Kafka快速入门
文章目录
- Kafka快速入门
- 1、相关概念介绍
- 前言
- 1.1 基本介绍
- 1.2 常见消息队列的比较
- 1.3 Kafka常见相关概念介绍
- 2、安装Kafka
- 3、初体验
- 前期准备
- 编码测试
- 配置介绍
- bug记录
Kafka快速入门

1、相关概念介绍
前言
在当今信息爆炸的时代,实时数据处理已经成为许多应用程序和系统不可或缺的一部分。Apache Kafka作为一个高吞吐量、低延迟的分布式消息队列系统,广泛应用于构建实时数据管道、流式处理应用等场景。无论是大数据分析、日志收集、监控告警还是在线机器学习模型等,Kafka都发挥着重要的作用。
本快速入门指南将带您进入Kafka的世界,探索其核心概念和基本操作。我们将从安装和配置开始,逐步介绍如何创建生产者和消费者,以及如何使用topic进行消息传递。通过这个入门指南,您将对Kafka有一个清晰的理解,并能够开始构建自己的实时数据流应用。
无需更多准备,让我们开始探索Kafka的奇妙世界吧!

1.1 基本介绍
-
Kafka是什么?
Kafka是一个开源的分布式消息中间件系统,用于处理大规模实时数据流。它是由LinkedIn公司开发的,后来成为Apache软件基金会的一个顶级项目。Kafka的主要目的是通过可靠地将消息传输到多个消费者,实现高吞吐量、低延迟的数据传输。
简单来说,Kafka可以帮助不同的应用程序和系统之间高效地传输消息,支持实时数据流处理、日志存储、数据集成等应用场景。
-
Kafka相关文档:
- 英文文档:https://kafka.apache.org
- 中文文档:https://kafka.apachecn.org
-
Kafka中文文档:Kafka 中文文档 - ApacheCN
-
Github开源地址:https://github.com/apache/kafka
-
-
Kafka有哪些用?
说到Kafka的作用,就要说MQ的作用了,MQ有如下一些常见的作用:
- 消息传输: Kafka可以在不同的应用程序和系统之间传输消息。生产者将消息发送到Kafka集群,然后消费者从Kafka中读取消息。这种解耦的方式使得系统能够更灵活地进行消息交换。
- 实时数据流处理: Kafka可以处理大规模的实时数据流,例如日志、传感器数据、网站活动日志等。它允许应用程序实时地处理这些数据,进行分析、计算、监控等操作。
- 日志存储: Kafka的消息被持久化存储在磁盘上,形成高可靠、高可用的日志系统。这些日志可以被用于数据恢复、审计、分析等用途。
- 数据集成: Kafka可以连接不同的数据系统,将数据从一个系统传输到另一个系统,实现数据的集成与同步。这种特性对于构建分布式系统、数据仓库等非常有用。
- 发布-订阅模型: Kafka采用发布-订阅模型,允许多个消费者同时订阅一个或多个主题(topics),并且每个消费者可以以自己的速度处理消息。
但是Kafka不仅仅是作为MQ使用,MQ只是Kafka的其中一个主要作用,它还有以下一些作用:
-
分布式文件系统:许多消息队列可以发布消息,除了消费消息之外还可以充当中间数据的存储系统。那么Kafka作为一个优秀的存储系统有什么不同呢?
数据写入Kafka后被写到磁盘,并且进行备份以便容错。直到完全备份,Kafka才让生产者认为完成写入,即使写入失败Kafka也会确保继续写入Kafka使用磁盘结构,具有很好的扩展性—50kb和50TB的数据在server上表现一致。
可以存储大量数据,并且可通过客户端控制它读取数据的位置,您可认为Kafka是一种高性能、低延迟、具备日志存储、备份和传播功能的分布式文件系统。
PS:关于Kafka提交日志存储和备份设计的更多细节,可以阅读 这页 。
-
流处理:Kafka 流处理不仅仅用来读写和存储流式数据,它最终的目的是为了能够进行实时的流处理。
Kafka提供了流处理API,可以用来进行实时数据分析和处理。通过Kafka Streams或者其他流处理框架,可以实现对数据流的实时处理、转换、聚合等操作。
-
Kafka常见应用
- 构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。 (相当于message queue)
- 构建实时流式应用程序,对这些流数据进行转换或者影响。 (就是流处理,通过kafka stream topic和topic之间内部进行变化)
-
Kafka四大核心API
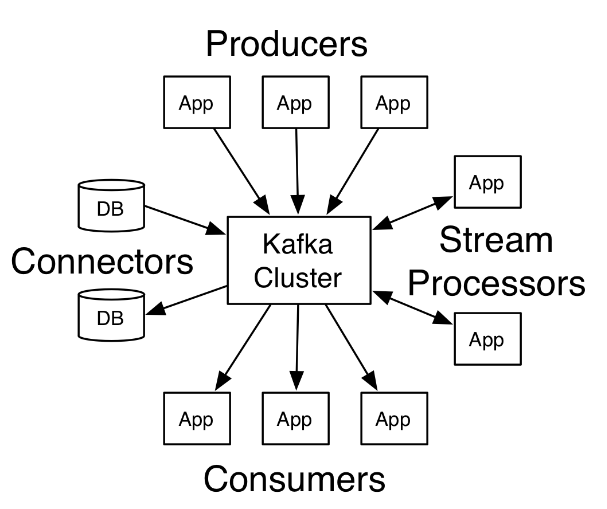
- The Producer API :允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic。
- The Consumer API :允许一个应用程序订阅一个或多个 topic ,并且对发布给他们的流式数据进行处理。
- The Streams API :允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换。
- The Connector API :允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。
-
Kafka的发展史
- 2011年: LinkedIn开发了Kafka,并将其作为开源项目提交到Apache软件基金会。在这一年,Kafka的第一个版本(0.7.0)发布。
- 2012年: Kafka 0.8.0版本发布,引入了新的特性,包括副本机制(Replication)和生产者确认(Producer Acknowledgements)等。这些特性增强了Kafka的可靠性和稳定性。
- 2013年: Kafka 0.8.1版本发布,引入了消费者位移存储在Kafka中的功能,这个特性使得Kafka可以跟踪消费者的位移信息,确保消费者可以从它们上次离开的地方继续消费消息。
- 2014年: Kafka 0.8.2版本发布,引入了Kafka Connect,这是一个用于连接Kafka与外部数据存储系统的框架。此外,0.8.2版本还引入了Kafka Streams,这是一个用于构建实时流处理应用程序的库。
- 2015年: Kafka 0.9.0版本发布,引入了新的消费者API,增加了对多订阅(multi-subscribe)和动态主题(dynamic topic subscriptions)的支持。这一版本还改进了Kafka的性能和稳定性。
- 2016年: Kafka 0.10.0版本发布,引入了重大的特性,包括Exactly-Once语义、消息时间戳、头部消息(header messages)等。这些特性使得Kafka更加强大和灵活。
- 2017年: Kafka 1.0.0版本发布,标志着Kafka的正式稳定版发布。该版本引入了KIP(Kafka Improvement Proposals)流程,用于管理和跟踪Kafka社区的改进提案。
- 之后的发展: Kafka持续迭代发展,引入了更多新特性,包括事务支持、KRaft模式(一种更加可靠的分布式复制模式)等。Kafka的社区也持续活跃,成为了一个非常受欢迎的消息中间件和流处理平台。
-
Kafka名字的由来
Kafka的名字来自于捷克作家弗朗茨·卡夫卡(Franz Kafka),他是一位以奇幻和荒谬主题著称的作家。这个名字被选择,部分原因是为了体现Kafka的持久性和韧性,就像卡夫卡的作品一样。
-
Kafka的logo
Kafka的Logo是一只飞翔的狐猴(Flying Squirrel)。这个Logo是由LinkedIn的设计团队创造的,象征着Kafka高效、快速的消息传递能力。
1.2 常见消息队列的比较
-
市面上常见消息中间件的对比

