python爬取Web of science论文信息
一、python爬取WOS总体思路
(一)拟实现功能描述
wos里面,爬取论文的名称,作者名称,作者单位,引用数量
要求:英文论文、期刊无论好坏
检索关键词:zhejiang academy of agricultural sciences、 xianghu lab
(二)操作思路介绍
在Python中,有多种思路可以用来爬取Web of Science(WOS)上的信息。以下是其中几种常见的思路:
-
使用HTTP请求库和HTML解析库:这是最常见的爬取网页数据的方法之一。你可以使用Python的
requests库发送HTTP请求获取网页内容,然后使用BeautifulSoup或其他HTML解析库对网页进行解析和提取所需的信息。 -
使用API:有些网站提供API接口,允许开发者通过API直接获取数据。如果WoS提供API,你可以通过调用API进行数据获取,通常这种方式更加稳定和高效。
-
使用自动化工具:有些情况下,使用传统的HTTP请求和HTML解析方式难以实现数据的完整爬取,例如需要登录或执行JavaScript等情况。此时,你可以使用自动化工具,如
Selenium,来模拟用户操作浏览器,实现完整的页面渲染和数据提取。
无论选择哪种思路,都需要先了解目标网站的页面结构和数据提取的逻辑。可以通过分析网页源代码、使用浏览器开发者工具等方式来理解网页的结构和数据的位置。
(三)操作步骤分解
以操作思路三为例,在WOS上爬取英文论文的名称、作者名称、作者单位和引用数量,以满足给定的检索关键词(zhejiang academy of agricultural sciences和xianghu lab)的操作步骤:
-
确定使用的爬虫库:可以使用Python的Selenium库进行网页自动化操作,实现模拟浏览器操作的效果。
-
安装必要的依赖库:需要安装Selenium库,以及用来管理Chrome浏览器驱动的webdriver-manager库。可以使用pip命令安装相关依赖库。
-
导入必要的模块:需要导入Selenium库的Webdriver和Service类,webdriver_manager库的ChromeDriverManager类,以及time库,用于实现等待页面元素加载的效果。
-
设置Chrome浏览器驱动并启动浏览器:通过创建ChromeDriverManager实例来管理Chrome浏览器驱动,并使用webdriver的Chrome类来启动浏览器。
-
打开Web of Science网站:使用driver.get()方法打开Web of Science网站,并使用time库实现等待页面加载,确保可以正常爬取相关信息。
-
在搜索框中输入关键词并进行搜索:使用find_element()方法找到搜索框的元素,并使用send_keys()方法输入需要搜索的关键词。然后,使用find_element()方法找到搜索按钮的元素,并使用click()方法点击搜索按钮,实现对关键词的检索。
-
切换到结果列表视图:使用find_element()方法找到结果列表视图下拉框的元素,并使用click()方法切换到结果列表视图。使用time库实现等待视图切换,确保可以正常爬取相关信息。
-
循环遍历每个检索结果,提取所需信息:使用find_elements()方法找到每个检索结果的元素列表,循环遍历列表中每一个元素,使用find_element()方法分别找到论文名称、作者名称、作者单位和引用数量的元素,并使用text属性来获取对应的文本信息。(整理格式成我们所需要的样子)
-
关闭浏览器:使用quit()方法关闭浏览器,释放相关系统资源。
备注:在实际操作中,需要注意遵守相关法律法规和网站的规定,以确保合规的操作。
二、python爬取实战步骤
(一)导入必要的库
import requests
from bs4 import BeautifulSoup
import csv
import time,random(二)存储和处理从HTML页面中提取的数据。
class HtmlData:def __init__(self, soup):self.title = '' # 存储文章标题self.author = '' # 存储文章作者self.abstract = '' # 存储文章摘要self.keywords = '' # 存储文章关键词self.author_data = '' # 存储作者信息self.author_unit = '' # 存储作者单位self.citation_count = '' # 存储引用数量self.data = '' # 存储数据信息self.soup = soup # 存储BeautifulSoup对象
# 第二步,HtmlData类的构造函数初始化了存储文章标题、作者、摘要、关键
# 词等信息的实例变量,并通过BeautifulSoup解析HTML文本提取这些信息。print(soup.prettify())self.title = soup.title.text# self.title = soup.find(attrs={'class':'title'}).text.replace('\n','') # 提取文章标题try:self.data = soup.find(attrs={'class':'block-record-info block-record-info-source'}).text # 提取数据信息except:passitems = soup.find_all(attrs={'class':'block-record-info'}) # 提取所有block-record-info元素for item in items:if len(item.attrs['class']) > 1:continueif 'By:' in item.text: # 提取作者信息和作者单位author_info = item.text.replace('By:', '').replace('\n', '').replace(' ', '').replace(' ]', ']')author_info_parts = author_info.split(',')if len(author_info_parts) > 1:self.author = author_info_parts[0].strip()self.author_unit = author_info_parts[1].strip()else:self.author = author_info_parts[0].strip()elif 'Times Cited:' in item.text: # 提取引用数量self.citation_count = item.text.replace('Times Cited:', '').strip()elif 'Abstract' in item.text: # 提取摘要信息self.abstract = item.textcontinueelif 'Keywords' in item.text: # 提取关键词信息self.keywords = item.textcontinueelif 'Author Information' in item.text: # 提取作者信息self.author_data = item.text continue
(三)提取html文本并保存到csv文件
scrape_data函数接收一个URL作为参数,发送HTTP请求获取页面内容,使用BeautifulSoup解析HTML文本,创建HtmlData对象提取数据,并将数据写入CSV文件。
