深度学习损失函数
Loss 是深度学习算法中重要的一部分,它的主要功能是评价网络预测的准确性和指导权重更新。合适 Loss 可以让网络收敛更快,预测更准。这个项目介绍了损失函数的基本概念以及7种常用损失函数的形式,性质,参数,使用场景及区别,并给出了开箱即用的Paddle实现。目前包含的Loss有:
L1(Mean Absolute Error)
L2(Mean Square Error)
Huber Loss
LogCosh Loss
Cross Entropy(Log Loss)
Focal Loss
Hinge Loss
未完待续…
关键概念
先引入一些概念,方便后面介绍。功能角度,我们可以形容深度学习是一种从训练数据中学习,进而形成问题解决方案的算法。如果训练数据是有标签的,那么它就属于一个监督学习任务(比如房价预测或手写数字识别)。形式化的,我们可以描述监督学习为: 给算法一个有标签的训练数据集
(
�
,
�
)
(X,Y),希望算法能学习出一个
�
−
�
X−>Y 的映射关系
�
f,使得不仅对于训练集中的
�
x,
�
(
�
)
f(x) 与对应的
�
y 接近,而且对不在训练集中的
�
x,
�
(
�
)
f(x) 也与实际的
�
y 接近。
听起来很美好,但具体怎么操作呢? 这里就要用到Loss。我们在理解监督学习概念的时候可以用 “接近” 这样定性的描述,但是算法需要一个函数来量化模型给出的预测和训练数据中对应标签的差异,我们把这个函数叫做Loss。形式化的,可以将Loss定义为网络预测值
�
p 和实际标签
�
y 的函数
�
(
�
,
�
)
L(p,y)。
Loss的性质
Loss函数需要满足一些性质,首先最明显的,它应该能够描述我们上面概念中的"接近"。预测值接近标签 Loss 应该小,否则 Loss 应该大。 其次,深度学习使用的梯度下降优化方法需要让模型权重沿着 Loss 导数的反向更新,所以这个函数需要是可导的,而且不能导数处处为0(这样权重动不了)。 此外有一些加分项,比如 MSE Loss 的梯度正比于 Loss 值,因此用 MSE 做训练收敛速度一般比 MAE 快。
Loss的分类
不同的深度学习任务定义 “接近” 的标准不同,因此 Loss 也有很多种,但大致可以分为两类: 回归 Loss 和 分类 Loss。两类问题最明显的区别是回归预测的结果是连续的(比如房价),而分类预测的结果是离散的(比如手写识别输出这个数字是几)。虽然很多实际的深度学习应用比上面的两个例子复杂但是也可以用回归和分类来描述。比如语义分割可以看成对图像中的每一个像素点进行分类,目标检测可以看成对Bounding Box在图像中的位置和大小进行回归,NLP总情感倾向分析可以看成对句子进行积极和消极分类。
符号
下面的表达式都按照这个符号标准:
x:训练数据集中的一个输入
y:训练数据集中的一个输出
p:网络针对一个输入给出的预测值
M:分类问题中的类别数量
N:输入loss的数据条数,可以理解为Batch Size
i:第i条数据
j:第j个输出
开篇的废话就这么多,下面首先回归之后分类进入正题。
回归 Loss
这里画出了所有 Loss 的函数图像,可以对照查看。
Mean Absolute Error (L1 Loss) 和 Mean Square Error(L2 Loss)
�
1
�
�
�
�
1
�
∑
∣
�
−
�
∣
L1Loss=
N
1
∑∣y−p∣
�
2
�
�
�
�
1
�
∑
(
�
−
�
)
2
L2Loss=
N
1
∑(y−p)
2
L1和L2 Loss很类似,而且一些性质比较着说更清楚,因此放在一起。首先计算方法上 L1 Loss 是求所有预测值和标签距离的平均数,L2 Loss 是求预测值和标签距离平方的平均数。二者的结构很类似,区别就是一个用了绝对值一个用了平方。在性质上,二者主要有三个方面的不同:离群点鲁棒性,梯度和是否可微。
离群点鲁棒性
离群点是数据中明显偏离整体分布的点。在深度学习任务中,离群点一般代表噪声,比如整理数据的时候 1.5 忘写小数点了变成了 15,其他数据还都是1.x,那这条数据就变成了离群点。但是在有些场景下一些数据点可能就是比较特殊,它们的确离群但不是数据中的错误。如果是第一种情况,我们在训练的过程中会希望降低脏数据对网络的影响。如果是第二种,离群点是特殊情况,我们会希望考虑这些特殊的信息,但不希望他们给网络整体性能带来太大的影响。L2 Loss 对于预测值和标签的距离做了平方,当距离大于 1 的时候平方操作会放大误差,因此离群点的Loss会非常大,导致 L2 Loss 对其倾斜更多的权重。相比之下 L1 Loss 的情况会好一些,因为只是做了绝对值,所以对离群点不如 L2 敏感。比如下面这组数据:
预测值 标签 L1 L1(离群) 变化 L2 L2(离群) 变化比率
1.1 1 0.1 0.1 0.01 0.01
1.2 1.2 0 0 0 0
1.3 1.5/3 0.2 1.7 0.04 2.89
0.1 0.6 6 0.016 0.97 60.6
网络预测值相同的情况下,如果数据1.5变成一个离群点,L1 Loss变大了6倍,L2 Loss变大了60倍。显然用L2 Loss拟合出的结果会对这个离群点更敏感:
黑线为用L1的结果,红线为用L2的结果
此外可以想象一个直观的例子,拟合一批
�
x 都一样的数据,比如
�
y 轴上的一些点,这样
�
x 都为0。拟合出来的结果和
�
y 轴的交点,如果用 L1 Loss 应该是中位数,如果用 L2 Loss 应该是平均数。对离群点来说,中位数比平均数显然更鲁棒。
梯度
对 L1 和 L2 Loss求导可以知道 L1 Loss 的梯度一直是
±
1
±1,而 L2 Loss 的梯度是正比于 Loss 值的,Loss 值越大梯度越大。在梯度的性质上L2是优于L1的,体现在两个方面。当Loss非常大的时候,L1的梯度一直是
1
1,这样收敛的速度比L2慢。其次当 Loss 很接近0的时候L1的梯度还是1,这个大梯度容易让网络越过 Loss 最低点,导致 Loss 在最低点附近震荡,相比之下 L2 在 Loss 接近0的时候梯度也接近0,不存在这样震荡的问题。
可微
因为L1 Loss是个分段函数,所以在最低点是不可微的。L2则全程可微,最后一定会稳定收敛到一个最优解。但是需要注意的是L2不是一个凸函数,因此收敛到的解不一定是全局最优解,也有可能是一个局部最优解。
L1和L2的选择
总体上来说L2训练收敛的速度快,选择L2的情况比较多。如果训练数据中存在比较多的脏数据应该选择L1 Loss避免其影响结果。
下面是实现:
In [1]
初始化一些环境,这个部分下面所有Loss都会用到
import paddle.fluid as fluid
import numpy as np
places = fluid.CPUPlace()
exe = fluid.Executor(places)
In [23]
def l1_loss(pred, label):
loss = fluid.layers.abs(pred - label)
loss = fluid.layers.reduce_mean(loss)
return loss
l1_program = fluid.Program()
with fluid.program_guard(l1_program):
pred = fluid.data(‘pred’, [3,1], dtype=“float32”)
