数据结构与算法 | 第三章:栈与队列
本文参考网课为 数据结构与算法 1 第三章栈,主讲人 张铭 、王腾蛟 、赵海燕 、宋国杰 、邹磊 、黄群。
本文使用IDE为 Clion,开发环境 C++14。
更新:2023 / 11 / 5
数据结构与算法 | 第三章:栈与队列
- 栈
- 概念
- 示例
- 实现
- 顺序栈
- 类定义
- 进出栈
- 进栈
- 出栈
- 链式栈
- 类定义
- 进出栈
- 进栈
- 出栈
- 顺序栈 V.S 链式栈
- 应用
- 表达式求值
- 中缀表达式
- 概念
- 后缀表达式
- 概念
- 示例
- 对后缀表达式求值
- 中缀表达式转换为后缀表达式
- 递归
- 概念
- 递归、迭代
- 递归函数
- 尾递归
- 示例
- 阶乘函数的调用栈
- 递归到非递归的转换
- 通用的机械转换步骤
- 队列
- 概念
- 实现
- 顺序队列
- 类定义
- 链式队列
- 类定义
- 顺序队列 V.S 链式队列
- 应用
- 宽度优先搜索
- 示例:人狼羊菜过河
- 初步分析
- 最终分析
- 参考链接
线性表 可以在表的任意位置进行元素的插入、删除等运算。而 栈( Stack )的运算只在表的一端进行,队列( Queue )的运算只在表的两端进行,因此可以将 栈 与 队列 视为操作受限的 线性表。
栈
概念
栈 是一种限制访问端口的 线性表,后进先出( Last In First Out )。
栈 的主要操作有 进栈( push )和 出栈( pop )。
栈 的应用有:
- 表达式求值
- 消除递归
- 深度优先搜索
栈 的抽象数据类型如下:
template <class T>
class stack{
public: // 栈的运算集void clear(); // 清空栈bool push(const T item); // push item入栈。成功推入,返回真;否则返回假bool pop(T& item); // 返回栈顶内容并弹出。成功弹出,返回真;否则返回假bool top(T& item); // 返回栈顶但不弹出。成功弹出,返回真;否则返回假bool isEmpty(); // 若栈已空,返回真bool isFull(); // 若栈已满,返回真
};
示例
假如给定一个入栈顺序 1、2、3、4,则出栈的顺序可以有哪些?
设 k 是最后一个出栈的,那么 k 把序列一分为二。在 k 之前入栈的元素,一定在比在 k 之后入栈的元素要提前出栈。
假设已知出栈顺序为 1、4、2、3,3 是最后1个出栈的,那么 3 将 1、2、3、4 分为 1、2 和 4。即 1、2 的出栈要在 4 之前。然而 2 不可能早于 4 出栈,因此 1、4、2、3 是不可能的。
再假设出栈顺序为 1、3、4、2,2 是最后1个出栈的,那么 2 将 1、2、3、4 分为 1 和 3、4。显然,1 是在 3、4 之前的,3 也是可以在 4 之前的。
那么,现在给定一个入栈序列,序列长度为 N,请计算有多少种出栈序列。
设有 f(N) 个出栈序列,如果 x 是最后一个出栈的,那么 x 个元素一定在 N-1-x 个元素之前出栈。
前面的 x 个元素有 f(x) 种出栈序列,后面的 N-1-x 个元素有 f(N-1-x) 种出栈序列。x 和 N-1-x 个元素之间的整体出栈顺序是确定的,但是它们内部的出栈顺序是不定的,所以:


x 可以从 0 到 N-1。
实现
栈 的物理实现有2种,1种称为 顺序栈( Array-based Stack ),另1种称为 链式栈( Linked Stack )。
顺序栈
使用向量实现,本质是 顺序表 的简化版。
关键是确定哪一端作为栈顶。
类定义
#include <iostream>
#include <iomanip>
using namespace std;template class <T> class arrStack:public Stack<T>{
private: // 栈的顺序存储int mSize; // 栈中最多可存放的元素个数int top; // 栈顶位置,应小于mSizeT *st; // 存放栈元素的数组
public:arrStack(int size){ // 构造函数,创建一个给定长度的顺序栈实例mSize = size; top = -1; st = new T[mSize];}~arrStack(){delete [] st;} // 析构函数void clear(){top = -1;} // 清空栈;将栈顶top指向栈底,过后,若有新的元素入栈则会覆盖栈内原有的元素
};
进出栈
进栈

当栈中已经有 maxsize 个元素时,如果再做进栈运算,会产生 上溢( overflow )。
因此,压入栈顶时需要做边界条件判定再进行入栈,如下:
bool arrStack<T>::push(const T item){if (top == mSize - 1){ // 满栈count << "栈满溢出" << endl;return false;}else{ // 新元素入栈并修改栈顶指针st[++top] == item; // top指针做自增return true;}
}
出栈

对 空栈 进行出栈运算时可能会出现 下溢( underflow )。
因此,弹出栈顶时需要做边界条件判定再进行出栈,如下:
bool arrStack<T>::pop(T& item){ // 出栈if (top == -1){ // 空栈cout << "空栈,不能出栈" << endl;return false;}else{item = st[top--]; // 返回栈顶,并缩减1return true;}
}
链式栈
用 单链表 方式存储,其中指针的方向是从栈顶向下链接。
类定义
template <class T> class lnkStack: public Stack<T>{
private: // 栈的链式存储Link<T>* top; // 指向栈顶的指针int size; // 存放元素的个数
public: // 栈运算的链式元素实现lnkStack(int defSize){ // 构造函数top = NULL; size = 0;}~lnkStack(){ // 析构函数clear();}
};
进出栈
进栈
bool lnkStack<T>::push(const T item){ // 入栈操作的链式实现Link<T>* tmp = new Link<T>(item, top);top = tmp;size ++;return true;
}
Link(const T info, Link* nextValue){ // 具有2个参数的Link构造函数data = info;next = nextValue;
}
出栈
bool lnkStack<T>::pop(T& item){Link <T> *tmp;if (size == 0){cout << "空栈,不能出栈" << endl;return false;}item = top -> data; // 将top的数据赋值给item,将item弹出去tmp = top -> next; // 将top的next指向tmpdelete top; // delete top对应的内存空间top = tmp; // 将tmp对应的数据赋值给topsize--; // 元素数量自减1return true;
}
顺序栈 V.S 链式栈
-
时间效率
- 所有操作都只需要常数时间。二者难分伯仲。
-
空间效率
顺序栈须说明一个固定的长度;链式栈的长度可变,但是增加结构性开销;
-
应用范围
- 实际应用中,
顺序栈比链式栈应用范围更广泛
应用
栈 的特点是后进先出。
栈 通常被用来处理具有递归结构的数据:
- 深度优先搜索
- 表达式求值
- 子程序 / 函数调用的管理
- 消除递归
表达式求值
表达式的递归定义:
- 基本符号集
{0,1,…,9,+,-,*,/,(,)} - 语法成分集
{<表达式>,<项>,<因子>,<常数>,<数字>}- 表达式
- 中缀表达式
23 + (34*45)/ (5 + 6 + 7) - 后缀表达式
23 34 45 * 5 6 + 7 + / +
- 中缀表达式
- 表达式
中缀表达式
概念
中缀表达式 的特点是:
- 运算符在中间
- 需要括号来改变优先级
中缀表达式 可以使用树状结构表示,例如,以下面的树状结构表达 4 * x * ( 2 * x + a ) - c:

