如何借助数据集更好的评估NLP模型的性能?

随着信息时代的迅猛发展,每天有无数文本、声音、图片和视频不断涌入互联网。如何从海量数据中提炼有意义信息成为学术界和工业界迫切需要解决的问题。在此背景下,自然语言处理(NLP)应运而生,成为人工智能领域最为活跃的研究领域之一。
NLP的目标是让计算机理解和生成人类语言,从而实现与人自然交流。这包括了基础的语言理解任务,如词性标注、句法分析,以及更复杂的应用,如情感分析、机器翻译和语音识别等。为了让机器更好地理解人类语言,研究者们开发了大量的算法和模型。然而,无论算法多么先进,如果没有大规模、高质量的数据支持,其效果都会受限。这就是为什么数据集在NLP领域如此至关重要。
数据集是NLP研究的基石,它们为研究者提供了评估和验证算法性能的基准,也是训练机器学习模型的关键资源。随着NLP领域的不断进展,涌现出大量数据集,涵盖了从基础到前沿的各种NLP任务。选择适当的数据集对于研究的成功至关重要。
在本文中,我们将详细介绍多种当前热门的NLP数据集。这些数据集包括文本分类、命名实体识别、机器翻译等各种任务。我们希望通过这篇文章,让您全面了解NLP数据集,以便为您的研究或项目选择合适的数据集提供指导。
一
数据集评估维度及其重要性

随着NLP领域的不断发展,出现了众多开源数据集,以支持各种研究任务。在选择和使用这些数据集时,了解它们的各种关键维度至关重要,这些维度不仅帮助我们理解数据集的特点和用途,还为我们提供了评估其适用性和质量的依据。以下是一些关键维度:
1
首先,我们应该了解数据集的名称和发布者。数据集的名称是其独特标识,有助于查找和引用。同时,了解数据集的发布者有助于评估数据集的可靠性和权威性。通常,来自知名机构或研究组的数据集更具可信度和认可度。
其次,我们需要了解数据集的内容、特点以及其对行业的影响。根据数据集的内容和特点,我们可以确定数据集适用的NLP任务类型,并了解数据集的设计目标和要求。这有助于判断数据集是否适合特定的研究或应用,以满足特定需求和挑战。此外,了解数据集的影响力可以告诉我们它在某些任务或领域中的广泛使用程度以及已被验证有效的程度。
2
3
此外,数据集的数据量和数据来源也是关键信息。数据量是评估数据集规模和深度的关键因素。大规模的数据集通常更适合用于训练复杂的模型,而小规模的数据集可能更适合特定任务或快速实验。了解数据的来源,即数据是如何生成和收集的,有助于评估其可靠性和代表性。选择来源可靠、具有代表性的数据集可以帮助避免偏见和误差。
综合而言,深入了解数据集的各个关键维度对于评估其适用性、可靠性和质量至关重要。选择合适的数据集是确保研究或项目成功的基础,因此我们应该花时间仔细研究并理解这些维度,以做出明智的决策。
二
NLP任务分类与数据集推荐的你

