基于深度学习的中文情感分类 - 卷积神经网络 情感分类 情感分析 情感识别 评论情感分类 计算机竞赛
文章目录
- 1 前言
- 2 情感文本分类
- 2.1 参考论文
- 2.2 输入层
- 2.3 第一层卷积层:
- 2.4 池化层:
- 2.5 全连接+softmax层:
- 2.6 训练方案
- 3 实现
- 3.1 sentence部分
- 3.2 filters部分
- 3.3 featuremaps部分
- 3.4 1max部分
- 3.5 concat1max部分
- 3.6 关键代码
- 4 实现效果
- 4.1 测试英文情感分类效果
- 4.2 测试中文情感分类效果
- 5 调参实验结论
- 6 建议
- 7 最后
1 前言
🔥 优质竞赛项目系列,今天要分享的是
基于深度学习的中文情感分类
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 情感文本分类
2.1 参考论文
Convolutional Neural Networks for Sentence
Classification
模型结构
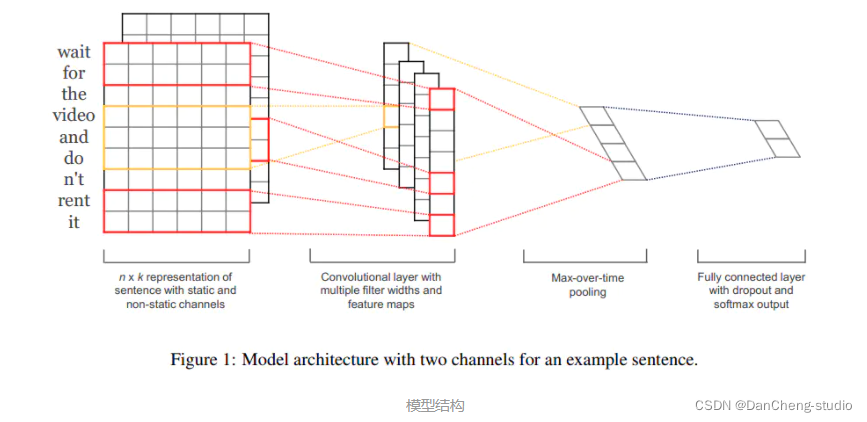
在短文本分析任务中,由于句子句长长度有限、结构紧凑、能够独立表达意思,使得CNN在处理这一类问题上成为可能,主要思想是将ngram模型与卷积操作结合起来
2.2 输入层
如图所示,输入层是句子中的词语对应的wordvector依次(从上到下)排列的矩阵,假设句子有 n 个词,vector的维数为 k ,那么这个矩阵就是 n
× k 的(在CNN中可以看作一副高度为n、宽度为k的图像)。
这个矩阵的类型可以是静态的(static),也可以是动态的(non static)。静态就是word
vector是固定不变的,而动态则是在模型训练过程中,word vector也当做是可优化的参数,通常把反向误差传播导致word
vector中值发生变化的这一过程称为Fine tune。(这里如果word
vector如果是随机初始化的,不仅训练得到了CNN分类模型,还得到了word2vec这个副产品了,如果已经有训练的word
vector,那么其实是一个迁移学习的过程)
对于未登录词的vector,可以用0或者随机小的正数来填充。
2.3 第一层卷积层:
输入层通过卷积操作得到若干个Feature Map,卷积窗口的大小为 h ×k ,其中 h 表示纵向词语的个数,而 k 表示word
vector的维数。通过这样一个大型的卷积窗口,将得到若干个列数为1的Feature Map。(熟悉NLP中N-GRAM模型的读者应该懂得这个意思)。
2.4 池化层:
接下来的池化层,文中用了一种称为Max-over-timePooling的方法。这种方法就是简单地从之前一维的Feature
Map中提出最大的值,文中解释最大值代表着最重要的信号。可以看出,这种Pooling方式可以解决可变长度的句子输入问题(因为不管Feature
Map中有多少个值,只需要提取其中的最大值)。最终池化层的输出为各个Feature Map的最大值们,即一个一维的向量。
2.5 全连接+softmax层:
池化层的一维向量的输出通过全连接的方式,连接一个Softmax层,Softmax层可根据任务的需要设置(通常反映着最终类别上的概率分布)。
2.6 训练方案
在倒数第二层的全连接部分上使用Dropout技术,Dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了,它是防止模型过拟合的一种常用的trikc。同时对全连接层上的权值参数给予L2正则化的限制。这样做的好处是防止隐藏层单元自适应(或者对称),从而减轻过拟合的程度。
在样本处理上使用minibatch方式来降低一次模型拟合计算量,使用shuffle_batch的方式来降低各批次输入样本之间的相关性(在机器学习中,如果训练数据之间相关性很大,可能会让结果很差、泛化能力得不到训练、这时通常需要将训练数据打散,称之为shuffle_batch)。
3 实现
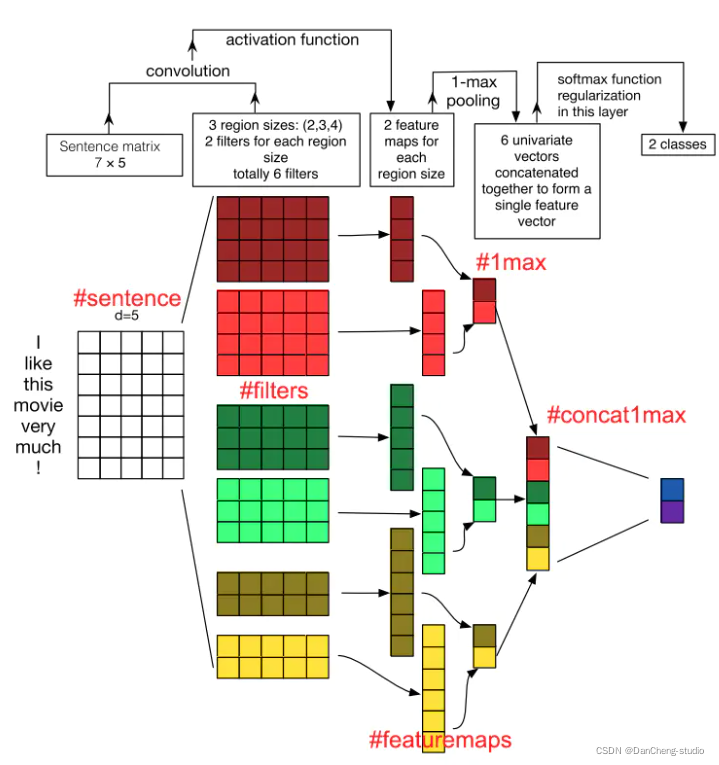
我们以上图为例,图上用红色标签标注了5部分,结合这5个标签,具体解释下整个过程的操作,来看看CNN如何解决文本分类问题的。
3.1 sentence部分
上图句子为“[I like this movie very much!”
,一共有两个单词加上一个感叹号,关于这个标点符号,不同学者有不同的操作,比如去除标点符号。在这里我们先不去除,那么整个句子有7个词,词向量维度为5,那么整个句子矩阵大小为7x5
3.2 filters部分
filters的区域大小可以使不同的,在这里取(2,3,4)3种大小,每种大小的filter有两个不同的值的filter,所以一共是有6个filter。
3.3 featuremaps部分
我们在句子矩阵和过滤器矩阵填入一些值,那么我们可以更好理解卷积计算过程,这和CNN原理那篇文章一样
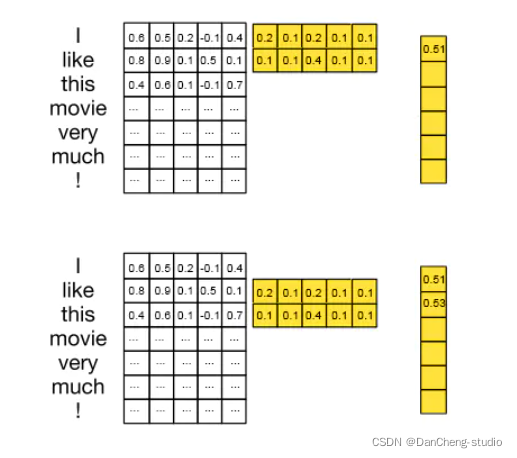
比如我们取大小为2的filter,最开始与句子矩阵的前两行做乘积相加,得到0.6 x 0.2 + 0.5 x 0.1 + … + 0.1 x 0.1 =
