三天吃透Java虚拟机面试八股文
本文已经收录到Github仓库,该仓库包含计算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享等核心知识点,欢迎star~
Github地址:https://github.com/Tyson0314/Java-learning
讲一下JVM内存结构?
JVM内存结构分为5大区域,程序计数器、虚拟机栈、本地方法栈、堆、方法区。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ie1i0RXL-1677401113026)(http://img.topjavaer.cn/image/jvm内存结构0.png)]
程序计数器
线程私有的,作为当前线程的行号指示器,用于记录当前虚拟机正在执行的线程指令地址。程序计数器主要有两个作用:
- 当前线程所执行的字节码的行号指示器,通过它实现代码的流程控制,如:顺序执行、选择、循环、异常处理。
- 在多线程的情况下,程序计数器用于记录当前线程执行的位置,当线程被切换回来的时候能够知道它上次执行的位置。
程序计数器是唯一一个不会出现 OutOfMemoryError 的内存区域,它的生命周期随着线程的创建而创建,随着线程的结束而死亡。
虚拟机栈
Java 虚拟机栈是由一个个栈帧组成,而每个栈帧中都拥有:局部变量表、操作数栈、动态链接、方法出口信息。每一次函数调用都会有一个对应的栈帧被压入虚拟机栈,每一个函数调用结束后,都会有一个栈帧被弹出。
局部变量表是用于存放方法参数和方法内的局部变量。
每个栈帧都包含一个指向运行时常量池中该栈所属方法的符号引用,在方法调用过程中,会进行动态链接,将这个符号引用转化为直接引用。
- 部分符号引用在类加载阶段的时候就转化为直接引用,这种转化就是静态链接
- 部分符号引用在运行期间转化为直接引用,这种转化就是动态链接
Java 虚拟机栈也是线程私有的,每个线程都有各自的 Java 虚拟机栈,而且随着线程的创建而创建,随着线程的死亡而死亡。Java 虚拟机栈会出现两种错误:StackOverFlowError 和 OutOfMemoryError。
可以通过-Xss参数来指定每个线程的虚拟机栈内存大小:
java -Xss2M
本地方法栈
虚拟机栈为虚拟机执行 Java 方法服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。Native 方法一般是用其它语言(C、C++等)编写的。
本地方法被执行的时候,在本地方法栈也会创建一个栈帧,用于存放该本地方法的局部变量表、操作数栈、动态链接、出口信息。
堆
堆用于存放对象实例,是垃圾收集器管理的主要区域,因此也被称作GC堆。堆可以细分为:新生代(Eden空间、From Survivor、To Survivor空间)和老年代。
通过 -Xms设定程序启动时占用内存大小,通过-Xmx设定程序运行期间最大可占用的内存大小。如果程序运行需要占用更多的内存,超出了这个设置值,就会抛出OutOfMemory异常。
java -Xms1M -Xmx2M
1.方法区
方法区与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
对方法区进行垃圾回收的主要目标是对常量池的回收和对类的卸载。
2.永久代
方法区是 JVM 的规范,而永久代PermGen是方法区的一种实现方式,并且只有 HotSpot 有永久代。对于其他类型的虚拟机,如JRockit没有永久代。由于方法区主要存储类的相关信息,所以对于动态生成类的场景比较容易出现永久代的内存溢出。
3.元空间
JDK 1.8 的时候,HotSpot的永久代被彻底移除了,使用元空间替代。元空间的本质和永久代类似,都是对JVM规范中方法区的实现。两者最大的区别在于:元空间并不在虚拟机中,而是使用直接内存。
为什么要将永久代替换为元空间呢?
永久代内存受限于 JVM 可用内存,而元空间使用的是直接内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,但是相比永久代内存溢出的概率更小。
运行时常量池
运行时常量池是方法区的一部分,在类加载之后,会将编译器生成的各种字面量和符号引号放到运行时常量池。在运行期间动态生成的常量,如 String 类的 intern()方法,也会被放入运行时常量池。
直接内存
直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用。而且也可能导致 OutOfMemoryError 错误出现。
NIO的Buffer提供了DirectBuffer,可以直接访问系统物理内存,避免堆内内存到堆外内存的数据拷贝操作,提高效率。DirectBuffer直接分配在物理内存中,并不占用堆空间,其可申请的最大内存受操作系统限制,不受最大堆内存的限制。
直接内存的读写操作比堆内存快,可以提升程序I/O操作的性能。通常在I/O通信过程中,会存在堆内内存到堆外内存的数据拷贝操作,对于需要频繁进行内存间数据拷贝且生命周期较短的暂存数据,都建议存储到直接内存。
Java对象的定位方式
Java 程序通过栈上的 reference 数据来操作堆上的具体对象。对象的访问方式由虚拟机实现而定,目前主流的访问方式有使用句柄和直接指针两种:
- 如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息。使用句柄来访问的最大好处是 reference 中存储的是稳定的句柄地址,在对象被移动时只会改变句柄中的实例数据指针,而 reference 本身不需要修改。
- 直接指针。reference 中存储的直接就是对象的地址。对象包含到对象类型数据的指针,通过这个指针可以访问对象类型数据。使用直接指针访问方式最大的好处就是访问对象速度快,它节省了一次指针定位的时间开销,虚拟机hotspot主要是使用直接指针来访问对象。
本文已经收录到Github仓库,该仓库包含计算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享等核心知识点,欢迎star~
Github地址:https://github.com/Tyson0314/Java-learning
说一下堆栈的区别?
-
堆的物理地址分配是不连续的,性能较慢;栈的物理地址分配是连续的,性能相对较快。
-
堆存放的是对象的实例和数组;栈存放的是局部变量,操作数栈,返回结果等。
-
堆是线程共享的;栈是线程私有的。
什么情况下会发生栈溢出?
- 当线程请求的栈深度超过了虚拟机允许的最大深度时,会抛出
StackOverFlowError异常。这种情况通常是因为方法递归没终止条件。 - 新建线程的时候没有足够的内存去创建对应的虚拟机栈,虚拟机会抛出
OutOfMemoryError异常。比如线程启动过多就会出现这种情况。
类文件结构
Class 文件结构如下:
ClassFile {u4 magic; //类文件的标志u2 minor_version;//小版本号u2 major_version;//大版本号u2 constant_pool_count;//常量池的数量cp_info constant_pool[constant_pool_count-1];//常量池u2 access_flags;//类的访问标记u2 this_class;//当前类的索引u2 super_class;//父类u2 interfaces_count;//接口u2 interfaces[interfaces_count];//一个类可以实现多个接口u2 fields_count;//字段属性field_info fields[fields_count];//一个类会可以有个字段u2 methods_count;//方法数量method_info methods[methods_count];//一个类可以有个多个方法u2 attributes_count;//此类的属性表中的属性数attribute_info attributes[attributes_count];//属性表集合
}
主要参数如下:
魔数:class文件标志。
文件版本:高版本的 Java 虚拟机可以执行低版本编译器生成的类文件,但是低版本的 Java 虚拟机不能执行高版本编译器生成的类文件。
常量池:存放字面量和符号引用。字面量类似于 Java 的常量,如字符串,声明为final的常量值等。符号引用包含三类:类和接口的全限定名,方法的名称和描述符,字段的名称和描述符。
访问标志:识别类或者接口的访问信息,比如这个Class是类还是接口,是否为 public 或者 abstract 类型等等。
当前类的索引:类索引用于确定这个类的全限定名。