def scrape_data(url):headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",}response = requests.get(url, headers=headers) # 发送HTTP请求获取页面内容if response.status_code == 200: # 检查请求的状态码是否为200(成功)html = response.text # 获取响应的HTML文本soup = BeautifulSoup(html, 'lxml') # 使用BeautifulSoup解析HTML文本html_data = HtmlData(soup) # 创建HtmlData对象进行数据提取和存储# 获取对象信息title = html_data.title # 获取标题authors = html_data.author # 获取作者author_unit = html_data.author_unit # 获取作者单位citation_count = html_data.citation_count # 获取引用数量abstract = html_data.abstract # 获取摘要keywords = html_data.keywords # 获取关键词# 存储数据到csvcsv_data = [title, authors, author_unit, citation_count, abstract, keywords, url] # 构建CSV行数据print(csv_data)with open('1.csv', encoding='utf-8', mode='a', newline='') as f:csv_writer = csv.writer(f) # 创建CSV写入器csv_writer.writerow(csv_data) # 将数据写入CSV文件(四)生成url列表,开始爬虫
第四步,main函数生成URL列表,遍历URL列表调用scrape_data函数进行数据爬取和处理。
def main():url_list = []search_keywords = 'zhejiang academy of agricultural sciences'#xianghu labfor i in range(1, 3218): # 构建URL列表url = f"http://apps.webofknowledge.com/full_record.do?product=UA&search_mode=GeneralSearch&qid=1&SID=5BrNKATZTPhVzgHulpJ&page=1&doc={i}&cacheurlFromRightClick=no"url += f"&field=Author&value={search_keywords}"url_list.append(url)time.sleep(1+random.random())# print(url_list) for url in url_list:scrape_data(url) # 遍历URL列表,爬取并处理数据if __name__ == '__main__':main()
(1) 备注:根据搜索完成页面进行爬取。
# 定义一个函数来获取单个页面的数据。这个函数将接受一个URL作为参数,
# 并返回一个包含论文名称、作者名称、作者单位和引用数量的字典列表。
def get_page_data(url):headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.79 Safari/537.36'}response = requests.get(url, headers=headers)soup = BeautifulSoup(response.text, 'html.parser')# Find the target elements based on their HTML tags and attributes# The actual tags and attributes might need to be adjusted based on the website's structurepapers = soup.find_all('div', attrs={'class': 'paper'})data = []for paper in papers:name = paper.find('div', attrs={'class': 'name'}).textauthor = paper.find('div', attrs={'class': 'author'}).textaffiliation = paper.find('div', attrs={'class': 'affiliation'}).textcitations = paper.find('div', attrs={'class': 'citations'}).textdata.append({'name': name,'author': author,'affiliation': affiliation,'citations': citations})return data# 定义一个函数来获取多个页面的数据。这个函数将接受一个基础URL和页面数量作为参数,
# 并返回一个包含所有页面数据的字典列表。
def get_multiple_pages(base_url, num_pages):all_data = []for i in range(1, num_pages+1):url = base_url + str(i)all_data.extend(get_page_data(url))time.sleep(1) # Add a delay between requests to avoid overloading the serverreturn all_data
(五)总体代码
# 导入必要的库
import requests
from bs4 import BeautifulSoup
import csv
import time,random# 第一步,定义HtmlData类,用于存储和处理从HTML页面中提取的数据。
class HtmlData:def __init__(self, soup):self.title = '' # 存储文章标题self.author = '' # 存储文章作者self.abstract = '' # 存储文章摘要self.keywords = '' # 存储文章关键词self.author_data = '' # 存储作者信息self.author_unit = '' # 存储作者单位self.citation_count = '' # 存储引用数量self.data = '' # 存储数据信息self.soup = soup # 存储BeautifulSoup对象
