ClickHouse高可用集群分片-副本实操(四)
目录
一、ClickHouse高可用之ReplicatedMergeTree引擎
二、 ClickHouse高可用架构准备-环境说明和ZK搭建
三、高可用集群架构-ClickHouse副本配置实操
四、ClickHouse高可用集群架构分片
4.1 ClickHouse高可用架构之两分片实操
4.2 ClickHouse高可用架构之两分片建表实操
一、ClickHouse高可用之ReplicatedMergeTree引擎
什么是CK的副本引擎:
两个相同数据的表, 作用是为了数据备份与安全,保障数据的高可用性。
副本是表级别的,不是整个服务器级的,服务器里可以同时有复制表和非复制表。
副本不依赖分片,每个分片有它自己的独立副本。
副本写入的流程和注意事项:(这是重点-面试问的多 哈哈)
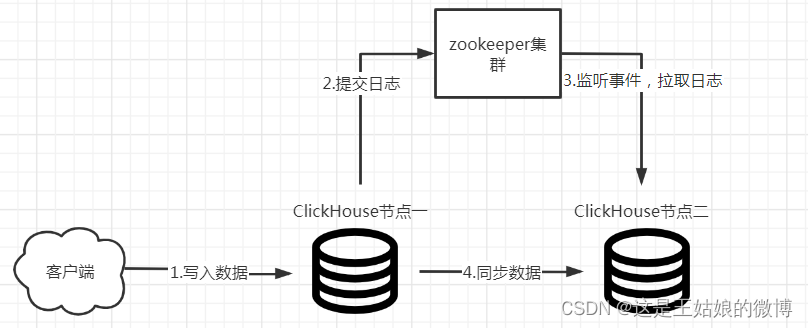
数据传输是不经过ZK的,ZK只是一个协调者的身份。
副本写入流程和注意事项:
复制是多主异步
1.数据会先插入到执行该语句的服务器上,然后被复制到其他服务器。(复制是多主异步的,客户端写完之后就可以返回)
2.由于它是异步的,在其他副本上最近插入的数据会有一些延迟。当部分副本挂了的时候,数据会在该副本恢复正常的时候,再继续进行同步
其中副本可用的情况下,会有些许延迟,那延迟的时长就是通过网络传输、压缩数据块所需的时间。
3.默认情况下,INSERT 语句仅等待一个副本写入成功后返回,如果数据只成功写入一个副本后该副本所在的服务器不再存在,则存储的数据会丢失
4.要启用数据写入多个副本才确认返回,使用 insert_quorum 进行配置,但是会影响性能
5.对于 INSERT 和 ALTER 语句操作数据的会在压缩的情况下被复制,而 CREATE,DROP,ATTACH,DETACH 和 RENAME 语句只会在单个服务器上执行,不会被复制。
副本合并树引擎ReplicatedMergeTree
如果有两个副本的话,相当于分布在两台clickhosue节点中的两个表,
这个两个表具有协调功能, 无论是哪个表执行insert或者alter操作,都会同步到另外一张表,副本就是相互同步数据的表
副本同步需要借助zookeeper实现数据的同步, 副本节点会在zk上进行监听,但数据同步过程是不经过zk的
zookeeper要求3.4.5以及以上版本
建表:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],...INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = ReplicatedMergeTree('{zoo_path}', '{replica_name}')
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
语句:
CREATE TABLE tb_order
(EventDate DateTime,CounterID UInt32,UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/tb_order', 'tb_order_01')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)ReplicatedMergeTree 参数
zoo_path — zk 中该表的路径,可自定义名称,同一张表的同一分片的不同副本,要定义相同的路径;
replica_name — zk 中的该表的副本名称,同一张表的同一分片的不同副本,要定义不同的名称;
«ZooKeeper 中该表的路径»对每个可复制表都要是唯一的,不同分片上的表要有不同的路径
推荐格式 即 【通用前缀】【分片标识部分】/clickhouse/tables/{shard}/{table_name}
大括号的部分的可以用参数替代
二、 ClickHouse高可用架构准备-环境说明和ZK搭建
高可用架构需要ZK
副本同步需要借助zookeeper实现数据的同步, 副本节点会在zk上进行监听,但数据同步过程是不 经过zk的,zk是个协调者
zookeeper要求3.4.5以及以上版本
使用Docker部署即可
机器准备
机器一:(Docker安装ZK) 112.xxx.xxx.240
机器二:(RPM安装ClickHouse) 120.xxx.xxx.49
机器三:(RPM安装ClickHouse) 120.xx.xxx.202
第一步:在机器一上面安装zk
Docker部署ZK
docker run -d --name zookeeper -p 2181:2181 -t zookeeper:3.7.0
第二步 :在机器二/三上面 通过RPM方式部署CK 版本:ClickHouse 22.1.2.2
安装文档地址:安装 | ClickHouse Docs
#各个节点上传到新建文件夹
/usr/local/software/*#安装
sudo rpm -ivh *.rpm#启动
systemctl start clickhouse-server#停止
systemctl stop clickhouse-server#重启
systemctl restart clickhouse-server#状态查看
sudo systemctl status clickhouse-server#查看端口占用,如果命令不存在 yum install -y lsof
lsof -i :8123
#查看日志
tail -f /var/log/clickhouse-server/clickhouse-server.log
tail -f /var/log/clickhouse-server/clickhouse-server.err.log
#开启远程访问,取消下面的注释
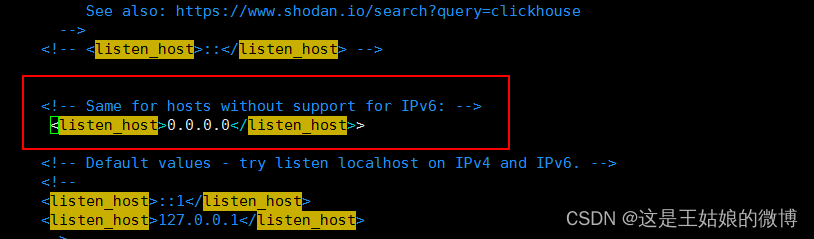
vim /etc/clickhouse-server/config.xml#编辑配置文件
<listen_host>0.0.0.0</listen_host>#重启
systemctl restart clickhouse-server
实操:
1. 先把几个rpm文件上传到/usr/local/software目录下
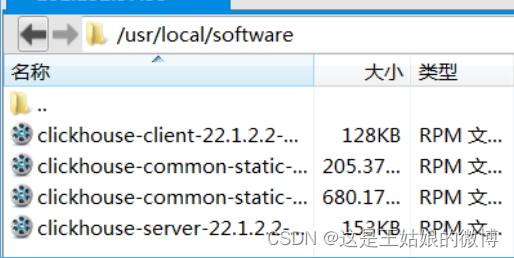
2.cd /usr/local/software sudo rpm -ivh *.rpm进行安装

