Node.js中的Buffer和Stream
Node.js中的Buffer和Stream
计算机只能理解二进制数据,即0和1形式的数据。这些数据的顺序移动称为流。以称为块(chunk)的破碎部分流式传输数据;计算机一收到数据块就开始处理数据,而不用等待整个数据。
我们这篇文章就将讲解一下Stream和Buffer。有时,处理速度小于接收块的速率或快于接收块的速率;在这两种情况下,都需要保存块,因为处理需要最少量的块,这是使用chunk完成的。
Buffer
Buffer是一种抽象,允许我们处理 Node.js 中的原始二进制数据。它们在处理文件和网络或一般 I/O 时特别有用。
缓冲区代表分配给我们计算机的一块内存。缓冲区的大小一旦设置就无法更改。缓冲区用于存储字节。
让我们用一些数据创建一些缓冲区:
// buffer-data.js// 创建一些缓冲区
const bufferFromString = Buffer.from('Ciao human')
const bufferFromByteArray = Buffer.from([67, 105, 97, 111, 32, 104, 117, 109, 97, 110])
const bufferFromHex = Buffer.from('4369616f2068756d616e', 'hex')
const bufferFromBase64 = Buffer.from('Q2lhbyBodW1hbg==', 'base64')// 数据以二进制格式存储
console.log(bufferFromString) // <Buffer 43 69 61 6f 20 68 75 6d 61 6e>
console.log(bufferFromByteArray) // <Buffer 43 69 61 6f 20 68 75 6d 61 6e>
console.log(bufferFromHex) // <Buffer 43 69 61 6f 20 68 75 6d 61 6e>
console.log(bufferFromBase64) // <Buffer 43 69 61 6f 20 68 75 6d 61 6e>// 原始缓冲区数据可以“可视化”为字符串、十六进制或 base64
console.log(bufferFromString.toString('utf-8')) // Ciao human (默认'utf-8')
console.log(bufferFromString.toString('hex')) // 4369616f2068756d616e
console.log(bufferFromString.toString('base64')) // Q2lhbyBodW1hbg==// 获取buffer的长度
console.log(bufferFromString.length) // 10
现在,让我们创建一个 Node.js 脚本,使用缓冲区将文件从一个位置复制到另一个位置:
// buffer-copy.jsimport {readFile,writeFile
} from 'fs/promises'async function copyFile (src, dest) {// 读取整个文件内容const content = await readFile(src)// 将该内容写入其他地方return writeFile(dest, content)
}// `src` 是来自 cli 的第一个参数,`dest` 是第二个
const [src, dest] = process.argv// 开始复制并处理结果
copyFile(src, dest).then(() => console.log(`${src} copied into ${dest}`)).catch((err) => {console.error(err)process.exit(1)})
可以按如下方式使用此脚本:
node ./buffer-copy.js <source-file> <dest-file>
但是我们有没有想过当尝试复制大文件(比如说 3Gb)时会发生什么?
发生的情况是,我们会看到脚本严重失败并出现以下错误:
RangeError [ERR_FS_FILE_TOO_LARGE]: File size (3221225472) is greater than 2 GBat readFileHandle (internal/fs/promises.js:273:11)at async copyFile (file:///...//buffer-copy.js:8:19) {code: 'ERR_FS_FILE_TOO_LARGE'
}
为什么会发生这种情况?
本质上是因为当我们使用fs.readFile时,我们使用Buffer对象从内存中的文件加载所有二进制内容。根据设计,缓冲区在内存中的大小受到限制。
可以使用以下代码创建具有最大允许大小的缓冲区:
// biggest-buffer.jsimport buffer from 'buffer'// 这将分配几 GB 内存
const biggestBuffer = Buffer.alloc(buffer.constants.MAX_LENGTH) // 创建一个具有最大可能大小的缓冲区
console.log(biggestBuffer) // <Buffer 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ... 4294967245 more bytes>
在某种程度上,我们可以将流视为一种抽象,它允许我们处理在不同时刻到达的数据部分(块)。每个块都是一个Buffer实例。
Stream
Stream是 Node.js 中处理流数据的抽象接口。Node.js中stream模块提供了用于实现流接口的 API。Node.js 提供了许多流对象。例如,对 HTTP 服务器的请求和process.stdout都是流实例。
我们需要 Node.js 中的流来处理和操作流数据,例如视频、大文件等。Node.js 中的 stream 模块用于管理所有流。流是一个抽象接口,用于与 Node.js 中的流数据一起工作。Node.js 为我们提供了许多流对象。
例如,如果我们请求HTTP 服务器和进程,则两者都被视为流实例。标准输出。流可以是可读的、可写的或两者兼而有之。所有流都是EventEmitter的实例。要访问流模块,要使用的语法是:
const stream = require('stream');
流的类型
Node.js 中有四种基本的流类型:
Writable:可以写入数据的流(例如,fs.createWriteStream())。Readable:可以从中读取数据的流(例如fs.createReadStream())。Duplex:既是Writable又是Readable的流(例如,net.Socket)。Transform:Duplex可以在写入和读取数据时修改或转换数据的流(例如,zlib.createDeflate())。
// stream-copy.jsimport {createReadStream,createWriteStream
} from 'fs'const [,, src, dest] = process.argv// 创建源流
const srcStream = createReadStream(src)// 创建目标流
const destStream = createWriteStream(dest)// 当源流上有数据时,
// 将其写入目标流
srcStream.on('data', (chunk) => destStream.write(chunk))
本质上,我们用createReadStream和createWriteStream替换readFile和writeFile。然后使用它们创建两个流实例srcStream和destStream。这些对象分别是一个 ReadableStream(输入)和一个 WritableStream(输出)的实例。
目前,唯一需要理解的重要细节是流并不急切;他们不会一次性读取所有数据。数据以块、小部分数据的形式读取。一旦块通过data事件可用,我们就可以立即使用它。当源流中有新的数据块可用时,我们立即将其写入目标流。这样,我们就不必将所有文件内容保存在内存中。
请记住,这里的实现并不是万无一失的,存在一些粗糙的边缘情况,但就目前而言,这足以理解 Node.js 中流处理的基本原理。
可读流 → 该流用于创建用于读取的数据流,例如读取大块文件。
例子:
const fs = require('fs');const readableStream = fs.createReadStream('./article.md', {highWaterMark: 10
});readableStream.on('readable', () => {process.stdout.write(`[${readableStream.read()}]`);
});readableStream.on('end', () => {console.log('DONE');
});
可写流 → 这将创建要写入的数据流。例如:向文件中写入大量数据。
例子:
const fs = require('fs');
const file = fs.createWriteStream('file.txt');
for (let i = 0; i < 10000; i++)
{
file.write('Hello world ' + i);
}
file.end();
双工流 → 该流用于创建同时可读和可写的流。
例子:
const server = http.createServer((req, res) => {let body = '';req.setEncoding('utf8');req.on('data', (chunk) => {body += chunk;});req.on('end', () => {console.log(body);try {res.write('Hello World');res.end();} catch (er) {res.statusCode = 400;return res.end(`error: ${er.message}`);}});
});
流动与非流动
Node 中有两种类型的可读流:
- 流动流 —— 用于从系统传递数据并将该数据提供给程序的流。
- 非流动流 —— 不自动推送数据的非流动流。相反,非流动流将数据存储在缓冲区中并显式调用
read方法来读取它。
内存/时间比较
让我们看看这两种实现(缓冲区和流式传输)在内存使用和执行时间方面的比较。
我们可以查看 Node.js 脚本在缓冲区中分配了多少数据的一种方法是调用process.memoryUsage().arrayBuffers方法。
const { pipeline } = require('node:stream/promises');
const fs = require('node:fs');
const zlib = require('node:zlib');async function run() {await pipeline(fs.createReadStream('archive.tar'),zlib.createGzip(),fs.createWriteStream('archive.tar.gz'),);console.log('Pipeline succeeded.');
}run().catch(console.error);
相关文章:

