2023最新MongoDB规范
前言
MongoDB是非关系型数据库的典型代表,DB-Engines Ranking 数据显示,近年来,MongoDB在 NoSQL领域一直独占鳌头。MongoDB是为快速开发互联网应用 而设计的数据库系统,其数据模型和持 久化策略就是为了构建高读/写的性能,并且可以方面的弹性拓展。随着MongoDB的普及和使用量的快 速增长,为了规范使用,便于管理和获取更高的性能,整理此文档。我们从 数据库设计规范、集合设计 规范、索引设计规范、文档设计规范、API使用规范、连接规范等方面进行阐述和要求。
存储选型
-
主要解决大量数据的访问效率问题, 减少mysql 压力。MongoDB内建了多种数据分片的特性,可 以很好的适应大数据量的需求。内建的Sharding分片特性避免系统在数据增长的过程中遇到性能瓶颈。
-
复杂数据结构,以多种不同查询条件去查询同一份数据。MongoDB的BSON数据格式非常适合文 档化格式的存储及查询;支持丰富的查询表达式,可轻易查询文档中内嵌的对象和数组及子文档。
-
非事务并且关联性集合不强的都可以使用(MongoDB4.0+支持跨Collection事务,MongoDB4.2+支持跨Shard事务)。
-
无多文档事务性需求及复杂关联检索。
-
业务快速迭代,需求频繁变动业务。
-
数据模型不固定,存储格式灵活场景。
-
单集群读写并发过大无法支撑业务增长。
-
期望 5 个 9 的数据库高可用场景。
一、库设计规范
-
【强制】数据库命名规范:db_xxxx
-
【强制】库名全部小写,禁止使用任何_以外的特殊字符,禁止使用数字打头的库名,如:123_abc;
说明:库以文件夹的形式存在,使用特殊字符或其它不规范的命名方式会导致命名混乱
3. 【强制】数据库名称最多为 64 个字符。
- 【强制】在创建新的库前应尽量评估该库的体积、QPS等,提前与DBA讨论是应该新建一个库还是专门为该库创建一个新的集群。
二、集合设计规范
1.【强制】集合名全部小写,禁止使用任何_以外的特殊字符,禁止使用数字打头的集合名,如:123_abc,禁止system打头; system是系统集合前缀;
2.【强制】集合名称最多为64字符;
3.【建议】一个库中写入较大的集合会影响其它集合的读写性能,如果业务比较繁忙的集合在一个DB中,建议最多80个集合,同时也要考虑磁盘I/O的性能;
4.【建议】如果评估单集合数据量较大,可以将一个大表拆分为多个小表,然后将每一个小表存放在独立的库中或者sharding分表;
5.【建议】MongoDB的集合拥有”自动清理过期数据”的功能,只需在该集合中文档的时间字段增加一个TTL索引即可实现该功能,但需要注意的是该字段的类型则必须是mongoDate(),一定要结合实际业务设计是否需要;
6.【建议】设计轮询集合—集合是否设计为Capped限制集,一定要结合实际业务设计是否需要。
创建集合规则
不同的业务场景是可以使用不同的配置;
db.createCollection(“logs”,
{ “storageEngine”: { “wiredTiger”:
{ “configString”: “internal_page_max=16KB,
leaf_page_max=16KB,leaf_value_max=8KB,os_cache_max=1GB”} }
})
a. 如果是读多写少的表在创建时我们可以尽量将 page size 设置的比较小 ,比如 16KB,如果表数据量不大 (“internal_page_max=16KB,leaf_page_max=16KB,leaf_value_max=8KB,os_cache_max=1GB”)
b. 如果这个读多写少的表数据量比较大,可以为其设置一个压缩算法,例如:”block_compressor=zlib, internal_page_max=16KB,leaf_page_max=16KB,leaf_value_max=8KB”
c. 注意:该zlib压缩算法不要使用,对cpu消耗特别大,如果使用snapp消耗20% cpu,而且使用zlib能消耗90%cpu,甚至100%
d. 如果是写多读少的表,可以将 leaf_page_max 设置到 1MB,并开启压缩算法,也可以为其制定操作系统层面 page cache 大小的 os_cache_max 值,让它不会占用太多的 page cache 内存,防止影响读操作
读多写少的表 internal_page_max=16KB 默认为4KB leaf_page_max=16KB 默认为32KB leaf_value_max=8KB 默认为64MB os_cache_max=1GB 默认为0 读多写少的表 而且数据量比较大 block_compressor=zlib 默认为snappy internal_page_max=16KB 默认为4KB leaf_page_max=16KB 默认为32KB leaf_value_max=8KB 默认为64M
三、文档设计规范
1.【强制】集合中的 key 禁止使用任何 “_”(下划线)以外的特殊字符。
2.【强制】尽量将同样类型的文档存放在一个集合中,将不同类型的文档分散在不同的集合中;相同类型的文档能够大幅度提高索引利用率,如果文档混杂存放则可能会出现查询经常需要全表扫描的情况;
3.【建议】禁止使用_id,如:向_id中写入自定义内容;
