全网最全的RDMA拥塞控制入门基础教程
RDMA-CC(全网最全的RDMA拥塞控制入门基础教程)
文章目录
- RDMA-CC(全网最全的RDMA拥塞控制入门基础教程)
- DMA
- RDMA
- RDMA举例
- RDMA优势
- RDMA的硬件实现方法
- RDMA基本术语
- Fabric
- CA(Channel Adapter)
- Verbs
- 核心概念
- Memory Registration
- Queues
- RDMA数据传输
- RDMA Send/Recv
- RDMA Read
- RDMA Write
- RDMA Write with Immediate Data
- RDMA数据面流程
- RoCE
- RoCEv1(RDMA封装协议)
- RoCEv2(RDMA封装协议)
- RDMA Send Receive
- RDMA Verbs操作
- Queue Pairs
- RDMA Send/Receive
- First Step
- Second Step
- Third Step
- Forth Step
- RDMA SGL
- ivc_post_send接口
- ibv_send_wr结构
- RDMA提交WR的流程
- First Step
- Second Step
- Third Step
- OFED Verbs
- RDMA CC
- 拥塞检测
- 基于丢包检测
- 基于ECN检测
- 基于RTT检测
- DCTCP
- 原理
- 特点
- PFC(Priority Flow Control)
- 原理
- 存在的问题
- HPCC
- DCQCN
- TIMELY
DMA
DMA(直接内存访问)是一种能力,允许在计算机主板上的设备直接把数据发送到内存中去,数据搬运不需要CPU的参与。
传统内存访问需要通过CPU进行数据copy来移动数据,通过CPU将内存中的Buffer1移动到Buffer2中。DMA模式:可以同DMA Engine之间通过硬件将数据从Buffer1移动到Buffer2,而不需要操作系统CPU的参与,大大降低了CPU Copy的开销。

RDMA
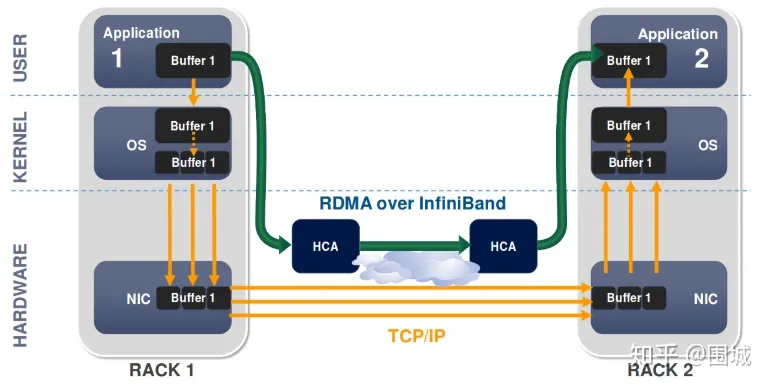
RDMA是一种概念,在两个或者多个计算机进行通讯的时候使用DMA,从一个主机的内存直接访问另一个主机的内存。当前RDMA在以太网上的传输协议是RoCEv2,RoCEv2是基于无连接协议的UDP协议,相比面向连接的TCP协议,UDP协议更加快速、占用CPU资源更少,但其不像TCP协议那样有滑动窗口、确认应答等机制来实现可靠传输,一旦出现丢包,依靠上层应用检查到了再做重传,会大大降低RDMA的传输效率。所以要想发挥出RDMA真正的性能,突破数据中心大规模分布式系统的网络性能瓶颈,势必要为RDMA搭建一套不丢包的无损网络环境,而实现不丢包的关键就是解决网络拥塞。
为什么需要无损网络:长期以来,HPC(高性能计算)的RDMA都是在Infiniband集群中使用,数据包丢失在此类群集中很少见,因此RDMA Infiniband传输层(在NIC上实现)的重传机制很简陋,既:go-back-N重传,但是现在RDMA的使用更广泛,在其他网络中,丢包的概率大于Infiniband集群,一旦丢包,使用RDMA的go-back-N重传机制效率非常低,会大大降低RDMA的传输效率,所以要想发挥出RDMA真正的性能,势必要为RDMA搭建一套不丢包的无损网络环境,go-back-N重传。

Remote:数据通过网络与远程机器间进行数据传输。
Direct:没有内核的参与,有关发送传输的所有内容都卸载到网卡上。
Memory:在用户空间虚拟内存与RNIC网卡直接进行数据传输不涉及到系统内核,没有额外的数据移动和复制。
Access:send、receive、read、write、atomic操作。

RDMA是一种host-offload, host-bypass技术,允许应用程序(包括存储)在它们的内存空间之间直接做数据传输。具有RDMA引擎的以太网卡(RNIC)–而不是host–负责管理源和目标之间的可靠连接。使用RNIC的应用程序之间使用专注的QP和CQ进行通讯:
- 每一个应用程序可以有很多QP和CQ
- 每一个QP包括一个SQ和RQ
- 每一个CQ可以跟多个SQ或者RQ相关联

RDMA举例

RDMA优势

传统的TCP/IP技术在数据包处理过程中,要经过操作系统及其他软件层,需要占用大量的服务器资源和内存总线带宽,数据在系统内存、处理器缓存和网络控制器缓存之间来回进行复制移动,给服务器的CPU和内存造成了沉重负担。尤其是网络带宽、处理器速度与内存带宽三者的严重"不匹配性",更加剧了网络延迟效应。
RDMA是一种新的直接内存访问技术,RDMA让计算机可以直接存取其他计算机的内存,而不需要经过处理器的处理。RDMA将数据从一个系统快速移动到远程系统的内存中,而不对操作系统造成任何影响。
在实现上,RDMA实际上是一种智能网卡与软件架构充分优化的远端内存直接高速访问技术,通过将RDMA协议固化于硬件(即网卡)上,以及支持Zero-copy和Kernel bypass这两种途径来达到其高性能的远程直接数据存取的目标。 使用RDMA的优势如下:
- 零拷贝(Zero-copy) - 应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下。数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。
- 内核旁路(Kernel bypass) - 应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换。
- 不需要CPU干预(No CPU involvement) - 应用程序可以访问远程主机内存而不消耗远程主机中的任何CPU。远程主机内存能够被读取而不需要远程主机上的进程(或CPU)参与。远程主机的CPU的缓存(cache)不会被访问的内存内容所填充。
- 消息基于事务(Message based transactions) - 数据被处理为离散消息而不是流,消除了应用程序将流切割为不同消息/事务的需求。
- 支持分散/聚合条目(Scatter/gather entries support) - RDMA原生态支持分散/聚合。也就是说,读取多个内存缓冲区然后作为一个流发出去或者接收一个流然后写入到多个内存缓冲区里去。
在具体的远程内存读写中,RDMA操作用于读写操作的远程虚拟内存地址包含在RDMA消息中传送,远程应用程序要做的只是在其本地网卡中注册相应的内存缓冲区。远程节点的CPU除在连接建立、注册调用等之外,在整个RDMA数据传输过程中并不提供服务,因此没有带来任何负载。
RDMA的硬件实现方法
RDMA作为一种host-offload, host-bypass技术,使低延迟、高带宽的直接的内存到内存的数据通信成为了可能。目前支持RDMA的网络协议有:
- InfiniBand(IB): 从一开始就支持RDMA的新一代网络协议。由于这是一种新的网络技术,因此需要支持该技术的网卡和交换机。
- RDMA过融合以太网(RoCE): 即RDMA over Ethernet(RDMA over Converged Ethernet), 允许通过以太网执行RDMA的网络协议。这允许在标准以太网基础架构(交换机)上使用RDMA,只不过网卡必须是支持RoCE的特殊的NIC。
- 互联网广域RDMA协议(iWARP): 即RDMA over TCP, 允许通过TCP执行RDMA的网络协议。这允许在标准以太网基础架构(交换机)上使用RDMA,只不过网卡要求是支持iWARP(如果使用CPU offload的话)的NIC。否则,所有iWARP栈都可以在软件中实现,但是失去了大部分的RDMA性能优势。



