推荐算法面试
当然可以,请看下面的解释和回答:
一面(7.5)
问题:推荐的岗位和其他算法岗(CV,NLP)有啥区别?
解释: 面试官可能想了解你对不同算法岗位的理解,包括它们的技术侧重点和应用领域。
回答:
推荐算法主要集中在个性化推荐领域,涉及协同过滤、深度学习等技术,用于分析用户行为和产品特征,从而进行个性化推荐。CV(计算机视觉)主要处理图像和视频相关任务,如图像识别、目标检测等。NLP(自然语言处理)则关注文本数据,包括文本分类、情感分析等任务。
问题:写个代码(补全训练过程,可以上网查,也可以复制自己的代码)。
解释: 面试官可能希望了解你的编程能力和对机器学习训练过程的理解。
回答:
import torch import torch.nn as nn import torch.optim as optim # 定义模型 class MyModel(nn.Module): def __init__(self): super(MyModel, self).__init__() self.fc = nn.Linear(in_features=10, out_features=1) # 线性层 def forward(self, x): return self.fc(x) # 定义数据和标签 inputs = torch.randn(100, 10) # 100个样本,每个样本10个特征 labels = torch.randn(100, 1) # 对应的标签 # 初始化模型、损失函数和优化器 model = MyModel() criterion = nn.MSELoss() # 选择均方误差损失函数 optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器,学习率为0.001 # 训练过程 num_epochs = 10 for epoch in range(num_epochs): outputs = model(inputs) # 前向传播 loss = criterion(outputs, labels) # 计算损失 optimizer.zero_grad() # 梯度清零 loss.backward() # 反向传播 optimizer.step() # 更新权重 print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}') # 输出每个epoch的loss信息 # 讲一遍刚才写的代码
这段代码演示了一个简单的线性回归模型的训练过程,使用了均方误差损失函数和Adam优化器。
问题:线性层和激活函数层如何交换?
解释: 面试官想了解你对神经网络结构的理解,以及在调整网络结构时的灵活性。
回答:
在神经网络中,线性层和激活函数层的顺序可以互换。通常,线性层(全连接层)负责学习特征的线性组合,而激活函数则引入非线性性质。在网络的不同位置使用激活函数可以引入非线性,提高网络的表达能力。激活函数常用的有ReLU、Sigmoid和Tanh等。在网络设计时,可以根据任务的需要在线性层和激活函数层之间灵活选择顺序,以及使用不同的激活函数。
问题:Adam优化器和SGD的区别?
解释: 面试官想考察你对优化算法的了解,特别是Adam和随机梯度下降(SGD)的区别。
回答:
Adam和SGD都是常用的优化算法。主要
区别在于学习率的调整和动量的使用。Adam是自适应学习率的优化算法,它能够根据每个参数的历史梯度自适应地调整学习率,适应性更强。而SGD则使用固定的学习率,需要手动设置学习率大小。另外,Adam引入了动量的概念,可以加速收敛过程,而SGD在没有动量的情况下可能会陷入局部最小值。
问题:分类问题为什么用交叉熵损失函数不用MSE?
解释: 面试官想了解你对损失函数选择的理解,特别是在分类问题中为什么使用交叉熵损失函数而不是均方误差(MSE)损失函数。
回答:
在分类问题中,输出是一个概率分布,通常使用Softmax函数将网络输出转换为概率分布。交叉熵损失函数(Cross-Entropy Loss)在衡量两个概率分布之间的差异时非常有效,特别适用于多分类任务。它的定义更符合分类问题的特性,可以最大化正确类别的概率。相比之下,均方误差损失函数(MSE)则用于回归问题,它衡量实际输出和目标值之间的差异。在分类问题中使用MSE损失函数可能不够合适,因为它不考虑类别之间的关系,不容易收敛到一个好的解。
- 基于图神经网络的推荐模型:
我曾经参与开发了一个基于图神经网络的推荐系统。该系统通过构建用户-商品交互图,利用图神经网络学习用户和商品的表示,从而实现个性化推荐。图神经网络能够捕捉用户和商品之间的复杂关系,提高推荐准确度。
- 一维卷积的作用:
一维卷积在处理序列数据(如文本、时间序列)时非常有用。它能够学习局部特征和模式,通过滑动窗口的方式在序列上提取特征,常用于文本分类、情感分析等任务。
- INfoNCELoss和BPRLoss:
INfoNCELoss(Noise Contrastive Estimation)和BPRLoss(Bayesian Personalized Ranking Loss)都是用于推荐系统中的损失函数。INfoNCELoss用于对比学习,帮助模型学习正样本和负样本之间的区别;而BPRLoss则用于排序任务,优化模型对正例和负例的排名顺序。
- 数据处理和Spark架构:
我具备丰富的数据处理经验,熟悉常用的数据清洗、特征工程等技术。关于Spark,它是一个分布式计算框架,拥有强大的数据处理能力,由于时间关系,我只能简单介绍其Map和Reduce功能,但我对其它组件,如Spark SQL、Spark Streaming等也有一定了解。
- 优化运算速度方法:
提高运算速度的方法包括使用更高效的算法、并行计算、硬件加速(如GPU加速)、分布式计算等。选择合适的算法和合理的数据结构,充分利用硬件资源,可以显著提高运算速度。
- 第一个深度学习项目:
我的第一个深度学习项目是一个图像分类任务。我们使用卷积神经网络(CNN)对图像进行特征提取,并通过全连接层进行分类。我负责了数据预处理、模型设计和训练、结果分析等工作。团队合作中,我积极提出了改进模型的建议,最终取得了良好的分类效果。
二面(7.6)
问题:感觉是个大佬,很厉害,问问题也处变不惊。
解释: 面试官对你的表现给予了正面评价,可能希望测试你的深度和对问题的逻辑思考能力。
问题:对于运算速度有什么优化方法嘛?
解释: 面试官可能想了解你对提高算法运行速度的方法了解程度,特别是在大规模数据处理中。
回答:
提高运算速度的方法有很多,比如使用并行计算、GPU加速、分布式计算、算法优化(如剪枝、近似算法)等。此外,针对具体任务,还可以选择合适的数据结构和算法,以及合理的缓存策略,来提高运算效率。
问题:决策树的生成过程,什么是信息增益?
解释: 面试官想测试你对决策树算法的理解,包括决策树的生成过程和相关概念。
回答:
决策树的生成过程通常使用信息增益(Information Gain)或基尼指数(Gini Index)来选择特征进行节点划分。信息增益是一种用于选择特征的指标,它表示在特定特征下,数据的不确定性减少的程度。在决策树的生成过程中,选择信息增益最大的特征作为当前节点的划分特征,使得子节点中的数据更加纯净。信息增益越大,表示选择该特征能够获得更多的信息,更好地划分数据。
问题:了解深度学习嘛,介绍一些模型。
解释: 面试官想测试你对深度学习领域的了解程度,以及是否熟悉常见的深度学习模型。
回答:
深度学习是机器学习的分支,主要基于神经网络模型。常见的深度学习模型包括多层感知机(MLP)、卷积神经网络(CNN)、循环神经网络(RNN)、长短时记忆网络(LSTM)、Transformer
等。这些模型在图像识别、自然语言处理、语音识别等领域取得了显著的成果。
问题:你觉得深度学习和机器学习的区别?
解释: 面试官希望了解你对深度学习和机器学习的认知,以及你是否能清晰区分它们之间的差异。
回答:
机器学习是一种广泛的概念,涵盖了各种各样的算法和技术,用于让计算机系统在没有被明确编程的情况下从数据中学习和提取规律。而深度学习则是机器学习的一个分支,它使用深层神经网络(通常包含多个隐藏层)来学习复杂的特征表示。深度学习通常需要大量的数据和计算资源,适用于处理大规模、高维度的数据,例如图像、语音、文本等。
问题:你觉得现在的大模型会如何影响算法工程师这个职业?
解释: 面试官希望了解你对当前技术趋势的看法,以及对未来算法工程师职业发展的预测。
回答:
现在的大模型(如GPT-3、BERT等)在自然语言处理和其他领域取得了巨大成功,但也面临挑战,例如计算资源的需求和模型的可解释性问题。这些大模型的出现增加了算法工程师处理复杂任务的能力,但也要求算法工程师具备更多的领域知识、深入了解模型的结构和原理,以及对实际问题的抽象和建模能力。未来,我认为算法工程师将更加需要具备跨学科的知识和综合能力,能够在大模型和实际应用之间找到平衡点,为解决实际问题提供创新性的解决方案。
问题:为什么问我选数据还是算法?