也可以使用语法公式表示,

也可以使用递归图示表示,

后缀表达式
概念
后缀表达式 的特点是:
- 运算符在后面
- 不需要括号
后缀表达式 可以使用树状结构表示,例如,以下面的树状结构表达 4x * 2x * a+ *c -:

示例
对后缀表达式求值
假设待处理后缀表达式为 34 45 * 5 6 + 7 + / +。
使用 栈 的概念对该后缀表达式进行求值的算法为:
依次顺序读入表达式的符号序列(假设以 = 作为输入序列的结束 ),并根据读入的元素符号逐一分析:
- 当遇到的是一个操作数,则压入栈顶;
- 当遇到的是一个运算符,则从栈中两次取出栈顶,按照运算符对这两个操作数进行计算。然后将计算结果压入栈顶。
如此继续,直到遇到符号 =,这时栈顶的值就是输入表达式的值。
以代码来表示上述算法思想,即:
class Calculator{
private:Stack<double> s; // 这个栈用于压入、保存操作数bool GetTwoOperands(double& opd1, double& opd2); // 操作1:从栈顶弹出两个操作数 opd1 和 opd2void Compute(char op); // 操作2:取两个操作数,并按op对两个操作数进行计算
public:Calculator(void){}; // 创建计算器实例,开辟一个空栈void Run(void); // 读入后缀表达式,遇 "=" 符号结束void Clear(void); // 清除计算器,为下一次计算做准备
};template<class ELEM>
bool Calculator<ELEM>::GetTwoOperands(ELEM& opnd1, ELEM& opnd2){if (S.IsEmpty()){ // 空栈。则无法按预期取出2个操作数。cerr << "Missing Operand!" << endl;return false;}opnd1 = S.Pop(); // 取出右操作数if (S.IsEmpty()){ // 取出右操作数后,栈空,则无法取到左操作数。cerr << "Missing Operand!" << endl;return false;}opnd2 = S.Pop(); // 取出左操作数return true;
}template <class ELEM> void Calculator<ELEM>::Compute(char op){bool result; ELEM operand1, operand2;result = GetTwoOperands(operand1, operand2);if (result == true)switch(op){case '+': S.Push(operand2 + operand1); break;case '-': S.Push(operand2 - operand1); break;case '*': S.Push(operand2 * operand1); break;case '/': if (operand1 == 0.0){cerr << "Divide by 0!" << endl;S.ClearStack();}else S.Push(operand2 / operand1);break;}else S.ClearStack();
}template <class ELEM> void Calculator<ELEM>::Run(void){char c; ELEM newoperand;while (cin >> c, c!='='){switch(c){case '+': case '-': case '*': case '/': // 如果碰到的是+-*/这种操作符,则调用compute运算Compute(c);break;default: // 如果碰到的不是+-*/这种运算符,把c这种char类型数据放回栈内并再次读取newoperand这种ELEMcin.putback(c); cin >> newoperand;S.Push(newoperand);break;}}if (!S.IsEmpty())cout << S.Pop() << endl; // 打印出最后结果
}
中缀表达式转换为后缀表达式
对后缀表达式求值时,向栈内存操作数;
转换中缀表达式为后缀表达式时,向栈内存操作符。因为所有的操作数载顺序上并没有变化,但是操作符的顺序有变化。
- 当输入是操作数,直接输出到后缀表达式序列;
- 当输入是左括号时,直接压栈;
- 当输入是运算符时,
- while
- if (栈非空 and 栈顶不是左括号 and 输入运算符的优先级 <= 栈顶运算符的优先级) 时,将当前栈顶元素弹栈,输出到后缀表达式序列中;
并将输入运算符压栈; - else 把输入的运算符压栈
- if (栈非空 and 栈顶不是左括号 and 输入运算符的优先级 <= 栈顶运算符的优先级) 时,将当前栈顶元素弹栈,输出到后缀表达式序列中;
- while
输入运算符的优先级别<=栈顶运算符的优先级,比如输入运算符
+、栈顶运算符*,则将栈顶*弹栈。
- 当输入是右括号时,先判断栈是否为空:
- 若栈为空,即无任何左括号已在栈内,则清栈退出;
- 若栈非空,则把栈中的元素依次弹出:
- 遇到第一个左括号为止,将弹出的元素输出到后缀表达式的序列中(弹出的开括号不放到序列中)
- 若未遇到开括号,说明括号不匹配,则清栈退出;
- 当中缀表达式的符号序列全部读入时,若栈内仍有元素,则把它们全部依次弹出,都放到后缀表达式序列尾部;
- 若弹出的元素遇到开括号,说明括号不匹配,需要做错误异常处理。
递归
概念
递归、迭代
递归 和 迭代 的异同点:
- 相同点
从小规模的相同问题来求解大规模问题 - 不同点
迭代先从小问题入手,然后自底向上组合成大问题递归先从大问题入手,然后自顶向下,对大问题进行分解
递归 更接近人类思维方式。因此,涉及递归算法比设计非递归算法往往更容易,大多数编程语言支持递归,许多函数式编程语言更是直接以递归为基础。
递归 在完成问题定义时,基本也同时完成了问题求解。
递归函数
在计算机中,我们通常以函数的方式对递归问题进行定义与求解。所谓 递归函数,指的是会直接或间接调用自身的函数。
递归函数 具有2个要素:一是基本的边界情形( 一般是规模小到不需要依赖子问题、可以直接求解的情形 ),二是递归规则( 决定如何将一个递归问题转化为规模更小的子问题 )。
计算机程序是一组顺序执行的指令序列。那么怎样用指令序列运行一个 递归函数 呢?
先看程序的内存分布,如下图:

