36、Flink 的 Formats 之Parquet 和 Orc Format
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
18、Flink的SQL 支持的操作和语法
19、Flink 的Table API 和 SQL 中的内置函数及示例(1)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(2)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(3)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(4)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
21、Flink 的table API与DataStream API 集成(1)- 介绍及入门示例、集成说明
21、Flink 的table API与DataStream API 集成(2)- 批处理模式和inser-only流处理
21、Flink 的table API与DataStream API 集成(3)- changelog流处理、管道示例、类型转换和老版本转换示例
21、Flink 的table API与DataStream API 集成(完整版)
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs(介绍、类型、java api和sql实现ddl、java api和sql操作catalog)-1
24、Flink 的table api与sql之Catalogs(java api操作数据库、表)-2
24、Flink 的table api与sql之Catalogs(java api操作视图)-3
24、Flink 的table api与sql之Catalogs(java api操作分区与函数)-4
25、Flink 的table api与sql之函数(自定义函数示例)
26、Flink 的SQL之概览与入门示例
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1)
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2)
27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3)
27、Flink 的SQL之SELECT (窗口聚合)介绍及详细示例(4)
27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(5)
27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介绍及详细示例(6)
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
28、Flink 的SQL之DROP 、ALTER 、INSERT 、ANALYZE 语句
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(1)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(2)
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
32、Flink table api和SQL 之用户自定义 Sources & Sinks实现及详细示例
33、Flink 的Table API 和 SQL 中的时区
35、Flink 的 Formats 之CSV 和 JSON Format
36、Flink 的 Formats 之Parquet 和 Orc Format
41、Flink之Hive 方言介绍及详细示例
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例–网上有些说法好像是错误的
文章目录
- Flink 系列文章
- 一、Orc Format
- 1、maven 依赖
- 2、Flink sql client 建表示例
- 1)、增加ORC文件解析的类库
- 2)、生成ORC文件
- 3)、建表
- 4)、验证
- 3、table api建表示例
- 1)、源码
- 2)、运行结果
- 3)、maven依赖
- 4、Format 参数
- 5、数据类型映射
- 二、Parquet Format
- 1、maven 依赖
- 2、Flink sql client 建表示例
- 1)、增加parquet文件解析类库
- 2)、生成parquet文件
- 3)、建表
- 4)、验证
- 3、table api建表示例
- 1)、源码
- 2)、运行结果
- 3)、maven依赖
- 4、Format 参数
- 5、数据类型映射
本文介绍了Flink 支持的数据格式中的ORC和Parquet,并分别以sql和table api作为示例进行了说明。
本文依赖flink、kafka、hadoop(3.1.4版本)集群能正常使用。
本文分为2个部分,即ORC和Parquet Format。
本文的示例是在Flink 1.17版本(flink 集群和maven均是Flink 1.17)中运行。
一、Orc Format
Apache Orc Format 允许读写 ORC 数据。
1、maven 依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-orc</artifactId><version>1.17.1</version>
</dependency>下面的依赖视情况而定,有些可能会出现guava的冲突,如果出现冲突可能需要把下面的maven依赖。
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>32.0.1-jre</version></dependency>
2、Flink sql client 建表示例
下面是一个用 Filesystem connector 和 Orc format 创建表格的例子
1)、增加ORC文件解析的类库
需要将flink-sql-orc-1.17.1.jar 放在 flink的lib目录下,并重启flink服务。
该文件可以在链接中下载。
2)、生成ORC文件
该步骤需要借助于原hadoop生成的文件,可以参考文章:21、MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件
测试数据文件可以自己准备,不再赘述。
特别需要说明的是ORC文件的SCHEMA 需要和建表的字段名称和类型保持一致。
struct<id:string,type:string,orderID:string,bankCard:string,ctime:string,utime:string>
源码
import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.orc.OrcConf;
import org.apache.orc.TypeDescription;
import org.apache.orc.mapred.OrcStruct;
import org.apache.orc.mapreduce.OrcOutputFormat;/*** @author alanchan* 读取普通文本文件转换为ORC文件*/
public class WriteOrcFile extends Configured implements Tool {static String in = "D:/workspace/bigdata-component/hadoop/test/in/orc";static String out = "D:/workspace/bigdata-component/hadoop/test/out/orc";public static void main(String[] args) throws Exception {Configuration conf = new Configuration();int status = ToolRunner.run(conf, new WriteOrcFile(), args);System.exit(status);}@Overridepublic int run(String[] args) throws Exception {// 设置SchemaOrcConf.MAPRED_OUTPUT_SCHEMA.setString(this.getConf(), SCHEMA);Job job = Job.getInstance(getConf(), this.getClass().getName());job.setJarByClass(this.getClass());job.setMapperClass(WriteOrcFileMapper.class);job.setMapOutputKeyClass(NullWritable.class);job.setMapOutputValueClass(OrcStruct.class);job.setNumReduceTasks(0);// 配置作业的输入数据路径FileInputFormat.addInputPath(job, new Path(in));// 设置作业的输出为MapFileOutputFormatjob.setOutputFormatClass(OrcOutputFormat.class);Path outputDir = new Path(out);outputDir.getFileSystem(this.getConf()).delete(outputDir, true);FileOutputFormat.setOutputPath(job, outputDir);return job.waitForCompletion(true) ? 0 : 1;}// 定义数据的字段信息
//数据格式
// id ,type ,orderID ,bankCard,ctime ,utime
// 2.0191130220014E+27,ALIPAY,191130-461197476510745,356886,,
// 2.01911302200141E+27,ALIPAY,191130-570038354832903,404118,2019/11/30 21:44,2019/12/16 14:24
// 2.01911302200143E+27,ALIPAY,191130-581296620431058,520083,2019/11/30 18:17,2019/12/4 20:26
// 2.0191201220014E+27,ALIPAY,191201-311567320052455,622688,2019/12/1 10:56,2019/12/16 11:54private static final String SCHEMA = "struct<id:string,type:string,orderID:string,bankCard:string,ctime:string,utime:string>";static class WriteOrcFileMapper extends Mapper<LongWritable, Text, NullWritable, OrcStruct> {// 获取字段描述信息private TypeDescription schema = TypeDescription.fromString(SCHEMA);// 构建输出的Keyprivate final NullWritable outputKey = NullWritable.get();// 构建输出的Value为ORCStruct类型private final OrcStruct outputValue = (OrcStruct) OrcStruct.createValue(schema);protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 将读取到的每一行数据进行分割,得到所有字段String[] fields = value.toString().split(",", 6);// 将所有字段赋值给Value中的列outputValue.setFieldValue(0, new Text(fields[0]));outputValue.setFieldValue(1, new Text(fields[1]));outputValue.setFieldValue(2, new Text(fields[2]));outputValue.setFieldValue(3, new Text(fields[3]));outputValue.setFieldValue(4, new Text(fields[4]));outputValue.setFieldValue(5, new Text(fields[5]));context.write(outputKey, outputValue);}}}
将生成的文件上传至hdfs://server1:8020/flinktest/orctest/下。
至此,准备环境与数据已经完成。
3)、建表
需要注意的是字段的名称与类型,需要和orc文件的schema保持一致,否则读取不到文件内容。
CREATE TABLE alan_orc_order (id STRING,type STRING,orderID STRING,bankCard STRING,ctime STRING,utime STRING
) WITH ('connector' = 'filesystem','path' = 'hdfs://server1:8020/flinktest/orctest/','format' = 'orc'
);Flink SQL> CREATE TABLE alan_orc_order (
> id STRING,
> type STRING,
> orderID STRING,
> bankCard STRING,
> ctime STRING,
> utime STRING
> ) WITH (
> 'connector' = 'filesystem',
> 'path' = 'hdfs://server1:8020/flinktest/orctest/',
> 'format' = 'orc'
> );
[INFO] Execute statement succeed.
