【深度学习】pytorch——Autograd
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~
深度学习专栏链接:
http://t.csdnimg.cn/dscW7
pytorch——Autograd
- Autograd简介
- requires_grad
- 计算图
- 没有梯度追踪的张量ensor.data 、tensor.detach()
- 非叶子节点的梯度
- 计算图特点总结
- 利用Autograd实现线性回归
Autograd简介
autograd是PyTorch中的自动微分引擎,它是PyTorch的核心组件之一。autograd提供了一种用于计算梯度的机制,使得神经网络的训练变得更加简洁和高效。
在深度学习中,梯度是优化算法(如反向传播)的关键部分。通过计算输入变量相对于输出变量的梯度,可以确定如何更新模型的参数以最小化损失函数。
autograd的工作原理是跟踪在张量上进行的所有操作,并构建一个有向无环图(DAG),称为计算图。这个计算图记录了张量之间的依赖关系,以及每个操作的梯度函数。当向前传播时,autograd会自动执行所需的计算并保存中间结果。当调用.backward()函数时,autograd会根据计算图自动计算梯度,并将梯度存储在每个张量的.grad属性中。
使用autograd非常简单。只需将需要进行梯度计算的张量设置为requires_grad=True,然后执行前向传播和反向传播操作即可。例如:
import torch as tx = t.tensor([2.0], requires_grad=True)
y = x**2 + 3*x + 1y.backward()print(x.grad) # 输出:tensor([7.])
在上述代码中,首先创建了一个张量 x,并设置了 requires_grad=True,表示想要计算关于 x 的梯度。然后,定义了一个计算图 y,通过对 x 进行一系列操作得到结果 y。最后,调用 .backward() 函数执行反向传播,并通过 x.grad 获取计算得到的梯度。
autograd的存在使得训练神经网络变得更加方便,无需手动计算和更新梯度。同时,它也为实现更复杂的计算图和自定义的梯度函数提供了灵活性和扩展性。
requires_grad
requires_grad是PyTorch中张量的一个属性,用于指定是否需要计算该张量的梯度。如果需要计算梯度,则需将其设置为True,否则设置为False。默认情况下,该属性值为False。
在深度学习中,通常需要对模型的参数进行优化,因此需要计算这些参数的梯度。通过将参数张量的requires_grad属性设置为True,可以告诉PyTorch跟踪其计算并计算梯度。除了参数张量之外,还可以将其他需要计算梯度的张量设置为requires_grad=True,以便计算它们的梯度。
需要注意的是,如果张量的requires_grad属性为True,则计算成本会略微增加,因为PyTorch需要跟踪该张量的计算并计算其梯度。因此,对于不需要计算梯度的张量,最好将其requires_grad属性设置为False,以减少计算成本。
计算图
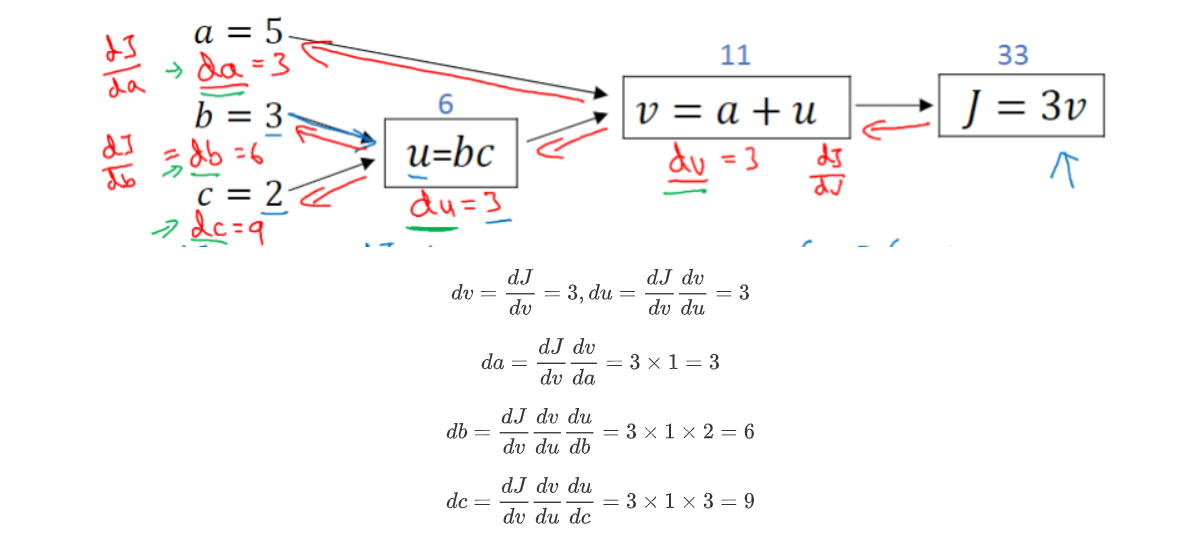
PyTorch中autograd的底层采用了计算图,计算图是一种特殊的有向无环图(DAG),用于记录算子与变量之间的关系。一般用矩形表示算子,椭圆形表示变量。其计算图如图所示,图中MUL,ADD都是算子, a \textbf{a} a, b \textbf{b} b, c \textbf{c} c即变量。
没有梯度追踪的张量ensor.data 、tensor.detach()
tensor.data和tensor.detach()都可以用于获取一个没有梯度追踪的张量副本,但它们之间有一些细微的区别。
