Dubbo 路由及负载均衡性能优化
作者:vivo 互联网中间件团队- Wang Xiaochuang
本文主要介绍在vivo内部针对Dubbo路由模块及负载均衡的一些优化手段,主要是异步化+缓存,可减少在RPC调用过程中路由及负载均衡的CPU消耗,极大提升调用效率。
一、概要
vivo内部Java技术栈业务使用的是Apache Dubbo框架,基于开源社区2.7.x版本定制化开发。在海量微服务集群的业务实践中,我们发现Dubbo有一些性能瓶颈的问题会极大影响业务逻辑的执行效率,尤其是在集群规模数量较大时(提供方数量>100)时,路由及负载均衡方面有着较大的CPU消耗,从采集的火焰图分析高达30%。为此我们针对vivo内部常用路由策略及负载均衡进行相关优化,并取得了较好的效果。接下来主要跟大家分析一下相关问题产生的根源,以及我们采用怎样的方式来解决这些问题。当前vivo内部使用的Dubbo的主流版本是基于2.7.x进行相关定制化开发。
二、背景知识
2.1 Dubbo客户端调用流程
1. 相关术语介绍

2. 主要流程
客户端通过本地代理Proxy调用ClusterInvoker,ClusterInvoker从服务目录Directory获取服务列表后经过路由链获取新的服务列表、负载均衡从路由后的服务列表中根据不同的负载均衡策略选取一个远端Invoker后再发起远程RPC调用。
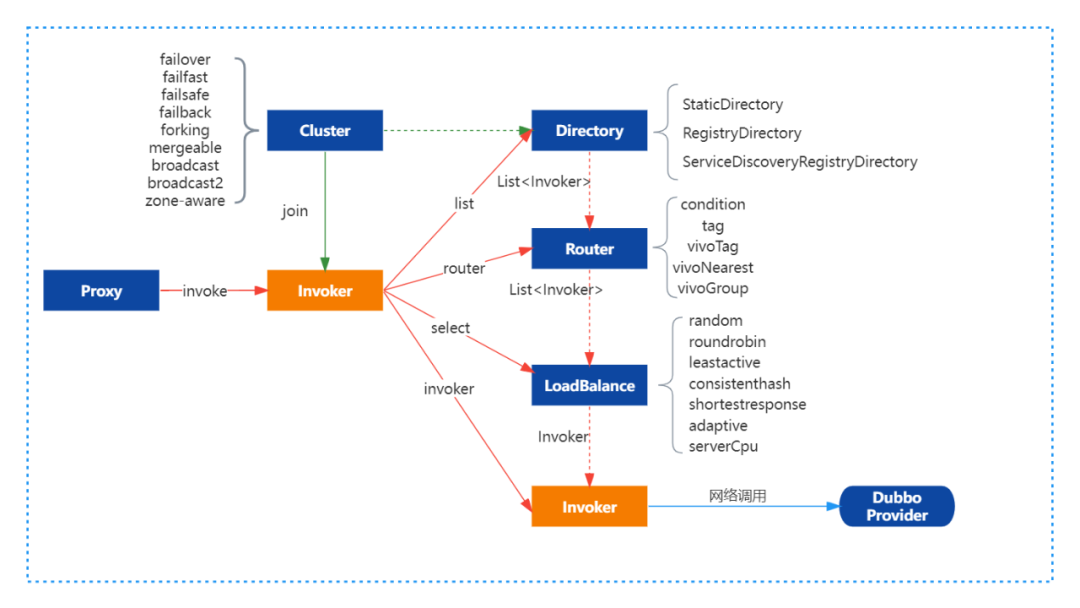
2.2 Dubbo路由机制
Dubbo的路由机制实际是基于简单的责任链模式实现,同时Router继承了Comparable接口,自定义的路由可以设置不同的优先级进而定制化责任链上Router的顺序。基于责任链模式可以支持多种路由策略串行执行如就近路由+标签路由,或条件路由+就近路由等,且路由的配置支持基于接口级的配置也支持基于应用级的配置。常见的路由方式主要有:就近路由,条件路由,标签路由等。具体的执行过程如下图所示:
1. 核心类
Dubbo路由的核心类主要有:RouterChain、RouterFactory 与 Router 。
(1)RouterChain
RouterChain是路由链的入口,其核心字段有
-
invokers(List<invoker> 类型)
初始服务列表由服务目录Directory设置,当前RouterChain要过滤的Invoker集合
-
builtinRouters(List类型)
当前RouterChain包含的自动激活的Router集合
-
routers(List类型)
包括所有要使用的路由由builtinRouters加上通过addRouters()方法添加的Router对象
RouterChain核心逻辑:
public class RouterChain<T> {// 注册中心最后一次推送的服务列表private List<Invoker<T>> invokers = Collections.emptyList();// 所有路由,包括原生Dubbo基于注册中心的路由规则如“route://” urls .private volatile List<Router> routers = Collections.emptyList();// 初始化自动激活的路由private List<Router> builtinRouters = Collections.emptyList();private RouterChain(URL url) {//通过ExtensionLoader加载可自动激活的RouterFactoryList<RouterFactory> extensionFactories = ExtensionLoader.getExtensionLoader(RouterFactory.class).getActivateExtension(url, ROUTER_KEY);// 由工厂类生成自动激活的路由策略List<Router> routers = extensionFactories.stream().map(factory -> factory.getRouter(url)).collect(Collectors.toList());initWithRouters(routers);}// 添加额外路由public void addRouters(List<Router> routers) {List<Router> newRouters = new ArrayList<>();newRouters.addAll(builtinRouters);newRouters.addAll(routers);Collections.sort(newRouters, comparator);this.routers = newRouters;}public List<Invoker<T>> route(URL url, Invocation invocation) {List<Invoker<T>> finalInvokers = invokers;// 遍历全部的Router对象,执行路由规则for (Router router : routers) {finalInvokers = router.route(finalInvokers, url, invocation);}return finalInvokers;}
}(2)RouterFactory为Router的工厂类
RouterFactory接口定义:
@SPI
public interface RouterFactory {@Adaptive("protocol")Router getRouter(URL url);
}(3)Router
Router是真正的路由实现策略,由RouterChain进行调用,同时Router继承了Compareable接口,可以根据业务逻辑设置不同的优先级。
Router主要接口定义:
public interface Router extends Comparable<Router> {/**** @param invokers 带过滤实例列表* @param url 消费方url* @param invocation 会话信息* @return routed invokers* @throws RpcException*/<T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException;/*** 当注册中心的服务列表发现变化,或有动态配置变更会触发实例信息的变化* 当时2.7.x的Dubbo并没有真正使用这个方法,可基于此方法进行路由缓存* @param invokers invoker list* @param <T> invoker's type*/default <T> void notify(List<Invoker<T>> invokers) {}}2. 同机房优先路由的实现
为方便大家了解路由的实现,给大家展示一下就近路由的核心代码逻辑:
public <T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL consumerUrl, Invocation invocation) throws RpcException {if (!this.enabled) {return invokers;}// 获取本地机房信息String local = getSystemProperty(LOC);if (invokers == null || invokers.size() == 0) {return invokers;}List<Invoker<T>> result = new ArrayList<Invoker<T>>();for (Invoker invoker: invokers) {// 获取与本地机房一致的invoker并加入列表中String invokerLoc = getProperty(invoker, invocation, LOC);if (local.equals(invokerLoc)) {result.add(invoker);}}if (result.size() > 0) {if (fallback){// 开启服务降级,available.ratio = 当前机房可用服务节点数量 / 集群可用服务节点数量int curAvailableRatio = (int) Math.floor(result.size() * 100.0d / invokers.size());if (curAvailableRatio <= availableRatio) {return invokers;}}return result;} else if (force) {return result;} else {return invokers;}}2.3 Dubbo负载均衡
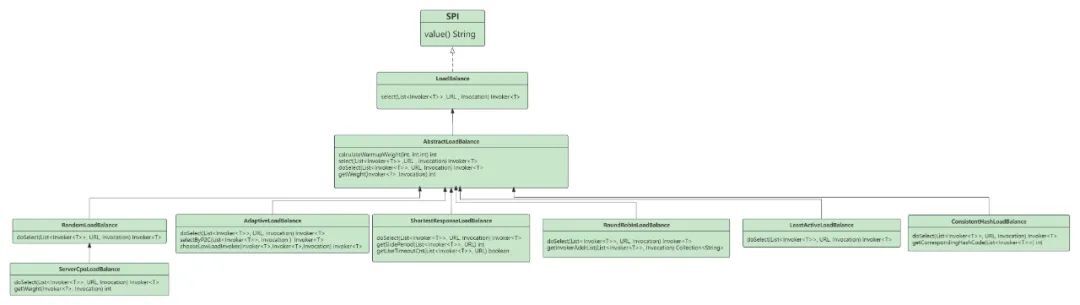
Dubbo的负载均衡实现比较简单基本都是继承抽象类进行实现,主要作用就是根据具体的策略在路由之后的服务列表中筛选一个实例进行远程RPC调用,默认的负载均衡策略是随机。
整体类图如下所示:
LoadBalance接口定义:
@SPI(RandomLoadBalance.NAME)
public interface LoadBalance {/*** 从服务列表中筛选一个.** @param invokers invokers.* @param url refer url* @param invocation invocation.* @return selected invoker.*/@Adaptive("loadbalance")<T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException;}随机负载均衡核心代码解析:
// 预热过程权重计算static int calculateWarmupWeight(int uptime, int warmup, int weight) {int ww = (int) (uptime / ((float) warmup / weight));return ww < 1 ? 1 : (Math.min(ww, weight));}int getWeight(Invoker<?> invoker, Invocation invocation) {int weight;URL url = invoker.getUrl();// 多注册中心场景下的,注册中心权重获取if (UrlUtils.isRegistryService(url)) {weight = url.getParameter(REGISTRY_KEY + "." + WEIGHT_KEY, DEFAULT_WEIGHT);} else {weight = url.getMethodParameter(invocation.getMethodName(), WEIGHT_KEY, DEFAULT_WEIGHT);if (weight > 0) {// 获取实例启动时间long timestamp = invoker.getUrl().getParameter(TIMESTAMP_KEY, 0L);if (timestamp > 0L) {long uptime = System.currentTimeMillis() - timestamp;if (uptime < 0) {return 1;}// 获取预热时间int warmup = invoker.getUrl().getParameter(WARMUP_KEY, DEFAULT_WARMUP);if (uptime > 0 && uptime < warmup) {weight = calculateWarmupWeight((int)uptime, warmup, weight);}}}}return Math.max(weight, 0);}@Overrideprotected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {// Number of invokersint length = invokers.size();// Every invoker has the same weight?boolean sameWeight = true;// the weight of every invokersint[] weights = new int[length];// the first invoker's weightint firstWeight = getWeight(invokers.get(0), invocation);weights[0] = firstWeight;// The sum of weightsint totalWeight = firstWeight;for (int i = 1; i < length; i++) {int weight = getWeight(invokers.get(i), invocation);// save for later useweights[i] = weight;// SumtotalWeight += weight;if (sameWeight && weight != firstWeight) {sameWeight = false;}}if (totalWeight > 0 && !sameWeight) {// If (not every invoker has the same weight & at least one invoker's weight>0), select randomly based on totalWeight.int offset = ThreadLocalRandom.current().nextInt(totalWeight);// Return a invoker based on the random value.for (int i = 0; i < length; i++) {offset -= weights[i];if (offset < 0) {return invokers.get(i);}}}// If all invokers have the same weight value or totalWeight=0, return evenly.return invokers.get(ThreadLocalRandom.current().nextInt(length));}预热解释
预热是为了让刚启动的实例流量缓慢增加,因为实例刚启动时各种资源可能还没建立连接,相关代码可能还是处于解释执行,仍未变为JIT执行,此时业务逻辑较慢,不应该加载过大的流量,否则有可能造成较多的超时。Dubbo默认预热时间为10分钟,新部署的实例的流量会在预热时间段内层线性增长,最终与其他实例保持一致。Dubbo预热机制的实现就是通过控制权重来实现。如默认权重100,预热时间10分钟,则第一分钟权重为10,第二分钟为20,以此类推。
具体预热效果图如下:
三、问题分析
使用Dubbo的业务方反馈,他们通过火焰图分析发现Dubbo的负载均衡模块+路由模块占用CPU超过了30%,框架层面的使用率严重影响了业务逻辑的执行效率急需进行优化。通过火焰图分析,具体占比如下图,其中该机器在业务忙时的CPU使用率在60%左右,闲时在30%左右。
通过火焰图分析,负载均衡主要的消耗是在 getWeight方法。