自然语言处理领域包含了多个子领域和任务,为了帮助研究者和开发者更便捷地找到适用于他们需求的数据集,我们将根据不同的NLP任务进行分类,并为每个任务推荐相关的数据集。
01
问答任务
问答任务主要关注模型对特定问题的答案生成或选择能力。
1.1 二值问题回答
这是一个特定类型的问题回答任务,主要关注于二值(是/否)答案。
推荐数据集:
BoolQ:由Google AI发布,是一个二值问题(是或否的问题)及其答案,包含约超过9k条数据,来源于从Wikipedia抽取。
下载地址(https://huggingface.co/datasets/boolq)
1.2 对话式问答
这是一个涉及对话上下文的问题回答任务。
推荐数据集:
CoQA:由斯坦福大学发布,是一个对话式的问答数据集,包含约12.7w+个问题答案对,来源于不同的来源,如维基百科、小说、新闻等。
下载地址(https://stanfordnlp.github.io/coqa/)
1.3 开放领域的问答
这个任务要求模型回答开放领域的问题。
推荐数据集:
WebQA:由百度发布,是一个开放领域的问答数据集,包含约42k个问题和566k个问题相关文本条数据,来源于基于Web的问答对。
下载地址(https://huggingface.co/datasets/suolyer/webqa)
TriviaQA:由University of Washington发布,是一个开放领域的问题和答案对,包含约65w条数据,来源于TriviaQA网站和其他Trivia游戏。
下载地址(https://huggingface.co/datasets/trivia_qa)
1.4 信息寻求对话
这个任务涉及与模型进行对话,以获得特定信息。
推荐数据集:
QuAC:由Allen Institute of Artificial Intelligence & DARPA CwC program发布,是一个模拟学生与教师之间的信息寻求对话,包含约1.4w多对话条数据,来源于隐藏的维基百科文本。
下载地址(https://huggingface.co/datasets/quac)
02
语言理解
2.1 预测段落最后一个单词
本任务用于评估模型对文本生成和连续性的理解。
推荐数据集:
LAMBADA:由University of Amsterdam&University of Trento发布,是一个预测文本的下一个词,包含约12,684条数据,来源于书籍和其他文学作品。
下载地址(https://huggingface.co/datasets/lambada/tree/main)
2.2 故事结束预测
这个任务需要模型预测故事的可能结束。
推荐数据集:
StoryCloze:由University of Rochester发布,是一个预测故事的正确结尾,包含约超过3,700条数据,来源于故事文本。
下载地址(https://huggingface.co/datasets/story_cloze)
2.3 阅读理解
阅读理解任务要求模型从给定的文本中提取或推断信息。
推荐数据集:
RACE:由CMU发布,是一个英语阅读理解数据集,包含约超过2.8w篇文章和近10w个问题,来源于中国的英语考试。
下载地址(https://www.cs.cmu.edu/~glai1/data/race/)
RACE-Middle:由CMU发布,是一个初中级阅读理解题目,包含约25,421条数据,来源于中国中学生英语考试。
下载地址(https://huggingface.co/datasets/race)
RACE-High:由CMU发布,是一个高中级阅读理解题目,包含约62,445条数据,来源于中国中学生英语考试。
下载地址(https://huggingface.co/datasets/race)
SQUADv2:由斯坦福大学发布,是一个阅读理解任务。该数据集包含约15w+个问题答案对,还有一些没有答案的问题。数据来源是维基百科,由众包人员对抗生成。
下载地址(https://huggingface.co/datasets/squad_v2)
CMRC2018:由哈工大讯飞联合实验室发布,是一个中文阅读理解任务,包含约近2w个真实问题条数据,来源于人类专家在维基百科的段落中注释。
下载地址(https://github.com/ymcui/cmrc2018)
2.4 多模态语言理解
这个任务关注于结合多种模式(如文本、图像和声音)来理解语言。
推荐数据集:
MMLU:由UC Berkele&Columbia University&Uchicago&UIUC发布,是一个多模态语言理解数据集,包含约5,822,552条数据,来源于研究生和本科生从免费的在线来源手动收集。包括研究生学历考试和美国医学执照考试等考试的练习题、为本科生课程设计的问题和为牛津大学出版社书籍读者设计的问题。
下载地址(https://huggingface.co/datasets/cais/mmlu)
03
推理模块
3.1常识推理
常识推理是测试模型对常识和逻辑的理解能力的任务。这个任务要求模型具备尝试推理能力,理解和推理因果关系。
推荐数据集:
HellaSwag:由University of Washington发布,是一个常识推理数据集,要求模型预测句子的正确结尾,包含约超过70,000条数据,来源于来自各种源,如教学视频、故事,但由研究人员进行修改。
下载地址(https://huggingface.co/datasets/hellaswag)
WinoGrande:由University of Washington发布,是一个常识推理挑战,基于Winograd模式,包含约44,000条数据,来源于人工构建。
下载地址(https://huggingface.co/datasets/winogrande/tree/main)
COPA:由Indiana University & University of Southern California发布,是一个评估模型在开放领域常识因果推理的进展,包含约1000个选择问题条数据,来源于人工设计。
下载地址(https://people.ict.usc.edu/~gordon/copa.html)
CSQA:由CommonsenseQA团队发布,是一个需要常识知识来回答的问答数据集,包含约20,000篇对话,大约1.6M个QA对,来源于注释员相互交流生成。
下载地址(https://amritasaha1812.github.io/CSQA/download/)
3.2 自然语言推理
这个任务要求模型根据给定的前提推断出结论。
推荐数据集:
ANLI:由Facebook AI发布,是一个人工生成的自然语言推理数据集,包含约超过120,000条数据,来源于众包平台。
下载地址(https://huggingface.co/datasets/anli)
XNLI:由Facebook AI发布,是一个多语言自然语言推理数据集,包含约超过390,000条数据,来源于15种语言的翻译。
下载地址(https://huggingface.co/datasets/xnli)
StrategyQA:由Tel Aviv University、Allen Institute for AI & University of Pennsylvania发布,是一个需要对多个证据进行推理的问答数据集,包含约约2700样例,来源于workers生成。
下载地址(https://storage.googleapis.com/ai2i/strategyqa/data/strategyqa_dataset.zip)
GLUE的MNLI、QNLI和 WNLI子数据集:GLUE是由纽约大学和华盛顿大学发布,是一个一组用于评估和分析多种NLP任务的数据集,包含约一共多个任务,不同任务有不同的数据量条数据,来源于各种NLP数据集的集合。
