深度学习与深度强化学习
1. 深度学习中卷积层的作用是什么?全连接层的作用是什么?二者有什么联系和区别?
在深度学习中,卷积层(Convolutional Layer)和全连接层(Fully Connected Layer)是神经网络中常见的两种层,各自有不同的作用和功能。
卷积层(Convolutional Layer)的作用:
1.特征提取: 卷积层通过滤波器(也称为卷积核)对输入数据进行卷积操作,从输入数据中提取特征。这些特征可以是边缘、纹理、形状等低级到高级的抽象特征。
2.参数共享: 卷积层通过卷积核在输入数据上滑动来提取特征,同时在整个输入数据区域内使用相同的权重(参数共享),这减少了模型的参数数量,提高了模型的效率,并且有助于捕获数据的局部模式。
3.空间关系保持: 卷积操作在局部区域内进行,因此卷积层有助于保持输入数据的空间结构,例如在图像中,图像的二维结构可以在卷积层中得到保留。
全连接层(Fully Connected Layer)的作用:
1.特征整合: 全连接层将前面卷积层或其他层的特征进行扁平化,并将所有特征都连接到下一层的每个神经元。它将前面层提取的特征整合为一个全局特征向量。
2.高度抽象表达: 全连接层可以对卷积层提取的特征进行更高级别的抽象表达,有助于学习数据之间更复杂的非线性关系。
二者之间的联系和区别:
1.联系: 卷积层通常用于提取输入数据的特征,保留输入数据的空间结构,并降低模型的参数量;全连接层用于整合前面层提取的特征,将其映射到最终输出。
2.区别: 主要区别在于操作方式和连接方式。卷积层使用滤波器对输入进行局部卷积操作,并保留空间结构;全连接层则将所有神经元与前一层的所有神经元相连接,没有空间结构上的考虑。
总体而言,卷积层和全连接层在深度学习模型中扮演着不同但相辅相成的角色,卷积层用于提取特征并保留空间信息,而全连接层用于整合和学习这些特征的高级表达。在卷积神经网络(CNN)中,通常会交替使用卷积层和全连接层来构建更复杂的模型,以处理图像、语音和文本等各种类型的数据。
2. 他们在深度神经网络中的位置有什么特点?
在深度神经网络中,卷积层和全连接层通常具有不同的位置和特点。以下是它们在深度神经网络中的常见位置和特点:
卷积层的位置和特点:
1.输入层后: 通常,卷积层是深度神经网络的第一层。它接受原始输入数据,例如图像,然后通过卷积操作提取局部特征。
2.多层叠加: 在深度神经网络中,卷积层通常会叠加多次,构建多层的卷积网络。每一层的卷积操作都有助于提取不同级别的抽象特征。
3.池化层结合: 通常,卷积层之后会跟随池化层(如最大池化或平均池化),用于降低特征图的空间维度,减少计算负担,并提高模型的平移不变性。
全连接层的位置和特点:
1.卷积层后: 一般而言,全连接层通常出现在卷积层之后。卷积层提取了局部特征,而全连接层则用于整合这些特征,形成最终的全局表达。
2.扁平化: 在连接到全连接层之前,通常需要对卷积层输出进行扁平化操作,将其转换为一维向量。这是因为全连接层要求输入是一维的。
3.输出层前: 在深度神经网络中,全连接层通常出现在网络的中间层,而输出层往往是一个全连接层,用于生成模型的最终输出。
总体特点和联系:
1.层级结构: 卷积层通常用于层次化地提取局部特征,而全连接层用于整合这些特征形成全局表达。
2.参数量: 卷积层通过参数共享的方式减少了模型参数的数量,而全连接层连接了整个输入,参数量相对较大。
3.处理不同层级的特征: 卷积层更适合处理低级别的局部特征,而全连接层更适合处理高级别的全局特征和复杂的非线性关系。
综合起来,卷积层和全连接层在深度神经网络中各自扮演重要的角色,通过协同工作,使得网络能够从原始输入中学到层次化的、抽象的表示,从而完成复杂的任务。
3.他们二者的输入和输出数据有什么特点,都由什么来决定?
