利用GPT-3 Fine-tunes训练专属语言模型
利用GPT-3 Fine-tunes训练专属语言模型

文章目录
- 什么是模型微调(fine-tuning)?
- 为什么需要模型微调?
- 微调 vs 重新训练
- 微调 vs 提示设计
- 训练专属模型
- 数据准备
- 清洗数据
- 构建模型
- 微调模型
- 评估模型
- 部署模型
- 总结
什么是模型微调(fine-tuning)?
ChatGPT已经使用来自互联网的海量开放数据进行了预训练,对于任何输入都可以给出通用回答。如果我们想让ChatGPT的回答更有针对性,我们可以在输入时给出示例,ChatGPT可以通过“示例学习”(few-shot learning)理解你希望它完成的任务,并产生类似的合理输出。
但是“示例学习”每次需要给出示例,使用起来很不方便。微调(fine-tuning)可以通过训练更多示例来改进“短学习”,使用微调后的模型将不再需要在输入中提供示例。 这样既可以节约成本又可以实现更低延迟的请求。
更重要的是,对于一些专业场景,预训练模型可能无法达到理想的输出效果。此时需要我们给出更加具体和对口的数据对模型进行专门的强化,使其能够更好地回答该领域的问题,从而提升整体效果。
简而言之,微调允许我们将自定义数据集与大型语言模型(LLM)相匹配,让模型在我们的特定任务场景下依然表现良好。
为什么需要模型微调?
微调 vs 重新训练
这里有必要区分一下微调(fine-tuning) 和 重新训练(re-training) 的概念。
简单地说,重新训练是用新数据从头开始训练模型,而微调是用新数据调整先前训练模型的参数。
针对特定任务场景,微调比重新训练无论从时间还是费用上都更快更经济。
从头重新训练GPT-3 或 ChatGPT成本高的惊人。据估算,GPT-3一次训练的成本大约140万美元,ChatGPT模型更大,一次训练大约需要1200万美元。这还不包括上万颗A100GPU的成本。一块Nvidia A100 80G显存显卡按5万计算,1万块A100显卡光初始费用就5个小目标!很少有企业能够负担得起这么巨大的软硬件支出。
在GPT-3上微调也有成本,以功能最强的Davinci为例,训练成本0.03美元/1千token,这个成本相比重新训练天壤之别。下图是微调模型的训练和使用成本:

所以目前对大多数企业来说,只适合在GPT-3上做微调,除了少数巨头,绝大多数企业都没实力和能力重新训练。
微调 vs 提示设计
GPT-3支持“示例学习”(few-shot learning),我们可以通过在输入prompt时给予示例来提升模型输出效果,但提升效果远不如微调的效果,下面是微调和提示设计的效果对比:

对比提示设计,微调模型可以获得如下优势:
- 更好的输出效果
- 比示例学习更多的训练数据
- 减少token消耗从而节约成本
- 请求延迟更低
训练专属模型
可以通过以下6个主要步骤开始创建微调模型。为了方便大家理解,我会结合我们在GPT-3上定制客服机器人的Python代码来演示微调过程。

数据准备
GPT-3微调需要的数据格式是专属JSONL格式,形式如下:
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
上面的数据格式很好理解——每行都包含一个prompt和一个completion,表示特定提示对应的理想文本。
我们日常系统中的数据一般不会保存为JSONL格式,因此需要先将数据转换为JSONL格式。OpenAI提供了命令行工具来帮我们将常见数据格式转化为JSONL格式,用法如下:
openai tools fine_tunes.prepare_data -f <LOCAL_FILE>
其中<LOCAL_FILE>传入本地数据文件,支持CSV、TSV、XLSX、JSON 和 JSONL格式,只要文件中的数据格式是包含 prompt 和 completion 列或关键字就行。
数据准备阶段大家经常问的一个问题是*“我要准备多少数据用于微调才够?”*。通常来说,自然是“多多益善”,但由于微调设计训练成本,我们需要从中取得一个平衡。Open AI建议至少提供150–200个微调示例,但我个人在实际项目中发现150-200个微调示例往往不够,建议先从几百到一千条数据作为起始测试,根据微调后的模型效果再决定是否追加更多训练数据。

