hiveSQL开窗函数详解
hive开窗函数
文章目录
- hive开窗函数
- 1. 开窗函数概述
- 1.1 窗口函数分类
- 1.2 窗口函数和普通聚合函数的区别
- 2. 窗口函数的基本用法
- 2.1 基本用法
- 2.2 设置窗口的方法
- 2.2.1 window_name
- 2.2.2 partition by
- 2.2.3 order by 子句
- 2.2.4 rows指定窗口大小
- 窗口框架
- 2.3 开窗函数中加 order by 和不加 order by 的区别
- 3. 窗口函数用法举例
- 3.1 序号函数: row_number() / rank() / dese_rank()
- 3.2 分布函数: percent_rank() / cume_dist()
- 3.2.1 percent_rank()
- 3.2.2 cume_dist()
- 3.2.3 前后函数lag(expr, n, defval) 、 lead(expr, n, defval)
- 3.2.4 头尾函数:first_value(expr) 、 last_value(expr)
- 4 聚合函数+窗口函数
1. 开窗函数概述
窗口函数也称OLAP函数,对数据库进行实时分析处理
1.1 窗口函数分类
- 序号函数:row_number() / rank() / dense_rank()
- 分布函数:percent_rank() / cume_dist()
- 前后函数:lag() / lead()
- 头尾函数:first_val() / last_val()
- 聚合函数+窗口函数:sum() over()、 max()/min() over() 、avg() over()
- 其他函数:nth_value() / nfile()
1.2 窗口函数和普通聚合函数的区别
聚合函数是将多条记录聚合成一条,窗口函数是每条记录都会执行,有几条记录执行完还是几条
窗口函数兼具group by子句的分组功能和order by子句的排序功能,但是partition by 子句不具备group by的汇总功能
2. 窗口函数的基本用法
准备基础数据
CREATE TABLE exam_record (uid int COMMENT '用户ID',exam_id int COMMENT '试卷ID',start_time timestamp COMMENT '开始时间',submit_time timestamp COMMENT '提交时间',score tinyint COMMENT '得分'
)
COMMENT '考试记录表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
TBLPROPERTIES ("skip.header.line.count"="1");INSERT INTO exam_record(uid,exam_id,start_time,submit_time,score) VALUES
(1006, 9003, '2021-09-07 10:01:01', '2021-09-07 10:21:02', 84),
(1006, 9001, '2021-09-01 12:11:01', '2021-09-01 12:31:01', 89),
(1006, 9002, '2021-09-06 10:01:01', '2021-09-06 10:21:01', 81),
(1005, 9002, '2021-09-05 10:01:01', '2021-09-05 10:21:01', 81),
(1005, 9001, '2021-09-05 10:31:01', '2021-09-05 10:51:01', 81),
(1004, 9002, '2021-09-05 10:01:01', '2021-09-05 10:21:01', 71),
