python不调用heapq库 实现大顶堆,小顶堆
参考了博客,并对其进行了堆的push() 和 降序排序的补充
【精选】图解堆排序及其Python实现_python 实现小顶堆-CSDN博客
目录
大顶堆
调用结果展示:
小顶堆:
调用结果展示:
此结果与调用heapq库中的heapify(arr)函数等效
其中定义的push()函数与heapy库中的heappush(arr,num)函数等效
大顶堆
import copy
# 导入copy 后面用到深拷贝 为排序不改变原值考虑class Heap(object):"""实现大顶堆及堆排序"""def __init__(self, arr: list):"""arr: 用户输入的待排序数组"""self.arr = arrself.len = len(arr)# self.sorted1_arr = []self.sorted2_arr = []# 一旦创建类即自动转为大顶堆数组self.create_heap()def heapify(self, parent_index):"""维护堆的性质"""# 假设当前父节点是子树中最大的值下标largest = parent_index# 左右孩子节点下标,有可能不存在left_child_index = parent_index * 2 + 1right_child_index = parent_index * 2 + 2# 判断左右子节点是否存在,并找出其中最大的值下标if left_child_index < self.len and self.arr[largest] < self.arr[left_child_index]:largest = left_child_indexif right_child_index < self.len and self.arr[largest] < self.arr[right_child_index]:largest = right_child_index# 需要进行位置调整,并进行递归调整if not (largest == parent_index):self.arr[parent_index], self.arr[largest] = self.arr[largest], self.arr[parent_index]self.heapify(largest)def create_heap(self):"""初始化堆"""last_parent_index = (self.len - 1) // 2 # 最后一个包含子节点的父节点下标for i in range(last_parent_index, -1 , -1):self.heapify(i)def pop(self):peak = self.arr[0]# 交换堆顶与最后一个元素,然后重新建堆self.arr[0] = self.arr[-1]self.arr.pop(-1)self.len -= 1self.heapify(0) # 从上到下维护堆return peak# 在某人博客基础上加了增加元素的def push(self,elem):self.arr.append(elem)self.len += 1 # 记录加入元素的下标及父节点下标tmp = self.len - 1parent_note = (tmp-1) // 2# 在所加入的那一条链上 不断比较与父节点的大小 并交换while parent_note>=0 and self.arr[parent_note] < self.arr[tmp]:self.arr[parent_note], self.arr[tmp] = self.arr[tmp], self.arr[parent_note]# 更新加入节点和父节点的下标tmp = parent_noteparent_note = (parent_note-1) // 2def heap_sort1(self):"""堆排序,输出排序后的数组,升序"""self.arr2 = copy.deepcopy(self.arr)self.sorted1_arr = [0] * len(self.arr)for i in range(len(self.arr)-1,-1,-1):self.sorted1_arr[i] = self.pop()self.arr = self.arr2return self.sorted1_arrdef heap_sort2(self):"""堆排序,输出排序后的数组,降序"""self.arr2 = copy.deepcopy(self.arr)for i in range(len(self.arr)):self.sorted2_arr.append(self.pop())self.arr = self.arr2return self.sorted2_arr调用结果展示:
h = Heap([18, 34, 26, 25, 30, 8, 28, 13])
print(h.arr)
print(h.pop())
h.push(36)
print(h.arr)
print(h.heap_sort2())
print(h.heap_sort1())#结果展示
[34, 30, 28, 25, 18, 8, 26, 13]
34
[36, 25, 30, 13, 18, 8, 26, 28]
[36, 30, 28, 26, 25, 18, 13, 8]
[25, 30, 13, 18, 8, 26, 28, 36]小顶堆:
搞懂大顶堆 小顶堆很快秒 只需改几个符号
import copy