路由的主要消耗是在route方法:
-
同机房优先路由

-
接口级标签路由+应用级标签路由

这些方法都有一个特点,那就是遍历执行。如负载均衡,针对每一个invoker都需要通过getWeight方法进行权重的计算;就近路由的router方法对于每一个invoker都需要通过url获取及机房信息进行匹配计算。
我们分析一下getWeight及router时间复杂度,发现是O(n)的时间复杂度,而且路由是由路由链组成的,每次每个 Router的route方法调用逻辑都会遍历实例列表,那么当实例列表数量过大时,每次匹配的计算的逻辑过大,那么就会造成大量的计算成本,导致占用大量cpu,同时也导致路由负载均衡效率低下。
综上所述,罪恶的的根源就是遍历导致的,当服务提供方数量越多,影响越大。
四、优化方案
知道了问题所在,我们来分析一下是否有优化空间。
4.1 路由优化
1. 优化一:关闭无效路由
通过火焰图分析,我们发现有部分业务即使完全不使用应用级的标签路由,原生的TagRouter也存在遍历逻辑,原因是为了支持静态的标签路由,其实这部分的开销也不少,那对于根本不会使用应用级标签路由的可以手动进行关闭。关闭方式如下:
-
客户端统一关闭
dubbo.consumer.router=-tag- 服务级别关闭
-
注解方式:
@DubboReference(parameters = {"router","-tag"})-
xml方式:
<dubbo:reference id="demoService" check="false" interface="com.dubbo.study.n.api.DemoService" router="-tag" />2. 优化二:提前计算路由结果并进行缓存
每次路由目前都是进行实时计算,但是在大多数情况下,我们的实例列表是稳定不变的,只有在发布窗口或配置变更窗口内实例列表才会发生变更,那我们是否可以考虑缓存呢。如就近路由,可以以机房为key进行机房实例的全量缓存。针对接口级标签路由可以缓存不同标签值指定的实例信息。
我们知道路由的执行过程是责任链模式,每一个Router的实例列表入参实际上是一个Router的结果,可参考公式:target = rn(…r3(r2(r1(src))))。那么所有的路由可以基于注册中心推送的原始服务列表进行路由计算并缓存,然后不同的路由结果相互取交集就能得到最终的结果,当实例信息发生变更时,缓存失效并重新计算。
3. 缓存更新时机
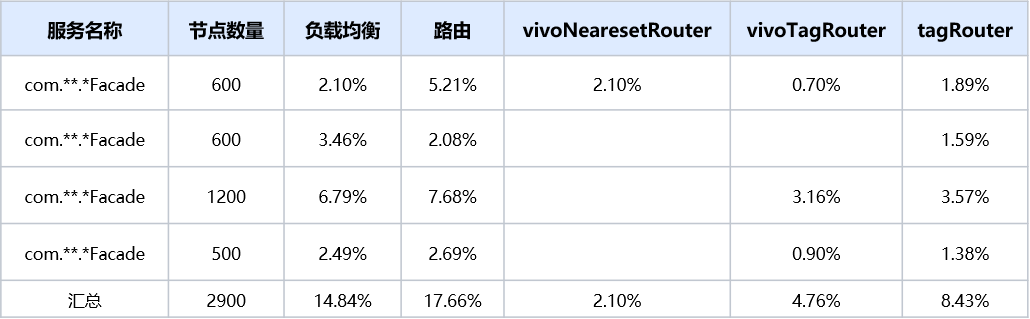
当注册中心或者动态配置有变更时,相关通知会给到服务目录Directory,Directory收到通知后会重新创建服务列表,并把服务列表同步到路由链RouterChain,RouterChain再按顺序通知其链上的Router,各个Router再进行缓存清除并重新进行路由结果的计算及进行缓存。相关时序图如下所示:
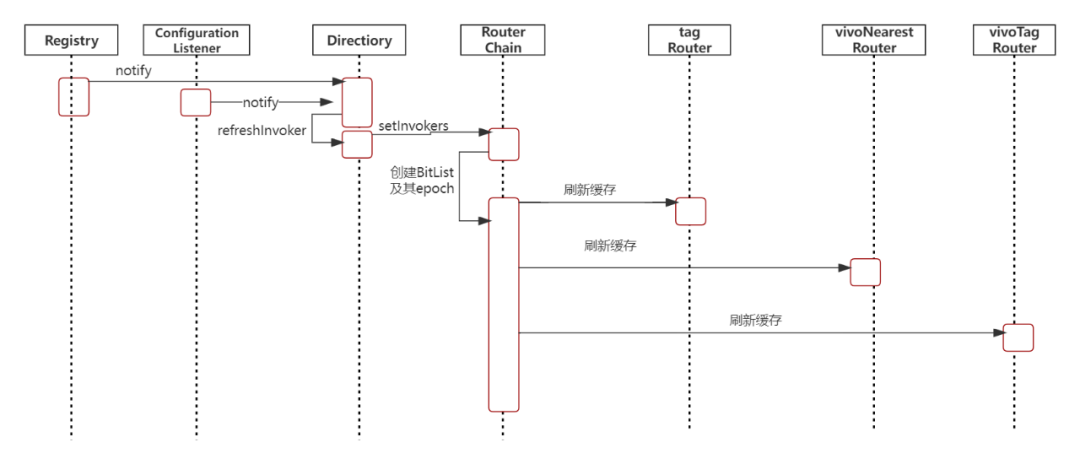
4. 具体路由流程
进入具体路由方法时,先判断是否存在缓存的路由值,且缓存值的epoch必须与上一个路由的epoch需一致,此时缓存才生效,然后缓存值与上个Router的结果取交集。
如果不存在缓存或epoch不一致则重新进行实时的路由计算。
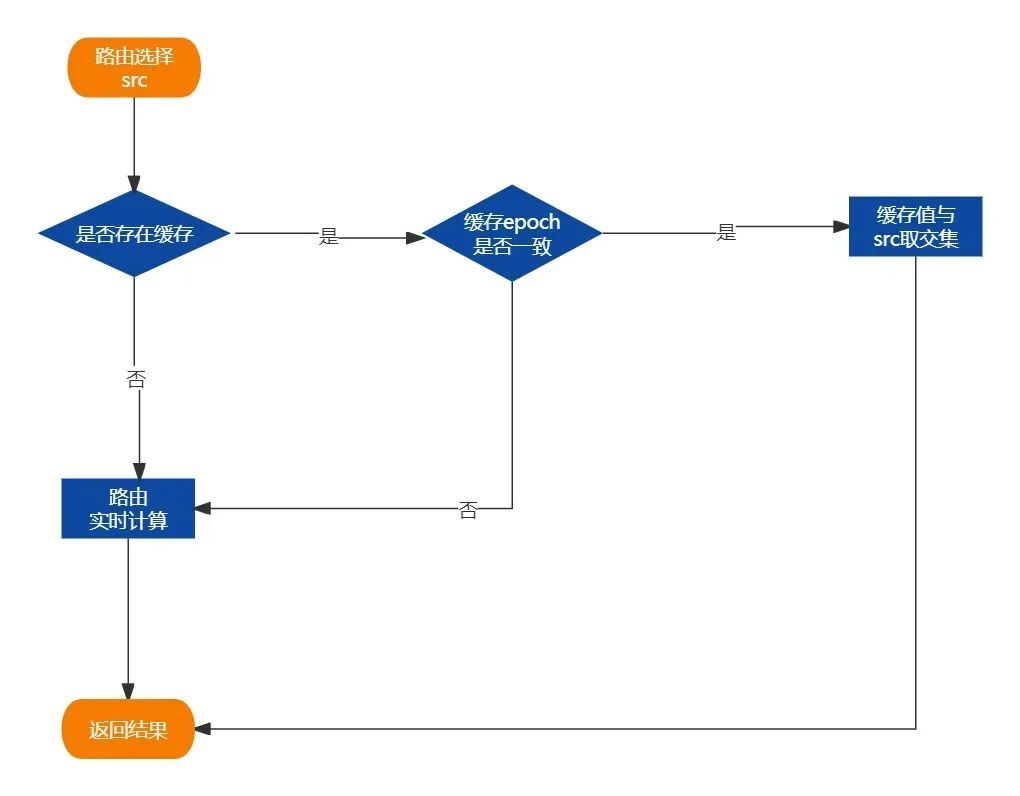
引入epoch的原因主要是保证各个路由策略缓存信息的一致性,保证所有的缓存计算都是基于同一份原始数据。当实例信息发生变更时,epoch会自动进行更新。
5. BitMap引入
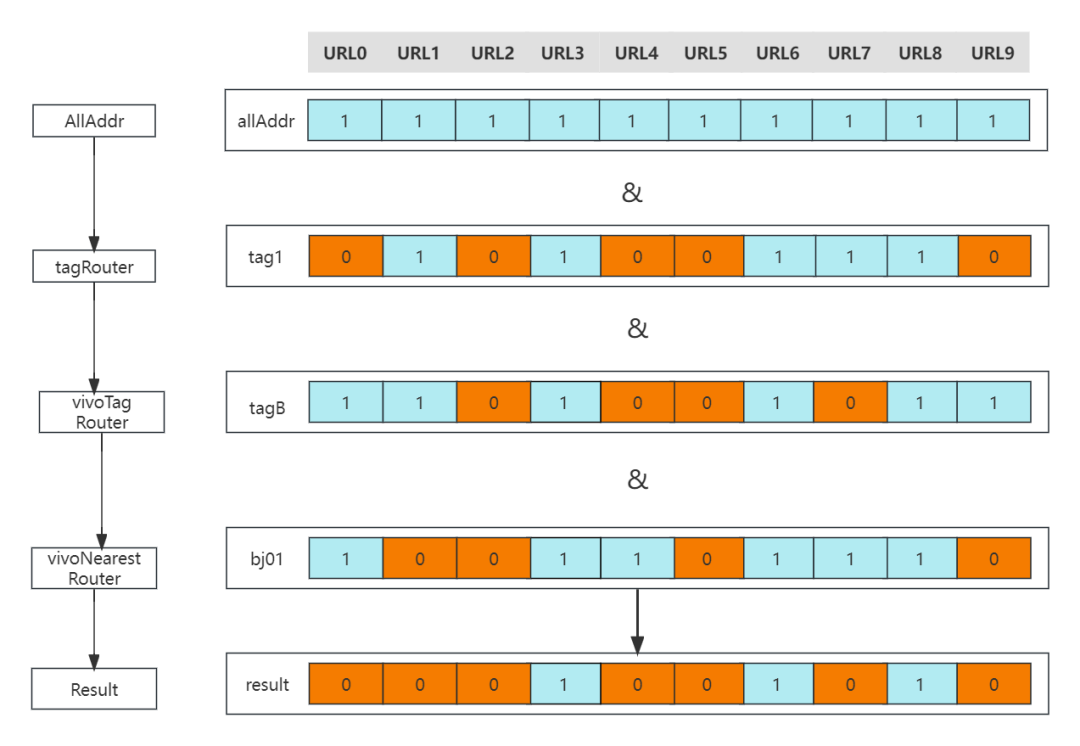
上文我们说到,不同的路由策略之间的结果是取交集的,然后最终的结果才送入负载均衡流程。那如何在缓存的同时,加快交集的计算呢。答案就是基于位图:BitMap。
