【PG】PostgreSQL高可用之自动故障转移-repmgrd
前言
上面的几篇文章介绍了repmgr的部署,手动进行 从节点提升,主从切换,孤立从从节点找到新的主库等操作,但是都是需要通过手动去执行命令。大家都知道,在线上生产环境中数据库每秒钟的不可用都会造成严重的事故,所以等到收到告警再去手动处理是不太能被接受的😠。我们需要一个自动化的程序去帮助我们发现故障,完成故障的自动切换,发送通知,记录问题等。repmgr提供了工具repmgrd可以完成以上的场景。本篇文章介绍repmrgd的配置参数,运维管理,测试repmrgd进行自动故障的切换。
目录
前言
1 简介
2 repmgrd 设置和配置
2.0 PostgreSQL必须配置
2.1 通用参数配置
2.2 自动故障转移的必须参数
2.3 自动故障转移的可选参数
2.4 repmgrd服务配置
2.5 监控配置
3 repmgrd 运维管理
3.1 repmgrd启停
3.2 repmgrd的PID文件
3.3 查看repmgrd进程
3.4 repmgrd连接设置
3.5 repmgrd日志轮转
3.6 repmgrd暂停功能
3.7 repmgrd WAL重放
3.8 repmgrd“降级监控”模式
3.9 repmgrd 监控数据
仅监控模式
4 实验验证自动故障切换
停止主库前查看状态
停止主库
查看日志
1 简介
repmgrd (" replication manager daemon") 是一个管理和监视守护进程,运行在复制集群中的每个节点上。它可以自动执行故障转移和更新备用数据库以遵循新主数据库等操作,并提供有关每个备用数据库状态的监控信息。
rempgrd的设计是易于设置,不需要额外的外部基础设施。
repmgrd 提供的功能包括:
- 丰富的配置选项
- 能够用一条命令暂停 所有节点上的 repmgrd
- 可执行自定义脚本,故障转移中不同点的事件通知
- “见证服务器”
- “位置”配置选项,用于将潜在的候选节点限制在单个位置(例如,当节点分布在多个数据中心时)
- 多种探活方式(PostgreSQL ping、查询执行或新连接)
- 保留监测统计数据(可选)
总结一下repmgrd的功能:
- 丰富的配置
- 管理方便
- 自定义脚本
- 见证服务器
- 多数据中心
- 多种探活方式
- 监控统计数据
2 repmgrd 设置和配置
repmgrd是一个守护进程,在每个 PostgreSQL 节点上运行,当运行在主节点上时可以监视本地节点,当运行在从节点上 可以监控它所连接的上游节点(上游节点可以是:主节点或级联复制的另一个中间节点)。
rempgrd可以配置为在主节点或上游节点变得无法访问时提供故障转移功能,向repmgr 元数据库提供监控数据。
从repmgr 4.4 开始,当在主节点上运行时,repmgrd还可以监控从节点 断开/重新连接的情况
2.0 PostgreSQL必须配置
要使用 repmgr,必须在 postgresql.conf设置一下参数 并重启postgresql才能生效。
shared_preload_libraries = 'repmgr'关于这个参数的官方文档 PostgreSQL: Documentation: 16: 20.11. Client Connection Defaults
2.1 通用参数配置
以下配置选项适用于所有情况下的 repmgrd :
monitor_interval_secs
检查上游节点可用性的时间间隔(以秒为单位,默认:2 )。
connection_check_type
该选项connection_check_type用于选择 repmgrd用于确定上游节点是否可用的方法。
可选的值为:
ping(默认)- 用于PQping()确定服务器可用性connection- 通过尝试与上游节点建立新连接来确定服务器可用性-
query- 通过现有连接在节点上执行 SQL 语句来确定服务器可用性该查询是一个最小的一次性查询
SELECT 1,用于确定服务器是否可以接受查询。
reconnect_attempts
在启动故障转移之前,将尝试重新连接到无法访问的上游节点 的次数(默认值:6) 。
每次重新连接尝试之间会有reconnect_interval几秒的间隔。
reconnect_interval
尝试重新连接到无法访问的上游节点之间的 时间间隔(以秒为单位,默认值:10) 。
重新连接尝试的次数由参数定义reconnect_attempts。
degraded_monitoring_timeout
如果被监视的任一服务器(本地节点和/或上游节点)不再可用(降级监视模式), repmgrd将终止的时间间隔(以秒为单位)。(默认 -1)完全禁用此超时。
2.2 自动故障转移的必须参数
必须在repmgr.conf中设置 以下repmgrd选项:
failoverpromote_commandfollow_command
示例
failover=automatic
promote_command='/usr/bin/repmgr standby promote -f /etc/repmgr.conf --log-to-file'
follow_command='/usr/bin/repmgr standby follow -f /etc/repmgr.conf --log-to-file --upstream-node-id=%n'每个选项的详细信息如下:
failover
failover可以是automatic或manual 之一。
promote_command
当rempgrd确定当前节点将成为新的主节点 时,将在故障转移情况下执行promote_command中定义的程序或脚本。
通常promote_command设置为repmgr的 repmgr standby promote命令。
还可以提供 shell 脚本,例如在升级当前节点之前执行用户定义的任务。在这种情况下,脚本必须 在某个时刻执行repmgr standby promote以提升节点;如果不这样做,repmgr 元数据将不会更新,并且 repmgr将不再可靠地运行。
举例
Promotion_command='/usr/bin/repmgrstandby Promotion -f /etc/repmgr.conf --log-to-file'
请注意,该--log-to-file选项将导致由 repmgrd 执行时 由 repmgr 命令生成的日志 输出记录到 repmgrd日志文件中
特别注意 pg_bindir执行 promote_command 或 follow_command 时, repmgr将不适用;这些可以是用户定义的脚本,因此必须始终指定shell脚本的完整路径。
promote_command
可以接受两种参数
1repmgr standby promote 命令2 自定义shell脚本
注意:shell 脚本需要是绝对路径 ,可以通过
--log-to-file 参数将日志输出到日志文件中
follow_command
当rempgrd确定当前节点将跟随新的主节点 时,将在故障转移情况下执行 follow_command中定义的程序或脚本
通常follow_command设置为repmgr的 repmgr standby follow命令。
follow_command参数提供的命令repmgr standby follow 需要添加参数 --upstream-node-id=%n 。%n将由带有新主节点 ID 的替换 。如果未提供此选项, repmgr standby follow 将尝试自行确定新的主节点,但如果在新的主节点升级后原始主节点重新上线,repmgr standby follow 则存在导致节点继续追随原始主节点的风险 。
还可以提供 shell 脚本,例如在升级当前节点之前执行用户定义的任务。在这种情况下,脚本必须 在某个时刻执行repmgr standby follow 以提升节点;如果不这样做,repmgr 元数据将不会更新,并且 repmgr将不再可靠地运行。
例子:
follow_command='/usr/bin/repmgr standby follow -f /etc/repmgr.conf --log-to-file --upstream-node-id=%n'
请注意,该--log-to-file选项将导致由 repmgrd 执行时由 repmgr 命令生成的输出记录到配置为接收repmgrd日志输出的同一目标。
follow_command
可以接受两种参数
1repmgr standby follow命令2 自定义shell脚本
注意:
shell 脚本需要是绝对路径 ,
可以通过
--log-to-file 参数将日志输出到日志文件中
需要添加参数--upstream-node-id=%n来传入新的主节点的node-id
2.3 自动故障转移的可选参数
priority
请注意,仅当两个或更多节点被确定为升级候选者时才应用优先级设置;在这种情况下,将选择具有较高优先级的节点。
值为0 将始终阻止节点升级为主节点,即使没有其他升级候选节点。
failover_validation_command
用户定义的脚本,用于为外部机制执行以验证由repmgrd 做出的故障转移决策。可以提供以下一个或多个参数占位符,这些占位符将被 repmgrd 替换为适当的值:
%n:节点ID%a: 节点名称%v:可见节点数%u:共享上游节点数量%t:节点总数
