【ETL工具】Datax-ETL-SqlServerToHDFS

🦄 个人主页——🎐个人主页 🎐✨🍁
🪁🍁🪁🍁🪁🍁🪁🍁 感谢点赞和关注 ,每天进步一点点!加油!🪁🍁🪁🍁🪁🍁🪁🍁
目录
🦄 个人主页——🎐个人主页 🎐✨🍁
一、DataX概览
1.1 DataX 简介
1.2 DataX框架
1.3 功能限制
1.4 Support Data Channels
二、配置样例
2.1 环境信息
2.2 SQLServer数据同步到HDFS
2.2 参数说明
一、DataX概览
1.1 DataX 简介
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、SQL Server、Oracle、PostgreSQL、HDFS、Hive、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。
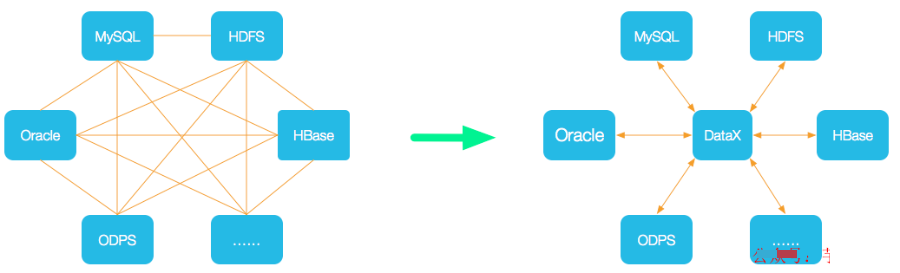
GitHub - alibaba/DataX: DataX是阿里云DataWorks数据集成的开源版本。
1.2 DataX框架
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
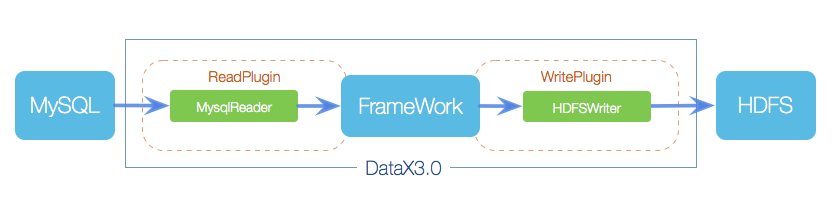
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
| 角色 | 作用 |
| Reader(采集模块) | 负责采集数据源的数据,将数据发送给 Framework。 |
| Writer(写入模块) | 负责不断向 Framework 中取数据,并将数据写入到目的端。 |
| Framework(中间商) | 负责连接 Reader 和 Writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。 |
HdfsWriter 提供向 HDFS 文件系统指定路径中写入 TEXTFILE 文件和 ORCFile 文件,文件内容可与 Hive 表关联。
1.3 功能限制
- 目前 HdfsWriter 仅支持 textfile 和 orcfile 两种格式的文件,且文件内容存放的必须是一张逻辑意义上的二维表;
- 由于 HDFS 是文件系统,不存在 schema 的概念,因此不支持对部分列写入;
- 目前仅支持与以下 Hive 数据类型:
数值型:TINYINT,SMALLINT,INT,BIGINT,FLOAT,DOUBLE
字符串类型:STRING,VARCHAR,CHAR
布尔类型:BOOLEAN
时间类型:DATE,TIMESTAMP
目前不支持:decimal、binary、arrays、maps、structs、union类型;
- 对于 Hive 分区表目前仅支持一次写入单个分区;
- 对于 textfile 需用户保证写入 hdfs 文件的分隔符与在 Hive 上创建表时的分隔符一致,从而实现写入 hdfs 数据与 Hive 表字段关联;
HdfsWriter 实现过程是:
首先根据用户指定的path,创建一个hdfs文件系统上不存在的临时目录,创建规则:path_随机; 然后将读取的文件写入这个临时目录; 全部写入后再将这个临时目录下的文件移动到用户指定目录(在创建文件时保证文件名不重复); 最后删除临时目录。 如果在中间过程发生网络中断等情况造成无法与hdfs建立连接,需要用户手动删除已经写入的文件和临时目录。
1.4 Support Data Channels
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图,详情请点击:DataX数据源参考指南
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| Kingbase | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADB | √ | 写 | ||
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | 写 | ||
| Hologres | √ | 写 | ||
| AnalyticDB For PostgreSQL | √ | 写 | ||
| 阿里云中间件 | datahub | √ | √ | 读 、写 |
| SLS | √ | √ | 读 、写 | |
| 图数据库 | 阿里云 GDB | √ | √ | 读 、写 |
| Neo4j | √ | 写 | ||
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| Phoenix5.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Cassandra | √ | √ | 读 、写 | |
| 数仓数据存储 | StarRocks | √ | √ | 读 、写 |
| ApacheDoris | √ | 写 | ||
| ClickHouse | √ | √ | 读 、写 | |
