学习LevelDB架构的检索技术
目录
一、LevelDB介绍
二、LevelDB优化检索系统关键点分析
三、读写分离设计和内存数据管理
(一)内存数据管理
跳表代替B+树
内存数据分为两块:MemTable(可读可写)+ Immutable MemTable(只读)
(二)读写分离设计
四、布隆过滤器和SSTable 的分层管理设计
(一)布隆过滤器(Bloom Filter)
(二)SSTable的分层管理设计
五、如何查找对应的 SSTable 文件
六、利用缓存加速检索 SSTable 文件的过程
Table Cache
Block Cache
七、对检索系统的启发
参考文章和技术
一、LevelDB介绍
LevelDB是一种高性能的键值存储系统,由Google开发。它被设计用于提供快速的读写访问,并且在许多应用中可以替代传统的数据库管理系统。以下是关于LevelDB的一些介绍:
-
键值存储:LevelDB是一种键值存储引擎,它将数据以键值对的形式进行存储和检索。每个键都唯一标识一个值,可以通过键来快速检索相关数据。
-
开源项目:LevelDB是一个开源项目,采用了类似BSD许可证的开源许可,这意味着开发者可以自由使用、修改和分发LevelDB的源代码。
-
高性能:LevelDB被设计为高性能的存储引擎,可以在读取和写入大量数据时提供出色的性能。它通过使用一些优化技巧,如内存映射、前缀压缩和多层次的存储结构,来加速数据的存储和检索。
-
跨平台支持:LevelDB支持多种操作系统,包括Linux、Windows和macOS,使其能够在各种环境下运行。
-
轻量级:LevelDB是一个相对轻量级的存储引擎,不包含复杂的查询语言或事务处理功能。它专注于提供快速的键值对存储和检索功能。
-
适用范围:LevelDB适用于需要高性能的应用程序,如缓存、日志存储、持久化存储、搜索引擎等。它在许多应用中被广泛使用,包括一些大规模的分布式系统。
虽然LevelDB在性能方面表现出色,但它并不是适合所有类型的应用程序。对于需要复杂查询、事务处理或高度并发的应用,可能需要选择更强大的数据库系统,如MySQL、PostgreSQL或NoSQL数据库。但对于那些需要快速、轻量级的键值存储的应用,LevelDB可能是一个很好的选择。此外,LevelDB的成功启发了其他键值存储系统的发展,如RocksDB等。
二、LevelDB优化检索系统关键点分析
LevelDB 是由 Google 开源的存储系统的代表,在工业界中被广泛地使用。它的性能非常突出,官方公布的 LevelDB 的随机读性能可以达到 6 万条记录 / 秒。LevelDB使用了多种技术和策略来优化检索系统以提高效率。