0.51,然后将filter向下移动1个位置得到0.53.最终生成的feature map大小为(7-2+1x1)=6。
为了获得feature map,我们添加一个bias项和一个激活函数,比如Relu
3.4 1max部分
因为不同大小的filter获取到的feature map大小也不一样,为了解决这个问题,然后添加一层max-
pooling,选取一个最大值,相同大小的组合在一起
3.5 concat1max部分
经过max-pooling操作之后,我们将固定长度的向量给sofamax,来预测文本的类别。
3.6 关键代码
下面是利用Keras实现的CNN文本分类部分代码:
# 创建tensorprint("正在创建模型...")inputs=Input(shape=(sequence_length,),dtype='int32')embedding=Embedding(input_dim=vocabulary_size,output_dim=embedding_dim,input_length=sequence_length)(inputs)reshape=Reshape((sequence_length,embedding_dim,1))(embedding)# cnnconv_0=Conv2D(num_filters,kernel_size=(filter_sizes[0],embedding_dim),padding='valid',kernel_initializer='normal',activation='relu')(reshape)conv_1=Conv2D(num_filters,kernel_size=(filter_sizes[1],embedding_dim),padding='valid',kernel_initializer='normal',activation='relu')(reshape)conv_2=Conv2D(num_filters,kernel_size=(filter_sizes[2],embedding_dim),padding='valid',kernel_initializer='normal',activation='relu')(reshape)maxpool_0=MaxPool2D(pool_size=(sequence_length-filter_sizes[0]+1,1),strides=(1,1),padding='valid')(conv_0)maxpool_1=MaxPool2D(pool_size=(sequence_length-filter_sizes[1]+1,1),strides=(1,1),padding='valid')(conv_1)maxpool_2=MaxPool2D(pool_size=(sequence_length-filter_sizes[2]+1,1),strides=(1,1),padding='valid')(conv_2)concatenated_tensor = Concatenate(axis=1)([maxpool_0, maxpool_1, maxpool_2])flatten = Flatten()(concatenated_tensor)dropout = Dropout(drop)(flatten)output = Dense(units=2, activation='softmax')(dropout)model=Model(inputs=inputs,outputs=output)**main.py**import osos.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" # see issue #152os.environ["CUDA_VISIBLE_DEVICES"] = ""import reimport numpy as npfrom flask import Flask, render_template, requestfrom keras.models import load_modelfrom data_helpers_english import build_input_englishfrom data_helpers_chinese import build_input_chineseapp = Flask(__name__)en_model = load_model('results/weights.007-0.7618.hdf5')ch_model = load_model('results/chinese.weights.003-0.9083.hdf5')# load 进来模型紧接着就执行一次 predict 函数print('test train...')print(en_model.predict(np.zeros((1, 56))))print(ch_model.predict(np.zeros((1, 50))))print('test done.')def en_predict(input_x):sentence = input_xinput_x = build_input_english(input_x)y_pred = en_model.predict(input_x)result = list(y_pred[0])result = {'sentence': sentence, 'positive': result[1], 'negative': result[0]}return resultdef ch_predict(input_x):sentence = input_xinput_x = build_input_chinese(input_x)y_pred = ch_model.predict(input_x)result = list(y_pred[0])result = {'sentence': sentence, 'positive': result[1], 'negative': result[0]}return result@app.route('/classification', methods=['POST', 'GET'])def english():if request.method == 'POST':review = request.form['review']# 来判断是中文句子/还是英文句子review_flag = re.sub(r"[^A-Za-z0-9(),!?\'\`]", " ", review) # 去除数字review_flag = re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+", "", review_flag)if review_flag:result = en_predict(review)# result = {'sentence': 'hello', 'positive': '03.87878', 'negative': '03.64465'}return render_template('index.html', result=result)else:result = ch_predict(review)# result = {'sentence': 'hello', 'positive': '03.87878', 'negative': '03.64465'}return render_template('index.html', result=result)return render_template('index.html')## if __name__ == '__main__':# app.run(host='0.0.0.0', debug=True)4 实现效果
4.1 测试英文情感分类效果
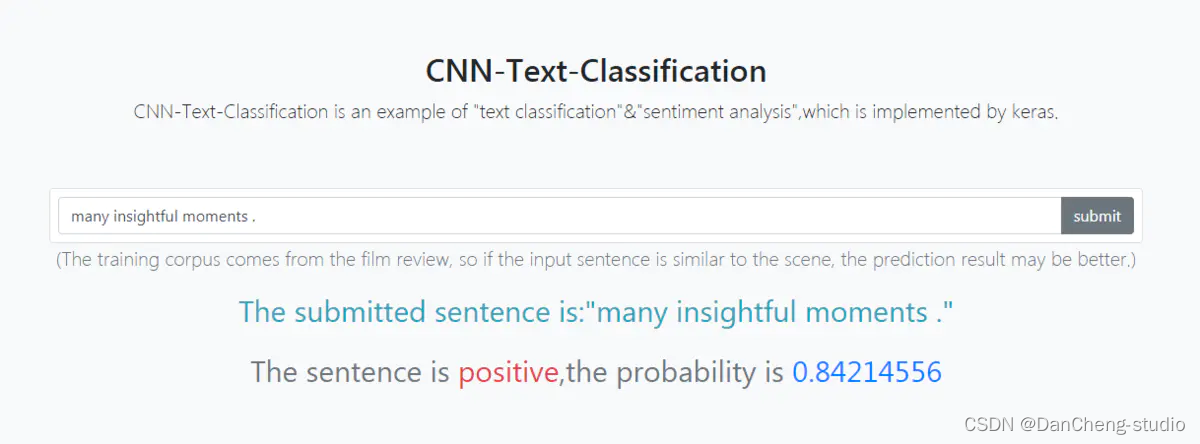
准训练结果:验证集76%左右
4.2 测试中文情感分类效果
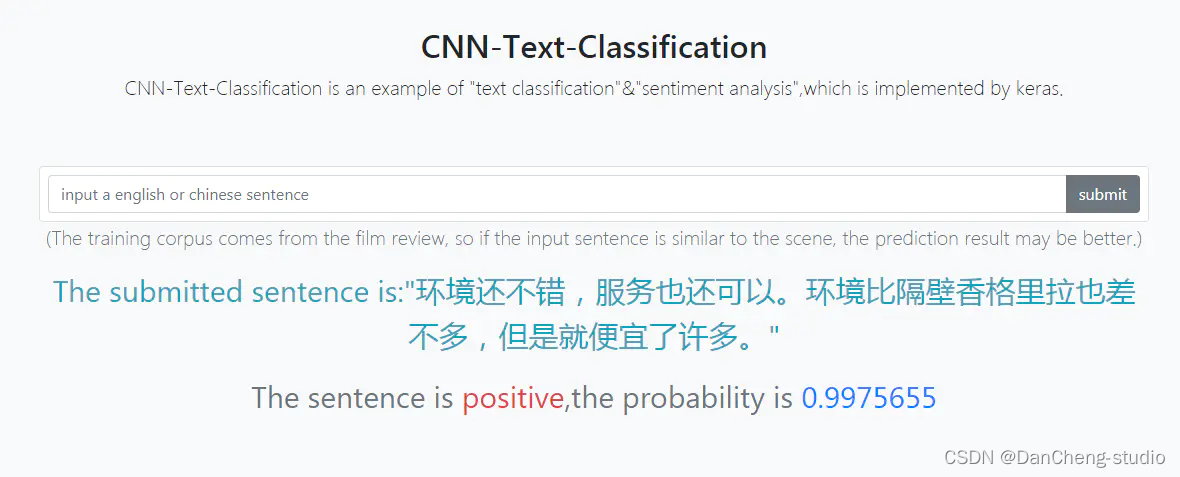
准训练结果:验证集91%左右
5 调参实验结论
- 由于模型训练过程中的随机性因素,如随机初始化的权重参数,mini-batch,随机梯度下降优化算法等,造成模型在数据集上的结果有一定的浮动,如准确率(accuracy)能达到1.5%的浮动,而AUC则有3.4%的浮动;
- 词向量是使用word2vec还是GloVe,对实验结果有一定的影响,具体哪个更好依赖于任务本身;
- Filter的大小对模型性能有较大的影响,并且Filter的参数应该是可以更新的;
- Feature Map的数量也有一定影响,但是需要兼顾模型的训练效率;
- 1-max pooling的方式已经足够好了,相比于其他的pooling方式而言;
- 正则化的作用微乎其微。
6 建议
- 使用non-static版本的word2vec或者GloVe要比单纯的one-hot representation取得的效果好得多;
- 为了找到最优的过滤器(Filter)大小,可以使用线性搜索的方法。通常过滤器的大小范围在1-10之间,当然对- 于长句,使用更大的过滤器也是有必要的;
- Feature Map的数量在100-600之间;
- 可以尽量多尝试激活函数,实验发现ReLU和tanh两种激活函数表现较佳;
- 使用简单的1-max pooling就已经足够了,可以没必要设置太复杂的pooling方式;
- 当发现增加Feature Map的数量使得模型的性能下降时,可以考虑增大正则的力度,如调高dropout的概率;
- 为了检验模型的性能水平,多次反复的交叉验证是必要的,这可以确保模型的高性能并不是偶然。
7 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
基于深度学习的中文情感分类 - 卷积神经网络 情感分类 情感分析 情感识别 评论情感分类 计算机竞赛
文章目录 1 前言2 情感文本分类2.1 参考论文2.2 输入层2.3 第一层卷积层:2.4 池化层:2.5 全连接softmax层:2.6 训练方案 3 实现3.1 sentence部分3.2 filters部分3.3 featuremaps部分3.4 1max部分3.5 concat1max部分3.6 关键代码 4 实现效果4.…...