RDMA基本术语
Fabric
所谓Fabric,就是支持RDMA的局域网(LAN)。
CA(Channel Adapter)
CA是Channel Adapter(通道适配器)的缩写。那么,CA就是将系统连接到Fabric的硬件组件。 在IBTA中,一个CA就是IB子网中的一个终端结点(End Node)。分为两种类型,一种是HCA, 另一种叫做TCA, 它们合称为xCA。其中, HCA(Host Channel Adapter)是支持"verbs"接口的CA, TCA(Target Channel Adapter)可以理解为"weak CA", 不需要像HCA一样支持很多功能。 而在IEEE/IETF中,CA的概念被实体化为RNIC(RDMA Network Interface Card), iWARP就把一个CA称之为一个RNIC。
Verbs
在RDMA的持续演进中,有一个组织叫做OpenFabric Alliance所做的贡献可谓功不可没。 Verbs这个词不好翻译,大致可以理解为访问RDMA硬件的“一组标准动作”。 每一个Verb可以理解为一个Function。
核心概念

Memory Registration
Memory Registration,内存注册,RDMA 就是用来对内存进行数据传输。那么怎样才能对内存进行传输,很简单,注册。 因为RDMA硬件对用来做数据传输的内存是有特殊要求的。
- 在数据传输过程中,应用程序不能修改数据所在的内存。
- 操作系统不能对数据所在的内存进行page out操作 – 物理地址和虚拟地址的映射必须是固定不变的。
注意无论是DMA或者RDMA都要求物理地址连续,这是由DMA引擎所决定的。 那么怎么进行内存注册呢?
- 创建两个key (local和remote)指向需要操作的内存区域
- 注册的keys是数据传输请求的一部分
注册一个Memory Region之后,这个时候这个Memory Region也就有了它自己的属性:
- context : RDMA操作上下文
- addr : MR被注册的Buffer地址
- length : MR被注册的Buffer长度
- lkey:MR被注册的本地key
- rkey:MR被注册的远程key
对Memrory Registration:Memory Registration只是RDMA中对内存保护的一种措施,只有将要操作的内存注册到RDMA Memory Region中,这快操作的内存就交给RDMA 保护域来操作了。这个时候我们就可以对这快内存进行操作,至于操作的起始地址、操作Buffer的长度,可以根据程序的具体需求进行操作。我们只要保证接受方的Buffer 接受的长度大于等于发送的Buffer长度。
Queues
RDMA一共支持三种队列,发送队列(SQ)和接收队列(RQ),完成队列(CQ)。其中,SQ和RQ通常成对创建,被称为Queue Pairs(QP)。
RDMA是基于消息的传输协议,数据传输都是异步操作。 RDMA操作其实很简单,可以理解为:
- Host提交工作请求(WR)到工作队列(WQ): 工作队列包括发送队列(SQ)和接收队列(RQ)。工作队列的每一个元素叫做WQE, 也就是WR。
- Host从完成队列(CQ)中获取工作完成(WC): 完成队列里的每一个叫做CQE, 也就是WC。
- 具有RDMA引擎的硬件(hardware)就是一个队列元素处理器。 RDMA硬件不断地从工作队列(WQ)中去取工作请求(WR)来执行,执行完了就给完成队列(CQ)中放置工作完成(WC)。从生产者-消费者的角度理解就是:
- Host生产WR, 把WR放到WQ中去
- RDMA硬件消费WR
- RDMA硬件生产WC, 把WC放到CQ中去
- Host消费WC

RDMA数据传输
RDMA Send/Recv
跟TCP/IP的send/recv是类似的,不同的是RDMA是基于消息的数据传输协议(而不是基于字节流的传输协议),所有数据包的组装都在RDMA硬件上完成的,也就是说OSI模型中的下面4层(传输层,网络层,数据链路层,物理层)都在RDMA硬件上完成。
RDMA Read
RDMA读操作本质上就是Pull操作, 把远程系统内存里的数据拉回到本地系统的内存里。
RDMA Write
RDMA写操作本质上就是Push操作,把本地系统内存里的数据推送到远程系统的内存里。
RDMA Write with Immediate Data
支持立即数的RDMA写操作本质上就是给远程系统Push(推送)带外(OOB)数据, 这跟TCP里的带外数据是类似的。可选地,immediate 4字节值可以与数据缓冲器一起发送。 该值作为接收通知的一部分呈现给接收者,并且不包含在数据缓冲器中。
RDMA数据面流程

RoCE
RoCEv1(RDMA封装协议)
这个协议是将RDMA数据段封装到以太网数据段内,再加上以太网的头部,因此属于二层数据包。为了对它进行分类,只能使用VLAN(IEEE 802.1q)头部中的PCP(Priority Code Point)域3 Bits来设置优先级值。

RoCEv2(RDMA封装协议)
这个协议是将RDMA数据段先封装到UDP数据段内,加上UDP头部,再加上IP头部,最后再加上以太网头部,属于三层数据包。对它进行分类,既可以使用以太网VLAN中的PCP域,也可以使用IP头部的DSCP域。