BitMap的基本原理就是用一个bit位来存放某种状态,适用于大规模数据的查找及位运算操作。如在路由场景,先基于全量的推送数据进行计算缓存。如果某个实例被路由选中,则其值为1,若两个路由的结果要取交集,那直接对BitMap进行"&"运行即可。
全量缓存示意图:
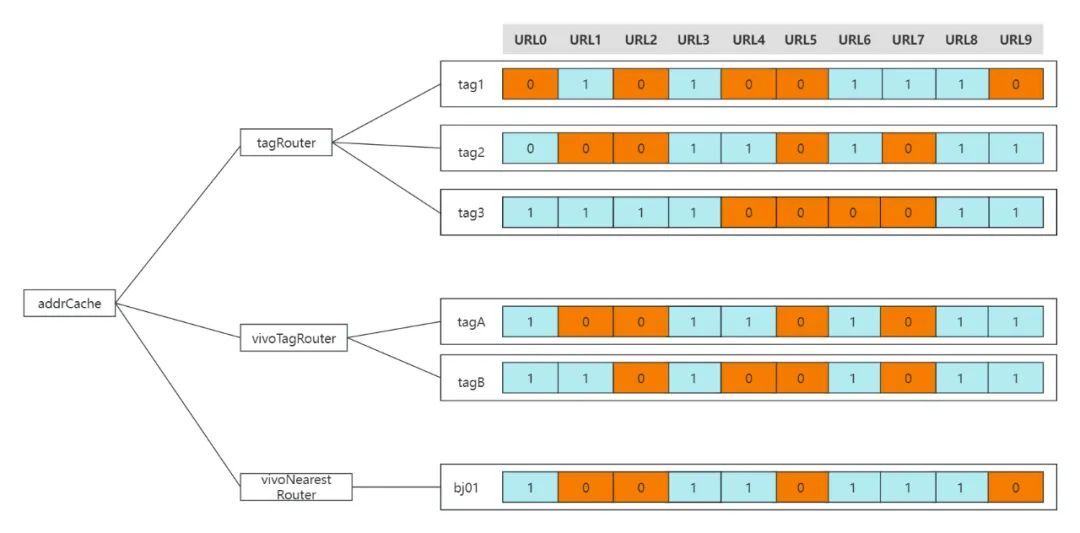
路由交集计算示步骤:
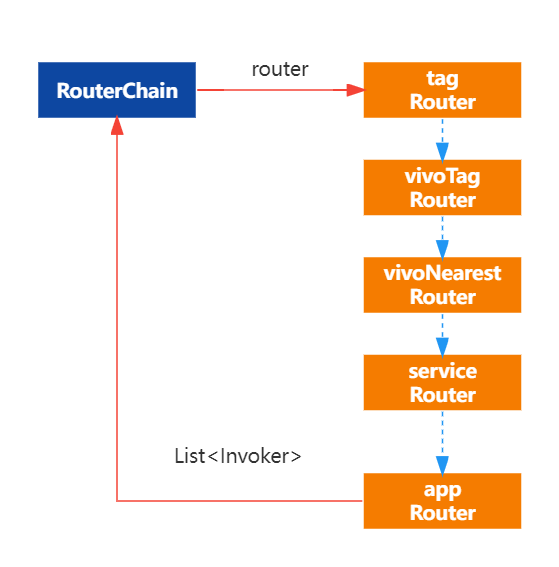
按照路由链依次计算,tagRouter->vivoTag->vivoNearestRouter
(1)tagRouter计算逻辑:
-
按照Invocation计算出目标的Tag,假设是tag1
-
然后从缓存Cache根据key:tag1,取出对应的targetAddrPool
-
将原始传入的addrPool与targetAddrPool,得到结果resultAddrPool
-
将resultAddrPool传入vivoTagRouter
(2)vivoTag计算逻辑:
-
按照Invocation计算出目标的Tag,假设是tabB
-
然后从缓存Cache根据key:tag1,取出对应的targetAddrPool
-
将上一次传入的addrPool与targetAddrPool,得到结果resultAddrPooll
-
将resultAddrPool传入vivoNearestRouter
(3)vivoNearestRouter计算逻辑
-
从环境变量取出当前机房,假设是bj01
-
然后从缓存Cache根据key:bj01,取出对应的targetAddrPool
-
将上一次传入的addrPool与targetAddrPool,取出resultAddrPool
-
将上一次传入的addrPool与targetAddrPool,得到结果resultAddrPool
-
将resultAddrPool为最终路由结果,传递给LoadBalance
6. 基于缓存的同机房优先路由源码解析
缓存刷新:
/*** Notify router chain of the initial addresses from registry at the first time.* Notify whenever addresses in registry change.*/public void setInvokers(List<Invoker<T>> invokers) {// 创建带epoch的BitListthis.invokers = new BitList<Invoker<T>>(invokers == null ? Collections.emptyList() : invokers,createBitListEpoch());routers.forEach(router -> router.notify(this.invokers));}同机房优先路由源码解读:
public <T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL consumerUrl, Invocation invocation) throws RpcException {…………//省略非核心代码BitList<Invoker<T>> bitList = (BitList<Invoker<T>>) invokers;//获取路由结果BitList<Invoker<T>> result = getNearestInvokersWithCache(bitList);if (result.size() > 0) {if (fallback) {// 开启服务降级,available.ratio = 当前机房可用服务节点数量 / 集群可用服务节点数量int