# 导入copy 后面用到深拷贝 为排序不改变原值考虑class Heap(object):"""实现小顶堆及堆排序"""def __init__(self, arr: list):"""arr: 用户输入的待排序数组"""self.arr = arrself.len = len(arr)# self.sorted1_arr = []self.sorted2_arr = []# 一旦创建类即自动转为大顶堆数组self.create_heap()def heapify(self, parent_index):"""维护堆的性质"""# 假设当前父节点是子树中最小的值下标largest = parent_index# 左右孩子节点下标,有可能不存在left_child_index = parent_index * 2 + 1right_child_index = parent_index * 2 + 2# 判断左右子节点是否存在,并找出其中最小的值下标if left_child_index < self.len and self.arr[largest] > self.arr[left_child_index]:largest = left_child_indexif right_child_index < self.len and self.arr[largest] > self.arr[right_child_index]:largest = right_child_index# 需要进行位置调整,并进行递归调整if not (largest == parent_index):self.arr[parent_index], self.arr[largest] = self.arr[largest], self.arr[parent_index]self.heapify(largest)def create_heap(self):"""初始化堆"""last_parent_index = (self.len - 1) // 2 # 最后一个包含子节点的父节点下标for i in range(last_parent_index, -1 , -1):self.heapify(i)def pop(self):peak = self.arr[0]# 交换堆顶与最后一个元素,然后重新建堆self.arr[0] = self.arr[-1]self.arr.pop(-1)self.len -= 1self.heapify(0) # 从上到下维护堆return peak# 在某人博客基础上加了增加元素的def push(self,elem):self.arr.append(elem)self.len += 1 # 记录加入元素的下标及父节点下标tmp = self.len - 1parent_note = (tmp-1) // 2# 在所加入的那一条链上 不断比较与父节点的大小 并交换while parent_note>=0 and self.arr[parent_note] > self.arr[tmp]:self.arr[parent_note], self.arr[tmp] = self.arr[tmp], self.arr[parent_note]# 更新加入节点和父节点的下标tmp = parent_noteparent_note = (parent_note-1) // 2def heap_sort1(self):"""堆排序,输出排序后的数组,降序"""self.arr2 = copy.deepcopy(self.arr)self.sorted1_arr = [0] * len(self.arr)for i in range(len(self.arr)-1,-1,-1):self.sorted1_arr[i] = self.pop()self.arr = self.arr2return self.sorted1_arrdef heap_sort2(self):"""堆排序,输出排序后的数组,升序"""self.arr2 = copy.deepcopy(self.arr)for i in range(len(self.arr)):self.sorted2_arr.append(self.pop())self.arr = self.arr2return self.sorted2_arr调用结果展示:
h = Heap([18, 34, 26, 25, 30, 8, 28, 13])
print(h.arr)
print(h.pop())
h.push(36)
print(h.arr)
print(h.heap_sort2())
print(h.heap_sort1())#结果展示
[8, 13, 18, 25, 30, 26, 28, 34]
8
[13, 25, 18, 34, 30, 26, 28, 36]
[13, 18, 25, 26, 28, 30, 34, 36]
[25, 18, 34, 30, 26, 28, 36, 13]基于python中的此库只能实现小顶堆
此结果与调用heapq库中的heapify(arr)函数等效
import heapqarr = [18, 34, 26, 25, 30, 8, 28, 13]
heapq.heapify(arr)
print(arr)#结果
[8, 13, 18, 25, 30, 26, 28, 34]其中定义的push()函数与heapy库中的heappush(arr,num)函数等效
将上述push()函数单独拿出来 就可以模拟heappush()功能
def push(arr,elem):arr.append(elem)n = len(arr)# 记录加入元素的下标及父节点下标tmp = n - 1parent_note = (tmp-1) // 2# 在所加入的那一条链上 不断比较与父节点的大小 并交换while parent_note>=0 and arr[parent_note] > arr[tmp]:arr[parent_note], arr[tmp] = arr[tmp], arr[parent_note]# 更新加入节点和父节点的下标tmp = parent_noteparent_note = (parent_note-1) // 2arr = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]
arr1 = []
for item in arr:push(arr1,item)
print(arr1)#结果
[5, 7, 21, 15, 10, 24, 27, 45, 17, 30, 36, 50]heappush(arr,num)的效果,可见效果一致!
import heapqarray = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]
heapq.heapify(array)#结果
[5, 7, 21, 15, 10, 24, 27, 45, 17, 30, 36, 50]
相关文章:

python不调用heapq库 实现大顶堆,小顶堆
参考了博客,并对其进行了堆的push() 和 降序排序的补充 【精选】图解堆排序及其Python实现_python 实现小顶堆-CSDN博客 目录 大顶堆 调用结果展示: 小顶堆: 调用结果展示: 此结果与调用heapq库中的heapify(arr)函数等效 …...

STM32F4X SDIO(二) SDIO协议
上一节简单介绍了SD卡的分类,本节将会介绍SD卡的通信协议,也就是SDIO协议。 STM32F4X SDIO(二)SDIO协议 SD 卡管脚和寄存器SD卡管脚分布SD卡通信协议SD卡寄存器SD卡内部结构 SDIO总线SDIO总线拓扑SDIO总线协议SDIO协议的基本结构…...

设计模式--7个原则
单一职责原则:一个类负责一项职责。 里氏替换原则:继承与派生的规则。 依赖倒置原则:高层模块不应该依赖基层模块,二者都应该依赖其抽象;抽象不应该依赖细节;细节应该依赖抽象。即针对接口编程࿰…...

AltiumDesigner原理图编译错误报告信息解释
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、ViolationsAssociated with Buses 有关总线电⽓错误的各类型(共 12 项)二、ViolationsAssociated Components 有关元件符号电⽓错误…...