以下是LevelDB在检索方面的一些关键优化:
-
SSTables和LSM-Tree结构: LevelDB的数据存储结构采用了Sorted String Table(SSTable)和Log-Structured Merge-Tree(LSM-Tree)的模型。这种结构允许数据按顺序写入,通过合并操作来维护和查询数据,从而提高了检索效率。数据在不同层次上组织,以支持范围查询和高效的合并操作。
-
内存映射: LevelDB使用内存映射文件的技术,将磁盘上的数据文件映射到内存中,以加速数据的读取。内存映射允许LevelDB通过内存进行数据访问,从而减少磁盘I/O的需求,提高了检索效率。
-
布隆过滤器: LevelDB采用了布隆过滤器(Bloom Filter)来减少不必要的磁盘访问。布隆过滤器是一种快速的数据结构,用于检查一个元素是否可能存在于数据中。通过使用布隆过滤器,LevelDB可以在不需要的情况下避免磁盘访问,从而提高了检索效率。
-
前缀压缩: LevelDB使用了前缀压缩技术,将相似的键前缀进行压缩存储,减小了存储空间和提高了检索速度。这可以在数据文件中减少不必要的重复信息,减少磁盘I/O。
-
多层次存储: 数据在LevelDB中分为多个层次,每个层次采用不同的合并策略。这种多层次的存储结构允许LevelDB在不同层次上实现快速的数据访问和合并操作,提高了整体的检索效率。
-
高效的数据迭代器: LevelDB提供了高效的数据迭代器,允许以非常低的开销遍历数据库中的数据。这有助于高效地执行范围查询和遍历操作。
-
Caches(缓存): LevelDB使用内存缓存来存储最常用的数据块,以减少对磁盘的频繁访问。这样,经常访问的数据可以从内存中快速检索,提高了检索效率。
总之,LevelDB通过采用合适的数据结构、优化技术和策略,以及高效的数据访问方法,实现了出色的检索效率。这使得它非常适合用于需要快速、高效的键值存储的应用程序,特别是在处理大量数据时表现突出。然而,要充分发挥LevelDB的性能,开发人员需要了解其工作原理并合理配置和使用它。
三、读写分离设计和内存数据管理
LevelDB的内存数据结构的设计确实经过精心考虑,允许它同时实现高性能的读取和写入操作,以提高检索效率和维护数据的一致性。下面将详细说明 LevelDB 的内存数据管理以及如何将数据写入磁盘的过程。
(一)内存数据管理
跳表代替B+树
LevelDB的第一个改进是在内存中的数据结构,使用跳表(Skip List)代替传统的B+树。跳表是一种高效的数据结构,对于有序数据的插入和查找操作非常快速。由于内存中的数据通常较小,跳表在这种情况下通常比B+树更高效。
内存数据分为两块:MemTable(可读可写)+ Immutable MemTable(只读)
- MemTable(可读可写): MemTable用于存储可读可写的数据,它是可以接受写入操作的数据结构。当新数据写入时,它会被添加到MemTable中,允许读取和写入操作同时进行。MemTable采用跳表的数据结构。
- Immutable MemTable(只读): Immutable MemTable用于存储只读的数据,一旦数据被写入其中,就会被标记为只读。这个数据结构也是跳表,但是只读,因此它保持了不可变性,不再接受写入操作。
(二)读写分离设计
LevelDB的读写分离设计允许同时进行读取和写入操作,而无需加锁。新写入的数据进入MemTable,而Immutable MemTable保持只读。这意味着LevelDB可以在不阻塞读取操作的情况下进行写入操作。

将内存数据写入磁盘
当MemTable的数据量达到一定阈值时,LevelDB将其切换为只读的Immutable MemTable,并生成一个新的MemTable以支持新数据的写入和查询。此时,将内存索引存储到磁盘的问题变成了将Immutable MemTable写入磁盘的问题。
延迟合并的设计
LevelDB采用了延迟合并的策略。具体来说,将Immutable MemTable中的数据顺序快速写入磁盘,直接生成SSTable(Sorted String Table)文件,而不直接与磁盘上的C1树进行归并。SSTable文件是一种有序的、可压缩的数据文件,其中包含键值对。这种设计避免了C0树和C1树昂贵的合并代价。
后台合并
合并SSTable文件通常在后台异步执行,因此不会阻塞读取和写入操作。在后台,LevelDB会合并多个SSTable文件以减少数据重叠和提高读取效率。这种合并策略也有助于降低频繁合并C0树和C1树所导致的大量磁盘I/O。
总之,LevelDB的内存数据管理和读写分离设计允许它在不阻塞读取操作的情况下高效进行写入操作,并通过延迟合并和后台合并等策略来优化数据写入磁盘的过程。这种设计有助于维护数据的一致性,同时提高了LevelDB的性能。 SStable文件的合并和管理是LevelDB中的关键部分,允许有效地管理和维护磁盘上的数据。
四、布隆过滤器和SSTable 的分层管理设计
SSTable 文件是由 Immutable MemTable 将数据顺序导入生成的。尽管 SSTable 中的数据是有序的,但是每个 SSTable 覆盖的数据范围都是没有规律的,所以 SSTable 之间的数据很可能有重叠。