内存被分为好几个区域,比如有内核、动态链接库、存放代码的只读区、存放全局变量的可读写区等等。
程序运行时,有两个区域的内存是不固定的:
- 栈
主要用于函数调用 - 堆
用于分配动态内存空间
递归函数 的相关操作主要发生在 栈 内。
在函数调用栈里,元素是一种被称为栈帧的数据结构,每个帧对应1次函数调用,保存当次函数调用时传入的参数、函数返回地址以及局部变量。
比如,调用阶乘函数来求4的阶乘,如下:

有一个阶乘4对应的帧;有一个阶乘3对应的帧。每个帧内保存了此次函数调用时的相关信息,比如传入的参数、函数的返回地址以及局部变量等。
计算机中的函数调用与退出主要就是对调用栈中的帧进行操作:
- 函数调用时
- 计算机在栈中压入一个帧
- 压入调用参数
- 压入返回地址
- 为局部变量分配空间
- 其它信息(寄存器信息)
- 计算机通过指令跳转到被调用函数开始的位置,开始执行
- 计算机在栈中压入一个帧
- 函数退出时
- 记录返回值
- 释放栈帧(局部变量、返回地址、调用函数及其它信息)
- 根据返回地址,跳回调用前位置继续执行
递归函数 的运行时的空间、时间开销分析如下:
- 空间
- 在每次调用时都需要创建栈帧并进行相应操作。在现实中,许多复杂函数的栈帧都很大,当调用次数很多时可能会把栈的空间全部用完,在一些系统上甚至可能会越界到动态链接库的区域,导致栈溢出的安全风险。
- 时间
- 栈操作需要消耗计算资源
- 函数调用与退出时的跳转指令相比于其他正常指令的开销也是较大的
因此,如果能将递归函数转换为非递归函数,就可以减少程序运行时的开销。
尾递归
尾递归 指的是函数仅有一次自身调用,且该调用时函数退出前的最后一个操作。
举例如下:
long fact(long n){if (n<=1)return 1;elsereturn n * fact(n-1);
}
虽然上面的阶乘递归函数只有一次对自身的调用,但是该调用并不是退出前的最后一个操作。因为在调用之后,还有一个乘法操作。所以该递归阶乘并非尾递归。
long fact_tail_rec(long n, long product){if (n<=1)return product;elsereturn fact_tail_rec(n-1, product * n)
}
上面的 尾递归 函数多了一个参数用来保存乘积,则原先的乘法结果可以以参数的形式在调用前进行传递,而不再需要在函数内进行乘法操作。这样,自身调用就时函数退出前的最后一个操作,因此,它是一个 尾递归 函数。
尾递归 可以很容易将 递归函数 转化为 非递归函数。尾递归 的本质是将单次计算的结果缓存起来以参数的形式传递给下一次调用,因此我们可以很容易地使用循环迭代的方式来保存这个累计的结果。
在 递归函数 转化为 非递归函数 之后,就可以消除栈开销与函数调用的开销。相比于原先线性增长的栈空间,转换之后只需要常数空间即可。
许多现代编程语言支持对 尾递归 的优化:
- 编译器/解释器
GCC、LLVM/Clang、Intel编译器、Java虚拟机 - 函数式编程语言
LISP、Scheme、Scala、Haskell、Erlang
示例
阶乘函数的调用栈
long fact(long n){if (n<1)return 1;elsereturn n*fact(n-1);int main(){int x=4;printf("%d\n", fact(x));return 0;}
}

递归到非递归的转换
背景:假如有n件物品,物品i的重量为w[i]。如果限定每种物品,要么完全放进背包、要么不放进背包,即物品是不可分割的。
问题:能否从这n件物品中选择若干件放入背包,使其重量之和恰好为s。
通用的机械转换步骤
- 定义栈帧,建立调用帧;
- 在栈中压入原始问题的帧( rd = 0 );
- 根据递归调用数 t,将程序划分为 t+1 个区域;
- 创建(t+2)个标签,逐区域翻译(除 return 语句、递归调用);
( t+2 )个标签为(t+1)个区域的边界 - 用 goto 实现递归调用
形式 “push stack;goto label 0”,第 i 个调用的 rd=i; - 用 goto 实现 return 语句;
将所有 “return” 替换为 “goto label (t+1)” - 在标签 t+1 后添加递归出口
使用 “switch” 语句,根据栈顶的 rd 值判断继续执行的标签
队列
概念
队列 是一种限制访问点的 线性表,先进先出( First In First Out )。
- 按照到达的顺序来释放元素;
- 所有的插入在表的一端进行,所有的删除都在表的另一端进行;
队列 的主要元素有 队头( front )、队尾( rear )。
队列 的主要操作:
- 入队列(
enQueue) - 出队列(
deQueue) - 取队首元素(
getFront) - 判断队列是否为空(
isEmpty)
队列 的抽象数据类型如下:
template <class T> class Queue{
public: // 队列的运算集void clear(); // 清空队列bool enQueue(const T item); // 将item插入队尾。成功则返回真,否则则返回假bool deQueue(T & item); // 返回队头元素并将其从队列中删除,成功则返回真bool getFront(T & item); // 返回队头元素,但不删除,成功则返回真bool isEmpty(); // 返回真,若队列已空bool isFull(); // 返回真,若队列已满
};
实现
队列 的物理实现有2种,1种称为 顺序队列( Array-based Stack ),另1种称为 链式队列( Linked Stack )。
顺序队列