gt = fluid.data(‘gt’, [3,1], dtype=“float32”)
loss = l1_loss(pred, gt)
pred_val = np.array([[1], [2], [3] ],dtype=“float32”)
gt_val = np.array([[1], [3], [6] ],dtype=“float32”)
loss_value=exe.run(l1_program, feed={ ‘pred’: pred_val , “gt”: gt_val },fetch_list=[loss])
print(“L1 Loss:”, loss_value)
L1 Loss: [array([1.3333334], dtype=float32)]
In [24]
def l2_loss(pred, label):
loss = (pred - label) ** 2
loss = fluid.layers.reduce_mean(loss)
return loss
l2_program = fluid.Program()
with fluid.program_guard(l2_program):
pred = fluid.data(‘pred’, shape=[3,1], dtype=‘float32’)
gt = fluid.data(‘gt’, shape=[3,1], dtype=‘float32’)
loss = l2_loss(pred, gt)
pred_val = np.array([[3], [2], [1]], dtype=‘float32’)
gt_val = np.array([[1], [2], [3]], dtype=‘float32’)
loss_value = exe.run(l2_program, feed={‘pred’: pred_val, ‘gt’: gt_val}, fetch_list= [loss])
print(“L2 Loss:”, loss_value)
L2 Loss: [array([2.6666667], dtype=float32)]
Mean Bias Error
�
�
�
�
�
�
�
�
�
�
�
�
�
1
�
(
�
−
�
)
MeanBiasError=
N
1
(p−y)
MBE是不做绝对值的L1 Loss,它的一个主要的问题是正负 Loss 会相互抵消,在深度学习的应用很少。但是因为没做绝对值所以可以看出网络预测的结果是偏大还是偏小。
In [25]
def mean_bias_error(pred, label):
loss = pred - label
loss = fluid.layers.reduce_mean(loss)
return loss
mbe_program = fluid.Program()
with fluid.program_guard(mbe_program):
pred = fluid.data(‘pred’, shape=[3,1], dtype=‘float32’)
gt = fluid.data(‘gt’, shape=[3,1], dtype=‘float32’)
loss = mean_bias_error(pred, gt)
pred_val = np.array([[3], [2], [1]], dtype=‘float32’)
gt_val = np.array([[1], [2], [3]], dtype=‘float32’) # 这组数据上正负的bias就抵消了,这也是深度学习基本不用这个loss的原因
loss_value = exe.run(mbe_program, feed={‘pred’: pred_val, ‘gt’: gt_val}, fetch_list= [loss])
print(“MBE:”, loss_value)
MBE: [array([0.], dtype=float32)]
Huber loss(Smooth L1 Loss)
注:Smooth L1 Loss 并不是Huber的别名,而是一个特殊情况。
�
�
�
�
�
�
�
�
�
{
1
2
(
�
−
�
)
2
∣
�
−
�
∣
<
�
�
∣
�
−
�
∣
−
1
2
�
2
�
�
ℎ
�
�
�
�
�
�
HuberLoss={
2
1
(y−p)
2
δ∣y−p∣−
2
1
δ
2
∣y−p∣<δ
otherwise
Huber是 L1 和 L2 Loss 的分段组合。前面我们已经知道 L1 在有离群点时性能好,L2 在接近零点处稳定收敛, 于是将二者组合:在零点附近用L2,其余位置用 L1 就形成了 Huber Loss。具体的选择范围用
�
δ 划分。
�
δ 取 1 的 Huber Loss 也叫 Smooth L1 Loss,所以说Smooth L1是Huber的一种特殊情况。分段组合克服了两个 Loss 各自的一部分弱点,Huber Loss对离群点没有 L2 敏感,在零点附近也不会出现 L1 的震荡。通过调节
�
δ 可以调节 Huber Loss 对离群点的敏感度,
�
δ 越大,使用L2的区间越大,对离群点越敏感; 反之
�
δ 越小越不敏感。
In [26]
def huber_loss(pred, label, delta=1): # 这个实现里面去掉了 1/2常数项 ,这样不需要用 if,更简洁
l2 = (pred - label) ** 2
l1 = fluid.layers.abs(pred - label) * delta
loss = fluid.layers.elementwise_min(l1, l2)
loss = fluid.layers.reduce_mean(loss)
return loss
huber_program = fluid.Program()
with fluid.program_guard(huber_program):
pred = fluid.data(‘pred’, shape=[3,1], dtype=‘float32’)
gt = fluid.data(‘gt’, shape=[3,1], dtype=‘float32’)
loss = huber_loss(pred, gt, delta=2)
pred_val = np.array([[4], [2], [1]], dtype=‘float32’)
gt_val = np.array([[1], [2], [3]], dtype=‘float32’)
loss_value = exe.run(huber_program, feed={‘pred’: pred_val, ‘gt’: gt_val}, fetch_list= [loss])
print(“Huber Loss:”, loss_value)
Huber Loss: [array([3.3333333], dtype=float32)]
log-cosh
�
�
�
�
�
�
ℎ
�
�
�
(
�
�
�
ℎ
(
�
−
�
)
)
LogCosh=log(cosh(y−p))
形如其名,Log-cosh 计算上是先做cosh之后做log。这个函数的特点是在 Loss 比较小的时候,值近似于
1
2
�
2
2
1
x
2
,而在值比较大的时候近似于
∣
�
−
�
∣
−
�
�
�
(
2
)
∣y−p∣−log(2)。 他基本和 Huber Loss的性质相同,但是处处二阶可微。(一些优化方法有这个要求)
