【消息中间件】Apache Kafka 教程
文章目录
- Apache Kafka 概述
- 什么是消息系统?
- 点对点消息系统
- 发布 - 订阅消息系统
- 什么是Kafka?
- 好处
- 用例
- 需要Kafka
- Apache Kafka 基础
- (一)消息系统
- 1、点对点的消息系统
- 2、发布-订阅消息系统
- (二)Apache Kafka 简介
- (三)Apache Kafka基本原理
- 1、分布式和分区(distributed、partitioned)
- 2、副本(replicated )
- 3、整体数据流程
- 4、消息传送机制
- Apache Kafka 集群架构
- Apache Kafka 工作流程
- 发布 - 订阅消息的工作流程
- 队列消息/用户组的工作流
- ZooKeeper 的作用
- Apache Kafka 安装步骤
- 步骤1 - 验证Java安装
- 步骤1.1 - 下载JDK
- 步骤1.2 - 提取文件
- 步骤1.3 - 移动到选择目录
- 步骤1.4 - 设置路径
- 步骤1.5 - Java替代
- 步骤1.6 - 现在使用第1步中说明的验证命令(java -version)验证java。
- 步骤2 - ZooKeeper框架安装
- 步骤2.1 - 下载ZooKeeper
- 步骤2.2 - 提取tar文件
- 步骤2.4 - 启动ZooKeeper服务器
- 步骤2.5 - 启动CLI
- 步骤2.6 - 停止Zookeeper服务器
- 步骤3 - Apache Kafka安装
- 步骤3.1 - 下载Kafka
- 步骤3.2 - 解压tar文件
- 步骤3.3 - 启动服务器
- 步骤4 - 停止服务器
- Apache Kafka 基本操作
- 启动ZooKeeper
- 启动消费者以接收消息
- 单节点多代理配置
- config / server-one.properties
- config / server-two.properties
- 启动多个代理 - 在三台服务器上进行所有更改后,打开三个新终端,逐个启动每个代理。
- 创建主题
- 启动生产者以发送消息
- 启动消费者以接收消息
- 修改主题
- 删除主题
- Apache Kafka 简单生产者示例
- KafkaProducer API
- 生产者API
- 生产者类
- public void close()
- 配置设置
- ProducerRecord API
- SimpleProducer应用程序
- 简单消费者示例
- ConsumerRecord API
- ConsumerRecords API
- 配置设置
- SimpleConsumer应用程序
- Apache Kafka 消费者组示例
- 消费者群体
- 重新平衡消费者
- Apache Kafka 整合 Storm
- 关于Storm
- 与Storm集成
- 概念流
- BrokerHosts - ZkHosts & StaticHosts
- SpoutConfig API
- SchemeAsMultiScheme
- KafkaSpout API
- 创建Bolt
- 提交拓扑
- 执行
- Apache Kafka 与Spark的集成
- 关于Spark
- 与Spark集成
- SparkConf API
- StreamingContext API
- KafkaUtils API
- 构建脚本
- 编译/包装
- 提交到Spark
- Apache Kafka 实时应用程序(Twitter)
- Twitter Streaming API
- 汇编
- 执行
- Apache Kafka 工具
- 系统工具
- 复制工具
- Apache Kafka 应用
- Netflix
- Mozilla
- Oracle
Apache Kafka 概述
在大数据中,使用了大量的数据。 关于数据,我们有两个主要挑战。第一个挑战是如何收集大量的数据,第二个挑战是分析收集的数据。 为了克服这些挑战,您必须需要一个消息系统。
Kafka专为分布式高吞吐量系统而设计。 Kafka往往工作得很好,作为一个更传统的消息代理的替代品。 与其他消息传递系统相比,Kafka具有更好的吞吐量,内置分区,复制和固有的容错能力,这使得它非常适合大规模消息处理应用程序。
什么是消息系统?
消息系统负责将数据从一个应用程序传输到另一个应用程序,因此应用程序可以专注于数据,但不担心如何共享它。 分布式消息传递基于可靠消息队列的概念。 消息在客户端应用程序和消息传递系统之间异步排队。 有两种类型的消息模式可用 - 一种是点对点,另一种是发布 - 订阅(pub-sub)消息系统。 大多数消息模式遵循 pub-sub 。
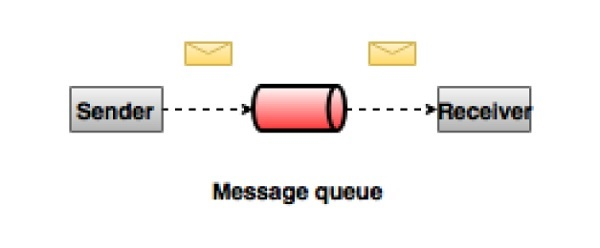
点对点消息系统
在点对点系统中,消息被保留在队列中。 一个或多个消费者可以消耗队列中的消息,但是特定消息只能由最多一个消费者消费。 一旦消费者读取队列中的消息,它就从该队列中消失。 该系统的典型示例是订单处理系统,其中每个订单将由一个订单处理器处理,但多个订单处理器也可以同时工作。 下图描述了结构。
发布 - 订阅消息系统
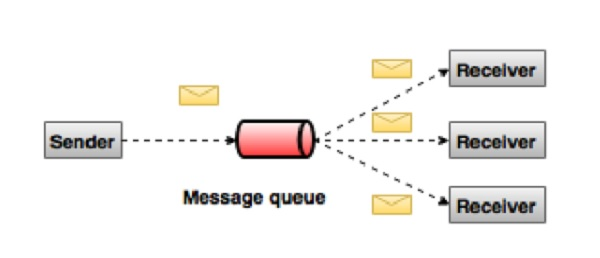
在发布 - 订阅系统中,消息被保留在主题中。 与点对点系统不同,消费者可以订阅一个或多个主题并使用该主题中的所有消息。 在发布 - 订阅系统中,消息生产者称为发布者,消息使用者称为订阅者。 一个现实生活的例子是Dish电视,它发布不同的渠道,如运动,电影,音乐等,任何人都可以订阅自己的频道集,并获得他们订阅的频道时可用。
什么是Kafka?