解释: 面试官可能想了解你的职业规划和兴趣方向,以及你在数据和算法领域的优势和倾向。
回答:
我认为数据和算法在实际应用中是相辅相成的。好的数据是算法成功的基础,而算法则能够从数据中挖掘出更深层次的信息。我个人更倾向于算法领域,因为我对算法的研究和应用有浓厚兴趣,也有一定的经验和技能。然而,我也深知数据对于算法的重要性,因此在工作中我会注重数据的质量和处理,以保证算法能够取得好的效果。
问题:工作内容?
解释: 面试官希望了解你在之前工作中具体负责的任务和项目,以及你的工作经验。
回答:
在之前的工作中,我主要负责数据预处理、特征工程、模型选择和调优等工作。我参与了一个电商推荐系统的开发项目,负责用户行为数据的处理和特征提取,以及推荐算法的选择和优化。我也参与了一个图像识别项目,负责数据清洗和标注,以及卷积神经网络(CNN)模型的训练和调试。通过这些项目,我积累了丰富的数据处理
和机器学习经验。
三面(7.7)
问题:直观地解释一下Transformer注意力机制。
解释: 面试官想测试你对Transformer模型中注意力机制的理解。
回答:
Transformer模型的注意力机制允许模型在处理序列数据时关注输入序列中不同位置的信息。在注意力机制中,输入序列的每个位置都有一个对应的权重,这个权重决定了该位置的重要性。通过加权求和,模型可以根据权重将不同位置的信息融合起来,从而形成最终的表示。这种机制使得模型能够处理长距离依赖关系,同时保留了输入序列的顺序信息。
问题:你用Transformer做的这个项目介绍一下。
解释: 面试官想了解你的项目经验,特别是使用Transformer模型的项目。
回答:
我使用Transformer模型参与了一个文本生成项目。项目的任务是根据给定的文本片段生成连贯、语义合理的文本。我们使用了Transformer的编码器-解码器结构,其中编码器负责将输入文本编码为隐藏表示,解码器则根据编码器的输出生成新的文本。我们使用了注意力机制,使得模型能够关注输入文本中不同位置的信息,提高了生成文本的质量。在项目中,我主要负责模型的搭建、训练和调优工作。
问题:你是怎么进行数据清洗的?
解释: 面试官想了解你在实际项目中如何处理数据质量问题。
回答:
在数据清洗过程中,我首先进行了缺失值和异常值的处理,使用均值、中位数等统计量填充缺失值,使用四分位数间距等方法识别和处理异常值。然后,我进行了数据标准化和归一化,确保不同特征的数值范围相似,避免特征间的差异影响模型训练。另外,我还进行了重复数据的识别和去重处理,保证数据的唯一性。最后,我进行了文本数据的预处理,包括分词、去停用词、词干化等操作,以便于后续的特征提取和模型训练。
问题:反问。
解释: 面试官会询问你是否有任何问题,这是一个展示你对公司和职位关注程度的机会。
回答:
- 我想了解一下公司对于未来发展方向和技术创新方面的规划,以及在新技术领域的研发投入情况。
- 我想知道团队中的合作氛围和团队成员之间的合作方式,以及团队在项目上的典型工作流程。
- 对于新员工,公司是否提供培训和职业发展的机会,例如技能培训、学术会议参与等。
希望这些回答能够帮助你准备面试!祝你好运!
一面:
- 对推荐算法了解程度:
我具备扎实的推荐算法基础,包括协同过滤、内容推荐、深度学习推荐模型等方面的知识。
- Kaggle比赛模型和优化:
在Kaggle比赛中,我使用了XGBoost和LightGBM等梯度提升树模型,并且进行了特征工程、调参等优化工作。
- 模型融合方法:
我通常使用加权平均、投票法等简单的模型融合方法,根据不同模型的性能和置信度分配权重。
- 关于权重参与训练的问题:
如果将权重作为变量参与训练,可以视作一种学习到的特征权重。与手动调参相比,这种方法具有更好的自适应性,但也会增加模型的复杂度。因此,需要在模型性能和计算资源之间取得平衡。
- 随机森林运行过程:
随机森林是由多个决策树组成的集成模型,它通过随机选择特征子集进行训练,最后将多个决策树的结果进行平均或投票。每个决策树根据特征的不纯度进行递归划分,直到满足停止条件。
- 过拟合和欠拟合判断与解决:
过拟合通常表现为在训练集上表现良好但在测试集上表现差,可以通过增加训练数据、降低模型复杂度、使用正则化等方法来缓解。欠拟合则通常表现为模型无法捕捉数据的复杂关系,可以通过增加特征维度、使用更复杂的模型等方法来改善。
- 梯度消失和梯度爆炸解决方法:
梯度消失问题可以通过使用非饱和激活函数(如ReLU)、Batch Normalization等方法缓解。梯度爆炸问题可以通过梯度截断(Gradient Clipping)等方法处理。
- 关于深度网络层数的选择:
当遇到梯度消失或梯度爆炸问题时,继续增加网络层数可能会加剧问题。因此,我会先尝试减少网络层数,看看是否能够改善问题。在实践中,选择合适的网络深度需要根据具体任务和数据进行实验验证。
二面:
- LR正则项原理:
LR中的正则项通常采用L1或L2范数来限制参数的大小,以防止过拟合。L1正则项倾向于生成稀疏模型,即让一部分特征的权重趋于零,而L2正则项则更倾向于平滑权重,避免参数过大。
- 参数学习与限制学习矛盾问题:
这是一个常见的问题。参数学习和限制学习之间需要权衡,过于自由可能导致过拟合,过于限制则可能导致欠拟合。合适的正则化和交叉验证可以帮助在两者之间找到平衡。
- Cross Validation训练步骤:
Cross Validation通常分为K折交叉验证,将训练集分成K份,其中K-1份用作训练,剩余
1份用作验证。这个过程重复K次,每次将不同的1份作为验证集,其余作为训练集。最后,将K次验证结果的平均作为模型的性能评估。
- Kaggle竞赛规模和Trick:
Kaggle竞赛通常有大规模的数据集和复杂的任务。在项目中,我尝试了一些特征工程的Trick,比如特征交叉、特征选择、数据集集成等,以及调整模型的超参数。这些Trick在提升模型性能方面起到了关键作用。
- 关于CNN和MLP在图像上的效果:
CNN具有卷积层和池化层,能够有效提取图像中的空间特征,因此在图像处理上表现出色。而传统的MLP(全连接神经网络)在处理高维图像数据时,参数量过大,容易引发过拟合,而且无法有效捕捉像素间的空间关系,因此效果相对较差。
- 对Transformer的理解:
Transformer是一种基于自注意力机制(Self-Attention)的深度学习模型,它可以处理不定长序列数据,适用于NLP等领域。Transformer的核心思想是自注意力机制,它能够根据输入序列中不同位置的信息动态分配权重,实现了更好的序列建模效果。同时,Transformer采用了位置编码(Positional Encoding)来保留输入序列的顺序信息。
1. **推荐算法基础:**
- **问题:** 什么是协同过滤推荐算法?它的优缺点是什么?
- **答案:** 协同过滤是一种根据用户之间的相似性或者物品之间的相似性来进行推荐的算法。它可以分为基于用户的协同过滤和基于物品的协同过滤。优点是简单且有效,缺点是可能受到稀疏性和冷启动问题的影响。
2. **机器学习和深度学习:**
- **问题:** 介绍一下你了解的推荐算法中的随机森林和神经网络的应用。
- **答案:** 随机森林可以用于推荐系统中的特征选择和用户行为预测。神经网络,特别是深度学习模型如多层感知机(MLP)、卷积神经网络(CNN)和循环神经网络(RNN),在推荐系统中可以用于学习用户和物品的复杂特征表示。
3. **数据处理和特征工程:**
- **问题:** 如何处理推荐系统中的稀疏数据?