| Databend | √ | 写 | ||
| Hive | √ | √ | 读 、写 | |
| kudu | √ | 写 | ||
| selectdb | √ | 写 | ||
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| TSDB | √ | √ | 读 、写 | |
| TDengine | √ | √ | 读 、写 |
二、配置样例
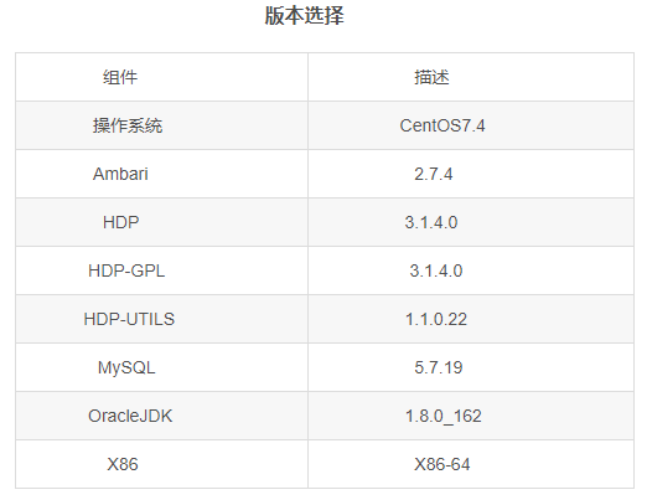
2.1 环境信息
集群HDP版本信息如下:
2.2 SQLServer数据同步到HDFS
site_traffic_inout.json 配置文件
[winner_hdp@hdp104 yd]$ cat site_traffic_inout.json
{"job": {"content": [{"reader": {"name": "sqlserverreader","parameter": {"username": "$IPVA_WSHOP_USER","password": "$IPVA_WSHOP_PASSWD","connection": [{"jdbcUrl": ["$IPVA_URL"],"querySql": ["SELECT StoreID,StoreName,SiteKey,SiteName from IPVA_WConfig.dbo.View_Site_Traffic_InOut;"]}]}},"writer": {"name": "hdfswriter","parameter": {"column": [{"name":"StoreID" , "type":"string"},{"name":"StoreName" , "type":"string"},{"name":"SiteKey" , "type":"string"},{"name":"SiteName", "type":"string"}],"path": "/winner/hadoop/winipva/wshop/tmp/", "defaultFS":"hdfs://winner","encoding": "UTF-8","fieldDelimiter": ",","hadoopConfig":{"dfs.nameservices": "winner","dfs.ha.namenodes.winner": "nn1,nn2","dfs.namenode.rpc-address.winner.nn1": "hdp103:8020","dfs.namenode.rpc-address.winner.nn2": "hdp104:8020","dfs.client.failover.proxy.provider.winner": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"},"haveKerberos": true,"kerberosKeytabFilePath": "/etc/security/keytabs/winner_hdp.keytab","kerberosPrincipal": "winner_hdp@WINNER.COM","fileType": "text","fileName": "000000","writeMode": "nonConflict",}}}],"setting": {"speed": {"channel": "5"},"errorLimit": {"record": 0}}}
}
运行脚本
# !/bin/bash
#
#
# 脚本功能: sqlServer 数据同步到 HDFS
# 作 者: kangll
# 创建时间: 2022-10-27
# 修改内容: 无
# 调度周期:
# 脚本参数: 无
#
set -x
set -e
## datatime
date=`date +%Y%m%d`## json config file path
json_src=/hadoop/datadir/windeploy/script/ETL/datax_json/
## datax path
data_py=/hadoop/software/datax/bin/datax.py
## ipva Wshop_config database connection
IPVA_USER=sa
IPVA_PASSWD='123456'
IPVA_URL="jdbc:sqlserver://192.168.2.103:1433;DatabaseName=IPVA_WConfig"###
Site_ReID_InOut_Func() {## 执行数据同步python $data_py ${json_src}site_reid_inout.json -p "-DIPVA_USER=${IPVA_USER} -DIPVA_PASSWD=${IPVA_PASSWD} -DIPVA_URL=${IPVA_URL} -Ddate=${date}"
}
######################## main ###############################