比如说,第一个 SSTable 中的数据从 1 到 1000,第二个 SSTable 中的数据从 500 到 1500。那么当要查询 600 这个数据时,我们并不清楚应该在第一个 SSTable 中查找,还是在第二个 SSTable 中查找。最差的情况是,我们需要查询每一个 SSTable,这会带来非常巨大的磁盘访问开销。
SSTable文件之间的数据重叠可能导致查询效率下降的问题。为了解决这个问题,LevelDB使用了"布隆过滤器"技术,以降低查询时的磁盘访问开销。同时SSTable的分层管理设计也确实是解决SSTable之间数据重叠的问题的一种方法。这种分层管理设计是LevelDB中的另一个关键优化,用于提高查询性能并降低合并开销。
(一)布隆过滤器(Bloom Filter)
布隆过滤器(Bloom Filter)是一种用于快速检查某个元素是否可能存在于数据集合中的数据结构。它可以有效地减少不必要的磁盘访问。在LevelDB中,每个SSTable都关联一个布隆过滤器,该过滤器包含了SSTable中的键的信息。
当进行查询时,LevelDB首先会使用布隆过滤器来检查查询的键是否可能存在于特定的SSTable中。如果布隆过滤器返回"可能存在",则LevelDB会继续在相应的SSTable中查找键,从而减少不必要的磁盘访问。如果布隆过滤器返回"不存在",则LevelDB可以避免打开并检索相应的SSTable,从而提高了查询效率。
虽然布隆过滤器并不是百分之百准确的,但它能够显著减少需要检索的SSTable的数量,特别是在范围查询中,减少了不必要的磁盘访问。这一技术有助于提高LevelDB的查询性能,特别是在具有大量SSTable的情况下SSTable之间有重叠的情况。
(二)SSTable的分层管理设计
在LevelDB中,数据被分为多个层次,每个层次的数据采用不同的合并策略。典型的层次包括:
- MemTable层(C0): 用于存储可读可写的数据,通常在内存中。
- Immutable MemTable层: 也用于存储可读可写的数据,但是数据被标记为只读。一旦Immutable MemTable写入磁盘,它不再接受写入操作。
- SSTable层(C1至Cn): 存储不同版本的数据,每个层次的数据量逐渐增加。较旧的数据被移动到更高层次,而新数据存储在更低层次。
分层管理的优势在于它可以降低合并的复杂度和开销。LevelDB的合并操作通常发生在不同层次的SSTable之间,而不是在所有SSTable之间。这可以减少合并的频率和开销,因为新写入的数据首先进入内存,然后以较大的单位合并到SSTable中。
此外,由于SSTable层次的数据是有序的,查询操作可以首先在较高层次的SSTable中查找,然后逐渐降级到较低层次,以降低磁盘访问的开销。这种分层管理设计有助于提高查询性能,并在保持数据一致性的同时减少了磁盘访问开销。
LevelDB的分层管理和滚动合并策略是为了降低多路归并过程中涉及的SSTable文件数量,从而减少磁盘IO开销和提高性能。
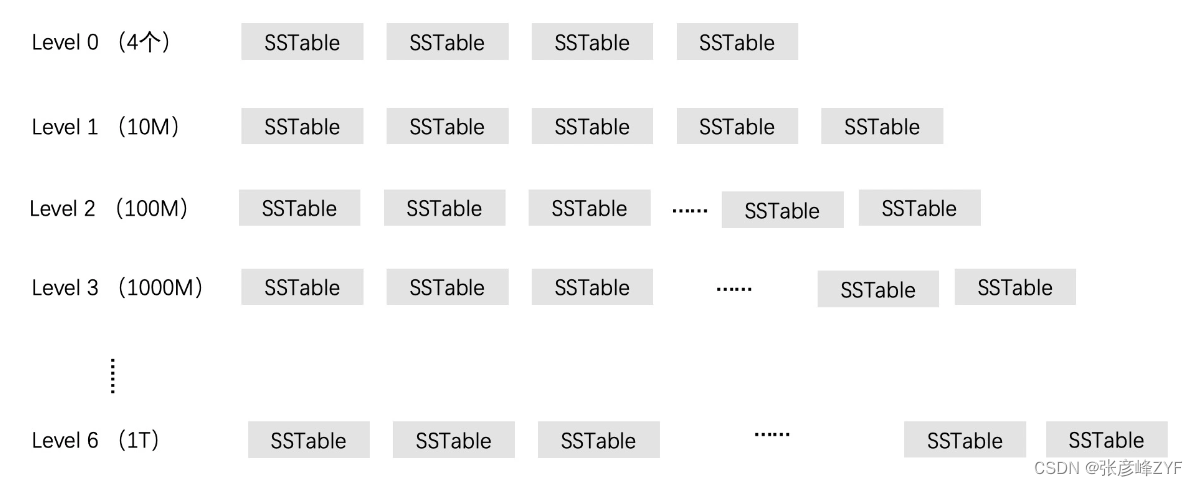
LevelDB的分层管理:
- Level 0 层: SSTable从Immutable MemTable转换成SSTable后,它们首先被放在Level 0层。Level 0层最多可以容纳4个SSTable文件。
- Level 1 层: 当Level 0层达到容量上限(默认设置为4个SSTable)时,这些SSTable文件将进行多路归并,生成一个新的有序SSTable文件集合,这个集合称为Level 1层。
- 逐层分层: 如果新的SSTable文件被写入Level 0层,而Level 1层中已经有一定数量的SSTable文件,那么这时LevelDB会将Level 0层和Level 1层中的SSTable进行多路归并,生成新的有序SSTable文件集合,这个集合成为Level 2层,以此类推。
控制容量上限:
- 每层SSTable容量上限: 为了避免合并时的磁盘IO代价过大,LevelDB为每个层次的SSTable文件设置一个总容量上限。默认情况下,Level 1层的总容量上限设置为10MB。这意味着当Level 1层的SSTable文件总容量达到10MB时,需要执行合并操作。
