《数据库系统概论》学习笔记——第七章 数据库设计
教材为数据库系统概论第五版(王珊)
这一章概念比较多。最重点就是7.4节。
7.1 数据库设计概述
数据库设计定义:
数据库设计是指对于一个给定的应用环境,构造(设计)优化的数据库逻辑模式和物理结构,并据此建立数据库及其应用系统,使之能够有效地存储和管理数据,满足各种用户的应用需求,包括信息管理要求和数据操作要求。
- 信息管理要求:在数据库中应该存储和管理哪些数据对象。
- 数据操作要求:对数据对象需要进行哪些操作,如增删改查
目标:为用户和各种应用系统提供一个信息基础设施和高效率的运行环境
高效率的运行环境
-
数据库数据的存取效率高;
-
数据库存储空间的利用率高;
-
数据库系统运行管理的效率高。
7.1.1 数据库设计的特点
-
三分技术,七分管理,十二分基础数据
-
管理
- 数据库建设项目管理
- 企业(即应用部门)的业务管理
-
基础数据
- 收集、入库
- 更新新的数据
-
结构(数据)设计和行为(处理)设计相结合
- 将数据库结构设计和数据处理设计密切结合
7.1.2 数据库设计方法
大型数据库设计是涉及多学科的综合性技术又是一项庞大的工程项目。它要求多方面的知识和技术。主要包括:
①计算机的基础知识;
②软件工程的原理和方法;
③程序设计的方法和技巧;
④数据库的基本知识;
⑤数据库设计技术;
⑥应用领域的知识。
- 手工与经验相结合方法
存在问题:
- 设计质量与设计人员的经验和水平有直接关系
- 缺乏科学理论和工程方法的支持,工程的质量难以保证。
- 数据库运行一段时间后常常不同程度地发现各种问题,增加了维护代价
- 规范设计法
基本思想:过程迭代和逐步求精
典型方法:
- 新奥尔良(New Orleans)方法:将数据库设计分为若干阶段和步骤
- 基于E-R模型的数据库设计方法:概念设计阶段广泛采用
- 3NF(第三范式)的设计方法:逻辑阶段可采用的有效方法
- ODL(Object Definition Language)方法:面向对象的数据库设计方法
- 计算机辅助设计:ORACLE Designer,SYBASE PowerDesigner
7.1.3 数据库设计的基本步骤
数据库设计分6个阶段(记住)
- 需求分析
- 概念结构设计
- 逻辑结构设计
- 物理结构设计
- 数据库实施
- 数据库运行和维护
需求分析和概念设计独立于任何数据库管理系统
逻辑设计和物理设计与选用的DBMS密切相关

