大模型在数据分析场景下的能力评测
“你们能对接国产大模型吗?”
“开源的 LLaMA 能用吗,中文支持怎么样?”
“私有化部署和在线服务哪个更合适?”
自 7 月 14 日发布 AI 数智助理 Kyligence Copilot 后,我们收到了很多类似上面的咨询,尤其是我们很多来自银行、保险等的大型金融客户。选择合适的大模型,是当下客户们的痛点,我们有些客户甚至把能找到的大模型都测试了一遍。“百模大战”中,客户如何为合适的场景选择合适的大模型,成了巨大的挑战。
“对接下 A 模型,下周老板 Luke 要去见客户”
“对接下 B 模型,某大客户销售说不对接客户部署的大模型,我们没法见领导”
“xxx 大模型公司又出了一个 xxx 亿参数的大模型,这个我们赶紧测试下”
我们的产研团队则在“百模大战”中疲于应付,对接和测试的速度远远赶不上各大大模型公司发版的速度。而在企业级市场,严谨、客观、实用则是企业级软件必须要做到的,我们必须要负责任地告诉我们的客户相关信息。我们更希望技术团队不需要为了适配各种大模型而浪费宝贵的资源和时间。
“我们搞一个大模型评测框架吧!”,来自我们研发副总的一句话,迅速成了一个大家积极推动的工作。在百忙之中,我们认真研究和探索,最终随着我们最近几个版本的升级,几个大模型的顺利对接,我们抽象出了一套 数据分析场景下的大模型能力评测框架(Kyligence LLM Benchmark for Data & Analytics)。有了这个评测框架,我们可以很轻松地在我们的数据和指标平台的场景下,对各种大模型进行快速的对接和评测,并通过对标 GPT,来获得不同维度的评分,为我们自己对接各种大模型带来了很大的便利,也为客户选择合适的大模型带来了有效的参考标准。
在这次评测中,我们对 OpenAI GPT-3.5、百川智能、智谱 AI、开源 Falcon-40B 和 LLaMa2-13B 等常见的国内外商业及开源大模型进行测试,并得出如图 1 所示的结果。从结果看到:
- 参数更多的大模型拥有更好的表现,而且在 400 亿参数以上时才能取得较好的综合体验;
- OpenAI GPT-3.5-Turbo 具有最好的综合表现;
- 智谱 AI 的 ChatGLM-Pro 在图表推荐、代码生成(指标)等方面略超过 GPT-3.5-Turbo;
- 百川智能 Baichuan2-53B 在结果可读性和洞察自动化方面表现更佳;
- 开源大模型 Falcon-40B 和 LLaMA2-13B 在中文报告撰写表现稍逊。
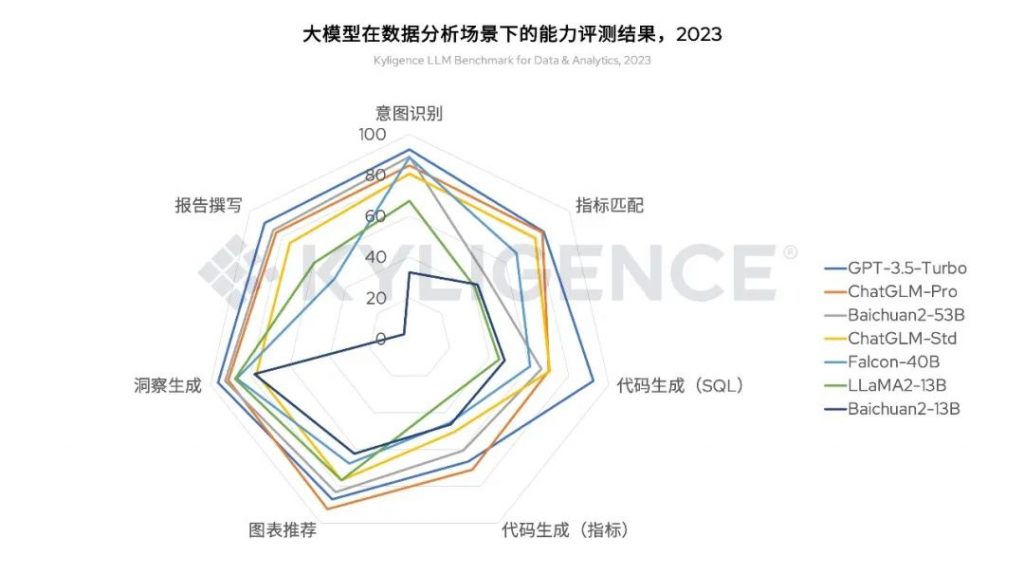
图 1 大模型在数据分析场景下的能力评测结果,2023
#01 大模型的常见数据分析场景
Gartner 在最近发布的《2024 年十大战略技术趋势》中提到,在全民化的生成式 AI 趋势下,“大型语言模型使企业能够通过丰富的语义理解,以对话的形式将员工与知识相连接。” 在这种趋势下,将大模型和大数据结合,用 AI 帮助企业提升数据使用效率、加速数据驱动业务决策,正在成为企业数智化转型的重要目标。
根据研究机构爱分析在文章《大模型+数据分析的应用场景与实现路径》中介绍(如图 2 所示),企业将大模型技术应用到数据分析场景中通常有以下几种常见形式:
- 生成类应用:以对话式交互、内容生成、代码开发、虚拟专家等方式,智能生成报表、分析报告等内容,缩短 Data-to-Insight 时间
- 决策类应用:通过自动化的结果风险预警、指标归因分析等方式,帮助用户提升决策效率