4)、验证
Flink SQL> select * from alan_orc_order limit 10;
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| op | id | type | orderID | bankCard | ctime | utime |
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| +I | 2.0191130220014E+27 | ALIPAY | 191130-461197476510745 | 356886 | | |
| +I | 2.01911302200141E+27 | ALIPAY | 191130-570038354832903 | 404118 | 2019/11/30 21:44 | 2019/12/16 14:24 |
| +I | 2.01911302200143E+27 | ALIPAY | 191130-581296620431058 | 520083 | 2019/11/30 18:17 | 2019/12/4 20:26 |
| +I | 2.0191201220014E+27 | ALIPAY | 191201-311567320052455 | 622688 | 2019/12/1 10:56 | 2019/12/16 11:54 |
| +I | 2.01912E+27 | ALIPAY | 191201-216073503850515 | 456418 | 2019/12/11 22:39 | |
| +I | 2.01912E+27 | ALIPAY | 191201-072274576332921 | 433668 | | |
| +I | 2.01912E+27 | ALIPAY | 191201-088486052970134 | 622538 | 2019/12/2 23:12 | |
| +I | 2.01912E+27 | ALIPAY | 191201-492457166050685 | 622517 | 2019/12/1 0:42 | 2019/12/14 13:27 |
| +I | 2.01912E+27 | ALIPAY | 191201-037136794432586 | 622525 | | |
| +I | 2.01912E+27 | ALIPAY | 191201-389779784790672 | 486494 | 2019/12/1 22:25 | 2019/12/16 23:32 |
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
Received a total of 10 rows3、table api建表示例
通过table api建表,参考文章:
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
为了简单起见,本示例仅仅是通过sql建表,数据准备见上述示例。
1)、源码
下面是在本地运行的,建表的path也是用本地的。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;/*** @author alanchan**/
public class TestORCFormatDemo {static String sourceSql = "CREATE TABLE alan_orc_order (\r\n" + " id STRING,\r\n" + " type STRING,\r\n" + " orderID STRING,\r\n" + " bankCard STRING,\r\n" + " ctime STRING,\r\n" + " utime STRING\r\n" + ") WITH (\r\n" + " 'connector' = 'filesystem',\r\n" + " 'path' = 'D:/workspace/bigdata-component/hadoop/test/out/orc',\r\n" + " 'format' = 'orc'\r\n" + ")";public static void test1() throws Exception {// 1、创建运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);// 建表tenv.executeSql(sourceSql);Table table = tenv.from("alan_orc_order"); table.printSchema();tenv.createTemporaryView("alan_orc_order_v", table);tenv.executeSql("select * from alan_orc_order_v limit 10").print();;
// table.execute().print();env.execute();}public static void main(String[] args) throws Exception {test1();}}
2)、运行结果
(`id` STRING,`type` STRING,`orderid` STRING,`bankcard` STRING,`ctime` STRING,`utime` STRING
)+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| op | id | type | orderID | bankCard | ctime | utime |
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| +I | 2.0191130220014E+27 | ALIPAY | 191130-461197476510745 | 356886 | | |
| +I | 2.01911302200141E+27 | ALIPAY | 191130-570038354832903 | 404118 | 2019/11/30 21:44 | 2019/12/16 14:24 |
| +I | 2.01911302200143E+27 | ALIPAY | 191130-581296620431058 | 520083 | 2019/11/30 18:17 | 2019/12/4 20:26 |
| +I | 2.0191201220014E+27 | ALIPAY | 191201-311567320052455 | 622688 | 2019/12/1 10:56 | 2019/12/16 11:54 |
| +I | 2.01912E+27 | ALIPAY | 191201-216073503850515 | 456418 | 2019/12/11 22:39 | |
| +I | 2.01912E+27 | ALIPAY | 191201-072274576332921 | 433668 | | |
| +I | 2.01912E+27 | ALIPAY | 191201-088486052970134 | 622538 | 2019/12/2 23:12 | |
| +I | 2.01912E+27 | ALIPAY | 191201-492457166050685 | 622517 | 2019/12/1 0:42 | 2019/12/14 13:27 |
| +I | 2.01912E+27 | ALIPAY | 191201-037136794432586 | 622525 | | |
| +I | 2.01912E+27 | ALIPAY | 191201-389779784790672 | 486494 | 2019/12/1 22:25 | 2019/12/16 23:32 |
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
10 rows in set
3)、maven依赖
<properties><encoding>UTF-8</encoding><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><java.version>1.8</java.version><scala.version>2.12</scala.version><flink.version>1.17.0</flink.version></properties><dependencies><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-sql-gateway --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-gateway</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-java-uber --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-uber</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-runtime --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-runtime</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.1.0-1.17</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.38</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-hive --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-hive_2.12</artifactId><version>1.17.0</version></dependency><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>32.0.1-jre</version></dependency> <!-- flink连接器 --><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-sql-connector-kafka --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-connector-kafka</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.commons/commons-compress --><dependency><groupId>org.apache.commons</groupId><artifactId>commons-compress</artifactId><version>1.24.0</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.2</version><!-- <scope>provided</scope> --></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-orc</artifactId><version>1.17.1</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-parquet</artifactId><version>1.17.1</version></dependency></dependencies>
