【Apache Flink】基于时间和窗口的算子-配置时间特性
文章目录
- 前言
- 配置时间特性
- 将时间特性设置为事件时间
- 时间戳分配器
- 周期性水位线分配器
- 创建一个实现AssignerWithPeriodicWatermarks接口的类,目的是为了周期性生成watermark
- 定点水位线分配器
- 示例
- 参考文档
前言
Apache Flink 它提供了多种类型的时间和窗口概念,使得用户能够进行准确的时间计算。在数据处理任务中,时间的概念是非常重要的,对于一些复杂的实时流处理任务,如事件按时间顺序的聚合、分割和窗口计算,时间更是关键所在。而在这类任务中,选择使用何种时间特性是决定结果准确性的非常重要的一部分。Flink提供了三种时间特性供用户选择:事件时间、处理时间和摄取时间。
在使用Flink进行流处理时,时间窗口的选择也至关重要。Flink的窗口操作可以帮助我们将无限的流数据切分为有限的块,方便我们对每个数据块进行计算。Flink提供了多种窗口类型,包括滑动窗口、滚动窗口、会话窗口和全局窗口,用户可以根据业务需求选择合适的窗口类型。
本文将详细介绍Apache Flink中基于时间和窗口的算子,以及如何配置数据流的时间特性, 深入地理解和使用Flink在实际流式处理任务中进行数据计算的能力。
配置时间特性
在Apache Flink中,时间的概念是极其关键的要素,尤其是当我们处理实时或近实时数据流的时候。Flink提供了三种不同的时间概念,分别用于处理不同的任务和场景。
-
事件时间 (Event Time): 事件时间是指数据产生的时间,这个时间通常由事件数据本身携带,例如每个事件的日志行通常都会记录时间戳。在处理可能存在乱序或延迟数据的流计算任务时,事件时间是最常用的处理策略,因为它可以按照事件的发生顺序处理信息,而不是它们被系统接收的顺序。
-
处理时间 (Processing Time): 处理时间则是事件在系统中被处理时的系统时间,即事件在引擎处理时的“现在”时间。处理时间对于想要最大性能、毫秒级结果的场景非常适用,比如实时监控或者实时报警这样对处理速度有极高要求的场景。
-
摄取时间 (Ingestion Time): 摄取时间属于事件时间和处理时间的一种折衷方案。它是指事件进入Flink系统的时间。如果在一些场合,事件的时间戳无法获取或者不准确,同时又需要一定的事件排序,那么摄取时间就派上用场了。其在源头就分配了时间戳,并在整个处理过程中保留。摄取时间比处理时间语义强,比事件时间性能好。
这三种时间概念的选用,在很大程度上,决定了Flink处理事件的顺序和方式,因此根据实际的场景选择最适合的时间策略是非常重要的。
- 事件时间 (Event Time)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
Flink会根据事件所携带的时间戳来处理数据,这就说明了数据是基于何时发生的进行处理的,而不是基于何时被处理的。比如在处理日志分析时,如果日志已经按照事件的发生时间排序,那么事件时间这种设置就会非常有用。
- 处理时间 (Processing Time)
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
Flink会按照数据进入系统的时间即系统处理的实时进行处理,无视事件自身的时间戳。比如对于实时监控或者实时报警这样对处理速度有极高要求的场景,处理时间是最适合的。
- 摄取时间 (Ingestion Time)
env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
在数据读入Flink时,会自动地获取数据的摄取时间,与处理时间的观念类似但在数据进入系统时就已经赋予了时间。比如在希望事件能在一定程度上按照顺序处理,但又无法获取准确的事件时间时,摄取时间是一个不错的选择。
将时间特性设置为事件时间
在 Flink 中,我们可以指定时间特性为事件时间(Event Time),这是处理一些具体问题(例如延迟数据、重新处理等)的关键。下面是如何在 Flink 中设置时间特性为事件时间的代码示例:
读入一些元素,为它们分配时间戳和水印,并打印出来。分配时间戳和水印是在使用事件时间进行窗口操作等处理时必须要做的。
创建一个执行环境,并设置为事件时间。然后创建一个简单的字符串流,并分配时间戳和水印。最后我们使用了一个时间窗口并打印出了所有的元素。。
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;public class EventTimeExample {public static void main(String[] args) throws Exception {// 创建执行环境final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置时间特性为事件时间env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// 创建一个数据源,这里我们用的是从集合中获取DataStream<String> stream = env.fromElements("element1", "element2", "element3");// 分配时间戳和水印,这里我们假设通过某种方法获取了一个递增的时间戳DataStream<String> withTimestampsAndWatermarks = stream.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<String>() {@Overridepublic long extractAscendingTimestamp(String element) {// 返回当前元素的时间戳,这儿仅作示例,实际应用需要根据具体需求获取return System.currentTimeMillis();}});// 对数据进行一些操作,比如过滤,这里的窗口大小为5秒withTimestampsAndWatermarks.timeWindowAll(Time.seconds(5)).apply(new AllWindowFunction<String, Object, TimeWindow>() {// 在应用函数中,我们做一些处理,这里简单地打印出所有元素public void apply(TimeWindow window, Iterable<String> values, Collector<Object> out) {for (String value : values) {System.out.println(value);}}});// 启动应用env.execute("Event Time Example");}
}
时间戳分配器
在数据处理系统中,特别是在事件驱动的系统或实时流处理系统中,时间戳分配器是一个非常重要的组件。时间戳分配器的任务就是为每一个事件或数据记录分配一个时间戳,这个时间戳表示该事件发生的时间。
在 Apache Flink 这样的流处理框架中,时间戳分配器通常在数据源(Source)接收到数据时运行,为每一个事件分配一个时间戳。基于事件时间处理的窗口运算、Watermark 生成等流处理任务依赖于这个时间戳。