Apache Kafka是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使您能够将消息从一个端点传递到另一个端点。 Kafka适合离线和在线消息消费。 Kafka消息保留在磁盘上,并在集群内复制以防止数据丢失。 Kafka构建在ZooKeeper同步服务之上。 它与Apache Storm和Spark非常好地集成,用于实时流式数据分析。
好处
以下是Kafka的几个好处 -
-
可靠性 - Kafka是分布式,分区,复制和容错的。
-
可扩展性 - Kafka消息传递系统轻松缩放,无需停机。
-
耐用性 - Kafka使用分布式提交日志,这意味着消息会尽可能快地保留在磁盘上,因此它是持久的。
-
性能 - Kafka对于发布和订阅消息都具有高吞吐量。 即使存储了许多TB的消息,它也保持稳定的性能。
Kafka非常快,并保证零停机和零数据丢失。
用例
Kafka可以在许多用例中使用。 其中一些列出如下 -
-
指标 - Kafka通常用于操作监控数据。 这涉及聚合来自分布式应用程序的统计信息,以产生操作数据的集中馈送。
-
日志聚合解决方案 - Kafka可用于跨组织从多个服务收集日志,并使它们以标准格式提供给多个服务器。
-
流处理 - 流行的框架(如Storm和Spark Streaming)从主题中读取数据,对其进行处理,并将处理后的数据写入新主题,供用户和应用程序使用。 Kafka的强耐久性在流处理的上下文中也非常有用。
需要Kafka
Kafka是一个统一的平台,用于处理所有实时数据Feed。 Kafka支持低延迟消息传递,并在出现机器故障时提供对容错的保证。 它具有处理大量不同消费者的能力。 Kafka非常快,执行2百万写/秒。 Kafka将所有数据保存到磁盘,这实质上意味着所有写入都会进入操作系统(RAM)的页面缓存。 这使得将数据从页面缓存传输到网络套接字非常有效。
Apache Kafka 基础
对于大数据,我们要考虑的问题有很多,首先海量数据如何收集(如 Flume),然后对于收集到的数据如何存储(典型的分布式文件系统 HDFS、分布式数据库 HBase、NoSQL 数据库 Redis),其次存储的数据不是存起来就没事了,要通过计算从中获取有用的信息,这就涉及到计算模型(典型的离线计算 MapReduce、流式实时计算Storm、Spark),或者要从数据中挖掘信息,还需要相应的机器学习算法。在这些之上,还有一些各种各样的查询分析数据的工具(如 Hive、Pig 等)。除此之外,要构建分布式应用还需要一些工具,比如分布式协调服务 Zookeeper 等等。
这里,我们讲到的是消息系统,Kafka 专为分布式高吞吐量系统而设计,其他消息传递系统相比,Kafka 具有更好的吞吐量,内置分区,复制和固有的容错能力,这使得它非常适合大规模消息处理应用程序。
(一)消息系统
首先,我们理解一下什么是消息系统:消息系统负责将数据从一个应用程序传输到另外一个应用程序,使得应用程序可以专注于处理逻辑,而不用过多的考虑如何将消息共享出去。
分布式消息系统基于可靠消息队列的方式,消息在应用程序和消息系统之间异步排队。实际上,消息系统有两种消息传递模式:一种是点对点,另外一种是基于发布-订阅(publish-subscribe)的消息系统。
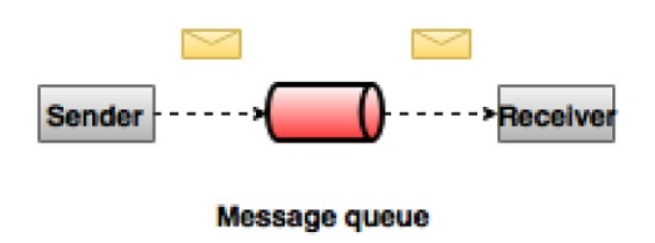
1、点对点的消息系统
在点对点的消息系统中,消息保留在队列中,一个或者多个消费者可以消耗队列中的消息,但是消息最多只能被一个消费者消费,一旦有一个消费者将其消费掉,消息就从该队列中消失。这里要注意:多个消费者可以同时工作,但是最终能拿到该消息的只有其中一个。最典型的例子就是订单处理系统,多个订单处理器可以同时工作,但是对于一个特定的订单,只有其中一个订单处理器可以拿到该订单进行处理。
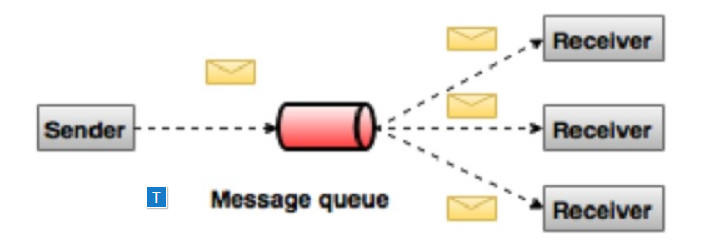
2、发布-订阅消息系统
在发布 - 订阅系统中,消息被保留在主题中。 与点对点系统不同,消费者可以订阅一个或多个主题并使用该主题中的所有消息。在发布 - 订阅系统中,消息生产者称为发布者,消息使用者称为订阅者。 一个现实生活的例子是Dish电视,它发布不同的渠道,如运动,电影,音乐等,任何人都可以订阅自己的频道集,并获得他们订阅的频道时可用。