always_promote
如果true,则升级本地节点,即使其 repmgr 元数据不是最新的。
通常,repmgr希望其元数据(存储在表中repmgr.nodes )是最新的,以便repmgrd可以在故障转移期间采取正确的操作。但是,在主数据库上进行的更新可能尚未传播到备用数据库(升级候选数据库)。在这种情况下,repmrd将默认不提升备用数据库。always_promote可以通过设置为 来覆盖此行为 true。
standby_disconnect_on_failover
PostgreSQL 9.5 及更高版本提供此选项。
repmgrd_exit_on_inactive_node
此参数在repmgr 5.3 及更高版本 中可用。
如果节点被标记为非活动但正在运行,并且此选项设置为 true,repmgrd将在启动时中止。
默认情况下,repmgrd_exit_on_inactive_node设置为false,在这种情况下,repmgrd将在启动时将节点记录设置为活动状态。
将此参数设置为true会导致rempgrd 的行为方式与在repmgr 5.2 及更早版本 中的行为方式相同。
以下选项可用于进一步微调故障转移行为。实际上,这些默认值不太可能需要更改,但如果需要,可以作为配置选项使用。
election_rerun_interval
如果failover_validation_command设置,并且命令返回错误,则在重新选举之前 将会暂停指定的秒数(默认值:15)。
sibling_nodes_disconnect_timeout
如果standby_disconnect_on_failover是,则等待其他备用数据库确认它们已断开其 WAL 接收器的 true最大时间长度(以秒为单位,默认值:30) 。
2.4 repmgrd服务配置
如果你想使用 repmgr daemon start 和 repmgr daemon stop 命令来管理repmgrd的进程,需要在配置文件 repmgr.conf 中设置参数:
repmgrd_service_start_commandrepmgrd_service_stop_command
举例
repmgrd_service_start_command='sudo systemctl repmgr12 start'
repmgrd_service_stop_command='sudo systemctl repmgr12 stop'2.5 监控配置
开启监控需要在配置文件repmgr.conf中设置
monitoring_history=yes每隔monitor_interval_secs 秒将会写一次监控数据。更多的详细详细 参考: Storing monitoring data.
监控从节点断开的信息 参考 Monitoring standby disconnections on the primary.
3 repmgrd 运维管理
3.1 repmgrd启停
如果从软件包安装,repmgrd可以通过操作系统的服务命令启动,例如在systemd中 使用systemctl。
通过命令 repmgr daemon start 和 repmgr daemon stop 命令来管理repmgrd的进程 ,参考本篇文章的2.4
可以像这样手动启动 repmgrd
repmgrd -f /etc/repmgr.conf --pid-file=/home/storage/repmgr/repmgrd.pid停止
kill `cat /home/storage/repmgr/repmgrd.pid`启动报错 1
[ERROR] unable to write to shared memory
[HINT] ensure "shared_preload_libraries" includes "repmgr"
$cat /home/storage/repmgr/repmgr.log
[2023-11-16 11:13:03] [NOTICE] repmgrd (repmgrd 5.3.3) starting up
[2023-11-16 11:13:03] [INFO] connecting to database "host=10.79.21.30 port=5432 user=repmgr dbname=repmgr connect_timeout=2"
[2023-11-16 11:13:03] [ERROR] unable to write to shared memory
[2023-11-16 11:13:03] [HINT] ensure "shared_preload_libraries" includes "repmgr"
[2023-11-16 11:13:03] [INFO] repmgrd terminating...解决
设置参数 shared_preload_libraries = 'repmgr' 然后重启
3.2 repmgrd的PID文件
rempgrd默认会生成一个 PID 文件。
PID 文件可以通过配置epmgr.conf中的参数 repmgrd_pid_file 指定。
也可以使用命令行参数在命令行上指定(如以前的版本)--pid-file。请注意,这将覆盖repmgr.conf中设置的任何值repmgrd_pid_file。 --pid-file可能会在未来版本中被弃用。
如果包维护者指定了 PID 文件位置,repmgrd 将使用该位置。这仅适用于从软件包安装 repmgr并且软件包维护者已指定 PID 文件位置的情况。
如果以上都不适用,repmgrd将在操作系统的临时目录中创建一个 PID 文件(由环境变量 确定 TMPDIR,或者如果未设置,将使用/tmp)。
要完全防止生成 PID 文件,请提供命令行选项 --no-pid-file。
要查看repmgrd将使用哪个PID 文件,请 使用选项执行repmgrd--show-pid-file。 如果提供此选项,repmgrd将不会启动。
请注意,显示的值是repmgrd下次启动时将使用的文件 ,不一定是当前使用的 PID 文件。
3.3 查看repmgrd进程
repmgr service status命令提供集群中所有节点上的 repmgrd守护程序状态(包括暂停状态) 的概述。
从repmgr 5.3开始。repmgr node check --repmgrd将用于检查本地节点上 repmgrd的状态(包括暂停状态)。
repmgr -f /etc/repmgr.conf node check --repmgrd
$repmgr -f /etc/repmgr.conf node check --repmgrd
OK (repmgrd running)3.4 repmgrd连接设置
除了repmgr配置设置之外,字符串中的参数 conninfo还会影响repmgr与 PostgreSQL 建立网络连接的方式。特别是,如果复制集群中的另一台服务器在网络级别无法访问,则系统网络设置将影响确定无法连接所需的时间长度。
特别是应考虑显式设置参数connect_timeout;该参数的最小值(2秒) 将确保尽快报告网络级别的连接故障,否则根据系统设置(例如 在 Linux 中tcp_syn_retries),可能会延迟一分钟或更长时间。
有关conninfo网络连接参数的更多详细信息,请参阅 PostgreSQL 文档。
3.5 repmgrd日志轮转
为了确保当前的repmgrd日志文件(在repmgr.conf参数 中指定log_file)不会无限期地增长,请将您的系统配置logrotate为定期轮换它。
每周轮换日志文件的示例配置,保留时间长达 52 周,如果文件增长超过 100Mb,则强制轮换:
vi /etc/logrotate.conf
/home/storage/repmgr/repmgr.log {missingokcompressrotate 52maxsize 100Mweeklycreate 0600 postgres postgrespostrotate/usr/bin/killall -HUP repmgrdendscript
}/home/storage/repmgr/repmgr.log : 指定需要轮转的日志文件的路径。
missingok: 如果日志文件不存在,不产生错误。
compress: 在轮转时使用 gzip 进行压缩。
rotate 52: 保留 52 个旧的日志文件备份。
maxsize 100M: 当日志文件大小达到 100MB 时触发轮转。
weekly: 指定日志文件每周轮转一次。
create 0600 postgres postgres: 在轮转后创建一个新的空日志文件,权限设置为 0600,属主和属组设置为 postgres。postrotate ... endscript: 在轮转后执行的脚本。在这里,它使用 killall 命令发送 SIGHUP 信号给 repmgrd 进程。这可以用于通知 repmgrd 重新加载配置或进行其他操作。
手动执行 /usr/bin/killall -HUP repmgrd 该命令 日志文件中会输出如下信息[2023-11-16 15:48:05] [NOTICE] received SIGHUP, reloading configuration
[2023-11-16 15:48:05] [INFO] reloading configuration file
