系列七、索引
一、索引概述
1.1、概述

1.2、演示

假如我们要执行的SQL语句为 : select * from user where age = 45;
1.2.1、无索引情况

在无索引情况下,就需要从第一行开始扫描,一直扫描到最后一行,我们称之为 全表扫描,性能很低。
1.2.2、有索引情况

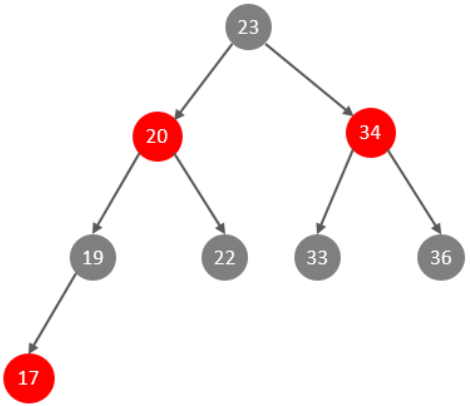
备注:这里我们只是假设索引的结构是二叉树,介绍一下索引的大概原理,只是一个示意图,并不是索引的真实结构,索引的真实结构,后面会详细介绍。
1.3、特点

二、索引结构
2.1、概述

2.2、不同存储引擎对索引结构的支持
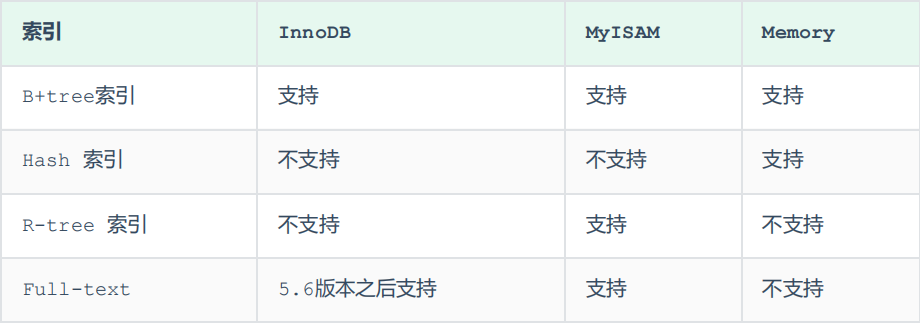
注意事项:我们平常所说的索引,如果没有特别指明,都是指B+树结构的索引。
2.3、二叉树
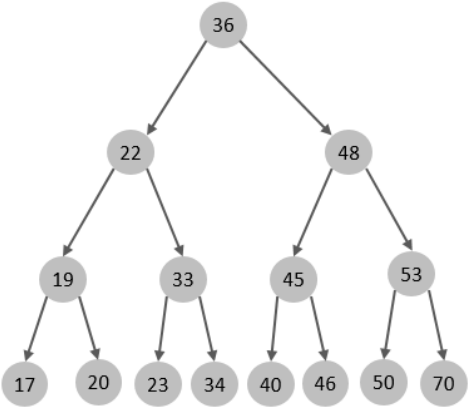

- 顺序插入时,会形成一个链表,查询性能大大降低。
- 大数据量情况下,层级较深,检索速度慢。
所以,在MySQL的索引结构中,并没有选择二叉树或者红黑树,而选择的是B+Tree,那么什么是B+Tree呢?在详解B+Tree之前,先来介绍一个B-Tree。
2.4、B-Tree
B-Tree,B树是一种多叉路衡查找树,相对于二叉树,B树每个节点可以有多个分支,即多叉。以一颗最大度数(max-degree)为5(5阶)的b-tree为例,那这个B树每个节点最多存储4个key,5个指针:

可视化网站
https://www.cs.usfca.edu/~galles/visualization/BTree.html# 测试数据
100 65 169 368 900 556 780 35 215 1200 234 888 158 90 1000 88
120 268 250特点
- 5阶的B树,每一个节点最多存储4个key,对应5个指针。
- 一旦节点存储的key数量到达5,就会裂变,中间元素向上分裂。
- 在B树中,非叶子节点和叶子节点都会存放数据。
2.5、B+Tree
B+Tree是B-Tree的变种,我们以一颗最大度数(max-degree)为4(4阶)的b+tree为例,来看一下其结构示意图:

- 绿色框框起来的部分,是索引部分,仅仅起到索引数据的作用,不存储数据。
- 红色框框起来的部分,是数据存储部分,在其叶子节点中要存储具体的数据。
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html# 测试数据
100 65 169 368 900 556 780 35 215 1200 234 888 158 90 1000 88
120 268 250

2.6、B+Tree和B-Tree的区别
- 所有的数据都会出现在叶子节点;
- 叶子节点形成一个单向链表;
- 非叶子节点仅仅起到索引数据作用,具体的数据都是在叶子节点存放的;

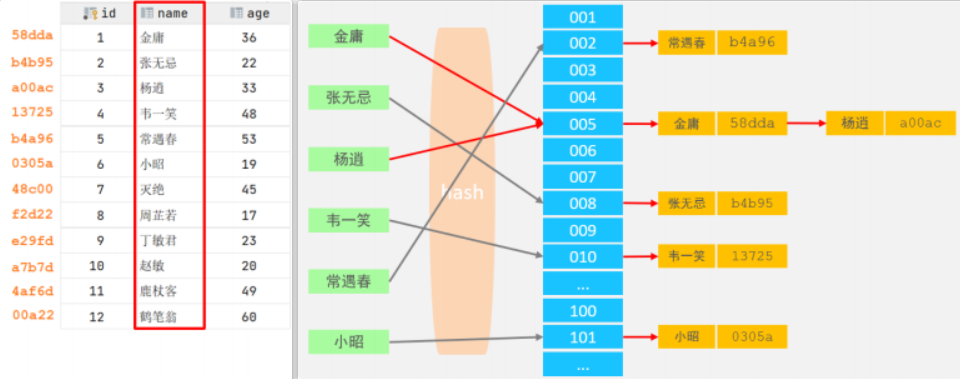
2.7、Hash
- 结构:哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。

如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可以通过链表来解决。
- 特点
- Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,< ,...)
- 无法利用索引完成排序操作
- 查询效率高,通常(不存在hash冲突的情况)只需要一次检索就可以了,效率通常要高于B+tree索引
- 存储引擎支持
在MySQL中,支持hash索引的是Memory存储引擎。 而InnoDB中具有自适应hash功能,hash索引是InnoDB存储引擎根据B+Tree索引在指定条件下自动构建的。
2.8、思考题:为什么InnoDB的存储引擎选择使用B+Tree索引结构?
- 相对于二叉树,层级更少,搜索效率高;
- 对于B-Tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低;
- 相对Hash索引,B+Tree支持范围匹配及排序操作;
三、索引分类
3.1、索引分类

3.2、聚集索引 & 二级索引

3.2.1、聚集索引选取规则
- 如果存在主键,主键索引就是聚集索引;
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引;
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引;
3.2.2、聚集索引和二级索引的具体结构
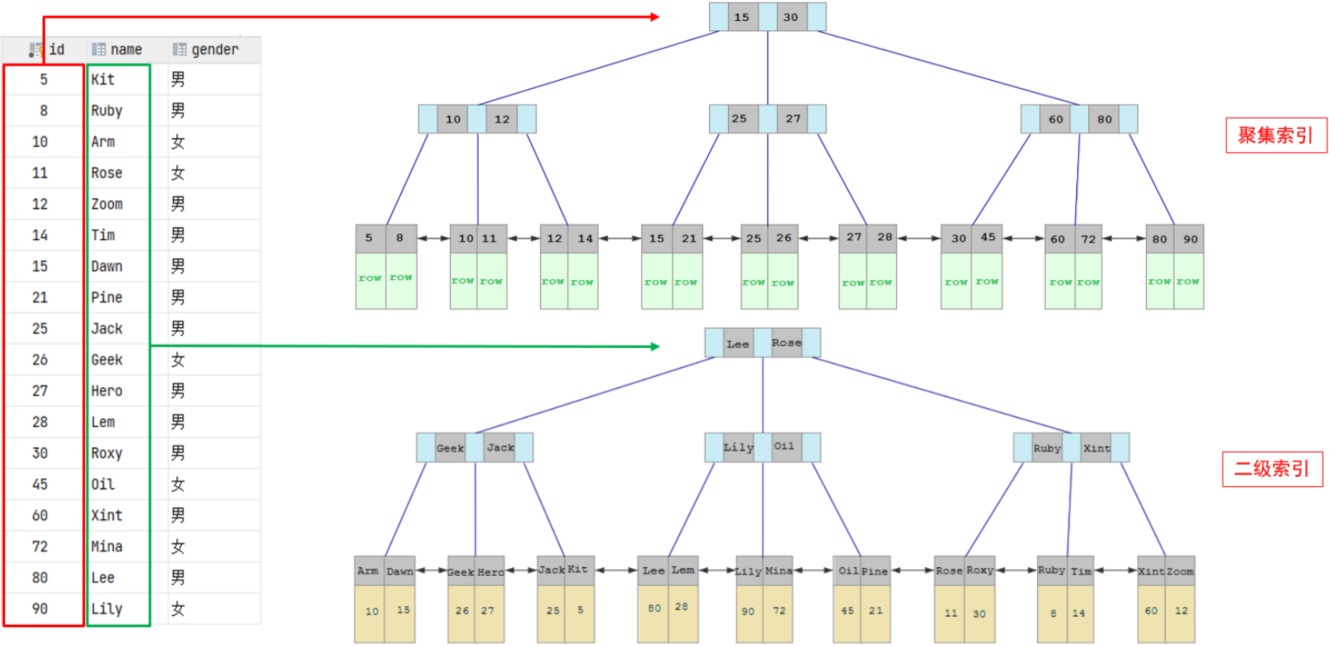
结论
- 聚集索引的叶子节点下挂的是这一行的数据;
- 二级索引的叶子节点下挂的是该字段值对应的主键值;
3.2.3、具体SQL的执行过程