1.需求分析阶段
- 准确了解与分析用户需求(包括数据与处理)
- 最困难、最耗费时间的一步
2.概念结构设计阶段
- 整个数据库设计的关键
- 通过对用户需求进行综合、归纳与抽象,形成一个独立于具体DBMS的概念模型
3.逻辑结构设计阶段
- 将概念结构转换为某个DBMS所支持的数据模型
- 对其进行优化
4.数据库物理设计阶段
为逻辑数据模型选取一个最适合应用环境的物理结构(包括存储结构和存取方法)
5.数据库实施阶段
运用DBMS提供的数据库语言(如SQL)及宿主语言,根据逻辑设计和物理设计的结果
- 建立数据库
- 编制与调试应用程序
- 组织数据入库
- 进行试运行
6.数据库运行和维护阶段
- 数据库应用系统经过试运行后即可投入正式运行
- 在数据库系统运行过程中必须不断地对其进行评价、调整与修改
设计一个完善的数据库应用系统往往是上述六个阶段的不断反复
7.1.4 数据库设计过程中的各级模式
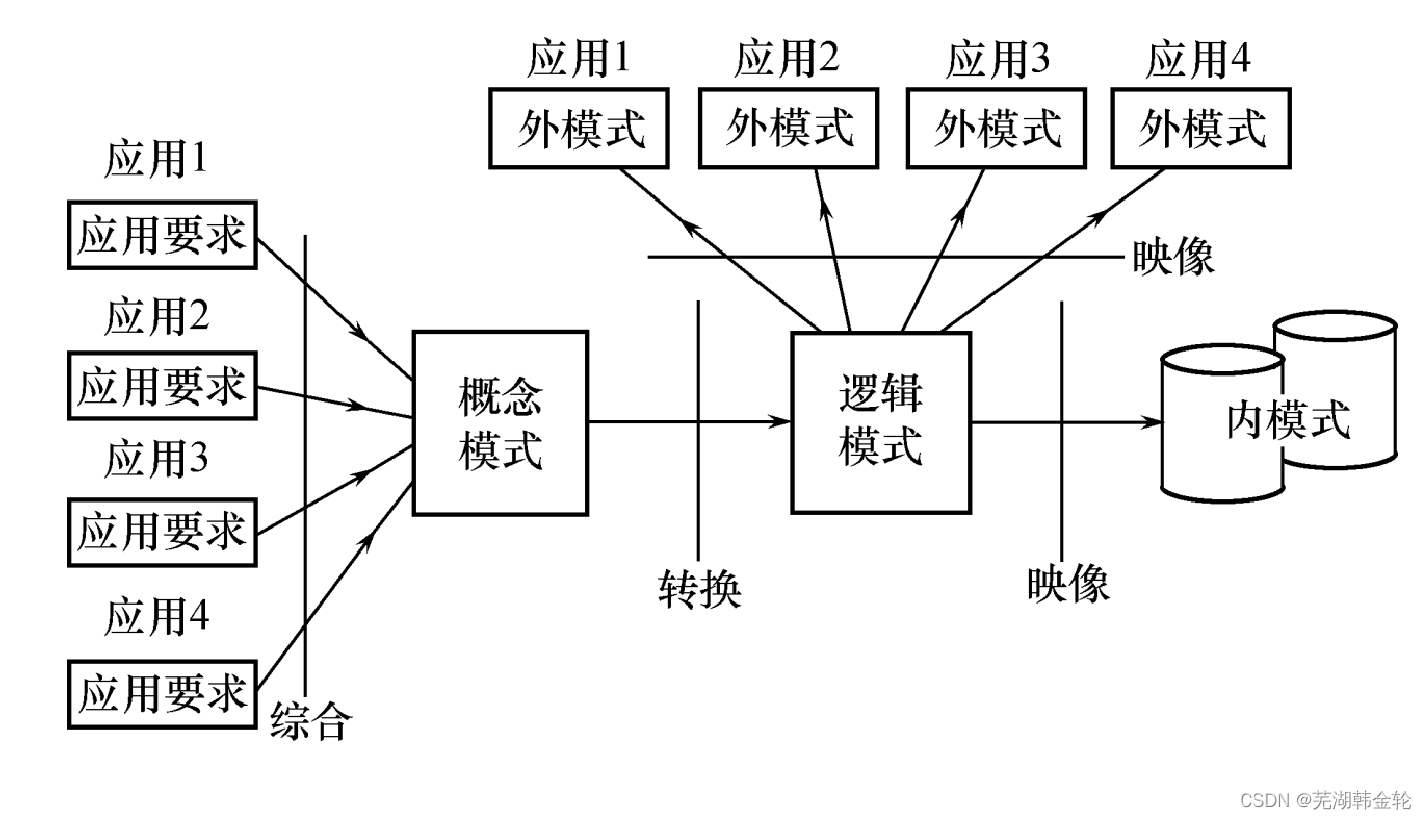
7.2 需求分析
7.2.1 需求分析的任务
- 详细调查现实世界要处理的对象(组织、部门、企业等)
- 充分了解原系统(手工系统或计算机系统)
- 明确用户的各种需求
- 确定新系统的功能,新系统需要充分考虑今后可能的扩充和改变
调查的重点是“数据”和“处理”,获得用户对数据库要求,包括信息要求,处理要求,安全性与完整性要求
7.2.2 需求分析的方法
目的:调查清楚用户的实际需求并进行初步分析最终与用户达成共识。
调查用户需求的具体步骤
- 调查组织机构情况
- 调查各部门的业务活动情况
- 在熟悉业务活动的基础上,协助用户明确对新系统的各种要求
- 确定新系统的边界
常用调查方法
- 跟班作业
- 开调查会
- 请专人介绍
- 询问
- 设计调查表请用户填写
- 查阅记录
- 结构化分析方法(Structured Analysis,简称SA方法),自顶向下、逐层分解分析系统

7.2.3 数据字典
数据字典是关于数据库中数据的描述,即元数据,不是数据本身。数据字典是在需求分析阶段建立,是进行详细的数据收集和数据分析所获得的,并在数据库设计过程中不断修改、充实、完善。
内容:数据项,数据结构,数据流,数据存储,处理过程
1.数据项:数据项是不可再分的数据单位
数据项描述={ 数据项名,数据项含义说明,别名,
数据类型,长度,取值范围,取值含义,
与其他数据项的逻辑关系,数据项之间的联系 }

2.数据结构:数据结构反映了数据之间的组合关系
数据结构描述={数据结构名,含义说明,
组成:{数据项或数据结构}}一个数据结构可以由若干个数据项组成,也可以由若干个数据结构组成,或由若干个数据项和数据结构混合组成

3.数据流:数据流是数据结构在系统内传输的路径
数据流描述={ 数据流名,说明,数据流来源,
数据流去向,组成:{数据结构},
平均流量,高峰期流量}

4.数据存储:数据存储是数据结构停留或保存的地方,也是数据流的来源和去向之一
数据存储描述={数据存储名,说明,编号,
输入的数据流 ,输出的数据流 ,
组成:{数据结构},数据量,存取频度,存取方式}

