【shell 常用脚本30例】
先了解下编写Shell过程中注意事项
- 开头加解释器:#!/bin/bash
- 语法缩进,使用四个空格;多加注释说明。
- 命名建议规则:全局变量名大写、局部变量小写,函数名小写,名字体现出实际作用。
- 默认变量是全局的,在函数中变量local指定为局部变量,避免污染其他作用域。
- 有两个命令能帮助我调试脚本:set -e 遇到执行非0时退出脚本,set-x 打印执行过程。
- 写脚本一定先测试再到生产上。
1、获取随机字符串或数字
获取随机8位字符串
方法1:
# echo $RANDOM |md5sum |cut -c 1-8
c9f36977
#这个命令使用$RANDOM变量生成一个随机的整数,然后将其经过MD5哈希处理,并使用cut命令截取前8个字符作为生成的随机字符串。
方法2:
# openssl rand -base64 4
f4C+pw==
#这个命令使用openssl命令生成一个长度为4的随机字节流
方法3:
# cat /proc/sys/kernel/random/uuid | cut -c 1-8
c1268803
#只是截取了 UUID 的前8个字符,并不是生成一个随机的8位字符串
获取随机8位数字
方法1:
# echo $RANDOM | cksum |cut -c 1-8
55264714
#这个命令使用$RANDOM变量生成一个随机的整数,并通过cksum命令对其进行校验和计算,然后使用cut命令截取校验和结果的前8个字符作为生成的随机8位数字
方法2:
# openssl rand -base64 4 |cksum |cut -c 1-8
30318431
#这个命令使用openssl rand命令生成一个长度为4的随机字节流,并通过cksum命令对其进行校验和计算,然后使用cut命令截取校验和结果的前8个字符作为生成的随机8位数字
方法3:
# date +%N |cut -c 1-8
94705141
#这个命令使用date命令获取当前时间的纳秒部分,并使用cut命令截取前8个字符作为生成的随机8位数字
2、定义一个颜色输出字符串函数
方法1:# 定义一个输出带颜色文本的函数
function echo_color() {# 判断参数值是否为 "green"if [ $1 == "green" ]; then# 使用绿色的前景色输出文本echo -e "\e[1;32m$2\e[0m"# 判断参数值是否为 "red"elif [ $1 == "red" ]; then# 使用红色的前景色输出文本echo -e "\033[31m$2\033[0m"fi
}
方法2:# 定义一个输出带颜色文本的函数
function echo_color() {# 根据参数值进行匹配case $1 in# 如果参数值为 "green"green)# 使用绿色的前景色输出文本echo -e "\e[1;32m$2\e[0m";;# 如果参数值为 "red"red)# 使用红色的前景色输出文本echo -e "\033[31m$2\033[0m";;*) # 参数值不在以上两种情况,则输出提示信息echo "Example: echo_color red string"esac
}
echo_color green "This is a green text" #这行代码会输出绿色的文本 “This is a green text”。
echo_color red "This is a red text" #这行代码会输出红色的文本 “This is a red text”。
3、批量创建用户
#!/bin/bash
DATE=$(date +%F_%T) # 当前日期和时间,用于备份文件的命名
USER_FILE=user.txt # 用户文件名# 定义一个输出带颜色文本的函数
echo_color(){if [ $1 == "green" ]; thenecho -e "\e[1;32m$2\e[0m" # 输出绿色文本elif [ $1 == "red" ]; thenecho -e "\033[31m$2\033[0m" # 输出红色文本fi
}# 如果用户文件存在并且大小大于0就备份
if [ -s $USER_FILE ]; thenmv $USER_FILE ${USER_FILE}-${DATE}.bak # 备份用户文件echo_color green "$USER_FILE exist, rename ${USER_FILE}-${DATE}.bak" # 输出提示信息,绿色文本
fiecho -e "User\tPassword" >> $USER_FILE # 在用户文件中添加表头
echo "----------------" >> $USER_FILE # 在用户文件中添加分隔线# 创建用户,并记录到用户文件中
for USER in user{1..10}; doif ! id $USER &>/dev/null; thenPASS=$(echo $RANDOM |md5sum |cut -c 1-8) # 生成随机密码useradd $USER # 创建用户echo $PASS |passwd --stdin $USER &>/dev/null # 设置用户密码echo -e "$USER\t$PASS" >> $USER_FILE # 在用户文件中添加用户名和密码echo "$USER User create successful." # 输出创建用户成功的提示信息elseecho_color red "$USER User already exists!" # 输出用户已存在的提示信息,红色文本fi
done
主要流程
- 获取当前日期和时间作为备份文件的命名。
- 定义了一个echo_color函数,用于输出带颜色的文本。
- 如果用户文件存在且文件大小大于0,则将用户文件进行备份,并输出相应提示信息(绿色文本)。
- 向用户文件中添加表头和分隔线。
- 使用循环创建10个用户,并记录到用户文件中。
- 如果用户不存在,则生成随机密码并创建用户,并将用户名和密码记录到用户文件中,同时输出创建用户成功的提示信息。
- 如果用户已经存在,则输出用户已存在的提示信息(红色文本)。
4、检查软件包是否安装
#!/bin/bash# 检查 sysstat 软件包是否已安装
if rpm -q sysstat &>/dev/null; thenecho "sysstat is already installed." # 输出已安装的提示信息
elseecho "sysstat is not installed!" # 输出未安装的提示信息
fi
- rpm -q sysstat命令用于查询系统中sysstat软件包的安装情况
- &>/dev/null用于将标准输出和标准错误输出重定向到空设备,即不显示输出信息
- 如果sysstat软件包已安装,则输出"sysstat is already installed.",表示已经存在且已安装
- 如果sysstat软件包未安装,则输出"sysstat is not installed!",表示尚未安装
5、检查服务状态
#!/bin/bash# 使用 ss 命令查找所有 UDP 连接,并使用 grep 统计包含 "123" 字符串的个数
PORT_C=$(ss -anu | grep -c 123)# 使用 ps 命令查找所有 ntpd 进程,并使用 grep 过滤掉 grep 进程本身,再统计过滤后的行数
PS_C=$(ps -ef | grep ntpd | grep -vc grep)# 如果统计到的端口数为 0 或统计到的进程数为 0,则执行下面的操作
if [ $PORT_C -eq 0 -o $PS_C -eq 0 ]; then# 通过 echo 命令输出邮件内容,然后使用 mail 命令发送邮件给指定的邮箱echo "内容" | mail -s "主题" dst@example.com
fi
- ss -anu命令用于查看系统中所有的UDP连接
- rep -c 123用于统计结果中包含"123"字符串的行数
- ps -ef命令用于查看系统中的所有进程
- grep ntpd用于过滤出包含"ntpd"字符串的行
- grep -vc grep用于过滤掉包含"grep"字符串的行,并统计过滤后的行数
6、检查主机存活状态
方法1:将错误IP放到数组里面判断是否ping失败三次
#!/bin/bashIP_LIST="192.168.18.1 192.168.1.1 192.168.18.2"# 循环处理 IP_LIST 中的每个 IP 地址
for IP in $IP_LIST; doNUM=1 # 用于记录当前重试次数的变量# 使用 while 循环,最多重试 3 次while [ $NUM -le 3 ]; do# 检测指定 IP 地址是否可以通过 ping 命令连通if ping -c 1 $IP > /dev/null; thenecho "$IP Ping is successful." # 输出提示信息,表示 Ping 成功break # 跳出当前循环,继续处理下一个 IP 地址else# 如果 ping 失败,记录失败次数和相应的 IP 地址FAIL_COUNT[$NUM]=$IPlet NUM++fidone# 如果连续失败次数达到 3 次,则输出错误信息并清空 FAIL_COUNT 数组if [ ${#FAIL_COUNT[*]} -eq 3 ];thenecho "${FAIL_COUNT[1]} Ping is failure!" # 输出提示信息,表示 Ping 失败unset FAIL_COUNT[*] # 清空 FAIL_COUNT 数组的内容fi
done
- IP_LIST 字符串包含要检测的多个 IP 地址。
- 使用 for 循环遍历每个 IP 地址。
- NUM 变量记录每个 IP 地址的重试次数。
代码的功能: - 对于 IP_LIST 中的每个 IP 地址
- 使用 while 循环尝试最多 3 次进行 ping 命令检测。
- 如果 ping 成功,则输出提示信息表示 Ping 成功,并跳出循环继续处理下一个 IP 地址。
- 如果 ping 失败,则记录失败次数和相应的 IP 地址。
- 如果连续失败次数达到 3 次,则输出错误信息并清空 FAIL_COUNT 数组。
方法2:将错误次数放到FAIL_COUNT变量里面判断是否ping失败三次
#!/bin/bashIP_LIST="192.168.18.1 192.168.1.1 192.168.18.2"# 循环处理 IP_LIST 中的每个 IP 地址
for IP in $IP_LIST; doFAIL_COUNT=0 # 用于记录失败次数的变量# 使用 for 循环尝试最多 3 次 ping 命令for ((i=1;i<=3;i++)); do# 检测指定 IP 地址是否可以通过 ping 命令连通if ping -c 1 $IP >/dev/null; thenecho "$IP Ping is successful." # 输出提示信息,表示 Ping 成功break # 跳出当前循环,继续处理下一个 IP 地址elselet FAIL_COUNT++ # 失败次数加 1fidone# 如果连续失败次数达到 3 次,则输出错误信息if [ $FAIL_COUNT -eq 3 ]; thenecho "$IP Ping is failure!" # 输出提示信息,表示 Ping 失败fi
done
- IP_LIST 字符串包含要检测的多个 IP 地址。
- 使用 for 循环遍历每个 IP 地址。
- FAIL_COUNT 变量用于记录每个 IP 地址的失败次数。
代码的功能: - 对于 IP_LIST 中的每个 IP 地址
- 使用 for 循环尝试最多 3 次 ping 命令检测。
- 如果 ping 成功,则输出提示信息表示 Ping 成功,并跳出循环继续处理下一个 IP 地址。
- 如果 ping 失败,则增加失败次数。
- 如果连续失败次数达到 3 次,则输出错误信息表示 Ping 失败。
方法3:利用for循环将ping通就跳出循环继续,如果不跳出就会走到打印ping失败
#!/bin/bash# 定义函数用于检测 Ping 状态并输出结果
ping_success_status() {if ping -c 1 $IP >/dev/null; thenecho "$IP Ping is successful." # 输出提示信息,表示 Ping 成功continue # 继续循环处理下一个 IP 地址fi
}IP_LIST="192.168.18.1 192.168.1.1 192.168.18.2"# 循环处理 IP_LIST 中的每个 IP 地址
for IP in $IP_LIST; doping_success_statusping_success_statusping_success_statusecho "$IP Ping is failure!" # 输出提示信息,表示 Ping 失败
done
-
ping_success_status() 函数用于检测指定IP地址的Ping状态并输出结果。
-
IP_LIST 字符串包含要检测的多个 IP 地址。
-
使用 for 循环遍历每个 IP 地址,对每个 IP 地址调用 ping_success_status() 函数进行 Ping 测试。
代码的功能: -
定义了一个名为 ping_success_status 的函数用于检测 Ping 状态并输出结果。
-
对于 IP_LIST 中的每个 IP 地址
- 分别调用 ping_success_status() 函数三次,进行 Ping 测试。
- 如果三次中有任意一次 Ping 成功,则输出提示信息表示 Ping 成功,并继续处理下一个 IP 地址。
- 如果三次都 Ping 失败,则输出提示信息表示 Ping 失败。
7、监控CPU、内存利用率
1)CPU
借助vmstat工具来分析CPU统计信息。
#!/bin/bashDATE=$(date +%F" "%H:%M) # 获取当前日期和时间
IP=$(ifconfig eth0 | awk -F"[ :]+" '/inet addr/{print $4}') # 获取 eth0 网卡的 IP 地址(在 CentOS 6 中)
MAIL="example@mail.com"# 检查系统是否安装了 vmstat 命令,如果没有找到,则输出错误信息并退出脚本
if ! which vmstat &>/dev/null; thenecho "vmstat command not found. Please install the procps package."exit 1
fi# 使用 vmstat 命令获取 CPU 相关的统计数据
US=$(vmstat 1 3 | awk 'NR==5{print $13}') # 用户CPU时间占用百分比
SY=$(vmstat 1 3 | awk 'NR==5{print $14}') # 系统CPU时间占用百分比
IDLE=$(vmstat 1 3 | awk 'NR==5{print $15}') # 空闲CPU时间百分比
WAIT=$(vmstat 1 3 | awk 'NR==5{print $16}') # IO等待百分比USE=$(($US+$SY)) # 计算用户CPU时间占用和系统CPU时间占用的总和# 检查 CPU 使用率是否超过阈值(80%),如果超过则发送电子邮件通知
if [ $USE -ge 80 ]; thenecho "Date: $DATEHost: $IPProblem: CPU utilization $USE" | mail -s "CPU Monitor" $MAIL
fi
代码的功能:
- 声明并初始化了 DATE 变量,用于存储当前的日期和时间。
- 使用 ifconfig 命令获取 eth0 网卡的 IP 地址(在 CentOS 6 中)。
- 设置邮件接收地址 MAIL。
- 检查系统是否安装了 vmstat 命令,如果没有找到,则输出错误信息并退出脚本。、使用 vmstat 命令获取 CPU 相关的统计数据,包括用户 CPU 时间占用、系统 CPU 时间占用、空闲 CPU 时间和 IO 等待时间。
- 计算用户 CPU 时间占用和系统 CPU 时间占用的总和,并存储在 USE 变量中。
- 检查 CPU 使用率是否超过阈值(80%),如果超过,则发送电子邮件通知,包括日期、主机名和问题描述。
2)内存
#!/bin/bashDATE=$(date +%F" "%H:%M) # 获取当前日期和时间
IP=$(ifconfig eth0 | awk -F"[ :]+" '/inet addr/{print $4}') # 获取 eth0 网卡的 IP 地址(在 CentOS 6 中)
MAIL="example@mail.com"# 使用 free 命令获取内存相关的统计数据
TOTAL=$(free -m | awk '/Mem/{print $2}') # 内存总量