下载地址(https://gluebenchmark.com/)
3.3 深度推理
这个任务要求模型进行更深入的推理以回答问题。
推荐数据集:
DROP:由Allen Institute for Artificial Intelligence发布,是一个需要深入推理的问答数据集,包含约77,409个问题答案对,来源于从维基百科中选择的段落。
下载地址(https://opendatalab.com/DROP/download)
3.4 数学推理
数学推理任务测试模型在数学问题上的推理能力。
推荐数据集:
GSM8K:由OpenAI发布,是一个由8.5K高质量的语言多样化的小学数学单词问题组成的数据集,包含约8500个问题条数据,来源于人类创造。
下载地址(https://github.com/openai/grade-school-math)
MATH:由UC Berkeley和UChicago发布,是一个初级代数、代数、计数与概率、数论与微积分等数学题,包含约12500道数学题条数据,来源于美国中学数学竞赛试题。
下载地址(https://huggingface.co/datasets/math_dataset)
Math23k:由Tencent AI Lab发布,是一个数学问题解决数据集,包含约约23,000个问题条数据,来源于从中文网站收集的数学题。
下载地址(https://ai.tencent.com/ailab/nlp/dialogue/datasets/Math_data.zip)
3.5 科学推理
科学推理任务要求模型对科学概念和事实进行推理。
推荐数据集:
ARC-Challenge:由AI2发布,是一个科学问题及其答案,需要深入推理,包含约2590条数据,来源于学科教育资源。
下载地址(https://huggingface.co/datasets/vietgpt/ARC-Challenge_en)
ARC:由AI2发布,是一个数据集分为简单和挑战两部分,包含约7787个问题,来源于学生科学挑战中的问题。
下载地址(https://opendatalab.com/ARC/download)
PIQA:由University of Washington&AI2发布,是一个针对物理互动的问题回答,包含约超过16,000条数据,来源于众包产生。
下载地址(https://huggingface.co/datasets/piqa/tree/main)
04
文本生成
文本生成任务是指让机器自动产生连贯、有意义的文本,通常基于给定的上下文或提示。代码生成也属于此列。
推荐数据集:
Wikitext103: 由Salesforce研究发布,是一个包含100多万的维基百科文章令牌,包含约103M令牌条数据,来源于维基百科的顶级文章。
下载地址(https://huggingface.co/datasets/wikitext)
PG19: 由DeepMind发布,是一个古腾堡书籍中1919年前出版制品集合,包含约28752篇文章条数据,来源于项目古腾堡。
下载地址(https://huggingface.co/datasets/pg19)
C4: 由DeepMind发布,是一个清洁的、多语言的数据集,包含约数百万篇文章,数十亿的令牌条数据,来源于网络爬取数据。
下载地址(https://huggingface.co/datasets/c4)
HumanEval:由OpenAI、Anthropic AI发布,是一个评估AI模型的问题解决能力,包含约164个手写编程问题,平均每个问题有7.7个测试条数据,来源于Openai员工手写。
下载地址(https://huggingface.co/datasets/openai_humaneval)
05
基础任务类
5.1句子对比
这个任务关注于比较两个句子的语义相似性或差异性。
推荐数据集:
PAWS-X:由Google Research发布,是一个多语言对比词序数据集,包含约49,401条数据,来源于Wikipedia和其他源的翻译。
下载地址(https://huggingface.co/datasets/paws-x)
LCQMC:由哈尔滨工业大学发布,是一个判断中文句子对是否具有相同的意图,包含约238,766个句子对条数据,来源于社交媒体平台、问答网站等。
下载地址(https://opendatalab.com/LCQMC/download)
5.2 词义消歧
这个任务关注于确定一个词在特定上下文中的正确含义。
推荐数据集:
WiC:由卡迪夫大学发布,是一个词义消歧的数据集,判断两个句子中的同一个词是否有相同的意思,包含约5428个问题条数据,来源于多语言资源。
下载地址(https://pilehvar.github.io/wic/)
5.3 代词消除歧义
这个任务关注于正确解决代词的歧义。
推荐数据集:
WSC:由Winograd Schema Challenge组织发布,是一个代词消除歧义,包含约285个问题条数据,来源于专家编写。
下载地址(https://huggingface.co/datasets/winograd_wsc)
5.4 文本蕴含
这个任务要求模型确定一个文本是否蕴含另一个文本。
推荐数据集:
GLUE的RTE子集
5.5 情感分析
情感分析任务旨在确定文本的情感倾向。
推荐数据集:
GLUE的SST-2 子集
06
其他
6.1 真实性评估
这个任务用于评估生成的回答的真实性。
推荐数据集:
Truthful-QA: 由University of Oxford&Open AI发布,是一个评估生成回答的真实性的数据集,包含约817条数据,来源于作者自编。下载地址(https://huggingface.co/datasets/truthful_qa)
6.2 评估刻板印象
这个任务旨在评估模型是否持有或传递某些刻板印象。
推荐数据集:
ETHOS:由Aristotle University of Thessaloniki发布,是一个包含刻板印象的语句及未包含的语句,包含约二分类任务有998条评论,多分类有433条评论条数据,来源于YouTube和Reddit评论。
下载地址(https://huggingface.co/datasets/ethos)
StereoSet:由MIT、Intel AI、Facebook CIFAR AI Chair and McGill University发布,是一个包含刻板印象的语句及未包含的语句,包含约17000个句子条数据,来源于不同的文本来源。
下载地址(https://huggingface.co/datasets/stereoset)
6.3 多任务评估
多任务评估关注于同时评估模型在多个任务上的性能。
推荐数据集:
SuperGLUE:由AI2 & University of Washington发布,是一个一组NLP任务的基准,是GLUE的扩展,包含约不同任务有不同数据量条数据,来源于多个NLP数据集的集合。
下载地址(https://huggingface.co/datasets/super_glue/tree/main)
BIG-bench:BIG-bench由Google发布,是一个大规模语言模型评估基准。该数据集包含多个子任务,但总数不详。数据来源于不同的子任务来源。
下载地址(https://github.com/google/BIG-bench)
以上是基于不同NLP任务的数据集推荐。每个数据集都有其特定的特点和用途,研究者和开发者应根据自己的需求和研究目标选择合适的数据集。同时,随着NLP领域的不断进展,可能会有更多的数据集和任务出现,我们应持续关注并不断更新我们的知识库。
三
结论