[2023-11-16 15:48:05] [DETAIL] using file "/etc/repmgr.conf"
[2023-11-16 15:48:05] [NOTICE] configuration was successfully changed
[2023-11-16 15:48:05] [DETAIL] following configuration items were changed:"monitoring_history" changed from "false" to "true"这个配置确保了 repmgrd 的日志文件能够被轮转,并在需要时进行压缩,同时保留一定数量的历史备份。轮转后会创建一个新的、空的日志文件,而 postrotate 部分用于触发某些操作,这里是发送 SIGHUP 信号给 repmgrd 进程。手动执行轮转 查看效果
logrotate -v /etc/logrotate.conf
3.6 repmgrd暂停功能
在正常操作中,repmgrd监视它正在运行的 PostgreSQL 节点的状态,如果检测到问题,将采取适当的操作,例如(如果如此配置)如果现有主节点已被确定为故障,则将节点提升为主节点。
但是,repmgrd无法区分计划中断(例如执行切换 或安装 PostgreSQL 维护版本)和实际服务器中断。在repmgr 4.2之前的版本中, 必须在所有节点上停止repmgrd(或者至少在为自动故障转移配置repmgrd 的所有节点上),以防止repmgrd对复制集群进行无意的更改。
从repmgr 4.2开始,repmgr 现在可以“暂停”,即指示不要采取任何操作,例如执行故障转移。这可以从集群中的任何节点完成,无需单独停止/重新启动每个repmgrd。
暂停是为了在有计划内中断
为了能够暂停/取消暂停repmgrd,必须满足以下先决条件:
- 所有节点上必须安装repmgr 4.2或更高版本。
- 必须在所有节点上安装相同的主要repmgr版本(例如 4.2)(最好是相同的次要版本)。
- 所有节点上的 PostgreSQL 必须可以从执行
pause/unpause操作的节点访问 ,使用conninfo所示的字符串repmgr cluster show。
暂停 repmgr -f /etc/repmgr.conf service pause
$repmgr -f /etc/repmgr.conf service pause
NOTICE: node 1 (node1) paused
NOTICE: node 2 (node2) paused# 暂停之后的状态$repmgr node check --repmgrd
WARNING (repmgrd running but paused)取消暂停
# 取消暂停
$repmgr -f /etc/repmgr.conf service unpause
NOTICE: node 1 (node1) unpaused
NOTICE: node 2 (node2) unpaused3.7 repmgrd WAL重放
如果 WAL 重放已暂停(pg_wal_replay_pause()在 PostgreSQL 9.6 及更早版本上使用pg_xlog_replay_pause(), ),在故障转移情况下,repmgrd将自动恢复 WAL 重放。
这是因为,如果 WAL 重放暂停,但 WAL 正在等待重放, WAL 重放之前,则在恢复PostgreSQL 的节点无法进行提升。
3.8 repmgrd“降级监控”模式
在某些情况下,repmgrd无法完成其监视节点上游服务器的主要任务。在这些情况下,它会进入“降级监控”模式,在该模式下,repmgrd保持活动状态,但正在等待情况得到解决。
发生这种情况的情况有:
- 发生故障转移情况,主节点所在位置的节点不可见
- 发生了故障转移情况,但没有可用的提升节点
- 发生了故障转移情况,但无法提升节点
- 发生了故障转移情况,但该节点无法成为新的主节点的从节点
- 发生了故障转移情况,但没有可用的主数据库
- 发生故障转移情况,但节点未启用自动故障转移
- repmgrd 正在监控主节点,但它不可用(并且没有其他节点被提升为主节点)
默认情况下,repmgrd将无限期地继续处于降级监控模式。然而,可以使用 degraded_monitoring_timeout 设置超时(以秒为单位),之后rempgrd将终止。
3.9 repmgrd 监控数据
当repmgrd使用选项运行时 monitoring_history=true,它会不断地将备用节点状态信息写入表中 monitoring_history,从而提供集群中所有节点上的复制状态的近乎实时的概述。
该视图replication_status显示每个节点的最新状态,例如:
select * from repmgr.replication_status;
select * from repmgr.replication_status;primary_node_id | standby_node_id | standby_name | node_type | active | last_monitor_time | last_wal_primary_location | last_wal_standby_location | replication_lag | replication_time_lag | apply_lag | communication_time_lag
-----------------+-----------------+--------------+-----------+--------+-------------------------------+---------------------------+---------------------------+-----------------+----------------------+-----------+------------------------2 | 1 | node1 | standby | t | 2023-11-16 15:53:33.529827+08 | 0/15028AF0 | 0/15028AF0 | 0 bytes | 00:00:00 | 0 bytes | 00:00:01.832594
(1 row)写入监控历史记录的时间间隔由配置参数控制monitor_interval_secs;默认值为 2。
因为这样会在repmgr.monitoring_history表中产生大量的监控数据 。建议使用repmgr cluster cleanup 命令定期清除历史数据;使用该-k/--keep-history选项指定应保留多少天的数据。
仅监控模式
通过在节点 repmgr.conf文件中进行设置 failover=manual ,可以使用repmgrd在某些或所有节点的监视模式下运行(没有自动故障转移功能)。如果节点的上游发生故障,则不会采取故障转移操作,并且节点将需要手动干预才能重新连接到复制。如果发生这种情况, 将创建 standby_disconnect_manual事件通知。
请注意,当备用节点不直接从其上游节点进行流传输时,例如从存档中恢复 WAL,apply_lag将始终显示为 0 bytes。
4 实验验证自动故障切换
停止主库前查看状态
$repmgr -f /etc/repmgr.conf cluster showID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+-------+---------+-----------+----------+----------+----------+----------+------------------------------------------------------------------------1 | node1 | standby | running | node2 | default | 100 | 4 | host=10.79.21.30 port=5432 user=repmgr dbname=repmgr connect_timeout=22 | node2 | primary | * running | | default | 100 | 4 | host=10.79.21.29 port=5432 user=repmgr dbname=repmgr connect_timeout=2停止主库
/usr/local/pgsql/bin/pg_ctl -D /home/storage/pgsql/data -l /home/storage/pgsql/data/server.log stop
查看日志
主节点
[2023-11-16 15:57:41] [DETAIL] attempted to connect using:user=repmgr connect_timeout=2 dbname=repmgr host=10.79.21.29 port=5432 fallback_application_name=repmgr options=-csearch_path=
[2023-11-16 15:57:41] [WARNING] reconnection to node "node2" (ID: 2) failed
[2023-11-16 15:57:41] [WARNING] unable to connect to local node