中间会停顿下让你输入密码,直接回车即可。
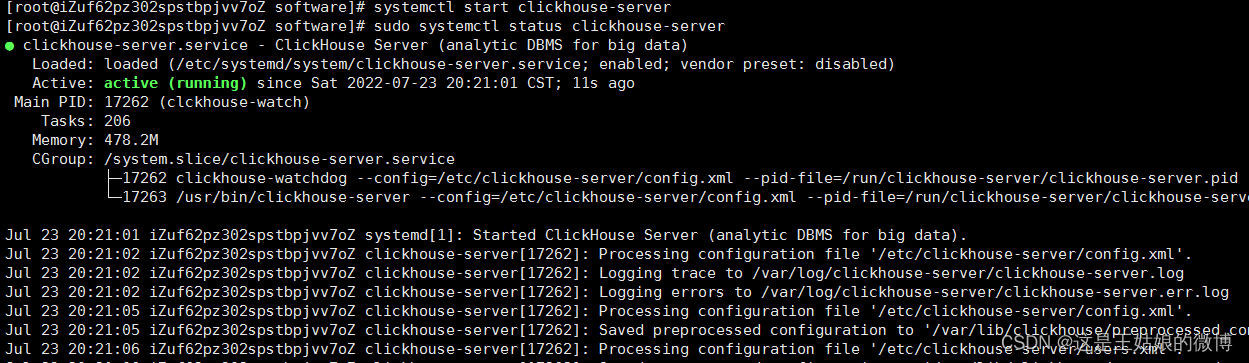
3.安装后需要启动 systemctl start clickhouse-server
查看启动状态:sudo systemctl status clickhouse-server
4.查看端口占用
 5.查看日志
5.查看日志
tail -f /var/log/clickhouse-server/clickhouse-server.log

6.取消下面的注释 开启远程访问
vim /etc/clickhouse-server/config.xml
7.重启ck
systemctl start clickhouse-server
8.远程工具连接