卷积层和全连接层在深度神经网络中的输入和输出数据有着不同的特点,这些特点受到网络架构和层之间连接方式的影响。
卷积层的输入和输出数据特点:
输入数据特点:
1.多维数据:卷积层的输入通常是多维的数据,比如图像数据可以是三维的(高度、宽度、通道)。
2.局部相关性:卷积层通过滤波器(卷积核)在输入数据的局部区域上进行滑动操作,因此保留了局部像素之间的相关性。
3.特征映射:每个卷积核都生成一个特征映射,对应着输入数据中的某种局部特征。
输出数据特点:
1.特征图:卷积层的输出数据通常被称为特征图,由多个特征映射组成。
2.尺寸变化:输出的特征图的尺寸可能会改变,这取决于卷积层的超参数设置(如步幅、填充)以及输入数据的尺寸。
全连接层的输入和输出数据特点:
.输入数据特点:
1.一维向量:全连接层的输入通常是一维向量,这意味着它接收的是扁平化后的数据,不再保留原始数据的空间结构。
2.全局关联:每个神经元都与前一层的所有神经元相连接,因此全连接层能够捕捉全局特征和关联。
.输出数据特点:
1.最终输出:全连接层的输出是最终的、整合了前一层所有信息的结果,可以直接连接到输出层(比如分类器的输出)或传递给其他层级继续处理。
由什么决定:
1.架构设计: 输入和输出数据的特点部分取决于神经网络的整体架构,包括层的类型、顺序和连接方式。
2.层之间的连接方式: 卷积层通过局部连接和参数共享保留了输入数据的空间结构和局部信息,而全连接层则通过全局连接获取整个输入层的信息。
3.超参数设置: 卷积层和全连接层的输出数据特点也受到超参数的影响,比如卷积核大小、步幅、填充等参数设置会影响卷积层输出的特征图尺寸。
总体而言,卷积层和全连接层的输入和输出数据特点受到网络结构、连接方式以及各自层级的设计和参数设置的影响。
4.池化层在上述两者中怎么起作用,一般会在什么情形下用到?
池化层是深度学习神经网络中的一种常见层,用于减小数据尺寸、降低计算量,并且有助于提取更显著的特征。池化层通常与卷积层结合使用,而在全连接层中使用池化层相对较少。
池化层的作用:
1.降采样: 池化层通过保留特征图中的最显著信息,减小特征图的尺寸,从而降低了后续层的计算复杂度。这有助于缓解过拟合问题,减小模型参数数量。
2.平移不变性: 池化操作是对局部输入区域的统计汇总,因此对输入的小平移具有一定的不变性。这意味着即使输入图像在某个方向上发生轻微的平移,池化层输出的结果仍然相对稳定。
3.特征提取: 池化操作有助于提取输入数据的主要特征,保留最显著的信息。这在图像识别等任务中尤为重要。
池化层的类型:
1.最大池化(Max Pooling): 对输入区域取最大值,保留最显著的特征。
2.平均池化(Average Pooling): 对输入区域取平均值,保留局部平均特征。
池化层的典型使用情形:
1.图像识别: 在卷积神经网络(CNN)中,池化层通常与卷积层交替使用,用于逐渐减小特征图的空间尺寸。
2.降维: 池化层在网络中的某些层上用于减小数据的维度,帮助网络处理更抽象和高级别的特征。
3.防止过拟合: 池化层的使用有助于减小模型的参数数量,从而减轻过拟合问题。
总体而言,池化层在卷积神经网络中是一个重要的组成部分,能够有效提取特征、降低计算复杂度,并在一定程度上提高模型的鲁棒性。
5. 如何用python语言来实现上述功能呢
在Python中,你可以使用深度学习框架如TensorFlow或PyTorch来实现卷积层和池化层。下面我将以TensorFlow为例,展示如何实现一个简单的卷积神经网络(CNN)模型,包括卷积层和池化层。
首先,确保你已经安装了TensorFlow:
pip install tensorflow
然后,可以使用以下代码来实现一个简单的CNN模型:
import tensorflow as tf
from tensorflow.keras import layers, models# 构建卷积神经网络模型
model = models.Sequential()# 添加卷积层
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
# 32表示卷积核的数量,(3, 3)表示卷积核的大小,activation='relu'表示使用ReLU激活函数
# input_shape=(28, 28, 1)表示输入图像的大小为28x28,通道数为1(灰度图像)# 添加最大池化层
model.add(layers.MaxPooling2D((2, 2)))
# (2, 2)表示池化窗口的大小,这里是2x2的最大池化# 添加Flatten层,将卷积层的输出拉平
model.add(layers.Flatten())# 添加全连接层
model.add(layers.Dense(64, activation='relu'))
# 64表示全连接层的神经元数量# 添加输出层
model.add(layers.Dense(10, activation='softmax'))
# 10表示输出层的神经元数量,如果是图像分类问题,通常对应类别数# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
上述代码创建了一个简单的CNN模型,包括卷积层、最大池化层、全连接层和输出层。你可以根据具体的任务需求修改模型结构和参数。