Node.js中的Buffer和Stream
Node.js中的Buffer和Stream 计算机只能理解二进制数据,即0和1形式的数据。这些数据的顺序移动称为流。以称为块(chunk)的破碎部分流式传输数据;计算机一收到数据块就开始处理数据,而不用等待整个数据。 我们这篇文章…...
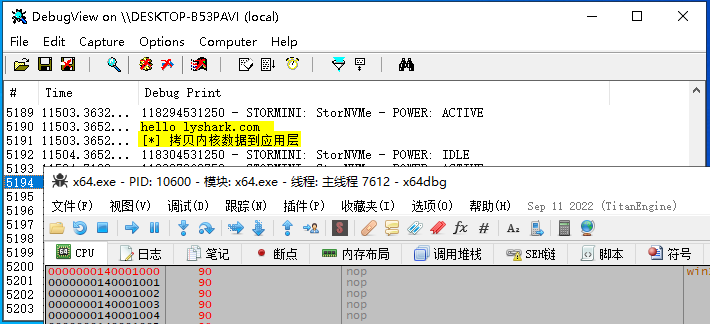
3.5 Windows驱动开发:应用层与内核层内存映射
在上一篇博文《内核通过PEB得到进程参数》中我们通过使用KeStackAttachProcess附加进程的方式得到了该进程的PEB结构信息,本篇文章同样需要使用进程附加功能,但这次我们将实现一个更加有趣的功能,在某些情况下应用层与内核层需要共享一片内存…...