提供一个基础的时间戳分配器示例,此处假设有一个MapFunction,它将输入的MyEvent转换为一个包含时间戳和事件数据的Tuple2:
MyTimestampAssigner实现了AssignerWithPunctuatedWatermarks接口,extractTimestamp()方法用于从数据元素中抽取出时间戳,checkAndGetNextWatermark()方法用于生成水印。在这里每处理一个元素都会调用checkAndGetNextWatermark()生成一个新的水印,这被称为 “punctuated” 模式。若要使用更常见的 “periodic” 模式,需要实现AssignerWithPeriodicWatermarks接口,这会定期(而不是每处理一个元素)生成水印。
public class MyTimestampAssigner implements AssignerWithPunctuatedWatermarks<MyEvent> {@Nullable@Overridepublic Watermark checkAndGetNextWatermark(MyEvent event, long extractTimestamp) {return new Watermark(extractTimestamp);}@Overridepublic long extractTimestamp(MyEvent element, long previousElementTimestamp) {return element.getCreationTime();}
}
然后,可以在流处理中使用这个MyTimestampAssigner来为数据流中的每一个元素分配时间戳:
DataStream<MyEvent> stream = ...
stream.assignTimestampsAndWatermarks(new MyTimestampAssigner());
源数据通常会有一个时间字段,它代表了数据的生成时间。我们可以基于这个时间字段来处理数据,并生成结果。为了让Flink知道每条数据的时间,我们需要自定义Timestamps/Watermarks。以下是一个简单的示例,该代码是在Flink中进行窗口计数的常见工作模式。
在水印生成部分设置了10秒的延迟时间,以处理乱序数据。这意味着,当窗口看到最新的水印时间大于其结束时间时,窗口才会触发进行执行计算。触发后的10秒内,该窗口还会接收更晚到达的数据。这对于处理乱序数据非常有用。
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction.SourceContext;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.api.java.tuple.Tuple2;public class TimeStampWaterMarkExample {public static void main(String[] args) throws Exception {// 创建执行环境,设置为事件时间模式StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// 元组的第一个参数是一个字符串,第二个参数是一个时间戳Tuple2[] data = new Tuple2[]{new Tuple2<>("a", 1558430842000L),new Tuple2<>("b", 1558430843000L),new Tuple2<>("c", 1558430845000L)};// 添加数据源DataStreamSource<Tuple2<String, Long>> dataSource = env.addSource(new SourceFunction<Tuple2<String, Long>>() {@Overridepublic void run(SourceContext<Tuple2<String, Long>> ctx) throws Exception {for (Tuple2<String, Long> datum : data) {ctx.collectWithTimestamp(datum, datum.f1);ctx.emitWatermark(new Watermark(datum.f1 - 1));}ctx.emitWatermark(new Watermark(Long.MAX_VALUE));}@Overridepublic void cancel() {}});// 添加我们的时间戳分配器和水印生成器SingleOutputStreamOperator<Tuple2<String, Long>> timestampOperator = dataSource.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Tuple2<String, Long>>(Time.seconds(10)) {@Overridepublic long extractTimestamp(Tuple2<String, Long> element) {return element.f1;}});// 执行滚动窗口操作timestampOperator.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(2))) // 定义滚动窗口.apply(new CountWindowFunction()).print();env.execute("job name");}
}
周期性水位线分配器
在流处理系统中,Watermark(水位线)是一种用于处理事件时间乱序的机制。在实时流处理系统中,来自不同源的事件可能以不同的顺序到达。这种顺序的不确定性会给处理系统带来挑战,因为系统必须确定何时所有相关事件都已到达,以便可以进行处理(例如,计算一个5分钟滑动窗口的平均值)。
Watermark就是流处理系统用于处理这种不确定性的一种手段。在Flink中,Watermark是一个特殊的事件或者信号,表示在此时间戳之前的所有事件都已经到达,没有更早的事件会到达。当Watermark t 到达时,说明在时间 t 或者更早的所有数据都已经收到,可以开始处理时间小于或等于 t 的窗口。
周期性水位线 (Periodic Watermark) 是一种定时生成的 Watermark。具体来说,数据流会周期性地调用 getCurrentWatermark() 方法获取新的 Watermark,并且插入到流中。这个周期默认是200ms,也可以通过 ExecutionConfig.setAutoWatermarkInterval(…) 来设置。
在定义 Watermark 生成逻辑时,通常会设置一个允许乱序到达的事件的最大延迟时间。例如,如果最大延迟时间设置为5秒,那么就意味着,Watermark t 只能保证时间戳小于 t-5s 的所有事件都已经到达。换句话说,水位线是滞后于事件时间的,即使水位线是周期性地生成的。