这只是一个简单的例子,实际应用中,你可能需要根据你的数据集和任务需求来调整模型的架构和参数。希望这能够帮助你入门使用Python和深度学习框架实现卷积神经网络。
6.上面示例中卷积核的数量和大小是怎么确定的
卷积核的数量和大小是卷积神经网络中的关键参数,它们的选择通常取决于你的具体任务、数据集和计算资源。以下是一些一般性的指导原则:
1.卷积核数量: 通常,初始的卷积层使用较少的卷积核,然后随着网络的深度逐渐增加卷积核的数量。较低层的卷积核数量用于捕获低级别的特征,如边缘和纹理,而较高层的卷积核数量则用于捕获更抽象和复杂的特征。具体的数量可以是2的幂次方,例如32、64、128等。
2.卷积核大小: 卷积核的大小通常由你的数据集和任务决定。对于较小的特征,可以选择小一些的卷积核,而对于更大的特征,可以选择更大的卷积核。常见的卷积核大小包括(3, 3)和(5, 5)。较小的卷积核有助于捕获更细粒度的特征。
在示例中,第一个卷积层使用了32个(3, 3)大小的卷积核。这个选择是一种常见的起点,可以根据实际情况进行调整。如果你的任务更为复杂或数据集更大,你可能需要更深的网络和更多的卷积核。
值得注意的是,这些参数的选择通常需要通过实验和调整来优化,以获得最佳的性能。你可以尝试不同的组合,然后通过交叉验证等方法来评估模型的性能。
7.上述深度学习的框架在深度强化学习中是怎么体现的
深度学习框架在深度强化学习(Deep Reinforcement Learning,DRL)中发挥了关键作用,用于构建和训练神经网络,从而实现智能体对环境的学习和决策。以下是深度学习框架在深度强化学习中的主要体现:
1.神经网络构建: 在深度强化学习中,神经网络通常被用作值函数近似器或策略网络。深度学习框架提供了构建各种类型的神经网络的工具和接口,包括卷积层、全连接层等,这些网络用于表示智能体的策略或值函数。
2.模型定义: 利用深度学习框架,可以方便地定义深度强化学习模型的结构和参数。例如,你可以使用 TensorFlow 或 PyTorch 来定义一个深度 Q 网络(Deep Q Network,DQN)或者策略梯度方法所需的神经网络结构。
3.自动求导: 深度学习框架提供了自动求导的功能,这对于训练深度强化学习模型至关重要。在训练中,智能体与环境交互,产生经验数据,然后使用这些数据来更新神经网络的参数。自动求导使得梯度计算自动而高效,加速了训练过程。
4.优化算法: 深度学习框架包含了各种优化算法,用于调整神经网络参数以最小化损失函数。在深度强化学习中,这些算法被用于优化值函数或策略,以提高智能体在环境中的性能。
5.集成强化学习算法: 深度学习框架通常提供了强化学习算法的实现,例如 DQN、DDPG(深度确定性策略梯度)、PPO(近端策略优化)等。这些算法已经被证明在各种任务中取得了良好的性能。
6.分布式计算: 深度学习框架支持分布式计算,这对于在大规模环境中进行深度强化学习的训练是至关重要的。分布式计算可以加速经验收集和神经网络训练的过程。
总体而言,深度学习框架为深度强化学习提供了灵活、高效的工具,使研究者和工程师能够更容易地实现、测试和部署各种强化学习算法。TensorFlow、PyTorch等框架在深度强化学习的研究和应用中广泛使用。
请设计一个深度强化学习的模型,并用python语言实现
设计一个深度强化学习模型涉及到多个步骤,包括环境定义、智能体设计、模型结构、训练过程等。下面我将演示一个简单的深度 Q 网络(Deep Q Network,DQN)模型的实现,用于解决一个离散动作空间的强化学习问题。在这个例子中,我将使用 OpenAI Gym 的 CartPole 环境。
首先,确保你已经安装了必要的库:
pip install tensorflow gym
接下来,可以使用以下代码实现一个简单的 DQN 模型:
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
import gym# 创建环境
env = gym.make('CartPole-v1')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n# 构建深度 Q 网络模型
model = tf.keras.Sequential([layers.Dense(24, input_dim=state_size, activation='relu'),layers.Dense(24, activation='relu'),layers.Dense(action_size, activation='linear')
])# 编译模型
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),loss='mse')# 定义经验回放缓存
class ExperienceReplayBuffer:def __init__(self, buffer_size=10000):self.buffer_size = buffer_sizeself.buffer = []def add_experience(self, experience):self.buffer.append(experience)if len(self.buffer) > self.buffer_size:self.buffer.pop(0)def sample_batch(self, batch_size):return np.random.choice(len(self.buffer), batch_size, replace=False)# 初始化经验回放缓存