简单来说,在二层网络的情况下,PFC使用VLAN中的PCP位来对数据流进行区分,在三层网络的情况下,PFC既可以使用PCP、也可以使用DSCP,使得不同数据流可以享受到独立的流控制。当下数据中心因多采用三层网络,因此使用DSCP比PCP更具有优势。
RDMA Send Receive
RDMA指的是远程直接内存访问,这是一种通过网络在两个应用程序之间搬运缓冲区里的数据的方法。RDMA与传统的网络接口不同,因为它绕过了操作系统。这允许实现了RDMA的程序具有如下特点:
- 绝对的最低时延
- 最高的吞吐量
- 最小的CPU足迹 (也就是说,需要CPU参与的地方被最小化)
RDMA Verbs操作
使用RDMA, 我们需要有一张实现了RDMA引擎的网卡。我们把这种卡称之为HCA(主机通道适配器)。 适配器创建一个贯穿PCIe总线的从RDMA引擎到应用程序内存的通道。一个好的HCA将在导线上执行的RDMA协议所需要的全部逻辑都在硬件上予以实现。这包括分组,重组以及流量控制和可靠性保证。因此,从应用程序的角度看,只负责处理所有缓冲区即可。

在RDMA中我们使用内核态驱动建立一个数据通道。我们称之为命令通道(Command Channel)。使用命令通道,我们能够建立一个数据通道(Data Channel),该通道允许我们在搬运数据的时候完全绕过内核。一旦建立了这种数据通道,我们就能直接读写数据缓冲区。
建立数据通道的API是一种称之为"verbs"的API。“verbs” API是由一个叫做OFED的Linux开源项目维护的。在站点http://www.openfabrics.org上,为Windows WinOF提供了一个等价的项目。“verbs” API跟你用过的socket编程API是不一样的。但是,一旦你掌握了一些概念后,就会变得非常容易,而且在设计你的程序的时候更简单。
Queue Pairs
RDMA操作开始于“搞”内存。当你在对内存进行操作的时候,就是告诉内核这段内存名花有主了,主人就是你的应用程序。于是,你告诉HCA,就在这段内存上寻址,赶紧准备开辟一条从HCA卡到这段内存的通道。我们将这一动作称之为注册一个内存区域(MR)。一旦MR注册完毕,我们就可以使用这段内存来做任何RDMA操作。在下面的图中,我们可以看到注册的内存区域(MR)和被通信队列所使用的位于内存区域之内的缓冲区(buffer)。
RDMA Memory Registration
struct ibv_mr {struct ibv_context *context;struct ibv_pd *pd;void *addr;size_t length;uint32_t handle;uint32_t lkey;uint32_t rkey;
};

RDMA硬件不断地从工作队列(WQ)中去取工作请求(WR)来执行,执行完了就给完成队列(CQ)中放置工作完成通知(WC)。这个WC意思就是Work Completion。表示这个WR RDMA请求已经被处理完成,可以从这个Completion Queue从取出来,表示这个RDMA请求已经被处理完毕。
RDMA通信基于三条队列(SQ, RQ和CQ)组成的集合。 其中, 发送队列(SQ)和接收队列(RQ)负责调度工作,他们总是成对被创建,称之为队列对(QP)。当放置在工作队列上的指令被完成的时候,完成队列(CQ)用来发送通知。
当用户把指令放置到工作队列的时候,就意味着告诉HCA那些缓冲区需要被发送或者用来接受数据。这些指令是一些小的结构体,称之为工作请求(WR)或者工作队列元素(WQE)。 WQE的发音为"WOOKIE",就像星球大战里的猛兽。一个WQE主要包含一个指向某个缓冲区的指针。一个放置在发送队列(SQ)里的WQE中包含一个指向待发送的消息的指针。一个放置在接受队列里的WQE里的指针指向一段缓冲区,该缓冲区用来存放待接受的消息。
RDMA Send Work Request
struct ibv_send_wr {uint64_t wr_id;struct ibv_send_wr *next;struct ibv_sge *sg_list;int num_sge;enum ibv_wr_opcode opcode;int send_flags;uint32_t imm_data; /* in network byte order */union {struct {uint64_t remote_addr;uint32_t rkey;} rdma;struct {uint64_t remote_addr;uint64_t compare_add;uint64_t swap;uint32_t rkey;} atomic;struct {struct ibv_ah *ah;uint32_t remote_qpn;uint32_t remote_qkey;} ud;} wr;
};
RDMA Receive Work Request
struct ibv_recv_wr {uint64_t wr_id;struct ibv_recv_wr *next;struct ibv_sge *sg_list;int num_sge;
};
RDMA是一种异步传输机制。因此我们可以一次性在工作队列里放置好多个发送或接收WQE。HCA将尽可能快地按顺序处理这些WQE。当一个WQE被处理了,那么数据就被搬运了。 一旦传输完成,HCA就创建一个完成队列元素(CQE)并放置到完成队列(CQ)中去。 相应地,CQE的发音为"COOKIE"。
RDMA Send/Receive
First Step
系统A和B都创建了他们各自的QP的完成队列(CQ), 并为即将进行的RDMA传输注册了相应的内存区域(MR)。 系统A识别了一段缓冲区,该缓冲区的数据将被搬运到系统B上。系统B分配了一段空的缓冲区,用来存放来自系统A发送的数据。

Second Step
系统B创建一个WQE并放置到它的接收队列(RQ)中。这个WQE包含了一个指针,该指针指向的内存缓冲区用来存放接收到的数据。系统A也创建一个WQE并放置到它的发送队列(SQ)中去,该WQE中的指针执行一段内存缓冲区,该缓冲区的数据将要被传送。

Third Step
系统A上的HCA总是在硬件上干活,看看发送队列里有没有WQE。HCA将消费掉来自系统A的WQE, 然后将内存区域里的数据变成数据流发送给系统B。当数据流开始到达系统B的时候,系统B上的HCA就消费来自系统B的WQE,然后将数据放到该放的缓冲区上去。在高速通道上传输的数据流完全绕过了操作系统内核。

Forth Step
当数据搬运完成的时候,HCA会创建一个CQE。 这个CQE被放置到完成队列(CQ)中,表明数据传输已经完成。HCA每消费掉一个WQE, 都会生成一个CQE。因此,在系统A的完成队列中放置一个CQE,意味着对应的WQE的发送操作已经完成。同理,在系统B的完成队列中也会放置一个CQE,表明对应的WQE的接收操作已经完成。如果发生错误,HCA依然会创建一个CQE。在CQE中,包含了一个用来记录传输状态的字段。

