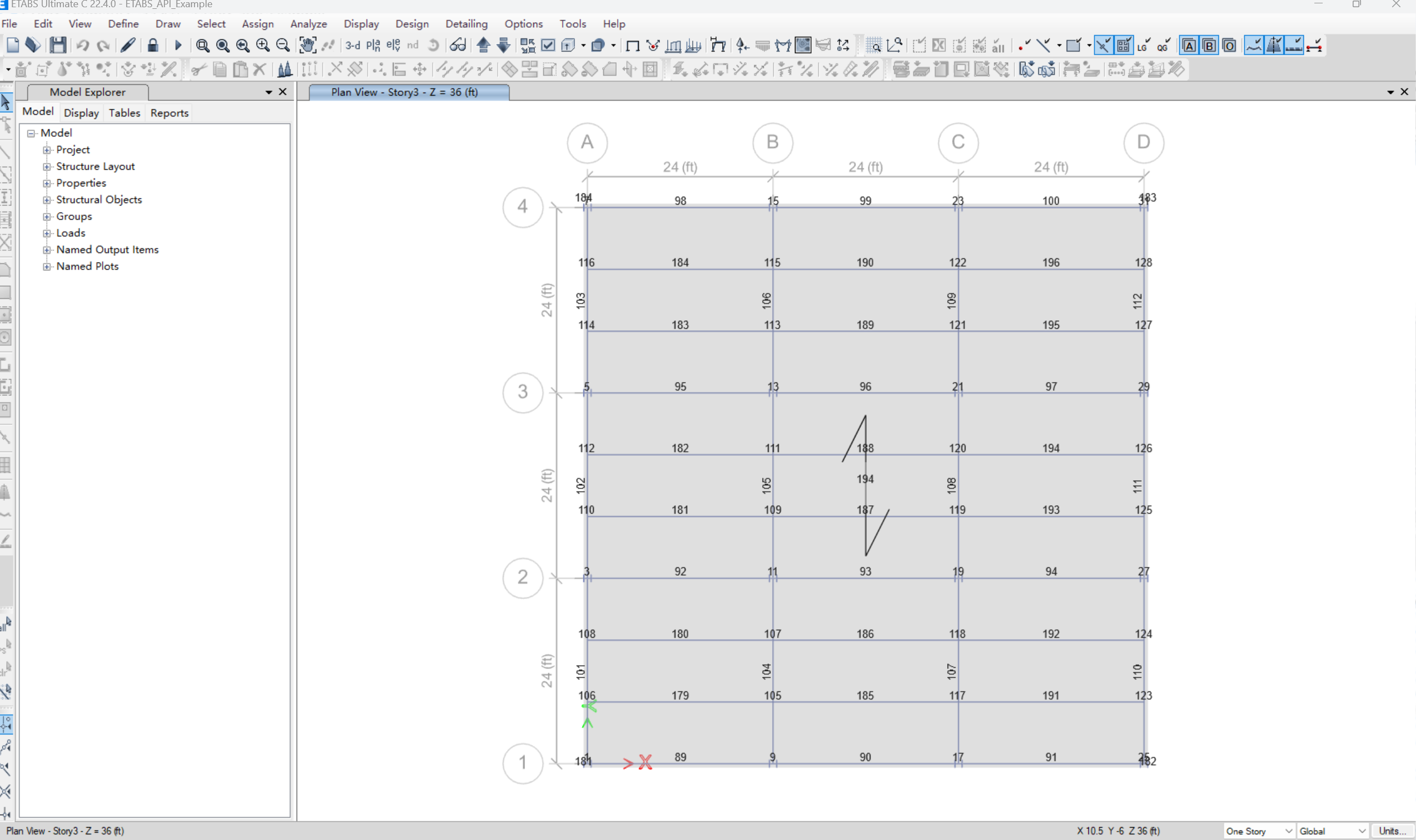
【Post-process】【VBA】ETABS VBA FrameObj.GetNameList and write to EXCEL
ETABS API实战:导出框架元素数据到Excel 在结构工程师的日常工作中,经常需要从ETABS模型中提取框架元素信息进行后续分析。手动复制粘贴不仅耗时,还容易出错。今天我们来用简单的VBA代码实现自动化导出。 🎯 我们要实现什么? 一键点击,就能将ETABS中所有框架元素的基…...