强化学习RL 01: Reinforcement Learning 基础
目录
RL理解要点
1. RL数学基础
1.1 Random Variable 随机变量
1.2 概率密度函数 Probability Density Function(PDF)
1.3 期望 Expectation
1.4 随机抽样 Random Sampling
2. RL术语 Terminologies
2.1 agent、state 和 action
2.2 策略 policy π
2.3 奖励 reward
2.4 状态转移 state transition
2.5 agent environment interaction 环境交互
2.6 强化学习中的随机性 Randomness in Reinforcement Learning
2.7 play the game using AI
2.8 rewards、returns
2.8.1 Discounted return Ut 折扣回报
2.8.2 Random in Returns
2.9 value function 价值函数
2.9.1 Action-value function Qπ(s, a)
2.9.2 Optimal action-value function Q*
2.9.3 State-value function Vπ
3. How does AI control the agent?
3.1 policy function π
3.2 Q*(s, a)函数
3.3 Open AI gym
参考
RL理解要点
- RL学什么呢?就是要学习policy策略函数
1. RL数学基础
1.1 Random Variable 随机变量
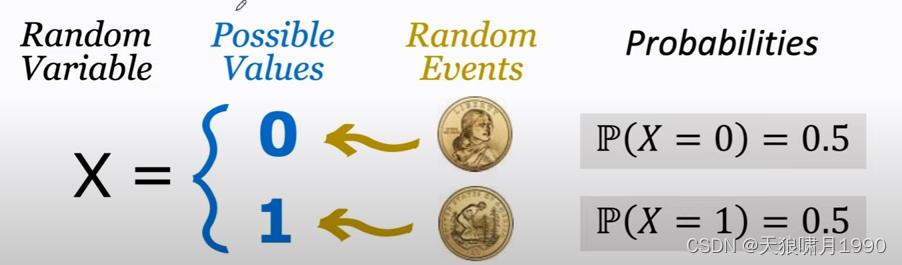
Random Variable: a variable whose values depend on outcomes of a random event. 随机变量是一个未知的量,它的值取决于随机事件的结果。
用大写字母表示随机变量 random variable,用小写字母表示随机变量观测值 observed value。
1.2 概率密度函数 Probability Density Function(PDF)
本质:就是一个概率分布(0.2, 0.3, 0.5)。
PDF provides a relative likelihood that the value of the random variable would equal that sample.
e.g. Gaussian distribution
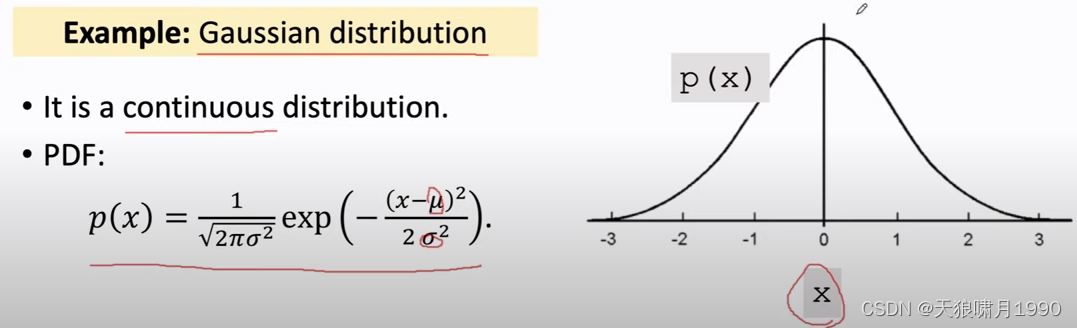
连续分布、离散分布。用表示其定义域domain