到这就完成RPM形式的单机部署~将机器三,也按照这种形式部署起来 然后继续下面的副本配置操作
注意:阿里云部署时,报错 <Error> DNSResolver: Cannot resolve host (iZwz9bg08mzvexxkzyu7iiZ), error 0: iZwz9bg08mzvexxkzyu7iiZ
DB::Exception: Not found address of host
解决:增加ip和host域名
sudo vim /etc/hosts
在集群副本的hosts文件中,增加局域网ip和hostname即可
三、高可用集群架构-ClickHouse副本配置实操
第一步:机器二、机器三都需要配置
vim /etc/clickhouse-server/config.xml
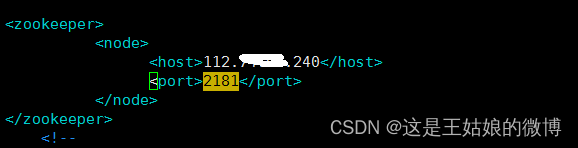
<zookeeper>
<node>
<host>112.xx.xxx.240</host>#一开始使用docker安装的那个zk公网IP地址
<port>2181</port>
</node>
</zookeeper><interserver_http_host>120.xx.xx.202</interserver_http_host>#当前机器的IP地址
wq!保存退出
重启:
实操 -->2台机器都要更改后重启:
更改1
更改2

第二步:在每个机器上创建表
副本同步,同步的是数据,表结构是不会同步的
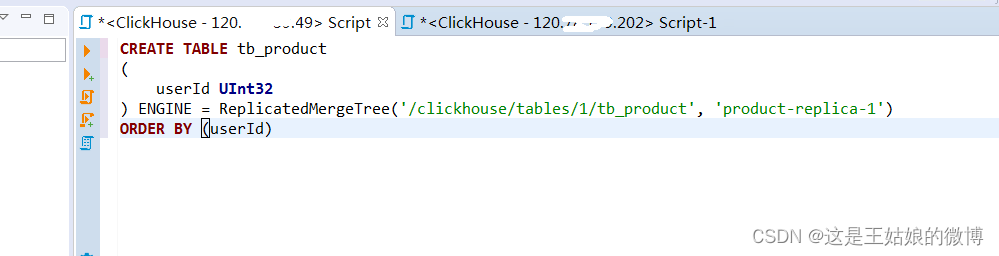
#节点一,zk路径一致,副本名称不一样
CREATE TABLE tb_product
(
userId UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/1/tb_product', 'product-replica-1')
ORDER BY (userId)#节点二,zk路径一致,副本名称不一样
CREATE TABLE tb_product
(
userId UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/1/tb_product', 'product-replica-2')
ORDER BY (userId)#查询zk配置
select * from system.zookeeper where path='/'
 注意:副本只能同步数据,不能同步表结构,需要在每台机器上手动建表
注意:副本只能同步数据,不能同步表结构,需要在每台机器上手动建表
演示:在其中任何一个节点插入数据,然后去另外一个节点上面查看

在202机器上可以查看到结果 
四、ClickHouse高可用集群架构分片
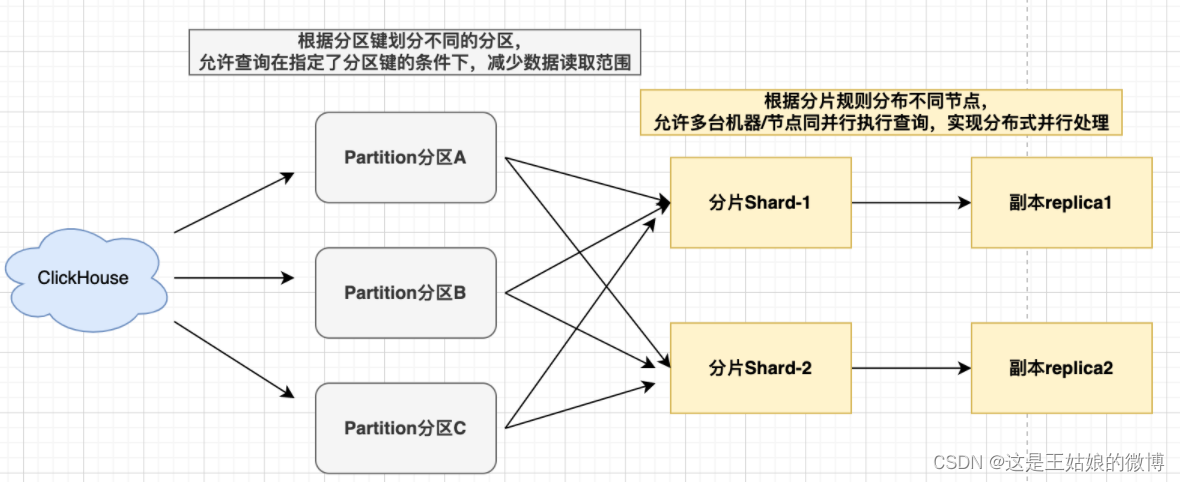
什么是ClickHouse的分片
数据分片-允许多台机器/节点同并行执行查询,实现了分布式并行计算
分片间的数据是不同的,不同的服务器存储同一张表的不同部分,作用是为了水平切分表,缓解单节点的压力
分布式表引擎Distributed
官方文档:分布式引擎 | ClickHouse Docs
分布式表引擎Distributed:Distributed表引擎主要是用于分布式,自身不存储任何数据,数据都分散存储在某一个分片上,能够自动路由数据至集群中的各个节点,需要和其他数据表引擎一起协同工作.主要起汇总返回的作用。
一张分布式表底层会对应多个分片数据表,由具体的分片表存储数据,分布式表与分片表是一对多的关系。分布式表主要有本地表(xxx_local)和分布式表(xxx_all)两部分组成