4、Format 参数

Orc 格式也支持来源于 Table properties 的表属性。
举个例子,你可以设置 orc.compress=SNAPPY 来允许spappy压缩。
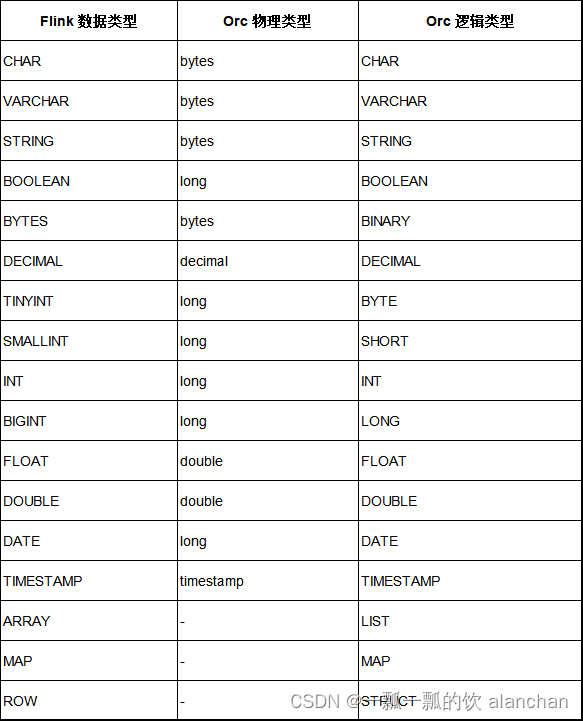
5、数据类型映射
Orc 格式类型的映射和 Apache Hive 是兼容的。
下面的表格列出了 Flink 类型的数据和 Orc 类型的数据的映射关系。
二、Parquet Format
Apache Parquet 格式允许读写 Parquet 数据.
1、maven 依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-parquet</artifactId><version>1.17.1</version>
</dependency>2、Flink sql client 建表示例
以下为用 Filesystem 连接器和 Parquet 格式创建表的示例
1)、增加parquet文件解析类库
需要将flink-sql-parquet-1.17.1.jar 放在 flink的lib目录下,并重启flink服务。
该文件可以在链接中下载。
2)、生成parquet文件
该步骤需要借助于原hadoop生成的文件,可以参考文章:21、MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件
测试数据文件可以自己准备,不再赘述。
import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.parquet.example.data.Group;
import org.apache.parquet.example.data.simple.SimpleGroupFactory;
import org.apache.parquet.hadoop.ParquetOutputFormat;
import org.apache.parquet.hadoop.example.GroupWriteSupport;
import org.apache.parquet.hadoop.metadata.CompressionCodecName;
import org.apache.parquet.schema.MessageType;
import org.apache.parquet.schema.OriginalType;
import org.apache.parquet.schema.PrimitiveType.PrimitiveTypeName;
import org.apache.parquet.schema.Types;
import org.springframework.util.StopWatch;/*** @author alanchan**/
public class WriteParquetFile extends Configured implements Tool {static String in = "D:/workspace/bigdata-component/hadoop/test/in/parquet";static String out = "D:/workspace/bigdata-component/hadoop/test/out/parquet";public static void main(String[] args) throws Exception {StopWatch clock = new StopWatch();clock.start(WriteParquetFile.class.getSimpleName());Configuration conf = new Configuration();int status = ToolRunner.run(conf, new WriteParquetFile(), args);System.exit(status);clock.stop();System.out.println(clock.prettyPrint());}@Overridepublic int run(String[] args) throws Exception {Configuration conf = getConf();// 此demo 输入数据为2列 city ip//输入文件格式:https://www.win.com/233434,8283140// https://www.win.com/242288,8283139MessageType schema = Types.buildMessage().required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8).named("city").required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8).named("ip").named("pair");System.out.println("[schema]==" + schema.toString());GroupWriteSupport.setSchema(schema, conf);Job job = Job.getInstance(conf, this.getClass().getName());job.setJarByClass(this.getClass());job.setMapperClass(WriteParquetFileMapper.class);job.setInputFormatClass(TextInputFormat.class);job.setMapOutputKeyClass(NullWritable.class);// 设置value是parquet的Groupjob.setMapOutputValueClass(Group.class);FileInputFormat.setInputPaths(job, in);// parquet输出job.setOutputFormatClass(ParquetOutputFormat.class);ParquetOutputFormat.setWriteSupportClass(job, GroupWriteSupport.class);Path outputDir = new Path(out);outputDir.getFileSystem(this.getConf()).delete(outputDir, true);FileOutputFormat.setOutputPath(job, new Path(out));ParquetOutputFormat.setOutputPath(job, new Path(out));
// ParquetOutputFormat.setCompression(job, CompressionCodecName.SNAPPY);job.setNumReduceTasks(0);return job.waitForCompletion(true) ? 0 : 1;}public static class WriteParquetFileMapper extends Mapper<LongWritable, Text, NullWritable, Group> {SimpleGroupFactory factory = null;protected void setup(Context context) throws IOException, InterruptedException {factory = new SimpleGroupFactory(GroupWriteSupport.getSchema(context.getConfiguration()));};public void map(LongWritable _key, Text ivalue, Context context) throws IOException, InterruptedException {Group pair = factory.newGroup();//截取输入文件的一行,且是以逗号进行分割String[] strs = ivalue.toString().split(",");pair.append("city", strs[0]);pair.append("ip", strs[1]);context.write(null, pair);}}
}
将生成的文件上传至hdfs://server1:8020/flinktest/parquettest/下。
3)、建表
需要注意的是字段的名称与类型,需要和parquet文件的schema保持一致,否则读取不到文件内容。
- schema
MessageType schema = Types.buildMessage()
.required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8).named("city")
.required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8).named("ip")
.named("pair");// 以下是schema的内容
[schema]==message pair {required binary city (UTF8);required binary ip (UTF8);
}- 建表
CREATE TABLE alan_parquet_cityinfo (city STRING,ip STRING
) WITH ('connector' = 'filesystem','path' = 'hdfs://server1:8020/flinktest/parquettest/','format' = 'parquet'
);Flink SQL> CREATE TABLE alan_parquet_cityinfo (
> city STRING,
> ip STRING
> ) WITH (
> 'connector' = 'filesystem',