main(){Site_ReID_InOut_Func
}
#############################################################
###
main同步成功

2.3 参数说明
- defaultFS
描述:Hadoop hdfs文件系统namenode节点地址。格式:hdfs://ip:端口;例如:hdfs://127.0.0.1:9000 必选:是 默认值:无
- fileType
描述:文件的类型,目前只支持用户配置为"text"或"orc"。 text表示textfile文件格式 orc表示orcfile文件格式 必选:是 默认值:无
- fileName
描述:HdfsWriter写入时的文件名,实际执行时会在该文件名后添加随机的后缀作为每个线程写入实际文件名。 必选:是 默认值:无
- column
描述:写入数据的字段,不支持对部分列写入。为与hive中表关联,需要指定表中所有字段名和字段类型,其中:
name指定字段名,type指定字段类型。 用户可以指定Column字段信息,配置如下:"column":[{"name": "userName","type": "string"},{"name": "age","type": "long"}]必选:是 默认值:无 - writeMode
描述:hdfswriter写入前数据清理处理模式: append,写入前不做任何处理,DataX hdfswriter直接使用filename写入,并保证文件名不冲突。 nonConflict,如果目录下有fileName前缀的文件,直接报错。 必选:是 默认值:无
- fieldDelimiter
描述:hdfswriter写入时的字段分隔符,需要用户保证与创建的Hive表的字段分隔符一致,否则无法在Hive表中查到数据 必选:是 默认值:无
- compress
描述:hdfs文件压缩类型,默认不填写意味着没有压缩。其中: text类型文件支持压缩类型有gzip、bzip2; orc类型文件支持的压缩类型有NONE、SNAPPY(需要用户安装SnappyCodec)。 必选:否 默认值:无压缩
- hadoopConfig
描述:hadoopConfig里可以配置与Hadoop相关的一些高级参数,比如HA的配置。"hadoopConfig":{"dfs.nameservices": "testDfs","dfs.ha.namenodes.testDfs": "namenode1,namenode2","dfs.namenode.rpc-address.aliDfs.namenode1": "","dfs.namenode.rpc-address.aliDfs.namenode2": "","dfs.client.failover.proxy.provider.testDfs": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"}
- encoding
描述:写文件的编码配置。 必选:否 默认值:utf-8,慎重修改
- haveKerberos
描述:是否有Kerberos认证,默认false 例如如果用户配置true,则配置项kerberosKeytabFilePath,kerberosPrincipal为必填。 必选:haveKerberos 为true必选 默认值:false
- kerberosKeytabFilePath
描述:Kerberos认证 keytab文件路径,绝对路径 必选:否 默认值:无
- kerberosPrincipal
描述:Kerberos认证Principal名,如xxxx/hadoopclient@xxx.xxx 必选:haveKerberos 为true必选 默认值:无
"haveKerberos": true,
"kerberosKeytabFilePath": "/etc/security/keytabs/winner_hdp.keytab",
"kerberosPrincipal": "winner_hdp@WINNER.COM",
相关文章:
【ETL工具】Datax-ETL-SqlServerToHDFS
🦄 个人主页——🎐个人主页 🎐✨🍁 🪁🍁🪁🍁🪁🍁🪁🍁 感谢点赞和关注 ,每天进步一点点!加油!&…...
概述)
Kubernetes (K8S)概述
1、K8S 是什么? K8S 的全称为 Kubernetes (K12345678S),PS:“嘛,写全称也太累了吧,不如整个缩写”。 1.1 作用 用于自动部署、扩展和管理“容器化(containerized)应用程序”的开源系统。 可以…...
11月14号|Move生态Meetup相约浪漫土耳其
Move是基于Rust编程语言,由Mysten Labs联合创始人兼CTO Sam Blackshear在Meta的Libra项目中开发而来,旨在为开发者提供比现有区块链语言更通用的开发语言。Sam的目标是创建Web3的JavaScript,即一种跨平台语言,使开发人员能够在多个…...

mac vim没有颜色 问题
vim ~/.vimrc syntax on set nu! set autoindent...