curAvailableRatio = (int) Math.floor(result.size() * 100.0d / invokers.size());if (curAvailableRatio <= availableRatio) {return invokers;}}return result;} else if (force) {return result;} else {return invokers;}} /*** 获取缓存列表* @param invokers* @param <T>* @return*/private <T> BitList<Invoker<T>> getNearestInvokersWithCache(BitList<Invoker<T>> invokers) {ValueWrapper valueWrapper = getCache(getSystemProperty(LOC));// 是否存在缓存if (valueWrapper != null) {BitList<Invoker<T>> invokerBitList = (BitList<Invoker<T>>) valueWrapper.get();// 缓存的epoch与源列表是否一致if (invokers.isSameEpoch(invokerBitList)) {BitList<Invoker<T>> tmp = invokers.clone();// 结果取交集return tmp.and(invokerBitList);}}// 缓存不存在 实时计算放回return getNearestInvokers(invokers);}/*** 新服务列表通知* @param invokers* @param <T>*/@Overridepublic <T> void notify(List<Invoker<T>> invokers) {clear();if (invokers != null && invokers instanceof BitList) {BitList<Invoker<T>> bitList = (BitList<Invoker<T>>) invokers;// 设置最后一次更新的服务列表lastNotify = bitList.clone();if (!CollectionUtils.isEmpty(invokers) && this.enabled) {// 获取机房相同的服务列表并进行缓存setCache(getSystemProperty(LOC), getNearestInvokers(lastNotify));}}}4.2 负载均衡优化
1. 优化一
针对getWeight方法,我们发现有部分业务逻辑较为消耗cpu,但是在大多数场景下业务方并不会使用到,于是进行优化。
getWeight方法优化:
优化前:
//这里主要要用多注册中心场景下,注册中心权重的获取,绝大多数情况下并不会有这个逻辑if (UrlUtils.isRegistryService(url)) {weight = url.getParameter(REGISTRY_KEY + "." + WEIGHT_KEY, DEFAULT_WEIGHT);}
优化后:if (invoker instanceof ClusterInvoker && UrlUtils.isRegistryService(url)) {weight = url.getParameter(REGISTRY_KEY + "." + WEIGHT_KEY, DEFAULT_WEIGHT);}2. 优化二
遍历是罪恶的源泉,而实例的数量决定这罪恶的深浅,我们有什么办法减少负载均衡过程中的遍历呢。一是根据group及version划分不同的集群,但是这需要涉及到业务方代码或配置层面的改动,会带来额外的成本。所以我们放弃了。