什么是类加载?类加载的过程?
类的加载指的是将类的class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个此类的对象,通过这个对象可以访问到方法区对应的类信息。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vMxRaDT2-1677401113038)(http://img.topjavaer.cn/image/类加载.png)]
加载
- 通过类的全限定名获取定义此类的二进制字节流
- 将字节流所代表的静态存储结构转换为方法区的运行时数据结构
- 在内存中生成一个代表该类的
Class对象,作为方法区类信息的访问入口
验证
确保Class文件的字节流中包含的信息符合虚拟机规范,保证在运行后不会危害虚拟机自身的安全。主要包括四种验证:文件格式验证,元数据验证,字节码验证,符号引用验证。
准备
为类变量分配内存并设置类变量初始值的阶段。
解析
虚拟机将常量池内的符号引用替换为直接引用的过程。符号引用用于描述目标,直接引用直接指向目标的地址。
初始化
开始执行类中定义的Java代码,初始化阶段是调用类构造器的过程。
什么是双亲委派模型?
一个类加载器收到一个类的加载请求时,它首先不会自己尝试去加载它,而是把这个请求委派给父类加载器去完成,这样层层委派,因此所有的加载请求最终都会传送到顶层的启动类加载器中,只有当父类加载器反馈自己无法完成这个加载请求时,子加载器才会尝试自己去加载。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pD5Z7I2M-1677401113047)(http://img.topjavaer.cn/image/双亲委派.png)]
双亲委派模型的具体实现代码在 java.lang.ClassLoader中,此类的 loadClass() 方法运行过程如下:先检查类是否已经加载过,如果没有则让父类加载器去加载。当父类加载器加载失败时抛出 ClassNotFoundException,此时尝试自己去加载。源码如下:
public abstract class ClassLoader {// The parent class loader for delegationprivate final ClassLoader parent;public Class<?> loadClass(String name) throws ClassNotFoundException {return loadClass(name, false);}protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {synchronized (getClassLoadingLock(name)) {// First, check if the class has already been loadedClass<?> c = findLoadedClass(name);if (c == null) {try {if (parent != null) {c = parent.loadClass(name, false);} else {c = findBootstrapClassOrNull(name);}} catch (ClassNotFoundException e) {// ClassNotFoundException thrown if class not found// from the non-null parent class loader}if (c == null) {// If still not found, then invoke findClass in order// to find the class.c = findClass(name);}}if (resolve) {resolveClass(c);}return c;}}protected Class<?> findClass(String name) throws ClassNotFoundException {throw new ClassNotFoundException(name);}
}
为什么需要双亲委派模型?
双亲委派模型的好处:可以防止内存中出现多份同样的字节码。如果没有双亲委派模型而是由各个类加载器自行加载的话,如果用户编写了一个java.lang.Object的同名类并放在ClassPath中,多个类加载器都去加载这个类到内存中,系统中将会出现多个不同的Object类,那么类之间的比较结果及类的唯一性将无法保证。
什么是类加载器,类加载器有哪些?
-
实现通过类的全限定名获取该类的二进制字节流的代码块叫做类加载器。
主要有一下四种类加载器:
- 启动类加载器:用来加载 Java 核心类库,无法被 Java 程序直接引用。
- 扩展类加载器:它用来加载 Java 的扩展库。Java 虚拟机的实现会提供一个扩展库目录。该类加载器在此目录里面查找并加载 Java 类。
- 系统类加载器:它根据应用的类路径来加载 Java 类。可通过
ClassLoader.getSystemClassLoader()获取它。 - 自定义类加载器:通过继承
java.lang.ClassLoader类的方式实现。
类的实例化顺序?
- 父类中的
static代码块,当前类的static代码块 - 父类的普通代码块
- 父类的构造函数
- 当前类普通代码块
- 当前类的构造函数
如何判断一个对象是否存活?
对堆垃圾回收前的第一步就是要判断那些对象已经死亡(即不再被任何途径引用的对象)。判断对象是否存活有两种方法:引用计数法和可达性分析。
引用计数法
给对象中添加一个引用计数器,每当有一个地方引用它,计数器就加 1;当引用失效,计数器就减 1;任何时候计数器为 0 的对象就是不可能再被使用的。
这种方法很难解决对象之间相互循环引用的问题。比如下面的代码,obj1 和 obj2 互相引用,这种情况下,引用计数器的值都是1,不会被垃圾回收。
public class ReferenceCount {Object instance = null;public static void main(String[] args) {ReferenceCount obj1 = new ReferenceCount();ReferenceCount obj2 = new ReferenceCount();obj1.instance = obj2;obj2.instance = obj1;obj1 = null;obj2 = null;}
}
可达性分析
通过GC Root对象为起点,从这些节点向下搜索,搜索所走过的路径叫引用链,当一个对象到GC Root没有任何的引用链相连时,说明这个对象是不可用的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oJqM5BZl-1677401113052)(http://img.topjavaer.cn/image/可达性分析0.png)]
可作为GC Roots的对象有哪些?
- 虚拟机栈中引用的对象
- 本地方法栈中Native方法引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
什么情况下类会被卸载?
需要同时满足以下 3 个条件类才可能会被卸载 :
- 该类所有的实例都已经被回收。
- 加载该类的类加载器已经被回收。
- 该类对应的
java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
虚拟机可以对满足上述 3 个条件的类进行回收,但不一定会进行回收。
强引用、软引用、弱引用、虚引用是什么,有什么区别?
强引用:在程序中普遍存在的引用赋值,类似Object obj = new Object()这种引用关系。只要强引用关系还存在,垃圾收集器就永远不会回收掉被引用的对象。
软引用:如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。
//软引用
SoftReference<String> softRef = new SoftReference<String>(str);
弱引用:在进行垃圾回收时,不管当前内存空间足够与否,都会回收只具有弱引用的对象。
//弱引用
WeakReference<String> weakRef = new WeakReference<String>(str);
虚引用:虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。虚引用主要是为了能在对象被收集器回收时收到一个系统通知。
GC是什么?为什么要GC?