# 第二步,HtmlData类的构造函数初始化了存储文章标题、作者、摘要、关键
# 词等信息的实例变量,并通过BeautifulSoup解析HTML文本提取这些信息。print(soup.prettify())self.title = soup.title.text# self.title = soup.find(attrs={'class':'title'}).text.replace('\n','') # 提取文章标题try:self.data = soup.find(attrs={'class':'block-record-info block-record-info-source'}).text # 提取数据信息except:passitems = soup.find_all(attrs={'class':'block-record-info'}) # 提取所有block-record-info元素for item in items:if len(item.attrs['class']) > 1:continueif 'By:' in item.text: # 提取作者信息和作者单位author_info = item.text.replace('By:', '').replace('\n', '').replace(' ', '').replace(' ]', ']')author_info_parts = author_info.split(',')if len(author_info_parts) > 1:self.author = author_info_parts[0].strip()self.author_unit = author_info_parts[1].strip()else:self.author = author_info_parts[0].strip()elif 'Times Cited:' in item.text: # 提取引用数量self.citation_count = item.text.replace('Times Cited:', '').strip()elif 'Abstract' in item.text: # 提取摘要信息self.abstract = item.textcontinueelif 'Keywords' in item.text: # 提取关键词信息self.keywords = item.textcontinueelif 'Author Information' in item.text: # 提取作者信息self.author_data = item.text continue# 第三步,scrape_data函数接收一个URL作为参数,发送HTTP请求获取页面内容,使用BeautifulSoup解析HTML文本,创建HtmlData对象提取数据,并将数据写入CSV文件。
def scrape_data(url):headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",}response = requests.get(url, headers=headers) # 发送HTTP请求获取页面内容if response.status_code == 200: # 检查请求的状态码是否为200(成功)html = response.text # 获取响应的HTML文本soup = BeautifulSoup(html, 'lxml') # 使用BeautifulSoup解析HTML文本html_data = HtmlData(soup) # 创建HtmlData对象进行数据提取和存储# 获取对象信息title = html_data.title # 获取标题authors = html_data.author # 获取作者author_unit = html_data.author_unit # 获取作者单位citation_count = html_data.citation_count # 获取引用数量abstract = html_data.abstract # 获取摘要keywords = html_data.keywords # 获取关键词# 存储数据到csvcsv_data = [title, authors, author_unit, citation_count, abstract, keywords, url] # 构建CSV行数据print(csv_data)with open('1.csv', encoding='utf-8', mode='a', newline='') as f:csv_writer = csv.writer(f) # 创建CSV写入器csv_writer.writerow(csv_data) # 将数据写入CSV文件# 第四步,main函数生成URL列表,遍历URL列表调用scrape_data函数进行数据爬取和处理。
def main():url_list = []search_keywords = 'zhejiang academy of agricultural sciences'#xianghu labfor i in range(1, 3218): # 构建URL列表url = f"http://apps.webofknowledge.com/full_record.do?product=UA&search_mode=GeneralSearch&qid=1&SID=5BrNKATZTPhVzgHulpJ&page=1&doc={i}&cacheurlFromRightClick=no"url += f"&field=Author&value={search_keywords}"url_list.append(url)time.sleep(1+random.random())# print(url_list) for url in url_list:scrape_data(url) # 遍历URL列表,爬取并处理数据if __name__ == '__main__':main()三、python爬取过程中可能遇到的问题及解决方案
(一)代码运行问题排除
Q1:ModuleNotFoundError: No module named 'webdriver_manager'
参考:使用ChromeDriverManager自动更新Chromedriver_Richard.sysout的博客-CSDN博客
解决方案:(1)安装的代码除了问题,输入的是:pip install webdrivermanager,应在控制台中输入以下内容:
pip install webdriver_manager(2)安装版本不对。
这里是selenium3.x的用法
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
#安装并返回安装成功的path
driver_path=ChromeDriverManager().install()
#使用对应path下的driver驱动Chrome
driver = webdriver.Chrome(executable_path=driver_path)当然如果使用的是selenium4.x:
# selenium 4
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManagerdriver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
通过它的源码,我们可以得知,基本的逻辑是将Chromedriver安装在某个目录下,将driver的目录返回给我们,创建对象的时候,将path 作为参数传入。
Q2:用soup.find()时出现错误AttributeError NoneType object has no attribute?
参考:AttributeError NoneType object has no attribute_soup.find 未找着-CSDN博客
原因及分析:我使用的soup.find()没有找到这个class为"ArticlePicBox Aid43 "的div中有空格。
Q3:如何更改浏览器内开发工具的位置?
解决办法:
1.打开浏览器,点击F12,打开开发工具;
2.点击开发工具右上角的三个竖点;
3.出现若干个选项如图所示,可选择适合自己的排版(左右下或新增页);
Q4:如何获取一个网页的User-Agent?
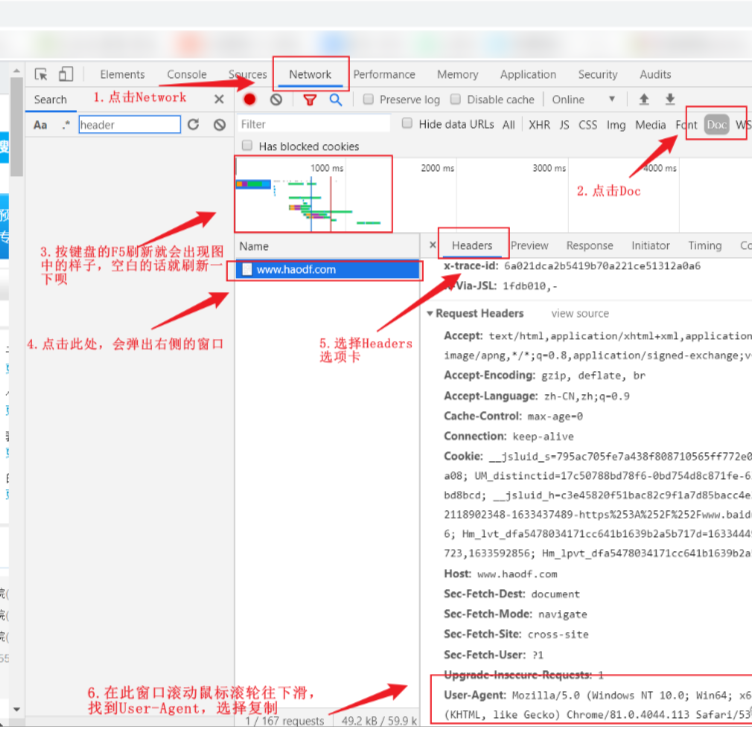