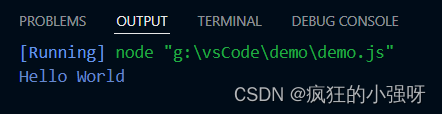
使用 Visual Studio Code 编写 TypeScript程序
安装 TypeScript 首先,确保你已经安装了 TypeScript,如果没有安装,请参考https://blog.csdn.net/David_house/article/details/134077973?spm1001.2014.3001.5502进行安装 创建 新建一个文件夹,用vs code打开,在文…...
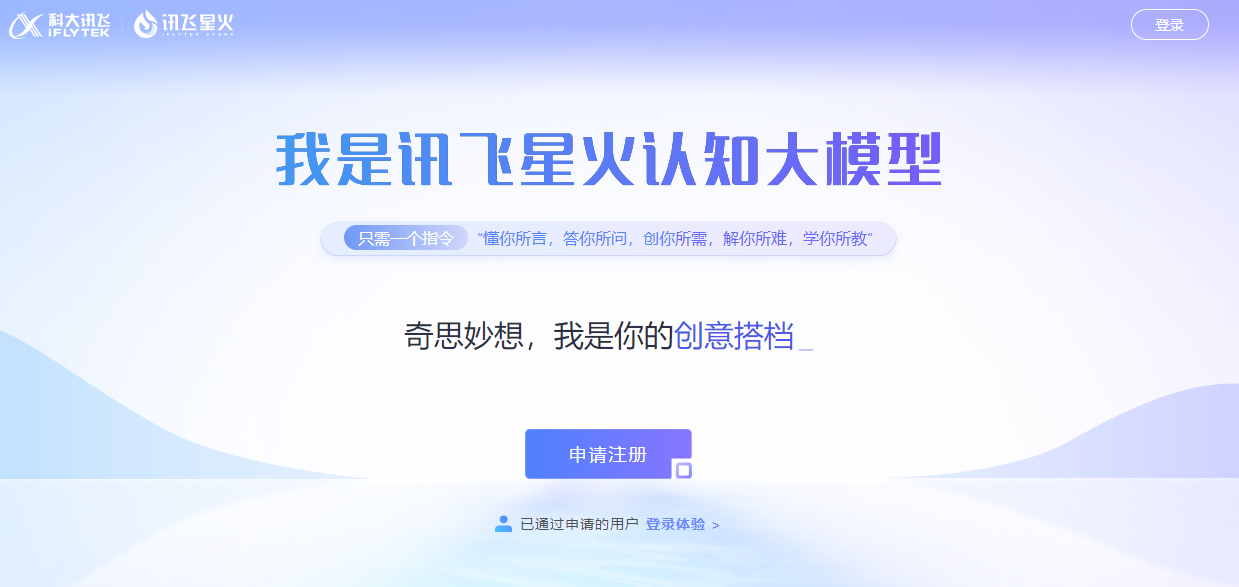
科大讯飞发布讯飞星火 3.0;开源AI的现状
🚀 科大讯飞发布讯飞星火 3.0,综合能力超越ChatGPT(非GPT-4版) 摘要:科大讯飞在2023全球1024开发者节上宣布讯飞星火 3.0正式发布,号称综合能力已超越ChatGPT。据介绍,星火认知大模型 V3.0在文…...
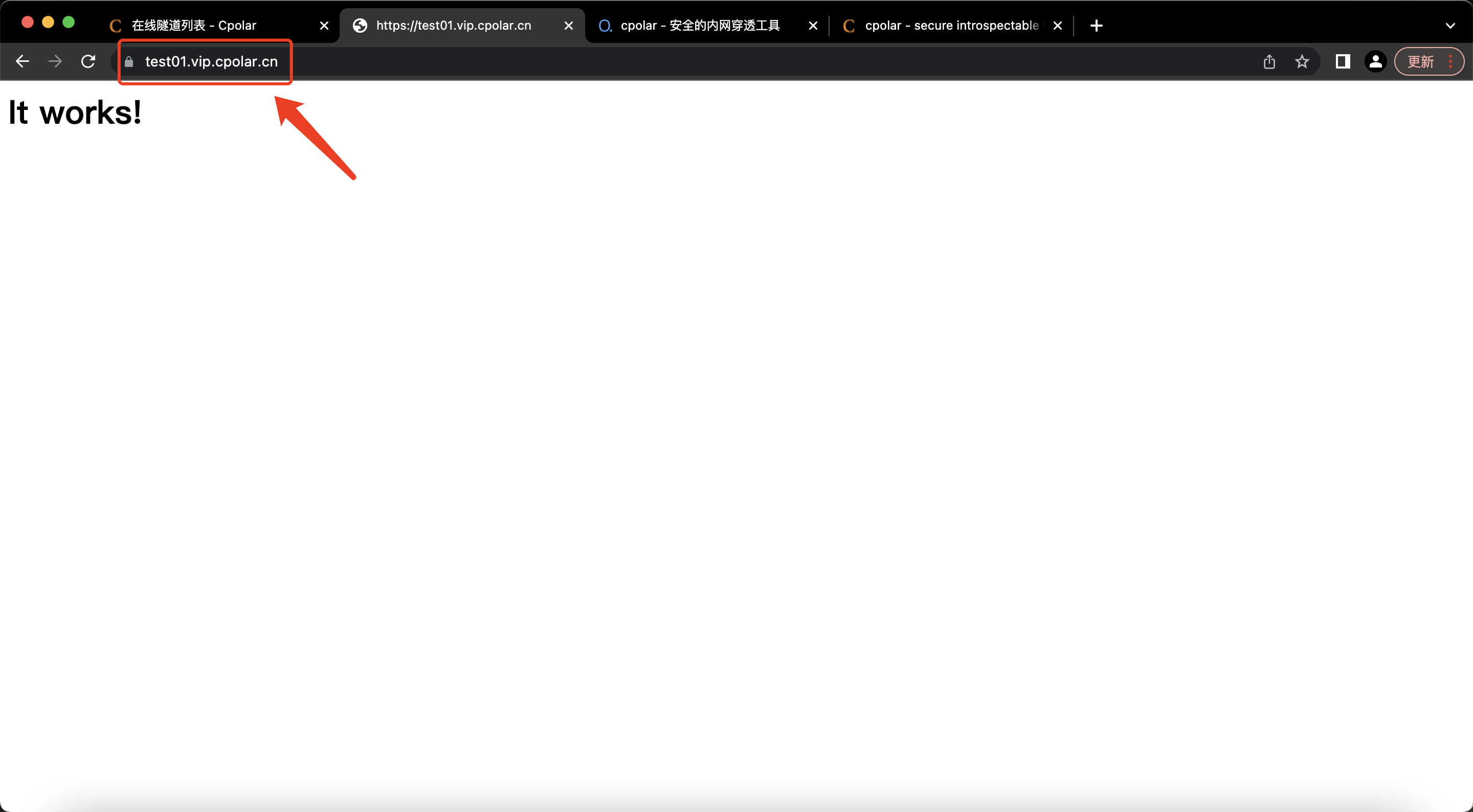