buffer = ExperienceReplayBuffer()# 定义训练参数
gamma = 0.99 # 折扣因子
epsilon = 1.0 # 探索率
epsilon_decay = 0.995 # 探索率衰减
min_epsilon = 0.01 # 最小探索率
batch_size = 64 # 批处理大小# 训练 DQN 模型
episodes = 1000for episode in range(episodes):state = env.reset()state = np.reshape(state, [1, state_size])total_reward = 0while True:# 选择动作if np.random.rand() <= epsilon:action = env.action_space.sample() # 随机探索else:Q_values = model.predict(state)action = np.argmax(Q_values[0])# 执行动作next_state, reward, done, _ = env.step(action)next_state = np.reshape(next_state, [1, state_size])# 存储经验buffer.add_experience((state, action, reward, next_state, done))# 更新状态state = next_statetotal_reward += reward# 经验回放if len(buffer.buffer) > batch_size:batch_indices = buffer.sample_batch(batch_size)for index in batch_indices:(batch_state, batch_action, batch_reward, batch_next_state, batch_done) = buffer.buffer[index]target = batch_rewardif not batch_done:target = (batch_reward + gamma * np.amax(model.predict(batch_next_state)[0]))target_f = model.predict(batch_state)target_f[0][batch_action] = target# 模型训练model.fit(batch_state, target_f, epochs=1, verbose=0)# 判断是否结束if done:break# 衰减探索率epsilon = max(min_epsilon, epsilon * epsilon_decay)# 打印每轮的总奖励print("Episode {}: Total Reward: {}".format(episode + 1, total_reward))# 训练结束后,你可以使用训练好的模型进行预测和决策。
请注意,这只是一个简单的 DQN 模型的示例,用于解决 CartPole 环境中的问题。在实际应用中,你可能需要根据不同的环境和任务进行更复杂的模型设计和超参数调整。深度强化学习中的模型设计和调整通常需要大量的实验和调试。
相关文章:

深度学习与深度强化学习
1. 深度学习中卷积层的作用是什么?全连接层的作用是什么?二者有什么联系和区别? 在深度学习中,卷积层(Convolutional Layer)和全连接层(Fully Connected Layer)是神经网络中常见的两…...

C++函数重载中形参是引用类型和常量引用类型的调用方法
void fun(int &a) {cout<<"调用func(int &a)<<endl; }void fun(const int &a) {cout<<"调用func(const int &a)<<endl; }int main() {// 1.调用引用类型的函数int a10;func(a);// 2.调用常量引用类型的函数,因为…...
Quest 3期间Sui上游戏处理了数百万笔交易
Sui固有的可扩展性和低且可预测的gas费使其成为Web3游戏的理想平台。在Quest 3中,参与的游戏项目处理了数百万笔交易,这毫无疑问地展示了Sui卓越的能力。 Quest 3的主题是游戏,让开发者有机会向潜在玩家介绍他们激动人心的创作。鼓励这些玩家…...

Python中如何定义类、基类、函数和变量?
在Python中,定义类、基类、函数和变量是非常常见的操作。以下是简单的示例: 定义类: class Animal:def __init__(self, name):self.name namedef make_sound(self):passclass Dog(Animal):def make_sound(self):return "Woof!"上…...