(二)相关知识补充
爬虫项目处理的一般步骤:1.找数据所在的地址(ur)是哪个? (网页性质分析<静态网页/动态网页>)<你要的/你不需要的》2.通过代码发送地址的请求(文本数据\js数据\css<祥式层叠表,数据\围片\...)3.数据的解析,解析你要的数据(正则表达式\css选择器 \xpath节点提取)4.数据保存(本地,数据库)。
(1)页面解析
# 据解析步聚# 1.转换数据类型(selector = parsel.Selector(html) # html字符串--> 对象# print(selector)# 2.css提取数据(# p = selector.css('p').get())。解析网页有三种方法:Xpath和正则表达式(re)及BeautifulSoup。
1)css选择器


2)Xpath
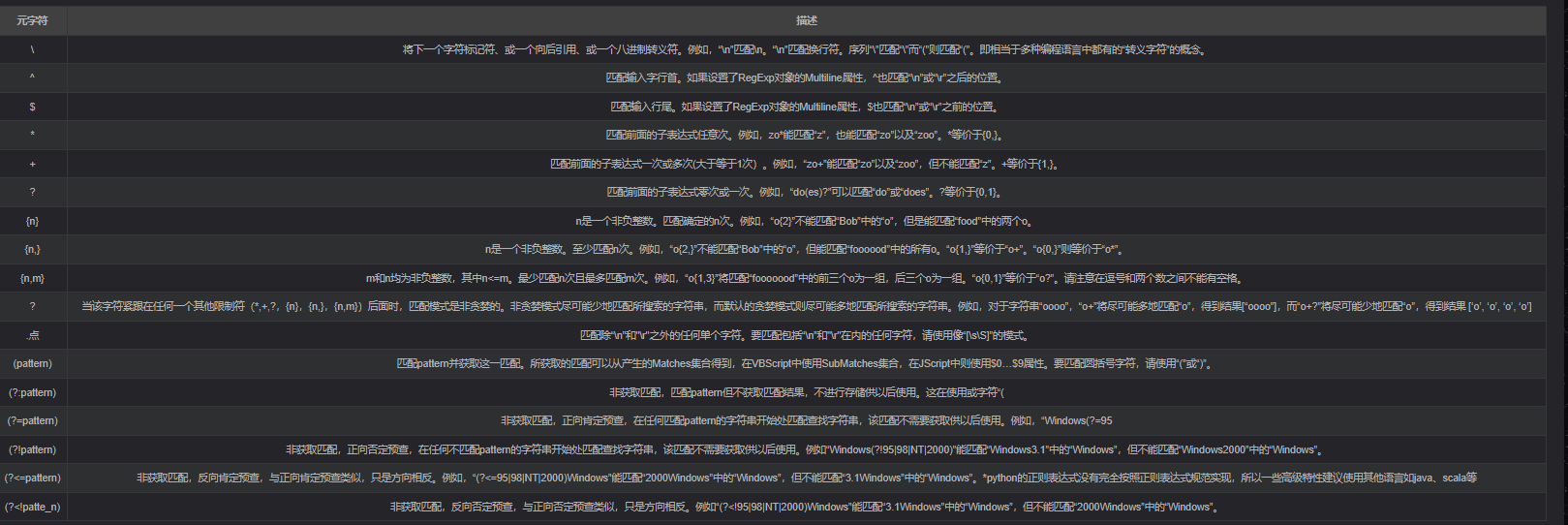
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的