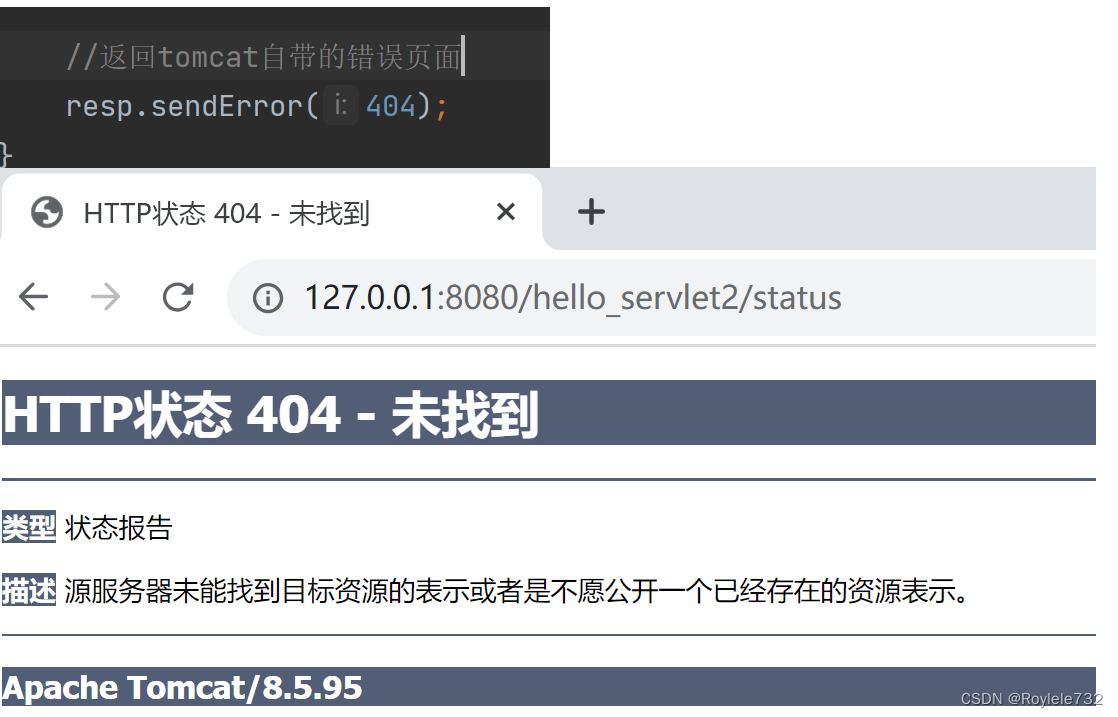
Servlet核心API
目录 HttpServlet init destory service 实例:处理get、post、put、delete请求 1.通过postman得到请求 2.通过ajax得到请求 HttpServletRequest 常见方法 前端给后端传参 1.GET,query string 2.POST,form 3.POST,json HttpSeverletRespons…...

crs 维护模式 exclusive mode
How To Validate ASM Instances And Diskgroups On A RAC Cluster (When CRS Does Not Start). (Doc ID 1609127.1)编辑To Bottom [rootrac1 ~]# ps -ef|grep grid root 2477 1 1 20:47 ? 00:00:51 /opt/oracle.ahf/jre/bin/java -server -Xms32m -Xmx64…...
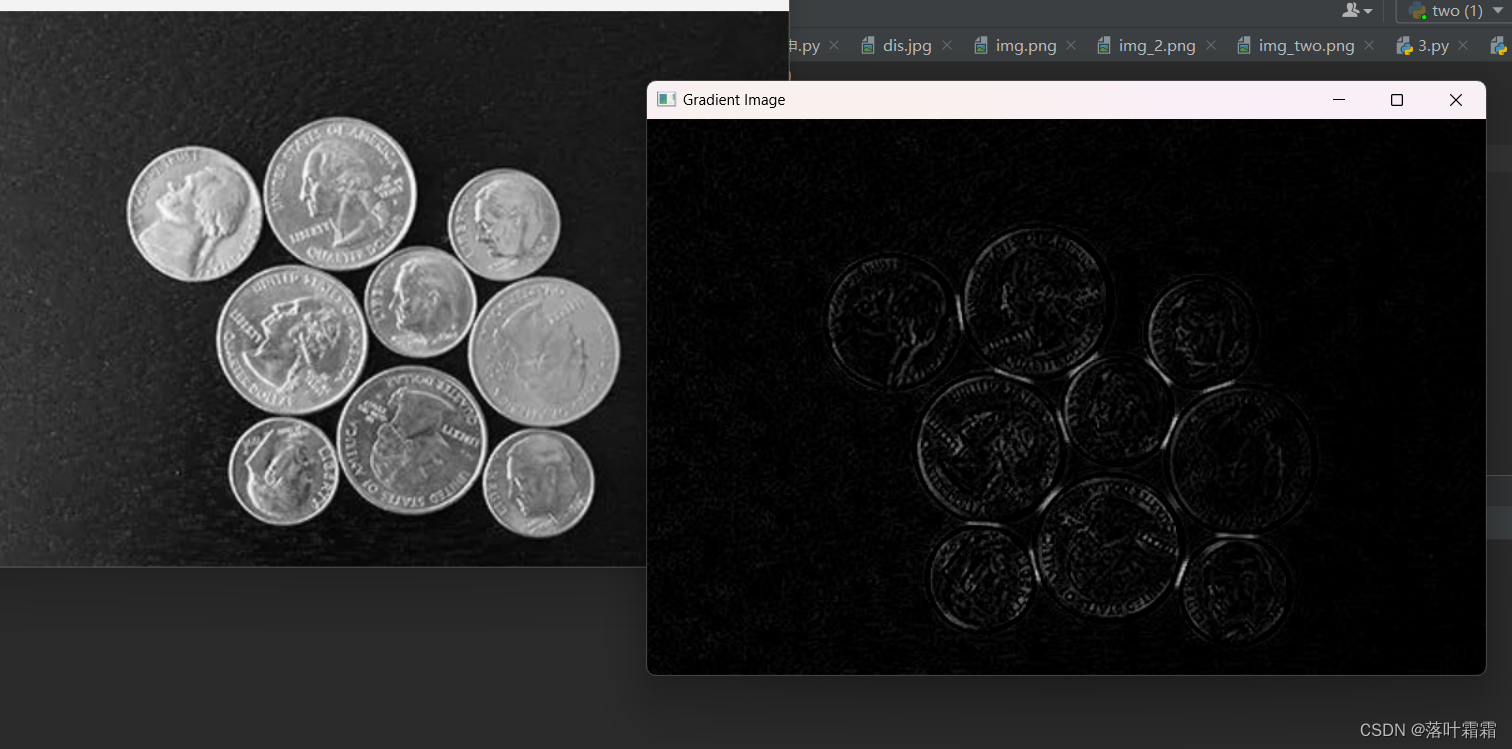
【OpenCV实现平滑图像形态学变化】
文章目录 概要目标腐蚀膨胀开运算结构元素(内核)小结 概要 形态学变化是一组简单的图像操作,主要用于处理二值图像,即只包含黑和白两种颜色的图像。这些操作通常需要两个输入,原始图像和一个内核(kernel&a…...