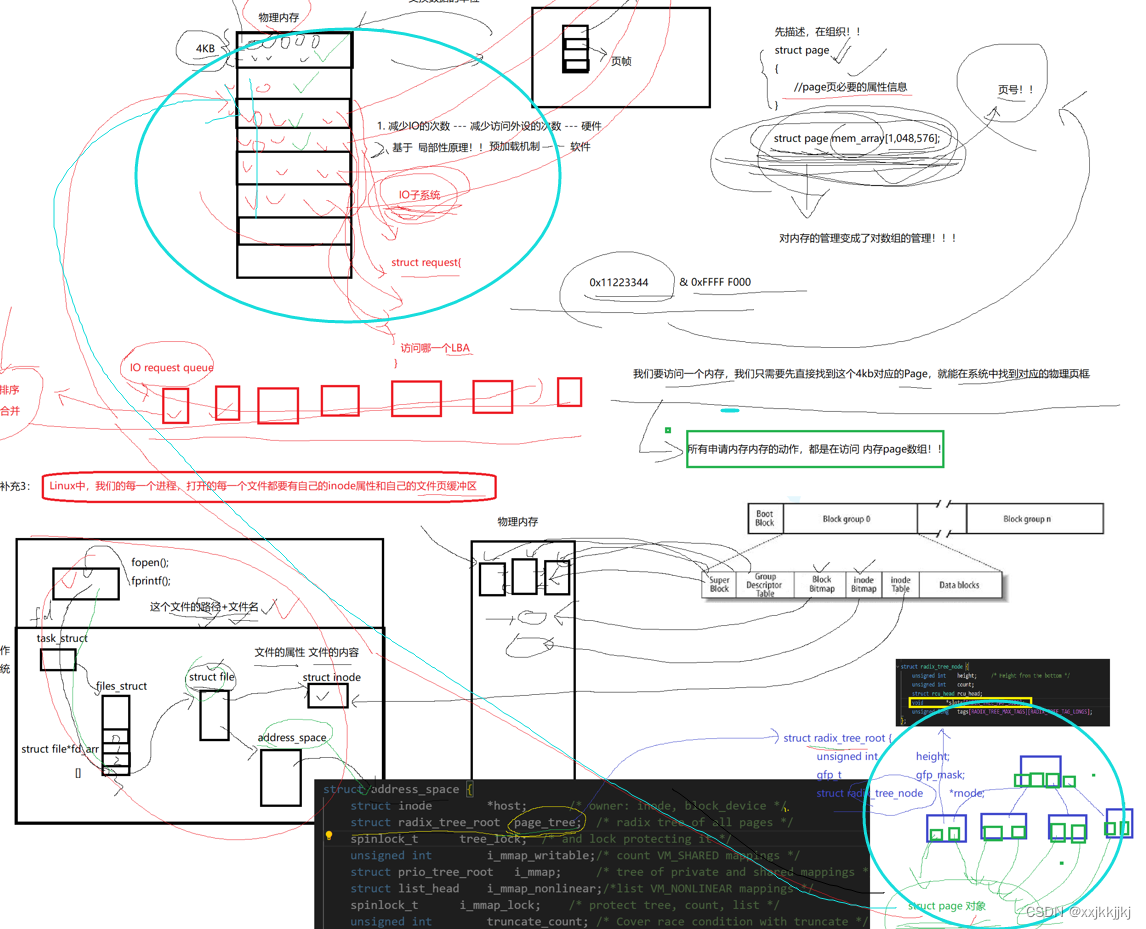
打开文件 和 文件系统的文件产生关联
补充1:硬件级别磁盘和内存之间数据交互的基本单位 OS的内存管理 内存的本质是对数据临时存/取,把内存看成很大的缓冲区 物理内存和磁盘交互的单位是4KB,磁盘中未被打开的文件数据块也是4KB,所以磁盘中页帧也是4KB,内存…...
【Rust】快速教程——模块mod与跨文件
前言 道尊:没有办法,你的法力已经消失,我的法力所剩无几,除非咱们重新修行,在这个世界里取得更多法力之后,或许有办法下降。——《拔魔》 \;\\\;\\\; 目录 前言跨文件mod多文件mod 跨文件mod //my_mod.rs…...
