第2篇 机器学习基础 —(4)k-means聚类算法

前言:Hello大家好,我是小哥谈。聚类算法是一种无监督学习方法,它将数据集中的对象分成若干个组或者簇,使得同一组内的对象相似度较高,不同组之间的对象相似度较低。聚类算法可以用于数据挖掘、图像分割、文本分类等领域。常见的聚类算法包括K-Means、层次聚类、DBSCAN、AP聚类、谱聚类等。本节课就简单介绍k-means聚类算法!~🌈
 前期回顾:
前期回顾:
第2篇 机器学习基础 —(1)机器学习概念和方式
第2篇 机器学习基础 —(2)分类和回归
第2篇 机器学习基础 —(3)机器学习库之Scikit-Learn
目录
🚀1.什么是聚类
🚀2.K-Means聚类算法
🚀3.K-means聚类优缺点
🚀4.聚类数据生成器

🚀1.什么是聚类
聚类算法是一种无监督学习方法,它将数据集中的对象分成若干个组或者簇,使得同一组内的对象相似度较高,不同组之间的对象相似度较低。聚类算法可以用于数据挖掘、图像分割、文本分类等领域。常见的聚类算法包括K-Means、层次聚类、DBSCAN、AP聚类、谱聚类等。其中,K-Means是一种基于距离的聚类算法,层次聚类是一种基于树形结构的聚类算法,DBSCAN是一种基于密度的聚类算法,AP聚类是一种基于相似度传播的聚类算法,谱聚类是一种基于图论的聚类算法。每种聚类算法都有其适用的场景和优缺点。
说明:♨️♨️♨️
聚类类似于分类,不同的是聚类所要求划分的类是未知的,也就是说不知道应该属于哪类,而是通过一定的算法自动分类。在实际应用中,聚类是一个将数据集中在某些方面相似的数据中,并进行分类组织的过程(简单地说,就是将相似数据聚在一起)。
聚类的主要应用领域:
商业:聚类分析被用来发现不同的客户群,并且通过购买模式刻画不同客户群的特征。
生物:聚类分析被用来对动植物分类和对基因进行分类,获取对种群固有结构的认识。
保险行业:聚类分析通过一个高的平均消费来鉴定汽车保险单持有者的分组,同时根据住宅类型、价值和地理位置来判断一个城市的房产分组。
因特网:聚类分析被用来在网上进行文档归类。
电子商务:聚类分析在电子商务网站建设数据挖掘中也是很重要的一个方面,通过分组聚类出具有相似浏览行为的客户,并分析客户的共同特征,可以更好地帮助电商了解自己的客户,向客户提供更合适的服务。
等等......🍉 🍓 🍑 🍈 🍌 🍐
🚀2.K-Means聚类算法
K-Means是一种常见的聚类算法,它的目标是将数据集分成K个簇,使得同一簇内的数据点相似度较高,不同簇之间的相似度较低。K-Means算法的基本思路是随机选择K个中心点,然后将每个数据点分配到距离最近的中心点所在的簇中,接着重新计算每个簇的中心点,重复以上步骤直到簇不再发生变化或达到预设的迭代次数。K-Means算法的优点是简单易懂,计算速度快,但是需要预先指定簇的数量K,且对于不同的初始中心点选择可能会得到不同的聚类结果。
k-means 算法是一种无监督学习算法,目的是将相似的对象归到同一个簇中。簇内的对象越相似,聚类的效果就越好。传统的聚类算法包括划分方法、层次方法、基于密度方法、基于网格方法和基于模型方法。本节主要介绍K-means 聚类算法,它是划分方法中较典型的一种,也可以称为k均值聚类算法。
说明:♨️♨️♨️
K-means聚类也称为k均值聚类,是著名的划分聚类的算法,由于简洁性和高效率,使得它成为所有聚类算法中应用最为广泛的一种。k均值聚类是给定一个数据点集合和需要的聚类数目k,k由用户指定,k均值算法将根据某个距离函数反复把数据分入k个聚类中。