具体过程:
- 由于是根据name字段进行查询,所以先根据name='Arm'到name字段的二级索引中进行匹配查找。但是在二级索引中只能查找到Arm对应的主键值10
- 由于查询返回的数据是*,所以此时,还需要根据主键值10,到聚集索引中查找10对应的记录,最终找到10对应的行row;
- 最终拿到这一行的数据,直接返回即可
3.2.4、回表查询
类似于3.2.3中这种先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取数据的方式,就称之为回表查询。
四、索引语法
4.1、创建索引
CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name (index_col_name,... ) ;4.2、查看索引
SHOW INDEX FROM table_name ;4.3、删除索引
DROP INDEX index_name ON table_name ;4.4、案例演示
4.4.1、初始表tb_user
use itheima;
drop table if exists tb_user;
create table tb_user(id int primary key auto_increment comment '主键',name varchar(50) not null comment '用户名',phone varchar(11) not null comment '手机号',email varchar(100) comment '邮箱',profession varchar(11) comment '专业',age tinyint unsigned comment '年龄',gender char(1) comment '性别 , 1: 男, 2: 女',status char(1) comment '状态',createtime datetime comment '创建时间'
) comment '系统用户表';INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('吕布', '17799990000', 'lvbu666@163.com', '软件工程', 23, '1','6', '2001-02-02 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('曹操', '17799990001', 'caocao666@qq.com', '通讯工程', 33,'1', '0', '2001-03-05 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('赵云', '17799990002', '17799990@139.com', '英语', 34, '1','2', '2002-03-02 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('孙悟空', '17799990003', '17799990@sina.com', '工程造价', 54,'1', '0', '2001-07-02 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('花木兰', '17799990004', '19980729@sina.com', '软件工程', 23,'2', '1', '2001-04-22 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('大乔', '17799990005', 'daqiao666@sina.com', '舞蹈', 22, '2','0', '2001-02-07 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('露娜', '17799990006', 'luna_love@sina.com', '应用数学', 24,'2', '0', '2001-02-08 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('程咬金', '17799990007', 'chengyaojin@163.com', '化工', 38,'1', '5', '2001-05-23 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('项羽', '17799990008', 'xiaoyu666@qq.com', '金属材料', 43,'1', '0', '2001-09-18 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('白起', '17799990009', 'baiqi666@sina.com', '机械工程及其自动化', 27, '1', '2', '2001-08-16 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('韩信', '17799990010', 'hanxin520@163.com', '无机非金属材料工程', 27, '1', '0', '2001-06-12 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('荆轲', '17799990011', 'jingke123@163.com', '会计', 29, '1','0', '2001-05-11 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('兰陵王', '17799990012', 'lanlinwang666@126.com', '工程造价',44, '1', '1', '2001-04-09 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('狂铁', '17799990013', 'kuangtie@sina.com', '应用数学', 43,'1', '2', '2001-04-10 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('貂蝉', '17799990014', '84958948374@qq.com', '软件工程', 40,'2', '3', '2001-02-12 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('妲己', '17799990015', '2783238293@qq.com', '软件工程', 31,'2', '0', '2001-01-30 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('芈月', '17799990016', 'xiaomin2001@sina.com', '工业经济', 35,'2', '0', '2000-05-03 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('嬴政', '17799990017', '8839434342@qq.com', '化工', 38, '1','1', '2001-08-08 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('狄仁杰', '17799990018', 'jujiamlm8166@163.com', '国际贸易',30, '1', '0', '2007-03-12 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('安琪拉', '17799990019', 'jdodm1h@126.com', '城市规划', 51,'2', '0', '2001-08-15 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('典韦', '17799990020', 'ycaunanjian@163.com', '城市规划', 52,'1', '2', '2000-04-12 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('廉颇', '17799990021', 'lianpo321@126.com', '土木工程', 19,'1', '3', '2002-07-18 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('后羿', '17799990022', 'altycj2000@139.com', '城市园林', 20,'1', '0', '2002-03-10 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status,createtime) VALUES ('姜子牙', '17799990023', '37483844@qq.com', '工程造价', 29,'1', '4', '2003-05-26 00:00:00');
4.4.2、案例一:name字段为姓名字段,该字段的值可能会重复,为该字段创建索引
CREATE INDEX idx_user_name ON tb_user(name);
4.4.2、案例二:phone手机号字段的值,是非空,且唯一的,为该字段创建唯一索引
CREATE UNIQUE INDEX idx_user_phone ON tb_user(phone); 
4.4.3、案例三:为profession、age、status创建联合索引
CREATE INDEX idx_user_pro_age_sta ON tb_user(profession,age,status); 
4.4.4、案例四:为email建立合适的索引来提升查询效率
CREATE INDEX idx_email ON tb_user(email);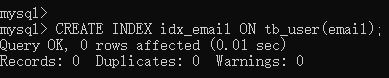
4.4.5、案例五、查看tb_user表的所有索引
show index from tb_user;
五、SQL性能分析
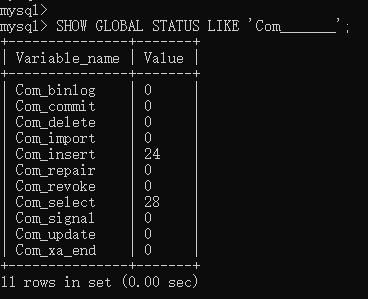
5.1、SQL执行频率
# 查看数据库的INSERT、UPDATE、DELETE、SELECT执行频率
-- session 是查看当前会话 ;
-- global 是查询全局数据 ;SHOW GLOBAL STATUS LIKE 'Com_______';Com_insert: 插入次数
Com_update: 更新次数
Com_delete: 删除次数
Com_select: 查询次数
5.2、百万级别数据导入
5.2.0、readme
由于1000w的数据量较大 , 如果直接加载1000w , 会非常耗费CPU及内存 ;已经拆分为5个部分 , 每一个部分为200w数据 , load 5次即可 ;
5.2.1、建表语句
drop table if exists `tb_sku`;
CREATE TABLE `tb_sku` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '商品id',`sn` varchar(100) NOT NULL COMMENT '商品条码',`name` varchar(200) NOT NULL COMMENT 'SKU名称',`price` int(20) NOT NULL COMMENT '价格(分)',`num` int(10) NOT NULL COMMENT '库存数量',`alert_num` int(11) DEFAULT NULL COMMENT '库存预警数量',`image` varchar(200) DEFAULT NULL COMMENT '商品图片',`images` varchar(2000) DEFAULT NULL COMMENT '商品图片列表',`weight` int(11) DEFAULT NULL COMMENT '重量(克)',`create_time` datetime DEFAULT NULL COMMENT '创建时间',`update_time` datetime DEFAULT NULL COMMENT '更新时间',`category_name` varchar(200) DEFAULT NULL COMMENT '类目名称',`brand_name` varchar(100) DEFAULT NULL COMMENT '品牌名称',`spec` varchar(200) DEFAULT NULL COMMENT '规格',`sale_num` int(11) DEFAULT '0' COMMENT '销量',`comment_num` int(11) DEFAULT '0' COMMENT '评论数',`status` char(1) DEFAULT '1' COMMENT '商品状态 1-正常,2-下架,3-删除',PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品表';5.2.2、查询 local_infile 的默认配置
SHOW GLOBAL VARIABLES LIKE 'local_infile';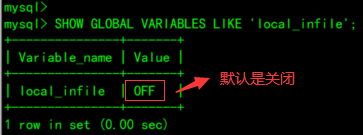
5.2.3、开启 local_infile 配置
SET GLOBAL local_infile = true; 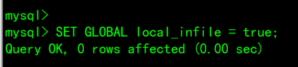
5.2.4、退出并重新登录
mysql --local-infile=1 -uroot -p123456 
5.2.5、再次查询 local_infile 配置
SHOW GLOBAL VARIABLES LIKE 'local_infile';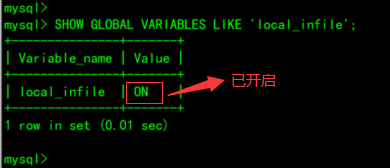
5.2.6、执行导入指令
load data local infile 'D:/temp/tb_sku1.sql' into table `tb_sku` fields terminated by ',' lines terminated by '\n';
load data local infile 'D:/temp/tb_sku2.sql' into table `tb_sku` fields terminated by ',' lines terminated by '\n';
load data local infile 'D:/temp/tb_sku3.sql' into table `tb_sku` fields terminated by ',' lines terminated by '\n';
load data local infile 'D:/temp/tb_sku4.sql' into table `tb_sku` fields terminated by ',' lines terminated by '\n';
load data local infile 'D:/temp/tb_sku5.sql' into table `tb_sku` fields terminated by ',' lines terminated by '\n';
5.2.7、sql脚本
链接:https://pan.baidu.com/s/1y7t6Ztq5Z6pz8q0hhN9jPA?pwd=yyds
提取码:yyds
5.3、慢查询日志