3)正则表达式(re)
可参考引用4。
(2)HTML元素



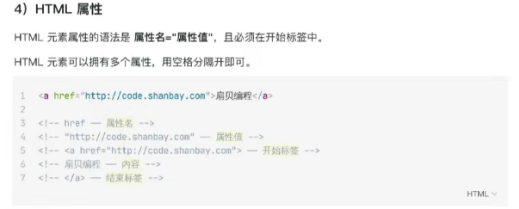

备注:html解析工具:HTML格式化 、HTML压缩- 站长工具 (sojson.com)
(3)多页面爬取url
典型的两段式爬取,每个页面有20篇文件,一共38页,分析页面url发现规律之后,只需要改变page={i},通过i的变化获取总url。在网页源代码中发现每篇文件单独的url都可以获取,任务相对比较简单。编写代码获取每篇文件的url,之后提取文字内容即可。
可参照参考三,其介绍的两类囊括了大部分提取方式。


(4)使用xpath、bs以及正则表达式获取页面url
# 导入必要的库
import requests
from bs4 import BeautifulSoup
import csv
import time,random
from lxml import html
import reurl_list = []# 存储所有url的列表# 页面url
base_url = 'https://webofscience.clarivate.cn/wos/woscc/summary/c23b8bbe-f8ca-4d1c-b3a6-0c05ee883fbd-b0d498e1/relevance/'# 遍历所有页面
# 构造当前页面的url
url = base_url + str(1)
# 发送GET请求,获取页面内容
headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
}
response = requests.get(url, headers=headers)
time.sleep(2)# (1)使用xpath# 使用正则表达式匹配页面内容中的链接
pattern = r'<a class="title title-link font-size-18 ng-star-inserted" href="(.+?)">'
links = re.findall(pattern, response.text)
for link in links:# 处理相对路径并打印链接full_url = f'https://webofscience.clarivate.cn{link}'url_list.append(full_url)time.sleep(1 + random.random())# (2)使用正则表达式
# # 使用lxml库解析页面内容
# tree = html.fromstring(response.content)# # 查找所有<a>标签,提取url并存储到列表中
# links = tree.xpath('//a[@class="title title-link font-size-18 ng-star-inserted"]/@href')# for link in links:
# # 处理相对路径并打印链接
# full_url = f'https://webofscience.clarivate.cn{link}'
# url_list.append(full_url)
# time.sleep(1+random.random())# (3)使用bs解析
# soup = BeautifulSoup(response.text, 'html.parser')# # 查找所有<a>标签,提取url并存储到列表中
# link_elements = soup.find_all('a', class_='title title-link font-size-18 ng-star-inserted', href=True)##提取不出标签为a的url链接
# for link_element in link_elements:
# # 处理相对路径并打印链接
# href = link_element['href']
# full_url = f'https://webofscience.clarivate.cn{href}'
# url_list.append(full_url)
# time.sleep(1+random.random()) 四、参考引用
[1]Web of science文章信息爬取_爬取web of science数据
[2]User-Agent||如何获取一个网页的User-Agent?-CSDN博客
[3]Python爬虫——爬取网站多页数据_爬虫多页爬取-CSDN博客
[4]Xpath和正则表达式及BeautifulSoup的比较-CSDN博客
相关文章:
python爬取Web of science论文信息
一、python爬取WOS总体思路 (一)拟实现功能描述 wos里面,爬取论文的名称,作者名称,作者单位,引用数量 要求:英文论文、期刊无论好坏 检索关键词:zhejiang academy of agricultural sciences、 xianghu lab…...
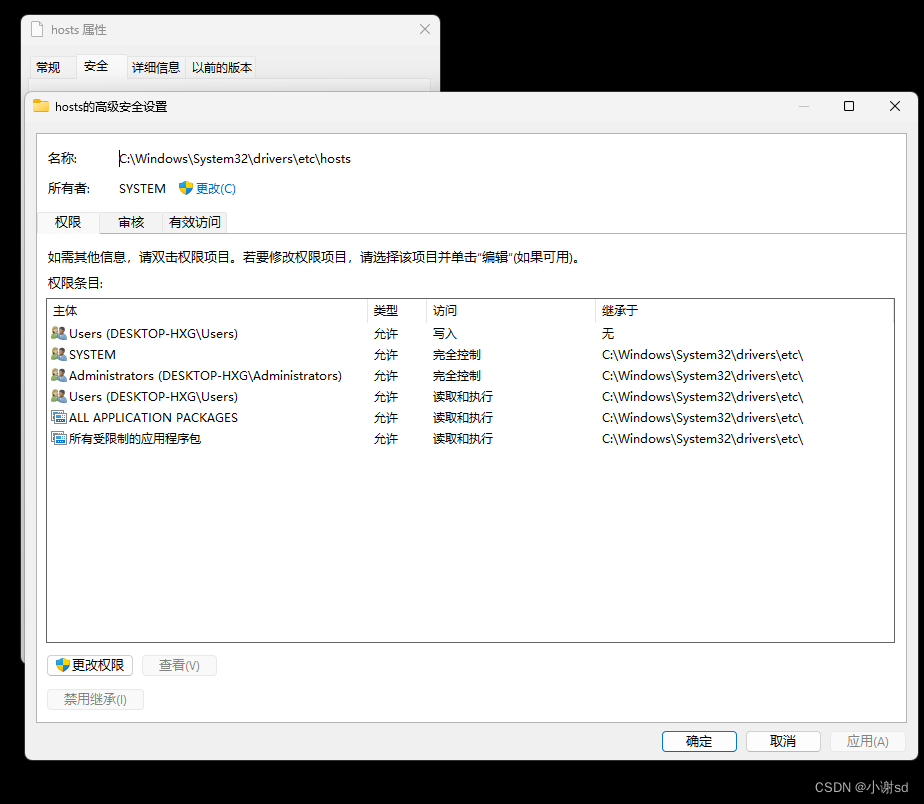
本地域名 127.0.0.1 / localhost
所谓本地域名就是 只能在本机使用的域名 ,一般在开发阶段使用。 编辑文件 C:\Windows\System32\drivers\etc\hosts。 127.0.0.1 www.baidu.com如果修改失败,可以修改该文件的权限。 原理: 在地址栏输入 域名 之后,浏览器会先进行 DNS…...

Python —— 不同类型的数据长度计算方式
在Python 中,不同类型的数据长度计算方式,有何不同👇 字符串(String) my_string "Hello, World!" string_length len(my_string) print("字符串的长度是:", string_length) //输出…...

NowCoder | 环形链表的约瑟夫问题
NowCoder | 环形链表的约瑟夫问题 OJ链接 思路: 创建带环链表带环链表的删除节点 代码如下: #include<stdlib.h>typedef struct ListNode ListNode; ListNode* ListBuyNode(int x) {ListNode* node (ListNode*)malloc(sizeof(ListNode));node…...

华为政企数据中心网络交换机产品集
产品类型产品型号产品说明 核心/汇聚交换机CE8850-EI-B-B0BCloudEngine 8850-64CQ-EI 提供 64 x 100 GE QSFP28,CloudEngine 8800系列交换机是面向数据中心推出的新一代高性能、高密度、低时延灵活插卡以太网交换机,可以与华为CloudEngine系列数据中心…...
多门店自助点餐+外卖二合一小程序源码系统 带完整搭建教程
随着餐饮业的快速发展和互联网技术的不断进步,越来越多的餐厅开始采用自助点餐和外卖服务。市场上许多的外卖小程序APP应运而生。下面罗峰来给大家介绍一款多门店自助点餐外卖二合一小程序源码系统。该系统结合了自助点餐和外卖服务的优势,为餐厅提供了一…...
kafka可视化工具
Offset Explorer kafka可视化工具...