说明:MongoDB的表与InnoDB相似,都是索引组织表,数据内容跟在主键后,而_id是MongoDB中的默认主键,一旦_id的值为非自增,当数据量达到一定程度之后,每一次写入都可能导致主键的二叉树大幅度调整,这将是一个代价极大的写入, 所以写入就会随着数据量的增大而下降,所以一定不要在_id中写入自定义的内容。
4.【建议】尽量不要让数组字段成为查询条件;
5.【建议】如果字段较大,应尽量压缩存放;
不要存放太长的字符串,如果这个字段为查询条件,那么确保该字段的值不超过1KB;MongoDB的索引仅支持1K以内的字段,如果你存入的数据长度超过1K,那么它将无法被索引
6.【建议】尽量存放统一了大小写后的数据 ;
7.【建议】如果评估单集合数据量较大,可以将一个大表拆分为多个小表,然后将每一个小表存放在独立的库中或者sharding分表。
四、索引设计规范
1.【强制】MongoDB 的组合索引使用策略与 MySQL 一致,遵循”最左原则”;
2.【强制】索引名称长度不要超过 128 字符;
3.【强制】应尽量综合评估查询场景,通过评估尽可能的将单列索引并入组合索引以降低所以数量,结合1,2点;
4.【建议】优先使用覆盖索引;
5.【建议】创建组合索引的时候,应评估索引中包含的字段,尽量将数据基数大(唯一值多的数据)的字段放在组合索引的前面;
6.【建议】MongoDB 支持 TTL 索引,该索引能够按你的需要自动删除XXX秒之前的数据并会尽量选择在业务低峰期执行删除操作;看业务是否需要这一类型索引;
7.【建议】在数据量较大的时候,MongoDB 索引的创建是一个缓慢的过程,所以应当在上线前或数据量变得很大前尽量评估,按需创建会用到的索引;
8.【建议】如果你存放的数据是地理位置信息,比如:经纬度数据。那么可以在该字段上添加 MongoDB 支持的地理索引:2d 及 2dsphere,但他们是不同的,混用会导致结果不准确。
五、API使用规范
1.【强制】在查询条件的字段或者排序条件的字段上必须创建索引;
2.【强制】查询结果只包含需要的字段,而不查询所有字段;
3.【强制】在文档级别更新是原子性的,这意味着一条更新 10 个文档的语句可能在更新 3 个文档后由于某些原因失败。应用程序必须根据自己的策略来处理这些失败;
4.【建议】单个文档的BSON size不能超过16M;
5.【建议】禁用不带条件的update、remove或者find语句;
6.【建议】限定返回记录条数,每次查询结果不超过 2000 条。如果需要查询 2000 条以上的数据,在代码中使用多线程并发查询;
7.【建议】在写入数据的时候,如果你需要实现类似 MySQL 中 INSERT INTO ON DUPLICATE KEY UPDATE 的功能,那么可以选择 upsert() 函数;
8.【建议】写入大量数据的时候可以选择使用 batchInsert,但目前 MongoDB 每一次能够接受的最大消息长度为48MB,如果超出48MB,将会被自动拆分为多个48MB的消息;
9.【建议】索引中的-1和1是不一样的,一个是逆序,一个是正序,应当根据自己的业务场景建立适合的索引排序,需要注意的是{a:1,b:-1} 和 {a:-1,b:1}是一样的;
10.【建议】在开发业务的时候尽量检查自己的程序性能,可以使用 explain() 函数检查你的查询执行详情,另外 hint() 函数相当于 MySQL 中的 force index();
11.【建议】如果你结合体积大小/文档数固定,那么建议创建 capped(封顶)集合,这种集合的写入性能非常高并无需专门清理老旧数据,需要注意的是 capped 表不支持remove() 和 update()操作;
12.【建议】查询中的某些操作符可能会导致性能低下,如ne,not,exists,nin,or,尽量在业务中不要使用;
exist:因为松散的文档结构导致查询必须遍历每一个文档
ne:如果当取反的值为大多数,则会扫描整个索引
not:可能会导致查询优化器不知道应当使用哪个索引,所以会经常退化为全表扫描
nin:全表扫描
or:有多少个条件就会查询多少次,最后合并结果集,所以尽可能的使用in
13.【建议】不要一次取出太多的数据进行排序,MongoDB 目前支持对32MB以内的结果集进行排序,如果需要排序,那么请尽量限制结果集中的数据量;
14.【建议】MongoDB 的聚合框架非常好用,能够通过简单的语法实现复杂的统计查询,并且性能也不错;
15.【建议】如果需要清理掉一个集合中的所有数据,那么 remove() 的性能是非常低下的,该场景下应当使用 drop();remove() 是逐行操作,所以在删除大量数据的时候性能很差;
16.【建议】在使用数组字段做为查询条件的时候,将与覆盖索引无缘;这是因为数组是保存在索引中的,即便将数组字段从需要返回的字段中剔除,这样的索引仍然无法覆盖查询;
17.【建议】在查询中如果有范围条件,那么尽量和定值条件放在一起进行过滤,并在创建索引的时候将定值查询字段放在范围查询字段前。
六、连接规范
1.【强制】正确连接副本集,副本集提供了数据的保护、高可用和灾难恢复的机制。如果主节点宕 机,其中一个从节点会自动提升为从节点。
2.【建议】合理控制连接池的大小,限制连接数资源,可通过Connection String URL中的 maxPoolSize 参数来配置连接池大小。
3.【建议】复制集读选项 默认情况下,复制集的所有读请求都发到Primary,Driver可通过设置的Read Preference 来将 读请求路由到其他的节点。
相关文章:

2023最新MongoDB规范
前言 MongoDB是非关系型数据库的典型代表,DB-Engines Ranking 数据显示,近年来,MongoDB在 NoSQL领域一直独占鳌头。MongoDB是为快速开发互联网应用 而设计的数据库系统,其数据模型和持 久化策略就是为了构建高读/写的性能&#x…...

gcc的使用,调试工具gdb的使用
gcc编译 gcc编译可以分为四个步骤,预处理、编译、汇编、链接。 预处理命令:gcc -E hello.c -o hello.i编译命令:gcc -S hello.i -o hello.s汇编命令: gcc -c hello.s -o hello.o链接命令:gcc hello.o -o hello gcc…...
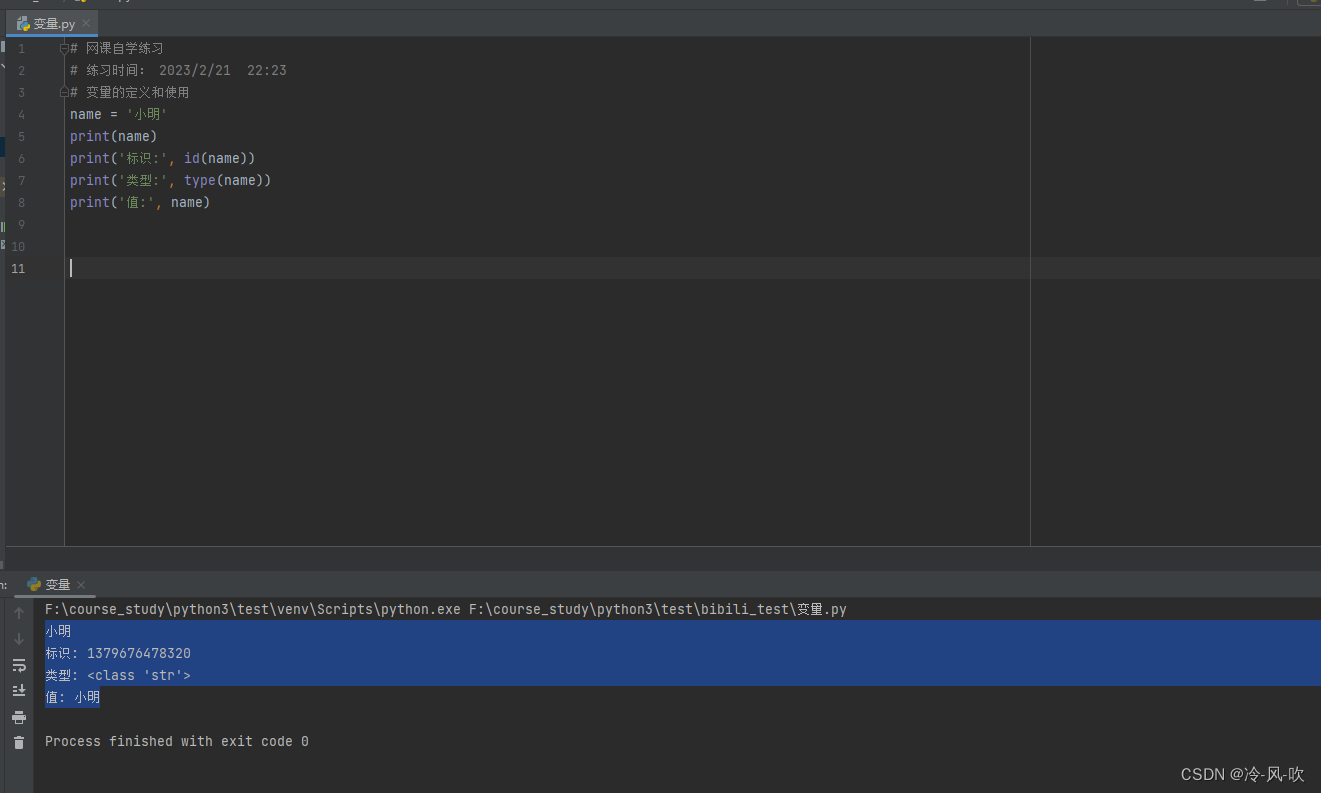
Python变量的定义和使用