用 向量 存储队列元素,用两个变量分别指向队列的前端( front )和尾端( rear )。
front:指向当前待出队的元素位置(地址)rear:指向当前待入队的元素位置(地址)
然而,这种 顺序队列 会有 溢出 的问题 ——
上溢
当队列满时,再做进队操作下溢
当队列空时,再做删除操作假溢出
当rear = mSize - 1时,再作插入运算就会产出溢出。如果这时队列的前端还有许多空位置,这种现象称为假溢出
为了避免 溢出 的出现,可以将 顺序队列 的首尾相连来变成一个 循环队列。
类定义
class arrQueue:public Queue<T>{
private:int mSize; // 声明队列的数组大小int front; // 表示队头所在位置的下标int rear; // 表示待入队元素所在位置的下标T *qu; // 存放类型为T的队列元素的数组
public:arrQueue(int size){ // 创建队列的实例mSize = size + 1; // 浪费一个存储空间,以此区别空队列和满队列qu = new T [mSize];front = rear = 0;}~arrQueue(){ // 消除该实例,并释放其空间delete[] qu;}
};bool arrQueue<T>::enQueue(const T item){// item入队,插入队尾if (((rear + 1) % mSize == front)){ // rear指针+1,再对mSize取模,如果等于front,说明队列已满cout << "队列已满,溢出" << endl;return false;}qu[rear] = item;rear = (rear + 1)%mSize; // 循环后继,将rear指针后移一位return true;
}bool arrQueue<T>::deQueue(T& item){ // 返回队头元素并从队列中删除if (front == rear){ // front指针等于rear指针,说明队列为空,不允许删除元素cout << "队列为空" << endl;return false;}item = qu[front]; // item为队首元素front = (front + 1)%mSize; // 循环后继,将front指针后移一位return true;
}
链式队列
链式队列 的本质是 单链表。用 单链表 方式存储,链接指针的方向是从队列的前端向尾端链接。

用 front 指向 单链表 的队首。用 rear 指针指向 单链表 的队尾。
我们把入队列和出队列限制在队首和队尾这两部分。不允许在其他部分进行操作。那么这其实就是一个 链式队列。
类定义
template <class T>
class lnkQueue:public Queue<T>{
private:int size; // 队列中当前元素的个数Link<T>* front; // 表示队头的指针Link<T>* rear; // 表示队尾的指针
public:lnkQueue(int size); // 创建队列的实例~lnkQueue(); // 消除该实例,并释放其空间
};bool enQueue(const T item){ // item入队,插入队尾if (rear == NULL){ // 空队列front = rear = new Link<T>(item, NULL);}else{ // 添加新元素rear -> next = new Link<T>(item, NULL); // rear的next指针指向新元素rear = rear -> next; // rear指针指向最后一个元素}size ++;return true;
}bool deQueue(T* item){ // 返回队头元素并从队列中删除Link<T> *tmp;if (size == 0){ // 队列为空,没有元素可出队cout << "队列为空" << endl;return false;}*item = front -> data; // 将front指针指向的队首元素传给itemtmp = front; // tmp指针记录front的位置front = front -> next; // 将front指针指向原队首的下一个元素delete tmp; // 删除tmpif (front == NULL) // 如果front是空的,则rear也为空rear = NULL;size --;return true;
}
顺序队列 V.S 链式队列
- 空间效率
顺序队列需要固定的存储空间;链式队列可以满足大小无法估计的情况;
应用
队列 满足先来先服务特性的应用,作为其数据组织方式或中间数据结构:
- 调度或缓冲
- 消息缓冲器
- 邮件缓冲器
- 计算机硬设备之间的通信也需要队列作为数据缓冲
- 操作系统的资源管理
- 宽度优先搜索
宽度优先搜索
示例:人狼羊菜过河
初步分析
- 问题抽象
“人狼羊菜” 乘船过河。只有人能撑船,船只有两个位置(包括人)。狼羊、羊菜不能在没有人时共处。
- 求解方案
求解该问题最简单的方法是使用试探法,即一步一步进行试探,每一步都搜索所有可能的选择,对前一步合适的选择再考虑下一步的各种方案。
用计算机实现上述求解的搜索过程可以采用两种不同的策略:
- 队列
- 宽度优先搜索
搜索该步的所有可能状态,再进一步考虑后面的各种情况
- 宽度优先搜索
- 栈
- 深度优先搜索
沿某一状态走下去,不行再回头
- 深度优先搜索
假定采用宽度优先搜索解决农夫过河问题:
- 采用队列作辅助结构,把下一步所有可能达到的状态都放在队列中,然后顺序取出对其分别处理。
- 由于队列的操作按照先进先出原则,因此只有前一步的所有情况都处理完之后才能进入下一步。
先对数据进行抽象,对每个角色的位置进行描述。人、狼、羊和菜,四个目标依次各用一位,目标在起始岸位置 0、目标岸 1。
0110 表示农夫、白菜在起始岸,而狼、羊在目标岸。此状态为不安全状态。
1000 ( 0x08 )表示人在目标岸,而狼、羊、菜在起始岸。
1111 (0x0F)表示人、狼、羊、菜都抵达目标岸。
如何从上述状态中得到每个角色所在位置?