5.处理过程:具体处理逻辑一般用判定表或判定树来描述
处理过程描述={处理过程名,说明,输入:{数据流}, 输出:{数据流},处理:{简要说明}}

小结:
- 设计人员应充分考虑到可能的扩充和改变,使设计易于更改,系统易于扩充
- 必须强调用户的参与
7.3 概念结构设计
7.3.1 概念结构
概念结构设计
- 将需求分析得到的用户需求抽象为信息结构即概念模型的过程就是概念结构设计
- 概念结构是各种数据模型的共同基础,它比数据模型更独立于机器、更抽象,从而更加稳定
- 概念结构设计是整个数据库设计的关键
概念结构设计的特点
- 能真实、充分地反映现实世界
- 易于理解
- 易于更改
- 易于向关系、网状、层次等各种数据模型转换
7.3.2 概念结构设计
概念设计的第一步就是对需求分析阶段收集到的数据进行分类、组织,确定实体、实体属性、实体间联系类型,形成E-R图,
1.实体与属性的划分原则
为了简化E-R图的处置,现实世界的事物能作为属性对待的,尽量作为属性对待。
两条准则:
- 作为属性,不能再具有需要描述的性质。属性必须是不可分的数据项,不能包含其他属性。
- 属性不能与其他实体具有联系,即E-R图中所表示的联系是实体之间的联系。
p225举有例子
2.E-R图的集成
E-R图的集成一般需要分两步:
- 第一步:合并。解决各分E-R图之间的冲突,将分E-R图合并起来生成初步E-R图。
- 第二步:修改和重构。消除不必要的冗余,生成基本E-R图。
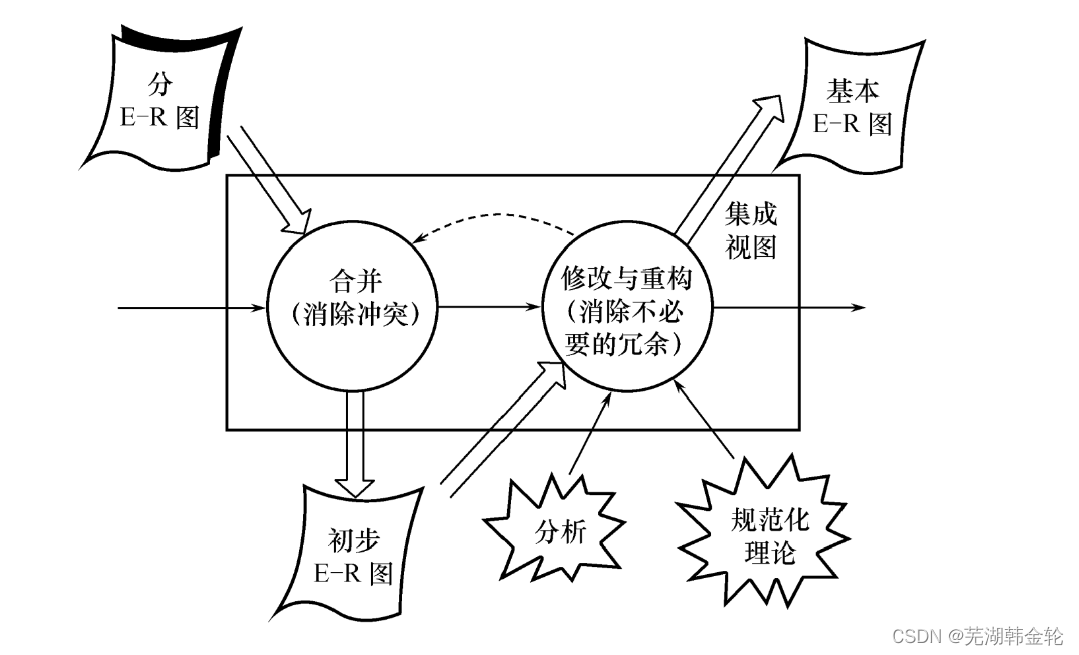
1)合并分E-R图,生成初步E-R图
各分E-R图存在冲突,各个分E-R图之间必定会存在许多不一致的地方(浅浅记一下)
- 属性冲突
- 命名冲突
- 结构冲突
1.属性冲突
- 属性域冲突
- 属性值的类型
- 取值范围
- 取值集合不同
- 属性取值单位冲突
2.命名冲突
- 同名异义:不同意义的对象在不同的局部应用中具有相同的名字 (如网络)
- 异名同义(一义多名):同一意义的对象在不同的局部应用中具有不同的名字(如工程、课题、项目)
3.结构冲突
- 同一对象在不同应用中具有不同的抽象
- 同一实体在不同分E-R图中所包含的属性个数和属性排列次序不完全相同
- 实体之间的联系在不同局部视图中呈现不同的类型
基本任务:消除不必要的冗余,设计基本E-R图
1.冗余
- 冗余的数据是指可由基本数据导出的数据
- 冗余的联系是指可由其他联系导出的联系
- 冗余数据和冗余联系容易破坏数据库的完整性,给数据库维护增加困难
- 消除不必要的冗余后的初步E-R图称为基本E-R图
消除冗余的方法
- 分析方法
- 以数据字典和数据流图为依据
- 根据数据字典中关于数据项之间的逻辑关系
- 效率VS冗余信息
- 需要根据用户的整体需求来确定
- 若人为地保留了一些冗余数据,则应把数据字典中数据关联的说明作为完整性约束条件
- 规范化理论
- 函数依赖的概念提供了消除冗余联系的形式化工具(略)
验证整体概念结构
视图集成后形成一个整体的数据库概念结构,对该整体概念结构还必须进行进一步验证,确保它能够满足下列条件:
- 整体概念结构内部必须具有一致性,不存在互相矛盾的表达
- 整体概念结构能准确地反映原来的每个视图结构,包括属性、实体及实体间的联系
- 整体概念结构能满足需要分析阶段所确定的所有要求
整体概念结构最终还应该提交给用户,征求用户和有关人员的意见,进行评审、修改和优化,然后把它确定下来,作为数据库的概念结构,作为进一步设计数据库的依据。
7.4 逻辑结构设计
逻辑结构设计的任务
把概念结构设计阶段设计好的基本E-R图转换为与选用DBMS产品所支持的数据模型相符合的逻辑结构
逻辑结构设计的步骤
- 将概念结构转化为一般的关系、网状、层次模型
- 转换来的关系、网状、层次模型向特定DBMS支持下的数据模型转换
- 对数据模型进行优化
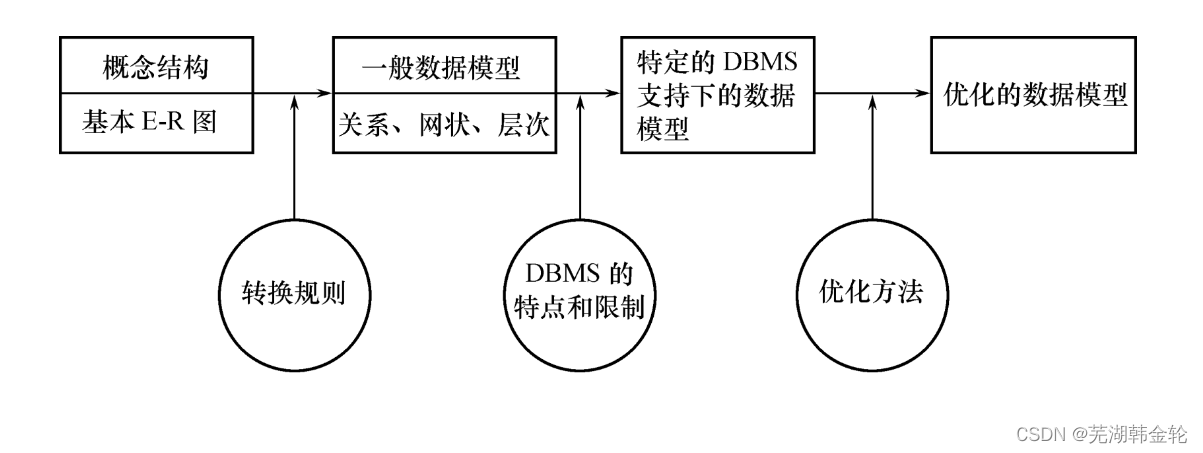
7.4.1 E-R图向关系模型的转换
实体型间的联系有以下不同情况 :
(1)一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应的关系模式合并。
-
转换为一个独立的关系模式
-
与某一端实体对应的关系模式合并(比如车队和司机之间有联系“聘用”,然后这个联系的属性可以和司机或者车队的属性合并起来,比如在司机的属性加上“聘期”)
(2)一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的关系模式合并。
- 转换为一个独立的关系模式
- 与n端对应的关系模式合并
(3)一个m:n联系转换为一个关系模式
(4)三个或三个以上实体间的一个多元联系转换为一个关系模式。
(5)具有相同码的关系模式可合并
- 目的:减少系统中的关系个数
- 合并方法:将其中一个关系模式的全部属性加入到另一个关系模式中,然后去掉其中的同义属性(可能同名也可能不同名),并适当调整属性的次序
一定要看这篇文章,直接弄懂!!!
http://t.csdn.cn/KEZMN
要弄懂这题
http://t.csdn.cn/TVPO7
7.4.2 数据模型的优化
得到初步数据模型后,还应该适当地修改、调整数据模型的结构,以进一步提高数据库应用系统的性能,这就是数据模型的优化
关系数据模型的优化通常以规范化理论为指导
优化数据模型的方法
- 确定数据依赖
按需求分析阶段所得到的语义,分别写出每个关系模式内部各属性之间的数据依赖以及不同关系模式属性之间数据依赖 - 消除冗余的联系
对于各个关系模式之间的数据依赖进行极小化处理,消除 冗余的联系。 - 确定所属范式
按照数据依赖的理论对关系模式逐一进行分析
考查是否存在部分函数依赖、传递函数依赖、多值依赖等
确定各关系模式分别属于第几范式 - 按照需求分析阶段得到的各种应用对数据处理的要求,分析对于这样的应用环境这些模式是否合适,确定是否要对它们进行合并或分解。
并不是规范化程度越高的关系就越优,一般说来,第三范式就足够了