数据集在自然语言处理领域中起到了至关重要的作用。无论是为了训练强大的模型,还是为了验证新的算法和策略,数据集都是不可或缺的资源。在本文中,我们介绍了43个NLP数据集,涵盖了从常识推理到问题回答的各种任务。每个数据集都有其独特的特点和应用场景,为研究者提供了丰富的选择。
但要注意,选择数据集不仅仅是根据其大小或者知名度。重要的是要确保数据集与研究或项目的目标相匹配。此外,数据集的质量、多样性和代表性也是需要考虑的关键因素。一个好的数据集应该能够为模型提供全面、均衡和有代表性的训练数据。
随着NLP领域的不断进展,我们预期未来还会有更多的数据集问世。而随着技术的进步,数据集的规模、质量和多样性也可能会得到进一步的提高。因此,研究者和开发者应始终保持警觉,关注最新的数据集和研究动态,确保他们的工作始终处于行业的前沿。
最后,我们鼓励读者深入探索上文提到的数据集,并挑战更多的NLP任务。希望这篇文章能为您提供一些有用的参考和启示,助您在NLP领域取得更大的成功。

欢迎关注微软 智汇AI 官方账号
一手资讯抢先了解




点击“阅读原文” | 了解更多 AI 赋能案例
相关文章:
如何借助数据集更好的评估NLP模型的性能?
随着信息时代的迅猛发展,每天有无数文本、声音、图片和视频不断涌入互联网。如何从海量数据中提炼有意义信息成为学术界和工业界迫切需要解决的问题。在此背景下,自然语言处理(NLP)应运而生,成为人工智能领域最为活跃的…...

2023年腾讯云服务器地域节点选择指南(亲自整理)
腾讯云轻量应用服务器地域是指轻量服务器数据中心所在的地理位置,如上海、广州和北京等地域,如何选择地域?腾讯云百科txybk.com建议地域选择遵循就近原则,用户距离轻量服务器地域越近,网络延迟越低,速度就越…...

