Docker Compose安装milvus向量数据库单机版-milvus基本操作
目录
- 安装Ubuntu 22.04 LTS
- 在power shell启动milvus容器
- 安装docker desktop
- 下载yaml文件
- 启动milvus容器
- Milvus管理软件Attu
- python连接milvus
- 配置
- 下载wget
- 示例
- 导入必要的模块和类
- 与Milvus数据库建立连接
- 创建名为"hello_milvus"的Milvus数据表
- 插入数据
- 创建索引
- 基于向量相似性的搜索
- 基于标量过滤条件的查询操作
- 基于向量相似性和标量过滤条件的混合搜索
- 基于主键值删除数据记录
- 删除Milvus数据表
- 停止所有docker容器
- 未完待续
安装Ubuntu 22.04 LTS
以管理员身份运行powershell

wsl
wsl --list --online
Ubuntu 22.04 LTS可以不装,wsl必须更新。。。
wsl --install -d Ubuntu-22.04
wsl.exe --update
如果 操作超时 ,可以试试开代理。

重启电脑。。。

设置用户名、密码

在power shell启动milvus容器
安装docker desktop
https://hub.docker.com/


重启电脑。。。


下载yaml文件
power shell输入以下命令,下载yaml文件到指定目录,并重命名为docker-compose.yml
Invoke-WebRequest -Uri https://github.com/milvus-io/milvus/releases/download/v2.3.2/milvus-standalone-docker-compose.yml -OutFile E:\codes\milvus\docker-compose.yml
或者
点击一下链接直接下载
https://github.com/milvus-io/milvus/releases/download/v2.3.2/milvus-standalone-docker-compose.yml
启动milvus容器
cd E:\codes\milvus
docker-compose up -d

a few moments later。。。
docker compose ps


Milvus管理软件Attu
https://github.com/zilliztech/attu/releases
https://github.com/zilliztech/attu/releases/download/v2.3.2/attu-Setup-2.3.2.exe