5.2.1、Windows开启慢查询日志
#1、 查询datadir的位置show variables like 'datadir';#2、在datadir找到my.ini文件,修改如下内容slow-query-log=1 # 开启MySQL慢日志查询开关long_query_time=2 # 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志#3、重启mysql服务
5.2.2、Linux开启慢查询日志
# 1、修改/etc/my.cnf# 2、修改内容如下slow_query_log=1 # 开启MySQL慢日志查询开关long_query_time=2 # 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志# 3、配置完毕之后,通过以下指令重新启动MySQL服务器进行测试,查看慢日志文件中记录的信息
/var/lib/mysql/${hostname}-slow.logsystemctl restart mysqld5.3.4、测试
- 执行如下sql,观察结果
select * from tb_user; -- 这条SQL执行效率比较高, 执行耗时 0.00sec select count(*) from tb_sku; -- 由于tb_sku表中, 预先存入了1000w的记录, count一次,耗时 8.32sec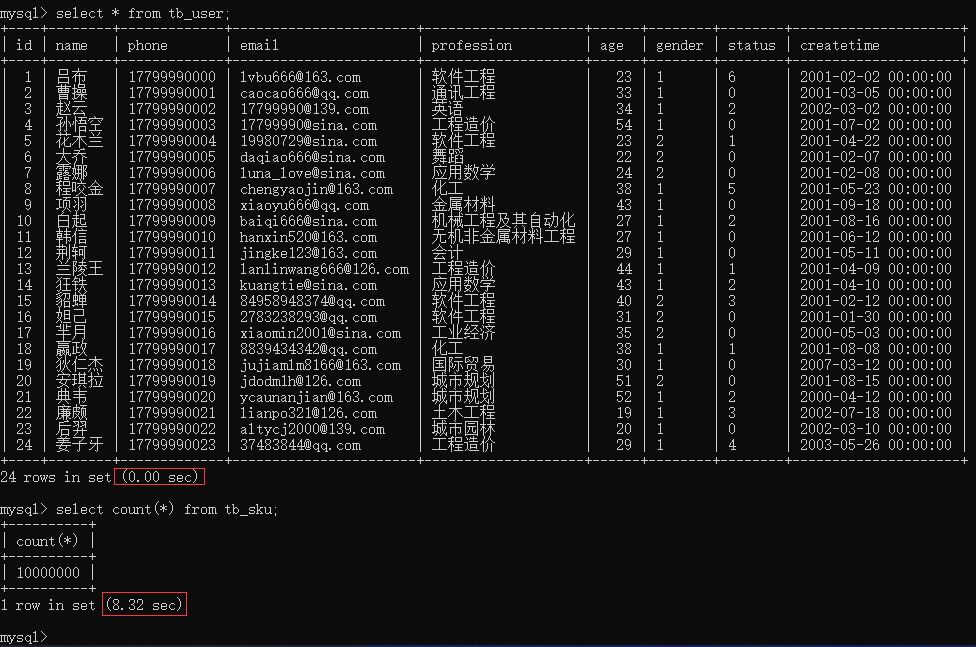
- 检查慢查询日志
最终我们发现,在慢查询日志中,只会记录执行时间超多我们预设时间(2s)的sql,执行较快的sql是不会记录的。
Windows中的日志:C:\ProgramData\MySQL\MySQL Server 8.0\Data\${name}-slow.log
Linux中的日志位置:/var/lib/mysql/${hostname}-slow.log
执行的指令:tail -f centos71-slow.log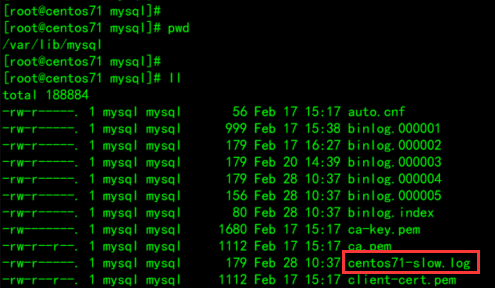
通过慢查询日志,就可以定位出执行效率比较低的SQL,从而有针对性的进行优化
5.4、profile详情
5.4.1、概述
show profiles 能够在做SQL优化时帮助我们了解时间都耗费到哪里去了。
5.4.2、查看当前MySQL是否支持profile操作
select @@have_profiling;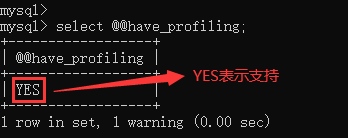
5.4.2、查看profile是否处于开启 状态
select @@profiling;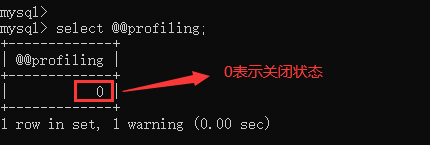
5.4.3、开启profile
SET [global|session] profiling = 1; 
5.4.4、profile已开启,下面执行的sql都会被记录
select * from tb_user;
select * from tb_user where id = 1;
select * from tb_user where name = '白起';
select count(*) from tb_sku;5.4.5、查看指令的执行耗时
- 查看每一条SQL的耗时基本情况
show profiles;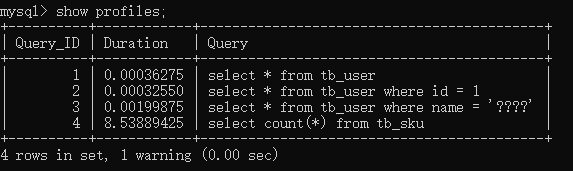
- 查看指定query_id的SQL语句各个阶段的耗时情况
# 语法 show profile for query query_id;# 案例 show profile for query 4;
- 查看指定query_id的SQL语句CPU的使用情况
# 语法: show profile cpu for query query_id;# 案例: show profile cpu for query 4;
5.5、explain
5.5.1、语法
-- 直接在select语句之前加上关键字 explain / desc
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件 ;
5.5.2、explain各个字段的含义
 六、索引使用
六、索引使用
6.1、验证索引效率
6.1.1、未使用索引执行count(*),观察执行结果
select count(*) from tb_sku;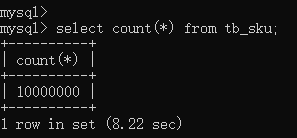
6.1.2、根据id查询,id有主键,观察执行结果
select * from tb_sku where id = 1\G;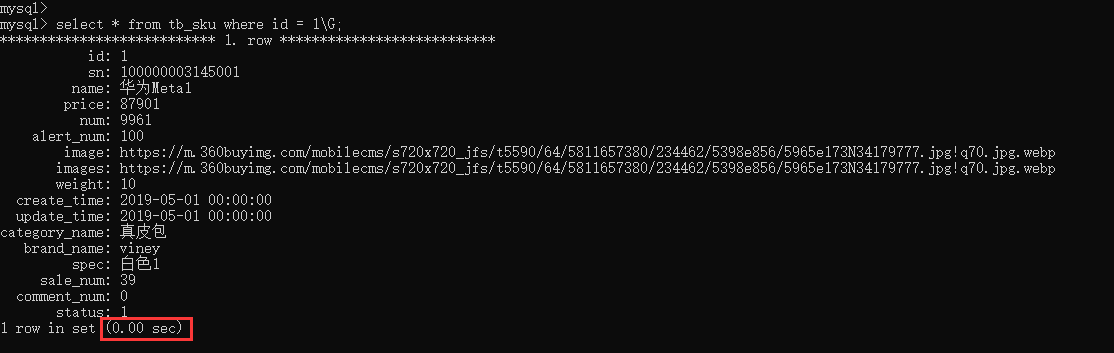
结果:可以看到即使有1000w的数据,根据id进行数据查询,性能依然很快,因为主键id是有索引的。
6.1.3、根据 sn 字段进行查询(sn字段无索引)
SELECT * FROM tb_sku WHERE sn = '100000003145001'\G;  结果: 到根据sn字段进行查询,查询返回了一条数据,结果耗时 20.78sec,就是因为sn没有索引,而造成查询效率很低
结果: 到根据sn字段进行查询,查询返回了一条数据,结果耗时 20.78sec,就是因为sn没有索引,而造成查询效率很低
6.1.4、根据 sn 字段进行查询(sn字段有索引)
# 在sn字段建立索引
create index idx_sku_sn on tb_sku(sn) ;SELECT * FROM tb_sku WHERE sn = '100000003145001'\G;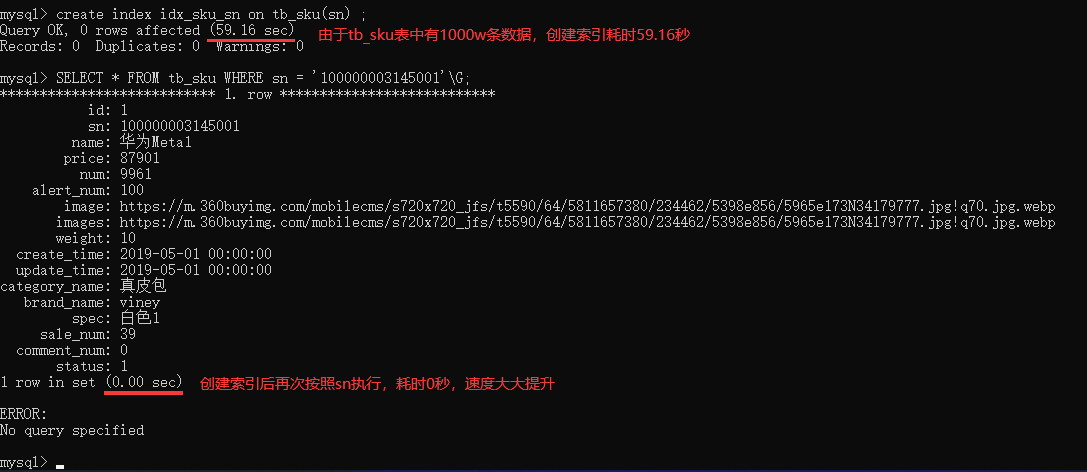
6.2、最左前缀法则
6.2.1、当前tb_user表中的所有索引
show index from tb_user;
6.2.2、案例1(满足最左前缀法则)
explain select * from tb_user where profession = '软件工程' and age = 31 and status = '0';
explain select * from tb_user where profession = '软件工程' and age = 31;
explain select * from tb_user where profession = '软件工程';
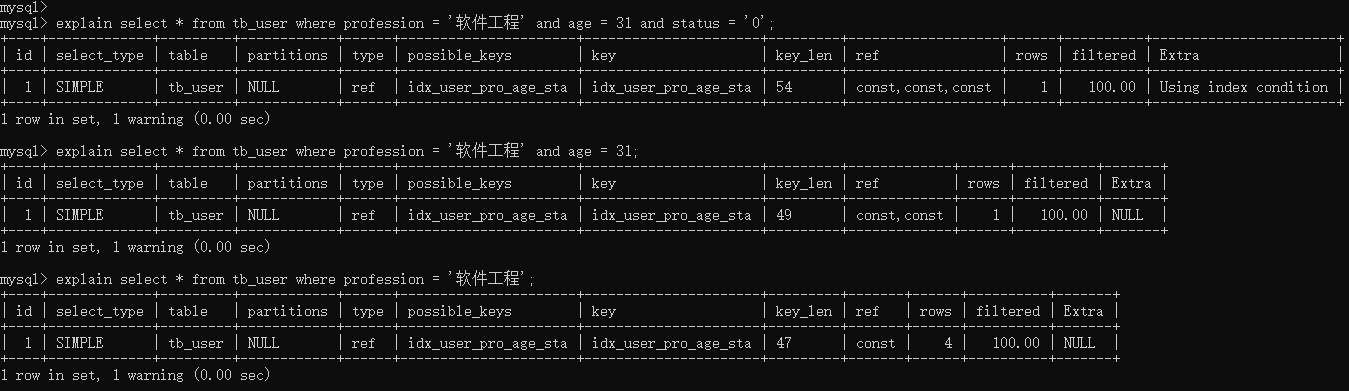
以上的这三组测试中,我们发现只要联合索引最左边的字段 profession存在,索引就会生效,只不过索引的长度不同。 而且由以上三组测试,我们也可以推测出profession字段索引长度为47、age字段索引长度为2、status字段索引长度为5。
6.2.3、案例2(不满足最左前缀法则)
explain select * from tb_user where age = 31 and status = '0';
explain select * from tb_user where status = '0'; 
通过上面的这两组测试,可以看到索引并未生效,原因是因为不满足最左前缀法则,联合索引最左边的列profession不存在。
6.2.4、案例3(满足最左前缀法则,跳过中间字段)
explain select * from tb_user where profession = '软件工程' and status = '0';
6.2.5、思考题