bool farmer(int status)
{return ((status & 0x08) != 0);}bool wolf(int status)
{return ((status & 0x04) != 0);}bool goat(int status)
{return ((status & 0x02) != 0);}bool cabbage(int status)
{return ((status & 0x01) != 0);}
函数返回值为真,表示所考察人或物在目标岸。否则,所考察人或物在起始岸;
在用以上方法拿到每个角色的所在位置之后可以对安全状态进行判断:
bool safe(int status) // 返回true 安全;返回false,不安全
{if ((goat(status) == cabbage(status)) && (goat(status) != farmer(status))) // 羊和白菜共处,但是人不在return(false);if ((goat(status) == wolf(status) && (goat(status) != farmer(status)))) // 狼和羊共处,但是人不在return(false);return(true);
}
最终分析
- 问题抽象
从状态 0000(整数0)出发,寻找全部由安全状态构成的状态序列,以 1111(整数15)为最终目标。
状态序列中每个状态都可以从前一状态通过农夫(可以带一样东西)划船过河的动作到达。
序列中不能出现重复状态。
- 算法设计
定义一个整数队列 moveTo,它的每个元素表示一个可以安全到达的中间状态。
还需要定义一个数据结构记录已被访问过的各个状态,以及已被发现的能够到达当前这个状态的路径。
- 用
顺序表route 的第i个元素记录状态i是否已被访问过 - 若route[i] 已被访问过,则在这个
顺序表元素中记入前驱状态值,-1表示未被访问 - route的大小(长度)为16
- 算法实现
void solve(){int movers, i, location, newlocation;vector<int> route(END+1, -1);queue<int> moveTo; // 定义初始队列,看它moveTo到哪些队列上去moveTo.push(0x00);route[0]=0;
}while (!moveTo.empty() && route[15] == -1){ //status = moveTo.front(); // 拿到moveTo的front指针moveTo.pop(); // 把当前状态pop出来for (movers = 1; movers <= 8; movers << = 1){ // 农夫总是在移动。movers指针逐渐左移if (farmer(status)) == (bool)(status & movers){ // farmer(status)获取农夫状态,是1还是0;// (status&movers)获取菜的状态,是1还是0;// 如果农夫和菜的状态一致newstatus = status ^ (0x08 | movers); // status ^ (0b1001 | 0b0001),即status 和 0b1001作异或操作,得0b0110if (safe(newstatus) && (route[newstatus] == -1)){ // 调用safe判断status的下一个状态newstatus是否安全。如果newstatus不安全,则不能变;// route[newstatus] == -1,说明newstatus未被访问过route[newstatus] = status;moveTo.push(newstatus); // 将newstatus计入moveTo队列}}}if (route[15] != -1){ // 如果最后一个状态0b1111对应的不是-1,说明最后一个状态已经达到cout << "The reverse path is:" << endl;for (int status = 15; status >= 0; status = route[status]){ // 从最后一个状态0b1111开始,cout << "The status is:" << status << endl;if (status == 0) break;}}elsecout << "No solution." << endl;
}
参考链接
数据结构与算法 ↩︎
相关文章:
数据结构与算法 | 第三章:栈与队列
本文参考网课为 数据结构与算法 1 第三章栈,主讲人 张铭 、王腾蛟 、赵海燕 、宋国杰 、邹磊 、黄群。 本文使用IDE为 Clion,开发环境 C14。 更新:2023 / 11 / 5 数据结构与算法 | 第三章:栈与队列 栈概念示例 实现顺序栈类定义…...
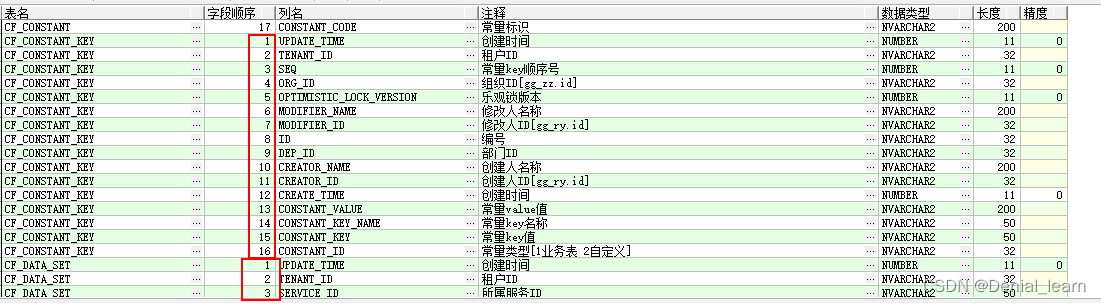
oracle查询数据库内全部的表名、列明、注释、数据类型、长度、精度等
Oracle查询数据库内全部的表名、列明、注释、数据类型、长度、精度 SELECT a.TABLE_NAME 表名, row_number() over(partition by a.TABLE_NAME order by a.COLUMN_NAME desc) 字段顺序,a.COLUMN_NAME 列名, b.COMMENTS 注释,a.DATA_TYPE 数据类型, a.DATA_LENGTH 长度,DATA_SC…...

数据可视化:折线图
1.初看效果 (1)效果一 (2)数据来源 2.JSON数据格式 其实JSON数据在JAVA后期的学习过程中我已经是很了解了,基本上后端服务器和前端交互数据大多是采用JSON字符串的形式 (1)JSON的作用 &#…...

Python语言_matplotlib包_共80种--全平台可用
Python语言_matplotlib包_共80种–全平台可用 往期推荐: Python语言_single_color_共140种–全平台可用 R语言_RColorBrewer包–全平台可用 R语言gplots包的颜色索引表–全平台可用 R语言中的自带的调色板–五种–全平台可用 R语言657中单色colors颜色索引表—全平台…...

OpenFeign 的超时重试机制以及底层实现原理
目录 1. 什么是 OpenFeign? 2. OpenFeign 的功能升级 3. OpenFeign 内置的超时重试机制 3.1 配置超时重试 3.2 覆盖 Retryer 对象 4. 自定义超时重试机制 4.1 为什么需要自定义超时重试机制 4.2 如何自定义超时重试机制 5. OpenFeign 超时重试的底层原理 5…...