(二)Apache Kafka 简介
Kafka is a distributed,partitioned,replicated commit logservice。
Apache Kafka 是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使你能够将消息从一个端点传递到另一个端点。 Kafka 适合离线和在线消息消费。 Kafka 消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka 构建在 ZooKeeper 同步服务之上。 它与 Apache Storm 和 Spark 非常好地集成,用于实时流式数据分析。
Kafka 是一个分布式消息队列,具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。
关键术语:
(1)生产者和消费者(producer和consumer):消息的发送者叫 Producer,消息的使用者和接受者是 Consumer,生产者将数据保存到 Kafka 集群中,消费者从中获取消息进行业务的处理。
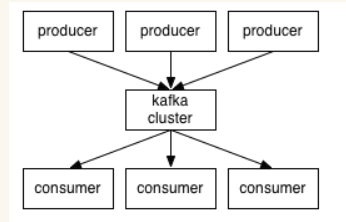
(2)broker:Kafka 集群中有很多台 Server,其中每一台 Server 都可以存储消息,将每一台 Server 称为一个 kafka 实例,也叫做 broker。
(3)主题(topic):一个 topic 里保存的是同一类消息,相当于对消息的分类,每个 producer 将消息发送到 kafka 中,都需要指明要存的 topic 是哪个,也就是指明这个消息属于哪一类。
(4)分区(partition):每个 topic 都可以分成多个 partition,每个 partition 在存储层面是 append log 文件。任何发布到此 partition 的消息都会被直接追加到 log 文件的尾部。为什么要进行分区呢?最根本的原因就是:kafka基于文件进行存储,当文件内容大到一定程度时,很容易达到单个磁盘的上限,因此,采用分区的办法,一个分区对应一个文件,这样就可以将数据分别存储到不同的server上去,另外这样做也可以负载均衡,容纳更多的消费者。
(5)偏移量(Offset):一个分区对应一个磁盘上的文件,而消息在文件中的位置就称为 offset(偏移量),offset 为一个 long 型数字,它可以唯一标记一条消息。由于kafka 并没有提供其他额外的索引机制来存储 offset,文件只能顺序的读写,所以在kafka中几乎不允许对消息进行“随机读写”。
综上,我们总结一下 Kafka 的几个要点:
- kafka 是一个基于发布-订阅的分布式消息系统(消息队列)
- Kafka 面向大数据,消息保存在主题中,而每个 topic 有分为多个分区
- kafka 的消息数据保存在磁盘,每个 partition 对应磁盘上的一个文件,消息写入就是简单的文件追加,文件可以在集群内复制备份以防丢失
- 即使消息被消费,kafka 也不会立即删除该消息,可以通过配置使得过一段时间后自动删除以释放磁盘空间
- kafka依赖分布式协调服务Zookeeper,适合离线/在线信息的消费,与 storm 和 spark 等实时流式数据分析常常结合使用
(三)Apache Kafka基本原理
通过之前的介绍,我们对 kafka 有了一个简单的理解,它的设计初衷是建立一个统一的信息收集平台,使其可以做到对信息的实时反馈。Kafka is a distributed,partitioned,replicated commit logservice。接下来我们着重从几个方面分析其基本原理。
1、分布式和分区(distributed、partitioned)
我们说 kafka 是一个分布式消息系统,所谓的分布式,实际上我们已经大致了解。消息保存在 Topic 中,而为了能够实现大数据的存储,一个 topic 划分为多个分区,每个分区对应一个文件,可以分别存储到不同的机器上,以实现分布式的集群存储。另外,每个 partition 可以有一定的副本,备份到多台机器上,以提高可用性。
总结起来就是:一个 topic 对应的多个 partition 分散存储到集群中的多个 broker 上,存储方式是一个 partition 对应一个文件,每个 broker 负责存储在自己机器上的 partition 中的消息读写。