定义:变量就是计算机内存中存储某些数据的位置的名称 形象理解变量就是一个存放东西的容器,该容器的名字就叫做变量,容器存放的东西就是变量的值 变量的组成: 标识:标识对象所储存的内存地址,使用内置函数i…...
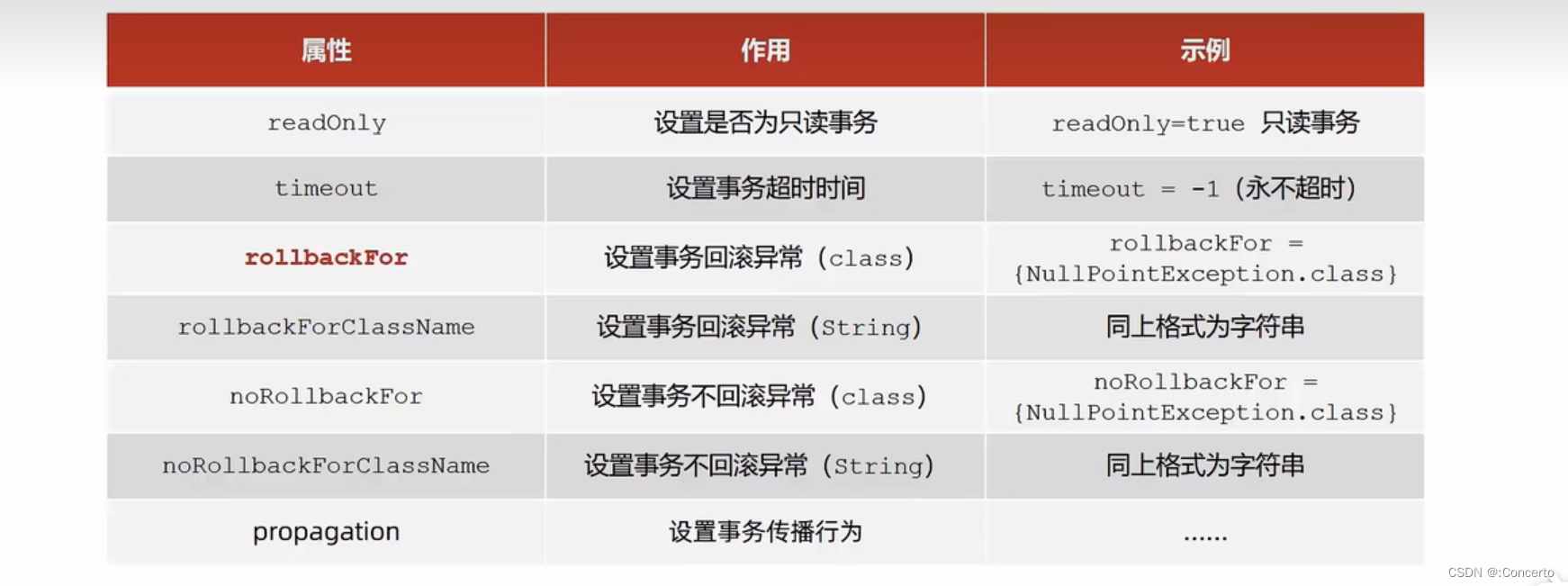
SSM框架-AOP概述、Spring事务
16 spring整合mybatis 16.1 前情代码 实体类 public class Account {private Integer id;private String name;private Double money;public Integer getId() {return id;}public void setId(Integer id) {this.id id;}public String getName() {return name;}public void …...