- 多路归并和文件选择: 在多路归并时,LevelDB会选择一个SSTable文件,将它并入下一层。为了保证公平性,选择文件的逻辑是轮流选择,也就是说,每次选择一个文件后,下次会选择下一个文件,以确保每个文件都有机会并入下一层。
- 层次扩展: 如果下一层的容量上限达到,那么同样的逻辑适用于下一层,容量上限会扩大为前一层的10倍。
这种分层管理和滚动合并策略有效地减少了多路归并时涉及的SSTable文件数量,降低了合并操作的复杂度和开销。这有助于提高LevelDB的查询性能,同时降低了磁盘IO开销。此外,这个设计还有助于维护数据的一致性,因为数据在逐层合并的过程中被排序和去重,减少了数据的冗余。
综合考虑,LevelDB的优化包括布隆过滤器和SSTable的分层管理设计,这两者结合起来使LevelDB能够高效地管理和查询数据,特别是在数据重叠的情况下。
五、如何查找对应的 SSTable 文件
在LevelDB中,查找对应的SSTable文件是根据数据键的范围和分层结构来执行的。当进行查询时,LevelDB需要找到包含查询键的正确SSTable文件。以下是LevelDB查找SSTable文件的一般流程:
-
检查MemTable: 首先,LevelDB会检查MemTable,即内存中的可读可写数据结构,以查找查询的键是否存在于其中。如果键存在于MemTable中,查询可以直接从内存中获得结果,无需访问磁盘。
-
检查Immutable MemTable: 如果键不在MemTable中,LevelDB会继续检查Immutable MemTable,即只读的内存数据结构。这是因为Immutable MemTable中可能包含了较早的版本数据。如果查询的键存在于Immutable MemTable中,LevelDB将返回相应的结果。
-
分层查找: 如果在内存中的数据结构中没有找到查询的键,LevelDB将进行分层查找。它从Level 0层开始,逐层向下查找,检查每个层次的SSTable文件,以查找查询键。查询的键将与每个层次的SSTable文件中的键范围进行比较,以确定在哪个SSTable文件中查找。
-
布隆过滤器: 在查找SSTable文件之前,LevelDB通常会使用布隆过滤器来检查查询键是否可能存在于特定的SSTable文件中。这可以减少不必要的SSTable文件打开和查找操作。
-
多路归并: 如果查询的键跨越多个SSTable文件,LevelDB可能需要执行多路归并操作,将这些文件合并成一个有序的结果,然后查找相应的键。
-
文件选择: 在多路归并时,LevelDB会选择一个或多个SSTable文件进行合并,通常根据策略选择合并哪些文件。
总之,LevelDB查找对应的SSTable文件涉及分层查找和比较查询键的范围,以确定在哪个SSTable文件中查找。它还使用布隆过滤器来提高查询效率,减少不必要的磁盘访问。如果查询涉及多个SSTable文件,LevelDB可能需要执行多路归并来生成有序的结果。文件选择和合并策略是由LevelDB的设计和配置来控制的。
六、利用缓存加速检索 SSTable 文件的过程
LevelDB使用缓存来加速检索SSTable文件的过程,以减少磁盘I/O操作,从而提高检索效率。两个主要的缓存是table cache和block cache,它们都使用LRU(最近最少使用)机制来管理缓存替换。
Table Cache
Table cache用于缓存最近使用的SSTable的Index Block,这些Index Blocks通常存储了SSTable文件中的键范围信息。当需要查找SSTable文件的Index Block时,LevelDB首先检查table cache。如果Index Block存在于table cache中,LevelDB可以直接从内存中获取,而无需执行磁盘I/O操作,从而提高检索效率。
Block Cache
Block cache用于缓存最近使用的SSTable文件中的Data Block。Data Blocks包含实际的键值数据。当需要查找SSTable文件中的Data Block时,LevelDB首先检查block cache。如果Data Block存在于block cache中,LevelDB可以直接从内存中获取,从而避免了磁盘I/O操作,进一步提高了检索效率。