2、副本(replicated )
kafka 还可以配置 partitions 需要备份的个数(replicas),每个 partition 将会被备份到多台机器上,以提高可用性,备份的数量可以通过配置文件指定。
这种冗余备份的方式在分布式系统中是很常见的,那么既然有副本,就涉及到对同一个文件的多个备份如何进行管理和调度。kafka 采取的方案是:每个 partition 选举一个 server 作为“leader”,由 leader 负责所有对该分区的读写,其他 server 作为 follower 只需要简单的与 leader 同步,保持跟进即可。如果原来的 leader 失效,会重新选举由其他的 follower 来成为新的 leader。
至于如何选取 leader,实际上如果我们了解 ZooKeeper,就会发现其实这正是 Zookeeper 所擅长的,Kafka 使用 ZK 在 Broker 中选出一个 Controller,用于 Partition 分配和 Leader 选举。
另外,这里我们可以看到,实际上作为 leader 的 server 承担了该分区所有的读写请求,因此其压力是比较大的,从整体考虑,有多少个 partition 就意味着会有多少个leader,kafka 会将 leader 分散到不同的 broker 上,确保整体的负载均衡。
3、整体数据流程
Kafka 的总体数据流满足下图,该图可以说是概括了整个 kafka 的基本原理。
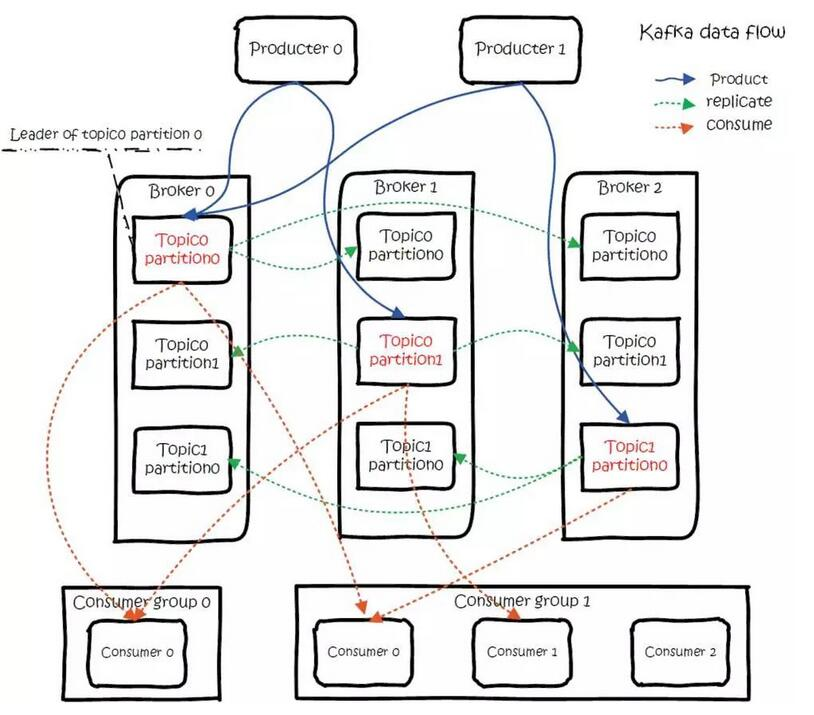
(1)数据生产过程(Produce)
对于生产者要写入的一条记录,可以指定四个参数:分别是 topic、partition、key 和 value,其中 topic 和 value(要写入的数据)是必须要指定的,而 key 和 partition 是可选的。
对于一条记录,先对其进行序列化,然后按照 Topic 和 Partition,放进对应的发送队列中。如果 Partition 没填,那么情况会是这样的:a、Key 有填。按照 Key 进行哈希,相同 Key 去一个 Partition。b、Key 没填。Round-Robin 来选 Partition。
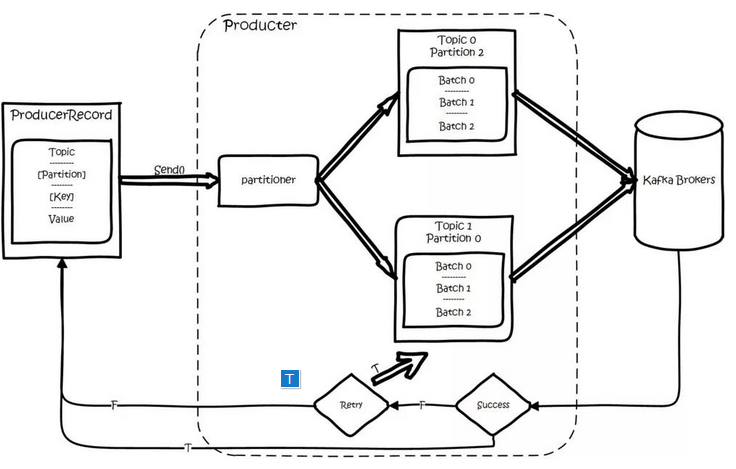
producer 将会和Topic下所有 partition leader 保持 socket 连接,消息由 producer 直接通过 socket 发送到 broker。其中 partition leader 的位置( host : port )注册在 zookeeper 中,producer 作为 zookeeper client,已经注册了 watch 用来监听 partition leader 的变更事件,因此,可以准确的知道谁是当前的 leader。
producer 端采用异步发送:将多条消息暂且在客户端 buffer 起来,并将他们批量的发送到 broker,小数据 IO 太多,会拖慢整体的网络延迟,批量延迟发送事实上提升了网络效率。
(2)数据消费过程(Consume)
对于消费者,不是以单独的形式存在的,每一个消费者属于一个 consumer group,一个 group 包含多个 consumer。特别需要注意的是:订阅 Topic 是以一个消费组来订阅的,发送到 Topic 的消息,只会被订阅此 Topic 的每个 group 中的一个 consumer 消费。
如果所有的 Consumer 都具有相同的 group,那么就像是一个点对点的消息系统;如果每个 consumer 都具有不同的 group,那么消息会广播给所有的消费者。
具体说来,这实际上是根据 partition 来分的,一个 Partition,只能被消费组里的一个消费者消费,但是可以同时被多个消费组消费,消费组里的每个消费者是关联到一个 partition 的,因此有这样的说法:对于一个 topic,同一个 group 中不能有多于 partitions 个数的 consumer 同时消费,否则将意味着某些 consumer 将无法得到消息。
同一个消费组的两个消费者不会同时消费一个 partition。