创建一个实现AssignerWithPeriodicWatermarks接口的类,目的是为了周期性生成watermark
BoundedOutOfOrdernessGenerator实现了AssignerWithPeriodicWatermarks接口。extractTimestamp()方法提取了每个元素的时间戳,getCurrentWatermark()则返回新的 watermark。这个实现假设元素可以最多晚3.5秒到达。使用当前最大时间戳减去这个延迟就得到了新的 watermark。这就意味着,即使有延迟的元素到达,只要其时间戳比当前的 watermark 大,它仍然可以用于窗口计算。
public class BoundedOutOfOrdernessGenerator implements AssignerWithPeriodicWatermarks<MyEvent> {// 最大的乱序容忍度设置为3500毫秒,也就是3.5秒private final long maxOutOfOrderness = 3500; // 当前收到的最大的时间戳private long currentMaxTimestamp;@Override// 此方法用于从数据元素中提取时间戳public long extractTimestamp(MyEvent element, long previousElementTimestamp) {long timestamp = element.getCreationTime();// 更新当前收到的最大的时间戳currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp);// 返回提取的时间戳return timestamp;}@Nullable@Override// 此方法返回当前的Watermark,Watermark值为收到的最大时间戳减去乱序容忍度public Watermark getCurrentWatermark() {return new Watermark(currentMaxTimestamp - maxOutOfOrderness);}
}
在流处理中用这个BoundedOutOfOrdernessGenerator为流中的每个元素分配时间戳,并定期生成水位线。
DataStream<MyEvent> stream = ...
// 对流中的元素调用assignTimestampsAndWatermarks函数,传入的参数为BoundedOutOfOrdernessGenerator的实例,这样就完成了对流中元素的时间戳分配和周期性的Watermark生成
stream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessGenerator());
定点水位线分配器
定点水位线分配器(Fixed Watermark Assigner)是一种特定类型的水位线分配器,它生成一个固定的水位线值。它通常在事件的时间戳已经有序且无乱序出现时使用。由于每个元素都有一个时间戳,在这种情况下,水位线可能仅被推进到元素的当前时间戳。在一些特定的应用场景中,这样可能就够用了。
在Apache Flink中,可以使用assignTimestampsAndWatermarks函数结合WatermarkStrategy实现水位线的分配。对于定点水位线分配器,可以创建一个固定的,不变的水位线,例如:
WatermarkStrategy.<YourEvent>forMonotonousTimestamps().withTimestampAssigner((event, timestamp) -> event.getTimestamp());
在这个例子中,forMonotonousTimestamps方法会创建一个定点水位线分配器,它将水位线固定在最近被处理的事件的时间戳。withTimestampAssigner方法定义了如何从事件中抽取时间戳。
定点水位线分配器用在那些时间戳严格递增的事件流中,如果在这样的流上使用定点水位线分配器,如果事件到达的顺序与时间戳的顺序不一致(例如,由于网络延迟、机器间的时钟偏移等),就有可能会得到错误的结果。
示例
在这个示例中假定事件是按照时间戳顺序处理的,所以可以有效地使用定点水位线分配器。如果事件的顺序可能会被打乱,那建议使用其他类型的水位线分配器。
创建一个水位线函数,对每一个输入的元素都分配它的时间戳,并产生连续定点的水位线。
public static class MyEvent {public long timestamp; // 定义保存时间戳的变量public String data; // 定义保存数据的变量public MyEvent(long timestamp, String data) { // 构造函数this.timestamp = timestamp;this.data = data;}public long getTimestamp() { // 获取时间戳的接口return timestamp;}
}
定义了事件类,包括时间戳和数据。
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;// 初始化执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 配置事件时间特性
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// 输入的数据流
DataStream<MyEvent> inputStream = env.fromElements(new MyEvent(System.currentTimeMillis(), "data1"),new MyEvent(System.currentTimeMillis() + 1000, "data2"),new MyEvent(System.currentTimeMillis() + 2000, "data3")
);// 使用水位线分配器给事件分配时间戳和水位线
DataStream<MyEvent> withTimestampsAndWatermarks = inputStream.assignTimestampsAndWatermarks(WatermarkStrategy.<MyEvent>forMonotonousTimestamps().withTimestampAssigner((event, timestamp) -> event.getTimestamp()));
参考文档
- https://nightlies.apache.org/flink/flink-docs-release-1.18/zh/
相关文章:
【Apache Flink】基于时间和窗口的算子-配置时间特性
文章目录 前言配置时间特性将时间特性设置为事件时间时间戳分配器周期性水位线分配器创建一个实现AssignerWithPeriodicWatermarks接口的类,目的是为了周期性生成watermark 定点水位线分配器示例 参考文档 前言 Apache Flink 它提供了多种类型的时间和窗口概念&…...