建表语法:
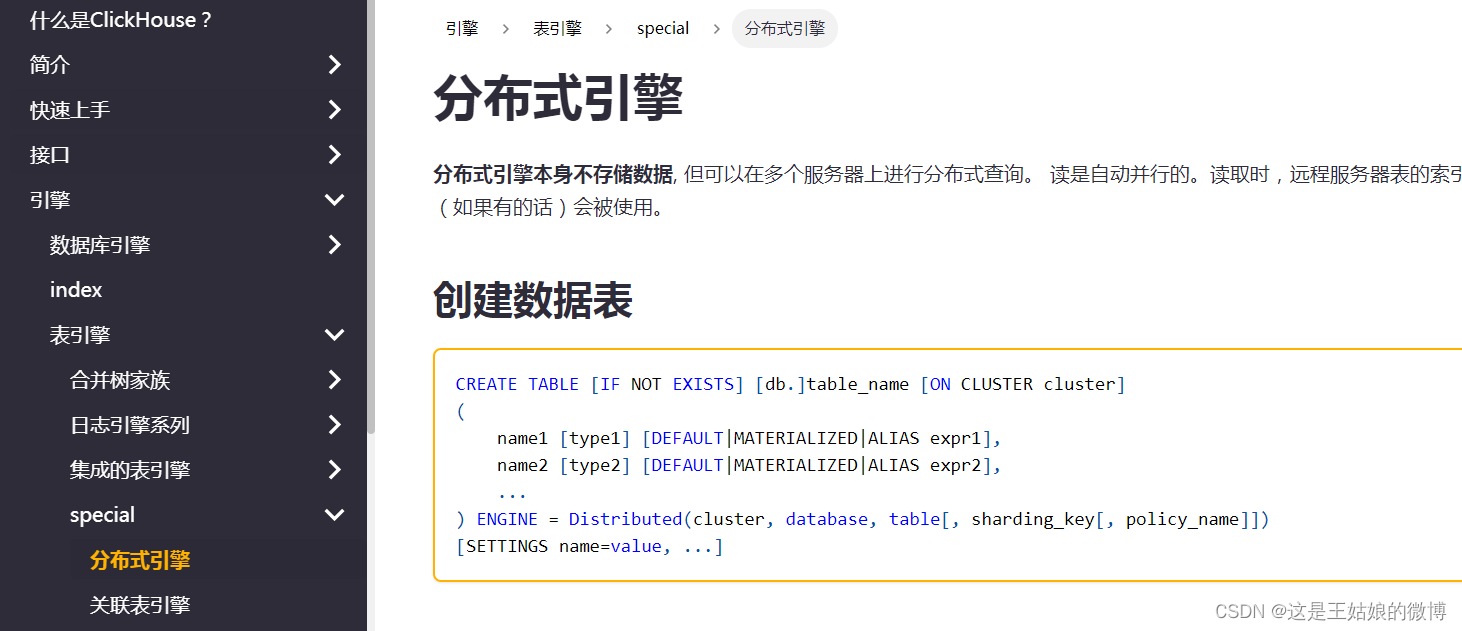
参数:
cluster:集群名称,与集群配置中的自定义名称相对应,比如 wnn_shard。
database:数据库名称
**table:本地表名称
sharding_key:可选参数,用于分片的key值,在写入的数据Distributed表引擎会依据分片key的规则,将数据分布到各个节点的本地表
user_id等业务字段、rand()随机函数等规则
参数详细说明,见官方文档 分布式引擎 | ClickHouse Docs
多分片表查询方式:
本着谁执行谁负责的原则,向ClickHouse发起分布式表执行SELECT * FROM distributed_table
它会转为如下形式SELECT * FROM local_table,先执行本地分片,再发送远端各分片执行
合并结果为临时表返回
4.1 ClickHouse高可用架构之两分片实操
第一步:在[每个ClickHouse机器上]做配置
#进入配置目录
cd /etc/clickhouse-server
#编辑配置文件
sudo vim config.xml
<!-- 2shard 1replica --><cluster_2shards_1replicas><!-- shard1 --><shard><replica><host>120.xx.xxx.49</host><port>9000</port></replica></shard><!-- shard2 --><shard><replica><host>120.xxx.xxx.202</host><port> 9000</port></replica></shard></cluster_2shards_1replicas>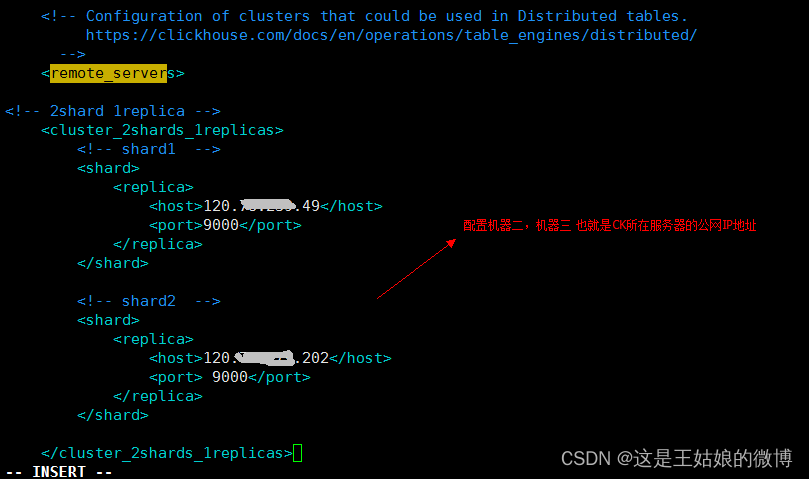
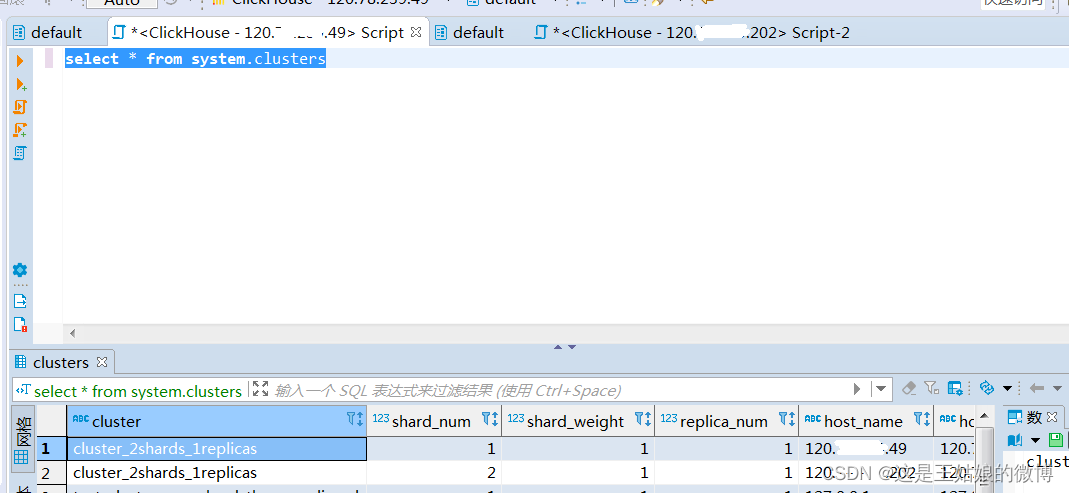
保存退出后,重启服务systemctl restart clickhouse-server
然后查询下分片是否成功:select * from system.clusters
可以看到集群名称 分片个数以及分片后的IP地址
每个节点重启ClickHouse
#重启
systemctl restart clickhouse-server
判断是否配置成功
重启ClickHouse前查询,查不到对应的集群名称,重启ClickHouse后能查询到
select * from system.clusters
4.2 ClickHouse高可用架构之两分片建表实操
分布式ddl指的是在一台服务器上执行sql,其他服务器同步执行,需要借助于cluster
建表实操:
#【选一个节点】创建好本地表后,在1个节点创建,会在其他节点都存在