(1004, 9001, '2021-09-05 10:31:01', '2021-09-05 10:51:01', 91),
(1004, 9002, '2021-09-05 10:01:01', '2021-09-05 10:21:01', 80),
(1004, 9001, '2021-09-05 10:31:01', '2021-09-05 10:51:01', 80);select * from exam_record;
exam_record.uid exam_record.exam_id exam_record.start_time exam_record.submit_time exam_record.score
1006 9001 2021-09-01 12:11:01 2021-09-01 12:31:01 89
1006 9002 2021-09-06 10:01:01 2021-09-06 10:21:01 81
1005 9002 2021-09-05 10:01:01 2021-09-05 10:21:01 81
1005 9001 2021-09-05 10:31:01 2021-09-05 10:51:01 81
1004 9002 2021-09-05 10:01:01 2021-09-05 10:21:01 71
1004 9001 2021-09-05 10:31:01 2021-09-05 10:51:01 91
1004 9002 2021-09-05 10:01:01 2021-09-05 10:21:01 80
1004 9001 2021-09-05 10:31:01 2021-09-05 10:51:01 80
2.1 基本用法
窗口函数语法
<窗口函数> over[(partition by <列表清单>)] order by <排序列表清单> [rows between 开始位置 and 结束位置]
窗口函数:指要使用的分析函数,
over(): 用来指定窗口函数的范围,如果括号中什么都不写,则窗口包含where的所有行
select uidscore,sum(score) over() as sum_score
from exam_record;
运行结果
uid score sum_score
1006 89 654
1006 81 654
1005 81 654
1005 81 654
1004 71 654
1004 91 654
1004 80 654
1004 80 654
2.2 设置窗口的方法
2.2.1 window_name
给窗口指定一个别名
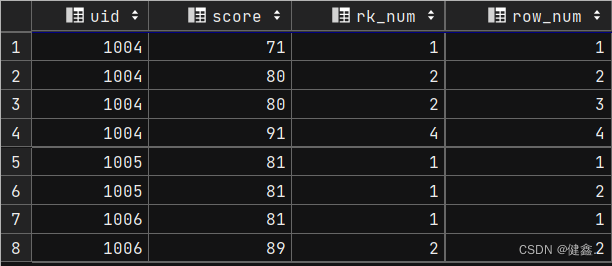
select uid,score,rank() over my_window_name as rk_num,row_number() over my_window_name as row_num
from exam_record
window my_window_name as (partition by uid order by score);
2.2.2 partition by
select uid,score,sum(score) over(partition by uid) as sum_score
from exam_record;
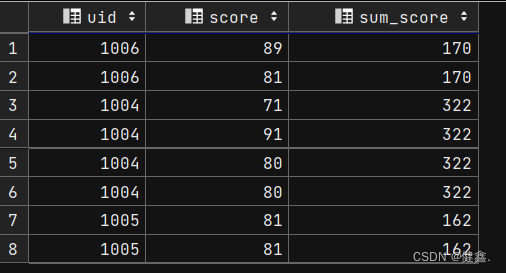
按照uid进行分组,分别求和
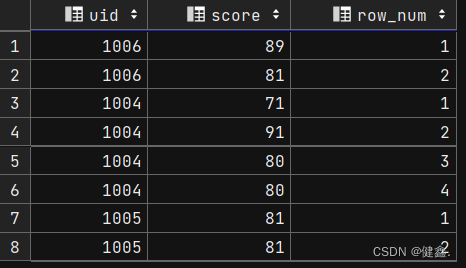
使用row_number()序号函数,表明序号
selectuid,score,row_number() over(partition by uid) as row_num
from exam_record;
2.2.3 order by 子句