GPT-3支持自定义模型的持续微调,因此你可以随时用新数据在之前微调的模型上做进一步微调。
清洗数据
相比数据数量,数据质量更为关键。
GPT-3本质上是一个大型神经网络,它对我们来说是一个黑盒。所以它是典型的“garbage in, garbage out”,模型输出质量与训练数据质量有着直接的关系。
数据质量和多样性越高,模型就会工作得越好。通常需要一组不同的示例,以确保模型能够很好地泛化到新的示例。最好能够提供一个正面示例和负面示例,以确保模型能够处理各种输入。
为了验证微调模型质量,我们通常会将数拆分为训练集和验证集,通常按照80%/20%80\%/20\%80%/20%的比例进行拆分。
⚠注意:除JSONL格式外,训练数据和验证数据文件必须是UTF-8编码,并包含字节顺序标记(BOM),文件大小不能超过200MB。
构建模型
微调数据准备好后,我们就协议开始着手微调模型了。在开始微调训练之前,我们需要先确定微调的基础模型。
每个微调工作都从一个基础模型开始,默认为curie。基础模型不同会影响模型的性能和微调模型的成本。目前支持微调的基础模型包括:ada、babbage、curie或davinci。
下面是用Python完成模型构建:
import openaiopenai.api_key = "YOUR_API_KEY"resp = openai.FineTune.create(training_file="training_file_path", validation_file="validation_file_path", check_if_files_exist=True, model="davinci")
job_id = resp["id"]
status = resp["status"]
print(f'微调任务ID: {job_id},状态: {status}\n')
上面的代码选择davinci作为基础模型,并传入了训练集和验证集的本地文件路径,创建微调任务。如果创建成功,则会返回微调任务的id及状态。
创建微调任务还支持其他参数,说明如下:
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
training_file | string | 训练集文件路径,必须是JSONL格式 | |
validation_file | string | null | 验证集文件路径,必须是JSONL格式 如果提供,则在微调期间,定期生成验证度量。这些指标可以在微调结果文件中查看。 训练集数据与验证集数据必须互斥。 |
check_if_files_exist | boolean | true | 是否检验文件是否存在 |
model | string | curie | 要微调的基础模型的名称。可以选择ada、babbage、curie、davinci或2022-04-21之后创建的微调模型。 |
n_epochs | int | 4 | 训练几轮。 |
batch_size | int | null | 训练的批次大小。默认情况下,批次大小将动态配置为训练集样本数的约0.2%,上限为256。通常来说较大的批次大小对于较大的数据集更有效。 |
learning_rate_multiplier | float | null | 学习率系数。微调学习率=预训练的原始学习率乘以该值。 默认情况下,学习率系数为0.05、0.1或0.2,具体取决于最终批次大小(较大的学习率往往在较大的批次大小下表现更好)。我们建议使用0.02到0.2范围内的值进行实验,以查看产生最佳结果的方法。 |
prompt_loss_weight | float | 0.01 | 提示损失权重。控制模型学习生成提示(生成输出的权重为1),并增加输出较短时训练的稳定性。 如果提示非常长(相对于输出),那么减少这个权重可以避免过度学习。 |
compute_classification_metrics | boolean | false | 如果为true,则在每轮训练结束时使用验证集计算效果,例如准确度和F-1 score 。这些指标可以在结果文件中查看。 |
classification_n_classes | int | null | 分类任务中的类别数。 多类别分类需要此参数。 |
classification_positive_class | string | null | 二分类任务中的正例。 在进行二分类时,需要此参数来生成精度、召回率和F1 score 。 |
classification_betas | array | null | 如果提供,将按照指定的beta值计算F-beta分数。F-beta是F-1的概括。仅用于二分类任务。 beta为1(即F-1分数)时,准确率和召回率的权重相同。beta越大,召回率的权重越大,准确率的权重越小。beta分数越小,准确率权重越高,召回率权重越低。 |
suffix | string | null | 最多40个字符的字符串,将添加到微调后的模型名称中。 |
微调模型
微调任务创建之后通常处于Pending状态,这是因为OpenAI系统中通常有其他任务排在你之前,我们的任务会先放在队列中,等待被处理。一般来说一旦进入训练状态,微调训练可能需要几分钟或几小时,具体取决于选择的基础模型和数据集的大小。我们可以用微调任务id来查询微调任务的状态:
while status not in ["succeeded", "failed"]:time.sleep(2)# 获取微调任务的状态status = openai.FineTune.retrieve(id=job_id)["status"]print(f'微调任务ID: {job_id},状态: {status}')print(f'微调任务ID: {job_id} 完成, 结束状态: {status}\n')
评估模型
微调成功后都会有训练结果输出,可以通过如下代码获取评估结果:
fine_tune = openai.FineTune.retrieve(id=job_id)
result_files = fine_tune.get("result_files", [])
if result_files:result_file = result_files[0]resp = openai.File.download(id=result_file["id"])print(resp.decode("utf-8"))
这里有丰富的模型评估数据,供我们对模型微调质量进行评估。
部署模型
如果模型效果满意,我们就可以将模型投入生产使用了。openai.FineTune.retrieve()方法返回的数据结构中的fine_tuned_model就是微调后的模型名称。可以直接拿这个模型名称在API中使用。
model_name = openai.FineTune.retrieve(id=job_id)["fine_tuned_model"]response = openai.Completion.create(model=model_name,prompt="今天晚上吃什么好呢?\n",temperature=0.7,max_tokens=256,top_p=1,frequency_penalty=0,presence_penalty=0,stop=["END"]
)
总结
ChatGPT最让人惊艳的一点,就在于能够像人一样去对话。这种流畅的人机对话背后所展现的强大的自然语言理解力和表达力,目前只表现在通用领域。一旦进入某个专业领域,ChatGPT经常会“一本正经,胡说八道”。此时用特定领域的知识对模型进行微调是时间成本和经济成本最高的解决方案。事实证明,哪怕是最小的训练数据,也会带来明显的表现提升。
未来随着LLM变得更大、更易访问和开源,相信在不久的将来,我们可以看到微调在自然语言处理中无处不在。同时我也非常期待边缘学习的突破,可以将大模型训练的成本降下来,那时我们再来看如何从头重新训练一个大模型。
相关文章:
利用GPT-3 Fine-tunes训练专属语言模型
利用GPT-3 Fine-tunes训练专属语言模型 文章目录什么是模型微调(fine-tuning)?为什么需要模型微调?微调 vs 重新训练微调 vs 提示设计训练专属模型数据准备清洗数据构建模型微调模型评估模型部署模型总结什么是模型微调࿰…...
kubeadm方式安装k8s高可用集群(版本1.26x)
K8S官网:https://kubernetes.io/docs/setup/ 高可用Kubernetes集群规划 配置备注系统版本CentOS 7.9Docker版本20.10.xPod网段172.16.0.0/12Service网段10.103.10.0/16 主机IP说明k8s-master01 ~ 03192.168.77.101 ~ 103master节点 * 3k8s-master-lb192.168.77.2…...