可以看到,是完全满足最左前缀法则的,索引长度54,联合索引是生效的。
6.3、范围查询
6.3.1、(>,<)
explain select * from tb_user where profession = '软件工程' and age > 30 and status = '0';
6.3.2、(>=,<=)
explain select * from tb_user where profession = '软件工程' and age >= 30 and status = '0';
当范围查询使用>= 或 <= 时,走联合索引了,但是索引的长度为54,就说明所有的字段都是走索引 的。
6.3.3、结论
6.4、索引失效情况
6.4.1、索引列运算
show index from tb_user;
- 根据phone字段进行等值查询(索引生效)
explain select * from tb_user where phone = '17799990015';
-
根据phone字段进行函数运算(索引失效)
explain select * from tb_user where substring(phone,10,2) = '15';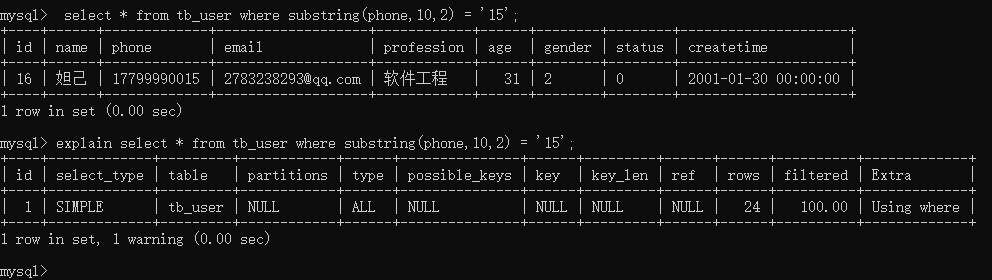
6.4.2、字符串不加引号
explain select * from tb_user where profession = '软件工程' and age = 31 and status = '0';
explain select * from tb_user where profession = '软件工程' and age = 31 and status = 0;
explain select * from tb_user where phone = '17799990015';
explain select * from tb_user where phone = 17799990015;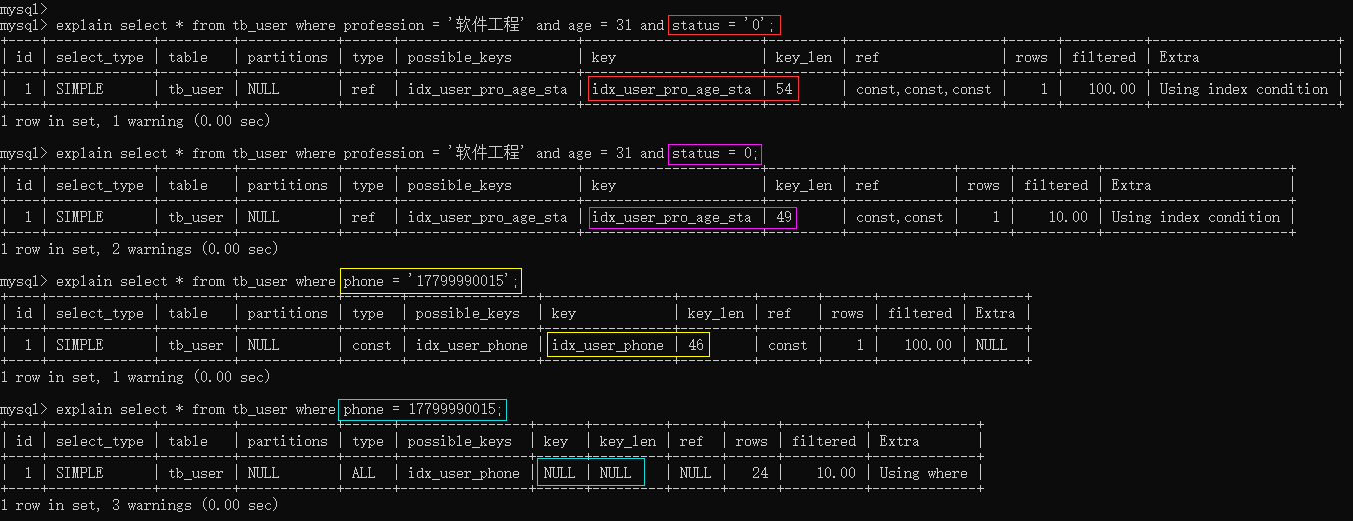
6.4.3、模糊查询
explain select * from tb_user where profession like '软件%';
explain select * from tb_user where profession like '%工程';
explain select * from tb_user where profession like '%工%';
6.4.4、or连接条件

explain select * from tb_user where id = 10 or age = 23;
explain select * from tb_user where phone = '17799990017' or age = 23;
explain select * from tb_user where id = 10 or phone = '17799990017';
针对age字段建立索引后,再次执行上述SQL
create index idx_user_age on tb_user(age);show index from tb_user;