非线性时滞系统的无模型预测控制
摘 要 非线性时滞系统的预测控制应用广泛,比如电子设备、石油化工、造纸等行业,都会运用到非线性时滞系统的预测控制系统或工具。更高效率和更高精度的非线性时滞系统的预测控制一直是研究的热点。在我们日常生活中,非线性时滞系统的预测控制…...

局域网内两台电脑共享文件夹(通过网线直连共享数据)
文章目录 2.设置共享文件夹3.访问共享文件夹 1.将两台电脑置于同一局域网下 用网线将两台电脑连接关闭两台电脑防火墙将两台电脑IP地址设置在同一局域网下 测试是否在同一局域网下,使用ping命令 ping 192.168.0.122.设置共享文件夹 选择想要共享的文件夹ÿ…...
什么是 CNN? 卷积神经网络? 怎么用 CNN 进行分类?(3)
参考视频:https://www.youtube.com/watch?vE5Z7FQp7AQQ&listPLuhqtP7jdD8CD6rOWy20INGM44kULvrHu 视频7:CNN 的全局架构 卷积层除了做卷积操作外,还要加上 bias ,再经过非线性的函数,这么做的原因是 “scaled p…...

一致性hash负载均衡
Hash算法的问题 今天看下一致性hash,常见的负载均衡可能使用过hash,比如nginx中,如果使用session最简单就是通过hash,比如根据用户的请求ip进行hash,让不同用户的请求打到同一台服务器,这样状态处理起来最…...