- **答案:** 可以使用技术如矩阵分解、特征组合、嵌入表示等来处理稀疏数据。矩阵分解方法如SVD++可以填充缺失值。嵌入表示方法将用户和物品映射到低维空间,提供了一种处理稀疏数据的方式。
4. **算法设计和优化:**
- **问题:** 介绍一下你在推荐算法中遇到的冷启动问题,并提出解决方案。
- **答案:** 冷启动问题包括用户冷启动和物品冷启动。对于用户冷启动,可以利用用户的社交网络信息或者基于内容的推荐方法进行推荐。对于物品冷启动,可以使用内容推荐或者基于标签的推荐。
5. **编程和算法实现:**
- **问题:** 请实现一个简单的协同过滤算法。
- **答案:** (以基于用户的协同过滤为例)
import numpy as np # 用户-物品矩阵 user_item_matrix = np.array([[1, 0, 2, 3], [4, 0, 0, 5], [0, 1, 2, 0], [1, 0, 0, 4]]) def user_based_collaborative_filtering(user_item_matrix): # 计算用户相似度(余弦相似度) similarity_matrix = np.dot(user_item_matrix, user_item_matrix.T) # 对角线置零(不考虑用户与自身的相似度) np.fill_diagonal(similarity_matrix, 0) # 计算每个用户的推荐分数 scores = np.dot(similarity_matrix, user_item_matrix) return scores # 调用函数得到推荐分数 recommendation_scores = user_based_collaborative_filtering(user_item_matrix) print(recommendation_scores)
这是一个简单的基于用户的协同过滤算法实现,使用余弦相似度计算用户相似度,并基于相似用户的评分进行推荐。
请注意,答案的具体内容可能会因问题的具体表达和面试官的追问而有所调整。在回答问题时,要清晰、简洁地表达观点,展现自己的算法和编程能力。
一面问题回答:
- 数据处理了解吗:
是的,我具备丰富的数据处理经验,包括数据清洗、特征工程、数据转换等。
- Spark架构:
Spark是一个分布式计算框架,它的核心概念包括驱动器(Driver)、任务(Task)、作业(Job)、阶段(Stage)等。除了Map和Reduce,Spark还包括连接器(Connectors)用于连接不同数据源、Spark SQL用于SQL查询、Spark Streaming用于实时数据处理等组件。
- 运算速度优化方法:
提高运算速度的方法包括算法优化、并行计算、硬件加速(如GPU加速)、分布式计算等。选择合适的算法和数据结构、充分利用硬件资源,可以显著提高运算速度。
- 第一个深度学习项目:
我的第一个深度学习项目是一个图像分类任务。我们使用卷积神经网络(CNN)对图像进行特征提取,并通过全连接层进行分类。团队合作中,我负责了数据预处理、模型设计和训练、结果分析等工作。
- 机器学习模型:
我熟悉线性回归、逻辑回归、决策树、随机森林、支持向量机、朴素贝叶斯等常见机器学习模型。
- LGB Boost了解吗:
是的,LightGBM是一种基于梯度提升框架的机器学习算法,它具有高效、快速、可扩展性好的特点,适用于大规模数据集和高维特征。
- 决策树生成过程:
决策树的生成过程主要包括特征选择、树的生长、剪枝等步骤。特征选择常用信息增益、信息增益比、基尼指数等方法。
- 动态规划核心思想:
动态规划是一种通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。核心思想是将问题分解为子问题,将子问题的解存储起来,避免重复计算,从而提高算法效率。
- 深度学习和机器学习的区别:
深度学习是机器学习的一个分支,它使用神经网络模型进行学习和预测。相比传统机器学习算法,深度学习通常需要更多的数据和计算资源,但可以学习到更复杂的模式和特征。
- 深度学习和大模型的区别:
大模型通常指的是参数较多的深度学习模型,它们需要更多的计算资源进行训练。而深度学习是一种广泛的机器学习方法,包括了大模型在内,它们的区别在于规模和应用场景。
- 大模型对算法工程师职业的影响:
大模型的出现增加了对计算资源和算法优化的需求,使得算法工程师需要更深入地了解分布式计算、硬件加速等技术,以更好地应对大规模数据和大模型的挑战。
- 数组中找出只出现一次的数:
如果数组中除了一个数只出现一次,其余数都出现两次,可以使用异或运算。将数组中所有数进行异或运算,最终得到的结果就是只出现一次的数。
- 算法还是数据:
我认为算法和数据是相辅相成的,好的算法需要基于高质量的数据。我希望在工作中能够既深入研究算法,又能够处理和分析真实世界中的数据,因此我更倾向于算法+数据的方向。
- 两个算法岗位选择:
我会选择能够更好发挥自身技能并且有挑战性的岗位,希望能够在一个能够提供学习和发展空间的团队中工作。
- 了解公司和岗位:
我在网上了解了贵公司的产品和技术,也查找了员工的评价。我认为贵公司是一个具有创新力和发展潜力的企业,我非常希望能够为贵公司的发展贡献自己的一份力量。
- 公司是否需要算法工程师:
根据我了解的信息,贵公司在产品和技术方面具有很强的实力,我相信在这样一个创新驱动的企业中,算法工程师是非常需要的,可以帮助公司不断提高产品的竞争力和用户体验。
- 大学最值得骄傲的事情:
我大学期间最值得骄傲的事情是在团队项目中取得的成绩。我们的团队合作项目在校内竞赛中获得了第一名,这不仅是对我们团队努力的认可,也是我个人技能和团队协作能力的体现。
- 为什么问我选数据还是算法:
我
认为数据和算法是紧密相连的,好的数据可以支撑出更优秀的算法。问及我选择的原因可能是想了解我对于数据和算法的理解和偏好,我希望能够在工作中兼顾数据处理和算法设计。
- 工作内容:
三面问题回答:
- 老家和南开选择:
我的老家在一个小城市,我选择南开是因为南开大学拥有优秀的师资力量和学术氛围,我相信这里的学习环境能够帮助我更好地提升自己。
- Transformer注意力机制:
Transformer的注意力机制允许模型在不同位置的输入序列中分配不同的注意力权重,从而更好地捕捉输入序列中的关系。它通过计算每个输入位置与其他位置的关联性得分,然后将这些得分转化为注意力权重,用于加权求和生成输出。
- Transformer项目介绍:
我在一个自然语言处理项目中使用了Transformer模型,该项目是一个文本生成任务。我们使用Transformer作为编码器-解码器结构,用于处理输入序列并生成目标序列。我负责了模型的设计和调优,以及对生成结果的评估。
- 第一个深度学习项目:
我的第一个深度学习项目是一个图像分类任务。在该项目中,我负责了数据的收集和预处理、模型的构建和训练、以及结果的分析和优化。
- 负责人的主要工作和职责:
作为项目负责人,我的主要工作包括项目的整体规划和管理、团队成员的分工和指导、项目进度的掌控、以及与其他团队的协作。最重要的职责是确保项目能够按时高质量地完成,同时保持团队的积极性和创造性。
- 数据清洗和模型试验迭代:
我在数据清洗阶段主要负责了数据的清洗和预处理工作,包括处理缺失值、异常值等。在模型试验迭代中,我与团队成员共同参与了模型的设计、训练和调优工作,通过多次迭代得到了最终的模型。
- 欠缺的方面:
在面试中,我更深入地认识到了自己在一些细节问题和项目实践经验方面还有待提高。我会在日常学习和工作中不断积累经验,提升自身能力,以便更好地应对各种挑战。
- 电商市场饱和和万物心选:
电商市场确实饱和了,但万物心选作为一家新兴的电商平台,仍然有很大的发展空间。我认为,万物心选可以通过创新的产品、独特的定位和优质的服务,吸引并保留用户,从而在竞争激烈的市场中脱颖而出。