这两种缓存的设计有助于避免频繁的磁盘访问,特别是对于SSTable文件的Index Block和Data Block。LRU机制确保了缓存中的数据是最近使用的数据,以最大程度地提高命中率。
通过使用table cache和block cache,LevelDB可以显著减少检索SSTable文件时的磁盘I/O操作,从而加速相关的检索操作。这对于减小性能开销和提高读取效率非常重要,尤其在处理大量SSTable文件时。缓存的使用还有助于维护数据的一致性,因为它减少了读取过程中的不一致性可能性。
七、对检索系统的启发
LevelDB的检索和存储设计提供了许多启发和优化方向,这些思想和技术可以在构建其他检索系统时考虑和借鉴,以提高性能、效率和可伸缩性。以下是一些从LevelDB设计中获得的启发:
-
分层管理和滚动合并: LevelDB的分层管理和滚动合并策略允许有效地管理大量数据,并减少合并操作的复杂度。这个思想可以用于其他存储系统,特别是在需要管理多个数据版本或大量数据的情况下。
-
布隆过滤器: 布隆过滤器可用于快速检查查询键是否可能存在于数据集合中,从而减少不必要的磁盘访问。它在查询系统中用于减少不必要的IO操作是一个有用的工具。
-
读写分离设计: LevelDB的读写分离设计允许同时进行读取和写入操作,而无需加锁。这个思想可以用于构建高并发的检索系统,以实现高性能的读写操作。
-
缓存机制: 缓存(如table cache和block cache)可以显著提高检索效率,减少磁盘IO操作。在检索系统中使用缓存是一种常见的性能优化方法,可以降低读取操作的延迟。
-
多路归并: 多路归并策略可以用于合并和管理大量数据,以减少合并操作的频率和开销。这个思想可以用于优化大规模的数据合并操作。
-
数据一致性管理: LevelDB采用了多种方法来确保数据的一致性,如数据排序、去重和版本控制。这些技术可以在构建复杂的检索系统时用于确保数据的完整性和一致性。
-
可配置性: LevelDB的设计允许用户根据具体需求进行各种配置,包括缓存大小、合并策略、数据压缩等。这种可配置性可以用于适应不同应用场景的需求。
-
优秀的文档和社区支持: LevelDB的文档和社区支持丰富,可以帮助用户更好地理解和使用存储引擎。这种资源的提供可以在构建检索系统时提供有力的支持。
总之,LevelDB的设计思想和优化方向可以为构建高性能、高效率、可扩展性的检索系统提供有益的启发。根据具体需求和场景,可以考虑和借鉴这些思想,以提高检索系统的性能和可靠性。
参考文章和技术
- 极客时间《检索技术核心 20 讲》【存储系统:从检索技术角度剖析LevelDB的架构设计思想】,陈东
- GitHub - google/leveldb: LevelDB is a fast key-value storage library written at Google that provides an ordered mapping from string keys to string values.
相关文章:
学习LevelDB架构的检索技术
目录 一、LevelDB介绍 二、LevelDB优化检索系统关键点分析 三、读写分离设计和内存数据管理 (一)内存数据管理 跳表代替B树 内存数据分为两块:MemTable(可读可写) Immutable MemTable(只读࿰…...
Docker Swarm实现容器的复制均衡及动态管理:详细过程版
Swarm简介 Swarm是一套较为简单的工具,用以管理Docker集群,使得Docker集群暴露给用户时相当于一个虚拟的整体。Swarm使用标准的Docker API接口作为其前端访问入口,换言之,各种形式的Docker Client(dockerclient in go, docker_py…...
Proteus仿真--1602LCD显示仿手机键盘按键字符(仿真文件+程序)
本文主要介绍基于51单片机的1602LCD显示仿手机键盘按键字符(完整仿真源文件及代码见文末链接) 仿真图如下 其中左下角12个按键模拟仿真手机键盘,使用方法同手机键一样,长按自动跳动切换键值,松手后确认选择ÿ…...