按照哪些字段进行排序,窗口函数将按照排序后的记录进行编号
selectuid,score,row_number() over (partition by uid order by score desc) as row_num
from exam_record
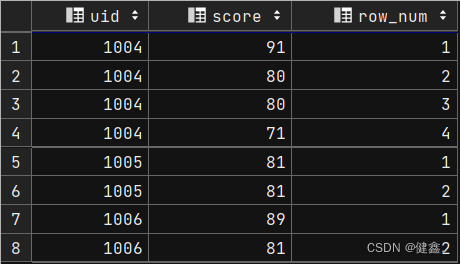
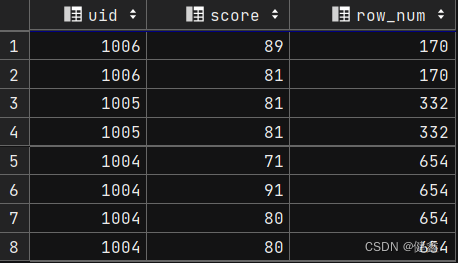
单独使用order by uid
selectuid,score,sum(score) over (order by uid desc) as row_num
from exam_record;
单独使用partition by uid
selectuid,score,sum(score) over (partition by uid) as row_num
from exam_record;
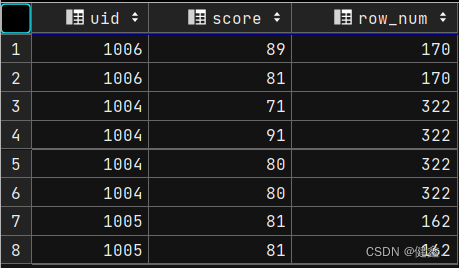
partition by进行分组内的求和,分区间独立
order by 对序号相同的进行求和,对序号不同的进行累加求和
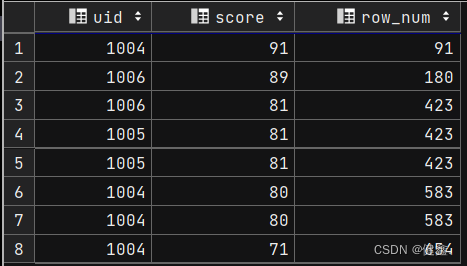
单独使用order by score
selectuid,score,sum(score) over (order by score desc) as row_num
from exam_record;
2.2.4 rows指定窗口大小
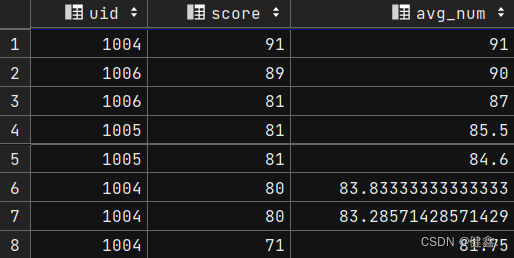
查看score的平均值
selectuid,score,avg(score) over(order by score desc) as avg_num
from exam_record
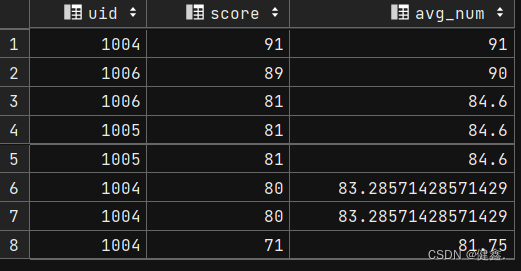
按照score降序排列,每一行计算前一行到当前行的score的平均值
selectuid,score,avg(score) over(order by row_score) as avg_num
from(selectuid,score,row_number() over(order by score desc) as row_scorefrom exam_record)res
窗口框架
指定窗口大小,框架是对窗口的进一步分区,框架有两种限定方式:
使用rows语句,通过指定当前行之前或之后的固定数目的行来限制分区中的行数
使用range语句,按照排列序列的当前值,根据相同值来确定分区中的行数
order by 字段名 range|rows 边界规则0 | [between 边界规则1] and 边界规则2
range和rows的区别
range按照值的范围进行范围的定义,rows按照行的范围进行范围的定义

- 使用框架时,必须要有order by子句,如果仅指定了order by子句未指定框架,则默认框架会使用range unbounded preceding and current row (从第一行到当前行的数据)
- 如果窗口函数没有指定order by子句,就不存在 rows|range 窗口的计算
- range 只支持使用unbounded 和 current row
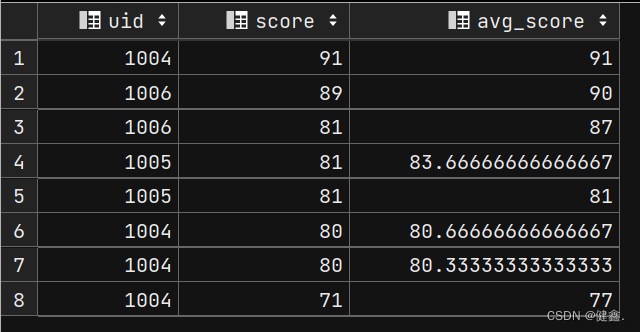
查询我与前两名的平均值
selectuid,score,avg(score) over(order by score desc rows 2 preceding) as avg_score
from exam_record;
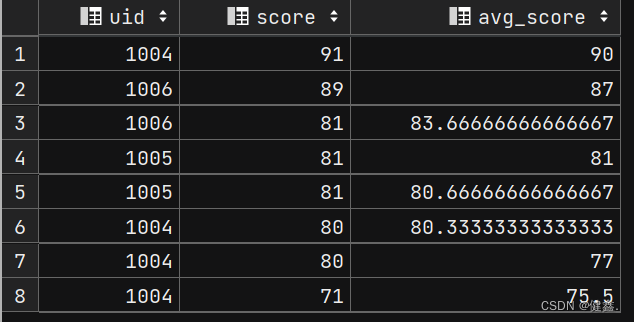
查询当前行及前后一行的平均值
