_improve-3
createElement过程
React.createElement(): 根据指定的第一个参数创建一个React元素
React.createElement(type,[props],[...children]
)
- 第一个参数是必填,传入的是似HTML标签名称,eg: ul, li
- 第二个参数是选填,表示的是属性,eg: className
- 第三个参数是选填, 子节点,eg: 要显示的文本内容
//写法一:var child1 = React.createElement('li', null, 'one');var child2 = React.createElement('li', null, 'two');var content = React.createElement('ul', { className: 'teststyle' }, child1, child2); // 第三个参数可以分开也可以写成一个数组ReactDOM.render(content,document.getElementById('example'));//写法二:var child1 = React.createElement('li', null, 'one');var child2 = React.createElement('li', null, 'two');var content = React.createElement('ul', { className: 'teststyle' }, [child1, child2]);ReactDOM.render(content,document.getElementById('example'));
----------@----------
调和阶段 setState内部干了什么
- 当调用 setState 时,React会做的第一件事情是将传递给 setState 的对象合并到组件的当前状态
- 这将启动一个称为和解(
reconciliation)的过程。和解(reconciliation)的最终目标是以最有效的方式,根据这个新的状态来更新UI。 为此,React将构建一个新的React元素树(您可以将其视为UI的对象表示) - 一旦有了这个树,为了弄清 UI 如何响应新的状态而改变,React 会将这个新树与上一个元素树相比较( diff )
通过这样做, React 将会知道发生的确切变化,并且通过了解发生什么变化,只需在绝对必要的情况下进行更新即可最小化 UI 的占用空间
----------@----------
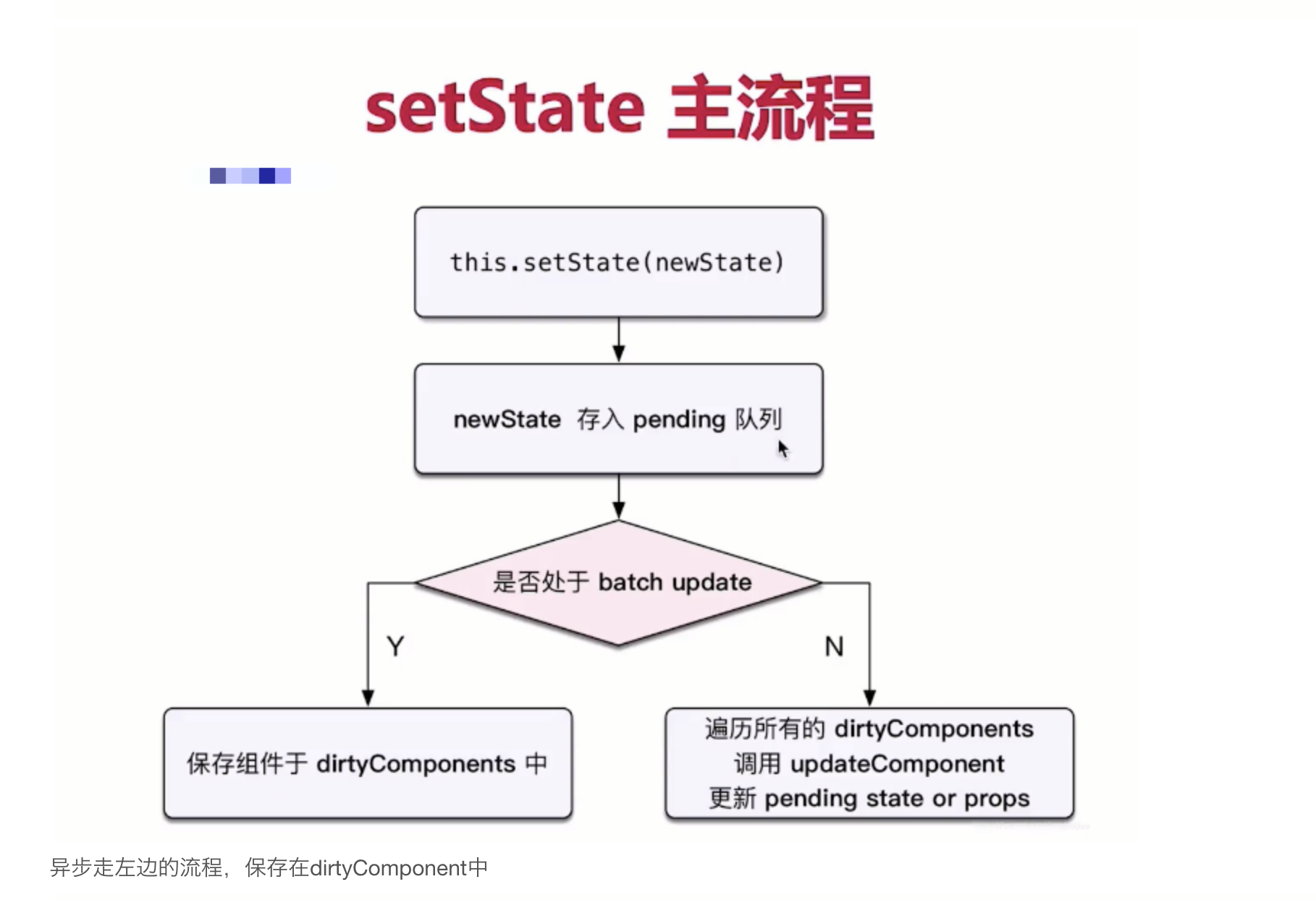
setState
在了解setState之前,我们先来简单了解下 React 一个包装结构: Transaction:
事务 (Transaction)
是 React 中的一个调用结构,用于包装一个方法,结构为: initialize - perform(method) - close。通过事务,可以统一管理一个方法的开始与结束;处于事务流中,表示进程正在执行一些操作
- setState: React 中用于修改状态,更新视图。它具有以下特点:
异步与同步: setState并不是单纯的异步或同步,这其实与调用时的环境相关:
- 在合成事件 和 生命周期钩子 (除 componentDidUpdate) 中,setState是"异步"的;
- 原因: 因为在setState的实现中,有一个判断: 当更新策略正在事务流的执行中时,该组件更新会被推入dirtyComponents队列中等待执行;否则,开始执行batchedUpdates队列更新;
- 在生命周期钩子调用中,更新策略都处于更新之前,组件仍处于事务流中,而componentDidUpdate是在更新之后,此时组件已经不在事务流中了,因此则会同步执行;
- 在合成事件中,React 是基于 事务流完成的事件委托机制 实现,也是处于事务流中;
- 问题: 无法在setState后马上从this.state上获取更新后的值。
- 解决: 如果需要马上同步去获取新值,setState其实是可以传入第二个参数的。setState(updater, callback),在回调中即可获取最新值;
- 原因: 因为在setState的实现中,有一个判断: 当更新策略正在事务流的执行中时,该组件更新会被推入dirtyComponents队列中等待执行;否则,开始执行batchedUpdates队列更新;
- 在 原生事件 和 setTimeout 中,setState是同步的,可以马上获取更新后的值;
- 原因: 原生事件是浏览器本身的实现,与事务流无关,自然是同步;而setTimeout是放置于定时器线程中延后执行,此时事务流已结束,因此也是同步;
- 批量更新 : 在 合成事件 和 生命周期钩子 中,setState更新队列时,存储的是 合并状态(Object.assign)。因此前面设置的 key 值会被后面所覆盖,最终只会执行一次更新;
- 函数式 : 由于 Fiber 及 合并 的问题,官方推荐可以传入 函数 的形式。setState(fn),在fn中返回新的state对象即可,例如this.setState((state, props) => newState);
- 使用函数式,可以用于避免setState的批量更新的逻辑,传入的函数将会被 顺序调用;
注意事项:
- setState 合并,在 合成事件 和 生命周期钩子 中多次连续调用会被优化为一次;
- 当组件已被销毁,如果再次调用setState,React 会报错警告,通常有两种解决办法
- 将数据挂载到外部,通过 props 传入,如放到 Redux 或 父级中;
- 在组件内部维护一个状态量 (isUnmounted),componentWillUnmount中标记为 true,在setState前进行判断;
总结
setState 并非真异步,只是看上去像异步。在源码中,通过
isBatchingUpdates来判断
setState是先存进state队列还是直接更新,如果值为 true 则执行异步操作,为 false 则直接更新。- 那么什么情况下
isBatchingUpdates会为true呢?在 React 可以控制的地方,就为 true,比如在 React 生命周期事件和合成事件中,都会走合并操作,延迟更新的策略。 - 但在 React 无法控制的地方,比如原生事件,具体就是在
addEventListener、setTimeout、setInterval等事件中,就只能同步更新。
一般认为,
做异步设计是为了性能优化、减少渲染次数,React 团队还补充了两点。
- 保持内部一致性。如果将 state 改为同步更新,那尽管 state 的更新是同步的,但是 props不是。
- 启用并发更新,完成异步渲染。

setState只有在 React 自身的合成事件和钩子函数中是异步的,在原生事件和 setTimeout 中都是同步的setState的异步并不是说内部由异步代码实现,其实本身执行的过程和代码都是同步的,只是合成事件和钩子函数中没法立马拿到更新后的值,形成了所谓的异步。当然可以通过 setState 的第二个参数中的 callback 拿到更新后的结果setState的批量更新优化也是建立在异步(合成事件、钩子函数)之上的,在原生事件和 setTimeout 中不会批量更新,在异步中如果对同一个值进行多次 setState,setState 的批量更新策略会对其进行覆盖,去最后一次的执行,如果是同时 setState 多个不同的值,在更新时会对其进行合并批量更新
- 合成事件中是异步
- 钩子函数中的是异步
- 原生事件中是同步
- setTimeout中是同步

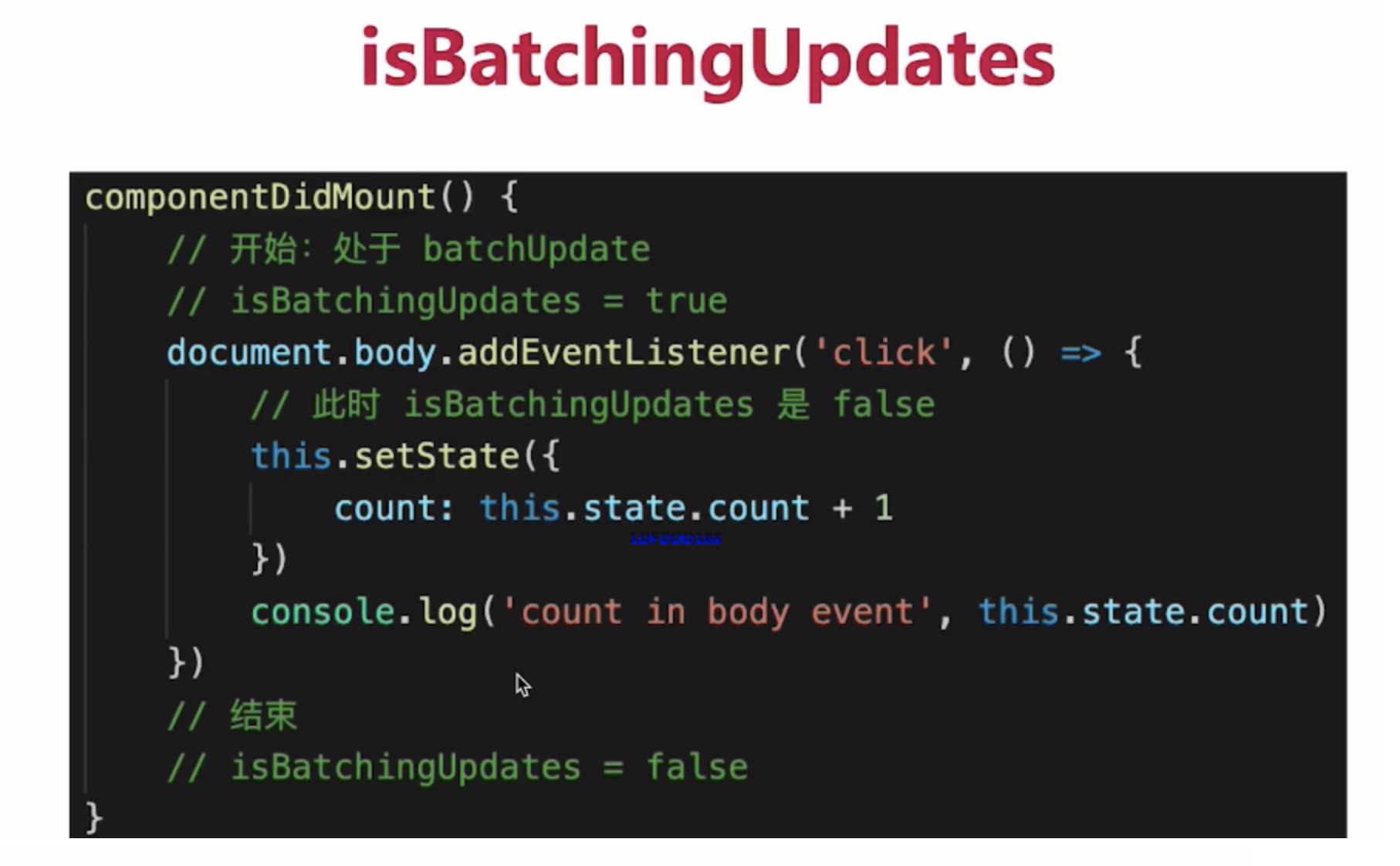



这是一道经常会出现的 React setState 笔试题:下面的代码输出什么呢?
class Test extends React.Component {state = {count: 0};componentDidMount() {this.setState({count: this.state.count + 1});console.log(this.state.count);this.setState({count: this.state.count + 1});console.log(this.state.count);setTimeout(() => {this.setState({count: this.state.count + 1});console.log(this.state.count);this.setState({count: this.state.count + 1});console.log(this.state.count);}, 0);}render() {return null;}
};
我们可以进行如下的分析:
- 首先第一次和第二次的
console.log,都在 React 的生命周期事件中,所以是异步的处理方式,则输出都为0; - 而在
setTimeout中的console.log处于原生事件中,所以会同步的处理再输出结果,但需要注意,虽然count在前面经过了两次的this.state.count + 1,但是每次获取的this.state.count都是初始化时的值,也就是0; - 所以此时
count是1,那么后续在setTimeout中的输出则是2和3。
所以完整答案是 0,0,2,3
同步场景
异步场景中的案例使我们建立了这样一个认知:setState 是异步的,但下面这个案例又会颠覆你的认知。如果我们将 setState 放在 setTimeout 事件中,那情况就完全不同了。
class Test extends Component {state = {count: 0}componentDidMount(){this.setState({ count: this.state.count + 1 });console.log(this.state.count);setTimeout(() => {this.setState({ count: this.state.count + 1 });console.log("setTimeout: " + this.state.count);}, 0);}render(){...}
}
那这时输出的应该是什么呢?如果你认为是 0,0,那么又错了。
正确的结果是 0,2。因为 setState 并不是真正的异步函数,它实际上是通过队列延迟执行操作实现的,通过 isBatchingUpdates 来判断 setState 是先存进 state 队列还是直接更新。值为 true 则执行异步操作,false 则直接同步更新
接下来这个案例的答案是什么呢
class Test extends Component {state = {count: 0}componentDidMount(){this.setState({count: this.state.count + 1}, () => {console.log(this.state.count)})this.setState({count: this.state.count + 1}, () => {console.log(this.state.count)})}render(){...}
}
如果你觉得答案是 1,2,那肯定就错了。这种迷惑性极强的考题在面试中非常常见,因为它反直觉。
如果重新仔细思考,你会发现当前拿到的 this.state.count 的值并没有变化,都是 0,所以输出结果应该是 1,1。
当然,也可以在 setState 函数中获取修改后的 state 值进行修改。
class Test extends Component {state = {count: 0}componentDidMount(){this.setState(preState=> ({count:preState.count + 1}),()=>{console.log(this.state.count)})this.setState(preState=>({count:preState.count + 1}),()=>{console.log(this.state.count)})}render(){...}
}
这些通通是异步的回调,如果你以为输出结果是 1,2,那就又错了,实际上是 2,2。
为什么会这样呢?当调用 setState 函数时,就会把当前的操作放入队列中。React 根据队列内容,合并 state 数据,完成后再逐一执行回调,根据结果更新虚拟 DOM,触发渲染。所以回调时,state 已经合并计算完成了,输出的结果就是 2,2 了。
----------@----------
setState原理分析
1. setState异步更新
- 我们都知道,
React通过this.state来访问state,通过this.setState()方法来更新state。当this.setState()方法被调用的时候,React会重新调用render方法来重新渲染UI - 首先如果直接在
setState后面获取state的值是获取不到的。在React内部机制能检测到的地方,setState就是异步的;在React检测不到的地方,例如setInterval,setTimeout,setState就是同步更新的
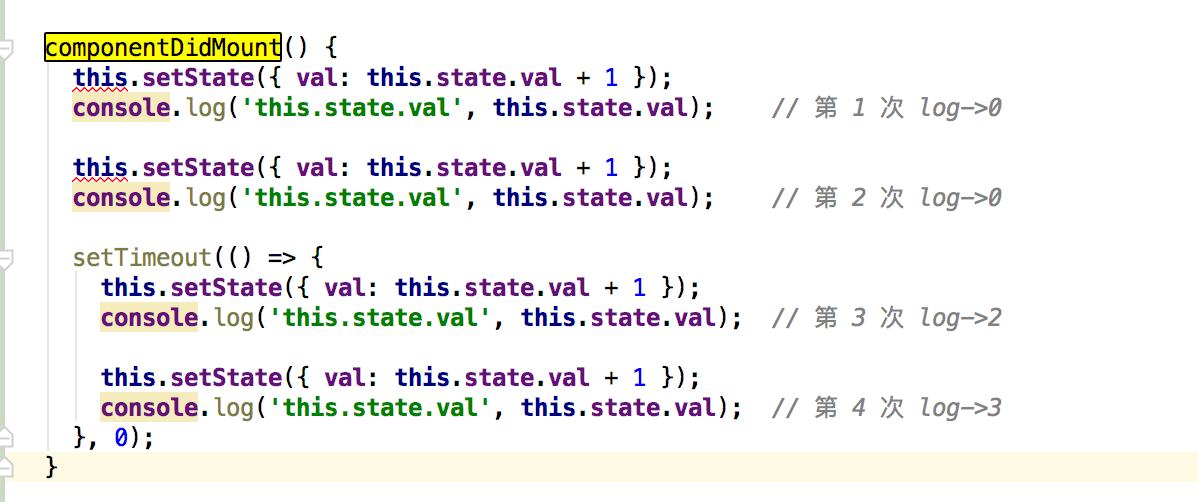
因为
setState是可以接受两个参数的,一个state,一个回调函数。因此我们可以在回调函数里面获取值

setState方法通过一个队列机制实现state更新,当执行setState的时候,会将需要更新的state合并之后放入状态队列,而不会立即更新this.state- 如果我们不使用
setState而是使用this.state.key来修改,将不会触发组件的re-render。 - 如果将
this.state赋值给一个新的对象引用,那么其他不在对象上的state将不会被放入状态队列中,当下次调用setState并对状态队列进行合并时,直接造成了state丢失
1.1 setState批量更新的过程
在
react生命周期和合成事件执行前后都有相应的钩子,分别是pre钩子和post钩子,pre钩子会调用batchedUpdate方法将isBatchingUpdates变量置为true,开启批量更新,而post钩子会将isBatchingUpdates置为false
isBatchingUpdates变量置为true,则会走批量更新分支,setState的更新会被存入队列中,待同步代码执行完后,再执行队列中的state更新。isBatchingUpdates为true,则把当前组件(即调用了setState的组件)放入dirtyComponents数组中;否则batchUpdate所有队列中的更新- 而在原生事件和异步操作中,不会执行
pre钩子,或者生命周期的中的异步操作之前执行了pre钩子,但是pos钩子也在异步操作之前执行完了,isBatchingUpdates必定为false,也就不会进行批量更新
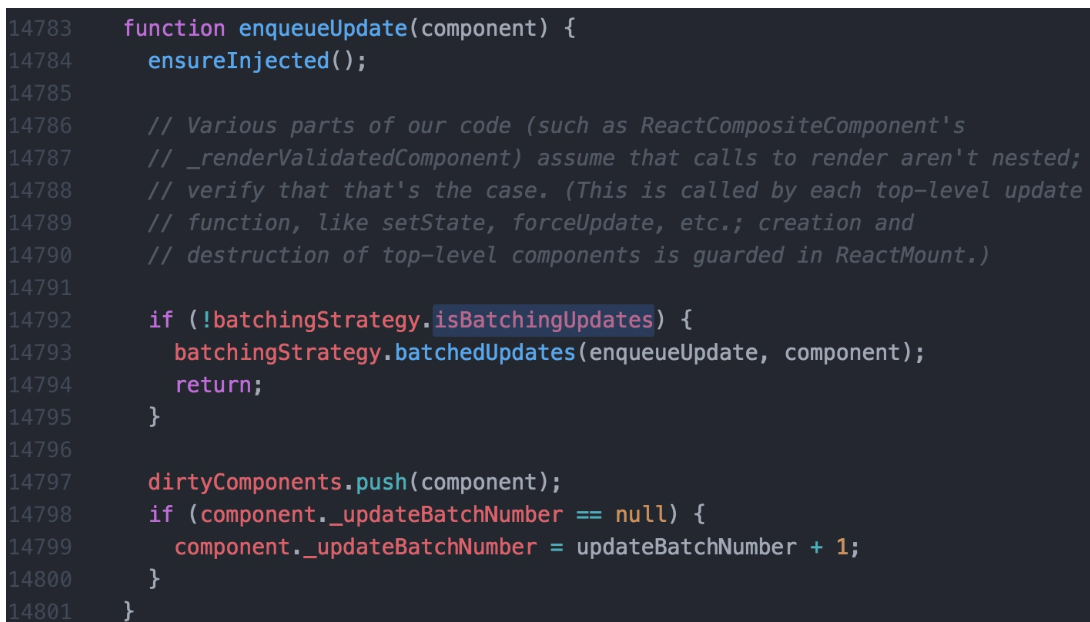
enqueueUpdate包含了React避免重复render的逻辑。mountComponent和updateComponent方法在执行的最开始,会调用到batchedUpdates进行批处理更新,此时会将isBatchingUpdates设置为true,也就是将状态标记为现在正处于更新阶段了。isBatchingUpdates为true,则把当前组件(即调用了setState的组件)放入dirtyComponents数组中;否则batchUpdate所有队列中的更新
1.2 为什么直接修改this.state无效
- 要知道
setState本质是通过一个队列机制实现state更新的。 执行setState时,会将需要更新的state合并后放入状态队列,而不会立刻更新state,队列机制可以批量更新state。 - 如果不通过
setState而直接修改this.state,那么这个state不会放入状态队列中,下次调用setState时对状态队列进行合并时,会忽略之前直接被修改的state,这样我们就无法合并了,而且实际也没有把你想要的state更新上去
1.3 什么是批量更新 Batch Update
在一些
mv*框架中,,就是将一段时间内对model的修改批量更新到view的机制。比如那前端比较火的React、vue(nextTick机制,视图的更新以及实现)
1.4 setState之后发生的事情
setState操作并不保证是同步的,也可以认为是异步的React在setState之后,会经对state进行diff,判断是否有改变,然后去diff dom决定是否要更新UI。如果这一系列过程立刻发生在每一个setState之后,就可能会有性能问题- 在短时间内频繁
setState。React会将state的改变压入栈中,在合适的时机,批量更新state和视图,达到提高性能的效果
1.5 如何知道state已经被更新
传入回调函数
setState({index: 1
}}, function(){console.log(this.state.index);
})
在钩子函数中体现
componentDidUpdate(){console.log(this.state.index);
}
2. setState循环调用风险
- 当调用
setState时,实际上会执行enqueueSetState方法,并对partialState以及_pending-StateQueue更新队列进行合并操作,最终通过enqueueUpdate执行state更新 - 而
performUpdateIfNecessary方法会获取_pendingElement,_pendingStateQueue,_pending-ForceUpdate,并调用receiveComponent和updateComponent方法进行组件更新 - 如果在
shouldComponentUpdate或者componentWillUpdate方法中调用setState,此时this._pending-StateQueue != null,就会造成循环调用,使得浏览器内存占满后崩溃
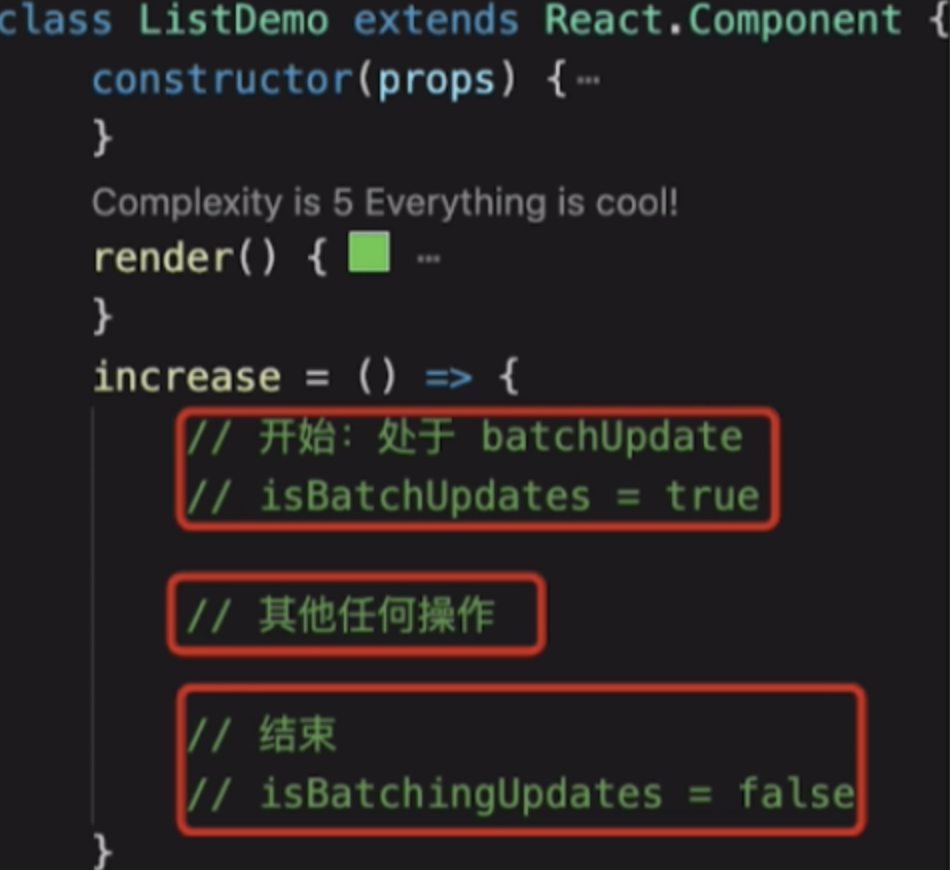
3 事务
- 事务就是将需要执行的方法使用
wrapper封装起来,再通过事务提供的perform方法执行,先执行wrapper中的initialize方法,执行完perform之后,在执行所有的close方法,一组initialize及close方法称为一个wrapper。 - 那么事务和
setState方法的不同表现有什么关系,首先我们把4次setState简单归类,前两次属于一类,因为它们在同一调用栈中执行,setTimeout中的两次setState属于另一类 - 在
setState调用之前,已经处在batchedUpdates执行的事务中了。那么这次batchedUpdates方法是谁调用的呢,原来是ReactMount.js中的_renderNewRootComponent方法。也就是说,整个将React组件渲染到DOM中的过程就是处于一个大的事务中。而在componentDidMount中调用setState时,batchingStrategy的isBatchingUpdates已经被设为了true,所以两次setState的结果没有立即生效 - 再反观
setTimeout中的两次setState,因为没有前置的batchedUpdates调用,所以导致了新的state马上生效
4. 总结
- 通过
setState去更新this.state,不要直接操作this.state,请把它当成不可变的 - 调用
setState更新this.state不是马上生效的,它是异步的,所以不要天真以为执行完setState后this.state就是最新的值了 - 多个顺序执行的
setState不是同步地一个一个执行滴,会一个一个加入队列,然后最后一起执行,即批处理
----------@----------
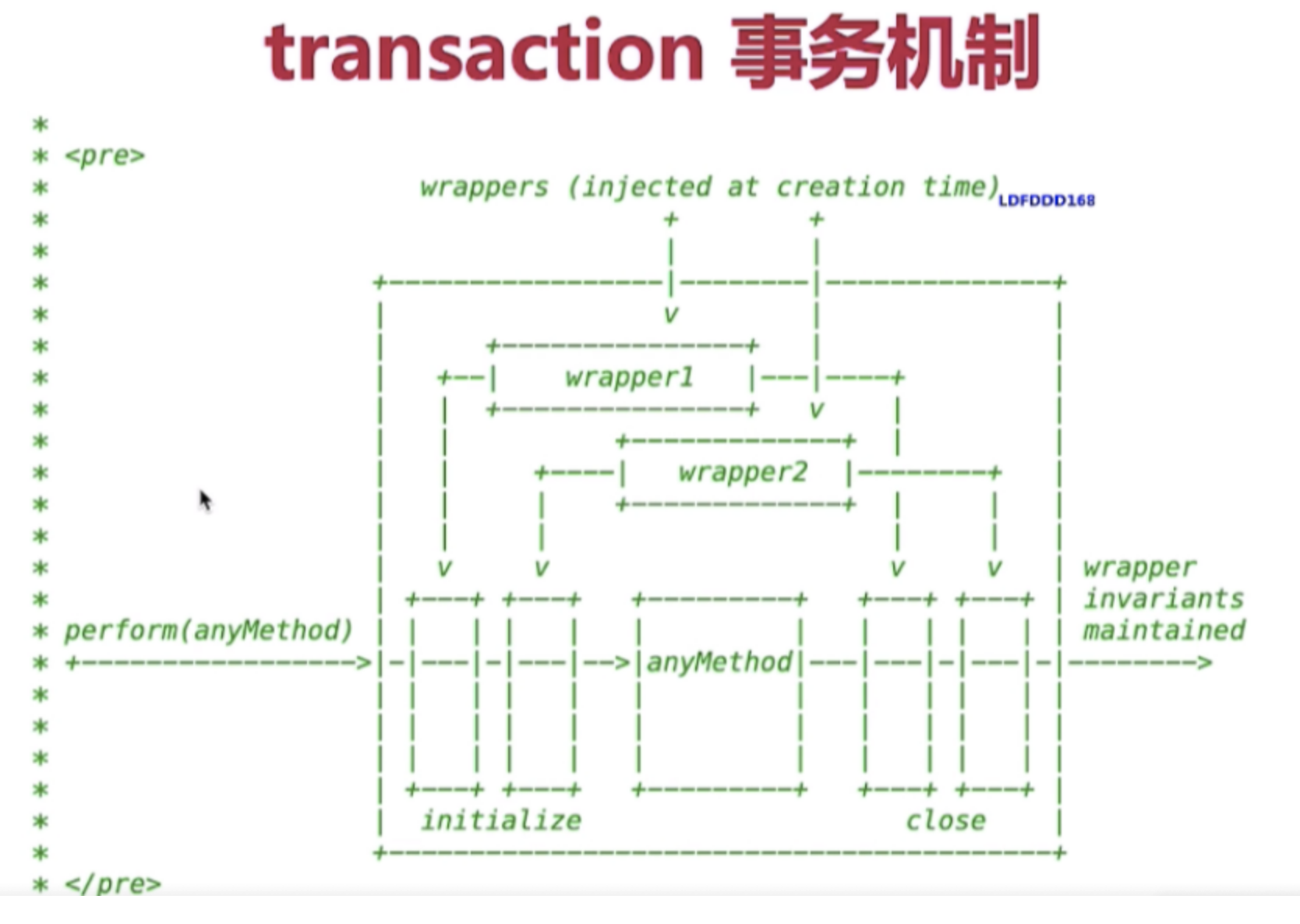
React事务机制

----------@----------
React组件和渲染更新过程
渲染和更新过程
- jsx如何渲染为页面
- setState之后如何更新页面
- 面试考察全流程
JSX本质和vdom
- JSX即
createElement函数 - 执行生成vnode
patch(elem,vnode)和patch(vnode,newNode)
组件渲染过程
props staterender()生成vnodepatch(elem, vnode)
组件更新过程
setState-->dirtyComponents(可能有子组件)render生成newVnodepatch(vnode, newVnode)
----------@----------
如何解释 React 的渲染流程