- ActiveMQ:
- 特点: ActiveMQ是一个开源的JMS(Java Message Service)消息中间件,支持多种协议,包括AMQP、MQTT等。
- 适用场景: Java生态系统中,特别是需要使用JMS标准的项目。
- 优点: 成熟的项目,易于使用,社区活跃。
- 缺点: 性能较差,相比较其他消息中间件,吞吐量相对较低。
- RabbitMQ:
- 特点: RabbitMQ是一个高度可靠、可扩展、开源的AMQP消息中间件。
- 适用场景: 强调可靠性、消息传递的顺序、复杂路由等需求的项目。
- 优点: 稳定可靠,支持多种消息协议,易于使用。
- 缺点: 性能相对较低,复杂路由可能会影响性能。
- RocketMQ:
- 特点: RocketMQ是阿里巴巴开源的分布式消息中间件,具有高可用性、高可靠性和高吞吐量。
- 适用场景: 适用于高吞吐量、大规模分布式系统。
- 优点: 性能优越,支持多种消息传递模式,易于水平扩展。
- 缺点: 社区相对较小,相比Kafka,知名度稍低。
- Kafka:
- 特点: Kafka是一个高吞吐量、持久化的分布式消息中间件,广泛用于大规模数据处理和实时流数据。
- 适用场景: 大规模实时数据处理、日志收集、事件溯源等需求。
- 优点: 高性能、持久性、可水平扩展,有大型社区支持。
- 缺点: 配置和管理相对较复杂。
如果你需要高吞吐量、持久性、适用于大规模实时数据处理的系统,Kafka是一个不错的选择。如果你在Java生态系统中,需要使用JMS标准,可以考虑ActiveMQ。如果你需要强调可靠性、消息传递的顺序等特性,RabbitMQ也是一个很好的选择。而如果你在阿里巴巴技术栈中,并且需要高可用性、高可靠性,RocketMQ是一个合适的选择。