分享5款堪称神器的免费软件,建议先收藏再下载
转眼间新年已经过去一个月了,最近陆陆续续收到好多小伙伴的咨询,这边也是抓紧整理出几个好用的软件,希望可以帮到大家。 1.电脑安全管家——火绒 火绒是一款电脑安全软件,病毒库更新及时,界面清晰干净,没…...
【项目实战】从0开始入门JDK源码 - LinkedList源码
一、源码位置 一般来说IDEA配置好JDK以后 ,JDK的源码其实也配置好了,本文是基于JDK1.8的源码说明 rt - java - util - LinkedList 二、 继承关系图 LinkedList public class LinkedList<E>extends AbstractSequentialList<E>implements...

Polygon zkEVM的gas定价
1. 引言 所有的zkEVM都存在一个有趣的问题: 如何给gas定价? 在Ethereum Virtual Machine (EVM)中,gas通过为每个计算设置economic fee,来保持网络安全。恶意行为,如拒绝服务(DoS)攻击&#x…...

stl中的智能指针类详解
C98/03的尝试——std::auto_ptr C11标准废弃了std::auto_ptr(在C17标准中被移除),取而代之的是std::unique_ptr, std::auto_ptr容易让人误用的地…...
Linux 阻塞和非阻塞 IO 实验
目录 一、阻塞和非阻塞简介 1、IO 概念 2、阻塞与非阻塞 二、等待队列 1、等待队列头 2、等待队列项 3、将队列项添加/移除等待队列头 4、等待唤醒 5、等待事件 三、轮询 1、应用程序的非阻塞函数 2、Linux 驱动下的 poll 操作函数 四、阻塞IO之等待事件唤醒 添加…...

你要的react+ts最佳实践指南
本文根据日常开发实践,参考优秀文章、文档,来说说 TypeScript 是如何较优雅的融入 React 项目的。 温馨提示:日常开发中已全面拥抱函数式组件和 React Hooks,class 类组件的写法这里不提及。 前沿 以前有 JSX 语法,…...