redis安装
redis安装 mac下直接安装 mac下安装redis还是很简单的(其实mac下安装什么软件都挺简单的,brew啥都有) brew install redis 之后就是漫长的等待,下了好久,终于下载完了 修改redis.conf中的配置 # 后台启动daemonize yes 启动服务端 redis-serv…...
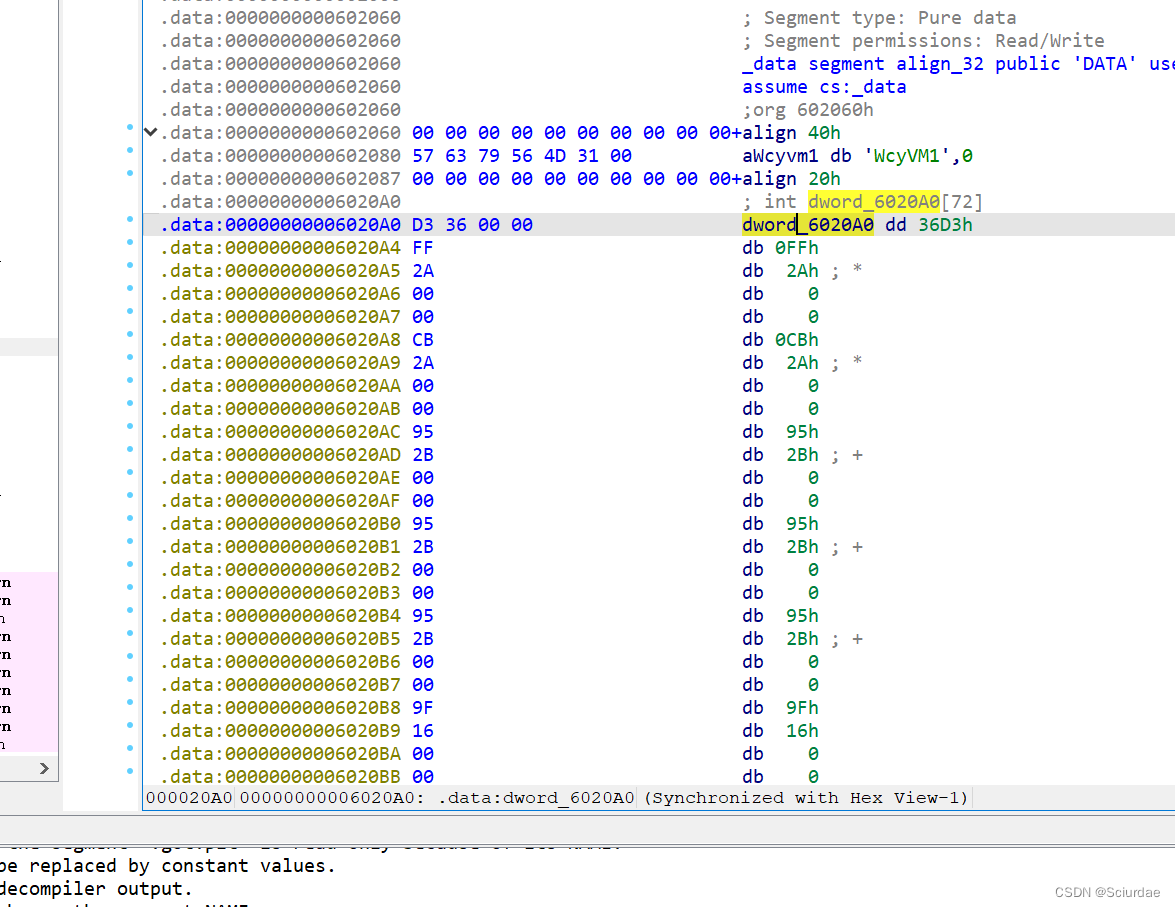
VM虚拟机逆向 --- [NCTF 2018]wcyvm 复现
文章目录 前言题目分析 前言 第四题了,搞定,算是独立完成比较多的一题,虽然在还原汇编的时候还是很多问题。 题目分析 代码很简单,就是指令很多。 opcode在unk_6021C0处,解密的数据在dword_6020A0处 opcode [0x08, …...

2024天津理工大学中环信息学院专升本机械设计制造自动化专业考纲
2024年天津理工大学中环信息学院高职升本科《机械设计制造及其自动化》专业课考试大纲《机械设计》《机械制图》 《机械设计》考试大纲 教 材:《机械设计》(第十版),高等教育出版社,濮良贵、陈国定、吴立言主编&#…...

华为OD机试 - 服务失效判断 - 逻辑分析(Java 2023 B卷 200分)
目录 专栏导读一、题目描述二、输入描述三、输出描述1、输入2、输出3、说明 四、解题思路五、Java算法源码六、效果展示1、输入2、输出3、说明 华为OD机试 2023B卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试(JAVA)真题&a…...