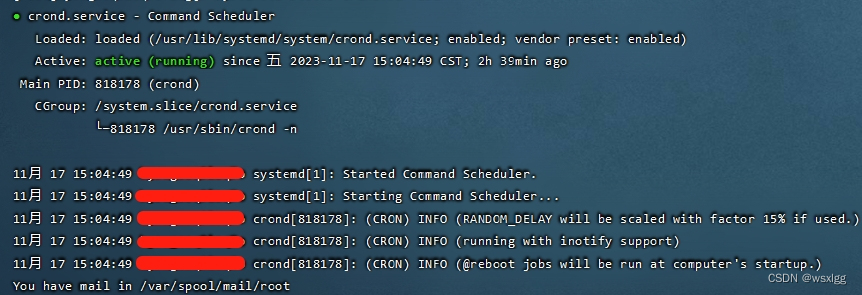
crontab定时任务是否执行
centos查看 crontab 是否启动 systemctl status crond.service 查看cron服务的启动状态 systemctl start crond.service 启动cron服务[命令没有提示] systemctl stop crond.service 停止cron服务[命令没有提示] systemctl restart crond.service 重启cron服务[命令没有提示] s…...

MATLAB程序设计:牛顿迭代法
function xnewton(x0,e,N,fx) %输入x0,误差限e,迭代次数N和函数Fx k1; while k<Nif subs(diff(fx),x0)0disp("输出奇异标志");break;endx1x0-subs(fx,x0)/subs(diff(fx),x0);if abs(x1-x0)<ebreak;endx0x1;kk1; end if k<Ndisp(x1); elsedisp("迭代失败…...

B031-网络编程 Socket Http TomCat
目录 计算机网络网络编程相关术语IP地址ip的概念InerAdress的了解与测试 端口URLTCP、UDP和7层架构TCPUDPTCP与UDP的区别和联系TCP的3次握手七层架构 Socket编程服务端代码客户端代码 http协议概念Http报文 Tomcat模拟 计算机网络 见文档 网络编程相关术语 见文档 IP地址 …...

gRPC之metadata