红色为Log-Cosh,紫色为Huber Loss
In [27]
def logcosh_loss(pred, label):
loss = pred - label
e = np.e * fluid.layers.ones_like(loss)
cosh = ( fluid.layers.elementwise_pow(e, loss) + fluid.layers.elementwise_pow(e, 0-loss) ) / 2
log = fluid.layers.log(cosh)
loss= fluid.layers.reduce_mean(log)
return loss
logcosh_program = fluid.Program()
with fluid.program_guard(logcosh_program):
pred = fluid.data(‘pred’, shape=[3,1], dtype=‘float32’)
gt = fluid.data(‘gt’, shape=[3,1], dtype=‘float32’)
loss = logcosh_loss(pred, gt)
pred_val = np.array([[4], [2], [1]], dtype=‘float32’)
gt_val = np.array([[1], [2], [3]], dtype=‘float32’)
loss_value = exe.run(logcosh_program, feed={‘pred’: pred_val, ‘gt’: gt_val}, fetch_list= [loss])
print(“Log-Cosh:”, loss_value)
Log-Cosh: [array([1.2114438], dtype=float32)]
Quantile Loss(分位数损失)
�
�
�
�
�
�
�
�
�
�
�
�
∑
�
:
�
�
�
�
(
1
−
�
)
∣
�
�
−
�
�
∣
+
∑
�
:
�
�
<
�
�
�
∣
�
�
−
�
�
∣
QuantileLoss=∑
i:p
i
y
i
(1−γ)∣y
i
−p
i
∣+∑
i:p
i
<y
i
γ∣y
i
−p
i
∣
在一些场景下(比如商业决策),用户可能会希望了解预测中的不确定性,并基于此进行决策。这种情况下希望算法给出一个预测区间而不是单一的一个值。 此外,前面的 Loss 关注的都是给出单一值的点预测,这种预测的假设是输入数据符合一个目标函数
�
(
�
)
f(x) 加上一个方差恒定的独立变量残差。 如果训练数据不满足这种性质那么线性回归模型就不成立,预测的效果不会好。即便对于具有变化方差或非正态分布的残差,基于分位数损失的回归也能给出合理的预测区间。
分位值
�
�
�
�
�
gamma 的选择取决于我们对高估和低估的重视程度。 从公式形式上,
�
γ 是低估部分的斜率,因此
�
γ 越大,对低估的惩罚越大,区间会偏高。
经常会看到的拟合
�
�
�
(
�
)
sin(x)
In [28]
def quantile_loss(pred, label, gamma):
dist = fluid.layers.abs(pred - label)
cond = fluid.layers.greater_than(pred, label)
ie = fluid.layers.IfElse(cond)
with ie.true_block():
loss = ie.input(dist)
loss = (1 - gamma) * loss
ie.output(loss)
with ie.false_block():
loss = ie.input(dist)
loss = gamma * loss
ie.output(loss)
loss = ie()[0] # 返回的是一个list
loss = fluid.layers.reduce_mean(loss)
return loss
quantile_program = fluid.Program()
with fluid.program_guard(quantile_program):
pred = fluid.data(‘pred’, shape=[4,1], dtype=‘float32’)
gt = fluid.data(‘gt’, shape=[4,1], dtype=‘float32’)
loss = quantile_loss(pred, gt, 0.5)
pred_val = np.array([[4], [2], [1], [3]], dtype=‘float32’)
gt_val = np.array([[1], [2], [3], [4]], dtype=‘float32’)
loss_value = exe.run(quantile_program, feed={‘pred’: pred_val, ‘gt’: gt_val}, fetch_list= [loss])
print(“quantile loss:”, loss_value)
quantile loss: [array([0.75], dtype=float32)]
最后是一张回归Loss的全家福:
在这里查看更清楚
分类 Loss
先说说为什么前面我们有了回归的 Loss 还需要特别分出来一类用来分类的 Loss,性质上分类 Loss 和回归 Loss 有什么不同。首先分类问题和回归问题最明显的区别是分类问题输出的是一些概率,范围是0~1。我们一般在网络的输出层用 Sigmoid 函数
1
1
+
�
−
�
1+e
−x
1
实现这个限制。为了说明方便,下文将网络最后一层进入启动函数 Sigmoid 之前的值称为
�
O,将经过 Sigmoid 之后的概率称为
�
P。下面是 Sigmoid 的函数图像
可以看出,这个函数的函数值在输入比较大和比较小的时候都极其接近1(函数值在4的时候已经是0.982),而且很平,导数很小。我们可以设想训练中的一个情况:使用MSE Loss而且网络最后一层的
�
O 比较大(初始化如果做的不好很可能第一个batch就是这样)。这种情况对应Sigmoid图像中X轴右侧的一个点,我们来分析此时 Loss 相对
�
O 的梯度。在这个位置 Sigmoid 很平,所以就算
�
O 有很大的变化对应的
�
P 变化也很小,反映到 Loss 上变化也很小。因此当
�
O 较大或较小的时候 Loss 的梯度都很小,会导致训练缓慢。相比之下分类 Loss 在输出接近0或1的时候极其敏感,一点很小的变化都会给 Loss 带来很大的变化,因此训练更快。
额外要说一下,分类问题里面有二分类(比如猫狗二分类)也有分成多类(比如ImageNet)的情况,虽然二分类可以看成一种分成两类的多分类情况,但是因为用的比较多而且好理解所以我们这里基本以二分类为例介绍。后期会逐步完善分成多类Loss的实现。
Cross entropy(交叉熵,Log Loss)
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
−
1
�
∑
�
1
�
[
�
�
�
�
�
(
�
�
)
+
(
1
−
�
�
)
�
�
�
(
1
−
�
�
)
]
BinaryCrossEntropy=−
N
1
∑
i=1
N
[y
i
log(p
i
)+(1−y
i
)log(1−p
i
)]