Excel 转 Json 、Node.js实现(应用场景:i18n国际化)
创作灵感来源于在线转换是按照换行符去转换excel内容换行符后很难处理 本文是按单元格转换 const xlsx require(node-xlsx) const fs require(fs) const xlsxData xlsx.parse(./demo.xlsx) // 需要转换的excel文件// 数据处理 方便粘贴复制 const data xlsxData[2].data …...
Redis7--基础篇2(Redis的十大数据类型及常用命令)
1. Redis的十大数据类型及常用命令 Redis是key-value键值对类型的数据库,我们所说的数据类型指的是value的数据类型,key的数据类型都是字符串。 1.1 字符串(String) string是redis最基本的类型,一个key对应一个val…...

1.HTML中网页介绍
1.网页 1.1 什么是网页 网站是指在因特网上根据一定的规则,使用HTML等制作的用于展示特定内容的相关的网页集合 网页是网站中的一“页”,通常是HTML格式文件,它要通过浏览器来阅读。 网页是构成网站的基本元素,它通常是有图片&am…...

执行sql报错only_full_group_by的解决方法
一、前言 最近老项目换新数据库(都是mysql),有些在老数据库可以执行的sql,在新数据库执行就会报错sql_modeonly_full_group_by 意思是说数据库的模式是sql_modeonly_full_group_by,group by的字段必须和查询字段一致…...
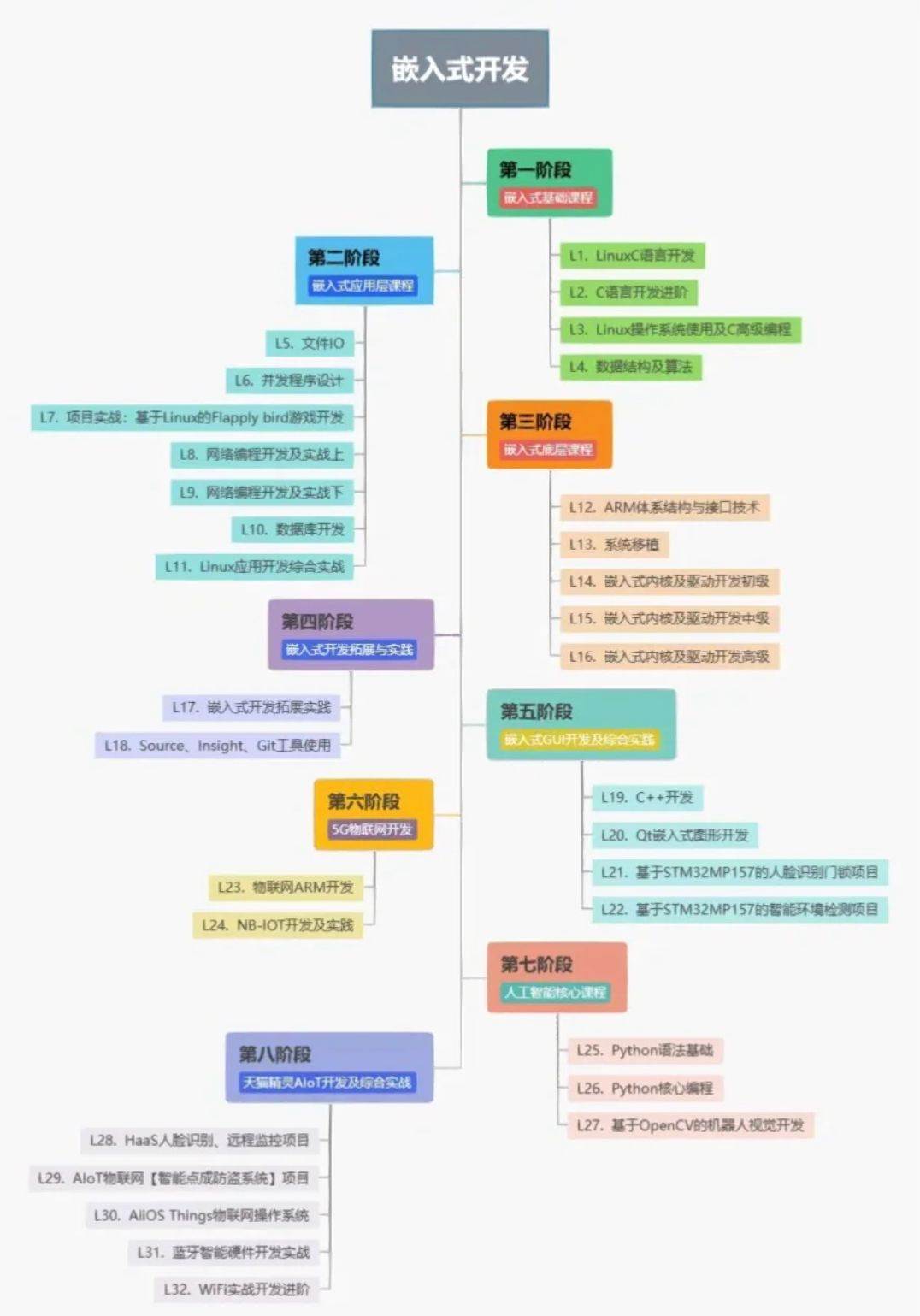
不学51直接学stm32可以吗?学stm32需要哪些基础?
不学51直接学stm32可以吗?学stm32需要哪些基础? 不管那些大佬技术多么牛逼,大多数入门都是从51单片机开始。 最近有一些入门的小伙伴问我说看到同学都从直接从STM32开始干了。最近很多小伙伴找我,说想要一些stm32的资料ÿ…...