刚入职因为粗心大意,把事情办砸了,十分后悔
刚入职,就踩大坑,相信有很多朋友有我类似的经历。 5年前,我入职一家在线教育公司,新的公司福利非常好,各种零食随便吃,据说还能正点下班,一切都超出我的期望,“可算让我找着神仙公司…...
Docker学习——③
文章目录 1、Docker Registry(镜像仓库)1.1 什么是 Docker Registry?1.2 镜像仓库分类1.3 镜像仓库工作机制1.4 常用的镜像仓库 2、镜像仓库命令3、镜像命令[部分]4、容器命令[部分]4.1 docker run4.2 docker ps 5、CentOS 搭建一个 nginx 服…...
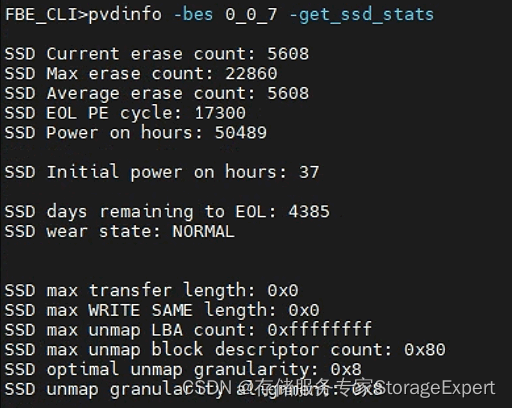
EMC Unity存储系统如何查看SSD的使用寿命
为什么要写这个博客? 客户对老的EMC unity的存储系统要扩容,如何确定SSD磁盘是全新的还是拆机二手的?很多时候客户还有一个奇葩的要求,就是要和5年前的磁盘PN一致,甚至要求固件版本一致,最关键的还要求是全…...
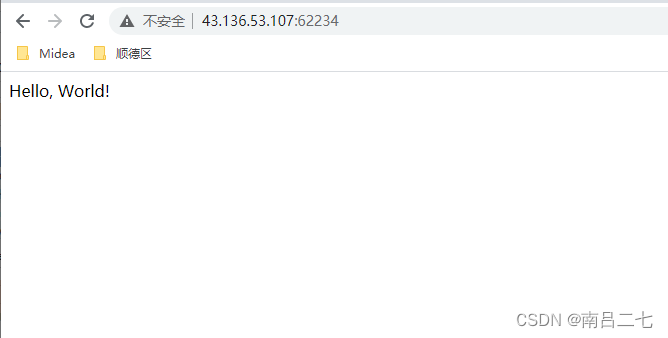
python创建一个简单的flask应用
下面用python在本地和服务器上分别创建一个简单的flask应用: 1.在pc本地 1)pip flask后创建一个简单的脚本flask_demo.py from flask import Flaskapp Flask(__name__)app.route(/) def hello_world():return Hello, World!winR进入命令行,…...
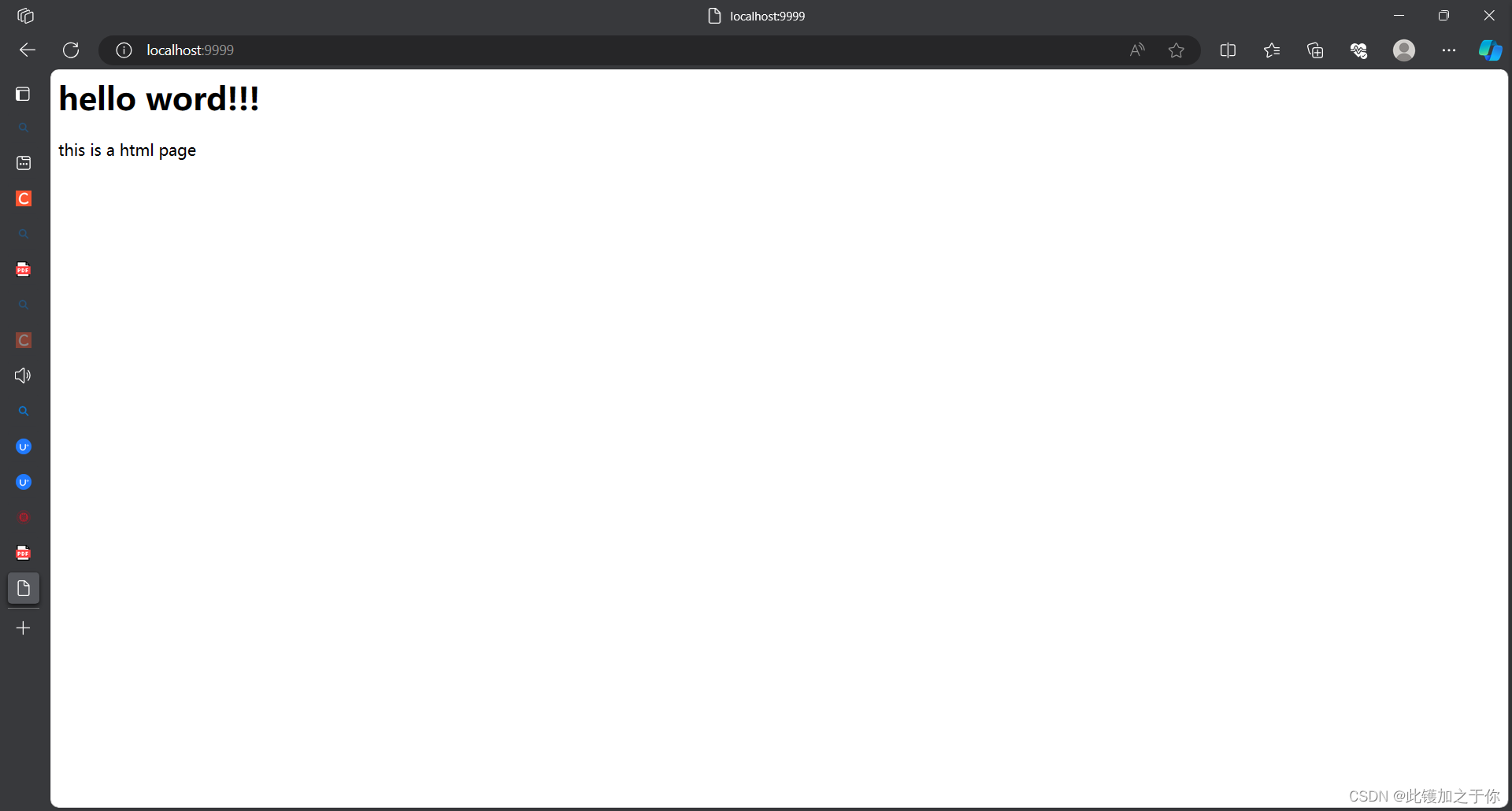
阿里云域名实战
一、准备阿里云服务器,实现网站功能 (1)百度搜索阿里云 (2)登录阿里云 可以使用支付宝,淘宝账号登录 (3)点击控制台 (4)创建实例,购买云服务器 (5&#x…...

git关联远程仓库自己分支自用
初始化仓库 cassielDESKTOP-KPKFOEU MINGW64 /d/code/api_test_202310232022 (tong) $ git init Reinitialized existing Git repository in D:/code/api_test_202310232022/.git/关联远程仓库并创建本地分支 cassielDESKTOP-KPKFOEU MINGW64 /d/code/api_test_202310232022 …...

eBPF BCC开源工具简介
目录 官方链接 编译安装 ubuntu版本 安装 examples tools hello_world.py demo 运行报错 网上目前的解决办法 错误分析过程 python版本检测 libbcc库检查 python3 bcc库检查 正常输出 监控进程切换 运行输出 监控CPU直方图 缓存命中率监控:caches…...
)
Linux上后台运行进程(nohub、screen和tmux )
文章目录 Linux上后台运行进程(nohub、screen和tmux )nohupscreen虚拟终端安装screen使用 tmux终端复用器[个人推荐]安装tmux使用 Linux上后台运行进程(nohub、screen和tmux ) 命令行的典型使用方式是,打开一个终端窗…...
javaee实验:搭建maven+spring boot开发环境,开发“Hello,Spring Boot”应用
目录 mavenspringboot实验目的实验内容环境的搭建 在开发中,maven和spring都是非常常用、非常重要的管理工具和框架,今天就在这里使用idea进行环境的搭建和创建第一个spring程序 maven 1.1maven是一个跨平台的项目管理工具(主要管理jar包&am…...
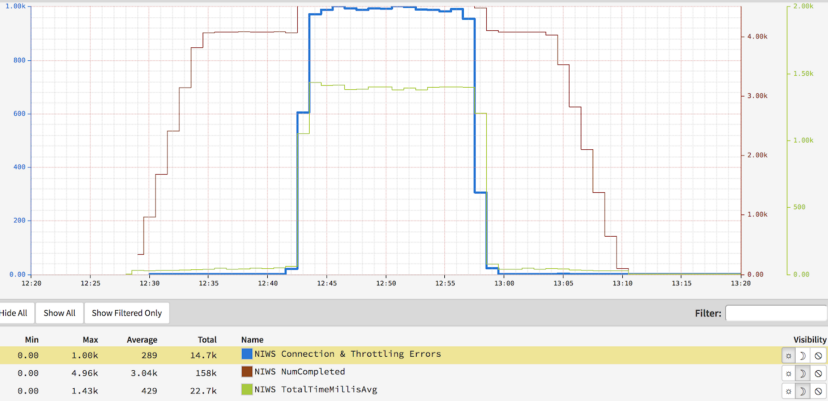
重新思考边缘负载均衡
本文介绍了Netflix在基于轮询的负载均衡的基础上,集成了包括服务器使用率在内的多因素指标,并对冷启动服务器进行了特殊处理,从而优化了负载均衡逻辑,提升了整体业务性能。原文: Rethinking Netflix’s Edge Load Balancing[1] 我…...