selectuid,score,avg(score) over(order by score desc rows between 1 preceding and 1 following) as avg_score
from exam_record;
2.3 开窗函数中加 order by 和不加 order by 的区别
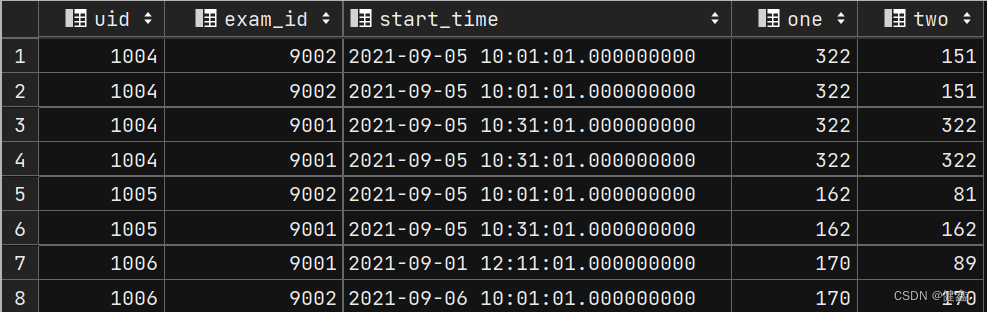
当开窗函数为排序函数时,如row_number()、rank()等,over中的order by 只起到窗口内排序的作用
当开窗函数为聚合函数时,如max、min、count等,over中的order by不仅对窗口内排序,还起到窗口内从当前行到之前所有行的聚合
selectuid,exam_id,start_time,sum(score) over(partition by uid) as one,sum(score) over(partition by uid order by start_time) as two
from exam_record
3. 窗口函数用法举例
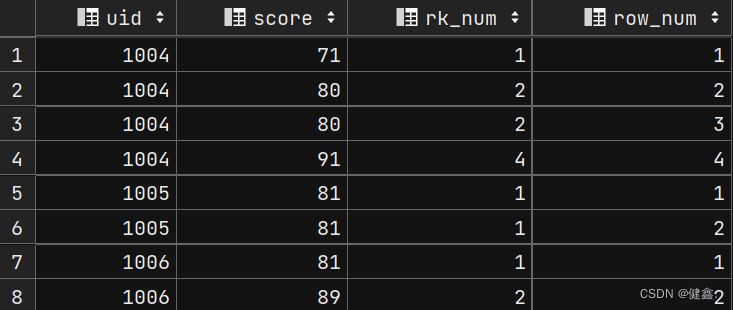
3.1 序号函数: row_number() / rank() / dese_rank()
区别:rank() : 并列排序,跳过重复序号------1、1、3
row_number() : 顺序排序——1、2、3
dese_rank() : 并列排序,不跳过重复序号——1、1、2
selectuid,score,rank() over my_window as rk_num,row_number() over my_window as row_num
from exam_record
window my_window as (partition by uid order by score);
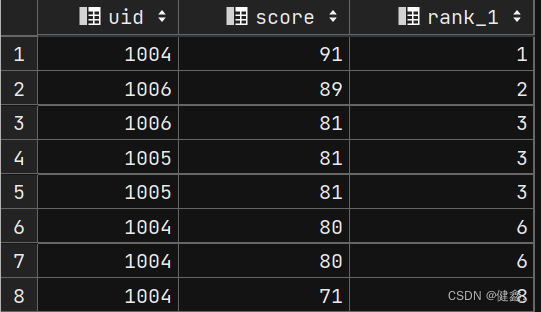
不使用窗口函数实现分数排序
SELECTP1.uid,P1.score,(SELECTCOUNT(P2.score)FROM exam_record P2WHERE P2.score > P1.score) + 1 AS rank_1
FROM exam_record P1
ORDER BY rank_1;
3.2 分布函数: percent_rank() / cume_dist()
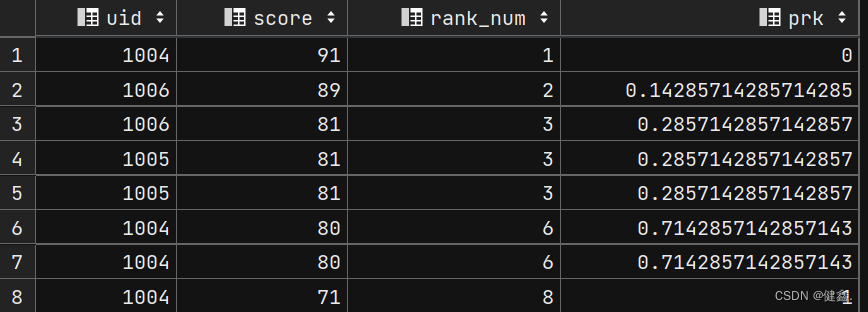
3.2.1 percent_rank()
percent_rank() 函数将某个数据在数据集的排位作为数据集的百分比值返回,范围0到1,
按照(rank - 1) / (rows - 1)进行计算,rank为rank()函数产生的序号,rows为当前窗口的记录总行数
selectuid,score,rank() over my_window as rank_num,percent_rank() over my_window as prk
from exam_record
window my_window as (order by score desc)
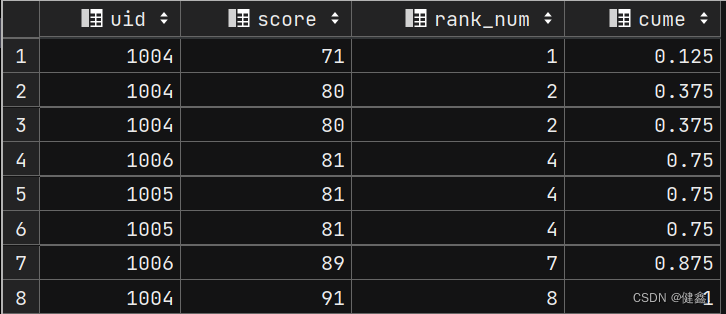
3.2.2 cume_dist()
如果升序排列,则统计:小于等于当前值的行数 / 总行数
如果降序排列,则统计:大于等于当前值的行数 / 总行数
查询小于等于当前score的比例
selectuid,score,rank() over my_window as rank_num,cume_dist() over my_window as cume
from exam_record
window my_window as (order by score asc);
3.2.3 前后函数lag(expr, n, defval) 、 lead(expr, n, defval)