MAC下安装Python
MAC基本信息: 执行命令: brew install cmake protobuf rust python3.10 git wget 遇到以下问题: > Downloading https://mirrors.aliyun.com/homebrew/homebrew-bottles/rust-1.59.0 Already downloaded: /Users/xxxx/Library/Caches/Ho…...

Android NDK开发详解之JNI中的库文件
Android NDK开发详解之JNI中的库文件 简介工作原理流程原生 activity 和应用 简介 本部分简要介绍了 NDK 的工作原理。Android NDK 是一组使您能将 C 或 C(“原生代码”)嵌入到 Android 应用中的工具。能够在 Android 应用中使用原生代码对于想执行以下…...
KNN模型
使用K-Nearest Neighbors (KNN)算法进行分类。首先加载一个数据集,然后进行预处理,选择最佳的K值,并训练一个KNN模型。 # encodingutf-8 import numpy as np datas np.loadtxt(datingTestSet2.txt) # 加载数据集,返回一个numpy数…...

Python 学习1 基础
文章目录 基础字符串字面量常用的值类型注释变量print语句数据类型数据类型转换标识符运算符 字符串拓展小结 2023.10.28 周六 最近打算学一下Python,毕竟确实简单方便,而且那个编程语言排名还是在第一。不过不打算靠它吃饭,深不深入暂且不说…...

网络协议--TCP的超时与重传
21.1 引言 TCP提供可靠的运输层。它使用的方法之一就是确认从另一端收到的数据。但数据和确认都有可能会丢失。TCP通过在发送时设置一个定时器来解决这种问题。如果当定时器溢出时还没有收到确认,它就重传该数据。对任何实现而言,关键之处就在于超时和重…...