- ActiveMQ:
1.3 Kafka常见相关概念介绍
-
消息队列(MQ,Message Queue):是一种用于在分布式系统中传输消息的通信机制,Kafka是MQ的一种具体实现
-
消息(Message):
-
消息键(key):用于消息的分区和数据路由的关键属性。每条消息都可以有一个可选的 key,它用于确定将消息发送到哪个特定分区。Kafka 会使用分区器对 key 进行处理,并根据特定的规则确定将消息发送到哪个分区。(一般建议指定 key,因为可以根据 key快速定位到消息所在的分区,如果不指定 key,则消息会被 kafka 随机放到某一个分区)
-
流(Stream):是一连串的事件记录,这些事件记录是按照时间顺序持续产生的
-
分布式(Distributed):一种计算机系统或应用程序的设计和组织方式。正如其名分布,一个系统的一个服务或多个服务是分布(部署)在不同的节点(服务器)上的,以此充分提高系统的高可用性
-
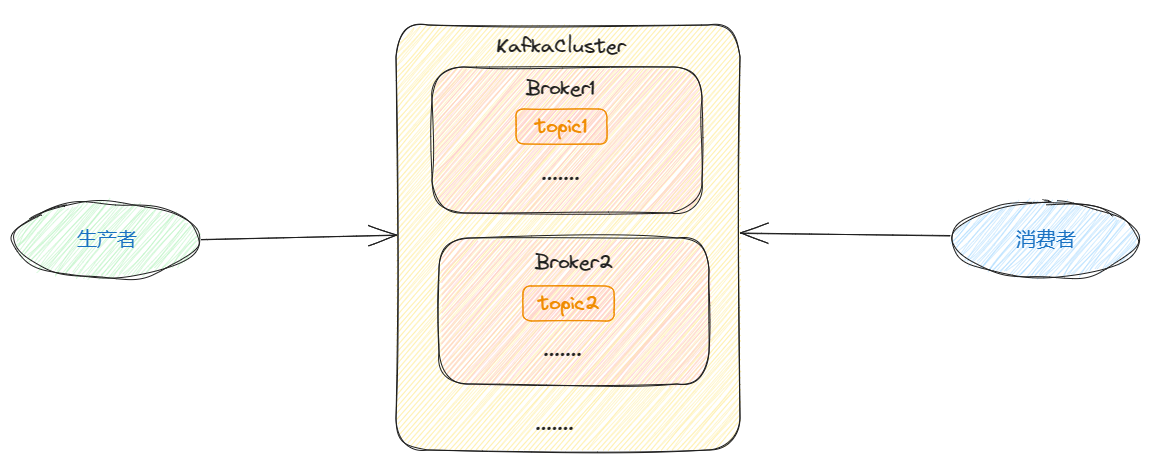
代理(Broker): Kafka集群由多个Broker组成,每个Broker是一个Kafka服务器节点。它负责存储消息,处理生产者发送的消息和消费者请求消息的动作。
-
主题(Topic): 主题是消息的类别,Kafka消息根据主题进行分类。生产者将消息发布到一个或多个主题,而消费者则订阅一个或多个主题来接收消息。
-
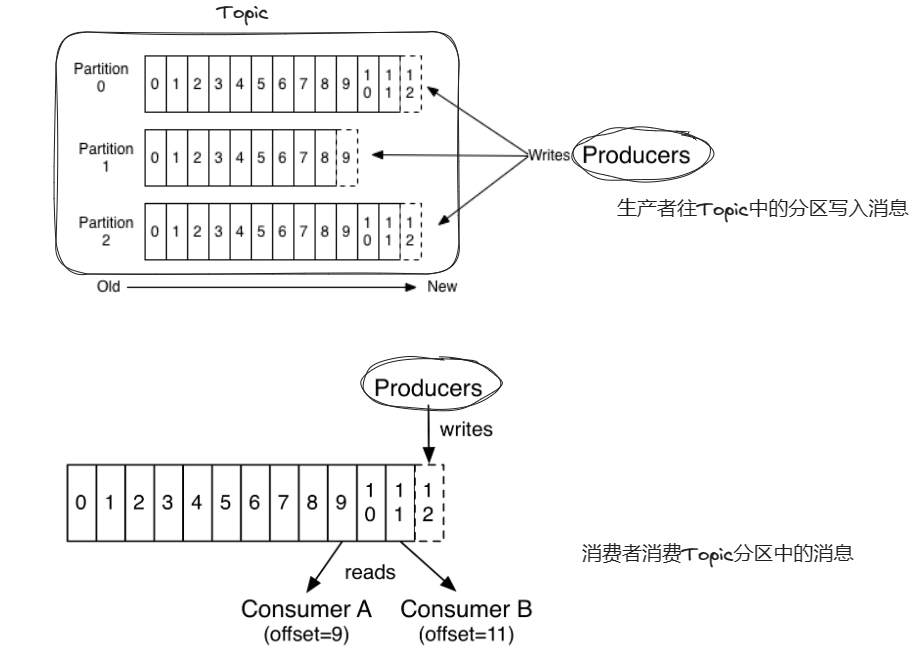
分区(Partition): 主题可以被分成多个分区,每个分区是一个有序的消息队列。分区允许主题的数据水平扩展,提高了消息处理的并发性。

-
生产者(Producer): 生产者负责向Kafka的Broker发送消息。它将消息发布到一个或多个主题,然后由Broker负责将消息存储到相应的分区中。
-
消费者(Consumer): 消费者订阅一个或多个主题,从Broker中拉取消息并进行处理。消费者可以以不同的方式进行消息的消费,包括消费一次(at most once)、至少消费一次(at least once)和精确一次(exactly once)。
-
消费者组(Consumer Group): 消费者组是一组消费者的集合,它们共同消费一个主题的消息。每个分区只能被消费者组中的一个消费者消费,这样可以实现消息的负载均衡和高可用性。

根据消息发送到消费者组数量的不同,可以分为两个不同的模型
- 所有的消费者都在一个组中,那么这就变成了queue模型
- 所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型
-
Zookeeper: Kafka使用Zookeeper来进行集群管理、元数据存储等任务。Zookeeper负责记录Broker的信息、分区的分配情况、消费者的偏移量等,确保Kafka集群的可靠性和稳定性。
PS:Kafka和Zookeeper是强依赖关系,Kafka内部是基于Zookeeper保存节点数据的,所以安装Kafka一定要同时安装Zookeeper
-
偏移量(Offset): 每条消息在分区中都有一个唯一的偏移量(偏移量类似于数组索引,后加入分区的消息offset值越大),用来表示消息在分区中的位置。消费者通过偏移量来追踪自己消费到哪条消息,以便实现断点续传。
-
备份机制(Replication):Kafka 允许 Topic 的 Partition 拥有若干副本,你可以在 Server 端配置 Partition 的副本数量。当集群中的节点出现故障时,能自动进行故障转移,保证数据的可用性。
Kafka副本分类两类,一类是领导者副本(Leader)副本,它负责处理读写请求;一类是追随者副本(Follower)副本,它负责复制 Leader 中的数据。两者的具体工作流程:当 Producer 发送消息到Kafka集群时,首先会将消息写入 Leader 副本的日志中,并等待 Leader 确认成功。一旦 Leader 确认成功,Producer 认为消息已经被持久化。同时,Leader 会将消息传播给所有 Follower 副本。Follower 副本会定期从 Leader 拉取数据进行复制,同步 Leader 的状态。如果 Leader 发生故障,某个 Follower 副本可以被选举为新的 Leader,确保持续提供服务。