lag()和lead()函数可以在同一次查询中取出同一字段前 n 行的数据和后 n 行的数据作为独立列
lag( exp_str,offset,defval) over(partition by .. order by …)lead(exp_str,offset,defval) over(partition by .. order by …)
- exp_str 是字段名
- offset是偏移量,即 n 的值
- defval默认值,如何当前行向前或向后 n 的位置超出表的范围,则会将defval的值作为返回值,默认为NULL
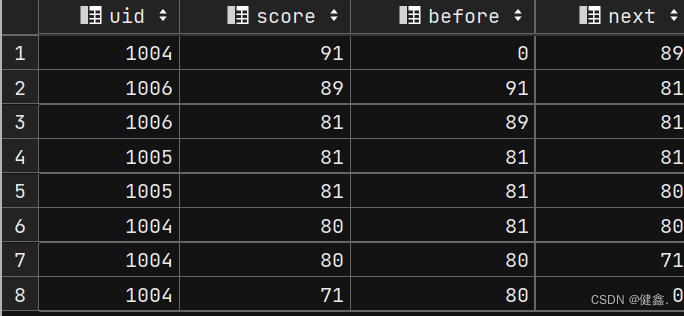
查询前1名同学和后一名同学的成绩和当前同学成绩的差值
- 先将前一名、后一名以及当前行的分数放在一起
selectuid,score,lag(score, 1, 0) over my_window as `before`,lead(score, 1, 0) over my_window as `next`
from exam_record
window my_window as (order by score desc);
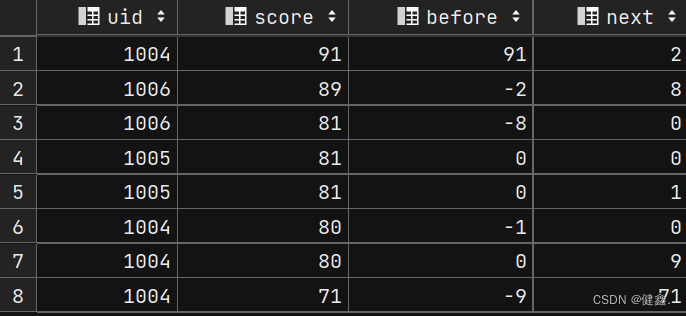
- 然后做差值
selectuid,score,score - before as before,score - next as next
from (selectuid,score,lag(score, 1, 0) over my_window as before,lead(score, 1, 0) over my_window as next
from exam_record
window my_window as (order by score desc))res
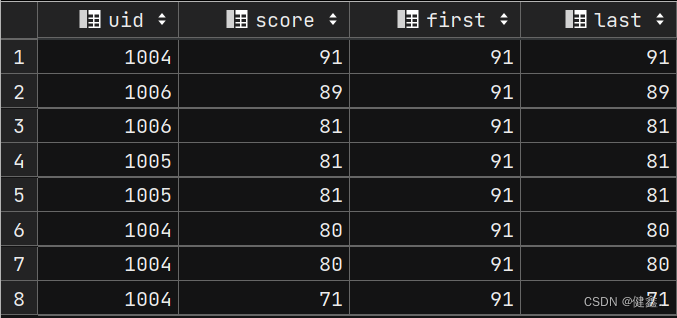
3.2.4 头尾函数:first_value(expr) 、 last_value(expr)
- 返回第一个expr:first_value(expr)
- 返回第二个expr:last_value(expr)
查询第一个和最后一个分数
selectuid,score,first_value(score) over my_window as first,last_value(score) over my_window as last
from exam_record
window my_window as (order by score desc);
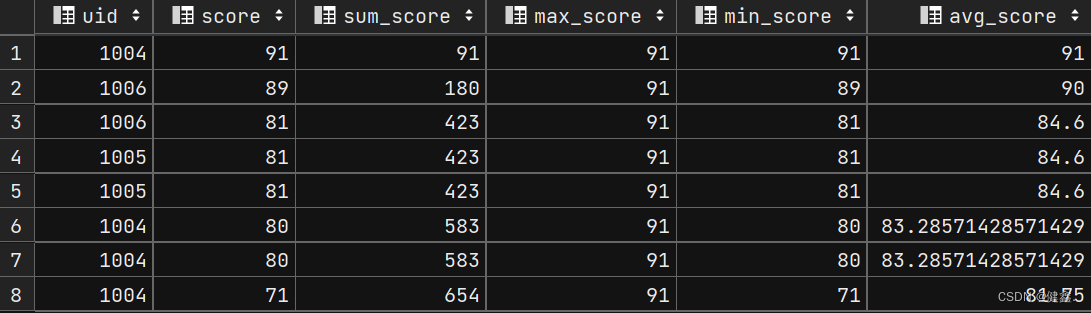
4 聚合函数+窗口函数
窗口函数在where之后执行,所以where需要用窗口函数作为条件
SELECTuid,score,sum(score) OVER my_window_name AS sum_score,max(score) OVER my_window_name AS max_score,min(score) OVER my_window_name AS min_score,avg(score) OVER my_window_name AS avg_scoreFROM exam_recordWINDOW my_window_name AS (ORDER BY score desc)
相关文章:
hiveSQL开窗函数详解
hive开窗函数 文章目录hive开窗函数1. 开窗函数概述1.1 窗口函数分类1.2 窗口函数和普通聚合函数的区别2. 窗口函数的基本用法2.1 基本用法2.2 设置窗口的方法2.2.1 window_name2.2.2 partition by2.2.3 order by 子句2.2.4 rows指定窗口大小窗口框架2.3 开窗函数中加 order by…...