软件测试人员会被替代吗?IT行业哪个方向的前景最好?字节12年测开是这样说的
互联网测试从业12年,前来作答。 逻辑上来说,软件工程最初始只需要两个岗位,一个是产品经理。,一个是研发(开发),剩余的 所有岗位都是由他们衍生而来的。 第三个岗位大概率就是测试,…...
十六、vue3.0之富文本编辑器的选择
在工作过程中我们会遇到很多的时候会使用到富文本编辑器,市场上流行的也是各种各样的,那么究竟如何选择呢,今天就给大家讲讲有哪一些,方便大家的选择。 一、TinyMCE TinyMCE 是富文本编辑器领域的头部玩家之一,主流富文本编辑器,功能非常全,你需要的大多数功能它都支持…...
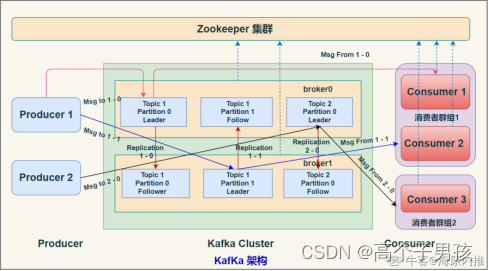
kafka(一) 的架构,各概念
Kafka架构 Kafak 总体架构图中包含多个概念: (1)ZooKeeper:Zookeeper负责保存broker集群元数据,并对控制器进行选举等操作。 (2)Producer: 生产者负责创建消息,将消息发…...

【ts的常用类型】
ts的常用类型前言安装ts常见类型原始类型 、数组、 any变量上的类型注解函数对象类型联合类型类型别名接口接口和类型别名的对比前言 typescript中为了使编写的代码更规范,更有利于维护,增加了类型校验,安装 安装 typescript npm i typescr…...