公网远程访问macOS本地web服务器
# 公网访问macOS本地web服务器【内网穿透】 文章目录 1. 启动Apache服务器2. 公网访问本地web服务2.1 本地安装配置cpolar2.2 创建隧道2.3 测试访问公网地址3. 配置固定二级子域名3.1 保留一个二级子域名3.2 配置二级子域名4. 测试访问公网固定二级子域名 以macOS自带的Apache…...
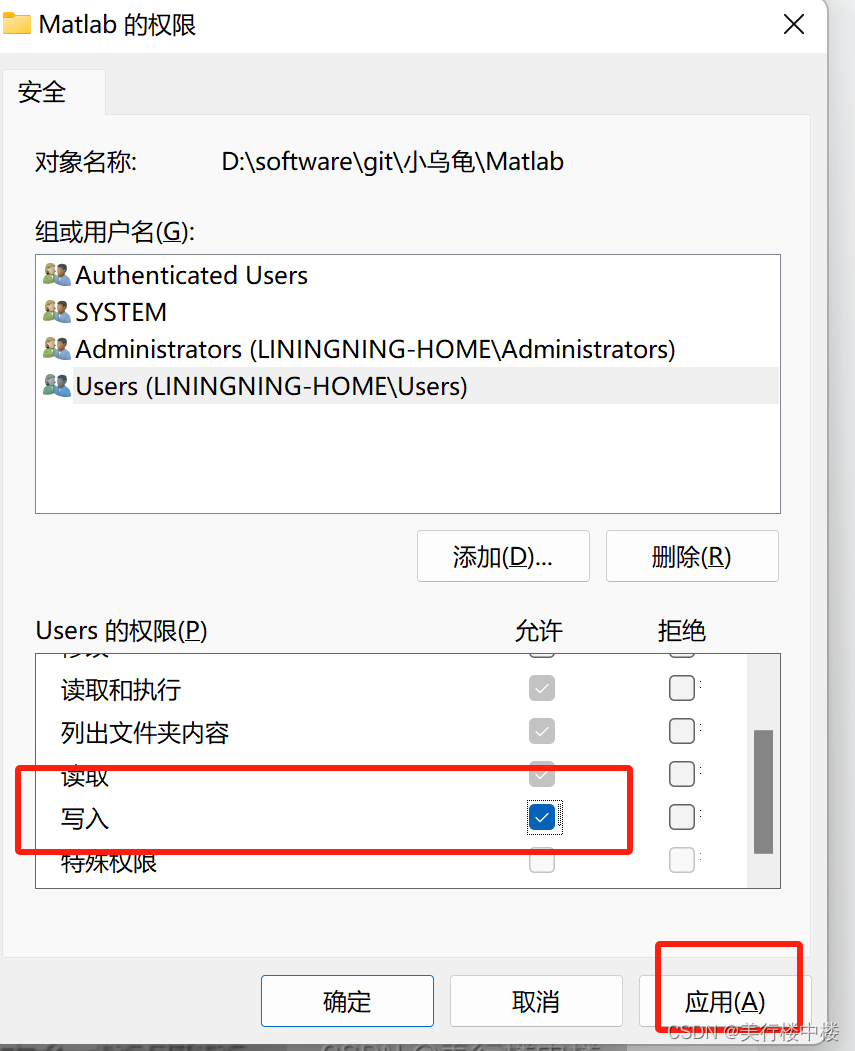
windows 安装小乌龟
这是什么 这里简单描述一下在windows上如何安装GIT代码管理工具和使用小乌龟版本来调用GIT,并且配置一下git相关信息,可以使用小乌龟来操作代码。也有一些常规git使用方法。 需要的资源 Git-2.42.0-64-bit.exe(这个是git代码管理工具&…...
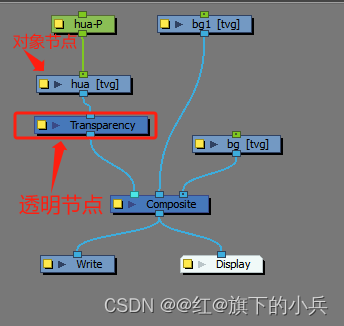
toon boom harmony基础
以下都是tbh快捷键使用,或者一些常用功能介绍 1、在节点视图中,按回车可直接弹出节点库搜索框 2、中心线编辑器 只能编辑用笔刷画出来的线条,铅笔画出来的线条无法编辑。 3、镜头标记 1 右键箭头方向,可弹出下拉,&am…...