> 'path' = 'hdfs://server1:8020/flinktest/parquettest/',
> 'format' = 'parquet'
> );
[INFO] Execute statement succeed.4)、验证
Flink SQL> select * from alan_parquet_cityinfo limit 10;
+----+--------------------------------+--------------------------------+
| op | city | ip |
+----+--------------------------------+--------------------------------+
| +I | https://www.win.com/237516 | 8284068 |
| +I | https://www.win.com/242247 | 8284067 |
| +I | https://www.win.com/243248 | 8284066 |
| +I | https://www.win.com/243288 | 8284065 |
| +I | https://www.win.com/240213 | 8284064 |
| +I | https://www.win.com/239907 | 8284063 |
| +I | https://www.win.com/235270 | 8284062 |
| +I | https://www.win.com/234366 | 8284061 |
| +I | https://www.win.com/229297 | 8284060 |
| +I | https://www.win.com/237757 | 8284059 |
+----+--------------------------------+--------------------------------+
Received a total of 10 rows3、table api建表示例
通过table api建表,参考文章:
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
为了简单起见,本示例仅仅是通过sql建表,数据准备见上述示例。
1)、源码
下面是在本地运行的,建表的path也是用本地的。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;/*** @author alanchan**/
public class TestParquetFormatDemo {static String sourceSql = "CREATE TABLE alan_parquet_cityinfo (\r\n" + " city STRING,\r\n" + " ip STRING\r\n" + ") WITH (\r\n" + " 'connector' = 'filesystem',\r\n" + " 'path' = 'D:/workspace/bigdata-component/hadoop/test/out/parquet',\r\n" + " 'format' = 'parquet'\r\n" + ");";public static void test1() throws Exception {// 1、创建运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);// 建表tenv.executeSql(sourceSql);Table table = tenv.from("alan_parquet_cityinfo");table.printSchema();tenv.createTemporaryView("alan_parquet_cityinfo_v", table);tenv.executeSql("select * from alan_parquet_cityinfo_v limit 10").print();// table.execute().print();env.execute();}public static void main(String[] args) throws Exception {test1();}}
2)、运行结果
(`city` STRING,`ip` STRING
)+----+--------------------------------+--------------------------------+
| op | city | ip |
+----+--------------------------------+--------------------------------+
| +I | https://www.win.com/237516 | 8284068 |
| +I | https://www.win.com/242247 | 8284067 |
| +I | https://www.win.com/243248 | 8284066 |
| +I | https://www.win.com/243288 | 8284065 |
| +I | https://www.win.com/240213 | 8284064 |
| +I | https://www.win.com/239907 | 8284063 |
| +I | https://www.win.com/235270 | 8284062 |
| +I | https://www.win.com/234366 | 8284061 |
| +I | https://www.win.com/229297 | 8284060 |
| +I | https://www.win.com/237757 | 8284059 |
+----+--------------------------------+--------------------------------+
10 rows in set3)、maven依赖
<properties><encoding>UTF-8</encoding><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><java.version>1.8</java.version><scala.version>2.12</scala.version><flink.version>1.17.0</flink.version></properties><dependencies><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-sql-gateway --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-gateway</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-java-uber --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-uber</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-runtime --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-runtime</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.1.0-1.17</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.38</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-hive --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-hive_2.12</artifactId><version>1.17.0</version></dependency><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>32.0.1-jre</version></dependency> <!-- flink连接器 --><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-sql-connector-kafka --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-connector-kafka</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.commons/commons-compress --><dependency><groupId>org.apache.commons</groupId><artifactId>commons-compress</artifactId><version>1.24.0</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.2</version><!-- <scope>provided</scope> --></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-orc</artifactId><version>1.17.1</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-parquet</artifactId><version>1.17.1</version></dependency></dependencies>
4、Format 参数
Parquet 格式也支持 ParquetOutputFormat 的配置。
例如, 可以配置 parquet.compression=GZIP 来开启 gzip 压缩。
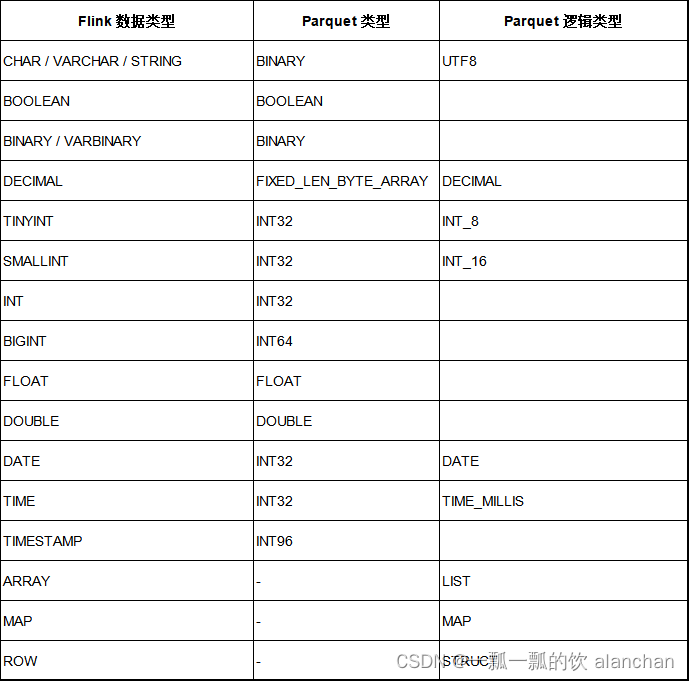
5、数据类型映射
截至Flink 1.17 版本 ,Parquet 格式类型映射与 Apache Hive 兼容,但与 Apache Spark 有所不同:
- Timestamp:不论精度,映射 timestamp 类型至 int96。
- Decimal:根据精度,映射 decimal 类型至固定长度字节的数组。
下表列举了 Flink 中的数据类型与 JSON 中的数据类型的映射关系。
以上,介绍了Flink 支持的数据格式中的ORC和Parquet,并分别以sql和table api作为示例进行了说明。
相关文章:
36、Flink 的 Formats 之Parquet 和 Orc Format
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...