- React 的渲染过程大致一致,但协调并不相同,以
React 16为分界线,分为Stack Reconciler和Fiber Reconciler。这里的协调从狭义上来讲,特指 React 的 diff 算法,广义上来讲,有时候也指 React 的reconciler模块,它通常包含了diff算法和一些公共逻辑。 - 回到
Stack Reconciler中,Stack Reconciler的核心调度方式是递归。调度的基本处理单位是事务,它的事务基类是Transaction,这里的事务是 React 团队从后端开发中加入的概念。在 React 16 以前,挂载主要通过 ReactMount 模块完成,更新通过ReactUpdate模块完成,模块之间相互分离,落脚执行点也是事务。 - 在
React 16及以后,协调改为了Fiber Reconciler。它的调度方式主要有两个特点,第一个是协作式多任务模式,在这个模式下,线程会定时放弃自己的运行权利,交还给主线程,通过requestIdleCallback实现。第二个特点是策略优先级,调度任务通过标记tag的方式分优先级执行,比如动画,或者标记为high的任务可以优先执行。Fiber Reconciler的基本单位是Fiber,Fiber基于过去的React Element提供了二次封装,提供了指向父、子、兄弟节点的引用,为diff工作的双链表实现提供了基础。 - 在新的架构下,整个生命周期被划分为
Render 和 Commit 两个阶段。Render 阶段的执行特点是可中断、可停止、无副作用,主要是通过构造workInProgress树计算出diff。以current树为基础,将每个Fiber作为一个基本单位,自下而上逐个节点检查并构造 workInProgress 树。这个过程不再是递归,而是基于循环来完成 - 在执行上通过
requestIdleCallback来调度执行每组任务,每组中的每个计算任务被称为work,每个work完成后确认是否有优先级更高的work需要插入,如果有就让位,没有就继续。优先级通常是标记为动画或者high的会先处理。每完成一组后,将调度权交回主线程,直到下一次requestIdleCallback调用,再继续构建workInProgress树 - 在
commit阶段需要处理effect列表,这里的effect列表包含了根据diff 更新 DOM 树、回调生命周期、响应 ref等。 - 但一定要注意,这个阶段是同步执行的,不可中断暂停,所以不要在
componentDidMount、componentDidUpdate、componentWiilUnmount中去执行重度消耗算力的任务 - 如果只是一般的应用场景,比如管理后台、H5 展示页等,两者性能差距并不大,但在动画、画布及手势等场景下,
Stack Reconciler的设计会占用占主线程,造成卡顿,而fiber reconciler的设计则能带来高性能的表现
----------@----------
diff算法是怎么运作
每一种节点类型有自己的属性,也就是prop,每次进行diff的时候,react会先比较该节点类型,假如节点类型不一样,那么react会直接删除该节点,然后直接创建新的节点插入到其中,假如节点类型一样,那么会比较prop是否有更新,假如有prop不一样,那么react会判定该节点有更新,那么重渲染该节点,然后在对其子节点进行比较,一层一层往下,直到没有子节点
- 把树形结构按照层级分解,只比较同级元素。
- 给列表结构的每个单元添加唯一的
key属性,方便比较。 React只会匹配相同class的component(这里面的class指的是组件的名字)- 合并操作,调用
component的setState方法的时候,React将其标记为 -dirty.到每一个事件循环结束,React检查所有标记dirty的component重新绘制. - 选择性子树渲染。开发人员可以重写
shouldComponentUpdate提高diff的性能
优化⬇️
为了降低算法复杂度,
React的diff会预设三个限制:
- 只对同级元素进行
Diff。如果一个DOM节点在前后两次更新中跨越了层级,那么React不会尝试复用他。 - 两个不同类型的元素会产生出不同的树。如果元素由
div变为p,React会销毁div及其子孙节点,并新建p及其子孙节点。 - 开发者可以通过
key prop来暗示哪些子元素在不同的渲染下能保持稳定。考虑如下例子:
Diff的思路
该如何设计算法呢?如果让我设计一个Diff算法,我首先想到的方案是:
- 判断当前节点的更新属于哪种情况
- 如果是
新增,执行新增逻辑 - 如果是
删除,执行删除逻辑 - 如果是
更新,执行更新逻辑
- 按这个方案,其实有个隐含的前提——不同操作的优先级是相同的
- 但是
React团队发现,在日常开发中,相较于新增和删除,更新组件发生的频率更高。所以Diff会优先判断当前节点是否属于更新。
基于以上原因,Diff算法的整体逻辑会经历两轮遍历:
- 第一轮遍历:处理
更新的节点。 - 第二轮遍历:处理剩下的不属于
更新的节点。
diff算法的作用
计算出Virtual DOM中真正变化的部分,并只针对该部分进行原生DOM操作,而非重新渲染整个页面。
传统diff算法
通过循环递归对节点进行依次对比,算法复杂度达到
O(n^3),n是树的节点数,这个有多可怕呢?——如果要展示1000个节点,得执行上亿次比较。。即便是CPU快能执行30亿条命令,也很难在一秒内计算出差异。
React的diff算法
- 什么是调和?
将Virtual DOM树转换成actual DOM树的最少操作的过程 称为 调和 。
- 什么是React diff算法?
diff算法是调和的具体实现。
diff策略
React用 三大策略 将O(n^3)复杂度 转化为 O(n)复杂度
策略一(tree diff):
- Web UI中DOM节点跨层级的移动操作特别少,可以忽略不计。
策略二(component diff):
- 拥有相同类的两个组件 生成相似的树形结构,
- 拥有不同类的两个组件 生成不同的树形结构。
策略三(element diff):
对于同一层级的一组子节点,通过唯一id区分。
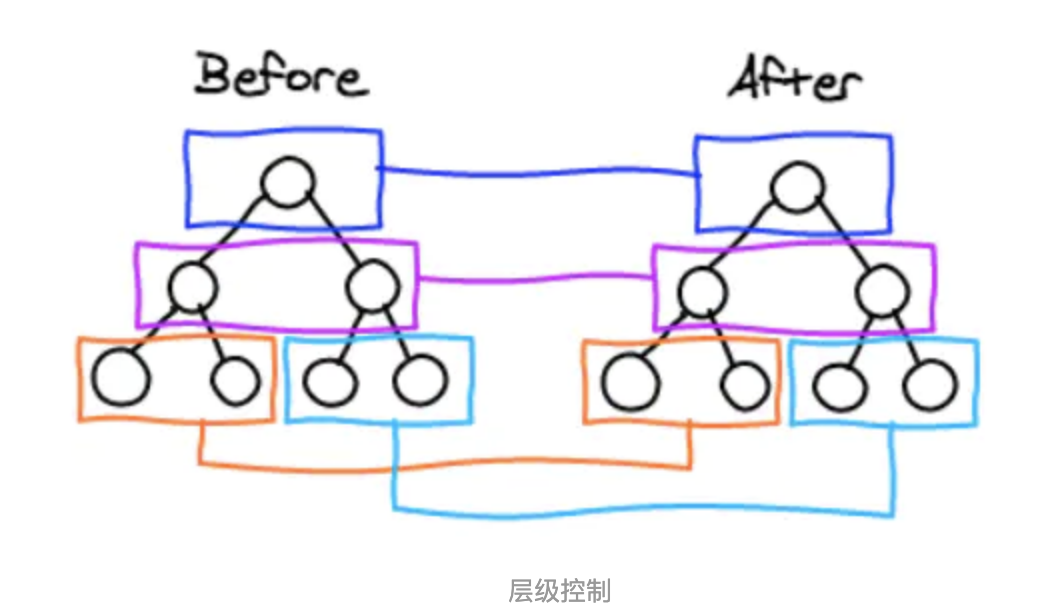
tree diff
- React通过updateDepth对Virtual DOM树进行层级控制。
- 对树分层比较,两棵树 只对同一层次节点 进行比较。如果该节点不存在时,则该节点及其子节点会被完全删除,不会再进一步比较。
- 只需遍历一次,就能完成整棵DOM树的比较。
那么问题来了,如果DOM节点出现了跨层级操作,diff会咋办呢?
答:diff只简单考虑同层级的节点位置变换,如果是跨层级的话,只有创建节点和删除节点的操作。
如上图所示,以A为根节点的整棵树会被重新创建,而不是移动,因此 官方建议不要进行DOM节点跨层级操作,可以通过CSS隐藏、显示节点,而不是真正地移除、添加DOM节点
component diff
React对不同的组件间的比较,有三种策略
- 同一类型的两个组件,按原策略(层级比较)继续比较Virtual DOM树即可。
- 同一类型的两个组件,组件A变化为组件B时,可能Virtual DOM没有任何变化,如果知道这点(变换的过程中,Virtual DOM没有改变),可节省大量计算时间,所以 用户 可以通过
shouldComponentUpdate()来判断是否需要 判断计算。 - 不同类型的组件,将一个(将被改变的)组件判断为
dirty component(脏组件),从而替换 整个组件的所有节点。
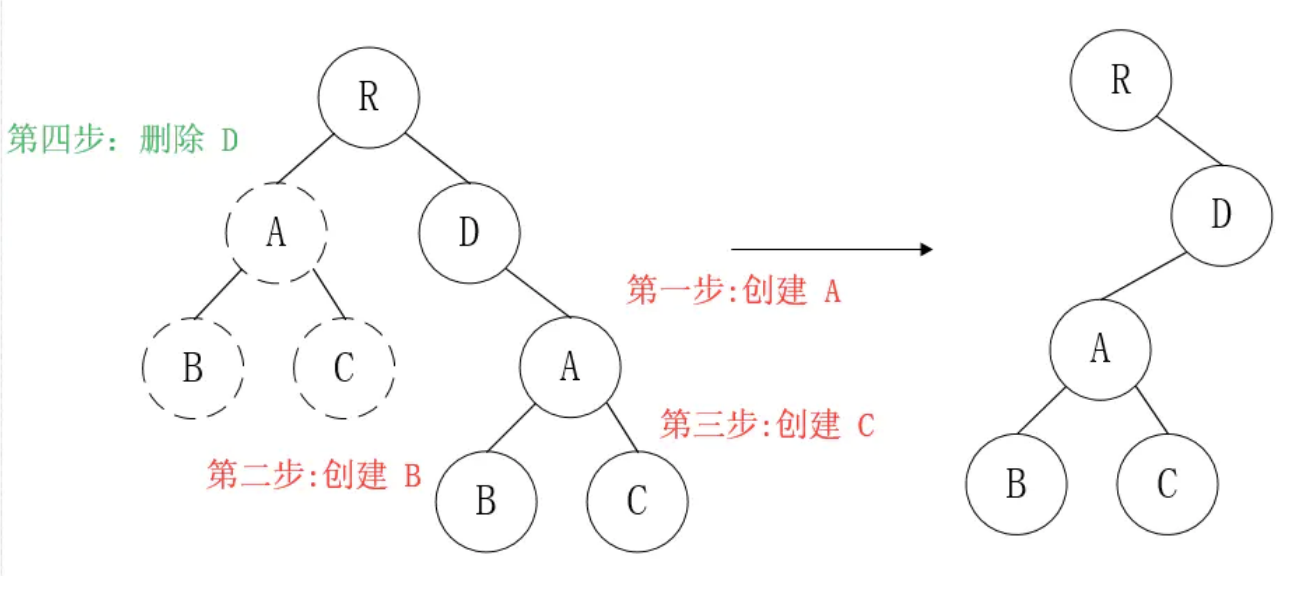
注意:如果组件D和组件G的结构相似,但是 React判断是 不同类型的组件,则不会比较其结构,而是删除 组件D及其子节点,创建组件G及其子节点。
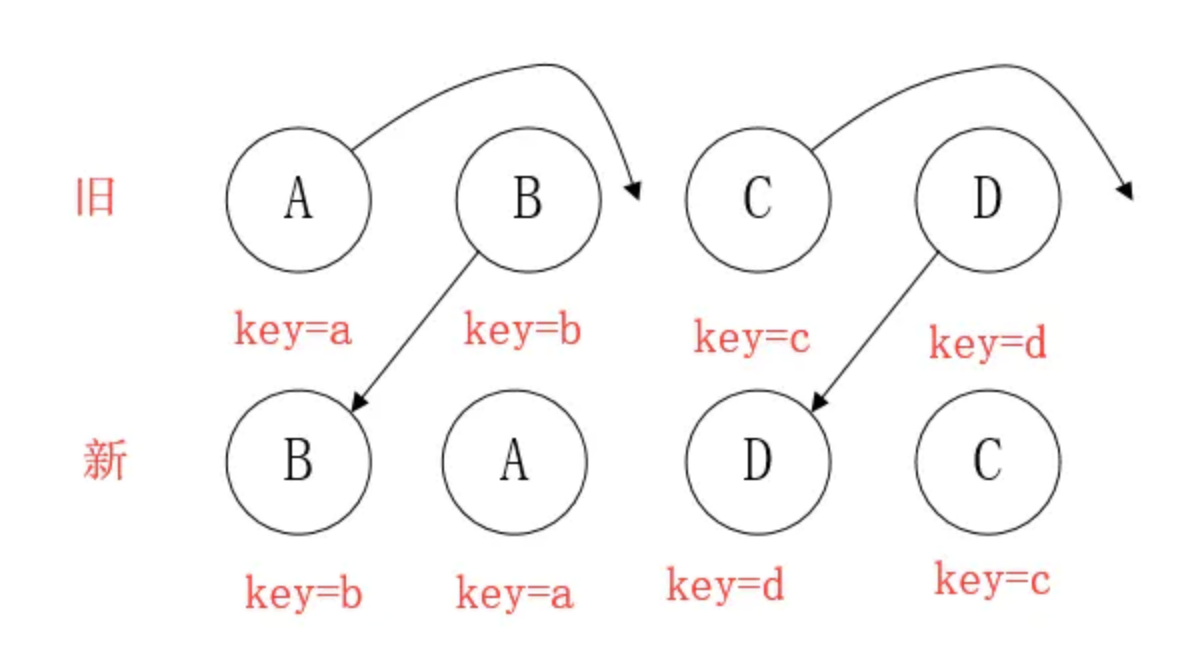
element diff
当节点处于同一层级时,diff提供三种节点操作:删除、插入、移动。
- 插入:组件 C 不在集合(A,B)中,需要插入
- 删除:
- 组件 D 在集合(A,B,D)中,但 D的节点已经更改,不能复用和更新,所以需要删除 旧的 D ,再创建新的。
- 组件 D 之前在 集合(A,B,D)中,但集合变成新的集合(A,B)了,D 就需要被删除。
- 移动:组件D已经在集合(A,B,C,D)里了,且集合更新时,D没有发生更新,只是位置改变,如新集合(A,D,B,C),D在第二个,无须像传统diff,让旧集合的第二个B和新集合的第二个D 比较,并且删除第二个位置的B,再在第二个位置插入D,而是 (对同一层级的同组子节点) 添加唯一key进行区分,移动即��。
总结
tree diff:只对比同一层的 dom 节点,忽略 dom 节点的跨层级移动
如下图,react 只会对相同颜色方框内的 DOM 节点进行比较,即同一个父节点下的所有子节点。当发现节点不存在时,则该节点及其子节点会被完全删除掉,不会用于进一步的比较。
这样只需要对树进行一次遍历,便能完成整个 DOM 树的比较。
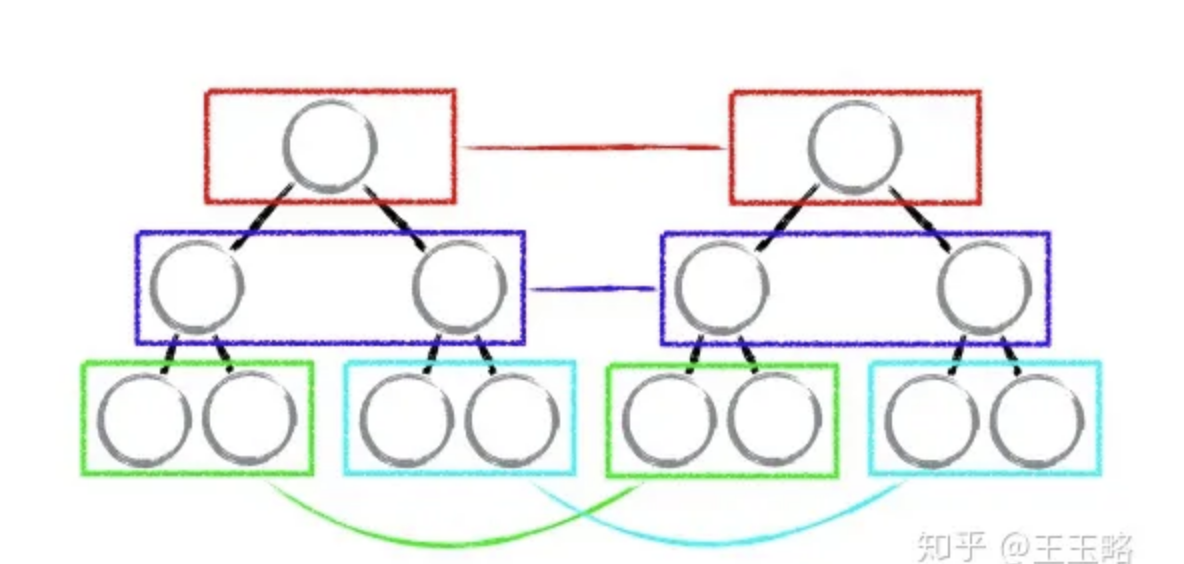
这就意味着,如果 dom 节点发生了跨层级移动,react 会删除旧的节点,生成新的节点,而不会复用。
component diff:如果不是同一类型的组件,会删除旧的组件,创建新的组件
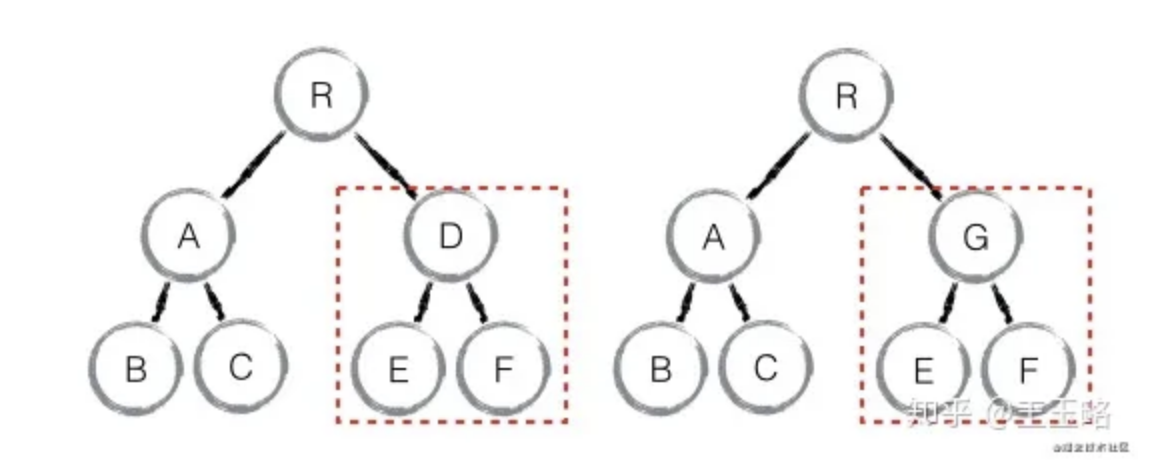
element diff:对于同一层级的一组子节点,需要通过唯一 id 进行来区分
- 如果没有 id 来进行区分,一旦有插入动作,会导致插入位置之后的列表全部重新渲染
- 这也是为什么渲染列表时为什么要使用唯一的 key。
diff的不足与待优化的地方
尽量减少类似将最后一个节点移动到列表首部的操作,当节点数量过大或更新操作过于频繁时,会影响React的渲染性能
与其他框架相比,React 的 diff 算法有何不同?
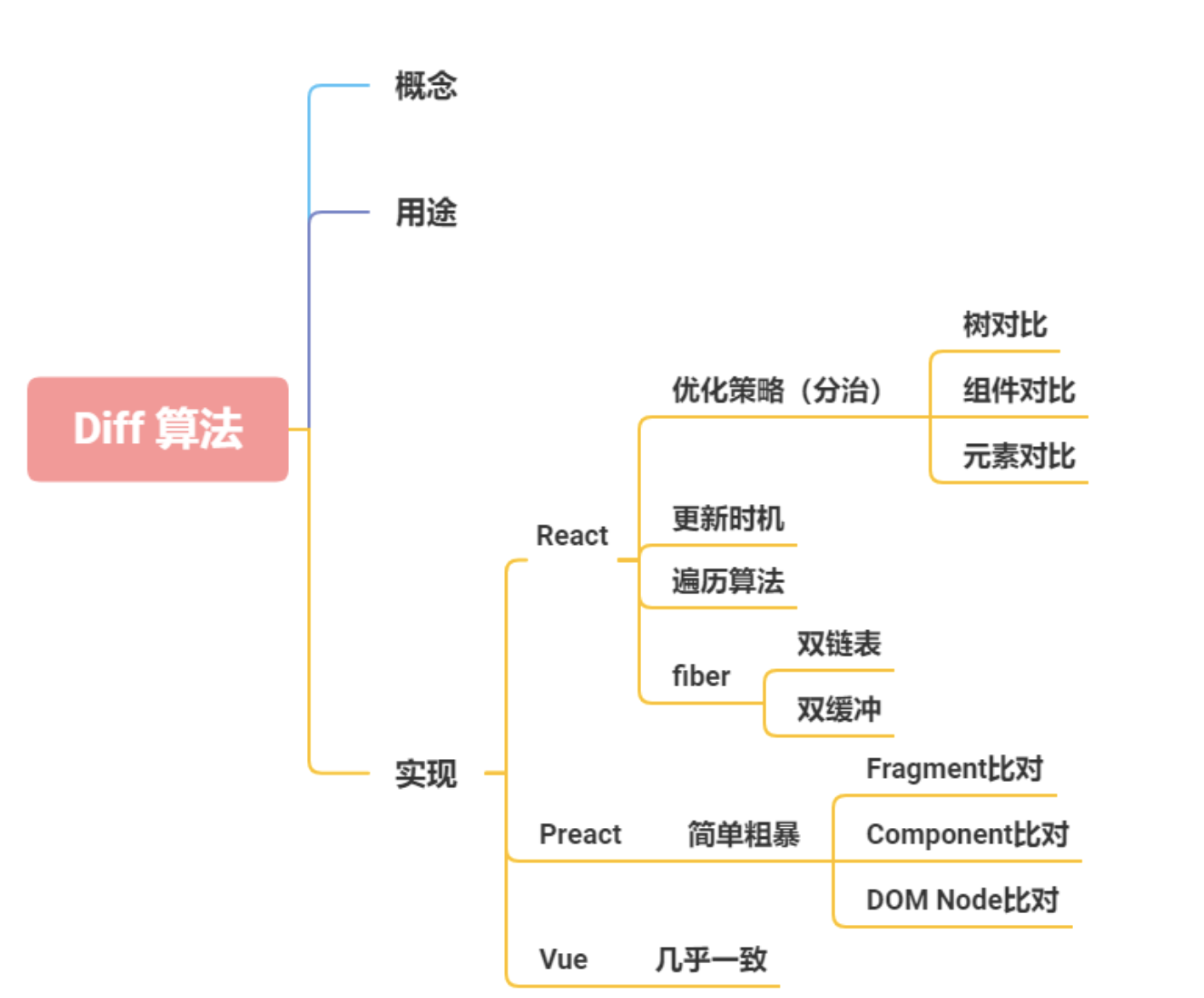
diff 算法探讨的就是虚拟 DOM 树发生变化后,生成 DOM 树更新补丁的方式。它通过对比新旧两株虚拟 DOM 树的变更差异,将更新补丁作用于真实 DOM,以最小成本完成视图更新
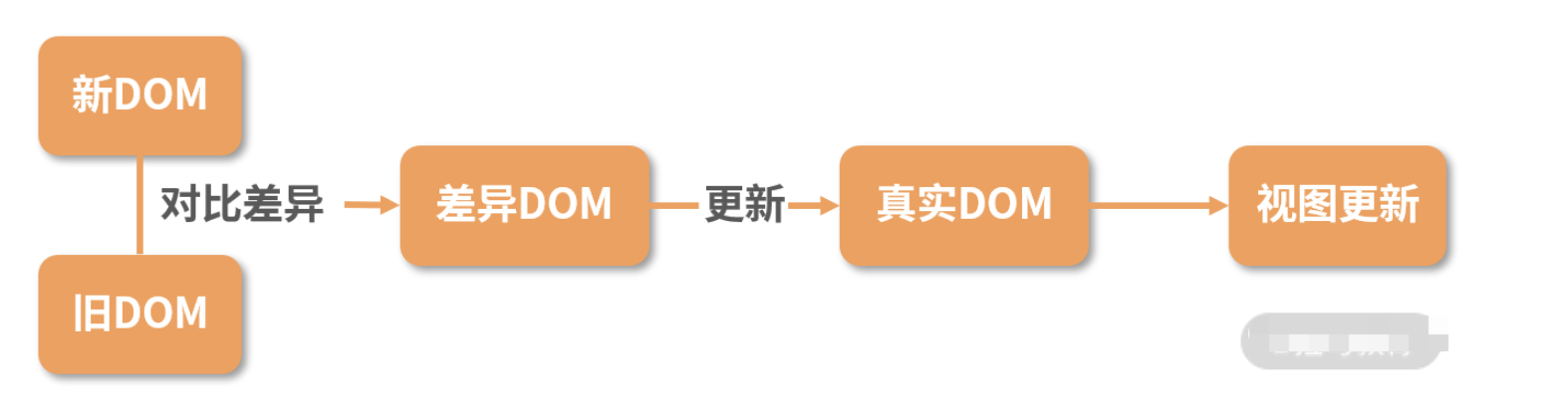
具体的流程是这样的:
- 真实 DOM 与虚拟 DOM 之间存在一个映射关系。这个映射关系依靠初始化时的 JSX 建立完成;
- 当虚拟 DOM 发生变化后,就会根据差距计算生成 patch,这个 patch 是一个结构化的数据,内容包含了增加、更新、移除等;
- 最后再根据 patch 去更新真实的 DOM,反馈到用户的界面上。
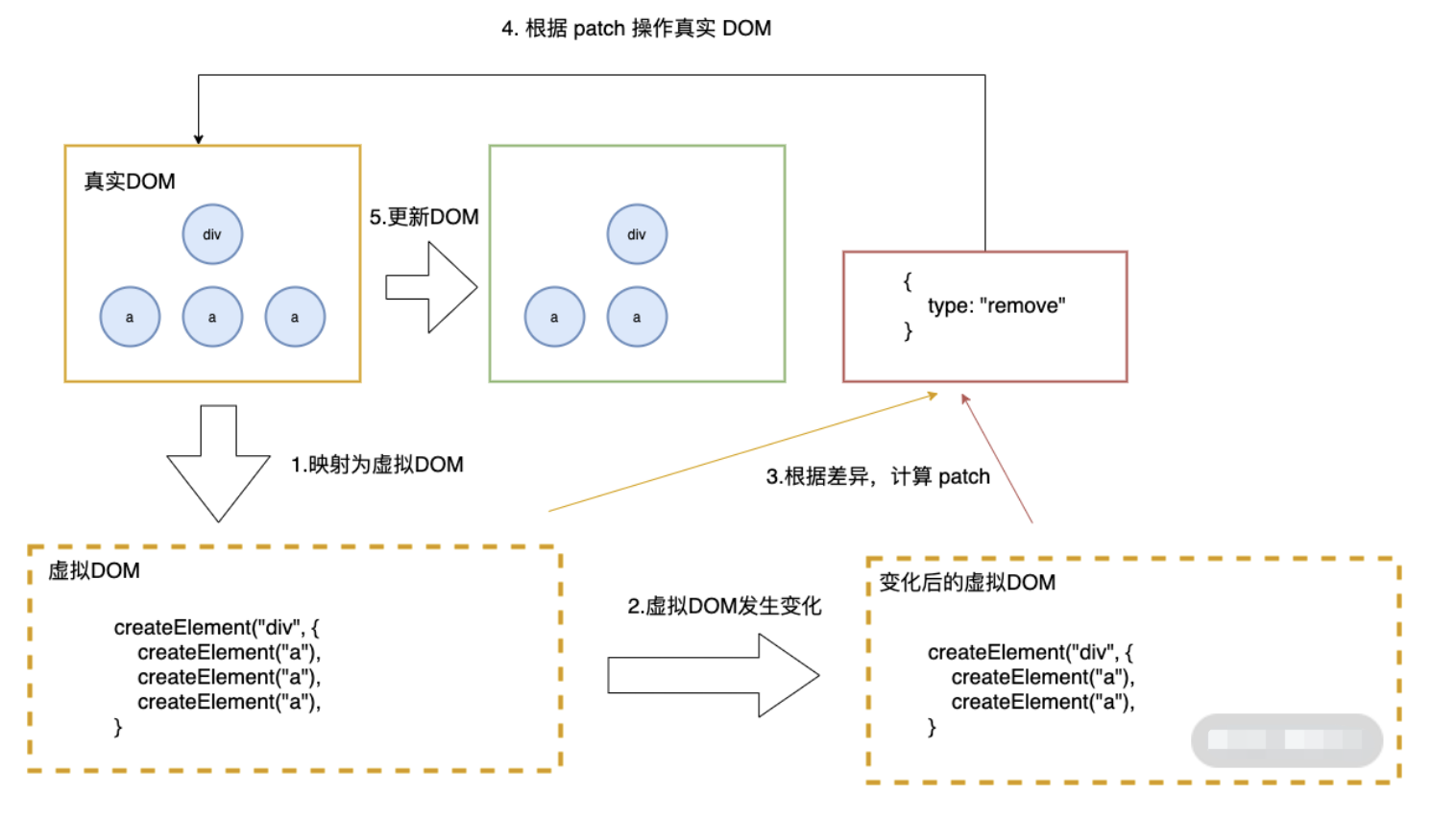
在回答有何不同之前,首先需要说明下什么是 diff 算法。
diff 算法是指生成更新补丁的方式,主要应用于虚拟 DOM 树变化后,更新真实 DOM。所以 diff 算法一定存在这样一个过程:触发更新 → 生成补丁 → 应用补丁- React 的 diff 算法,触发更新的时机主要在 state 变化与 hooks 调用之后。此时触发虚拟 DOM 树变更遍历,采用了深度优先遍历算法。但传统的遍历方式,效率较低。为了优化效率,使用了分治的方式。
将单一节点比对转化为了 3 种类型节点的比对,分别是树、组件及元素,以此提升效率。树比对:由于网页视图中较少有跨层级节点移动,两株虚拟 DOM 树只对同一层次的节点进行比较。组件比对:如果组件是同一类型,则进行树比对,如果不是,则直接放入到补丁中。元素比对:主要发生在同层级中,通过标记节点操作生成补丁,节点操作对应真实的 DOM 剪裁操作。同一层级的子节点,可以通过标记 key 的方式进行列表对比。
- 以上是经典的 React diff 算法内容。
自 React 16 起,引入了 Fiber 架构。为了使整个更新过程可随时暂停恢复,节点与树分别采用了FiberNode 与 FiberTree 进行重构。fiberNode 使用了双链表的结构,可以直接找到兄弟节点与子节点 - 然后拿 Vue 和 Preact 与 React 的 diff 算法进行对比
Preact的Diff算法相较于React,整体设计思路相似,但最底层的元素采用了真实DOM对比操作,也没有采用Fiber设计。Vue 的Diff算法整体也与React相似,同样未实现Fiber设计
- 然后进行横向比较,
React 拥有完整的 Diff 算法策略,且拥有随时中断更新的时间切片能力,在大批量节点更新的极端情况下,拥有更友好的交互体验。 - Preact 可以在一些对性能要求不高,仅需要渲染框架的简单场景下应用。
- Vue 的整体
diff 策略与 React 对齐,虽然缺乏时间切片能力,但这并不意味着 Vue 的性能更差,因为在 Vue 3 初期引入过,后期因为收益不高移除掉了。除了高帧率动画,在 Vue 中其他的场景几乎都可以使用防抖和节流去提高响应性能。
**学习原理的目的就是应用。那如何根据 React diff 算法原理优化代码呢?**这个问题其实按优化方式逆向回答即可。
- 根据
diff算法的设计原则,应尽量避免跨层级节点移动。 - 通过设置唯一
key进行优化,尽量减少组件层级深度。因为过深的层级会加深遍历深度,带来性能问题。 - 设置
shouldComponentUpdate或者React.pureComponet减少diff次数。
----------@----------
合成事件原理
为了解决跨浏览器兼容性问题,
React会将浏览器原生事件(Browser Native Event)封装为合成事件(SyntheticEvent)传入设置的事件处理器中。这里的合成事件提供了与原生事件相同的接口,不过它们屏蔽了底层浏览器的细节差异,保证了行为的一致性。另外有意思的是,React并没有直接将事件附着到子元素上,而是以单一事件监听器的方式将所有的事件发送到顶层进行处理。这样React在更新DOM的时候就不需要考虑如何去处理附着在DOM上的事件监听器,最终达到优化性能的目的
- 所有的事件挂在document上,DOM 事件触发后冒泡到 document;React 找到对应的组件,造出一个合成事件出来;并按组件树模拟一遍事件冒泡。
- event不是原生的,是SyntheticEvent合成事件对象
- 和Vue事件不同,和DOM事件也不同
React 17 之前的事件冒泡流程图
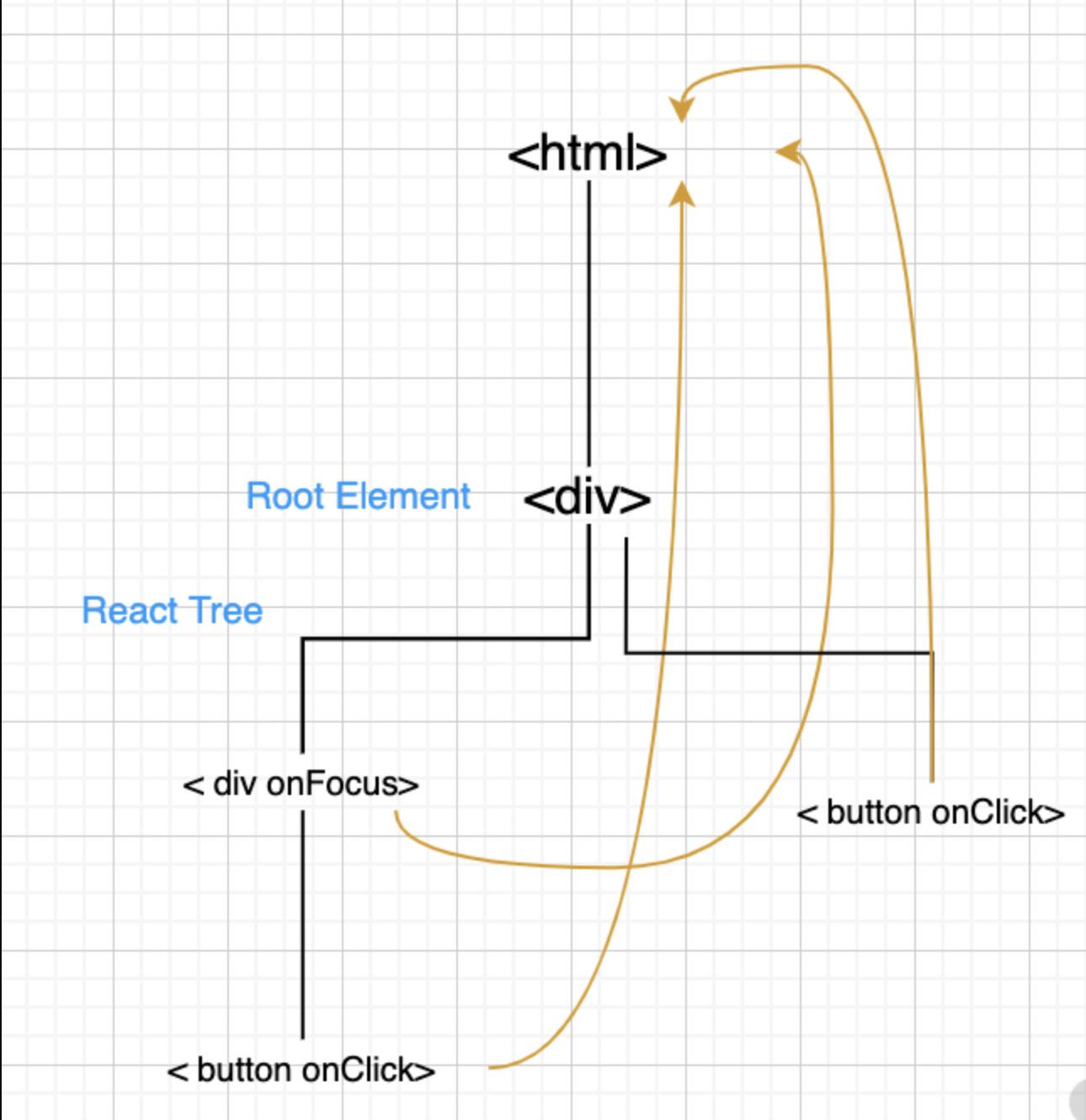
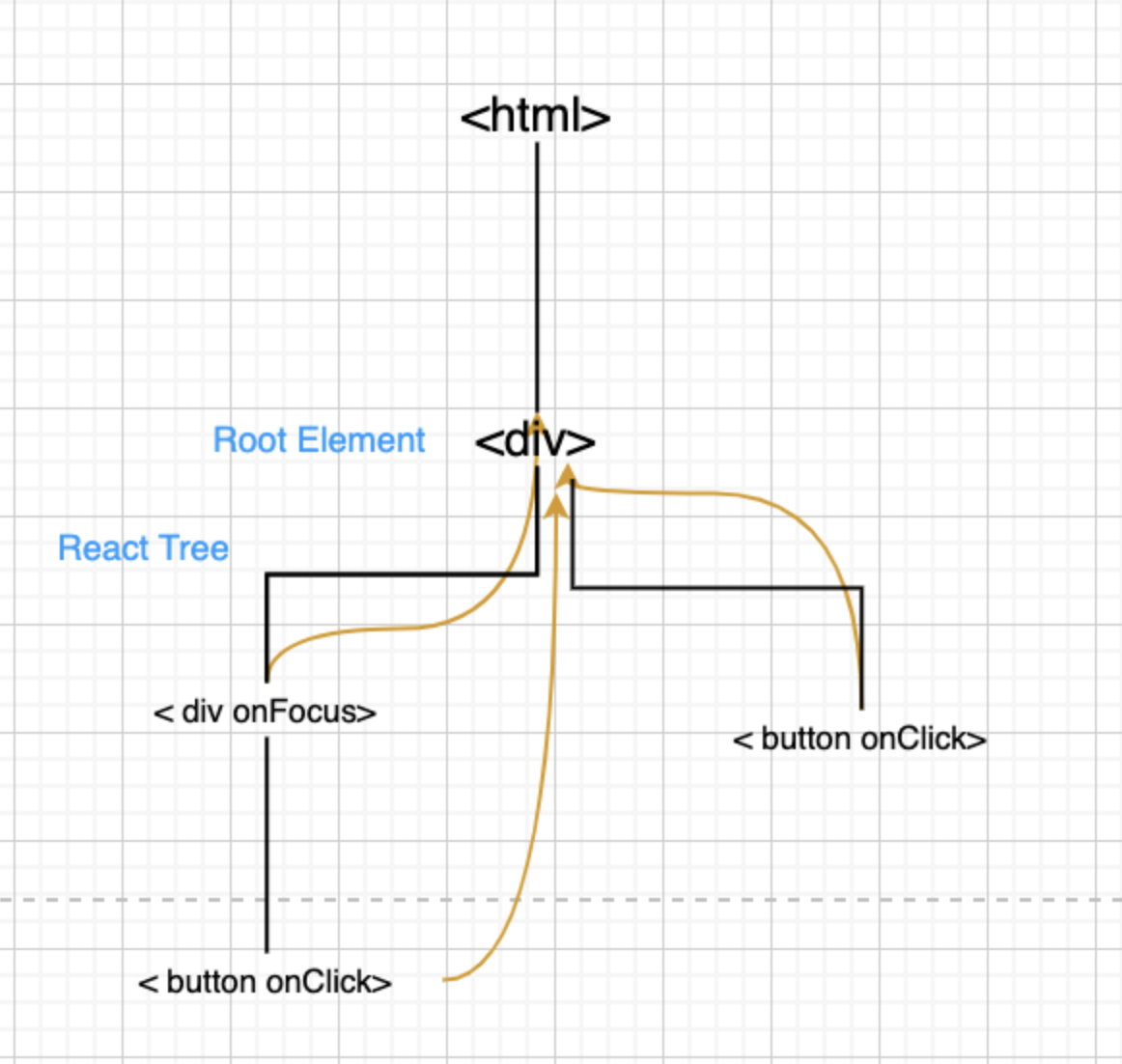
所以这就造成了,在一个页面中,只能有一个版本的 React。如果有多个版本,事件就乱套了。值得一提的是,这个问题在 React 17 中得到了解决,事件委托不再挂在 document 上,而是挂在 DOM 容器上,也就是
ReactDom.Render所调用的节点上。
React 17 后的事件冒泡流程图
那到底哪些事件会被捕获生成合成事件呢?可以从 React 的源码测试文件中一探究竟。下面的测试快照中罗列了大量的事件名,也只有在这份快照中的事件,才会被捕获生成合成事件。
// react/packages/react-dom/src/__tests__/__snapshots__/ReactTestUtils-test.js.snap
Array ["abort","animationEnd","animationIteration","animationStart","auxClick","beforeInput","blur","canPlay","canPlayThrough","cancel","change","click","close","compositionEnd","compositionStart","compositionUpdate","contextMenu","copy","cut","doubleClick","drag","dragEnd","dragEnter","dragExit","dragLeave","dragOver","dragStart","drop","durationChange","emptied","encrypted","ended","error","focus","gotPointerCapture","input","invalid","keyDown","keyPress","keyUp","load","loadStart","loadedData","loadedMetadata","lostPointerCapture","mouseDown","mouseEnter","mouseLeave","mouseMove","mouseOut","mouseOver","mouseUp","paste","pause","play","playing","pointerCancel","pointerDown","pointerEnter","pointerLeave","pointerMove","pointerOut","pointerOver","pointerUp","progress","rateChange","reset","scroll","seeked","seeking","select","stalled","submit","suspend","timeUpdate","toggle","touchCancel","touchEnd","touchMove","touchStart","transitionEnd","volumeChange","waiting","wheel",]
如果DOM上绑定了过多的事件处理函数,整个页面响应以及内存占用可能都会受到影响。React为了避免这类DOM事件滥用,同时屏蔽底层不同浏览器之间的事件系统的差异,实现了一个中间层 - SyntheticEvent
- 当用户在为onClick添加函数时,React并没有将Click绑定到DOM上面
- 而是在document处监听所有支持的事件,当事件发生并冒泡至document处时,React将事件内容封装交给中间层 SyntheticEvent (负责所有事件合成)
- 所以当事件触发的时候, 对使用统一的分发函数 dispatchEvent 将指定函数执行
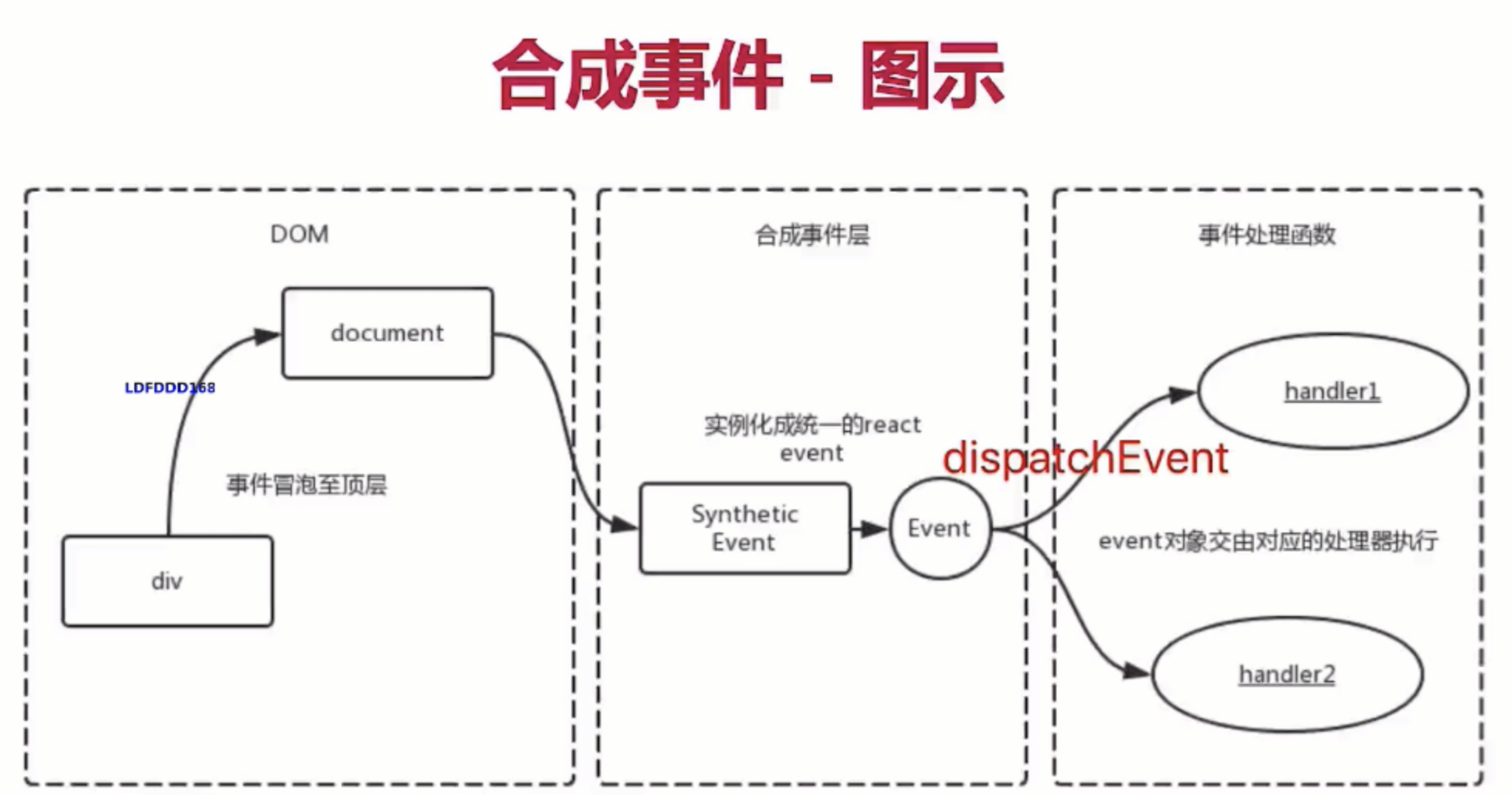
为何要合成事件
- 兼容性和跨平台
- 挂在统一的document上,减少内存消耗,避免频繁解绑
- 方便事件的统一管理(事务机制)
- dispatchEvent事件机制
----------@----------
JSX语法糖本质
JSX是语法糖,通过babel转成
React.createElement函数,在babel官网上可以在线把JSX转成React的JS语法
- 首先解析出来的话,就是一个
createElement函数 - 然后这个函数执行完后,会返回一个
vnode - 通过vdom的patch或者是其他的一个方法,最后渲染一个页面


script标签中不添加
text/babel解析jsx语法的情况下
<script>const ele = React.createElement("h2", null, "Hello React!");ReactDOM.render(ele, document.getElementById("app"));
</script>
JSX的本质是React.createElement()函数
createElement函数返回的对象是ReactEelement对象。
createElement的写法如下
class App extends React.Component {constructor() {super()this.state = {}}render() {return React.createElement("div", null,/*第一个子元素,header*/React.createElement("div", { className: "header" },React.createElement("h1", { title: "\u6807\u9898" }, "\u6211\u662F\u6807\u9898")),/*第二个子元素,content*/React.createElement("div", { className: "content" },React.createElement("h2", null, "\u6211\u662F\u9875\u9762\u7684\u5185\u5BB9"),React.createElement("button", null, "\u6309\u94AE"),React.createElement("button", null, "+1"),React.createElement("a", { href: "http://www.baidu.com" },"\u767E\u5EA6\u4E00\u4E0B")),/*第三个子元素,footer*/React.createElement("div", { className: "footer" },React.createElement("p", null, "\u6211\u662F\u5C3E\u90E8\u7684\u5185\u5BB9")));}
}ReactDOM.render(<App />, document.getElementById("app"));
实际开发中不会使用createElement来创建ReactElement的,一般都是使用JSX的形式开发。
ReactElement在程序中打印一下
render() {let ele = (<div><div className="header"><h1 title="标题">我是标题</h1></div><div className="content"><h2>我是页面的内容</h2><button>按钮</button><button>+1</button><a href="http://www.baidu.com">百度一下</a></div><div className="footer"><p>我是尾部的内容</p></div></div>)console.log(ele);return ele;
}
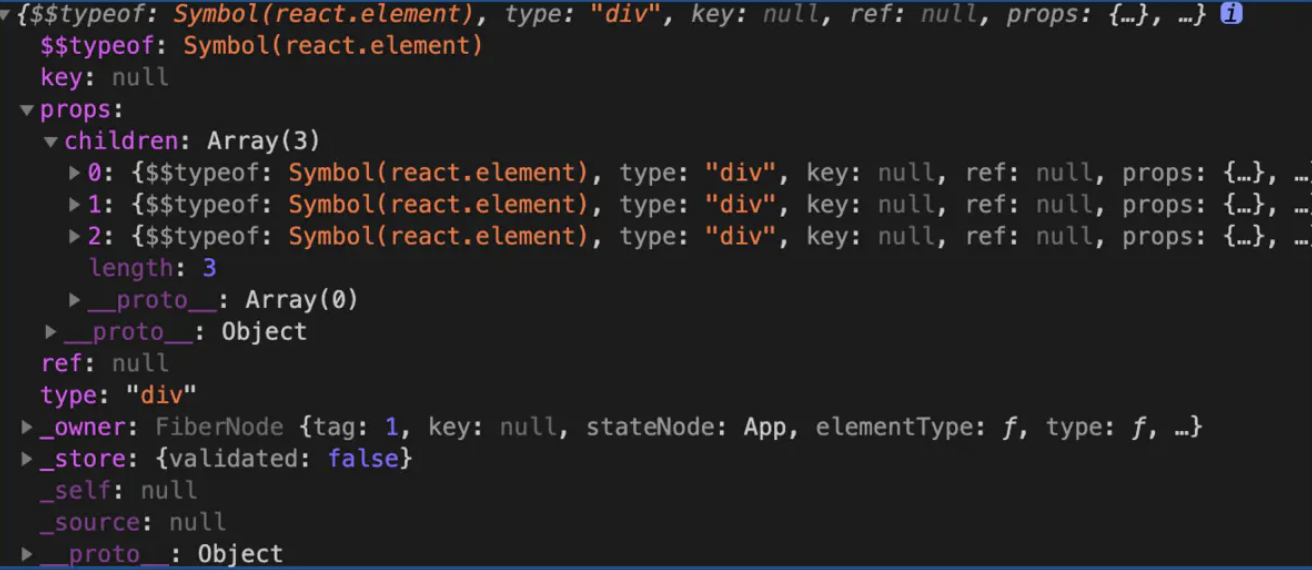
react通过babel把JSX转成
createElement函数,生成ReactElement对象,然后通过ReactDOM.render函数把ReactElement渲染成真实的DOM元素
为什么 React 使用 JSX
- 在回答问题之前,我首先解释下什么是 JSX 吧。JSX 是一个
JavaScript的语法扩展,结构类似 XML。 - JSX 主要用于声明
React元素,但 React 中并不强制使用JSX。即使使用了JSX,也会在构建过程中,通过 Babel 插件编译为React.createElement。所以 JSX 更像是React.createElement的一种语法糖 - 接下来与 JSX 以外的三种技术方案进行对比
- 首先是模板,React 团队认为模板不应该是开发过程中的关注点,因为引入了模板语法、模板指令等概念,是一种不佳的实现方案
- 其次是模板字符串,模板字符串编写的结构会造成多次内部嵌套,使整个结构变得复杂,并且优化代码提示也会变得困难重重
- 所以 React 最后选用了 JSX,因为 JSX 与其设计思想贴合,不需要引入过多新的概念,对编辑器的代码提示也极为友好。
Babel 插件如何实现 JSX 到 JS 的编译? 在 React 面试中,这个问题很容易被追问,也经常被要求手写。
它的实现原理是这样的。Babel 读取代码并解析,生成 AST,再将 AST 传入插件层进行转换,在转换时就可以将 JSX 的结构转换为 React.createElement 的函数。如下代码所示:
module.exports = function (babel) {var t = babel.types;return {name: "custom-jsx-plugin",visitor: {JSXElement(path) {var openingElement = path.node.openingElement;var tagName = openingElement.name.name;var args = []; args.push(t.stringLiteral(tagName)); var attribs = t.nullLiteral(); args.push(attribs); var reactIdentifier = t.identifier("React"); //objectvar createElementIdentifier = t.identifier("createElement"); var callee = t.memberExpression(reactIdentifier, createElementIdentifier)var callExpression = t.callExpression(callee, args);callExpression.arguments = callExpression.arguments.concat(path.node.children);path.replaceWith(callExpression, path.node); },},};
};
React.createElement源码分析
/**101. React的创建元素方法*/
export function createElement(type, config, children) {// propName 变量用于储存后面需要用到的元素属性let propName; // props 变量用于储存元素属性的键值对集合const props = {}; // key、ref、self、source 均为 React 元素的属性,此处不必深究let key = null;let ref = null; let self = null; let source = null; // config 对象中存储的是元素的属性if (config != null) { // 进来之后做的第一件事,是依次对 ref、key、self 和 source 属性赋值if (hasValidRef(config)) {ref = config.ref;}// 此处将 key 值字符串化if (hasValidKey(config)) {key = '' + config.key; }self = config.__self === undefined ? null : config.__self;source = config.__source === undefined ? null : config.__source;// 接着就是要把 config 里面的属性都一个一个挪到 props 这个之前声明好的对象里面for (propName in config) {if (// 筛选出可以提进 props 对象里的属性hasOwnProperty.call(config, propName) &&!RESERVED_PROPS.hasOwnProperty(propName) ) {props[propName] = config[propName]; }}}// childrenLength 指的是当前元素的子元素的个数,减去的 2 是 type 和 config 两个参数占用的长度const childrenLength = arguments.length - 2; // 如果抛去type和config,就只剩下一个参数,一般意味着文本节点出现了if (childrenLength === 1) { // 直接把这个参数的值赋给props.childrenprops.children = children; // 处理嵌套多个子元素的情况} else if (childrenLength > 1) { // 声明一个子元素数组const childArray = Array(childrenLength); // 把子元素推进数组里for (let i = 0; i < childrenLength; i++) { childArray[i] = arguments[i + 2];}// 最后把这个数组赋值给props.childrenprops.children = childArray; } // 处理 defaultPropsif (type && type.defaultProps) {const defaultProps = type.defaultProps;for (propName in defaultProps) { if (props[propName] === undefined) {props[propName] = defaultProps[propName];}}}// 最后返回一个调用ReactElement执行方法,并传入刚才处理过的参数return ReactElement(type,key,ref,self,source,ReactCurrentOwner.current,props,);
}
入参解读:创造一个元素需要知道哪些信息
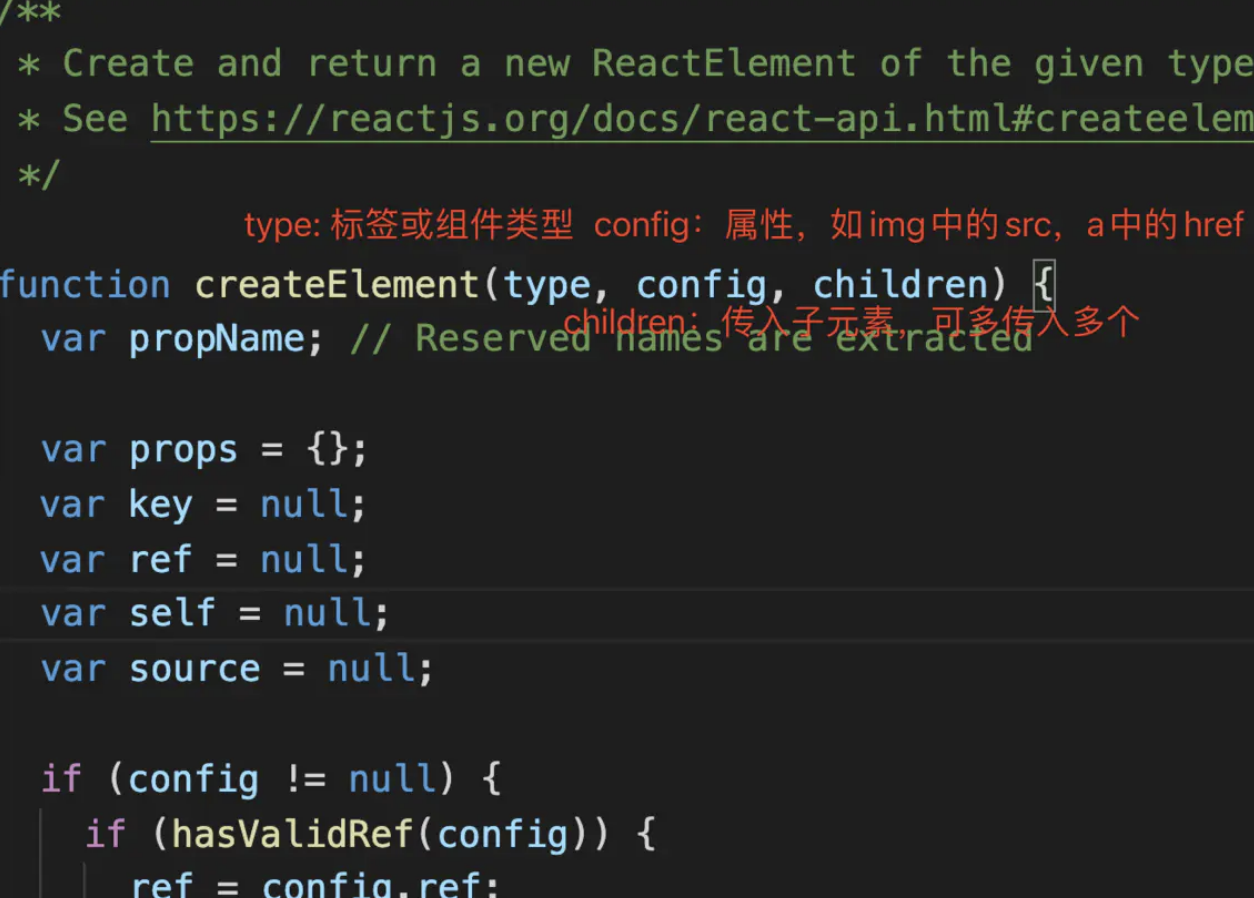
export function createElement(type, config, children)
createElement 有 3 个入参,这 3 个入参囊括了 React 创建一个元素所需要知道的全部信息。
type:用于标识节点的类型。它可以是类似“h1”“div”这样的标准 HTML 标签字符串,也可以是 React 组件类型或React fragment类型。config:以对象形式传入,组件所有的属性都会以键值对的形式存储在 config 对象中。children:以对象形式传入,它记录的是组件标签之间嵌套的内容,也就是所谓的“子节点”“子元素”
React.createElement("ul", {// 传入属性键值对className: "list"// 从第三个入参开始往后,传入的参数都是 children
}, React.createElement("li", {key: "1"
}, "1"), React.createElement("li", {key: "2"
}, "2"));
这个调用对应的 DOM 结构如下:
<ul className="list"><li key="1">1</li><li key="2">2</li>
</ul>
createElement 函数体拆解
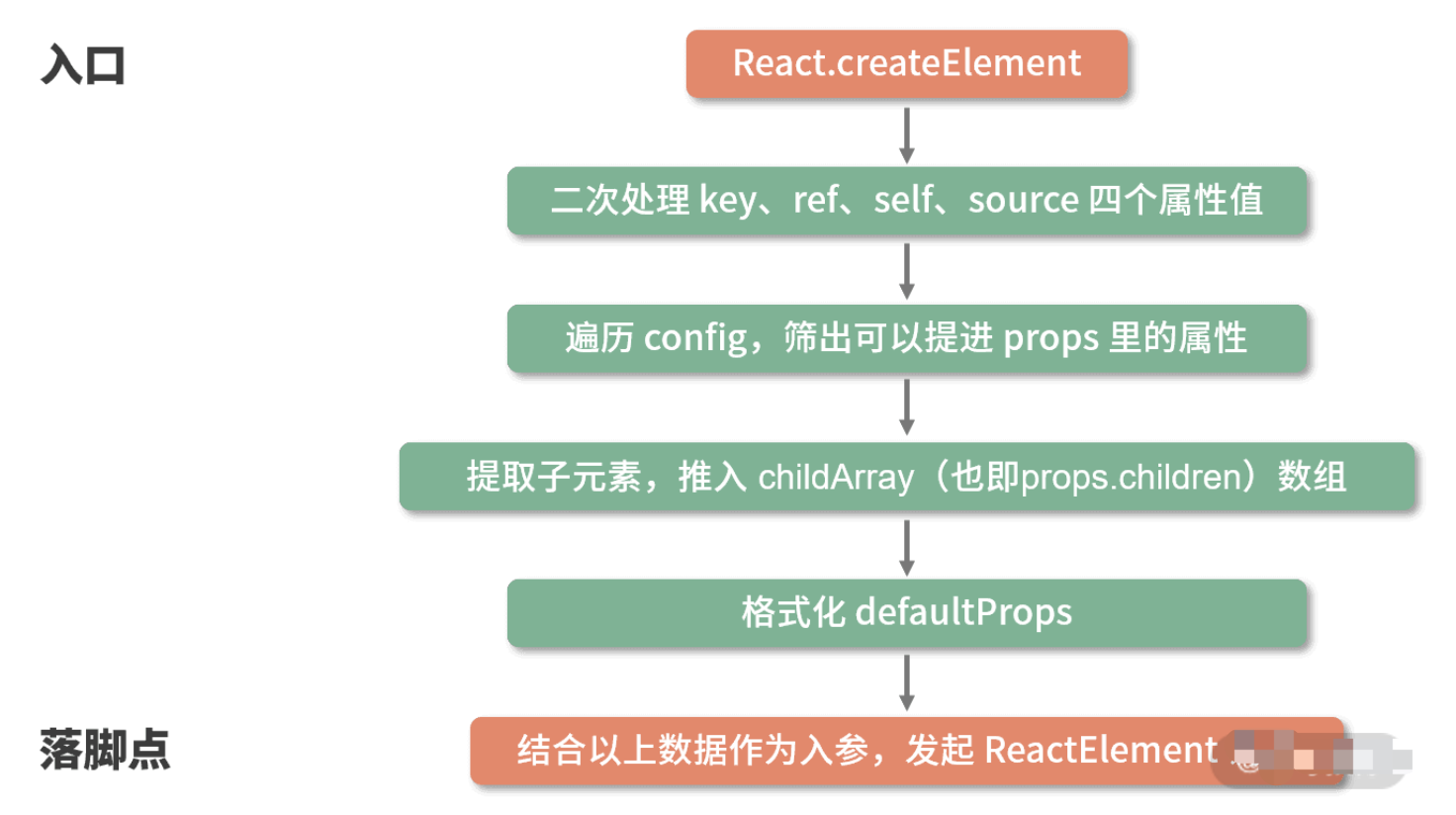
createElement 中并没有十分复杂的涉及算法或真实 DOM 的逻辑,它的每一个步骤几乎都是在格式化数据。