python连接milvus
https://milvus.io/docs/example_code.md
配置
python环境
conda create -n milvus-env python=3.9
conda env list
conda activate milvus-env
pip install ipykernel -i https://pypi.tuna.tsinghua.edu.cn/simple/
python -m ipykernel install --name milvus-env
pip install pymilvus==2.3.2 -i https://pypi.tuna.tsinghua.edu.cn/simple/
下载wget
https://eternallybored.org/misc/wget/
wget.exe文件放到C:\Windows\System32
!wget https://raw.githubusercontent.com/milvus-io/pymilvus/master/examples/hello_milvus.py
示例
下面演示如何使用PyMilvus库连接到Milvus数据库,创建数据表,插入数据,创建索引,进行搜索、查询、分页查询,以及删除数据表等操作。
导入必要的模块和类
-
connections: 这是PyMilvus库的模块,用于建立与Milvus数据库的连接。 -
utility: 这也是PyMilvus库的模块,包含了一些实用的函数,用于执行Milvus的管理和操作。 -
FieldSchema,CollectionSchema,DataType,Collection: 这些类属于PyMilvus库,用于定义数据表的字段结构、数据类型、数据表模式和执行数据表操作。
变量fmt、search_latency_fmt、num_entities和dim:用于格式化输出和指定示例中使用的实体数量和维度。
import timeimport numpy as np
from pymilvus import (connections,utility,FieldSchema, CollectionSchema, DataType,Collection,
)fmt = "\n=== {:30} ===\n"
search_latency_fmt = "search latency = {:.4f}s"
num_entities, dim = 3000, 8
与Milvus数据库建立连接
与Milvus数据库建立连接并检查是否存在名为"hello_milvus"的数据表
- 使用
connections模块的connect函数来建立连接,指定了连接别名(“default”)以及Milvus服务器的主机地址和端口。在这里,连接别名是"default",表示使用默认的连接配置,Milvus服务器的地址是"localhost",端口是"19530"。 - 使用
utility模块的has_collection函数检查是否存在名为"hello_milvus"的数据表。如果数据表存在,它将返回True,否则返回False。
print(fmt.format("start connecting to Milvus"))
connections.connect("default", host="localhost", port="19530")has = utility.has_collection("hello_milvus")
print(f"Does collection hello_milvus exist in Milvus: {has}")
output:
=== start connecting to Milvus ===Does collection hello_milvus exist in Milvus: False
创建名为"hello_milvus"的Milvus数据表
创建名为"hello_milvus"的Milvus数据表,并定义数据表的字段结构和模式。
-
fields: 这是一个包含了数据表字段结构的列表。每个字段由FieldSchema对象表示,其中包括字段名称、数据类型、是否是主键、主键是否自动生成、以及其他相关属性。在这个示例中,定义了三个字段:- “pk” 字段是主键字段,数据类型为VARCHAR,主键不自动生成(auto_id=False),并且设置最大长度为100字符。
- “random” 字段是双精度浮点数字段,数据类型为DOUBLE。
- “embeddings” 字段是浮点向量字段,数据类型为FLOAT_VECTOR,并且指定向量维度(dim)为之前定义的
dim变量的值(8维)。
-
schema: 这是一个CollectionSchema对象,它用于定义数据表的模式。schema包含了字段结构和数据表的描述信息。 -
创建Milvus数据表:使用Collection对象来创建数据表,指定数据表的名称(“hello_milvus”),数据表模式(schema对象),以及一致性级别(“Strong”)。一致性级别用于控制数据表的数据一致性。
| field name | field type | other attributes | field description | |
|---|---|---|---|---|
| 1 | “pk” | VarChar | is_primary=True , auto_id=False | “primary field” |
| 2 | “random” | Double | “a double field” | |
| 3 | “embeddings” | FloatVector | dim=8 | “float vector with dim 8” |
fields = [FieldSchema(name="pk", dtype=DataType.VARCHAR, is_primary=True, auto_id=False, max_length=100),FieldSchema(name="random", dtype=DataType.DOUBLE),FieldSchema(name="embeddings", dtype=DataType.FLOAT_VECTOR, dim=dim)
]schema = CollectionSchema(fields, "hello_milvus is the simplest demo to introduce the APIs")print(fmt.format("Create collection `hello_milvus`"))
hello_milvus = Collection("hello_milvus", schema, consistency_level="Strong")
插入数据
插入数据记录到Milvus数据表"hello_milvus"中
-
entities: 这是一个包含要插入的数据记录的列表。数据记录按字段分组,其中每个字段的数据以列表的形式包含在entities列表中。具体描述如下:-
第一个子列表
[str(i) for i in range(num_entities)]包含了主键字段 “pk” 的值,使用字符串表示。这些字符串是根据主键字段的定义生成的,因为auto_id设置为False,所以需要提供主键值。 -
第二个子列表
rng.random(num_entities).tolist()包含了双精度浮点数字段 “random” 的值,这些值是使用随机数生成器生成的,并转换为列表格式。 -