GC(Garbage Collection),垃圾回收,是Java与C++的主要区别之一。作为Java开发者,一般不需要专门编写内存回收和垃圾清理代码。这是因为在Java虚拟机中,存在自动内存管理和垃圾清理机制。对JVM中的内存进行标记,并确定哪些内存需要回收,根据一定的回收策略,自动的回收内存,保证JVM中的内存空间,防止出现内存泄露和溢出问题。
Minor GC 和 Full GC的区别?
-
Minor GC:回收新生代,因为新生代对象存活时间很短,因此
Minor GC会频繁执行,执行的速度一般也会比较快。 -
Full GC:回收老年代和新生代,老年代的对象存活时间长,因此
Full GC很少执行,执行速度会比Minor GC慢很多。
内存的分配策略?
对象优先在 Eden 分配
大多数情况下,对象在新生代 Eden 上分配,当 Eden 空间不够时,触发 Minor GC。
大对象直接进入老年代
大对象是指需要连续内存空间的对象,最典型的大对象有长字符串和大数组。可以设置JVM参数 -XX:PretenureSizeThreshold,大于此值的对象直接在老年代分配。
长期存活的对象进入老年代
通过参数 -XX:MaxTenuringThreshold 可以设置对象进入老年代的年龄阈值。对象在Survivor区每经过一次 Minor GC,年龄就增加 1 岁,当它的年龄增加到一定程度,就会被晋升到老年代中。
动态对象年龄判定
并非对象的年龄必须达到 MaxTenuringThreshold 才能晋升老年代,如果在 Survivor 中相同年龄所有对象大小的总和大于 Survivor 空间的一半,则年龄大于或等于该年龄的对象可以直接进入老年代,无需达到 MaxTenuringThreshold 年龄阈值。
空间分配担保
在发生 Minor GC 之前,虚拟机先检查老年代最大可用的连续空间是否大于新生代所有对象总空间,如果条件成立的话,那么 Minor GC 是安全的。如果不成立的话虚拟机会查看 HandlePromotionFailure 的值是否允许担保失败。如果允许,那么就会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试着进行一次 Minor GC;如果小于,或者 HandlePromotionFailure 的值为不允许担保失败,那么就要进行一次 Full GC。
Full GC 的触发条件?
对于 Minor GC,其触发条件比较简单,当 Eden 空间满时,就将触发一次 Minor GC。而 Full GC 触发条件相对复杂,有以下情况会发生 full GC:
调用 System.gc()
只是建议虚拟机执行 Full GC,但是虚拟机不一定真正去执行。不建议使用这种方式,而是让虚拟机管理内存。
老年代空间不足
老年代空间不足的常见场景为前文所讲的大对象直接进入老年代、长期存活的对象进入老年代等。为了避免以上原因引起的 Full GC,应当尽量不要创建过大的对象以及数组、注意编码规范避免内存泄露。除此之外,可以通过 -Xmn 参数调大新生代的大小,让对象尽量在新生代被回收掉,不进入老年代。还可以通过 -XX:MaxTenuringThreshold 调大对象进入老年代的年龄,让对象在新生代多存活一段时间。
空间分配担保失败
使用复制算法的 Minor GC 需要老年代的内存空间作担保,如果担保失败会执行一次 Full GC。
JDK 1.7 及以前的永久代空间不足
在 JDK 1.7 及以前,HotSpot 虚拟机中的方法区是用永久代实现的,永久代中存放的为一些 Class 的信息、常量、静态变量等数据。当系统中要加载的类、反射的类和调用的方法较多时,永久代可能会被占满,在未配置为采用 CMS GC 的情况下也会执行 Full GC。如果经过 Full GC 仍然回收不了,那么虚拟机会抛出 java.lang.OutOfMemoryError。
垃圾回收算法有哪些?
垃圾回收算法有四种,分别是标记清除法、标记整理法、复制算法、分代收集算法。
标记清除算法
首先利用可达性去遍历内存,把存活对象和垃圾对象进行标记。标记结束后统一将所有标记的对象回收掉。这种垃圾回收算法效率较低,并且会产生大量不连续的空间碎片。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l7TBE8ED-1677401113057)(http://img.topjavaer.cn/image/标记清除.png)]
复制清除算法
半区复制,用于新生代垃圾回收。将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。
特点:实现简单,运行高效,但可用内存缩小为了原来的一半,浪费空间。
标记整理算法
根据老年代的特点提出的一种标记算法,标记过程仍然与标记-清除算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉边界以外的内存。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RUqyiJts-1677401113062)(http://img.topjavaer.cn/image/标记整理.png)]
分类收集算法
根据各个年代的特点采用最适当的收集算法。
一般将堆分为新生代和老年代。
- 新生代使用复制算法
- 老年代使用标记清除算法或者标记整理算法
在新生代中,每次垃圾收集时都有大批对象死去,只有少量存活,使用复制算法比较合适,只需要付出少量存活对象的复制成本就可以完成收集。老年代对象存活率高,适合使用标记-清理或者标记-整理算法进行垃圾回收。
有哪些垃圾回收器?
垃圾回收器主要分为以下几种:Serial、ParNew、Parallel Scavenge、Serial Old、Parallel Old、CMS、G1。
这7种垃圾收集器的特点:
| 收集器 | 串行、并行or并发 | 新生代/老年代 | 算法 | 目标 | 适用场景 |
|---|---|---|---|---|---|
| Serial | 串行 | 新生代 | 复制算法 | 响应速度优先 | 单CPU环境下的Client模式 |
| ParNew | 并行 | 新生代 | 复制算法 | 响应速度优先 | 多CPU环境时在Server模式下与CMS配合 |
| Parallel Scavenge | 并行 | 新生代 | 复制算法 | 吞吐量优先 | 在后台运算而不需要太多交互的任务 |
| Serial Old | 串行 | 老年代 | 标记-整理 | 响应速度优先 | 单CPU环境下的Client模式、CMS的后备预案 |
| Parallel Old | 并行 | 老年代 | 标记-整理 | 吞吐量优先 | 在后台运算而不需要太多交互的任务 |
| CMS | 并发 | 老年代 | 标记-清除 | 响应速度优先 | 集中在互联网站或B/S系统服务端上的Java应用 |
| G1 | 并发 | both | 标记-整理+复制算法 | 响应速度优先 | 面向服务端应用,将来替换CMS |
Serial 收集器
单线程收集器,使用一个垃圾收集线程去进行垃圾回收,在进行垃圾回收的时候必须暂停其他所有的工作线程( Stop The World ),直到它收集结束。
特点:简单高效;内存消耗小;没有线程交互的开销,单线程收集效率高;需暂停所有的工作线程,用户体验不好。
ParNew 收集器
Serial收集器的多线程版本,除了使用多线程进行垃圾收集外,其他行为、参数与 Serial 收集器基本一致。
Parallel Scavenge 收集器
新生代收集器,基于复制清除算法实现的收集器。特点是吞吐量优先,能够并行收集的多线程收集器,允许多个垃圾回收线程同时运行,降低垃圾收集时间,提高吞吐量。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值(吞吐量 = 运行用户代码时间 /(运行用户代码时间 + 垃圾收集时间))。Parallel Scavenge 收集器关注点是吞吐量,高效率的利用 CPU 资源。CMS 垃圾收集器关注点更多的是用户线程的停顿时间。
Parallel Scavenge收集器提供了两个参数用于精确控制吞吐量,分别是控制最大垃圾收集停顿时间的-XX:MaxGCPauseMillis参数以及直接设置吞吐量大小的-XX:GCTimeRatio参数。
-
-XX:MaxGCPauseMillis参数的值是一个大于0的毫秒数,收集器将尽量保证内存回收花费的时间不超过用户设定值。 -
-XX:GCTimeRatio参数的值大于0小于100,即垃圾收集时间占总时间的比率,相当于吞吐量的倒数。
Serial Old 收集器