构建一个CAN报文周期任务类
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、can周期任务类构建总结 前言 提示:这里可以添加本文要记录的大概内容: 最近想着有时间实现总线报文收发的动态的配置,…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

day36-多路IO复用
一、基本概念 (服务器多客户端模型) 定义:单线程或单进程同时监测若干个文件描述符是否可以执行IO操作的能力 作用:应用程序通常需要处理来自多条事件流中的事件,比如我现在用的电脑,需要同时处理键盘鼠标…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...

ubuntu系统文件误删(/lib/x86_64-linux-gnu/libc.so.6)修复方案 [成功解决]
报错信息:libc.so.6: cannot open shared object file: No such file or directory: #ls, ln, sudo...命令都不能用 error while loading shared libraries: libc.so.6: cannot open shared object file: No such file or directory重启后报错信息&…...

DiscuzX3.5发帖json api
参考文章:PHP实现独立Discuz站外发帖(直连操作数据库)_discuz 发帖api-CSDN博客 简单改造了一下,适配我自己的需求 有一个站点存在多个采集站,我想通过主站拿标题,采集站拿内容 使用到的sql如下 CREATE TABLE pre_forum_post_…...
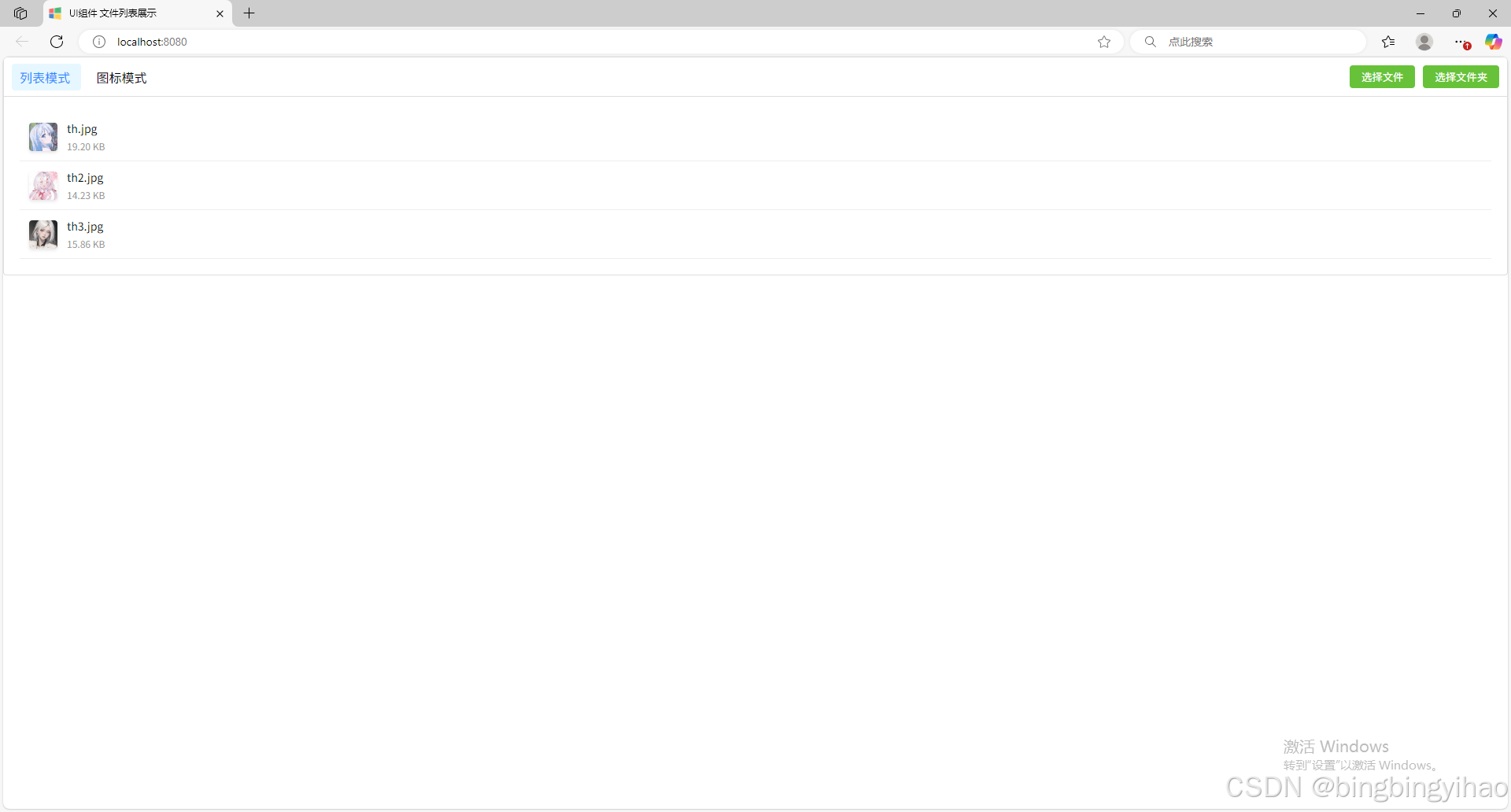
ui框架-文件列表展示
ui框架-文件列表展示 介绍 UI框架的文件列表展示组件,可以展示文件夹,支持列表展示和图标展示模式。组件提供了丰富的功能和可配置选项,适用于文件管理、文件上传等场景。 功能特性 支持列表模式和网格模式的切换展示支持文件和文件夹的层…...