- 按照需求分析阶段得到的各种应用对数据处理的要求,对关系模式进行必要的分解,以提高数据操作的效率和存储空间的利用率
- 常用分解方法:水平分解,垂直分解
- 水平分解:把(基本)关系的元组分为若干子集合,定义每个子集合为一个子关系,以提高系统的效率
- 水平分解的适用范围:满足“80/20原则”的应用并发事务经常存取不相交的数据
- 垂直分解:把关系模式R的属性分解为若干子集合,形成若干子关系模式
- 垂直分解的适用范围:取决于分解后R上的所有事务的总效率是否得到了提高
7.4.3 设计用户子模式
定义用户外模式时应该注重的问题包括三个方面:
(1) 使用更符合用户习惯的别名
(2) 针对不同级别的用户定义不同的View ,以满足系统对安全性的要求。
(3) 简化用户对系统的使用
7.5 数据库的物理设计
数据库的物理设计
数据库在物理设备上的存储结构与存取方法称为数据库的物理结构,它依赖于选定的数据库管理系统
为一个给定的逻辑数据模型选取一个最适合应用环境的物理结构的过程,就是数据库的物理设计
数据库物理设计的步骤
- 确定数据库的物理结构,在关系数据库中主要指存取方法和存储结构
- 对物理结构进行评价,评价的重点是时间和空间效率
如果评价结果满足原设计要求,则可进入到物理实施阶段,否则,就需要重新设计或修改物理结构,有时甚至要返回逻辑设计阶段修改数据模型
7.5.1 数据库物理设计的内容和方法
设计物理数据库结构的准备工作
- 对要运行的事务进行详细分析,获得选择物理数据库设计所需参数
- 充分了解所用RDBMS的内部特征,特别是系统提供的存取方法和存储结构
选择物理数据库设计所需参数
- 数据库查询事务
- 查询的关系
- 查询条件所涉及的属性
- 连接条件所涉及的属性
- 查询的投影属性
- 数据更新事务
- 被更新的关系
- 每个关系上的更新操作条件所涉及的属性
- 修改操作要改变的属性值
- 每个事务在各关系上运行的频率和性能要求
关系数据库物理设计的内容
- 为关系模式选择存取方法(建立存取路径)
- 设计关系、索引等数据库文件的物理存储结构
7.5.2 关系模式存取方法选择
数据库系统是多用户共享的系统,对同一个关系要建立多条存取路径才能满足多用户的多种应用要求
物理设计的任务之一就是要确定选择哪些存取方法,即建立哪些存取路径
DBMS常用存取方法
- 索引方法
- 目前主要是B+树索引方法
- 经典存取方法,使用最普遍
- 聚簇(Cluster)方法
- HASH方法
选择索引存取方法的一般规则
- 如果一个(或一组)属性经常在查询条件中出现,则考虑在这个(或这组)属性上建立索引(或组合索引)
- 如果一个属性经常作为最大值和最小值等聚集函数的参数,则考虑在这个属性上建立索引
- 如果一个(或一组)属性经常在连接操作的连接条件中出现,则考虑在这个(或这组)属性上建立索引
选择HASH存取方法的规则
当一个关系满足下列两个条件时,可以选择HASH存取方法
- 该关系的属性主要出现在等值连接条件中或主要出现在相等比较选择条件中
- 该关系的大小可预知,而且不变;或该关系的大小动态改变,但所选用的DBMS提供了动态HASH存取方法
聚簇存取方法的选择
为了提高某个属性(或属性组)的查询速度,把这个或这些属性(称为聚簇码)上具有相同值的元组集中存放在连续的物理块称为聚簇
作用:
- 大大提高按聚簇码进行查询的效率
- 节省存储空间
局限:
聚簇只能提高某些特定应用的性能
建立与维护聚簇的开销相当大
聚簇的适用范围
- 既适用于单个关系独立聚簇,也适用于多个关系组合聚簇
- 当通过聚簇码进行访问或连接是该关系的主要应用,与聚簇码无关的其他访问很少或者是次要的时,可以使用聚簇。
设计候选聚簇
- 对经常在一起进行连接操作的关系可以建立聚簇
- 如果一个关系的一组属性经常出现在相等比较条件中,则该单个关系可建立聚簇
- 如果一个关系的一个(或一组)属性上的值重复率很高,则此单个关系可建立聚簇。即对应每个聚簇码值的平均元组数不太少。太少了,聚簇的效果不明显
优化聚簇设计
- 从聚簇中删除经常进行全表扫描的关系;
- 从聚簇中删除更新操作远多于连接操作的关系;
- 不同的聚簇中可能包含相同的关系,一个关系可以在某一个聚簇中,但不能同时加入多个聚簇
7.5.3 确定数据库的存储结构
- 确定数据的存放位置
确定数据存放位置和存储结构的因素
- 存取时间
- 存储空间利用率
- 维护代价
易变部分与稳定部分分开存放,存取频率较高部分与存取频率较低部分,分开存放
- 确定系统配置
DBMS产品一般都提供了一些存储分配参数
- 同时使用数据库的用户数
- 同时打开的数据库对象数
- 内存分配参数
- 使用的缓冲区长度、个数
- 存储分配参数
7.5.4 评价物理结构
评价内容
对数据库物理设计过程中产生的多种方案进行细致的评价,从中选择一个较优的方案作为数据库的物理结构
7.6 数据库的实施和维护
7.6.1 数据的载入和应用程序的调试
数据库结构建立好后,就可以向数据库中装载数据了。组织数据入库是数据库实施阶段最主要的工作。
数据装载方法:
- 人工方法
- 计算机辅助数据入库
应用程序的编码和调试
- 数据库应用程序的设计应该与数据设计并行进行
- 在组织数据入库的同时还要调试应用程序
7.6.2 数据库的试运行
在原有系统的数据有一小部分已输入数据库后,就可以开始对数据库系统进行联合调试,称为数据库的试运行
数据库试运行主要工作包括:
- 功能测试
- 性能测试
强调:分期分批组织数据入库 ,做好数据库的转储和恢复
7.6.3 数据库的运行和维护
在数据库运行阶段,对数据库经常性的维护工作主要是由DBA完成的,包括:
- 数据库的转储和恢复
- 数据库的安全性、完整性控制
- 数据库性能的监督、分析和改进
- 数据库的重组织和重构造
相关文章:
《数据库系统概论》学习笔记——第七章 数据库设计
教材为数据库系统概论第五版(王珊) 这一章概念比较多。最重点就是7.4节。 7.1 数据库设计概述 数据库设计定义: 数据库设计是指对于一个给定的应用环境,构造(设计)优化的数据库逻辑模式和物理结构&#x…...