其中,追随者副本 Follower 也有两类,一类是同步副本(In-Sync Replica,简称 ISR),它负责同步备份 Leader 副本中的数据;一类是落后副本(Out-of-Sync Replica,简称OSR),它负责异步备份 Leader 副本中的数据
如果 Leader 失效后,需要选出新的 Leader,选举的原则如下:
- 选举时优先从 ISR 中选定,因为这个列表中 Follower 的数据是与 Leader 同步的
- 如果 ISR 列表中的 Follower 都不行了,就只能从其他 Follower 中选取
还可能存在一种极端情况,那就是所有的副本全都失效,此时有以下方案:
- 等待 ISR 中的一个活过来,选为 Leader,数据可靠,但活过来的时间不确定
- 选择第一个活过来的副本(Replication),不一定是 ISR 中的(可能是 Follower),选为 Leader,以最快速度恢复可用性,但数据不一定完整(因为 Follower 是异步复制,可能并没有讲 Leader 中的数据复制完全)
-
Kafka是如何确保消息消费的有序性?
在Kafka中,Topic 分区中消息只能由消费者组中的唯一的一个消费者处理,所以消息肯定是按照先后顺序进行处理的。但是它也仅仅是保证 Topic 的一个分区顺序处理,不能保证跨分区的消息先后处理顺序。 所以,如果你想要顺序的处理 Topic 的所有消息,那就只提供一个分区。
-
Kafka的再均衡问题是什么意思?
Kafka的再均衡(Rebalancing)是指当消费者组内的消费者发生变化时(比如摸一个消费者出现故障),Kafka会重新分配分区给各个消费者,以实现负载均衡和高可用性。再均衡主要在以下情况下发生:
- 增加或减少消费者:当消费者加入或退出消费者组时,触发再均衡。
- 分区的增加或减少:当主题的分区数发生变化时,例如添加或删除分区,会触发再均衡。
- 消费者心跳超时:如果一个消费者长时间没有发送心跳,Kafka会认为该消费者故障,并触发再均衡。
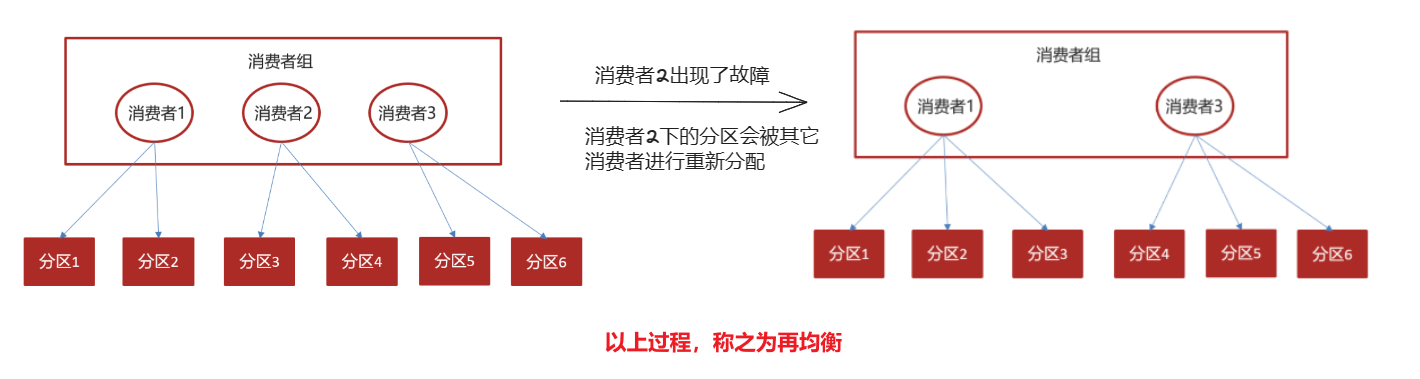
再均衡会引发一下常见问题
- 消息被重复消费:如果消费者提交的偏移量小于消费者实际消费消息的偏移量。
- 消息发生丢失:如果消费者提交的偏移量大于消费者实际消费消息的偏移量。
原因:Kafka内部是通过一个
_consumer_offset特殊的 Topic 来记录没用过消费者消费到哪一条消息的,消费者每消费一条消息后都会向_consumer_offset主题发送对应消息的 offset。如果消费者在消费了消息准备提交偏移量前出现了故障,导致提交偏移量小于消费者,同时由于这个分区的故障,导致发生了再均衡,这时其它消费者再消费这个分区的消息时,通过
_consumer_offset定位到上一次消费的消息,但是实际上上一条消息的后一条消息已经被消费了,从而导致重复消费;消息发生丢失这个可能性是比较小的,因为消息都是在消费成功后才提交偏移量的
-
Kafka再均衡发生的常见情况:
- consumer group 中的新增或删除某个consumer,导致其所消费的分区需要分配到组内其他的 consumer 上;
- consumer 订阅的 Topic 发生变化,比如订阅的 Topic 采用的是正则表达式的形式,如 test-* 此时如果有一个新建了一个 Topic test-user,那么这个 Topic 的所有分区也是会自动分配给当前的 consumer 的,此时就会发生再平衡;
- consumer 所订阅的 Topic 发生了新增分区的行为,那么新增的分区就会分配给当前的 consumer,此时就会触发再平衡。
参考:【精选】Kafka再平衡机制详解_wrr-cat的博客-CSDN博客
-
Kafka提交偏移量的方式
-
自动提交:当
enable.auto.commit被设置为true,提交方式就是让消费者自动提交偏移量,每隔5秒消费者会自动把从poll()方法接收的最大偏移量提交上去 -
手动提交:当
enable.auto.commit被设置为false可以有以下三种提交方式-
同步提交:在这种方式下,消费者通过调用
commitSync()方法来进行偏移量的提交。该方法会阻塞直到提交请求完成,并返回提交结果(成功或失败)。如果提交失败,可以根据需要进行重试。备注:同步提交容易出现阻塞,不推荐使用这种方式
-
异步提交:在这种方式下,消费者通过调用
commitAsync()方法来进行偏移量的提交。该方法是非阻塞的,它将提交请求发送到 Kafka 服务器并立即返回。同时,还需要传入一个回调函数(Callback)来处理提交结果。备注:多个异步提交容易出现偏移量覆盖
-
同步和异步组合提交:在这种方式下,消费者可以结合使用同步和异步提交,以提高提交的效率和容错性。可以先进行异步提交,然后定期或在特定条件下进行同步提交,以确保偏移量的提交最终得到确认。
备注:这种方式编写起来比较麻烦,但是更加推荐
-
-
2、安装Kafka
略……详情参考【Kafka安装教程】
3、初体验