Serial 收集器的老年代版本,单线程收集器,使用标记整理算法。
Parallel Old 收集器
Parallel Scavenge 收集器的老年代版本。多线程垃圾收集,使用标记整理算法。
CMS 收集器
Concurrent Mark Sweep ,并发标记清除,追求获取最短停顿时间,实现了让垃圾收集线程与用户线程基本上同时工作。
CMS 垃圾回收基于标记清除算法实现,整个过程分为四个步骤:
- 初始标记: 暂停所有用户线程(
Stop The World),记录直接与GC Roots直接相连的对象 。 - 并发标记:从
GC Roots开始对堆中对象进行可达性分析,找出存活对象,耗时较长,但是不需要停顿用户线程。 - 重新标记: 在并发标记期间对象的引用关系可能会变化,需要重新进行标记。此阶段也会暂停所有用户线程。
- 并发清除:清除标记对象,这个阶段也是可以与用户线程同时并发的。
在整个过程中,耗时最长的是并发标记和并发清除阶段,这两个阶段垃圾收集线程都可以与用户线程一起工作,所以从总体上来说,CMS收集器的内存回收过程是与用户线程一起并发执行的。
优点:并发收集,停顿时间短。
缺点:
- 标记清除算法导致收集结束有大量空间碎片。
- 产生浮动垃圾,在并发清理阶段用户线程还在运行,会不断有新的垃圾产生,这一部分垃圾出现在标记过程之后,
CMS无法在当次收集中回收它们,只好等到下一次垃圾回收再处理;
G1收集器
G1垃圾收集器的目标是在不同应用场景中追求高吞吐量和低停顿之间的最佳平衡。
G1将整个堆分成相同大小的分区(Region),有四种不同类型的分区:Eden、Survivor、Old和Humongous。分区的大小取值范围为 1M 到 32M,都是2的幂次方。分区大小可以通过-XX:G1HeapRegionSize参数指定。Humongous区域用于存储大对象。G1规定只要大小超过了一个分区容量一半的对象就认为是大对象。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5bUgqw5K-1677401113066)(http://img.topjavaer.cn/image/g1分区.png)]
G1 收集器对各个分区回收所获得的空间大小和回收所需时间的经验值进行排序,得到一个优先级列表,每次根据用户设置的最大回收停顿时间,优先回收价值最大的分区。
特点:可以由用户指定期望的垃圾收集停顿时间。
G1 收集器的回收过程分为以下几个步骤:
- 初始标记。暂停所有其他线程,记录直接与
GC Roots直接相连的对象,耗时较短 。 - 并发标记。从
GC Roots开始对堆中对象进行可达性分析,找出要回收的对象,耗时较长,不过可以和用户程序并发执行。 - 最终标记。需对其他线程做短暂的暂停,用于处理并发标记阶段对象引用出现变动的区域。
- 筛选回收。对各个分区的回收价值和成本进行排序,根据用户所期望的停顿时间来制定回收计划,然后把决定回收的分区的存活对象复制到空的分区中,再清理掉整个旧的分区的全部空间。这里的操作涉及存活对象的移动,会暂停用户线程,由多条收集器线程并行完成。
常用的 JVM 调优的命令都有哪些?
jps:列出本机所有 Java 进程的进程号。
常用参数如下:
-m输出main方法的参数-l输出完全的包名和应用主类名-v输出JVM参数
jps -lvm
//output
//4124 com.zzx.Application -javaagent:E:\IDEA2019\lib\idea_rt.jar=10291:E:\IDEA2019\bin -Dfile.encoding=UTF-8
jstack:查看某个 Java 进程内的线程堆栈信息。使用参数-l可以打印额外的锁信息,发生死锁时可以使用jstack -l pid观察锁持有情况。
jstack -l 4124 | more
输出结果如下:
"http-nio-8001-exec-10" #40 daemon prio=5 os_prio=0 tid=0x000000002542f000 nid=0x4028 waiting on condition [0x000000002cc9e000]java.lang.Thread.State: WAITING (parking)at sun.misc.Unsafe.park(Native Method)- parking to wait for <0x000000077420d7e8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)at java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)at org.apache.tomcat.util.threads.TaskQueue.take(TaskQueue.java:103)at org.apache.tomcat.util.threads.TaskQueue.take(TaskQueue.java:31)at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61)at java.lang.Thread.run(Thread.java:748)Locked ownable synchronizers:- None
WAITING (parking)指线程处于挂起中,在等待某个条件发生,来把自己唤醒。
jstat:用于查看虚拟机各种运行状态信息(类装载、内存、垃圾收集等运行数据)。使用参数-gcuitl可以查看垃圾回收的统计信息。
jstat -gcutil 4124S0 S1 E O M CCS YGC YGCT FGC FGCT GCT0.00 0.00 67.21 19.20 96.36 94.96 10 0.084 3 0.191 0.275
参数说明:
- S0:
Survivor0区当前使用比例 - S1:
Survivor1区当前使用比例 - E:
Eden区使用比例 - O:老年代使用比例
- M:元数据区使用比例
- CCS:压缩使用比例
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
jmap:查看堆内存快照。通过jmap命令可以获得运行中的堆内存的快照,从而可以对堆内存进行离线分析。
查询进程4124的堆内存快照,输出结果如下:
>jmap -heap 4124
Attaching to process ID 4124, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.221-b11using thread-local object allocation.
Parallel GC with 6 thread(s)Heap Configuration:MinHeapFreeRatio = 0MaxHeapFreeRatio = 100MaxHeapSize = 4238344192 (4042.0MB)NewSize = 88604672 (84.5MB)MaxNewSize = 1412431872 (1347.0MB)OldSize = 177733632 (169.5MB)NewRatio = 2SurvivorRatio = 8MetaspaceSize = 21807104 (20.796875MB)CompressedClassSpaceSize = 1073741824 (1024.0MB)MaxMetaspaceSize = 17592186044415 MBG1HeapRegionSize = 0 (0.0MB)Heap Usage:
PS Young Generation
Eden Space:capacity = 327155712 (312.0MB)used = 223702392 (213.33922576904297MB)free = 103453320 (98.66077423095703MB)68.37795697725736% used
From Space:capacity = 21495808 (20.5MB)used = 0 (0.0MB)free = 21495808 (20.5MB)0.0% used
To Space:capacity = 23068672 (22.0MB)used = 0 (0.0MB)free = 23068672 (22.0MB)0.0% used
PS Old Generationcapacity = 217579520 (207.5MB)used = 41781472 (39.845916748046875MB)free = 175798048 (167.65408325195312MB)19.20285144484187% used27776 interned Strings occupying 3262336 bytes.