【Datawhale图机器学习】半监督节点分类:标签传播和消息传递
半监督节点分类:标签传播和消息传递 半监督节点分类问题的常见解决方法: 特征工程图嵌入表示学习标签传播图神经网络 基于“物以类聚,人以群分”的Homophily假设,讲解了Label Propagation、Relational Classificationÿ…...
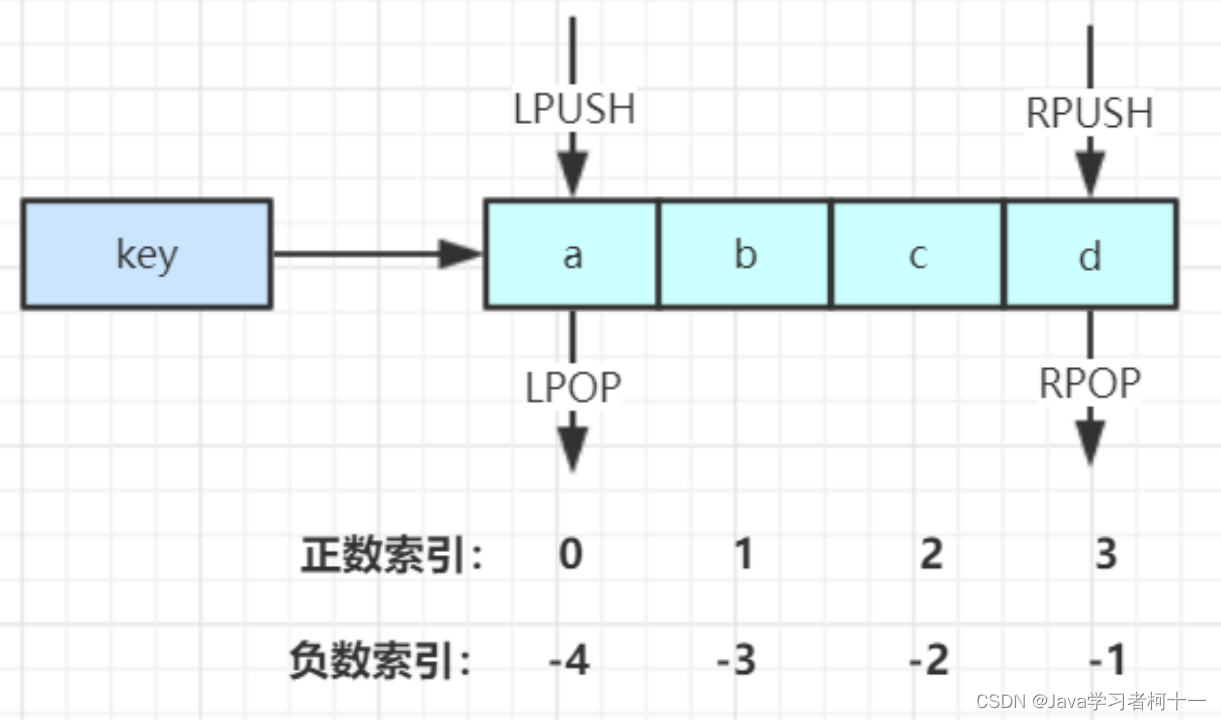
【分布式缓存学习篇】Redis数据结构
一、Redis的数据结构 二、String 数据结构 2.1 字符串常用操作 //存入字符串键值对 SET key value //批量存储字符串键值对 MSET key value [key value ...] //存入一个不存在的字符串键值对 SETNX key value //获取一个字符串键值 GET ke…...