--安装)
Docker 笔记(一)--安装
Docker 笔记(一)–安装 记录Docker 安装操作记录,便于查询。 参考 链接: Docker 入门到实战教程(二)安装Docker链接: docker入门(利用docker部署web应用)链接: 阿里云容器镜像服务/镜像加速器/操作文档链接: 网易镜像中心链接: 阿里云镜像…...

endnote20如何导入已经下载好的ris和pdf文件
查看此链接 1 文献导入 1.1 PDF导入 (1)方法一 打开:菜单栏–>Import–>FIle或folder 单个导入PDF或导入一个文件夹的PDF或通过拖曳多个PDF进入空白处完成导入 1.3 导入已经整理好的文献资料 已有的ris文件 打开:菜单栏–…...
x程无忧sign逆向分析
x程无忧sign逆向分析: 详情页sign: 详情页网站: import base64 # 解码 result base64.b64decode(aHR0cHM6Ly9qb2JzLjUxam9iLmNvbS9ndWFuZ3pob3UvMTUxODU1MTYyLmh0bWw/cz1zb3Vfc291X3NvdWxiJnQ9MF8wJnJlcT0zODQ4NGQxMzc2Zjc4MDY2M2Y1MGY2Y…...

Rust8.1 Smart Pointers
Rust学习笔记 Rust编程语言入门教程课程笔记 参考教材: The Rust Programming Language (by Steve Klabnik and Carol Nichols, with contributions from the Rust Community) Lecture 15: Smart Pointers src/main.rs use crate::List::{Cons, Nil}; use std::ops::Deref…...

MATLAB与Excel的数据交互
准备阶段 clear all % 添加Excel函数 try Excel=actxGetRunningServer(Excel.Application); catch Excel=actxserver(Excel.application); end % 设置Excel可见 Excel.visible=1; 插入数据 % % 激活eSheet1 % eSheet1.Activate; % 或者 % Activate(eSheet1); % % 打开…...

使用.NET 4.0、3.5时,UnmanagedFunctionPointer导致堆栈溢出
本文介绍了使用.NET 4.0、3.5时,UnmanagedFunctionPointer导致堆栈溢出的处理方法,对大家解决问题具有一定的参考价值,需要的朋友们下面随着小编来一起学习吧! 问题描述 我在带有try catch块的点击处理程序中有一个简单的函数。…...
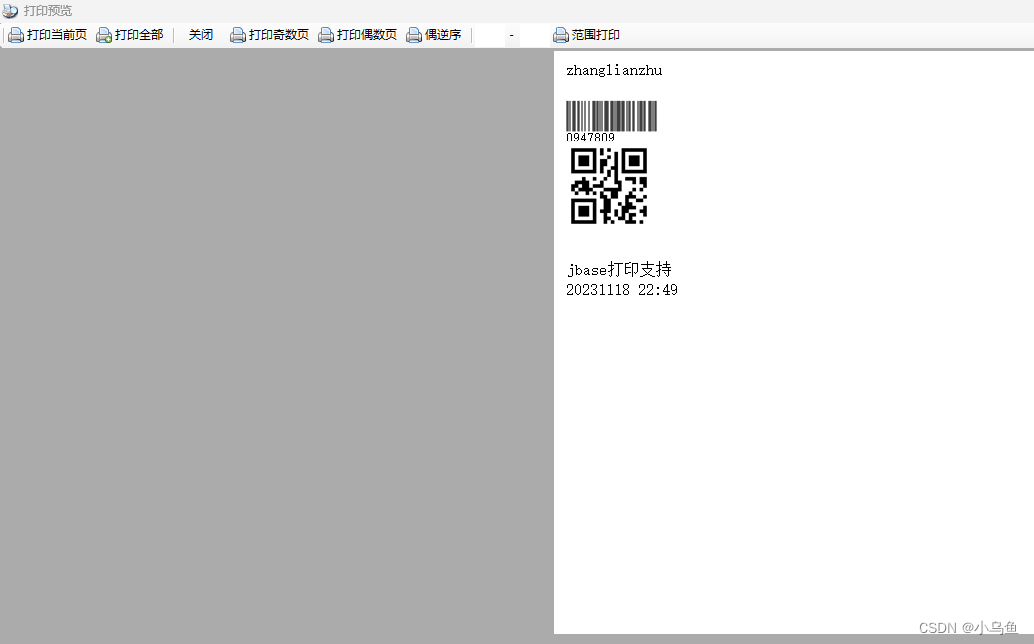
jbase打印导出实现
上一篇实现了虚拟M层,这篇基于虚拟M实现打印导出。 首先对接打印层 using Newtonsoft.Json; using System; using System.Collections.Generic; using System.Linq; using System.Net; using System.Text; using System.Threading.Tasks; using System.Xml;namesp…...

特征缩放和转换以及自定义Transformers(Machine Learning 研习之九)
特征缩放和转换 您需要应用于数据的最重要的转换之一是功能扩展。除了少数例外,机器学习算法在输入数值属性具有非常不同的尺度时表现不佳。住房数据就是这种情况:房间总数约为6至39320间,而收入中位数仅为0至15间。如果没有任何缩放,大多数…...

前端算法面试之堆排序-每日一练
如果对前端八股文感兴趣,可以留意公重号:码农补给站,总有你要的干货。 今天分享一个非常热门的算法--堆排序。堆的运用非常的广泛,例如,Python中的heapq模块提供了堆排序算法,可以用于实现优先队列…...
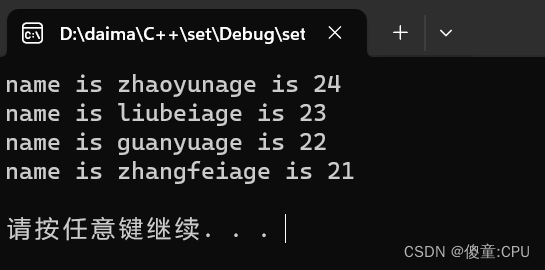
C++之set/multise容器
C之set/multise容器 set基本概念 set构造和赋值 #include <iostream> #include<set> using namespace std;void PrintfSet(set<int>&s) {for(set<int>::iterator it s.begin();it ! s.end();it){cout<<*it<<" ";}cout&l…...

本地部署AutoGPT
我们都了解ChatGPT,是Openai退出的基于GPT模型的新一代 AI助手,可以帮助解决我们在多个领域的问题。但是你会发现,在某些问题上,ChatGPT 需要经过不断的调教与沟通,才能得到接近正确的答案。对于你不太了解的领域领域&…...