Thread
Thread 线程启动线程第一种创建线程线程的第二种创建方式使用匿名内部类完成线程的两种创建 Thread API线程的优先级线程提供的静态方法守护线程用户线程和守护线程的区别体现在进程结束时 多线并发安全问题同步块 线程 启动线程 启动线程:调用线程的start方法,而不是直接调用…...
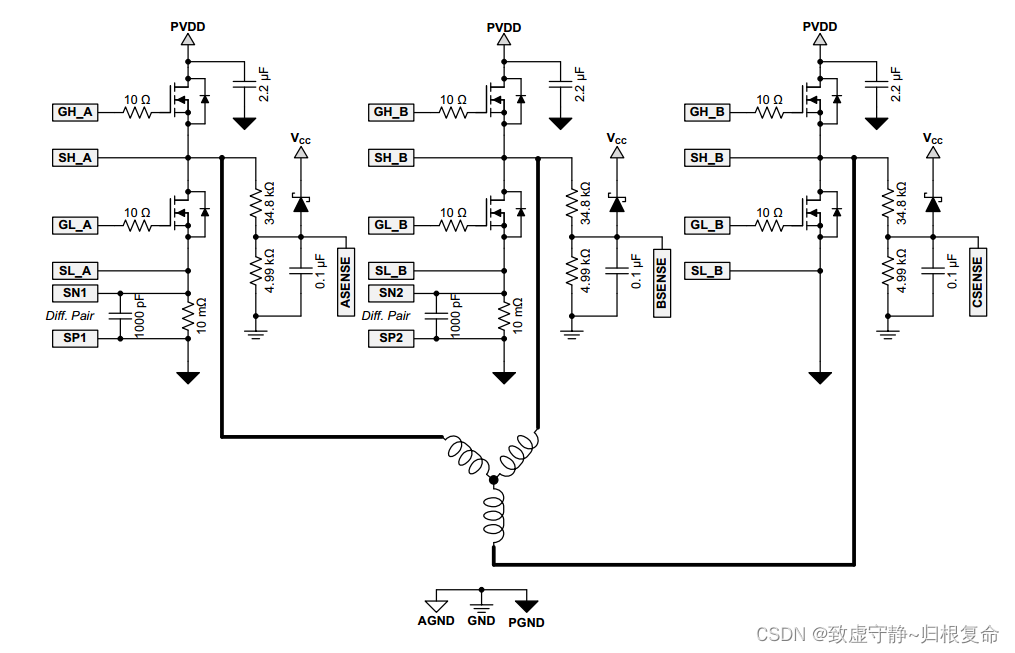
FOC系列(二)----继续学习DRV8301芯片
一、 程序框图 跟随上篇博客咱们继续往下看,下面是芯片内部的程序框图: 1.1 BUCK电路 1.2 内部各电源 1.3 SPI通信、栅极驱动器和时序控制器 1.4 MOSFET驱动电路 1.5 电流采样放大电路 数据手册只是给出了这一部分框图,但是没有更加详细的介…...

A. Directional Increase -前缀和与差分理解 + 思维
题面 分析 观察指针移动的性质,可以发现每一段都是从起点走到终点,在原路返回,这样每一段也就表示,在起点处加一,在终点处减一,形成了很明显的差分结构,思考能否构造出a数组的关键就是他的前缀…...

openpnp - java调试环境 - 最好只保留一套jdk环境
文章目录 openpnp - java调试环境 - 最好只保留一套jdk环境概述END openpnp - java调试环境 - 最好只保留一套jdk环境 概述 没注意做了啥操作, 前天好好的, 昨天下午开始, 编译好的openpnp程序就无法正常打开了. 故障表现: 程序运行后, 最多只能看到欢迎对话框(显示版本和发…...

AI技术的钓鱼邮件有多强
如今,人工智能技术的迅猛发展给各个领域都带来了前所未有的变革和进步。2023年上半年ChatGPT的火爆出圈,让人们看到了AI惊艳表现的光彩一面,但同时黑暗的一面也正在暗自发力,野蛮生长。 AI技术不仅可用于维护网络安全,…...

vue/react项目刷新页面出现404报错的原因及解决办法
Vue项目打包部署到线上后,刷新页面会提示404,下面这篇文章主要给大家介绍了关于vue/react项目刷新页面出现404报错的原因及解决办法,文中将解决的办法介绍的很详细,需要的朋友可以参考下 背景解决办法 法1:将vue/react路由模式由history路由改为has…...

黑客技术(网络安全)——如何高效学习
前言 前几天发布了一篇 网络安全(黑客)自学 没想到收到了许多人的私信想要学习网安黑客技术!却不知道从哪里开始学起!怎么学 今天给大家分享一下,很多人上来就说想学习黑客,但是连方向都没搞清楚就开始学习…...