我们刚刚举例说明的是一个RDMA Send操作。在IB或RoCE中,传送一个小缓冲区里的数据耗费的总时间大约在1.3µs。通过同时创建很多WQE, 就能在1秒内传输存放在数百万个缓冲区里的数据。
RDMA SGL
在使用RDMA操作之前,我们需要了解一些RDMA API中的一些需要的值。其中在ibv_send_wr我们需要一个sg_list的数组,sg_list是用来存放ibv_sge元素,那么什么是SGL以及什么是sge呢?对于一个使用RDMA进行开发的程序员来说,我们需要了解这一系列细节。
在NVMe over PCIe中,I/O命令支持SGL(Scatter Gather List 分散聚合表)和PRP(Physical Region Page 物理(内存)区域页), 而管理命令只支持PRP;而在NVMe over Fabrics中,无论是管理命令还是I/O命令都只支持SGL。
RDMA编程中,SGL(Scatter/Gather List)是最基本的数据组织形式。 SGL是一个数组,该数组中的元素被称之为SGE(Scatter/Gather Element),每一个SGE就是一个Data Segment(数据段)。RDMA支持Scatter/Gather操作,具体来讲就是RDMA可以支持一个连续的Buffer空间,进行Scatter分散到多个目的主机的不连续的Buffer空间。Gather指的就是多个不连续的Buffer空间,可以Gather到目的主机的一段连续的Buffer空间。
ibv_sge
struct ibv_sge {uint64_t addr;uint32_t length;uint32_t lkey;
};
- addr: 数据段所在的虚拟内存的起始地址 (Virtual Address of the Data Segment (i.e. Buffer))
- length: 数据段长度(Length of the Data Segment)
- lkey: 该数据段对应的L_Key (Key of the local Memory Region)
ivc_post_send接口
ibv_post_send()的函数原型
#include <infiniband/verbs.h>int ibv_post_send(struct ibv_qp *qp, struct ibv_send_wr *wr,struct ibv_send_wr **bad_wr);
ibv_post_send()将以send_wr开头的工作请求(WR)的列表发布到Queue Pair的Send Queue。 它会在第一次失败时停止处理此列表中的WR(可以在发布请求时立即检测到),并通过bad_wr返回此失败的WR。
参数wr是一个ibv_send_wr结构,如中所定义。
ibv_send_wr结构
struct ibv_send_wr {uint64_t wr_id; /* User defined WR ID */struct ibv_send_wr *next; /* Pointer to next WR in list, NULL if last WR */struct ibv_sge *sg_list; /* Pointer to the s/g array */int num_sge; /* Size of the s/g array */enum ibv_wr_opcode opcode; /* Operation type */int send_flags; /* Flags of the WR properties */uint32_t imm_data; /* Immediate data (in network byte order) */union {struct {uint64_t remote_addr; /* Start address of remote memory buffer */uint32_t rkey; /* Key of the remote Memory Region */} rdma;struct {uint64_t remote_addr; /* Start address of remote memory buffer */uint64_t compare_add; /* Compare operand */uint64_t swap; /* Swap operand */uint32_t rkey; /* Key of the remote Memory Region */} atomic;struct {struct ibv_ah *ah; /* Address handle (AH) for the remote node address */uint32_t remote_qpn; /* QP number of the destination QP */uint32_t remote_qkey; /* Q_Key number of the destination QP */} ud;} wr;
};
在调用ibv_post_send()之前,必须填充好数据结构wr。 wr是一个链表,每一个结点包含了一个sg_list(i.e. SGL: 由一个或多个SGE构成的数组), sg_list的长度为num_sge。
RDMA提交WR的流程
First Step

从上图中,我们可以看到wr链表中的每一个结点都包含了一个SGL,SGL是一个数组,包含一个或多个SGE。通过ibv_post_send提交一个RDMA SEND 请求。这个WR请求中,包括一个sg_list的元素。它是一个SGE链表,SGE指向具体需要发送数据的Buffer。
Second Step

我们在发送一段内存地址的时候,我们需要将这段内存地址通过Memory Registration注册到RDMA中。也就是说注册到PD内存保护域当中。一个SGL至少被一个MR保护, 多个MR存在同一个PD中。如图所示一段内存MR可以保护多个SGE元素。
Third Step

在上图中,一个SGL数组包含了3个SGE, 长度分别为N1, N2, N3字节。我们可以看到,这3个buffer并不连续,它们Scatter(分散)在内存中的各个地方。RDMA硬件读取到SGL后,进行Gather(聚合)操作,于是在RDMA硬件的Wire上看到的就是N3+N2+N1个连续的字节。换句话说,通过使用SGL, 我们可以把分散(Scatter)在内存中的多个数据段(不连续)交给RDMA硬件去聚合(Gather)成连续的数据段。
OFED Verbs

RDMA CC
RDMA拥塞控制,用于管理和控制在RDMA网络中可能出现的网络拥塞情况,以确保数据传输的可靠性和性能。
- 流量控制:RDMA网络中的流量控制是一种基本的拥塞控制机制,用于确保发送方不会以太快的速度发送数据,从而超负荷了网络。RDMA可以使用不同的流控制机制,如基于信令或基于令牌的机制,来确保数据发送速率适应网络容量。
- 拥塞检测:RDMA网络中的拥塞检测是指检测网络中是否存在拥塞的迹象。这可以通过监视网络的性能指标(如延迟、丢包率、带宽利用率)来实现。如果检测到拥塞,就需要采取相应的措施来减轻拥塞,例如降低发送速率或重新路由数据。
- 拥塞控制算法:RDMA拥塞控制算法是用于管理和减轻拥塞的具体策略。一些常见的拥塞控制算法包括基于反馈的算法,如ECN(显式拥塞通知),以及基于源的算法,如基于窗口的拥塞控制。这些算法根据网络状态来自动调整发送速率以防止拥塞。
- 负载均衡:在RDMA网络中,负载均衡是一种重要的策略,用于将数据流量均匀分配到不同的网络路径或节点,以避免某一路径或节点成为瓶颈。负载均衡可以减少拥塞的可能性,从而提高整体性能。
- QoS(Quality of Service)设置:为了确保关键应用程序的性能,RDMA网络通常支持QoS设置,这意味着可以为不同类型的数据流量分配不同的服务质量级别。这有助于确保关键任务的数据传输不会受到非关键任务的拥塞影响。
拥塞检测
基于丢包检测
基于丢包检测的原理很显然,丢包是拥塞持续得不到缓解的最终结果。TCP 经典的 Tahoe 算法和 CUBIC 算法,都是基于丢包来做检测的。丢包对于 RDMA 的性能影响要比 TCP 大得多,如果等到已经丢包再进行控制成本就太高了,因此 RDMA 不能采用这种方式。
基于ECN检测
ECN(Explicit Congestion Notification)是 IP 头部 Differentiated Services 字段的后两位,用于指示是否发生了拥塞。它的四种取值的含义如下:

| 代码 | 状态 | 解释 |
|---|---|---|
| 00 | None ECN-Capable Transport | 表示发送方不支持ECN |
| 01 | ECN Capable Transport | 表示发送方支持ECN |
| 10 | ECN Capable Transport | 表示发送方支持ECN |
| 11 | Conjestion Encountered | 表示发生了拥塞 |
部署 ECN 功能一般需要交换机同时开启 RED。如果通信双方都支持 ECN(ECN 为 01 或者 10),当拥塞出现时,交换机会更新报文的 ECN 为 11(Congestion Encountered),再转发给下一跳。接收方可以根据 ECN 标志向发送方汇报拥塞情况,调节发送速率。
RED,即 Random Early Drop,是交换机处理拥塞的一种手段。交换机监控当前的队列深度,当队列接近满了,会开始随机地丢掉一些包。丢弃包的概率与当前队列深度正相关。随机丢弃带来的好处是,对于不同的流显得更公平,发送的包越多,那么被丢弃的概率也越大。
当 RED 和 ECN 同时开启,拥塞发生时交换机不再随机丢包,而是随机为报文设置 ECN。
基于RTT检测
RTT(Round-Trip Time)是发送方将数据包发送出去,到接收到对端的确认包之间的时间间隔。RTT 能够反映端到端的网络延迟,如果发生拥塞,数据包会在接收队列中排队等待,RTT 也会相应较高。而 ECN 只能够反映超过队列阈值的包数量,无法精确量化延迟。
RTT 可以选择在软件层或者硬件层做统计。一般网卡接收到数据包后,通过中断通知上层,由操作系统调度中断处理收包事件。中断和调度都将引入一些误差。因此,更精确地统计最好由硬件完成,当网卡接收到包时,网卡立即回复一个 ACK 包,发送方可以根据它的到达时间计算 RTT。
需要注意的是,ACK 回复包如果受到其他流量影响遇到拥塞,那么 RTT 计算会有偏差。可以为 ACK 回复包设置更高优先级。或者保证收发两端网卡的时钟基本上同步,然后在回复包加上时间戳信息。另外,网络路径的切换也会带来一些延迟的变化。
DCTCP
DCTCP,Data Center TCP,扩展TCP的拥塞控制算法,在交换机中使用显式拥塞通知(ECN)来检测并响应网络拥塞,这由交换机的ECN标记序列表示。
DCTCP的设计旨在充分利用数据中心网络的特性,如低延迟、高吞吐量和低丢包率,并且它在典型的数据中心工作负载下表现出色。它是一种用于改进TCP在数据中心环境中的性能的技术,有助于确保数据中心内的应用程序能够获得良好的网络性能和可靠性。但需要注意的是,DCTCP通常需要在数据中心网络设备和主机之间的配置和协同操作,才能充分发挥其优势。
DCTCP算法包含三个主要组成部分:
- 交换机上的简单标记:一种简单的主动队列管理方案。只有一个参数,标记阈值K。如果到达队列的队列占用大于K,则使用CE代码点标记到达的数据包。否则,它不会被标记。该方案可以适用于已有的方案RED标记方案。
- 接收方的ECN-Echo:DCTCP接收方和TCP接收方之间的唯一区别是CE代码点中的信息传递回发送方的方式。DCTCP接收方尝试将标记的数据包的确切顺序传达回发送者。
- 发送方的控制器:发送方维护数据包标记部分的估计值,该值针对每个数据窗口(大约一个RTT)更新一次。DCTCP发送方和TCP发送方之间的唯一区别在于,它们各自对接收到带有ECN-Echo标志设置的ACK的反应。
原理
以下是有关DCTCP的关键特点和原理:
- 拥塞检测:DCTCP使用一种称为ECN(显式拥塞通知)的机制来检测网络中的拥塞。当网络设备(如交换机)检测到拥塞时,它可以向发送方发送ECN标记,告知发送方网络出现拥塞。这比传统TCP的拥塞检测要更快,因为它不需要等待丢包。
- ECN标记反馈:当DCTCP接收到ECN标记,它会以更低的速率发送数据,以减轻网络拥塞。这种反馈机制使得DCTCP可以更快地适应拥塞情况,减少了数据中心网络中的拥塞峰值。
- 流量控制:DCTCP使用一种叫做“ECN校准”的机制,以更准确地调整发送速率,从而确保数据流在不引发网络拥塞的情况下传输。这可以帮助提高网络吞吐量和降低延迟。
- 不公平性的处理:DCTCP还包括一种叫做“公平性模型”的机制,以确保不同连接的流量在共享网络资源时可以公平竞争,避免某些连接占用过多的带宽而影响其他连接的性能。
- 快速恢复:DCTCP还具备快速恢复机制,以便在网络拥塞情况得到解决后,迅速增加发送速率,以充分利用可用的网络带宽。
特点
-
拥塞敏感性:DCTCP是一种拥塞敏感的TCP变种,它的目标是更加敏感地检测和响应拥塞。传统TCP在数据中心环境中的表现不佳,因为它的拥塞控制算法设计时考虑了丢包率,而数据中心网络通常具有非常低的丢包率。DCTCP则专注于监测拥塞信号。
-
ECN支持:DCTCP使用ECN(显式拥塞通知)作为主要拥塞信号的依据。当网络中出现拥塞时,路由器可以标记数据包上的ECN位,告知发送端有拥塞发生。DCTCP的接收端会检测这些ECN标志,并向发送端发送通知,告知它有拥塞信号。
-
拥塞窗口调整:DCTCP使用了一种称为“拥塞响应函数”的算法来计算发送端的拥塞窗口大小。它根据检测到的ECN标志的数量来调整拥塞窗口的大小。当ECN标志出现时,拥塞窗口减小,以减缓数据流量,减轻网络拥塞。这使得DCTCP能够更快速地响应拥塞信号,而不必等待数据包丢失,这是传统TCP拥塞控制的问题之一。
-
流级别拥塞控制:DCTCP还支持流级别的拥塞控制。这意味着每个TCP流都可以独立调整其拥塞窗口大小,而不会互相影响。这有助于确保不同应用程序和流之间的公平性和性能隔离。
-
低延迟:DCTCP旨在减少数据包排队和传输延迟,以满足数据中心应用程序对低延迟的需求。通过更快速地响应拥塞信号,DCTCP可以减少数据包排队时间,提供更好的延迟性能。
-
部署要求:要部署DCTCP,需要支持ECN的网络设备,以及运行DCTCP协议栈的主机。此外,需要适当配置和调整DCTCP的参数,以便最大化其性能。
PFC(Priority Flow Control)
RoCEv1和v2是基于ifinite band的解决方案,数据在ifinite band交换时需要无损lossless,因此RoCE也需要交换机支持lossless。但其中RoCEv1不需要PFC(Priority Flow Control),而RoCEv2需要。因为RoCEv1只支持链路层转发,只考虑同一交换机两个端口之间转发的情况,由于ib交换机本身支持无损网络,因此不需要PFC。但RoCEv2支持第三层IP路由,要考虑跨交换机转发数据,一旦跨交换机就没法保证无损了,因此需要QoS做PFC功能保证无损。也就是说PFC保证链路lossless,让RDMA能在三层下正常运行。
让RDMA仅仅运行起来是不够的,实际环境下网络中基本的拥塞问题仍需解决。RoCEv2使用了DCQCN作为拥塞控制算法,算法使用的拥塞反馈信号主要是ECN(Explicit Congestion Notification)。因此使用ECN目的是解决网络拥塞,提高RDMA的传输性能。
原理
PFC,Priority Flow Control,基于优先级的流量控制。
PFC+ECN(Priority Flow Control with Explicit Congestion Notification)(流控制发生前进行拥塞避免)是一种结合了以太网拥塞控制机制和显式拥塞通知机制的网络技术。它通常用于数据中心网络中,以提供更有效的拥塞管理和更低的网络延迟。以下是关于PFC+ECN的详细描述:
-
Priority Flow Control (PFC):PFC是一种用于以太网交换网络的拥塞管理机制。它允许交换机在传输数据帧时,对不同数据流设置不同的优先级,以确保高优先级数据流在拥塞情况下能够获得更好的服务。PFC允许交换机使用802.1p标记或其他方式来区分数据流的优先级,并在网络拥塞时,暂时暂停低优先级数据流的传输,以让高优先级流量传输。
-
Explicit Congestion Notification (ECN):ECN是一种显式拥塞通知机制,通常用于IP网络。当网络设备(例如路由器或交换机)在网络拥塞时,可以标记传出数据包上的ECN位,以通知接收端和发送端发生了拥塞。接收端会将这个信息反馈给发送端,以触发拥塞控制机制。ECN有助于更快速地检测拥塞并减轻拥塞,而无需等待数据包丢失,这通常是传统TCP拥塞控制的做法。
-
PFC+ECN结合:PFC+ECN结合了PFC和ECN,以提供更细粒度的拥塞管理和更好的网络性能。在PFC+ECN网络中,PFC用于标识和管理不同数据流的优先级,同时ECN用于提供显式拥塞通知。这允许网络设备更好地控制拥塞和数据流的优先级,以确保高优先级数据能够快速传输,而低优先级数据会在拥塞情况下暂停。
-
性能和灵活性:PFC+ECN提供了更好的性能和灵活性,以满足数据中心网络的需求。它可以应对不同数据流之间的竞争,减少网络拥塞,提供低延迟和更好的数据传输质量。
总之,PFC+ECN是一种用于数据中心网络的先进拥塞管理机制,结合了PFC的数据流优先级和ECN的显式拥塞通知,以提供更好的性能和可靠性,特别是在面对大量数据流的情况下。这有助于确保网络中的关键数据能够得到及时的传输和响应。
存在的问题
- 死锁(PFCDeadLock),PFC死锁,是指当多个交换机之间因微环路等原因同时出现拥塞,各自端口缓存消耗超过阈值,而又相互等待对方释放资源,从而导致所有交换机上的数据流都永久阻塞的一种网络状态。即使在无环网络中形成短暂环路时,也可能发生死锁。虽然经过修复短暂环路会很快消失,但它们造成的死锁不是暂时的,即便重启服务器中断流量,死锁也不能自动恢复。
- 队头阻塞(HOL Blocking/堵塞问题/Head-Of-Line Blocking)