【小黑送书—第八期】>>别再吐槽大学教材了,来看看这些网友强推的数学神作!
导读:关于大学数学教材的吐槽似乎从来没停止过。有人慨叹:数学教材晦涩难懂。错!难懂,起码还可以读懂。数学教材你根本读不懂;也有人说:数学教材简直就是天书。 数学教材有好有坏,这话不假&…...
MatLab的下载、安装与使用(亲测有效)
1、概述 MatLab是由MathWorks公司开发并发布的,支持线性代数、矩阵运算、绘制函数和数据、信号处理、图像处理以及视频处理等功能。广泛用于算法开发、数据可视化、数据分析以及数值计算等。 Matlab 的主要特性包括: 简单易用的语法,使得程…...

无人智能货柜:引领便捷购物新体验
无人智能货柜:引领便捷购物新体验 无人智能货柜利用人工智能技术,将传统货架与电子商务相结合,形成智能销售终端。其采用先拿货后付款的购物模式,用户只需扫码、拿货、关门三个简洁流畅的步骤,极大地提升了消费者的购物…...
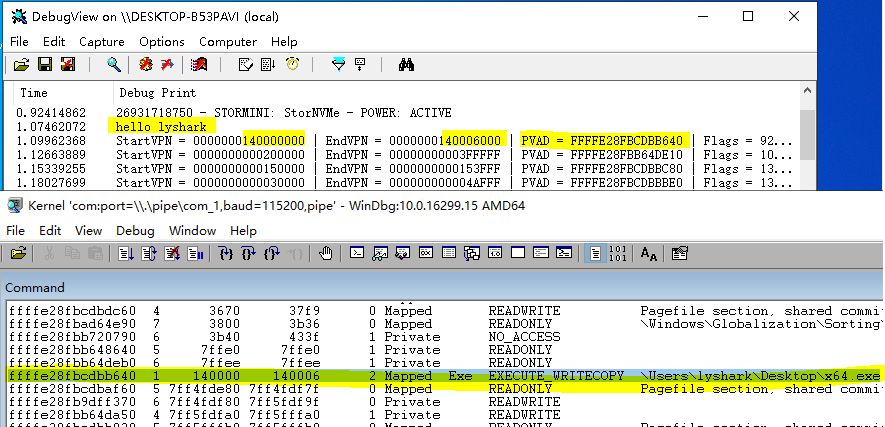
4.6 Windows驱动开发:内核遍历进程VAD结构体
在上一篇文章《内核中实现Dump进程转储》中我们实现了ARK工具的转存功能,本篇文章继续以内存为出发点介绍VAD结构,该结构的全程是Virtual Address Descriptor即虚拟地址描述符,VAD是一个AVL自平衡二叉树,树的每一个节点代表一段虚…...

基于世界杯算法优化概率神经网络PNN的分类预测 - 附代码
基于世界杯算法优化概率神经网络PNN的分类预测 - 附代码 文章目录 基于世界杯算法优化概率神经网络PNN的分类预测 - 附代码1.PNN网络概述2.变压器故障诊街系统相关背景2.1 模型建立 3.基于世界杯优化的PNN网络5.测试结果6.参考文献7.Matlab代码 摘要:针对PNN神经网络…...
NPM 与 XUI 共存!Nginx Proxy Manager 搭配 X-UI 实现 Vless+WS+TLS 教程!
之前分享过搭建可以与宝塔共存的一个 “魔法” 服务器状态监控应用 ——xui,支持 VmessWSTLS。 最近 Docker 视频出的比较多,前阵子又出现了宝塔国内版存在隐私泄露的问题,很多小伙伴其实都不用宝塔了,那么,在我们现在…...