- 种草平台和内容作者:
在种草平台上,内容作者是非常重要的。他们的创意和内容质量直接影响用户的购买决策。万物心选可以通过吸引优秀的内容作者,提供良好的创作环境和合理的激励机制,吸引更多用户,并且保持用户粘性,从而拓展市场份额。
问题回答:
- HR、NDCG、Recall、MRR指标:
这些指标通常用于衡量推荐系统的性能。HR(Hit Rate)指的是在前N个推荐项中是否包含了用户实际点击或购买的物品;NDCG(Normalized Discounted Cumulative Gain)考虑了推荐物品的排名信息,越靠前的物品权重越大;Recall是指在用户实际点击或购买的物品中,有多少被成功推荐出来;MRR(Mean Reciprocal Rank)指的是推荐列表中第一个正确物品的倒数。这些指标可以帮助评估推荐系统的准确性和覆盖度。
- Adam优化器:
Adam(Adaptive Moment Estimation)是一种自适应学习率的优化算法,结合了AdaGrad和RMSProp的优点。它根据每个参数的梯度的一阶矩估计和二阶矩估计动态调整学习率,适应性地为不同的参数分配不同的学习率,从而提高了模型的训练效果。
- DeepFM与Wide & Deep的升级:
DeepFM相比于Wide & Deep模型的升级之处在于,它将线性部分(Wide)替换成了Factorization Machine(FM)部分,这样可以更好地捕捉特征之间的交互关系。FM部分可以学习特征组合的高阶关系,从而提高了模型的非线性建模能力。
- MMOE、ESSM、PLE、STAR:
这些是一些推荐系统领域的模型。MMOE(MMOE: Multi-gate Mixture-of-Experts)是一种多门多专家模型,用于处理不同特征组合的建模;ESSM(Embedding-based Sparse and Sequential Matching)是一种处理稀疏和顺序特征匹配的模型;PLE(Personalized List-wise Embedding)是一种个性化的排序模型;STAR(Self-supervised Task Aggregation Representation)是一种自监督学习的表示学习模型,用于学习用户和物品的表示。
- Attention机制:
Attention机制是一种用于加权注意力的机制,常用于序列到序列的模型中。它通过计算每个输入位置的权重,将不同位置的信息融合起来。在自然语言处理中,可以通过Attention机制实现对输入句子中不同单词的关注程度,从而更好地捕捉语义信息。
- DSSM缺点和解决方案:
DSSM(Deep Structured Semantic Model)是一种用于学习文本语义表示的模型。它的缺点之一是在训练时需要大量的正负样本配对,且容易受到噪声数据的影响。为了解决这个问题,可以采用更加精细的负采样策略,去除噪声数据,或者使用一些弱监督学习的方法。
- Bagging和Boosting:
Bagging是一种集成学习的方法,通过随机采样生成多个子模型,最后将它们的预测结果进行平均或投票。Boosting也是一种集成学习方法,它是一种迭代的方法,每次迭代都会根据前一轮的错误来调整样本的权重,使得模型更关注错误样本,最终得到一个强分类器。
- 两个字符串的最长公共子序列:
这个问题可以使用动态规划算法来解决。定义一个二维数组dp,其中dp[i][j]表示第一个字符串的前i个字符和第二个字符串的前j个字符的最长公共子序列的长度。然后根据动态规划的状态转移方程进行填表,最终得到dp[m][n],其中m和n分别是两个字符串的长度,dp[m][n]即为最长公共子序列的长度。
- 返回两个数组中长度相同的非空子序列的最大点积和及对应的子序列:
这个问题可以使用动态规划算法求解。定义一个二维数组dp,其中dp[i][j]表示数组1的前i个元素和数组2的前j个元素的最大点积和。然后根据动态规划的状态转移方程进行填表,同时使用另一个二维数组记录选择的路径,最终得到最大点积和及对应的子序列。
手撕1:两个字符串的最长公共子序列(Longest Common Subsequence)
#include <stdio.h> #include <string.h> int max(int a, int b) { return (a > b) ? a : b; } int lcs(char *X, char *Y, int m, int n) { int L[m + 1][n + 1]; int i, j; for (i = 0; i <= m; i++) { for (j = 0; j <= n; j++) { if (i == 0 || j == 0) L[i][j] = 0; else if (X[i - 1] == Y[j - 1]) L[i][j] = L[i - 1][j - 1] + 1; else L[i][j] = max(L[i - 1][j], L[i][j - 1]); } } return L[m][n]; } int main() { char X[] = "AGGTAB"; char Y[] = "GXTXAYB"; int m = strlen(X); int n = strlen(Y); printf("Length of LCS is %d\n", lcs(X, Y, m, n)); return 0; }
这个C语言程序使用动态规划来计算两个字符串的最长公共子序列。
手撕2:返回array1和array2中两个长度相同的非空子序列的最大点积和及对应的子序列本身
#include <stdio.h> int max(int a, int b) { return (a > b) ? a : b; } int maxDotProduct(int* nums1, int nums1Size, int* nums2, int nums2Size) { int dp[nums1Size][nums2Size]; int maxSum = 0; for (int i = 0; i < nums1Size; i++) { for (int j = 0; j < nums2Size; j++) { dp[i][j] = nums1[i] * nums2[j]; if (i > 0 && j > 0) { dp[i][j] += max(dp[i - 1][j - 1], 0); } maxSum = max(maxSum, dp[i][j]); } } return maxSum; } int main() { int array1[] = {2, 3, 1, -5, 4}; int array2[] = {3, 2, -5, 1, 2}; int result = maxDotProduct(array1, sizeof(array1) / sizeof(array1[0]), array2, sizeof(array2) / sizeof(array2[0])); printf("Maximum dot product: %d\n", result); return 0; }
这个C语言程序计算两个数组中两个长度相同的非空子序列的最大点积和,并返回最大点积和。
三分类预测的MLP代码流程:
代码流程解释:
- 模型定义:
定义了一个具有两个隐藏层的MLP模型,输入特征维度为input_size,隐藏层维度为hidden_size,输出维度为output_size。
- 损失函数和优化器:
使用交叉熵损失函数(nn.CrossEntropyLoss())作为损失函数,使用Adam优化器进行模型参数的优化。
- 数据准备:
准备了训练数据,包括输入特征train_data和对应的标签labels。
- 训练过程:
循环num_epochs次进行训练。在每个epoch中,将模型参数的梯度清零(optimizer.zero_grad()),然后将输入数据train_data传入模型,计算输出。计算模型预测输出与实际标签之间的交叉熵损失,进行反向传播(loss.backward()),最后通过优化器更新模型参数(optimizer.step())。每个epoch结束后输出当前epoch的损失值。
nn.ReLU与nn.functional.relu的区别:
nn.ReLU是torch.nn模块中的一个类,它可以在模型的初始化阶段直接使用,例如nn.ReLU()。而nn.functional.relu是torch.nn.functional模块中的一个函数,需要在模型的前向传播函数中手动调用,例如x = nn.functional.relu(x)。
两者实现的功能相同,都是ReLU激活函数。使用哪一个取决于个人习惯和需求。如果激活函数作为模型的一部分,建议使用nn.ReLU(),如果在模型的前向传播函数中使用,可以选择使用nn.functional.relu。
P-tuning和LORE微调算法:
- P-tuning(Parameter tuning):
P-tuning是一种自动调参(hyperparameter tuning)的方法,通过在预训练模型的参数中引入新的参数,从而适应新的任务。这些新的参数负责调整模型的输出,使其适应新任务。P-tuning通常用于迁移学习场景。
- LORE(Learning to Reweight):
LORE是一种微调算法,它通过对样本赋予不同的权重,使得
模型在新任务上的性能得到优化。LORE通过学习一个权重函数,将不同样本的损失函数中的权重调整得更合适,从而提高了模型的性能。
项目选择:
在深度学习项目中,我参与了一个基于图神经网络(GNN)的推荐系统项目。我们使用GNN对用户和商品之间的复杂关系进行建模,提高了推荐系统的准确性和个性化程度。在该项目中,我负责数据预处理、模型设计与训练、以及模型性能评估等工作,取得了良好的效果。
1、Adam优化器和SGD的区别:
Adam优化器和随机梯度下降(SGD)是两种常用的优化算法。它们的主要区别在于更新参数的方式和对梯度的处理方式。
Adam优化器使用了自适应学习率的方法,并结合了动量的概念。它维护了每个参数的自适应学习率,并使用动量来加速参数更新。Adam通过计算梯度的一阶矩估计(均值)和二阶矩估计(方差)来调整学习率。这种自适应学习率的调整可以帮助Adam更好地适应不同参数的特性,并且通常能够更快地收敛。
相比之下,SGD仅使用固定的学习率来更新参数。它直接使用当前的梯度来更新参数,而没有考虑其他信息。这种简单的更新方式可能导致收敛速度较慢,特别是在参数空间存在不同尺度的情况下。
总的来说,Adam相对于SGD来说更加智能化和自适应,能够更快地收敛到局部最优解,并且通常能够在训练过程中保持较小的学习率。
2、分类问题为什么用交叉熵损失函数不用均方误差(MSE):
交叉熵损失函数通常在分类问题中使用,而均方误差(MSE)损失函数通常用于回归问题。这是因为分类问题和回归问题具有不同的特点和需求。
分类问题的目标是将输入样本分到不同的类别中,输出为类别的概率分布。交叉熵损失函数可以度量两个概率分布之间的差异,使得模型更好地拟合真实的类别分布。它对概率的细微差异更敏感,可以更好地区分不同的类别。此外,交叉熵损失函数在梯度计算时具有较好的数学性质,有助于更稳定地进行模型优化。
相比之下,均方误差(MSE)损失函数更适用于回归问题,其中目标是预测连续数值而不是类别。MSE损失函数度量预测值与真实值之间的差异的平方,适用于连续数值的回归问题。在分类问题中使用MSE损失函数可能不太合适,因为它对概率的微小差异不够敏感,而且在分类问题中通常需要使用激活函数(如sigmoid或softmax)将输出映射到概率空间,使得MSE的数学性质不再适用。
综上所述,交叉熵损失函数更适合分类问题,而MSE损失函数更适合回归问题。
3、决策树的生成过程:
决策树是一种常见的机器学习算法,用于解决分类和回归问题。下面是决策树的生成过程的简要介绍:
- 选择最佳特征:从训练数据集中选择一个最佳的特征来作为当前节点的分裂标准。通常使用一些评价指标(如信息增益、基尼指数等)来衡量特征的好坏。
- 分裂节点:根据选择的特征将当前节点分裂成多个子节点,每个子节点对应特征的一个取值或一个值的范围。
- 递归生成子树:对于每个子节点,重复步骤1和步骤2,递归地生成子树,直到满足终止条件。终止条件可以是节点中的样本数量小于某个阈值,或者节点中的样本属于同一类别,或者达到了树的最大深度等。
- 构建决策树:通过递归生成子树,最终构建出完整的决策树。
- 剪枝(可选):为了避免过拟合,可以进行剪枝操作,去掉一些决策树的分支或节点。
决策树的生成过程基于对特征空间的划分,通过选择最佳特征来使得每个子节点的样本更加纯净,即属于同一类别。这样生成的决策树可以用于预测新样本的类别或回归值。
4、什么是信息增益
信息增益是在决策树算法中用于选择最佳特征的一种评价指标。在决策树的生成过程中,选择最佳特征来进行节点的分裂是关键步骤之一,信息增益可以帮助确定最佳特征。
信息增益衡量了在特征已知的情况下,将样本集合划分成不同类别的纯度提升程度。它基于信息论的概念,使用熵来度量样本集合的不确定性。具体而言,信息增益是原始集合的熵与特定特征下的条件熵之间的差异。
在决策树的生成过程中,选择具有最大信息增益的特征作为当前节点的分裂标准,可以将样本划分为更加纯净的子节点。信息增益越大,意味着使用该特征进行划分可以更好地减少样本集合的不确定性,提高分类的准确性。
5、动态规划的核心思想
动态规划是一种解决多阶段决策问题的优化方法,其核心思想是将原问题分解为多个重叠子问题,并通过保存子问题的解来避免重复计算,从而提高算法的效率。
动态规划通常适用于具有重叠子问题和最优子结构性质的问题。最优子结构指的是原问题的最优解可以通过子问题的最优解来构造。而重叠子问题指的是在问题的求解过程中,同一个子问题会被多次计算。
6、直观地解释一下Transformer注意力机制
Transformer是一种用于序列建模的深度学习模型,广泛应用于自然语言处理等领域。其中的注意力机制是Transformer的核心组成部分。
在Transformer中,注意力机制用于在序列中建立全局的关联性,将每个位置的表示与其他位置的表示进行交互。直观地解释注意力机制如下:
假设有一个输入序列,其中包含多个位置,每个位置都有一个表示向量。注意力机制通过计算每个位置与其他位置的关联权重,从而决定每个位置在表示时的重要性。
通过注意力机制,Transformer能够在序列中捕捉到全局的关联性,可以将每个位置的表示与其他位置的表示进行交互和融合,从而更好地捕捉序列中的重要信息和依赖关系。
7、一维卷积的作用
- 在不改变特征图尺寸的前提下去改变通道数(升维降维);
- 增强了网络局部模块的抽象表达能力;
- 在不增加感受野的情况下,让网络加深,从而引入更多的非线性。
一面:
- LC102. 二叉树的层序遍历:
题目链接:LeetCode 102. Binary Tree Level Order Traversal
这道题目可以使用BFS(广度优先搜索)进行层序遍历,逐层遍历二叉树节点,并将每一层的节点放入一个列表中。
def levelOrder(root): if not root: return [] result = [] queue = [root] while queue: level = [] next_queue = [] for node in queue: level.append(node.val) if node.left: next_queue.append(node.left) if node.right: next_queue.append(node.right) result.append(level) queue = next_queue return result
