apscheduler 定时任务框架
Apscheduler 介绍
四大组件
- triggers:触发器,用于设定触发任务的条件
- job stores:作业存储器,用于存放任务,可以存放在数据库或内存,默认内存
- executors:执行器,用于执行任务,可以设定执行默认为单线程或线程池
- schedulers:调度器,将上述三个组件作为参数,通过创建调度器实例来执行
触发器 triggers
每个任务都有自己的触发器,它可以决定任务触发的条件,触发器默认是无状态的。
作业存储器 job stores
默认存储在内存中,若存储到数据库中会有个序列化和反序列化的过程,同时修改和搜索任务的功能也是由它实现。
一个作业存储器不要共享给多个调度器,不然会造成状态混乱
执行器 executors
将任务放入线程或线程池中执行,执行完毕通知调度器
调度器 schedulers
调度器提供接口,可以将触发器、作业存储器和执行器整合起来,从而实现对任务的操作。
调度器组件
- BlockingScheduler 阻塞式调度器:适用于只跑调度器的程序。
- BackgroundScheduler 后台调度器:适用于非阻塞的情况,调度器会在后台独立运行。
- AsyncIOScheduler AsyncIO调度器,适用于应用使用AsnycIO的情况。
- GeventScheduler Gevent调度器,适用于应用通过Gevent的情况。
- TornadoScheduler Tornado调度器,适用于构建Tornado应用。
- TwistedScheduler Twisted调度器,适用于构建Twisted应用。
- QtScheduler Qt调度器,适用于构建Qt应用。
选择正确的调度器、作业存储器、触发器和执行器
1、作业存储器
- 作业不需要持久化:默认的
MemoryJobStore - 作业需要持久化:作业在调度程序重启或应用程序奔溃后继续存在,推荐采用:
SQLAlchemyJobStore + PostgreSQL
2、执行器
- 默认
ThreadPoolExecutor线程池足以满足大多数场景 - CPU 密集型操作:应考虑
ProcessPoolExecutor进程池,来充分利用多核算力。也可以将ProcessPoolExecutor作为第二执行器,混合使用两种不同的执行器。
触发器详解
一个任务可以设定多种触发器,如全部条件满足触发、满足其一触发以及复合触发等:
可参考:https://apscheduler.readthedocs.io/en/latest/modules/triggers/combining.html#module-apscheduler.triggers.combining
内置的三种触发器类型
date:在特定时间仅允许一次作业interval:固定时间间隔允许作业cron:一天中特定时间定期允许作业
指定时间任务 date
三种类型:date/datetime/字符串,不加时间则立即执行:
from datetime import date, datetimefrom apscheduler.schedulers.blocking import BlockingSchedulersched = BlockingScheduler()def my_job(text):print(text)sched.add_job(my_job, 'date', run_date=date(2009, 11, 6), args=['text'])
sched.add_job(my_job, 'date', run_date=datetime(2020, 1, 7, 14, 35, 2), args=['text'])
sched.add_job(my_job, 'date', run_date='2009-11-06 16:30:05', args=['text'])
sched.add_job(my_job, args=['text'])sched.start()
参考:apscheduler.triggers.date
间隔任务 interval
from datetime import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
import osdef tick():print('当前时间:', datetime.now())if __name__ == '__main__':scheduler = BlockingScheduler() # 默认调度器,存入在内存中scheduler.add_job(tick, 'interval', seconds=3) # 添加到作业中print('按 Ctrl+{0} 终端任务'.format('Break' if os.name == 'nt' else 'c '))try:scheduler.start()except (KeyboardInterrupt, SystemError):pass
运行结果如下:
按 Ctrl+Break 终端任务
当前时间: 2020-01-07 13:55:37.540614
当前时间: 2020-01-07 13:55:40.540879
当前时间: 2020-01-07 13:55:43.542759
当前时间: 2020-01-07 13:55:46.542512
当前时间: 2020-01-07 13:55:49.541907
当前时间: 2020-01-07 13:55:52.541845
当前时间: 2020-01-07 13:55:55.542011
当前时间: 2020-01-07 13:55:58.542533
指定开始、结束时间:
# 指定开始、结束时间
from datetime import date, datetimefrom apscheduler.schedulers.blocking import BlockingSchedulersched = BlockingScheduler()def my_job():print('当前时间:', datetime.now())sched.add_job(my_job, 'interval', seconds=3, start_date='2020-01-07 14:45:20', end_date='2020-01-07 14:46:20')sched.start()