create table default.wnn_order on cluster cluster_2shards_1replicas
(id Int8,name String) engine =MergeTree order by id;#【选一个节点】创建分布式表名 wnn_order_all,在1个节点创建,会在其他节点都存在
create table wnn_order_all on cluster cluster_2shards_1replicas (
id Int8,name String
)engine = Distributed(cluster_2shards_1replicas,default, wnn_order,hiveHash(id));#分布式表插入
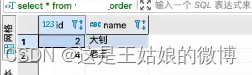
insert into wnn_order_all values(1,'冰冰'),(2,'大钊'),(3,'小D'),(4,'老王');#【任意节点查询-分布式,全部数据】
SELECT * from wnn_order_all#【任意本地节点查询,部分数据】
SELECT * from wnn_order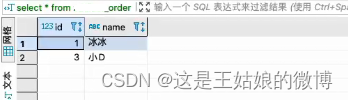
如何往集群中写入数据,方法有两种:
方式一:
自已指定要将哪些数据写入哪些服务器,并直接在每个分片上执行写入。
在分布式表上«查询»,在数据表上 INSERT
可以使用任何分片方案,对于复杂业务特性的需求,数据可以完全独立地写入不同的分片。
方式二
在分布式表上执行 INSERT。在这种情况下,分布式表会跨服务器分发插入数据。
为了写入分布式表,必须要配置分片键(最后一个参数)
如果只有一个分片,则写操作在没有分片键的情况下也能工作,这种情况下分片键没有意义
每个分片都可以在配置文件中定义权重。默认情况下,权重等于1。数据依据分片权重按比例分发到分片上
如果有两个分片,第一个分片的权重是9,而第二个分片的权重是10,则发送 9 / 19 的行到第一个分片, 10 / 19 的行到第二个分片。
注意:
每个clickhouse-server实例只能放一个分片的一个备份,3分片2备份需要6台机器,1个机器不能存放两个副本
相关文章:
ClickHouse高可用集群分片-副本实操(四)
目录 一、ClickHouse高可用之ReplicatedMergeTree引擎 二、 ClickHouse高可用架构准备-环境说明和ZK搭建 三、高可用集群架构-ClickHouse副本配置实操 四、ClickHouse高可用集群架构分片 4.1 ClickHouse高可用架构之两分片实操 4.2 ClickHouse高可用架构之两分片建表实操 一…...