Ubuntu服务器中java -jar 后台运行Spring Boot项目
问:我在我的服务器中java -jar 运行springboot项目,但是我操作不了命令了,必须要终止掉才能执行后面的操作,怎么样才能让他后台运行呢?比如我的jar包名是tools-boot-0.0.1-SNAPSHOT.jar 使用nohup命令: 在…...

微服务parent工程和子工程pom文件配置注意
parent工程 重要配置: <!-- 父工程 --><packaging>pom</packaging><!-- 聚合 --><modules><module>../base</module><module>../gateway</module><module>../user-service</module><mod…...
STM32G030F6P6点灯闪烁
前言 (1)如果有嵌入式企业需要招聘湖南区域日常实习生,任何区域的暑假Linux驱动实习岗位,可C站直接私聊,或者邮件:zhangyixu02gmail.com,此消息至2025年1月1日前均有效 (2࿰…...

K8s开发人员也需要了解的相关知识
工作变动总结一下之前的笔记,整理一个速查的东西,方便之后查阅 K8s开发相关 1、k8s yml apiverison: Kubernetes (k8s) 的 API 版本表示资源定义在 API 服务器中的稳定性和支持程度。API 版本由一个字符串表示,如 v1 或 apps/v1,…...
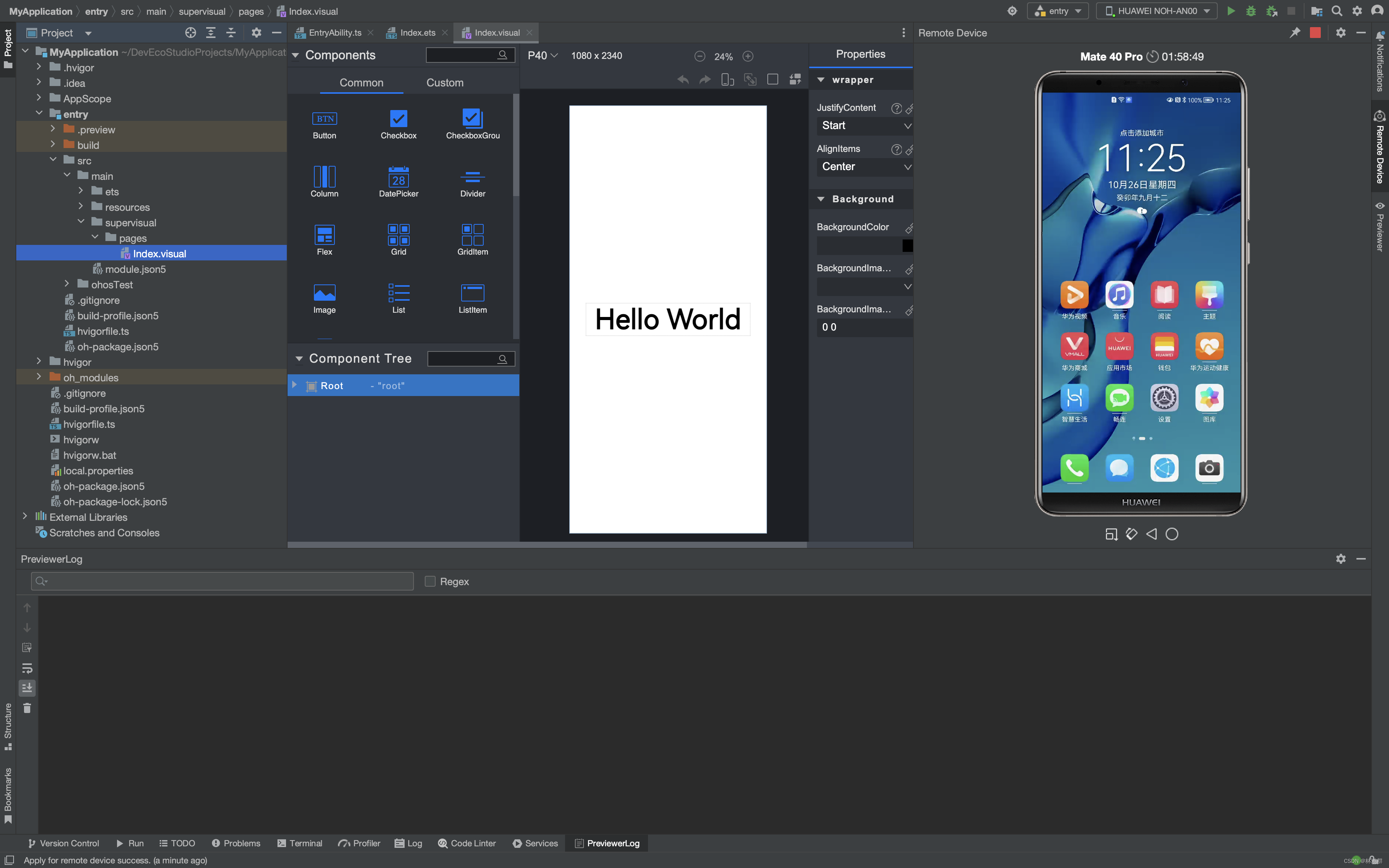