装饰器:
@sched.scheduled_job('interval', id='job_id', seconds=3)
def my_job():print('当前时间:', datetime.now())
jitter 振动参数,给每次触发添加一个随机浮动秒数,一般适用于多服务器,避免同时运行造成服务拥堵。
# 每小时(上下浮动120秒区间内)运行`job_function`
sched.add_job(job_function, 'interval', hours=1, jitter=120)
参考:apscheduler.triggers.interval
crontab表达式 cron
参数
pscheduler.triggers.cron.CronTrigger(year = None,month = None,day = None,week = None,day_of_week = None,hour = None,minutes = None,second = None,start_date = None,end_date = None,timezone = None,jitter = None )
参数详解
- year (int|str) – 4-digit year
- month (int|str) – month (1-12)
- day (int|str) – day of the (1-31)
- week (int|str) – ISO week (1-53)
- day_of_week (int|str) – number or name of weekday (0-6 or mon,tue,wed,thu,fri,sat,sun)
- hour (int|str) – hour (0-23)
- minute (int|str) – minute (0-59)
- second (int|str) – second (0-59)
- start_date (datetime|str) :开始触发事件
- end_date (datetime|str) :结束时间
- timezone (datetime.tzinfo|str) 用于日期、时间计算的时区,默认为调度程序时区
- jitter (int|None) :作业最多延迟多久执行
表达式类型
| 表达式 | 参数类型 | 描述 |
|---|
- | 所有 | 通配符,minute=* 即每分钟触发一次
*/a | 所有 | 可被 a 整除的通配符
a-b | 所有 | 范围 a -b 触发
a-b/c | 所有 | 范围 a-b,且可被 c 整除时触发
xth y | 日 | 第几个星期几触发,x 为第几个,y 为星期几
last x | 日 | 一个月中,最后那个星期几触发
last | 日 | 一个月中最后一天触发
x,y,z | 所有 | 组合表达式,可组合确定值或上方表达式
示例一
from datetime import date, datetimefrom apscheduler.schedulers.blocking import BlockingSchedulersched = BlockingScheduler()def my_job():print('当前时间:', datetime.now())# 6/7/8 和 11/12 月的第三个周五的 0/1/2/3 点触发
sched.add_job(my_job, 'cron', month='6-8, 11-12', day='3rd fri', hour='0-3')sched.start()
示例二:指定时间范围
# 周一到周日,每天 15::9 触发,截止时间:2020-01-08
sched.add_job(my_job, 'cron', day_of_week='0-6', hour=15, minute=29, end_date='2020-01-08')
示例三:装饰器
# 每个月的最后一个星期日触发
@sched.scheduled_job('cron', id='job_id', day='last 6')
def my_job():print('当前时间:', datetime.now())
示例四:标准 crontab 表达式
sched.add_job(my_job, CronTrigger.from_crontab('0 0 1-15 may-aug *'))
添加 jitter 随机执行,适用于多台服务器在不同时间执行:
# 每小时上下浮动120秒触发
sched.add_job(my_job, 'cron', hour='*', jitter=120)
夏令时问题
有些时区可能因为夏令时问题,导致时区切换时,任务不执行或执行两次,这不是错误,要避免这个问题,可使用 UTC 时间,或提前规避,以下写法可能会导致错误:
# 在Europe/Helsinki时区, 在三月最后一个周一就不会触发;在十月最后一个周一会触发两次
sched.add_job(job_function, 'cron', hour=3, minute=30)
参考:apscheduler.triggers.cron
配置调度器
可通过直接传字典、传参或实例一个调度器对象,再添加配置信息的形式来配置调度器。
创建一个默认作业存储器和执行器:
from apscheduler.schedulers.background import BackgroundSchedulerscheduler = BackgroundScheduler()
- 调度器:
default的MemoryJonStore(内存任务存储器) - 执行器:
default,最大线程数为 10 的ThreadPoolExecutor线程池执行器
示例
应用场景:
两个作业存储器搭配两个执行器,同时又要修改作业的默认参数,还有修改时区。