K-Means聚类流程:
随机选取k个点作为初始质心(质心即簇中所有点的中心),然后将数据集中的每个点分配到一个簇中。具体来说,为每个点找距其最近的质心,并将其分配给该质心所对应的簇。这一步完成之后,每个簇的质心更新为该簇所有点的平均值。这个过程将不断重复直到满足某个终止条件。
终止条件可以是以下中的任何一个:
- 没有(或最小数目)对象被重新分配给不同的聚类。
- 没有(或最小数目)聚类中心再发生变化。
- 误差平方和局部最小。
通过以上介绍,相信您对K-means聚类算法已经有了初步的认识,而在Python中应用该算法无需手动编写代码,因为Python的第三方模块Scikit-Learn已经帮我们写好了,在性能和稳定性上会好得多,只需在程序中调用即可,没必要自己造轮子。
关于Scikit-Learn的介绍及应用,请参考文章:
第2篇 机器学习基础 —(3)机器学习库之Scikit-Learn
🚀3.K-means聚类优缺点
K-means是一种常用的聚类算法,其优缺点如下:
优点:
- 原理简单,容易实现。
- 可解释度较强。
- 可以通过加速算法来提高效率。
- 具有良好的可扩展性,适用于大规模数据集。
- 聚类效果较好,适用于一些简单的数据集。
缺点:
- K值很难确定。
- 容易陷入局部最优解。
- 对噪音和异常点敏感。
- 需要样本存在均值,限定数据种类。
- 聚类效果依赖于聚类中心的初始化。
- 对于非凸数据集或类别规模差异太大的数据效果不好。
🚀4.聚类数据生成器
Scikit-Learn 中的make_blobs方法用于生成聚类算法的测试数据,直观地说,make_blobs 方法可以根据用户指定的特征数量、中心点数量、范围等来生成几类不同的数据,这些数据可用于测试聚类算法的效果。
make_blobs 方法的语法如下:
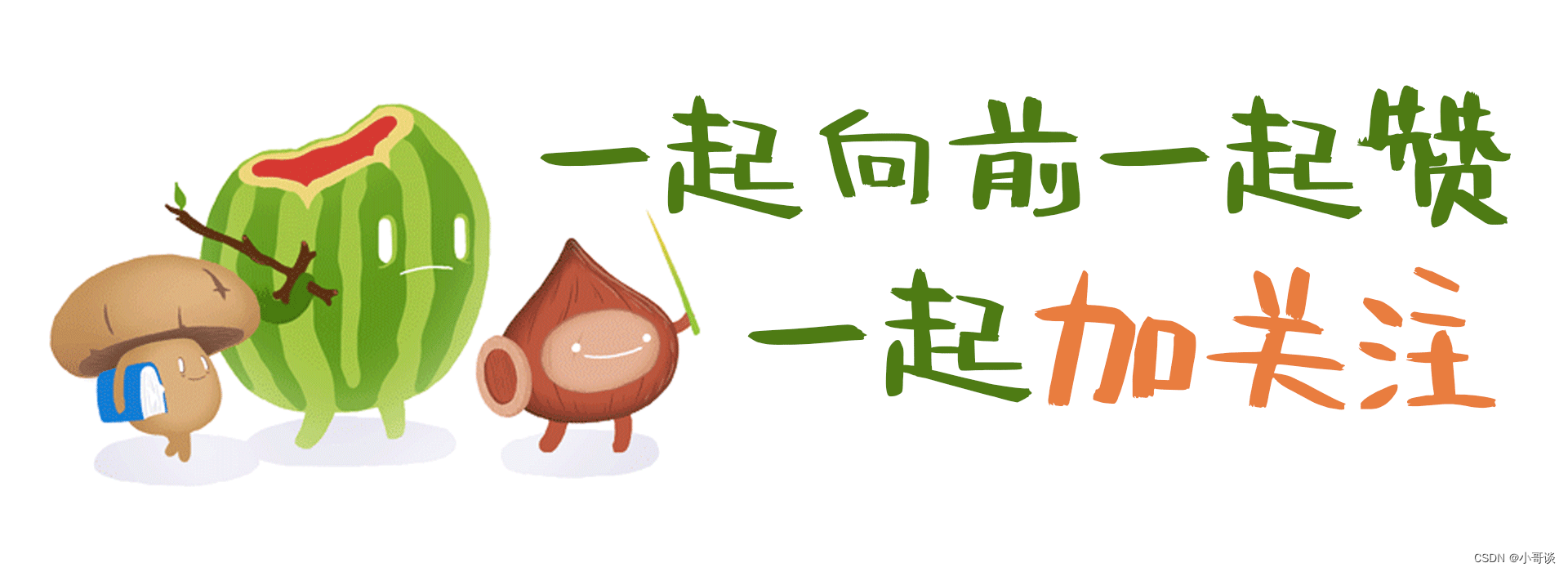
sklearn.datasets.make_blobs(n_samples=100,n_features=2,centers=3,cluster_std=1.0,center_box=(-10.0,10.0),shuffle=True,random_state=None)常用参数说明:
n_samples:待生成的样本的总数。
n_features:每个样本的特征数。
centers:类别数。
cluster_std:每个类别的方差。例如,生成两类数据,其中一类比另一类具有更大的方差,可以将cluster_std 参数设置为[1.0,3.0]。
举例:
生成用于聚类的数据(500 个样本,每个样本中含有2 个特征),程序代码如下:
from sklearn.datasets import make_blobs
from matplotlib import pltx,y = make_blobs(n_samples=500, n_features=2, centers=3)接下来,通过K-Means 方法对测试数据进行聚类,形成散点图,程序代码如下:
from sklearn.cluster import KMeansy_pred = KMeans(n_clusters=4, random_state=9).fit_predict(x)
plt.scatter(x[:, 0], x[:, 1], c=y_pred)
plt.show()运行程序,效果如下图所示:

从分析结果得知:相似的数据聚在一起,分成了4堆,也就是4类,并以不同的颜色显示,看上去更加清晰直观。✅
相关文章:
第2篇 机器学习基础 —(4)k-means聚类算法
前言:Hello大家好,我是小哥谈。聚类算法是一种无监督学习方法,它将数据集中的对象分成若干个组或者簇,使得同一组内的对象相似度较高,不同组之间的对象相似度较低。聚类算法可以用于数据挖掘、图像分割、文本分类等领域…...

【Python爬虫+可视化】解析小破站热门视频,看看播放量为啥会这么高!评论、弹幕主要围绕什么展开
大家早好、午好、晚好吖 ❤ ~欢迎光临本文章 如果有什么疑惑/资料需要的可以点击文章末尾名片领取源码 环境使用 Python 3.8 Pycharm 模块使用 import requests import csv import datetime import hashlib import time 一. 数据来源分析 明确需求 明确采集网站以及数…...

Mac电脑专业三维模型展UV贴图编辑工具RizomUV RS + VS 2023有哪些特点
RizomUV RS VS是一款功能强大的UV展开软件,用于在三维模型上创建和编辑UV贴图。它具有直观的用户界面和丰富的功能,能够帮助艺术家和设计师更高效地进行UV展开工作。 RizomUV RS VS支持多种模型格式,包括OBJ、FBX、DAE和3DS等,使…...

Linux文件描述符和文件指针互转
本文研究的主要是Linux中文件描述符fd与文件指针FILE*互相转换的相关内容,具体介绍如下。 简介 1.文件描述符fd的定义: 文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当…...
C++11线程
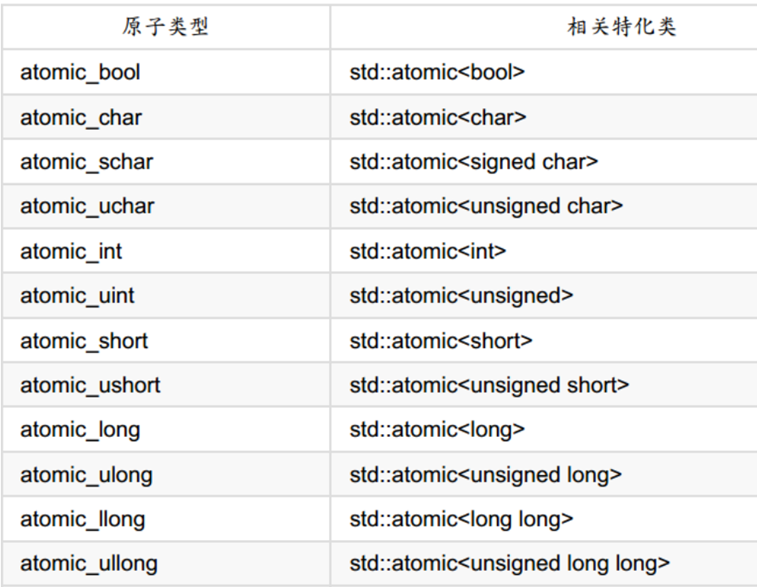
C11线程 创建线程 创建线程需要包含头文件<thread>,使用线程类std::thread 构造函数 默认构造函数 thread() noexcept; 默认构造函数,构造一个线程对象,但它不会启动任何实际的线程执行。 任务函数构造函数 template< class Fun…...