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
−
1
�
∑
�
1
�
∑
�
1
�
�
�
�
�
�
�
(
�
�
�
)
CategoricalCrossEntropy=−
N
1
∑
i=1
N
∑
j=1
M
y
ij
log(p
ij
)
分类问题中最常用的是交叉熵Loss。这个Loss来自香农的信息论,原理介绍就略过了,但是通过图像可以十分直观的看出来为什么这种 Log 的形式适合做分类的 Loss 。
上升的曲线对应标签
�
0
y=0 的情况,下降的曲线对应
�
1
y=1的情况。比如在
�
0
y=0 时,如果预测结果
�
p 也是 0 ,那么皆大欢喜 Loss 为 0。但是如果
�
p 不是 0,那么
�
p 越接近 1 Loss 越大而且增长的非常快。
In [29]
def bce_loss(pred, label, epsilon=1e-05): # 标签都是 0或1,但是计算上log(0)不合法,所以一般将label和pred卡到[eps, 1-eps]范围内
label = fluid.layers.clip(label, epsilon, 1-epsilon)
pred = fluid.layers.clip(pred, epsilon, 1-epsilon) # 防止出现log(0)
loss = -1 * (label * fluid.layers.log(pred) + (1 - label) * fluid.layers.log(1 - pred))
loss = fluid.layers.reduce_mean(loss)
return loss
bce_program = fluid.Program()
with fluid.program_guard(bce_program):
pred = fluid.data(‘pred’, shape=[3,1], dtype=‘float32’)
gt = fluid.data(‘gt’, shape=[3,1], dtype=‘float32’)
loss = bce_loss(pred, gt)
pred_val = np.array([[0.9], [0.1], [1]], dtype=‘float32’)
gt_val = np.array([[1], [0], [1]], dtype=‘float32’)
loss_value = exe.run(bce_program, feed={‘pred’: pred_val, ‘gt’: gt_val}, fetch_list= [loss])
print(“BCE Loss:”, loss_value)
BCE Loss: [array([0.07029679], dtype=float32)]
Weighed Cross Entropy和Balanced Cross Entropy
�
�
�
�
ℎ
�
�
�
�
�
�
�
�
�
�
�
�
�
�
−
1
�
∑
�
1
�
�
�
�
�
�
�
(
�
�
)
+
(
1
−
�
�
)
�
�
�
(
1
−
�
�
)
WeighedCrossEntropy=−
N
1
∑
i=1
N
wy
i
log(p
i
)+(1−y
i
)log(1−p
i
)
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
−
1
�
∑
�
1
�
�
�
�
�
�
�
(
1
−
�
�
)
+
(
1
−
�
)
(
1
−
�
�
)
�
�
�
(
�
�
)
BalancedCrossEntropy=−
N
1
∑
i=1
N
βy
i
log(1−p
i
)+(1−β)(1−y
i
)log(p
i
)
这两个 Loss 都是在BCE的基础上给
�
1
y=1 和
�
0
y=0 赋了不同的权重。这个权重主要解决类别不均衡的问题。比如一个猫狗二分类数据集里面有 80 张猫和 20 张狗。就算算法根本不看输入的是什么而只是全都分类成猫,在训练集上也能取得 80% 的准确率。这显然不是我们想要的。WCE和BCE通过给不同的类别的数据产生的 Loss 赋予不同的权重客服标签不均衡。比如 WCE 给
�
1
y=1 的类别一个权重
�
w,
�
0
y=0 的类别相当于给了权重
1
1。如果 w=1 这就是标准交叉熵,但是比如现在
�
1
y=1 的类别占数据集中的1/3,
�
0
y=0 的类别占数据集中的2/3。这种情况下
�
w 给2,表示可以理解为分错了一个
�
1
y=1 的情况相于分错了两个,这就平衡了两个类别数量不均衡的情况。Balanced Cross Entropy也类似,只是这个函数分别给了
�
0
y=0 和
�
1
y=1
1
−
�
1−β 和
�
β的权重,可以认为这个beta设为
�
0
y=0 的类别在数据集中的比例正好能平衡两个类别的不均衡现象。
In [30]
def wce_loss(pred, label, w=1, epsilon=1e-05): # w 是给到 y=1 类别的权重,越大越重视
label = fluid.layers.clip(label, epsilon, 1-epsilon)
pred = fluid.layers.clip(pred, epsilon, 1-epsilon)
loss = -1 * (w * label * fluid.layers.log(pred) + (1 - label) * fluid.layers.log(1 - pred))
loss = fluid.layers.reduce_mean(loss)
return loss
wce_program = fluid.Program()
with fluid.program_guard(wce_program):
pred = fluid.data(‘pred’, shape=[3,1], dtype=‘float32’)
gt = fluid.data(‘gt’, shape=[3,1], dtype=‘float32’)
loss = wce_loss(pred, gt)
pred_val = np.array([[0.9], [0.1], [1]], dtype=‘float32’)
gt_val = np.array([[1], [0], [1]], dtype=‘float32’)
loss_value = exe.run(wce_program, feed={‘pred’: pred_val, ‘gt’: gt_val}, fetch_list= [loss])
print(“WCE Loss:”, loss_value)
WCE Loss: [array([0.07029679], dtype=float32)]
In [31]
def balanced_ce_loss(pred, label, beta=0.5, epsilon=1e-05): # beta 是给到 y=1 类别的权重,越大越重视,范围在(0-1)
label = fluid.layers.clip(label, epsilon, 1-epsilon)
pred = fluid.layers.clip(pred, epsilon, 1-epsilon)
loss = -1 * (beta * label * fluid.layers.log(pred) + (1-beta) * (1 - label) * fluid.layers.log(1 - pred))