- 名为 mongo 的 MemoryDBJobStore
- 名为 default 的 SQLAlchemyJobStore
- 名为 TreadPoolExecutor 的 ThreadPoolExecutor,最大线程 20
- 名为 processpool 的 ProcessPoolExecutor,最大进程 5
- UTC 时区作为默认调度器时区
- 默认为新任务关闭合并模式
- 设置新任务的默认最大实例数为 3
1、方法一:
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.mongodb import MongoDBJobStore
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor# 作业存储器
jobstores = {'mongo': MongoDBJobStore(),'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}# 执行器
executors = {'default': ThreadPoolExecutor(20),'processpool': ProcessPoolExecutor(5)
}job_defaults = {'coalesce': False, # 关闭作业合并'max_instances': 3
}scheduler = BackgroundScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)
2、方法二:
from apscheduler.schedulers.background import BackgroundScheduler# The "apscheduler." prefix is hard coded
scheduler = BackgroundScheduler({'apscheduler.jobstores.mongo': {'type': 'mongodb'},'apscheduler.jobstores.default': {'type': 'sqlalchemy','url': 'sqlite:///jobs.sqlite'},'apscheduler.executors.default': {'class': 'apscheduler.executors.pool:ThreadPoolExecutor','max_workers': '20'},'apscheduler.executors.processpool': {'type': 'processpool','max_workers': '5'},'apscheduler.job_defaults.coalesce': 'false','apscheduler.job_defaults.max_instances': '3','apscheduler.timezone': 'UTC',
})
3、方法三:
from pytz import utcfrom apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ProcessPoolExecutorjobstores = {'mongo': {'type': 'mongodb'},'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = {'default': {'type': 'threadpool', 'max_workers': 20},'processpool': ProcessPoolExecutor(max_workers=5)
}
job_defaults = {'coalesce': False,'max_instances': 3
}
scheduler = BackgroundScheduler()# .. do something else here, maybe add jobs etc.scheduler.configure(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)
启用调度
调用 start() 即可启用调度,对于非阻塞的会立即返回,对于 BlockingScheduler 会阻塞的 start 位置,因此运行其他代码要写在 start 之前。
调度器启动后,就不能修改配置了。
添加任务
add_job():返回一个实例对象,通过对象可以修改、删除任务- 装饰器:
scheduled_job():运行时不能修改任务
任何时候都可添加任务,若调度器未启动,那么任务会处于一个暂存状态。当调度器启动时,才会计算下次运行时间。
若执行器和作业存储器是要序列化的任务的,那么必须满足
- 回调函数必须全局可用
- 回调函数参数必须可用被序列化
内置任务储存器中,只有MemoryJobStore不会序列化任务;内置执行器中,只有ProcessPoolExecutor会序列化任务。
另外若程序初始化时,从数据库读取任务,则必须为每个任务定义一个 ID,并使用 replace_existing=True,否则每次重启程序,都会得到一个新的任务拷贝,即前一个任务状态不会被保存。
Tips:立即执行任务,可在添加任务时省略 trigger 参数
移除任务
从调度器移除任务,也必须移除作业存储器中的任务。
remove_job(任务 ID):参数为任务 ID 或作业存储器名称- 调用
job=add_job()、job.remove()移除
对于通过 scheduled_job() 创建的任务,只能选择第一种方式。
示例:
job = sched.add_job(func, 'interval', minutes=2)
job.remove()sched.add_job(func, 'interval', minute=2, id='job_id')
sched.remove_job('job_id')
暂停恢复任务