VIVO应用商店评论数据抓取
VIVO应用商店的app评论数据抓取 每个应用的评论能获取到最新的 100页 数据 每页20条,也就是 2000条评论数据 接口: pl.appstore.vivo.com.cn/port/comments/ 爬取运行截图:...

第00章_写在前面
第00章_写在前面 讲师:尚硅谷-宋红康(江湖人称:康师傅) 官网:http://www.atguigu.comhttp://www.atguigu.com/) 一、MySQL数据库基础篇大纲 MySQL数据库基础篇分为5个篇章: 1. 数据库概述与MySQL安装篇…...
测绘人注意,你可能会改变历史!
你也许想不到,曾经有一个测绘人员在进行实地测量作业时,在地图上就这么随手一标注,却让这个地方成为了如今的网红打卡地。 这个地方就是外地游客慕名而来的“宽窄巷子”,如果连这个地方都不知道的成都人,就应该不能算…...

MySQL - 慢查询
慢查询日志用于记录执行时间超过设定的时间阈值的 SQL 查询语句。它的目的是帮助数据库管理员识别和优化执行时间较长的查询,以提高数据库性能: 慢查询定义:慢查询日志记录那些执行时间超过 long_query_time 参数设定的时间阈值的 SQL 查询语…...
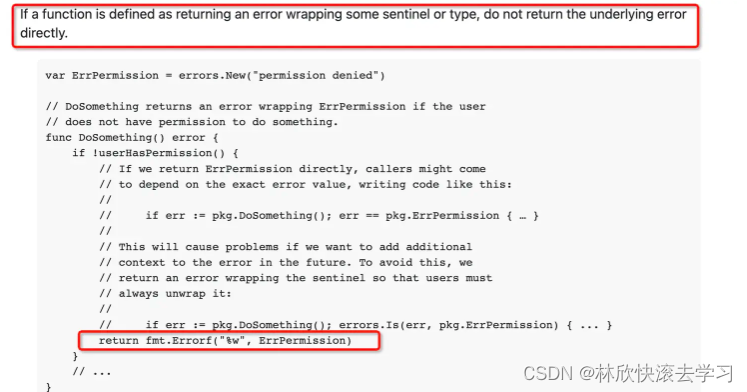
go中“哨兵错误”的由来及使用建议
“哨兵错误(sentinel error)”这个词的出处。之前我也只是在一些书籍和资料中见到过,也没深究。当这个网友问了我之后,就深入的翻了翻资料,在golang的官方博客中找到了这个词的提法,也算是比较官方的了吧。…...

【Python百练——第2练】使用Python做一个猜数字小游戏
💐作者:insist-- 💐个人主页:insist-- 的个人主页 理想主义的花,最终会盛开在浪漫主义的土壤里,我们的热情永远不会熄灭,在现实平凡中,我们终将上岸,阳光万里 ❤️欢迎点…...
Power BI 傻瓜入门 18. 让您的数据熠熠生辉
本章内容包括: 配置Power BI以使数据增量刷新发现使用Power BI Desktop and Services保护数据集的方法在不影响性能和完整性的情况下管理海量数据集 如果有更新的、更相关的数据可用,旧数据对组织没有好处。而且,老实说,如果数据…...
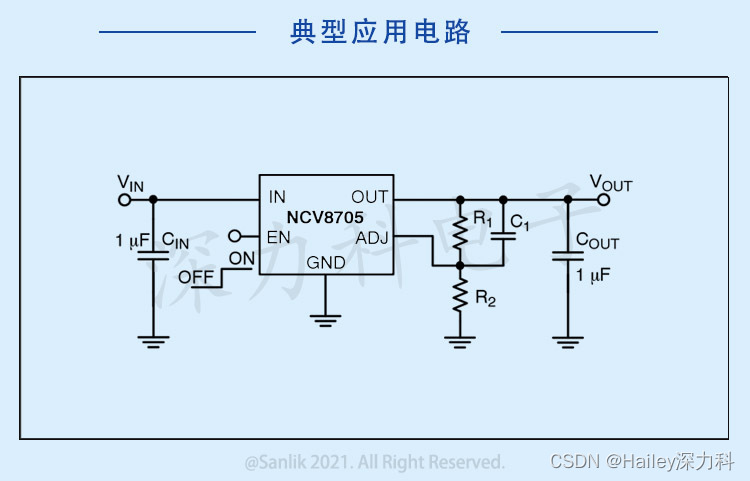
什么是车规级芯片?一起探讨车规级芯片NCV8705MTADJTCG LDO线性稳压器 工作原理、特性参数
关于车规级芯片(Automotive Grade Chip),车规级芯片是专门用于汽车行业的芯片,具有高可靠性、高稳定性和低功耗等特点,以满足汽车电子系统的严格要求。这些芯片通常用于车载电子控制单元(ECU)和…...