Hyper-V与安卓模拟器不共存
一是某些新的模拟器已经开始使用新接口开发,支持了共存,安装这种新的安卓模拟器即可。 对于不支持共存的模拟器,只得增加一个windows开机后的系统选项,如果需要切换这两种不同选项使用系统,每次切换都需要重启windows系…...
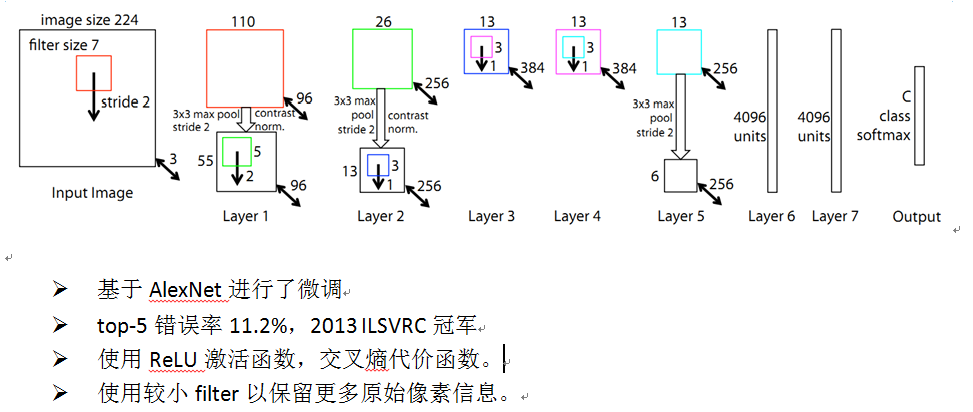
【图像分类】卷积神经网络之ZFNet网络模型结构详解
写在前面: 首先感谢兄弟们的关注和订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。 1. 前言 由于AlexNet的提出,大型卷积网络开始变得流行起来,但是人们对于网络究竟为什么能表现的这么好,以及怎…...
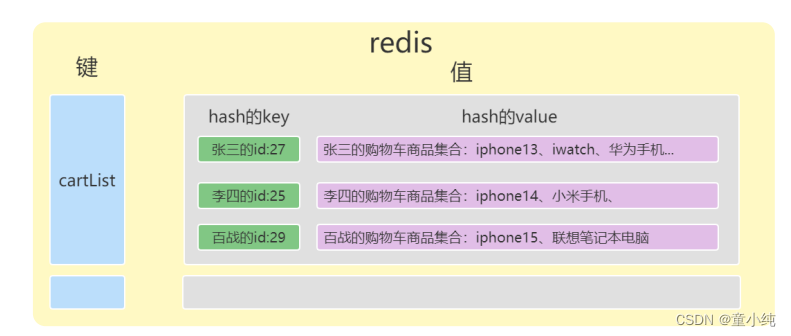
亿级高并发电商项目-- 实战篇 --万达商城项目 十三(编写购物车、优化修改商品、下架商品方法、购物车模块监听修改商品、删除商品消息)
👏作者简介:大家好,我是小童,Java开发工程师,CSDN博客博主,Java领域新星创作者 📕系列专栏:前端、Java、Java中间件大全、微信小程序、微信支付、若依框架、Spring全家桶 Ǵ…...
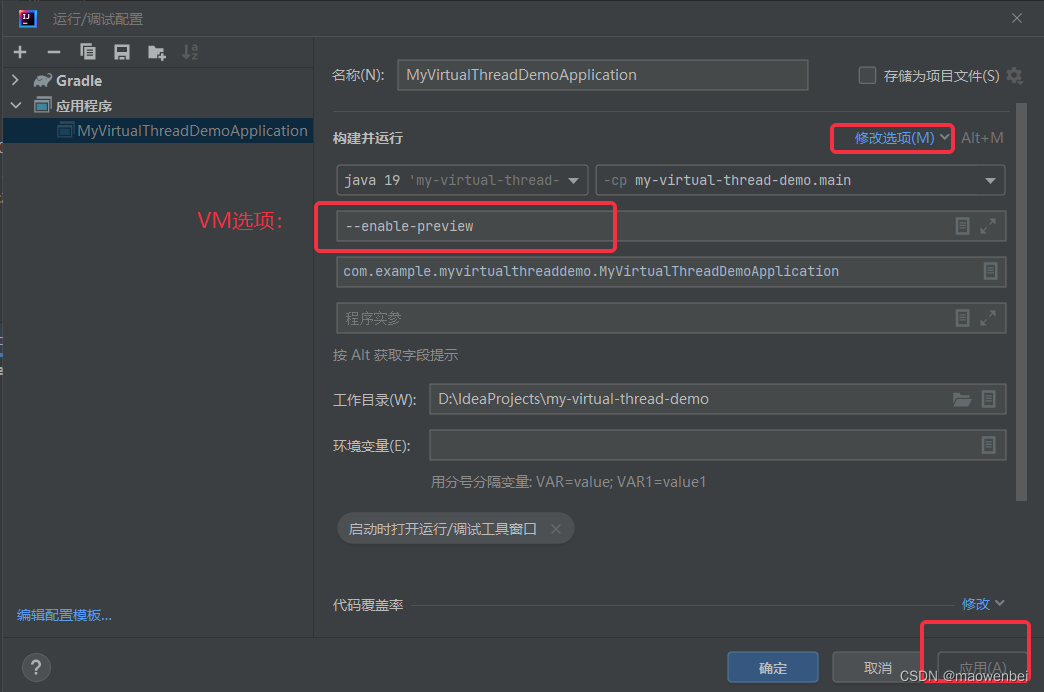
springboot 虚拟线程demo
jd19支持虚拟线程,虚拟线程是轻量级的线程,它们不与操作系统线程绑定,而是由 JVM 来管理。它们适用于“每个请求一个线程”的编程风格,同时没有操作系统线程的限制。我们能够创建数以百万计的虚拟线程而不会影响吞吐。 做个 spri…...

CTFer成长之路之逻辑漏洞
逻辑漏洞CTF 访问url: http://1b43ac78-61f7-4b3c-9ab7-d7e131e7da80.node3.buuoj.cn/ 登录页面用随意用户名密码登录 访问url: http://1b43ac78-61f7-4b3c-9ab7-d7e131e7da80.node3.buuoj.cn/user.php 登陆后有商品列表,共三个商品,点击购买flag 钱…...
)
入门力扣自学笔记238 C++ (题目编号:1144)
1144. 递减元素使数组呈锯齿状 题目: 给你一个整数数组 nums,每次 操作 会从中选择一个元素并 将该元素的值减少 1。 如果符合下列情况之一,则数组 A 就是 锯齿数组: 每个偶数索引对应的元素都大于相邻的元素,即 A…...