6.1二叉树的递归遍历(LC144,LC15,LC94)
什么是递归函数? 递归函数是一种函数调用自身的编程技巧。 在递归函数中,函数通过不断调用自身来解决一个问题,直到达到基本情况(递归终止条件)并返回结果。 递归函数在解决一些问题时非常有用,特别是那些…...
Spring基础(3):复习
为了让大家更容易接受我的一些观点,上一篇很多笔墨都用在了思路引导上,所以导致文章可能比较臃肿。 这一篇来总结一下,会稍微精简一些,但整体趣味性不如第二篇。 (上一篇说过了,目前介绍的2种注入方式的说法其实不够…...
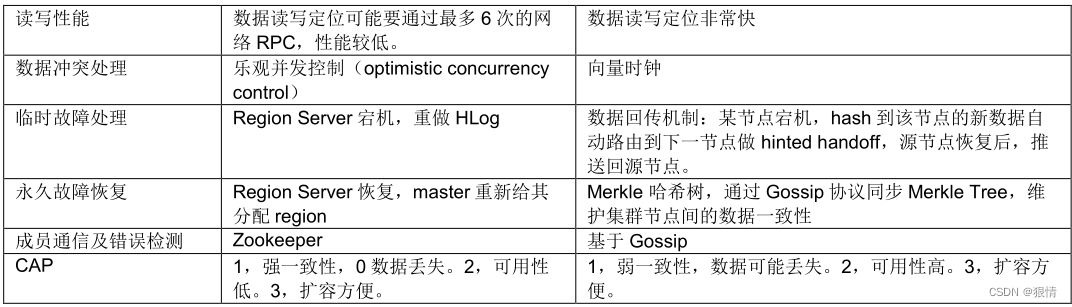
Java-Hbase介绍
1.1. 概念 base 是分布式、面向列的开源数据库(其实准确的说是面向列族)。HDFS 为 Hbase 提供可靠的 底层数据存储服务,MapReduce 为 Hbase 提供高性能的计算能力,Zookeeper 为 Hbase 提供 稳定服务和 Failover 机制,…...
。。。。。。。】)
【PHP】【Too few arguments to function Firebase\JWT\JWT::encode()。。。。。。。】
1.安装jwt composer require firebase/php-jwtuse Firebase\JWT\JWT;public function hello($name ThinkPHP5){$secret_key "YOUR_SECRET_KEY";$issuer_claim "THE_ISSUER";$audience_claim "THE_AUDIENCE";$issuedat_claim time(); // is…...
时常用的命令wget、rpm、yum分别是什么意思和作用?)
Centos系统上安装包(软件)时常用的命令wget、rpm、yum分别是什么意思和作用?
本文以在Centos上安装mysql-5.7.26的前三步为例,说明命令wget、rpm、yum的意思和作用。 安装mysql-5.7.26的步骤如下: 下载MySQL 5.7.26的RPM存储库文件: wget https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm安装R…...
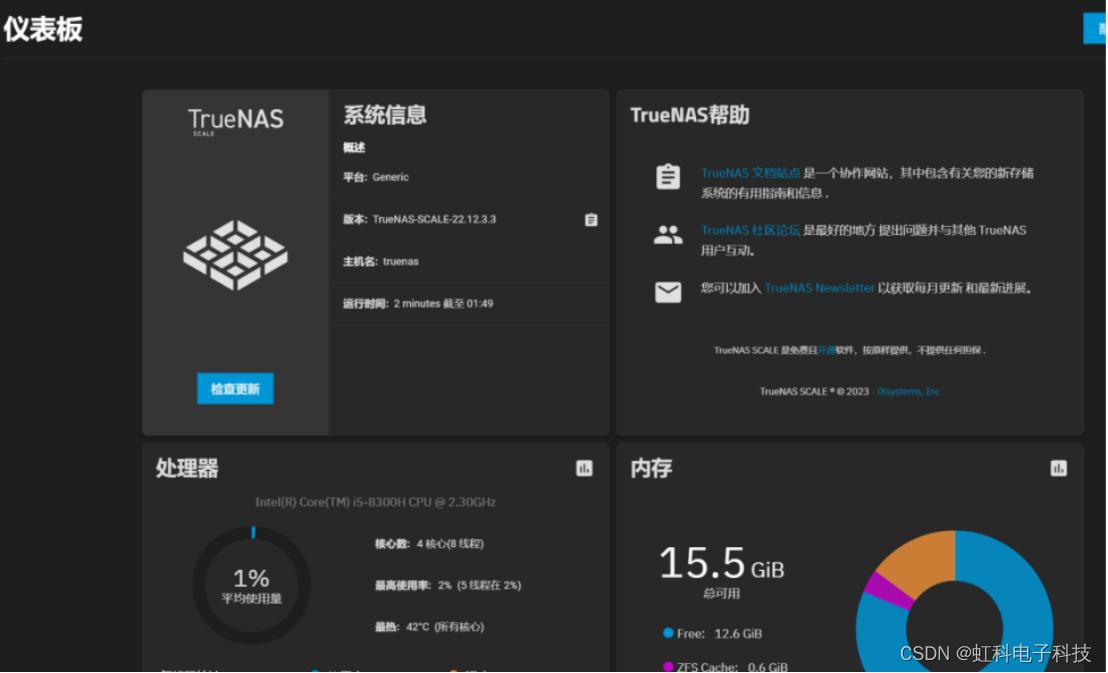
虹科干货 | 旧电脑别急着扔,手把手教你搭建NAS系统存储照片
一、前期准备 我们的目的是让设备物尽其用,将旧电脑做成NAS存储系统后可以使用新电脑进行访问(Windows / Linux / IOS系统都可以访问)。在开始之前先来看看安装成功效果图吧! 1.设备准备 (1)一台旧电脑&am…...
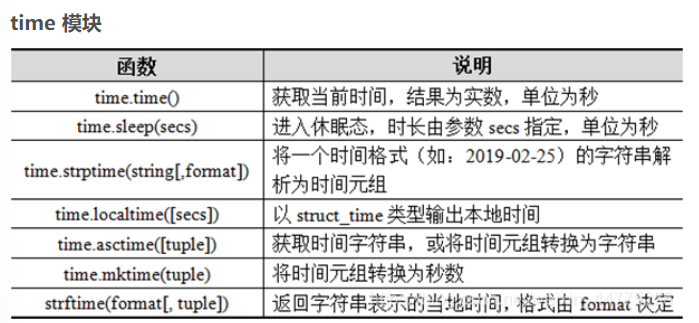
python基础(Python高级特性(切片、列表生成式)、字符串的正则表达式、函数、模块、Python常用内置函数、错误处理)培训讲义
文章目录 1. Python高级特性(切片、列表生成式)a) 切片的概念、列表/元组/字符串的切片切片的概念列表切片基本索引简单切片超出有效索引范围缺省 扩展切片step为正数step为负数 b) 列表生成式以及使用列表生成式需要注意的地方概念举例说明1. 生成一个列…...