二是没有什么是加一层解决不了的问题,为了尽量减少进入负载均衡的节点数量,考虑新增一个垫底的路由策略,在走完所有的路由策略后,若节点数量>自定义数量后,进行虚拟分组,虚拟分组的策略也可进行自定义,然后随机筛选一组进入负载均衡。此时进入负载均衡的实例数量就会有倍数的下降。
需要注意的是分组路由必须保证是在路由链的最后一环,否则会导致其他路由计算错误。
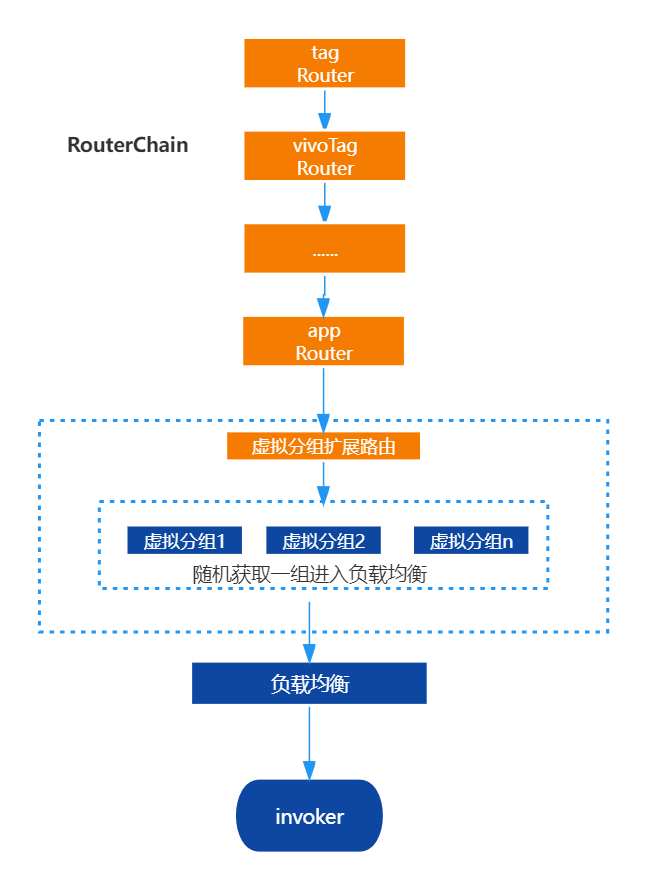
分组路由示意:
/*** * @param invokers 待分组实例列表* @param groupNum 分组数量* @param <T>* @return*/public <T> List<Invoker<T>> doGroup(List<Invoker<T>> invokers, int groupNum) {int listLength = invokers.size() / groupNum;List<Invoker<T>> result = new ArrayList<>(listLength);int random = ThreadLocalRandom.current().nextInt(groupNum);for (int i = random; i < invokers.size(); i = i + groupNum) {result.add(invokers.get(i));}return result;}五、优化效果
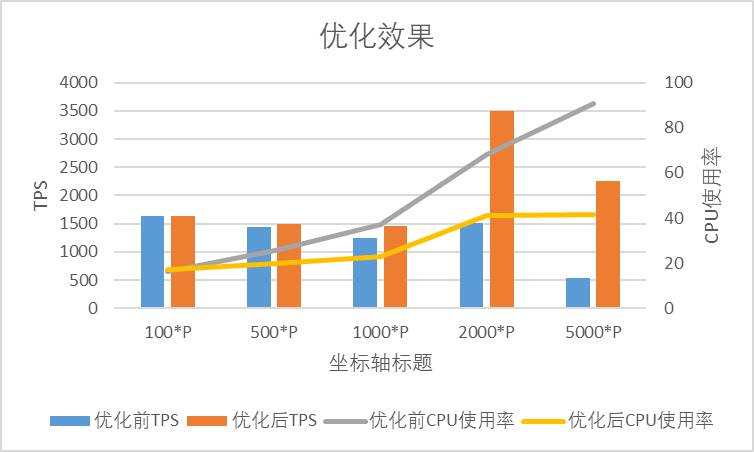
针对优化前和优化后,我们编写Demo工程分别压测了不配置路由/配置就近+标签路由场景。Provider节点梯度设置100/500/1000/2000/5000,TPS在1000左右,记录了主机的cpu等性能指标,并打印火焰图。发现,配置路由后,采用相同并发,优化后的版本tps明显高于优化前版本,且新版本相较于没有配置路由时tps显著提高,下游节点数大于2000时,tps提升达到100%以上,下游节点数越多,AvgCpu优化效果越明显,并且路由及负载均衡CPU占比明显更低,详细数据可见下表:
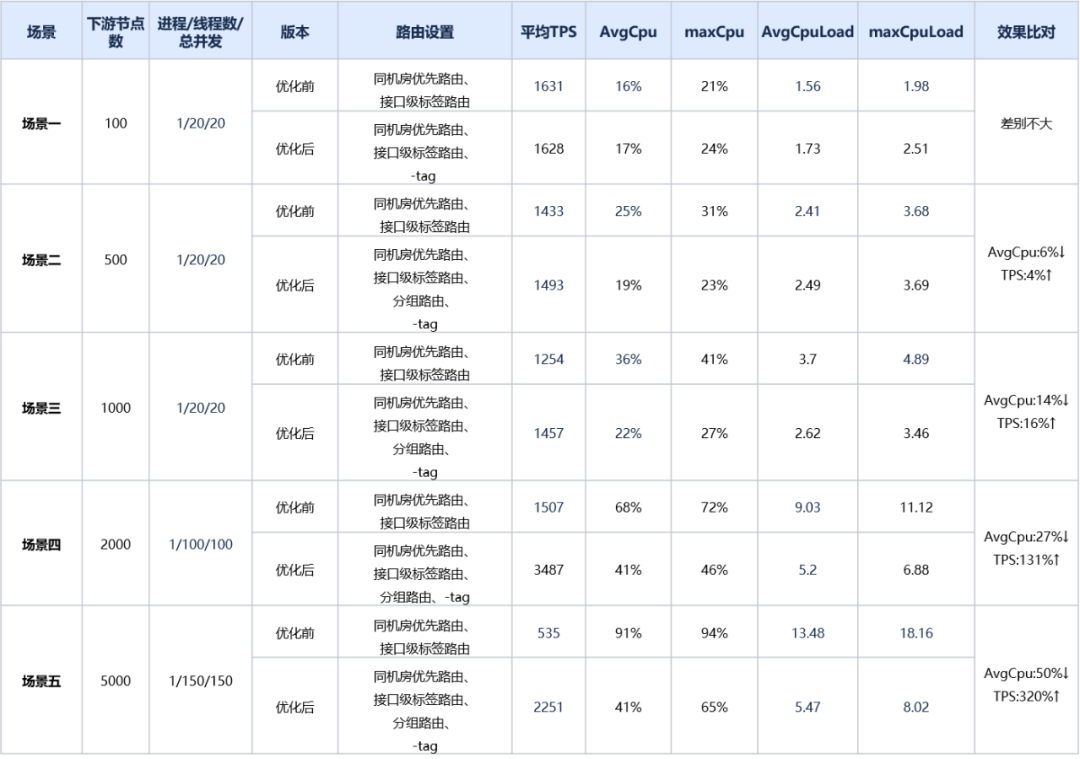
备注:-tag,表示显示禁用原生Dubbo应用级标签路由。该路由默认开启。
六、总结
经过我们关闭不必要的路由逻辑、对路由缓存+异步化计算、新增分组路由等优化后,Dubbo在负载均衡及路由模块整体的性能有了显著的提升,为业务方节省了不少CPU资源。在正常业务场景下当提供方数量达到2000及以上时,tps提升可达100%以上,消费方平均CPU使用率下降约27%,且提供方数量越多优化效果越明显。但是我们也发现当前的随机负载均衡依然还是会消耗一定的CPU资源,且只能保证流量是均衡的。当前我们的应用基本部署在虚拟机及容器上。这两者均存在超卖的状况,且同等配置的宿主机性能存在较大差异等问题。最终会导致部分请求超时、无法最大化利用提供方的资源。我们下一步将会引入Dubbo 3.2的自适应负载均衡并进行调优减少其CPU使用率波动较大的问题,其次我们自身也扩展了基于CPU负载均衡的单一因子算法,最终实现不同性能的机器CPU负载趋于均衡,最大程度发挥集群整体的性能。
参考资料:
-
Dubbo 负载均衡
-
Dubbo 流量管控
-
Dubbo 3 StateRouter:下一代微服务高效流量路由
相关文章:
Dubbo 路由及负载均衡性能优化
作者:vivo 互联网中间件团队- Wang Xiaochuang 本文主要介绍在vivo内部针对Dubbo路由模块及负载均衡的一些优化手段,主要是异步化缓存,可减少在RPC调用过程中路由及负载均衡的CPU消耗,极大提升调用效率。 一、概要 vivo内部Java…...