USE=$(free -m | awk '/Mem/{print $3-$6-$7}') # 已使用的内存量
FREE=$(($TOTAL-$USE)) # 剩余内存量# 如果剩余内存小于 1G,则发送电子邮件通知
if [ $FREE -lt 1024 ]; thenecho "Date: $DATEHost: $IPProblem: Total=$TOTAL, Use=$USE, Free=$FREE" | mail -s "Memory Monitor" $MAIL
fi
代码的功能:
- 声明并初始化了 DATE 变量,用于存储当前的日期和时间。
- 使用 ifconfig 命令获取 eth0 网卡的 IP 地址(在 CentOS 6 中)。
- 设置邮件接收地址 MAIL。
- 使用 free 命令获取内存相关的统计数据,包括内存总量、已使用的内存量和剩余的内存量。
- 计算剩余内存量(Total - Use)并存储在 FREE 变量中。
- 检查剩余内存量是否小于 1G(1024MB),如果小于则发送电子邮件通知,包括日期、主机名和问题描述。
8、批量主机磁盘利用率监控
前提监控端和被监控端SSH免交互登录或者密钥登录。
写一个配置文件保存被监控主机SSH连接信息,文件内容格式:IP User Port
#!/bin/bashHOST_INFO=host.info # 主机信息保存的文件路径
rm -f mail.txt # 删除已存在的邮件内容文件# 遍历主机信息文件中的每个 IP 地址
for IP in $(awk '/^[^#]/{print $1}' $HOST_INFO); do# 获取用户名和端口信息USER=$(awk -v ip=$IP 'ip==$1{print $2}' $HOST_INFO)PORT=$(awk -v ip=$IP 'ip==$1{print $3}' $HOST_INFO)TMP_FILE=/tmp/disk.tmp # 临时文件路径,用于保存磁盘信息# 通过公钥登录到远程主机,获取磁盘信息,并保存到临时文件中ssh -p $PORT $USER@$IP 'df -h' > $TMP_FILE# 从临时文件中提取磁盘利用率信息,并保存到变量 USE_RATE_LIST 中USE_RATE_LIST=$(awk 'BEGIN{OFS="="}/^\/dev/{print $NF,int($5)}' $TMP_FILE)# 对磁盘利用率进行循环判断for USE_RATE in $USE_RATE_LIST; doPART_NAME=${USE_RATE%=*} # 获取挂载点部分,即等号(=)左边的值USE_RATE=${USE_RATE#*=} # 获取磁盘利用率部分,即等号(=)右边的值# 判断磁盘利用率是否超过阈值(80%),如果超过则将警告信息添加到邮件内容文件中if [ $USE_RATE -ge 80 ]; thenecho "Warning: $PART_NAME Partition usage $USE_RATE%!" >> mail.txtelseecho "服务器$IP的$PART_NAME目录空间良好"fidone# 发送邮件,将邮件内容文件作为内容,邮件主题为 "空间不足警告"cat mail.txt | mail -s "空间不足警告" xiaobai@cdeledu.com
done
代码的功能:
- 定义 HOST_INFO 变量,表示保存主机信息的文件路径。
- 删除已存在的邮件内容文件 mail.txt。
- 使用 awk 从主机信息文件中提取非注释行的 IP 地址,并依次处理每个 IP。
- 从主机信息文件中获取用户名和端口信息。
- 定义临时文件路径 TMP_FILE,用于保存远程主机的磁盘信息。
- 使用 ssh 命令通过公钥登录到远程主机,在远程主机上执行 df -h 命令,并将输出重定向到临时文件中。
- 从临时文件中提取磁盘利用率信息,并保存到 USE_RATE_LIST 变量中。
- 使用循环遍历磁盘利用率列表,并进行判断。
- 获取挂载点部分和磁盘利用率部分。
- 如果磁盘利用率超过阈值(80%),将警告信息添加到邮件内容文件 mail.txt 中。
- 如果磁盘利用率未超过阈值,则输出相应信息表示磁盘空间良好。
- 使用 cat 命令将邮件内容文件作为邮件内容,向 xiaobai@cdeledu.com 发送邮件,邮件主题为 “空间不足警告”。
9、检查网站可用性
1)检查URL可用性
# 方法1:使用 curl 命令检查 URL 的访问状态
check_url() {HTTP_CODE=$(curl -o /dev/null --connect-timeout 3 -s -w "%{http_code}" $1)# 使用 curl 命令测试 HTTP 头以检查 URL 的访问状态,超时时间为 3 秒,并将 HTTP 状态码保存到变量 HTTP_CODE 中if [ $HTTP_CODE -ne 200 ]; thenecho "Warning: $1 Access failure!"# 如果 HTTP 状态码不等于 200(即不成功),则输出警告信息,表示 URL 访问失败fi
}# 方法2:使用 wget 命令检查 URL 的访问状态
check_url() {if ! wget -T 10 --tries=1 --spider $1 >/dev/null 2>&1; then # 使用 wget 命令以爬虫模式检查 URL 的访问状态,超时时间为 10 秒,并尝试访问 1 次,将输出重定向到 /dev/null,将错误输出重定向到标准输出并丢弃echo "Warning: $1 Access failure!"# 如果 wget 命令返回非零退出码,则输出警告信息,表示 URL 访问失败fi
}
代码的功能:
- 方法1:使用 curl 命令。通过设置选项 -o /dev/null,–connect-timeout 3,-s 和 -w “%{http_code}”,来测试 HTTP 头,并将 HTTP 状态码保存到变量 HTTP_CODE 中。然后,检查 HTTP 状态码是否等于 200,如果不等于,则输出警告信息,表示 URL 访问失败。
- 方法2:使用 wget 命令。通过设置选项 -T 10,–tries=1 和 --spider,以爬虫模式测试URL的访问状态,并设置超时时间为10秒,尝试访问1次。使用重定向将输出和错误信息都丢弃。然后,检查 wget 命令的返回值,如果返回非零退出码,则输出警告信息,表示 URL 访问失败。
2)判断三次URL可用性
方法1:利用循环技巧,如果成功就跳出当前循环,否则执行到最后一行
#!/bin/bash# 检查URL的访问状态
check_url() {HTTP_CODE=$(curl -o /dev/null --connect-timeout 3 -s -w "%{http_code}" $1)# 使用 curl 命令测试 HTTP 头以检查 URL 的访问状态,超时时间为 3 秒,并将 HTTP 状态码保存到变量 HTTP_CODE 中if [ $HTTP_CODE -eq 200 ]; thencontinue# 如果 HTTP 状态码等于 200(即成功),则继续循环,不执行后续操作fi
}URL_LIST="www.baidu.com www.agasgf.com"
# 存储待检查的 URL 列表for URL in $URL_LIST; docheck_url $URL# 依次遍历 URL 列表,调用 check_url 函数检查每个 URL 的访问状态# 如果返回的 HTTP 状态码等于 200,则继续循环,不执行后续操作check_url $URLcheck_url $URL# 连续调用 check_url 函数,最多尝试三次echo "Warning: $URL Access failure!"# 输出警告信息,表示 URL 访问失败
done
代码的功能:
- 定义了函数 check_url(),用于检查 URL 的访问状态。通过设置选项 -o /dev/null,–connect-timeout 3,-s 和 -w “%{http_code}”,使用 curl 命令测试 HTTP 头,并将返回的 HTTP 状态码保存到变量 HTTP_CODE 中。
- 在函数中,如果返回的 HTTP 状态码等于 200,那么继续循环,不执行后续操作。
- 定义了一个字符串变量 URL_LIST,用于存储待检查的 URL 列表。
- 使用 for 循环遍历 URL_LIST 中的每个 URL,依次调用 check_url 函数来检查 URL 的访问状态。
- 在每次循环中,连续调用 check_url 函数,最多尝试三次。
- 如果访问失败(即返回的 HTTP 状态码不等于 200),则输出警告信息,表示 URL 访问失败。
方法2:错误次数保存到变量
#!/bin/bashURL_LIST="www.baidu.com www.agasgf.com"
# 存储待检查的 URL 列表for URL in $URL_LIST; doFAIL_COUNT=0# 用于统计 URL 访问失败的次数的变量for ((i=1;i<=3;i++)); do# 进行最多三次的访问尝试HTTP_CODE=$(curl -o /dev/null --connect-timeout 3 -s -w "%{http_code}" $URL)# 使用 curl 命令测试 HTTP 头以检查 URL 的访问状态,超时时间为 3 秒,并将 HTTP 状态码保存到变量 HTTP_CODE 中if [ $HTTP_CODE -ne 200 ]; thenlet FAIL_COUNT++# 如果 HTTP 状态码不等于 200(即访问失败),则将失败次数加一elsebreak# 如果 HTTP 状态码等于 200(即访问成功),则跳出循环,不执行后续尝试fidoneif [ $FAIL_COUNT -eq 3 ]; thenecho "Warning: $URL Access failure!"# 如果 URL 访问失败的次数等于 3,即尝试了三次都失败,则输出警告信息,表示 URL 访问失败fi
done
代码的功能:
- 定义了一个字符串变量 URL_LIST,用于存储待检查的 URL 列表。
- 使用 for 循环遍历 URL_LIST 中的每个 URL。
- 在每次循环中,初始化变量 FAIL_COUNT 为 0,用于统计 URL 访问失败的次数。
- 使用 for 循环进行最多三次的访问尝试。
- 在每次尝试中,使用 curl 命令测试 URL 的 HTTP 头,超时时间为 3 秒,并将返回的 HTTP 状态码保存到变量 HTTP_CODE 中
- 如果 HTTP 状态码不等于 200(即访问失败),则将 FAIL_COUNT 的值加一。
- 如果 HTTP 状态码等于 200(即访问成功),则跳出循环,不执行后续尝试。
- 在完成三次访问尝试后,如果失败次数等于 3,则输出警告信息,表示 URL 访问失败。
方法3:错误次数保存到数组
#!/bin/bashURL_LIST="www.baidu.com www.agasgf.com"
# 存储待检查的 URL 列表for URL in $URL_LIST; doNUM=1# 用于计数的变量 NUM,初始值为 1while [ $NUM -le 3 ]; do# 进行最多三次的访问尝试HTTP_CODE=$(curl -o /dev/null --connect-timeout 3 -s -w "%{http_code}" $URL)# 使用 curl 命令测试 HTTP 头以检查 URL 的访问状态,超时时间为 3 秒,并将 HTTP 状态码保存到变量 HTTP_CODE 中if [ $HTTP_CODE -ne 200 ]; thenFAIL_COUNT[$NUM]=$IP# 如果 HTTP 状态码不等于 200(即访问失败),则将失败的 URL 存储到数组 FAIL_COUNT 中,以 NUM 作为下标,IP 作为元素let NUM++# 数量加一,进行下一次尝试elsebreak# 如果 HTTP 状态码等于 200(即访问成功),则跳出循环,不再进行尝试fidoneif [ ${#FAIL_COUNT[*]} -eq 3 ]; thenecho "Warning: $URL Access failure!"unset FAIL_COUNT[*]# 如果 FAIL_COUNT 数组中有三个元素,即进行了三次尝试都失败,则输出警告信息,表示 URL 访问失败,并清空 FAIL_COUNT 数组fi
done
代码的功能:
- 定义了一个字符串变量 URL_LIST,用于存储待检查的 URL 列表。
- 使用 for 循环遍历 URL_LIST 中的每个 URL。
- 在每次循环中,初始化变量 NUM 为 1,用于计数访问尝试的次数。
- 使用 while 循环进行最多三次的访问尝试。
- 在每次尝试中,使用 curl 命令测试 URL 的 HTTP 头,超时时间为 3 秒,并将返回的 HTTP 状态码保存到变量 HTTP_CODE 中。
- 如果 HTTP 状态码不等于 200(即访问失败),则将失败的 URL 存储到 FAIL_COUNT 数组中,以 NUM 作为下标,IP 作为元素。然后,NUM 加一,进行下一次尝试。
- 如果 HTTP 状态码等于 200(即访问成功),则跳出循环,不再进行尝试。
使用 for 循环遍历 URL_LIST 中的每个 URL。 - 在完成三次访问尝试后,如果 FAIL_COUNT 数组中有三个元素(即进行了三次尝试都失败),则输出警告信息,表示 URL 访问失败,并清空 FAIL_COUNT 数组。
10、检查MySQL主从同步状态
#!/bin/bashUSER=bak
PASSWD=123456IO_SQL_STATUS=$(mysql -u$USER -p$PASSWD -e show slave statusG | awk -F: /Slave_.*_Running/{gsub(": ",":");print $0})
# 执行 mysql 命令获取 MySQL 主从状态,并使用 awk 命令根据关键字 "Slave_.*_Running" 解析出对应的行,并去除冒号后的空格for i in $IO_SQL_STATUS; doTHREAD_STATUS_NAME=${i%:*}# 通过 %:* 取 THREAD_STATUS_NAME 字符串变量,获取冒号前的部分THREAD_STATUS=${i#*:}# 通过 #*: 取 THREAD_STATUS 字符串变量,获取冒号后的部分if [ "$THREAD_STATUS" != "Yes" ]; thenecho "Error: MySQL Master-Slave $THREAD_STATUS_NAME status is $THREAD_STATUS!"# 如果 THREAD_STATUS 不等于 "Yes",则输出错误信息,表示 MySQL 主从状态异常fi
done
代码的功能:
- 定义了字符串变量 USER 和 PASSWD,分别存储登录 MySQL 的用户名和密码。
- 使用 mysql 命令执行查询语句 show slave statusG,获取 MySQL 主从复制的状态。-u$ USER 指定用户名,-p$PASSWD 指定密码,-e 后面跟查询语句,G 匹配 show slave status 的输出格式。
- 使用 awk 命令根据关键字 “Slave_.*_Running” 解析出对应的行,并去除冒号后的空格。
- 使用 for 循环遍历 $IO_SQL_STATUS 中的每个值。
- 在每次循环中,通过 %:* 取出冒号前的部分,赋值给 THREAD_STATUS_NAME 变量。
- 通过 #*: 取出冒号后的部分,赋值给 THREAD_STATUS 变量。
- 如果 THREAD_STATUS 不等于 “Yes”,则输出错误信息,表示 MySQL 主从状态异常。
11、iptables自动屏蔽访问网站频繁的IP
场景:恶意访问,安全防范
1)屏蔽每分钟访问超过200的IP
方法1:根据访问日志(Nginx为例)
#!/bin/bashDATE=$(date +%d/%b/%Y:%H:%M)
# 获取当前日期和时间,并格式化为 "%d/%b/%Y:%H:%M" 的形式,赋值给变量 DATEABNORMAL_IP=$(tail -n 5000 access.log | grep $DATE | awk '{a[$1]++}END{for(key in a)if(a[key]>100)print key}')
# 使用 tail 命令读取文件 access.log 的最后 5000 行日志,然后通过 grep 过滤出包含当前日期的行,最后使用 awk 命令统计 IP 地址出现的次数,如果次数大于 100,则将 IP 地址打印出来,赋值给变量 ABNORMAL_IPfor IP in $ABNORMAL_IP; do# 使用 for 循环遍历 ABNORMAL_IP 中的每个 IP 地址if [ $(iptables -vnL |grep -c "$IP") -eq 0 ]; then# 使用 iptables 命令查看当前防火墙规则,并使用 grep 过滤出包含指定 IP 地址的行,并使用 -c 参数统计匹配行的数量# 如果匹配行的数量等于 0,表示当前 IP 地址不在防火墙规则中iptables -I INPUT -s $IP -j DROP# 在 INPUT 链的开头插入一条规则,拒绝指定 IP 地址的所有输入流量fi
done