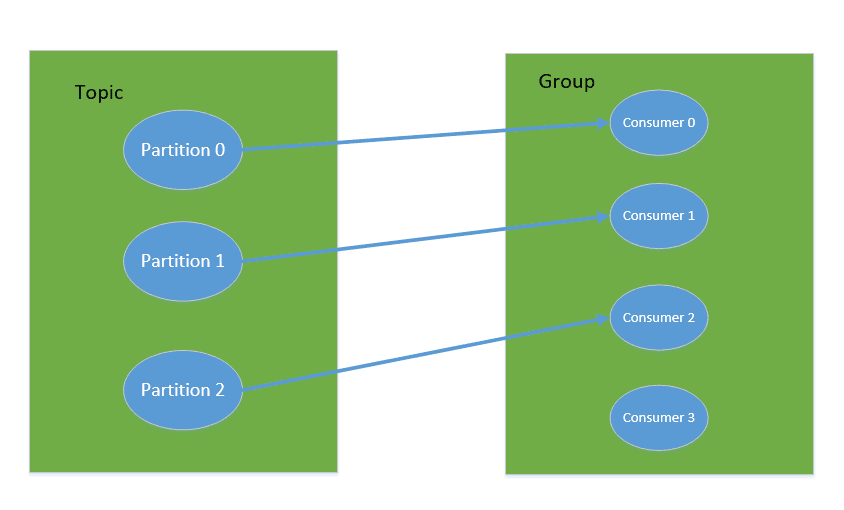
在 kafka 中,采用了 pull 方式,即 consumer 在和 broker 建立连接之后,主动去 pull(或者说 fetch )消息,首先 consumer 端可以根据自己的消费能力适时的去 fetch 消息并处理,且可以控制消息消费的进度(offset)。
partition 中的消息只有一个 consumer 在消费,且不存在消息状态的控制,也没有复杂的消息确认机制,可见 kafka broker 端是相当轻量级的。当消息被 consumer 接收之后,需要保存 Offset 记录消费到哪,以前保存在 ZK 中,由于 ZK 的写性能不好,以前的解决方法都是 Consumer 每隔一分钟上报一次,在 0.10 版本后,Kafka 把这个 Offset 的保存,从 ZK 中剥离,保存在一个名叫 consumeroffsets topic 的 Topic 中,由此可见,consumer 客户端也很轻量级。
4、消息传送机制
Kafka 支持 3 种消息投递语义,在业务中,常常都是使用 At least once 的模型。
- At most once:最多一次,消息可能会丢失,但不会重复。
- At least once:最少一次,消息不会丢失,可能会重复。
- Exactly once:只且一次,消息不丢失不重复,只且消费一次。
Apache Kafka 集群架构
看看下面的插图。 它显示Kafka的集群图。
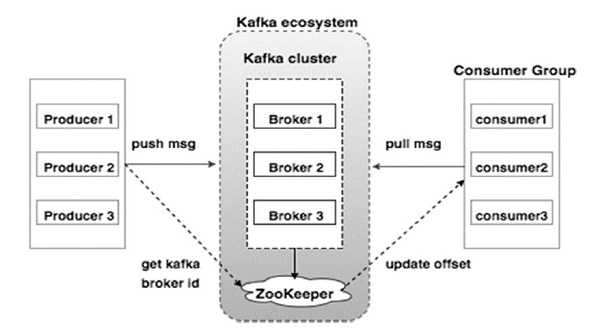
下表描述了上图中显示的每个组件。
| S.No | 组件和说明 |
|---|---|
| 1 | Broker(代理):Kafka集群通常由多个代理组成以保持负载平衡。 Kafka代理是无状态的,所以他们使用ZooKeeper来维护它们的集群状态。 一个Kafka代理实例可以每秒处理数十万次读取和写入,每个Broker可以处理TB的消息,而没有性能影响。 Kafka经纪人领导选举可以由ZooKeeper完成。 |
| 2 | ZooKeeper:ZooKeeper用于管理和协调Kafka代理。 ZooKeeper服务主要用于通知生产者和消费者Kafka系统中存在任何新代理或Kafka系统中代理失败。 根据Zookeeper接收到关于代理的存在或失败的通知,然后生产者和消费者采取决定并开始与某些其他代理协调他们的任务。 |
| 3 | Producers(生产者):生产者将数据推送给经纪人。 当新代理启动时,所有生产者搜索它并自动向该新代理发送消息。 Kafka生产者不等待来自代理的确认,并且发送消息的速度与代理可以处理的一样快。 |
| 4 | Consumers(消费者):因为Kafka代理是无状态的,这意味着消费者必须通过使用分区偏移来维护已经消耗了多少消息。 如果消费者确认特定的消息偏移,则意味着消费者已经消费了所有先前的消息。 消费者向代理发出异步拉取请求,以具有准备好消耗的字节缓冲区。 消费者可以简单地通过提供偏移值来快退或跳到分区中的任何点。 消费者偏移值由ZooKeeper通知。 |
Apache Kafka 工作流程
到目前为止,我们讨论了 Kafka 的核心概念。 让我们现在来看一下 Kafka 的工作流程。
Kafka 只是分为一个或多个分区的主题的集合。Kafka 分区是消息的线性有序序列,其中每个消息由它们的索引(称为偏移)来标识。Kafka 集群中的所有数据都是不相连的分区联合。 传入消息写在分区的末尾,消息由消费者顺序读取。 通过将消息复制到不同的代理提供持久性。
Kafka 以快速,可靠,持久,容错和零停机的方式提供基于pub-sub 和队列的消息系统。 在这两种情况下,生产者只需将消息发送到主题,消费者可以根据自己的需要选择任何一种类型的消息传递系统。 让我们按照下一节中的步骤来了解消费者如何选择他们选择的消息系统。
发布 - 订阅消息的工作流程
以下是 Pub-Sub 消息的逐步工作流程 -
- 生产者定期向主题发送消息。
- Kafka 代理存储为该特定主题配置的分区中的所有消息。 它确保消息在分区之间平等共享。 如果生产者发送两个消息并且有两个分区,Kafka 将在第一分区中存储一个消息,在第二分区中存储第二消息。
- 消费者订阅特定主题。