前期准备
-
Step1:安装Kafka,同时安装Zeekooper
详情参考【Kafka安装教程】
-
Step2:启动Zeekooper和Kafka
备注:先启动Zeekooper,后启动Kafka
-
Step3:创建Maven项目
-
Step4:导入依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId> </dependency>
编码测试
-
Step1:编写生产者
package demo;import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;/*** 生产者*/ public class ProducerDemo {public static void main(String[] args) {// 1、编写kafka的配置信息Properties properties = new Properties();properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.88.130:9092"); // 配置kafka的连接地址properties.put(ProducerConfig.RETRIES_CONFIG, 5); // 发送失败,失败的重试次数properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); // 消息key的序列化器properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); // 消息value的序列化器// 2、创建生产者对象KafkaProducer<String, String> producer = new KafkaProducer<>(properties);// 3、封装发送的消息/*参数一:Topic,主题(相当于RabbitMQ中的 routingKey)参数二:消息的key参数三:消息的value*/ProducerRecord<String, String> record =new ProducerRecord<>("demo.topic", "100001", "hello kafka");// 4、发送消息producer.send(record);System.out.println("消息发送成功");// 5、关闭消息通道,必须关闭,否则消息发送不成功producer.close();}} -
Step2:编写消费者
package demo;import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer;import java.time.Duration; import java.util.Collections; import java.util.Properties;/*** 消费者*/ public class ConsumerDemo {public static void main(String[] args) {// 1、添加kafka的配置信息Properties properties = new Properties();properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.88.130:9092"); // kafka的连接地址properties.put(ConsumerConfig.GROUP_ID_CONFIG, "demo_1"); // 消费者组properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); // 消息key的序列化器properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); // 消息value的序列化器// 2、创建消费者对象KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);// 3、配置订阅主题consumer.subscribe(Collections.singletonList("demo.topic"));// 死循环,为了让当前线程一直处于监听状态while (true) {// 4、获取消息,每隔1000ms拉取一次ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println("============================");System.out.println(consumerRecord.key());System.out.println(consumerRecord.value());}}}} -
Step3:测试
启动生产者和消费者,两者启动顺序没有要求,每次启动一次生产者,都能在消费者控制台中看到打印消息
配置介绍
-
auto-offset-reset:配置消费起始偏移量-
earliest:从主题的最早可用消息开始消费,即从主题的起始位置开始。 -
latest:从主题的最新消息开始消费。 -
none:如果没有存储有效的偏移量信息,消费者会抛出异常,而不会自动重置偏移量。这样的设置通常用于强制消费者只能从有效的偏移量处开始消费。
-
bug记录
-
bug:
问题背景:
问题原因:
问题解决:
-
bug1:Kafka连接失败
问题背景:消费者发送消息失败,报错
java.io.IOException: Connection to 192.168.88.130:9092 (id: -1 rack: null) failed.
问题原因:虚拟机没有关闭防火墙
问题解决:关闭虚拟机的防火墙
相关文章:
Kafka快速入门
文章目录 Kafka快速入门1、相关概念介绍前言1.1 基本介绍1.2 常见消息队列的比较1.3 Kafka常见相关概念介绍 2、安装Kafka3、初体验前期准备编码测试配置介绍 bug记录 Kafka快速入门 1、相关概念介绍 前言 在当今信息爆炸的时代,实时数据处理已经成为许多应用程序和…...
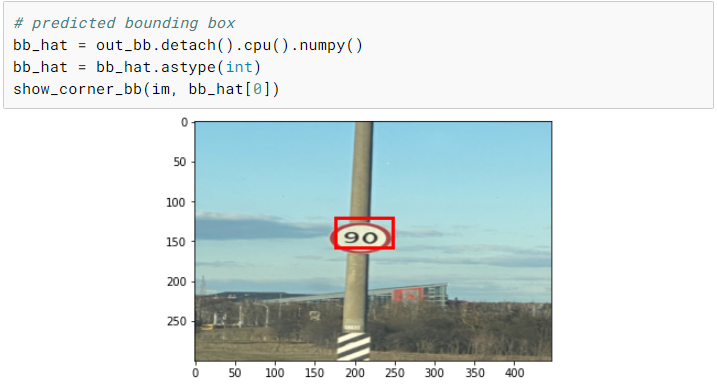
基于Pytorch的从零开始的目标检测
引言 目标检测是计算机视觉中一个非常流行的任务,在这个任务中,给定一个图像,你预测图像中物体的包围盒(通常是矩形的) ,并且识别物体的类型。在这个图像中可能有多个对象,而且现在有各种先进的技术和框架来解决这个问…...
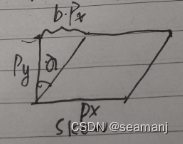
interview review
M: intrinsic matrix [ f x s c x 0 f y c y 0 0 1 ] \begin{bmatrix}f_x & s & c_x \\ 0 & f_y & c_y \\ 0 & 0 & 1\end{bmatrix} fx00sfy0cxcy1 ( c x , c y ) (c_x, c_y) (cx,cy): camera center in pixels ( f x , f y …...

layui表头多出一列(已解决)
问题描述 :layui表头多出来一列,但是表体没有内容,很影响美观。 好像是原本的表格有滚轮,我操作放大之后滚轮没有了,但是滚轮自带的表头样式还在, 之后手动把这个样式隐藏掉了,代码如下…...