现在看来,
createElement原来只是个“参数中介”。此时我们的注意力自然而然地就聚焦在了ReactElement上
出参解读:初识虚拟 DOM
createElement执行到最后会 return 一个针对 ReactElement 的调用。这里关于 ReactElement,我依然先给出源码 + 注释形式的解析
const ReactElement = function(type, key, ref, self, source, owner, props) {const element = {// REACT_ELEMENT_TYPE是一个常量,用来标识该对象是一个ReactElement$$typeof: REACT_ELEMENT_TYPE,// 内置属性赋值type: type,key: key,ref: ref,props: props,// 记录创造该元素的组件_owner: owner,};// if (__DEV__) {// 这里是一些针对 __DEV__ 环境下的处理,对于大家理解主要逻辑意义不大,此处我直接省略掉,以免混淆视听}return element;
};
ReactElement其实只做了一件事情,那就是“创建”,说得更精确一点,是“组装”:ReactElement把传入的参数按照一定的规范,“组装”进了element对象里,并把它返回给了eact.createElement,最终React.createElement又把它交回到了开发者手中
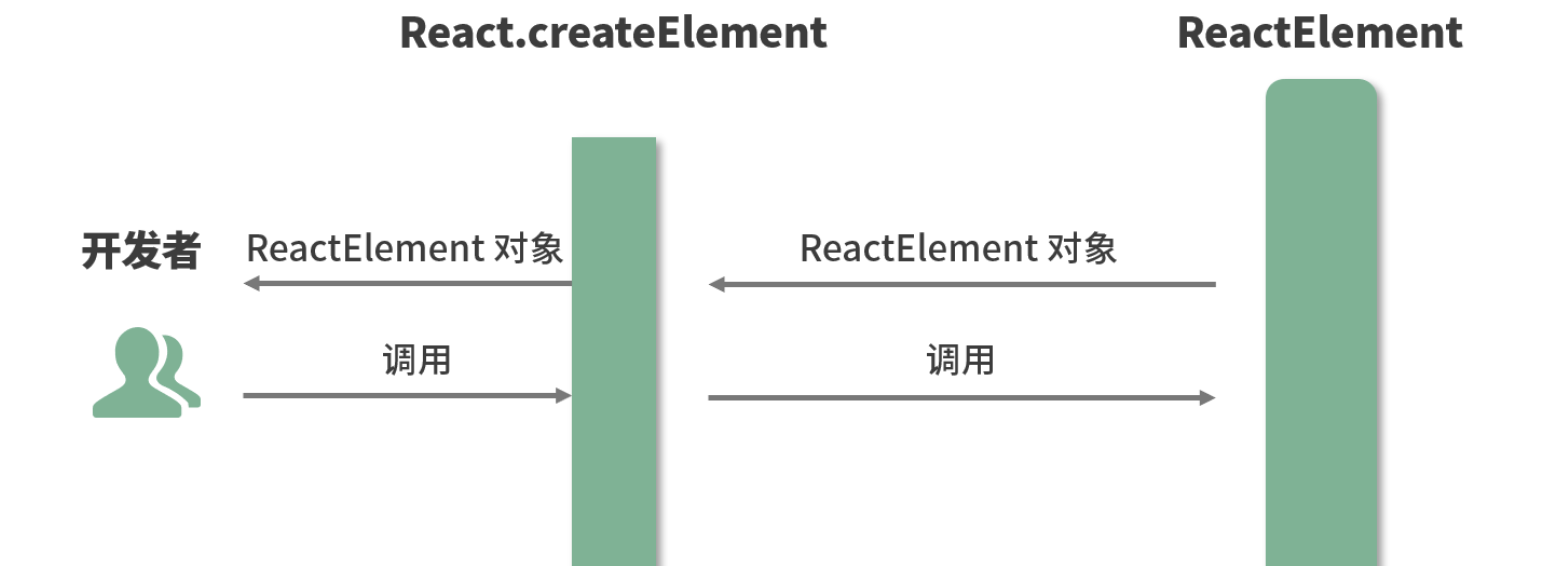
const AppJSX = (<div className="App"><h1 className="title">I am the title</h1><p className="content">I am the content</p>
</div>)console.log(AppJSX)
你会发现它确实是一个标准的 ReactElement 对象实例

这个 ReactElement 对象实例,本质上是以 JavaScript 对象形式存在的对 DOM 的描述,也就是老生常谈的“虚拟 DOM”(准确地说,是虚拟 DOM 中的一个节点)
----------@----------
为什么 React 元素有一个 $$typeof 属性
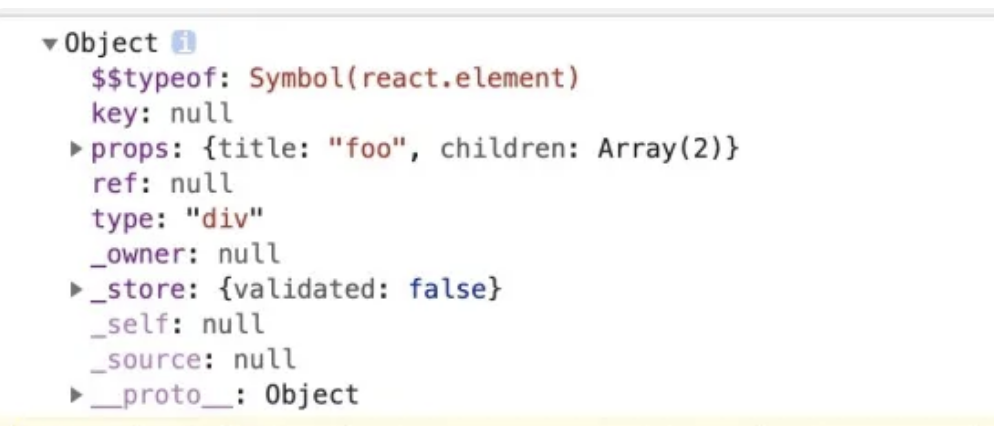
目的是为了防止 XSS 攻击。因为 Synbol 无法被序列化,所以 React 可以通过有没有 $$typeof 属性来断出当前的 element 对象是从数据库来的还是自己生成的。
- 如果没有 $$typeof 这个属性,react 会拒绝处理该元素。
- 在 React 的古老版本中,下面的写法会出现 XSS 攻击:
// 服务端允许用户存储 JSON
let expectedTextButGotJSON = {type: 'div',props: {dangerouslySetInnerHTML: {__html: '/* 把你想的搁着 */'},},// ...
};
let message = { text: expectedTextButGotJSON };// React 0.13 中有风险
<p>{message.text}
</p>
----------@----------
Virtual DOM 的工作原理是什么
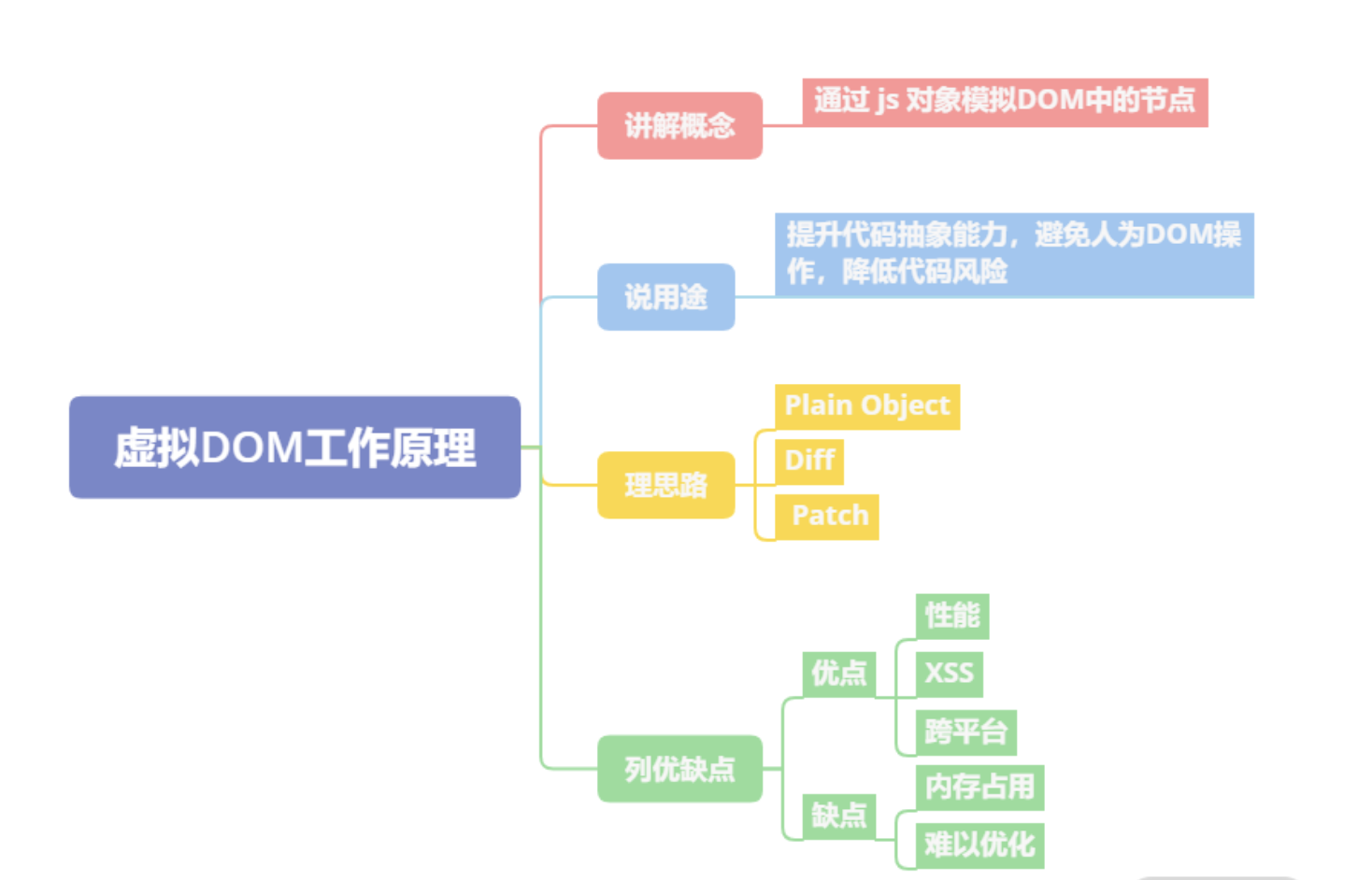
- 虚拟 DOM 的工作原理是
通过 JS 对象模拟 DOM 的节点。在 Facebook 构建 React 初期时,考虑到要提升代码抽象能力、避免人为的 DOM 操作、降低代码整体风险等因素,所以引入了虚拟 DOM - 虚拟 DOM 在实现上通常是
Plain Object,以 React 为例,在render函数中写的JSX会在Babel插件的作用下,编译为React.createElement执行JSX中的属性参数 React.createElement执行后会返回一个Plain Object,它会描述自己的tag类型、props属性以及children情况等。这些Plain Object通过树形结构组成一棵虚拟DOM树。当状态发生变更时,将变更前后的虚拟DOM树进行差异比较,这个过程称为diff,生成的结果称为patch。计算之后,会渲染Patch完成对真实DOM的操作。- 虚拟 DOM 的优点主要有三点:
改善大规模DOM操作的性能、规避 XSS 风险、能以较低的成本实现跨平台开发。 - 虚拟 DOM 的缺点在社区中主要有两点
- 内存占用较高,因为需要模拟整个网页的真实
DOM - 高性能应用场景存在难以优化的情况,类似像 Google Earth 一类的高性能前端应用在技术选型上往往不会选择 React
- 内存占用较高,因为需要模拟整个网页的真实
除了渲染页面,虚拟 DOM 还有哪些应用场景?
这个问题考验面试者的想象力。通常而言,我们只是将虚拟 DOM 与渲染绑定在一起,但实际上虚拟 DOM 的应用更为广阔。比如,只要你记录了真实 DOM 变更,它甚至可以应用于埋点统计与数据记录等。
SSR原理
借助虚拟dom,服务器中没有dom概念的,react巧妙的借助虚拟dom,然后可以在服务器中nodejs可以运行起来react代码。
----------@----------
React有哪些优化性能的手段
类组件中的优化手段
- 使用纯组件
PureComponent作为基类。 - 使用
shouldComponentUpdate生命周期函数来自定义渲染逻辑。
方法组件中的优化手段
- 使用
React.memo高阶函数包装组件,React.memo可以实现类似于shouldComponentUpdate或者PureComponent的效果 - 使用
useMemo- 使用
React.useMemo精细化的管控,useMemo 控制的则是是否需要重复执行某一段逻辑,而React.memo 控制是否需要重渲染一个组件
- 使用
- 使用
useCallBack。
其他方式
- 在列表需要频繁变动时,使用唯一 id 作为 key,而不是数组下标。
- 必要时通过改变 CSS 样式隐藏显示组件,而不是通过条件判断显示隐藏组件。
- 使用
Suspense和 lazy 进行懒加载,例如:
import React, { lazy, Suspense } from "react";export default class CallingLazyComponents extends React.Component {render() {var ComponentToLazyLoad = null;if (this.props.name == "Mayank") {ComponentToLazyLoad = lazy(() => import("./mayankComponent"));} else if (this.props.name == "Anshul") {ComponentToLazyLoad = lazy(() => import("./anshulComponent"));}return (<div><h1>This is the Base User: {this.state.name}</h1><Suspense fallback={<div>Loading...</div>}><ComponentToLazyLoad /></Suspense></div>)}
}
----------@----------
Redux实现原理解析
在 Redux 的整个工作过程中,数据流是严格单向的。这一点一定一定要背下来,面试的时候也一定一定要记得说
为什么要用redux
在
React中,数据在组件中是单向流动的,数据从一个方向父组件流向子组件(通过props),所以,两个非父子组件之间通信就相对麻烦,redux的出现就是为了解决state里面的数据问题
Redux设计理念
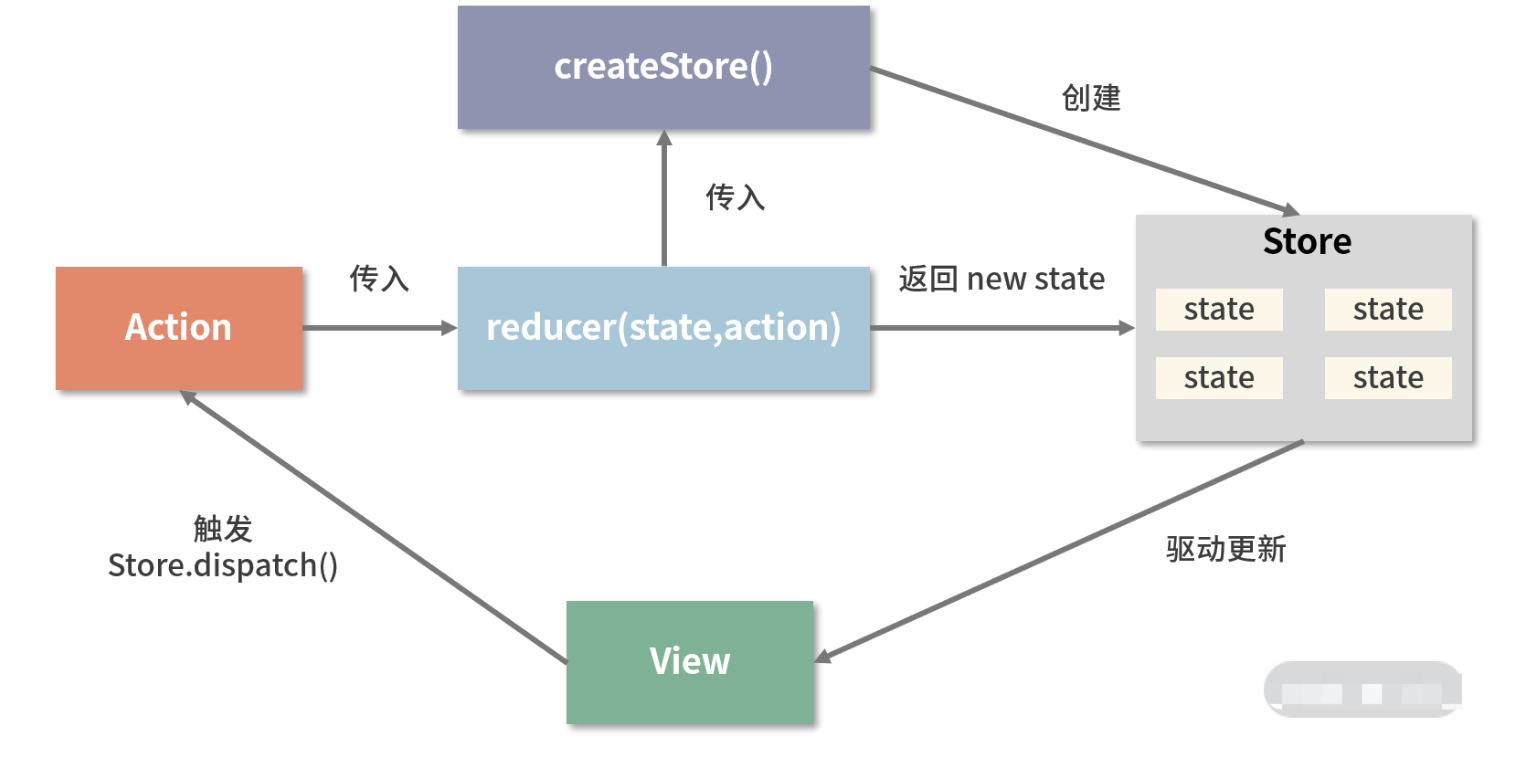
Redux是将整个应用状态存储到一个地方上称为store,里面保存着一个状态树store tree,组件可以派发(dispatch)行为(action)给store,而不是直接通知其他组件,组件内部通过订阅store中的状态state来刷新自己的视图

如果你想对数据进行修改,
只有一种途径:派发 action。action 会被 reducer 读取,进而根据 action 内容的不同对数据进行修改、生成新的 state(状态),这个新的 state 会更新到 store 对象里,进而驱动视图层面做出对应的改变。
Redux三大原则
- 唯一数据源
整个应用的state都被存储到一个状态树里面,并且这个状态树,只存在于唯一的store中
- 保持只读状态
state是只读的,唯一改变state的方法就是触发action,action是一个用于描述以发生时间的普通对象
- 数据改变只能通过纯函数来执行
使用纯函数来执行修改,为了描述
action如何改变state的,你需要编写reducers
从编码的角度理解 Redux 工作流
- 使用
createStore 来完成 store 对象的创建
// 引入 redux
import { createStore } from 'redux'
// 创建 store
const store = createStore(reducer,initial_state,applyMiddleware(middleware1, middleware2, ...)
);
createStore 方法是一切的开始,它接收三个入参:
-
reducer;
-
初始状态内容;
-
指定中间件
reducer 的作用是将新的 state 返回给 store
一个 reducer 一定是一个纯函数,它可以有各种各样的内在逻辑,但它最终一定要返回一个 state:
const reducer = (state, action) => {// 此处是各种样的 state处理逻辑return new_state
}
当我们基于某个 reducer 去创建 store 的时候,其实就是给这个 store 指定了一套更新规则:
// 更新规则全都写在 reducer 里
const store = createStore(reducer)
- action 的作用是通知 reducer “让改变发生”
要想让 state 发生改变,就必须用正确的 action 来驱动这个改变。
const action = {type: "ADD_ITEM",payload: '<li>text</li>'
}
action 对象中允许传入的属性有多个,但只有 type 是必传的。type 是 action 的唯一标识,reducer 正是通过不同的 type 来识别出需要更新的不同的 state,由此才能够实现精准的“定向更新”。
- 派发 action,靠的是 dispatch
action 本身只是一个对象,要想让 reducer 感知到 action,还需要“派发 action”这个动作,这个动作是由 store.dispatch 完成的。这里我简单地示范一下:
import { createStore } from 'redux'
// 创建 reducer
const reducer = (state, action) => {// 此处是各种样的 state处理逻辑return new_state
}
// 基于 reducer 创建 state
const store = createStore(reducer)
// 创建一个 action,这个 action 用 “ADD_ITEM” 来标识
const action = {type: "ADD_ITEM",payload: '<li>text</li>'
}
// 使用 dispatch 派发 action,action 会进入到 reducer 里触发对应的更新
store.dispatch(action)
以上这段代码,是从编码角度对 Redux 主要工作流的概括,这里我同样为你总结了一张对应的流程图:
Redux源码
let createStore = (reducer) => {let state;//获取状态对象//存放所有的监听函数let listeners = [];let getState = () => state;//提供一个方法供外部调用派发actionlet dispath = (action) => {//调用管理员reducer得到新的statestate = reducer(state, action);//执行所有的监听函数listeners.forEach((l) => l())}//订阅状态变化事件,当状态改变发生之后执行监听函数let subscribe = (listener) => {listeners.push(listener);}dispath();return {getState,dispath,subscribe}
}
let combineReducers=(renducers)=>{//传入一个renducers管理组,返回的是一个renducerreturn function(state={},action={}){let newState={};for(var attr in renducers){newState[attr]=renducers[attr](state[attr],action)}return newState;}
}
export {createStore,combineReducers};
聊聊 Redux 和 Vuex 的设计思想
- 共同点
首先两者都是处理全局状态的工具库,大致实现思想都是:全局
state保存状态---->dispatch(action)------>reducer(vuex里的mutation)----> 生成newState; 整个状态为同步操作;
- 区别
最大的区别在于处理异步的不同,vuex里面多了一步
commit操作,在action之后commit(mutation)之前处理异步,而redux里面则是通过中间件处理
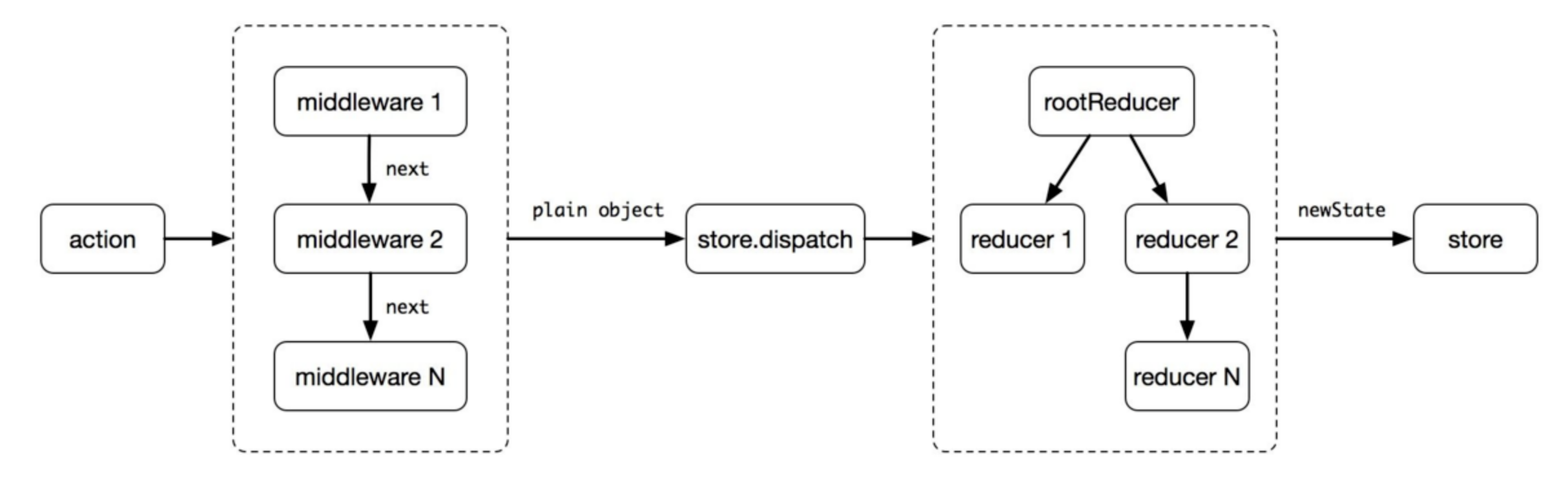
redux 中间件
中间件提供第三方插件的模式,自定义拦截 action -> reducer 的过程。变为 action -> middlewares -> reducer 。这种机制可以让我们改变数据流,实现如异步 action ,action 过 滤,日志输出,异常报告等功能
常见的中间件:
redux-logger:提供日志输出;redux-thunk:处理异步操作;redux-promise: 处理异步操作;actionCreator的返回值是promise
redux中间件的原理是什么
applyMiddleware
为什么会出现中间件?
- 它只是一个用来加工dispatch的工厂,而要加工什么样的dispatch出来,则需要我们传入对应的中间件函数
- 让每一个中间件函数,接收一个dispatch,然后返回一个改造后的dispatch,来作为下一个中间件函数的next,以此类推。
function applyMiddleware(middlewares) {middlewares = middlewares.slice()middlewares.reverse()let dispatch = store.dispatchmiddlewares.forEach(middleware =>dispatch = middleware(store)(dispatch))return Object.assign({}, store, { dispatch })
}
上面的
middleware(store)(dispatch)就相当于是const logger = store => next => {},这就是构造后的dispatch,继续向下传递。这里middlewares.reverse(),进行数组反转的原因,是最后构造的dispatch,实际上是最先执行的。因为在applyMiddleware串联的时候,每个中间件只是返回一个新的dispatch函数给下一个中间件,实际上这个dispatch并不会执行。只有当我们在程序中通过store.dispatch(action),真正派发的时候,才会执行。而此时的dispatch是最后一个中间件返回的包装函数。然后依次向前递推执行。
action、store、reducer分析
redux的核心概念就是store、action、reducer,从调用关系来看如下所示
store.dispatch(action) --> reducer(state, action) --> final state
// reducer方法, 传入的参数有两个
// state: 当前的state
// action: 当前触发的行为, {type: 'xx'}
// 返回值: 新的state
var reducer = function(state, action){switch (action.type) {case 'add_todo':return state.concat(action.text);default:return state;}
};// 创建store, 传入两个参数
// 参数1: reducer 用来修改state
// 参数2(可选): [], 默认的state值,如果不传, 则为undefined
var store = redux.createStore(reducer, []);// 通过 store.getState() 可以获取当前store的状态(state)
// 默认的值是 createStore 传入的第二个参数
console.log('state is: ' + store.getState()); // state is:// 通过 store.dispatch(action) 来达到修改 state 的目的
// 注意: 在redux里,唯一能够修改state的方法,就是通过 store.dispatch(action)
store.dispatch({type: 'add_todo', text: '读书'});
// 打印出修改后的state
console.log('state is: ' + store.getState()); // state is: 读书store.dispatch({type: 'add_todo', text: '写作'});
console.log('state is: ' + store.getState()); // state is: 读书,写作
- store、reducer、action关联
store
store在这里代表的是数据模型,内部维护了一个state变量store有两个核心方法,分别是getState、dispatch。前者用来获取store的状态(state),后者用来修改store的状态
// 创建store, 传入两个参数
// 参数1: reducer 用来修改state
// 参数2(可选): [], 默认的state值,如果不传, 则为undefined
var store = redux.createStore(reducer, []);// 通过 store.getState() 可以获取当前store的状态(state)
// 默认的值是 createStore 传入的第二个参数
console.log('state is: ' + store.getState()); // state is:// 通过 store.dispatch(action) 来达到修改 state 的目的
// 注意: 在redux里,唯一能够修改state的方法,就是通过 store.dispatch(action)
store.dispatch({type: 'add_todo', text: '读书'});
action
- 对行为(如用户行为)的抽象,在
redux里是一个普通的js对象 action必须有一个type字段来标识这个行为的类型
{type:'add_todo', text:'读书'}
{type:'add_todo', text:'写作'}
{type:'add_todo', text:'睡觉', time:'晚上'}
reducer
- 一个普通的函数,用来修改
store的状态。传入两个参数state、action - 其中,
state为当前的状态(可通过store.getState()获得),而action为当前触发的行为(通过store.dispatch(action)调用触发) reducer(state, action)返回的值,就是store最新的state值
// reducer方法, 传入的参数有两个
// state: 当前的state
// action: 当前触发的行为, {type: 'xx'}
// 返回值: 新的state
var reducer = function(state, action){switch (action.type) {case 'add_todo':return state.concat(action.text);default:return state;}
};
- 关于
actionCreator
actionCreator(args) => action
var addTodo = function(text){return {type: 'add_todo',text: text};
};addTodo('睡觉'); // 返回:{type: 'add_todo', text: '睡觉'}
异步Action及操作
- 创建同步Action
Action是数据从应用传递到store/state的载体,也是开启一次完成数据流的开始
普通的action对象
const action = {type:'ADD_TODO',name:'poetries'
}dispatch(action)
封装action creator
function actionCreator(data){return {type:'ADD_TODO',data:data}
}dispatch(actionCreator('poetries'))
bindActionCreators合并
function a(name,id){reurn {type:'a',name,id}
}
function b(name,id){reurn {type:'b',name,id}
}let actions = Redux.bindActionCreators({a,b},store.dispatch)//调用
actions.a('poetries','id001')
actions.b('jing','id002')
action创建的标准
在Flux的架构中,一个Action要符合 FSA(Flux Standard Action) 规范,需要满足如下条件
- 是一个纯文本对象
- 只具备
type、payload、error和meta中的一个或者多个属性。type字段不可缺省,其它字段可缺省 - 若
Action报错,error字段不可缺省,切必须为true
payload是一个对象,用作Action携带数据的载体
标准action示例
- A basic Flux Standard Action:
{type: 'ADD_TODO',payload: {text: 'Do something.' }
}
- An FSA that represents an error, analogous to a rejected Promise
{type: 'ADD_TODO',payload: new Error(),error: true
}
https://github.com/acdlite/flux-standard-action
- 可以采用如下一个简单的方式检验一个
Action是否符合FSA标准
// every有一个匹配不到返回false
let isFSA = Object.keys(action).every((item)=>{return ['payload','type','error','meta'].indexOf(item) > -1
})
- 创建异步action的多种方式
最简单的方式就是使用同步的方式来异步,将原来同步时一个
action拆分成多个异步的action的,在异步开始前、异步请求中、异步正常返回(异常)操作分别使用同步的操作,从而模拟出一个异步操作了。这样的方式是比较麻烦的,现在已经有redux-saga等插件来解决这些问题了
异步action的实现方式一:setTimeout
redux-thunk中间处理解析
function thunkAction(data) {reutrn (dispatch)=>{setTimeout(function(){dispatch({type:'ADD_TODO',data})},3000)}
}
异步action的实现方式二:promise实现异步action
redux-promise中间处理这种action
function promiseAction(name){return new Promise((resolve,reject) => {setTimeout((param)=>{resolve({type:'ADD_TODO',name})},3000)}).then((param)=>{dispatch(action("action2"))return;}).then((param)=>{dispatch(action("action3"))})
}
- redux异步流程
-
首先发起一个action,然后通过中间件,这里为什么要用中间件呢,因为这样
dispatch的返回值才能是一个函数。 -
通过
store.dispatch,将状态的的改变传给store的小弟reducer,reducer根据action的改变,传递新的状态state。 -
最后将所有的改变告诉给它的大哥,
store。store保存着所有的数据,并将数据注入到组件的顶部,这样组件就可以获得它需要的数据了
- Redux异步方案选型
redux-thunk
Redux本身只能处理同步的Action,但可以通过中间件来拦截处理其它类型的action,比如函数(Thunk),再用回调触发普通Action,从而实现异步处理
- 发送异步的
action其实是被中间件捕获的,函数类型的action就被middleware捕获。至于怎么定义异步的action要看你用哪个中间件,根据他们的实例来定义,这样才会正确解析action
Redux本身不处理异步行为,需要依赖中间件。结合redux-actions使用,Redux有两个推荐的异步中间件
redux-thunkredux-promise
redux-thunk的源码如下
function createThunkMiddleware(extraArgument) {return ({ dispatch, getState }) => next => action => {if (typeof action === 'function') {return action(dispatch, getState, extraArgument);}return next(action);};
}const thunk = createThunkMiddleware();
thunk.withExtraArgument = createThunkMiddleware;export default thunk;
源码可知,
action creator需要返回一个函数给redux-thunk进行调用,示例如下
export let addTodoWithThunk = (val) => async (dispatch, getState)=>{//请求之前的一些处理let value = await Promise.resolve(val + ' thunk');dispatch({type:CONSTANT.ADD_TO_DO_THUNK,payload:{value}});
};
- 而它使用起来最大的问题,就是重复的模板代码太多
//action types
const GET_DATA = 'GET_DATA',GET_DATA_SUCCESS = 'GET_DATA_SUCCESS',GET_DATA_FAILED = 'GET_DATA_FAILED';//action creator
const getDataAction = (id) => (dispatch, getState) => {dispatch({type: GET_DATA, payload: id})api.getData(id) //注:本文所有示例的api.getData都返回promise对象.then(response => {dispatch({type: GET_DATA_SUCCESS,payload: response})}).catch(error => {dispatch({type: GET_DATA_FAILED,payload: error})}) }
}//reducer
const reducer = (oldState, action) => {switch(action.type) {case GET_DATA : return oldState;case GET_DATA_SUCCESS : return successState;case GET_DATA_FAILED : return errorState;}
}
这已经是最简单的场景了,请注意:我们甚至还没写一行业务逻辑,如果每个异步处理都像这样,重复且无意义的工作会变成明显的阻碍
- 另一方面,像
GET_DATA_SUCCESS、GET_DATA_FAILED这样的字符串声明也非常无趣且易错 上例中,GET_DATA这个action并不是多数场景需要的
redux-promise
由于
redux-thunk写起来实在是太麻烦了,社区当然会有其它轮子出现。redux-promise则是其中比较知名的
- 它自定义了一个
middleware,当检测到有action的payload属性是Promise对象时,就会- 若
resolve,触发一个此action的拷贝,但payload为promise的value,并设status属性为"success" - 若
reject,触发一个此action的拷贝,但payload为promise的reason,并设status属性为"error"
- 若
//action types
const GET_DATA = 'GET_DATA';//action creator
const getData = function(id) {return {type: GET_DATA,payload: api.getData(id) //payload为promise对象}
}//reducer
function reducer(oldState, action) {switch(action.type) {case GET_DATA: if (action.status === 'success') {return successState} else {return errorState}}
}
redux-promise为了精简而做出的妥协非常明显:无法处理乐观更新
场景解析之:乐观更新
多数异步场景都是悲观更新的,即等到请求成功才渲染数据。而与之相对的乐观更新,则是不等待请求成功,在发送请求的同时立即渲染数据
- 由于乐观更新发生在用户操作时,要处理它,意味着必须有action表示用户的初始动作
- 在上面
redux-thunk的例子中,我们看到了GET_DATA,GET_DATA_SUCCESS、GET_DATA_FAILED三个action,分别表示初始动作、异步成功和异步失败,其中第一个action使得redux-thunk具备乐观更新的能力 - 而在
redux-promise中,最初触发的action被中间件拦截然后过滤掉了。原因很简单,redux认可的action对象是plain JavaScript objects,即简单对象,而在redux-promise中,初始action的payload是个Promise
redux-promise-middleware
redux-promise-middleware相比redux-promise,采取了更为温和和渐进式的思路,保留了和redux-thunk类似的三个action
//action types
const GET_DATA = 'GET_DATA',GET_DATA_PENDING = 'GET_DATA_PENDING',GET_DATA_FULFILLED = 'GET_DATA_FULFILLED',GET_DATA_REJECTED = 'GET_DATA_REJECTED';//action creator
const getData = function(id) {return {type: GET_DATA,payload: {promise: api.getData(id),data: id}}
}//reducer
const reducer = function(oldState, action) {switch(action.type) {case GET_DATA_PENDING :return oldState; // 可通过action.payload.data获取idcase GET_DATA_FULFILLED : return successState;case GET_DATA_REJECTED : return errorState;}
}
- redux异步操作代码演示
- 根据官网的async例子分析 https://github.com/lewis617/react-redux-tutorial/tree/master/redux-examples/async
action/index.js
import fetch from 'isomorphic-fetch'
export const RECEIVE_POSTS = 'RECEIVE_POSTS'//获取新闻成功的action
function receivePosts(reddit, json) {return {type: RECEIVE_POSTS,reddit: reddit,posts: json.data.children.map(child =>child.data)}
}function fetchPosts(subreddit) {return function (dispatch) {return fetch(`http://www.subreddit.com/r/${subreddit}.json`).then(response => response.json()).then(json =>dispatch(receivePosts(subreddit, json)))}
}//如果需要则开始获取文章
export function fetchPostsIfNeeded(subreddit) {return (dispatch, getState) => {return dispatch(fetchPosts(subreddit))}
}
fetchPostsIfNeeded这里就是一个中间件。redux-thunk会拦截fetchPostsIfNeeded这个action,会先发起数据请求,如果成功,就将数据传给action从而到达reducer那里
reducers/index.js
import { combineReducers } from 'redux'
import {RECEIVE_POSTS
} from '../actions'function posts(state = {items: []
}, action) {switch (action.type) {case RECEIVE_POSTS:// Object.assign是ES6的一个语法。合并对象,将对象合并为一个,前后相同的话,后者覆盖强者。详情可以看这里// https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/assignreturn Object.assign({}, state, {items: action.posts //数据都存在了这里})default:return state}
}// 将所有的reducer结合为一个,传给store
const rootReducer = combineReducers({postsByReddit
})export default rootReducer
这个跟正常的
reducer差不多。判断action的类型,从而根据action的不同类型,返回不同的数据。这里将数据存储在了items这里。这里的reducer只有一个。最后结合成rootReducer,传给store
store/configureStore.js
import { createStore, applyMiddleware } from 'redux'
import thunkMiddleware from 'redux-thunk'
import createLogger from 'redux-logger'
import rootReducer from '../reducers'const createStoreWithMiddleware = applyMiddleware(thunkMiddleware, createLogger()
)(createStore)export default function configureStore(initialState) {const store = createStoreWithMiddleware(rootReducer, initialState)if (module.hot) {// Enable Webpack hot module replacement for reducersmodule.hot.accept('../reducers', () => {const nextRootReducer = require('../reducers')store.replaceReducer(nextRootReducer)})}return store
}
- 我们是如何在
dispatch机制中引入Redux Thunk middleware的呢? 我们使用了applyMiddleware() - 通过使用指定的
middleware,action creator除了返回action对象外还可以返回函数 - 这时,这个
action creator就成为了thunk
界面上的调用:在containers/App.js
//初始化渲染后触发componentDidMount() {const { dispatch} = this.props// 这里可以传两个值,一个是 reactjs 一个是 frontenddispatch(fetchPostsIfNeeded('frontend'))}
改变状态的时候也是需要通过
dispatch来传递的
- 数据的获取是通过
provider,将store里面的数据注入给组件。让顶级组件提供给他们的子孙组件调用。代码如下:
import 'babel-core/polyfill'
import React from 'react'
import { render } from 'react-dom'
import { Provider } from 'react-redux'
import App from './containers/App'
import configureStore from './store/configureStore'
const store = configureStore()
render(<Provider store={store}><App /></Provider>,document.getElementById('root')
)
这样就完成了
redux的异步操作。其实最主要的区别还是action里面还有中间件的调用,其他的地方基本跟同步的redux差不多的。搞懂了中间件,就基本搞懂了redux的异步操作
----------@----------
谈谈你对状态管理的理解
- 首先介绍 Flux,Flux 是一种使用单向数据流的形式来组合 React 组件的应用架构。
- Flux 包含了 4 个部分,分别是
Dispatcher、Store、View、Action。Store存储了视图层所有的数据,当Store变化后会引起 View 层的更新。如果在视图层触发一个Action,就会使当前的页面数据值发生变化。Action 会被 Dispatcher 进行统一的收发处理,传递给 Store 层,Store 层已经注册过相关 Action 的处理逻辑,处理对应的内部状态变化后,触发 View 层更新。 Flux 的优点是单向数据流,解决了 MVC 中数据流向不清的问题,使开发者可以快速了解应用行为。从项目结构上简化了视图层设计,明确了分工,数据与业务逻辑也统一存放管理,使在大型架构的项目中更容易管理、维护代码。其次是 Redux,Redux 本身是一个 JavaScript 状态容器,提供可预测化状态的管理。社区通常认为 Redux 是 Flux 的一个简化设计版本,它提供的状态管理,简化了一些高级特性的实现成本,比如撤销、重做、实时编辑、时间旅行、服务端同构等。- Redux 的核心设计包含了三大原则:
单一数据源、纯函数 Reducer、State 是只读的。 - Redux 中整个数据流的方案与 Flux 大同小异
- Redux 中的另一大核心点是处理“副作用”,AJAX 请求等异步工作,或不是纯函数产生的第三方的交互都被认为是 “副作用”。这就造成在纯函数设计的 Redux 中,处理副作用变成了一件至关重要的事情。社区通常有两种解决方案:
- 第一类是在
Dispatch的时候会有一个middleware 中间件层,拦截分发的Action 并添加额外的复杂行为,还可以添加副作用。第一类方案的流行框架有Redux-thunk、Redux-Promise、Redux-Observable、Redux-Saga等。 - 第二类是允许
Reducer层中直接处理副作用,采取该方案的有React Loop,React Loop在实现中采用了 Elm 中分形的思想,使代码具备更强的组合能力。 - 除此以外,社区还提供了更为工程化的方案,比如
rematch 或 dva,提供了更详细的模块架构能力,提供了拓展插件以支持更多功能。
- 第一类是在
- Redux 的优点很多:
- 结果可预测;
- 代码结构严格易维护;
- 模块分离清晰且小函数结构容易编写单元测试;
Action触发的方式,可以在调试器中使用时间回溯,定位问题更简单快捷;- 单一数据源使服务端同构变得更为容易;社区方案多,生态也更为繁荣。
最后是 Mobx,Mobx 通过监听数据的属性变化,可以直接在数据上更改触发UI 的渲染。在使用上更接近 Vue,比起Flux 与 Redux的手动挡的体验,更像开自动挡的汽车。Mobx 的响应式实现原理与 Vue 相同,以Mobx 5为分界点,5 以前采用Object.defineProperty的方案,5 及以后使用Proxy的方案。它的优点是样板代码少、简单粗暴、用户学习快、响应式自动更新数据让开发者的心智负担更低。- Mobx 在开发项目时简单快速,但应用 Mobx 的场景 ,其实完全可以用 Vue 取代。如果纯用 Vue,体积还会更小巧