2022年中国工业机器人行业市场回顾及2023年发展前景预测分析
工业机器人是一种能自动定位控制、可重复编程的、多功能的、多自由度的操作机,广泛应用于码垛、冲压、分拣、焊接、切割、喷涂、上下料等工业场景中,极大提高了生产效率、安全性以及智能化水平。工业机器人作为我国高端制造业的典型代表,近年…...
Gehpi的网络布局
Gehpi的网络布局1. 力引导布局2. 辅助布局布局是网络可视化中的重要概念,指将点和边通过某种策略进行排布,应尽可能满足以下4个原则: 节点均匀分布在有限的区域内避免边的交叉和弯曲保持边的长度一致整体布局能反映图内在的特性 Gephi的布局…...

华为OD机试用Python实现 -【天然蓄水库 or 天然蓄水池】(2023-Q1 新题)
华为OD机试题 华为OD机试300题大纲天然蓄水库 or 天然蓄水池题目描述输入描述输出描述说明示例一输入输出说明示例二输入输出说明示例三输入输出说明Python 代码实现算法思路华为OD机试300题大纲 参加华为...
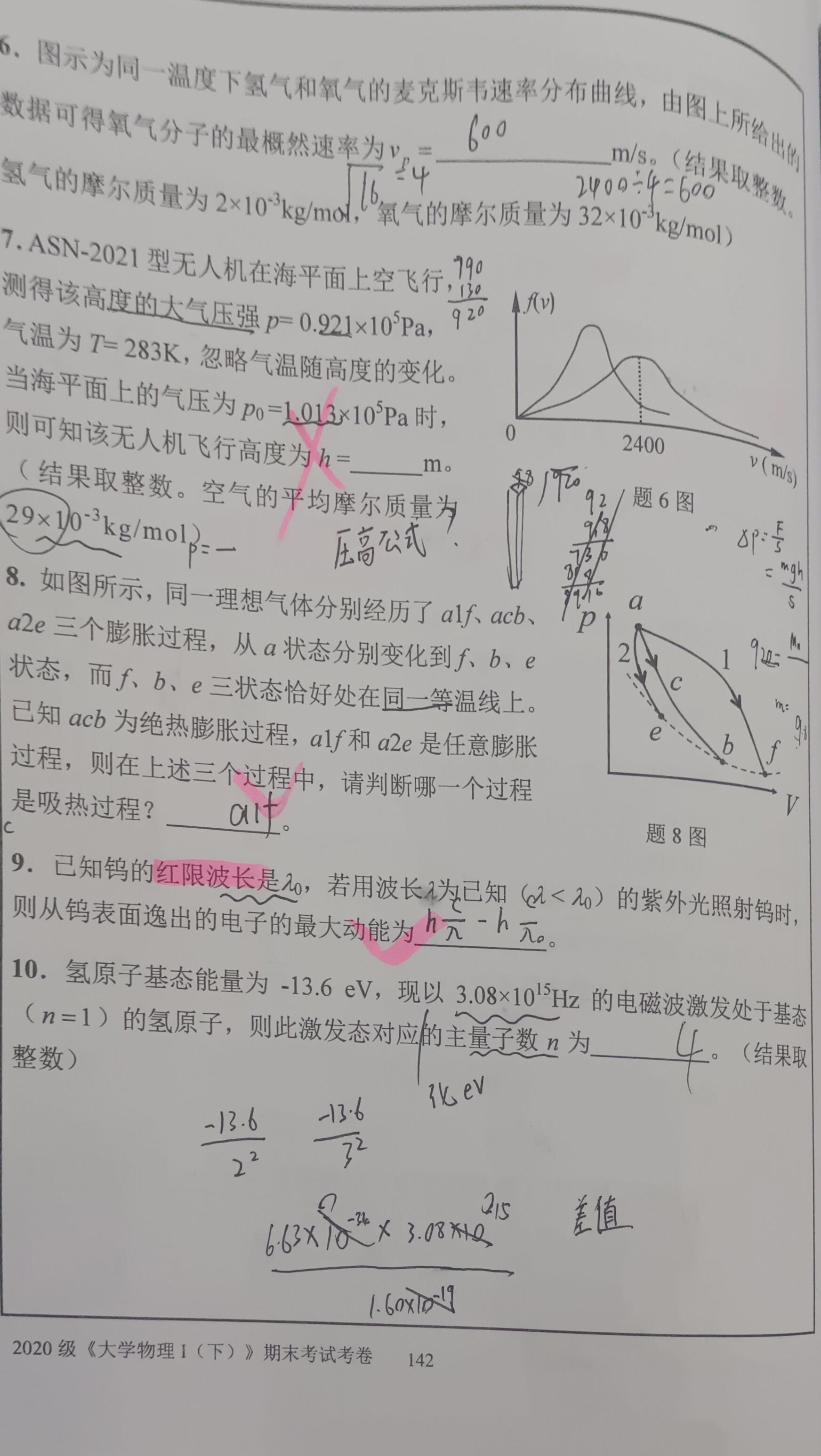
西北工业大学大学物理(I)下期末考试2021-2022选填解析
11 告诉你n2了,那么l0或者1,后续限制类推。2 几乎每年都出。散射波波长的偏移只与散射角有关。3 产生激光的条件。先认识到激光就是受激幅射光放大。受激辐射是产生激光的必要条件,粒子数偏转是产生激光的必要条件,谐振腔也需要。…...