53.MongoDB分片集群高级集群架构详解
MongoDB分片集群架构详解 为什么要使用分片 分片(shard)是指在将数据进行水平切分之后,将其存储到多个不同的服务器节点上的一种扩展方式。 一个复制集能承载的容量和负载是有限的,遇到以下场景就需要考虑使用分片 存储容量需…...
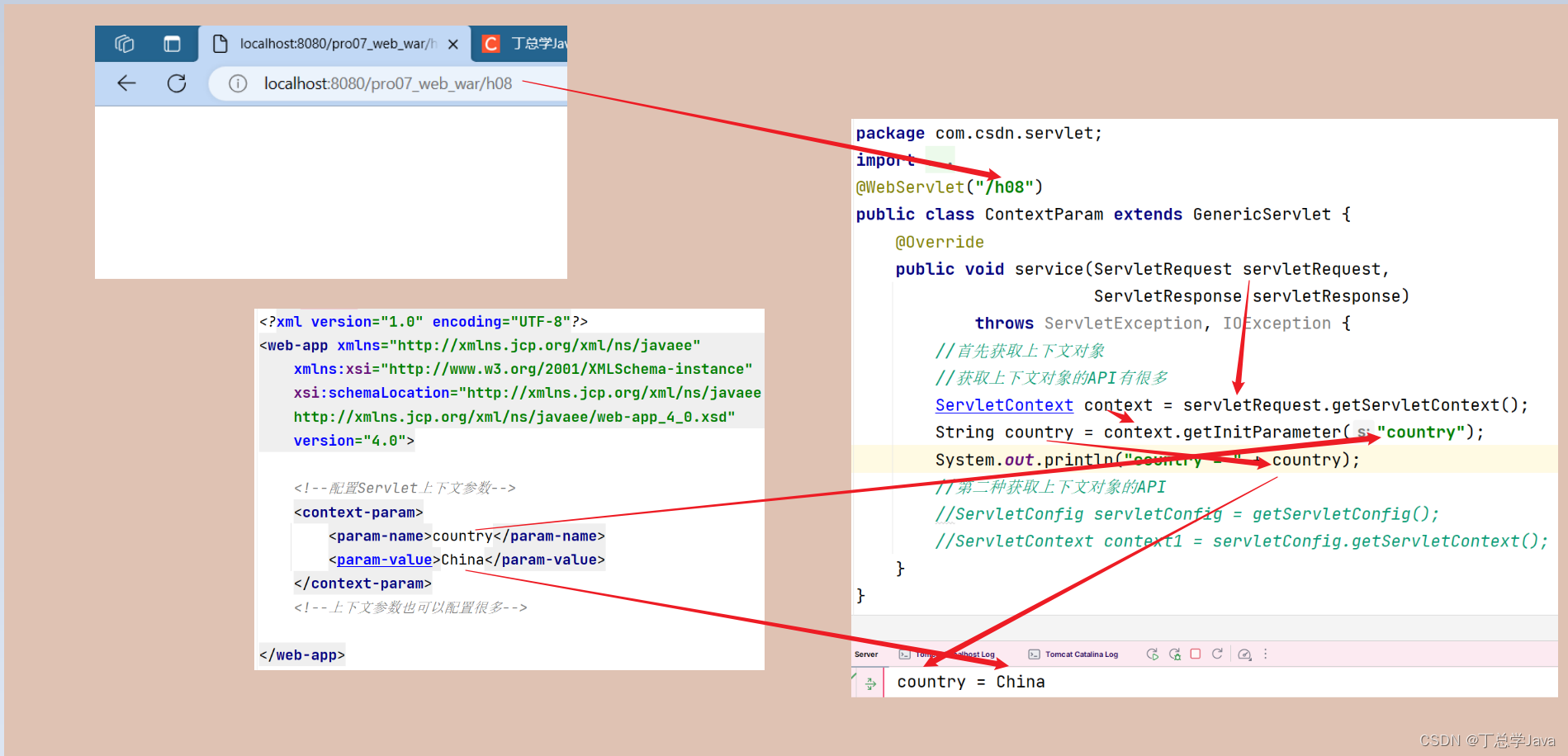
Servlet 上下文参数
7)Servlet上下文对象:ServletContext生活中的例子:张三和李四在不远处窃窃私语,并且频繁的对着你坏笑。你肯定会跑过去问:你们俩在聊什么?注意:此处的聊什么,其实就是你在咨询他们聊天的上下文&…...