1.3 期望 Expectation
本质:是平均值,是预估结果。

1.4 随机抽样 Random Sampling

2. RL术语 Terminologies
2.1 agent、state 和 action
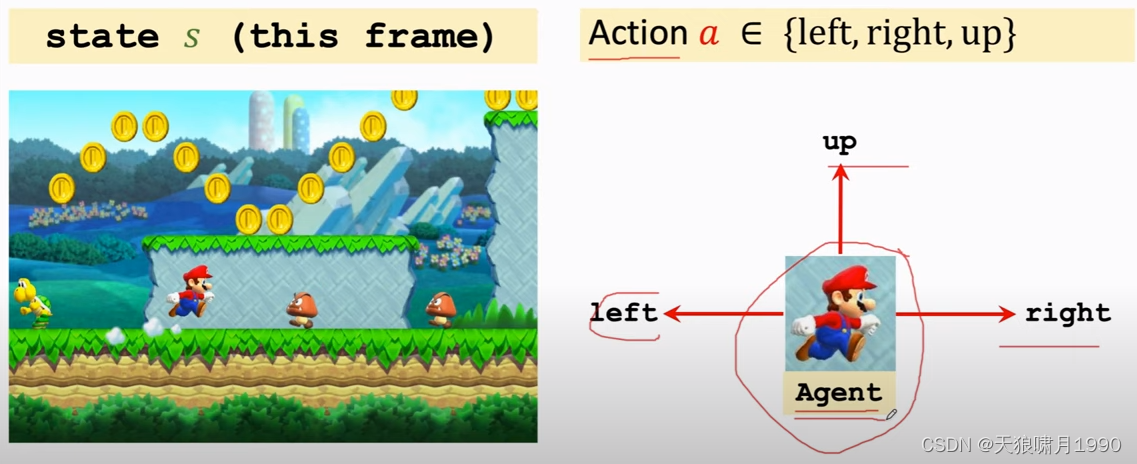
- 可以近似理解当前图片frame就是state
- agent,翻译为“智能体”
- 当前state,agent可以做的动作叫action,包括{'left', 'right', 'up'}
2.2 策略 policy π
本质:policy策略是一个概率密度函数,就是根据state生成一个动作action概率分布。
policy根绝观测到状态state,做出决策,然后控制agent运动。
Note that policy函数是随机的。

2.3 奖励 reward
agent做出一个动作,游戏就会给出一个奖励reward
奖励定义的好坏,非常影响强化学习的结果。

2.4 状态转移 state transition
agent做出一个动作,游戏就会给出一个新的状态state,这个过程就叫state transition。
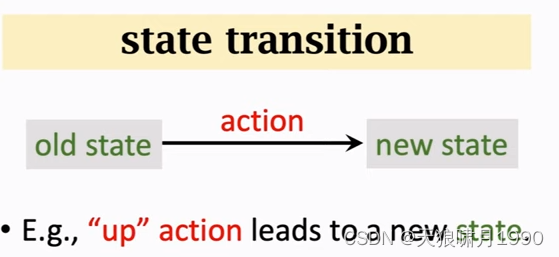
- state transition can be random.
- randomness is from the environment. 状态转移的随机性是从环境中来的,这里的环境是游戏的程序。
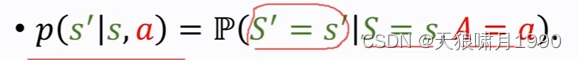
可以把状态转移用p函数来表示,这是个条件概率密度函数,意思是如果观测到当前状态s和动作a ,p函数就表示s prime的概率。
2.5 agent environment interaction 环境交互

agent和environment,agent看到状态st之后,要做出一个动作at,agent做出动作at后,环境environment会更新状态、把状态变成st+1,同时environment还会给agent一个奖励rt。
2.6 强化学习中的随机性 Randomness in Reinforcement Learning
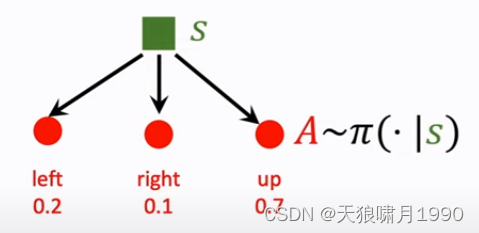
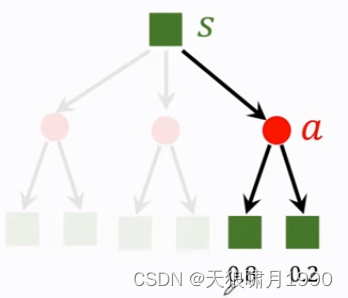
- Actions have randomness. actions是根据policy函数随机抽样得到的,我们用policy函数来控制agent,给定当前状态s,agent输出的动作a是根据策略函数policy输出的概率分布来随机抽样。
- state transitions have randomness. 假定agent做出了up action,环境environment就要生成下一个状态s',这个状态s'具有随机性,environment用状态概率转移函数p算出概率,然后用概率来随机抽样得到下一个状态s',
2.7 play the game using AI
通过强化学习学出policy function π,AI就是用policy函数来控制agent。