Python数据可视化入门指南
Matplotlib和Plotly是两个在Python中广泛使用的数据可视化库,它们具有丰富的API和功能,用于创建各种类型的图表和图形。在本篇博客中,我们将介绍它们的主要特点和基本用法。 Matplotlib 主要特点: 高度自定义: Matp…...
我的ChatGPT的几个使用场景
示例一,工作辅助、写函数代码: 这里展示了一个完整的代码,修正,然后最终输出的过程。GPT具备足够丰富的相关的小型代码生成能力,语法能力也足够好。这类应用场景,在我的GPT使用中,能占到65%以上…...
3 — NLP 中的标记化:分解文本数据的艺术
一、说明 这是一个系列文章的第三篇文章, 文章前半部分分别是: 1 — NLP 的文本预处理技术2 — NLP中的词干提取和词形还原:文本预处理技术 在本文中,我们将介绍标记化主题。在开始之前,我建议您阅读我之前介绍…...

C++-类与对象(上)
一、 auto关键字 1.自动识别数据类型 2.auto的初始化 3.auto简化for循环 nullptr的使用 二、类与对象 1.c中类的定义 2.c语言与c的比较 3.类的访问限定符以及封装 3.1访问限定符 3.2封装 3.3类的作用域 3.4类的声明与定义分离 🗡CSDN主页:d1ff1cult.&…...

多进程间通信学习之无名管道
无名管道:首先它是内核空间的实现机制;然后只能用于亲缘进程间通信;它在内核所占的大小是64KB;它采用半双工的通信方式;请勿使用lseek函数;读写特点:若读端存在写管道,那么有多少数据…...

flink常用的几种调优手段的优缺点
背景: 不管是基于减少反压还是基于减少端到端的延迟的目的,我们有时候都需要对flink进行调优,本文就整理下几种常见的调优手段以及他们的优缺点 flink调优手段 1.使用事件时间EventTime模式时,可以设置水位线发送的时间间隔,比…...

如何选择安全又可靠的文件数据同步软件?
数据实时同步价值体现在它能够确保数据在多个设备或系统之间实时更新和保持一致。这种技术可以应用于许多领域,如电子商务、社交媒体、金融服务等。在这些领域中,数据实时同步可以带来很多好处,如提高工作效率、减少数据不一致、提高用户体验…...

使用反射调用类的私有内部类的私有方法
文章目录 使用反射调用类的私有方法类实现方法实现代码 使用反射调用类的私有内部类的私有方法类实现方法实现代码 在进行单元测试时,我们往往需要直接访问某个类的内部类或者某个类的私有方法,此时正常的调用就无能为力了,因此我们可以使用反…...

记一次 AWD 比赛中曲折的 Linux 提权
前提背景: 今天一场 AWD 比赛中,遇到一个场景:PHP网站存在SQL注入和文件上传漏洞, MYSQL当前用户为ROOT,文件上传蚁剑连接SHELL是权限很低的用户。我需要想办法进行提权,才能读取到 /root 目录下的 flag。 一、sqlmap …...

[SpringCloud] Feign 与 Gateway 简介
目录 一、Feign 简介 1、RestTemplate 远程调用中存在的问题 2、定义和使用 Feign 客户端 3、Feign 自定义配置 4、Feign 性能优化 5、Feign 最佳实践 6、Feign 使用问题汇总 二、Gateway 网关简介 1、搭建网关服务 2、路由断言工厂 3、路由的过滤器配置 4、全局过…...