创建并启动华为HarmonyOS本地与远程模拟器及远程真机
1.打开设备管理器 2.选择要添加的手机设备,然后点击安装 3.正在下载华为手机模拟器 4.下载完成 5.创建新模拟器 下载系统镜像 点击下一步,创建模拟器 创建成功 启动模拟器 华为模拟器启动成功 6.登陆华为账号并使用远程模拟器 7.使用远程真机...
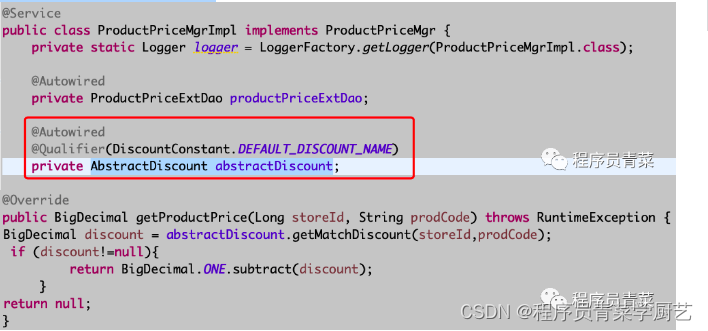
责任链模式应用案例
前几天系统商品折扣功能优化,同事采用了责任链模式重构了代码,现整理如下。 一、概念 责任链模式是为请求创建一个处理者对象的链条,所有处理者(除最末端)都含有下一个对象的引用从而形成一条处理链,该模…...

给你一个整数 num ,返回 num 中能整除 num 的数位的数目
给你一个整数 num ,返回 num 中能整除 num 的数位的数目。 如果满足 nums % val 0 ,则认为整数 val 可以整除 nums 。 示例 1: 输入:num 7 输出:1 解释:7 被自己整除,因此答案是 1 。 示例 2&…...
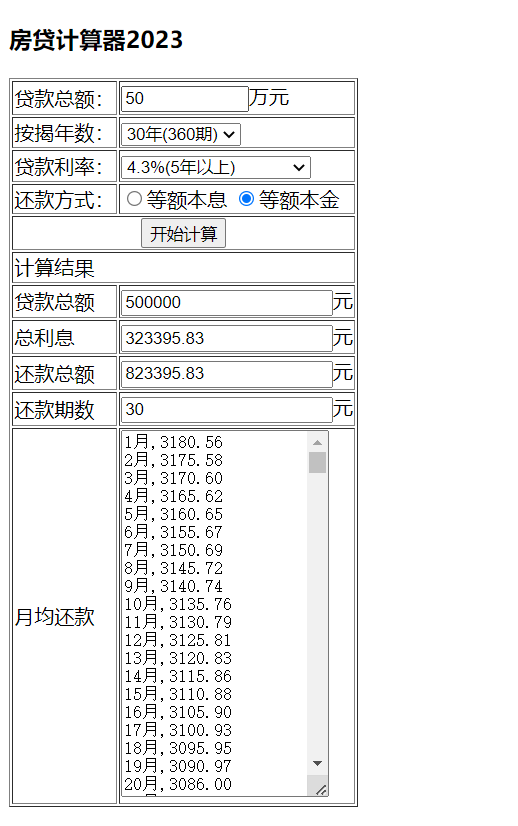
Java后端开发——房贷计算器(Ajax版、Json版、等额本息+等额本金)
MVC房贷计算器(Ajax版) 1.新建一个JavaWeb项目hslcalweb,设置tomcat10。 2.创建房贷计算器JavaBean:HslCalBean.java,增加以下的属性,并生成Getter/Setter方法。 private double total; //贷款额度pr…...