一文搞定Android Vsync原理简析
屏幕渲染原理"现代计算机之父"冯诺依曼提出了计算机的体系结构: 计算机由运算器,存储器,控制器,输入设备和输出设备构成,每部分各司其职,它们之间通过控制信号进行交互。计算机发展到现在,已经出…...
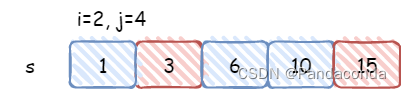
第八届蓝桥杯省赛 C++ B组 - K 倍区间
✍个人博客:https://blog.csdn.net/Newin2020?spm1011.2415.3001.5343 📚专栏地址:蓝桥杯题解集合 📝原题地址:K 倍区间 📣专栏定位:为想参加蓝桥杯的小伙伴整理常考算法题解,祝大家…...
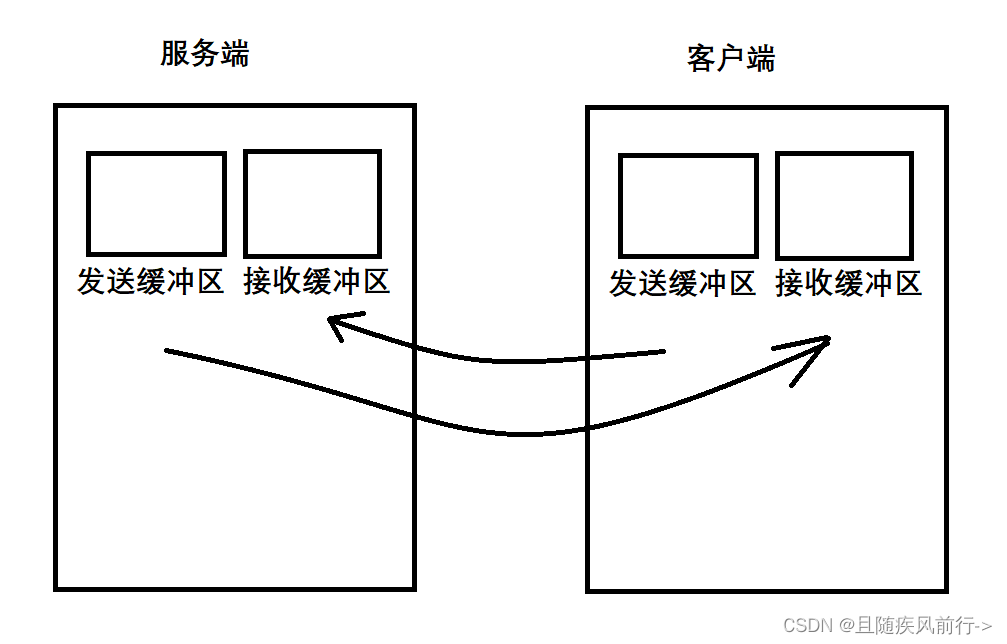
UDP与TCP协议
目录 UDP协议 协议报头 UDP协议特点: 应用场景: TCP TCP协议报头 确认应答机制 理解可靠性 超时重传机制 连接管理机制 三次握手: 四次挥手: 滑动窗口 如何理解缓冲区和滑动窗口? 倘若出现丢包…...