jinfo:jinfo -flags 1。查看当前的应用JVM参数配置。
Attaching to process ID 1, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.111-b14
Non-default VM flags: -XX:CICompilerCount=2 -XX:InitialHeapSize=31457280 -XX:MaxHeapSize=480247808 -XX:MaxNewSize=160038912 -XX:MinHeapDeltaBytes=196608 -XX:NewSize=10485760 -XX:OldSize=20971520 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops
Command line:
查看所有参数:java -XX:+PrintFlagsFinal -version。用于查看最终值,初始值可能被修改掉(查看初始值可以使用java -XX:+PrintFlagsInitial)。
[Global flags]uintx AdaptiveSizeDecrementScaleFactor = 4 {product}uintx AdaptiveSizeMajorGCDecayTimeScale = 10 {product}uintx AdaptiveSizePausePolicy = 0 {product}uintx AdaptiveSizePolicyCollectionCostMargin = 50 {product}uintx AdaptiveSizePolicyInitializingSteps = 20 {product}uintx AdaptiveSizePolicyOutputInterval = 0 {product}uintx AdaptiveSizePolicyWeight = 10 {product}uintx AdaptiveSizeThroughPutPolicy = 0 {product}uintx AdaptiveTimeWeight = 25 {product}bool AdjustConcurrency = false {product}bool AggressiveOpts = false {product}....
本文已经收录到Github仓库,该仓库包含计算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享等核心知识点,欢迎star~
Github地址:https://github.com/Tyson0314/Java-learning
对象头了解吗?
Java 内存中的对象由以下三部分组成:对象头、实例数据和对齐填充字节。
而对象头由以下三部分组成:mark word、指向类信息的指针和数组长度(数组才有)。
mark word包含:对象的哈希码、分代年龄和锁标志位。
对象的实例数据就是 Java 对象的属性和值。
对齐填充字节:因为JVM要求对象占的内存大小是 8bit 的倍数,因此后面有几个字节用于把对象的大小补齐至 8bit 的倍数。
内存对齐的主要作用是:
- 平台原因:不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
- 性能原因:经过内存对齐后,CPU的内存访问速度大大提升。
main方法执行过程
以下是示例代码:
public class Application {public static void main(String[] args) {Person p = new Person("大彬");p.getName();}
}class Person {public String name;public Person(String name) {this.name = name;}public String getName() {return this.name;}
}
执行main方法的过程如下:
- 编译
Application.java后得到Application.class后,执行这个class文件,系统会启动一个JVM进程,从类路径中找到一个名为Application.class的二进制文件,将Application类信息加载到运行时数据区的方法区内,这个过程叫做类的加载。 - JVM 找到
Application的主程序入口,执行main方法。 main方法的第一条语句为Person p = new Person("大彬"),就是让 JVM 创建一个Person对象,但是这个时候方法区中是没有Person类的信息的,所以 JVM 马上加载Person类,把Person类的信息放到方法区中。- 加载完
Person类后,JVM 在堆中分配内存给Person对象,然后调用构造函数初始化Person对象,这个Person对象持有指向方法区中的 Person 类的类型信息的引用。 - 执行
p.getName()时,JVM 根据 p 的引用找到 p 所指向的对象,然后根据此对象持有的引用定位到方法区中Person类的类型信息的方法表,获得getName()的字节码地址。 - 执行
getName()方法。
对象创建过程
- 类加载检查:当虚拟机遇到一条
new指令时,首先检查是否能在常量池中定位到这个类的符号引用,并且检查这个符号引用代表的类是否已被加载过、解析和初始化过。如果没有,那先执行类加载。 - 分配内存:在类加载检查通过后,接下来虚拟机将为对象实例分配内存。
- 初始化。分配到的内存空间都初始化为零值,通过这个操作保证了对象的字段可以不赋初始值就直接使用,程序能访问到这些字段的数据类型所对应的零值。
- 设置对象头。
Hotspot虚拟机的对象头包括:存储对象自身的运行时数据(哈希码、分代年龄、锁标志等等)、类型指针和数据长度(数组对象才有),类型指针就是对象指向它的类信息的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。 - 按照
Java代码进行初始化。
如何排查 OOM 的问题?
线上JVM必须配置
-XX:+HeapDumpOnOutOfMemoryError和-XX:HeapDumpPath=/tmp/heapdump.hprof,当OOM发生时自动 dump 堆内存信息到指定目录
排查 OOM 的方法如下:
- 查看服务器运行日志日志,捕捉到内存溢出异常
- jstat 查看监控JVM的内存和GC情况,评估问题大概出在什么区域
- 使用MAT工具载入dump文件,分析大对象的占用情况
什么是内存溢出和内存泄露?
内存溢出指的是程序申请内存时,没有足够的内存供申请者使用,比如给了你一块存储int类型数据的存储空间,但是你却存储long类型的数据,那么结果就是内存不够用,此时就会报错OOM,即内存溢出。
内存泄露是指程序中间动态分配了内存,但在程序结束时没有释放这部分内存,从而造成那部分内存不可用的情况。这种情况重启计算机可以解决,但也有可能再次发生内存泄露。内存泄露和硬件没有关系,它是由软件设计缺陷引起的。
像IO操作或者网络连接等,在使用完成之后没有调用close()方法将其连接关闭,那么它们占用的内存是不会自动被GC回收的,此时就会产生内存泄露。
比如操作数据库时,通过SessionFactory获取一个session:
Session session=sessionFactory.openSession();
完成后我们必须调用session.close()方法关闭,否则就会产生内存泄露,因为sessionFactory这个长生命周期对象一直持有session这个短生命周期对象的引用。
那两者有什么不同呢?
内存泄露可以通过完善代码来避免,内存溢出可以通过调整配置来减少发生频率,但无法彻底避免。
如何避免内存泄露和溢出呢?
- 尽早释放无用对象的引用。比如使用临时变量的时候,让引用变量在退出活动域后自动设置为null,暗示垃圾收集器来收集该对象,防止发生内存泄露。
- 尽量少用静态变量。因为静态变量是全局的,GC不会回收。
- 避免集中创建对象尤其是大对象,如果可以的话尽量使用流操作。
- 尽量运用池化技术(数据库连接池等)以提高系统性能。
- 避免在循环中创建过多对象。
参考资料
- 周志明. 深入理解 Java 虚拟机 [M]. 机械工业出版社
最后给大家分享一个Github仓库,上面有大彬整理的300多本经典的计算机书籍PDF,包括C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生等,可以star一下,下次找书直接在上面搜索,仓库持续更新中~