总结:当or连接的条件,左右两侧字段都有索引时,索引才会生效。
6.4.5、数据分布影响
explain select * from tb_user where phone >= '17799990005';
explain select * from tb_user where phone >= '17799990015';
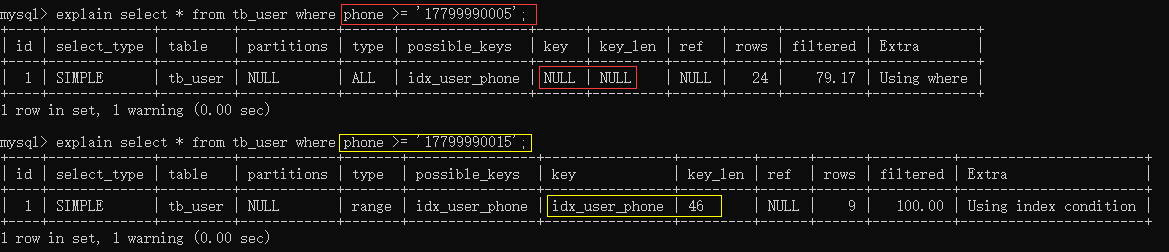
经过测试我们发现,相同的SQL语句,只是传入的字段值不同,最终的执行计划也完全不一样,这是为 什么呢? 就是因为MySQL在查询时,会评估使用索引的效率与走全表扫描的效率,如果走全表扫描更快,则放弃索引走全表扫描。 因为索引是用来索引少量数据的,如果通过索引查询返回大批量的数据,则还不如走全表扫描来的快,此时索引就会失效。
验证 is null 与 is not null 操作是否走索引
explain select * from tb_user where profession is null;
explain select * from tb_user where profession is not null;

将tb_user表的profession字段全部置为null,再次执行上述SQL,观察结果
update tb_user set profession = null;
最终我们看到,一模一样的SQL语句,先后执行了两次,结果查询计划是不一样的,为什么会出现这种现象呢,这是和数据库的数据分布有关系。查询时MySQL会评估,走索引快,还是全表扫描快,如果全表扫描更快,则放弃索引走全表扫描。 因此,is null 、is not null是否走索引,得具体情况具体分析,并不是固定的。
6.5、SQL提示
6.5.1、当前tb_user表的数据情况及索引情况
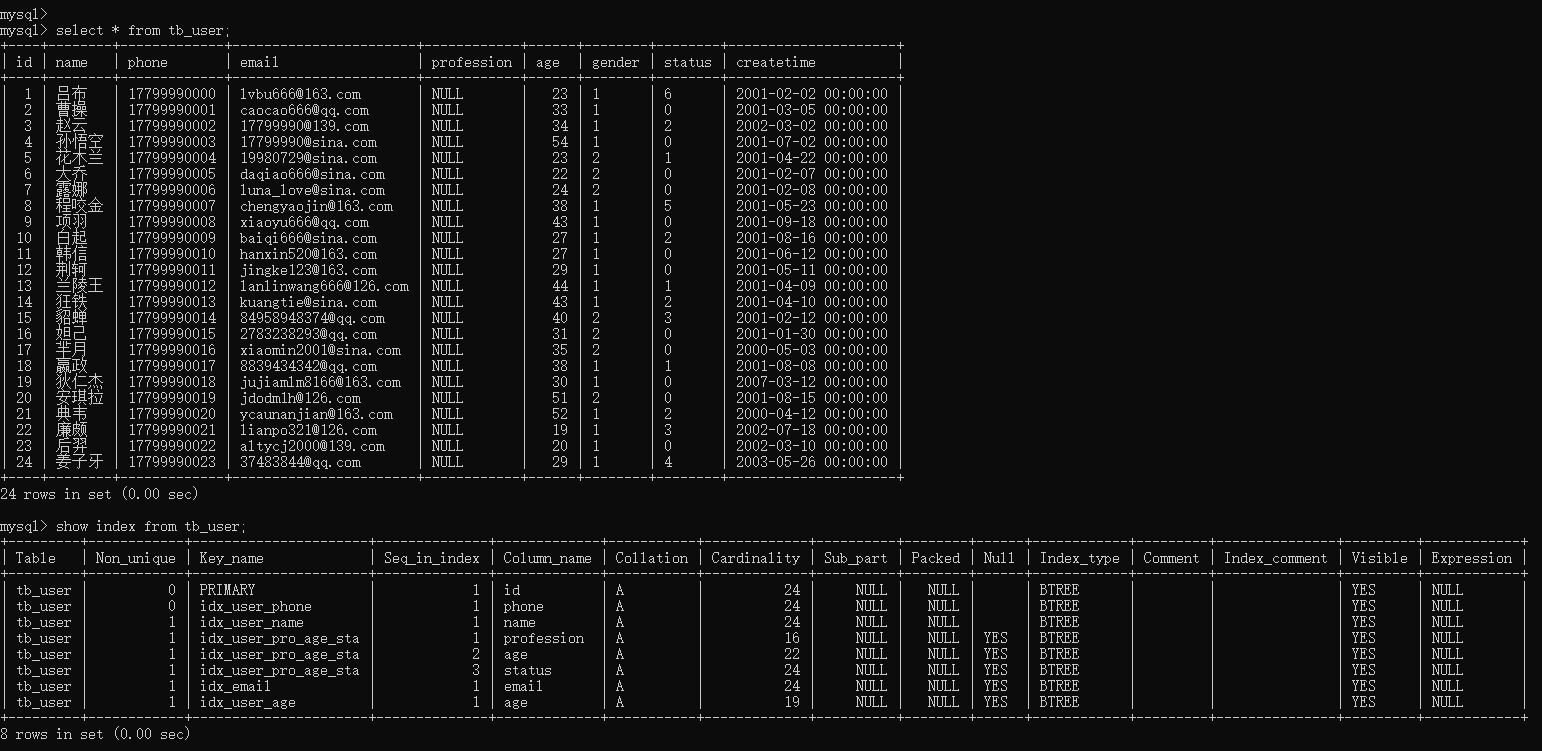
6.5.2、删除索引 idx_email 和 idx_user_age
drop index idx_user_age on tb_user;
drop index idx_email on tb_user;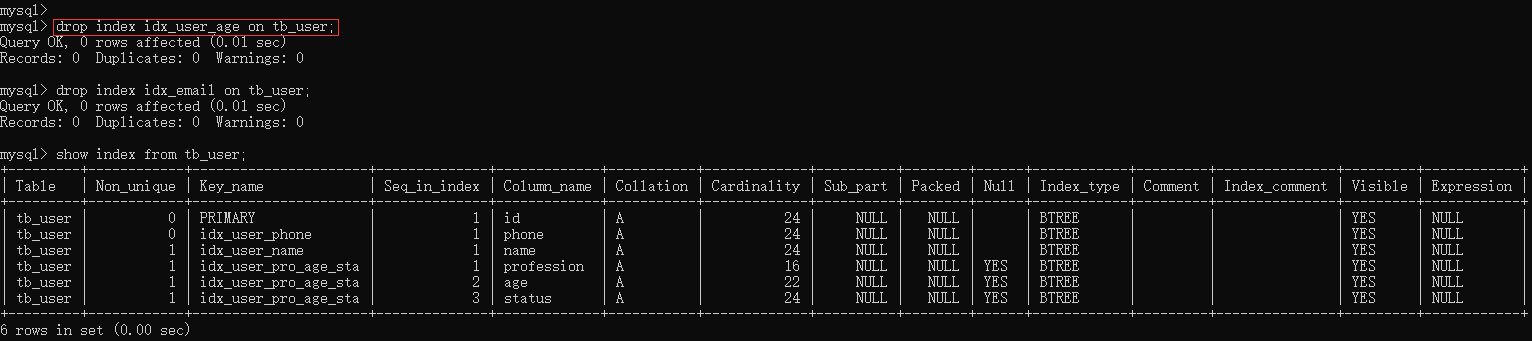
6.5.3、创建profession的单列索引,执行查询观察结果
create index idx_user_pro on tb_user(profession);
show index from tb_user;
explain select * from tb_user where profession = '软件工程';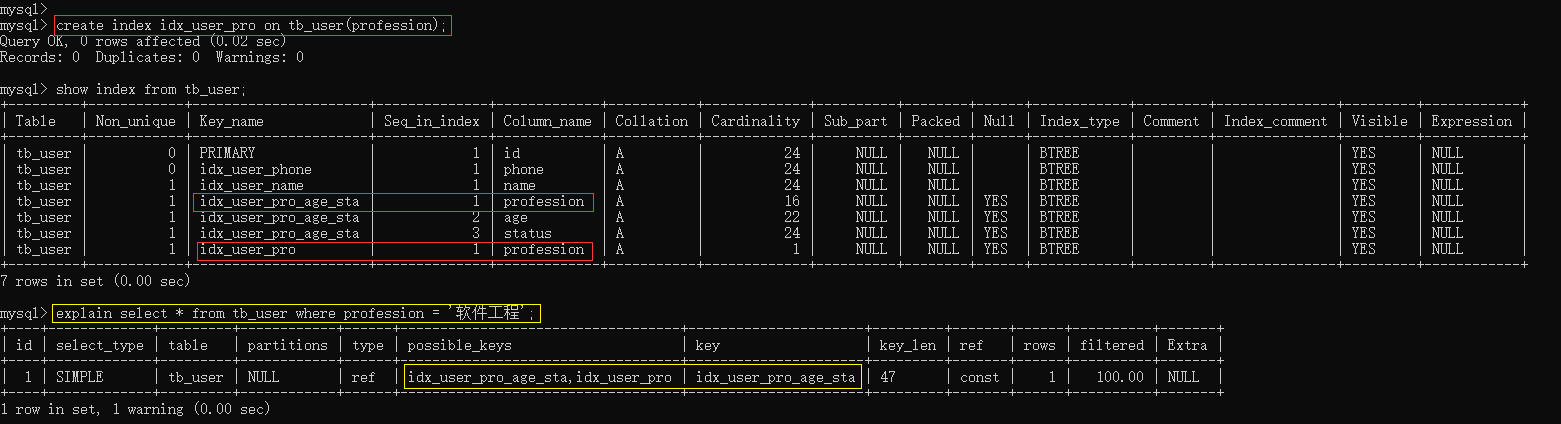 测试结果我们可以看到,possible_keys中 idx_user_pro_age_sta,idx_user_pro 这两个索引都可能用到,最终MySQL选择了idx_user_pro_age_sta索引。这是MySQL自动选择的结果。那么,我们能不能在查询的时候,自己来指定使用哪个索引呢? 答案是肯定的,此时就可以借助于MySQL的SQL提示来完成。 接下来,介绍一下SQL提示。SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示来达到优化操作的目的。
测试结果我们可以看到,possible_keys中 idx_user_pro_age_sta,idx_user_pro 这两个索引都可能用到,最终MySQL选择了idx_user_pro_age_sta索引。这是MySQL自动选择的结果。那么,我们能不能在查询的时候,自己来指定使用哪个索引呢? 答案是肯定的,此时就可以借助于MySQL的SQL提示来完成。 接下来,介绍一下SQL提示。SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示来达到优化操作的目的。
6.5.4、use index
explain select * from tb_user use index(idx_user_pro) where profession = '软件工程';
6.5.5、ignore index
忽略指定的索引。
explain select * from tb_user ignore index(idx_user_pro) where profession = '软件工程';
6.5.6、force index
强制使用索引。
explain select * from tb_user force index(idx_user_pro) where profession = '软件工程';
6.6、覆盖索引
6.6.1、概述
explain select id, profession from tb_user where profession = '软件工程' and age = 31 and status = '0' ;explain select id,profession,age, status from tb_user where profession = '软件工程' and age = 31 and status = '0' ;explain select id,profession,age, status, name from tb_user where profession = '软件工程' and age = 31 and status = '0' ;explain select * from tb_user where profession = '软件工程' and age = 31 and status = '0';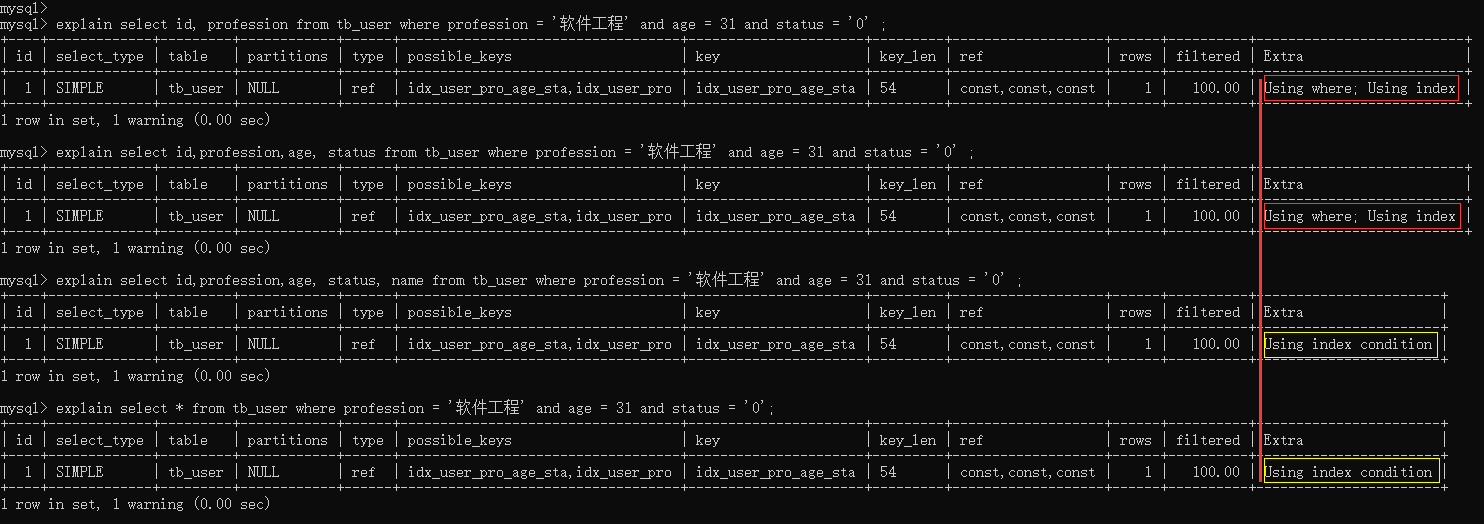
从上述的执行计划我们可以看到,这四条SQL语句的执行计划前面所有的指标都是一样的,看不出来差异。但是此时,我们主要关注的是后面的Extra,前面两天SQL的结果为 Using where; Using Index ; 而后面两条SQL的结果为: Using index condition。