from datetime import date, datetimefrom apscheduler.schedulers.blocking import BlockingSchedulersched = BlockingScheduler()def my_job():print('当前时间:', datetime.now())job = sched.add_job(my_job, 'cron', id='job_id', month='6-8, 11-12', day='3rd fri', hour='0-3')# 暂停作业
job.pause()
sched.pause_job('job_id')# 恢复作业
job.resume()
sched.remove_job('job_id')sched.start()
获取任务列表
from datetime import date, datetimefrom apscheduler.schedulers.blocking import BlockingSchedulersched = BlockingScheduler()def my_job():print('当前时间:', datetime.now())job = sched.add_job(my_job, 'cron', id='job_id', month='6-8, 11-12', day='3rd fri', hour='0-3')print('当前任务', sched.get_job('job_id'))
print('任务列表', sched.get_jobs())
print('格式化作业列表', sched.print_jobs())sched.start()
运行结果如下:
当前任务 my_job (trigger: cron[month='6-8,11-12', day='3rd fri', hour='0-3'], pending)
任务列表 [<Job (id=job_id name=my_job)>]
Pending jobs:my_job (trigger: cron[month='6-8,11-12', day='3rd fri', hour='0-3'], pending)
格式化作业列表 None
print_jobs() 可以快速打印格式化的任务列表,包含触发器,下次运行时间等信息。
修改任务
# 可修改除 ID 以外其他任务属性
job.modify(max_instances=6, name='Alternate name')
sched.modify_job(max_instances=6, name='Alternate name')# 修改触发器
# job.reschedule('job_id', trigger='cron', minute='*/5')
sched.reschedule_job('job_id', trigger='interval', minutes=4)
示例:
from datetime import date, datetimefrom apscheduler.schedulers.blocking import BlockingSchedulersched = BlockingScheduler()def my_job():print('当前时间:', datetime.now())job = sched.add_job(my_job, 'interval', id='job_id', minutes=3)print('当前任务', sched.get_job('job_id'))# job.reschedule('job_id', trigger='cron', minute='*/5')
sched.reschedule_job('job_id', trigger='interval', minutes=4)
print('修改后的任务:', sched.get_job('job_id'))sched.start()
运行结果如下:
当前任务 my_job (trigger: interval[0:03:00], pending)
修改后的任务: my_job (trigger: interval[0:04:00], next run at: 2020-01-07 16:44:45 CST)
关闭调度
sched.shutdown()
sched.shutdown(wait=False) # 不等待正在运行的任务
限制作业并发执行实例数量
默认情况下,在同一时间,一个任务只允许一个执行中的实例在运行。比如说,一个任务是每5秒执行一次,但是这个任务在第一次执行的时候花了6秒,也就是说前一次任务还没执行完,后一次任务又触发了,由于默认一次只允许一个实例执行,所以第二次就丢失了。为了杜绝这种情况,可以在添加任务时,设置 max_instances 参数,为指定任务设置最大实例并行数。
丢失任务的执行与合并
有时,任务会由于一些问题没有被执行。最常见的情况就是,在数据库里的任务到了该执行的时间,但调度器被关闭了,那么这个任务就成了“哑弹任务”。错过执行时间后,调度器才打开了。这时,调度器会检查每个任务的 misfire_grace_time 参数 int 值,即哑弹上限,来确定是否还执行哑弹任务(这个参数可以全局设定的或者是为每个任务单独设定)。此时,一个哑弹任务,就可能会被连续执行多次。
但这就可能导致一个问题,有些哑弹任务实际上并不需要被执行多次。 coalescing 合并参数就能把一个多次的哑弹任务揉成一个一次的哑弹任务。也就是说,coalescing 为 True 能把多个排队执行的同一个哑弹任务,变成一个,而不会触发哑弹事件。
注!如果是由于线程池/进程池满了导致的任务延迟,执行器就会跳过执行。要避免这个问题,可以添加进程或线程数来实现或把 misfire_grace_time 值调高。
调度事件监听
任务执行时有可能会出现错误,那么如何第一时间指定在哪发生错误呢? apscheduler
给我们提供了事件监听来解决这个问题。
from datetime import date, datetimefrom apscheduler.schedulers.blocking import BlockingSchedulersched = BlockingScheduler()def my_job():print('当前时间:', datetime.now())print(1/0)