[2023-11-16 15:57:41] [INFO] checking state of node 2, 1 of 6 attempts
[2023-11-16 15:57:41] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=10.79.21.29 port=5432 fallback_application_name=repmgr"
[2023-11-16 15:57:41] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-11-16 15:57:41] [INFO] sleeping 10 seconds until next reconnection attempt
[2023-11-16 15:57:51] [INFO] checking state of node 2, 2 of 6 attempts
[2023-11-16 15:57:51] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=10.79.21.29 port=5432 fallback_application_name=repmgr"
[2023-11-16 15:57:51] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-11-16 15:57:51] [INFO] sleeping 10 seconds until next reconnection attempt
[2023-11-16 15:58:01] [INFO] checking state of node 2, 3 of 6 attempts
[2023-11-16 15:58:01] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=10.79.21.29 port=5432 fallback_application_name=repmgr"
[2023-11-16 15:58:01] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-11-16 15:58:01] [INFO] sleeping 10 seconds until next reconnection attempt
[2023-11-16 15:58:11] [INFO] checking state of node 2, 4 of 6 attempts
[2023-11-16 15:58:11] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=10.79.21.29 port=5432 fallback_application_name=repmgr"
[2023-11-16 15:58:11] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-11-16 15:58:11] [INFO] sleeping 10 seconds until next reconnection attempt
[2023-11-16 15:58:21] [INFO] checking state of node 2, 5 of 6 attempts
[2023-11-16 15:58:21] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=10.79.21.29 port=5432 fallback_application_name=repmgr"
[2023-11-16 15:58:21] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-11-16 15:58:21] [INFO] sleeping 10 seconds until next reconnection attempt
[2023-11-16 15:58:31] [INFO] checking state of node 2, 6 of 6 attempts
[2023-11-16 15:58:31] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=10.79.21.29 port=5432 fallback_application_name=repmgr"
[2023-11-16 15:58:31] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-11-16 15:58:31] [WARNING] unable to reconnect to node 2 after 6 attempts
[2023-11-16 15:58:31] [NOTICE] unable to connect to local node, falling back to degraded monitoring
[2023-11-16 15:58:31] [WARNING] unable to ping "host=10.79.21.29 port=5432 user=repmgr dbname=repmgr connect_timeout=2"
[2023-11-16 15:58:31] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-11-16 15:58:31] [ERROR] unable to determine if server is in recovery
[2023-11-16 15:58:31] [DETAIL] query text is:
SELECT pg_catalog.pg_is_in_recovery()
[2023-11-16 15:58:31] [WARNING] unable to determine node recovery status
[2023-11-16 15:58:33] [WARNING] unable to ping "host=10.79.21.29 port=5432 user=repmgr dbname=repmgr connect_timeout=2"
[2023-11-16 15:58:33] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-11-16 15:58:33] [WARNING] connection to node "node2" (ID: 2) lost
[2023-11-16 15:58:33] [DETAIL]
connection pointer is NULL从节点
[2023-11-16 15:57:40] [WARNING] unable to ping "host=10.79.21.29 port=5432 user=repmgr dbname=repmgr connect_timeout=2"
[2023-11-16 15:57:40] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-11-16 15:57:40] [WARNING] unable to connect to upstream node "node2" (ID: 2)
[2023-11-16 15:57:40] [INFO] checking state of node "node2" (ID: 2), 1 of 6 attempts
[2023-11-16 15:57:40] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=10.79.21.29 port=5432 fallback_application_name=repmgr"
[2023-11-16 15:57:40] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-11-16 15:57:40] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2023-11-16 15:57:50] [INFO] checking state of node "node2" (ID: 2), 2 of 6 attempts
[2023-11-16 15:57:50] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=10.79.21.29 port=5432 fallback_application_name=repmgr"
[2023-11-16 15:57:50] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-11-16 15:57:50] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2023-11-16 15:58:00] [INFO] checking state of node "node2" (ID: 2), 3 of 6 attempts