ProtocolBuffers(protobuf)详解
目录 前言特点语法定义关键字JSON与Protocol Buffers互相转换gRPC与Protocol Buffers的关系 前言 Protocol Buffers(通常简称为protobuf)是Google公司开发的一种数据描述语言,它能够将结构化数据序列化,可用于数据存储、通信协议…...
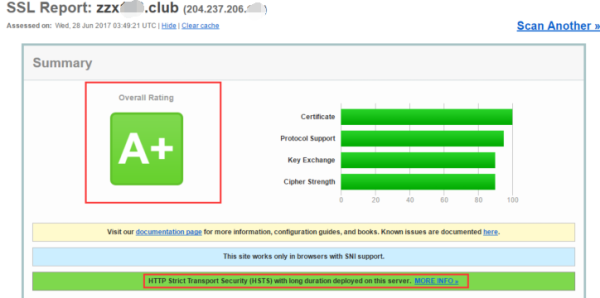
HTTP 到 HTTPS 再到 HSTS 的转变
近些年,随着域名劫持、信息泄漏等网络安全事件的频繁发生,网站安全也变得越来越重要,也促成了网络传输协议从 HTTP 到 HTTPS 再到 HSTS 的转变。 HTTP HTTP(超文本传输协议) 是一种用于分布式、协作式和超媒体信息系…...
清华学霸告诉你:如何自学人工智能?
清华大学作为中国顶尖的学府之一,培养了许多优秀的人才,其中不乏在人工智能领域有所成就的学霸。通过一位清华学霸的经验分享,揭示如何自学人工智能,帮助你在这场科技浪潮中勇往直前。 一、夯实基础知识 数学基础:学习…...
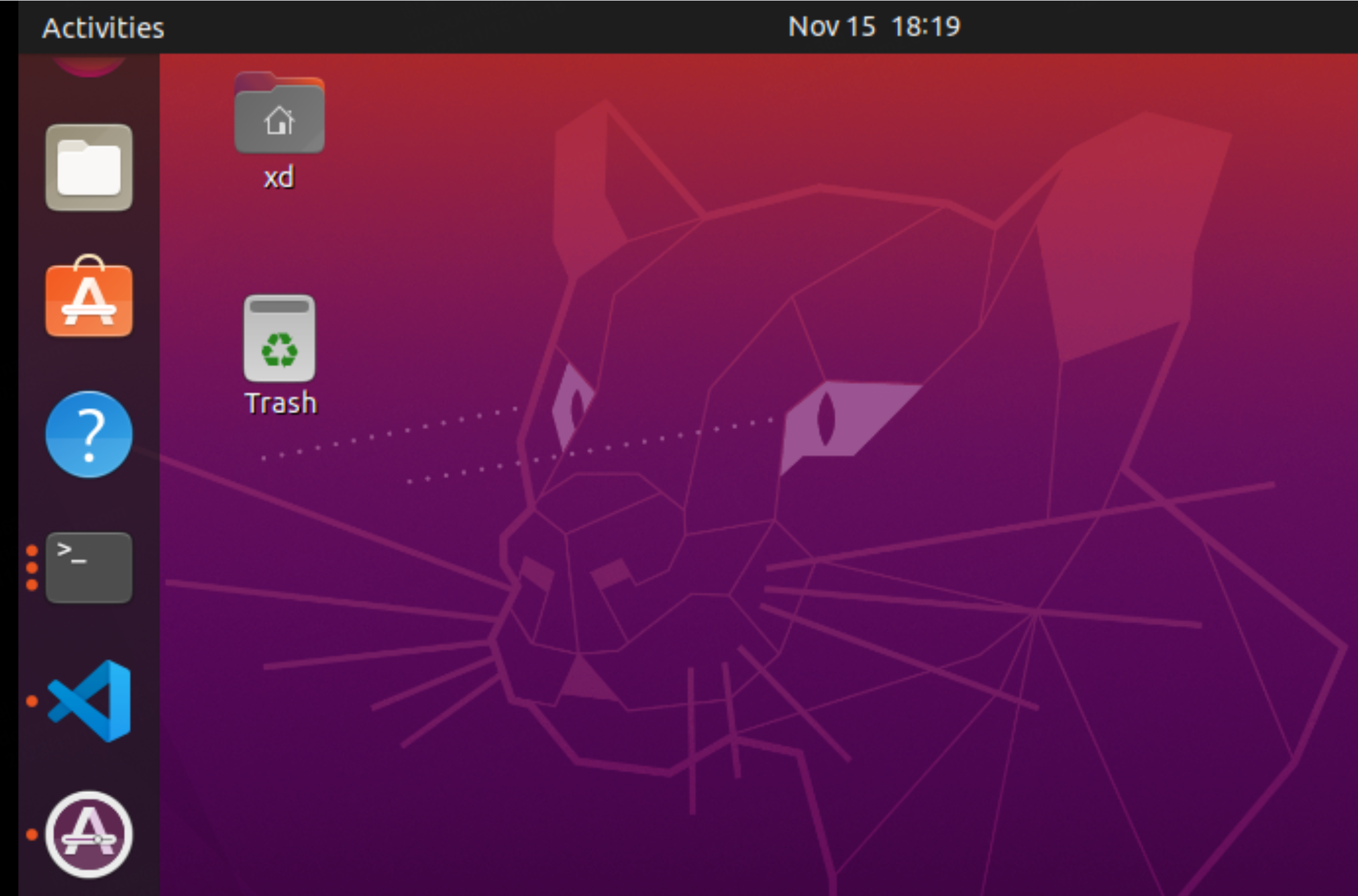
Ubuntu 安装VMware Tools选项显示灰色,如何安装VMware Tools
切换apt源为阿里云: https://qq742971636.blog.csdn.net/article/details/134291339 只要你的网络没问题,你直接执行这几个命令,重启ubuntu虚拟机即可、 sudo dpkg --configure -a sudo apt-get autoremove open-vm-tools sudo apt-get ins…...

SpringBoot 2.x 实战仿B站高性能后端项目
SpringBoot 2.x 实战仿B站高性能后端项目 下栽の地止:请看文章末尾 通常SpringBoot新建项目,默认是集成了Maven,然后所有内容都在一个主模块中。 如果项目架构稍微复杂一点,就需要用到Maven多模块。 本文简单概述一下,…...