LeetCode解法汇总307. 区域和检索 - 数组可修改
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 描述: 给你一个数…...
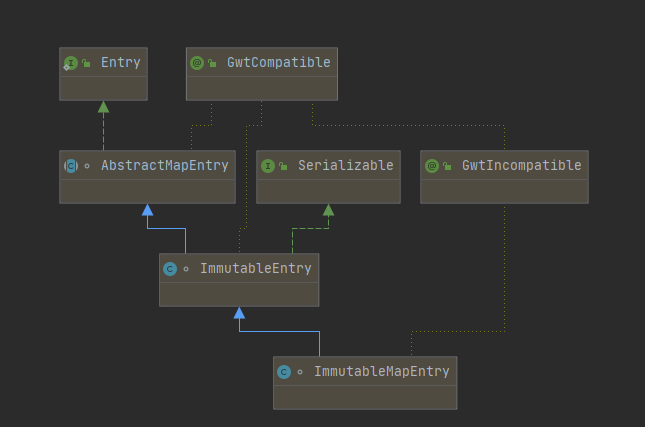
Java源码分析:Guava之不可变集合ImmutableMap的源码分析
原创/朱季谦 一、案例场景 遇到过这样的场景,在定义一个static修饰的Map时,使用了大量的put()方法赋值,就类似这样—— public static final Map<String,String> dayMap new HashMap<>(); static {dayMap.put("Monday&q…...
详解自动化测试之 Selenium
目录 1. 什么是自动化 2.自动化测试的分类 3. selenium(web 自动化测试工具) 1)选择 selenium 的原因 2)环境部署 3)什么是驱动? 4. 一个简单的自动化例子 5.selenium 常用方法 5.1 查找页面元素&…...
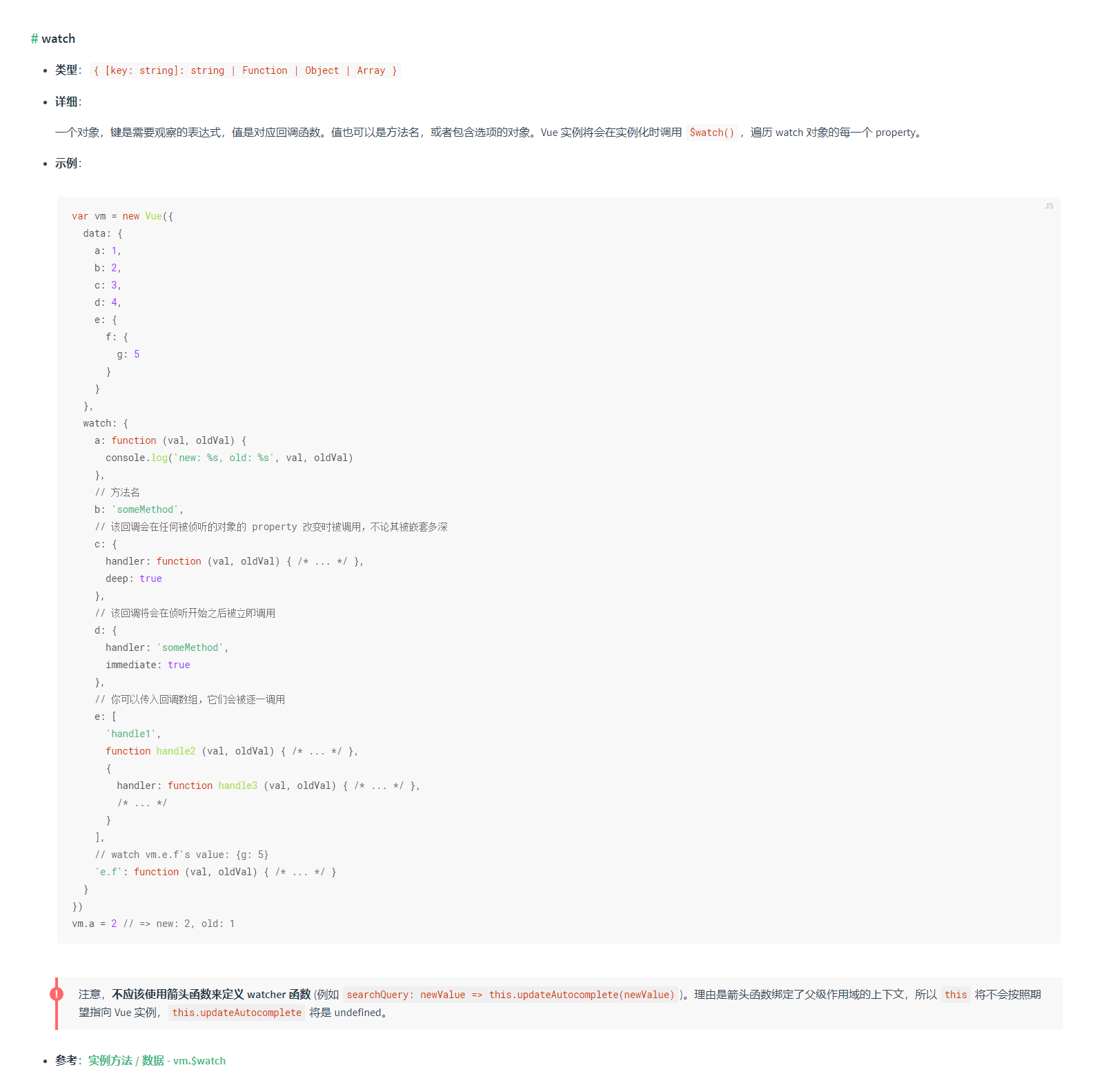
vue监听对象属性值变化
一、官方文档 二、实现方法 方法一、直接根据watch来监听 export default {data() {return {object: {username: ,password: }}},watch: {object.username(newVal, oldVal) {console.log(newVal, oldVal)}} }方法二:利用watch和computed来实现监听 利用computed定…...
)
Unicode编码的emoji表情如何在前端页面展示(未完成)
Unicode编码的emoji表情如何在前端页面展示 一、首先几个定义解决办法 一、首先几个定义 U1F601 和 0x1F601 表示同一个 Unicode 代码点,即笑脸 Emoji 的代码点。它们之间的区别在于表示方式和数据类型。 1.U1F601 是一种常见的表示方式,也称为 “U” 标…...
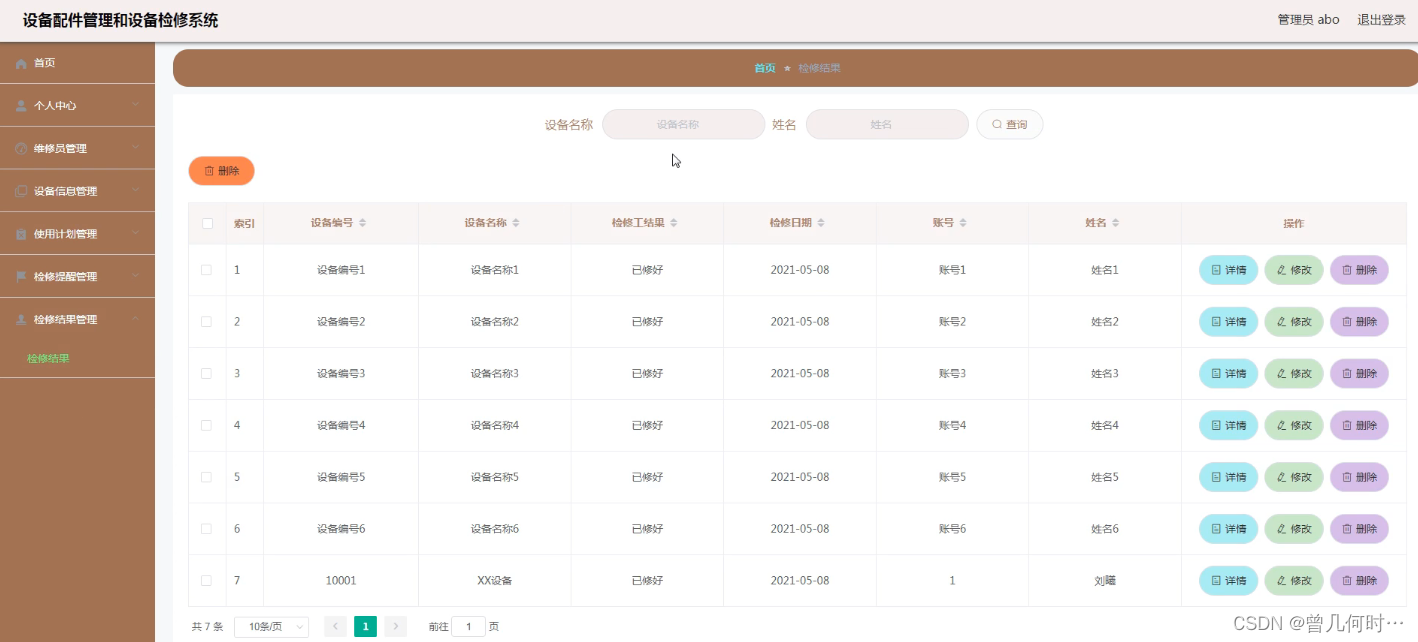
基于SSM的设备配件管理和设备检修系统
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...
鸿蒙开发|鸿蒙系统项目开发前的准备工作
文章目录 鸿蒙项目开发的基本流程介绍鸿蒙项目开发和其他项目有什么不同成为华为开发者-注册和实名认证1.登录官方网站 鸿蒙项目开发的基本流程介绍 直接上图,简单易懂! 整个项目的开发通过4个模块进行:开发准备、开发应用、运行调试测试和发…...
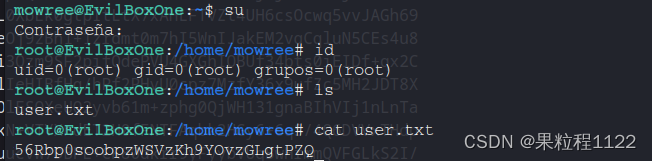
Evil靶场
Evil 1.主机发现 使用命令探测存活主机,80.139是kali的地址,所以靶机地址就是80.134 fping -gaq 192.168.80.0/242.端口扫描 开放80,22端口 nmap -Pn -sV -p- -A 192.168.80.1343.信息收集 访问web界面 路径扫描 gobuster dir -u http…...