tensor.data是一个属性,用于返回一个与原始张量共享数据存储的新张量,但不会共享梯度信息。这意味着对返回的张量进行操作不会影响到原始张量的梯度。然而,如果在计算图中使用了这个新的张量,梯度仍会通过原始张量进行传播。
以下是一个示例说明:
import torchx = torch.tensor([2.0], requires_grad=True)
y = x**2 + 3*x + 1z = y.data
z *= 2 # 操作z不会影响到y的梯度y.backward()print(x.grad) # 输出:tensor([7.])
在上述代码中,我们首先创建了一个张量x,并设置了requires_grad=True,表示我们希望计算关于x的梯度。然后,我们定义了一个计算图y,并将其赋值给z,通过操作z不会影响到y的梯度。最后,我们调用.backward()方法计算相对于x的梯度,并将梯度存储在x.grad属性中。
tensor.detach()是一个函数,用于返回一个新的张量,与原始张量具有相同的数据内容,但不会共享梯度信息。与tensor.data不同的是,tensor.detach()可以应用于任何张量,而不仅限于具有requires_grad=True的张量。
以下是使用tensor.detach()的示例:
import torchx = torch.tensor([2.0], requires_grad=True)
y = x**2 + 3*x + 1z = y.detach()
z *= 2 # 操作z不会影响到y的梯度y.backward()print(x.grad) # 输出:tensor([7.])
在上述代码中,我们执行了与前面示例相同的操作,将y赋值给z,并通过操作z不会影响到y的梯度。最后,我们调用.backward()方法计算相对于x的梯度,并将梯度存储在x.grad属性中。
总结来说,tensor.data和tensor.detach()都可以用于获取一个没有梯度追踪的张量副本,但tensor.detach()更加通用,可应用于任何张量。
非叶子节点的梯度
在反向传播过程中,非叶子节点的梯度默认情况下是被清空的。
1.使用.retain_grad()方法:在创建张量时,可以使用.retain_grad()方法显式指定要保留梯度信息。然后,在反向传播后,可以访问这些非叶子节点的梯度。
import torchx = torch.tensor([2.0], requires_grad=True)
y = x**2 + 3*x + 1y.retain_grad()z = y.mean()z.backward()grad_y = y.gradprint(grad_y) # 输出:tensor([1.])2.第二种方法:使用hook。hook是一个函数,输入是梯度,不应该有返回值
import torchdef variable_hook(grad):print('y的梯度:',grad)x = torch.ones(3, requires_grad=True)
w = torch.rand(3, requires_grad=True)
y = x * w
# 注册hook
hook_handle = y.register_hook(variable_hook)
z = y.sum()
z.backward()# 除非你每次都要用hook,否则用完之后记得移除hook
hook_handle.remove()
计算图特点总结
在PyTorch中,计算图是一种用于表示计算过程的数据结构。
动态计算图:PyTorch使用动态计算图,这意味着计算图是根据实际执行流程动态构建的。这使得在每次前向传播过程中可以根据输入数据的不同而灵活地构建计算图。
自动微分:PyTorch的计算图不仅用于表示计算过程,还支持自动微分。通过计算图,PyTorch可以自动计算梯度,无需手动编写反向传播算法。这大大简化了深度学习模型的训练过程。
基于节点的表示:计算图由一系列节点(Node)和边(Edge)组成,其中节点表示操作(如张量运算)或变量(如权重),边表示数据的流动。每个节点都包含了前向计算和反向传播所需的信息。