Github地址:https://github.com/Tyson0314/java-books
相关文章:
三天吃透Java虚拟机面试八股文
本文已经收录到Github仓库,该仓库包含计算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享等核心知识点,欢迎star~ Github地址:https://github.com/…...

Spring Cloud Alibaba全家桶(二)——微服务组件Nacos注册中心
前言 本文为微服务组件Nacos注册中心相关知识,下边将对什么是 Nacos,Nacos注册中心(包括:注册中心演变及其设计思想、核心功能),Nacos Server部署(包括:单机模式、集群模式ÿ…...
命令执行漏洞 | iwebsec
文章目录1 靶场环境2 命令执行漏洞介绍3 靶场练习01-命令执行漏洞02-命令执行漏洞空格绕过03-命令执行漏洞关键命令绕过04-命令执行漏洞通配符绕过05-命令执行漏洞base64编码绕过4 命令执行漏洞危害01-读写系统文件02-执行系统命令03-种植恶意木马04-反弹shellpython反弹shellp…...

2023.02.26 学习周报
文章目录摘要文献阅读1.题目2.摘要3.介绍4.模型4.1 SESSION-PARALLEL MINI-BATCHES4.2 SAMPLING ON THE OUTPUT4.3 RANKING LOSS5.实验5.1 数据集5.2 验证方式5.3 baselines5.4 实验结果6.结论深度学习元胞自动机1.定义2.构成3.特性4.思想5.统计特征流形学习1.降维2.空间3.距离…...
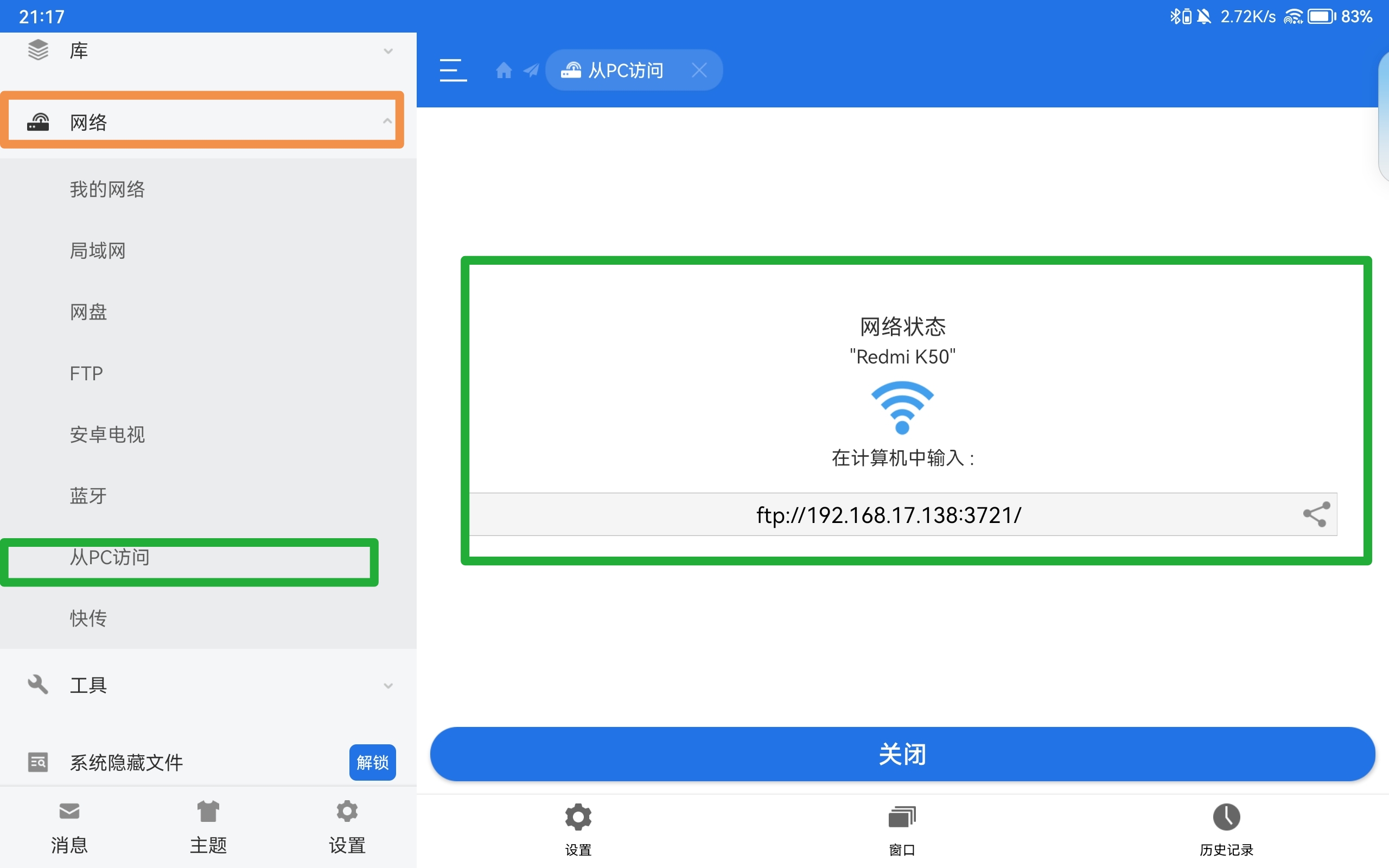
局域网实现PC、Pad、Android互联
文章目录局域网实现PC、Pad、Android互联一、网络邻居1、 Windows 配置1.1 开启共享功能1.2 设置用户1.3 共享文件夹2、 Pad 连接二、 FTP & HTTP1、 电脑配置1.1 HTTP 服务1.2 FTP 服务2、 连接3、 电脑连接 FTP三、 其他方式局域网实现PC、Pad、Android互联 在我们使用多…...
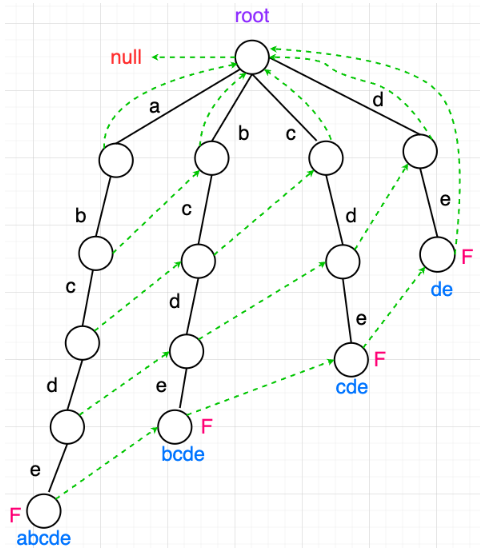
AC自动机
AC自动机 该模型应用场景是什么样的?假如有一篇很长的文章,然后有一个敏感词表单,请从这篇文章里找出包含了哪些敏感词。即便是用KMP进行快速匹配,那也只能每次遍历整篇文章才能找到一种敏感词,KMP只适用于单一子串匹配…...