【跟着ChatGPT学深度学习】ChatGPT带我入门NLP
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...

RGB888与RGB565颜色
颜色名称RGB888原色RGB565还原色英RGB888[Hex]RGB888_R[Hex]RGB888_G[Hex]RGB888_B[Hex]RGB565[Hex]RGB565_R[Hex]RGB565_G[Hex]RGB565_B[Hex]黑色Black0x0000000000000x0000000昏灰Dimgray0x6969696969690x6B4DD1AD灰色Gray0x8080808080800x8410102010暗灰Dark Gray0xA9A9A9A9…...

常见的域名后缀有哪些?不同域名后缀的含义是什么?
域名发展至今,已演变出各种各样的域名后缀,导致很多网站管理人员在注册域名时不知该如何选择。下面,中科三方针对常见域名后缀种类,以及不同域名后缀的含义做下简单介绍。 什么是域名后缀? 域名是由一串由点分隔开的…...
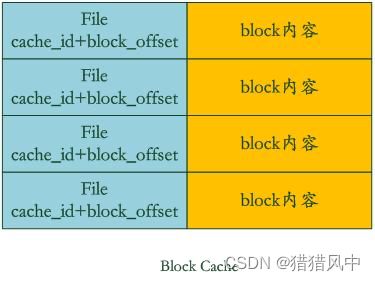
LevelDB架构介绍以及读、写和压缩流程
LevelDB 基本介绍 是一个key/value存储,key值根据用户指定的comparator排序。 特性 keys 和 values 是任意的字节数组。数据按 key 值排序存储。调用者可以提供一个自定义的比较函数来重写排序顺序。提供基本的 Put(key,value),Get(key),…...