游戏当前状态s1,AI用policy函数来算一个概率,然后随机抽样得到动作a1,然后环境会生成下一个状态s2,并且给agent一个奖励r1,然后环境会拿新的状态s2作为输入,并用policy function来算概率,然后随机抽样得到新的动作a2,然后这样一直循环下去,直到打赢游戏或game over。
得到一个轨迹(state, action, reward)trajectory:s1,a1,r1,s2,a2,r2,...,st,at,rt。
2.8 rewards、returns
Return翻译为“回报”,也称作cumulative future reward,“未来的累积奖励”。
把t时刻的return记作Ut,就是把从t时刻开始的reward全都加起来,一直加到游戏结束时的最后一个奖励。
Question: Are Rt and Rt+1 equally important?
Future reward is less valuable than present reward.
Rt+1 should be given less weight than Rt. --> Discounted return
2.8.1 Discounted return Ut 折扣回报
γ,折扣率 discount rate gamma(tuning hyper-parameter),介于[0, 1]。

折扣率是个超参数,需要我们自己来调,折扣率的设置对强化学习的效果有一定的影响。
Ut用来衡量未来总收益。
2.8.2 Random in Returns
Return Ut的随机性。假如游戏已经结束了,所有的奖励已经观测到了,那么奖励是数值,用rt表示;如果在t时刻游戏还没结束,那么奖励还是随机变量,还没被观测到,用Rt表示。

随机性有两个来源:一是action a是从policy概率分布中随机抽样得到的;二是下一状态new state,状态转移函数p输出一个概率分布,environment从中随机抽样得到一个新的状态s'。
- For any i ≥ t, the reward Ri depends on Si and Ai. 当前agent处在的状态s和做出的动作a,就决定了奖励Ri是什么。
- 回报Ut是Rt、Rt+1等等的加权求和,而Ri是由Si和Ai决定的,所以给定st,Ut跟t时刻开始所有的动作At,At+1,At+2,..和状态St+1,St+2,...都有关了。
2.9 value function 价值函数
2.9.1 Action-value function Qπ(s, a)

在t时刻,你并不知道Ut是什么。Ut是个随机变量,它依赖于未来所有的动作At,At+1,At+2,...和未来所有的状态St,St+1,St+2,...
Ut未知,那我该怎么评估当前的形势呢?
对Ut求期望,把里面的随机性都用积分积掉,得到一个实数。
把Ut当作未来所有动作Ai和所有状态Si的一个函数,未来的动作和状态都有随机性,动作Ai的概率密度函数是policy function π,状态Si的概率密度函数是状态转移函数p,期望就是针对未来Si和Ai求得,出了St和At,其余的随机变量都是积分积掉,被积掉的是At+1,At+2等动作、St+1,St+2等动作,求期望得到的动作价值函数Qπ,其只跟当前动作at、状态st有关。
函数Qπ还与policy function π有关,因为积分时会用到policy函数,π函数不一样,Qπ就会不一样。
Qπ的直观意义:如果用状态价值函数Qπ,那么在当前状态st下做动作at是好还是坏。
已知policy函数π,那么Qπ就会给当前状态下所有动作A打分,然后就知道哪个动作好、哪个动作不好。
2.9.2 Optimal action-value function Q*
如何把action-value function中的π去掉呢?
可以对Qπ关于π求最大化。意思是我们有无数种policy函数π,但我们应该使用最好的那一种!
最好的policy函数就是让Qπ最大化的那个π,得到函数Q*称为optimal action-value function。