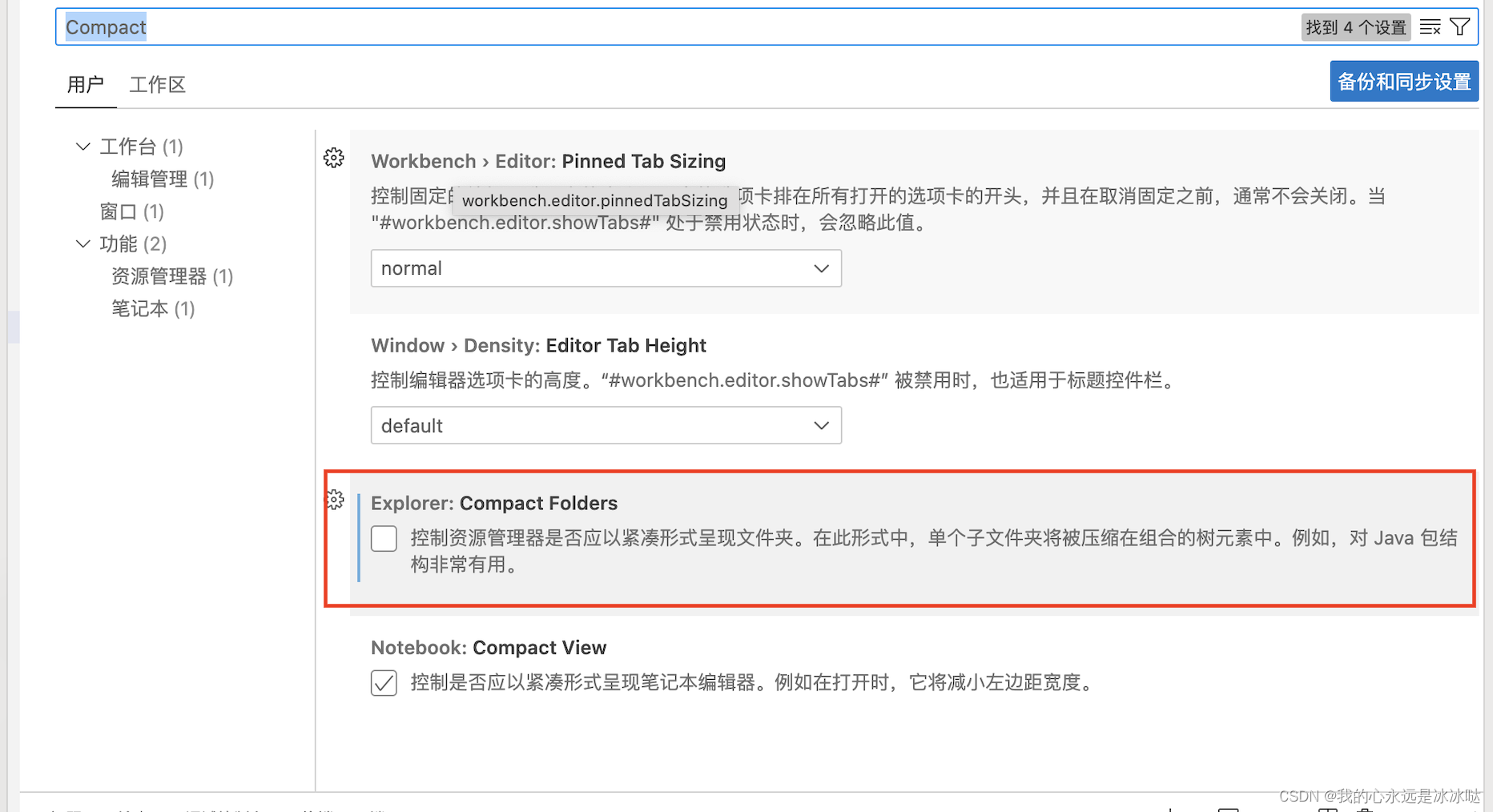
vscode文件夹折叠问题
今天发现一个vscode的文件夹显示的问题,首先是这样的,就是我的文件夹里又一个子文件夹,子文件夹里有一些文件,但是我发现无法折叠起这个子文件夹,总是显示全部的文件,这让我备份很难,具体参考 h…...
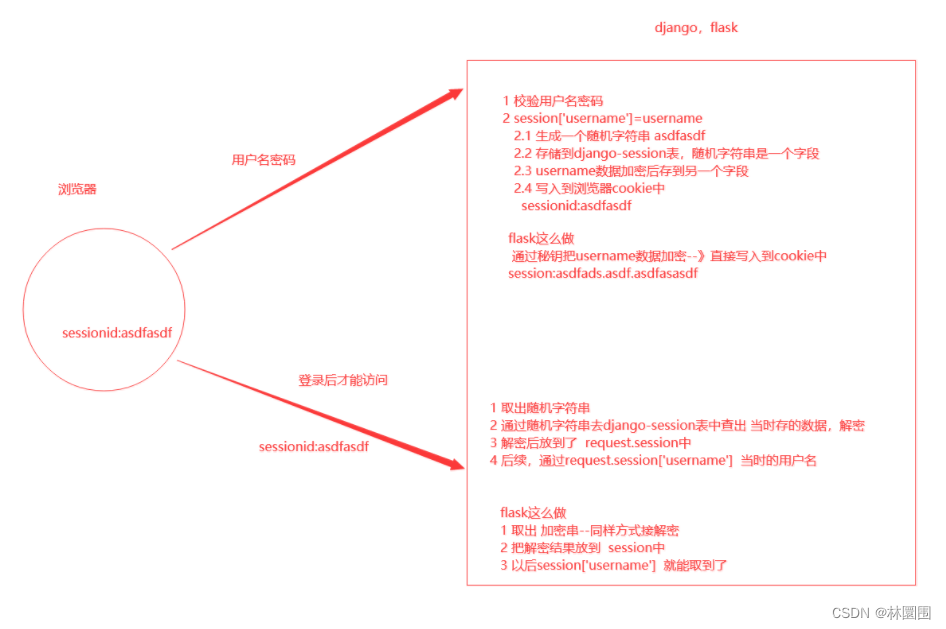
4-flask-cbv源码、Jinja2模板、请求响应、flask中的session、flask项目参考
1 flask中cbv源码 2 Jinja2模板 3 请求响应 4 flask中的session 5 flask项目参考 1 flask中cbv源码 ***flask的官网文档:***https://flask.palletsprojects.com/en/3.0.x/views/1 cbv源码执行流程1 请求来了,路由匹配成功---》执行ItemAPI.as_view(item…...