[2023-11-16 15:58:00] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=10.79.21.29 port=5432 fallback_application_name=repmgr"
[2023-11-16 15:58:00] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-11-16 15:58:00] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2023-11-16 15:58:10] [INFO] checking state of node "node2" (ID: 2), 4 of 6 attempts
[2023-11-16 15:58:10] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=10.79.21.29 port=5432 fallback_application_name=repmgr"
[2023-11-16 15:58:10] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-11-16 15:58:10] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2023-11-16 15:58:20] [INFO] checking state of node "node2" (ID: 2), 5 of 6 attempts
[2023-11-16 15:58:20] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=10.79.21.29 port=5432 fallback_application_name=repmgr"
[2023-11-16 15:58:20] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-11-16 15:58:20] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2023-11-16 15:58:30] [INFO] checking state of node "node2" (ID: 2), 6 of 6 attempts
[2023-11-16 15:58:30] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=10.79.21.29 port=5432 fallback_application_name=repmgr"
[2023-11-16 15:58:30] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-11-16 15:58:30] [WARNING] unable to reconnect to node "node2" (ID: 2) after 6 attempts
[2023-11-16 15:58:30] [INFO] 0 active sibling nodes registered
[2023-11-16 15:58:30] [INFO] 2 total nodes registered
[2023-11-16 15:58:30] [INFO] primary node "node2" (ID: 2) and this node have the same location ("default")
[2023-11-16 15:58:30] [INFO] no other sibling nodes - we win by default
[2023-11-16 15:58:30] [NOTICE] this node is the only available candidate and will now promote itself
[2023-11-16 15:58:30] [INFO] promote_command is:"/usr/local/pgsql/bin/repmgr standby promote -f /etc/repmgr.conf --log-to-file"
[2023-11-16 15:58:30] [NOTICE] redirecting logging output to "/home/storage/repmgr/repmgr.log"[2023-11-16 15:58:30] [NOTICE] promoting standby to primary
[2023-11-16 15:58:30] [DETAIL] promoting server "node1" (ID: 1) using pg_promote()
[2023-11-16 15:58:30] [NOTICE] waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete
[2023-11-16 15:58:31] [NOTICE] STANDBY PROMOTE successful
[2023-11-16 15:58:31] [DETAIL] server "node1" (ID: 1) was successfully promoted to primary
[2023-11-16 15:58:31] [INFO] checking state of node 1, 1 of 6 attempts
[2023-11-16 15:58:31] [NOTICE] node 1 has recovered, reconnecting
[2023-11-16 15:58:31] [INFO] connection to node 1 succeeded
[2023-11-16 15:58:31] [INFO] original connection is still available
[2023-11-16 15:58:31] [INFO] 0 followers to notify
[2023-11-16 15:58:31] [INFO] switching to primary monitoring mode
[2023-11-16 15:58:31] [NOTICE] monitoring cluster primary "node1" (ID: 1)查看状态
$repmgr -f /etc/repmgr.conf cluster showID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+-------+---------+-----------+----------+----------+----------+----------+------------------------------------------------------------------------1 | node1 | primary | * running | | default | 100 | 5 | host=10.79.21.30 port=5432 user=repmgr dbname=repmgr connect_timeout=22 | node2 | primary | - failed | ? | default | 100 | | host=10.79.21.29 port=5432 user=repmgr dbname=repmgr connect_timeout=2WARNING: following issues were detected- unable to connect to node "node2" (ID: 2)TODO
配合VIP或者自定义脚本的切换
相关文章:

【PG】PostgreSQL高可用之自动故障转移-repmgrd
前言 上面的几篇文章介绍了repmgr的部署,手动进行 从节点提升,主从切换,孤立从从节点找到新的主库等操作,但是都是需要通过手动去执行命令。大家都知道,在线上生产环境中数据库每秒钟的不可用都会造成严重的事故&am…...
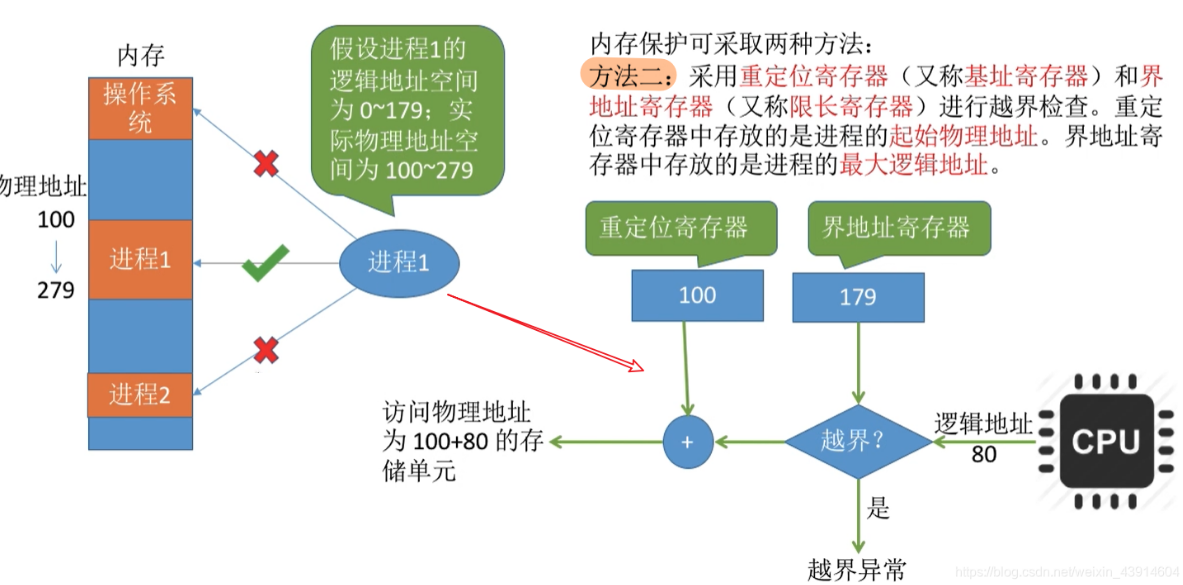
操作系统OS/存储管理/内存管理/内存管理的主要功能_基本原理_要求
基本概念 内存管理的主要功能/基本原理/要求 **内存管理的主要功能: ** 内存空间的分配与回收。由操作系统完成主存储器空间的分配和管理,使程序员摆脱存储分配的麻烦,提高编程效率。地址转换。在多道程序环境下,程序中的逻辑地…...

【手写数据库toadb】SQL解析器的实现架构,create table/insert 多values语句的解析树生成流程和输出结构分析
SQL解析器架构和实现 专栏内容: 手写数据库toadb 本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。 本专栏会定期更新,对应的代码也会定期更新,每个阶段的代码会打上tag,方…...
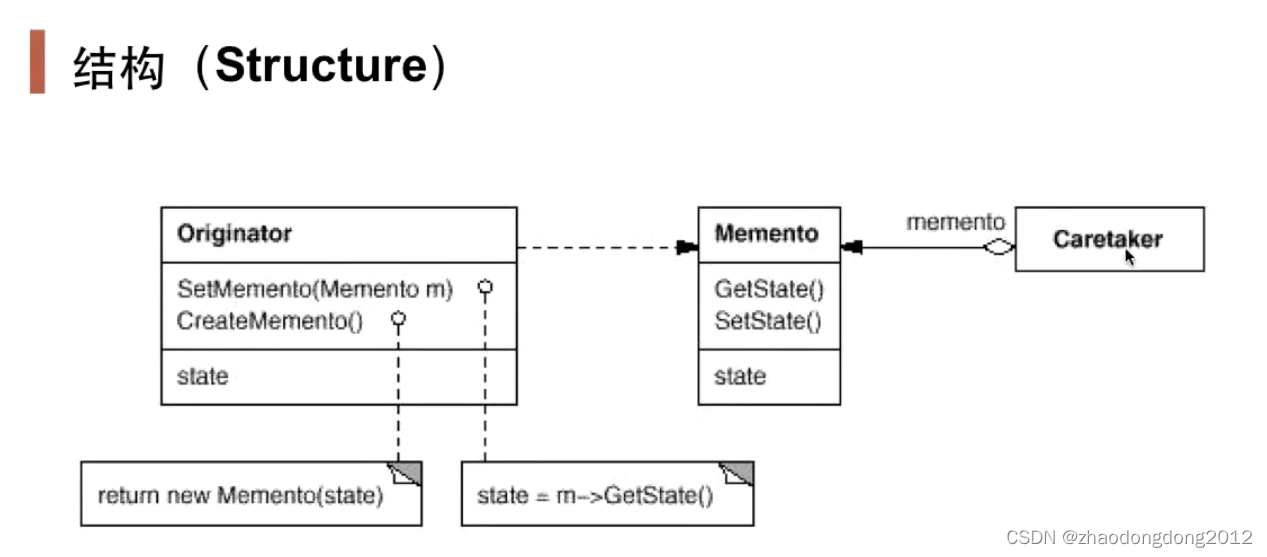
设计模式-备忘录模式-笔记
动机(Motivation) 在软件构建过程中,某些对象的状态在转换过程中,可能由于某种需要,要求程序能够回溯到对象之前处于某个点时的状态。如果使用一些公有接口来让其他对象得到对象的状态,便会暴露对象的细节…...