叶子节点和非叶子节点:在计算图中,叶子节点是没有输入边的节点,通常表示输入数据或需要求梯度的变量。非叶子节点是具有输入边的节点,表示计算操作。在反向传播过程中,默认情况下,只有叶子节点的梯度会被计算和保留,非叶子节点的梯度会被清空。
延迟执行:PyTorch中的计算图是按需执行的。也就是说,在前向传播过程中,只有实际需要计算的节点才会被执行,不需要计算的节点会被跳过。这种延迟执行的方式提高了效率,尤其对于大型模型和复杂计算图来说。
计算图优化:PyTorch内部使用了一些优化技术来提高计算图的效率。例如,通过共享内存缓存中间结果,避免重复计算;通过融合多个操作为一个操作,减少计算和内存开销等。这些优化技术可以提高计算速度,并减少内存占用。
利用Autograd实现线性回归
【深度学习】pytorch——线性回归:http://t.csdnimg.cn/7KsP3
上一篇文章为手动计算梯度,这里来利用Autograd实现自动计算梯度
import torch as t
%matplotlib inline
from matplotlib import pyplot as plt
from IPython import display
import numpy as np# 设置随机数种子,保证在不同电脑上运行时下面的输出一致
t.manual_seed(1000) def get_fake_data(batch_size=8):''' 产生随机数据:y=x*2+3,加上了一些噪声'''x = t.rand(batch_size, 1, device=device) * 5y = x * 2 + 3 + t.randn(batch_size, 1, device=device)return x, y# 随机初始化参数
w = t.rand(1,1, requires_grad=True)
b = t.zeros(1,1, requires_grad=True)
losses = np.zeros(500)lr =0.02 # 学习率for ii in range(500):x, y = get_fake_data(batch_size=4)# forward:计算lossy_pred = x.mm(w) + b.expand_as(y) loss = 0.5 * (y_pred - y) ** 2 # 均方误差loss = loss.sum()losses[ii] = loss.item()# backward:自动计算梯度loss.backward()# 更新参数w.data.sub_(lr * w.grad.data)b.data.sub_(lr * b.grad.data)# 梯度清零w.grad.data.zero_()b.grad.data.zero_()if ii%50 ==0:# 画图display.clear_output(wait=True)x = t.arange(0, 6).view(-1, 1).float()y = x.mm(w.data) + b.data.expand_as(x)plt.plot(x.numpy(), y.numpy(),color='b') # predictedx2, y2 = get_fake_data(batch_size=100) plt.scatter(x2.numpy(), y2.numpy(),color='r') # true dataplt.xlim(0,5)plt.ylim(0,15) plt.show()plt.pause(0.5)print('w: ', w.item(), 'b: ', b.item())
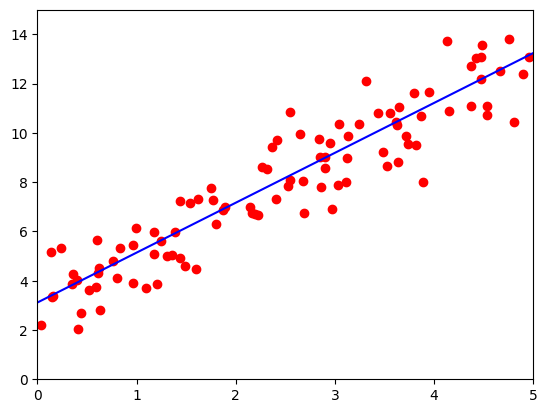
w: 2.036161422729492 b: 3.095750331878662
以下是代码的主要步骤:
-
定义了一个