- 不公平问题(PFCUnfairness)

在(d)图中,Ingress1和Ingress2是同时暂停和恢复的,因此Ingress1和Ingress2相对,Flow2和Flow3需要竞争Ingress2,从而导致了Flow1总是比Flow2或者Flow3可以获得更高的带宽,这就体现了带宽分配的不公平性。
HPCC
拥塞控制(CC)是在高速网络中实现超低延迟、高带宽和网络稳定性的关键。根据多年运行大规模高速RDMA网络的经验,我们发现现有的高速CC方案在实现这些目标方面存在固有的局限性。在本文中,我们提出了HPCC(高精度拥塞控制),一种新的高速CC机制,它同时实现了这三个目标。HPCC利用网络遥测(INT)获得精确的链路负载信息并精确控制流量。通过解决诸如在拥塞期间延迟INT信息和对INT信息的过度反应等难题,HPCC可以快速收敛以利用空闲带宽,同时避免拥塞,并且可以在网络队列中保持接近零的数据堆积以实现超低的延迟。HPCC也公平且易于在硬件中部署。我们使用商品可编程NIC和交换机实现HPCC。在我们的评估中,与DCQCN和TIMELY相比,HPCC将流量完成时间缩短了95%,即使在大规模Incast情况下也几乎不会造成拥塞。


HPCC是一种基于窗口的CC方案,用于控制inflight字节数。inflight字节表示已发送但尚未在发送方确认的数据量。

DCQCN
数据中心量化拥塞通知 (DCQCN) 是 ECN 和 PFC 的组合,可支持端到端无损以太网。ECN 有助于克服 PFC 的限制,实现无损以太网。DCQCN 背后的理念是允许 ECN 在拥塞时降低传输速率,从而尽量缩短触发 PFC 的时间,从而完全停止流量,从而控制流量。
DCQCN 正确操作需要平衡两个冲突要求:
- 确保 PFC 不会太早触发,也就是说,在让 ECN 有机会发送拥塞反馈之前,使流量变慢。
- 确保 PFC 未因太晚而触发,因此导致数据包丢失(由于缓冲区溢出)。
有三个重要参数需要正确计算和配置,才能满足上述关键要求:
- Headroom Buffers—发送至上游设备的 PAUSE 消息需要一些时间到达并生效。为避免丢包,PAUSE 发送方必须保留足够的缓冲区,以处理在此期间可能收到的任何数据包。这包括发送 PAUSE 时正在传输的数据包,以及上游设备在处理 PAUSE 消息时发送的数据包。在 QFX5000 系列交换机中,根据优先级按端口分配余量缓冲区。而空间缓冲则从全局共享缓冲区中精心分配。您可以使用拥塞通知配置文件中的 MRU 和电缆长度参数控制分配给每个端口的缓冲量和优先级。即使触发了 PFC 后,也发现有细微入口下降,您可以通过增加该端口和优先级组合的库缓冲来消除这些入口的下降。
- PFC Threshold— 这是一个入口阈值。这是在将 PAUSE 消息发送至上游设备之前入口优先级组可以增长为的最大大小。每个 PFC 优先级在每个入口端口都有自己的优先级组。在每个入口端口按优先级组设置 PFC 阈值。对于QFX 系列,PFC 阈值有两个组件:
PG MIN阈值和PG shared阈值。到达PG MIN优先级组的阈值后,PG shared将为此相应优先级生成 PFC。当队列下降到 PFC 阈值以下时,交换机将发送恢复消息。 - ECN Threshold—这是一个出口阈值。ECN 阈值等于 WRED 开始填充级别值。一旦出口队列超过此阈值,交换机将开始为该队列中的数据包进行 ECN 标记。DCQCN 要有效,此阈值必须低于入口 PFC 阈值,以确保 PFC 不会在交换机有机会使用 ECN 标记数据包之前触发。设置非常低的 WRED 填充级别可提高 ECN 标记概率。例如,使用默认共享缓冲区设置,WRED 开始填充级别为 10%可确保标记无丢失数据包。但是,如果填充级别较高,则 ECN 标记的概率降低。例如,如果两个入口端口流量无损地发到同一出口端口,并且 WRED 启动填充级别为 50%,则不会进行 ECN 标记,因为将首先满足入口 PFC 阈值。
DCQCN总体框架:

发送方(RP)以最高速开始发送,沿途过程中如果有拥塞,会被标记ECN显示拥塞,当这个被标记的报文转发到接收方(NP)的时候,接收方(NP)会回应一个CNP报文,通知发送方(RP)。收到CNP报文的发送方(RP),就会开始降速。当发送方没有收到CNP报文时,就开始又提速了,上述过程就是DCQCN的基本思路。
DCQCN拥塞点控制:

当队列长度超过ECN标记阈值时,数据包在ECN位上标记,其概率与队列长度成比例。 这些标记的数据包是显示发生拥塞的信号。
优先流控制PFC 用于防止数据包丢失。 当队列长度超过PFC阈值时,PFC数据包将发送到上游端口以阻止它们发送。
DCQCN通知点:

当拥塞点(流的接收端)接收数据包时,它检查其ECN位。
如果一个接收端接收到带有ECN标记的分组,则它向流的发送端发送拥塞通知分组a congestion notification packet (CNP),并且在下一个固定的时间段内,例如50微秒,它将不再针对相同的流发送CNP。
CNP是拥塞信号,通知发送者控制流速。
DCQCN反应点:

当流量发送端接收到CNP时,它会按比例减少流量,该切割比的计算类似于DCTCP。当接收到CNP时,切割比率增加。 并且当流速增加时,切割比降低。

定时器和字节计数器用于发送端以进行速率恢复,当发送方未在固定时间内收到CNP时,它会根据其先前的状态增加流量。
加速有三种状态,如QCN,快速恢复,加性增加和超增加。
在快速恢复中,发送方将流速增加到上次切割前的速率。快速恢复将持续到,恢复到目标速率
在加性增长中,流速相加地增加,也就是说,使用固定的增加步骤。
在超级增长中,增加步骤随着增加的时间增长而增长。

CNP数据包:

TIMELY
数据中心网络环境的特点是,通过高带宽,低延迟路径上紧密耦合的计算形式,产生大量突发消息工作负载。在许多方面,它与传统的广域网相反。带宽充足,而最重要的是流程计算时间(例如,对于远程过程调用(RPC))。对于短RPC,最小完成时间由传播和序列化延迟确定。因此,我们尝试最小化任何排队延迟以保持RTT低。尾部延迟很重要,因为当即使一小部分数据包延迟时,应用性能也会大幅度下降。一致的低延迟意味着低排队延迟和接近零的数据包丢失,因为恢复操作可能会大大增加消息延迟。较长的RPC将具有较大的完成时间,因为在共享网络上传输更多数据需要花费时间。为了使增加的时间保持较小,我们必须保持较高的总吞吐量以使所有流量受益,并保持近似的公平性,从而使任何流量都不会受到惩罚。
我们评估的主要指标是RTT(第99个百分位)和总吞吐量,因为它们确定我们完成短期和长期RPC的速度(假设有些公平)。 当吞吐量和数据包RTT之间存在冲突时,我们宁愿以牺牲少量带宽为代价将RTT保持在较低水平。 这是因为带宽一开始就足够,RTT的增加直接影响短传输的完成时间。 实际上,我们试图将吞吐量/等待时间曲线拖延到尾部等待时间变得不可接受的地步。 次要指标是公平性和损失。 我们将二者作为检查报告,而不是对其进行详细研究。 最后,相对于较高的平均值,我们更倾向于采用稳定的设计,但为了可预测的性能而采用振荡速率。
TIMELY的拥塞控制器通过对延迟梯度或排队随时间变化的微分做出反应,从而实现了低延迟,而不是试图保持排队。 这是可能的,因为我们可以准确地测量表明排队延迟发生变化的RTT的差异。 由于RTT增加而导致的正延迟梯度表示队列增加,而负梯度表示队列减少。 通过使用梯度,我们可以对队列增长做出反应,而无需等待队列的形成–一种有助于我们实现低延迟的策略。

络上传输更多数据需要花费时间。为了使增加的时间保持较小,我们必须保持较高的总吞吐量以使所有流量受益,并保持近似的公平性,从而使任何流量都不会受到惩罚。
我们评估的主要指标是RTT(第99个百分位)和总吞吐量,因为它们确定我们完成短期和长期RPC的速度(假设有些公平)。 当吞吐量和数据包RTT之间存在冲突时,我们宁愿以牺牲少量带宽为代价将RTT保持在较低水平。 这是因为带宽一开始就足够,RTT的增加直接影响短传输的完成时间。 实际上,我们试图将吞吐量/等待时间曲线拖延到尾部等待时间变得不可接受的地步。 次要指标是公平性和损失。 我们将二者作为检查报告,而不是对其进行详细研究。 最后,相对于较高的平均值,我们更倾向于采用稳定的设计,但为了可预测的性能而采用振荡速率。
TIMELY的拥塞控制器通过对延迟梯度或排队随时间变化的微分做出反应,从而实现了低延迟,而不是试图保持排队。 这是可能的,因为我们可以准确地测量表明排队延迟发生变化的RTT的差异。 由于RTT增加而导致的正延迟梯度表示队列增加,而负梯度表示队列减少。 通过使用梯度,我们可以对队列增长做出反应,而无需等待队列的形成–一种有助于我们实现低延迟的策略。
[外链图片转存中…(img-xeiZULyy-1698808810473)]
相关文章:
全网最全的RDMA拥塞控制入门基础教程
RDMA-CC(全网最全的RDMA拥塞控制入门基础教程) 文章目录 RDMA-CC(全网最全的RDMA拥塞控制入门基础教程)DMARDMARDMA举例RDMA优势RDMA的硬件实现方法RDMA基本术语FabricCA(Channel Adapter)Verbs 核心概念Me…...
分布式消息队列:RabbitMQ(1)
目录 一:中间件 二:分布式消息队列 2.1:是消息队列 2.1.1:消息队列的优势 2.1.1.1:异步处理化 2.1.1.2:削峰填谷 2.2:分布式消息队列 2.2.1:分布式消息队列的优势 2.2.1.1:数据的持久化 2.2.1.2:可扩展性 2.2.1.3:应用解耦 2.2.1.4:发送订阅 2.2.2:分布式消息队列…...