loss = fluid.layers.reduce_mean(loss)
return loss
balanced_ce_program = fluid.Program()
with fluid.program_guard(balanced_ce_program):
pred = fluid.data(‘pred’, shape=[3,1], dtype=‘float32’)
gt = fluid.data(‘gt’, shape=[3,1], dtype=‘float32’)
loss = balanced_ce_loss(pred, gt)
pred_val = np.array([[0.9], [0.1], [1]], dtype=‘float32’)
gt_val = np.array([[1], [0], [1]], dtype=‘float32’)
loss_value = exe.run(balanced_ce_program, feed={‘pred’: pred_val, ‘gt’: gt_val}, fetch_list= [loss])
print(“Balanced Cross Entropy:”, loss_value)
Balanced Cross Entropy: [array([0.03514839], dtype=float32)]
Focal Loss
�
�
�
�
�
�
�
�
�
−
1
�
∑
�
1
�
−
(
�
(
1
−
�
�
)
�
�
�
�
�
�
(
�
�
)
)
+
(
1
−
�
)
�
�
�
(
1
−
�
�
�
�
�
(
1
−
�
�
)
)
FocalLoss=−
N
1
∑
i=1
N
−(α(1−p
i
)
γ
y
i
log(p
i
))+(1−α)p
i
γ
(1−y
i
log(1−p
i
))
Focal Loss 是 Log Loss 的进一步改进。从上面的公式可以看出它在 Balanced Cross Entropy 基础上,在
�
0
y=0 时乘上了一个预测值的
�
γ 次方,
�
1
y=1 时乘上了一个 (1-预测值) 的
�
γ 次方。这项的意思是让算法更加关注那些不确定的情况,忽略很确定的情况。比如如果
�
0
y=0 说明我们希望
�
0
p=0 ,如果此时
�
p 已经接近 0 了那么
�
�
�
�
�
�
p
gamma
就会很接近0,这样这项的 Loss 就会很小,反之会很大。因此通过这一项Focal Loss实现了让网络关注更难的case的功能。
In [32]
def focal_loss(pred, label, alpha=0.25,gamma=2,epsilon=1e-6):
‘’’
alpha 越大越关注y=1的情况
gamma 越大越关注不确定的情况
‘’’
pred = fluid.layers.clip(pred,epsilon,1-epsilon)
label = fluid.layers.clip(label,epsilon,1-epsilon)
loss = -1 * (alpha * fluid.layers.pow((1 - pred), gamma) * label * fluid.layers.log(pred) + (1 - alpha) * fluid.layers.pow(pred, gamma ) * (1 - label) * fluid.layers.log(1 - pred))
loss = fluid.layers.reduce_mean(loss)
return loss
focal_program = fluid.Program()
with fluid.program_guard(focal_program):
pred = fluid.data(‘pred’, shape=[3,1], dtype=‘float32’)
gt = fluid.data(‘gt’, shape=[3,1], dtype=‘float32’)
loss = focal_loss(pred, gt)
pred_val = np.array([[0.9], [0.1], [1]], dtype=‘float32’)
gt_val = np.array([[1], [0], [1]], dtype=‘float32’)
loss_value = exe.run(focal_program, feed={‘pred’: pred_val, ‘gt’: gt_val}, fetch_list= [loss])
print(“Focal Loss:”, loss_value)
Focal Loss: [array([0.00035533], dtype=float32)]
Hinge Loss
�
�
�
�
�
�
�
�
�
1
�
∑
�
1
�
�
�
�
(
0
,
1
−
�
�
�
�
)
HingeLoss=
N
1
∑
i=1
N
max(0,1−y
i
p
i
)
Hinge Loss 主要用在支持向量机中,它的标签和之前的0/1不同,正例的标签是1,负例的标签是-1。Hinge Loss的图像如下:
可以看出它不仅惩罚错误的预测,而且惩罚不自信的正确预测。和前面的交叉熵相比,Hinge Loss形式上更简单,运算更快,而且因为一些情况下Loss是0不需要进行反向传递因此训练速度较快。如果不是很关注正确性但是需要作出实时决策Hinge是很合适的。
In [33]
def hinge_loss(pred, label):
‘’’
alpha 越大越关注y=1的情况
gamma 越大越关注不确定的情况
‘’’
zeros = fluid.layers.zeros_like(pred)
loss = fluid.layers.elementwise_max(zeros, 1 - pred * label)
loss = fluid.layers.reduce_sum(loss)
return loss
hinge_program = fluid.Program()
with fluid.program_guard(hinge_program):
pred = fluid.data(‘pred’, shape=[3,1], dtype=‘float32’)
gt = fluid.data(‘gt’, shape=[3,1], dtype=‘float32’)
loss = focal_loss(pred, gt)
pred_val = np.array([[0.9], [-0.1], [1]], dtype=‘float32’)
gt_val = np.array([[1], [-1], [1]], dtype=‘float32’)
loss_value = exe.run(hinge_program, feed={‘pred’: pred_val, ‘gt’: gt_val}, fetch_list= [loss])
print(“Hinge Loss:”,loss_value)
Hinge Loss: [array([9.292055e-05], dtype=float32)]
相关文章:

深度学习损失函数
Loss 是深度学习算法中重要的一部分,它的主要功能是评价网络预测的准确性和指导权重更新。合适 Loss 可以让网络收敛更快,预测更准。这个项目介绍了损失函数的基本概念以及7种常用损失函数的形式,性质,参数,使用场景及…...