git入门
目录 1. git简介 1.1 git是什么 1.2 git与svn的区别 2. github 2.1 创建仓库 2.2 删除仓库 2.3 新建文件及文件夹 3. git的基本操作 3.1 配置账户及邮箱 3.2 git文件状态与工作区域 3.3 常用命令 3.4 克隆(clone) 3.5 查看git仓库的状态 3.…...
RK3568编译Android11和目录讲解
文章目录 前言一、下载android11源码二、环境搭建1.增加交换内存三、编译瑞芯微原厂源码四、目录讲解总结前言 本文记录在Ubuntu18.04中编译Android11,只有编译了源码,后面才能进行驱动的开发,有兴趣的小伙伴可以和我一起学习吧! 提示:以下是本篇文章正文内容,下面案例可…...
)
java泛型学习篇(二)
java泛型学习篇(二) 1 自定义泛型类 1.1 基本语法 Class 类型 <T,R,M...>{ //成员,其中...代表<>括号里面的参数可以有多个ja }1.2 注意点 1.2.1 属性和方法都是可以使用泛型的 T t;//属性使用泛型,合法public T getT() {return t;} //方法使用泛型,合法 publi…...

Java基础
Java基础Java基础一、课前问答二、概述三、Java的历史四、Java的特点五、计算机执行机制以及Java执行机制5.1 计算机的执行机制5.2 Java的执行机制六、常用DOS命令七、第一个Java程序八、包的使用九、编码规范十、注释Java基础 一、课前问答 1、什么是程序 2、什么是语言 3、什…...