因为,在tb_user表中有一个联合索引 idx_user_pro_age_sta,该索引关联了三个字段 profession、age、status,而这个索引也是一个二级索引,所以叶子节点下面挂的是这一行的主键id。 所以当我们查询返回的数据在 id、profession、age、status 之中,则直接走二级索引直接返回数据了。 如果超出这个范围,就需要拿到主键id,再去扫描聚集索引,再获取额外的数据了,这个过程就是回表。 而我们如果一直使用select * 查询返回所有字段值,很容易就会造成回表查询(除非是根据主键查询,此时只会扫描聚集索引)。
6.6.2、覆盖索引 & 回表查询
A、表结构及其示意图

id是主键,是一个聚集索引。 name字段建立了普通索引,是一个二级索引(辅助索引)
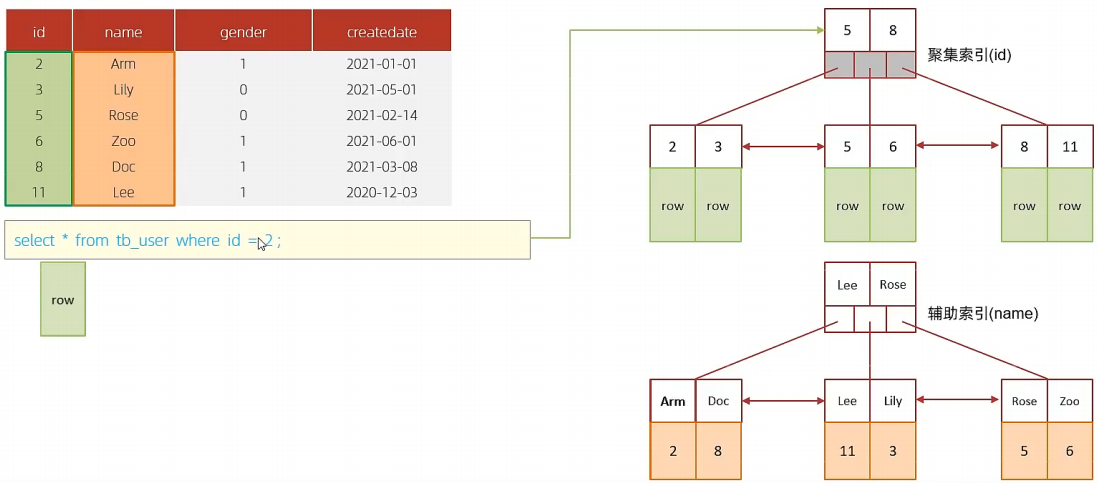

D、执行SQL:selet id,name,gender from tb_user where name = 'Arm';

6.6.3、思考
6.7、前缀索引
6.7.1、概述
6.7.2、语法
create index idx_xxxx on table_name(column(n)) ;示例:为tb_user表的email字段,建立长度为5的前缀索引
create index idx_email_5 on tb_user(email(5));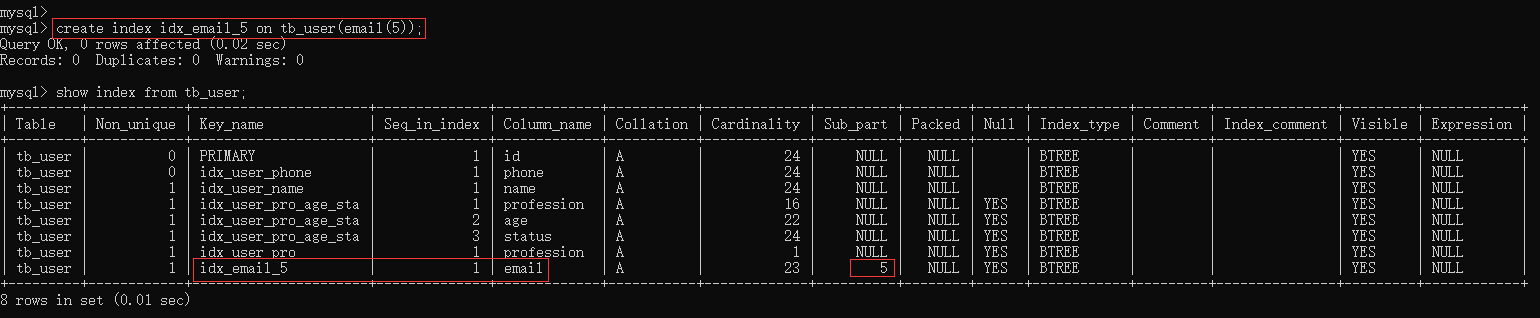
6.7.3、前缀长度
可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高, 唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
select count(distinct email) / count(*) from tb_user ;
select count(distinct substring(email,1,5)) / count(*) from tb_user ; 
6.7.4、前缀索引的查询流程