第三个子列表
rng.random((num_entities, dim))包含了浮点向量字段 “embeddings” 的值,这些值是使用随机数生成器生成的,维度(dim)由之前定义的变量确定。
-
-
使用Milvus数据表的
insert方法将数据记录插入到数据表中。插入后,insert_result将包含插入操作的结果信息,如主键值等。 -
flush(): 刷新数据表,确保插入的数据被持久化保存到磁盘中。在Milvus中,数据通常在内存中进行操作,然后通过flush操作将其持久保存。
print(fmt.format("Start inserting entities"))
rng = np.random.default_rng(seed=19530)
entities = [# provide the pk field because `auto_id` is set to False[str(i) for i in range(num_entities)],rng.random(num_entities).tolist(), # field random, only supports listrng.random((num_entities, dim)), # field embeddings, supports numpy.ndarray and list
]insert_result = hello_milvus.insert(entities)hello_milvus.flush()
print(f"Number of entities in Milvus: {hello_milvus.num_entities}") # check the num_entities
output:
=== Start inserting entities ===Number of entities in Milvus: 3000
创建索引
在Milvus数据表"hello_milvus"的浮点向量字段"embeddings"上创建一个IVF_FLAT索引。
-
index: 这是一个字典,包含了索引的相关参数。在这个示例中,定义了以下索引参数:-
“index_type”: 指定了索引类型为 “IVF_FLAT”,这是一种基于倒排列表的索引类型,适用于浮点向量字段。
-
“metric_type”: 指定了距离度量类型为 “L2”,表示使用欧几里德距离来衡量向量之间的相似性。
-
“params”: 这是一个包含索引参数的字典,包括 “nlist” 参数,它指定了索引的列表数量,这里设置为128。
-
-
使用Milvus数据表的
create_index方法,在名为"embeddings"的字段上创建了指定的IVF_FLAT索引。参数 “embeddings” 表示要在哪个字段上创建索引,而index字典包含了索引的配置信息。
通过这段代码,IVF_FLAT索引被创建在"hello_milvus"数据表的"embeddings"字段上,用于加速相似性搜索操作。索引的创建有助于提高查询性能,特别是对于包含大量浮点向量数据的场景。索引类型和参数可以根据具体需求进行调整和优化。
print(fmt.format("Start Creating index IVF_FLAT"))
index = {"index_type": "IVF_FLAT","metric_type": "L2","params": {"nlist": 128},
}hello_milvus.create_index("embeddings", index)
基于向量相似性的搜索
-
hello_milvus.load(): 将数据表"hello_milvus"中的数据加载到内存中,以便后续的搜索和查询操作可以更快地执行。在Milvus中,数据通常是存储在磁盘上的,加载数据到内存可以提高查询性能。 -
vectors_to_search = entities[-1][-2:]: 从entities中获取浮点向量字段"embeddings"的值。entities[-1]表示最后一个子列表,而[-2:]表示获取该子列表的最后两个元素,即浮点向量数据。这些向量数据将用于相似性搜索。 -
search_params: 这是一个包含搜索参数的字典。在这个示例中,定义了以下参数:-
“metric_type”: 指定了距离度量类型为 “L2”,表示使用欧几里德距离来衡量向量之间的相似性。
-
“params”: 这是一个包含搜索参数的字典,包括 “nprobe” 参数,它指定了搜索时的候选集数量,这里设置为10。
-
-
search(): 使用Milvus数据表的search方法执行相似性搜索操作。参数包括搜索的向量数据(vectors_to_search)、搜索的字段名称(“embeddings”)、搜索参数(search_params)、返回结果的数量限制(limit=3),以及要返回的输出字段(“random”)。搜索操作将返回与搜索向量相似的数据记录。 -
遍历搜索结果,遍历每个搜索结果中的数据记录。
print(fmt.format("Start loading"))
hello_milvus.load()# -----------------------------------------------------------------------------
# search based on vector similarity
print(fmt.format("Start searching based on vector similarity"))
vectors_to_search = entities[-1][-2:]
search_params = {"metric_type": "L2","params": {"nprobe": 10},
}start_time = time.time()
result = hello_milvus.search(vectors_to_search, "embeddings", search_params, limit=3, output_fields=["random"])
end_time = time.time()for hits in result:for hit in hits:print(f"hit: {hit}, random field: {hit.entity.get('random')}")
print(search_latency_fmt.format(end_time - start_time))
output:
=== Start loading ====== Start searching based on vector similarity ===hit: id: 2998, distance: 0.0, entity: {'random': 0.9728033590489911}, random field: 0.9728033590489911
hit: id: 1262, distance: 0.08883658051490784, entity: {'random': 0.2978858685751561}, random field: 0.2978858685751561
hit: id: 1265, distance: 0.09590047597885132, entity: {'random': 0.3042039939240304}, random field: 0.3042039939240304