这段代码的功能是根据 access.log 中的日志数据,检测发起请求次数超过设定阈值的 IP 地址,并将这些 IP 地址加入防火墙规则,拒绝其输入流量。
代码的功能:
- 定义了字符串变量 DATE,使用 date 命令获取当前日期和时间,并使用 %d/%b/%Y:%H:%M 格式化。
- 使用 tail 命令读取文件 access.log 的最后 5000 行日志。
- 使用 grep 过滤出包含当前日期的行。
- 使用 awk 命令统计 IP 地址出现的次数,将出现次数大于 100 的 IP 地址打印出来,赋值给变量 ABNORMAL_IP。
- 使用 for 循环遍历 ABNORMAL_IP 中的每个 IP 地址。
- 使用 iptables 命令查看当前防火墙规则,使用 grep 过滤出包含指定 IP 地址的行,并使用 -c 参数统计匹配行的数量。
- 如果匹配行的数量等于 0,表示当前 IP 地址不在防火墙规则中。
- 使用 iptables 命令在 INPUT 链的开头插入一条规则,拒绝指定 IP 地址的所有输入流量。
方法2:通过TCP建立的连接
#!/bin/bashABNORMAL_IP=$(netstat -an | awk '$4~/:80$/ && $6~/ESTABLISHED/{gsub(/:[0-9]+/,"",$5);{a[$5]++}}END{for(key in a)if(a[key]>100)print key}')
# 使用 netstat 命令获取网络连接状态,通过 awk 过滤出本地端口为 80 的已建立连接(ESTABLISHED)的行,并使用 gsub 函数去除客户端 IP 地址中的冒号和端口号,然后统计每个 IP 地址的出现次数,如果次数大于 100,则将 IP 地址打印出来,赋值给变量 ABNORMAL_IPfor IP in $ABNORMAL_IP; do# 使用 for 循环遍历 ABNORMAL_IP 中的每个 IP 地址if [ $(iptables -vnL |grep -c "$IP") -eq 0 ]; then# 使用 iptables 命令查看当前防火墙规则,并使用 grep 过滤出包含指定 IP 地址的行,并使用 -c 参数统计匹配行的数量# 如果匹配行的数量等于 0,表示当前 IP 地址不在防火墙规则中iptables -I INPUT -s $IP -j DROP# 在 INPUT 链的开头插入一条规则,拒绝指定 IP 地址的所有输入流量fi
done
这段代码的功能是通过 netstat 命令检测当前与本地端口 80 建立的连接,并统计每个客户端 IP 地址的连接次数,如果连接次数超过设定阈值,就将对应 IP 地址加入防火墙规则。
代码的功能:
- 使用 netstat 命令获取当前的网络连接状态。
- 使用 awk 过滤出本地端口为 80 的已建立连接(ESTABLISHED)的行,并使用 gsub 函数将客户端 IP 地址中的冒号和端口号去除。
- 统计每个 IP 地址的出现次数,如果次数大于 100,则将 IP 地址打印出来,赋值给变量 ABNORMAL_IP。
- 使用 for 循环遍历 ABNORMAL_IP 中的每个 IP 地址。
- 使用 iptables 命令查看当前防火墙规则,使用 grep 过滤出包含指定 IP 地址的行,并使用 -c 参数统计匹配行的数量。
- 如果匹配行的数量等于 0,表示当前 IP 地址不在防火墙规则中。
- 使用 iptables 命令在 INPUT 链的开头插入一条规则,拒绝指定 IP 地址的所有输入流量。
2)屏蔽每分钟SSH尝试登录超过10次的IP
方法1:通过lastb获取登录状态
#!/bin/bashDATE=$(date +"%a %b %e %H:%M")
# 获取当前日期和时间,并使用格式化字符串 "%a %b %e %H:%M" 赋值给变量 DATE
# %a: 星期几的缩写(例如:Mon、Tue)
# %b: 月份的缩写(例如:Jan、Feb)
# %e: 月份中的天数(仅用一个数字表示,如:7)
# %H: 小时(24小时制)
# %M: 分钟ABNORMAL_IP=$(lastb | grep "$DATE" | awk '{a[$3]++}END{for(key in a)if(a[key]>10)print key}')
# 使用 lastb 命令获取登录失败的记录,通过 grep 过滤出包含当前日期的行,然后使用 awk 命令统计每个 IP 地址出现的次数,如果次数大于 10,则将 IP 地址打印出来,赋值给变量 ABNORMAL_IPfor IP in $ABNORMAL_IP; do# 使用 for 循环遍历 ABNORMAL_IP 中的每个 IP 地址if [ $(iptables -vnL | grep -c "$IP") -eq 0 ]; then# 使用 iptables 命令查看当前防火墙规则,并使用 grep 过滤出包含指定 IP 地址的行,并使用 -c 参数统计匹配行的数量# 如果匹配行的数量等于 0,表示当前 IP 地址不在防火墙规则中iptables -I INPUT -s $IP -j DROP# 在 INPUT 链的开头插入一条规则,拒绝指定 IP 地址的所有输入流量fi
done
这段代码的功能是检测最近登录失败的记录(使用 lastb 命令),并统计每个 IP 地址的登录失败次数。如果登录失败次数超过设定阈值,就将对应 IP 地址加入防火墙规则,禁止其输入流量。
代码的功能:
- 使用 date 命令获取当前日期和时间,并使用格式化字符串 “%a %b %e %H:%M” 格式化成星期几、月份、日期、小时和分钟的形式,赋值给变量 DATE。
- 使用 lastb 命令获取登录失败的记录。
- 使用 grep 过滤出包含当前日期的行。
- 使用 awk 命令统计每个 IP 地址出现的次数,如果次数大于 10,则将 IP 地址打印出来,赋值给变量 ABNORMAL_IP。
- 使用 for 循环遍历 ABNORMAL_IP 中的每个 IP 地址。
- 使用 iptables 命令查看当前防火墙规则,使用 grep 过滤出包含指定 IP 地址的行,并使用 -c 参数统计匹配行的数量。
- 如果匹配行的数量等于 0,表示当前 IP 地址不在防火墙规则中。
- 使用 iptables 命令在 INPUT 链的开头插入一条规则,拒绝指定 IP 地址的所有输入流量。
方法2:通过日志获取登录状态
#!/bin/bashDATE=$(date +"%b %d %H")
# 获取当前日期和时间,并使用格式化字符串 "%b %d %H" 格式化成月份、日期、小时的形式,赋值给变量 DATE
# %b: 月份的缩写(例如:Jan、Feb)
# %d: 月份中的天数(例如:07)
# %H: 小时(24小时制)ABNORMAL_IP="$(tail -n10000 /var/log/auth.log | grep "$DATE" | awk '/Failed/{a[$(NF-3)]++}END{for(key in a)if(a[key]>5)print key}')"
# 使用 tail 命令读取文件 /var/log/auth.log 的最后10000行日志
# 通过 grep 过滤出包含当前日期的行
# 使用 awk 命令找出包含 "Failed" 关键词的行,并以行中倒数第 3 个字段(即 IP 地址)为 key,统计出现次数
# 如果次数大于 5,则将 IP 地址打印出来,赋值给变量 ABNORMAL_IPfor IP in $ABNORMAL_IP; do# 使用 for 循环遍历 ABNORMAL_IP 中的每个 IP 地址if [ $(iptables -vnL | grep -c "$IP") -eq 0 ]; then# 使用 iptables 命令查看当前防火墙规则,并使用 grep 过滤出包含指定 IP 地址的行,并使用 -c 参数统计匹配行的数量# 如果匹配行的数量等于 0,表示当前 IP 地址不在防火墙规则中iptables -A INPUT -s $IP -j DROP# 在 INPUT 链的末尾追加一条规则,拒绝指定 IP 地址的所有输入流量echo "$(date +"%F %T") - iptables -A INPUT -s $IP -j DROP" >> ~/ssh-login-limit.log# 将执行的 iptables 命令和时间记录到 ~/ssh-login-limit.log 日志文件中fi
done
这段代码的功能是检测 /var/log/auth.log 文件中最近出现的登录失败记录,并统计每个 IP 地址的登录失败次数。如果登录失败次数超过设定阈值,就将对应 IP 地址加入防火墙规则,禁止其输入流量,并将执行的 iptables 命令和时间记录到 ~/ssh-login-limit.log 日志文件中。
代码的功能:
- 使用 date 命令获取当前日期和时间,并使用格式化字符串 “%b %d %H” 格式化成月份、日期、小时的形式,赋值给变量 DATE。
- 使用 tail 命令读取文件 /var/log/auth.log 的最后10000行日志。
- 使用 grep 过滤出包含当前日期的行。
- 使用 awk 命令找出包含 “Failed” 关键词的行,并以行中倒数第 3 个字段(即 IP 地址)为 key,统计出现次数。
- 如果次数大于 5,则将 IP 地址打印出来,赋值给变量 ABNORMAL_IP。
- 使用 for 循环遍历 ABNORMAL_IP 中的每个 IP 地址。
- 使用 iptables 命令查看当前防火墙规则,使用 grep 过滤出包含指定 IP 地址的行,并使用 -c 参数统计匹配行的数量。
- 如果匹配行的数量等于 0,表示当前 IP 地址不在防火墙规则中。
- 使用 iptables 命令在 INPUT 链的末尾追加一条规则,拒绝指定 IP 地址的所有输入流量。
- 使用 echo 命令将执行的 iptables 命令和时间记录到 ~/ssh-login-limit.log 日志文件中。
12、判断用户输入的是否为IP地址
方法1:
#!/bin/bash# 定义函数 check_ip,用于检查输入的 IP 地址是否合法
function check_ip(){local IP=$1VALID_CHECK=$(echo $IP | awk -F"." '{if($1<=255&&$2<=255&&$3<=255&&$4<=255) print "yes"; else print "no"}')# 将 IP 地址按照 "." 分隔成四个字段,并使用 awk 判断每个字段的取值范围是否合法(0-255)if echo $IP | grep -E "^[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$" > /dev/null; then# 使用正则表达式验证 IP 地址的格式,必须为 1-3 位数字 + "." + 1-3 位数字 + "." + 1-3 位数字 + "." + 1-3 位数字# 将匹配结果重定向到 /dev/null,即丢弃匹配结果if [[ "$VALID_CHECK" == "yes" ]]; thenecho "$IP available."return 0elseecho "$IP not available!"return 1fielseecho "Format error!"return 1fi
}while true; doread -p "Please enter IP: " ip# 提示用户输入 IP 地址,并将输入保存到变量 ip 中check_ip $ip# 调用函数 check_ip,传入用户输入的 IP 地址作为参数进行检查# 如果函数返回值为 0,表示 IP 地址合法,跳出循环# 如果函数返回值为 1,表示 IP 地址不合法,继续循环
done
这段代码实现了一个循环,提示用户输入 IP 地址,并通过调用函数 check_ip 对输入的 IP 地址进行检查,直到用户输入合法的 IP 地址为止。
代码的功能:
- 定义了一个函数 check_ip,用于检查输入的 IP 地址是否合法。
- 在函数内部,首先将 IP 地址按照 “.” 分隔成四个字段,并使用 awk 判断每个字段的取值范围是否合法(0-255)。
- 使用正则表达式验证 IP 地址的格式,必须为 1-3 位数字 + “.” + 1-3 位数字 + “.” + 1-3 位数字 + “.” + 1-3 位数字。
- 如果 IP 地址格式合法并且每个字段的取值也合法,输出 “IP available.”。
- 如果 IP 地址格式合法但有字段取值不合法,输出 “IP not available!”。
- 如果 IP 地址格式不合法,输出 “Format error!”。
- 在 while 循环中,使用 read 命令提示用户输入 IP 地址,并将输入保存到变量 ip 中。
- 调用 check_ip 函数,传入用户输入的 IP 地址作为参数进行检查。
- 如果函数返回值为 0,表示 IP 地址合法,跳出循环。
- 如果函数返回值为 1,表示 IP 地址不合法,继续循环。
方法2:
#!/bin/bash# 定义函数 check_ip,用于检查输入的 IP 地址是否合法
function check_ip(){IP=$1if [[ $IP =~ ^[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$ ]]; then# 使用正则表达式验证 IP 地址的格式,必须为 1-3 位数字 + "." + 1-3 位数字 + "." + 1-3 位数字 + "." + 1-3 位数字FIELD1=$(echo $IP|cut -d. -f1)FIELD2=$(echo $IP|cut -d. -f2)FIELD3=$(echo $IP|cut -d. -f3)FIELD4=$(echo $IP|cut -d. -f4)# 使用 cut 命令按照 "." 分割 IP 地址,并分别将每个字段赋值给对应的变量if [ $FIELD1 -le 255 -a $FIELD2 -le 255 -a $FIELD3 -le 255 -a $FIELD4 -le 255 ]; then# 判断每个字段的取值是否都小于等于 255echo "$IP available."# 输出 IP 地址合法elseecho "$IP not available!"# 输出 IP 地址不合法,至少有一个字段的取值大于 255fielseecho "Format error!"# 输出 IP 地址格式错误fi
}check_ip 192.168.1.1
# 调用 check_ip 函数,传入参数 192.168.1.1 进行检查check_ip 256.1.1.1
# 调用 check_ip 函数,传入参数 256.1.1.1 进行检查
这段代码定义了一个函数 check_ip,用于检查输入的 IP 地址是否合法,并对两个 IP 地址进行了检查。
代码的功能:
- 定义了一个函数 check_ip,用于检查输入的 IP 地址是否合法。
- 使用正则表达式验证 IP 地址的格式,必须为 1-3 位数字 + “.” + 1-3 位数字 + “.” + 1-3 位数字 + “.” + 1-3 位数字。
- 使用 cut 命令按照 “.” 分割 IP 地址,并分别将每个字段赋值给对应的变量。
- 判断每个字段的取值是否都小于等于 255。
- 如果 IP 地址合法且每个字段的取值都小于等于 255,输出 “IP available.”。
- 如果 IP 地址合法但至少有一个字段的取值大于 255,输出 “IP not available!”。
- 如果 IP 地址不合法,输出 “Format error!”。
在主程序中,调用 check_ip 函数进行两次检查:
- 第一次传入参数 192.168.1.1 进行检查,输出 “192.168.1.1 available.”,表示该 IP 地址合法。
- 第二次传入参数 256.1.1.1 进行检查,输出 “256.1.1.1 not available!”,表示该 IP 地址不合法,有一个字段的取值大于 255。
13、判断用户输入的是否为数字
方法1:
#!/bin/bash# 使用正则表达式判断参数是否为数字
if [[ $1 =~ ^[0-9]+$ ]]; thenecho "Is Number."# 如果参数是由一个或多个数字组成,输出 "Is Number."