rosbag相关使用工具
文章目录一、 rosbag 导出指定话题生成新rosbag二、 rosbag 导出视频1. 脚本工具源码2. 操作2.1 安装 ffmpeg2.2 导出视频3. 视频截取4. 压缩视频附录:rosbag2video.py 源码一、 rosbag 导出指定话题生成新rosbag rosbag filter 2023-02-25-19-16-01.bag depth.bag…...

数据结构与算法—栈stack
目录 栈 栈的复杂度 空间复杂度O(1) 时间复杂度O(1) 栈的应用 1、栈在函数调用中的应用; 2、栈在求表达式的值的应用: 栈的实现 栈 后进先出,先进后出,只允许在一端插入和删除 从功能上,数组和链表可以代替栈…...

【学习笔记】[ARC150F] Constant Sum Subsequence
第一眼看上去,这道题一点都不套路 第二眼看上去,大概是要考dpdpdp优化,那没事了,除非前面333道题都做完了否则直接做这道题肯定很亏 首先我们要定义一个好的状态。废话 设fsf_{s}fs表示BBB序列的和为sss时,能达到…...

Node.js实现大文件断点续传—浅析
Node.js简介: 当谈论Node.js时,通常指的是一个基于Chrome V8 JavaScript引擎构建的开源、跨平台的JavaScript运行时环境。以下是一些Node.js的内容: 事件驱动编程:Node.js采用了事件驱动的编程范式,这意味着它可以异步…...
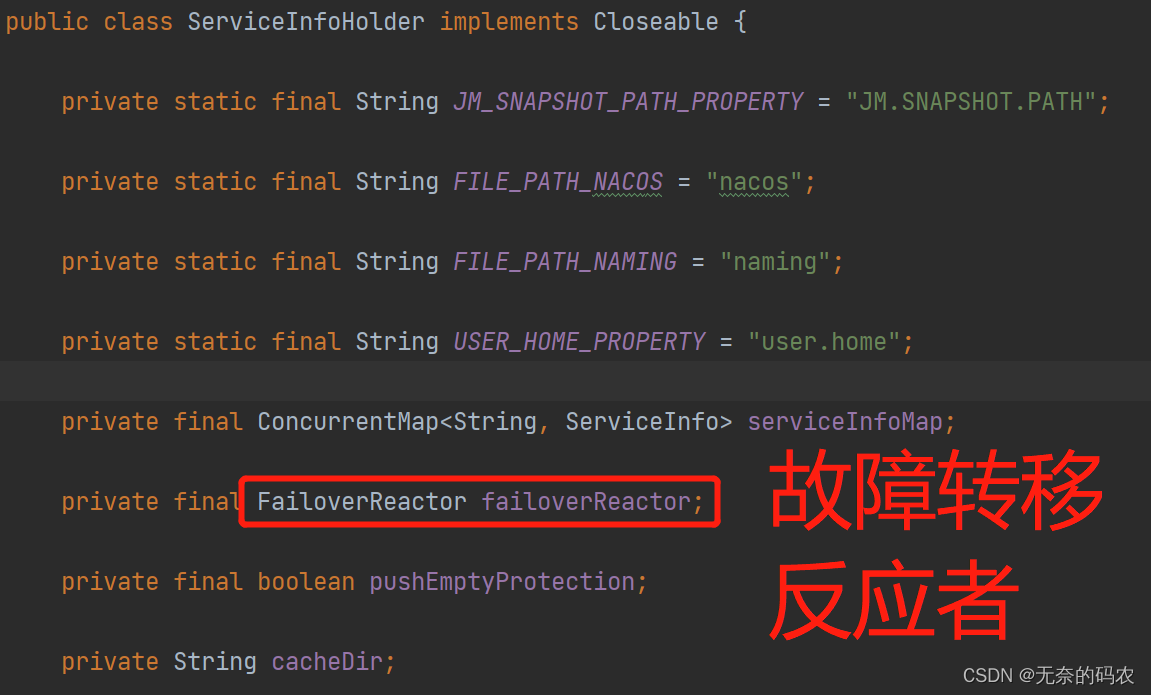
Spring Cloud Nacos源码讲解(九)- Nacos客户端本地缓存及故障转移
Nacos客户端本地缓存及故障转移 在Nacos本地缓存的时候有的时候必然会出现一些故障,这些故障就需要进行处理,涉及到的核心类为ServiceInfoHolder和FailoverReactor。 本地缓存有两方面,第一方面是从注册中心获得实例信息会缓存在内存当…...