【网络奇遇记】那年我与计算机网络的浅相知
🌈个人主页:聆风吟 🔥系列专栏:网络奇遇记、数据结构 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 一. 计算机网络的定义1.1 计算机早期的一个最简单的定义1.2 现阶段计算机网络的一个较好的定义 二. …...
)
LeetCode26.删除有序数组中的重复项(双指针法)
LeetCode26.删除有序数组中的重复项 1.问题描述2.解题思路3.代码 1.问题描述 给你一个 非严格递增排列 的数组 nums ,请你** 原地** 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然…...

原型网络Prototypical Network的python代码逐行解释,新手小白也可学会!!-----系列8
文章目录 前言一、原始代码二、对每一行代码的解释:总结 前言 这是该系列原型网络的最后一段代码及其详细解释,感谢各位的阅读! 一、原始代码 if __name__ __main__:##载入数据labels_trainData, labels_testData load_data() # labels_…...

黑马点评回顾 redis实现共享session
文章目录 传统session缺点整体访问流程代码实现生成验证码登录 问题具体思路 传统session缺点 传统单体项目一般是把session存入tomcat,但是每个tomcat中都有一份属于自己的session,假设用户第一次访问第一台tomcat,并且把自己的信息存放到第一台服务器…...

Redis篇---第八篇
系列文章目录 文章目录 系列文章目录前言一、说说 Redis 哈希槽的概念?二、Redis 常见性能问题和解决方案有哪些?三、假如 Redis 里面有 1 亿个 key,其中有 10w 个 key 是以某个固定的已知的前缀开头的,如果将它们全部找出来?前言 前些天发现了一个巨牛的人工智能学习网站…...

Unity使用Visual Studio Code 调试
Unity 使用Visual Studio Code 调试C# PackageManager安装Visual Studio EditorVisual Studio Code安装Unity 插件修改Unity配置调试 PackageManager安装Visual Studio Editor 打开 Window->PackageManger卸载 Visual Studio Code Editor ,这个已经被官方废弃安…...

【Linux】进程替换|exec系列函数
文章目录 一、看一看单进程版的进程替换二、进程替换的原理三、多进程版——验证各种程序替换接口exec系列函数execlexeclpexecvexecvp tipsexecleexecve 四、总结 一、看一看单进程版的进程替换 #include<stdio.h> #include<unistd.h> #include<stdlib.h>i…...

Java编程技巧:将图片导出成pdf文件
目录 一、pom依赖二、代码三、测试链接 一、pom依赖 <!-- pdf插件 start --> <dependency><groupId>com.itextpdf</groupId><artifactId>itextpdf</artifactId><version>5.5.3</version> </dependency> <dependency…...

二项分布和泊松分布
一、二项分布 1.1 n重伯努利试验 若是二项分布,则必是n重伯努利试验概型。即:每次试验只有两种结果 与 ,且在每次试验中A发生的概率相等,即P(A)p,将这种试验独立重复n次,则称这种试验为n重伯努利试验&#…...