hit: id: 2999, distance: 0.0, entity: {'random': 0.02316334456872482}, random field: 0.02316334456872482
hit: id: 1580, distance: 0.05628091096878052, entity: {'random': 0.3855988746044062}, random field: 0.3855988746044062
hit: id: 2377, distance: 0.08096685260534286, entity: {'random': 0.8745922204004368}, random field: 0.8745922204004368
search latency = 0.3700s
基于标量过滤条件的查询操作
基于标量过滤条件的查询操作,以及查询结果的分页操作。
-
hello_milvus.query(expr="random > 0.5", output_fields=["random", "embeddings"]): 使用Milvus数据表的query方法执行查询操作。筛选"random > 0.5"的数据记录,返回的输出字段(“random"和"embeddings”)。 -
result是一个包含查询结果的列表,每个元素是一个包含查询结果字段的字典。在这里,打印了第一个查询结果的信息。 -
hello_milvus.query(expr="random > 0.5", limit=4, output_fields=["random"]): 分页查询,限制结果数量为4条。参数limit=4指定了返回结果的最大数量,只返回满足条件的前4条数据,并指定了要返回的输出字段为 “random”。 -
hello_milvus.query(expr="random > 0.5", offset=1, limit=3, output_fields=["random"]): 另一个分页查询,设置了偏移量offset=1和限制结果数量limit=3,以返回满足条件的数据记录的第2到第4条数据,并同样指定了要返回的输出字段为 “random”。
print(fmt.format("Start querying with `random > 0.5`"))start_time = time.time()
result = hello_milvus.query(expr="random > 0.5", output_fields=["random", "embeddings"])
end_time = time.time()print(f"query result:\n-{result[0]}")
print(search_latency_fmt.format(end_time - start_time))# -----------------------------------------------------------------------------
# pagination
r1 = hello_milvus.query(expr="random > 0.5", limit=4, output_fields=["random"])
r2 = hello_milvus.query(expr="random > 0.5", offset=1, limit=3, output_fields=["random"])
print(f"query pagination(limit=4):\n\t{r1}")
print(f"query pagination(offset=1, limit=3):\n\t{r2}")
output:
=== Start querying with `random > 0.5` ===query result:
-{'random': 0.6378742006852851, 'embeddings': [0.20963514, 0.39746657, 0.12019053, 0.6947492, 0.9535575, 0.5454552, 0.82360446, 0.21096309], 'pk': '0'}
search latency = 0.4006s
query pagination(limit=4):[{'random': 0.6378742006852851, 'pk': '0'}, {'random': 0.5763523024650556, 'pk': '100'}, {'random': 0.9425935891639464, 'pk': '1000'}, {'random': 0.7893211256191387, 'pk': '1001'}]
query pagination(offset=1, limit=3):[{'random': 0.5763523024650556, 'pk': '100'}, {'random': 0.9425935891639464, 'pk': '1000'}, {'random': 0.7893211256191387, 'pk': '1001'}]
基于向量相似性和标量过滤条件的混合搜索
-
hello_milvus.search(vectors_to_search, "embeddings", search_params, limit=3, expr="random > 0.5", output_fields=["random"]): 使用Milvus数据表的search方法执行混合搜索操作。参数包括搜索的向量数据(vectors_to_search)、搜索的字段名称(“embeddings”)、搜索参数(search_params),限制结果数量(limit=3),以及标量过滤条件表达式(expr="random > 0.5")。混合搜索操作将返回同时满足向量相似性和标量条件的数据记录。 -
遍历混合搜索结果,遍历每个搜索结果中的数据记录。
基于向量相似性和标量过滤条件的混合搜索操作,检索同时满足这两种条件的数据记录,并输出了混合搜索结果。混合搜索可用于更精确地筛选满足多个条件的数据记录。
print(fmt.format("Start hybrid searching with `random > 0.5`"))start_time = time.time()
result = hello_milvus.search(vectors_to_search, "embeddings", search_params, limit=3, expr="random > 0.5", output_fields=["random"])
end_time = time.time()for hits in result:for hit in hits:print(f"hit: {hit}, random field: {hit.entity.get('random')}")
print(search_latency_fmt.format(end_time - start_time))
output:
=== Start hybrid searching with `random > 0.5` ===hit: id: 2998, distance: 0.0, entity: {'random': 0.9728033590489911}, random field: 0.9728033590489911
hit: id: 747, distance: 0.14606499671936035, entity: {'random': 0.5648774800635661}, random field: 0.5648774800635661