get_fake_data函数,用于生成带有噪声的随机数据,数据的真实关系为 y = x ∗ 2 + 3 y=x*2+3 y=x∗2+3。 -
初始化参数
w和b,并设置requires_grad=True以便自动计算梯度。 -
进行500轮训练,每轮训练包括以下步骤:
- 从
get_fake_data函数中获取一个小批量的训练数据。 - 前向传播:计算模型的预测值
y_pred,即 x x x与参数w和b的线性组合。 - 计算均方误差损失函数。
- 反向传播:自动计算参数
w和b的梯度。 - 更新参数:通过梯度下降法更新参数
w和b。 - 清零梯度:将参数的梯度置零,以便下一轮计算梯度。
- 每50轮训练,可视化当前模型的预测结果和真实数据的散点图。
- 从
-
训练结束后,打印出最终学得的参数
w和b。
plt.plot(losses)
plt.ylim(0,50)
实现了对损失函数随训练轮数变化的可视化。losses是一个长度为500的数组,记录了每一轮训练后的损失函数值。plt.plot(losses)会将这些损失函数值随轮数的变化连成一条曲线,可以直观地看到模型在训练过程中损失函数的下降趋势。
plt.ylim(0,50)用于设置y轴的范围,保证曲线能够完整显示在图像中。
相关文章:
【深度学习】pytorch——Autograd
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~ 深度学习专栏链接: http://t.csdnimg.cn/dscW7 pytorch——Autograd Autograd简介requires_grad计算图没有梯度追踪的张量ensor.data 、tensor.detach()非叶子节点的梯度计算图特点总结 利用Autograd实…...

【ARM 安全系列介绍 1 -- 奇偶校验与海明码校验详细介绍】
文章目录 奇偶校验介绍奇偶校验 python 实现奇偶校验C代码实现 海明码详细介绍 奇偶校验介绍 奇偶校验是一种错误检测方法,广泛应用于计算机内部以及数据通信领域。其基本原理是为了使得一组数据(通常是一字节8位)中的“1”的个数为偶数或奇…...

分享34个发布商会PPT,总有一款适合您
分享34个发布商会PPT,总有一款适合您 链接:https://pan.baidu.com/s/1jP9toqTZONWeDIcxvw1wxg?pwd8888 提取码:8888 Python采集代码下载链接:采集代码.zip - 蓝奏云 学习知识费力气,收集整理更不易。知识付费甚…...

047_第三代软件开发-日志分离
第三代软件开发-日志分离 文章目录 第三代软件开发-日志分离项目介绍日志分离用法 关键字: Qt、 Qml、 log、 日志、 分离 项目介绍 欢迎来到我们的 QML & C 项目!这个项目结合了 QML(Qt Meta-Object Language)和 C 的强…...

ChinaSoft 论坛巡礼 | 系统与网络安全论坛
2023年CCF中国软件大会(CCF ChinaSoft 2023)由CCF主办,CCF系统软件专委会、形式化方法专委会、软件工程专委会以及复旦大学联合承办,将于2023年12月1-3日在上海国际会议中心举行。 本次大会主题是“智能化软件创新推动数字经济与社…...
装)
Ubuntu Gitlab安javascript:void(‘numberedlist‘)装
原因: 代码越改越多,越难维护,开发代码和发布代码融为一体;2人以上开发,都会修改代码,修改次数一多,代码难以维护 其中:前往Gitlab官网:gitlab/gitlab-ce - Packages pa…...
11.4-GPT4AllTools版本已开始对小部分GPT3.5用户内测推送
OpenAI已经开始小规模推送GPT4 AllTools功能,部分GPT博主已经第一时间体验了此功能,此功能特色是整合目前的多模态功能以及文件上传和联网模块,无需切换,更要全面综合 可上传包括 PDF、数据文件在内的任意文档,并进行分…...