数组的优点和缺点
数组的优点和缺点: 优点: 随机访问:数组支持常量时间的随机访问,即通过索引可以直接访问元素。这使得数组在查找特定元素时非常高效。内存连续性:数组的元素在内存中是连续存储的,这可以减少缓存未命中的…...

接口返回响应,统一封装(ResponseBodyAdvice + Result)(SpringBoot)
需求 接口的返回响应,封装成统一的数据格式,再返回给前端。 依赖 对于SpringBoot项目,接口层基于 SpringWeb,也就是 SpringMVC。 <dependency><groupId>org.springframework.boot</groupId><artifactId&g…...
苹果cms模板MXone V10.7魔改版源码 全开源
苹果cms模板MXone V10.7魔改版源码 全开源 苹果cms模板MXone魔改版短视大气海报样式 安装模板教程说明: 1、将模板压缩包上传到苹果CMS程序/template下解压 2、网站模板选择mxone 模板目录填写html 3、网站模板选择好之后一定要先访问前台,然后再进…...

ArcGIS笔记13_利用ArcGIS制作岸线与水深地形数据?建立水动力模型之前的数据收集与处理?
本文目录 前言Step 1 岸线数据Step 2 水深地形数据Step 3 其他数据及资料 前言 在利用MIKE建立水动力模型(详见【MIKE水动力笔记】系列)之前,需要收集、处理和制作诸多数据和资料,主要有岸线数据、水深地形数据、开边界潮位驱动数…...