hit: id: 2527, distance: 0.1530652642250061, entity: {'random': 0.8928974315571507}, random field: 0.8928974315571507
hit: id: 2377, distance: 0.08096685260534286, entity: {'random': 0.8745922204004368}, random field: 0.8745922204004368
hit: id: 2034, distance: 0.20354536175727844, entity: {'random': 0.5526117606328499}, random field: 0.5526117606328499
hit: id: 958, distance: 0.21908017992973328, entity: {'random': 0.6647383716417955}, random field: 0.6647383716417955
search latency = 0.3875s
基于主键值删除数据记录
-
insert_result.primary_keys: 从之前插入数据的结果对象insert_result中获取了插入操作生成的主键值(PK)。这些主键值被保存在primary_keys属性中。 -
expr = f'pk in ["{ids[0]}" , "{ids[1]}"]': 使用主键值来指定要删除的数据记录。 -
hello_milvus.query(expr=expr, output_fields=["random", "embeddings"]): 使用Milvus数据表的query方法执行查询操作,以验证删除操作前的查询结果。查询操作使用之前构建的布尔表达式expr,并指定要返回的输出字段为 “random” 和 “embeddings”。 -
hello_milvus.delete(expr): 使用Milvus数据表的delete方法执行删除操作,根据之前构建的布尔表达式expr删除满足条件的数据记录。 -
hello_milvus.query(expr=expr, output_fields=["random", "embeddings"]): 再次使用query方法执行查询操作,以验证删除操作后的查询结果。由于之前的数据记录已经被删除,查询结果应该为空。
ids = insert_result.primary_keysexpr = f'pk in ["{ids[0]}" , "{ids[1]}"]'
print(fmt.format(f"Start deleting with expr `{expr}`"))result = hello_milvus.query(expr=expr, output_fields=["random", "embeddings"])
print(f"query before delete by expr=`{expr}` -> result: \n-{result[0]}\n-{result[1]}\n")hello_milvus.delete(expr)result = hello_milvus.query(expr=expr, output_fields=["random", "embeddings"])
print(f"query after delete by expr=`{expr}` -> result: {result}\n")
output:
=== Start deleting with expr `pk in ["0" , "1"]` ===query before delete by expr=`pk in ["0" , "1"]` -> result:
-{'embeddings': [0.20963514, 0.39746657, 0.12019053, 0.6947492, 0.9535575, 0.5454552, 0.82360446, 0.21096309], 'pk': '0', 'random': 0.6378742006852851}
-{'embeddings': [0.52323616, 0.8035404, 0.77824664, 0.80369574, 0.4914803, 0.8265614, 0.6145269, 0.80234545], 'pk': '1', 'random': 0.43925103574669633}query after delete by expr=`pk in ["0" , "1"]` -> result: []
删除Milvus数据表
使用utility模块中的drop_collection函数,删除名为"hello_milvus"的Milvus数据表(集合)。删除数据表会彻底删除其中的所有数据记录和索引,并释放相关资源。
这个操作可以用于在不再需要数据表时释放资源和空间。
print(fmt.format("Drop collection `hello_milvus`"))
utility.drop_collection("hello_milvus")
停止所有docker容器
docker stop $(docker ps -q)
未完待续
相关文章:
Docker Compose安装milvus向量数据库单机版-milvus基本操作
目录 安装Ubuntu 22.04 LTS在power shell启动milvus容器安装docker desktop下载yaml文件启动milvus容器Milvus管理软件Attu python连接milvus配置下载wget示例导入必要的模块和类与Milvus数据库建立连接创建名为"hello_milvus"的Milvus数据表插入数据创建索引基于向量…...
极致性能优化:前端SSR渲染利器Qwik.js | 京东云技术团队
引言 前端性能已成为网站和应用成功的关键要素之一。用户期望快速加载的页面和流畅的交互,而前端框架的选择对于实现这些目标至关重要。然而,传统的前端框架在某些情况下可能面临性能挑战且存在技术壁垒。 在这个充满挑战的背景下,我们引入…...
)
ES6~ES13新特性(二)
文章目录 一、ES71.Array Includes2.指数exponentiation运算符 二、ES81.Object values2.Object entries3.String Padding4.Trailing Commas5.Object Descriptors 三、ES9四、ES101.flat flatMap2.Object fromEntries3.trimStart、trimEnd4.其他知识点 五、ES111.BigInt2.Nulli…...
soildwork2022怎么样添加螺纹孔?
1.退出草图模式,点击需要添加螺纹孔的物体面,选中“特征”中的“异形孔向导” 2.选中“孔类型”为“直螺纹孔”,“标准”,“类型”,“孔规格”终止条件等。 3.设置完之后选择“位置” 4.鼠标左键在物体面上点一下&…...
【t5 pytorch版源码学习】t5-pegasus-pytorch源码学习
0. 项目来源 中文生成式预训练模型,以mT5为基础架构和初始权重,通过类似PEGASUS的方式进行预训练。 bert4keras版:t5-pegasus pytorch版:t5-pegasus-pytorch 本次主要学习pytorch版的代码解读。 项目结构: train…...