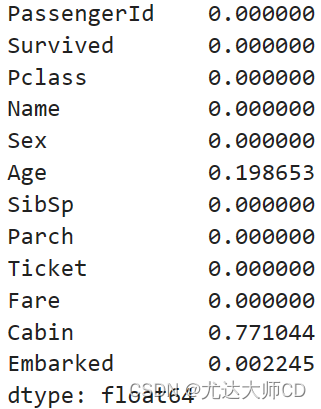
2.Pandas数据预处理
2.1 数据清洗 以titanic数据为例。 df pd.read_csv(titanic.csv) 2.1.1 缺失值 (1)缺失判断 df.isnull() (2)缺失统计 # 列缺失统计 df.isnull().sum(axis0) # 行缺失统计 df.isnull().sum(axis1) # 统计缺失率 df.isnu…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...

如何配置一个sql server使得其它用户可以通过excel odbc获取数据
要让其他用户通过 Excel 使用 ODBC 连接到 SQL Server 获取数据,你需要完成以下配置步骤: ✅ 一、在 SQL Server 端配置(服务器设置) 1. 启用 TCP/IP 协议 打开 “SQL Server 配置管理器”。导航到:SQL Server 网络配…...

深入浅出WebGL:在浏览器中解锁3D世界的魔法钥匙
WebGL:在浏览器中解锁3D世界的魔法钥匙 引言:网页的边界正在消失 在数字化浪潮的推动下,网页早已不再是静态信息的展示窗口。如今,我们可以在浏览器中体验逼真的3D游戏、交互式数据可视化、虚拟实验室,甚至沉浸式的V…...

2025年- H71-Lc179--39.组合总和(回溯,组合)--Java版
1.题目描述 2.思路 当前的元素可以重复使用。 (1)确定回溯算法函数的参数和返回值(一般是void类型) (2)因为是用递归实现的,所以我们要确定终止条件 (3)单层搜索逻辑 二…...

前端工具库lodash与lodash-es区别详解
lodash 和 lodash-es 是同一工具库的两个不同版本,核心功能完全一致,主要区别在于模块化格式和优化方式,适合不同的开发环境。以下是详细对比: 1. 模块化格式 lodash 使用 CommonJS 模块格式(require/module.exports&a…...
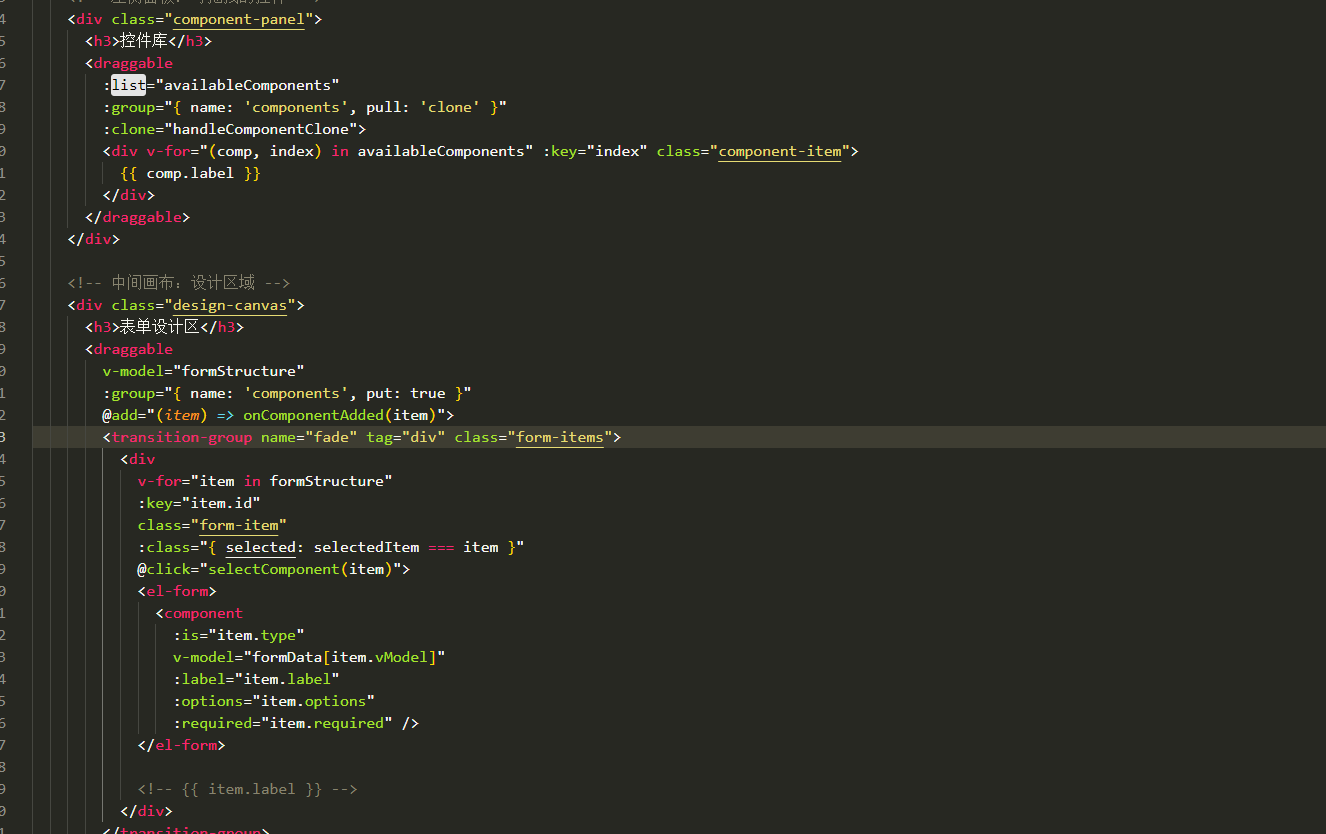
表单设计器拖拽对象时添加属性
背景:因为项目需要。自写设计器。遇到的坑在此记录 使用的拖拽组件时vuedraggable。下面放上局部示例截图。 坑1。draggable标签在拖拽时可以获取到被拖拽的对象属性定义 要使用 :clone, 而不是clone。我想应该是因为draggable标签比较特。另外在使用**:clone时要将…...