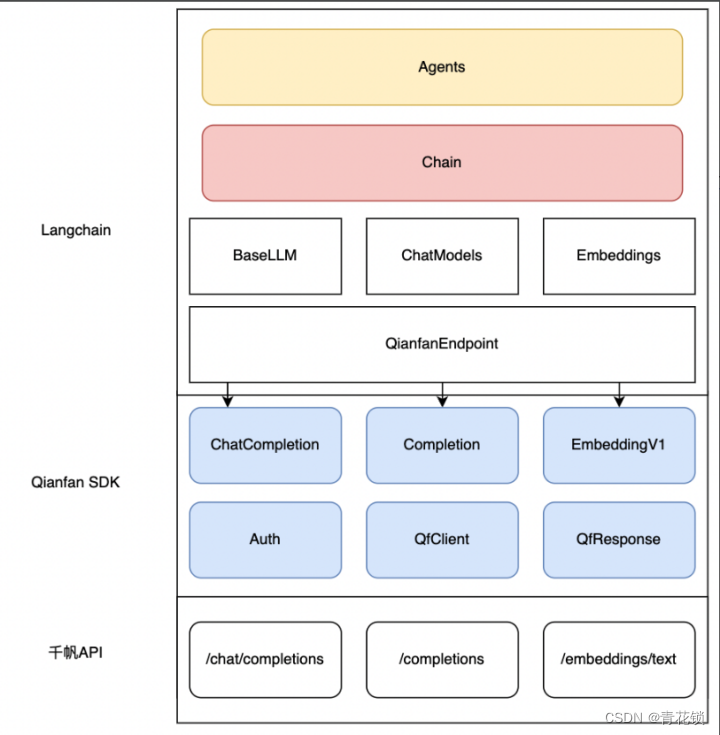
百度智能云正式上线Python SDK版本并全面开源
文章目录 前言一、SDK的优势二、千帆SDK:快速落地LLM应用三、如何快速上手千帆SDK3.1、SDK快速启动3.2. SDK进阶指引 3.3. 通过Langchain接入千帆SDK4、开源社区 前言 百度智能云千帆大模型平台再次升级!在原有API基础上,百度智能云正式上线…...
Elasticsearch的配置学习笔记
文/朱季谦 Elasticsearch是一个基于Lucene的搜索服务器。它提供一个分布式多用户能力的全文搜索引擎,基于RESTful web接口,Elasticsearch是用Java语言开发的。 关于Elasticsearch系列笔记,主要从Elasticsearch的配置、核心组件、架构设计、使…...
LeetCode(25)验证回文串【双指针】【简单】
目录 1.题目2.答案3.提交结果截图 链接: 验证回文串 1.题目 如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。 字母和数字都属于字母数字字符。 给你一个字符串 s&…...

Android设计模式--工厂模式
一,定义 工厂模式与Android 设计模式--单例模式-CSDN博客,Android设计模式--Builder建造者模式-CSDN博客,Android设计模式--原型模式-CSDN博客 一样,都是创建型设计模式。 工厂模式就是定义一个用于创建对象的接口,让…...
EasyExcel入门使用教程
文章目录 简介一、工程创建🎑二、读操作🎊二、写操作🎄总结 简介 数据导入导出意义 后台管理系统是管理、处理企业业务数据的重要工具,在这样的系统中,数据的导入和导出功能是非常重要的,其主要意义包括以下…...
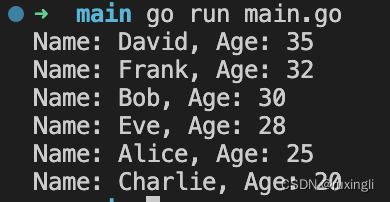
Golang实现一个一维结构体,根据某个字段排序
package mainimport ("fmt""sort" )type Person struct {Name stringAge int }func main() {// 创建一个一维结构体切片people : []Person{{"Alice", 25},{"Bob", 30},{"Charlie", 20},{"David", 35},{"Eve…...

python语言实现背包问题动态规划
背包问题是一个经典的动态规划问题,实现方式如下: 假设有一个背包,容量为 W,有 n 个物品,每个物品有两个属性:体积 v 和价值 w。要求在不超过背包容量的情况下,选取一些物品放入背包࿰…...

将Python程序(.py)转换为Windows可执行文件(.exe)
python开发者向普通windows用户分享程序,要给程序加图形化的界面(传送门:这可能是最好玩的python GUI入门实例! http://www.jianshu.com/p/8abcf73adba3),并要将软件打包为可执行文件(.exe结尾),那如何将.py转为.exe ? 将.py转为.exe 第一步:安装pyinstaller(临时调用了国内豆…...