蓝桥杯-寒假作业
没有白走的路,每一步都算数🎈🎈🎈 题目描述: 有四个等式,每个等式的运算规则已经定好了,也就是我们常见的小学的四则运算,但是能够用来四则运算的数字非常有限,包括1~13…...
测试用例篇
1.测试用例的意义 测试用例(Test Case)是为了实施测试而向被测试的系统提供的一组集合,这组集合包含:测试环境、操作步骤、测试数据、预期结果等要素。 测试用例的意义是为了帮助测试人员了解测什么,怎么测 eg&#x…...

二手交易平台信任度调查:闲鱼交易安全性深度解析
二手交易平台信任度调查:闲鱼交易安全性深度解析随着循环经济的兴起,中国二手交易市场规模在2023年突破万亿元大关。作为阿里巴巴旗下的C2C二手交易平台,闲鱼凭借5亿注册用户和日均10亿元的交易规模,已成为国内最大的闲置物品流转…...

2026实测不踩坑!6款成品PPT网站客观测评
2026实测不踩坑!6款成品PPT网站客观测评作为常年深耕AI工具测评的博主,日常需应对各类PPT创作需求,也经常收到粉丝咨询相关工具选择。经过实测多款成品PPT网站后,整理出6款适配性较强的平台,涵盖不同需求场景ÿ…...

**发散创新:基于微应用架构的轻量级权限控制实战设计**在现代前端开
发散创新:基于微应用架构的轻量级权限控制实战设计 在现代前端开发中,**微应用(Micro Frontend)*8 已成为构建复杂单页应用(SPA)的标准方案之一。它允许团队独立开发、部署和维护各自的功能模块,…...

从make clean到build.prop:揭秘Android系统属性生成的完整链条
从make clean到build.prop:揭秘Android系统属性生成的完整链条 当你通过adb shell getprop ro.build.display.id查看设备版本号时,是否好奇过这个字符串背后的生成逻辑?在Android编译系统中,从Makefile执行到最终生成build.prop文…...

Vue 中的 deep、v-deep 和 >>> 有什么区别?什么时候该用
点赞 收藏 学会🤣🤣🤣 “你用 Element Plus 写了个按钮,想改下 hover 颜色,结果死活不生效!最后查了半天,发现得加个 :deep() 才行” 其实,这是 Vue 中一个非常常见的坑…...

新手最值得入的一款ai音乐工具
2026年,ai音乐爆发的一年。国内国外各种AI音乐工具层出不穷。想要尝试AI音乐的新手宝宝该怎么去选择呢?市面上大大小小的ai音乐创作软件我基本都尝试过。我觉得只有一款工具是最值得推荐的,也是我使用的最多的。那就是蘑兔AI,你们…...

2026年全国优质网站建设公司权威甄选榜,推荐十家公司官网搭建与设计制作服务商能力评估正式发布
据Gartner、QuestMobile联合发布的2026年企业数字化服务报告显示,国内网站建设行业市场规模突破1870亿元,同比增长19.3%;上海作为长三角数字经济核心枢纽,企业官网新建与升级需求同比提升27.8%,其中高端定制建站需求增…...
)
别再手动整理了!用Python脚本5分钟搞定ImageNet验证集标签映射(附完整代码)
5分钟极速搞定ImageNet验证集标签映射:Python自动化实战指南 每次处理ImageNet验证集时,你是否也对着那些晦涩的数字标签头疼不已?手动查表不仅效率低下,还容易出错。今天我们就来彻底解决这个痛点——用Python脚本自动完成标签映…...
)
FPGA新手避坑指南:用Xilinx MIG IP核驱动DDR3内存的完整配置流程(以MT41J256M16为例)
FPGA新手避坑指南:Xilinx MIG IP核驱动DDR3内存的完整配置流程(以MT41J256M16为例) 第一次接触FPGA与DDR3接口设计时,面对密密麻麻的芯片手册和复杂的IP核配置界面,很多工程师都会感到无从下手。本文将手把手带你完成从…...

Intent-MPC论文复现手记:我是如何用Docker搞定ROS多版本环境隔离的
Intent-MPC论文复现实战:基于Docker的ROS多版本环境隔离方案 当我在复现Intent-MPC这篇关于无人机动态环境轨迹预测的前沿论文时,最头疼的不是算法理解,而是环境配置——ROS Noetic的依赖冲突、系统库版本不匹配、图形界面无法显示等问题接踵…...