第77题. 组合
原题链接:第77题. 组合 全代码: class Solution { private:vector<vector<int>> result; // 存放符合条件结果的集合vector<int> path; // 用来存放符合条件结果void backtracking(int n, int k, int startIndex) {if (path.size() …...

读书笔记:彼得·德鲁克《认识管理》第21章 企业与政府
一、章节内容概述 企业社会责任最重要的维度之一是政企关系。无论对于企业的顺利运作,还是对于政府的顺利运作,政企关系都至关重要。然而,重商主义典范和宪政主义典范这两种传统理论越来越不适应社会现实,越来越失效。虽然当前尚…...

C/C++疫情集中隔离 2021年12月电子学会青少年软件编程(C/C++)等级考试一级真题答案解析
目录 C/C疫情集中隔离 一、题目要求 1、编程实现 2、输入输出 二、算法分析 三、程序编写 四、程序说明 五、运行结果 六、考点分析 C/C疫情集中隔离 2021年12月 C/C编程等级考试一级编程题 一、题目要求 1、编程实现 A同学12月初从国外回来,按照防疫要…...

052-第三代软件开发-系统监测
第三代软件开发-系统监测 文章目录 第三代软件开发-系统监测项目介绍系统监测 关键字: Qt、 Qml、 cpu、 内存、memory 项目介绍 欢迎来到我们的 QML & C 项目!这个项目结合了 QML(Qt Meta-Object Language)和 C 的强大功…...

向量矩阵范数pytorch
向量矩阵范数pytorch 矩阵按照某个维度求和(dim就是shape数组的下标)1. torch1.1 Tensors一些常用函数 一些安装问题cd进不去不去目录PyTorch里面_表示重写内容 在默认情况下,PyTorch会累积梯度,我们需要清除之前的值 范数是向量或…...
NVIDIA Jetson OTA升级
从 JetPack 4.4 开始,可以使用包管理工具升级到下一个 JetPack 版本。请按照以下步骤执行升级。 1,小版本升级 (如,从 JetPack 4.4 升级到 JetPack 4.4.1) 第一步: sudo apt update 第二步: apt list --upgradable 第三步: sudo apt upgrade更新完之后重新启动即可 …...