- 一旦消费者订阅主题,Kafka 将向消费者提供主题的当前偏移,并且还将偏移保存在 Zookeeper 系统中。
- 消费者将定期请求 Kafka (如100 Ms)新消息。
- 一旦 Kafka 收到来自生产者的消息,它将这些消息转发给消费者。
- 消费者将收到消息并进行处理。
- 一旦消息被处理,消费者将向 Kafka 代理发送确认。
- 一旦 Kafka 收到确认,它将偏移更改为新值,并在 Zookeeper 中更新它。 由于偏移在 Zookeeper 中维护,消费者可- - 以正确地读取下一封邮件,即使在服务器暴力期间。
- 以上流程将重复,直到消费者停止请求。
- 消费者可以随时回退/跳到所需的主题偏移量,并阅读所有后续消息。
队列消息/用户组的工作流
在队列消息传递系统而不是单个消费者中,具有相同组 ID 的一组消费者将订阅主题。 简单来说,订阅具有相同 Group ID 的主题的消费者被认为是单个组,并且消息在它们之间共享。 让我们检查这个系统的实际工作流程。
- 生产者以固定间隔向某个主题发送消息。
- Kafka存储在为该特定主题配置的分区中的所有消息,类似于前面的方案。
- 单个消费者订阅特定主题,假设 Topic-01 为 Group ID 为 Group-1 。
- Kafka 以与发布 - 订阅消息相同的方式与消费者交互,直到新消费者以相同的组 ID 订阅相同主题Topic-01 1 。
-一旦新消费者到达,Kafka 将其操作切换到共享模式,并在两个消费者之间共享数据。 此共享将继续,直到用户数达到为该特定主题配置的分区数。 - 一旦消费者的数量超过分区的数量,新消费者将不会接收任何进一步的消息,直到现有消费者取消订阅任何一个消费者。 出现这种情况是因为 Kafka 中的每个消费者将被分配至少一个分区,并且一旦所有分区被分配给现有消费者,新消费者将必须等待。
- 此功能也称为使用者组。 同样,Kafka 将以非常简单和高效的方式提供两个系统中最好的。
ZooKeeper 的作用
Apache Kafka 的一个关键依赖是 Apache Zookeeper,它是一个分布式配置和同步服务。Zookeeper 是 Kafka 代理和消费者之间的协调接口。Kafka 服务器通过 Zookeeper 集群共享信息。Kafka 在 Zookeeper 中存储基本元数据,例如关于主题,代理,消费者偏移(队列读取器)等的信息。
由于所有关键信息存储在 Zookeeper 中,并且它通常在其整体上复制此数据,因此Kafka代理/ Zookeeper 的故障不会影响 Kafka 集群的状态。Kafka 将恢复状态,一旦 Zookeeper 重新启动。 这为Kafka带来了零停机时间。Kafka 代理之间的领导者选举也通过使用 Zookeeper 在领导者失败的情况下完成。
Apache Kafka 安装步骤
以下是在机器上安装Java的步骤。
步骤1 - 验证Java安装
希望你已经在你的机器上安装了java,所以你只需使用下面的命令验证它。
$ java -version
如果java在您的机器上成功安装,您可以看到已安装的Java的版本。
步骤1.1 - 下载JDK
如果没有下载Java,请通过访问以下链接并下载最新版本来下载最新版本的JDK。
http://www.oracle.com/technetwork/java/javase/downloads/index.html
现在最新的版本是JDK 8u 60,文件是“jdk-8u60-linux-x64.tar.gz"。 请在您的机器上下载该文件。
步骤1.2 - 提取文件
通常,正在下载的文件存储在下载文件夹中,验证它并使用以下命令提取tar设置。
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gz
步骤1.3 - 移动到选择目录
要将java提供给所有用户,请将提取的java内容移动到 usr / local / java / folder。
$ su
password: (type password of root user)
$ mkdir /opt/jdk
$ mv jdk-1.8.0_60 /opt/jdk/
步骤1.4 - 设置路径
要设置路径和JAVA_HOME变量,请将以下命令添加到〜/ .bashrc文件。
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/bin