Q*跟π无关,它的直观意义:Q*可以用来对当前动作at做评价--分数,比如下围棋是,你把棋子放在这个位置胜算有多大,你把棋子放在那个位置胜算有多大。
Q*非常有用,agent可以根据Q*对actions的评价来做决策。
2.9.3 State-value function Vπ

状态价值函数Vπ,它是action-value function动作价值函数Qπ的期望。
Qπ与状态st、动作A有关,可以把A当作随机变量,求期望把它消掉,这样Vπ只跟st和π有关。
Vπ直观意义:Vπ可以告诉我们当前局势好不好,比如下围棋,Vπ可以告诉我们当前胜算有多大,是快赢了还是快输了。
![]()
这里的期望是根据A求得,A的概率密度函数是policy function π。根据期望定义,可以把期望写成连加或积分的形式。
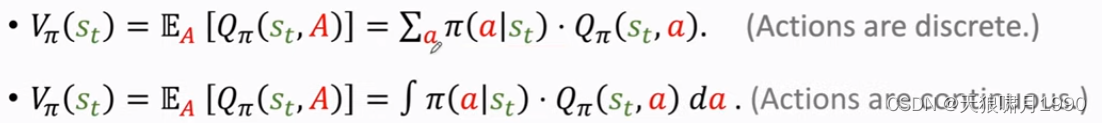
For fixed policy π, Vπ(s) evaluates how good the situation is in state s.
Es[Vπ(S)] evaluates how good the policy π is.
3. How does AI control the agent?
3.1 policy function π
一种方法是学一个策略函数policy π
有了policy 函数π,就可以用来控制agent来做动作。

3.2 Q*(s, a)函数
另一种方法是学习optimal action-value function Q*(s, a)函数,它是value based model
假如有了Q*函数,agent可以根据Q*函数来做动作了。
如果处在状态s,那么做动作a是好还是坏。没观测到一个状态st,就把st作为Q*函数的输入,让Q*函数对每一个函数做一个评价,假如up move的q值最大,因为q值是对未来奖励reward总和的期望,所以选up获取以期在未来获得更多奖励。

3.3 Open AI gym
- 经典控制问题
- atari game
- 连续控制问题 continuous control tasks


参考
1. 王树森~强化学习 Reinforcement Learning
2. https://www.cnblogs.com/pinard/category/1254674.html
相关文章:
强化学习RL 01: Reinforcement Learning 基础
目录 RL理解要点 1. RL数学基础 1.1 Random Variable 随机变量 1.2 概率密度函数 Probability Density Function(PDF) 1.3 期望 Expectation 1.4 随机抽样 Random Sampling 2. RL术语 Terminologies 2.1 agent、state 和 action 2.2 策略 policy π 2.3 奖励 reward …...

C语言之练习题合集
💗 💗 博客:小怡同学 💗 💗 个人简介:编程小萌新 💗 💗 如果博客对大家有用的话,请点赞关注再收藏 🌞 文章目录leetcode 题号:728. 自除数leetcode 题号:238.…...
sublimeText3新建文件自动添加注释头
参考: https://github.com/shiyanhui/FileHeader/blob/master/README.rst https://packagecontrol.io/packages/FileHeader https://github.com/shiyanhui/FileHeader fileheader:https://codeload.github.com/shiyanhui/FileHeader/zip/refs/heads/m…...

AndroidStudio打包HBuilderX的H5+项目为安卓App【一次过,无任何异常报错】
目录 1.查看HBuilderX的版本号 2.下载Dcloud上对应的安卓SDK 3.下载完安卓SDK后,我们解压它,注意不要放在任何有中文组成的文件夹中【是否有中文决定于你鼠标单击上面路径后,第一张图还没鼠标单击,第二张已鼠标单击,…...