----------@----------
connect组件原理分析
1. connect用法
作用:连接
React组件与Redux store
connect([mapStateToProps], [mapDispatchToProps], [mergeProps],[options])
// 这个函数允许我们将 store 中的数据作为 props 绑定到组件上
const mapStateToProps = (state) => {return {count: state.count}
}
- 这个函数的第一个参数就是
Redux的store,我们从中摘取了count属性。你不必将state中的数据原封不动地传入组件,可以根据state中的数据,动态地输出组件需要的(最小)属性 - 函数的第二个参数
ownProps,是组件自己的props
当
state变化,或者ownProps变化的时候,mapStateToProps都会被调用,计算出一个新的stateProps,(在与ownProps merge后)更新给组件
mapDispatchToProps(dispatch, ownProps): dispatchProps
connect的第二个参数是mapDispatchToProps,它的功能是,将action作为props绑定到组件上,也会成为MyComp的 `props
2. 原理解析
首先
connect之所以会成功,是因为Provider组件
- 在原应用组件上包裹一层,使原来整个应用成为
Provider的子组件 - 接收
Redux的store作为props,通过context对象传递给子孙组件上的connect
connect做了些什么
它真正连接
Redux和React,它包在我们的容器组件的外一层,它接收上面Provider提供的store里面的state和dispatch,传给一个构造函数,返回一个对象,以属性形式传给我们的容器组件
3. 源码
connect是一个高阶函数,首先传入mapStateToProps、mapDispatchToProps,然后返回一个生产Component的函数(wrapWithConnect),然后再将真正的Component作为参数传入wrapWithConnect,这样就生产出一个经过包裹的Connect组件,该组件具有如下特点
- 通过
props.store获取祖先Component的store props包括stateProps、dispatchProps、parentProps,合并在一起得到nextState,作为props传给真正的Component componentDidMount时,添加事件this.store.subscribe(this.handleChange),实现页面交互shouldComponentUpdate时判断是否有避免进行渲染,提升页面性能,并得到nextStatecomponentWillUnmount时移除注册的事件this.handleChange
// 主要逻辑export default function connect(mapStateToProps, mapDispatchToProps, mergeProps, options = {}) {return function wrapWithConnect(WrappedComponent) {class Connect extends Component {constructor(props, context) {// 从祖先Component处获得storethis.store = props.store || context.storethis.stateProps = computeStateProps(this.store, props)this.dispatchProps = computeDispatchProps(this.store, props)this.state = { storeState: null }// 对stateProps、dispatchProps、parentProps进行合并this.updateState()}shouldComponentUpdate(nextProps, nextState) {// 进行判断,当数据发生改变时,Component重新渲染if (propsChanged || mapStateProducedChange || dispatchPropsChanged) {this.updateState(nextProps)return true}}componentDidMount() {// 改变Component的statethis.store.subscribe(() = {this.setState({storeState: this.store.getState()})})}render() {// 生成包裹组件Connectreturn (<WrappedComponent {...this.nextState} />)}}Connect.contextTypes = {store: storeShape}return Connect;}
}
----------@----------
React Hooks
- 代码逻辑聚合,逻辑复用
- HOC嵌套地狱
- 代替class
React 中通常使用 类定义 或者 函数定义 创建组件:
在类定义中,我们可以使用到许多 React 特性,例如 state、 各种组件生命周期钩子等,但是在函数定义中,我们却无能为力,因此 React 16.8 版本推出了一个新功能 (React Hooks),通过它,可以更好的在函数定义组件中使用 React 特性。
函数组件与类组件的对比:无关“优劣”,只谈“不同”
- 类组件需要继承 class,函数组件不需要;
- 类组件可以访问生命周期方法,函数组件不能;
- 类组件中可以获取到实例化后的 this,并基于这个 this 做各种各样的事情,而函数组件不可以;
- 类组件中可以定义并维护 state(状态),而函数组件不可以;
但是类组件它太重了,对于解决许多问题来说,编写一个类组件实在是一个过于复杂的姿势。复杂的姿势必然带来高昂的理解成本,这也是我们所不想看到的
react hooks的好处:
-
跨组件复用: 其实 render props / HOC 也是为了复用,相比于它们,Hooks 作为官方的底层 API,最为轻量,而且改造成本小,不会影响原来的组件层次结构和传说中的嵌套地狱;
-
类定义更为复杂
-
不同的生命周期会使逻辑变得分散且混乱,不易维护和管理;
-
时刻需要关注this的指向问题;
-
代码复用代价高,高阶组件的使用经常会使整个组件树变得臃肿;
- 状态与UI隔离: 正是由于 Hooks 的特性,状态逻辑会变成更小的粒度,并且极容易被抽象成一个自定义 Hooks,组件中的状态和 UI 变得更为清晰和隔离。
注意:
- 避免在 循环/条件判断/嵌套函数 中调用 hooks,保证调用顺序的稳定;
- 只有 函数定义组件 和 hooks 可以调用 hooks,避免在 类组件 或者 普通函数 中调用;
- 不能在useEffect中使用useState,React 会报错提示;
- 类组件不会被替换或废弃,不需要强制改造类组件,两种方式能并存;
重要钩子
- 状态钩子 (useState): 用于定义组件的 State,其到类定义中this.state的功能;
// useState 只接受一个参数: 初始状态
// 返回的是组件名和更改该组件对应的函数
const [flag, setFlag] = useState(true);
// 修改状态
setFlag(false)// 上面的代码映射到类定义中:
this.state = {flag: true
}
const flag = this.state.flag
const setFlag = (bool) => {this.setState({flag: bool,})
}
- 生命周期钩子 (useEffect):
类定义中有许多生命周期函数,而在 React Hooks 中也提供了一个相应的函数 (useEffect),这里可以看做componentDidMount、componentDidUpdate和componentWillUnmount的结合。
useEffect(callback, [source])接受两个参数
- callback: 钩子回调函数;
- source: 设置触发条件,仅当 source 发生改变时才会触发;
- useEffect钩子在没有传入[source]参数时,默认在每次 render 时都会优先调用上次保存的回调中返回的函数,后再重新调用回调;
useEffect(() => {// 组件挂载后执行事件绑定console.log('on')addEventListener()// 组件 update 时会执行事件解绑return () => {console.log('off')removeEventListener()}
}, [source]);// 每次 source 发生改变时,执行结果(以类定义的生命周期,便于大家理解):
// --- DidMount ---
// 'on'
// --- DidUpdate ---
// 'off'
// 'on'
// --- DidUpdate ---
// 'off'
// 'on'
// --- WillUnmount ---
// 'off'
通过第二个参数,我们便可模拟出几个常用的生命周期:
- componentDidMount: 传入[]时,就只会在初始化时调用一次
const useMount = (fn) => useEffect(fn, [])
- componentWillUnmount: 传入[],回调中的返回的函数也只会被最终执行一次
const useUnmount = (fn) => useEffect(() => fn, [])
- mounted: 可以使用 useState 封装成一个高度可复用的 mounted 状态;
const useMounted = () => {const [mounted, setMounted] = useState(false);useEffect(() => {!mounted && setMounted(true);return () => setMounted(false);}, []);return mounted;
}
- componentDidUpdate: useEffect每次均会执行,其实就是排除了 DidMount 后即可;
const mounted = useMounted()
useEffect(() => {mounted && fn()
})
- 其它内置钩子:
-
useContext: 获取 context 对象 -
useReducer: 类似于 Redux 思想的实现,但其并不足以替代 Redux,可以理解成一个组件内部的 redux:- 并不是持久化存储,会随着组件被销毁而销毁;
- 属于组件内部,各个组件是相互隔离的,单纯用它并无法共享数据;
- 配合useContext`的全局性,可以完成一个轻量级的 Redux;(easy-peasy)
-
useCallback: 缓存回调函数,避免传入的回调每次都是新的函数实例而导致依赖组件重新渲染,具有性能优化的效果; -
useMemo: 用于缓存传入的 props,避免依赖的组件每次都重新渲染; -
useRef: 获取组件的真实节点; -
useLayoutEffect- DOM更新同步钩子。用法与useEffect类似,只是区别于执行时间点的不同
- useEffect属于异步执行,并不会等待 DOM 真正渲染后执行,而useLayoutEffect则会真正渲染后才触发;
- 可以获取更新后的 state;
- 自定义钩子(useXxxxx): 基于 Hooks 可以引用其它 Hooks 这个特性,我们可以编写自定义钩子,如上面的useMounted。又例如,我们需要每个页面自定义标题:
function useTitle(title) {useEffect(() => {document.title = title;});
}// 使用:
function Home() {const title = '我是首页'useTitle(title)return (<div>{title}</div>)
}
React Hooks 的限制

- 不要在
循环、条件或嵌套函数中调用 Hook; - 在 React 的函数组件中调用
Hook
那为什么会有这样的限制呢?就得从 Hooks 的设计说起。Hooks 的设计初衷是为了改进 React 组件的开发模式。在旧有的开发模式下遇到了三个问题。
- 组件之间难以复用状态逻辑。过去常见的解决方案是高阶组件、
render props及状态管理框架。 - 复杂的组件变得难以理解。生命周期函数与业务逻辑耦合太深,导致关联部分难以拆分。
- 常见的有 this 的问题,但在 React 团队中还有类难以优化的问题,他们希望在编译优化层面做出一些改进。
这三个问题在一定程度上阻碍了 React 的后续发展,所以为了解决这三个问题,Hooks 基于函数组件开始设计。然而第三个问题决定了 Hooks 只支持函数组件。
那为什么不要在循环、条件或嵌套函数中调用 Hook 呢?因为 Hooks 的设计是基于数组实现。在调用时按顺序加入数组中,如果使用循环、条件或嵌套函数很有可能导致数组取值错位,执行错误的 Hook。当然,实质上 React 的源码里不是数组,是链表。
这些限制会在编码上造成一定程度的心智负担,新手可能会写错,为了避免这样的情况,可以引入 ESLint 的 Hooks 检查插件进行预防。
useEffect 与 useLayoutEffect 区别在哪里
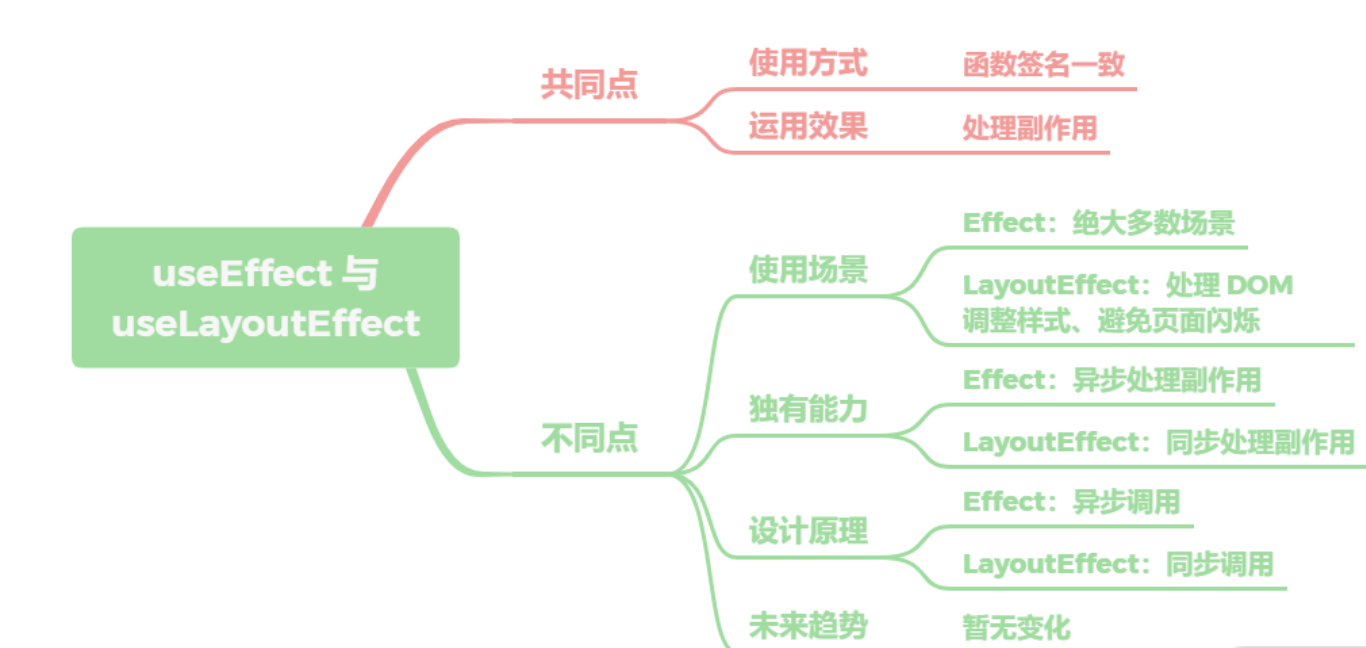
- 它们的共同点很简单,底层的函数签名是完全一致的,都是调用的
mountEffectImpl,在使用上也没什么差异,基本可以直接替换,也都是用于处理副作用。 - 那不同点就很大了,
useEffect在 React 的渲染过程中是被异步调用的,用于绝大多数场景,而LayoutEffect会在所有的 DOM 变更之后同步调用,主要用于处理 DOM 操作、调整样式、避免页面闪烁等问题。也正因为是同步处理,所以需要避免在LayoutEffect做计算量较大的耗时任务从而造成阻塞。 - 在未来的趋势上,两个 API 是会长期共存的,暂时没有删减合并的计划,需要开发者根据场景去自行选择。React 团队的建议非常实用,如果实在分不清,先用
useEffect,一般问题不大;如果页面有异常,再直接替换为useLayoutEffect即可。
----------@----------
受控组件和非受控组件
<FInput value = {x} onChange = {fn} />
// 上面的是受控组件 下面的是非受控组件
<FInput defaultValue = {x} />
- 当你一个组件同时传递一个value以及onChange事件时,它就是一个受控组件,收入输出都是我来控制的。
- 第二个只是传递了默认的初时值,并没有传onchange事件,
- 非受控组件是一种反模式,它的值不受组件自身的state或props控制
----------@----------
如何避免ajax数据请求重新获取
一般而言,ajax请求的数据都放在redux中存取。
----------@----------
组件之间通信
- 父子组件通信
- 自定义事件
- redux和context
context如何运用
- 父组件向其下所有子孙组件传递信息
- 如一些简单的信息:主题、语言
- 复杂的公共信息用redux
在跨层级通信中,主要分为一层或多层的情况
- 如果只有一层,那么按照 React 的树形结构进行分类的话,主要有以下三种情况:
父组件向子组件通信,子组件向父组件通信以及平级的兄弟组件间互相通信。 - 在父与子的情况下 ,因为 React 的设计实际上就是传递
Props即可。那么场景体现在容器组件与展示组件之间,通过Props传递state,让展示组件受控。 - 在子与父的情况下 ,有两种方式,分别是回调函数与实例函数。回调函数,比如输入框向父级组件返回输入内容,按钮向父级组件传递点击事件等。实例函数的情况有些特别,主要是在父组件中
通过 React 的 ref API 获取子组件的实例,然后是通过实例调用子组件的实例函数。这种方式在过去常见于 Modal 框的显示与隐藏 - 多层级间的数据通信,有两种情况 。第一种是一个容器中包含了多层子组件,需要最底部的子组件与顶部组件进行通信。在这种情况下,如果不断透传 Props 或回调函数,不仅代码层级太深,后续也很不好维护。第二种是两个组件不相关,在整个 React 的组件树的两侧,完全不相交。那么基于多层级间的通信一般有三个方案。
- 第一个是使用 React 的
Context API,最常见的用途是做语言包国际化 - 第二个是使用全局变量与事件。
- 第三个是使用状态管理框架,比如 Flux、Redux 及 Mobx。优点是由于引入了状态管理,使得项目的开发模式与代码结构得以约束,缺点是学习成本相对较高
- 第一个是使用 React 的

----------@----------
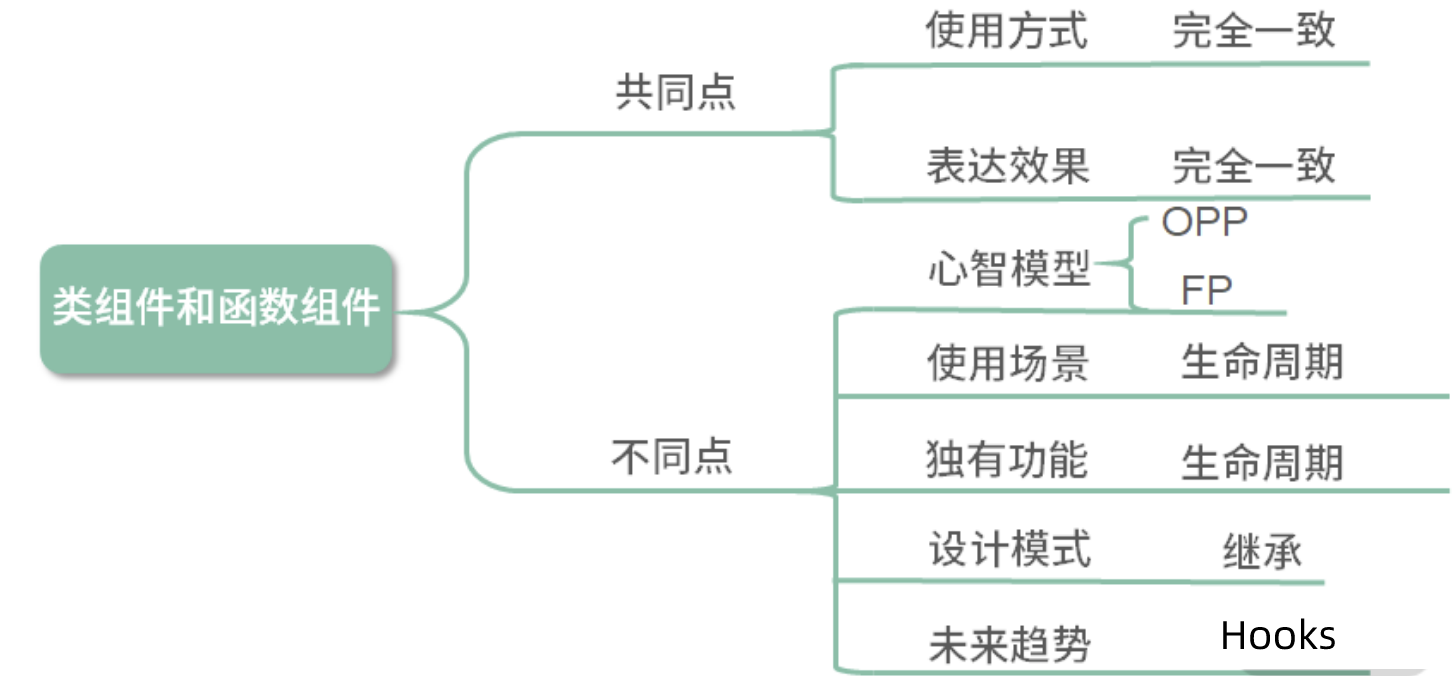
类组件与函数组件有什么区别呢?
- 作为组件而言,类组件与函数组件在使用与呈现上没有任何不同,性能上在现代浏览器中也不会有明显差异
- 它们在开发时的心智模型上却存在巨大的差异。类组件是基于面向对象编程的,它主打的是继承、生命周期等核心概念;而函数组件内核是函数式编程,主打的是 immutable、没有副作用、引用透明等特点。
- 之前,在使用场景上,如果存在需要使用生命周期的组件,那么主推类组件;设计模式上,如果需要使用继承,那么主推类组件。
- 但现在由于 React Hooks 的推出,生命周期概念的淡出,函数组件可以完全取代类组件。
- 其次继承并不是组件最佳的设计模式,官方更推崇“组合优于继承”的设计概念,所以类组件在这方面的优势也在淡出。
- 性能优化上,类组件主要依靠
shouldComponentUpdate阻断渲染来提升性能,而函数组件依靠React.memo缓存渲染结果来提升性能。 - 从上手程度而言,类组件更容易上手,从未来趋势上看,由于React Hooks 的推出,函数组件成了社区未来主推的方案。
- 类组件在未来时间切片与并发模式中,由于生命周期带来的复杂度,并不易于优化。而函数组件本身轻量简单,且在 Hooks 的基础上提供了比原先更细粒度的逻辑组织与复用,更能适应 React 的未来发展。
----------@----------
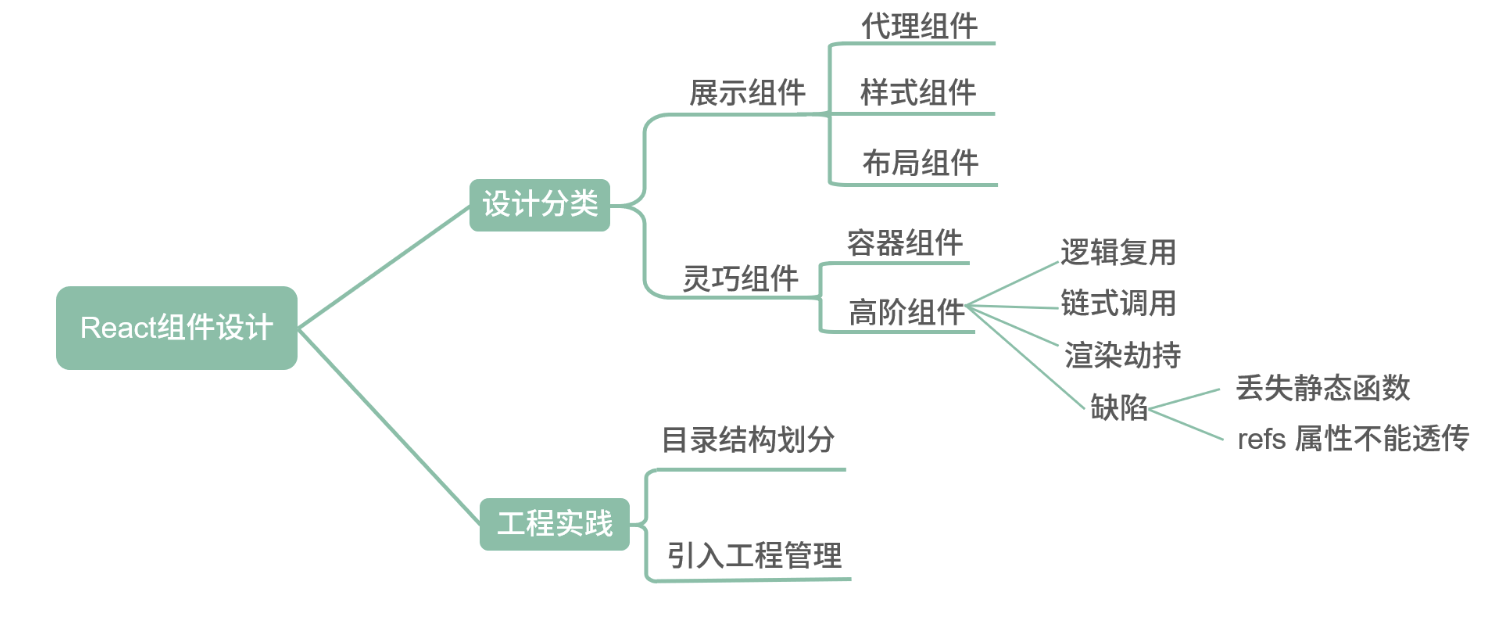
如何设计React组件
React 组件应从设计与工程实践两个方向进行探讨
从设计上而言,社区主流分类的方案是展示组件与灵巧组件
展示组件内部没有状态管理,仅仅用于最简单的展示表达。展示组件中最基础的一类组件称作代理组件。代理组件常用于封装常用属性、减少重复代码。很经典的场景就是引入 Antd 的 Button 时,你再自己封一层。如果未来需要替换掉 Antd 或者需要在所有的 Button 上添加一个属性,都会非常方便。基于代理组件的思想还可以继续分类,分为样式组件与布局组件两种,分别是将样式与布局内聚在自己组件内部。- 从工程实践而言,通过文件夹划分的方式切分代码。我初步常用的分割方式是将页面单独建立一个目录,将复用性略高的 components 建立一个目录,在下面分别建立 basic、container 和 hoc 三类。这样可以保证无法复用的业务逻辑代码尽量留在 Page 中,而可以抽象复用的部分放入 components 中。其中 basic 文件夹放展示组件,由于展示组件本身与业务关联性较低,所以可以使用 Storybook 进行组件的开发管理,提升项目的工程化管理能力
----------@----------
组件的协同及(不)可控组件
为什么要进行组件的协同
- 我们在实际的开发项目的时候,不会只用几个组件,有时候遇到大型的项目,可能会有成千上百的组件,难免会遇到有功能重复的组件。要进行修改,就会修改大部分的文件。所以我们需要进行组件的协同开发。

什么是组件的协同使用?
- 组件的协同本质上是对组件的一种组织、管理的方式。
- 目的:
- 逻辑清晰:这是组件与组件之间的逻辑
- 代码模块化
- 封装细节:像面向对象一样将常用的方法以及数据封装起来
- 提高代码的复用性:因为是组件,相当于一个封装好的东西,用的时候直接调用
如何实现组件的协同使用
- 第一种:增加一个父组件,将其他的组件进行嵌套,更多的是实现代码的封装
- 第二种:通过一些操作从后台获取数据,
React中的Mixin,更多的是实现代码的复用
组件嵌套的含义
- 组件嵌套的本质是父子关系

组件嵌套的优缺点
- 优点:
- 逻辑清晰:父子关系类似于人类中的父子关系
- 模块化开发:每个模块对应一个功能,不同的模块可以同步开发
- 封装细节:开发者必须要关注组件的功能,不需要了解细节
- 缺点:
- 编写难度高:父子组件的关系需要经过深思熟虑,贸然编写可能导致关系混乱,代码难以维护
- 无法掌握所有细节:使用者只知道组件的用法,不知道实现细节,遇到问题难以修复
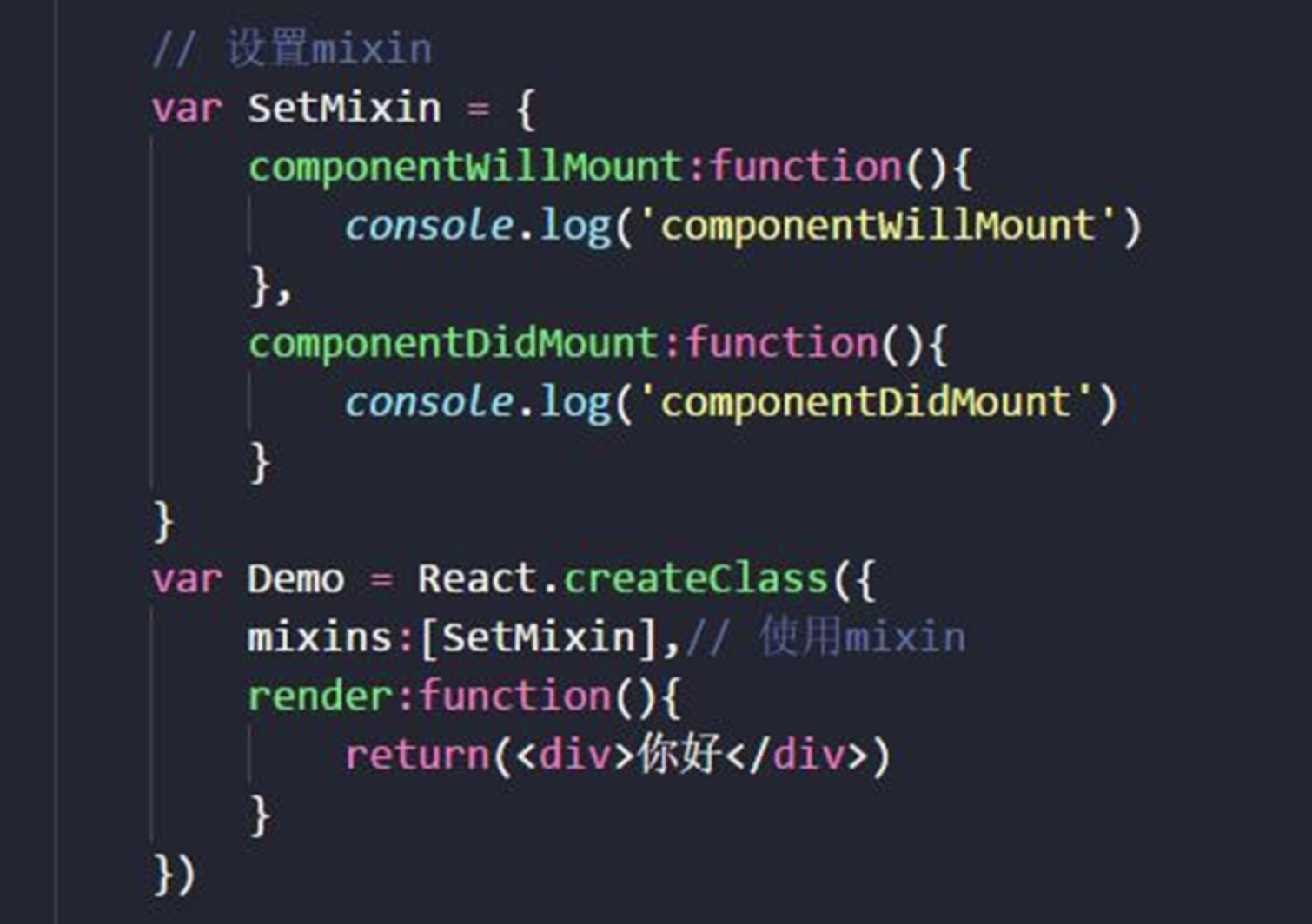
Mixin
Mixin的含义
Mixin=一组方法。- 他的目的是横向抽离出组件的相似代码,把组件的共同作用以及效果的代码提出来
Mixin的优缺点
- 优点
- 代码复用:抽离出通用的代码,减少开发成本,提高开发效率
- 即插即用:可以使用许多现有的
Mixin来开发自己的代码 - 适应性强:改动一次代码,影响多个组件
- 缺点
- 编写难度高:
Mixin可能被用在各种环境中,想要兼容多种环境就需要更多的 - 码与逻辑,通用的代价是提高复杂度 - 降低代码的可读性:组件的优势在于将逻辑与是界面直接结合在一起,
Mixin本质上会分散逻辑,理解起来难度大
- 编写难度高:
不可控组件

- 上图:
defaultValue的值是固定的,这就是一个不可控组件 - 如果要获取
input的value值,只有使用ref获取节点来获取值
可控组件

defaultValue的值是根据状态确定了,只需要拿到this.state.value的值就可以了- 这里需要注意一下:使用
value的值是不可修改的,defaultValue的值是可以修改的
可控组件的优点
- 符合
React的数据流 - 数据存储在
state中,便于获取 - 便于处理数据
----------@----------
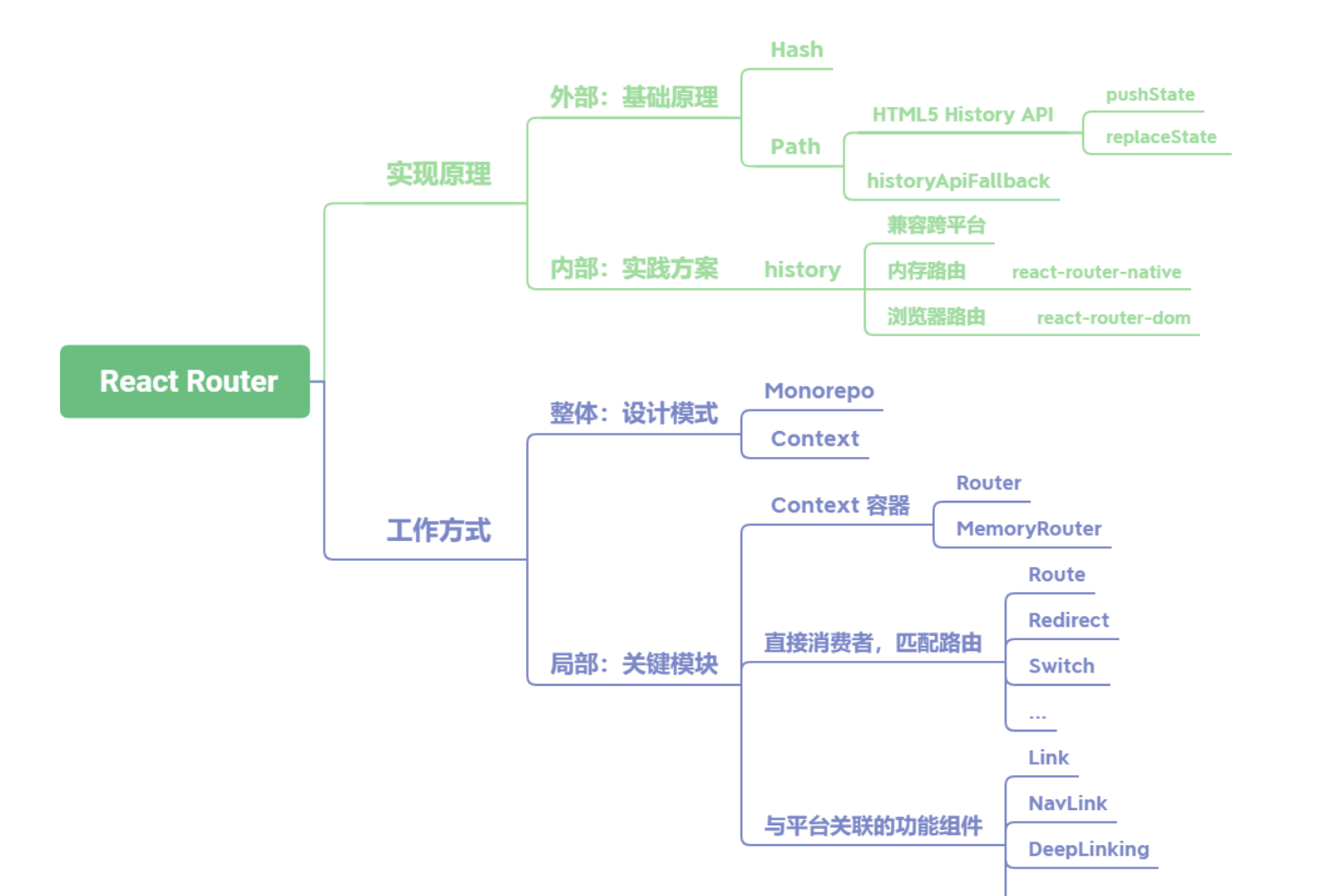
React-Router 的实现原理及工作方式分别是什么
React Router路由的基础实现原理分为两种,如果是切换 Hash的方式,那么依靠浏览器Hash变化即可;如果是切换网址中的Path,就要用到HTML5 History API中的pushState、replaceState等。在使用这个方式时,还需要在服务端完成historyApiFallback配置- 在
React Router内部主要依靠history库完成,这是由React Router自己封装的库,为了实现跨平台运行的特性,内部提供两套基础history,一套是直接使用浏览器的History API,用于支持react-router-dom;另一套是基于内存实现的版本,这是自己做的一个数组,用于支持react-router-native。 React Router的工作方式可以分为设计模式与关键模块两个部分。从设计模式的角度出发,在架构上通过Monorepo进行库的管理。Monorepo具有团队间透明、迭代便利的优点。其次在整体的数据通信上使用了 Context API 完成上下文传递。- 在关键模块上,主要分为三类组件:
第一类是 Context 容器,比如 Router 与 MemoryRouter;第二类是消费者组件,用以匹配路由,主要有 Route、Redirect、Switch 等;第三类是与平台关联的功能组件,比如Link、NavLink、DeepLinking等。