2023.10.28 关于 synchronized 原理
目录 synchronized 特性 synchronized 优化机制 锁升级(锁膨胀) 其他优化机制 锁消除 锁粗化 synchronized 特性 开始时是乐观锁,如果锁冲突频繁,就转为悲观锁开始是轻量级锁,如果锁被持有的时间较长,…...

力扣 27. 移除元素
目录 1.解题思路2.代码实现 1.解题思路 利用双指针思路,当让一个指针先走,指针指向的位置不等于val时,将此时该指针的值给另一个指针并且两个指针都加一,如果等于val,则让该指针加一继续走.最后另一个指针的下标就为排好的数组的…...
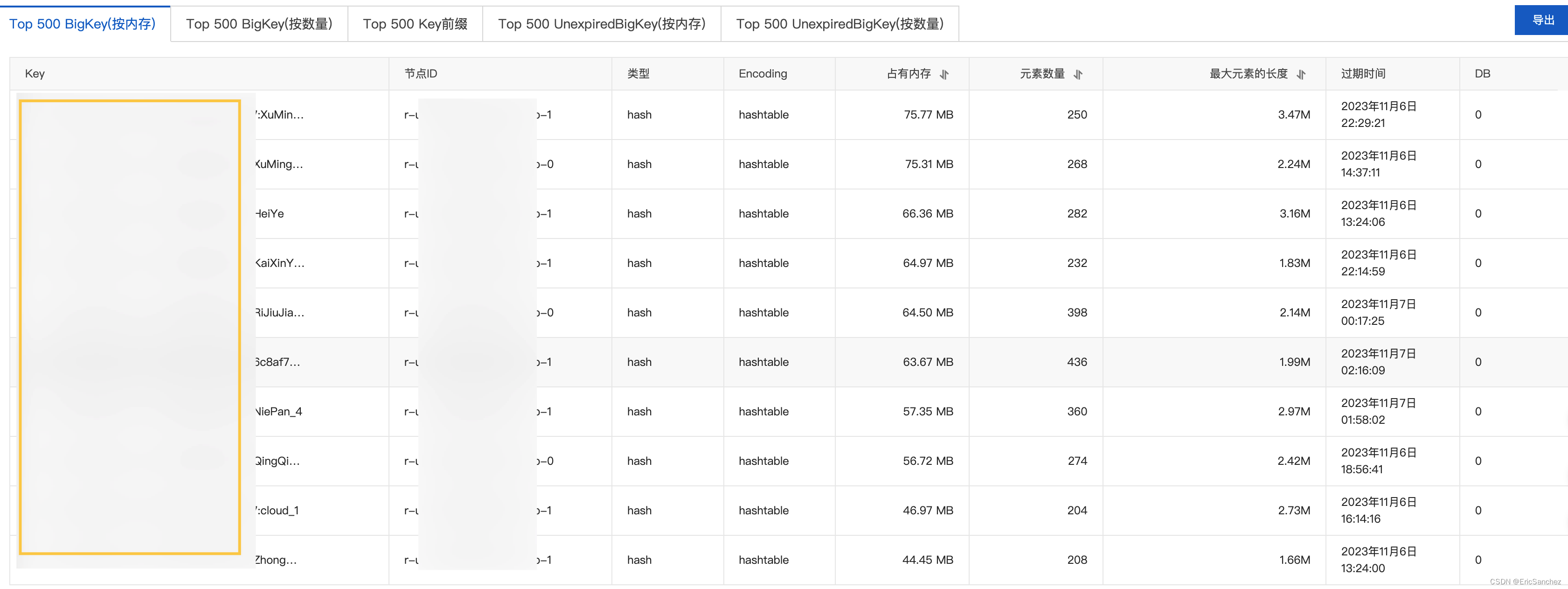
redis爆满导致数据丢失
记一则redis爆满导致数据丢失的一场事故 某功能上线后,发现出现问题,最后定位到了 redis. 由于存储的数据过多,导致阿里云4G大小的 redis 爆满,触发了回收策略。 于是临时扩容,运维同学当时未找到阿里云配置。 后面我用工具连接了…...
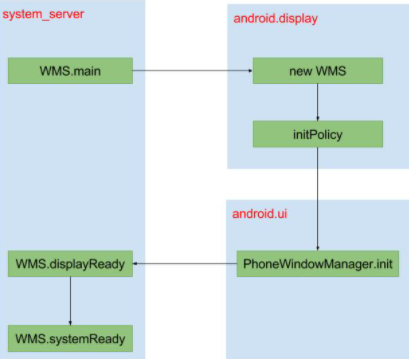
Android14 WMS启动流程
一 概述 本文Android14源代码可参考:Search 在 Android 系统中,从设计的角度来看,窗口管理系统是基于 C/S 模式的。整个窗口系统分为服务端和客户端两大部分,客户端负责请求创建窗口和使用窗口,服务端完成窗口的维护…...