1、metadata 服务间使用 Http 相互调用时,经常会设置一些业务自定义 header 如时间戳、trace信息等,gRPC使用 HTTP/2 协议自然也是支持的,gRPC 通过 google.golang.org/grpc/metadata 包内的 MD 类型提供相关的功能接口。 1.1 类型定义 /…...
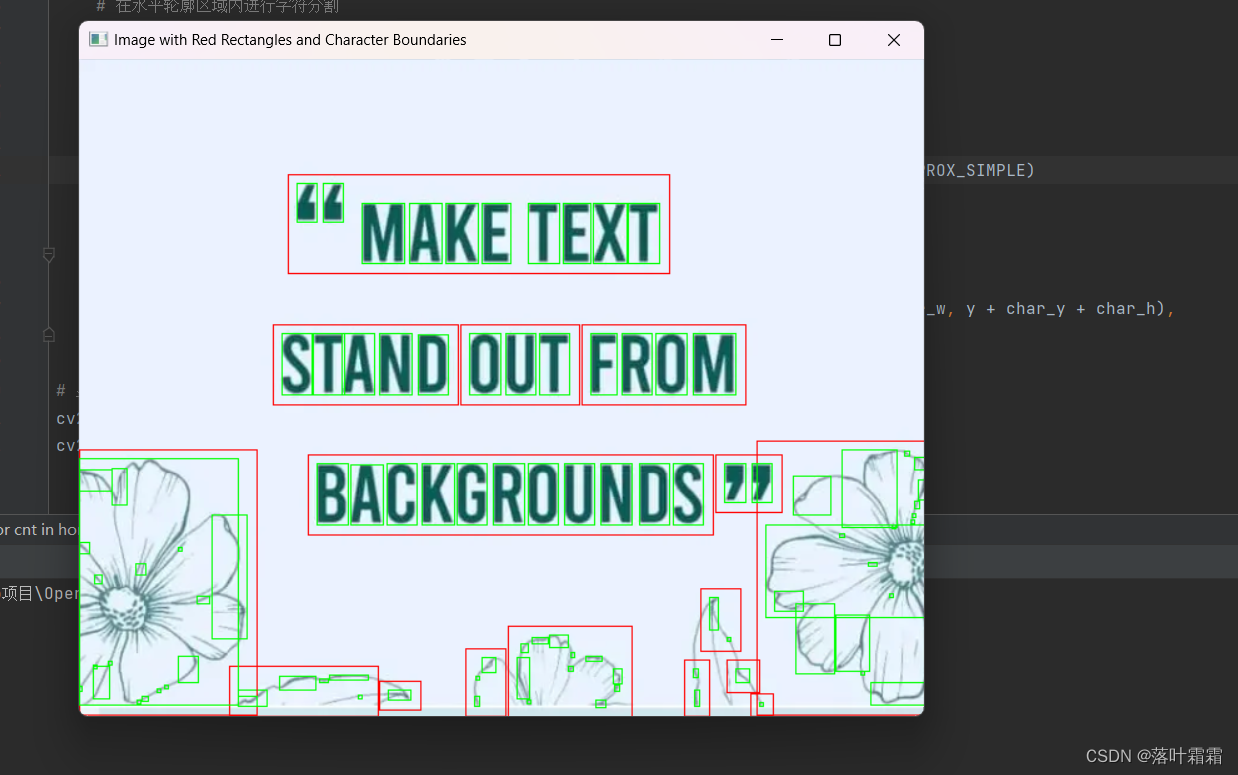
【OpenCV实现图像:OpenCV进行OCR字符分割】
文章目录 概要基本概念读入图像图像二值化小结 概要 在处理OCR(Optical Character Recognition,光学字符识别)时,利用传统的图像处理方法进行字符切分仍然是一种有效的途径。即便当前计算机视觉领域主导的是卷积神经网络…...

景联文科技入选量子位智库《中国AIGC数据标注产业全景报告》数据标注行业代表机构
量子位智库《中国AIGC数据标注产业全景报告》中指出,数据标注处于重新洗牌时期,更高质量、专业化的数据标注成为刚需。未来五年,国内AI基础数据服务将达到百亿规模,年复合增长率在27%左右。 基于数据基础设施建设、大模型/AI技术理…...
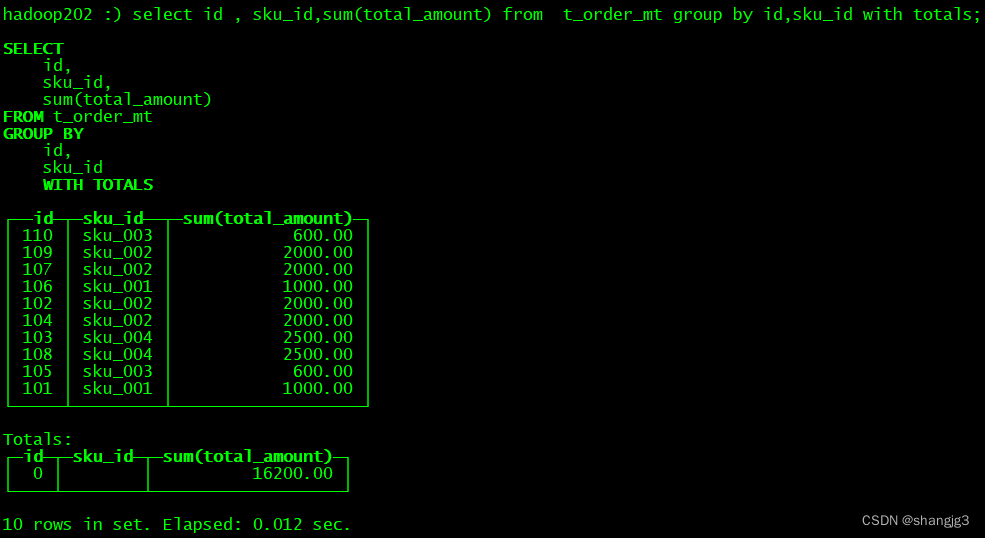
ClickHouse SQL操作
基本上来说传统关系型数据库(以MySQL为例)的SQL语句,ClickHouse基本都支持,这里不会从头讲解SQL语法只介绍ClickHouse与标准SQL(MySQL)不一致的地方。 1 Insert 基本与标准SQL(MySQL)…...
)
Ubuntu安装Python环境(使用VSCode)
想在Ubuntu上安装Python环境,选择了VSCode,而不想多装Anaconda等环境,最后参考了这篇博客: python入门开发:ubuntu下搭建python开发环境(vscode)...