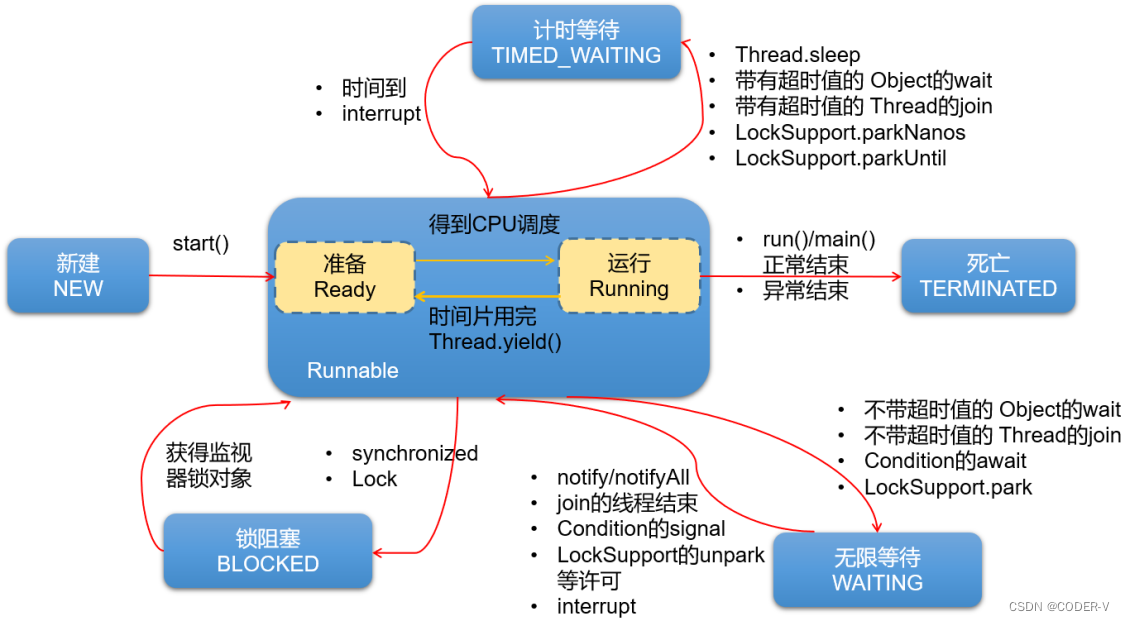
【Linux】进程概念
目录 一、基本概念 二、查看进程 三、系统调用获取进程标示符 1、获取自己的PID 2、获取父进程的PID 四、创建进程 1、初识fork 2、使用fork的方式 五、进程状态 1、阻塞 2、挂起 3、R状态 4、S状态 5、D状态 6、T状态 6.1、kill指令 6.2、暂停进程与继续进程 …...

使用pyinstaller库打包exe时显示KeyError怎么办
PyInstaller是一个Python库,用于将Python应用程序转换为独立的可执行文件(executable)文件,支持多平台。它可以将Python解释器、依赖的库和脚本打包成一个单独的可执行文件,从而使应用程序可以独立运行,而无…...

k8s新增节点机器,无法拉取和推送镜像的解决方案
1、首先检查配置,查看镜像仓库是否已授权,若无授权,则进行授权。 命令:cat /etc/systemd/system/docker.service.d/docker-options.conf内容如果有这样一句就是已经授权,如果没有,就需要把这句加进去&…...

测试报告踩坑的点
测试报告作为测试人员的核心输出项,是体现自己工作价值的重要承载工具,需要我们认真对待,所以我们要重视测试报告的输出,那么在编写测试报告的时候,我们有哪些点需要注意的呢? 01 不要乱用模板 很多测试新人在编写测试…...
【Java】创建多线程的四种方式
一、方式1:继承Thread类 步骤: 创建一个继承于Thread类的子类重写Thread类的run()方法 ----> 此线程执行的操作声明在方法体中创建当前Thread子类的对象通过实例对象调用start()方法,启动线程 ----> Java虚拟机会调用run()方法 注意…...