Oracle 查找非系统用户结合了10,11,12,19
oracle 12开始有了INHERITEDYES;字段来区分系统用户 select username from dba_users where INHERITEDYES; 对于12以下的版本,按created日期字段筛选会发现创建时间间隔比较大,好区分。 本人当前有个需求需要找出所有数据库的非系统用户,来…...

c++虚函数纯虚函数详解加代码解释
c虚函数纯虚函数详解加代码解释 一.概念:二.虚函数示例及解析:三.纯虚函数示例及解析:四.验证和实际使用及解析:1.子类没有对父类的函数重载,mian()函数调用,是直接返回父类的值2.子类对父类的函数重载&…...

kotlin retrofit
参考博客 【Android】【Kotlin】使用【Retrofit】基本使用 如何在kotlin中正确使用retrofit 将kotlin协程用于网络请求—完整实例,看这一篇就够了 Kotlin协程Retorfit网络请求框架封装...

Web 开发中 route 和 router 有什么区别?
什么是路由? 在 Web 开发中,会经常和路由打交道,可能有的同学并没有仔细思考过到底什么是路由。路由是根据用户请求的 URL 来确定返回给用户的内容或页面的技术,即将 HTTP 请求映射到相应的处理代码,使得用户能够通过…...

VBA技术资料MF83:将Word文档批量另存为PDF文件
我给VBA的定义:VBA是个人小型自动化处理的有效工具。利用好了,可以大大提高自己的工作效率,而且可以提高数据的准确度。我的教程一共九套,分为初级、中级、高级三大部分。是对VBA的系统讲解,从简单的入门,到…...
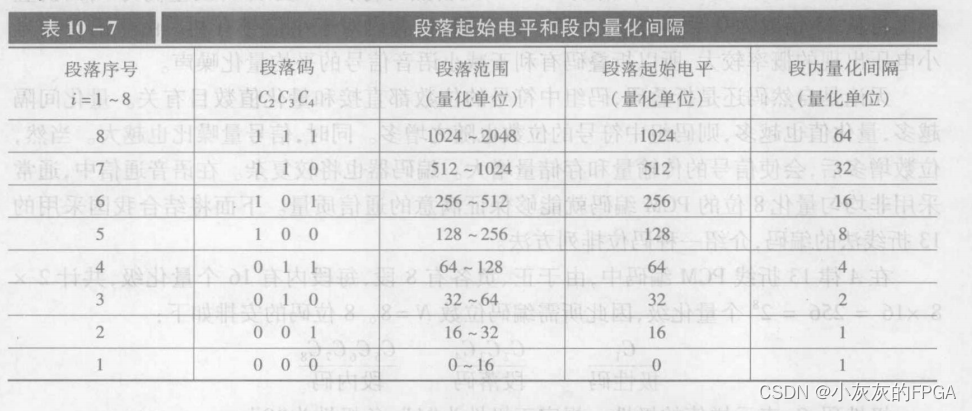
通信原理板块——脉冲编码调制(PCM)
微信公众号上线,搜索公众号小灰灰的FPGA,关注可获取相关源码,定期更新有关FPGA的项目以及开源项目源码,包括但不限于各类检测芯片驱动、低速接口驱动、高速接口驱动、数据信号处理、图像处理以及AXI总线等 1、脉冲编码调制PCM原理 将模拟信号…...
绕过类安全问题分析方法
什么是绕过 逻辑漏洞是指程序设计中逻辑不严密,使攻击者能篡改、绕过或中断程序,令其偏离开发人员预期的执行。 常见表现形式 1、接口(功能类)绕过:即接口或功能中通过某参数,绕过程序校验 2、流程类绕…...