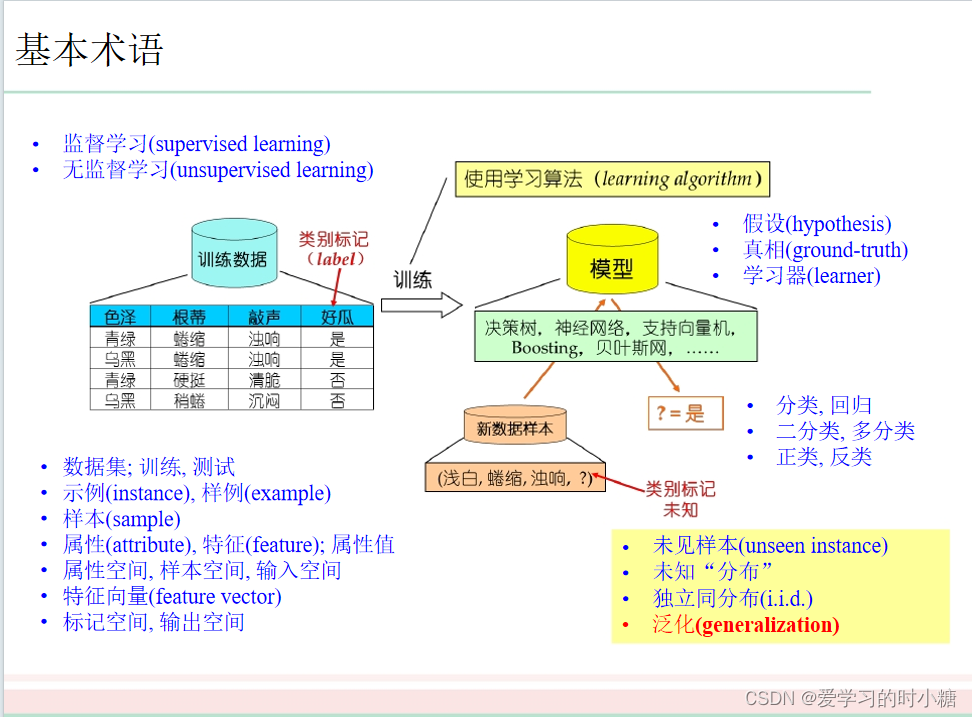
机器学习—基本术语
目录 1.样本(示例) 2.属性 3.属性值 4.属性空间 5.样本空间 6.学习(训练) 7.数据集 8.测试 9.假设 10.学习器 11.标记 12.样例 13.标记空间(样例空间) 14.分类与回归 15.有监督学习、无监督…...

pytorch单精度、半精度、混合精度、单卡、多卡(DP / DDP)、FSDP、DeepSpeed模型训练
pytorch单精度、半精度、混合精度、单卡、多卡(DP / DDP)、FSDP、DeepSpeed(环境没搞起来)模型训练代码,并对比不同方法的训练速度以及GPU内存的使用 代码:pytorch_model_train FairScale(你真…...
基于PHP的纺织用品商城系统
有需要请加文章底部Q哦 可远程调试 基于PHP的纺织用品商城系统 一 介绍 此纺织用品商城系统基于原生PHP开发,数据库mysql,前端bootstrap。用户可注册登录,购物下单,评论等。管理员登录后台可对纺织用品,用户…...

Go使用命令行输出二维码
引言 二维码(QR code)是一种矩阵条码的标准,广泛应用于商业、移动支付和数据存储等领域。在开发过程中,我们可能需要在命令行中显示二维码,这可以帮助我们快速生成和分享二维码信息。本文将介绍如何使用Go语言生成二维…...

最长连续序列[中等]
优质博文:IT-BLOG-CN 一、题目 给定一个未排序的整数数组nums,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。请你设计并实现时间复杂度为O(n)的算法解决此问题。 示例 1: 输入:nums […...
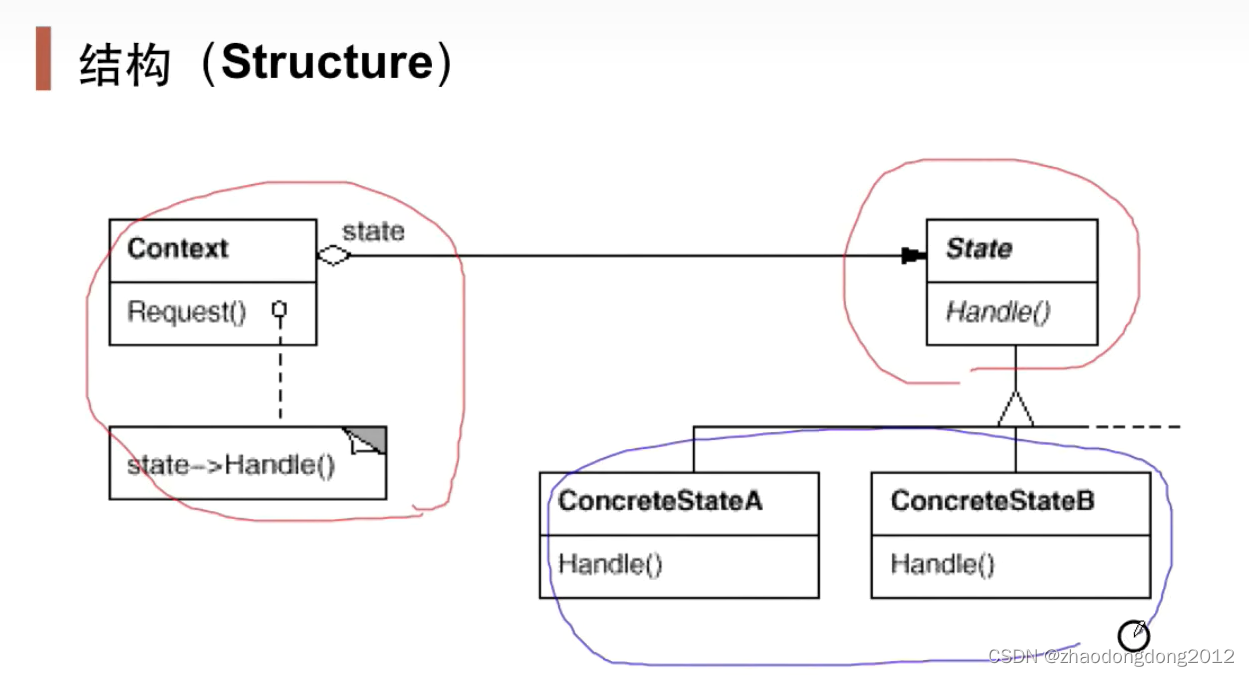
设计模式-状态模式-笔记
状态模式State 在组件构建过程中,某些对象的状态经常面临变化,如何对这些变化进行有效的管理?同时又维持高层模块的稳定?“状态变化”模式为这一问题提供了一种解决方案。 经典模式:State、Memento 动机(…...