【数据结构】手撕红黑树
目录 一、红黑树简介 1、红黑树的简介 2、红黑树的性质 二、红黑树的插入(看叔叔的颜色就行) 1、为什么新插入的节点必须给红色? 2、插入红色节点后,判定红黑树性质是否被破坏 2.1情况一:uncle存在且为红 2.2情…...

Linux基础命令-which查找命令文件位置
文章目录 which 命令功能 语法格式 基本参数 参考实例 1)查找chmod命令的文件位置 2)查找chmod命令的所有路径 3)一次性查找多个命令路径 4)组合其他命令一起使用 5)显示命令的版本信息 命令总结 which 命…...

在Python中,导入拓展库的规范如下:
在Python中,导入拓展库的规范如下: Import 模块名 [as 别名] from 模块名Import 对象名 [as 别名] from 模块名 import * 1.导入标准库和第三方库的方式应该不同 Python标准库已经默认安装在Python解释器中,因此在导入标准库时不需要…...
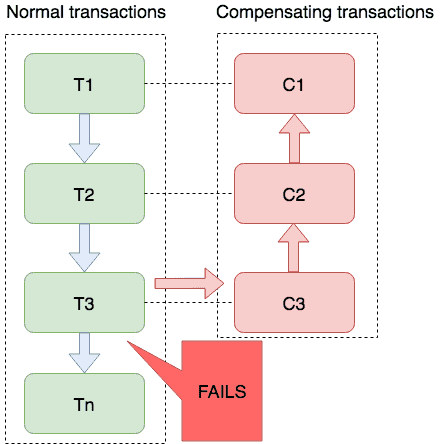
SEATA是什么?它的四种分布式事务模式
一、SEATA是什么? Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。 在继续学习使用SEATA之前,对s…...
【华为OD机试模拟题】用 C++ 实现 - 去重求和(2023.Q1)
最近更新的博客 【华为OD机试模拟题】用 C++ 实现 - 获得完美走位(2023.Q1) 文章目录 最近更新的博客使用说明去重求和题目输入输出示例一输入输出说明示例一输入输出说明Code使用说明 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过率才会高。…...