----------@----------
React 17 带来了哪些改变
最重要的是以下三点:
- 新的
JSX转换逻辑 - 事件系统重构
Lane 模型的引入
1. 重构 JSX 转换逻辑
在过去,如果我们在 React 项目中写入下面这样的代码:
function MyComponent() {return <p>这是我的组件</p>
}
React 是会报错的,原因是 React 中对 JSX 代码的转换依赖的是 React.createElement 这个函数。因此但凡我们在代码中包含了 JSX,那么就必须在文件中引入 React,像下面这样:
import React from 'react';
function MyComponent() {return <p>这是我的组件</p>
}
而 React 17 则允许我们在不引入 React 的情况下直接使用 JSX。这是因为在 React 17 中,编译器会自动帮我们引入 JSX 的解析器,也就是说像下面这样一段逻辑:
function MyComponent() {return <p>这是我的组件</p>
}
会被编译器转换成这个样子:
import {jsx as _jsx} from 'react/jsx-runtime';
function MyComponent() {return _jsx('p', { children: '这是我的组件' });
}
react/jsx-runtime 中的 JSX 解析器将取代 React.createElement 完成 JSX 的编译工作,这个过程对开发者而言是自动化、无感知的。因此,新的 JSX 转换逻辑带来的最显著的改变就是降低了开发者的学习成本。
react/jsx-runtime 中的 JSX 解析器看上去似乎在调用姿势上和 React.createElement 区别不大,那么它是否只是 React.createElement 换了个马甲呢?当然不是,它在内部实现了 React.createElement 无法做到的性能优化和简化。在一定情况下,它可能会略微改善编译输出内容的大小
2. 事件系统重构
事件系统在 React 17 中的重构要从以下两个方面来看:
- 卸掉历史包袱
- 拥抱新的潮流
2.1 卸掉历史包袱:放弃利用 document 来做事件的中心化管控
React 16.13.x 版本中的事件系统会通过将所有事件冒泡到 document 来实现对事件的中心化管控
这样的做法虽然看上去已经足够巧妙,但仍然有它不聪明的地方——document 是整个文档树的根节点,操作 document 带来的影响范围实在是太大了,这将会使事情变得更加不可控
在 React 17 中,React 团队终于正面解决了这个问题:事件的中心化管控不会再全部依赖
document,管控相关的逻辑被转移到了每个 React 组件自己的容器 DOM 节点中。比如说我们在 ID 为 root 的 DOM 节点下挂载了一个 React 组件,像下面代码这样:
const rootElement = document.getElementById("root");
ReactDOM.render(<App />, rootElement);
那么事件管控相关的逻辑就会被安装到 root 节点上去。这样一来, React 组件就能够自己玩自己的,再也无法对全局的事件流构成威胁了
2.2 拥抱新的潮流:放弃事件池
在 React 17 之前,合成事件对象会被放进一个叫作“事件池”的地方统一管理。这样做的目的是能够实现事件对象的复用,进而提高性能:每当事件处理函数执行完毕后,其对应的合成事件对象内部的所有属性都会被置空,意在为下一次被复用做准备。这也就意味着事件逻辑一旦执行完毕,我们就拿不到事件对象了,React 官方给出的这个例子就很能说明问题,请看下面这个代码
function handleChange(e) {// This won't work because the event object gets reused.setTimeout(() => {console.log(e.target.value); // Too late!}, 100);
}
异步执行的
setTimeout回调会在handleChange这个事件处理函数执行完毕后执行,因此它拿不到想要的那个事件对象e。
要想拿到目标事件对象,必须显式地告诉 React——我永远需要它,也就是调用 e.persist() 函数,像下面这样:
function handleChange(e) {// Prevents React from resetting its properties:e.persist();setTimeout(() => {console.log(e.target.value); // Works}, 100);
}
在 React 17 中,我们不需要 e.persist(),也可以随时随地访问我们想要的事件对象。
3. Lane 模型的引入
初学 React 源码的同学由此可能会很自然地认为:优先级就应该是用 Lane 来处理的。但事实上,React 16 中处理优先级采用的是 expirationTime 模型。
expirationTime模型使用expirationTime(一个时间长度) 来描述任务的优先级;而Lane 模型则使用二进制数来表示任务的优先级:
lane 模型通过将不同优先级赋值给一个位,通过 31 位的位运算来操作优先级。
Lane 模型提供了一个新的优先级排序的思路,相对于 expirationTime 来说,它对优先级的处理会更细腻,能够覆盖更多的边界条件。
----------@----------
性能优化
DNS 预解析
DNS解析也是需要时间的,可以通过预解析的方式来预先获得域名所对应的IP
<link rel="dns-prefetch" href="//blog.poetries.top">
缓存
- 缓存对于前端性能优化来说是个很重要的点,良好的缓存策略可以降低资源的重复加载提高网页的整体加载速度
- 通常浏览器缓存策略分为两种:强缓存和协商缓存
强缓存
实现强缓存可以通过两种响应头实现:
Expires和Cache-Control。强缓存表示在缓存期间不需要请求,state code为200
Expires: Wed, 22 Oct 2018 08:41:00 GMT
Expires是HTTP / 1.0的产物,表示资源会在Wed, 22 Oct 2018 08:41:00 GMT后过期,需要再次请求。并且Expires受限于本地时间,如果修改了本地时间,可能会造成缓存失效
Cache-control: max-age=30
Cache-Control出现于HTTP / 1.1,优先级高于Expires。该属性表示资源会在30秒后过期,需要再次请求
协商缓存
- 如果缓存过期了,我们就可以使用协商缓存来解决问题。协商缓存需要请求,如果缓存有效会返回 304
- 协商缓存需要客户端和服务端共同实现,和强缓存一样,也有两种实现方式
Last-Modified 和 If-Modified-Since
Last-Modified表示本地文件最后修改日期,If-Modified-Since会将Last-Modified的值发送给服务器,询问服务器在该日期后资源是否有更新,有更新的话就会将新的资源发送回来- 但是如果在本地打开缓存文件,就会造成
Last-Modified被修改,所以在HTTP / 1.1出现了ETag
ETag 和 If-None-Match
ETag类似于文件指纹,If-None-Match会将当前ETag发送给服务器,询问该资源 ETag 是否变动,有变动的话就将新的资源发送回来。并且ETag优先级比Last-Modified高
选择合适的缓存策略
对于大部分的场景都可以使用强缓存配合协商缓存解决,但是在一些特殊的地方可能需要选择特殊的缓存策略
- 对于某些不需要缓存的资源,可以使用
Cache-control: no-store,表示该资源不需要缓存 - 对于频繁变动的资源,可以使用
Cache-Control: no-cache并配合ETag使用,表示该资源已被缓存,但是每次都会发送请求询问资源是否更新。 - 对于代码文件来说,通常使用
Cache-Control: max-age=31536000并配合策略缓存使用,然后对文件进行指纹处理,一旦文件名变动就会立刻下载新的文件
使用 HTTP / 2.0
- 因为浏览器会有并发请求限制,在
HTTP / 1.1时代,每个请求都需要建立和断开,消耗了好几个RTT时间,并且由于TCP慢启动的原因,加载体积大的文件会需要更多的时间 - 在
HTTP / 2.0中引入了多路复用,能够让多个请求使用同一个TCP链接,极大的加快了网页的加载速度。并且还支持Header压缩,进一步的减少了请求的数据大小
预加载
- 在开发中,可能会遇到这样的情况。有些资源不需要马上用到,但是希望尽早获取,这时候就可以使用预加载
- 预加载其实是声明式的
fetch,强制浏览器请求资源,并且不会阻塞onload事件,可以使用以下代码开启预加载
<link rel="preload" href="http://example.com">
预加载可以一定程度上降低首屏的加载时间,因为可以将一些不影响首屏但重要的文件延后加载,唯一缺点就是兼容性不好
预渲染
可以通过预渲染将下载的文件预先在后台渲染,可以使用以下代码开启预渲染
<link rel="prerender" href="http://poetries.com">
- 预渲染虽然可以提高页面的加载速度,但是要确保该页面百分百会被用户在之后打开,否则就白白浪费资源去渲染
总结
defer和async在网络读取的过程中都是异步解析defer是有顺序依赖的,async只要脚本加载完后就会执行preload可以对当前页面所需的脚本、样式等资源进行预加载prefetch加载的资源一般不是用于当前页面的,是未来很可能用到的这样一些资源
懒执行与懒加载
懒执行
- 懒执行就是将某些逻辑延迟到使用时再计算。该技术可以用于首屏优化,对于某些耗时逻辑并不需要在首屏就使用的,就可以使用懒执行。懒执行需要唤醒,一般可以通过定时器或者事件的调用来唤醒
懒加载
- 懒加载就是将不关键的资源延后加载
懒加载的原理就是只加载自定义区域(通常是可视区域,但也可以是即将进入可视区域)内需要加载的东西。对于图片来说,先设置图片标签的
src属性为一张占位图,将真实的图片资源放入一个自定义属性中,当进入自定义区域时,就将自定义属性替换为src属性,这样图片就会去下载资源,实现了图片懒加载
- 懒加载不仅可以用于图片,也可以使用在别的资源上。比如进入可视区域才开始播放视频等
文件优化
图片优化
对于如何优化图片,有 2 个思路
- 减少像素点
- 减少每个像素点能够显示的颜色
图片加载优化
- 不用图片。很多时候会使用到很多修饰类图片,其实这类修饰图片完全可以用
CSS去代替。 - 对于移动端来说,屏幕宽度就那么点,完全没有必要去加载原图浪费带宽。一般图片都用 CDN 加载,可以计算出适配屏幕的宽度,然后去请求相应裁剪好的图片
- 小图使用
base64格式 - 将多个图标文件整合到一张图片中(雪碧图)
- 选择正确的图片格式:
- 对于能够显示
WebP格式的浏览器尽量使用WebP格式。因为WebP格式具有更好的图像数据压缩算法,能带来更小的图片体积,而且拥有肉眼识别无差异的图像质量,缺点就是兼容性并不好 - 小图使用
PNG,其实对于大部分图标这类图片,完全可以使用SVG代替 - 照片使用
JPEG
- 对于能够显示
其他文件优化
CSS文件放在head中- 服务端开启文件压缩功能
- 将
script标签放在body底部,因为JS文件执行会阻塞渲染。当然也可以把script标签放在任意位置然后加上defer,表示该文件会并行下载,但是会放到HTML解析完成后顺序执行。对于没有任何依赖的JS文件可以加上async,表示加载和渲染后续文档元素的过程将和JS文件的加载与执行并行无序进行。 执行JS代码过长会卡住渲染,对于需要很多时间计算的代码 - 可以考虑使用
Webworker。Webworker可以让我们另开一个线程执行脚本而不影响渲染。
CDN
静态资源尽量使用
CDN加载,由于浏览器对于单个域名有并发请求上限,可以考虑使用多个CDN域名。对于CDN加载静态资源需要注意CDN域名要与主站不同,否则每次请求都会带上主站的Cookie
其他
使用 Webpack 优化项目
- 对于
Webpack4,打包项目使用production模式,这样会自动开启代码压缩 - 使用
ES6模块来开启tree shaking,这个技术可以移除没有使用的代码 - 优化图片,对于小图可以使用
base64的方式写入文件中 - 按照路由拆分代码,实现按需加载
- 给打包出来的文件名添加哈希,实现浏览器缓存文件
监控
对于代码运行错误,通常的办法是使用
window.onerror拦截报错。该方法能拦截到大部分的详细报错信息,但是也有例外
- 对于跨域的代码运行错误会显示
Script error. 对于这种情况我们需要给script标签添加crossorigin属性 - 对于某些浏览器可能不会显示调用栈信息,这种情况可以通过
arguments.callee.caller来做栈递归 - 对于异步代码来说,可以使用
catch的方式捕获错误。比如Promise可以直接使用 catch 函数,async await可以使用try catch - 但是要注意线上运行的代码都是压缩过的,需要在打包时生成
sourceMap文件便于debug。 - 对于捕获的错误需要上传给服务器,通常可以通过
img标签的src发起一个请求
如何根据chrome的timing优化
性能优化API
Performance。performance.now()与new Date()区别,它是高精度的,且是相对时间,相对于页面加载的那一刻。但是不一定适合单页面场景window.addEventListener("load", "");window.addEventListener("domContentLoaded", "");Img的onload事件,监听首屏内的图片是否加载完成,判断首屏事件RequestFrameAnmation和RequestIdleCallbackIntersectionObserver、MutationObserver,PostMessageWeb Worker,耗时任务放在里面执行
检测工具
Chrome Dev ToolsPage SpeedJspref
前端指标

window.onload = function(){setTimeout(function(){let t = performance.timingconsole.log('DNS查询耗时 :' + (t.domainLookupEnd - t.domainLookupStart).toFixed(0))console.log('TCP链接耗时 :' + (t.connectEnd - t.connectStart).toFixed(0))console.log('request请求耗时 :' + (t.responseEnd - t.responseStart).toFixed(0))console.log('解析dom树耗时 :' + (t.domComplete - t.domInteractive).toFixed(0))console.log('白屏时间 :' + (t.responseStart - t.navigationStart).toFixed(0))console.log('domready时间 :' + (t.domContentLoadedEventEnd - t.navigationStart).toFixed(0))console.log('onload时间 :' + (t.loadEventEnd - t.navigationStart).toFixed(0))if(t = performance.memory){console.log('js内存使用占比 :' + (t.usedJSHeapSize / t.totalJSHeapSize * 100).toFixed(2) + '%')}})
}
DNS预解析优化
dns解析是很耗时的,因此如果解析域名过多,会让首屏加载变得过慢,可以考虑dns-prefetch优化
DNS Prefetch 应该尽量的放在网页的前面,推荐放在 后面。具体使用方法如下:
<meta http-equiv="x-dns-prefetch-control" content="on">
<link rel="dns-prefetch" href="//www.zhix.net">
<link rel="dns-prefetch" href="//api.share.zhix.net">
<link rel="dns-prefetch" href="//bdimg.share.zhix.net">
request请求耗时
- 不请求,用cache(最好的方式就是尽量引用公共资源,同时设置缓存,不去重新请求资源,也可以运用PWA的离线缓存技术,可以帮助wep实现离线使用)
- 前端打包时压缩
- 服务器上的zip压缩
- 图片压缩(比如tiny),使用webp等高压缩比格式
- 把过大的包,拆分成多个较少的包,防止单个资源耗时过大
- 同一时间针对同一域名下的请求有一定数量限制,超过限制数目的请求会被阻塞。如果资源来自于多个域下,可以增大并行请求和下载速度
- 延迟、异步、预加载、懒加载
- 对于非首屏的资源,可以使用 defer 或 async 的方式引入
- 也可以按需加载,在逻辑中,只有执行到时才做请求
- 对于多屏页面,滚动时才动态载入图片
移动端优化

1. 概述
PC优化手段在Mobile侧同样适用- 在
Mobile侧我们提出三秒种渲染完成首屏指标 - 基于第二点,首屏加载
3秒完成或使用Loading - 基于联通3G网络平均
338KB/s(2.71Mb/s),所以首屏资源不应超过1014KB Mobile侧因手机配置原因,除加载外渲染速度也是优化重点- 基于第五点,要合理处理代码减少渲染损耗
- 基于第二、第五点,所有影响首屏加载和渲染的代码应在处理逻辑中后置
- 加载完成后用户交互使用时也需注意性能
2. 加载优化
加载过程是最为耗时的过程,可能会占到总耗时的
80%时间,因此是优化的重点
2.1 缓存
使用缓存可以减少向服务器的请求数,节省加载时间,所以所有静态资源都要在服务器端设置缓存,并且尽量使用长
Cache(长Cache资源的更新可使用时间戳)
2.2 压缩HTML、CSS、JavaScript
减少资源大小可以加快网页显示速度,所以要对
HTML、CSS、JavaScript等进行代码压缩,并在服务器端设置GZip
- a) 压缩(例如,多余的空格、换行符和缩进)
- b) 启用
GZip
2.3 无阻塞
写在
HTML头部的JavaScript(无异步),和写在HTML标签中的Style会阻塞页面的渲染,因此CSS放在页面头部并使用Link方式引入,避免在HTML标签中写Style,JavaScript放在页面尾部或使用异步方式加载
2.4 使用首屏加载
首屏的快速显示,可以大大提升用户对页面速度的感知,因此应尽量针对首屏的快速显示做优化。
2.5 按需加载
将不影响首屏的资源和当前屏幕资源不用的资源放到用户需要时才加载,可以大大提升重要资源的显示速度和降低总体流量。
PS:按需加载会导致大量重绘,影响渲染性能
- a)
LazyLoad - b) 滚屏加载
- c) 通过
Media Query加载
2.6 预加载
大型重资源页面(如游戏)可使用增加
Loading的方法,资源加载完成后再显示页面。但Loading时间过长,会造成用户流失。
对用户行为分析,可以在当前页加载下一页资源,提升速度。
- a)可感知
Loading - b)不可感知的
Loading(如提前加载下一页)
2.7 压缩图片
图片是最占流量的资源,因此尽量避免使用他,使用时选择最合适的格式(实现需求的前提下,以大小判断),合适的大小,然后使用智图压缩,同时在代码中用
Srcset来按需显示
PS:过度压缩图片大小影响图片显示效果
- a)使用智图( http://zhitu.tencent.com/ )
- b)使用其它方式代替图片(1. 使用
CSS32. 使用SVG3. 使用IconFont) - c)使用
Srcset - d)选择合适的图片(1.
webP优于JPG2.PNG8优于GIF) - e)选择合适的大小(1. 首次加载不大于
1014KB2. 不宽于640(基于手机屏幕一般宽度))
2.8 减少Cookie
Cookie会影响加载速度,所以静态资源域名不使用Cookie。
2.9 避免重定向
重定向会影响加载速度,所以在服务器正确设置避免重定向。
2.10 异步加载第三方资源
第三方资源不可控会影响页面的加载和显示,因此要异步加载第三方资源
2.11 减少HTTP请求
因为手机浏览器同时响应请求为4个请求(
Android支持4个,iOS5后可支持6个),所以要尽量减少页面的请求数,首次加载同时请求数不能超过4个
- a)合并
CSS、JavaScript - b)合并小图片,使用雪碧图
3. 三、脚本执行优化
脚本处理不当会阻塞页面加载、渲染,因此在使用时需当注意
CSS写在头部,JavaScript写在尾部或异步- 避免图片和
iFrame等的空Src,空Src会重新加载当前页面,影响速度和效率。 - 尽量避免重设图片大小
- 重设图片大小是指在页面、
CSS、JavaScript等中多次重置图片大小,多次重设图片大小会引发图片的多次重绘,影响性能 - 图片尽量避免使用
DataURL,DataURL图片没有使用图片的压缩算法文件会变大,并且要解码后再渲染,加载慢耗时长
4. CSS优化
尽量避免写在HTML标签中写
Style属性
4.1 css3过渡动画开启硬件加速
.translate3d{-webkit-transform: translate3d(0, 0, 0);-moz-transform: translate3d(0, 0, 0);-ms-transform: translate3d(0, 0, 0);transform: translate3d(0, 0, 0);}
4.2 避免CSS表达式
CSS表达式的执行需跳出CSS树的渲染,因此请避免CSS表达式。
4.3 不滥用Float
Float在渲染时计算量比较大,尽量减少使用
4.4 值为0时不需要任何单位
为了浏览器的兼容性和性能,值为0时不要带单位
5. JavaScript执行优化
5.1 减少重绘和回流
- 避免不必要的Dom操作
- 尽量改变
Class而不是Style,使用classList代替className - 避免使用
document.write - 减少
drawImage
5.2 TOUCH事件优化
使用
touchstart、touchend代替click,因快影响速度快。但应注意Touch响应过快,易引发误操作
6. 渲染优化
6.1 HTML使用Viewport
Viewport可以加速页面的渲染,请使用以下代码
<meta name=”viewport” content=”width=device-width, initial-scale=1″>
6.2 动画优化
- 尽量使用
CSS3动画 - 合理使用
requestAnimationFrame动画代替setTimeout - 适当使用
Canvas动画5个元素以内使用css动画,5个以上使用Canvas动画(iOS8可使用webGL)
6.3 高频事件优化
Touchmove、Scroll事件可导致多次渲染
- 使用
requestAnimationFrame监听帧变化,使得在正确的时间进行渲染 - 增加响应变化的时间间隔,减少重绘次数
6.4 GPU加速
CSS中以下属性(CSS3 transitions、CSS3 3D transforms、Opacity、Canvas、WebGL、Video)来触发GPU渲染,请合理使用
----------@----------
工程化
介绍一下 webpack 的构建流程
核心概念
entry:入口。webpack是基于模块的,使用webpack首先需要指定模块解析入口(entry),webpack从入口开始根据模块间依赖关系递归解析和处理所有资源文件。output:输出。源代码经过webpack处理之后的最终产物。loader:模块转换器。本质就是一个函数,在该函数中对接收到的内容进行转换,返回转换后的结果。因为 Webpack 只认识 JavaScript,所以 Loader 就成了翻译官,对其他类型的资源进行转译的预处理工作。plugin:扩展插件。基于事件流框架Tapable,插件可以扩展 Webpack 的功能,在 Webpack 运行的生命周期中会广播出许多事件,Plugin 可以监听这些事件,在合适的时机通过 Webpack 提供的 API 改变输出结果。module:模块。除了js范畴内的es module、commonJs、AMD等,css @import、url(...)、图片、字体等在webpack中都被视为模块。
解释几个 webpack 中的术语
module:指在模块化编程中我们把应用程序分割成的独立功能的代码模块chunk:指模块间按照引用关系组合成的代码块,一个chunk中可以包含多个modulechunk group:指通过配置入口点(entry point)区分的块组,一个chunk group中可包含一到多个 chunkbundling:webpack 打包的过程asset/bundle:打包产物
webpack 的打包思想可以简化为 3 点:
- 一切源代码文件均可通过各种
Loader转换为 JS 模块 (module),模块之间可以互相引用。 - webpack 通过入口点(
entry point)递归处理各模块引用关系,最后输出为一个或多个产物包js(bundle)文件。 - 每一个入口点都是一个块组(
chunk group),在不考虑分包的情况下,一个chunk group中只有一个chunk,该 chunk 包含递归分析后的所有模块。每一个chunk都有对应的一个打包后的输出文件(asset/bundle)
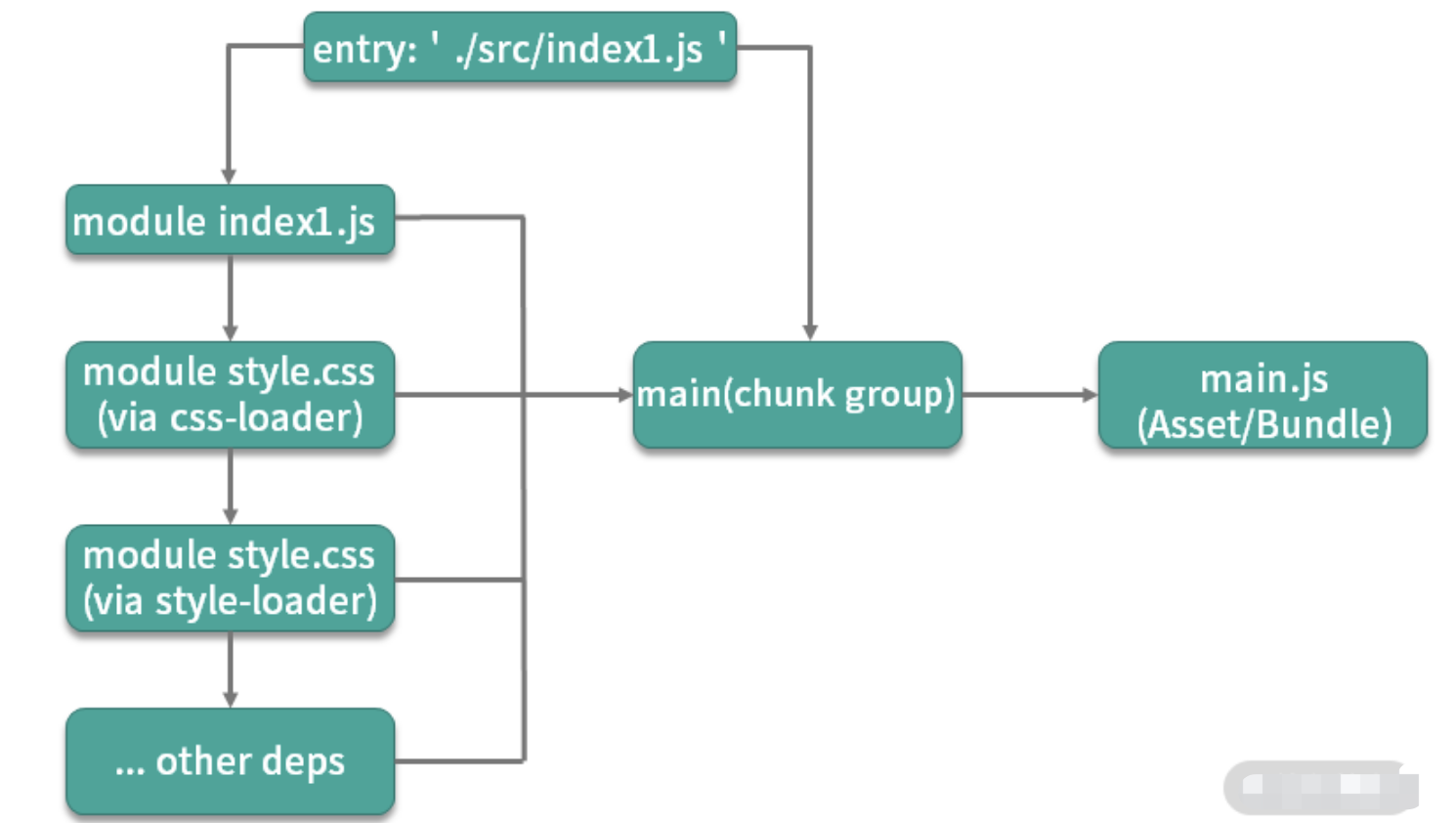
打包流程
- 初始化参数:从配置文件和 Shell 语句中读取并合并参数,得出最终的配置参数。
- 开始编译:从上一步得到的参数初始化
Compiler对象,加载所有配置的插件,执行对象的run方法开始执行编译。 - 确定入口:根据配置中的
entry找出所有的入口文件。 - 编译模块:从入口文件出发,调用所有配置的
loader对模块进行翻译,再找出该模块依赖的模块,这个步骤是递归执行的,直至所有入口依赖的模块文件都经过本步骤的处理。 - 完成模块编译:经过第 4 步使用 loader 翻译完所有模块后,得到了每个模块被翻译后的最终内容以及它们之间的依赖关系。
- 输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的
chunk,再把每个chunk转换成一个单独的文件加入到输出列表,这一步是可以修改输出内容的最后机会。 - 输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统。
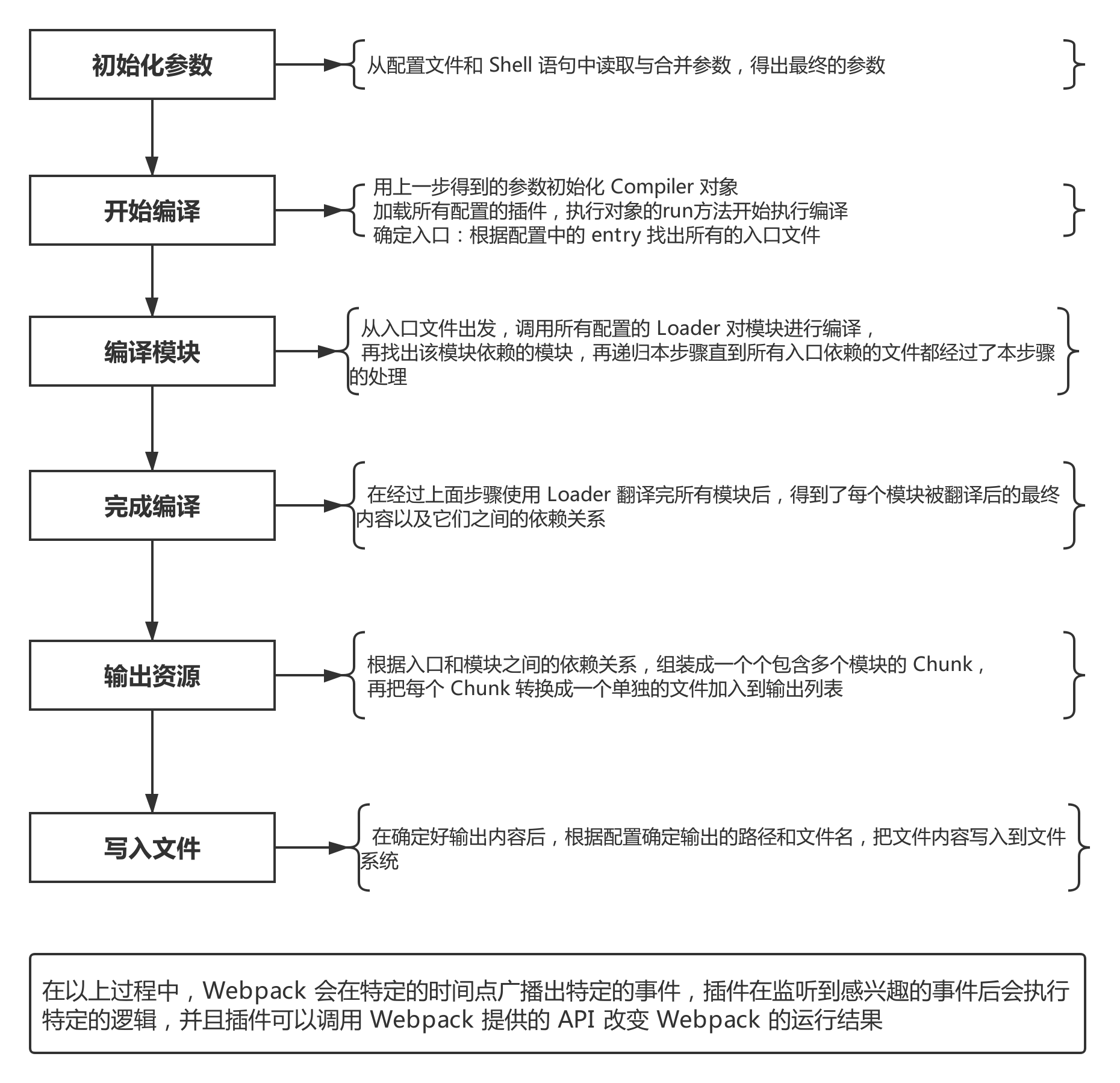
简版
- Webpack CLI 启动打包流程;
- 载入 Webpack 核心模块,创建
Compiler对象; - 使用
Compiler对象开始编译整个项目; - 从入口文件开始,解析模块依赖,形成依赖关系树;
- 递归依赖树,将每个模块交给对应的 Loader 处理;
- 合并 Loader 处理完的结果,将打包结果输出到 dist 目录。
在以上过程中,
Webpack 会在特定的时间点广播出特定的事件,插件在监听到相关事件后会执行特定的逻辑,并且插件可以调用 Webpack 提供的 API 改变 Webpack 的运行结果
构建流程核心概念:
Tapable:一个基于发布订阅的事件流工具类,Compiler和Compilation对象都继承于TapableCompiler:compiler对象是一个全局单例,他负责把控整个webpack打包的构建流程。在编译初始化阶段被创建的全局单例,包含完整配置信息、loaders、plugins以及各种工具方法Compilation:代表一次 webpack 构建和生成编译资源的的过程,在watch模式下每一次文件变更触发的重新编译都会生成新的Compilation对象,包含了当前编译的模块module, 编译生成的资源,变化的文件, 依赖的状态等- 而每个模块间的依赖关系,则依赖于
AST语法树。每个模块文件在通过Loader解析完成之后,会通过acorn库生成模块代码的AST语法树,通过语法树就可以分析这个模块是否还有依赖的模块,进而继续循环执行下一个模块的编译解析。
最终Webpack打包出来的bundle文件是一个IIFE的执行函数。
// webpack 5 打包的bundle文件内容(() => { // webpackBootstrapvar __webpack_modules__ = ({'file-A-path': ((modules) => { // ... })'index-file-path': ((__unused_webpack_module, __unused_webpack_exports, __webpack_require__) => { // ... })})// The module cachevar __webpack_module_cache__ = {};// The require functionfunction __webpack_require__(moduleId) {// Check if module is in cachevar cachedModule = __webpack_module_cache__[moduleId];if (cachedModule !== undefined) {return cachedModule.exports;}// Create a new module (and put it into the cache)var module = __webpack_module_cache__[moduleId] = {// no module.id needed// no module.loaded neededexports: {}};// Execute the module function__webpack_modules__[moduleId](module, module.exports, __webpack_require__);// Return the exports of the modulereturn module.exports;}// startup// Load entry module and return exports// This entry module can't be inlined because the eval devtool is used.var __webpack_exports__ = __webpack_require__("./src/index.js");
})
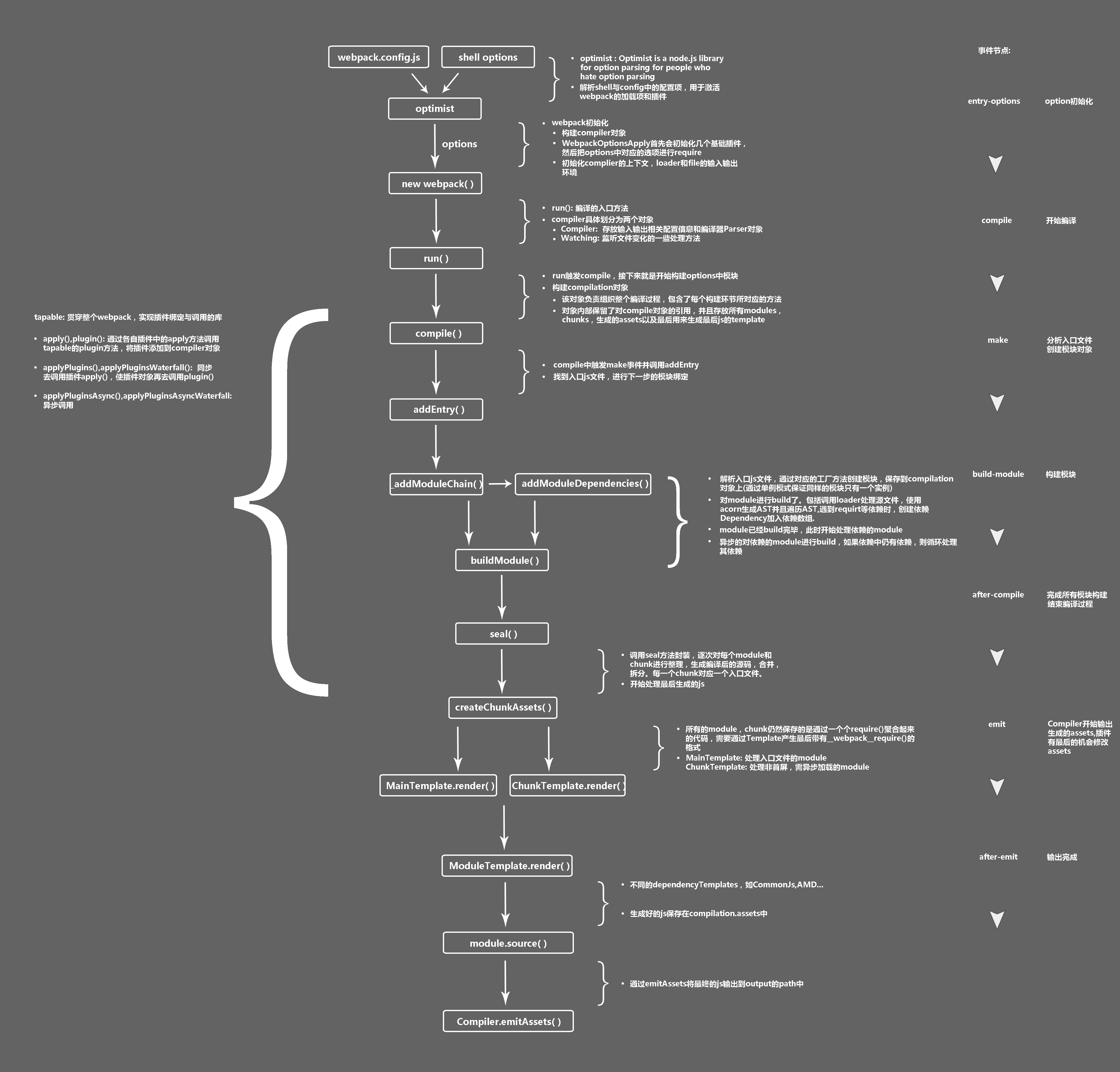
webpack详细工作流程
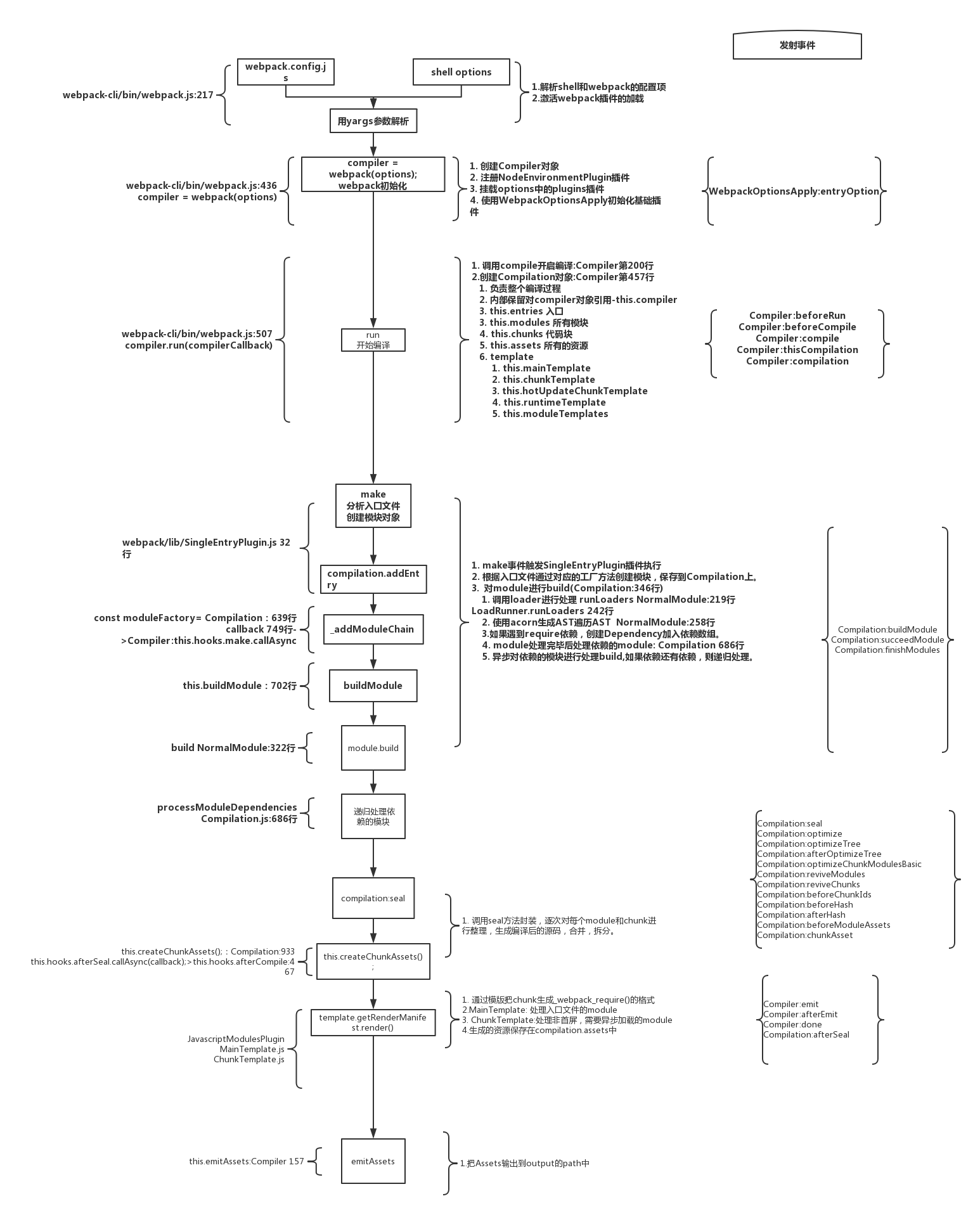
----------@----------
介绍 Loader
常用 Loader:
file-loader: 加载文件资源,如 字体 / 图片 等,具有移动/复制/命名等功能;url-loader: 通常用于加载图片,可以将小图片直接转换为 Date Url,减少请求;babel-loader: 加载 js / jsx 文件, 将 ES6 / ES7 代码转换成 ES5,抹平兼容性问题;ts-loader: 加载 ts / tsx 文件,编译 TypeScript;style-loader: 将 css 代码以<style>标签的形式插入到 html 中;css-loader: 分析@import和url(),引用 css 文件与对应的资源;postcss-loader: 用于 css 的兼容性处理,具有众多功能,例如 添加前缀,单位转换 等;less-loader / sass-loader: css预处理器,在 css 中新增了许多语法,提高了开发效率;
编写原则:
- 单一原则: 每个 Loader 只做一件事;
- 链式调用: Webpack 会按顺序链式调用每个 Loader;
- 统一原则: 遵循 Webpack制定的设计规则和结构,输入与输出均为字符串,各个 Loader 完全独立,即插即用;
----------@----------
介绍 plugin
插件系统是 Webpack 成功的一个关键性因素。在编译的整个生命周期中,Webpack 会触发许多事件钩子,Plugin 可以监听这些事件,根据需求在相应的时间点对打包内容进行定向的修改。
一个最简单的 plugin 是这样的:
class Plugin{// 注册插件时,会调用 apply 方法// apply 方法接收 compiler 对象// 通过 compiler 上提供的 Api,可以对事件进行监听,执行相应的操作apply(compiler){// compilation 是监听每次编译循环// 每次文件变化,都会生成新的 compilation 对象并触发该事件compiler.plugin('compilation',function(compilation) {})}
}
注册插件:
// webpack.config.js
module.export = {plugins:[new Plugin(options),]
}
事件流机制:
Webpack 就像工厂中的一条产品流水线。原材料经过 Loader 与 Plugin 的一道道处理,最后输出结果。
- 通过链式调用,按顺序串起一个个 Loader;
- 通过事件流机制,让 Plugin 可以插入到整个生产过程中的每个步骤中;
Webpack 事件流编程范式的核心是基础类 Tapable,是一种 观察者模式 的实现事件的订阅与广播:
const { SyncHook } = require("tapable")const hook = new SyncHook(['arg'])// 订阅
hook.tap('event', (arg) => {// 'event-hook'console.log(arg)
})// 广播
hook.call('event-hook')
Webpack中两个最重要的类Compiler与Compilation便是继承于Tapable,也拥有这样的事件流机制。
- Compiler : 可以简单的理解为 Webpack 实例,它包含了当前 Webpack 中的所有配置信息,如 options, loaders, plugins 等信息,全局唯一,只在启动时完成初始化创建,随着生命周期逐一传递;
Compilation: 可以称为 编译实例。当监听到文件发生改变时,Webpack 会创建一个新的 Compilation 对象,开始一次新的编译。它包含了当前的输入资源,输出资源,变化的文件等,同时通过它提供的 api,可以监听每次编译过程中触发的事件钩子;- 区别:
Compiler全局唯一,且从启动生存到结束;Compilation对应每次编译,每轮编译循环均会重新创建;
- 常用 Plugin:
- UglifyJsPlugin: 压缩、混淆代码;
- CommonsChunkPlugin: 代码分割;
- ProvidePlugin: 自动加载模块;
- html-webpack-plugin: 加载 html 文件,并引入 css / js 文件;
- extract-text-webpack-plugin / mini-css-extract-plugin: 抽离样式,生成 css 文件; DefinePlugin: 定义全局变量;
- optimize-css-assets-webpack-plugin: CSS 代码去重;
- webpack-bundle-analyzer: 代码分析;
- compression-webpack-plugin: 使用 gzip 压缩 js 和 css;
- happypack: 使用多进程,加速代码构建;
- EnvironmentPlugin: 定义环境变量;
- 调用插件
apply函数传入compiler对象 - 通过
compiler对象监听事件
loader和plugin有什么区别?
webapck默认只能打包JS和JOSN模块,要打包其它模块,需要借助loader,loader就可以让模块中的内容转化成webpack或其它laoder可以识别的内容。
loader就是模块转换化,或叫加载器。不同的文件,需要不同的loader来处理。plugin是插件,可以参与到整个webpack打包的流程中,不同的插件,在合适的时机,可以做不同的事件。
webpack中都有哪些插件,这些插件有什么作用?
html-webpack-plugin自动创建一个HTML文件,并把打包好的JS插入到HTML文件中clean-webpack-plugin在每一次打包之前,删除整个输出文件夹下所有的内容mini-css-extrcat-plugin抽离CSS代码,放到一个单独的文件中optimize-css-assets-plugin压缩css
----------@----------
webpack 热更新实现原理
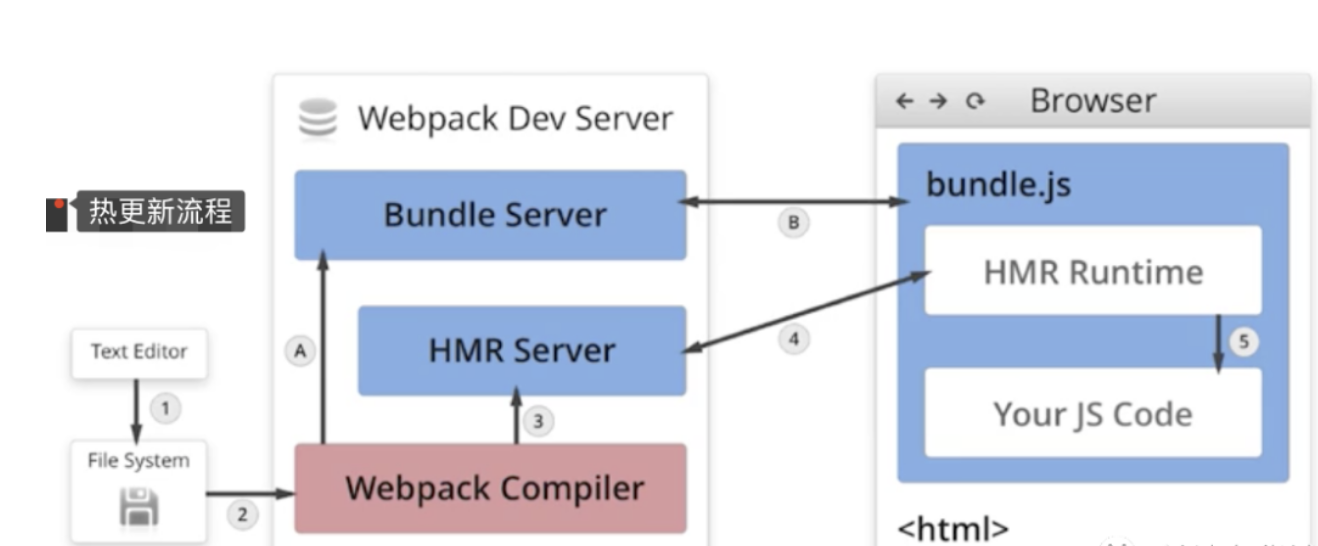
HMR 的基本流程图