深度学习基础实例与总结
一、神经网络 1 深度学习 1 什么是深度学习? 简单来说,深度学习就是一种包括多个隐含层 (越多即为越深)的多层感知机。它通过组合低层特征,形成更为抽象的高层表示,用以描述被识别对象的高级属性类别或特征。 能自生成数据的中…...

在 WIndows 下安装 Apache Tinkerpop (Gremlin)
一、安装 JDK 首先安装 Java JDK,这个去官网下载即可,我下载安装的 JDK19(jdk-19_windows-x64_bin.msi),细节不赘述。 二、去 Tinkerpop 网站下载 Gremlin 网址:https://tinkerpop.apache.org/ 点击下面…...

从软件的角度看待PCI和PCIE(一)
1.最容易访问的设备是什么? 是内存! 要读写内存,知道它的地址就可以了,不需要什么驱动程序; volatile unsigned int *p 0xffff8811; unsigned int val; *p val; val *p;只有内存能这样简单、方便的使用吗…...

DSP_TMS320F28377D_ADC学习笔记
前言 DSP各种模块的使用,基本上就是 GPIO复用配置、相关控制寄存器的配置、中断的配置。本文主要记录本人对ADC模块的学习笔记。TMS320F28377D上面有24路ADC专用IO,这意味着不需要进行GPIO复用配置。 只需要考虑相关控制寄存器和中断的配置。看代码请直…...
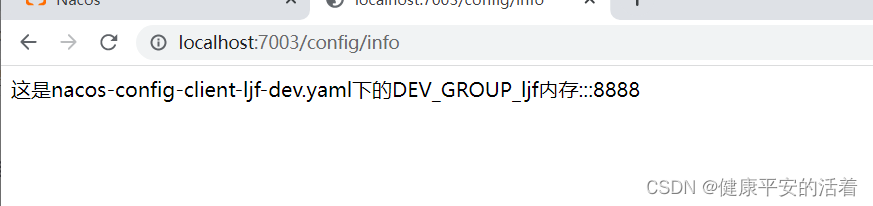
springcloud3 Nacos中namespace和group,dataId的联系
一 Namespance和group和dataId的联系 1.1 3者之间的联系 话不多说,上答案,如下图: namespance用于区分部署环境,group和dataId用于逻辑上区分两个目标对象。 二 案例:实现读取注册中心的不同环境下的配置文件 …...
[YOLO] yolo理解博客笔记
YOLO v2和V3 关于设置生成anchorbox,Boundingbox边框回归的过程详细解读 YOLO v2和V3 关于设置生成anchorbox,Boundingbox边框回归的个人理解https://blog.csdn.net/shenkunchang1877/article/details/105648111YOLO v1网络结构计算 Yolov1-pytorch版 …...

清华源pip安装Python第三方包
一、更换PIP源PIP源在国外,速度慢,可以更换为国内源,以下是国内一些常用的PIP源。豆瓣(douban) http://pypi.douban.com/simple/ (推荐)清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/阿里云 http://mirrors.aliyun.com/pypi/simple/中…...

python线程池【ThreadPoolExecutor()】批量获取博客园标题数据
转载:蚂蚁学python 网址:【【2021最新版】Python 并发编程实战,用多线程、多进程、多协程加速程序运行】 https://www.bilibili.com/video/BV1bK411A7tV/?p8&share_sourcecopy_web&vd_sourced0ef3d08fdeef1740bab49cdb3e96467实战案…...