一些k8s集群操作命令
参考: 【K8S系列】Pod重启策略及重启可能原因_k8s查看pod重启原因-CSDN博客 #查看加入集群命令 kubeadm token create --print-join-command #kubeadm重置k8s kubeadm reset -f ipvsadm --clear systemctl stop kubelet rm -rf /etc/kubernetes/* reboot …...
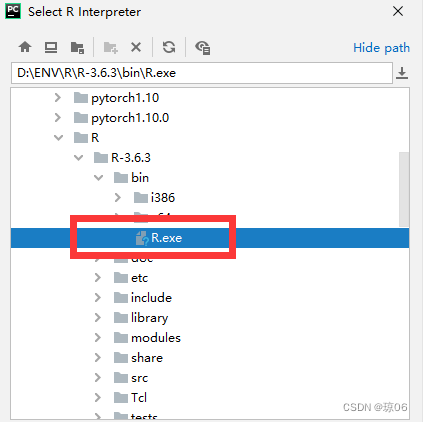
pycharm运行R语言脚本(win10环境下安装)
文章目录 简介1. pycharm安装插件2. 安装R语言解释器2.1下载安装包2.2具体安装过程 3.编辑环境变量4 检验是否安装成功:5.安装需要的library6.pycharm中配置安装好的R语言解释器 简介 pycharm 安装 R language for Intellij R language for Intellij 是一个插件&am…...

Java进击框架:Spring-Test(六)
Java进击框架:Spring-Test(六) 前言单元测试模拟对象 集成测试上下文管理和缓存事务管理集成测试的支持类执行SQL脚本WebTestClientMockMvc JDBC测试支持其它注释 前言 Spring团队提倡测试驱动开发(TDD)。Spring团队发现,控制反转…...
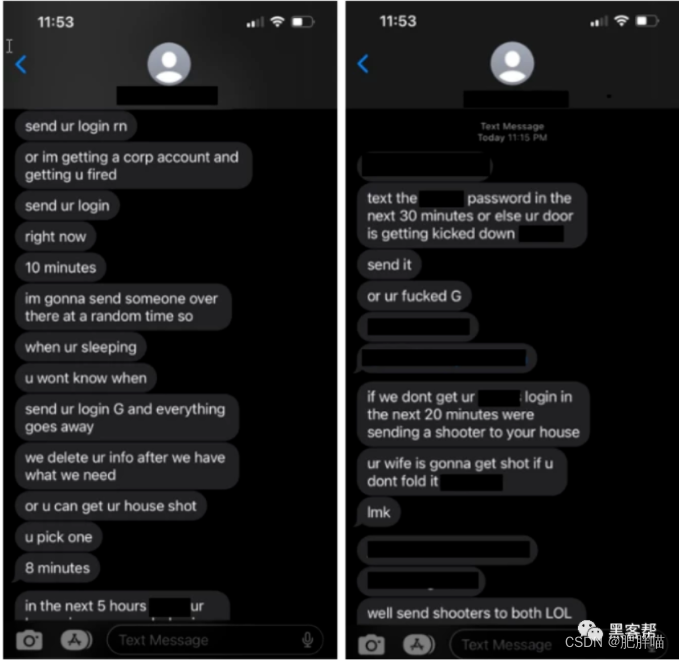
微软:Octo Tempest是最危险的金融黑客组织之一
导语 最近,微软发布了一份关于金融黑客组织Octo Tempest的详细报告。这个组织以其高级社交工程能力而闻名,专门针对从事数据勒索和勒索软件攻击的企业。Octo Tempest的攻击手段不断演变,目标范围也不断扩大,成为了电缆电信、电子邮…...

JS加密/解密之逻辑运算符加密进阶篇
前言 前篇给大家介绍了运算符不为人知的基础知识。他们的各种表达形式,今天我们从这个基础上,继续进一步告诉大家,如何对字符串进行加密处理。还是那句话,技术人不废话,直接晒代码。 示例源代码 // 字符串加密示…...
【ROS入门】机器人系统仿真——URDF集成Gazebo
文章结构 URDF与Gazebo基本集成流程创建功能包编写URDF或Xacro文件启动 Gazebo 并显示机器人模型 URDF集成Gazebo相关设置collisioninertial颜色设置 URDF集成Gazebo实操编写封装惯性矩阵算法的 xacro 文件复制相关 xacro 文件,并设置 collision inertial 以及 colo…...

互联多区域电网的负荷频率控制研究
摘要 电力行业的发展程度是衡量国民经济水平以及国家安全保障的一项重要指标。多区域负荷频率控制系统作为现代电力系统发展的重要趋势,在可靠性、经济性和稳定性上都具备一定的优势。保证系统稳定和输出电能的质量是电网运行的关键。电力系统输出电能质量的优劣取决…...
【java学习—九】模板方法(TemplateMethod)设计模式(4)
文章目录 1. 在java中什么是模板2. 模板方法设计解决了什么问题?3. 代码化理解 1. 在java中什么是模板 抽象类体现的就是一种模板模式的设计,抽象类作为多个子类的通用模板,子类在抽象类的基础上进行扩展、改造,但子类总体上会保留…...