上述代码每 5 秒钟执行一次,每次都会发生错误。我们给其添加一个回调函数和日志记录来监听:
from datetime import date, datetime
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.events import EVENT_JOB_EXECUTED, EVENT_JOB_ERROR
import logginglogging.basicConfig(level=logging.INFO,format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',datefmt='%Y-%m-%d %H:%M:%S',filename='log.txt',filemode='a')sched = BlockingScheduler()def my_job():print('当前时间:', datetime.now())print(1 / 0)def test_job():print('正常任务!', datetime.now())def my_listener(event):if event.exception:print('任务运行出错!', datetime.now())else:print('任务正常运行!', datetime.now())job = sched.add_job(my_job, 'cron', second='*/5')
job1 = sched.add_job(test_job, 'interval', seconds=3)
sched.add_listener(my_listener, EVENT_JOB_EXECUTED | EVENT_JOB_ERROR)
sched._logger = loggingsched.start()
事件类型
| Constant | Description | Event class |
|---|---|---|
| EVENT_SCHEDULER_STARTED | The scheduler was started SchedulerEvent | |
| EVENT_SCHEDULER_SHUTDOWN | The scheduler was shut down SchedulerEvent | |
| EVENT_SCHEDULER_PAUSED | Job processing in the scheduler was paused SchedulerEvent | |
| EVENT_SCHEDULER_RESUMED | Job processing in the scheduler was resumed SchedulerEvent | |
| EVENT_EXECUTOR_ADDED | An executor was added to the scheduler SchedulerEvent | |
| EVENT_EXECUTOR_REMOVED | An executor was removed to the scheduler SchedulerEvent | |
| EVENT_JOBSTORE_ADDED | A job store was added to the scheduler SchedulerEvent | |
| EVENT_JOBSTORE_REMOVED | A job store was removed from the scheduler SchedulerEvent | |
| EVENT_ALL_JOBS_REMOVED | All jobs were removed from either all job stores or one particular job store SchedulerEvent | |
| EVENT_JOB_ADDED | A job was added to a job store JobEvent | |
| EVENT_JOB_REMOVED | A job was removed from a job store JobEvent | |
| EVENT_JOB_MODIFIED | A job was modified from outside the scheduler JobEvent | |
| EVENT_JOB_SUBMITTED | A job was submitted to its executor to be run JobSubmissionEvent | |
| EVENT_JOB_MAX_INSTANCES | A job being submitted to its executor was not accepted by the executor because the job has already reached its maximum concurrently executing instances JobSubmissionEvent | |
| EVENT_JOB_EXECUTED | A job was executed successfully JobExecutionEvent | |
| EVENT_JOB_ERROR | A job raised an exception during execution JobExecutionEvent | |
| EVENT_JOB_MISSED | A job’s execution was missed JobExecutionEvent | |
| EVENT_ALL | A catch-all mask that includes every event type N/A |
日志
import logginglogging.basicConfig()
logging.getLogger('apscheduler').setLevel(logging.DEBUG)
相关文章:

apscheduler 定时任务框架
Apscheduler 介绍 四大组件 triggers:触发器,用于设定触发任务的条件job stores:作业存储器,用于存放任务,可以存放在数据库或内存,默认内存executors:执行器,用于执行任务&#x…...

Softing OPC Tunnel——绕过DCOM配置实现OPC Classic广域网通信
一 摘要 Softing OPC Tunnel是dataFEED OPC Suite的一个组件,可避免跨设备OPC Classic通信中出现的DCOM配置问题,同时可保证跨网络数据交换的高性能和可靠性。OPC Tunnel内部集成的存储转发功能,可在连接中断时缓存数据,并在重新…...

Java的运算操作
个人主页:平行线也会相交 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 平行线也会相交 原创 收录于专栏【JavaSE_primary】 文章目录算术运算符增量运算符注意自增自减运算符关系运算符逻辑运算符逻辑与&&逻辑或||逻辑非!…...

基于OBD系统的量产车评估测试(PVE)
在轻型汽车污染物排放限值及测量方法(中国第六阶段)中,除了对汽车尾气排放等制定了更为严格的限制之外,也在OBD系统认证项目中增加了新的要求——量产车评估(Production Vehicle Evaluation)测试。该测试由…...

【蓝桥杯集训10】Tire树 字典树 最大异或对专题(3 / 3)
目录 字典树模板 1、插入操作 2、查询操作 143. 最大异或对 - trie 二进制 3485. 最大异或和 - 前缀和Trie滑动窗口 字典树模板 活动 - AcWing 字典树:高效存储和查找字符串集合的数据结构 son[节点1地址][值]节点2地址 —— 节点1的子节点为节点2cnt[节点地…...
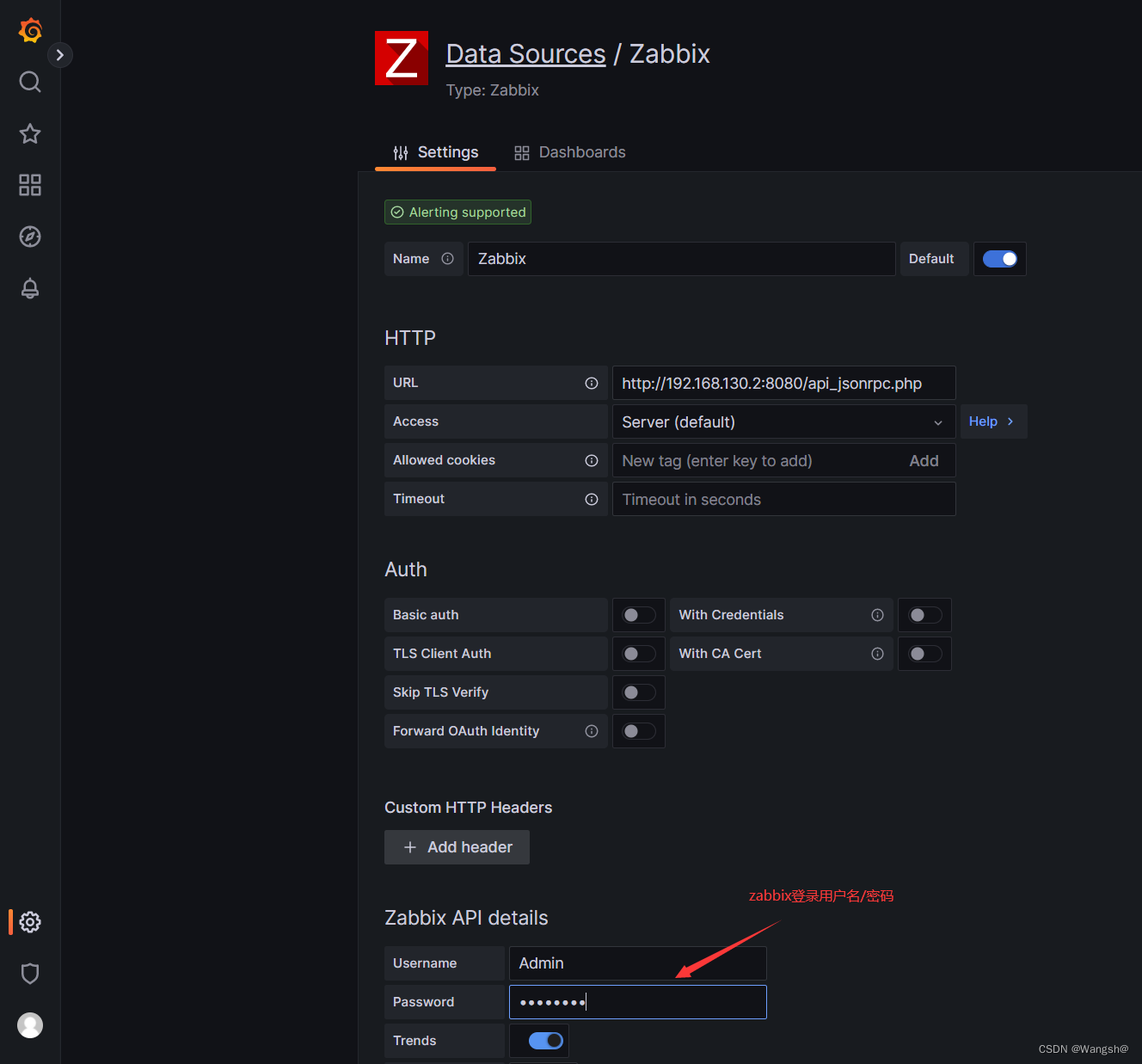
docker部署zabbix6.2.7+grafana
目录 1、下载docker 2、下载相关镜像文件 3、创建一个供zabbix系统使用的网络环境 4、创建一个供mysql数据库存放文件的目录 5、启动mysql容器 6、为zabbix-server创建一个持久卷 7、启动zabbix-server容器 8、创建语言存放目录 9、启动zabbix-web容器 10、启动zabbix…...

【Java开发】JUC基础 04:Synchronized、死锁、Lock锁
1 概念介绍并发:同一个对象被多个线程同时操作📌 线程同步现实生活中,我们会遇到“同一个资源,多个人都想使用”的问题,比如,食堂排队打饭,每个人都想吃饭,最天然的解决办法就是,排队…...