图 2 大模型在数据分析落地场景,引用自爱分析《大模型+数据分析的应用场景与实现路径》
Kyligence Copilot 在指标平台之上结合大语言模型能力,已基本覆盖了这些主流场景。下面是部分有代表性的场景截图,以帮助读者直观理解这些应用场景:
- 生成类应用:支持自然语言方式搜索业务指标,评估 KPI 并生成分析报告,自动化指标计算等能力
- 决策类应用:内置自动归因分析、评估风险指标、协作工具集成等能力,实现组织决策智能

图 3 对话式交互分析

图 4 自动生成分析报告(内容生成)

图 5 对指标和结果进行自动归因分析(智能决策)
#02 评测标准
我们对以上场景的公共能力进行抽象归纳,并初步总结了一套评测标准。首先,数据是企业开展经营决策的重要依据,准确性毋庸置疑是底线要求。除此之外,AI 产生的分析结论是否能被客户完整理解,以及是否能自动产生用户未知的洞察,诸如此类也是大模型在数据分析场景下的重要能力。综合考虑这些能力,我们将从以下三个方面设置评测标准:
- 数据准确性:作为底线要求,AI 计算的指标结果必须是准确的
- 结果可读性:AI 能够提供较好的交互体验,以向用户展示和解释分析结论
- 洞察自动化:除了回答用户问题,AI 还能自动从数据中发现未知洞察
根据这三方面评测标准,我们重点评估如下图所示的几个关键步骤:
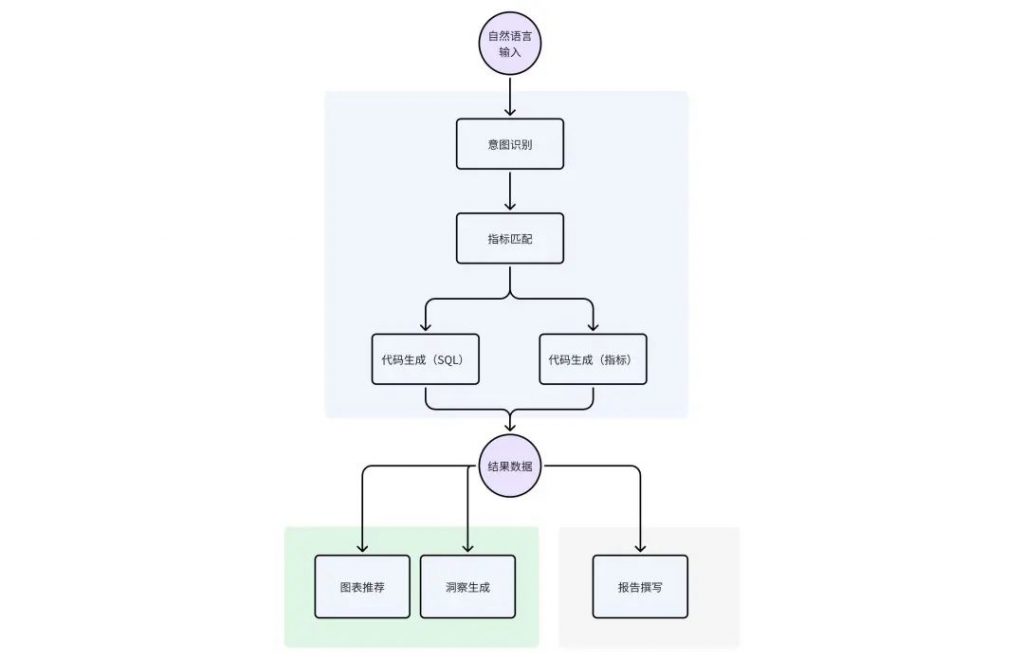
图 6 影响评测结果的关键步骤
2.1 数据准确性
AI 从获取自然语言输入的指令到返回结果,往往分为以下几个步骤。只有确保每个步骤准确无误,才能保证整体的数据准确性。
- 意图识别:从用户输入的自然语言中理解用户的分析意图(如指标查询、归因分析、报告生成等)
- 指标匹配:根据用户意图,搜索并匹配所使用的业务指标
- 代码生成:根据所匹配的业务指标,翻译成从底层数据平台获取数据的请求代码
值得说明的是,在“代码生成”这一步,业界常见有两种不同的做法:
- 生成 SQL:从底层数据源直接获取数据;即根据所匹配的业务指标的计算逻辑,生成 SQL 语句并访问数据库(通常是宽表)
- 生成指标 API 请求:从指标平台获取数据;即根据所匹配的业务指标口径,调用指标平台 API 获取指标结果,好处是指标平台从架构上统一管理指标口径,可保证指标业务逻辑合理性
2.2 结果可读性
获取结果数据之后,AI 需要基于这些数据生成用户容易读懂的内容,如图表、文字等:
- 图表推荐:根据获取的结果数据,按用户需求或指标特征推荐可视化图表,为用户提供直观的可视化体验
- 洞察生成:根据获取的结果数据,以自然语言的形式生成洞察总结,便于用户理解
2.3 洞察自动化
Gartner 在 2023 年的《增强分析市场指引》报告中指出,洞察自动化(Automated Insights)是实现 AI 增强分析的重要能力。洞察自动化不仅能大幅提高数据分析的效率,更能通过发现未知洞察,为数据分析师和业务用户提供新的价值。此类应用场景通常包括自动化生成报告、自动创建仪表盘、自动归因分析、自动推送任务等。