【MyBatis Plus】初识 MyBatis Plus,在 Spring Boot 项目中集成 MyBatis Plus,理解常用注解以及常见配置
文章目录 一、初识 MyBatis Plus1.1 MyBatis Plus 是什么1.2 MyBatis Plus 和 MyBatis 的区别 二、在 Spring Boot 项目中集成 MyBatis Plus2.1 环境准备2.2 引入 MyBatis Plus 依赖2.3 定义 Mapper2.4 测试 MyBatis Plus 的使用 三、MyBatis Plus 常用注解3.1 为什么需要注解3…...

Centos7 安装和配置 Redis 5 教程
在Centos上安装Redis 5,如果是 Centos8,那么 yum 仓库中默认的 redis 版本就是 5,直接 yum install 即可。但如果是 Centos7,yum 仓库中默认的 redis 版本是 3 系列,比较老: 通过 yum list | grep redis 命…...
使用 RAG、Langchain 和 Streamlit 制作用于文档问答的 AI 聊天机器人
在这篇文章中,我们将探索创建一个简单但有效的聊天机器人,该机器人根据上传的 PDF 或文本文件的内容响应查询。该聊天机器人使用 Langchain、FAISS 和 OpenAI 的 GPT-4 构建,将为文档查询提供友好的界面,同时保持对话上下文完整。…...

论文阅读——RoBERTa
一、LM效果好但是各种方法之间细致比较有挑战性,因为训练耗费资源多、并且在私有的不同大小的数据集上训练,不同超参数选择对结果影响很大。使用复制研究的方法对BERT预训练的超参数和数据集的影响细致研究,发现BERT训练不够,提出…...
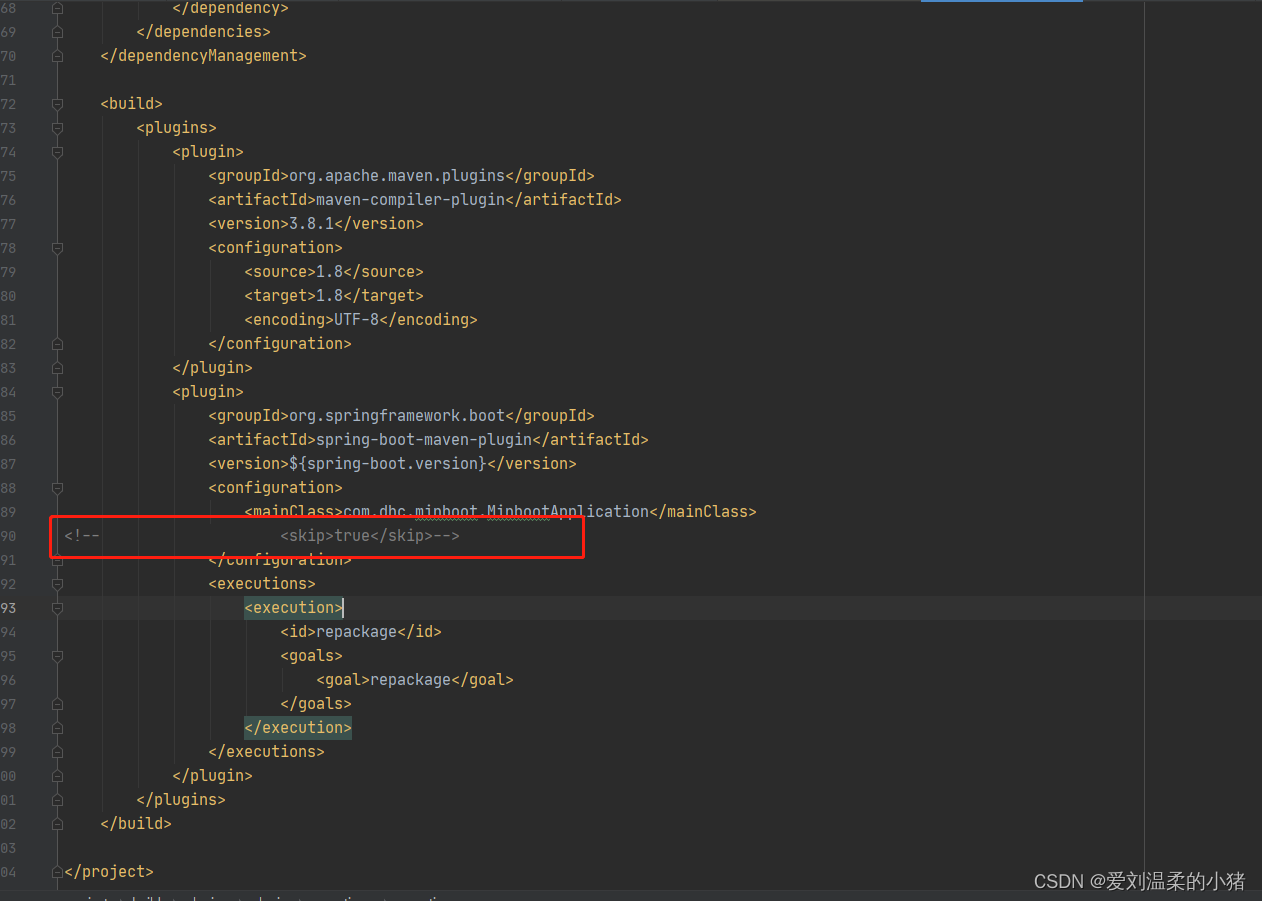
springboot项目打jar包,运行时提示jar中没有主清单属性
可能性一: 没有在pom中加入maven插件 在pom中加入下方代码即可。 <build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</ve…...