Stream流基础使用
目录 Stream出现时间: 作用: 什么是 Stream? 生成流 forEach map filter limit...

防数据泄密的解决方案
防数据泄密的解决方案 安企神数据防泄密系统下载使用 现代化企业离不开信息数据,数据对企业的经营至关重要,也是企业发展的命脉。为了保护公司数据不被泄露,尤其是在防止数据泄密方面,公司面临着巨大的挑战,需要采取…...

禁用swagger
springfox: documentation: auto-startup: false...
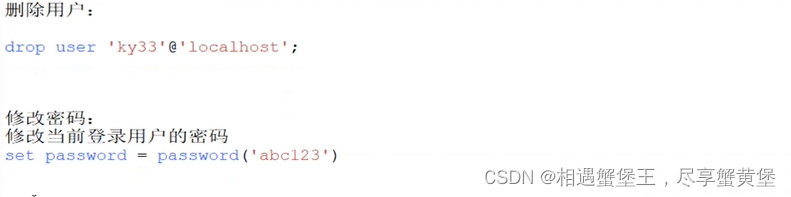
Mysql数据库中的用户管理与授权
ddl: create drop alter dml:对数据进行管理update insert into delete truncate dql:查询语句 select dcl:权限控制语句grant revoke 创建用户 create user 用户名主机 identified by 密码 加密 SELECT PASSWORD(密码); #先获取加密的密码 CREATE USER lisiloca…...
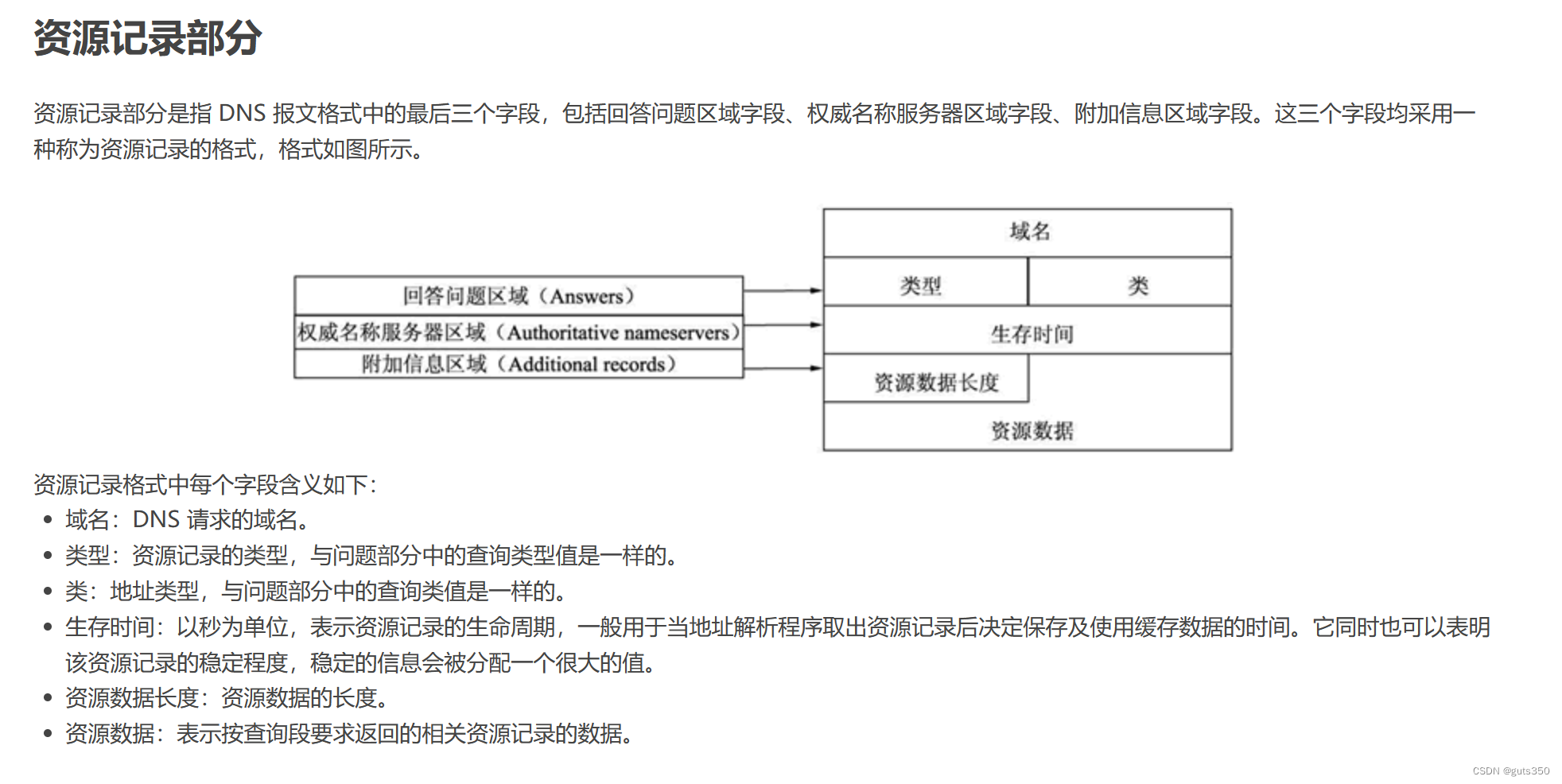
wireshark捕获DNS
DNS解析: 过滤项输入dns: dns查询报文 应答报文: 事务id相同,flag里 QR字段1,表示响应,answers rrs变成了2. 并且响应报文多了Answers 再具体一点,得到解析出的ip地址(最底下的add…...