ChatGPT正在测试原生文件分析功能,DALL·E 3能P图啦!
10月29日,有部分用户在社交平台上分享,ChatGPT Plus正在测试原生文件上传、分析功能,可以通过文本问答的方式,对上传的PDF等数据文件进行提问、搜索。 例如,上传一份50页的员工手册PDF文件,然后向ChatGPT提…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

Web后端基础(基础知识)
BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。 优点:维护方便缺点:体验一般 CS架构:Client/Server,客户端/服务器架构模式。需要单独…...

Cursor AI 账号纯净度维护与高效注册指南
Cursor AI 账号纯净度维护与高效注册指南:解决限制问题的实战方案 风车无限免费邮箱系统网页端使用说明|快速获取邮箱|cursor|windsurf|augment 问题背景 在成功解决 Cursor 环境配置问题后,许多开发者仍面临账号纯净度不足导致的限制问题。无论使用 16…...
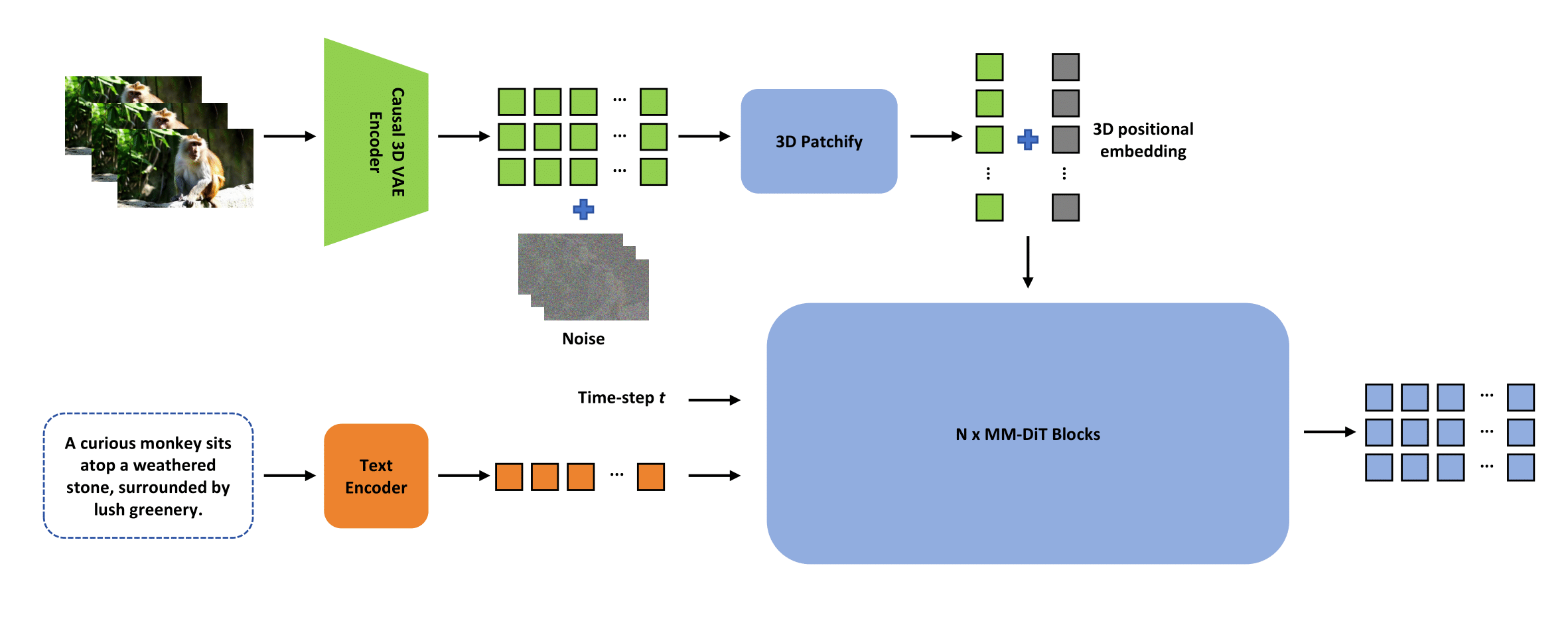
【字节拥抱开源】字节团队开源视频模型 ContentV: 有限算力下的视频生成模型高效训练
本项目提出了ContentV框架,通过三项关键创新高效加速基于DiT的视频生成模型训练: 极简架构设计,最大化复用预训练图像生成模型进行视频合成系统化的多阶段训练策略,利用流匹配技术提升效率经济高效的人类反馈强化学习框架&#x…...