华为OD机试模拟题 用 C++ 实现 - 快递货车(2023.Q1)
最近更新的博客 【华为OD机试模拟题】用 C++ 实现 - 最多获得的短信条数(2023.Q1)) 文章目录 最近更新的博客使用说明快递货车题目输入输出示例一输入输出Code使用说明 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过率才会高。 华为 OD 清单…...
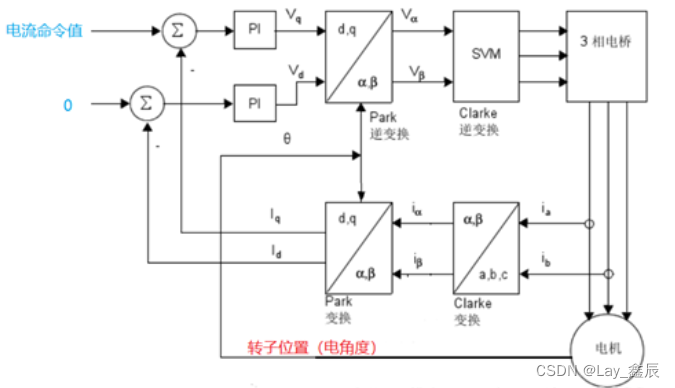
伺服三环控制深层原理解析
我们平时使用的工业伺服,通常是成套伺服,即驱动器和电机型号存在配对关系。 但有些时候,我们要用电机定转子和编码器制作非成套电机,这种时候,我们需要对驱动器进行各种设置才能驱动电机。 此篇文章将通过介绍伺服控制的三环控制原理入手来说明我们调试非成套伺服时需要…...
)
Cornerstone完整的基于 Web 的医学成像平台(一)
1.简介 Cornerstone是一个开源的基于Web的医学成像平台,它提供了一个易于使用的界面,可以用于加载、显示和处理医学图像。Cornerstone可以用于许多医学图像处理应用程序,例如计算机断层扫描(CT)、磁共振成像ÿ…...
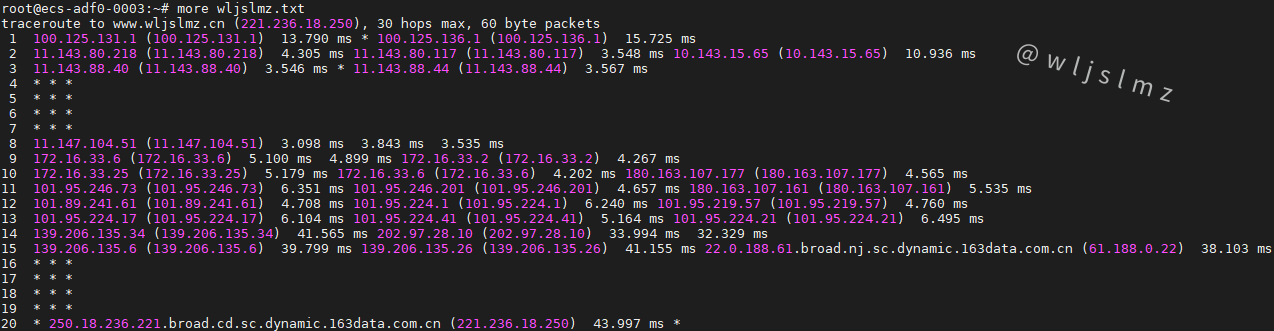
老板让我在Linux中使用traceroute排查服务器网络问题,幸好我收藏了这篇文章!
一、前言 作为网络工程师或者运维工程师,traceroute命令不会陌生,它的作用类似于ping命令,用于诊断网络的连通性,不过traceroute命令输出的命令会比ping命令丰富的多,可以跟踪从源系统到目标系统的路径。 很多工程师…...

一文读懂【数据埋点】
数据埋点是数据采集领域(尤其是用户行为数据采集领域)的术语,指的是针对特定用户行为或事件进行捕获、处理和发送的相关技术及其实施过程。比如用户某个icon点击次数、观看某个视频的时长等等。 数据分析是我们获得需求的来源之一,…...

Qt图片定时滚动播放器+透明过渡动画
目录参考结构PicturePlay.promain.cppmyqlabel.h 自定义QLabelmyqlabel.cpp自定义QLabelpictureplay.hpictureplay.cpppictureplay.uistyle.qss效果源码参考 Qt图片浏览器 QT制作一个图片播放器 Qt中自适应的labelpixmap充满窗口后,无法缩小只能放大 Qt的动画类修改…...

手把手带你做一套毕业设计-征程开启
本文是《手把手带你做一套毕业设计》专栏的开篇,文本将会包含我们创作这个专栏的初衷,专栏的主体内容,以及我们专栏的后续规划。关于这套毕业设计的作者呢前端部分由狗哥负责,服务端部分则由天哥操刀。我们力求毕业生或者新手通过…...

万字解析 Linux 中 CPU 利用率是如何算出来的?
在线上服务器观察线上服务运行状态的时候,绝大多数人都是喜欢先用 top 命令看看当前系统的整体 cpu 利用率。例如,随手拿来的一台机器,top 命令显示的利用率信息如下 这个输出结果说简单也简单,说复杂也不是那么容易就能全部搞明白…...
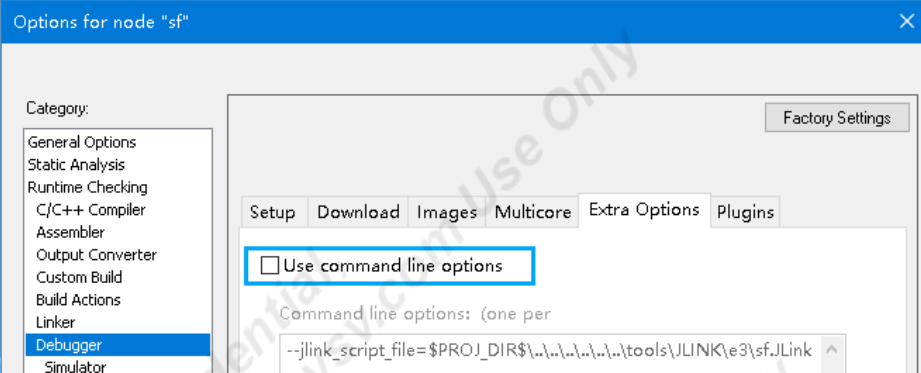
芯驰(E3-gateway)开发板环境搭建
1-Windows下环境配置 可以在Windows上使用命令行或者IAR IDE编译SSDK项目。Windows编译依赖的工具已经包含在 prebuilts/windows 目录中,包括编译器、Python和命令行工具。 1.1.1 CMD SSDK集成 msys 工具,可以在Windows命令行中完成SDK的配置、编译和…...
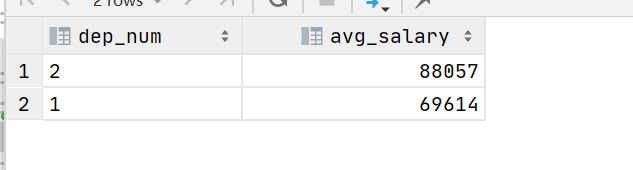
HiveSql一天一个小技巧:如何巧用分布函数percent_rank()求去掉最大最小值的平均薪水问题
0 问题描述参考链接(3条消息) HiveSql面试题12--如何分析去掉最大最小值的平均薪水(字节跳动)_莫叫石榴姐的博客-CSDN博客文中已经给出了三种解法,这里我们借助于此题,来研究如何用percent_rank()函数求解,简化解题思路…...