华媒舍:日韩媒体发稿推广中8个关键因素帮助你实现突破
在当今经济全球化的时代背景下,日韩地域媒体影响力日益提高。对于需要在这一地区开展发稿推广的人来讲,掌握适度的思路和流程是十分重要的。下面我们就为大家介绍8个关键因素,以帮助你在日韩地域媒体发稿推广中实现突破。 1.科学研究行业在逐…...
Docker数据卷
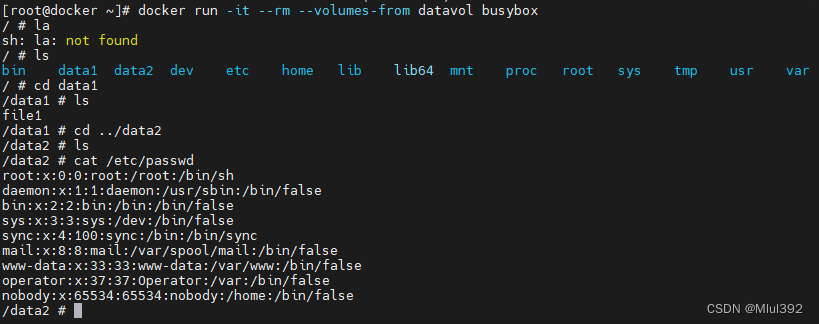
目录 1.bind mount 2.docker managed volume 1.bind mount docker run -it --rm -v /tmp/data1:/data1 -v /tmp/data2:/data2:ro -v /etc/passwd:/mnt/passwd:ro busybox 2.docker managed volume docker run -d --name web1 webserver:v3 docker inspect web1 cd/var/lib/doc…...
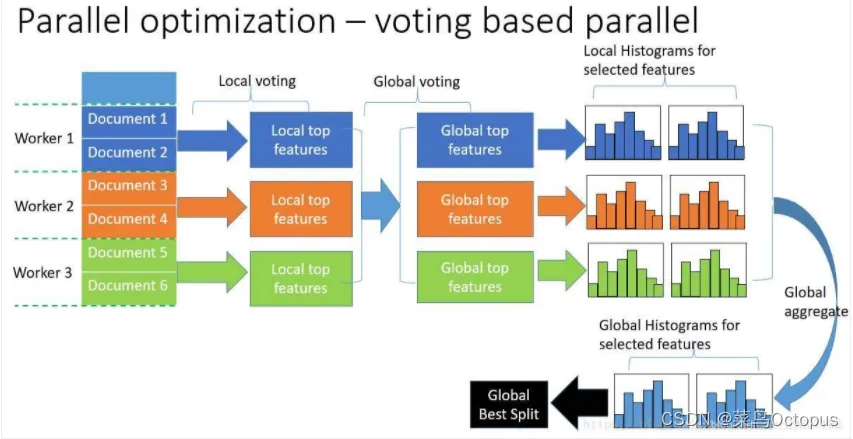
LightGBM 的完整解释 - 最快的梯度提升模型
文章最前: 我是Octopus,这个名字来源于我的中文名--章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的…...

Think-Queue3一直提示[Exception]redis扩展未安装
场景 tp6tq3实现的任务队列,使用redis作为数据驱动,目前是tp6可以正常使用redis了,但tq3不行,一直提示[Exception]redis扩展未安装。 解决思路 1.分析tq3源码 定位到是这一行出了问题 if (!extension_loaded(redis)) {throw n…...

Spring cloud教程Gateway服务网关
Spring cloud教程|Gateway服务网关 写在前面的话: 本笔记在参考网上视频以及博客的基础上,只做个人学习笔记,如有侵权,请联系删除,谢谢! Spring Cloud Gateway 是 Spring Cloud 的一个全新项目,…...