【springboot】spring的Aop结合Redis实现对短信接口的限流
前言 场景: 为了限制短信验证码接口的访问次数,防止被刷,结合Aop和redis根据用户ip对用户限流 1.准备工作 首先我们创建一个 Spring Boot 工程,引入 Web 和 Redis 依赖,同时考虑到接口限流一般是通过注解来标记,而注解…...

【MedusaSTears】怎么禁用edge浏览器截图功能?
版本 Microsoft Edge 版本 119.0.2151.44 (正式版本) (64 位) Ctrl Shift S 竟然是浏览器的截屏? 特么的啥时候多了这么个快捷键? 然后还没办法禁用,真TMD傻哔 edge://settings/accessibility解决方式: 参考资料: 怎么禁用edge浏览器截图功能? 您好&#x…...
【计算机网络】(谢希仁第八版)第三章课后习题答案
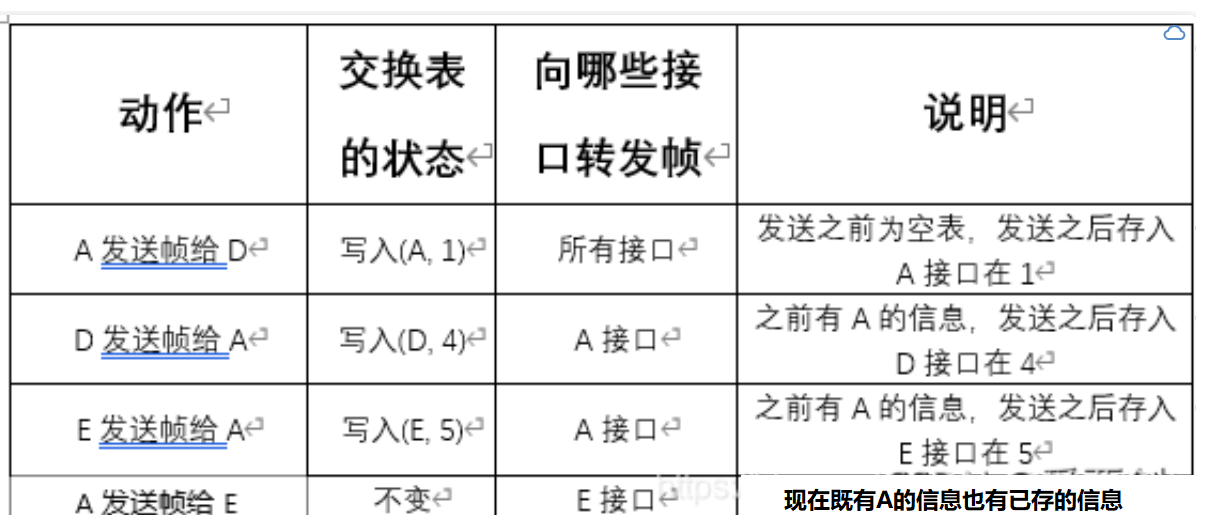
第三章 1.数据链路(即逻辑链路)与链路(即物理链路)有何区别? “电路接通了”与”数据链路接通了”的区别何在? 答:数据链路与链路的区别在于数据链路出链路外,还必须有一些必要的规程来控制数据的传输,因此,数据链路比链路多了…...