在本次评测中,我们加入了一个在运营管理工作中撰写报告的场景示例:
- 报告撰写:融合了结果分析、归因分析、指标预警等能力,根据指标完成情况自动撰写总结报告,包含整体进展分析、高风险目标、业务建议等,且支持文档下载
#03 评测方案
为开展本次测评,我们兼顾公平性、效率、成本等多方因素,采用了“统一数据集 + 大模型裁判员”的形式,即在同样的评测数据集(带标准答案)上,对不同大模型服务进行实测,并引入一个标准的大模型服务作为裁判员,对各个大模型服务的实测结果进行打分,最终的打分结果即代表最终评测的结果。
3.1 评测数据集
我们从金融、零售等行业的常见数据分析场景总结归纳了一套由问答组(问题 + 标准答案)构成的评测数据集,根据上一小节提到的评测标准分为 7 个分类,其中为每个分类精选最有代表性的 20 组问答,共计 140 组。值得说明的是,该评测数据集以中文为主,以更贴合国内数据分析真实场景。
3.2 评分方案
整体评分过程分为两部分:1)对每个受测大模型,在评测数据集上进行测试,并产生结果集;2)针对每个受测大模型产生的结果集,由一个公认通用能力较强的大模型担任裁判员,按照百分制对受测模型的结果集进行打分。分数最高者为获胜者。
在本次评测中,我们使用 OpenAI GPT-4 担任裁判员,打分时主要考虑以下几个方面:
- 是否符合用户问题和查询上下文
- 和标准答案的差距
- 回答是不是对用户查询有帮助
- 要尽量客观公平的给出答案
#04 评测结果
根据上述方案,我们对 OpenAI GPT-3.5-Turbo、智谱 AI 的 ChatGLM-Pro 和 ChatGLM-Std、百川智能 Baichuan2-53B 和 Baichuan2-13B、开源 Falcon-40B 和 LLaMA2-13B 等国内外主流的商业、开源大模型服务进行了评测。以下是各受测大模型在不同评测标准下的打分数据:
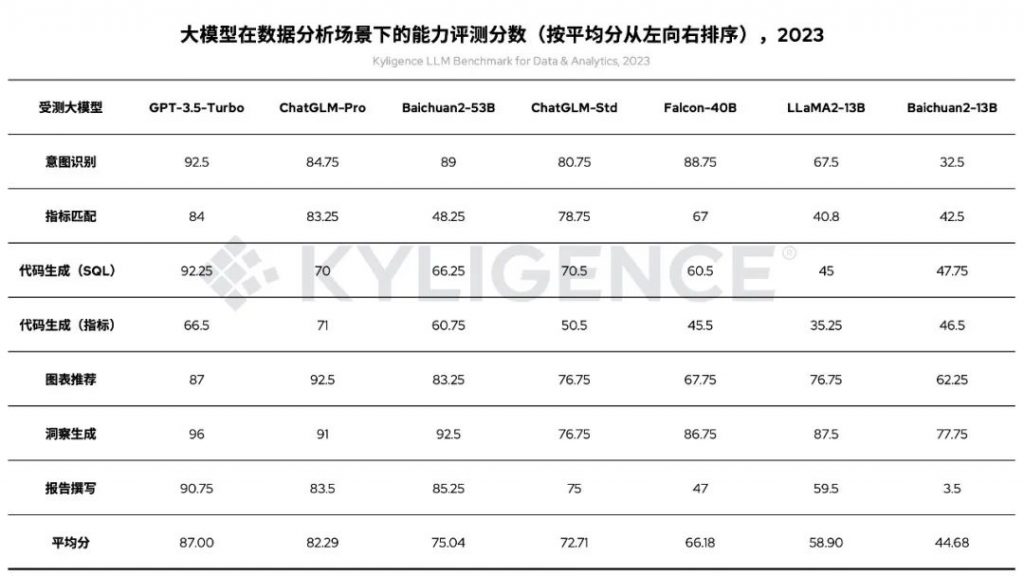
图 7 大模型在数据分析场景下的能力评测分数(按平均分从左向右排序),2023
根据这个数据,我们使用雷达图对各受测大模型的能力评测结果进行可视化展示:
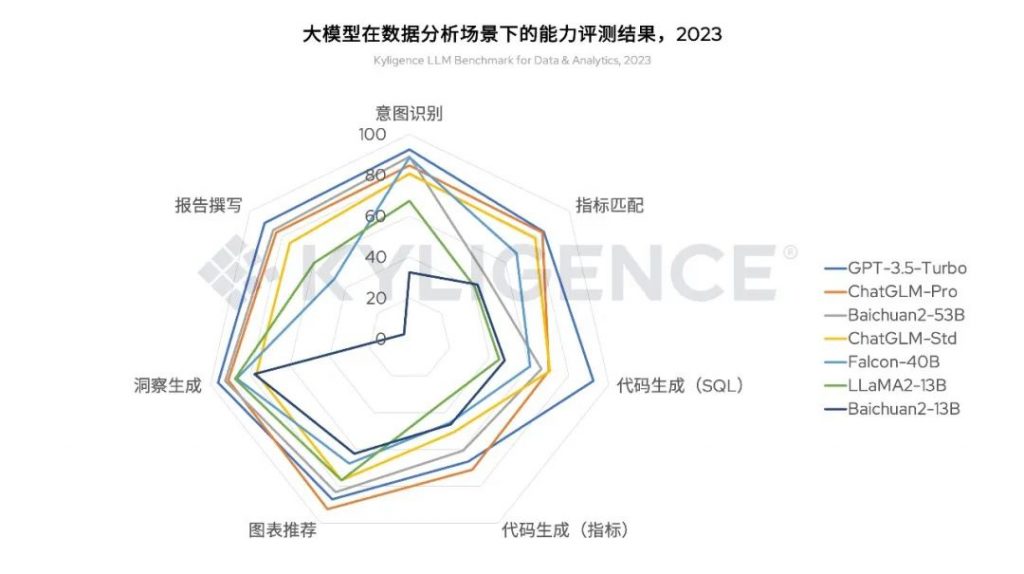
图 8 大模型在数据分析场景下的能力评测结果,2023
根据以上测试结果,我们初步得出以下结论:
- 参数更多的大模型拥有更好的表现。但参数越多所消耗的算力资源也越多,建议用户从成本和收益角度综合评判;
- 在该评测框架下,OpenAI GPT-3.5-Turbo 具有最好的综合表现,智谱 AI 的 ChatGLM-Pro 在图表推荐、代码生成(指标)等方面已超越 GPT-3.5-Turbo,百川智能 Baichuan2-53B 在结果可读性和洞察自动化方面表现更佳;