Java中for、foreach、stream区别和性能比较
文章目录 性能比较区别使用方式和行为 性能比较 最终总结:如果数据在1万以内的话,for循环效率高于foreach和stream;如果数据量在10万的时候,stream效率最高,其次是foreach,最后是for。另外需要注意的是如果数据达到10…...
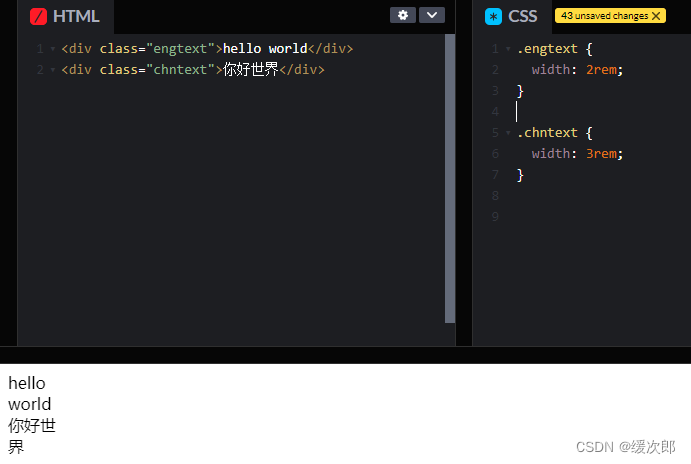
[CSS] 文本折行
文本折行一般分为两种情况: CJK(Chinese/Japanese/Korean) 字符和非 CJK 字符。一般非 CJK 字符折行发生在两个单词的空格中间,见下图: 图中文本 “hello world” 包裹容器的宽度为 2rem,但是 hello 并没有…...
)
033-从零搭建微服务-日志插件(一)
写在最前 如果这个项目让你有所收获,记得 Star 关注哦,这对我是非常不错的鼓励与支持。 源码地址(后端):mingyue: 🎉 基于 Spring Boot、Spring Cloud & Alibaba 的分布式微服务架构基础服务中心 源…...
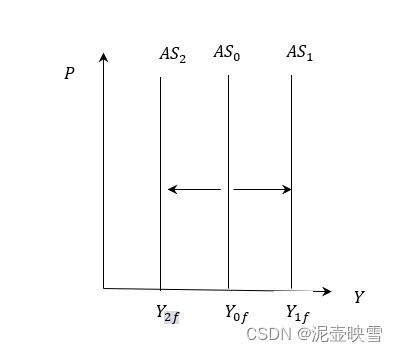
短期经济波动:均衡国民收入决定理论(三)
短期经济波动:国民收入决定理论(三) 文章目录 短期经济波动:国民收入决定理论(三)[toc]1 总需求曲线及其变动1.1 总需求曲线含义1.2 总需求曲线推导1.2.1 代数推导1.2.2 几何推导 1.3 AD曲线及其变动1.3.1 扩张性财政政策1.3.2 扩张性货币政策 2 总供给曲…...

电力感知边缘计算网关产品设计方案-网关软件架构
边缘计算网关采用ARM定制硬件平台架构,包含上位机端(内网)和FPGA网关端(外网)两部分,通过芯片间的高速信号总线实现边缘计算网关工业数据采集、数据实时传输、数据存储、网关状态信息收集等功能。 边缘计算网关上位机端(内网)重点完成工业数据采集、业务软件运算、客户…...
最新AI创作系统ChatGPT系统运营源码/支持最新GPT-4-Turbo模型/支持DALL-E3文生图
一、AI创作系统 SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如…...

Java使用Redis的几种客户端介绍
Redis是一种高性能的内存数据库,可以提供快速的数据读写操作。在Java中使用Redis,需要使用Redis客户端。目前,Java中常用的Redis客户端有以下几种: Jedis Jedis是Java中最流行的Redis客户端之一,它提供了丰富的API和…...

程序员的护城河
程序员的护城河 算法,一定是过硬的算法!!!举个栗子:算法不硬吃大亏写在最后 算法,一定是过硬的算法!!! 其实会什么技术不重要,掌握多少种编程语言也不重要&a…...
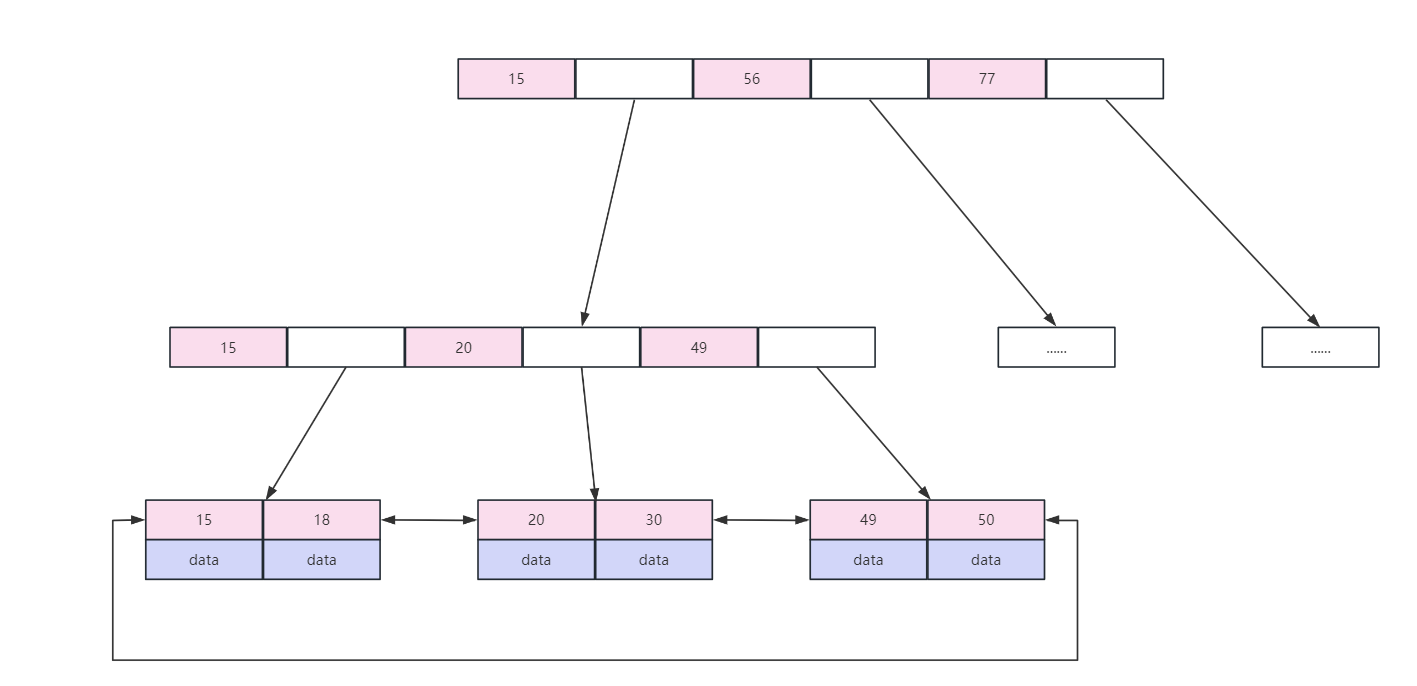
常见面试题-MySQL软删除以及索引结构
为什么 mysql 删了行记录,反而磁盘空间没有减少? 答: 在 mysql 中,当使用 delete 删除数据时,mysql 会将删除的数据标记为已删除,但是并不去磁盘上真正进行删除,而是在需要使用这片存储空间时…...