MySQL知识点小结
事务 进行数据库提交操作时使用事务就是为了保证四大特性,原子性,一致性,隔离性,持久性Durability. 持久性:事务一旦提交,对数据库的改变是永久的. 事务的日志用于保存对数据的更新操作. 这个操作T1事务操作的会发生丢失,因为最后是T2提交的修改,而且T2先进行一次查询,按照A…...
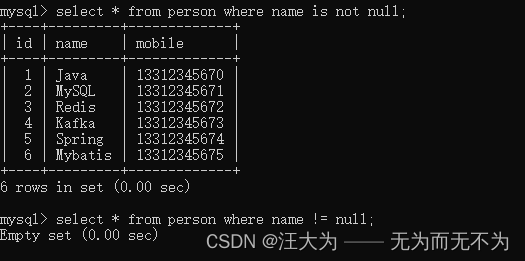
MySQL关于NULL值,常见的几个坑
数据库版本MySQL8。 1.count 函数 觉得 NULL值 不算数 ,所以开发中要避免count的时候丢失数据。 如图所示,以下有7条记录,但是count(name)却只有6条。 为什么丢失数据?因为MySQL的count函数觉得 Null值不算数,就是说…...

OllyDbgqaqazazzAcxsaZ
本文通过吾爱破解论坛上提供的OllyDbg版本为例,讲解该软件的使用方法 F2对鼠标所处的位置打下断点,一般表现为鼠标所属地址位置背景变红F3加载一个可执行程序,进行调试分析,表现为弹出打开文件框F4执行程序到光标处F5缩小还原当前…...

Elasticsearch7.8.0版本进阶——自定义分析器
目录一、自定义分析器的概述二、自定义的分析器的测试示例一、自定义分析器的概述 Elasticsearch 带有一些现成的分析器,然而在分析器上 Elasticsearch 真正的强大之 处在于,你可以通过在一个适合你的特定数据的设置之中组合字符过滤器、分词器、词汇单 …...

spring事务-创建代理对象
用来开启事务的注解EnableTransactionManagement上通过Import导入了TransactionManagementConfigurationSelector组件,TransactionManagementConfigurationSelector类的父类AdviceModeImportSelector实现了ImportSelector接口,因此会调用public final St…...

Linux 配置NFS与autofs自动挂载
目录 配置NFS服务器 安装nfs软件包 配置共享目录 防火墙放行相关服务 配置NFS客户端 autofs自动挂载 配置autofs 配置NFS服务器 nfs主配置文件参数(/etc/exports) 共享目录 允许地址1访问(选项1,选项2) 循序地…...
【编程入门】应用市场(Python版)
背景 前面已输出多个系列: 《十余种编程语言做个计算器》 《十余种编程语言写2048小游戏》 《17种编程语言10种排序算法》 《十余种编程语言写博客系统》 《十余种编程语言写云笔记》 《N种编程语言做个记事本》 目标 为编程初学者打造入门学习项目,使…...

异常信息记录入库
方案介绍 将异常信息放在日志里面,如果磁盘定期清理,会导致很久之前的日志丢失,因此考虑将日志中的异常信息存在表里,方便后期查看定位问题。 由于项目是基于SpringBoot构架的,所以采用AdviceControllerExceptionHand…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...