Rust语言和curl库编写程序
这是一个使用Rust语言和curl库编写的爬虫程序,用于爬取视频。 use std::env; use std::net::TcpStream; use std::io::{BufReader, BufWriter}; fn main() {// 获取命令行参数let args: Vec<String> env::args().collect();let proxy_host args[1].clon…...
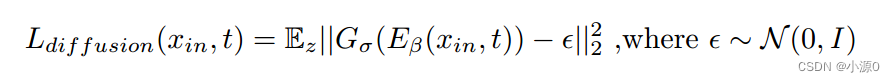
FSDiffReg:心脏图像的特征和分数扩散引导无监督形变图像配准
论文标题: FSDiffReg: Feature-wise and Score-wise Diffusion-guided Unsupervised Deformable Image Registration for Cardiac Images 翻译: FSDiffReg:心脏图像的特征和分数扩散引导无监督形变图像配准 摘要 无监督可变形图像配准是医学…...

音视频技术开发周刊 | 318
每周一期,纵览音视频技术领域的干货。 新闻投稿:contributelivevideostack.com。 日程揭晓!速览深圳站大会专题议程详解 LiveVideoStackCon 2023 音视频技术大会深圳站,保持着往届强大的讲师阵容以及高水准的演讲质量。两天的参会…...

asp.net docker-compose添加sql server
打开docker-compose.yml 添加 sqldata:image: mysql:8.1.0 打开docker-compose.override.yml 添加 sqldata:environment:- MYSQL_ROOT_PASSWORDPasswordports:- "8080:8080"volumes:- killsb-one-sqldata:/etc/mysql/conf.d 在docker里面就有了sql server容器镜像…...
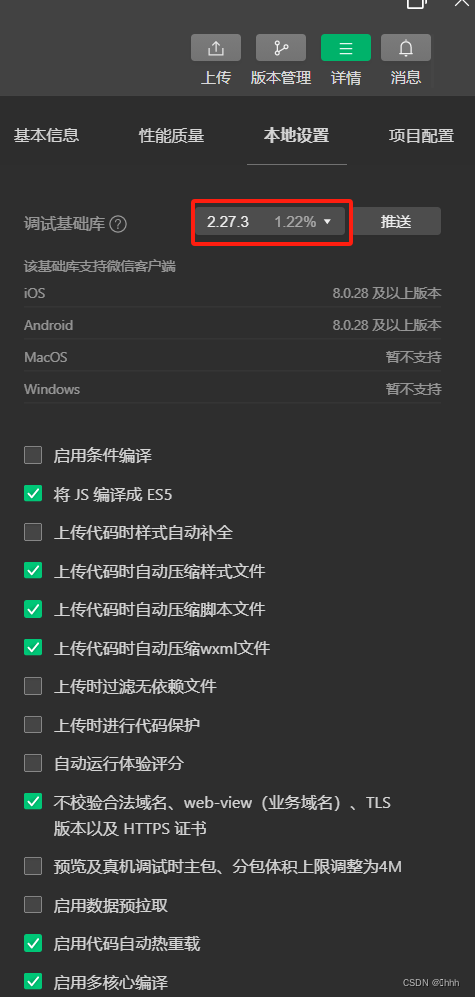
uniapp 微信小程序 uni-file-picker上传图片报错 chooseAndUploadFile
这个问题真的很搞, 原因是微信开发者工具更新了,导致图片上传问题。 解决方法: 将微信开发者工具的基础库改为2.33.0一下即可。 在微信开发者工具详情 - 本地设置中(记得点击‘推送’按钮):...
《向量数据库指南》——用 Milvus Cloud和 NVIDIA Merlin 搭建高效推荐系统结论
如何搭建一个高效的推荐系统? 简单来说,现代推荐系统由训练/推理流水线(pipeline)组成,涉及数据获取、数据预处理、模型训练和调整检索、过滤、排名和评分相关的超参数等多个阶段。走遍这些流程之后,推荐系统能够给出高度个性化的推荐结果,从而提升产品的用户体验。 为…...