- 在该评测框架下,开源大模型 Falcon-40B 和 LLaMA2-13B 在中文报告撰写表现稍逊,可能因为对中文语言生成支持不足;
- 在该评测框架下,当大模型参数量在 400 亿以上时,一般才会有比较好的综合表现;
- 算力资源主要影响大模型性能,以及可部署的模型参数量级,对数据分析应用场景的表现影响不大。
#05 已知限制和情况说明
- 本次测评数据集基于 Kyligence Copilot 使用场景总结,可能不适用于企业所有数据分析场景
- 本次测评基于各大模型服务的默认配置,未进行任何调参;值得说明的一点是,对大模型服务进行调优可能进一步优化评测结果
- 本次测评针对不同大模型所使用的算力情况如下:
- GPT-3.5-Turbo / ChatGLM / Baichuan2-53B 均基于厂商提供的 SaaS 服务,算力资源不详
- Falcon-40B / Baichuan2-13B / LLaMa2-13B 是基于对应的开源模型在实验室私有化部署了本地服务,算力为 4 块 NVIDIA RTX 4090 24GB 显卡
- 因算力有限等因素,我们尚未对 LLaMa2-70B 完成评测;同时,我们期待在开源大模型有更好中文支持的情况下再次进行评测
#06 结语
该评测方案是从我们开发 Kyligence Copilot 期间对各类大模型进行能力评测的工作总结而来,希望对您有所帮助。如果您正在对大模型进行技术选型,或正在探索大模型在数据分析场景的落地应用,欢迎点击链接
与我们进一步沟通。
关于 Kyligence
跬智信息(Kyligence)由 Apache Kylin 创始团队于 2016 年创办,是领先的大数据分析和指标平台供应商,提供企业级 OLAP(多维分析)产品 Kyligence Enterprise 和一站式指标平台 Kyligence Zen,为用户提供企业级的经营分析能力、决策支持系统及各种基于数据驱动的行业解决方案。
Kyligence 已服务中国、美国、欧洲及亚太的多个银行、证券、保险、制造、零售、医疗等行业客户,包括建设银行、平安银行、浦发银行、北京银行、宁波银行、太平洋保险、中国银联、上汽、长安汽车、星巴克、安踏、李宁、阿斯利康、UBS、MetLife 等全球知名企业,并和微软、亚马逊云科技、华为、安永、德勤等达成全球合作伙伴关系。Kyligence 获得来自红点、宽带资本、顺为资本、斯道资本、Coatue、浦银国际、中金资本、歌斐资产、国方资本等机构多次投资。
相关文章:
大模型在数据分析场景下的能力评测
“你们能对接国产大模型吗?” “开源的 LLaMA 能用吗,中文支持怎么样?” “私有化部署和在线服务哪个更合适?” 自 7 月 14 日发布 AI 数智助理 Kyligence Copilot 后,我们收到了很多类似上面的咨询,尤其…...