【C++代码】爬楼梯,不同路径,整数拆分,不同搜索树,动态规划--代码随想录
动态规划,英文:Dynamic Programming,简称DP,如果某一问题有很多重叠子问题,使用动态规划是最有效的。所以动态规划中每一个状态一定是由上一个状态推导出来的,这一点就区分于贪心,贪心没有状态推…...
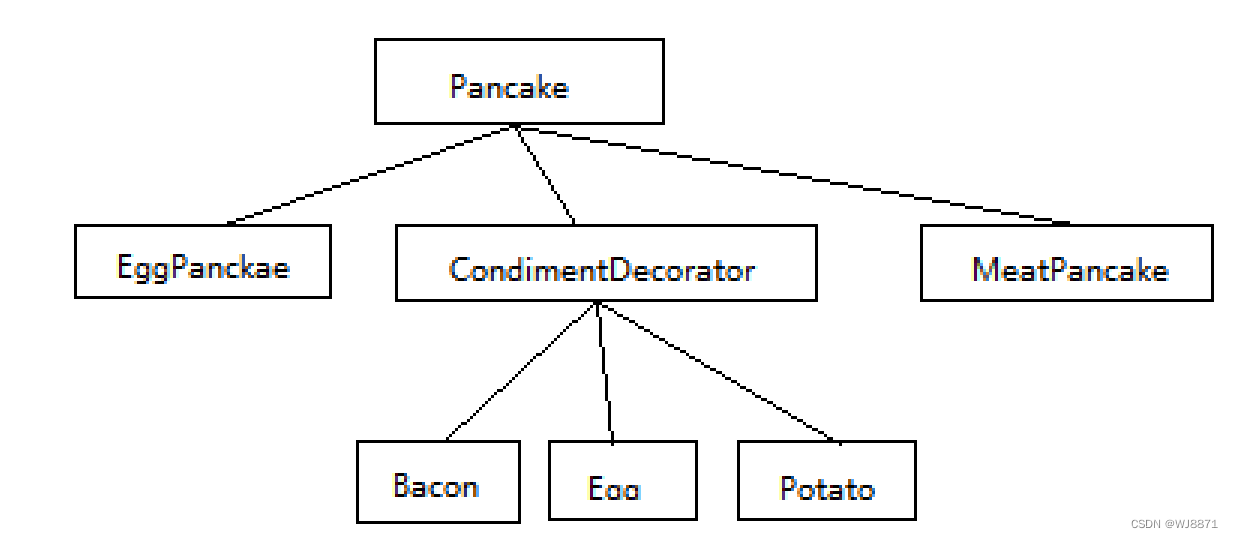
设计模式(单例模式、工厂模式及适配器模式、装饰器模式)
目录 0 、设计模式简介 一、单例模式 二、工厂模式 三、适配器模式 四、装饰器模式 0 、设计模式简介 设计模式可以分为以下三种: 创建型模式:用来描述 “如何创建对象”,它的主要特点是 “将对象的创建和使用分离”。包括单例、原型、工厂方法、…...

为wget命令设置代理
使用-e参数 wget本身没有专门设置代理的命令行参数,但是有一个"-e"参数,可以在命令行上指定一个原本出现在".wgetrc"中的设置。于是可以变相在命令行上指定代理: -e, --executeCOMMAND 执行.wgetrc格式的命令 例如&…...
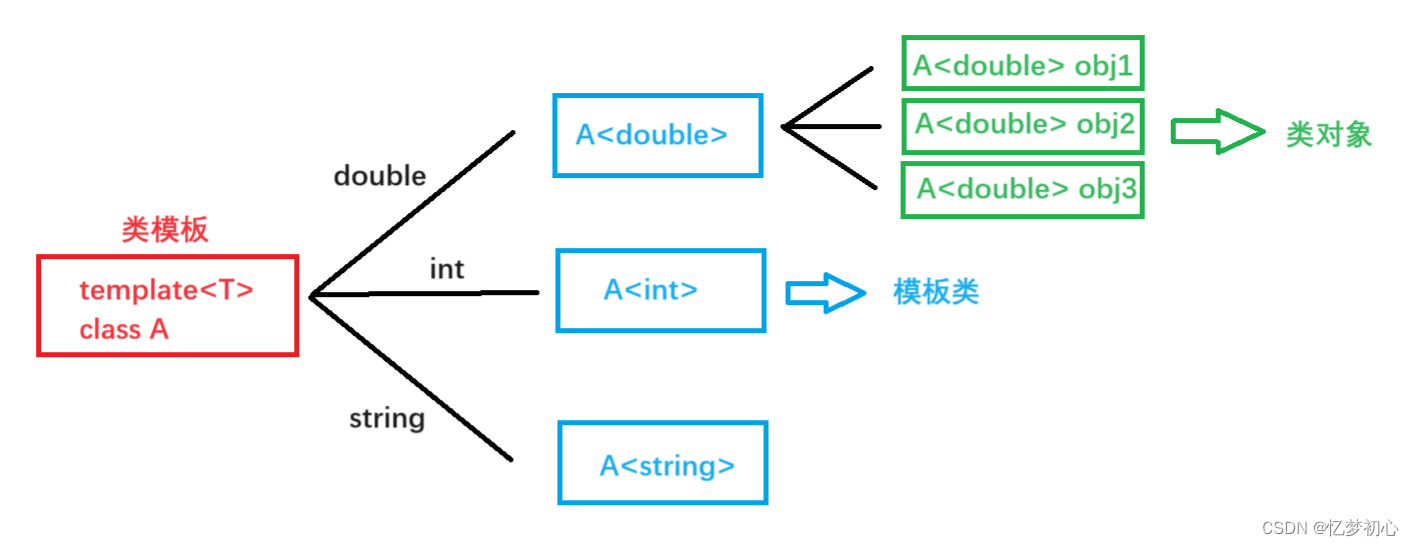
【C++深入浅出】模版初识
目录 一. 前言 二. 泛型编程 三. 函数模版 3.1 函数模版的概念 3.2 函数模版的格式 3.3 函数模版的原理 3.4 函数模板的实例化 3.5 模板参数的匹配原则 四. 类模版 4.1 类模版的定义 4.2 类模版的实例化 一. 前言 本期我们要介绍的是C的又一大重要功能----模版。通…...