elseecho "No Number."# 如果参数不是由一个或多个数字组成,输出 "No Number."
fi
段代码使用正则表达式判断参数是否为数字。
代码的功能:
- 使用正则表达式 ^ [0-9]+$ 判断参数是否由一个或多个数字组成。
- ^ 表示匹配字符串的起始位置。
- [0-9] 表示匹配数字字符的范围,即 0 到 9。
- +表示匹配前面的元素一次或多次。
- $表示匹配字符串的结束位置。
- 如果参数是由一个或多个数字组成,即满足正则表达式的匹配条件,输出 “Is Number.”。
- 如果参数不是由一个或多个数字组成,即不满足正则表达式的匹配条件,输出 “No Number.”。
方法2:
#!/bin/bash# 判断参数是否为一个数字
if [ $1 -gt 0 ] 2>/dev/null; thenecho "Is Number."# 如果参数大于 0,即参数是一个数字,输出 "Is Number."
elseecho "No Number."# 如果参数不是一个数字,输出 "No Number."
fi
这段代码使用条件判断语句判断参数是否为一个数字。
代码的功能:
- 使用条件判断语句 [ … ] 判断 $1 是否大于 0。
- $1 表示脚本或函数的第一个参数,用于接收命令行传入的参数。
- -gt 是一个数值比较操作符,表示大于。
- 2>/dev/null 表示将标准错误输出重定向到 /dev/null,即丢弃错误输出。
- 这是为了避免在参数不是一个数字时生成不必要的错误输出。
- 如果参数大于 0,即满足条件判断,输出 “Is Number.”。
- 如果参数不是一个数字,即不满足条件判断,输出 “No Number.”。
方法3:
#!/bin/bashecho $1 | awk '{print $0~/^[0-9]+$/?"Is Number.":"No Number."}'
# 使用 awk 命令打印判断结果,使用三元运算符进行条件判断# 解释:
# - `echo $1` 打印第一个参数
# - `awk` 命令用于处理文本数据
# - `{print $0~/^[0-9]+$/?"Is Number.":"No Number."}` 是 awk 的脚本部分,用于判断参数是否为一个数字并进行打印
# - `$0` 表示当前行的文本内容,即传入的参数
# - `~` 是 awk 的匹配操作符
# - `/^[0-9]+$/` 是正则表达式,用于匹配一个或多个数字的字符串
# - `?` 是三元运算符的条件部分,即判断参数是否匹配正则表达式
# - 如果参数匹配正则表达式,返回 "Is Number.",否则返回 "No Number."这段代码使用了 awk 命令和三元运算符来判断参数是否是一个数字,并进行相应的输出。
14、给定目录找出包含关键字的文件
#!/bin/bashDIR=$1 # 存储目录路径
KEY=$2 # 存储要搜索的关键词# 使用循环逐个遍历目录下的文件
for FILE in $(find $DIR -type f); do# 在文件中搜索关键词,并将输出重定向到 `/dev/null`,即丢弃匹配结果if grep $KEY $FILE &>/dev/null; thenecho "--> $FILE"# 如果搜索到关键词,输出文件路径fi
done
这段代码的功能是在给定的目录中搜索包含指定关键词的文件,并输出文件的路径。
代码的功能:
- DIR=$1,将第一个命令行参数赋值给变量 DIR,用于存储目录路径。
- KEY=$2,将第二个命令行参数赋值给变量 KEY,用于存储要搜索的关键词。
- for FILE in $(find $DIR -type f); do … done,使用循环逐个遍历目录下的文件。
- find $DIR -type f,使用 find 命令在目录 $DIR 中搜索所有类型为文件的项,并将结果以空格分隔输出。
- grep $KEY $FILE &>/dev/null,在文件 $FILE 中搜索关键词 $KEY,并将匹配结果重定向到 /dev/null,即丢弃匹配结果。
- grep 命令用于在文本中搜索指定的模式,这里用于搜索关键词。
- &> 是重定向的语法,将标准输出和标准错误输出都重定向到同一个地方,这里是 /dev/null,即丢弃匹配结果。
- if grep $KEY $FILE &>/dev/null; then … fi,如果搜索到关键词,则进入条件判断语句。
- echo “–> $FILE”,在终端输出带有 --> 前缀的文件路径,即输出搜索到的文件路径。
15、监控目录,将新创建的文件名追加到日志中
场景:记录目录下文件操作。
需先安装inotify-tools软件包。
-m #持续监听
-r #使用递归形式监控目录
-q #减少冗余信息,只打印出需要的信息
-e #指定要监控的事件,多个事件使用逗号隔开access #访问,读取文件modify #修改,文件内容被修改attrib #属性,文件元数据被修改move #移动,对文件进行移动操作 move_to move_fromcreate #创建,生成新文件open #打开,对文件进行打开操作close #关闭,对文件进行关闭操作 close_write close_nowritedelete #删除,文件被删除 delete_selfunmount #卸载文件或目录的文件系统
--timefmt #时间格式 y 年 m月 d日 H小时 M分钟
--format #监控事件发生后的信息输出格式%w #表示发生事件的目录%f #表示发生事件的文件%e #表示发生的事件%Xe #事件以“X”分隔%T #使用由 --timefmt定义的时间格式
--exclude #排除文件或目录时,大小写敏感# --exclude="(.*.swp)|(.*~$)|(.*.swx)"使用正则匹配排除文件
# inotifywait + rsync 同步,放在后台跑#!/bin/bash
MON_DIR=/tmp # 要监视的目录
# 使用 inotifywait 监视 $MON_DIR 目录中的文件创建事件,并输出文件名
inotifywait -mq --format %f -e create $MON_DIR | \
while read files; do# 对每个文件执行 rsync 命令echo rsync -avz $files admin@ip:/tmp
done
这段代码的功能是使用 inotifywait 监视指定目录中的文件创建事件,并在有文件创建时执行 rsync 命令。
代码的功能:
- MON_DIR=/tmp,将 /tmp 目录路径赋值给变量 MON_DIR,表示要监视的目录。
- inotifywait -mq --format %f -e create $MON_DIR,使用 inotifywait 命令监视目录 $MON_DIR 中的文件创建事件,并以简洁的格式输出文件名。
- while read files; do … done,使用 while 循环逐行读取输出的文件名。
- echo rsync -avz $files admin@ip:/tmp,对于每个读取的文件名,输出 rsync 命令。
- rsync 命令用于文件同步和传输。
- -avz 表示启用归档模式并压缩传输。
- $files 表示读取到的文件名,即待同步的文件。
- admin@ip:/tmp 表示目标地址,具体的 IP 地址和目录可以根据实际情况进行修改。
16、给用户提供多个网卡选择
场景:服务器多个网卡时,获取指定网卡,例如网卡流量
#!/bin/bashfunction local_nic() {local NUM ARRAY_LENGTHNUM=0for NIC_NAME in $(ls /sys/class/net | grep -vE "lo|docker0"); doNIC_IP=$(ifconfig $NIC_NAME | awk -F'[: ]+' '/inet addr/{print $4}')if [ -n "$NIC_IP" ]; thenNIC_IP_ARRAY[$NUM]="$NIC_NAME:$NIC_IP"# 将网卡名和对应IP放到数组let NUM++fidoneARRAY_LENGTH=${#NIC_IP_ARRAY[*]}# 获取数组长度if [ $ARRAY_LENGTH -eq 1 ]; then# 如果数组里面只有一条记录,说明只有一个网卡NIC=${NIC_IP_ARRAY[0]%:*}# 获取网卡名称(去除IP地址部分)return 0elif [ $ARRAY_LENGTH -eq 0 ]; then# 如果没有记录,说明没有可用的网卡echo "No available network card!"exit 1else# 如果有多条记录,则提醒输入选择for NIC in ${NIC_IP_ARRAY[*]}; doecho $NIC# 输出所有网卡名称和对应的IP地址donewhile true; doread -p "Please enter the name of the network card to use: " INPUT_NIC_NAME# 提示用户输入要使用的网卡名称COUNT=0for NIC in ${NIC_IP_ARRAY[*]}; doNIC_NAME=${NIC%:*}if [ $NIC_NAME == "$INPUT_NIC_NAME" ]; thenNIC=${NIC_IP_ARRAY[$COUNT]%:*}# 获取用户输入网卡名称对应的IP地址return 0elseCOUNT+=1fidoneecho "Not match! Please input again."# 如果输入不匹配,要求用户重新输入donefi
}local_nic
这段代码的功能是获取本地可用的网卡和对应的IP地址,并要求用户选择要使用的网卡。
代码的功能:
- function local_nic(),定义了一个名为 local_nic 的函数。
- NUM=0,设置一个变量 NUM 为 0,用于记录数组的索引。
- for NIC_NAME in $(ls /sys/class/net | grep -vE “lo|docker0”); do … done,循环遍历 /sys/class/net 目录下的网卡名称,排除 lo(本地回环接口)和 docker0(Docker 网络接口)。
- NIC_IP=$(ifconfig $NIC_NAME | awk -F’[: ]+’ ‘/inet addr/{print $4}’),获取每个网卡的 IP 地址,并将结果赋值给 NIC_IP。
- if [ -n “$NIC_IP” ]; then … fi,如果 NIC_IP 不为空(即获取到了 IP 地址),则执行条件判断的代码块。
- NIC_IP_ARRAY[$ NUM]=“$ NIC_NAME:$NIC_IP”,将网卡名称和对应的 IP 地址放入数组 NIC_IP_ARRAY 中,索引为 $NUM。
- let NUM++,将 NUM 的值加 1,用于下次循环时的数组索引。
- ARRAY_LENGTH=${#NIC_IP_ARRAY[*]},获取数组 NIC_IP_ARRAY 的长度。
- if [ $ARRAY_LENGTH -eq 1 ]; then … fi,如果数组长度为 1,说明只有一个可用网卡。
- NIC=${NIC_IP_ARRAY[0]%:*},将数组中的第一个元素赋值给变量 NIC,并去除末尾的 IP 地址部分。
- return 0,函数执行成功,返回 0。
- elif [ $ARRAY_LENGTH -eq 0 ]; then … fi,如果数组长度为 0,说明没有可用的网卡。
- echo “No available network card!”,输出提示信息 “No available network card!”。
- exit 1,正常退出脚本并返回状态码 1。
- else,如果有多条可用网卡,则要求用户选择要使用的网卡。
- for NIC in ${NIC_IP_ARRAY[*]}; do … done,循环遍历数组 NIC_IP_ARRAY 中的每个元素,即每个网卡名称和对应的 IP 地址。
- echo $NIC,输出每个网卡的名称和对应的 IP 地址。
- while true; do … done,使用无限循环,要求用户输入网卡名称并进行匹配。
- read -p "Please enter the name of the network card to use: " INPUT_NIC_NAME,提示用户输入要使用的网卡名称,将其保存在变量 INPUT_NIC_NAME 中。
- COUNT=0,设置一个变量 COUNT 为 0,用于记录数组的索引。
- for NIC in ${NIC_IP_ARRAY[*]}; do … done,循环遍历数组 NIC_IP_ARRAY 中的每个元素,即每个网卡名称和对应的 IP 地址。
- NIC_NAME=${NIC%: *},将数组元素中的 IP 地址部分截取掉,只保留网卡名称。
- if [ $ NIC_NAME == “$INPUT_NIC_NAME” ]; then … fi,如果网卡名称与用户输入的名称匹配。
- NIC=$ {NIC_IP_ARRAY[$COUNT]%: *},将数组元素中的 IP 地址部分截取掉,只保留网卡名称,赋值给变量 NIC。
- return 0,函数执行成功,返回 0。
- else,如果输入不匹配,输出提示信息并要求用户重新输入。
- done,结束内层循环。
- done,结束函数的整体逻辑。
- local_nic,调用 local_nic 函数。
17、查看网卡实时流量
适用于CentOS操作系统。
#!/bin/bash# Description: Only CentOS# traffic_unit_conv函数将流量转换为合适的单位(KB/s或MB/s)
traffic_unit_conv() {local traffic=$1if [ $traffic -gt 1024000 ]; thenprintf "%.1f%s" "$(($traffic/1024/1024))" "MB/s"# 如果流量大于1024000(1024KB),将流量转换为MB/s并保留1位小数elif [ $traffic -lt 1024000 ]; thenprintf "%.1f%s" "$(($traffic/1024))" "KB/s"# 如果流量小于1024000(1024KB),将流量转换为KB/s并保留1位小数fi
}NIC=$1 # 获取用户传入的参数作为要监测的网卡名称echo -e " In ------ Out"
# 打印标题 "In ------ Out"while true; do# 进入无限循环,监测流量变化OLD_IN=$(awk -F'[: ]+' '$0~"'$NIC'"{print $3}' /proc/net/dev)# 获取旧的接收流量(使用awk命令从/proc/net/dev中提取)OLD_OUT=$(awk -F'[: ]+' '$0~"'$NIC'"{print $11}' /proc/net/dev)# 获取旧的发送流量(使用awk命令从/proc/net/dev中提取)sleep 1# 等待1秒,以便获取新的流量数据NEW_IN=$(awk -F'[: ]+' '$0~"'$NIC'"{print $3}' /proc/net/dev)# 获取新的接收流量NEW_OUT=$(awk -F'[: ]+' '$0~"'$NIC'"{print $11}' /proc/net/dev)# 获取新的发送流量IN=$(($NEW_IN-$OLD_IN))# 计算接收的流量差值OUT=$(($NEW_OUT-$OLD_OUT))# 计算发送的流量差值echo "$(traffic_unit_conv $IN) $(traffic_unit_conv $OUT)"# 调用traffic_unit_conv函数将流量差值转换为合适的单位并打印sleep 1# 等待1秒,以便下一次获取流量数据
done
# 结束循环
这段代码的功能是监测指定网卡的接收和发送流量,并每秒打印一次流量值。
代码的功能:
- #Description: Only CentOS6,描述脚本的作用,限定适用于 CentOS 系统。