- 当修改了一个或多个文件;
- 文件系统接收更改并通知
webpack; webpack重新编译构建一个或多个模块,并通知 HMR 服务器进行更新;HMR Server使用webSocket通知HMR runtime需要更新,HMR运行时通过HTTP请求更新jsonpHMR运行时替换更新中的模块,如果确定这些模块无法更新,则触发整个页面刷新
----------@----------
webpack 层面如何做性能优化
优化前的准备工作
- 准备基于时间的分析工具:我们需要一类插件,来帮助我们统计项目构建过程中在编译阶段的耗时情况。
speed-measure-webpack-plugin分析插件加载的时间 - 使用
webpack-bundle-analyzer分析产物内容
代码优化:
无用代码消除,是许多编程语言都具有的优化手段,这个过程称为 DCE (dead code elimination),即 删除不可能执行的代码;
例如我们的 UglifyJs,它就会帮我们在生产环境中删除不可能被执行的代码,例如:
var fn = function() {return 1;// 下面代码便属于 不可能执行的代码;// 通过 UglifyJs (Webpack4+ 已内置) 便会进行 DCE;var a = 1;return a;
}
摇树优化 (Tree-shaking),这是一种形象比喻。我们把打包后的代码比喻成一棵树,这里其实表示的就是,通过工具 “摇” 我们打包后的 js 代码,将没有使用到的无用代码 “摇” 下来 (删除)。即 消除那些被 引用了但未被使用 的模块代码。
- 原理: 由于是在编译时优化,因此最基本的前提就是语法的静态分析,ES6的模块机制 提供了这种可能性。不需要运行时,便可进行代码字面上的静态分析,确定相应的依赖关系。
- 问题: 具有 副作用 的函数无法被
tree-shaking- 在引用一些第三方库,需要去观察其引入的代码量是不是符合预期;
- 尽量写纯函数,减少函数的副作用;
- 可使用
webpack-deep-scope-plugin,可以进行作用域分析,减少此类情况的发生,但仍需要注意;
code-spliting: 代码分割技术 ,将代码分割成多份进行 懒加载 或 异步加载,避免打包成一份后导致体积过大,影响页面的首屏加载;
Webpack中使用SplitChunksPlugin进行拆分;- 按 页面 拆分: 不同页面打包成不同的文件;
- 按 功能 拆分:
- 将类似于播放器,计算库等大模块进行拆分后再懒加载引入;
- 提取复用的业务代码,减少冗余代码;
- 按 文件修改频率 拆分: 将第三方库等不常修改的代码单独打包,而且不改变其文件 hash 值,能最大化运用浏览器的缓存;
scope hoisting : 作用域提升,将分散的模块划分到同一个作用域中,避免了代码的重复引入,有效减少打包后的代码体积和运行时的内存损耗;
编译性能优化:
- 升级至 最新 版本的
webpack,能有效提升编译性能; - 使用
dev-server/ 模块热替换 (HMR) 提升开发体验;- 监听文件变动 忽略 node_modules 目录能有效提高监听时的编译效率;
- 缩小编译范围
modules: 指定模块路径,减少递归搜索;mainFields: 指定入口文件描述字段,减少搜索;noParse: 避免对非模块化文件的加载;includes/exclude: 指定搜索范围/排除不必要的搜索范围;alias: 缓存目录,避免重复寻址;
babel-loader- 忽略
node_moudles,避免编译第三方库中已经被编译过的代码 - 使用
cacheDirectory,可以缓存编译结果,避免多次重复编译
- 忽略
- 多进程并发
webpack-parallel-uglify-plugin: 可多进程并发压缩 js 文件,提高压缩速度;HappyPack: 多进程并发文件的Loader解析;
- 第三方库模块缓存:
DLLPlugin和DLLReferencePlugin可以提前进行打包并缓存,避免每次都重新编译;
- 使用分析
Webpack Analyse / webpack-bundle-analyzer对打包后的文件进行分析,寻找可优化的地方- 配置profile:true,对各个编译阶段耗时进行监控,寻找耗时最多的地方
source-map:- 开发:
cheap-module-eval-source-map - 生产:
hidden-source-map;
- 开发:
优化webpack打包速度
- 减少文件搜索范围
- 比如通过别名
loader的test,include & exclude
Webpack4默认压缩并行Happypack并发调用babel也可以缓存编译Resolve在构建时指定查找模块文件的规则- 使用
DllPlugin,不用每次都重新构建 externals和DllPlugin解决的是同一类问题:将依赖的框架等模块从构建过程中移除。它们的区别在于- 在 Webpack 的配置方面,
externals更简单,而DllPlugin需要独立的配置文件。 DllPlugin包含了依赖包的独立构建流程,而externals配置中不包含依赖框架的生成方式,通常使用已传入 CDN 的依赖包externals配置的依赖包需要单独指定依赖模块的加载方式:全局对象、CommonJS、AMD 等- 在引用依赖包的子模块时,
DllPlugin无须更改,而externals则会将子模块打入项目包中
- 在 Webpack 的配置方面,
优化打包体积
- 提取第三方库或通过引用外部文件的方式引入第三方库
- 代码压缩插件
UglifyJsPlugin - 服务器启用
gzip压缩 - 按需加载资源文件
require.ensure - 优化
devtool中的source-map - 剥离
css文件,单独打包 - 去除不必要插件,通常就是开发环境与生产环境用同一套配置文件导致
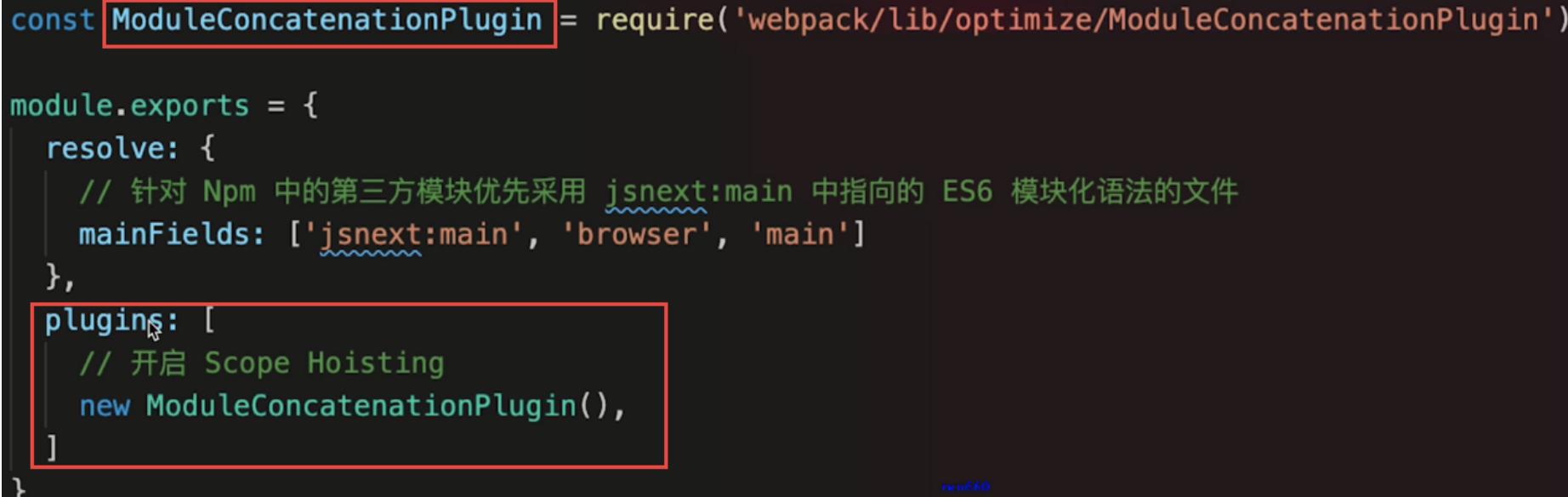
Tree Shaking在构建打包过程中,移除那些引入但未被使用的无效代码- 开启
scope hosting- 体积更小
- 创建函数作用域更小
- 代码可读性更好

----------@----------
介绍一下 Tree Shaking
对tree-shaking的了解
作用:
它表示在打包的时候会去除一些无用的代码
原理 :
ES6的模块引入是静态分析的,所以在编译时能正确判断到底加载了哪些模块- 分析程序流,判断哪些变量未被使用、引用,进而删除此代码
特点:
- 在生产模式下它是默认开启的,但是由于经过
babel编译全部模块被封装成IIFE,它存在副作用无法被tree-shaking掉 - 可以在
package.json中配置sideEffects来指定哪些文件是有副作用的。它有两种值,一个是布尔类型,如果是false则表示所有文件都没有副作用;如果是一个数组的话,数组里的文件路径表示改文件有副作用 rollup和webpack中对tree-shaking的层度不同,例如对babel转译后的class,如果babel的转译是宽松模式下的话(也就是loose为true),webpack依旧会认为它有副作用不会tree-shaking掉,而rollup会。这是因为rollup有程序流分析的功能,可以更好的判断代码是否真正会产生副作用。
原理
ES6 Module引入进行静态分析,故而编译的时候正确判断到底加载了那些模块- 静态分析程序流,判断那些模块和变量未被使用或者引用,进而删除对应代码
依赖于
import/export
通过导入所有的包后再进行条件获取。如下:
import foo from "foo";
import bar from "bar";if(condition) {// foo.xxxx
} else {// bar.xxx
}
ES6的import语法完美可以使用tree shaking,因为可以在代码不运行的情况下就能分析出不需要的代码
CommonJS的动态特性模块意味着tree shaking不适用 。因为它是不可能确定哪些模块实际运行之前是需要的或者是不需要的。在ES6中,进入了完全静态的导入语法:import。这也意味着下面的导入是不可行的:
// 不可行,ES6 的import是完全静态的
if(condition) {myDynamicModule = require("foo");
} else {myDynamicModule = require("bar");
}
----------@----------
介绍一下 webpack scope hosting
作用域提升,将分散的模块划分到同一个作用域中,避免了代码的重复引入,有效减少打包后的代码体积和运行时的内存损耗;
----------@----------
Webpack Proxy工作原理?为什么能解决跨域
1. 是什么
webpack proxy,即webpack提供的代理服务
基本行为就是接收客户端发送的请求后转发给其他服务器
其目的是为了便于开发者在开发模式下解决跨域问题(浏览器安全策略限制)
想要实现代理首先需要一个中间服务器,webpack中提供服务器的工具为webpack-dev-server
2. webpack-dev-server
webpack-dev-server是 webpack 官方推出的一款开发工具,将自动编译和自动刷新浏览器等一系列对开发友好的功能全部集成在了一起
目的是为了提高开发者日常的开发效率,「只适用在开发阶段」
关于配置方面,在webpack配置对象属性中通过devServer属性提供,如下:
// ./webpack.config.js
const path = require('path')module.exports = {// ...devServer: {contentBase: path.join(__dirname, 'dist'),compress: true,port: 9000,proxy: {'/api': {target: 'https://api.github.com'}}// ...}
}
devServetr里面proxy则是关于代理的配置,该属性为对象的形式,对象中每一个属性就是一个代理的规则匹配
属性的名称是需要被代理的请求路径前缀,一般为了辨别都会设置前缀为/api,值为对应的代理匹配规则,对应如下:
target:表示的是代理到的目标地址pathRewrite:默认情况下,我们的/api-hy也会被写入到URL中,如果希望删除,可以使用pathRewritesecure:默认情况下不接收转发到https的服务器上,如果希望支持,可以设置为falsechangeOrigin:它表示是否更新代理后请求的headers中host地址
2. 工作原理
proxy工作原理实质上是利用http-proxy-middleware这个http代理中间件,实现请求转发给其他服务器
举个例子:
在开发阶段,本地地址为http://localhost:3000,该浏览器发送一个前缀带有/api标识的请求到服务端获取数据,但响应这个请求的服务器只是将请求转发到另一台服务器中
const express = require('express');
const proxy = require('http-proxy-middleware');const app = express();app.use('/api', proxy({target: 'http://www.example.org', changeOrigin: true}));
app.listen(3000);// http://localhost:3000/api/foo/bar -> http://www.example.org/api/foo/bar
3. 跨域
在开发阶段,
webpack-dev-server会启动一个本地开发服务器,所以我们的应用在开发阶段是独立运行在localhost的一个端口上,而后端服务又是运行在另外一个地址上
所以在开发阶段中,由于浏览器同源策略的原因,当本地访问后端就会出现跨域请求的问题
通过设置webpack proxy实现代理请求后,相当于浏览器与服务端中添加一个代理者
当本地发送请求的时候,代理服务器响应该请求,并将请求转发到目标服务器,目标服务器响应数据后再将数据返回给代理服务器,最终再由代理服务器将数据响应给本地
在代理服务器传递数据给本地浏览器的过程中,两者同源,并不存在跨域行为,这时候浏览器就能正常接收数据
注意:
「服务器与服务器之间请求数据并不会存在跨域行为,跨域行为是浏览器安全策略限制」
----------@----------
介绍一下 babel原理
babel的编译过程分为三个阶段: parsing 、 transforming 、 generating ,以 ES6 编译为 ES5 作为例子:
ES6代码输入;babylon进行解析得到 AST;plugin用babel-traverse对AST树进行遍历编译,得到新的AST树;- 用
babel-generator通过AST树生成ES5代码。
----------@----------
介绍一下Rollup
Rollup 是一款 ES Modules 打包器。它也可以将项目中散落的细小模块打包为整块代码,从而使得这些划分的模块可以更好地运行在浏览器环境或者 Node.js 环境。
Rollup优势:
- 输出结果更加扁平,执行效率更高;
- 自动移除未引用代码;
- 打包结果依然完全可读。
缺点
- 加载非 ESM 的第三方模块比较复杂;
- 因为模块最终都被打包到全局中,所以无法实现
HMR; - 浏览器环境中,代码拆分功能必须使用
Require.js这样的AMD库
- 我们发现如果我们开发的是一个应用程序,需要大量引用第三方模块,同时还需要 HMR 提升开发体验,而且应用过大就必须要分包。那这些需求 Rollup 都无法满足。
- 如果我们是开发一个 JavaScript 框架或者库,那这些优点就特别有必要,而缺点呢几乎也都可以忽略,所以在很多像 React 或者 Vue 之类的框架中都是使用的 Rollup 作为模块打包器,而并非 Webpack
总结一下 :Webpack 大而全,Rollup 小而美。
在对它们的选择上,我的基本原则是:应用开发使用 Webpack,类库或者框架开发使用 Rollup。
不过这并不是绝对的标准,只是经验法则。因为 Rollup 也可用于构建绝大多数应用程序,而 Webpack 同样也可以构建类库或者框架。

----------@----------
HTTP状态码
- 1xx 信息性状态码 websocket upgrade
- 2xx 成功状态码
- 200 服务器已成功处理了请求
- 204(没有响应体)
- 206(范围请求 暂停继续下载)
- 3xx 重定向状态码
- 301(永久) :请求的页面已永久跳转到新的url
- 302(临时) :允许各种各样的重定向,一般情况下都会实现为到
GET的重定向,但是不能确保POST会重定向为POST - 303 只允许任意请求到
GET的重定向 - 304 未修改:自从上次请求后,请求的网页未修改过
- 307:
307和302一样,除了不允许POST到GET的重定向
- 4xx 客户端错误状态码
- 400 客户端参数错误
- 401 没有登录
- 403 登录了没权限 比如管理系统
- 404 页面不存在
- 405 禁用请求中指定的方法
- 5xx 服务端错误状态码
- 500 服务器错误:服务器内部错误,无法完成请求
- 502 错误网关:服务器作为网关或代理出现错误
- 503 服务不可用:服务器目前无法使用
- 504 网关超时:网关或代理服务器,未及时获取请求
----------@----------
HTTP前生今世

HTTP协议始于三十年前蒂姆·伯纳斯 - 李的一篇论文HTTP/0.9是个简单的文本协议,只能获取文本资源;HTTP/1.0确立了大部分现在使用的技术,但它不是正式标准;HTTP/1.1是目前互联网上使用最广泛的协议,功能也非常完善;HTTP/2基于 Google 的SPDY协议,注重性能改善,但还未普及;HTTP/3基于 Google 的QUIC协议,是将来的发展方向
----------@----------
HTTP世界全览
- 互联网上绝大部分资源都使用
HTTP协议传输; - 浏览器是 HTTP 协议里的请求方,即
User Agent; - 服务器是 HTTP 协议里的应答方,常用的有
Apache和Nginx; CDN位于浏览器和服务器之间,主要起到缓存加速的作用;- 爬虫是另一类
User Agent,是自动访问网络资源的程序。 TCP/IP是网络世界最常用的协议,HTTP通常运行在TCP/IP提供的可靠传输基础上DNS域名是IP地址的等价替代,需要用域名解析实现到IP地址的映射;URI是用来标记互联网上资源的一个名字,由“协议名 + 主机名 + 路径”构成,俗称 URL;HTTPS相当于“HTTP+SSL/TLS+TCP/IP”,为HTTP套了一个安全的外壳;- 代理是
HTTP传输过程中的“中转站”,可以实现缓存加速、负载均衡等功能
----------@----------
HTTP分层

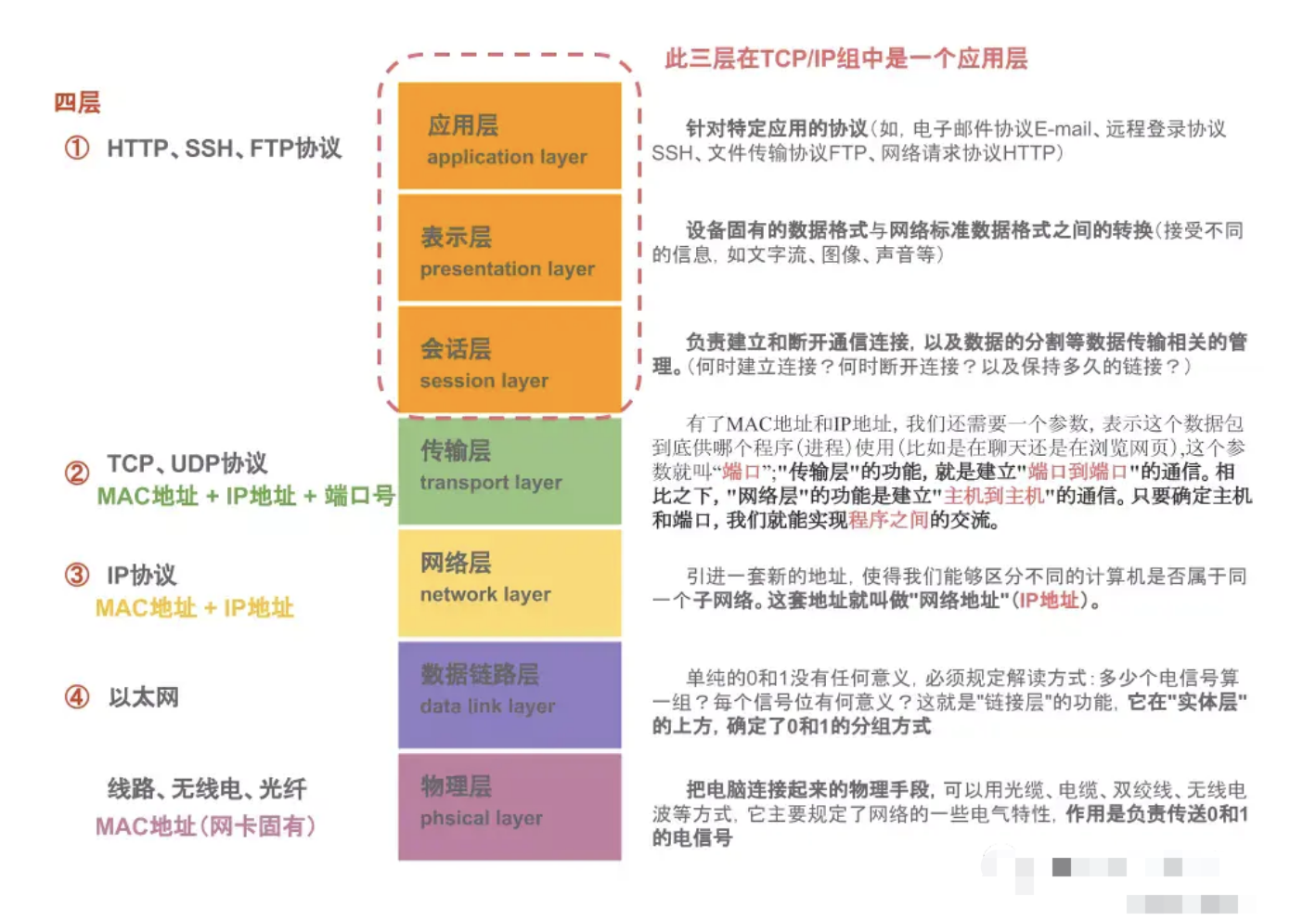
- 第一层:物理层,
TCP/IP里无对应; - 第二层:数据链路层,对应
TCP/IP的链接层; - 第三层:网络层,对应
TCP/IP的网际层; - 第四层:传输层,对应
TCP/IP的传输层; - 第五、六、七层:统一对应到
TCP/IP的应用层
总结
TCP/IP分为四层,核心是二层的IP和三层的TCP,HTTP在第四层;OSI分为七层,基本对应TCP/IP,TCP在第四层,HTTP在第七层;OSI可以映射到TCP/IP,但这期间一、五、六层消失了;- 日常交流的时候我们通常使用
OSI模型,用四层、七层等术语; HTTP利用TCP/IP协议栈逐层打包再拆包,实现了数据传输,但下面的细节并不可见
有一个辨别四层和七层比较好的(但不是绝对的)小窍门,“两个凡是”:凡是由操作系统负责处理的就是四层或四层以下,否则,凡是需要由应用程序(也就是你自己写代码)负责处理的就是七层
----------@----------
HTTP报文是什么样子的
HTTP 协议的请求报文和响应报文的结构基本相同,由三大部分组成
- 起始行(start line):描述请求或响应的基本信息;
- 头部字段集合(header):使用
key-value形式更详细地说明报文; - 消息正文(entity):实际传输的数据,它不一定是纯文本,可以是图片、视频等二进制数据
这其中前两部分起始行和头部字段经常又合称为“请求头”或“响应头”,消息正文又称为“实体”,但与“header”对应,很多时候就直接称为“body”。
一个完整的 HTTP 报文就像是下图的这个样子,注意在 header 和 body 之间有一个“空行”