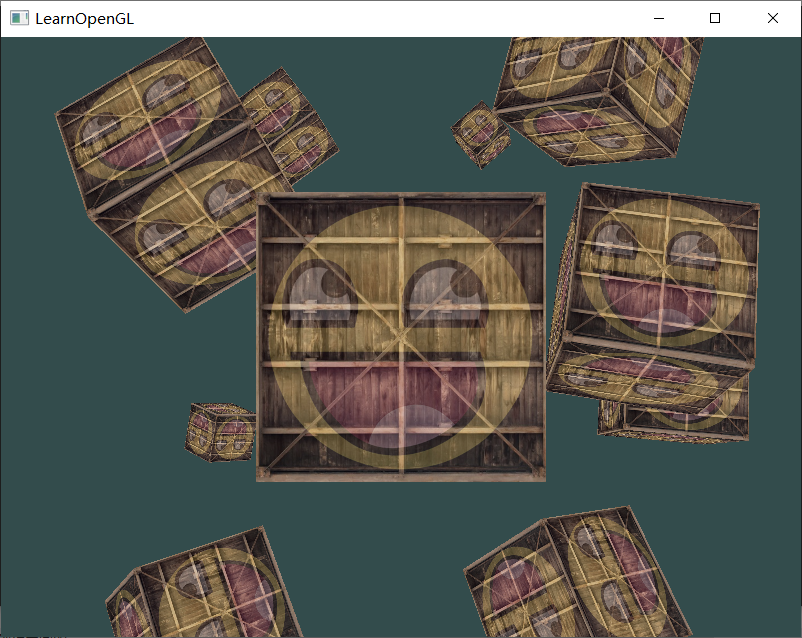
LearnOpenGL-入门-8.坐标系统
本人刚学OpenGL不久且自学,文中定有代码、术语等错误,欢迎指正 我写的项目地址:https://github.com/liujianjie/LearnOpenGLProject LearnOpenGL中文官网:https://learnopengl-cn.github.io/ 文章目录坐标系统概述局部空间世界空…...

windows10使用wsl2安装docker
配环境很麻烦,想利用docker的镜像环境跑一下代码整个安装过程的原理是:windows使用docker,必须先安装一个linux虚拟机,才可运行docker,而采用wsl2安装虚拟机是目前最好的方法第一步 windows安装wsl2控制面板->程序-…...

Javascript的API基本内容(六)
一、正则表达式 1.定义规则 const reg /表达式/ 其中/ /是正则表达式字面量正则表达式也是对象 2.使用正则 test()方法 用来查看正则表达式与指定的字符串是否匹配如果正则表达式与指定的字符串匹配 ,返回true,否则false 3.元字符 比如࿰…...

电压放大器和电流放大器的区别是什么意思
在日常电子实验测试中,很多电子工程师都会使用到电压放大器和电流放大器,但是很多新手工程师却无法区分两者的区别,下面就让安泰电子来为我们讲解电压放大器和电流放大器的区别是什么意思。 一、电压放大器介绍: 电压放大器是一种…...

cast提前!最简单有效的神经网络优化方法,没有之一!
做优化有时候真的很头疼,绞尽脑汁的想怎么做算法等价,怎么把神经网络各层指令流水起来,在确保整网精度的同时,又有高性能。 但有时做了半天,却发现流水根本就流不起来,总是莫名其妙地被卡住。 真的是一顿…...
)
LeetCode刷题——动态规划(C/C++)
文章目录[简单]买股票的最佳时机[简单]爬楼梯[中等]最长递增子序列[中等]最大连续子数组和[简单]买股票的最佳时机 原题链接 题解 min:今天之前买股的最低价 res:最大利润 每一天比较今天和往前的最低价差值能否比最大利润还大 class Solution { publ…...

车载智能终端TBOX
YD886 终端设备是基于GSM/WCDMA全网通讯方式的GPS定位移动终端,车载设备具有强大的车辆监控管理、CAN总线数据采集等功能,可以满足不同用户的需求,同时具备汽车行驶记录功能扩展应用。具体功能请以终端实际情况为准! 一、移动管家 车载智能终…...