- traffic_unit_conv(),定义了一个名为 traffic_unit_conv 的函数,用于将流量转换为合适的单位(KB/s或MB/s)。
- local traffic=$1,将传入的第一个参数赋值给变量 traffic,表示要转换的流量值。
if [ $traffic -gt 1024000 ]; then … fi,如果流量值大于 1024000(1024KB),执行条件判断的代码块。 - printf “%.1f%s” “$ (($traffic/1024/1024))” “MB/s”,将流量值除以1024再除以1024,并保留1位小数,表示为 MB/s。
- elif [ $ traffic -lt 1024000 ]; then … fi,如果流量值小于 1024000(1024KB),执行条件判断的代码块。
- printf “%.1f%s” “$ (($ traffic/1024))” “KB/s”,将流量值除以1024,保留1位小数,表示为 KB/s。
- NIC=$ 1,将传入的第一个参数赋值给变量 NIC,表示要监测的网卡名称。
- echo -e " In ------ Out",打印标题 “In ------ Out”,使用 -e 选项表示支持特殊字符的解释。
- while true; do … done,进入无限循环,用于持续监测流量变化。
- OLD_IN=$ (awk -F’[: ]+’ ‘$ 0~"’$ NIC’"{print $ 3}’ /proc/net/dev),使用 awk 命令获取当前网卡的旧的接收流量值。
- OLD_OUT=$ (awk -F’[: ]+’ ‘$ 0~"’$ NIC’"{print $ 11}’ /proc/net/dev),使用 awk 命令获取当前网卡的旧的发送流量值。
- sleep 1,等待1秒,以便获取新的流量数据。
- NEW_IN=$ (awk -F’[: ]+’ ‘$ 0~"’$ NIC’"{print $ 3}’ /proc/net/dev),使用 awk 命令获取当前网卡的新的接收流量值。
- NEW_OUT=$ (awk -F’[: ]+’ ‘$ 0~"’$NIC’"{print $11}’ /proc/net/dev),使用 awk 命令获取当前网卡的新的发送流量值。
- IN=$ (($ NEW_IN-$ OLD_IN)),计算接收的流量差值。
- OUT=$ (($ NEW_OUT-$ OLD_OUT)),计算发送的流量差值。
- echo “$(traffic_unit_conv $IN) $(traffic_unit_conv $OUT)”,调用 traffic_unit_conv 函数将流量差值转换为合适的单位,并打印接收和发送流量。
- sleep 1,等待1秒,以便下一次获取流量数据。
- done,结束内层循环。
使用:./traffic.sh eth0
18、MySQL数据库备份
#!/bin/bashDATE=$(date +%F_%H-%M-%S) # 获取当前日期和时间,用于备份文件名
HOST=192.168.1.120 # 数据库主机地址
DB=test # 数据库名称
USER=bak # 数据库用户名
PASS=123456 # 数据库密码
MAIL="zhangsan@example.com lisi@example.com" # 接收备份结果通知的邮件地址
BACKUP_DIR=/data/db_backup # 备份文件存储路径
SQL_FILE=${DB}_full_$DATE.sql # 生成的 SQL 备份文件名
BAK_FILE=${DB}_full_$DATE.zip # 生成的压缩备份文件名cd $BACKUP_DIR # 切换到备份文件存储路径# 使用 mysqldump 命令备份数据库,并将结果输出到 SQL 备份文件中
if mysqldump -h$HOST -u$USER -p$PASS --single-transaction --routines --triggers -B $DB > $SQL_FILE; then# 如果备份成功,则将 SQL 备份文件压缩为压缩备份文件,并删除原始 SQL 备份文件zip $BAK_FILE $SQL_FILE && rm -f $SQL_FILE# 如果压缩备份文件为空,则表示备份数据可能出错,发送邮件通知if [ ! -s $BAK_FILE ]; thenecho "$DATE 内容" | mail -s "主题" $MAILfi
else# 如果备份失败,发送邮件通知echo "$DATE 内容" | mail -s "主题" $MAIL
fi# 删除14天前的压缩备份文件
find $BACKUP_DIR -name '*.zip' -ctime +14 -exec rm {} \;这段代码的功能是备份指定数据库,并将备份文件压缩,最后删除过期的备份文件。
代码的功能:
- DATE=$ (date +%F_%H-%M-%S),使用 date 命令获取当前的日期和时间,并赋值给变量 DATE,用于生成备份文件名。
- HOST=192.168.1.120,设置数据库主机地址。
- DB=test,设置要备份的数据库名称。
- USER=bak,设置连接数据库所使用的用户名。
- PASS=123456,设置连接数据库所使用的密码。
- MAIL=“zhangsan@example.com lisi@example.com”,设置接收备份结果通知的邮件地址,多个邮件地址之间使用空格分隔。
- BACKUP_DIR=/data/db_backup,设置备份文件存储路径。
- SQL_FILE=$ {DB}full$ DATE.sql,生成 SQL 备份文件的文件名。
- BAK_FILE=$ {DB}full$ DATE.zip,生成的压缩备份文件名。
- cd $ BACKUP_DIR,切换到备份文件存储路径。
- if mysqldump -h$ HOST -u$ USER -p$ PASS --single-transaction --routines --triggers -B $ DB > $ SQL_FILE; then … fi,使用 mysqldump 命令备份指定数据库,并将结果输出到 SQL 备份文件中。如果备份成功,则执行条件判断的代码块。
- zip $ BAK_FILE $ SQL_FILE && rm -f $ SQL_FILE,将 SQL 备份文件压缩为压缩备份文件,并删除原始 SQL 备份文件。
- if [ ! -s $ BAK_FILE ]; then … fi,如果压缩备份文件为空(没有内容),执行条件判断的代码块。
- echo “$DATE 内容” | mail -s “主题” $MAIL,使用 mail 命令发送邮件通知,邮件主题为 “主题”,邮件内容包含当前的日期和时间。
- else … fi,如果备份失败,执行条件判断的代码块。
- find $BACKUP_DIR -name ‘*.zip’ -ctime +14 -exec rm {} ;,使用 find 命令查找指定路径下14天前的所有压缩备份文件,并删除它们。
19、Nginx服务管理脚本
场景:使用源码包安装Nginx不含带服务管理脚本,也就是不能使用"service nginx start"或"/etc/init.d/nginx start",所以写了以下的服务管理脚本。
#!/bin/bash
# Description: Only support RedHat system. /etc/init.d/functionsWORD_DIR=/usr/local/nginx # Nginx安装目录
DAEMON=$WORD_DIR/sbin/nginx # Nginx可执行文件路径
CONF=$WORD_DIR/conf/nginx.conf # Nginx配置文件路径
NAME=nginx # 进程名称
PID=$(awk -F'[; ]+' '/^[^#]/{if($0~/pid;/)print $2}' $CONF) # 获取配置文件中定义的PID文件路径# 如果配置文件中未定义PID文件路径,设置默认的PID文件路径
if [ -z "$PID" ]; thenPID=$WORD_DIR/logs/nginx.pid
elsePID=$WORD_DIR/$PID
fistop() {$DAEMON -s stop # 发送信号停止Nginx进程sleep 1# 判断PID文件是否存在,根据结果输出不同的操作提示[ ! -f $PID ] && action "* Stopping $NAME" /bin/true || action "* Stopping $NAME" /bin/false
}start() {$DAEMON # 启动Nginx进程sleep 1# 判断PID文件是否存在,根据结果输出不同的操作提示[ -f $PID ] && action "* Starting $NAME" /bin/true || action "* Starting $NAME" /bin/false
}reload() {$DAEMON -s reload # 发送信号重新加载Nginx配置
}test_config() {$DAEMON -t # 检查Nginx配置文件语法是否正确
}case "$1" instart)# 如果PID文件不存在,启动Nginx进程;否则输出进程正在运行的提示if [ ! -f $PID ]; thenstartelseecho "$NAME is running..."exit 0fi;;stop)# 如果PID文件存在,停止Nginx进程;否则输出进程未运行的提示if [ -f $PID ]; thenstopelseecho "$NAME not running!"exit 0fi;;restart)# 如果PID文件不存在,输出进程未运行的提示并启动Nginx进程;否则先停止再启动if [ ! -f $PID ]; thenecho "$NAME not running!" startelsestopstartfi;;reload)# 发送信号重新加载Nginx配置reload;;testconfig)# 检查Nginx配置文件语法是否正确test_config;;status)# 根据PID文件是否存在输出不同的状态提示[ -f $PID ] && echo "$NAME is running..." || echo "$NAME not running!";;*)# 输出脚本的使用方法,并退出脚本(返回退出码3)echo "Usage: $0 {start|stop|restart|reload|testconfig|status}"exit 3;;
esac
这段脚本实现了对 Nginx 服务的启停、重启、重新加载配置文件以及检查配置文件语法的功能。
代码的功能:
- . /etc/init.d/functions,引入 /etc/init.d/functions 文件,该文件包含用于输出提示信息的函数。
- WORD_DIR=/usr/local/nginx,设置 Nginx 的安装目录。
- DAEMON=$WORD_DIR/sbin/nginx,设置 Nginx 可执行文件的路径。
- CONF=$ WORD_DIR/conf/nginx.conf,设置 Nginx 的配置文件路径。
- NAME=nginx,设置进程名称为 “nginx”。
- PID=$ (awk -F’[; ]+’ ‘/^ [ ^#]/{if($ 0~/pid;/)print $ 2}’ $ CONF),使用 awk 命令从配置文件中提取 PID 文件路径。
- if [ -z “$ PID” ]; then … else … fi,如果 PID 文件路径为空,则设置默认的 PID 文件路径为 $ WORD_DIR/logs/nginx.pid。
- stop() { … },定义一个函数 stop,用于停止 Nginx 进程。
- start() { … },定义一个函数 start,用于启动 Nginx 进程。
- reload() { … },定义一个函数 reload,用于重新加载 Nginx 配置文件。
- test_config() { … },定义一个函数 test_config,用于检查 Nginx 配置文件的语法是否正确。
- case “$1” in … esac,根据脚本传入的参数执行不同的操作。
- action “* Stopping $NAME” /bin/true,输出停止进程的操作提示,后面的 /bin/true 表示操作成功。
- action “* Starting $NAME” /bin/true,输出启动进程的操作提示,后面的 /bin/true 表示操作成功。
- action “* Stopping $NAME” /bin/false,输出停止进程的操作提示,后面的 /bin/false 表示操作失败。
- action “* Starting $NAME” /bin/false,输出启动进程的操作提示,后面的 /bin/false 表示操作失败。
- if [ ! -f $PID ]; then … else … fi,如果 PID 文件不存在,则启动 Nginx 进程;否则输出进程正在运行的提示。
- if [ -f $PID ]; then … else … fi,如果 PID 文件存在,则停止 Nginx 进程;否则输出进程未运行的提示。
- if [ ! -f $PID ]; then … else … fi,如果 PID 文件不存在,则输出进程未运行的提示并启动 Nginx - ;否则先停止再启动。
- reload,发送信号重新加载 Nginx 配置。
- test_config,检查 Nginx 配置文件的语法是否正确。
- [ -f $ PID ] && echo “$ NAME is running…” || echo “$NAME not running!”,根据 PID 文件是否存在输出不同的状态提示。
- echo “Usage: $0 {start|stop|restart|reload|testconfig|status}”,输出脚本的使用方法。
- exit 3,退出脚本,返回退出码 3。
20、用户根据菜单选择要连接的Linux主机
Linux主机SSH连接信息:
# cat host.txt
Web 192.168.1.10 root 22
DB 192.168.1.11 root 22
内容格式:主机名 IP User Port
#!/bin/bashPS3="Please input number: " # 设置 select 命令的提示信息HOST_FILE=host.txt # 存储主机连接信息的文件路径# 无限循环,用于不断提供主机选择菜单
while true; do# 使用 select 命令选择主机名(从 host.txt 文件中获取)select NAME in $(awk '{print $1}' $HOST_FILE) quit; do# 如果选择的主机名为 "quit",退出脚本[ ${NAME:=empty} == "quit" ] && exit 0# 根据选择的主机名从 host.txt 文件中获取对应的 IP、用户名和端口号IP=$(awk -v NAME=${NAME} '$1==NAME{print $2}' $HOST_FILE)USER=$(awk -v NAME=${NAME} '$1==NAME{print $3}' $HOST_FILE)PORT=$(awk -v NAME=${NAME} '$1==NAME{print $4}' $HOST_FILE)if [ $IP ]; thenecho "Name: $NAME, IP: $IP"# 使用 ssh 命令连接远程主机,使用密钥免交互登录ssh -o StrictHostKeyChecking=no -p $PORT -i id_rsa $USER@$IPbreakelseecho "Input error, Please enter again!"breakfidone
done
这段脚本实现了根据主机名从 host.txt 文件中获取主机的连接信息,并使用 SSH 命令连接远程主机的功能。
代码的功能:
- PS3="Please input number: ",设置 select 命令的提示信息,用于用户选择主机时显示。
- HOST_FILE=host.txt,设置存储主机连接信息的文件路径为 host.txt。
- while true; do … done,无限循环,用于不断提供主机选择菜单。
- select NAME in $(awk ‘{print $1}’ $HOST_FILE) quit; do … done,使用 select 命令选择主机名(从 host.txt 文件中获取),并加上 quit 选项用于退出脚本。
- [ ${NAME:=empty} == “quit” ] && exit 0,如果选择的主机名为 quit,则退出脚本。
- IP=$ (awk -v NAME=${NAME} ‘$1==NAME{print $2}’ $HOST_FILE),根据选择的主机名从 host.txt 文件中获取对应的 IP 地址。
- USER=$ (awk -v NAME=${NAME} ‘$1==NAME{print $3}’ $HOST_FILE),根据选择的主机名从 - host.txt 文件中获取对应的用户名。
- PORT=$ (awk -v NAME=${NAME} ‘$1==NAME{print $4}’ $HOST_FILE),根据选择的主机名从 host.txt 文件中获取对应的端口号。
- if [ $IP ]; then … else … fi,如果 IP 地址存在,则输出主机名和 IP 地址,并使用 SSH 命令连接远程主机;否则输出输入错误的提示信息。
- echo “Name: $NAME, IP: $IP”,输出选择的主机名和对应的 IP 地址。
- ssh -o StrictHostKeyChecking=no -p $ PORT -i id_rsa $ USER@$IP,使用 SSH 命令连接远程主机,其中使用 -o StrictHostKeyChecking=no 参数禁止严格的主机密钥检查,-p $PORT 指定连接的端口号,-i id_rsa 指定使用密钥文件进行免交互登录。
- break,结束当前循环,回到外层的无限循环,等待下一次主机选择。
- echo “Input error, Please enter again!”,输出输入错误的提示信息。
- exit 0,退出脚本,返回退出码 0。
21、从FTP服务器下载文件
#!/bin/bash# 检查参数数量是否为1
if [ $# -ne 1 ]; thenecho "Usage: $0 filename"
fi# 获取指定文件的目录和文件名
dir=$(dirname $1)
file=$(basename $1)# 使用 ftp 命令连接 FTP 服务器并执行操作
ftp -n -v << EOF # -n 自动登录
open 192.168.1.10 # ftp服务器
user admin password # 使用指定的用户名和密码登录
binary # 设置ftp传输模式为二进制,避免MD5值不同或.tar.gz压缩包格式错误
cd $dir # 切换到指定的目录
get "$file" # 下载指定的文件
EOF
这段脚本实现了通过 FTP 下载指定文件的功能。
代码的功能:
- if [ $# -ne 1 ]; then … fi,检查传入的参数数量是否为1,如果不是1个参数,输出用法提示信息。
- echo “Usage: $0 filename”,输出用法提示信息,告知用户正确的参数输入格式。
- dir=$(dirname $1),获取指定文件的目录路径。
- file=$(basename $1),获取指定文件的文件名。
- ftp -n -v << EOF,使用 ftp 命令连接 FTP 服务器并执行操作,-n 参数表示在连接后不执行任何自动登录操作,-v 参数表示输出详细的执行过程信息。
- open 192.168.1.10,使用 ftp 命令连接到指定的 FTP 服务器,其中 192.168.1.10 是 FTP 服务器的 IP 地址。
- user admin password,使用指定的用户名 admin 和密码 password 进行登录。
- binary,设置 FTP 传输模式为二进制,以确保传输的文件保持原样,避免出现 MD5 值不同或 .tar.gz 压缩包格式错误的问题。
- cd $dir,切换到指定的目录。
- get “$ file”,下载指定的文件,其中 $ 用于获取变量的值,“$file” 使用双引号包围变量值,以处理文件名中可能包含的特殊字符。
- EOF,表示结束 ftp 命令的输入。
22、连续输入5个100以内的数字,统计和、最小和最大
#!/bin/bash# 初始化计数器、和、最小值、最大值
COUNT=1
SUM=0
MIN=0
MAX=100# 循环5次,读取用户输入的整数并进行相关操作
while [ $COUNT -le 5 ]; doread -p "请输入1-10个整数:" INT # 提示用户输入1-10个整数if [[ ! $INT =~ ^[0-9]+$ ]]; then # 判断输入是否为整数echo "输入必须是整数!"exit 1 # 若输入不是整数,退出脚本,返回退出码 1elif [[ $INT -gt 100 ]]; then # 判断输入是否小于等于100echo "输入必须是100以内!"exit 1 # 若输入大于100,退出脚本,返回退出码 1fiSUM=$(($SUM+$INT)) # 累加输入的整数到和变量[ $MIN -lt $INT ] && MIN=$INT # 更新最小值变量[ $MAX -gt $INT ] && MAX=$INT # 更新最大值变量let COUNT++ # 计数器自增
done# 输出计算结果
echo "SUM: $SUM" # 输出和
echo "MIN: $MIN" # 输出最小值
echo "MAX: $MAX" # 输出最大值
这段脚本实现了读取用户输入的整数,计算输入的整数的和、最小值和最大值,并输出结果。
代码的功能:
- COUNT=1,初始化计数器变量为1。
- SUM=0,初始化和变量为0。
- MIN=0,初始化最小值变量为0。
- MAX=100,初始化最大值变量为100。
- while [ $COUNT -le 5 ]; do … done,循环5次,用于接收和处理用户输入的整数。
- read -p “请输入1-10个整数:” INT,提示用户输入1-10个整数,并将输入的值保存到变量 INT。
- if [[ ! $ INT =~ ^ [0-9]+$ ]]; then … fi,如果输入的值不是整数,则提示错误并退出脚本。
- echo “输入必须是整数!”,输出提示信息,告知用户输入必须是整数。
- exit 1,退出脚本,返回退出码 1。
- elif [[ $INT -gt 100 ]]; then … fi,如果输入的值大于100,则提示错误并退出脚本。
- echo “输入必须是100以内!”,输出提示信息,告知用户输入必须是100以内的整数。
- SUM=$ (($ SUM+$INT)),将输入的整数累加到和变量。
- [ $ MIN -lt $ INT ] && MIN=$INT,更新最小值变量,如果新输入的整数大于最小值,则更新最小值。
- [ $ MAX -gt $ INT ] && MAX=$INT,更新最大值变量,如果新输入的整数小于最大值,则更新最大值。
- let COUNT++,将计数器自增。
- echo “SUM: $SUM”,输出计算的和。
- echo “MIN: $MIN”,输出计算的最小值。
- echo “MAX: $MAX”,输出计算的最大值。
23、将结果分别赋值给变量
应用场景:希望将执行结果或者位置参数赋值给变量,以便后续使用。
方法1:
for i in $(echo "4 5 6"); do # 循环遍历 "4 5 6"eval a$i=$i # 为变量 a4、a5、a6 赋值,变量名由 $i 决定,值为 $i 的值
done
echo $a4 $a5 $a6 # 输出变量 a4、a5、a6 的值# 这段代码的目的是创建变量 a4、a5、a6,并将其赋值为 4、5、6
这段代码使用 for 循环遍历列表 “4 5 6”,对于每个列表中的元素,使用 eval 命令动态创建变量 a4、a5、a6,并赋值为相应的值。最后通过 echo 命令输出变量 a4、a5、a6 的值。
方法2:将位置参数192.168.1.1{1,2}拆分为到每个变量
num=0 # 初始化计数器变量为0
for i in $(eval echo $*); do # 循环遍历命令行参数,并使用 eval 命令展开参数中的花括号拓展表达式let num+=1 # 计数器自增eval node${num}="$i" # 动态创建变量 node1、node2、node3,并赋值为相应的参数值
done
echo $node1 $node2 $node3 # 输出变量 node1、node2、node3 的值# 示例运行命令:bash a.sh 192.168.1.1{1,2}
# 输出:192.168.1.11 192.168.1.12# 这段代码的目的是根据命令行参数动态创建变量,并赋予相应的值
这段代码通过 for 循环遍历命令行参数(使用 $* 获取所有参数),使用 eval 命令将参数中的花括号拓展表达式展开(如 192.168.1.1{1,2} 拓展为 192.168.1.11 192.168.1.12),然后在循环中,计数器 num 自增,然后使用 eval 命令动态创建变量 node1、node2、node3,并赋值为相应的参数值。最后通过 echo 命令输出变量 node1、node2、node3 的值。
方法3:
arr=(4 5 6) # 创建包含元素 4、5、6 的数组 arrINDEX1=$(echo ${arr[0]}) # 获取数组 arr 中的第一个元素,并将其赋值给变量 INDEX1
INDEX2=$(echo ${arr[1]}) # 获取数组 arr 中的第二个元素,并将其赋值给变量 INDEX2
INDEX3=$(echo ${arr[2]}) # 获取数组 arr 中的第三个元素,并将其赋值给变量 INDEX3# 这段代码的目的是从数组 arr 中提取元素,并赋值给相应的变量
这段代码创建了一个名为 arr 的数组,其中包含了元素 4、5、6。
然后,使用 ${arr[index]} 的形式从数组 arr 中提取特定索引位置的元素,并使用 echo 命令将其输出。通过将提取的元素赋值给相应的变量(INDEX1、INDEX2、INDEX3),来存储和使用这些值。
- INDEX1=$(echo ${arr[0]}),将数组 arr 的第一个元素(索引为 0)赋值给变量 INDEX1。
- INDEX2=$(echo ${arr[1]}),将数组 arr 的第二个元素(索引为 1)赋值给变量 INDEX2。
- INDEX3=$(echo ${arr[2]}),将数组 arr 的第三个元素(索引为 2)赋值给变量 INDEX3。
通过这种方式,变量 INDEX1、INDEX2 和 INDEX3 将分别包含数组 arr 中对应索引位置的值。
24、批量修改文件名
示例:
# touch article_{1..3}.html
# ls
article_1.html article_2.html article_3.html
目的:把article改为bbs
方法1:
for file in $(ls *html); do # 循环遍历当前目录下以 html 结尾的文件mv $file bbs_${file#*_} # 将文件名修改为 bbs_ 后加上原文件名中第一个下划线后的部分# 同等效果的替代方法1:# mv $file $(echo $file |sed -r 's/.*(_.*)/bbs\1/')# 同等效果的替代方法2:# mv $file $(echo $file |echo bbs_$(cut -d_ -f2)
done
这段代码的作用是遍历当前目录下以 .html 结尾的文件,并将文件名进行修改。
- for file in $(ls *html),使用 *html 通配符来查找当前目录下以 .html 结尾的文件,并逐个进行处理。
- mv $ file bbs_$ {file#},使用 mv 命令将文件名修改为 bbs 后再加上原文件名第一个下划线后的部分。${file#_} 是一种字符串截取的方式,表示获取变量 file 中第一个下划线后的部分。
-
替代方法1:mv $file $(echo $file |sed -r 's/*(_.* )/bbs\1/'),使用 sed 命令进行正则表达式的替换操作,将文件名中的第一个下划线及其后的部分替换为 bbs_ 加上对应的部分。 -
替代方法2:mv $ file $ (echo $ file |echo bbs_$(cut -d_ -f2),使用 cut 命令提取文件名中第一个下划线后的部分,然后将其拼接为 bbs_ 加上对应的部分。
这段代码的目的是对当前目录下以 .html 结尾的文件进行批量重命名,将文件名修改为以 bbs_ 开头并保留原文件名中第一个下划线后的部分。
方法2:
for file in $(find . -maxdepth 1 -name "*html"); do # 使用 find 命令查找当前目录下的以 html 结尾的文件mv $file bbs_${file#*_} # 将文件名修改为 bbs_ 后加上原文件名中第一个下划线后的部分
done
这段代码的作用是在当前目录下查找以 .html 结尾的文件,并将这些文件的文件名进行修改。
- . -maxdepth 1 -name “*html”,使用 find 命令在当前目录下查找满足以下条件的文件:
- -maxdepth 1:仅在当前目录进行查找,不递归查找子目录。
- -name “*html”:文件名以 .html 结尾。
- for file in $(find . -maxdepth 1 -name “*html”),将查找到的文件列表循环处理。
- mv $ file bbs_$ {file#},使用 mv 命令将文件名修改为 bbs 后再加上原文件名中第一个下划线后的部分。${file#_} 是一种字符串截取的方式,表示获取变量 file 中第一个下划线后的部分。
- 例如文件名为 prefix_filename.html,那么 ${file#*_} 的值就是 filename.html,然后将文件名修改为 bbs_filename.html。
这段代码的目的是在当前目录下查找以 .html 结尾的文件,并将这些文件的文件名批量修改为以 bbs_ 开头并保留原文件名中第一个下划线后的部分。
方法3:
# rename article bbs *.html
这段代码使用了 rename 命令,对当前目录下以 .html 结尾的文件进行批量重命名。
- rename 命令用于批量重命名文件名中的指定部分。
- article 是要被替换的部分,bbs 是替换后的部分。
- *.html 是要进行重命名操作的文件匹配模式,表示当前目录下所有以 .html 结尾的文件。
这段代码的目的是将当前目录下以 .html 结尾的文件名中的 article 替换为 bbs,实现文件名的批量重命名操作。
25、统计当前目录中以.html结尾的文件总大
方法1:
# find . -name "*.html" -exec du -k {} \; |awk '{sum+=$1}END{print sum}'
这段代码使用了find命令、du命令和awk命令来计算当前目录下以.html结尾的文件的总大小(以KB为单位)。
- find . -name “*.html”:使用find命令在当前目录及其子目录下查找文件名以.html结尾的文件。
- -exec du -k {} ;:对于每个找到的文件,使用du -k命令以KB为单位显示文件大小。通过-exec选项和{}占位符将找到的文件传递给du命令进行处理。
- |:使用管道(pipe)将du命令的输出传递给下一个命令。