【python实现华为OD机试真题】优雅子数组【2023 Q1 | 200分】
题目描述 如果一个数组Q中出现次数最多的元素出现大于等于K次,被称为k-优雅数组,k也可以被称为优雅阈值只。 例如: 数组1,2, 3, 1、2, 3, 1,它是一个3-优雅数组,因为元素1出现次数大于等于3次, 数组[1,2, 3, 1, 2]就不是一一个3-优雅数组,因为其中出现次数最多的元素是1和…...

九种分布式ID解决方案
文章目录背景1、UUID2、数据库自增ID2.1、主键表2.2、ID自增步长设置3、号段模式4、Redis INCR5、雪花算法6、美团(Leaf)7、百度(Uidgenerator)8、滴滴(TinyID)总结比较背景 在复杂的分布式系统中,往往需要对大量的数据进行唯一标识,比如在对一个订单表…...

RocketMQ源码分析
RocketMQ源码深入剖析 1 RocketMQ介绍 RocketMQ 是阿里巴巴集团基于高可用分布式集群技术,自主研发的云正式商用的专业消息中间件,既可为分布式应用系统提供异步解耦和削峰填谷的能力,同时也具备互联网应用所需的海量消息堆积、高吞吐、可靠…...
)
一声唤醒 万物响应|AtomGit 首款开源鸿蒙 AI 硬件「小鸿」发布(附网页地址)
2026 年 4 月 28 日,AtomGit 在深圳正式发布首款开源鸿蒙 AI 硬件 XiaoHong「小鸿」。本次发布会以「一声唤醒,万物响应」为主题,推出基于 OpenHarmony 原生打造的开放式智能中枢,标志着 AI 硬件从“设备”迈向“入口”的重要一步…...

如何在MZmine3中高效处理DIA数据?5个关键问题与解决方案解析
如何在MZmine3中高效处理DIA数据?5个关键问题与解决方案解析 【免费下载链接】mzmine3 mzmine source code repository 项目地址: https://gitcode.com/gh_mirrors/mz/mzmine3 MZmine3是一款功能强大的开源质谱数据处理平台,特别在DIA(…...

微信聊天记录永久保存与智能分析:3步掌握你的数字记忆主权
微信聊天记录永久保存与智能分析:3步掌握你的数字记忆主权 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/W…...

这道 AI 考题,99% 的人都选错了——不是因为他们笨
这道 AI 考题,99% 的人都选错了——不是因为他们笨 ——关于"本体"这道题,今天一次性讲透 说实话,我看到这道题的时候,第一反应是:完了,这是哲学题还是计算机题? “本体”(…...

19.AI开发感悟
现在的AI大模型的能力一直在提升,但是算力跟不上,体现为上下文越长,AI越是乱来,这时遇到bug都不知道怎么修。如果你是这个领域的小白,不懂这个方向的技术,你根本不知道怎么办,如果你是这个领域的…...
速度曲线及其在STM上的应用)
舵机控制中的半正弦(S型)速度曲线及其在STM上的应用
先回顾:三次握手(建立连接)核心流程(实际版) 为了让挥手流程衔接更顺畅,咱们先快速回顾三次握手的实际核心,避免上下文脱节: 第一步(客户端→服务器)&#…...
)
别再乱刷了!手把手教你读懂Android卡刷包里的updater-script脚本(附权限设置详解)
深度解析Android卡刷包:从updater-script脚本到安全刷机实践 在Android设备刷机过程中,updater-script脚本扮演着至关重要的角色。这个看似简单的文本文件实际上控制着整个刷机流程的每一个细节操作。对于想要深入了解刷机原理或自行定制ROM的用户来说&a…...

HarmonyOS Tabs组件自定义遮罩效果全解析
引言:提升tabBar视觉体验的遮罩技术在HarmonyOS应用开发中,Tabs组件作为常见的导航控件,广泛应用于各类内容切换场景。然而,当tabBar页签内容过长且采用可滚动模式时,简单的背景色设置往往无法提供理想的视觉体验——用…...

如何在Mac上免费实现NTFS完美读写?终极解决方案来了!
如何在Mac上免费实现NTFS完美读写?终极解决方案来了! 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and man…...

DSU Sideloader:安全便捷的安卓双系统安装工具
DSU Sideloader:安全便捷的安卓双系统安装工具 【免费下载链接】DSU-Sideloader A simple app made to help users easily install GSIs via DSUs Android feature. 项目地址: https://gitcode.com/gh_mirrors/ds/DSU-Sideloader 还在为刷机风险而担忧吗&…...