Redis集群脑裂
1. 概述 Redis 集群脑裂(Cluster Split Brain)是指在 Redis 集群中,由于网络分区或通信问题,导致集群中的节点无法相互通信,最终导致集群内部发生分裂,出现多个子集群,每个子集群认为自己是有效…...

GEE教程——随机样本点添加经纬度信息
简介: 有没有办法在绘制散点图后将样本的坐标信息(纬度/经度)添加到.CSV表格数据中? 这里我们很多时候我们需要加载样本点的基本信息作为属性,本教程主要的目的就是我们选取一个研究区,然后产生随机样本点,然后利用坐标函数,进行样本点的获取经纬度,然后通过循环注意…...
:神经网络-非线性激活)
PyTorch入门学习(十):神经网络-非线性激活
目录 一、简介 二、常见的非线性激活函数 三、实现非线性激活函数 四、示例:应用非线性激活函数 一、简介 在神经网络中,激活函数的主要目的是引入非线性特性,从而使网络能够对非线性数据建模。如果只使用线性变换,那么整个神…...
)
《golang设计模式》第三部分·行为型模式-03-解释器模式(Interpreter)
文章目录 1. 概述1.1 角色1.2 类图1.3 优缺点 2. 代码示例2.1 设计2.2 代码2.3 类图 1. 概述 解释器模式(Interpreter)是用于表达语言语法树和封装语句解释(或运算)行为的对象。 1.1 角色 AbstractExpression(抽象表…...

Windows个性化颜色睡眠后经常改变
问题再现 我把系统颜色换成了一种红色,结果每次再打开电脑又变回去了(绿色); 原因是因为wallpaper engine在捣蛋 需要禁用修改windows配色这一块选项; 完事!原来是wallpaper engine的问题;...

calico ipam使用
calico ipam使用 前面的文章pod获取ip地址的过程中提到过calico使用的IP地址的管理模块是其自己开发的模块calico-ipam,本篇文章来讲述下其具体用法。 一、环境信息 版本信息 本环境使用版本是k8s 1.25.3 [rootnode1 ~]# kubectl get node NAME STATUS ROLES …...
-Redis持久化-AOF方式)
Redis系统学习(高级篇)-Redis持久化-AOF方式
目录 一、是什么AOF? 二、AOF如何开启 以及触发策略有哪些 三、AOF文件重写 四、AOF与RDB对比 一、是什么AOF? 就是通过每次记录写操作,最终通过来依次这些命令来达到恢复数据的目的 二、AOF如何开启 以及触发策略有哪些 save "&q…...
云安全-云原生基于容器漏洞的逃逸自动化手法(CDK check)
0x00 docker逃逸的方法种类 1、不安全的配置: 容器危险挂载(挂载procfs,Scoket) 特权模式启动的提权(privileged) 2、docker容器自身的漏洞 3、linux系统内核漏洞 这里参考Twiki的云安全博客,下…...

精选10款Python可视化工具,请查收
今天我们会介绍一下10个适用于多个学科的Python数据可视化库,其中有名气很大的也有鲜为人知的。 1、matplotlib matplotlib 是Python可视化程序库的泰斗。经过十几年它仍然是Python使用者最常用的画图库。它的设计和在1980年代被设计的商业化程序语言MATLAB非常接近…...
-skew-GroupBy)
大数据(21)-skew-GroupBy
&&大数据学习&& 🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博主哦ᾑ…...

window压缩包安装mongodb并注册系统服务
下载解压包 https://fastdl.mongodb.org/windows/mongodb-windows-x86_64-5.0.22.zip启动mongod 解压压缩包 至 d:\mongodb目录中,创建目录data、logs。并创建配置文件mongod.conf输入以下配置 dbpath d:\mongodb\data logpath d:\mongodb\logs\mongo.log loga…...
)
【Java每日一题】——第四十五题:综合案例:模拟物流快递系统。(2023.11.1)
🎃个人专栏: 🐬 算法设计与分析:算法设计与分析_IT闫的博客-CSDN博客 🐳Java基础:Java基础_IT闫的博客-CSDN博客 🐋c语言:c语言_IT闫的博客-CSDN博客 🐟MySQL:…...
二十二、Arcpy批量波段组合——结合Landat数据城市建成区提取
一、前言 其实波段组合和GIS中栅格计算有点类似,实质上就是对每个像素点对应的DN值进行数学计算,也就是可以进行运算表达式是三个或多个变量相加、相减……每一个变量对应于一个图像数据,对这三个或多个图像数据求值并输出结果图像。 二、具体操作 1、实验具体目标 将202…...

电脑上数据恢复的详细操作
在日常使用电脑过程中,我们可能会遇到数据丢失的情况。无论是因为误删除、格式化、病毒攻击还是硬件故障,数据恢复都是我们迫切需要解决的问题。本文将介绍电脑数据恢复的详细操作步骤,帮助读者在面临数据丢失时能够迅速地恢复重要文件。 一…...

3.1 linux控制内核打印printk demsg DEBUG
本文主要内容: 1 列出内核打印级别 2 修改内核打印级别 方法1 编译时 方法2 uboot时 方法3 启动后 3 DEBUG宏控制妙用 4 内存中各种打印函数封装 5 测试示例代码 1 打印级别 #define KERN_EMERG "<0>" /* system is unusable */ #define KERN_ALERT …...

关于爬虫API常见的技术问题和解答
随着互联网的快速发展,数据获取变得越来越重要。爬虫API作为一种高效的数据获取手段,被广泛应用于各种场景。然而,在实际使用过程中,我们经常会遇到一些技术问题。本文将详细介绍爬虫API的常见技术问题及相应的解决方案。 一、爬…...

在CentOS上用yum方式安装MySQL8过程记录
此文参考官方文档一步一步记录安装到正常运行全过程 安装环境:centos7 mysql版本:8.0.35 安装过程主要参考下面两边文章: 1.官方文档 https://dev.mysql.com/doc/refman/8.0/en/linux-installation-yum-repo.html 2.linux yum安装mysql8 安…...

CEYEE希亦新品洗地机Pro系列发布, 领跑行业的「水汽混动」技术的旗舰新杰作
CEYEE希亦全新一代洗地机T800 PRO正式上市,采用双滚刷,双倍活水洗拖洗方式,达到拖一遍抵两遍,相对于10倍洁净效果! 这款希亦Pro系列产品不仅刷新了洗地机行业技术水准,满足了用户愈发极致的清洁效能追求&a…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...