【Codeforces】 CF79D Password
题目链接 CF方向 Luogu方向 题目解法 看到区间异或,一个经典的套路是做差分,我们即在 l l l 处异或一次,在 r 1 r1 r1 处异或一次,然后前缀和起来 于是我们可以将问题转化成:有一个序列初始全 0 0 0,…...

叛乱沙漠风暴server安装 ubuntu 22.04
最新版沙暴已经不支持centos了,还是使用ubuntu比较顺利 官方文档: https://sandstorm-support.newworldinteractive.com/hc/en-us/articles/360049211072-Server-Admin-Guide // 安装steamcmd依赖 sudo add-apt-repository multiverse sudo apt inst…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...
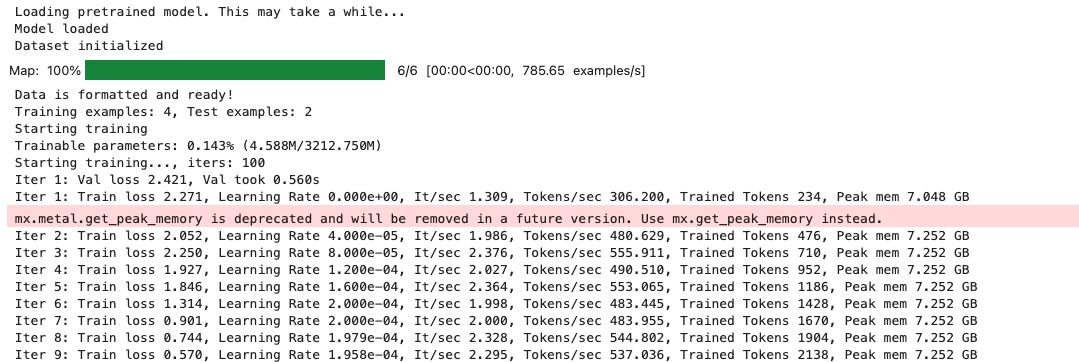
mac:大模型系列测试
0 MAC 前几天经过学生优惠以及国补17K入手了mac studio,然后这两天亲自测试其模型行运用能力如何,是否支持微调、推理速度等能力。下面进入正文。 1 mac 与 unsloth 按照下面的进行安装以及测试,是可以跑通文章里面的代码。训练速度也是很快的。 注意…...

DBLP数据库是什么?
DBLP(Digital Bibliography & Library Project)Computer Science Bibliography是全球著名的计算机科学出版物的开放书目数据库。DBLP所收录的期刊和会议论文质量较高,数据库文献更新速度很快,很好地反映了国际计算机科学学术研…...

React从基础入门到高级实战:React 实战项目 - 项目五:微前端与模块化架构
React 实战项目:微前端与模块化架构 欢迎来到 React 开发教程专栏 的第 30 篇!在前 29 篇文章中,我们从 React 的基础概念逐步深入到高级技巧,涵盖了组件设计、状态管理、路由配置、性能优化和企业级应用等核心内容。这一次&…...