Linux学习-kubernetes之Ingress
资源下载 IngressController IngressYAML Ingress安装部署 #1.将下载的ingress.tar.gz通过docker的方式导入harbor仓库 [rootmaster ingress]# docker load -i ingress.tar.xz [rootmaster ingress]# docker images|while read i t _;do[[ "${t}" "TAG"…...

diamond大基因序列快速比对工具使用详解-包含超算集群多节点计算使用方法
Diamond是一款快速的序列比对工具,其使用方法如下: 1. 安装Diamond: 可从官方网站(https://github.com/bbuchfink/diamond/releases)下载安装包,并安装到本地电脑中。当然还有docker,conda以及…...

大话软工笔记—需求分析概述
需求分析,就是要对需求调研收集到的资料信息逐个地进行拆分、研究,从大量的不确定“需求”中确定出哪些需求最终要转换为确定的“功能需求”。 需求分析的作用非常重要,后续设计的依据主要来自于需求分析的成果,包括: 项目的目的…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

深入解析C++中的extern关键字:跨文件共享变量与函数的终极指南
🚀 C extern 关键字深度解析:跨文件编程的终极指南 📅 更新时间:2025年6月5日 🏷️ 标签:C | extern关键字 | 多文件编程 | 链接与声明 | 现代C 文章目录 前言🔥一、extern 是什么?&…...

省略号和可变参数模板
本文主要介绍如何展开可变参数的参数包 1.C语言的va_list展开可变参数 #include <iostream> #include <cstdarg>void printNumbers(int count, ...) {// 声明va_list类型的变量va_list args;// 使用va_start将可变参数写入变量argsva_start(args, count);for (in…...
HubSpot推出与ChatGPT的深度集成引发兴奋与担忧
上周三,HubSpot宣布已构建与ChatGPT的深度集成,这一消息在HubSpot用户和营销技术观察者中引发了极大的兴奋,但同时也存在一些关于数据安全的担忧。 许多网络声音声称,这对SaaS应用程序和人工智能而言是一场范式转变。 但向任何技…...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...