系统架构设计师-第18章-安全架构设计理论与实践-软考学习笔记
安全架构概述 信息的可用性、元略性、机密性、可控性和不可抵赖性等安全保障显得尤为重要,而满足这些诉求,离不开好的架构设计. 信息安全面临的威胁 常见的安全威胁有以下几种. (1)信息泄露 (2) 破坏信息的元整性: 数据被非授极地进行增删、修改成破坏…...

2023年吉安市“振兴杯”职业技能大赛网络安全项目样题
2023年吉安市“振兴杯”职业技能大赛 网络安全项目样题 需要竞赛环境可私信博主 赛题说明 一、竞赛项目简介 竞赛共分为:A.基础设施设置与安全加固;B.网络安全事件响应、数字取证调查和应用安全;C.CTF夺旗-攻击;D.CTF夺旗-防御等四…...

python爬虫selenium和ddddocr使用
python爬虫selenium和ddddocr使用 selenium使用 selenium实际上是web自动化测试工具,能够通过代码完全模拟人使用浏览器自动访问目标站点并操作来进行web测试。 通过pythonselenium结合来实现爬虫十分巧妙。 由于是模拟人的点击来操作,所以实际上被反…...

【vim 学习系列文章 12 -- vimrc 那点事】
文章目录 系统级及本地 vimrc 文件设置 vimrc 的路径 系统级及本地 vimrc 文件 当 Vim 启动时,编辑器会去搜索一个系统级的 vimrc 文件来进行系统范围内的默认初始化工作。 这个文件通常在你系统里 $VIM/vimrc 的路径下,如果没在那里,那你可…...