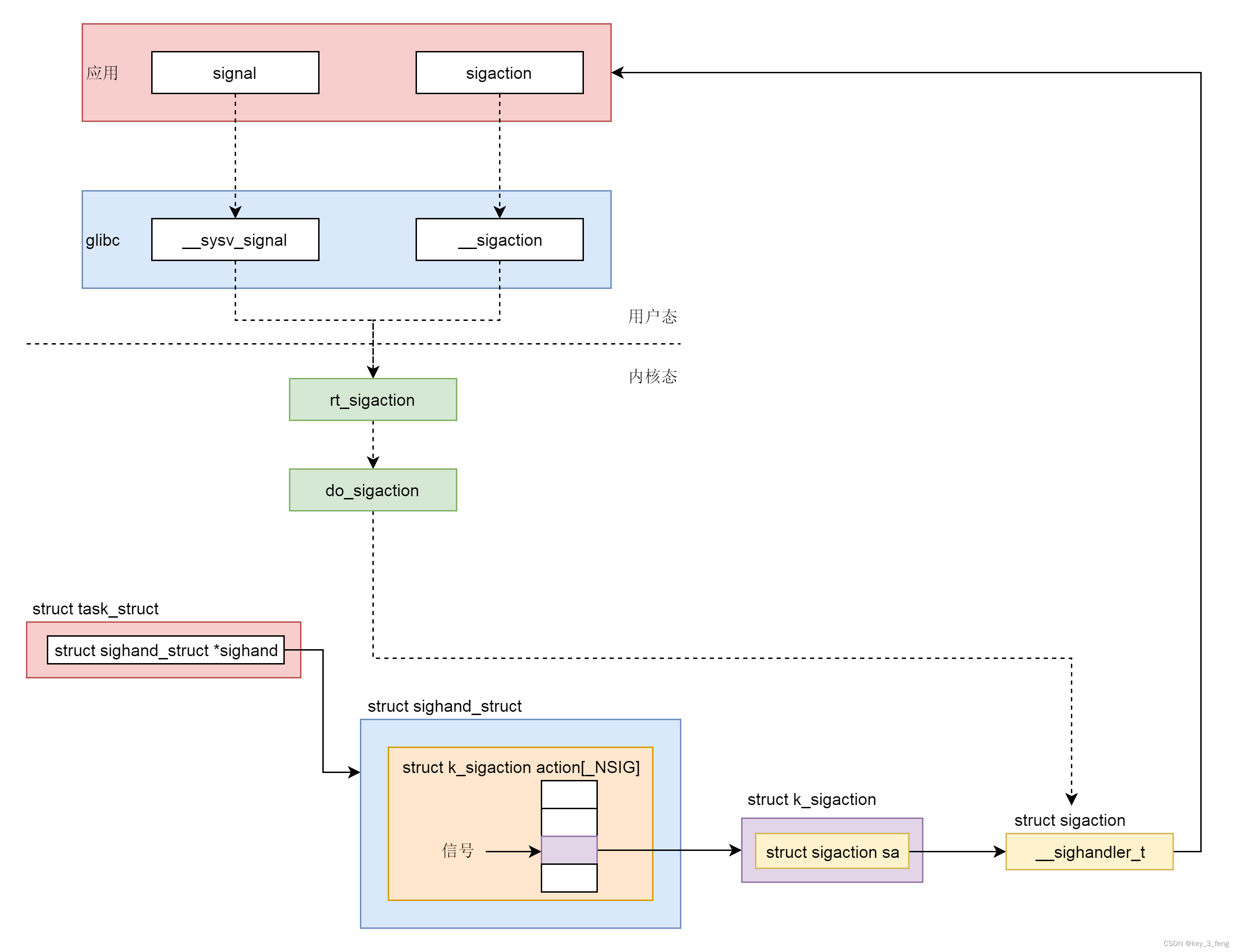
信号的机制——信号处理函数的注册
在 Linux 操作系统中,为了响应各种各样的事件,也是定义了非常多的信号。我们可以通过 kill -l 命令,查看所有的信号。 # kill -l1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP6) SIGABRT 7) SIGBUS …...

UE5 学习系列(二)用户操作界面及介绍
这篇博客是 UE5 学习系列博客的第二篇,在第一篇的基础上展开这篇内容。博客参考的 B 站视频资料和第一篇的链接如下: 【Note】:如果你已经完成安装等操作,可以只执行第一篇博客中 2. 新建一个空白游戏项目 章节操作,重…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

java 实现excel文件转pdf | 无水印 | 无限制
文章目录 目录 文章目录 前言 1.项目远程仓库配置 2.pom文件引入相关依赖 3.代码破解 二、Excel转PDF 1.代码实现 2.Aspose.License.xml 授权文件 总结 前言 java处理excel转pdf一直没找到什么好用的免费jar包工具,自己手写的难度,恐怕高级程序员花费一年的事件,也…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

vue3 定时器-定义全局方法 vue+ts
1.创建ts文件 路径:src/utils/timer.ts 完整代码: import { onUnmounted } from vuetype TimerCallback (...args: any[]) > voidexport function useGlobalTimer() {const timers: Map<number, NodeJS.Timeout> new Map()// 创建定时器con…...