[笔记] 关于y1变量取名冲突的问题
参考博客 遇到的问题和这位老哥的一模一样。 结论是:当我们用math头文件的时候,不能在全局定义 y0 和 y1,j0、j1、jn、yn。...
)
js笔记(函数参数、面向对象、装饰器、高级函数、捕获异常)
JavaScript 笔记 函数参数 默认参数 在 JavaScript 中,我们可以为函数的参数设置默认值。如果调用函数时没有传递参数,那么参数将使用默认值。 function greet(name World) {console.log(Hello, ${name}!); }greet(); // 输出:Hello, Wo…...
- Istio 动态准入 Webhook 配置)
Istio实战(八)- Istio 动态准入 Webhook 配置
准入 Webhook 是 HTTP 方式的回调,接收准入请求并对其进行相关操作。 可定义两种类型的准入 Webhook,Validating 准入 Webhook 和 Mutating 准入 Webhook。使用 Validating Webhook,可以通过自定义的准入策略来拒绝请求; 使用 Mut…...

Vue的安装
----------------------------------------------------前置---------------------------------------------------- 1.node.js的下载安装、缓存路径的设置 ①安装 ②设置npm prefix, cache 2.NODE_PATH、PATH ①系统变量中加 ②PATH中加 3.配置镜像源 -----------------------…...