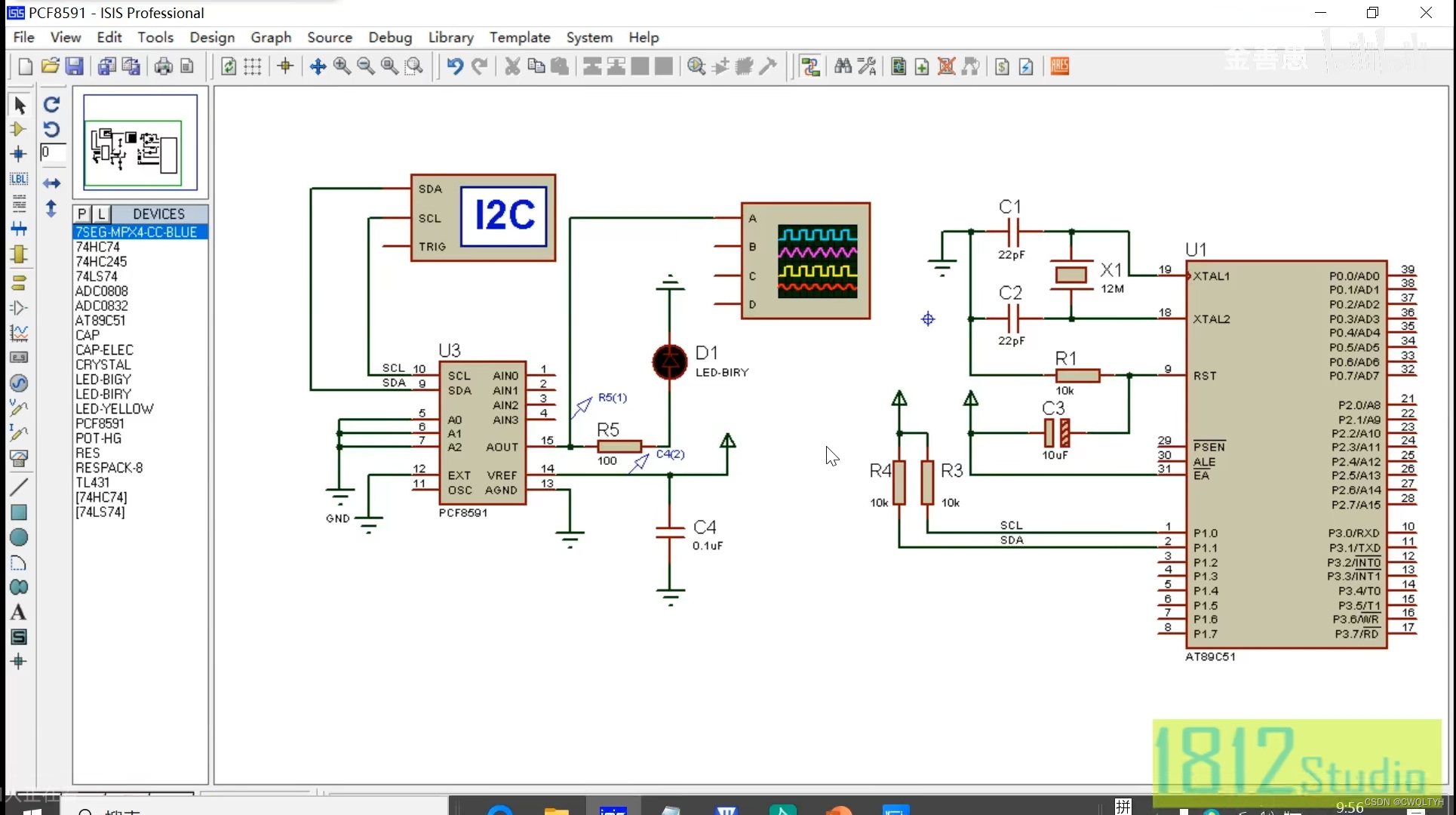
基于STC12C5A60S2系列1T 8051单片的IIC总线器件数模芯片PCF8591实现数模转换应用
基于STC12C5A60S2系列1T 8051单片的IIC总线器件数模芯片PCF8591实现数模转换应用 STC12C5A60S2系列1T 8051单片机管脚图STC12C5A60S2系列1T 8051单片机I/O口各种不同工作模式及配置STC12C5A60S2系列1T 8051单片机I/O口各种不同工作模式介绍IIC总线器件数模芯片PCF8591介绍通过按…...

2023年中国骨质疏松治疗仪发展趋势分析:小型且智能将成为产品优化方向[图]
骨质疏松治疗仪利用磁场镇静止痛、消肿消炎的治疗作用迅速缓解患者腰背疼痛等骨质疏松临床症状。同时利用磁场的磁-电效应产生的感生电势和感生电流,改善骨的代谢和骨重建,通过抑制破骨细胞、促进成骨细胞的活性来阻止骨量丢失、提高骨密度。 骨质疏松治…...
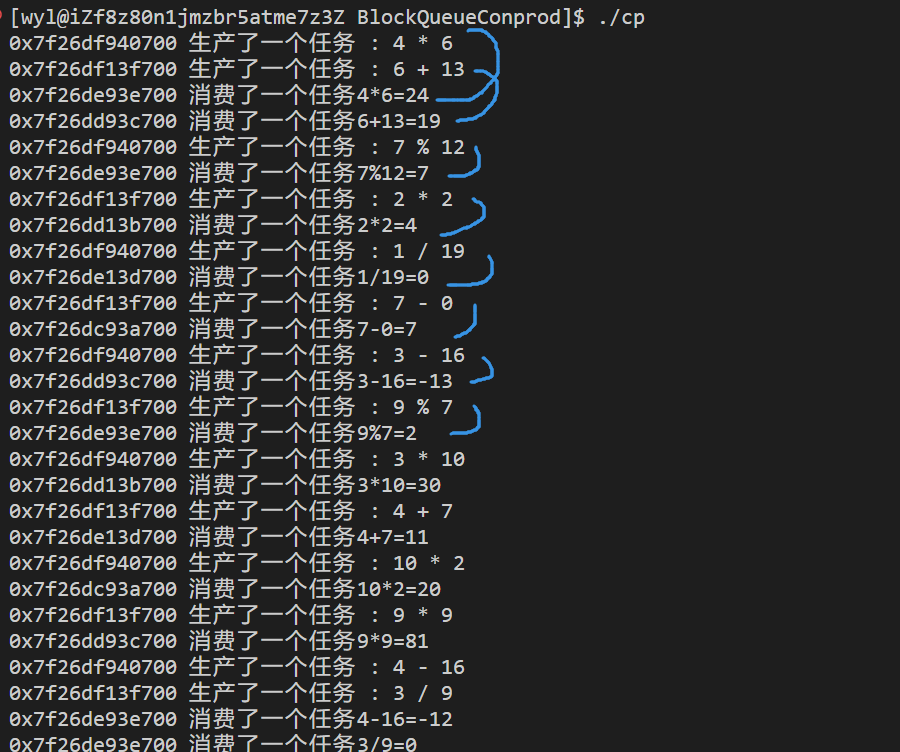
并发编程之生产者消费者模型
什么是生产者消费者模型 生产者消费者模型是多线程中一个比较典型的模型。 打个比方:你是一个客户,你去超市里买火腿肠。 这段话中的 "你"就是消费者, 那么给超市提供火腿肠的供货商就是生产者。超市呢?超市是不是被…...

Java要将字符串转换为Map
Java要将字符串转换为Map,可以使用以下方法: import com.google.gson.Gson; import com.google.gson.reflect.TypeToken; import java.lang.reflect...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

QT: `long long` 类型转换为 `QString` 2025.6.5
在 Qt 中,将 long long 类型转换为 QString 可以通过以下两种常用方法实现: 方法 1:使用 QString::number() 直接调用 QString 的静态方法 number(),将数值转换为字符串: long long value 1234567890123456789LL; …...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...