JPA联合主键
在实际工作中,我们会经常遇到联合主键的情况,所以我用简单例子列举JPA两种实现联合主键的方式。 1、如何通过IdClass 实现联合主键 第一步:新建一个UserInfoID类,里面是联合主键 Data Builder NoArgsConstructor AllArgsConstructor pu…...

水性杨花:揭秘CSS响应式界面设计,让内容灵活自如,犹如水之变幻
🎬 江城开朗的豌豆:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 📝 个人网站 :《 江城开朗的豌豆🫛 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 ⭐ 专栏简介 📘 文章引言 一、是…...

fio performance test
fio参数解释 可以使用fio -help查看每个参数,具体的参数左右可以在官网查看how to文档,如下为几个常见的参数描述 filename/dev/emcpowerb 支持文件系统或者裸设备,-filename/dev/sda2或-filename/dev/sdb 或 -filename/dev/nvme0n1direct…...

DevOps持续集成-Jenkins(1)
文章目录 DevOpsDevOps概述Code阶段工具(centos7-gitlab主机)Windows下安装Git(作用是:使我们可以上传代码到GitLab)Linux下安装GitLab⭐(作用是:运行一个GitLab接收代码)环境准备先…...

Pytorch代码入门学习之分类任务(二):定义数据集
一、导包 import torch import torchvision import torchvision.transforms as transforms 二、下载数据集 2.1 代码展示 # 定义数据加载进来后的初始化操作: transform transforms.Compose([# 张量转换:transforms.ToTensor(),# 归一化操作&#x…...

oracle 里常用的一些 create insert update table
1、获得数据库里某个指定的库 SELECT COUNT(*) FROM ALL_TABLES ut WHERE ut.OWNERTJFX AND ut.TABLE_NAME CUR_TIME_BILL; 2、创建一个表,里面的数据可以从一个已存在的表里转移过来 CREATE TABLE temptable AS SELECT * FROM old_tbName //使用现有的表创建一…...

从Mysql架构看一条查询sql的执行过程
1. 通信协议 我们的程序或者工具要操作数据库,第一步要做什么事情? 跟数据库建立连接。 首先,MySQL必须要运行一个服务,监听默认的3306端口。在我们开发系统跟第三方对接的时候,必须要弄清楚的有两件事。 第一个就是通…...
Linux系统下DHCP服务安装部署和使用实例详解(蜜罐)
目录 一、概述 二、具体配置如下: 一、概述 DHCP :动态主机设置协议(英语:Dynamic Host Configuration Protocol,DHCP)是一个局域网的网络协议,使用UDP协议工作,主要有两个用途&…...