spring.factories介绍
spring.factories 是 Spring Framework 中的一个配置文件,它用于自动装配和加载 Spring 应用程序中的各种组件。该文件位于 META-INF/spring.factories,通常位于 JAR 文件的资源路径下。 spring.factories 文件采用键值对的形式,每个键代表一…...
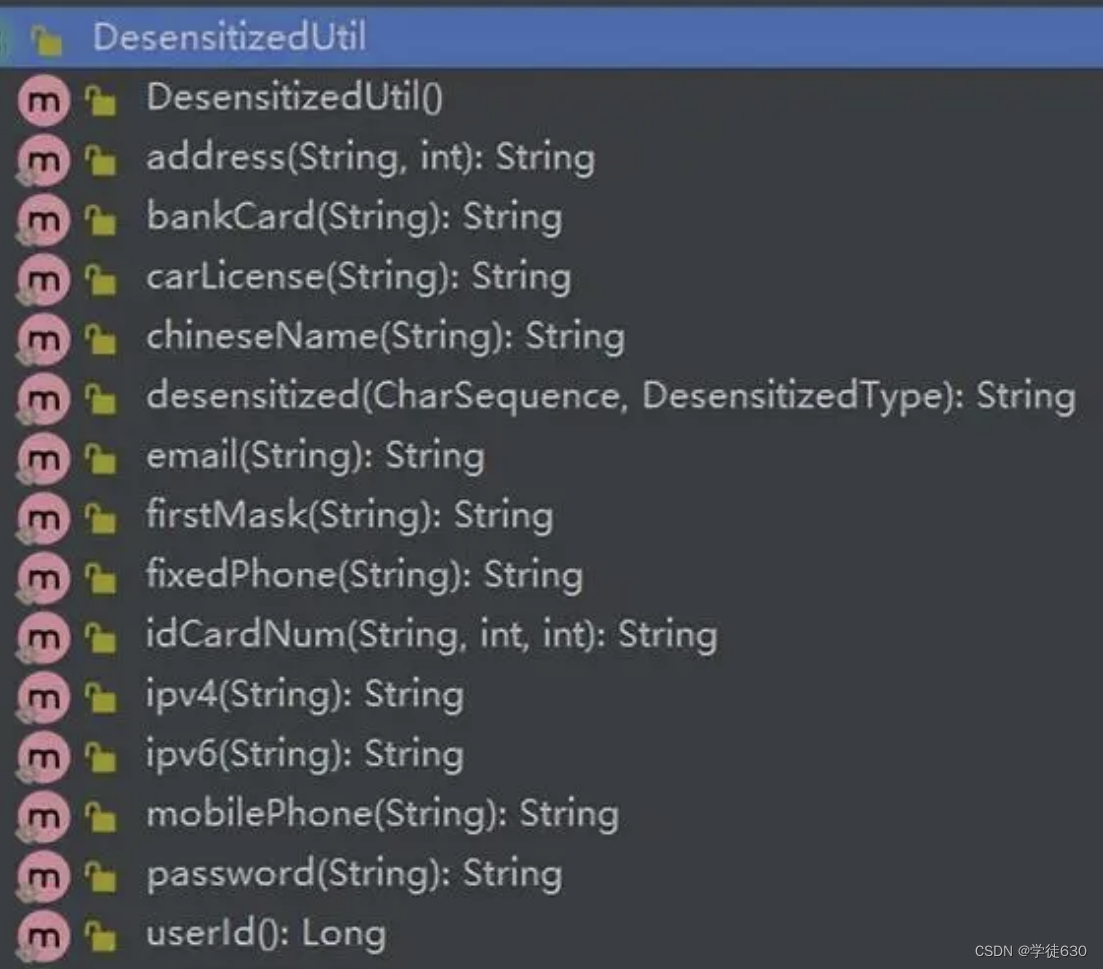
业务设计——用户敏感信息展示脱敏及其反脱敏
业务需求 将用户敏感信息脱敏展示到前端是出于保护用户隐私和信息安全的考虑。 敏感信息包括但不限于手机号码、身份证号、银行卡号等,这些信息泄露可能导致用户个人信息的滥用、身份盗用等严重问题。脱敏是一种常用的保护用户隐私的方式,它的目的是减少…...

Hadoop分布式安装
首先准备好三台服务器或者虚拟机,我本机安装了三个虚拟机,安装虚拟机的步骤参考我之前的一篇 virtualBox虚拟机安装多个主机访问虚拟机虚拟机访问外网配置-CSDN博客 jdk安装 参考文档:Linux 环境下安装JDK1.8并配置环境变量_linux安装jdk1.8并…...

Python——PyQt5以及Pycharm相关配置
PyQt5目录 常见的GUI框架一、安装pyqt5pip install pyqt5pip install pyqt5-tools二、Qt Designer三、在PyCharm中配置相关toolQtDisigner配置PyUIC配置PyRCC配置常见的GUI框架 Tkinter:Python内置的GUI框架,使用TCL实现,Python中内嵌了TCL解释器,使用它的时候不用安装额外…...

java集成海康预览抓图出现内存一直上涨问题
求助:在java 中集成海康sdk后批量抓图出现内存上涨问题,不论是预览后不关闭继续预览,还是预览后关闭预览,然后重新预览都没有解决这个问题(抓图正常),尝试使用第三方解码器ffmpeg来进行解码&…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

学校招生小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的学校招生小程序源码,专为学校招生场景量身打造,功能实用且操作便捷。 从技术架构来看,ThinkPHP提供稳定可靠的后台服务,FastAdmin加速开发流程,UniApp则保障小程序在多端有良好的兼…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...

基于IDIG-GAN的小样本电机轴承故障诊断
目录 🔍 核心问题 一、IDIG-GAN模型原理 1. 整体架构 2. 核心创新点 (1) 梯度归一化(Gradient Normalization) (2) 判别器梯度间隙正则化(Discriminator Gradient Gap Regularization) (3) 自注意力机制(Self-Attention) 3. 完整损失函数 二…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...

怎么让Comfyui导出的图像不包含工作流信息,
为了数据安全,让Comfyui导出的图像不包含工作流信息,导出的图像就不会拖到comfyui中加载出来工作流。 ComfyUI的目录下node.py 直接移除 pnginfo(推荐) 在 save_images 方法中,删除或注释掉所有与 metadata …...