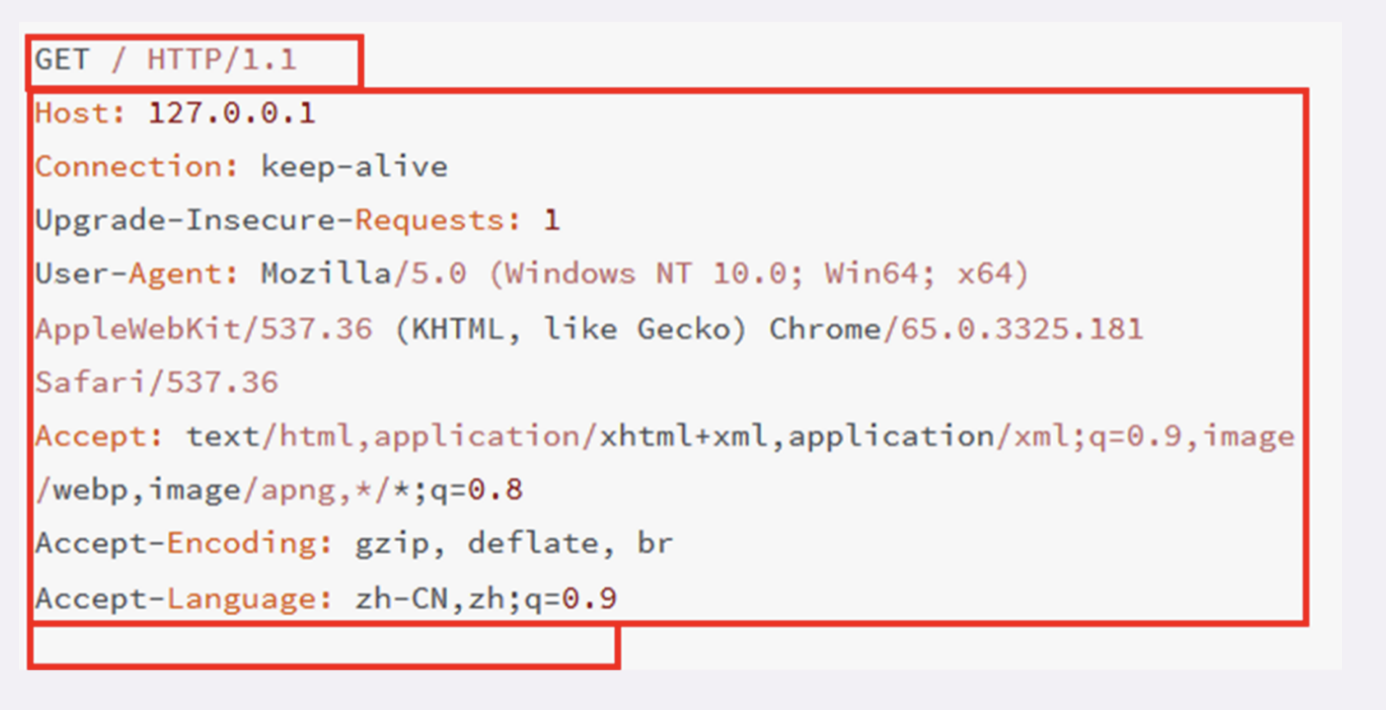
----------@----------
HTTP之URL

URI是用来唯一标记服务器上资源的一个字符串,通常也称为 URL;URI通常由scheme、host:port、path和query四个部分组成,有的可以省略;scheme叫“方案名”或者“协议名”,表示资源应该使用哪种协议来访问;- “
host:port”表示资源所在的主机名和端口号; path标记资源所在的位置;query表示对资源附加的额外要求;- 在
URI里对“@&/”等特殊字符和汉字必须要做编码,否则服务器收到HTTP报文后会无法正确处理
----------@----------
HTTP实体数据
1. 数据类型与编码
- text:即文本格式的可读数据,我们最熟悉的应该就是
text/html了,表示超文本文档,此外还有纯文本text/plain、样式表text/css等。 image:即图像文件,有image/gif、image/jpeg、image/png等。audio/video:音频和视频数据,例如audio/mpeg、video/mp4等。application:数据格式不固定,可能是文本也可能是二进制,必须由上层应用程序来解释。常见的有application/json,application/javascript、application/pdf等,另外,如果实在是不知道数据是什么类型,像刚才说的“黑盒”,就会是application/octet-stream,即不透明的二进制数据
但仅有
MIME type还不够,因为HTTP在传输时为了节约带宽,有时候还会压缩数据,为了不要让浏览器继续“猜”,还需要有一个“Encoding type”,告诉数据是用的什么编码格式,这样对方才能正确解压缩,还原出原始的数据。
比起 MIME type 来说,Encoding type 就少了很多,常用的只有下面三种
gzip:GNU zip压缩格式,也是互联网上最流行的压缩格式;deflate:zlib(deflate)压缩格式,流行程度仅次于gzip;br:一种专门为HTTP优化的新压缩算法(Brotli)
2. 数据类型使用的头字段
有了 MIME type 和 Encoding type,无论是浏览器还是服务器就都可以轻松识别出 body 的类型,也就能够正确处理数据了。
HTTP 协议为此定义了两个 Accept 请求头字段和两个 Content 实体头字段,用于客户端和服务器进行“内容协商”。也就是说,客户端用 Accept 头告诉服务器希望接收什么样的数据,而服务器用 Content 头告诉客户端实际发送了什么样的数据
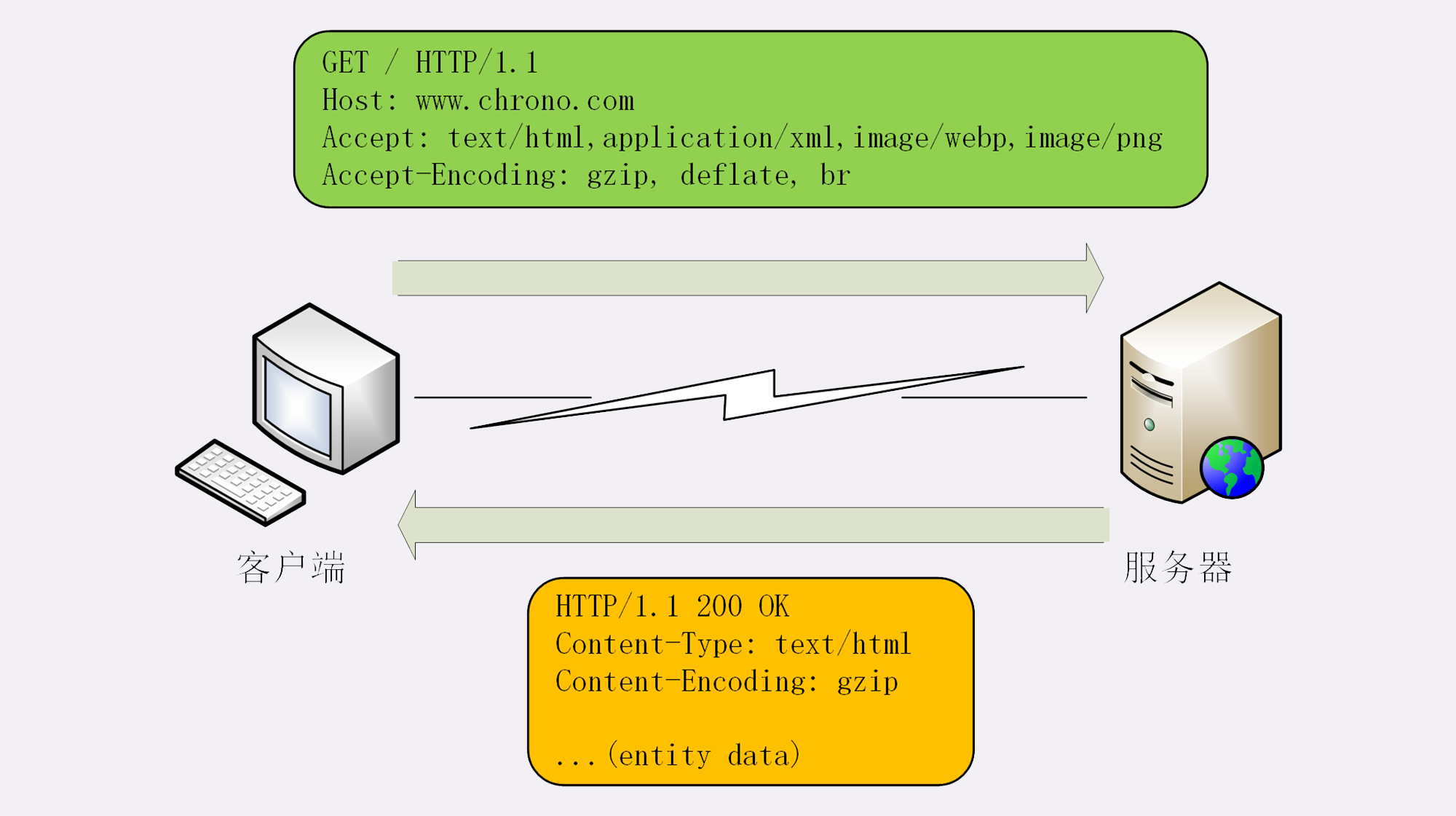
Accept字段标记的是客户端可理解的MIMEtype,可以用“,”做分隔符列出多个类型,让服务器有更多的选择余地,例如下面的这个头:
Accept: text/html,application/xml,image/webp,image/png
这就是告诉服务器:“我能够看懂 HTML、XML 的文本,还有 webp 和 png 的图片,请给我这四类格式的数据”。
相应的,服务器会在响应报文里用头字段Content-Type告诉实体数据的真实类型:
Content-Type: text/html
Content-Type: image/png
这样浏览器看到报文里的类型是“text/html”就知道是 HTML 文件,会调用排版引擎渲染出页面,看到“image/png”就知道是一个 PNG 文件,就会在页面上显示出图像。
Accept-Encoding字段标记的是客户端支持的压缩格式,例如上面说的 gzip、deflate 等,同样也可以用“,”列出多个,服务器可以选择其中一种来压缩数据,实际使用的压缩格式放在响应头字段Content-Encoding里
Accept-Encoding: gzip, deflate, br
Content-Encoding: gzip
不过这两个字段是可以省略的,如果请求报文里没有 Accept-Encoding 字段,就表示客户端不支持压缩数据;如果响应报文里没有 Content-Encoding 字段,就表示响应数据没有被压缩
3. 语言类型使用的头字段
同样的,HTTP 协议也使用 Accept 请求头字段和 Content 实体头字段,用于客户端和服务器就语言与编码进行“内容协商”。
Accept-Language字段标记了客户端可理解的自然语言,也允许用“,”做分隔符列出多个类型,例如:
Accept-Language: zh-CN, zh, en
这个请求头会告诉服务器:“最好给我 zh-CN 的汉语文字,如果没有就用其他的汉语方言,如果还没有就给英文”。
相应的,服务器应该在响应报文里用头字段Content-Language告诉客户端实体数据使用的实际语言类型
Content-Language: zh-CN
- 字符集在
HTTP里使用的请求头字段是Accept-Charset,但响应头里却没有对应的Content-Charset,而是在Content-Type字段的数据类型后面用“charset=xxx”来表示,这点需要特别注意。 - 例如,浏览器请求
GBK或UTF-8的字符集,然后服务器返回的是UTF-8编码,就是下面这样
Accept-Charset: gbk, utf-8
Content-Type: text/html; charset=utf-8
不过现在的浏览器都支持多种字符集,通常不会发送 Accept-Charset,而服务器也不会发送 Content-Language,因为使用的语言完全可以由字符集推断出来,所以在请求头里一般只会有 Accept-Language 字段,响应头里只会有 Content-Type字段
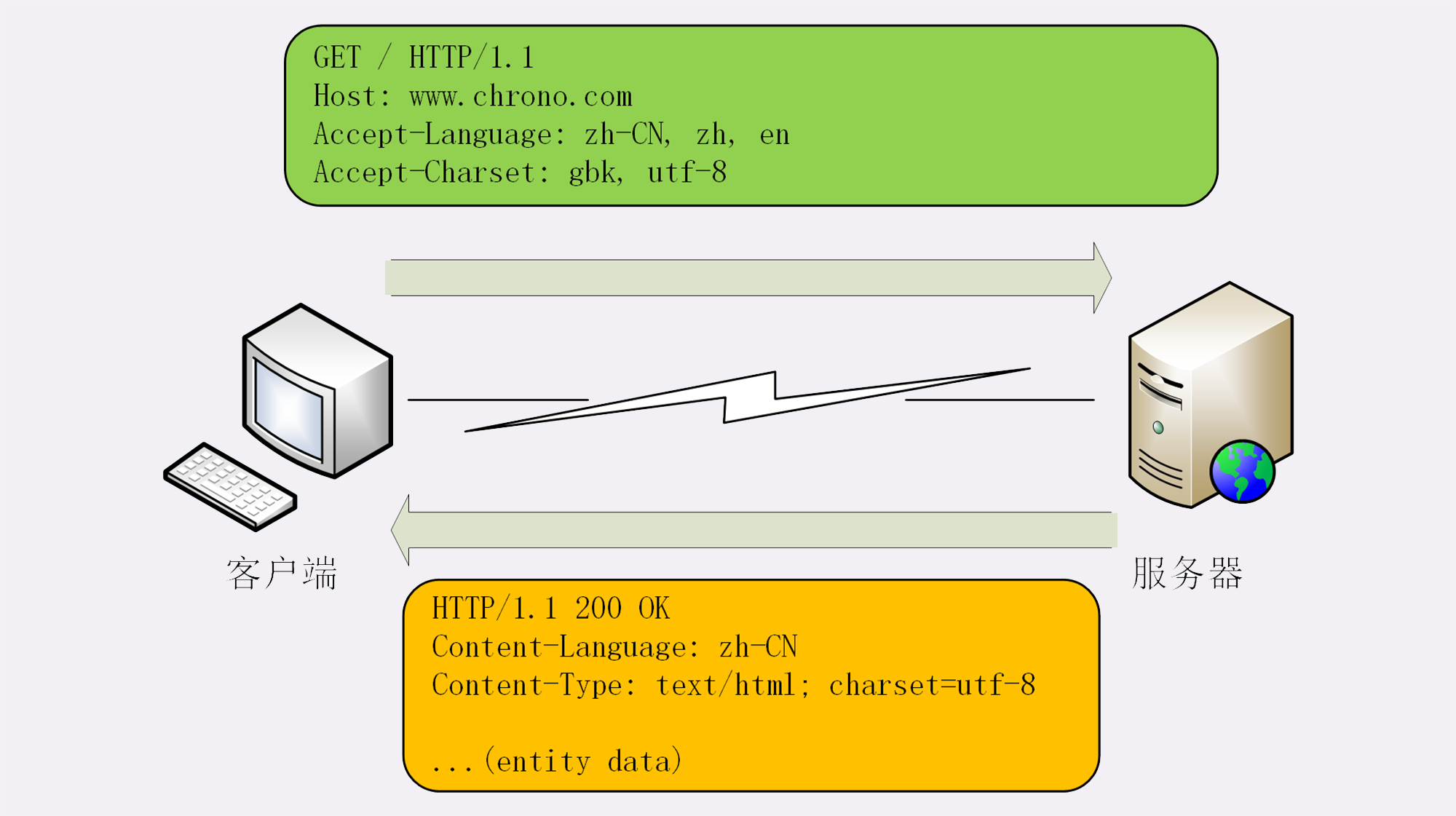
4. 内容协商的质量值
在 HTTP 协议里用 Accept、Accept-Encoding、Accept-Language 等请求头字段进行内容协商的时候,还可以用一种特殊的“q”参数表示权重来设定优先级,这里的“q”是“quality factor”的意思。
权重的最大值是 1,最小值是 0.01,默认值是 1,如果值是 0 就表示拒绝。具体的形式是在数据类型或语言代码后面加一个“;”,然后是“q=value”。
这里要提醒的是“;”的用法,在大多数编程语言里“;”的断句语气要强于“,”,而在 HTTP 的内容协商里却恰好反了过来,“;”的意义是小于“,”的。
例如下面的 Accept 字段:
Accept: text/html,application/xml;q=0.9,*/*;q=0.8
它表示浏览器最希望使用的是 HTML 文件,权重是 1,其次是 XML 文件,权重是 0.9,最后是任意数据类型,权重是0.8。服务器收到请求头后,就会计算权重,再根据自己的实际情况优先输出 HTML 或者 XML
5. 内容协商的结果
内容协商的过程是不透明的,每个 Web 服务器使用的算法都不一样。但有的时候,服务器会在响应头里多加一个Vary字段,记录服务器在内容协商时参考的请求头字段,给出一点信息,例如:
Vary: Accept-Encoding,User-Agent,Accept
这个 Vary 字段表示服务器依据了 Accept-Encoding、User-Agent 和 Accept 这三个头字段,然后决定了发回的响应报文。
Vary 字段可以认为是响应报文的一个特殊的“版本标记”。每当 Accept 等请求头变化时,Vary 也会随着响应报文一起变化。也就是说,同一个 URI 可能会有多个不同的“版本”,主要用在传输链路中间的代理服务器实现缓存服务,这个之后讲“HTTP 缓存”时还会再提到
6. 小结
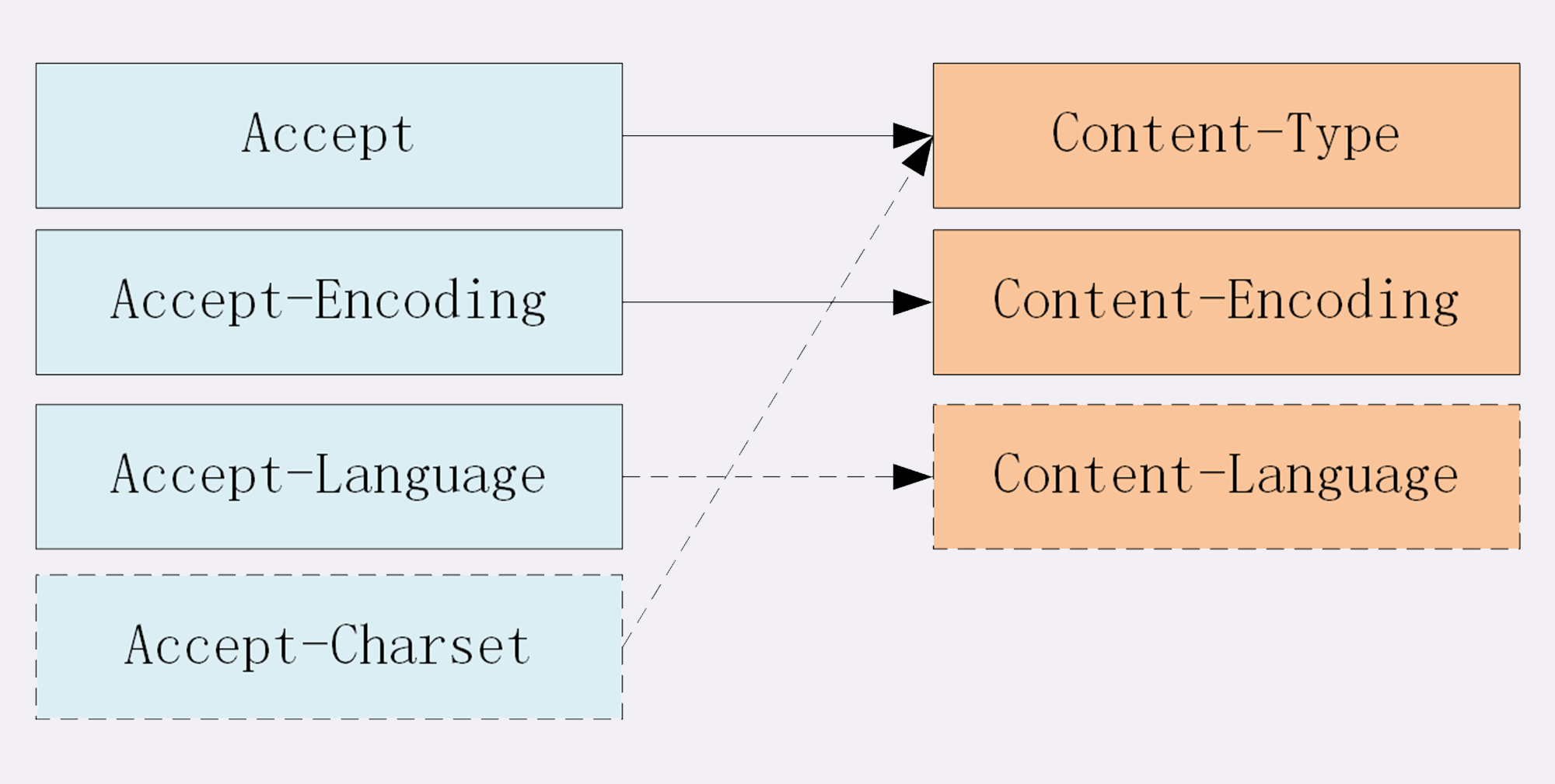
- 数据类型表示实体数据的内容是什么,使用的是
MIME type,相关的头字段是Accept和Content-Type; - 数据编码表示实体数据的压缩方式,相关的头字段是
Accept-Encoding和Content-Encoding; - 语言类型表示实体数据的自然语言,相关的头字段是
Accept-Language和Content-Language; - 字符集表示实体数据的编码方式,相关的头字段是
Accept-Charset和 Content-Type; - 客户端需要在请求头里使用
Accept等头字段与服务器进行“内容协商”,要求服务器返回最合适的数据;Accept等头字段可以用“,”顺序列出多个可能的选项,还可以用“;q=”参数来精确指定权重
----------@----------
谈一谈HTTP协议优缺点
超文本传输协议, HTTP 是一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范 。
- HTTP 特点
- 灵活可扩展 。一个是语法上只规定了基本格式,空格分隔单词,换行分隔字段等。另外一个就是传输形式上不仅可以传输文本,还可以传输图片,视频等任意数据。
- 请求-应答模式 ,通常而言,就是一方发送消息,另外一方要接受消息,或者是做出相应等。
- 可靠传输 ,HTTP是基于TCP/IP,因此把这一特性继承了下来。
- 无状态 ,这个分场景回答即可。
- HTTP 缺点
- 无状态 ,有时候,需要保存信息,比如像购物系统,需要保留下顾客信息等等,另外一方面,有时候,无状态也会减少网络开销,比如类似直播行业这样子等,这个还是分场景来说。
- 明文传输 ,即协议里的报文(主要指的是头部)不使用二进制数据,而是文本形式。这让HTTP的报文信息暴露给了外界,给攻击者带来了便利。
- 队头阻塞 ,当http开启长连接时,共用一个
TCP连接,当某个请求时间过长时,其他的请求只能处于阻塞状态,这就是队头阻塞问题。
http 无状态无连接
http协议对于事务处理没有记忆能力- 对同一个
url请求没有上下文关系 - 每次的请求都是独立的,它的执行情况和结果与前面的请求和之后的请求是无直接关系的,它不会受前面的请求应答情况直接影响,也不会直接影响后面的请求应答情况
- 服务器中没有保存客户端的状态,客户端必须每次带上自己的状态去请求服务器
- 人生若只如初见,请求过的资源下一次会继续进行请求
http协议无状态中的 状态 到底指的是什么?!
- 【状态】的含义就是:客户端和服务器在某次会话中产生的数据
- 那么对应的【无状态】就意味着:这些数据不会被保留
- 通过增加
cookie和session机制,现在的网络请求其实是有状态的 - 在没有状态的
http协议下,服务器也一定会保留你每次网络请求对数据的修改,但这跟保留每次访问的数据是不一样的,保留的只是会话产生的结果,而没有保留会话
----------@----------
说一说HTTP 的请求方法
- HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法
- HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT
http/1.1规定了以下请求方法(注意,都是大写):
- GET: 请求获取Request-URI所标识的资源
- POST: 在Request-URI所标识的资源后附加新的数据
- HEAD: 请求获取由Request-URI所标识的资源的响应消息报头
- PUT: 请求服务器存储一个资源,并用Request-URI作为其标识(修改数据)
- DELETE: 请求服务器删除对应所标识的资源
- TRACE: 请求服务器回送收到的请求信息,主要用于测试或诊断
- CONNECT: 建立连接隧道,用于代理服务器
- OPTIONS: 列出可对资源实行的请求方法,用来跨域请求
从应用场景角度来看,Get 多用于无副作用,幂等的场景,例如搜索关键字。Post 多用于副作用,不幂等的场景,例如注册。
options 方法有什么用
- OPTIONS 请求与 HEAD 类似,一般也是用于客户端查看服务器的性能。
- 这个方法会请求服务器返回该资源所支持的所有 HTTP 请求方法,该方法会用’*'来代替资源名称,向服务器发送 OPTIONS 请求,可以测试服务器功能是否正常。
- JS 的 XMLHttpRequest对象进行 CORS 跨域资源共享时,对于复杂请求,就是使用 OPTIONS 方法发送嗅探请求,以判断是否有对指定资源的访问权限。
----------@----------
谈一谈GET 和 POST 的区别
本质上,只是语义上的区别,GET 用于获取资源,POST 用于提交资源。
具体差别👇
- 从缓存角度看,GET 请求后浏览器会主动缓存,POST 默认情况下不能。
- 从参数角度来看,GET请求一般放在URL中,因此不安全,POST请求放在请求体中,相对而言较为安全,但是在抓包的情况下都是一样的。
- 从编码角度看,GET请求只能经行URL编码,只能接受ASCII码,而POST支持更多的编码类型且不对数据类型限值。
- GET请求幂等,POST请求不幂等,幂等指发送 M 和 N 次请求(两者不相同且都大于1),服务器上资源的状态一致。
- GET请求会一次性发送请求报文,POST请求通常分为两个TCP数据包,首先发 header 部分,如果服务器响应 100(continue), 然后发 body 部分。
----------@----------
谈一谈队头阻塞问题
什么是队头阻塞?
对于每一个HTTP请求而言,这些任务是会被放入一个任务队列中串行执行的,一旦队首任务请求太慢时,就会阻塞后面的请求处理,这就是HTTP队头阻塞问题。
有什么解决办法吗👇
并发连接
我们知道对于一个域名而言,是允许分配多个长连接的,那么可以理解成增加了任务队列,也就是说不会导致一个任务阻塞了该任务队列的其他任务,在
RFC规范中规定客户端最多并发2个连接,不过实际情况就是要比这个还要多,举个例子,Chrome中是6个。
域名分片
- 顾名思义,我们可以在一个域名下分出多个二级域名出来,而它们最终指向的还是同一个服务器,这样子的话就可以并发处理的任务队列更多,也更好的解决了队头阻塞的问题。
- 举个例子,比如
TianTian.com,可以分出很多二级域名,比如Day1.TianTian.com,Day2.TianTian.com,Day3.TianTian.com,这样子就可以有效解决队头阻塞问题。
----------@----------
谈一谈HTTP数据传输
大概遇到的情况就分为定长数据 与 不定长数据的处理吧。
定长数据
对于定长的数据包而言,发送端在发送数据的过程中,需要设置Content-Length,来指明发送数据的长度。
当然了如果采用了Gzip压缩的话,Content-Length设置的就是压缩后的传输长度。
我们还需要知道的是👇
Content-Length如果存在并且有效的话,则必须和消息内容的传输长度完全一致,也就是说,如果过短就会截断,过长的话,就会导致超时。- 如果采用短链接的话,直接可以通过服务器关闭连接来确定消息的传输长度。
- 那么在HTTP/1.0之前的版本中,Content-Length字段可有可无,因为一旦服务器关闭连接,我们就可以获取到传输数据的长度了。
- 在HTTP/1.1版本中,如果是Keep-alive的话,chunked优先级高于
Content-Length,若是非Keep-alive,跟前面情况一样,Content-Length可有可无。
那怎么来设置Content-Length
举个例子来看看👇
const server = require('http').createServer();
server.on('request', (req, res) => {if(req.url === '/index') {// 设置数据类型res.setHeader('Content-Type', 'text/plain');res.setHeader('Content-Length', 10);res.write("你好,使用的是Content-Length设置传输数据形式");}
})server.listen(3000, () => {console.log("成功启动--TinaTian");
})
不定长数据
现在采用最多的就是HTTP/1.1版本,来完成传输数据,在保存Keep-alive状态下,当数据是不定长的时候,我们需要设置新的头部字段👇
Transfer-Encoding: chunked
通过chunked机制,可以完成对不定长数据的处理,当然了,你需要知道的是
- 如果头部信息中有
Transfer-Encoding,优先采用Transfer-Encoding里面的方法来找到对应的长度。 - 如果设置了Transfer-Encoding,那么Content-Length将被忽视。
- 使用长连接的话,会持续的推送动态内容。
那我们来模拟一下吧👇
const server = require('http').createServer();
server.on('request', (req, res) => {if(req.url === '/index') {// 设置数据类型res.setHeader('Content-Type', 'text/html; charset=utf8');res.setHeader('Content-Length', 10);res.setHeader('Transfer-Encoding', 'chunked');res.write("你好,使用的是Transfer-Encoding设置传输数据形式");setTimeout(() => {res.write("第一次传输数据给您<br/>");}, 1000);res.write("骚等一下");setTimeout(() => {res.write("第一次传输数据给您");res.end()}, 3000);}
})server.listen(3000, () => {console.log("成功启动--TinaTian");
})
上面使用的是nodejs中
http模块,有兴趣的小伙伴可以去试一试,以上就是HTTP对定长数据和不定长数据传输过程中的处理手段。
----------@----------
cookie 和 session
session: 是一个抽象概念,开发者为了实现中断和继续等操作,将user agent和server之间一对一的交互,抽象为“会话”,进而衍生出“会话状态”,也就是session的概念cookie:它是一个世纪存在的东西,http协议中定义在header中的字段,可以认为是session的一种后端无状态实现
现在我们常说的
session,是为了绕开cookie的各种限制,通常借助cookie本身和后端存储实现的,一种更高级的会话状态实现
session 的常见实现要借助cookie来发送 sessionID
----------@----------
介绍一下HTTPS和HTTP区别
HTTPS 要比 HTTPS 多了 secure 安全性这个概念,实际上, HTTPS 并不是一个新的应用层协议,它其实就是 HTTP + TLS/SSL 协议组合而成,而安全性的保证正是 SSL/TLS 所做的工作。
SSL
安全套接层(Secure Sockets Layer)
TLS
(传输层安全,Transport Layer Security)
现在主流的版本是 TLS/1.2, 之前的 TLS1.0、TLS1.1 都被认为是不安全的,在不久的将来会被完全淘汰。
HTTPS 就是身披了一层 SSL 的 HTTP 。
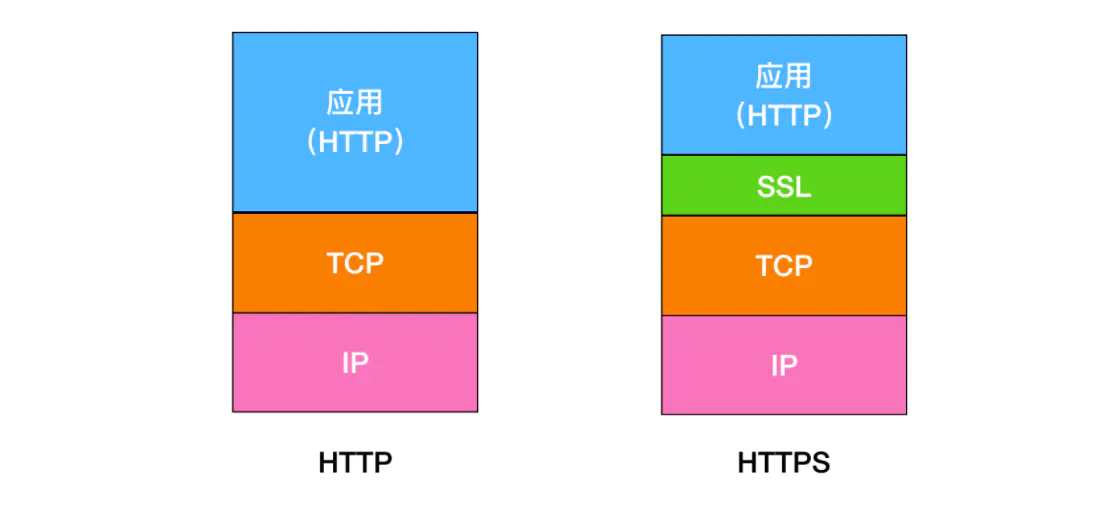
那么区别有哪些呢👇
- HTTP 是明文传输协议,HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 HTTP 协议安全。
- HTTPS比HTTP更加安全,对搜索引擎更友好,利于SEO,谷歌、百度优先索引HTTPS网页。
- HTTPS标准端口443,HTTP标准端口80。
- HTTPS需要用到SSL证书,而HTTP不用。
我觉得记住以下两点HTTPS主要作用就行👇
- 对数据进行加密,并建立一个信息安全通道,来保证传输过程中的数据安全;
- 对网站服务器进行真实身份认证。
HTTPS的缺点
- 证书费用以及更新维护。
- HTTPS 降低一定用户访问速度(实际上优化好就不是缺点了)。
- HTTPS 消耗 CPU 资源,需要增加大量机器。
----------@----------
HTTPS握手过程
- 第一步,客户端给出协议版本号、一个客户端生成的随机数(Client random),以及客户端支持的加密方法
- 第二步,服务端确认双方使用的加密方法,并给出数字证书、以及一个服务器生成的随机数
- 第三步,客户端确认数字证书有效,然后生成一个新的随机数(Premaster secret),并使用数字证书中的公钥,加密这个随机数,发给服务端
- 第四步,服务端使用自己的私钥,获取客户端发来的随机数(即Premaster secret)。
- 第五步,客户端和服务端根据约定的加密方法,使用前面的三个随机数,生成"对话密钥"(session key),用来加密接下来的整个对话过程
总结
- 客户端发起 HTTPS 请求,服务端返回证书,客户端对证书进行验证,验证通过后本地生成用于构造对称加密算法的随机数
- 通过证书中的公钥对随机数进行加密传输到服务端(随机对称密钥),服务端接收后通过私钥解密得到随机对称密钥,之后的数据交互通过对称加密算法进行加解密。(既有对称加密,也有非对称加密)
----------@----------
介绍一个HTTPS工作原理
我们可以把HTTPS理解成HTTPS = HTTP + SSL/TLS
TLS/SSL 的功能实现主要依赖于三类基本算法:
散列函数、对称加密和非对称加密,其利用非对称加密实现身份认证和密钥协商,对称加密算法采用协商的密钥对数据加密,基于散列函数验证信息的完整性。
1. 对称加密
加密和解密用同一个秘钥的加密方式叫做对称加密。Client客户端和Server端共用一套密钥,这样子的加密过程似乎很让人理解,但是随之会产生一些问题。
问题一: WWW万维网有许许多多的客户端,不可能都用秘钥A进行信息加密,这样子很不合理,所以解决办法就是使用一个客户端使用一个密钥进行加密。
问题二:既然不同的客户端使用不同的密钥,那么对称加密的密钥如何传输? 那么解决的办法只能是 一端生成一个秘钥,然后通过HTTP传输给另一端 ,那么这样子又会产生新的问题。
问题三: 这个传输密钥的过程,又如何保证加密?如果被中间人拦截,密钥也会被获取, 那么你会说对密钥再进行加密,那又怎么保存对密钥加密的过程,是加密的过程?
到这里,我们似乎想明白了,使用对称加密的方式,行不通,所以我们需要采用非对称加密👇
2. 非对称加密
通过上面的分析,对称加密的方式行不通,那么我们来梳理一下非对称加密。采用的算法是RSA,所以在一些文章中也会看见 传统RSA握手 ,基于现在TLS主流版本是1.2,所以接下来梳理的是 TLS/1.2握手过程 。
非对称加密中,我们需要明确的点是👇
- 有一对秘钥,公钥和 私钥 。
- 公钥加密的内容,只有私钥可以解开,私钥加密的内容,所有的公钥都可以解开,这里说的 公钥都可以解开,指的是一对秘钥 。
- 公钥可以发送给所有的客户端,私钥只保存在服务器端。
3. 主要工作流程
梳理起来,可以把TLS 1.2 握手过程分为主要的五步👇
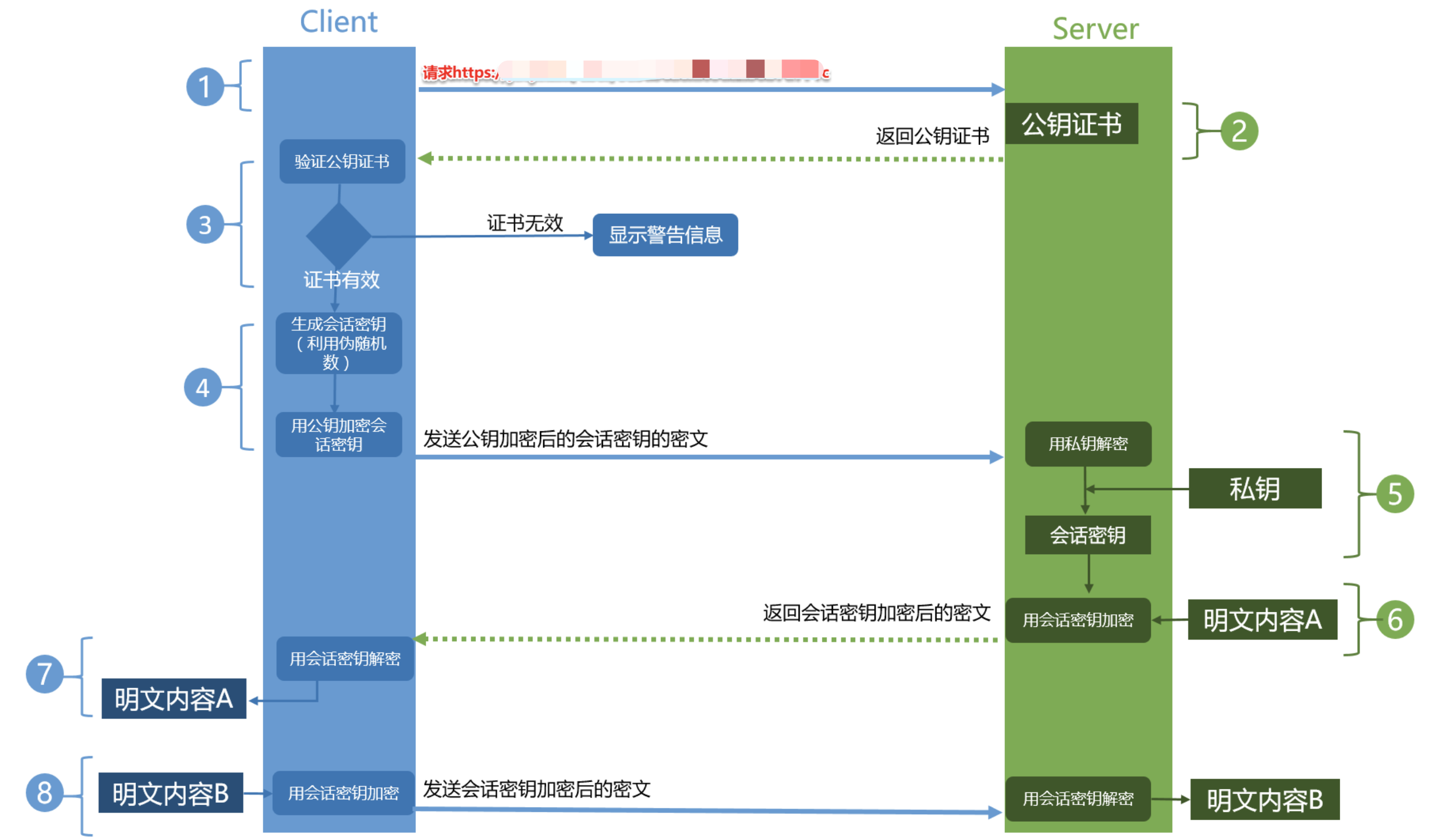
- 步骤一:Client发起一个HTTPS请求,连接443端口。这个过程可以理解成是 请求公钥的过程 。
- 步骤二:Server端收到请求后,通过第三方机构私钥加密,会把数字证书(也可以认为是公钥证书)发送给Client。
- 步骤三:
- 浏览器安装后会自动带一些权威第三方机构公钥,使用匹配的公钥对数字签名进行解密。
- 根据签名生成的规则对网站信息进行本地签名生成,然后两者比对。
- 通过比对两者签名,匹配则说明认证通过,不匹配则获取证书失败。
- 步骤四:在安全拿到服务器公钥后,客户端Client随机生成一个 对称密钥 ,使用 服务器公钥 (证书的公钥)加密这个 对称密钥 ,发送给Server(服务器)。
- 步骤五:Server(服务器)通过自己的私钥,对信息解密,至此得到了 对称密钥 ,此时两者都拥有了相同的 对称密钥 。
接下来,就可以通过该对称密钥对传输的信息加密/解密啦,从上面图举个例子👇
- Client用户使用该对称密钥加密’明文内容B’,发送给Server(服务器)
- Server使用该对称密钥进行解密消息,得到明文内容B。
接下来考虑一个问题,如果公钥被中间人拿到纂改怎么办呢?
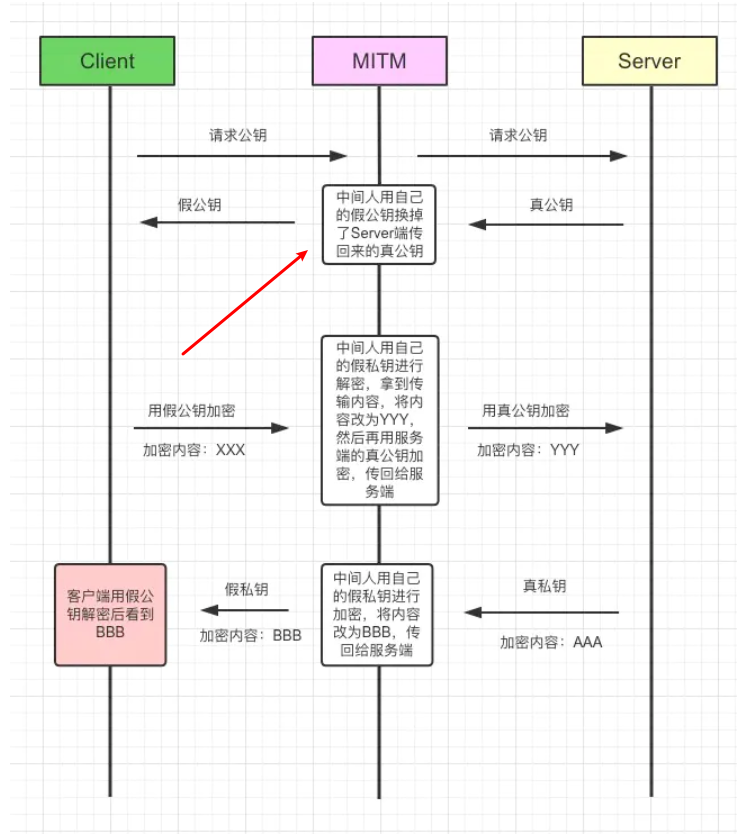
客户端可能拿到的公钥是假的,解决办法是什么呢?
3. 第三方认证
客户端无法识别传回公钥是中间人的,还是服务器的,这是问题的根本,我们是不是可以通过某种规范可以让客户端和服务器都遵循某种约定呢?那就是通过第三方认证的方式
在HTTPS中,通过 证书 + 数字签名来解决这个问题。
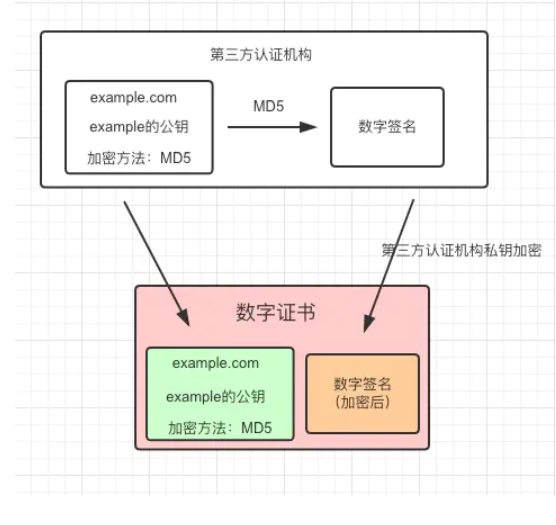
这里唯一不同的是,假设对网站信息加密的算法是MD5,通过MD5加密后, 然后通过第三方机构的私钥再次对其加密,生成数字签名 。
这样子的话,数字证书包含有两个特别重要的信息👉某网站公钥+数字签名
我们再次假设中间人截取到服务器的公钥后,去替换成自己的公钥,因为有数字签名的存在,这样子客户端验证发现数字签名不匹配,这样子就防止中间人替换公钥的问题。
那么客户端是如何去对比两者数字签名的呢?
- 浏览器会去安装一些比较权威的第三方认证机构的公钥,比如VeriSign、Symantec以及GlobalSign等等。
- 验证数字签名的时候,会直接从本地拿到相应的第三方的公钥,对私钥加密后的数字签名进行解密得到真正的签名。
- 然后客户端利用签名生成规则进行签名生成,看两个签名是否匹配,如果匹配认证通过,不匹配则获取证书失败。
4. 数字签名作用
数字签名:将网站的信息,通过特定的算法加密,比如MD5,加密之后,再通过服务器的私钥进行加密,形成 加密后的数字签名 。
第三方认证机构是一个公开的平台,中间人可以去获取。
如果没有数字签名的话,这样子可以就会有下面情况👇

从上面我们知道,如果只是对网站信息进行第三方机构私钥加密的话,还是会受到欺骗。
因为没有认证,所以中间人也向第三方认证机构进行申请,然后拦截后把所有的信息都替换成自己的,客户端仍然可以解密,并且无法判断这是服务器的还是中间人的,最后造成数据泄露。
5. 总结
- HTTPS就是使用SSL/TLS协议进行加密传输
- 大致流程:客户端拿到服务器的公钥(是正确的),然后客户端随机生成一个 对称加密的秘钥 ,使用该公钥加密,传输给服务端,服务端再通过解密拿到该 对称秘钥 ,后续的所有信息都通过该对称秘钥进行加密解密,完成整个HTTPS的流程。
- 第三方认证 ,最重要的是 数字签名 ,避免了获取的公钥是中间人的。
----------@----------
SSL 连接断开后如何恢复
一共有两种方法来恢复断开的 SSL 连接,一种是使用 session ID,一种是 session ticket。
通过session ID
使用 session ID 的方式,每一次的会话都有一个编号,当对话中断后,下一次重新连接时,只要客户端给出这个编号,服务器如果有这个编号的记录,那么双方就可以继续使用以前的秘钥,而不用重新生成一把。目前所有的浏览器都支持这一种方法。但是这种方法有一个缺点是,session ID 只能够存在一台服务器上,如果我们的请求通过负载平衡被转移到了其他的服务器上,那么就无法恢复对话。
通过session ticket
另一种方式是 session ticket 的方式,session ticket 是服务器在上一次对话中发送给客户的,这个 ticket 是加密的,只有服务器能够解密,里面包含了本次会话的信息,比如对话秘钥和加密方法等。这样不管我们的请求是否转移到其他的服务器上,当服务器将 ticket 解密以后,就能够获取上次对话的信息,就不用重新生成对话秘钥了。
----------@----------
谈一谈你对HTTP/2理解
首先补充一下,http 和 https 的区别,相比于 http,https 是基于 ssl 加密的 http 协议
简要概括:http2.0 是基于 1999 年发布的 http1.0 之后的首次更新
- 提升访问速度 (可以对于,请求资源所需时间更少,访问速度更快,相比 http1.0)
- 允许多路复用 :多路复用允许同时通过单一的 HTTP/2 连接发送多重请求-响应信息。改 善了:在
http1.1中,浏览器客户端在同一时间,针对同一域名下的请求有一定数量限 制(连接数量),超过限制会被阻塞 - 二进制分帧 :HTTP2.0 会将所有的传输信息分割为更小的信息或者帧,并对他们进行二 进制编码
- 首部压缩
- 服务器端推送
头部压缩
HTTP 1.1版本会出现 User-Agent、Cookie、Accept、Server、Range 等字段可能会占用几百甚至几千字节,而 Body 却经常只有几十字节,所以导致头部偏重。
HTTP 2.0 使用 HPACK 算法进行压缩。
多路复用
- HTTP 1.x 中,如果想并发多个请求,必须使用多个 TCP 链接,且浏览器为了控制资源,还会对单个域名有 6-8个的TCP链接请求限制。
HTTP2中:
- 同域名下所有通信都在单个连接上完成。
- 单个连接可以承载任意数量的双向数据流。
- 数据流以消息的形式发送,而消息又由一个或多个帧组成,多个帧之间可以乱序发送,因为根据帧首部的流标识可以重新组装,也就是
Stream ID,流标识符,有了它,接收方就能从乱序的二进制帧中选择ID相同的帧,按照顺序组装成请求/响应报文。
服务器推送
浏览器发送一个请求,服务器主动向浏览器推送与这个请求相关的资源,这样浏览器就不用发起后续请求。
相比较http/1.1的优势👇
- 推送资源可以由不同页面共享
- 服务器可以按照优先级推送资源
- 客户端可以缓存推送的资源
- 客户端可以拒收推送过来的资源
二进制分帧
之前是明文传输,不方便计算机解析,对于回车换行符来说到底是内容还是分隔符,都需要内部状态机去识别,这样子效率低,HTTP/2采用二进制格式,全部传输01串,便于机器解码。
这样子一个报文格式就被拆分为一个个二进制帧,用Headers帧存放头部字段,Data帧存放请求体数据。这样子的话,就是一堆乱序的二进制帧,它们不存在先后关系,因此不需要排队等待,解决了HTTP队头阻塞问题。
在客户端与服务器之间,双方都可以互相发送二进制帧,这样子 双向传输的序列 ,称为流,所以HTTP/2中以流来表示一个TCP连接上进行多个数据帧的通信,这就是多路复用概念。
那乱序的二进制帧,是如何组装成对于的报文呢?
- 所谓的乱序,值的是不同ID的Stream是乱序的,对于同一个Stream ID的帧是按顺序传输的。
- 接收方收到二进制帧后,将相同的Stream ID组装成完整的请求报文和响应报文。
- 二进制帧中有一些字段,控制着
优先级和流量控制等功能,这样子的话,就可以设置数据帧的优先级,让服务器处理重要资源,优化用户体验。
HTTP2的缺点
- TCP 以及 TCP+TLS建立连接的延时,HTTP/2使用TCP协议来传输的,而如果使用HTTPS的话,还需要使用TLS协议进行安全传输,而使用TLS也需要一个握手过程,在传输数据之前,导致我们需要花掉 3~4 个 RTT。
- TCP的队头阻塞并没有彻底解决。在HTTP/2中,多个请求是跑在一个TCP管道中的。但当HTTP/2出现丢包时,整个 TCP 都要开始等待重传,那么就会阻塞该TCP连接中的所有请求。
----------@----------
HTTP3
Google 在推SPDY的时候就已经意识到了这些问题,于是就另起炉灶搞了一个基于 UDP 协议的“QUIC”协议,让HTTP跑在QUIC上而不是TCP上。主要特性如下:
- 实现了类似TCP的流量控制、传输可靠性的功能。虽然UDP不提供可靠性的传输,但QUIC在UDP的基础之上增加了一层来保证数据可靠性传输。它提供了数据包重传、拥塞控制以及其他一些TCP中存在的特性
- 实现了快速握手功能。由于QUIC是基于UDP的,所以QUIC可以实现使用0-RTT或者1-RTT来建立连接,这意味着QUIC可以用最快的速度来发送和接收数据。
- 集成了TLS加密功能。目前QUIC使用的是TLS1.3,相较于早期版本TLS1.3有更多的优点,其中最重要的一点是减少了握手所花费的RTT个数。
- 多路复用,彻底解决TCP中队头阻塞的问题。
----------@----------
HTTP/1.0 HTTP1.1 HTTP2.0版本之间的差异
- HTTP 0.9 :1991年,原型版本,功能简陋,只有一个命令GET,只支持纯文本内容,该版本已过时。
- HTTP 1.0
- 任何格式的内容都可以发送,这使得互联网不仅可以传输文字,还能传输图像、视频、二进制等文件。
- 除了GET命令,还引入了POST命令和HEAD命令。
- http请求和回应的格式改变,除了数据部分,每次通信都必须包括头信息(HTTP header),用来描述一些元数据。
- 只使用 header 中的 If-Modified-Since 和 Expires 作为缓存失效的标准。
- 不支持断点续传,也就是说,每次都会传送全部的页面和数据。
- 通常每台计算机只能绑定一个 IP,所以请求消息中的 URL 并没有传递主机名(hostname)
- HTTP 1.1 http1.1是目前最为主流的http协议版本,从1999年发布至今,仍是主流的http协议版本。
- 引入了持久连接( persistent connection),即TCP连接默认不关闭,可以被多个请求复用,不用声明Connection: keep-alive。长连接的连接时长可以通过请求头中的
keep-alive来设置 - 引入了管道机制( pipelining),即在同一个TCP连接里,客户端可以同时发送多个 请求,进一步改进了HTTP协议的效率。
- HTTP 1.1 中新增加了 E-tag,If-Unmodified-Since, If-Match, If-None-Match 等缓存控制标头来控制缓存失效。
- 支持断点续传,通过使用请求头中的
Range来实现。 - 使用了虚拟网络,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。
- 新增方法:PUT、 PATCH、 OPTIONS、 DELETE。
- 引入了持久连接( persistent connection),即TCP连接默认不关闭,可以被多个请求复用,不用声明Connection: keep-alive。长连接的连接时长可以通过请求头中的
- http1.x版本问题
- 在传输数据过程中,所有内容都是明文,客户端和服务器端都无法验证对方的身份,无法保证数据的安全性。
- HTTP/1.1 版本默认允许复用TCP连接,但是在同一个TCP连接里,所有数据通信是按次序进行的,服务器通常在处理完一个回应后,才会继续去处理下一个,这样子就会造成队头阻塞。
- http/1.x 版本支持Keep-alive,用此方案来弥补创建多次连接产生的延迟,但是同样会给服务器带来压力,并且的话,对于单文件被不断请求的服务,Keep-alive会极大影响性能,因为它在文件被请求之后还保持了不必要的连接很长时间。
- HTTP 2.0
二进制分帧这是一次彻底的二进制协议,头信息和数据体都是二进制,并且统称为"帧":头信息帧和数据帧。头部压缩HTTP 1.1版本会出现 User-Agent、Cookie、Accept、Server、Range 等字段可能会占用几百甚至几千字节,而 Body 却经常只有几十字节,所以导致头部偏重。HTTP 2.0 使用HPACK算法进行压缩。多路复用复用TCP连接,在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,且不用按顺序一一对应,这样子解决了队头阻塞的问题。服务器推送允许服务器未经请求,主动向客户端发送资源,即服务器推送。请求优先级可以设置数据帧的优先级,让服务端先处理重要资源,优化用户体验。
----------@----------
DNS如何工作的
DNS 的作用就是通过域名查询到具体的 IP。DNS 协议提供的是一种主机名到 IP 地址的转换服务,就是我们常说的域名系统。是应用层协议,通常该协议运行在UDP协议之上,使用的是53端口号。
因为 IP 存在数字和英文的组合(IPv6),很不利于人类记忆,所以就出现了域名。你可以把域名看成是某个 IP 的别名,DNS 就是去查询这个别名的真正名称是什么。
当你在浏览器中想访问 www.google.com 时,会通过进行以下操作:
- 本地客户端向服务器发起请求查询 IP 地址
- 查看浏览器有没有该域名的 IP 缓存
- 查看操作系统有没有该域名的 IP 缓存
- 查看 Host 文件有没有该域名的解析配置
- 如果这时候还没得话,会通过直接去 DNS 根服务器查询,这一步查询会找出负责
com这个一级域名的服务器 - 然后去该服务器查询
google.com这个二级域名 - 接下来查询
www.google.com这个三级域名的地址 - 返回给 DNS 客户端并缓存起来

我们通过一张图来看看它的查询过程吧 👇

这张图很生动的展示了DNS在本地DNS服务器是如何查询的,一般向本地DNS服务器发送请求是递归查询的
本地 DNS 服务器向其他域名服务器请求的过程是迭代查询的过程👇

递归查询和迭代查询
- 递归查询指的是查询请求发出后,域名服务器代为向下一级域名服务器发出请求,最后向用户返回查询的最终结果。使用递归 查询,用户只需要发出一次查询请求。
- 迭代查询指的是查询请求后,域名服务器返回单次查询的结果。下一级的查询由用户自己请求。使用迭代查询,用户需要发出 多次的查询请求。
所以一般而言, 本地服务器查询是递归查询 ,而本地 DNS 服务器向其他域名服务器请求的过程是迭代查询的过程
DNS缓存
缓存也很好理解,在一个请求中,当某个DNS服务器收到一个DNS回答后,它能够回答中的信息缓存在本地存储器中。返回的资源记录中的 TTL 代表了该条记录的缓存的时间。
DNS实现负载平衡
它是如何实现负载均衡的呢?首先我们得清楚DNS 是可以用于在冗余的服务器上实现负载平衡。
原因: 这是因为一般的大型网站使用多台服务器提供服务,因此一个域名可能会对应 多个服务器地址。
举个例子来说👇
- 当用户发起网站域名的 DNS 请求的时候,DNS 服务器返回这个域名所对应的服务器 IP 地址的集合
- 在每个回答中,会循环这些 IP 地址的顺序,用户一般会选择排在前面的地址发送请求。
- 以此将用户的请求均衡的分配到各个不同的服务器上,这样来实现负载均衡。
DNS 为什么使用 UDP 协议作为传输层协议?
DNS 使用 UDP 协议作为传输层协议的主要原因是为了避免使用 TCP 协议时造成的连接时延
- 为了得到一个域名的 IP 地址,往往会向多个域名服务器查询,如果使用 TCP 协议,那么每次请求都会存在连接时延,这样使 DNS 服务变得很慢。
- 大多数的地址查询请求,都是浏览器请求页面时发出的,这样会造成网页的等待时间过长。
总结
- DNS域名系统,是应用层协议,运行UDP协议之上,使用端口43。
- 查询过程,本地查询是递归查询,依次通过浏览器缓存
—>>本地hosts文件—>>本地DNS解析器—>>本地DNS服务器—>>其他域名服务器请求。 接下来的过程就是迭代过程。 - 递归查询一般而言,发送一次请求就够,迭代过程需要用户发送多次请求。
----------@----------
短轮询、长轮询和 WebSocket 间的区别
1. 短轮询
短轮询的基本思路:
- 浏览器每隔一段时间向浏览器发送 http 请求,服务器端在收到请求后,不论是否有数据更新,都直接进行 响应。
- 这种方式实现的即时通信,本质上还是浏览器发送请求,服务器接受请求的一个过程,通过让客户端不断的进行请求,使得客户端能够模拟实时地收到服务器端的数据的变化。
优缺点👇
- 优点是比较简单,易于理解。
- 缺点是这种方式由于需要不断的建立 http 连接,严重浪费了服务器端和客户端的资源。当用户增加时,服务器端的压力就会变大,这是很不合理的。
2. 长轮询
长轮询的基本思路:
- 首先由客户端向服务器发起请求,当服务器收到客户端发来的请求后,服务器端不会直接进行响应,而是先将 这个请求挂起,然后判断服务器端数据是否有更新。
- 如果有更新,则进行响应,如果一直没有数据,则到达一定的时间限制才返回。客户端 JavaScript 响应处理函数会在处理完服务器返回的信息后,再次发出请求,重新建立连接。
优缺点👇
- 长轮询和短轮询比起来,它的优点是 明显减少了很多不必要的 http 请求次数 ,相比之下节约了资源。
- 长轮询的缺点在于,连接挂起也会导致资源的浪费
3. WebSocket
- WebSocket 是 Html5 定义的一个新协议,与传统的 http 协议不同,该协议允许由服务器主动的向客户端推送信息。
- 使用 WebSocket 协议的缺点是在服务器端的配置比较复杂。WebSocket 是一个全双工的协议,也就是通信双方是平等的,可以相互发送消息。
----------@----------
说一说正向代理和反向代理
正向代理
我们常说的代理也就是指正向代理,正向代理的过程,它隐藏了真实的请求客户端,服务端不知道真实的客户端是谁,客户端请求的服务都被代理服务器代替来请求。
反向代理
这种代理模式下,它隐藏了真实的服务端,当我们向一个网站发起请求的时候,背后可能有成千上万台服务器为我们服务,具体是哪一台,我们不清楚,我们只需要知道反向代理服务器是谁就行,而且反向代理服务器会帮我们把请求转发到真实的服务器那里去,一般而言反向代理服务器一般用来实现负载平衡。
负载平衡的两种实现方式?
- 一种是使用反向代理的方式,用户的请求都发送到反向代理服务上,然后由反向代理服务器来转发请求到真实的服务器上,以此来实现集群的负载平衡。
- 另一种是 DNS 的方式,DNS 可以用于在冗余的服务器上实现负载平衡。因为现在一般的大型网站使用多台服务器提供服务,因此一个域名可能会对应多个服务器地址。当用户向网站域名请求的时候,DNS 服务器返回这个域名所对应的服务器 IP 地址的集合,但在每个回答中,会循环这些 IP 地址的顺序,用户一般会选择排在前面的地址发送请求。以此将用户的请求均衡的分配到各个不同的服务器上,这样来实现负载均衡。这种方式有一个缺点就是,由于 DNS 服务器中存在缓存,所以有可能一个服务器出现故障后,域名解析仍然返回的是那个 IP 地址,就会造成访问的问题。
----------@----------
介绍一下Connection:keep-alive
什么是keep-alive
我们知道HTTP协议采用“请求-应答”模式,当使用普通模式,即非KeepAlive模式时,每个请求/应答客户和服务器都要新建一个连接,完成 之后立即断开连接(HTTP协议为无连接的协议);
当使用Keep-Alive模式(又称持久连接、连接重用)时,Keep-Alive功能使客户端到服 务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。
为什么要使用keep-alive
keep-alive技术的创建目的,能在多次HTTP之前重用同一个TCP连接,从而减少创建/关闭多个 TCP 连接的开销(包括响应时间、CPU 资源、减少拥堵等),参考如下示意图
客户端如何开启
在HTTP/1.0协议中,默认是关闭的,需要在http头加入"Connection: Keep-Alive”,才能启用Keep-Alive;
Connection: keep-alive
http 1.1中默认启用Keep-Alive,如果加入"Connection: close “,才关闭。
Connection: close
目前大部分浏览器都是用http1.1协议,也就是说默认都会发起Keep-Alive的连接请求了,所以是否能完成一个完整的Keep- Alive连接就看服务器设置情况。
----------@----------
http/https 协议总结
1.0 协议缺陷:
- 无法复用链接,完成即断开,重新慢启动和
TCP 3次握手 head of line blocking: 线头阻塞,导致请求之间互相影响
1.1 改进:
- 长连接(默认
keep-alive),复用 host字段指定对应的虚拟站点- 新增功能:
- 断点续传
- 身份认证
- 状态管理
cache缓存Cache-ControlExpiresLast-ModifiedEtag
2.0:
- 多路复用
- 二进制分帧层: 应用层和传输层之间
- 首部压缩
- 服务端推送
https: 较为安全的网络传输协议
- 证书(公钥)
SSL加密- 端口
443
TCP:
- 三次握手
- 四次挥手
- 滑动窗口: 流量控制
- 拥塞处理
- 慢开始
- 拥塞避免
- 快速重传
- 快速恢复
缓存策略: 可分为 强缓存 和 协商缓存
Cache-Control/Expires: 浏览器判断缓存是否过期,未过期时,直接使用强缓存,Cache-Control的max-age优先级高于Expires- 当缓存已经过期时,使用协商缓存
- 唯一标识方案:
Etag(response携带) &If-None-Match(request携带,上一次返回的Etag): 服务器判断资源是否被修改 - 最后一次修改时间:
Last-Modified(response) & If-Modified-Since(request,上一次返回的Last-Modified)- 如果一致,则直接返回 304 通知浏览器使用缓存
- 如不一致,则服务端返回新的资源
- 唯一标识方案:
Last-Modified缺点:- 周期性修改,但内容未变时,会导致缓存失效
- 最小粒度只到
s,s以内的改动无法检测到
Etag的优先级高于Last-Modified
----------@----------
TCP为什么要三次握手
客户端和服务端都需要直到各自可收发,因此需要三次握手
- 第一次握手成功让服务端知道了客户端具有发送能力
- 第二次握手成功让客户端知道了服务端具有接收和发送能力,但此时服务端并不知道客户端是否接收到了自己发送的消息
- 所以第三次握手就起到了这个作用。`经过三次通信后,服务端
你可以能会问,2 次握手就足够了?。但其实不是,因为服务端还没有确定客户端是否准备好了。比如步骤 3 之后,服务端马上给客户端发送数据,这个时候客户端可能还没有准备好接收数据。因此还需要增加一个过程