如何用 chatGPT,给大家来一个自我介绍
大家好,我是不吃西红柿的无线机械键盘,我的名字叫 Keychron K3 Pro。今天,我通过西红柿主人的手,使用 chatGPT 来介绍一下我自己。我的与众不同 我是由精密机械元件制作而成,并采用抗键渗设计,以提供更快、…...
进程管理之基本概念
目录 关于进程的基本概念 进程描述符 查看进程 进程标识 进程的生命周期 僵尸进程、孤儿进程 写时拷贝技术 fork()函数 vfork()函数 终止进程 进程优先级和权重 进程地址空间 关于进程的基本概念 进程和程序是操作系统领域的两个重要的概念,进程是执行…...
nginx安装部署实战手册
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录一、虚拟机安装nginx1.下载安装包2.安装编译工具和库文件3.编译安装4.启动nginx5.访问首页6.开机自启结尾一、虚拟机安装nginx 1.下载安装包 官网下载地址…...

XXL-JOB任务调度平台
什么是xxl-job? xxl-job是一个分布式的任务调度平台,其核心设计目标是:学习简单、开发迅速、轻量级、易扩展,现在已经开放源代码并接入多家公司的线上产品线,开箱即用。xxl是xxl-job的开发者大众点评的许雪里名称的拼…...

android UI优化的基本原理和实战方法
任何Android应用都需要UI跟用户交互.UI是否好坏更是直接影响到用户的体验.如今UI的优化视乎是应用开发中一个绕不过去的话题。所以本篇文章小编带大家全面了解Android ui优化的主要知识和优化方法。 一、UI优化 UI优化知识点主要分为三部分: 第一部分,…...

指针的进阶【中篇】
文章目录📀4.数组参数💿4.1.一维数组传参💿4.2.二维数组传参📀5.指针参数💿5.1.一级指针传参💿5.2.二级指针传参📀6.函数指针💿6.1. 代码1💿6.2. 代码2📀7.函…...
华为OD机试题,用 Java 解【删除字符串中出现次数最少的字符】问题
最近更新的博客 华为OD机试 - 猴子爬山 | 机试题算法思路 【2023】华为OD机试 - 分糖果(Java) | 机试题算法思路 【2023】华为OD机试 - 非严格递增连续数字序列 | 机试题算法思路 【2023】华为OD机试 - 消消乐游戏(Java) | 机试题算法思路 【2023】华为OD机试 - 组成最大数…...

【C语言每日一题】猜名次
【C语言每日一题】—— 猜名次😎😎😎 💡前言🌞: 💛猜名次题目💛 💪 解题思路的分享💪 😊题目源码的分享😊 👉 本菜鸡…...

89. 格雷编码
89. 格雷编码题目数学公式动态规划回溯题目 传送门:https://leetcode.cn/problems/gray-code/ 数学公式 int gray(int n) { // 计算第n位格雷码公式return n ^ (n >> 1); }然后你写一个for循环,计算从1到n的所有格雷码,添加到答…...

线性回归算法和逻辑斯谛回归算法详细介绍及其原理详解
相关文章 K近邻算法和KD树详细介绍及其原理详解朴素贝叶斯算法和拉普拉斯平滑详细介绍及其原理详解决策树算法和CART决策树算法详细介绍及其原理详解线性回归算法和逻辑斯谛回归算法详细介绍及其原理详解 文章目录相关文章前言一、线性回归二、逻辑斯谛回归总结前言 今天给大家…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

在四层代理中还原真实客户端ngx_stream_realip_module
一、模块原理与价值 PROXY Protocol 回溯 第三方负载均衡(如 HAProxy、AWS NLB、阿里 SLB)发起上游连接时,将真实客户端 IP/Port 写入 PROXY Protocol v1/v2 头。Stream 层接收到头部后,ngx_stream_realip_module 从中提取原始信息…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...