离散数学---期末复习知识点
一、 数理逻辑 [复习知识点] 1、命题与联结词(否定¬、析取∨、合取∧、蕴涵→、等价↔),命题(非真既假的陈述句),复合命题(由简单命题通过联结词联结而成的命题) 2、命题公式与赋值(成真、成假)&#x…...

在线安装ESP32和ESP8266 Arduino开发环境
esp32和esp8266都是乐鑫科技开发的单片机产品,esp8266价格便宜开发板只需要十多块钱就可以买到,而esp32是esp8266的升级版本,比esp8266的功能和性能更强大,开发板价格大约二十多元就可以买到。 使用Arduino开发esp32和esp8266需要…...

【Python实战】激情澎湃,2023极品劲爆舞曲震撼全场,爬虫一键采集DJ大串烧,一曲醉人女声DJ舞曲,人人都听醉~(排行榜采集,妙啊~)
导语 哈喽!大家好。我是木木子吖~今天给大家带来爬虫的内容哈。 所有文章完整的素材源码都在👇👇 粉丝白嫖源码福利,请移步至CSDN社区或文末公众hao即可免费。 今天教大家Python爬虫实战一键采集大家喜欢的DJ舞曲哦! …...

[SSD综述 1.5] SSD固态硬盘参数图文解析_选购固态硬盘就像买衣服?
版权声明:付费作品,未经许可,不可转载前言SSD (Solid State Drive),即固态硬盘,通常是一种以半导体闪存(NAND Flash)作为介质的存储设备。SSD 以半导体作为介质存储数据&…...
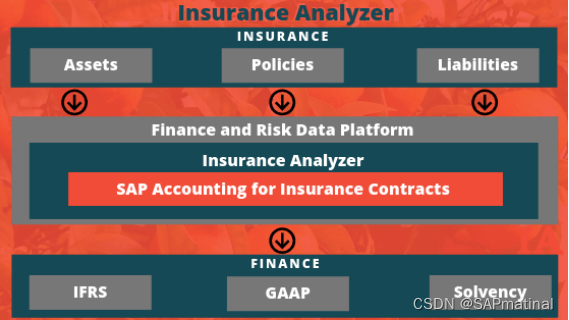
SAP Insurance Analyzer
SAP Insurance Analyzer 是一款用于保险公司财务和风险管理的软件。SAP Insurance analyzer 支持基于 IFRS 17 或 Solvency II 的保险合同估值和计算要求。SAP Insurance Analyzer 于 2013 年 5 月推出,为源数据和结果数据集成了一个预配置的保险数据模型。 源数据…...

自动化测试 ——自动卸载软件
在平常的测试工作中,经常要安装软件,卸载软件, 即繁琐又累。 安装和卸载完全可以做成自动化。 安装软件我们可以通过自动化框架,自动点击Next,来自动安装。 卸载软件我们可以通过msiexec命令行工具自动化卸载软件 用msiexec 命令来卸载软件 …...

05 封装
在对 context 的封装中,我们只是将 request、response 结构直接放入 context 结构体中,对应的方法并没有很好的封装。 函数封装并不是一件很简单、很随意的事情。相反,如何封装出易用、可读性高的函数是非常需要精心考量的,框架中…...

clean
clean code 记得以前写过这题,写的乱七八糟,分析来分析去。 后悔应该早点写代码,leetcode大一就该刷了。 https://leetcode.cn/problems/plus-one/submissions/ class Solution { public:vector<int> plusOne(vector<int>&…...

佛科院计算机软件技术基础——线性表
一、基础知识了解:结构体的理解:我们知道整型是由1位符号位和15位数值位组成,而就可以把结构体理解为我们定义的数据类型,如:typedef struct {int data[2]; //存储顺序表中的元素int len; …...

linux下终端操作mysql数据库
目录 一.检查mysql是否安装 1. 查看文件安装路径 2. 查询运行文件所在路径(文件夹地址) 二.登录mysql 三.列出mysql全部用户 四.常用指令 1.查看全部数据库 2.选择数据库 …...