现在将所有更改应用到当前运行的系统。
$ source ~/.bashrc
步骤1.5 - Java替代
使用以下命令更改Java Alternatives。
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100
步骤1.6 - 现在使用第1步中说明的验证命令(java -version)验证java。
步骤2 - ZooKeeper框架安装
步骤2.1 - 下载ZooKeeper
要在您的计算机上安装ZooKeeper框架,请访问以下链接并下载最新版本的ZooKeeper。
http://zookeeper.apache.org/releases.html
现在,最新版本的ZooKeeper是3.4.6(ZooKeeper-3.4.6.tar.gz)。
步骤2.2 - 提取tar文件
使用以下命令提取tar文件
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz
$ cd zookeeper-3.4.6
$ mkdir data
步骤2.3 - 创建配置文件
使用命令vi“conf / zoo.cfg"打开名为 conf / zoo.cfg 的配置文件,并将所有以下参数设置为起点。
$ vi conf/zoo.cfg
tickTime=2000
dataDir=/path/to/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2
一旦配置文件成功保存并再次返回终端,您可以启动zookeeper服务器。
步骤2.4 - 启动ZooKeeper服务器
$ bin/zkServer.sh start
执行此命令后,您将得到如下所示的响应 -
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg
$ Starting zookeeper ... STARTED
步骤2.5 - 启动CLI
$ bin/zkCli.sh
输入上面的命令后,您将被连接到zookeeper服务器,并将获得以下响应。
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]
步骤2.6 - 停止Zookeeper服务器
连接服务器并执行所有操作后,可以使用以下命令停止zookeeper服务器 -
$ bin/zkServer.sh stop
现在你已经在你的机器上成功安装了Java和ZooKeeper。 让我们看看安装Apache Kafka的步骤。
步骤3 - Apache Kafka安装
让我们继续以下步骤在您的机器上安装Kafka。
步骤3.1 - 下载Kafka
要在您的机器上安装Kafka,请点击以下链接 -
https://www.apache.org/dyn/closer.cgi?path=/kafka/0.9.0.0/kafka_2.11-0.9.0.0.tgz
现在最新版本,即 - kafka_2.11_0.9.0.0.tgz 将下载到您的计算机上。
步骤3.2 - 解压tar文件
使用以下命令提取tar文件 -
$ cd opt/
$ tar -zxf kafka_2.11.0.9.0.0 tar.gz
$ cd kafka_2.11.0.9.0.0
现在您已经在您的机器上下载了最新版本的Kafka。
步骤3.3 - 启动服务器
您可以通过给出以下命令来启动服务器 -
$ bin/kafka-server-start.sh config/server.properties
服务器启动后,您会在屏幕上看到以下响应:
$ bin/kafka-server-start.sh config/server.properties
[2016-01-02 15:37:30,410] INFO KafkaConfig values:
request.timeout.ms = 30000
log.roll.hours = 168
inter.broker.protocol.version = 0.9.0.X
log.preallocate = false
security.inter.broker.protocol = PLAINTEXT
…………………………………………….
…………………………………………….