【飞控调试】DJIF450机架+Pixhawk6c mini+v1.13.3固件+好盈Platinium 40A电调无人机调试
1 背景 由于使用了一种新的航电设备组合,在调试无人机起飞的时候遇到了之前没有遇到的问题。之前用的飞控(Pixhawk 6c)和电调(Hobbywing X-Rotor 40A),在QGC里按默认参数配置来基本就能平稳飞行࿰…...
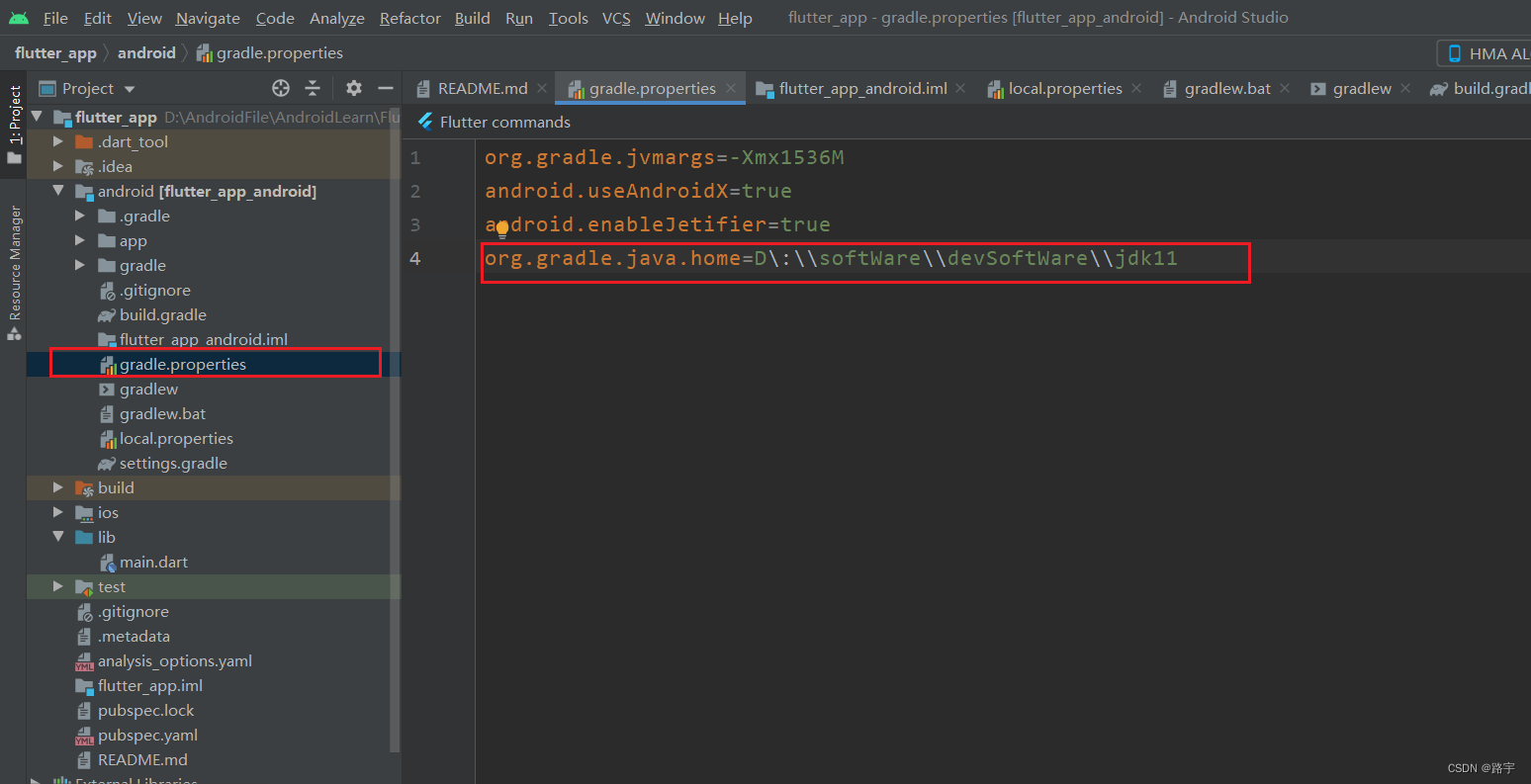
Android studio配置Flutter开发环境报错问题解决
博主前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住也分享一下给大家 👉点击跳转到教程 报错问题截图 报错原因已经给出: You need Java 11 or higher to build your app with this version of G…...

2023.11.18 -自用hadoop高可用环境搭建命令
启动hadoop高可用环境 # 1.先恢复快照到高可用环境 # 2.三台服务器启动zookeeper服务 [rootnode1 ~]# zkServer.sh start [rootnode2 ~]# zkServer.sh start [rootnode3 ~]# zkServer.sh start 查看服务状态: [rootnode]# zkServer.sh status 关闭zk服务的命令是: [rootnode]# …...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

线程与协程
1. 线程与协程 1.1. “函数调用级别”的切换、上下文切换 1. 函数调用级别的切换 “函数调用级别的切换”是指:像函数调用/返回一样轻量地完成任务切换。 举例说明: 当你在程序中写一个函数调用: funcA() 然后 funcA 执行完后返回&…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...