MySQL参数优化之thread_cache_size
1.thread_cache_size简介 每建立一个连接,都需要一个线程来与之匹配,此参数用来缓存空闲的线程,以至不被销毁,如果线程缓存中有空闲线程,这时候如果建立新连接,MYSQL就会很快的响应连接请求。 show statu…...
:gRPC健康检查协议详解)
gRPC服务健康检查(二):gRPC健康检查协议详解
gRPC健康检查协议健康检查用于检测服务端能否正常处理rpc请求,客户端对服务端的健康检查可以点对点进行,也可以通过某些控制系统(如负载平衡)进行。客户端可以根据服务端返回的状态执行对应的策略。因为GRPC服务可以用于简单的客户…...
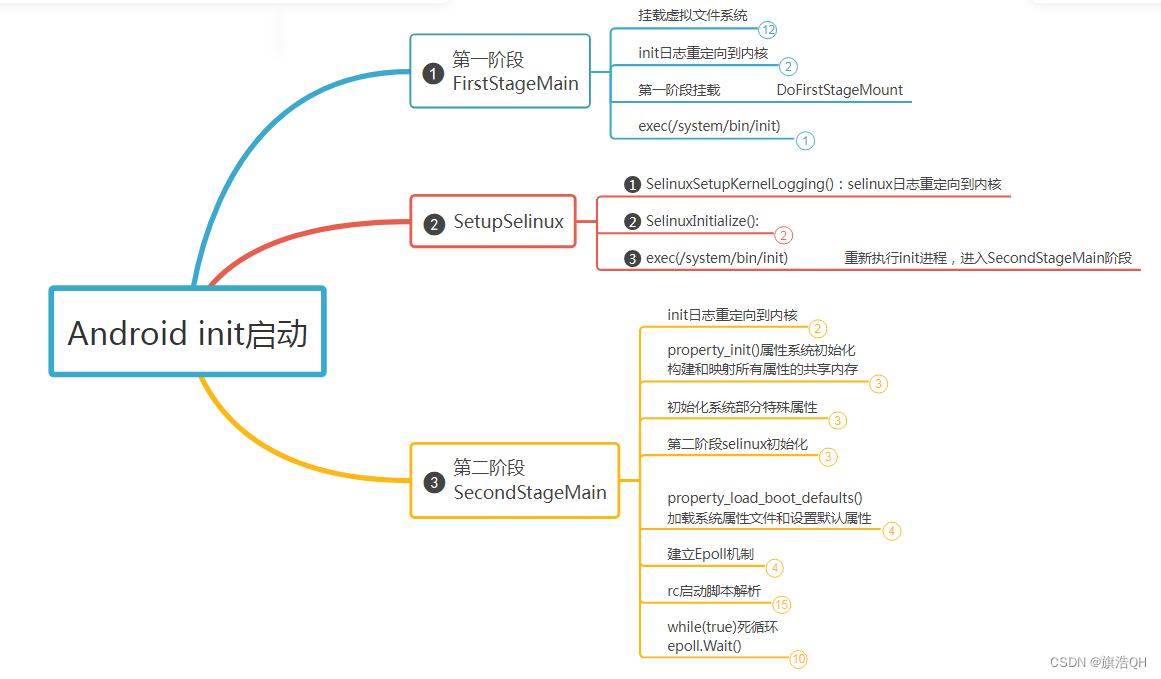
Android系统10 RK3399 init进程启动(四十七) Android init 进程整体代码逻辑简述
配套系列教学视频链接:安卓系列教程之ROM系统开发-百问100ask说明系统:Android10.0设备: FireFly RK3399 (ROC-RK3399-PC-PLUS)前言本文简单描述一下android init祖先进程启动的基本执行流程,让大家有一个整…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

铭豹扩展坞 USB转网口 突然无法识别解决方法
当 USB 转网口扩展坞在一台笔记本上无法识别,但在其他电脑上正常工作时,问题通常出在笔记本自身或其与扩展坞的兼容性上。以下是系统化的定位思路和排查步骤,帮助你快速找到故障原因: 背景: 一个M-pard(铭豹)扩展坞的网卡突然无法识别了,扩展出来的三个USB接口正常。…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...
)
是否存在路径(FIFOBB算法)
题目描述 一个具有 n 个顶点e条边的无向图,该图顶点的编号依次为0到n-1且不存在顶点与自身相连的边。请使用FIFOBB算法编写程序,确定是否存在从顶点 source到顶点 destination的路径。 输入 第一行两个整数,分别表示n 和 e 的值(1…...