- awk ‘{sum+=$1}END{print sum}’:使用awk命令对du命令的输出进行处理,计算文件大小的总和。awk命令中的代码逐行读取du命令的输出,并将每一行的第一个字段(文件大小)累加到变量sum中。最后,在处理完所有行后,在END部分使用print sum打印出总和。
这段代码的目的是计算当前目录下以.html结尾的文件的总大小(以KB为单位)。
方法2:
for size in $(ls -l *.html | awk '{print $5}'); do # 获取当前目录下以 .html 结尾的文件的大小列表sum=$(($sum+$size)) # 对每个文件的大小进行累加
done
echo $sum # 打印所有文件大小的总和
这段代码的作用是计算当前目录下以 .html 结尾的文件的总大小(以字节为单位)。
- ls -l *.html | awk ‘{print $5}’:使用 ls -l 命令获取当前目录下以 .html 结尾的文件的详细列表,并通过管道将结果传递给 awk 命令。awk ‘{print $5}’ 表示只输出每行的第五个字段(文件大小)。
- for size in $(ls -l *.html | awk ‘{print $5}’):将获取到的文件大小列表逐个赋值给变量 size 进行循环处理。
- sum=$ (($ sum+$ size)):将每个文件的大小累加到变量 sum 中。$ sum+$ size 表示将变量 sum 和 size 的值相加。$((…)) 是一种算术表达式的写法。
- echo $sum:打印所有文件大小的总和。
这段代码的目的是计算当前目录下以 .html 结尾的文件的总大小(以字节为单位),将每个文件的大小累加到变量 sum 中,并最后打印出总和。
26、扫描主机端口状态
#!/bin/bash
HOST=$1 # 获取第一个命令行参数,作为主机名或 IP 地址
PORT="22 25 80 8080" # 定义要检测的端口列表for PORT in $PORT; do # 遍历端口列表if echo &>/dev/null > /dev/tcp/$HOST/$PORT; then # 使用 /dev/tcp 文件系统,尝试与指定的主机和端口建立 TCP 连接echo "$PORT open" # 如果 TCP 连接成功,则输出端口为开放状态elseecho "$PORT close" # 如果 TCP 连接失败,则输出端口为关闭状态fi
done
这段代码的作用是检测指定主机的一些常见端口是否开放。
- #!/bin/bash:指定该脚本以 Bash 解释器运行。
- HOST=$1:将第一个命令行参数赋值给变量 HOST,表示要检测的主机名或 IP 地址。
- PORT=“22 25 80 8080”:定义要检测的端口列表,包括 22、25、80 和 8080。
- for PORT in $PORT; do:遍历端口列表。
- if echo &>/dev/null > /dev/tcp/$ HOST/$PORT; then:使用 /dev/tcp 文件系统,尝试与指定的主机和端口建立 TCP 连接。通过重定向输入输出到 /dev/null 来实现静默连接的效果。
- echo “$PORT open”:如果 TCP 连接成功,则输出该端口为开放状态。
- echo “$PORT close”:如果 TCP 连接失败,则输出该端口为关闭状态。
这段代码的目的是遍历指定主机的端口列表,并尝试与每个端口建立 TCP 连接,通过输出端口状态来告知该端口是否开放。
27、Expect实现SSH免交互执行命令
Expect是一个自动交互式应用程序的工具,如telnet,ftp,passwd等。
需先安装expect软件包。
方法1:EOF标准输出作为expect标准输入
#!/bin/bash
USER=root # 设置要登录的远程主机的用户名
PASS=123.com # 设置远程主机用户的登录密码
IP=192.168.1.120 # 设置远程主机的 IP 地址expect << EOF # 使用 expect 来编写自动化交互脚本
set timeout 30 # 设置超时时间为 30 秒spawn ssh $USER@$IP # 使用 spawn 命令启动 ssh 进行远程登录连接expect {"(yes/no)" {send "yes\r"; exp_continue} # 如果出现 "(yes/no)" 提示,自动发送 "yes" 并继续等待"password:" {send "$PASS\r"} # 如果出现 "password:" 提示,自动发送密码进行登录
}expect "$USER@*" {send "$1\r"} # 在成功登录后,根据需要执行的操作,这里发送了一个 $1 变量
expect "$USER@*" {send "exit\r"} # 执行完操作后,发送 "exit" 命令退出登录
expect eof # 等待所有交互完成后,终止 expect 脚本
EOF
这段代码使用了 expect 工具编写了一个自动化交互脚本,用于实现通过 SSH 远程登录到指定主机,并执行一些操作。
- USER=root:将要登录的远程主机的用户名设置为 root。
- PASS=123.com:将远程主机用户的登录密码设置为 123.com。
- IP=192.168.1.120:设置远程主机的 IP 地址为 192.168.1.120。
在 expect 命令的使用过程中:
- set timeout 30:设置超时时间为 30 秒,用于控制登录的等待时间。
- spawn ssh U S E R @ USER@ USER@IP:使用 spawn 命令启动 ssh 进程进行远程登录连接。
- expect 块中使用模式匹配来等待特定的交互信息,并根据不同的提示进行相应的操作。
- send 命令用于向程序发送输入信息,完成自动化交互。
- $1 是一个变量,它被发送给远程主机以执行特定操作。
- expect eof:等待所有交互完成后,终止 expect 脚本。
这段代码的目的是使用 expect 实现自动化登录远程主机,并在登录后执行指定的操作。
方法2:
#!/bin/bash
USER=root # 设置要登录的远程主机的用户名
PASS=123.com # 设置远程主机的登录密码
IP=192.168.1.120 # 设置远程主机的 IP 地址expect -c " # 使用 expect 命令编写内联脚本spawn ssh $USER@$IP # 使用 spawn 命令启动 ssh 进程进行远程登录连接expect {\"(yes/no)\" {send \"yes\r\"; exp_continue} # 如果出现 "(yes/no)" 提示,自动发送 "yes" 并继续等待\"password:\" {send \"$PASS\r\"; exp_continue} # 如果出现 "password:" 提示,自动发送密码并继续等待\"$USER@*\" {send \"df -h\r exit\r\"; exp_continue} # 如果成功登录,发送 "df -h" 命令查看磁盘使用情况,并发送 "exit" 命令退出登录}"
这段代码使用了 expect 工具以内联脚本的方式编写,实现了通过 SSH 登录到指定主机,并执行特定命令的自动化操作。
- USER=root:将要登录的远程主机的用户名设置为 root。
- PASS=123.com:将远程主机的登录密码设置为 123.com。
- IP=192.168.1.120:设置远程主机的 IP 地址为 192.168.1.120。
在 expect -c 命令中:
- spawn ssh $ USER@$IP:使用 spawn 命令启动 ssh 进程进行远程登录连接。
- expect 块中使用模式匹配来等待特定的交互信息,并根据不同的提示进行相应的操作。
- send 命令用于向程序发送输入信息,完成自动化交互。
- “(yes/no)” {send “yes\r”; exp_continue}:如果出现 “(yes/no)” 提示,自动发送 “yes” 并继续等待。
- “password:” {send “$PASS\r”; exp_continue}:如果出现 “password:” 提示,自动发送密码并继续等待。
- “$USER@*” {send “df -h\r exit\r”; exp_continue}:如果成功登录,则发送 “df -h” 命令查看磁盘使用情况,并发送 “exit” 命令退出登录。
- exp_continue:使 expect 继续等待下一个匹配。
这段代码的目的是通过 expect 实现自动化登录远程主机,并在登录后执行特定命令,如查看磁盘使用情况,并最后退出登录。
28、批量修改服务器用户密码
Linux主机SSH连接信息:旧密码
# cat old_pass.txt
192.168.18.217 root 123456 22
192.168.18.218 root 123456 22
内容格式:IP User Password Port
SSH远程修改密码脚本:新密码随机生成
#!/bin/bash
OLD_INFO=old_pass.txt # 存储旧密码信息的文件路径
NEW_INFO=new_pass.txt # 存储新密码信息的文件路径for IP in $(awk '/^[^#]/{print $1}' $OLD_INFO); do # 使用 awk 命令遍历获取每行的 IP 地址USER=$(awk -v I=$IP 'I==$1{print $2}' $OLD_INFO) # 根据 IP 地址获取对应的用户名PASS=$(awk -v I=$IP 'I==$1{print $3}' $OLD_INFO) # 根据 IP 地址获取对应的密码PORT=$(awk -v I=$IP 'I==$1{print $4}' $OLD_INFO) # 根据 IP 地址获取对应的端口号NEW_PASS=$(mkpasswd -l 8) # 使用 mkpasswd 命令生成一个具有 8 个字符长度的随机密码echo "$IP $USER $NEW_PASS $PORT" >> $NEW_INFO # 将新的密码信息追加到新密码文件中expect -c "spawn ssh -p$PORT $USER@$IP # 使用 spawn 命令启动 ssh 进程进行远程登录连接set timeout 2 # 设置超时时间为 2 秒expect {\"(yes/no)\" {send \"yes\r\"; exp_continue} # 如果出现 "(yes/no)" 提示,自动发送 "yes" 并继续等待\"password:\" {send \"$PASS\r\"; exp_continue} # 如果出现 "password:" 提示,自动发送旧密码并继续等待\"$USER@*\" {send \"echo \'$NEW_PASS\' | passwd --stdin $USER\r exit\r\"; exp_continue} # 如果成功登录,发送命令将新密码设置为随机生成的新密码,并发送 "exit" 命令退出登录}"
done
生成新密码文件:
# cat new_pass.txt
192.168.18.217 root n8wX3mU% 22
192.168.18.218 root c87;ZnnL 22
29、打印九九乘法口诀
for ((i=1;i<=9;i++)); do # 外层循环,控制行数,从 1 到 9for ((j=1;j<=i;j++)); do # 内层循环,控制每行的乘法表达式,从 1 到当前行数result=$(($i*$j)) # 计算乘法结果echo -n "$j*$i=$result " # 打印乘法表达式和结果,不换行doneecho # 内层循环结束后换行
done
这段代码的作用是打印一个简单的乘法表,从 1 到 9,按行输出。
在外层循环中,i 控制当前行数,从 1 到 9 逐渐增加。
在内层循环中,j 控制每行的乘法表达式,从 1 到当前行数 逐渐增加。
在每次内层循环中,计算乘法结果 result 的值,并使用 echo -n 打印乘法表达式和结果,不换行。
内层循环结束后,使用 echo 单独打印一个换行符,换行后进入下一行的循环。
这段代码的输出结果是一个九九乘法表。
30、斐波那契数列
#!/bin/bashecho "请输入斐波那契数列的长度:"
read length # 获取用户输入的斐波那契数列长度# 初始化前两个斐波那契数
num1=0 # 第一个斐波那契数为 0
num2=1 # 第二个斐波那契数为 1# 输出前两个数
echo "斐波那契数列的前 $length 个数为:"
echo -n "$num1 $num2" # 输出第一个和第二个斐波那契数# 循环计算并输出斐波那契数列
for ((i=2;i<$length;i++))
dosum=$(($num1 + $num2)) # 计算下一个斐波那契数echo -n " $sum" # 输出计算得到的斐波那契数num1=$num2 # 更新第一个斐波那契数为当前的第二个斐波那契数num2=$sum # 更新第一个斐波那契数为当前的计算结果
doneecho "" # 输出换行符,使结果美观
这段代码的作用是根据用户输入的长度,生成并输出相应长度的斐波那契数列。
- echo “请输入斐波那契数列的长度:”:提示用户输入斐波那契数列的长度。
- read length:将用户输入的长度保存到变量 length 中。
通过循环计算斐波那契数列,并输出结果:
- num1 和 num2 分别用于保存当前计算的斐波那契数列的前两个数。
- 使用 echo -n 输出前两个数。
- 利用循环计算出剩余的斐波那契数,并使用 echo -n 输出结果。
- 在每次循环中,更新 num1 和 num2 的值,并继续计算下一个斐波那契数。
相关文章:

【shell 常用脚本30例】
先了解下编写Shell过程中注意事项 开头加解释器:#!/bin/bash语法缩进,使用四个空格;多加注释说明。命名建议规则:全局变量名大写、局部变量小写,函数名小写,名字体现出实际作用。默认变量是全局的…...

【我和Python算法的初相遇】——体验递归的可视化篇
🌈个人主页: Aileen_0v0 🔥系列专栏:PYTHON数据结构与算法学习系列专栏💫"没有罗马,那就自己创造罗马~" 目录 递归的起源 什么是递归? 利用递归解决列表求和问题 递归三定律 递归应用-整数转换为任意进制数 递归可视化 画…...
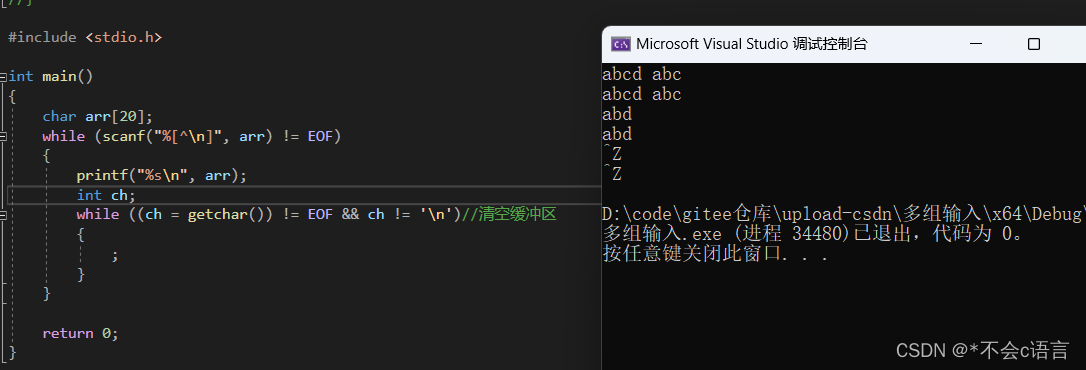
【C语言的秘密】密探—深究C语言中多组输入的秘密!
场景引入: 你是否在刷题过程中,经常遇到以下场景呢? 场景一: 场景二: 从这些题上都能看见输入描述中提出了一条多组输入,那啥是多组输入?如何实现它呢? 多组输入:在输入…...

ClickHouse 语法优化规则
ClickHouse 的 SQL 优化规则是基于RBO(Rule Based Optimization),下面是一些优化规则 1 准备测试用表 1)上传官方的数据集 将visits_v1.tar和hits_v1.tar上传到虚拟机,解压到clickhouse数据路径下 // 解压到clickhouse数据路径 sudo tar -xvf…...

3-运行第一个docker image-hello world
CentOS7.9下安装完成docker后,我们开始部署第一个docker image-hello world 1.以root用户登录CentOS7.9服务器,拉取centos7 images 命令: docker pull hello-world [root@centos79 ~]# docker pull hello-world Using default tag: latest latest: Pulling from library…...
【漏洞复现】泛微e-Weaver SQL注入
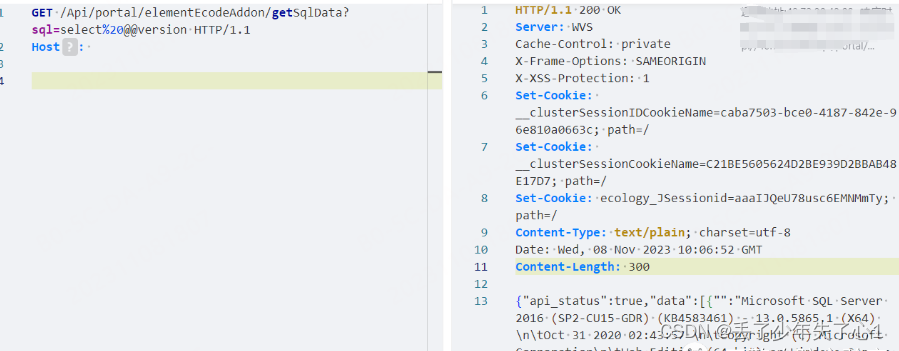
漏洞描述 泛微e-Weaver(FANWEI e-Weaver)是一款广泛应用于企业数字化转型领域的集成协同管理平台。作为中国知名的企业级软件解决方案提供商,泛微软件(广州)股份有限公司开发和推广了e-Weaver平台。 泛微e-Weaver旨在…...