致:CSGO游戏搬砖人的一封信
最近大家还在坚持操作CSGO游戏搬砖项目不? 这个项目虽是稳赚项目,但也有行情好和行情不好的时候,平台的大中小各种活动的举办,都会对我们的项目造成一定影响。行情的上下波动势必然会影响卡价的波动,影响选品的快慢&a…...

MuLogin浏览器如何在一台设备上安全登录和管理多个LinkedIn账户?
一、LinkedIn多个账户的用处 LinkedIn作为世界上最大的专业人士社交平台,具有许多有用的功能,对于个人和企业来说都非常重要。以下是多个LinkedIn账户的一些典型用途: 1. 分行业账户:如果您在不同的行业从事职业活动,…...

STM32_project:led_beep
代码: 主要部分: #include "stm32f10x.h" // Device header #include "delay.h"// 给蜂鸣器IO口输出低电平,响,高,不向。 //int main (void) //{ // // 开启时钟 // RC…...

[go 反射] 入门
[go 反射] 入门 首先认识go 反射的两大概念,反射之路少不了他们 reflect.Type(接口)获取类型,和列名就找它reflect.Value(结构体)获取值,设置值找它 [tips] 通常是用这两者手底下的方法,reflect.Value结构体中有什么自行查看 …...
【计算机网络】数据链路层-MAC和ARP协议
文章目录 1. 认识以太网2. MAC协议MAC帧的格式MAC地址和IP地址的区别MTU 3. 局域网通信原理碰撞检测和避免 4. ARP协议ARP数据报的格式ARP缓存 1. 认识以太网 网络层解决的是跨网络点到点传输的问题,数据链路层解决的是同一网络中的通信。 数据链路层负责在同一局域…...
本周三商店更新:多款套装下线,四款升级武器带异色皮肤返厂
本周三将迎来26.2版本更新与11商店大更新,版本更新可点击26.2版本更新公告进行查看,这里不一一赘述了,下面大概罗列一下商店更新,有皮肤下架,大家还能趁最后时间入手,最重要的是四款升级武器返厂咯。 危险玩…...
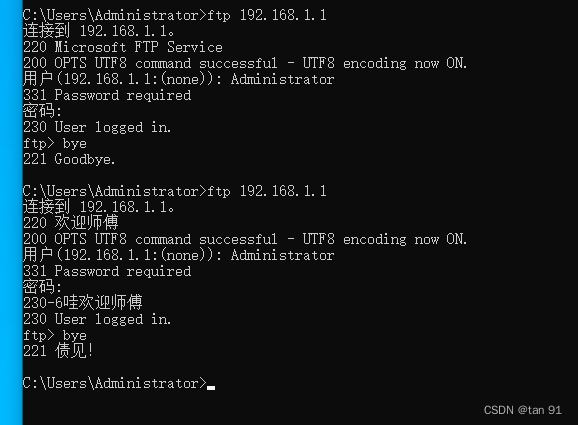
WindowsServer2019-搭建FTP服务器
这里写自定义目录标题 一、基础配置IP地址安装FTP服务检查连通性Windows10连接FTP服务 二、了解和使用FTP具体模块及其配置1、FTP IP地址和域限制2、FTP SSL设置3、FTP当前会话4、FTP防火墙5、FTP目录浏览6、FTP请求筛选7、FTP日志8、FTP身份验证9、FTP授权规则10、FTP消息11、…...

国际阿里云服务器买哪种好用点?
在当时数字化年代,云核算已经成为了企业进行事务运营和数据存储的重要东西。而阿里云作为我国最大的云核算服务供给商,其服务器产品线也适当丰厚。那么,对于用户来说,阿里云服务器买哪种好用点呢?这需求依据个人和企业…...

2023NOIP A层联测25 总结