macOS M1安装wxPython报错
macOS12.6.6 M1安装wxPython失败: 报错如下: imagtiff.cpp:37:14: fatal error: tiff.h file not found解决办法: 下载源文件重新编译(很快,5分钟全部搞定),分三步走: 第一步&…...
【数据结构】交换排序
⭐ 作者:小胡_不糊涂 🌱 作者主页:小胡_不糊涂的个人主页 📀 收录专栏:浅谈数据结构 💖 持续更文,关注博主少走弯路,谢谢大家支持 💖 冒泡、快速排序 1. 冒泡排序2. 快速…...

腾讯云2023年双11服务器优惠活动及价格表
腾讯云2023年双11大促活动正在火热进行中,腾讯云推出了一系列服务器优惠活动,云服务器首年1.8折起,买1年送3个月!境外云服务器15元/月起,买更多省更多!下面给大家分享腾讯云双11服务器优惠活动及价格表&…...
PointNet++复现、论文和代码研读
文章目录 复现1.创建虚拟环境并进入2.安装pytorch3.分割模型的训练和测试3.1.下载数据处理数据3.2.训练分割模型3.3分割模型的测试 4.分类模型的训练和测试 论文研读制作自己的数据集流程分割模型数据集准备 复现 https://github.com/yanx27/Pointnet_Pointnet2_pytorch 1.创…...

轨迹规划 | 图解路径跟踪PID算法(附ROS C++/Python/Matlab仿真)
目录 0 专栏介绍1 PID控制基本原理2 基于PID的路径跟踪3 仿真实现3.1 ROS C实现3.2 Python实现3.3 Matlab实现 0 专栏介绍 🔥附C/Python/Matlab全套代码🔥课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等)&a…...
吴恩达《机器学习》1-3:监督学习
一、监督学习 例如房屋价格的数据集。在监督学习中,我们将已知的房价作为"正确答案",并将这些价格与房屋的特征数据一起提供给学习算法。学习算法使用这些已知答案的数据来学习模式和关系,以便在未知情况下预测其他房屋的价格。这就…...

Flutter PopupMenuButton下拉菜单
下拉菜单是移动应用交互中一种常见的交互方式,可以使用下拉列表来展示多个内容标签,实现页面引导的作用。在Flutter开发中,实现下拉弹框主要有两种方式,一种是继承Dialog组件使用自定义布局的方式实现,另一种则是使用官方的PopupMenuButton组件进行实现。 如果没有特殊的…...

国家数据局正式揭牌,数据专业融合型人才迎来发展良机【文末送书五本】
国家数据局正式揭牌,数据专业融合型人才迎来发展良机 国家数据局正式揭牌,数据专业融合型人才迎来发展良机 摘要书籍简介数据要素安全流通Python数据挖掘:入门、进阶与实用案例分析数据保护:工作负载的可恢复性Data Mesh权威指南分…...
H5游戏源码分享-像素小鸟游戏(类似深海潜艇)
H5游戏源码分享-像素小鸟游戏(类似深海潜艇) 点击屏幕控制小鸟的飞行高度 整个小游戏就用JS完成 项目地址:https://download.csdn.net/download/Highning0007/88483228 <!DOCTYPE HTML> <html><head><meta http-equiv…...

Vue 3 响应式对象:ref 和 reactive 的使用和区别
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是尘缘,一个在CSDN分享笔记的博主。📚📚 👉点击这里,就可以查看我的主页啦!👇&#x…...