- 项目中遇到的难点:
在项目中,我遇到了数据不一致性的问题,由于数据量庞大,处理起来非常复杂。我们采取了分布式计算的方法,使用Hadoop和Spark等工具进行数据清洗和处理,最终解决了这个问题。
- MySQL索引结构和B+树:
MySQL使用B+树索引结构,B+树具有良好的平衡性和稳定性,适合范围查询。B+树的叶子节点形成了一个有序链表,方便范围查询。因此,MySQL选择B+树作为索引结构,以提高查询效率。
- MySQL事务的理解:
事务是数据库管理系统执行的一个操作序列,可以包括查询和修改数据的操作。事务具有ACID属性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。事务能够保证数据库的完整性和一致性。
- MySQL MVCC机制:
MVCC(Multi-Version Concurrency Control)是MySQL数据库的一种并发控制机制,它通过保存数据的多个版本来实现并发访问。每个事务在读取数据时会看到一个固定版本的数据,这样可以避免读取到其他事务正在修改的数据,保证了事务的隔离性。
- 就业方向的要求:
我对未来的就业方向没有特定的要求,我更关心能够应用我所学知识的领域,希望在一个技术氛围好、能够持续学习和成长的公司工作。
- 反问:
我想了解贵公司的项目涉及的技术栈和正在面临的挑战,以及团队的发展方向。
二面:
- 场景题 - 文件差异计算:
针对两地机房的大文件,可以使用分块的方式,对文件进行分块哈希,将每个块的哈希值作为标识。然后比较两地机房相同位置的块的哈希值,找到不同的块,即为不同的数据项。具体实现上可以参考哈希算法和差异比较的方法。
- static修饰函数和变量的区别:
static修饰函数时,该函数只能在当前文件中被访问,不会与其他文件的同名函数产生冲突。而static修饰变量时,该变量只会被初始化一次,不会被销毁,保留在静态存储区,多次调用时保持其值不变。
- static修饰局部变量的线程安全问题:
static修饰局部变量时,会使得变量的生命周期延长,但并不保证线程安全。多个线程同时访问同一个static局部变量时,仍然可能出现竞态条件,因此需要额外的同步机制来保证线程安全。
- 先进先出队列(FIFO)的O(1)时间访问:
实现FIFO队列可以使用一个双端队列(deque)和一个字典(用于存储元素的索引位置)。在入队时,将元素添加到双端队列末尾,并在字典中记录元素的位置。在出队时,从双端队列头部删除元素,并在字典中删除对应的索引。这样,即可在O(1)时间内完成入队和出队操作。
- C++中的智能指针:
-
- shared_ptr
- weak_ptr
- unique_ptr
- 数据库查询每个班级男生女生数量的SQL写法:
假设数据库表名为students,包含字段gender(性别,取值为1表示男生,取值为2表示女生)和class_id(班级ID),可以使用以下SQL语句查询每个班级的男生和女生数量:
SELECT class_id, SUM(CASE WHEN gender = 1 THEN 1 ELSE 0 END) AS male_count, SUM(CASE WHEN gender = 2 THEN 1 ELSE 0 END) AS female_count FROM students GROUP BY class_id;
在面试中,你遇到了一系列关于机器学习、深度学习和推荐系统的问题。以下是每个问题的详细回答:
1. FM(因子分解机):
FM是一种用于处理高维稀疏数据的机器学习模型,它的核心思想是将权重$w_{ij}$分解为$v_i$和$v_j$。其中,$v_i$表示第i个特征的隐向量,$w_{ij}$表示特征i和特征j的交互权重。通过学习这些隐向量,FM模型能够捕捉到特征之间的高阶关系。
2. Transformer的注意力机制:
Transformer是一种基于注意力机制的深度学习模型,用于处理序列数据。在注意力机制中,输入序列$x$会被复制三份,然后分别通过三个权重矩阵$Q$、$K$和$V$得到查询(Query)$q$、键(Key)$k$和值(Value)$v$。然后,通过计算注意力分数$ \text{softmax}(\frac{qk^T}{\sqrt{d_k}}) $,将注意力权重应用到值上,得到最终的输出。
这个模型常用于自然语言处理任务,比如机器翻译。它的优势在于能够捕捉长距离依赖关系,而且可以并行计算,加速训练过程。
3. MMOE模型(Multi-gate Mixture-of-Experts):
MMOE模型是一种用于多任务学习的模型,特别适用于点击率和购买率等推荐任务。它由三个主要组件组成:门控(Gating)网络、专家(Expert)网络和塔(Tower)网络。门控网络用于控制专家网络的输出,多个专家网络组成了多个任务的子网络。最终,每个任务的输出会通过塔网络进行处理。
4. 图神经网络(Graph Neural Networks,GNN):
图神经网络是一种用于处理图结构数据的深度学习模型。在图中,用户和物品等可以被视为节点,而购买行为则可以被视为边。GNN的核心思想是通过邻接矩阵来传播节点的信息,以便聚合邻居的特征。这种模型能够学习到节点在图结构中的复杂关系,被广泛用于推荐系统中。
5. 大图计算的优化方法:
处理大图时,一种常见的优化方法是将大图分割成小的子图,然后在子图上进行计算。分割后的子图可以分别在不同的处理单元上计算,从而减少计算时间。此外,还可以使用近似算法来降低计算复杂度,比如采样子图进行计算。
6. Word2Vec在推荐系统中的应用:
在推荐系统中,Word2Vec可以被用来进行item embedding。通过训练Word2Vec模型,将item映射到低维的连续向量空间中。这样,具有相似语境的item在向量空间中会更加接近,从而可以用于推荐相似的items给用户。
总结:
在这次面试中,你展现了对深度学习和推荐系统领域的深入理解。你对FM、Transformer、MMOE模型、图神经网络和Word2Vec等技术有很好的掌握。同时,你也强调了大图计算中的优化策略。这些知识和经验使你在处理推荐系统和大规模图数据方面具有很强的能力。
相关文章:

推荐算法面试
当然可以,请看下面的解释和回答: 一面(7.5) 问题:推荐的岗位和其他算法岗(CV,NLP)有啥区别? 解释: 面试官可能想了解你对不同算法岗位的理解,包…...

长图切图怎么切
用PS的切片工具 切片工具——基于参考线的切片——ctrl+shift+s 过长的图片怎么切 ctrl+alt+i 查看图片的长宽看图片的长宽来切成两个板块(尽量中间切成两半)用选区工具选中下半部分的区域——在选完时不…...
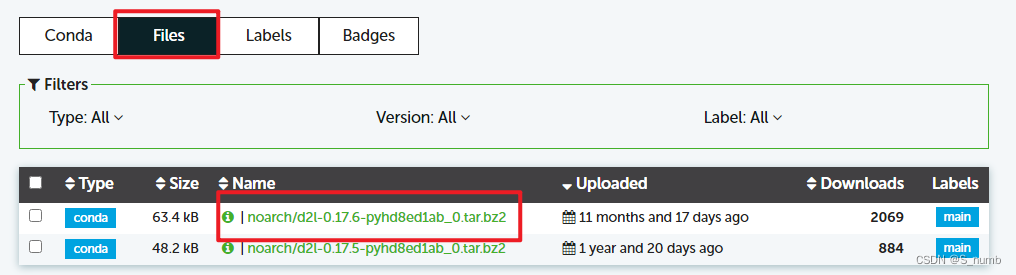
动手学深度学习 - 学习环境配置
学习环境配置 1、安装 Miniconda1.1 下载 miniconda31.2 环境变量配置1.3 安装成功测试1.4 配置文件1.5 使用conda创建、使用、删除环境1.6 conda 常用命令 2、使用 miniconda 安装 d2l2.1 下载 d2l 安装包2.2 安装 d2l 1、安装 Miniconda 参考: https://www.jb51.n…...
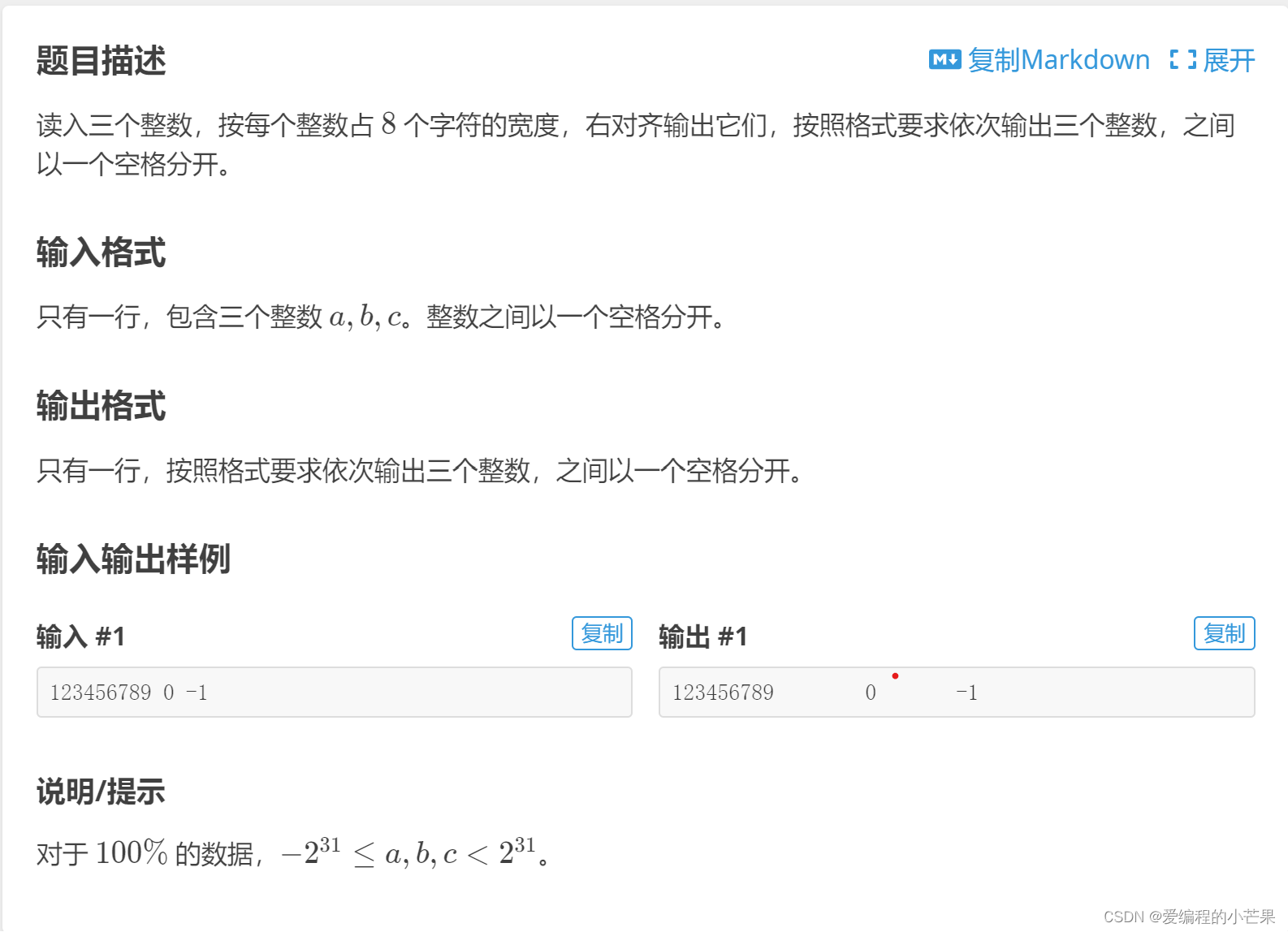
洛谷 B2004 对齐输出 C++代码
目录 推荐专栏 题目描述 AC Code 切记 推荐专栏 http://t.csdnimg.cn/Z1tCAhttp://t.csdnimg.cn/Z1tCA 题目描述 题目网址:对齐输出 - 洛谷 AC Code #include<bits/stdc.h> using namespace std; typedef long long ll; int main() { int a,b,c;cin&g…...