[Unity] 个人编码规范与命名准则参考
Unity C# 在写的过程中, 和纯 C# 是有很大出入的. 甚至说, Unity C# 就是邪教. 例如它的命名规范与 C# 是不一致的, 而且由于游戏引擎的介入, 编写时的习惯相较于 C# 来讲, 也需要有所改变. 通用编码规范 常见的一些编码规范就不需要过多提及了, 这里只做简单列举. 添加合适…...
堆栈与队列算法-以链表来实现队列
目录 堆栈与队列算法-以链表来实现队列 C代码 堆栈与队列算法-以链表来实现队列 队列除了能以数组的方式来实现外,也可以用链表来实现。在声明队列的类中,除了和队列相关的方法外,还必须有指向队列前端和队列末尾的指针,即fron…...
快速入门:使用 Spring Boot 构建 Web 应用程序
前言 本文将讨论以下主题: 安装 Java JDK、Gradle 或 Maven 和 Eclipse 或 IntelliJ IDEA创建一个新的 Spring Boot 项目运行 Spring Boot 应用程序编写一个简单的 Web 应用程序打包应用程序以用于生产环境 通过这些主题,您将能够开始使用 Spring Boo…...
01.CentOS7静默安装oracle11g
CentOS7静默安装oracle11g 一、下载Oracle11g安装包二、开始安装oracle11g三、配置Oracle监听程序四、添加数据库实例五、设置开机启动六、登录后解除锁定 一、下载Oracle11g安装包 下载链接:https://pan.baidu.com/s/1gcLMFGX7-8ju7OoFOFLzQA 提取码:6…...

SASE安全访问服务边缘
自存用: 参考文档: 什么是安全访问服务边缘 (SASE)? | Microsoft 安全 网安人必读 |一文读懂SASE - 知乎...
k8s集群升级
目录 1. 部署cri-docker (所有集群节点) 2. 升级master节点 3. 升级worker节点 4. 部署containerd 1. 部署cri-docker (所有集群节点) k8s从1.24版本开始移除了dockershim,所以需要安装cri-docker插件才能使用docker …...
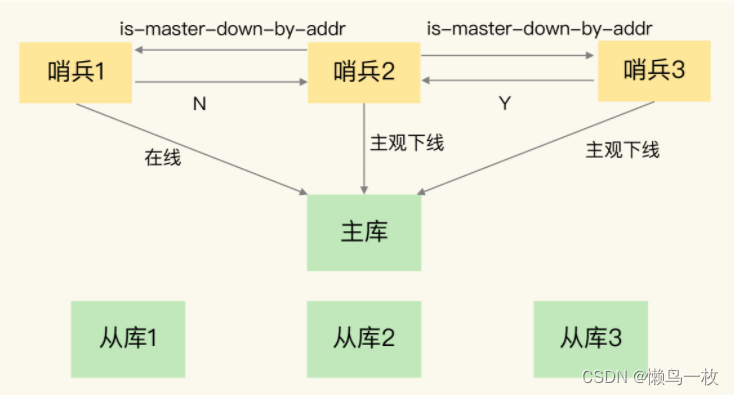
redis原理 主从同步和哨兵集群
主从库如何实现数据一致 我们总说的 Redis 具有高可靠性,又是什么意思呢?其实,这里有两层含义:一是数据尽量少丢失,二是服务尽量少中断。AOF 和 RDB 保证了前者,而对于后者,Redis 的做法就是增…...

四季古诗赏析
春晓 春眠不觉晓,处处闻啼鸟。夜来风雨声,花落知多少。 夏意 别院深深夏簟清,石榴开遍透帘明。树阴满地日当午,梦觉流莺时一声。 秋词 自古逢秋悲寂寥,我言秋日胜春朝。晴空一鹤排云上,便引诗情到碧霄。 …...
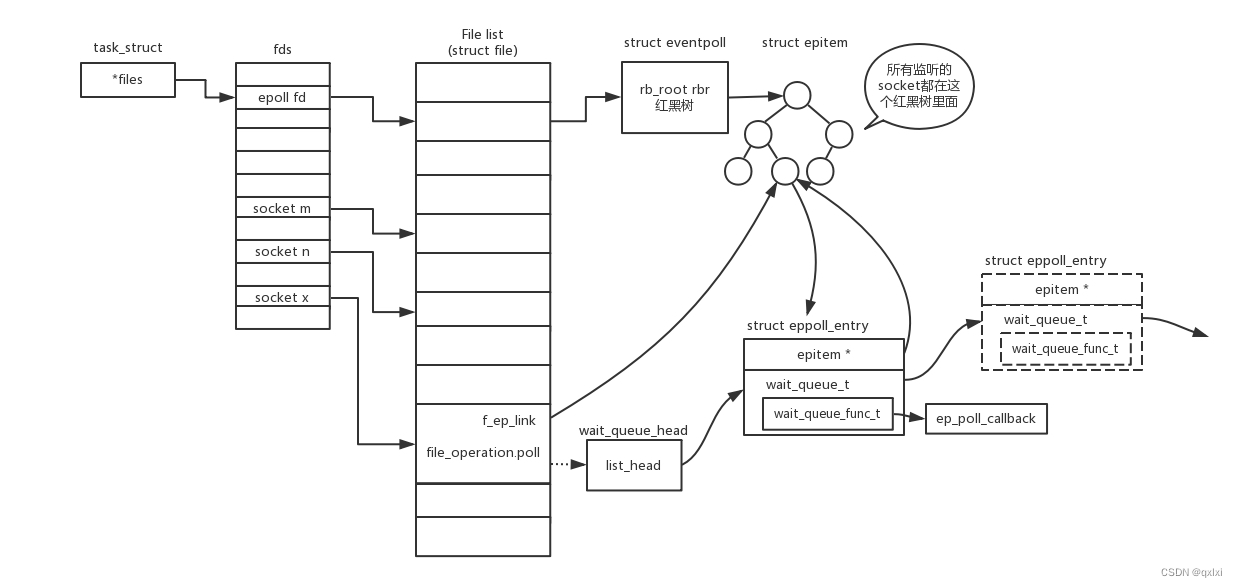
【网络协议】聊聊套接字socket
网络编程我们知道是通过socket进行编程的,其实socket也是基于TCP和UDP协议进行编程的。但是在socket层面是感知不到下层的,所以在设置参数的时候,其实是端到端协议智商的网络层和传输层。TCP是数据流所以设置为SOCK_STREAM,而UDP是…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...