【堆垛策略】设计方法
堆垛策略的设计是积木堆叠系统的核心,直接影响堆叠的稳定性、效率和容错能力。以下是分层次的堆垛策略设计方法,涵盖基础规则、优化算法和容错机制: 1. 基础堆垛规则 (1) 物理稳定性优先 重心原则: 大尺寸/重量积木在下…...
)
ArcPy扩展模块的使用(3)
管理工程项目 arcpy.mp模块允许用户管理布局、地图、报表、文件夹连接、视图等工程项目。例如,可以更新、修复或替换图层数据源,修改图层的符号系统,甚至自动在线执行共享要托管在组织中的工程项。 以下代码展示了如何更新图层的数据源&…...
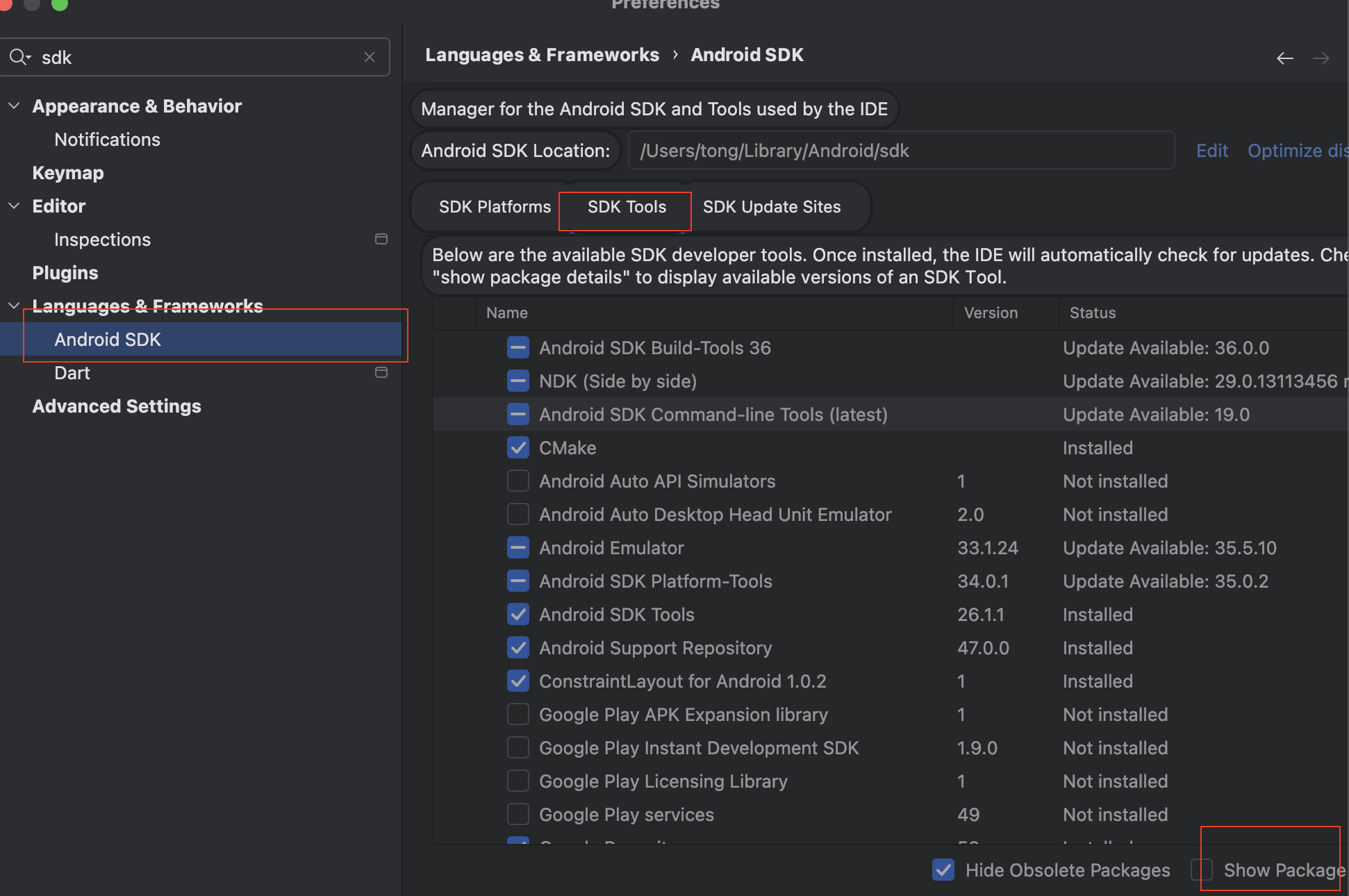
Mac flutter环境搭建
一、下载flutter sdk 制作 Android 应用 | Flutter 中文文档 - Flutter 中文开发者网站 - Flutter 1、查看mac电脑处理器选择sdk 2、解压 unzip ~/Downloads/flutter_macos_arm64_3.32.2-stable.zip \ -d ~/development/ 3、添加环境变量 命令行打开配置环境变量文件 ope…...