骨骼控制(一)——动画动态节点(AnimDynamics)
文章目录一、引言二、骨骼控制三、UE蓝图中提供的骨骼控制节点——AnimDynamics动画蓝图节点1、什么是AnimDynamics动画蓝图节点①使用盒体计算惯性②使用约束来限制移动2、AnimDynamics节点的几种常用例子①单骨骼模拟②骨骼链模拟 <h2 id1>③群魔乱舞(这是错…...
Linux系统下搭建maven环境
文章目录前述从官网下载安装包安装 maven修改maven配置修改环境变量测试前述 安装 maven 环境前,需要先安装 java 环境,如果没有安装 java 环境,可以参考:https://blog.csdn.net/weixin_45583303/article/details/118631855 从官…...

English Learning - L2 语音作业打卡 Day3 2023.2.23 周四
English Learning - L2 语音作业打卡 Day3 2023.2.23 周四💌 发音小贴士:💌 当日目标音发音规则/技巧:🍭 Part 1【热身练习】🍭 Part2【练习内容】🍭【练习感受】🍓元音[ ɔ: ]&…...

RK3568平台开发系列讲解(驱动基础篇)GIC v3中断控制器
🚀返回专栏总目录 文章目录 一、什么是GIC二、GIC v3中断类型三、GIC v3基本结构3.1、Distributor3.2、CPU interface简介3.3、Redistributor简介3.4、ITS(Interrupt translation service)4、中断状态和处理流程沉淀、分享、成长,让自己和他人都能有所收获!😄 📢ARM多核…...

决策树、随机森林、极端随机树(ERT)
声明:本文仅为个人学习记录所用,参考较多,如有侵权,联系删除 决策树 通俗来说,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话: 女儿&#x…...

软件测试之因果图法
因果图法 1. 概述 因果图法是一种**利用图解法分析输入条件、输出结果的各种组合情况,**从而设计测试用例的方法. 因果图法适用于有多个输入和多个输出,而且输入和输入之间有相互的组合关系,输入和输出之间有相互的制约和依赖关系. 使用场景和判定表…...
vue中子组件间接修改父组件传递过来的值
一、前言 Vue官方文档Props单向数据流讲解 Vue中遵循单向数据流,所有的 props 都遵循着单向绑定原则,props 因父组件的更新而变化,自然地将新的状态向下流往子组件,而不会逆向传递。这避免了子组件意外修改父组件的状态的情况&a…...

Java I/O
前言 关于IO, 想必你听过很多中I/O方式, 有的是OS视角的, 有的是JDK本身支持的, 有的是纯实现视角。但是作为一个developer, 我希望你能先搞清楚上下文之后, 再去理解内容, 否则容易抬杠。这个上下文有横向和纵向两个维度。纵向维度包括JDK底层, JDK上层包装库, 开发框架(如Ne…...

pytorch学习日记之图片的简单卷积、池化
导入图片并转化为张量 import torch import torch.nn as nn import matplotlib.pyplot as plt import numpy as np from PIL import Image mymi Image.open("pic/123.png") # 读取图像转化为灰度图片转化为numpy数组 myimgray np.array(mymi.convert("L"…...

【java基础】抽象类和抽象方法
文章目录基本介绍抽象类抽象方法使用总结基本介绍 在面向对象的概念中,所有的对象都是通过类来描绘的,但是反过来,并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

腾讯云V3签名
想要接入腾讯云的Api,必然先按其文档计算出所要求的签名。 之前也调用过腾讯云的接口,但总是卡在签名这一步,最后放弃选择SDK,这次终于自己代码实现。 可能腾讯云翻新了接口文档,现在阅读起来,清晰了很多&…...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...

论文阅读:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving 摘要翻译 自动驾驶技术作为推动交通和城市出行变革的催化剂,正从基于规则的系统向数据驱动策略转变。传统的模块化系统受限于级联模块间的累积误差和缺乏灵活性的预设规则。…...
mac:大模型系列测试
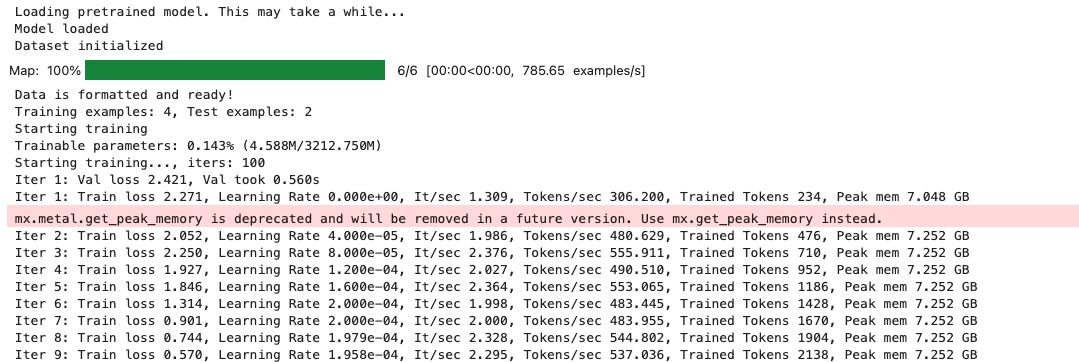
0 MAC 前几天经过学生优惠以及国补17K入手了mac studio,然后这两天亲自测试其模型行运用能力如何,是否支持微调、推理速度等能力。下面进入正文。 1 mac 与 unsloth 按照下面的进行安装以及测试,是可以跑通文章里面的代码。训练速度也是很快的。 注意…...
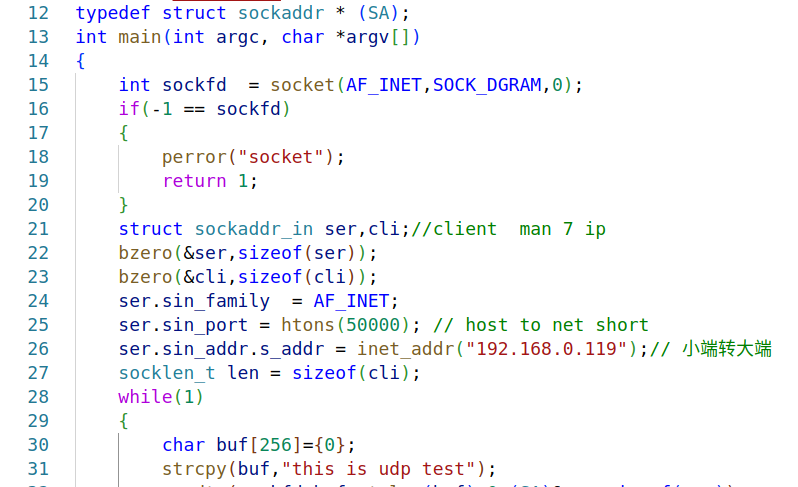
嵌入式学习之系统编程(九)OSI模型、TCP/IP模型、UDP协议网络相关编程(6.3)
目录 一、网络编程--OSI模型 二、网络编程--TCP/IP模型 三、网络接口 四、UDP网络相关编程及主要函数 编辑编辑 UDP的特征 socke函数 bind函数 recvfrom函数(接收函数) sendto函数(发送函数) 五、网络编程之 UDP 用…...