TCP有6种标示:SYN(建立联机) ACK(确认) PSH(传送) FIN(结束) RST(重置) URG(紧急)
举例:已失效的连接请求报文段
client发送了第一个连接的请求报文,但是由于网络不好,这个请求没有立即到达服务端,而是在某个网络节点中滞留了,直到某个时间才到达server- 本来这已经是一个失效的报文,但是
server端接收到这个请求报文后,还是会想client发出确认的报文,表示同意连接。 - 假如不采用三次握手,那么只要
server发出确认,新的建立就连接了,但其实这个请求是失效的请求,client是不会理睬server的确认信息,也不会向服务端发送确认的请求 - 但是
server认为新的连接已经建立起来了,并一直等待client发来数据,这样,server的很多资源就没白白浪费掉了 - 采用三次握手就是为了防止这种情况的发生,server会因为收不到确认的报文,就知道
client并没有建立连接。这就是三次握手的作用
三次握手过程中可以携带数据吗
- 第一次、第二次握手不可以携带数据,因为一握二握时还没有建立连接,会让服务器容易受到攻击
- 而第三次握手,此时客户端已经处于
ESTABLISHED (已建立连接状态),对于客户端来说,已经建立起连接了,并且也已经知道服务器的接收、发送能力是正常的了,所以能携带数据也是没问题的。
为什么建立连接只通信了三次,而断开连接却用了四次?
- 客户端要求断开连接,发送一个断开的请求,这个叫作(FIN)。
- 服务端收到请求,然后给客户端一个 ACK,作为 FIN 的响应。
- 这里你需要思考一个问题,可不可以像握手那样马上传 FIN 回去?
- 其实这个时候服务端不能马上传 FIN,因为断开连接要处理的问题比较多,比如说服务端可能还有发送出去的消息没有得到 ACK;也有可能服务端自己有资源要释放。因此断开连接不能像握手那样操作——将两条消息合并。所以,
服务端经过一个等待,确定可以关闭连接了,再发一条 FIN 给客户端。 - 客户端收到服务端的 FIN,同时客户端也可能有自己的事情需要处理完,比如客户端有发送给服务端没有收到 ACK 的请求,客户端自己处理完成后,再给服务端发送一个 ACK。
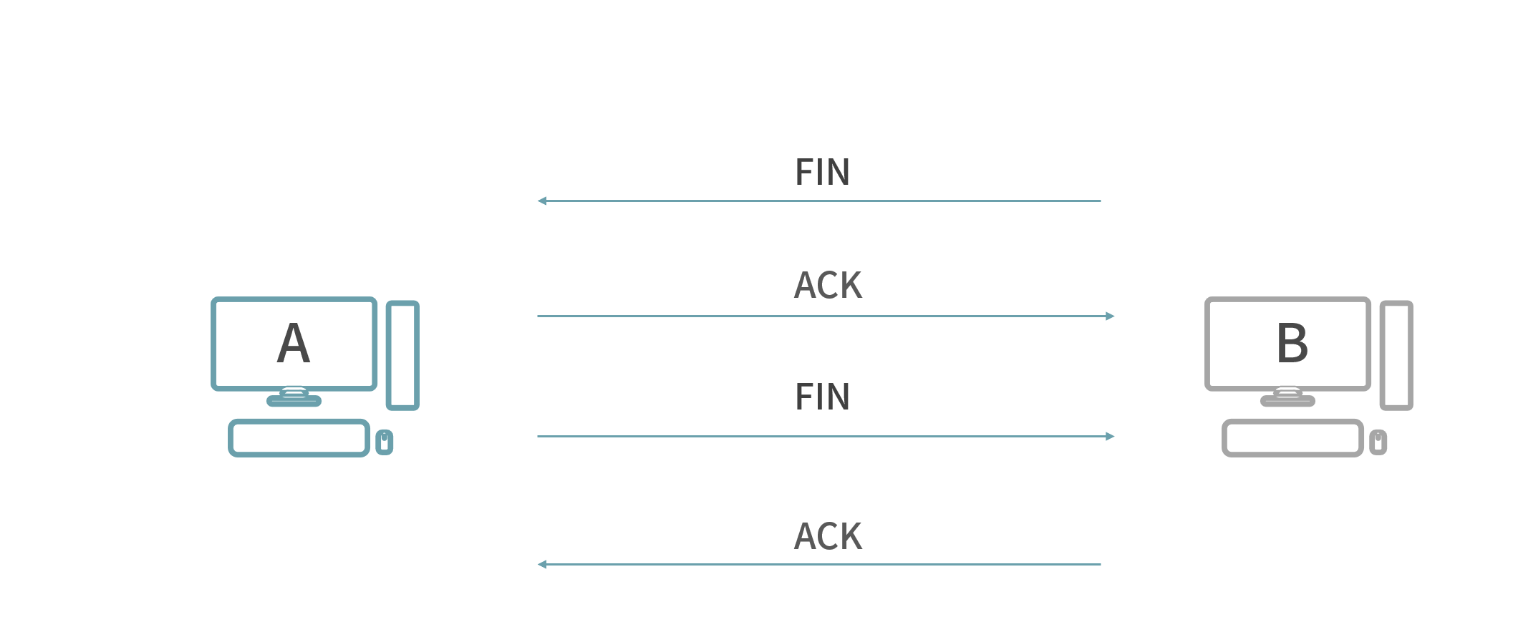
为了确保数据能够完成传输。因为当服务端收到客户端的 FIN 报文后,发送的 ACK 报文只是用来应答的,并不表示服务端也希望立即关闭连接。
当只有服务端把所有的报文都发送完了,才会发送 FIN 报文,告诉客户端可以断开连接了,因此在断开连接时需要四次挥手。
- 关闭连接时,当收到对方的FIN报文通知时,它仅仅表示对方没有数据发送给你了;但未必你所有的数据都全部发送给对方了
- 所以你未必会马上关闭
SOCKET,也即你可能还需要发送一些数据给对方之后,再发送FIN报文给对方来表示你同意现在可以关闭连接了,所以它这里的ACK报文和FIN报文多数情况下都是分开发送的。
----------@----------
为什么要有 WebSocket
已经有了被广泛应用的 HTTP 协议,为什么要再出一个 WebSocket 呢?它有哪些好处呢?
其实 WebSocket 与 HTTP/2 一样,都是为了解决 HTTP 某方面的缺陷而诞生的。HTTP/2 针对的是“队头阻塞”,而
WebSocket 针对的是“请求 - 应答”通信模式。
那么,“请求 - 应答”有什么不好的地方呢?
- “请求 - 应答”是一种“半双工”的通信模式,虽然可以双向收发数据,但同一时刻只能一个方向上有动作,传输效率低。更关键的一点,它是一种“被动”通信模式,服务器只能“被动”响应客户端的请求,无法主动向客户端发送数据。
- 虽然后来的 HTTP/2、HTTP/3 新增了 Stream、Server Push 等特性,但“请求 - 应答”依然是主要的工作方式。这就导致 HTTP 难以应用在动态页面、即时消息、网络游戏等要求“实时通信”的领域。
- 在 WebSocket 出现之前,在浏览器环境里用 JavaScript 开发实时 Web 应用很麻烦。因为浏览器是一个“受限的沙盒”,不能用 TCP,只有 HTTP 协议可用,所以就出现了很多“变通”的技术,“轮询”(polling)就是比较常用的的一种。
- 简单地说,轮询就是不停地向服务器发送 HTTP 请求,问有没有数据,有数据的话服务器就用响应报文回应。如果轮询的频率比较高,那么就可以近似地实现“实时通信”的效果。
- 但轮询的缺点也很明显,反复发送无效查询请求耗费了大量的带宽和 CPU 资源,非常不经济。
- 所以,为了克服 HTTP“请求 - 应答”模式的缺点,WebSocket 就“应运而生”了
WebSocket 的特点
- WebSocket 是一个真正“全双工”的通信协议,与 TCP 一样,客户端和服务器都可以随时向对方发送数据
- WebSocket
采用了二进制帧结构,语法、语义与 HTTP 完全不兼容,但因为它的主要运行环境是浏览器,为了便于推广和应用,就不得不“搭便车”,在使用习惯上尽量向 HTTP 靠拢,这就是它名字里“Web”的含义。 - 服务发现方面,WebSocket 没有使用 TCP 的“IP 地址 + 端口号”,而是延用了 HTTP 的 URI 格式,但开头的协议名不是“http”,引入的是两个新的名字:“ws”和“wss”,分别表示明文和加密的 WebSocket 协议。
WebSocket 的默认端口也选择了 80 和 443,因为现在互联网上的防火墙屏蔽了绝大多数的端口,只对 HTTP 的 80、443 端口“放行”,所以 WebSocket 就可以“伪装”成 HTTP 协议,比较容易地“穿透”防火墙,与服务器建立连接
ws://www.chrono.com
ws://www.chrono.com:8080/srv
wss://www.chrono.com:445/im?user_id=xxx
WebSocket 的握手
和 TCP、TLS 一样,WebSocket 也要有一个握手过程,然后才能正式收发数据。
这里它还是搭上了 HTTP 的“便车”,利用了 HTTP 本身的“协议升级”特性,“伪装”成 HTTP,这样就能绕过浏览器沙盒、网络防火墙等等限制,这也是 WebSocket 与 HTTP 的另一个重要关联点。
WebSocket 的握手是一个标准的 HTTP GET 请求,但要带上两个协议升级的专用头字段:
- “Connection: Upgrade”,表示要求协议“升级”;
- “Upgrade: websocket”,表示要“升级”成 WebSocket 协议。
另外,为了防止普通的 HTTP 消息被“意外”识别成 WebSocket,握手消息还增加了两个额外的认证用头字段(所谓的“挑战”,Challenge):
Sec-WebSocket-Key:一个 Base64 编码的 16 字节随机数,作为简单的认证密钥;Sec-WebSocket-Version:协议的版本号,当前必须是 13。

服务器收到 HTTP 请求报文,看到上面的四个字段,就知道这不是一个普通的 GET 请求,而是 WebSocket 的升级请求,于是就不走普通的 HTTP 处理流程,而是构造一个特殊的“101 Switching Protocols”响应报文,通知客户端,接下来就不用 HTTP 了,全改用 WebSocket 协议通信
小结
浏览器是一个“沙盒”环境,有很多的限制,不允许建立 TCP 连接收发数据,而有了 WebSocket,我们就可以在浏览器里与服务器直接建立“TCP 连接”,获得更多的自由。
不过自由也是有代价的,WebSocket 虽然是在应用层,但使用方式却与“TCP Socket”差不多,过于“原始”,用户必须自己管理连接、缓存、状态,开发上比 HTTP 复杂的多,所以是否要在项目中引入 WebSocket 必须慎重考虑。
HTTP的“请求 - 应答”模式不适合开发“实时通信”应用,效率低,难以实现动态页面,所以出现了 WebSocket;WebSocket是一个“全双工”的通信协议,相当于对 TCP 做了一层“薄薄的包装”,让它运行在浏览器环境里;WebSocket使用兼容 HTTP 的 URI 来发现服务,但定义了新的协议名“ws”和“wss”,端口号也沿用了80 和 443;WebSocket使用二进制帧,结构比较简单,特殊的地方是有个“掩码”操作,客户端发数据必须掩码,服务器则不用;WebSocket利用 HTTP 协议实现连接握手,发送 GET 请求要求“协议升级”,握手过程中有个非常简单的认证机制,目的是防止误连接。
----------@----------
UDP和TCP有什么区别
- TCP协议在传送数据段的时候要给段标号;UDP协议不
- TCP协议可靠;UDP协议不可靠
- TCP协议是面向连接;UDP协议采用无连接
- TCP协议负载较高,采用虚电路;UDP采用无连接
- TCP协议的发送方要确认接收方是否收到数据段(3次握手协议)
- TCP协议采用窗口技术和流控制

----------@----------
9种前端常见的设计模式
1. 外观模式
外观模式是最常见的设计模式之一,它为子系统中的一组接口提供一个统一的高层接口,使子系统更容易使用。简而言之外观设计模式就是把多个子系统中复杂逻辑进行抽象,从而提供一个更统一、更简洁、更易用的API。很多我们常用的框架和库基本都遵循了外观设计模式,比如JQuery就把复杂的原生DOM操作进行了抽象和封装,并消除了浏览器之间的兼容问题,从而提供了一个更高级更易用的版本。其实在平时工作中我们也会经常用到外观模式进行开发,只是我们不自知而已
兼容浏览器事件绑定
let addMyEvent = function (el, ev, fn) {if (el.addEventListener) {el.addEventListener(ev, fn, false)} else if (el.attachEvent) {el.attachEvent('on' + ev, fn)} else {el['on' + ev] = fn}
};
封装接口
let myEvent = {// ...stop: e => {e.stopPropagation();e.preventDefault();}
};
场景
- 设计初期,应该要有意识地将不同的两个层分离,比如经典的三层结构,在数据访问层和业务逻辑层、业务逻辑层和表示层之间建立外观Facade
- 在开发阶段,子系统往往因为不断的重构演化而变得越来越复杂,增加外观Facade可以提供一个简单的接口,减少他们之间的依赖。
- 在维护一个遗留的大型系统时,可能这个系统已经很难维护了,这时候使用外观Facade也是非常合适的,为系系统开发一个外观Facade类,为设计粗糙和高度复杂的遗留代码提供比较清晰的接口,让新系统和Facade对象交互,Facade与遗留代码交互所有的复杂工作。
优点
- 减少系统相互依赖。
- 提高灵活性。
- 提高了安全性
缺点
不符合开闭原则,如果要改东西很麻烦,继承重写都不合适。
2. 代理模式
是为一个对象提供一个代用品或占位符,以便控制对它的访问
假设当A 在心情好的时候收到花,小明表白成功的几率有60%,而当A 在心情差的时候收到花,小明表白的成功率无限趋近于0。小明跟A 刚刚认识两天,还无法辨别A 什么时候心情好。如果不合时宜地把花送给A,花被直接扔掉的可能性很大,这束花可是小明吃了7 天泡面换来的。但是A 的朋友B 却很了解A,所以小明只管把花交给B,B 会监听A 的心情变化,然后选择A 心情好的时候把花转交给A,代码如下:
let Flower = function() {}
let xiaoming = {sendFlower: function(target) {let flower = new Flower()target.receiveFlower(flower)}
}
let B = {receiveFlower: function(flower) {A.listenGoodMood(function() {A.receiveFlower(flower)})}
}
let A = {receiveFlower: function(flower) {console.log('收到花'+ flower)},listenGoodMood: function(fn) {setTimeout(function() {fn()}, 1000)}
}
xiaoming.sendFlower(B)
场景
HTML元 素事件代理
<ul id="ul"><li>1</li><li>2</li><li>3</li>
</ul>
<script>let ul = document.querySelector('#ul');ul.addEventListener('click', event => {console.log(event.target);});
</script>
优点
- 代理模式能将代理对象与被调用对象分离,降低了系统的耦合度。代理模式在客户端和目标对象之间起到一个中介作用,这样可以起到保护目标对象的作用
- 代理对象可以扩展目标对象的功能;通过修改代理对象就可以了,符合开闭原则;
缺点
处理请求速度可能有差别,非直接访问存在开销
3. 工厂模式
工厂模式定义一个用于创建对象的接口,这个接口由子类决定实例化哪一个类。该模式使一个类的实例化延迟到了子类。而子类可以重写接口方法以便创建的时候指定自己的对象类型。
class Product {constructor(name) {this.name = name}init() {console.log('init')}fun() {console.log('fun')}
}class Factory {create(name) {return new Product(name)}
}// use
let factory = new Factory()
let p = factory.create('p1')
p.init()
p.fun()
场景
- 如果你不想让某个子系统与较大的那个对象之间形成强耦合,而是想运行时从许多子系统中进行挑选的话,那么工厂模式是一个理想的选择
- 将new操作简单封装,遇到new的时候就应该考虑是否用工厂模式;
- 需要依赖具体环境创建不同实例,这些实例都有相同的行为,这时候我们可以使用工厂模式,简化实现的过程,同时也可以减少每种对象所需的代码量,有利于消除对象间的耦合,提供更大的灵活性
优点
- 创建对象的过程可能很复杂,但我们只需要关心创建结果。
- 构造函数和创建者分离, 符合“开闭原则”
- 一个调用者想创建一个对象,只要知道其名称就可以了。
- 扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。
缺点
- 添加新产品时,需要编写新的具体产品类,一定程度上增加了系统的复杂度
- 考虑到系统的可扩展性,需要引入抽象层,在客户端代码中均使用抽象层进行定义,增加了系统的抽象性和理解难度
什么时候不用
当被应用到错误的问题类型上时,这一模式会给应用程序引入大量不必要的复杂性.除非为创建对象提供一个接口是我们编写的库或者框架的一个设计上目标,否则我会建议使用明确的构造器,以避免不必要的开销。
由于对象的创建过程被高效的抽象在一个接口后面的事实,这也会给依赖于这个过程可能会有多复杂的单元测试带来问题。
4. 单例模式
顾名思义,单例模式中Class的实例个数最多为1。当需要一个对象去贯穿整个系统执行某些任务时,单例模式就派上了用场。而除此之外的场景尽量避免单例模式的使用,因为单例模式会引入全局状态,而一个健康的系统应该避免引入过多的全局状态。
实现单例模式需要解决以下几个问题:
- 如何确定Class只有一个实例?
- 如何简便的访问Class的唯一实例?
- Class如何控制实例化的过程?
- 如何将Class的实例个数限制为1?
我们一般通过实现以下两点来解决上述问题:
- 隐藏Class的构造函数,避免多次实例化
- 通过暴露一个
getInstance()方法来创建/获取唯一实例
Javascript中单例模式可以通过以下方式实现:
// 单例构造器
const FooServiceSingleton = (function () {// 隐藏的Class的构造函数function FooService() {}// 未初始化的单例对象let fooService;return {// 创建/获取单例对象的函数getInstance: function () {if (!fooService) {fooService = new FooService();}return fooService;}}
})();
实现的关键点有:
- 使用 IIFE创建局部作用域并即时执行;
- getInstance() 为一个 闭包 ,使用闭包保存局部作用域中的单例对象并返回。
我们可以验证下单例对象是否创建成功:
const fooService1 = FooServiceSingleton.getInstance();
const fooService2 = FooServiceSingleton.getInstance();console.log(fooService1 === fooService2); // true
场景例子
- 定义命名空间和实现分支型方法
- 登录框
- vuex 和 redux中的store
优点
- 划分命名空间,减少全局变量
- 增强模块性,把自己的代码组织在一个全局变量名下,放在单一位置,便于维护
- 且只会实例化一次。简化了代码的调试和维护
缺点
- 由于单例模式提供的是一种单点访问,所以它有可能导致模块间的强耦合
- 从而不利于单元测试。无法单独测试一个调用了来自单例的方法的类,而只能把它与那个单例作为一 个单元一起测试。
5. 策略模式
策略模式简单描述就是:对象有某个行为,但是在不同的场景中,该行为有不同的实现算法。把它们一个个封装起来,并且使它们可以互相替换
<html>
<head><title>策略模式-校验表单</title><meta content="text/html; charset=utf-8" http-equiv="Content-Type">
</head>
<body><form id = "registerForm" method="post" action="http://xxxx.com/api/register">用户名:<input type="text" name="userName">密码:<input type="text" name="password">手机号码:<input type="text" name="phoneNumber"><button type="submit">提交</button></form><script type="text/javascript">// 策略对象const strategies = {isNoEmpty: function (value, errorMsg) {if (value === '') {return errorMsg;}},isNoSpace: function (value, errorMsg) {if (value.trim() === '') {return errorMsg;}},minLength: function (value, length, errorMsg) {if (value.trim().length < length) {return errorMsg;}},maxLength: function (value, length, errorMsg) {if (value.length > length) {return errorMsg;}},isMobile: function (value, errorMsg) {if (!/^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|17[7]|18[0|1|2|3|5|6|7|8|9])\d{8}$/.test(value)) {return errorMsg;} }}// 验证类class Validator {constructor() {this.cache = []}add(dom, rules) {for(let i = 0, rule; rule = rules[i++];) {let strategyAry = rule.strategy.split(':')let errorMsg = rule.errorMsgthis.cache.push(() => {let strategy = strategyAry.shift()strategyAry.unshift(dom.value)strategyAry.push(errorMsg)return strategies[strategy].apply(dom, strategyAry)})}}start() {for(let i = 0, validatorFunc; validatorFunc = this.cache[i++];) {let errorMsg = validatorFunc()if (errorMsg) {return errorMsg}}}}// 调用代码let registerForm = document.getElementById('registerForm')let validataFunc = function() {let validator = new Validator()validator.add(registerForm.userName, [{strategy: 'isNoEmpty',errorMsg: '用户名不可为空'}, {strategy: 'isNoSpace',errorMsg: '不允许以空白字符命名'}, {strategy: 'minLength:2',errorMsg: '用户名长度不能小于2位'}])validator.add(registerForm.password, [ {strategy: 'minLength:6',errorMsg: '密码长度不能小于6位'}])validator.add(registerForm.phoneNumber, [{strategy: 'isMobile',errorMsg: '请输入正确的手机号码格式'}])return validator.start()}registerForm.onsubmit = function() {let errorMsg = validataFunc()if (errorMsg) {alert(errorMsg)return false}}</script>
</body>
</html>
场景例子
- 如果在一个系统里面有许多类,它们之间的区别仅在于它们的’行为’,那么使用策略模式可以动态地让一个对象在许多行为中选择一种行为。
- 一个系统需要动态地在几种算法中选择一种。
- 表单验证
优点
- 利用组合、委托、多态等技术和思想,可以有效的避免多重条件选择语句
- 提供了对开放-封闭原则的完美支持,将算法封装在独立的strategy中,使得它们易于切换,理解,易于扩展
- 利用组合和委托来让Context拥有执行算法的能力,这也是继承的一种更轻便的代替方案
缺点
- 会在程序中增加许多策略类或者策略对象
- 要使用策略模式,必须了解所有的strategy,必须了解各个strategy之间的不同点,这样才能选择一个合适的strategy
6. 迭代器模式
如果你看到这,ES6中的迭代器 Iterator 相信你还是有点印象的,上面第60条已经做过简单的介绍。迭代器模式简单的说就是提供一种方法顺序一个聚合对象中各个元素,而又不暴露该对象的内部表示。
迭代器模式解决了以下问题:
- 提供一致的遍历各种数据结构的方式,而不用了解数据的内部结构
- 提供遍历容器(集合)的能力而无需改变容器的接口
一个迭代器通常需要实现以下接口:
- hasNext():判断迭代是否结束,返回Boolean
- next():查找并返回下一个元素
为Javascript的数组实现一个迭代器可以这么写:
const item = [1, 'red', false, 3.14];function Iterator(items) {this.items = items;this.index = 0;
}Iterator.prototype = {hasNext: function () {return this.index < this.items.length;},next: function () {return this.items[this.index++];}
}
验证一下迭代器是否工作:
const iterator = new Iterator(item);while(iterator.hasNext()){console.log(iterator.next());
}
//输出:1, red, false, 3.14
ES6提供了更简单的迭代循环语法 for…of,使用该语法的前提是操作对象需要实现 可迭代协议(The iterable protocol),简单说就是该对象有个Key为 Symbol.iterator 的方法,该方法返回一个iterator对象。
比如我们实现一个 Range 类用于在某个数字区间进行迭代:
function Range(start, end) {return {[Symbol.iterator]: function () {return {next() {if (start < end) {return { value: start++, done: false };}return { done: true, value: end };}}}}
}
验证一下:
for (num of Range(1, 5)) {console.log(num);
}
// 输出:1, 2, 3, 4
7. 观察者模式
观察者模式又称发布-订阅模式(Publish/Subscribe Pattern),是我们经常接触到的设计模式,日常生活中的应用也比比皆是,比如你订阅了某个博主的频道,当有内容更新时会收到推送;又比如JavaScript中的事件订阅响应机制。观察者模式的思想用一句话描述就是:被观察对象(subject)维护一组观察者(observer),当被观察对象状态改变时,通过调用观察者的某个方法将这些变化通知到观察者。
观察者模式中Subject对象一般需要实现以下API:
- subscribe(): 接收一个观察者observer对象,使其订阅自己
- unsubscribe(): 接收一个观察者observer对象,使其取消订阅自己
- fire(): 触发事件,通知到所有观察者
用JavaScript手动实现观察者模式:
// 被观察者
function Subject() {this.observers = [];
}Subject.prototype = {// 订阅subscribe: function (observer) {this.observers.push(observer);},// 取消订阅unsubscribe: function (observerToRemove) {this.observers = this.observers.filter(observer => {return observer !== observerToRemove;})},// 事件触发fire: function () {this.observers.forEach(observer => {observer.call();});}
}
验证一下订阅是否成功:
const subject = new Subject();function observer1() {console.log('Observer 1 Firing!');
}function observer2() {console.log('Observer 2 Firing!');
}subject.subscribe(observer1);
subject.subscribe(observer2);
subject.fire();//输出:
Observer 1 Firing!
Observer 2 Firing!
验证一下取消订阅是否成功:
subject.unsubscribe(observer2);
subject.fire();//输出:
Observer 1 Firing!
场景
- DOM事件
document.body.addEventListener('click', function() {console.log('hello world!');
});
document.body.click()
- vue 响应式
优点
- 支持简单的广播通信,自动通知所有已经订阅过的对象
- 目标对象与观察者之间的抽象耦合关系能单独扩展以及重用
- 增加了灵活性
- 观察者模式所做的工作就是在解耦,让耦合的双方都依赖于抽象,而不是依赖于具体。从而使得各自的变化都不会影响到另一边的变化。
缺点
过度使用会导致对象与对象之间的联系弱化,会导致程序难以跟踪维护和理解
8. 中介者模式
- 在中介者模式中,中介者(Mediator)包装了一系列对象相互作用的方式,使得这些对象不必直接相互作用,而是由中介者协调它们之间的交互,从而使它们可以松散偶合。当某些对象之间的作用发生改变时,不会立即影响其他的一些对象之间的作用,保证这些作用可以彼此独立的变化。
- 中介者模式和观察者模式有一定的相似性,都是一对多的关系,也都是集中式通信,不同的是中介者模式是处理同级对象之间的交互,而观察者模式是处理Observer和Subject之间的交互。中介者模式有些像婚恋中介,相亲对象刚开始并不能直接交流,而是要通过中介去筛选匹配再决定谁和谁见面。
场景
例如购物车需求,存在商品选择表单、颜色选择表单、购买数量表单等等,都会触发change事件,那么可以通过中介者来转发处理这些事件,实现各个事件间的解耦,仅仅维护中介者对象即可。
var goods = { //手机库存'red|32G': 3,'red|64G': 1,'blue|32G': 7,'blue|32G': 6,
};
//中介者
var mediator = (function() {var colorSelect = document.getElementById('colorSelect');var memorySelect = document.getElementById('memorySelect');var numSelect = document.getElementById('numSelect');return {changed: function(obj) {switch(obj){case colorSelect://TODObreak;case memorySelect://TODObreak;case numSelect://TODObreak;}}}
})();
colorSelect.onchange = function() {mediator.changed(this);
};
memorySelect.onchange = function() {mediator.changed(this);
};
numSelect.onchange = function() {mediator.changed(this);
};
- 聊天室里
聊天室成员类:
function Member(name) {this.name = name;this.chatroom = null;
}Member.prototype = {// 发送消息send: function (message, toMember) {this.chatroom.send(message, this, toMember);},// 接收消息receive: function (message, fromMember) {console.log(`${fromMember.name} to ${this.name}: ${message}`);}
}
聊天室类:
function Chatroom() {this.members = {};
}Chatroom.prototype = {// 增加成员addMember: function (member) {this.members[member.name] = member;member.chatroom = this;},// 发送消息send: function (message, fromMember, toMember) {toMember.receive(message, fromMember);}
}
测试一下:
const chatroom = new Chatroom();
const bruce = new Member('bruce');
const frank = new Member('frank');chatroom.addMember(bruce);
chatroom.addMember(frank);bruce.send('Hey frank', frank);//输出:bruce to frank: hello frank
优点
- 使各对象之间耦合松散,而且可以独立地改变它们之间的交互
- 中介者和对象一对多的关系取代了对象之间的网状多对多的关系
- 如果对象之间的复杂耦合度导致维护很困难,而且耦合度随项目变化增速很快,就需要中介者重构代码
缺点
系统中会新增一个中介者对象,因为对象之间交互的复杂性,转移成了中介者对象的复杂性,使得中介者对象经常是巨大的。中介 者对象自身往往就是一个难以维护的对象。
9. 访问者模式
访问者模式 是一种将算法与对象结构分离的设计模式,通俗点讲就是:访问者模式让我们能够在不改变一个对象结构的前提下能够给该对象增加新的逻辑,新增的逻辑保存在一个独立的访问者对象中。访问者模式常用于拓展一些第三方的库和工具。
// 访问者
class Visitor {constructor() {}visitConcreteElement(ConcreteElement) {ConcreteElement.operation()}
}
// 元素类
class ConcreteElement{constructor() {}operation() {console.log("ConcreteElement.operation invoked"); }accept(visitor) {visitor.visitConcreteElement(this)}
}
// client
let visitor = new Visitor()
let element = new ConcreteElement()
elementA.accept(visitor)
访问者模式的实现有以下几个要素:
- Visitor Object:访问者对象,拥有一个visit()方法
- Receiving Object:接收对象,拥有一个 accept() 方法
- visit(receivingObj):用于Visitor接收一个Receiving Object
- accept(visitor):用于Receving Object接收一个Visitor,并通过调用Visitor的 visit() 为其提供获取Receiving Object数据的能力
简单的代码实现如下:
Receiving Object:function Employee(name, salary) {this.name = name;this.salary = salary;
}Employee.prototype = {getSalary: function () {return this.salary;},setSalary: function (salary) {this.salary = salary;},accept: function (visitor) {visitor.visit(this);}
}
Visitor Object:function Visitor() { }Visitor.prototype = {visit: function (employee) {employee.setSalary(employee.getSalary() * 2);}
}
验证一下:
const employee = new Employee('bruce', 1000);
const visitor = new Visitor();
employee.accept(visitor);console.log(employee.getSalary());//输出:2000
场景
对象结构中对象对应的类很少改变,但经常需要在此对象结构上定义新的操作
需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而需要避免让这些操作"污染"这些对象的类,也不希望在增加新操作时修改这些类。
优点
- 符合单一职责原则
- 优秀的扩展性
- 灵活性
缺点
- 具体元素对访问者公布细节,违反了迪米特原则
- 违反了依赖倒置原则,依赖了具体类,没有依赖抽象。
- 具体元素变更比较困难
相关文章:
_improve-3
createElement过程 React.createElement(): 根据指定的第一个参数创建一个React元素 React.createElement(type,[props],[...children] )第一个参数是必填,传入的是似HTML标签名称,eg: ul, li第二个参数是选填,表示的是属性&#…...
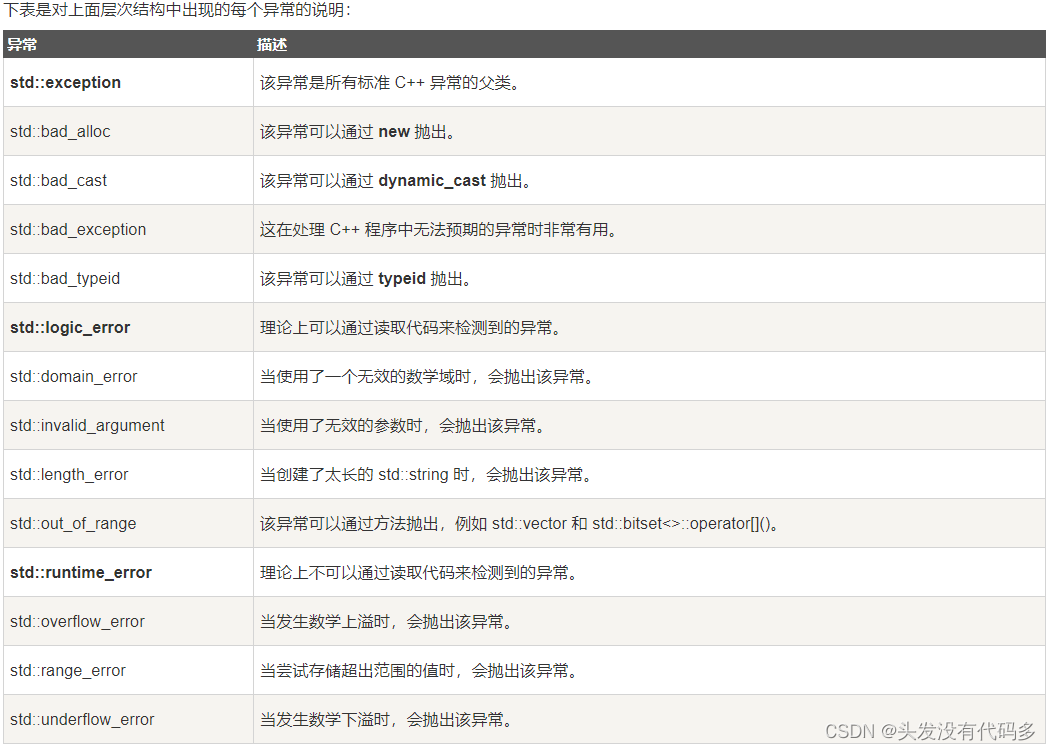
C++——异常
目录 C语言传统的处理错误的方式 C异常概念 异常的使用 异常的抛出和匹配原则 在函数调用链中异常栈展开匹配原则 自定义异常体系 异常的重新抛出 编辑 异常安全 异常规范 C标准库的异常体系 异常的优缺点 C语言传统的处理错误的方式 传统的错误处理机制: …...
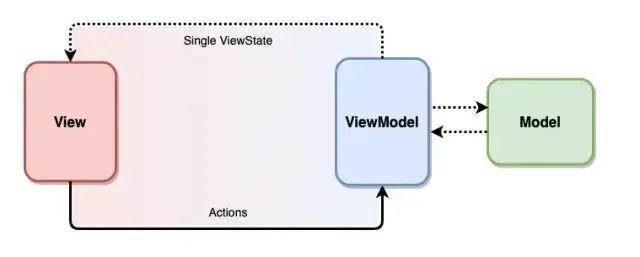
MVVM 架构进阶:MVI 架构详解
前言Android开发发展到今天已经相当成熟了,各种架构大家也都耳熟能详,如MVC,MVP,MVVM等,其中MVVM更是被官方推荐,成为Android开发中的显学。不过软件开发中没有银弹,MVVM架构也不是尽善尽美的,在使用过程中…...
有没有必要考PMP证书?
其实针对有没有必要考试吗,这个可以根本不同行业的人来决定的。 1.高等教育项目管理专业科班出身的人员。 在我国本科学历和硕士研究生学历中,项目管理也有开设。不管以后从事的工作是否为项目管理或其他管理,作为本专业的同学,…...
1 机器学习基础
1 机器学习概述 1.1 数据驱动的问题求解 大数据-Big Data 大数据的多面性 1.2 数据分析 机器学习:海量的数据,获取有用的信息 专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之…...
java基础系列(六) sleep()和wait() 区别
一.前言 关于并发编程这块, 线程的一些基础知识我们得搞明白, 本篇文章来说一下这两个方法的区别,对Android中的HandlerThread机制原理可以有更深的理解, HandlerThread源码理解,请查看笔者的这篇博客: HandlerThread源码理解_handlerthread 源码_broadview_java的博客-CSDN博…...

Urho3D序列化
从Serializable派生的类可以通过定义属性将其自动序列化为二进制或XML格式。属性存储到每个类的上下文中。场景加载/保存和网络复制都是通过从Serializable派生Node和Component类来实现的。 支持的属性类型是Variant支持的所有属性类型,不包括指针和自定义值。 属性…...
企业级信息系统开发学习1.3——利用注解配置取代Spring配置文件
文章目录一、利用注解配置类取代Spring配置文件(一)打开项目(二)创建新包(三)拷贝类与接口(四)创建注解配置类(五)创建测试类(六)运行…...

VUE DIFF算法之快速DIFF
VUE DIFF算法系列讲解 VUE 简单DIFF算法 VUE 双端DIFF算法 文章目录VUE DIFF算法系列讲解前言一、快速DIFF的代码实现二、实践练习1练习2总结前言 本节我们来写一下VUE3中新的DIFF算法-快速DIFF,顾名思义,也就是目前最快的DIFF算法(在VUE中&…...

一文掌握如何轻松稿定项目风险管理【静说】
风险管理对于每个项目经理和PMO都非常重要,如果管理不当会出现很多问题,咱们以前分享过很多风险管理的内容: 风险无处不在,一旦发生,会对一个或多个项目目标产生积极或消极影响的确定事件或条件。那么接下来介绍下五大…...
操作系统权限提升(十四)之绕过UAC提权-基于白名单AutoElevate绕过UAC提权
系列文章 操作系统权限提升(十二)之绕过UAC提权-Windows UAC概述 操作系统权限提升(十三)之绕过UAC提权-MSF和CS绕过UAC提权 注:阅读本编文章前,请先阅读系列文章,以免造成看不懂的情况!! 基于白名单AutoElevate绕过…...
ecology9-谷歌浏览器下-pdf.js在渲染时部分发票丢失文字 问题定位及解决
问题 问题描述 : 在谷歌浏览器下,pdf.js在渲染时部分发票丢失文字;360浏览器兼容模式不存在此问题 排查思路:1、对比谷歌浏览器的css样式和360浏览器兼容模式下的样式,没有发现关键差别 2、✔使用Fiddler修改网页js D…...

JavaScript Window Navigator
文章目录JavaScript Window NavigatorWindow Navigator警告!!!浏览器检测JavaScript Window Navigator window.navigator 对象包含有关访问者浏览器的信息。 Window Navigator window.navigator 对象在编写时可不使用 window 这个前缀。 实例 <div id"example"…...

Linux基础命令-du查看文件的大小
文章目录 du 命令介绍 语法格式 基本参数 参考实例 1)以人类可读形式显示指定的文件大小 2)显示当前目录下所有文件大小 3)只显示目录的大小 4)显示根下哪个目录文件最大 5)显示所有文件的大小 6࿰…...
文献计量分析方法:Citespace安装教程
Citespace是一款由陈超美教授开发的可用于海量文献可视化分析的软件,可对Web of Science,Scopus,Pubmed,CNKI等数据库的海量文献进行主题、关键词,作者单位、合作网络,期刊、发表时间,文献被引等…...

MVI 架构更佳实践:支持 LiveData 属性监听
前言MVI架构为了解决MVVM在逻辑复杂时需要写多个LiveData(可变不可变)的问题,使用ViewState对State集中管理,只需要订阅一个 ViewState 便可获取页面的所有状态通过集中管理ViewState,只需对外暴露一个LiveData,解决了MVVM模式下LiveData膨胀…...

LeetCode438 找到字符串中所有字母异位词 带输入和输出
题目: 给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。 异位词 指由相同字母重排列形成的字符串(包括相同的字符串)。 示例 1: 输入: s “cbaebabacd”, …...

ACSC 2023 比赛复现
Admin Dashboard 在 index.php 中可以看到需要访问者是 admin 权限,才可以看到 flag。 report.php 中可以让 admin bot 访问我们输入的 url,那么也就是说可以访问 addadmin.php 添加用户。 在 addadmin.php 中可以添加 admin 用户,但是需…...

【Linux驱动开发100问】什么是模块?如何编写和使用模块?
🥇今日学习目标:什么是Linux内核? 🤵♂️ 创作者:JamesBin ⏰预计时间:10分钟 🎉个人主页:嵌入式悦翔园个人主页 🍁专栏介绍:Linux驱动开发100问 什么是模块…...

Android 9.0 Recent列表不显示某个app
1.概述 在9.0的系统产品rom定制化开发中,在一些产品定制化需求中,也是有很多重要的功能实现的,比如在某些app的开发中 由于不想被杀掉,所以就不想出现在recent的列表中,因此就需要从recent的列表中,去掉这个app的显示,然后这里有 两种方法实现这个功能,一种是在app中就…...
)
别再瞎调参了!用TensorFlow Benchmark脚本精准评估你的GPU性能(附ResNet50/VGG16实测对比)
科学评估GPU性能:TensorFlow Benchmark深度实践指南 当你拿到一块新GPU或配置云服务器时,第一反应可能是跑个深度学习模型试试速度。但你是否遇到过这些困惑:为什么同样的模型在不同batch_size下性能差异巨大?显存不足导致的"…...

Windows Precision Touchpad 驱动深度解析:Apple 触控板在 Windows 系统的技术实现
Windows Precision Touchpad 驱动深度解析:Apple 触控板在 Windows 系统的技术实现 【免费下载链接】mac-precision-touchpad Windows Precision Touchpad Driver Implementation for Apple MacBook / Magic Trackpad 项目地址: https://gitcode.com/gh_mirrors/m…...

XV7021BB SPI驱动开发:嵌入式陀螺仪底层通信与工程实践
1. XV7021BB SPI驱动库技术解析:面向嵌入式工程师的底层实现与工程实践1.1 传感器核心特性与硬件约束Epson XV7021BB 是一款高精度、低噪声、单轴角速率陀螺仪,采用MEMS微机械结构设计,专为工业级姿态检测、惯性导航辅助和振动监测等严苛场景…...

m4s-converter:解决B站缓存视频无法播放问题的格式转换工具
m4s-converter:解决B站缓存视频无法播放问题的格式转换工具 【免费下载链接】m4s-converter 将bilibili缓存的m4s转成mp4(读PC端缓存目录) 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 当你在旅行途中想观看缓存的B站教学视频却发现无法用手…...

深入源码:ArrayList的removeAll和retainAll方法性能优化技巧
深入源码:ArrayList的removeAll和retainAll方法性能优化技巧 在Java集合框架中,ArrayList作为最常用的动态数组实现,其性能表现直接影响着应用程序的整体效率。特别是当处理大规模数据集时,像removeAll和retainAll这样的批量操作方…...

嵌入式C宏高级技巧:#、##与__VA_ARGS__工程实践
1. 嵌入式C语言宏定义中特殊操作符的工程化应用在嵌入式固件开发实践中,宏定义远不止于简单的文本替换。当项目规模扩大、模块耦合度提高、调试需求增强时,#、##和__VA_ARGS__这三类预处理操作符成为构建可维护、可追溯、可扩展代码基的关键基础设施。它…...

COMSOL电磁超声仿真:L型铝板裂纹检测的电磁超声测量技术
COMSOL电磁超声仿真: Crack detection in L-shaped aluminum plate via electromagnetic ultrasonic measurements"啪嗒"一声点击鼠标,模型库里那个L型铝板突然裂了条缝——当然,这只是我今早在COMSOL里建的仿真模型。要说电磁超声检测裂纹这事…...

STM32F103驱动MAX30102
时隔数月,距离上一次更新不知道是什么时候了,最近也是重新拾起单片机开始我的课设项目,用到了有MAX30102心率传感器,调好代码之后来分享一下,并在文章末尾分析代码文件。这里我先给大家看看实物图吧,上来就…...

粒子群算法求解IEEE 33节点最优潮流模型
粒子群算法求解 IEEE 33bus最优潮流模型关键词:粒子群算法 PSO 最优潮流 牛顿迭代 仿真平台:MATLAB 主要内容:这是一个用粒子群来解IEEE 33的最优潮流模型,潮流模型是用牛顿迭代法写的 模型包含了柴油机,储能ÿ…...

别再手动点选了!Star-CCM+里用这个技巧批量命名零部件面,效率翻倍
Star-CCM批量命名技巧:告别低效手动操作,解锁工程仿真新姿势 每次打开包含数百个流道面的动力电池包模型时,你是否会对着密密麻麻的未命名面感到绝望?当领导要求在两小时内完成发动机缸体所有热源面的分组命名时,你的…...