QTcpSocket发送结构体的做法
作者:朱金灿 来源:clever101的专栏 为什么大多数人学不会人工智能编程?>>> QTcpSocket发送结构体其实很简单:使用QByteArray类对象进行封装发送,示例代码如下: /* 消息结构体 */ struct stMsg {int m_A…...
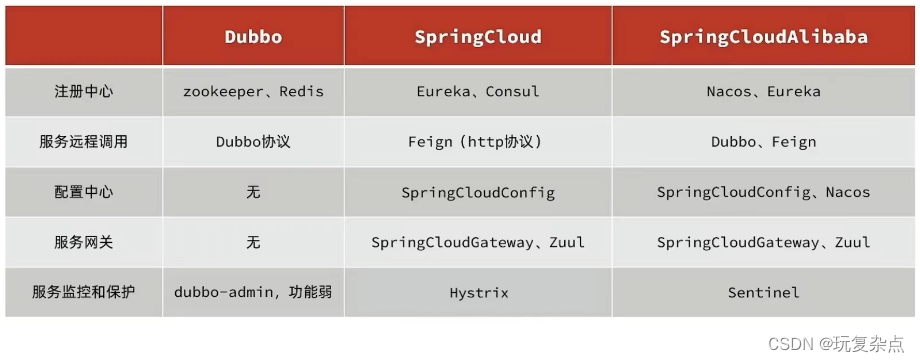
微服务学习 | Ribbon负载均衡、Nacos注册中心、微服务技术对比
Ribbon负载均衡 负载均衡流程 负载均衡策略 通过定义IRule实现可以修改负载均衡规则,有两种方式: 1. 代码方式:在服务消费者order-service中的OrderApplication类中,定义一个新的IRule: 2.配置文件方式: 在order-service的application.yml…...

【FPGA】zynq 单端口RAM 双端口RAM 读写冲突 写写冲突
RAMRAM读写分类RAM原理及实现RAM三种读写模式不变模式写优先读优先 单端口 RAM伪双端口 RAM真双端口 RAM读写冲突和写写冲突读写冲突写写冲突总结: RAM RAM 的英文全称是 Random Access Memory,即随机存取存储器,简称随机存储器,…...
【备忘】websocket学习之挖坑埋自己
背景故事 以前没有好好学习过websocket,只知道它有什么用途,也知道是个好东西,平时在工作中没用过,所以对它并不知所以然。如今要做个自己的项目,要在付款的时候实时播报声音。自己是个开发者,也不想用别人…...

大数据研发工程师面试
文章目录 面试1.AUC,ROC,准确率与召回率都是怎么计算的?2.数据清洗是如何清洗的,要做哪些清洗的工作?3.什么是数据的完整性?4.数仓是怎么设计的?5.linux查看进程的命令是什么,如何查看具体某一行的内容(查看第n至m行࿰…...
【星海出品】云存储 ceph
https://ceph.com/en/ ceph组件介绍 Monitor 一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。 OSD OSD全称Object Storage Device,也就是负责响应客户端请求返回具体数据的进程。一个Ceph集群一般都有…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

并发编程 - go版
1.并发编程基础概念 进程和线程 A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。C.一个进程可以创建和撤销多个线程;同一个进程中…...

提升移动端网页调试效率:WebDebugX 与常见工具组合实践
在日常移动端开发中,网页调试始终是一个高频但又极具挑战的环节。尤其在面对 iOS 与 Android 的混合技术栈、各种设备差异化行为时,开发者迫切需要一套高效、可靠且跨平台的调试方案。过去,我们或多或少使用过 Chrome DevTools、Remote Debug…...

数学建模-滑翔伞伞翼面积的设计,运动状态计算和优化 !
我们考虑滑翔伞的伞翼面积设计问题以及运动状态描述。滑翔伞的性能主要取决于伞翼面积、气动特性以及飞行员的重量。我们的目标是建立数学模型来描述滑翔伞的运动状态,并优化伞翼面积的设计。 一、问题分析 滑翔伞在飞行过程中受到重力、升力和阻力的作用。升力和阻力与伞翼面…...

Vue3中的computer和watch
computed的写法 在页面中 <div>{{ calcNumber }}</div>script中 写法1 常用 import { computed, ref } from vue; let price ref(100);const priceAdd () > { //函数方法 price 1price.value ; }//计算属性 let calcNumber computed(() > {return ${p…...