【数据结构】队列的接口实现(附图解和源码)
队列的接口实现(附图解和源码) 文章目录队列的接口实现(附图解和源码)前言一、定义结构体二、接口实现(附图解源码)1.初始化队列2.销毁队列3.队尾入队列4.判断队列是否为空5.队头出队列6.获取队列头部元素7…...

日本知名动画公司东映动画加入 The Sandbox 元宇宙
与 Minto 合作将东映动画的 IP 呈现在元宇宙。 The Sandbox 很荣幸能与东映动画合作,与 Minto 携手在 The Sandbox 元宇宙中创建基于东映动画 IP 的相关体验。 作为日本动画的先驱,东映动画制作了日本最大和世界领先的动画作品,包括《龙珠》、…...

QuickHMI Hawk R3 Crack
基于网络的 SCADA / HMI 系统 QuickHMI Hawk R3 QuickHMI是一个 100% 基于网络的SCADA/HMI 系统。 得益于HTML5、SVG和Javascript等现代网络技术,可视化可以在任何当前浏览器和设备中显示。作为浏览器的替代品,可以使用“独立查看器”和移动应用程序。 Q…...

【C语言】寻找隐藏字母游戏
编程实现一个游戏程序,会将连续三个字母中的一个隐去,由玩家填写隐去的那个字母,如屏幕上显示A ? C,则玩家需要输入B;屏幕上显示?B C,则玩家需要输入A。记录玩家完成20次游戏的时间以及正确率。…...

【C++】list 相关接口的模拟实现
list 模拟实现回顾准备构造析构函数的构造构造方法析构方法赋值运算符重载容量相关接口元素获取元素修改相关接口push 、popinserterase清空交换迭代器 **(重点)迭代器基本概念迭代器模拟实现回顾 在上一篇博客中我们大致了解了 list 相关接口的使用方法…...

快速找到外贸客户的9种方法(建议收藏)
所有外贸企业想要做好外贸出口的头等大事,就是要快速的找到优质的外贸客户和订单,没有订单的达成,所有的努力都是图劳,还有可能会陷入一种虚假的繁荣,每天都很忙,但是没有结果。今天,小编就来分…...

TCP状态转换
欢迎关注博主 Mindtechnist 或加入【Linux C/C/Python社区】一起探讨和分享Linux C/C/Python/Shell编程、机器人技术、机器学习、机器视觉、嵌入式AI相关领域的知识和技术。 TCP状态转换专栏:《Linux从小白到大神》《网络编程》 TCP状态转换示意图如下 针对上面的示…...

3500年里,印度被11个文明征服
转自:3500年里,印度被11个文明征服,如今看似统一,实际上却是缝合怪 (qq.com)今天的印度是亚洲第二大国,南亚第一大国,世界第二人口大国。如果我们将时间线拉长,纵观历史的长河,就会惊…...
)
Java编程问题top100---基础语法系列(一)
Java编程问题top100---基础语法系列一一、Java 操作符实质二、将InputStream转换为String使用IOUtils自己写轮子三、将数组转换为List四、如何遍历map对象使用For-Each迭代entries(方法一)使用For-Each迭代keys和values(方法二)使…...

【C#基础】C# 异常处理操作
序号系列文章6【C#基础】C# 常用语句讲解7【C#基础】C# 常用数据结构8【C#基础】C# 面向对象编程文章目录前言1,异常的概念2,处理异常3,自定义异常4,编译器异常结语前言 🌷大家好,我是writer桑,…...

系统分析师---操作系统思维导图
进程管理(5星) 进程与线程:共享:内存地址空间、代码、数据、文件等不能共享:独立的cpu运行上下文和栈指针、寄存器 信号量与PV操作:信号量,一种特殊的变量分为:信号量可以表示资源数…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...

省略号和可变参数模板
本文主要介绍如何展开可变参数的参数包 1.C语言的va_list展开可变参数 #include <iostream> #include <cstdarg>void printNumbers(int count, ...) {// 声明va_list类型的变量va_list args;// 使用va_start将可变参数写入变量argsva_start(args, count);for (in…...