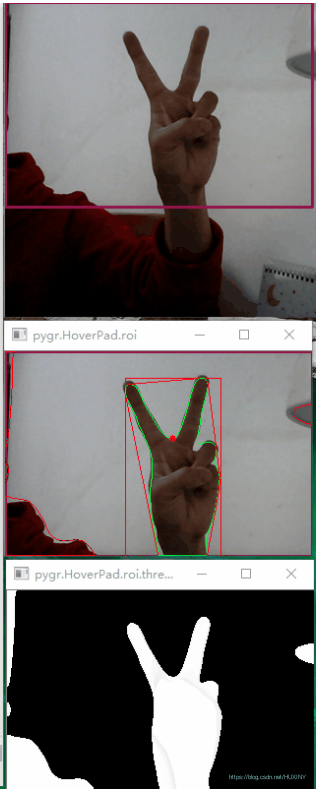
竞赛选题 深度学习手势检测与识别算法 - opencv python
文章目录 0 前言1 实现效果2 技术原理2.1 手部检测2.1.1 基于肤色空间的手势检测方法2.1.2 基于运动的手势检测方法2.1.3 基于边缘的手势检测方法2.1.4 基于模板的手势检测方法2.1.5 基于机器学习的手势检测方法 3 手部识别3.1 SSD网络3.2 数据集3.3 最终改进的网络结构 4 最后…...

语言模型AI——聊聊GPT使用情形与影响
GPT的出现象征着人工智能自然语言处理技术的一次巨大飞跃。从编程助手到写作利器,它的身影在各个行业中越来越常见。百度【文心一言】、CSDN【C知道】等基于GPT的产品相继推出,让我们看到了其广泛的应用前景。然而,随着GPT的普及,…...
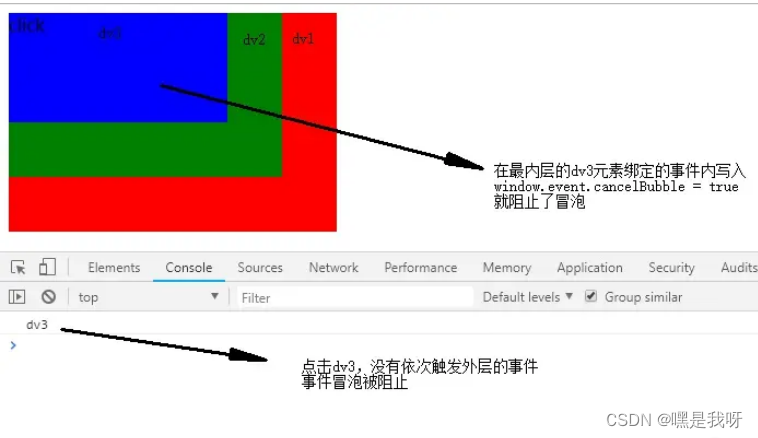
浅谈事件冒泡和事件捕获
事件冒泡和事件捕获分别由微软和网景公司提出,这两个概念都是为了解决页面中事件流(事件发生顺序)的问题。 <div id"div1"><div id"div2"><div id"div3">click</div></div> <…...
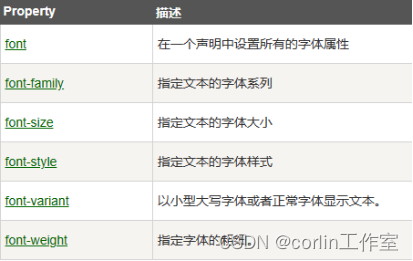
CSS 背景、文本、字体
CSS背景: CSS背景属性用于定义HTML元素的背景。CSS属性定义背景效果:background-color;background-image;background-repeat;background-attachment;background-position。 background-color属性定义元素…...

爬取Elastic Stack采集的Nginx内容
以下是一个简单的Go语言爬虫程序,用于爬取Elastic Stack采集的Nginx内容。请注意,这只是一个基本的示例,实际使用时可能需要根据具体情况进行修改和扩展。 package mainimport ("fmt""net/http""io/ioutil" )…...
python 机器学习 常用函数
一 np.random.randint "randint" 是 "random integer" 的缩写,表示生成随机整数。 np.random.randint 是 NumPy 库中的一个函数,用于生成随机整数。以下是该函数的一般语法: np.random.randint(low, high, size)其中…...

手写操作系统篇:环境配置
文章目录 前言C环境配置Rust环境配置Qemu安装 前言 这篇博客先配置好我们之后的开发环境,下载一些依赖的软件包 建议大家使用ubuntu操作系统 C环境配置 sudo apt-get update && sudo apt-get upgrade sudo apt-get install git wget build-essential gdb…...