T1 让你构造 40 40 40\times40 4040 的只含 r,y,x 的矩阵,含有 r y x ryx ryx 的个数恰好为 n n n, n ≤ 2222 n\le2222 n≤2222。看完题后就开始想构造,一开始想构造 3 ∗ 3 3*3 3∗3, 5 ∗ 5 5*5 5∗5 的单位矩阵的,但是始…...

Thread类的基本操作(JAVA多线程)
线程是操作系统中的概念,操作系统内核实现了线程这样的机制,并提供了一些API供外部使用。 JAVA中 Thread类 将系统提供的API又近一步进行了抽象和封装,所以如果想要使用多线程就离不开 Thread 这个类。 线程的创建(Thread类) 在JAVA中 创建…...

Redis 的三种部署模式
提前叠个 buff:这个文章不涉及图(画起来比较麻烦),只是记录我的胡思乱想。 redis 从单点 -> 集群总共有三个部署模式:单机模式,主从模式,哨兵模式,集群模式 单机模式 新手入门模…...

大话软工笔记—需求分析概述
需求分析,就是要对需求调研收集到的资料信息逐个地进行拆分、研究,从大量的不确定“需求”中确定出哪些需求最终要转换为确定的“功能需求”。 需求分析的作用非常重要,后续设计的依据主要来自于需求分析的成果,包括: 项目的目的…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

Admin.Net中的消息通信SignalR解释
定义集线器接口 IOnlineUserHub public interface IOnlineUserHub {/// 在线用户列表Task OnlineUserList(OnlineUserList context);/// 强制下线Task ForceOffline(object context);/// 发布站内消息Task PublicNotice(SysNotice context);/// 接收消息Task ReceiveMessage(…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

08. C#入门系列【类的基本概念】:开启编程世界的奇妙冒险
C#入门系列【类的基本概念】:开启编程世界的奇妙冒险 嘿,各位编程小白探险家!欢迎来到 C# 的奇幻大陆!今天咱们要深入探索这片大陆上至关重要的 “建筑”—— 类!别害怕,跟着我,保准让你轻松搞…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...

C# 表达式和运算符(求值顺序)
求值顺序 表达式可以由许多嵌套的子表达式构成。子表达式的求值顺序可以使表达式的最终值发生 变化。 例如,已知表达式3*52,依照子表达式的求值顺序,有两种可能的结果,如图9-3所示。 如果乘法先执行,结果是17。如果5…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...