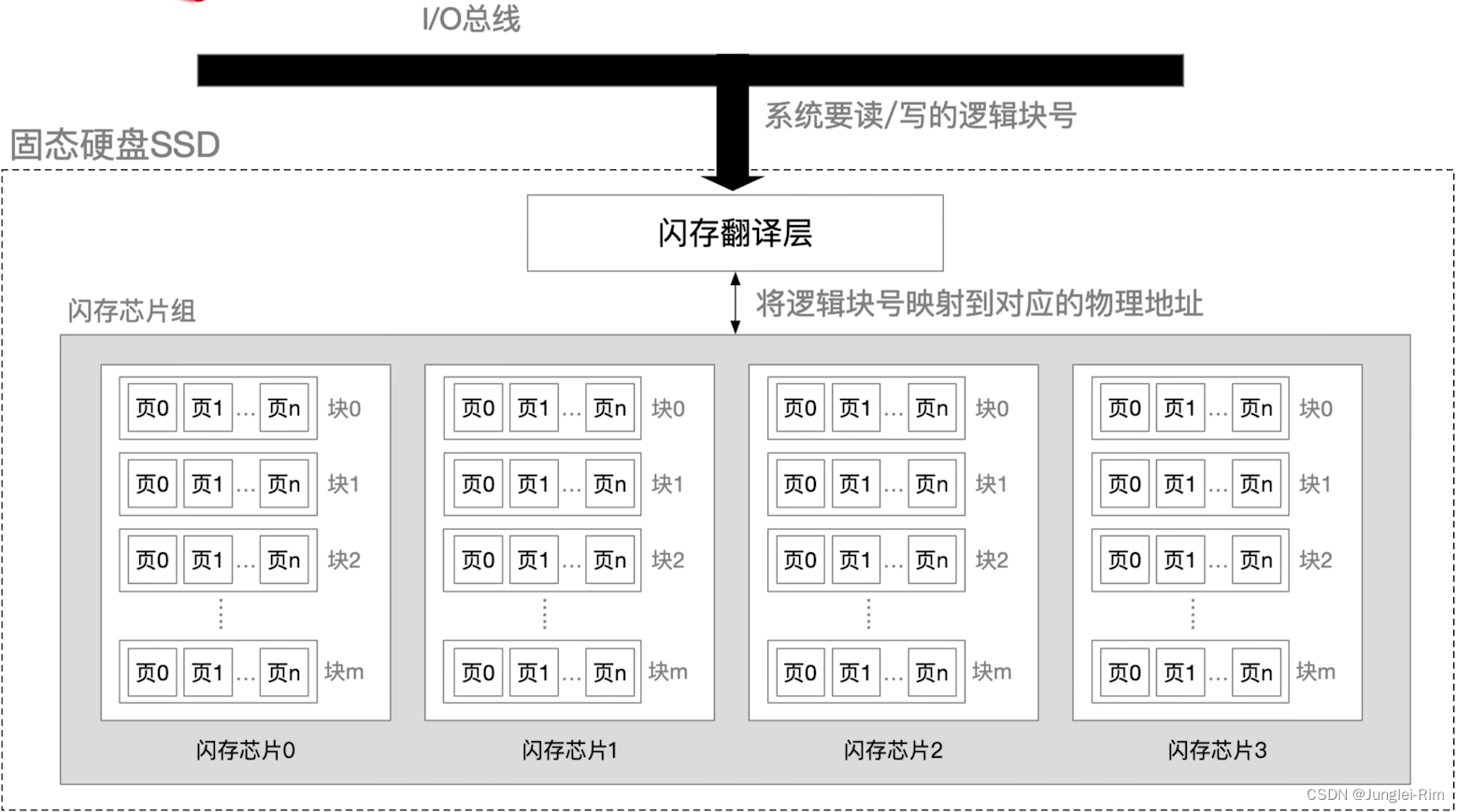
磁盘管理(初始化,引导块,坏块管理,固态硬盘)
目录 1.磁盘初始化2.引导块3.坏块的管理1.坏块检查2.坏块链表3.扇区备用 4.固态硬盘(SSD)1.原理2.组成3.读写性能特性4.与机械硬盘相比5.磨损均衡技术 1.磁盘初始化 ①进行低级格式化(物理格式化),将磁盘的各个磁道划分…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...

NPOI Excel用OLE对象的形式插入文件附件以及插入图片
static void Main(string[] args) {XlsWithObjData();Console.WriteLine("输出完成"); }static void XlsWithObjData() {// 创建工作簿和单元格,只有HSSFWorkbook,XSSFWorkbook不可以HSSFWorkbook workbook new HSSFWorkbook();HSSFSheet sheet (HSSFSheet)workboo…...