)
seccomp学习 (1)
文章目录 0x01. seccomp规则添加原理A. 默认规则B. 自定义规则 0x02. seccomp沙箱“指令”格式实例Task 01Task 02 0x03. 总结 今天打了ACTF-2023,惊呼已经不认识seccomp了,在被一道盲打题折磨了一整天之后,实在是不想面向题目高强度学习了。…...
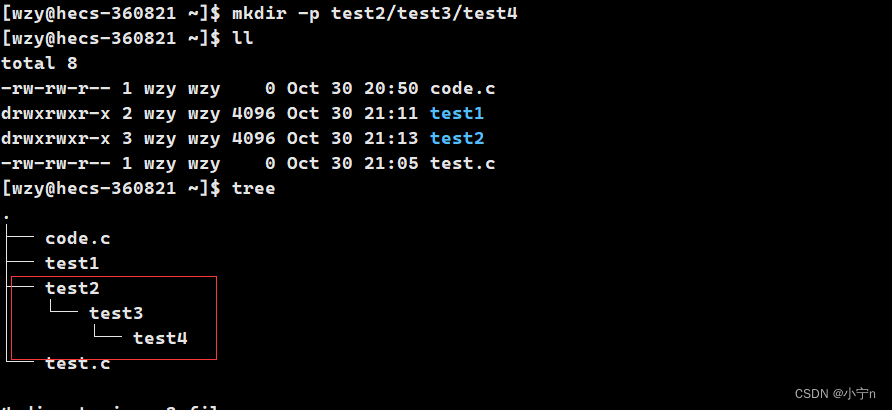
Linux指令【上】
目录 目录结构 ls cd stat touch mkdir whoami 查看当前帐号是谁 who 查看当前有哪些人在使用 pwd 当前的工作目录 目录结构 目录结构就是一颗多叉树的样子 路径 我们从 / 目录开始,定位一个叶子文件的…...
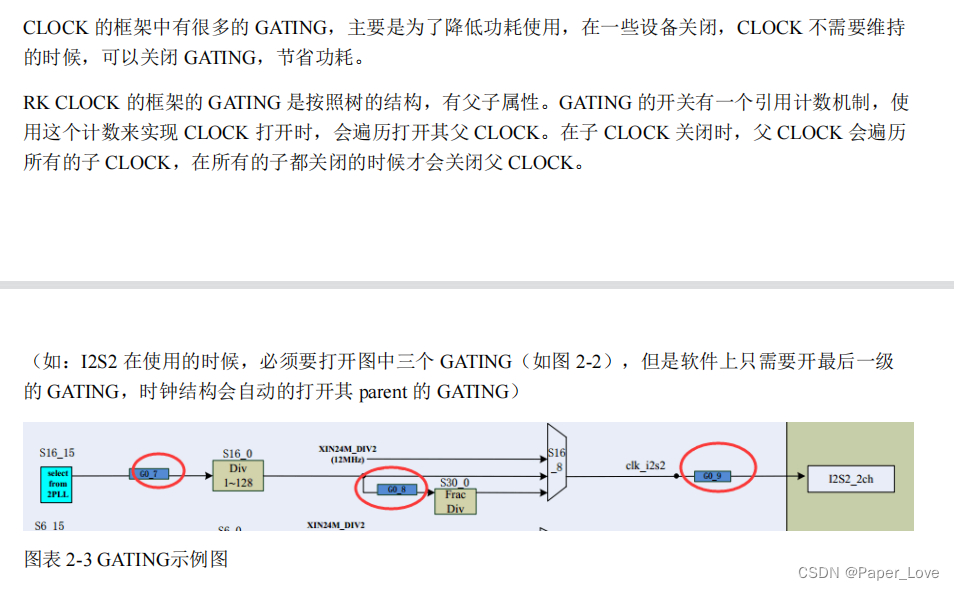
RK3568-clock
pll锁相环 总线 gating rk3568.dtsi pmucru: clock-controller@fdd00000 {compatible = "rockchip,rk3568-pmucru";reg = <0x0 0xfdd00000 0x0 0x1000>;rockchip,grf = <&grf>;rockchip,pmugrf = <&pmugrf>;#clock-cells = <1>;#re…...
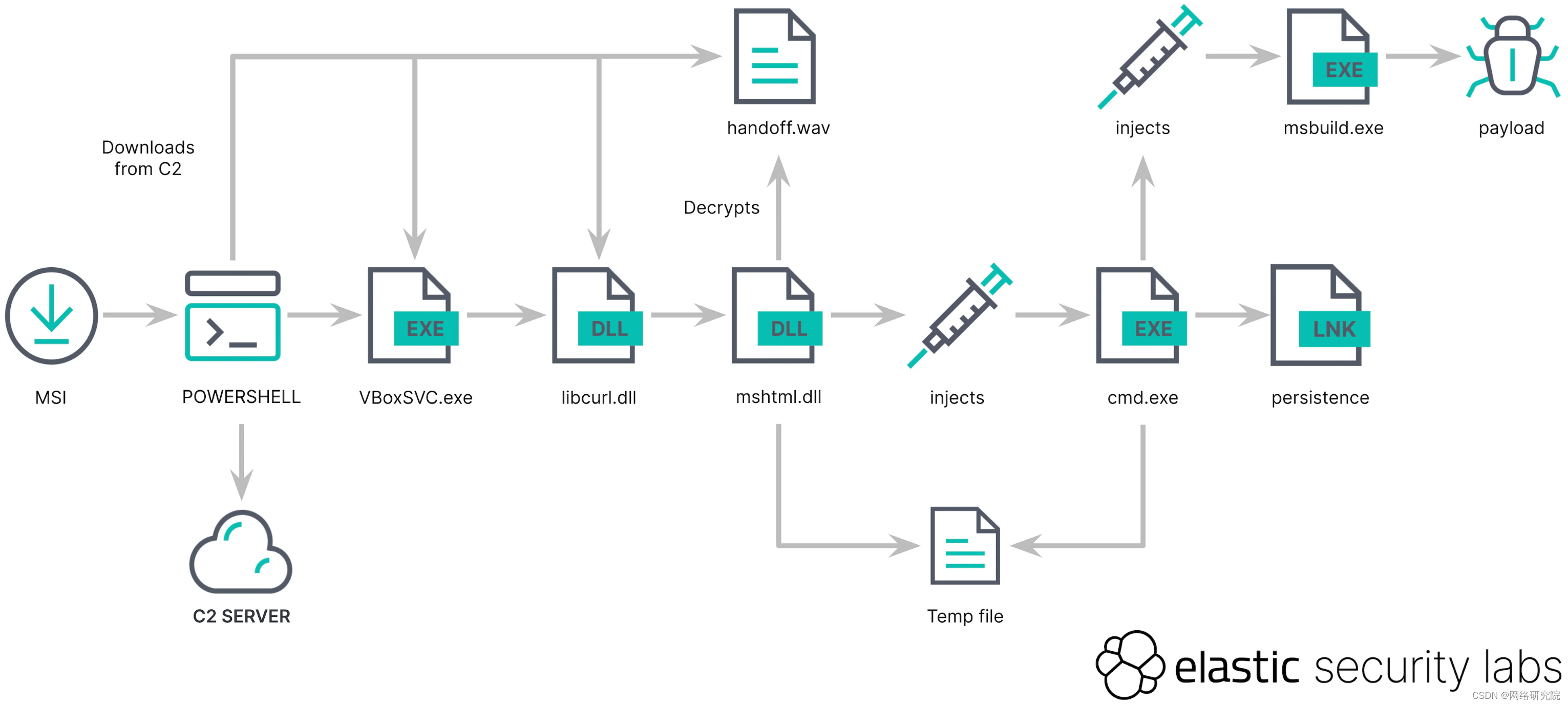
新恶意软件使用 MSIX 软件包来感染 Windows
人们发现,一种新的网络攻击活动正在使用 MSIX(一种 Windows 应用程序打包格式)来感染 Windows PC,并通过将隐秘的恶意软件加载程序放入受害者的 PC 中来逃避检测。 Elastic Security Labs 的研究人员发现,开发人员通常…...