批量异步任务处理
当我们在项目中遇到很多业务同时处理,如果是串行肯定是影响性能的,这时候就需要异步执行了,说道异步肯定就有很多方案了 方案一: 比如使用spring的异步注解,比如下面的代码,每个方法上面都是异步注解,当时…...

宜昌市公安局、点军区政府与中科升哲达成战略合作,共建视频图像联合创新实验室
11月3日,宜昌视频图像联合创新战略合作签约仪式在宜昌市公安局举行。 宜昌市副市长、市公安局党委书记、局长上官福令,市公安局党委副书记、副局长龚海波,宜昌市点军区委书记万红,点军区委副书记、区长黄文云,升哲科技…...
java版小程序商城免费搭建-直播商城平台规划及常见的营销模式有哪些?电商源码/小程序/三级分销
1. 涉及平台 平台管理、商家端(PC端、手机端)、买家平台(H5/公众号、小程序、APP端(IOS/Android)、微服务平台(业务服务) 2. 核心架构 Spring Cloud、Spring Boot、Mybatis、Redis 3. 前端框架…...
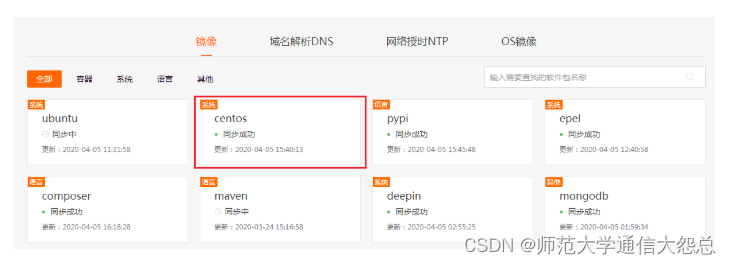
Linux下yum源配置实战
一、Linux下软件包的管理 1、软件安装方式 ① RPM包管理(需要单独解决依赖问题) ② YUM包管理(需要有网络及YUM仓库的支持,会自动从互联网下载软件,自动解决依赖) ③ 源码安装(安装过程比较…...
, JSONP劫持)
JSONP 跨域访问(2), JSONP劫持
JSONP 跨域访问(2), JSONP劫持 一, 利用 XSS 漏洞执行jsonp 1. 利用过程 发现有jsonp的请求: <script type"text/javascript" src"http://192.168.112.200/security/jsonp.php?callbackjsonpCallback"></script>向xss漏洞的位置注入代码…...
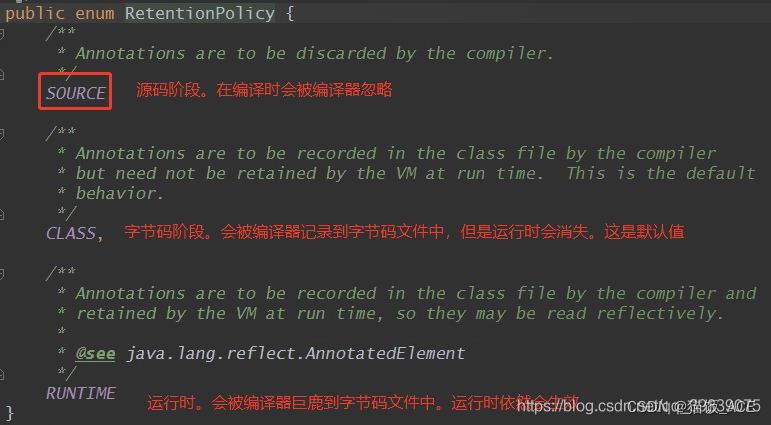
【java】实现自定义注解校验——方法一
自定义注解校验的实现步骤: 1.创建注解类,编写校验注解,即类似NotEmpty注解 2.编写自定义校验的逻辑实体类,编写具体的校验逻辑。(这个类可以实现ConstraintValidator这个接口,让注解用来校验) 3.开启使用自定义注解进…...
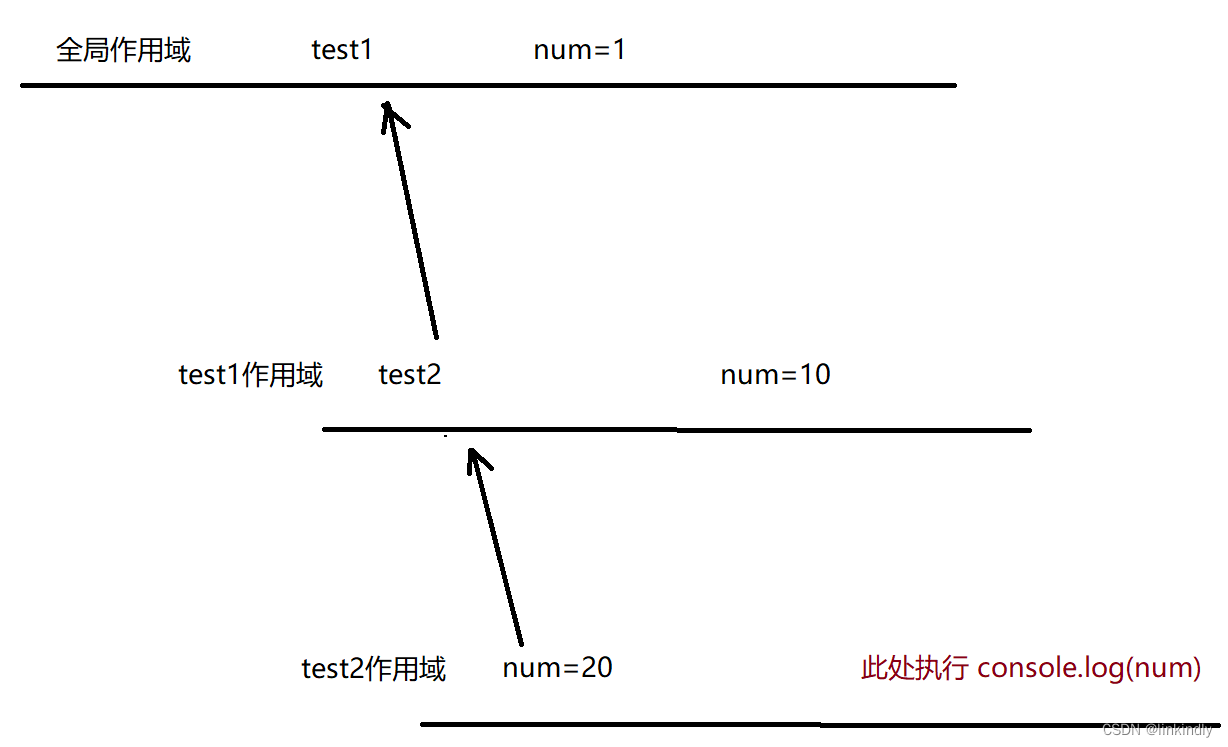
JavaScript基础入门03
目录 1.条件语句 1.1if 语句 1.1.1基本语法格式 1.1.2练习案例 1.2三元表达式 1.3switch 2.循环语句 2.1while 循环 2.2continue 2.3break 2.4for 循环 3.数组 3.1创建数组 3.2获取数组元素 3.3新增数组元素 3.3.1. 通过修改 length 新增 3.3.2. 通过下标新增 …...