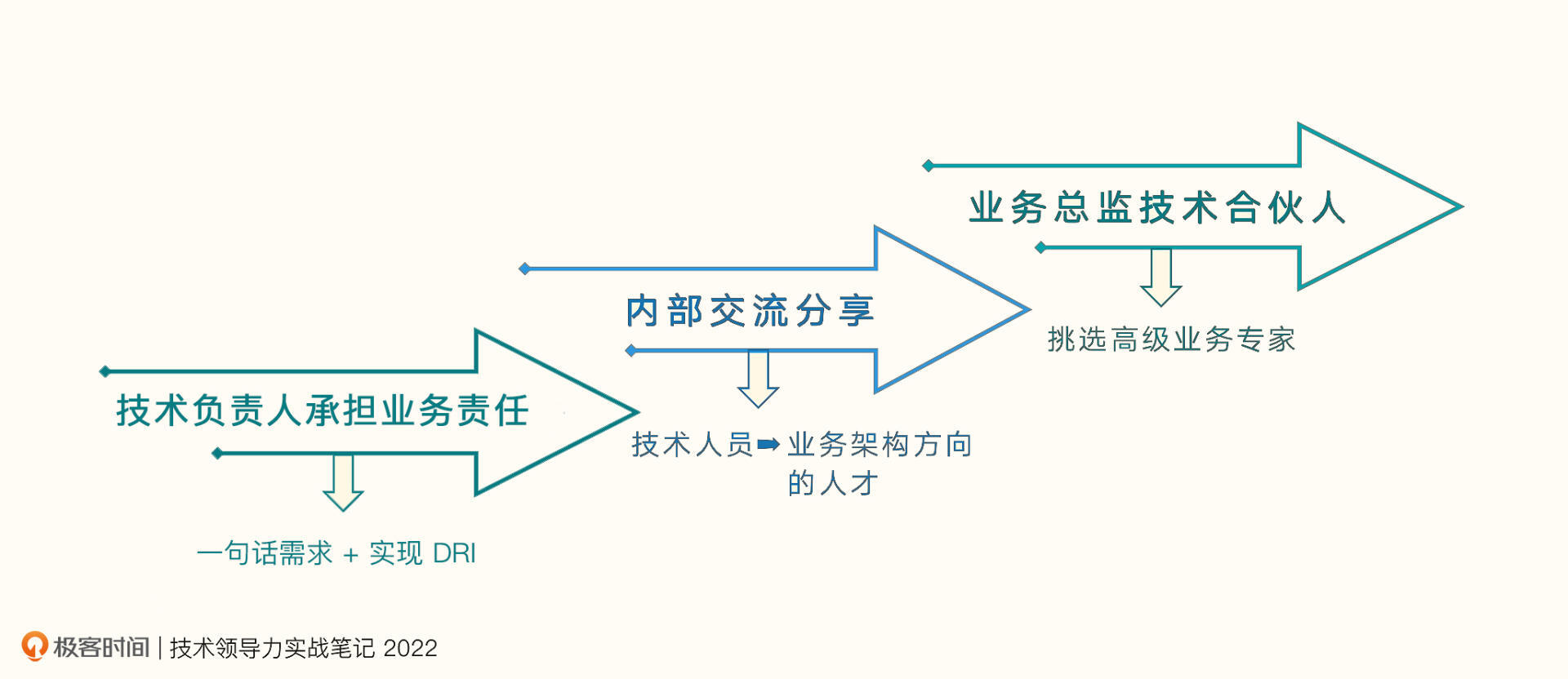
技术分担产品之忧(上):挑选有业务专家潜力的人
你好,我是王植萌,去哪儿网的高级技术总监、TC主席。从2014年起,担任一个部门的技术负责人,有8年技术总监经验、5年TC主席的经验。这节课我会从去哪儿网产研融合的经验出发,和你聊一聊怎么让技术分担产品之忧。 技术分…...
 树上机器人规划(简单版) BFS 二进制)
UVa 12569 Planning mobile robot on Tree (EASY Version) 树上机器人规划(简单版) BFS 二进制
题目链接:Planning mobile robot on Tree (EASY Version) 题目描述: 给定一棵树,树上有一个位置存在一个机器人,其他mmm个位置存在石头,保证初始状态一个结点最多一个物体(一个石头或者一个机器人或者为空…...
intel的集成显卡(intel(r) uhd graphics) 配置stable diffusion
由于很多商务本没有独立显卡,只有Intel的集成显卡,在配置安装stable diffusion 时候需要特殊对待,参考不少帖子,各取部分现稍加整合。整体思路分两个部分:第一步是先配置环境,主要是安装Anaconda Pytorch&…...

【数据库的基础知识(2)】
🌹作者:云小逸 📝个人主页:云小逸的主页 📝Github:云小逸的Github 🤟motto:要敢于一个人默默的面对自己,强大自己才是核心。不要等到什么都没有了,才下定决心去做。种一颗树,最好的时间是十年前…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...

绕过 Xcode?使用 Appuploader和主流工具实现 iOS 上架自动化
iOS 应用的发布流程一直是开发链路中最“苹果味”的环节:强依赖 Xcode、必须使用 macOS、各种证书和描述文件配置……对很多跨平台开发者来说,这一套流程并不友好。 特别是当你的项目主要在 Windows 或 Linux 下开发(例如 Flutter、React Na…...