地理信息系统原理-空间数据结构(7)
四叉树编码 1.四叉树编码定义 四叉树数据结构是一种对栅格数据的压缩编码方法,其基本思想是将一幅栅格数据层或图像等分为四部分,逐块检查其格网属性值(或灰度);如果某个子区的所有格网值都具有相同的值࿰…...
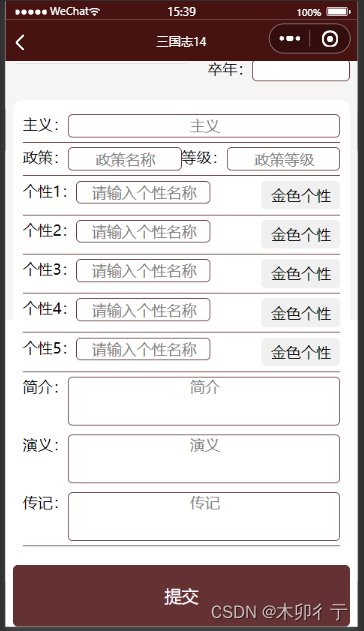
三国志14信息查询小程序(历史武将信息一览)制作更新过程03-主要页面的设计
1,小程序的默认显示 分为三部分,头部的标题、中间的内容区和底部的标签栏。点击标签可以切换不同页面,这是在app.json文件中配置的。代码如下: //所有用到的页面都需要在 pages 数组中列出,否则小程序可能会出现错误或…...
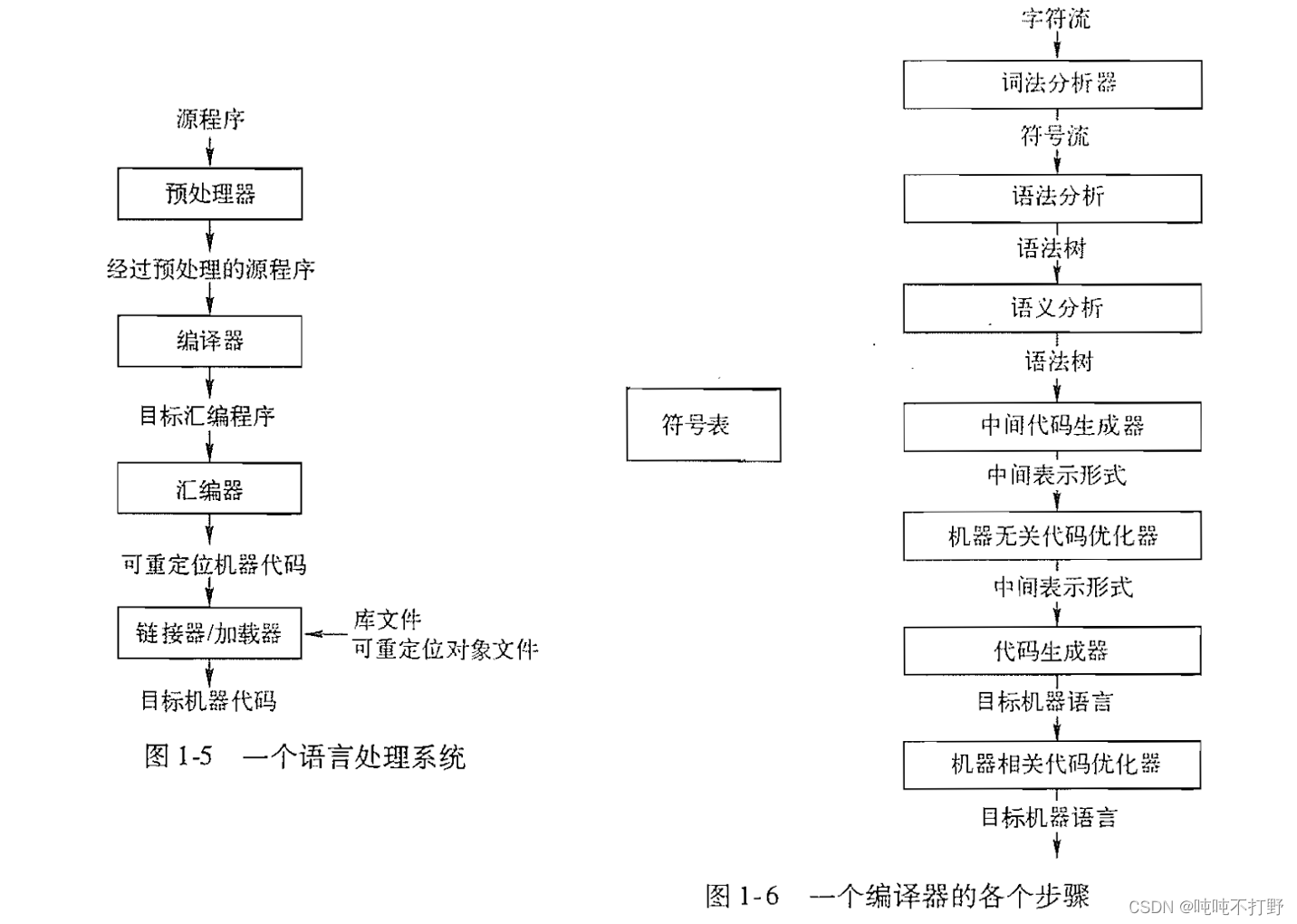
学习Opencv(蝴蝶书/C++)相关——2.用clang++或g++命令行编译程序
文章目录 1. c/cpp程序的执行1.1 cpp程序的编译过程1.2 预处理指令1.3 编译过程的细节2. macOS下使用Clang看cpp程序的编译过程2.1 示例2.1.1 第一步 预处理器-preprocessor2.1.2 第二步 编译器-compiler2.1.3 第三步 汇编器-assembler2.1.4 第四步 链接器-linker2.1.5 链接其他…...
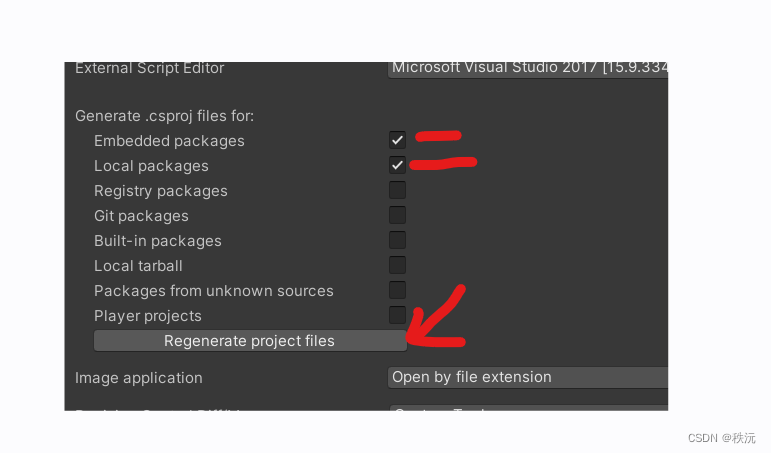
【Unity细节】VS不能附加到Unity程序中解决方法大全
👨💻个人主页:元宇宙-秩沅 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 秩沅 原创 😶🌫️收录于专栏:unity细节和bug 😶🌫️优质专栏 ⭐【…...

线上 kafka rebalance 解决
上周末我们服务上线完毕之后发生了一个kafka相关的异常,线上的kafka频繁的rebalance,详细的报错我已经贴到下面,根据字面意思:消费者异常 org.apache.kafka.clients.consumer.CommitFailedException: 无法完成提交,因为…...
)
[100天算法】-第一个错误的版本(day 62)
题目描述 你是产品经理,目前正在带领一个团队开发新的产品。不幸的是,你的产品的最新版本没有通过质量检测。由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的。假设你有 n 个版本 [1, 2, ..., n],你…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数
高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数 在软件开发中,单例模式(Singleton Pattern)是一种常见的设计模式,确保一个类仅有一个实例,并提供一个全局访问点。在多线程环境下,实现单例模式时需要注意线程安全问题,以防止多个线程同时创建实例,导致…...

力扣热题100 k个一组反转链表题解
题目: 代码: func reverseKGroup(head *ListNode, k int) *ListNode {cur : headfor i : 0; i < k; i {if cur nil {return head}cur cur.Next}newHead : reverse(head, cur)head.Next reverseKGroup(cur, k)return newHead }func reverse(start, end *ListNode) *ListN…...