P1903 [国家集训队] 数颜色 / 维护队列
带修改的莫队 带修改的莫队就是在基础莫队的基础上增加了一维属性,之前只需要维护l,r现在还需要维护一下时间t,排序还是先按照左端点块儿号排序,然后右端点块儿号排序,最后按时间排序。其它的都是差不多的。 #include…...

uniapp 请求接口的方式
在UniApp中,我们可以使用多种方式来发送请求接口。以下是几种常用的方式: 1、使用unmireuest方法:uni.reuest是uniApp提供的原生AP,可以发送HTTP请,我们可以通过传递一个图对象来设置请求的参数,RL、请求方法GET/POST…...

怎么查看当前vue项目,要求的node.js版本
要查看当前 Vue 项目所需的 Node.js 版本,你可以查看项目根目录下的 package.json 文件中的 engines 属性。该属性定义了项目所需的 Node.js 版本范围。 例如,以下是一个示例 package.json 文件: {"name": "my-vue-project&…...

QT5自适应
//集成屏幕自适应功能 QApplication::setAttribute(Qt::AA_EnableHighDpiScaling); QCoreApplication::setAttribute(Qt::AA_UseHighDpiPixmaps); DEVMODE NewDevMode; //获取屏幕设置中的分辨率 EnumDisplaySettings(0, ENUM_CURRENT_SETTINGS, &NewDevMo…...
)
蓝桥杯官网练习题(日期问题)
题目描述 小明正在整理一批历史文献。这些历史文献中出现了很多日期。小明知道这些日期都在 1960 年 1 月 1 日至 2059 年 12 月 31 日。令小明头疼的是,这些日期采用的格式非常不统一,有采用年/月/日的,有采用月/日/年的,还有采…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...

排序算法总结(C++)
目录 一、稳定性二、排序算法选择、冒泡、插入排序归并排序随机快速排序堆排序基数排序计数排序 三、总结 一、稳定性 排序算法的稳定性是指:同样大小的样本 **(同样大小的数据)**在排序之后不会改变原始的相对次序。 稳定性对基础类型对象…...

【Linux系统】Linux环境变量:系统配置的隐形指挥官
。# Linux系列 文章目录 前言一、环境变量的概念二、常见的环境变量三、环境变量特点及其相关指令3.1 环境变量的全局性3.2、环境变量的生命周期 四、环境变量的组织方式五、C语言对环境变量的操作5.1 设置环境变量:setenv5.2 删除环境变量:unsetenv5.3 遍历所有环境…...