「git 系列」git 如何存储代码的?
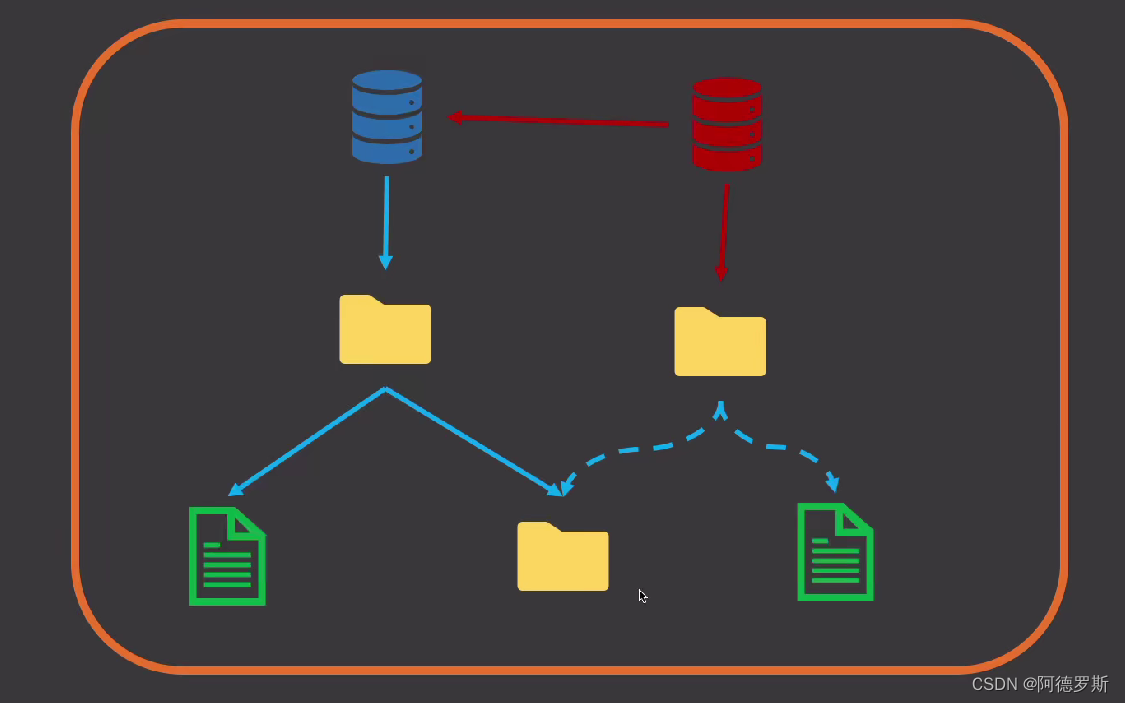
这里写自定义目录标题 git 文件存储位置git 数据模型示例分析分析前准备命令哈希值 具体示例 不同版本的提交,git 做了什么工作?snapshot vs delta-based vs backup参考资料 git 文件存储位置 想要了解如何存储,首先需要知道存储位置。 当我…...
IDEA 集成 Docker 插件一键部署 SpringBoot 应用
目录 前言IDEA 安装 Docker 插件配置 Docker 远程服务器编写 DockerFileSpringBoot 部署配置SpringBoot 项目部署结语 前言 随着容器化技术的崛起,Docker成为了现代软件开发的关键工具。在Java开发中,Spring Boot是一款备受青睐的框架,然而&…...
IDEA无法查看源码是.class,而不是.java解决方案?
问题:在idea中,ctrl鼠标左键进入源码,但是有时候会出现无法查看反编译的源码,如图! 而我们需要的是方法1: mvn dependency:resolve -Dclassifiersources 注意:需要该模块的目录下,不是该文件目…...

机器视觉系统选型-定光照强度
同一个外形结构的光源,光照强度受如下影响: 单颗灯珠的亮度灯珠排列的数量和密度漫射板/防护板的材质(透明、半透明、全漫射) 在合理范围内提升光照强度,可降低对相机曝光时长的要求 外形结构尺寸相同的两款光源&am…...
ChatGLM3-6B:新一代开源双语对话语言模型,流畅对话与低部署门槛再升级
项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实…...

StoneDB顺利通过中科院软件所 2023 开源之夏 结项审核
近日,中科院软件所-开源软件供应链点亮计划-开源之夏2023的结项名单正式出炉,经过三个月的项目开发和一个多月的严格审核,共产生 418个成功结项项目!其中,StoneDB 作为本次参与开源社区,社区入选的两个项目…...
Linux本地docker一键部署traefik+内网穿透工具实现远程访问Web UI管理界面
文章目录 前言1. Docker 部署 Trfɪk2. 本地访问traefik测试3. Linux 安装cpolar4. 配置Traefik公网访问地址5. 公网远程访问Traefik6. 固定Traefik公网地址 前言 Trfɪk 是一个云原生的新型的 HTTP 反向代理、负载均衡软件,能轻易的部署微服务。它支持多种后端 (D…...

SpringCloud FeignClient声明式服务调用采坑记录(A调用服务B/C,B/C重启后必须重启A后才能成功调用配置项)
SpringCloud FeignClient声明式服务调用(A调用服务B/C,B/C重启后必须重启A后才能成功调用配置项采坑记录) 1. 报错(info级别的警告信息)2. 原因:使用了默认了cache负载均衡,或者禁用了ribbonLoa…...

安装银河麒麟linux系统docker(docker-compose)环境,注意事项(一定能解决,有环境资源)
1:安装docker环境必须使用麒麟的版本如下 2:使用docker-compse up -d启动容器遇到的文件 故障1:如果运行docker-compose up 报“Cannot create redo log files because data files are corrupt or the database was not shut down cleanly a…...
BUG:编写springboot单元测试,自动注入实体类报空指针异常
原因:修饰测试方法的Test注解导入错误 造成错误的原因是 import org.junit.Test;正确的应该是 import org.junit.jupiter.api.Test前者是Junit4,后者是Junit5 junit4的使用似乎要在测试类除了添加SpringbootTest还要添加RunWith(SpringRunner.class) 同时要注意spring-boot-s…...

深度解析 InterpretML:打开机器学习模型的黑箱
深度解析 InterpretML:打开机器学习模型的黑箱 机器学习模型的高性能往往伴随着模型的复杂性,这使得模型的决策过程变得不透明,难以理解。在这个背景下,可解释性机器学习成为了一个备受关注的领域。本文将介绍 InterpretML&#…...

数据结构初阶leetcodeOJ题(二)
目录 第一题 思路: 第二题 思路 第三题 描述 示例1 思路 总结:这种类似的题,都是用快慢指针,相差一定的距离然后输出慢指针。 第一题 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val…...
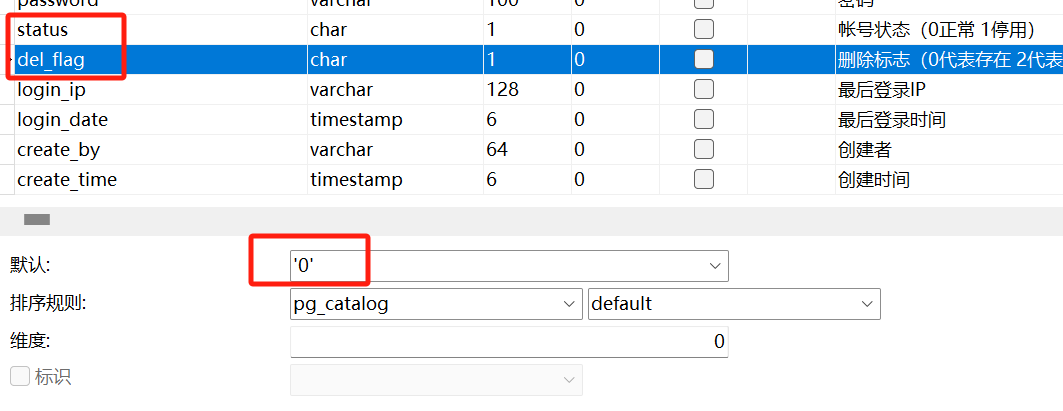
若依框架数据源切换为pg库
一 切换数据源 在ruoyi-admin项目里引入pg数据库驱动 <dependency><groupId>org.postgresql</groupId><artifactId>postgresql</artifactId><version>42.2.18</version> </dependency>修改配置文件里的数据源为pg spring:d…...
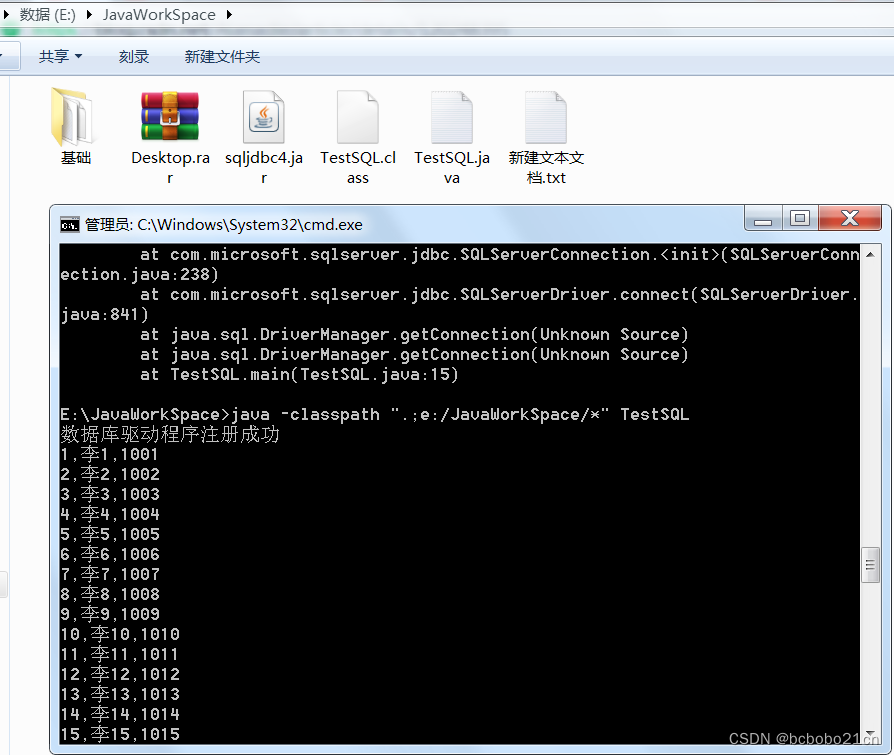
java 访问sqlserver 和 此驱动程序不支持jre1.8错误
sqlserver数据如下; TestSQL.java; import java.sql.*;public class TestSQL {public static void main(String[] args) throws ClassNotFoundException, SQLException {String driverName "com.microsoft.sqlserver.jdbc.SQLServerDriver";…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...

Caliper 配置文件解析:fisco-bcos.json
config.yaml 文件 config.yaml 是 Caliper 的主配置文件,通常包含以下内容: test:name: fisco-bcos-test # 测试名称description: Performance test of FISCO-BCOS # 测试描述workers:type: local # 工作进程类型number: 5 # 工作进程数量monitor:type: - docker- pro…...

BLEU评分:机器翻译质量评估的黄金标准
BLEU评分:机器翻译质量评估的黄金标准 1. 引言 在自然语言处理(NLP)领域,衡量一个机器翻译模型的性能至关重要。BLEU (Bilingual Evaluation Understudy) 作为一种自动化评估指标,自2002年由IBM的Kishore Papineni等人提出以来,…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...
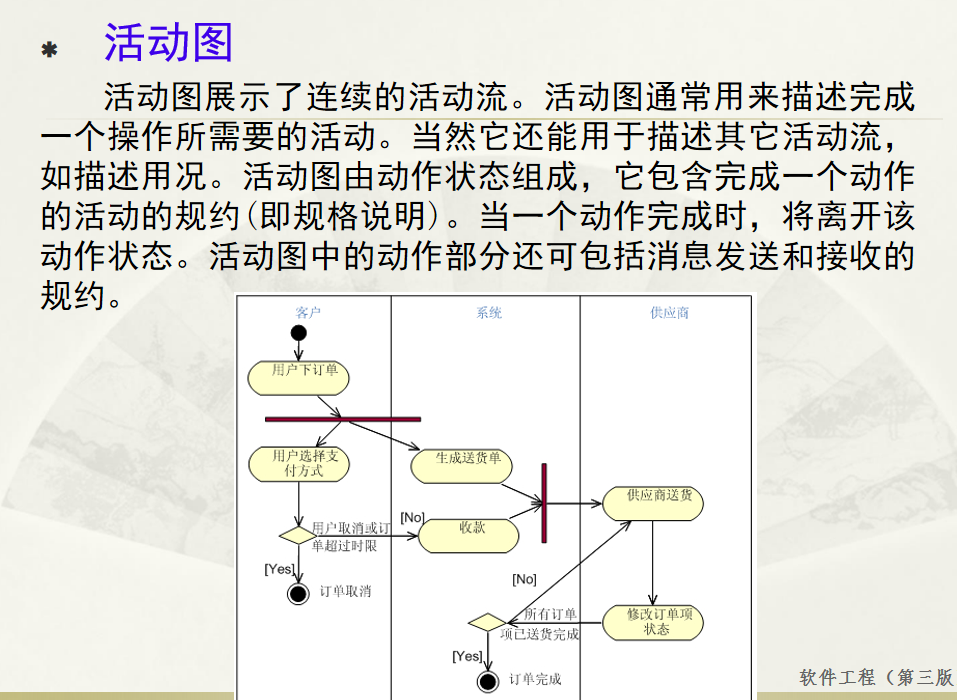
软件工程 期末复习
瀑布模型:计划 螺旋模型:风险低 原型模型: 用户反馈 喷泉模型:代码复用 高内聚 低耦合:模块内部功能紧密 模块之间依赖程度小 高内聚:指的是一个模块内部的功能应该紧密相关。换句话说,一个模块应当只实现单一的功能…...