【算法】算法题-20231118
这里写目录标题 一、16.17. 连续数列二、合并两个有序数组(力扣88)三、存在重复元素(217)四、有效的字母异位词(242) 一、16.17. 连续数列 简单 给定一个整数数组,找出总和最大的连续数列&…...
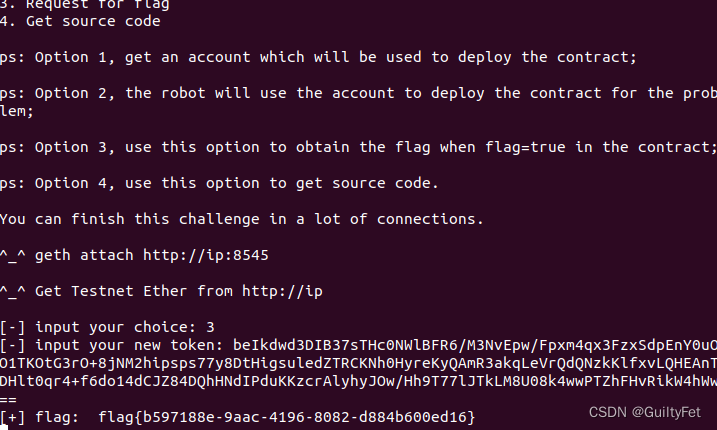
某60区块链安全之整数溢出漏洞实战学习记录
区块链安全 文章目录 区块链安全整数溢出漏洞实战实验目的实验环境实验工具实验原理攻击过程分析合约源代码漏洞EXP利用 整数溢出漏洞实战 实验目的 学会使用python3的web3模块 学会以太坊整数溢出漏洞分析及利用 实验环境 Ubuntu18.04操作机 实验工具 python3 实验原理…...

新手必看:5分钟掌握微信小程序showToast、showModal、showLoading的常见坑与解决方案
微信小程序弹框实战指南:从基础使用到高阶避坑 第一次接触微信小程序开发时,我被官方文档里琳琅满目的API搞得眼花缭乱。特别是那些看似简单却暗藏玄机的弹框组件——showToast、showModal和showLoading,表面上看几行代码就能实现功能&#x…...

GLM-4v-9b多场景落地:银行柜面业务凭证识别+风险字段高亮预警系统
GLM-4v-9b多场景落地:银行柜面业务凭证识别风险字段高亮预警系统 1. 引言:当银行柜员遇上“火眼金睛”的AI助手 想象一下这个场景:一位银行柜员正在处理一笔复杂的对公转账业务,面前堆着客户提交的转账凭证、合同附件和身份证明…...

使用STM32CubeMX配置口罩检测嵌入式系统
使用STM32CubeMX配置口罩检测嵌入式系统 1. 项目概述与环境搭建 今天咱们来聊聊怎么用STM32CubeMX快速搭建一个口罩检测的嵌入式系统。这个项目特别适合想要入门嵌入式AI的开发者,不需要深厚的机器学习背景,只要跟着步骤走,就能让STM32板子…...

SiameseUIE Anaconda环境配置:Python虚拟环境最佳实践
SiameseUIE Anaconda环境配置:Python虚拟环境最佳实践 1. 为什么需要虚拟环境? 如果你曾经在Python项目中遇到过"这个包版本不对"、"那个依赖冲突"的情况,那么虚拟环境就是你的救星。特别是在使用SiameseUIE这样的信息…...

Pixel Dimension Fissioner步骤详解:如何导出维度手稿为Markdown/PDF/JSON
Pixel Dimension Fissioner步骤详解:如何导出维度手稿为Markdown/PDF/JSON 1. 工具概览 Pixel Dimension Fissioner是一款基于MT5-Zero-Shot-Augment核心引擎构建的文本增强工具,它将传统AI工具转化为一个充满活力的16-bit像素冒险工坊。通过这款工具&…...
)
Kurtosis私链搭建全攻略:从Docker安装到MetaMask连接(附常见问题排查)
Kurtosis私链实战指南:从零搭建到智能合约部署全流程 在区块链开发领域,本地测试环境的重要性不言而喻。Kurtosis作为新一代的区块链开发工具链,通过容器化技术简化了私链搭建流程,让开发者能够快速构建符合需求的测试网络。本文将…...
小白友好:用Ollama快速体验translategemma-27b-it,实现本地图文翻译自由
小白友好:用Ollama快速体验translategemma-27b-it,实现本地图文翻译自由 1. 为什么你应该试试这个本地翻译神器 想象一下这个场景:你收到一份满是外文的产品说明书截图,或者一张国外社交媒体的有趣图片,想快速知道上…...

# 发散创新:基于Go语言的链路追踪实战——从零构建分布式系统可观测性核心组件 在微服务架构日益普及的今天,**链路追踪(D
发散创新:基于Go语言的链路追踪实战——从零构建分布式系统可观测性核心组件 在微服务架构日益普及的今天,链路追踪(Distributed Tracing) 已成为保障系统稳定性和性能调优的关键手段。本文将带你使用 Go语言 深度实践一个轻量级但…...

OpenCore Auxiliary Tools:黑苹果配置的一站式解决方案
OpenCore Auxiliary Tools:黑苹果配置的一站式解决方案 【免费下载链接】OCAuxiliaryTools Cross-platform GUI management tools for OpenCore(OCAT) 项目地址: https://gitcode.com/gh_mirrors/oc/OCAuxiliaryTools 价值主张&#x…...

ChromePass:三分钟快速找回Chrome浏览器所有保存密码的实用方案
ChromePass:三分钟快速找回Chrome浏览器所有保存密码的实用方案 【免费下载链接】chromepass Get all passwords stored by Chrome on WINDOWS. 项目地址: https://gitcode.com/gh_mirrors/chr/chromepass 你是否曾经遇到过这样的情况:明明在Chro…...