6.8、单列索引与联合索引
6.8.1、概述
6.8.2、当前tb_user表的索引情况
show index from tb_user;
在查询出来的索引中,既有单列索引,又有联合索引。 接下来执行一条SQL语句,看看其执行计划
explain select id,phone,name from tb_user where phone = '17799990010' and name = '韩信';
分析:通过上述执行计划可以看出来,在and连接的两个字段 phone、name上都是有单列索引的,但是最终mysql只会选择一个索引,也就是说,只能走一个字段的索引,此时是会回表查询的,效率不是最高。
在tb_user表中创建phone和name的联合索引后,再次执行上述SQL,观察结果:
create unique index idx_user_phone_name on tb_user(phone,name);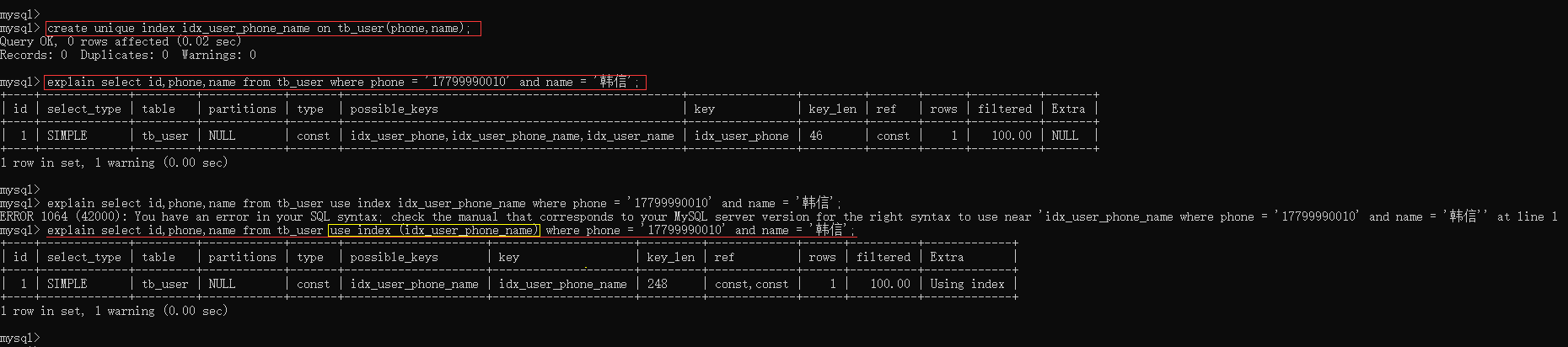
6.8.3、联合索引执行示意图

七、索引设计原则
相关文章:
系列七、索引
一、索引概述 1.1、概述 索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就可以…...
Java开发 - Elasticsearch初体验
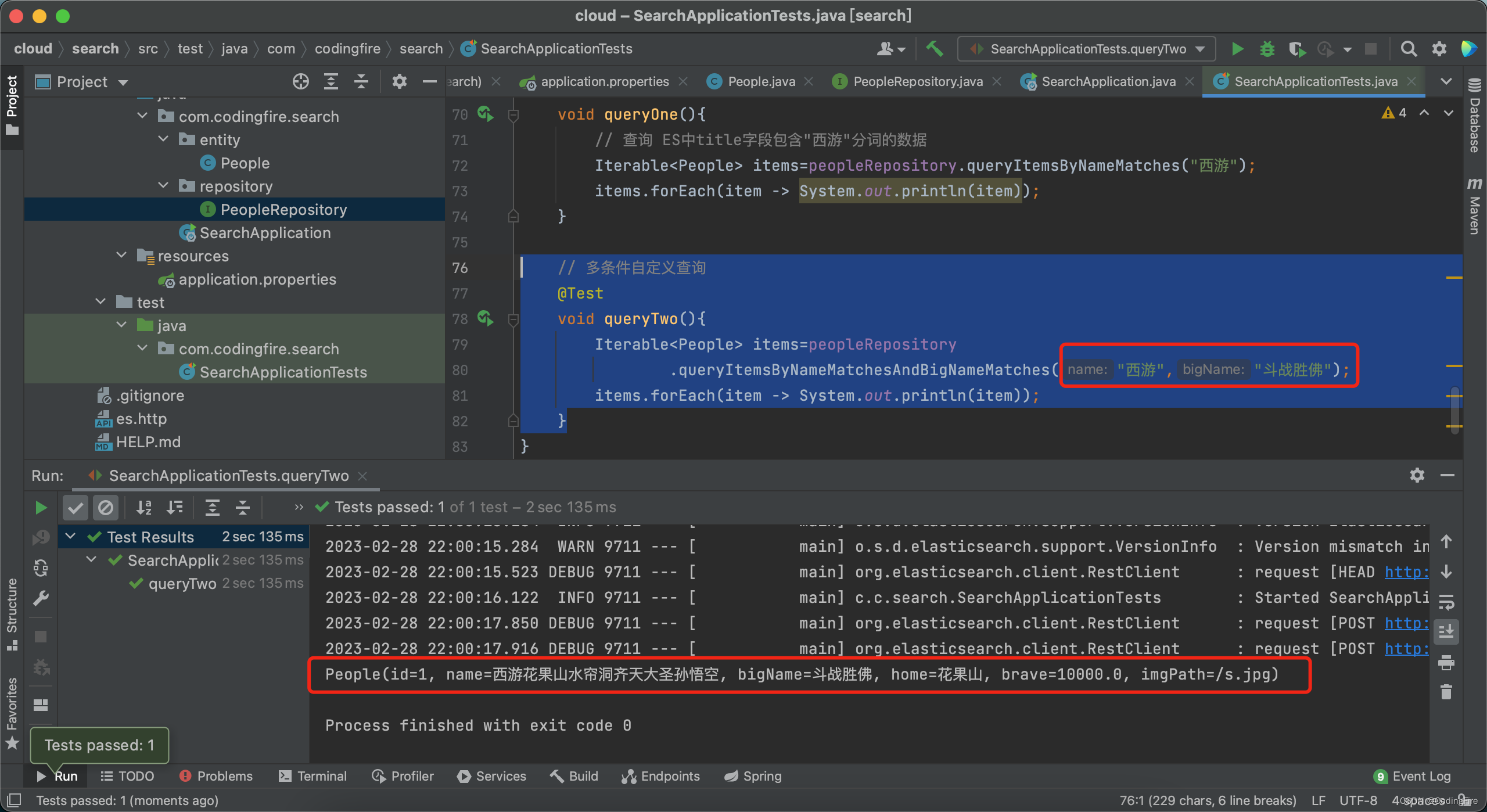
目录 前言 什么是es? 为什么要使用es? es查询的原理? es需要准备什么? es基本用法 创建工程 添加依赖 创建操作es的文件 使用ik分词插件 Spring Data 项目中引入Spring Data 添加依赖 添加配置 创建操作es的业务逻…...
mysql进阶
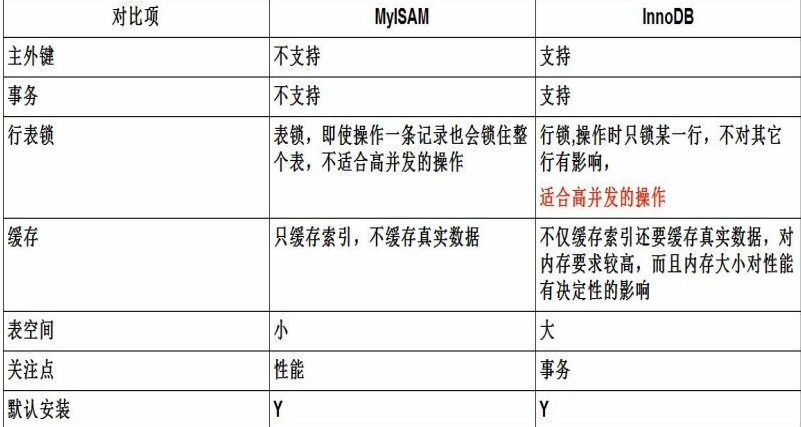
mysql进阶视图视图是一个基于查询的虚拟表,封装了一条sql语句,通俗的解释,视图就是一条select查询之后的结果集,视图并不存储数据,数据仍旧存储在表中。创建视图语句:create view view_admin as select * from admin使…...
SD卡损坏了?储存卡恢复数据就靠这3个方法
作为一种方便的储存设备,SD卡在我们的日常生活中使用非常广泛。但是,有时候我们可能会遇到SD卡损坏的情况,这时候里面存储的数据就会受到影响。SD卡里面保存着我们很多重要的数据,有些还是工作必须要使用的。 如果您遇到了这种情…...
)
springboot+实践(总结到位)
一。【SpringBoot注解-1】 牛逼:云深i不知处 【SpringBoot注解-1】:常见注解总览_云深i不知处的博客-CSDN博客 二。【SpringBoot-3】Lombok使用详解 【SpringBoot-3】Lombok使用详解_云深i不知处的博客-CSDN博客_springboot lombok 三࿰…...
CorelDRAW2023新功能有哪些?最新版cdr下载安装教程
使用 CorelDRAW2023,随时随都能进行设计创作。在 Windows或Mac上使用专为此平台设计的直观界面,以自己的风格尽情自由创作。同全球数百万信赖CorelDRAW Graphics Suite 的艺术家、设计者及小型企业主一样,大胆展现真我,创作出众的…...