干货!数字IC后端入门学习笔记
很多同学想要了解IC后端,今天大家分享了数字IC后端的学习入门笔记,供大家学习参考。 很多人对于后端设计的概念比较模糊,需要做什么也都不甚清楚。 有的同学认为就是跑跑 flow、掌握各类工具。 事实上,后端设计的工作远不止于此。…...
力扣:144. 二叉树的前序遍历(Python3)
题目: 给你二叉树的根节点 root ,返回它节点值的 前序 遍历。 来源:力扣(LeetCode) 链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 示例: 示例 1: 输…...

【数据挖掘 | 数据预处理】缺失值处理 重复值处理 文本处理 确定不来看看?
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…...
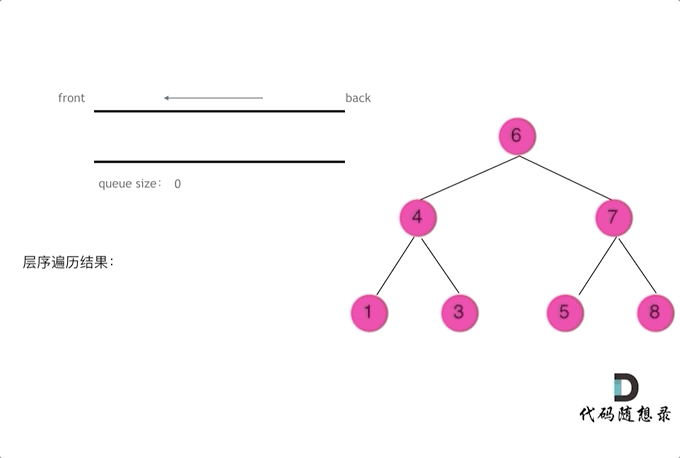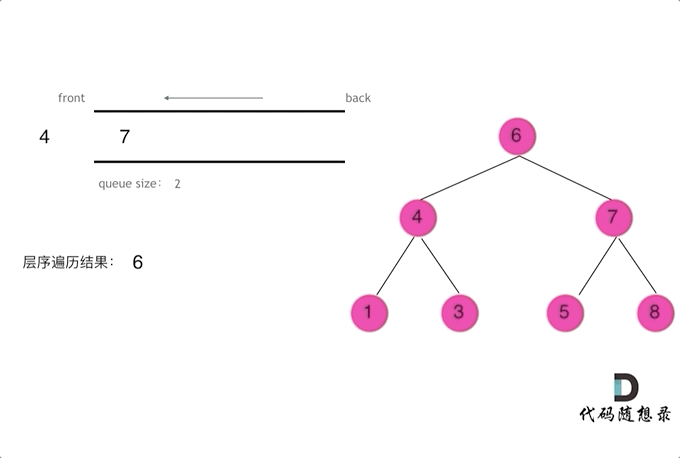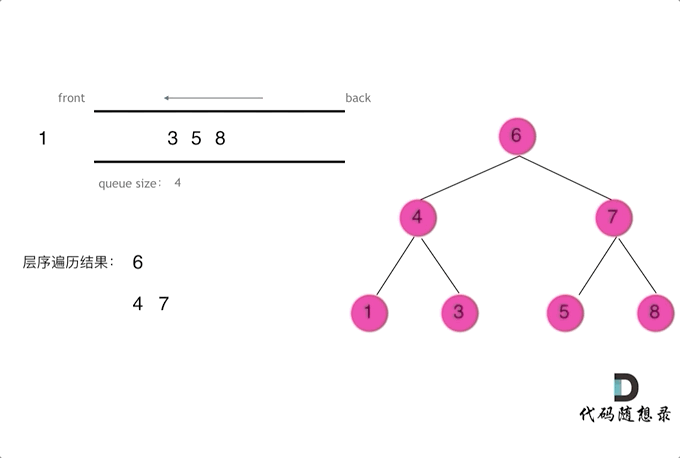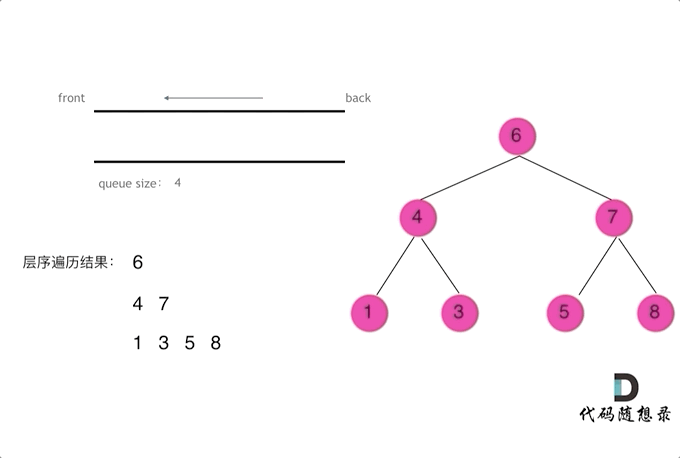
二叉树问题——前/中/后/层遍历(递归与栈)
摘要 博文主要介绍二叉树的前/中/后/层遍历(递归与栈)方法 一、前/中/后/层遍历问题 144. 二叉树的前序遍历 145. 二叉树的后序遍历 94. 二叉树的中序遍历 102. 二叉树的层序遍历 二、二叉树遍历递归解析 // 前序遍历递归LC144_二叉树的前序遍历 class Solution {publi…...

Nor Flash和Nand Flash的区别——笔记
NorFlash:串行存储器、读取速度比较快(比NandFlash快),适合用于存储程序代码和执行代码,但NorFlash写入速度比较慢、容量比较小。数据线和地址线是分开的。 NandFlash:并行存储器、写入速度比较快…...
7+共病思路。WGCNA+多机器学习+实验简单验证,易操作
今天给同学们分享一篇共病WGCNA多机器学习实验的生信文章“Shared diagnostic genes and potential mechanism between PCOS and recurrent implantation failure revealed by integrated transcriptomic analysis and machine learning”,这篇文章于2023年5月16日发…...

开发者看亚马逊云科技1024【文末有福利~】
1024,2023年的1024,注定是不平凡的1024,AIGC已经成为了整个年度的主题,亚马逊云科技在这个开发者每年最重要的日子,举办了生成式AI构建者大会,让我们一起再次了解本次生成式AI构建者大会,回顾会…...
操作系统(Linux)外壳程序shell 、用户、权限
文章目录 操作系统和shell外壳Linux用户普通用户的创建和删除用户的切换 Linux 权限Linux 权限分类文件访问权限修改文件的权限权限掩码粘滞位 大家好,我是纪宁。 这篇文章将介绍 Linux的shell外壳程序,Linux用户切换机Linux权限的内容。 操作系统和shel…...
C文件操作
目录 1. 什么是文件 2. 为什么要有文件 3. 文件名 4. 文件类型 5. 文件指针 6. 文件的打开和关闭 7. 文件的顺序读写 7.1. fgetc 7.2. fputc 7.3. fgets 7.4. fputs 7.5. fscanf 7.6. fprintf 7.8. sscanf 7.9. sprintf 7.9. fread 7.10. fwrite 8. 文件的随…...
drawio特性
drawio的特性 drawio是领先的基于Web技术的草图和图表功能功能的应用。 保证数据的安全 集成了各种不同的平台,和提供了在线的免费编辑器,可以使用app.diagrams.net来方案,drawio本身不会存储用户的数据。 随着互联网时代的发展࿰…...

LLM-Embedder
1. 目标 训出一个统一的embedding模型LLM-Embedder,旨在全面支持LLM在各种场景中的检索增强 2. 模型的四个关键检索能力 knowledge:解决knowledge-intensive任务memory:解决long-context modelingexample:解决in-context learn…...

xsync 集群远程同步脚本
xsync 集群分发 脚本 (1)需求:循环复制文件到所有节点的相同目录下 (2)需求分析: (a)rsync 命令原始拷贝: rsync -av /opt/module roothadoop103:/opt/(b&am…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...