模数转换器-ADC基础
文章目录 一、ADC是什么二、ADC处理采样保持量化编码三、ADC采样的重要参数:测量范围:分辨率(Resolution):精度:采样时间:采样率(Sampling Rate):信噪比(Signal-to-Noise Ratio, SNR):转换时间:一、ADC是什么 ADC(Analog-to-Digital Converter):模拟数字转换器…...

Linux:【1】Linux中的文件权限概念和相关命令
Linux:【1】Linux中的文件权限概念和相关命令 1、什么是文件权限?1.1、文件权限的表示方式 2、理解文件权限2.1、用户权限2.2、组权限2.3、其他权限 3、设置文件权限3.1、chmod 命令3.2、权限符号表示法3.3、权限数字表示法 4、查看文件权限4.1、ls 命令…...

JS实用小计
1.如何创建一个数组大小为100,每个值都为0的数组 // 方法一: Array(100).fill(0);// 方法二: // 注: 如果直接使用 map,会出现稀疏数组 Array.from(Array(100), (x) > 0);// 方法二变体: Array.from({ length: 100 }, (x) > 0); 2.如何逆序一个字…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...

Qt 事件处理中 return 的深入解析
Qt 事件处理中 return 的深入解析 在 Qt 事件处理中,return 语句的使用是另一个关键概念,它与 event->accept()/event->ignore() 密切相关但作用不同。让我们详细分析一下它们之间的关系和工作原理。 核心区别:不同层级的事件处理 方…...

springboot 日志类切面,接口成功记录日志,失败不记录
springboot 日志类切面,接口成功记录日志,失败不记录 自定义一个注解方法 import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target;/***…...
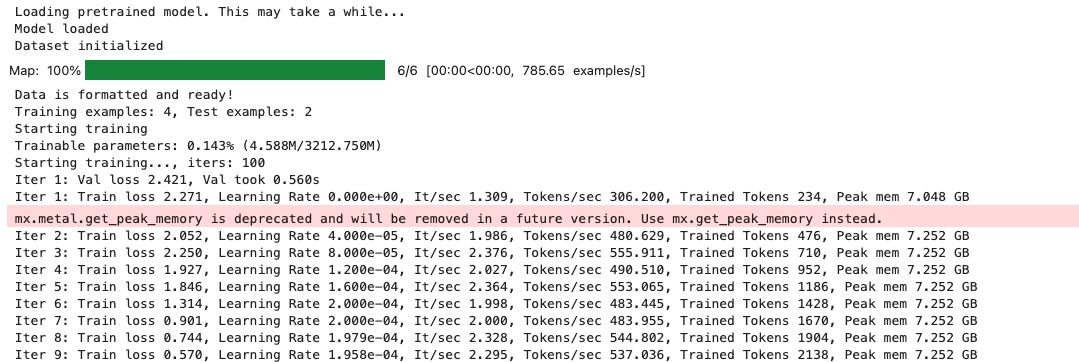
mac:大模型系列测试
0 MAC 前几天经过学生优惠以及国补17K入手了mac studio,然后这两天亲自测试其模型行运用能力如何,是否支持微调、推理速度等能力。下面进入正文。 1 mac 与 unsloth 按照下面的进行安装以及测试,是可以跑通文章里面的代码。训练速度也是很快的。 注意…...

如何在Windows本机安装Python并确保与Python.NET兼容
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

对象回调初步研究
_OBJECT_TYPE结构分析 在介绍什么是对象回调前,首先要熟悉下结构 以我们上篇线程回调介绍过的导出的PsProcessType 结构为例,用_OBJECT_TYPE这个结构来解析它,0x80处就是今天要介绍的回调链表,但是先不着急,先把目光…...