PLC 程序设计标准化方法
PLC 程序设计的标准化方法先从内容或者方法层面进行流程的分解,将分解的内容称为要素,要素的有机结合便构成了标准化的设计。流程标准化设计完成之后需要对各个要素分别进行标准化的设计。2.1、 PLC 程序设计的要素分解与有机结合根据软件程序设计的一般性方法结合PLC 程序设计…...
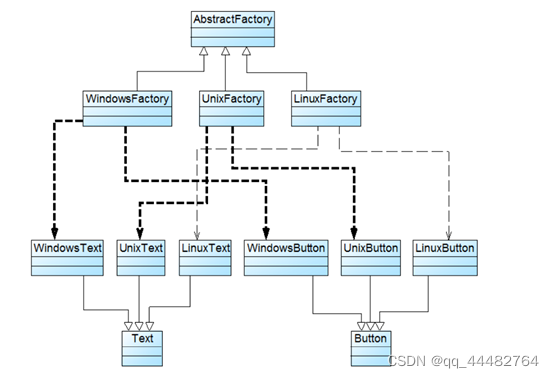
设计模式-笔记
文章目录七大原则单例模式桥模式 bridge观察者模式 observer责任链模式 Chain of Responsibility命令模式 Command迭代器模式 Iterator中介者模式 Mediator享元模式 Flyweight Pattern组合模式 composite装饰模式 Decorator外观模式 Facade简单工厂模式工厂方法模式工厂抽象模式…...
)
【全志T113-S3_100ask】12-3 Linux蓝牙通信实战(基于BlueZ的C语言BLE蓝牙编程)
【全志T113-S3_100ask】12-3 Linux蓝牙通信实战(基于BlueZ的C语言BLE蓝牙编程 背景(一)获取BlueZ源码(二)首次编译2-1 编写Makefile2-2 make编译2-3 首次测试2-3-1 开发板操作2-3-2 安卓端操作(三)源码分析3-1 程序入口3-2 蓝牙设备名称3-3 GATT服务(四)实战4-1 添加B…...

Java学习之路003——集合
1、 代码演示 【1】新增一个类,用来测试集合。先创建一组数组,数组可以存放不同的数据类型。对于Object类型的数组元素,可以通过.getClass方法获取到具体类型。 【2】如果数组指定类型为int的时候,使用.getClass()就会提示错误。 …...
生成和查看dump文件
在日常开发中,即使代码写得有多谨慎,免不了还是会发生各种意外的事件,比如服务器内存突然飙高,又或者发生内存溢出(OOM)。当发生这种情况时,我们怎么去排查,怎么去分析原因呢? 1. 什么是dump文…...

K8S集群1.24使用docker作为容器运行时出现就绪探针间歇性异常
文章目录1. 环境介绍2. 异常信息3. 分析问题3.1 kubernetes 健康检查3.1.1 存活探针3.1.2 就绪探针3.1.3 启动探针3.2 检测方法4. 解决办法1. 环境介绍 组件版本kubernetes1.24.2docker18.03.1-cecri-docker0.2.6 2. 异常信息 最近监测到 kubernetes 集群上 calico-node Pod 运…...

士大夫身份第三方水电费第三方
package com.snmocha.snbpm.job;import org.springframework.stereotype.Component;import com.xxl.job.core.handler.annotation.XxlJob;import lombok.extern.slf4j.Slf4j;/*** Demo定时任务.* Author:zhoudd* Date:2023-01-15*/ Component Slf4j publ…...
RDO一体化部署OpenStack
RDO一体化部署OpenStack 环境准备 安装centos7 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J785hZvT-1677578418769)(C:\Users\HONOR\AppData\Roaming\Typora\typora-user-images\image-20230228171254675.png)] 使用vmware安装安装centos7&a…...
CC2530+ESP8266使用MQTT协议上传阿里云的问题
ATMQTTPUB<LinkID>,<"topic">,<"data">,<qos>,<retain>LinkID: 当前只支持 0 topic: 发布主题, 最长 64 字节 data: 发布消息, data 不能包含 \0, 请确保整条 ATMQTTPUB 不超过 AT 指令的最大长度限制 qos: 发布服务质量, 参…...

Java基础:爬虫
1.本地爬虫 Pattern:表示正则表达式 Matcher:文本匹配器,作用按照正则表达式的规则去读取字符串,从头开始读取。在大串中去找符合匹配规则的子串。 1.2.获取Pattern对象 通过Pattern p Pattern.compile("正则表达式");获得 1.3.获取Matc…...
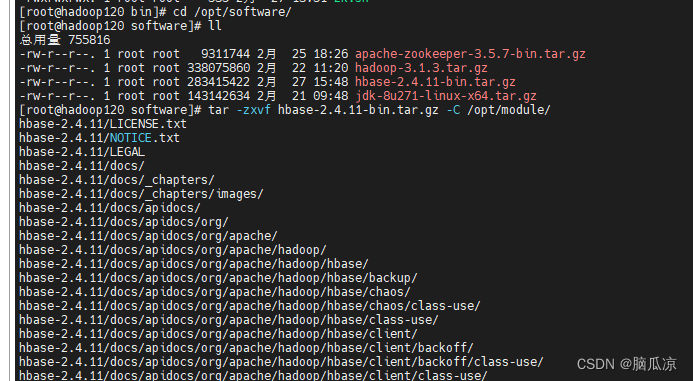
纯手动搭建大数据集群架构_记录008_搭建Hbase集群_配置集群高可用---大数据之Hadoop3.x工作笔记0169
首先准备安装包 然后将安装包分发到集群的其他机器上去 然后因为运行hbase需要zookeeper支持,所以这里首先要去,启动zk 走到/opt/module/hadoop-3.1.3/bin/zk.sh 然后 zk.sh start 启动一下,可以看到启动了已经 然后zk.sh status 可以看zookeeper的状态 然后我们再去启动一下…...

Linux系统认知——驱动认知
文章目录一、驱动相关概念1.什么是驱动2.被驱动设备分类3.设备文件的主设备号和次设备号4.设备驱动整体调用过程二、基于框架编写驱动代码1.驱动代码框架2.驱动代码的编译和测试三、树莓派I/O口驱动的编写1.微机的总线地址、物理地址、虚拟地址介绍2.通过树莓派芯片手册确定需要…...

Spring boot装载模板代码并自动运行
Spring boot装载模板代码涉及的子模块及准备省心Clickhouse批量写JSON多层级数据自动映射值模板代码生成及移交控制权给Spring IOC涉及的子模块及准备 最近比较有空,之前一直好奇,提交到线上考试的代码是如何执行测试的,在实现了基础的demo后…...

全国领先——液力悬浮仿生型人工心脏上市后在同济医院成功植入
2023年2月22日,华中科技大学同济医学院附属同济医院(同济医院)心脏大血管外科团队举办了一场气氛热烈的小规模庆祝活动,魏翔主任、程才副主任、王星宇副主任医师和李师亮医师到场,为终末期心衰患者黄先生“庆生”&…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

绕过 Xcode?使用 Appuploader和主流工具实现 iOS 上架自动化
iOS 应用的发布流程一直是开发链路中最“苹果味”的环节:强依赖 Xcode、必须使用 macOS、各种证书和描述文件配置……对很多跨平台开发者来说,这一套流程并不友好。 特别是当你的项目主要在 Windows 或 Linux 下开发(例如 Flutter、React Na…...

webpack面试题
面试题:webpack介绍和简单使用 一、webpack(模块化打包工具)1. webpack是把项目当作一个整体,通过给定的一个主文件,webpack将从这个主文件开始找到你项目当中的所有依赖文件,使用loaders来处理它们&#x…...

React核心概念:State是什么?如何用useState管理组件自己的数据?
系列回顾: 在上一篇《React入门第一步》中,我们已经成功创建并运行了第一个React项目。我们学会了用Vite初始化项目,并修改了App.jsx组件,让页面显示出我们想要的文字。但是,那个页面是“死”的,它只是静态…...

【大模型】RankRAG:基于大模型的上下文排序与检索增强生成的统一框架
文章目录 A 论文出处B 背景B.1 背景介绍B.2 问题提出B.3 创新点 C 模型结构C.1 指令微调阶段C.2 排名与生成的总和指令微调阶段C.3 RankRAG推理:检索-重排-生成 D 实验设计E 个人总结 A 论文出处 论文题目:RankRAG:Unifying Context Ranking…...

13.10 LangGraph多轮对话系统实战:Ollama私有部署+情感识别优化全解析
LangGraph多轮对话系统实战:Ollama私有部署+情感识别优化全解析 LanguageMentor 对话式训练系统架构与实现 关键词:多轮对话系统设计、场景化提示工程、情感识别优化、LangGraph 状态管理、Ollama 私有化部署 1. 对话训练系统技术架构 采用四层架构实现高扩展性的对话训练…...