计讯物联高精度GNSS接收机:担当小型水库大坝安全监测解决方案的“护航者”
应用背景 水库大坝作为水利工程建筑物,承担着灌溉、发电、供水、生态等重任。一旦水库大坝发生安全事故,后果将不堪设想。因此,水库大坝的安全监测对保障水利工程顺利运行具有重要意义。 计讯物联作为水利行业专家型企业,多年来…...

从静态到动态:ES-ImageNet如何用边缘检测器革新SNN训练数据
1. 从静态到动态:ES-ImageNet的诞生背景 脉冲神经网络(SNN)这几年在计算机视觉领域越来越火,但训练数据却成了大问题。传统DVS相机采集的数据集成本高、规模小,就像用老式胶片相机拍电影——效率低还烧钱。我在实验室第…...
)
手把手教你用Python处理JSON和TXT销售数据(黑马程序员案例解析)
Python多源销售数据处理实战:从JSON/TXT到可视化分析 电商平台每天产生海量销售数据,这些数据往往以不同格式存储——有的团队习惯用TXT记录,有的系统默认输出JSON。作为数据分析师,能否高效处理这些异构数据,直接决定…...

LeetCode 热题 100 之 160. 相交链表 206. 反转链表 234. 回文链表 141. 环形链表 142. 环形链表 II
160. 相交链表 206. 反转链表 234. 回文链表 141. 环形链表 142. 环形链表 II 160. 相交链表 public class Solution {public ListNode getIntersectionNode(ListNode headA, ListNode headB) {if (headA null || headB null) return null;ListNode pA headA, pB headB;whi…...

Asian Beauty Z-Image Turbo 模型原理浅析:LSTM在序列生成中的角色
Asian Beauty Z-Image Turbo 模型原理浅析:LSTM在序列生成中的角色 最近在体验一些图像生成模型时,我发现一个挺有意思的现象。像Asian Beauty Z-Image Turbo这类主打特定风格和快速生成的模型,虽然核心架构肯定是基于当下最流行的Transform…...

Java类间变量共享与进度更新的实现策略
本文旨在探讨如何在Java中安全有效地共享和更新不同操作类别之间的变量值,特别是在需要实时监控操作进度的场景中。我们将通过三种核心策略-观察者模式(推动模型)、轮询模式(拉模式)和基于多线程的共享状态管理——详细说明如何实现类间通信和…...
Transformer-BiLSTM、Transformer、CNN-BiLSTM、BiLSTM、CNN五模型时序预测研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Youtu-2B快速上手教程:WebUI交互界面部署详解
Youtu-2B快速上手教程:WebUI交互界面部署详解 想体验一个既轻快又聪明的AI对话助手吗?今天要介绍的Youtu-2B,就是一个能在普通电脑上流畅运行,还能帮你写代码、解数学题、创作文案的全能小帮手。它基于腾讯优图实验室开源的轻量化…...
)
虚拟机玩家必备:CentOS7密码重置最全指南(含LANG报错处理+自动标记技巧)
虚拟机玩家必备:CentOS7密码重置全流程精解与技术内幕 作为开发测试人员,我们经常需要配置和维护多个CentOS7虚拟机环境。当密码遗忘或需要重置时,传统的教程往往只提供基础步骤,而忽略了虚拟机环境下特有的技术细节和潜在问题。本…...
)
ROS2新手必看:rqt可视化工具从安装到实战(附小乌龟控制技巧)
ROS2实战指南:rqt可视化工具深度解析与小乌龟控制秘籍 引言 在机器人操作系统ROS2的生态中,可视化工具扮演着至关重要的角色。作为ROS2官方推荐的GUI工具套件,rqt以其模块化设计和丰富的功能插件,为开发者提供了直观高效的交互方式…...

PE文件之TLS
PE文件之TLS 是什么线程局部存储 线程局部存储(Thread Local Storage,TLS)是各线程独立的数据存储空间,使用TLS可以像修改自身局部变量一样修改进程的全局变量而不影响其它线程。这很好地解决了多线程程序设计中变量的同步问题。 …...