H5游戏源码分享-密室逃脱小游戏(考验反应能力)
H5游戏源码分享-密室逃脱小游戏(考验反应能力) 预判安全位置,这个需要快速的反应能力 源码 <!DOCTYPE html> <html> <head> <meta http-equiv"Content-Type" content"text/html; charsetutf-8" /&…...
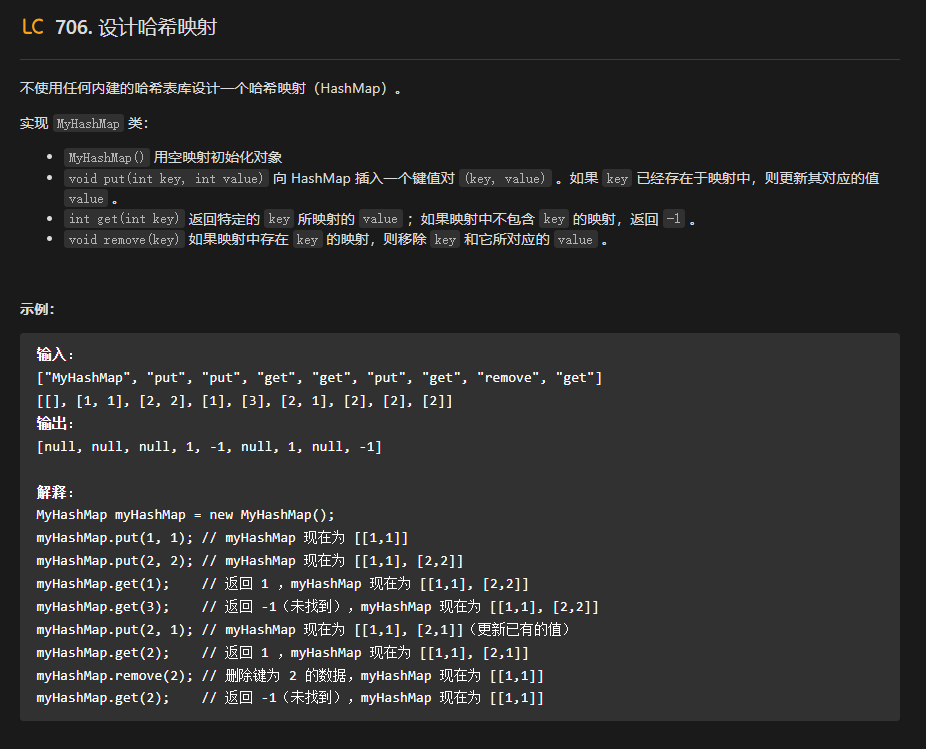
【LeetCode刷题-哈希】--706.设计哈希映射
706.设计哈希映射 class MyHashMap {private class Pair{private int key;private int value;public Pair(int key ,int value){this.key key;this.value value;}public int getKey(){return key;}public int getValue(){return value;}public void setValue(int value){this…...
前端 : 用HTML ,CSS ,JS 做一个点名器
1.HTML: <body><div id "content"><div id"top"><div id "name">XAiot2302班点名器</div></div><div id "center"><div id "word">你准备好了吗?</di…...
css:button实现el-radio效果
先看最终效果: 思路: 一、 首先准备好按钮内容:const a [one,two,three] 将按钮循环展示出来,并设置一些样式,将按钮背景透明: <button v-for"(item,index) in a" :key"in…...

算法工程师-机器学习-数据科学家面试准备4-ML系统设计
https://github.com/LongxingTan/Machine-learning-interview 算法工程师-机器学习-数据科学家面试准备1- 概述 外企和国外公司、春招、秋招算法工程师-机器学习-数据科学家面试准备2- Leetcode 300算法工程师-机器学习-数据科学家面试准备3-系统设计算法工程师-机器学习-数据…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

[免费]微信小程序问卷调查系统(SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的微信小程序问卷调查系统(SpringBoot后端Vue管理端)【论文源码SQL脚本】,分享下哈。 项目视频演示 【免费】微信小程序问卷调查系统(SpringBoot后端Vue管理端) Java毕业设计_哔哩哔哩_bilibili 项…...