步骤4 - 停止服务器
执行所有操作后,可以使用以下命令停止服务器 -
$ bin/kafka-server-stop.sh config/server.properties
现在我们已经讨论了Kafka安装,我们可以在下一章中学习如何对Kafka执行基本操作。
Apache Kafka 基本操作
首先让我们开始实现单节点单代理配置,然后我们将我们的设置迁移到单节点多代理配置。
希望你现在可以在你的机器上安装 Java,ZooKeeper 和 Kafka 。 在迁移到 Kafka Cluster Setup 之前,首先需要启动 ZooKeeper,因为 Kafka Cluster 使用 ZooKeeper。
启动ZooKeeper
打开一个新终端并键入以下命令 -
bin/zookeeper-server-start.sh config/zookeeper.properties
要启动 Kafka Broker,请键入以下命令 -
bin/kafka-server-start.sh config/server.properties
启动 Kafka Broker后,在 ZooKeeper 终端上键入命令 jps ,您将看到以下响应 -
821 QuorumPeerMain
928 Kafka
931 Jps
现在你可以看到两个守护进程运行在终端上,QuorumPeerMain 是 ZooKeeper 守护进程,另一个是 Kafka 守护进程。
单节点 - 单代理配置
在此配置中,您有一个 ZooKeeper 和代理 id 实例。 以下是配置它的步骤 -
创建 Kafka 主题 - Kafka 提供了一个名为 kafka-topics.sh 的命令行实用程序,用于在服务器上创建主题。 打开新终端并键入以下示例。
语法
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1
--partitions 1 --topic topic-name
示例
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1
--partitions 1 --topic Hello-Kafka
我们刚刚创建了一个名为 Hello-Kafka 的主题,其中包含一个分区和一个副本因子。 上面创建的输出将类似于以下输出 -
输出 - 创建主题 Hello-Kafka
创建主题后,您可以在 Kafka 代理终端窗口中获取通知,并在 config / server.properties 文件中的“/ tmp / kafka-logs /"中指定的创建主题的日志。
主题列表
要获取 Kafka 服务器中的主题列表,可以使用以下命令 -
语法
bin/kafka-topics.sh --list --zookeeper localhost:2181
输出
Hello-Kafka
由于我们已经创建了一个主题,它将仅列出 Hello-Kafka 。 假设,如果创建多个主题,您将在输出中获取主题名称。
启动生产者以发送消息
语法
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic-name
从上面的语法,生产者命令行客户端需要两个主要参数 -
代理列表 - 我们要发送邮件的代理列表。 在这种情况下,我们只有一个代理。 Config / server.properties 文件包含代理端口 ID,因为我们知道我们的代理正在侦听端口 9092,因此您可以直接指定它。
主题名称 - 以下是主题名称的示例。
示例
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-Kafka
生产者将等待来自 stdin 的输入并发布到 Kafka 集群。 默认情况下,每个新行都作为新消息发布,然后在 config / producer.properties 文件中指定默认生产者属性。 现在,您可以在终端中键入几行消息,如下所示。
输出
$ bin/kafka-console-producer.sh --broker-list localhost:9092
--topic Hello-Kafka[2016-01-16 13:50:45,931]
WARN property topic is not valid (kafka.utils.Verifia-bleProperties)
Hello
My first message
My second message
启动消费者以接收消息
与生产者类似,在config / consumer.proper-ties 文件中指定了缺省使用者属性。 打开一个新终端并键入以下消息消息语法。
语法
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic topic-name
--from-beginning
示例
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Hello-Kafka
--from-beginning
输出
Hello
My first message
My second message
最后,您可以从制作商的终端输入消息,并看到他们出现在消费者的终端。 到目前为止,您对具有单个代理的单节点群集有非常好的了解。 现在让我们继续讨论多个代理配置。
单节点多代理配置
在进入多个代理集群设置之前,首先启动 ZooKeeper 服务器。
创建多个Kafka Brokers - 我们在配置/ server.properties 中已有一个 Kafka 代理实例。 现在我们需要多个代理实例,因此将现有的 server.prop-erties 文件复制到两个新的配置文件中,并将其重命名为 server-one.properties 和 server-two.properties。 然后编辑这两个新文件并分配以下更改 -
config / server-one.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
# The port the socket server listens on
port=9093
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs-1
config / server-two.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=2
# The port the socket server listens on
port=9094
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs-2
启动多个代理 - 在三台服务器上进行所有更改后,打开三个新终端,逐个启动每个代理。
Broker1
bin/kafka-server-start.sh config/server.properties
Broker2
bin/kafka-server-start.sh config/server-one.properties
Broker3
bin/kafka-server-start.sh config/server-two.properties
现在我们有三个不同的经纪人在机器上运行。 自己尝试,通过在 ZooKeeper 终端上键入 jps 检查所有守护程序,然后您将看到响应。
创建主题
让我们为此主题将复制因子值指定为三个,因为我们有三个不同的代理运行。 如果您有两个代理,那么分配的副本值将是两个。
语法
bin/kafka-topics.sh
--create
--zookeeper localhost:2181
--replication-factor 3
-partitions 1
--topic topic-name
示例
bin/kafka-topics.sh
--create
--zookeeper localhost:2181
--replication-factor 3
-partitions 1
--topic Multibrokerapplication
输出
created topic “Multibrokerapplication"
Describe 命令用于检查哪个代理正在侦听当前创建的主题,如下所示 -
bin/kafka-topics.sh
--describe
--zookeeper localhost:2181
--topic Multibrokerappli-cation
输出
bin/kafka-topics.sh
--describe
--zookeeper localhost:2181
--topic Multibrokerappli-cationTopic:Multibrokerapplication PartitionCount:1
ReplicationFactor:3 Configs:Topic:Multibrokerapplication Partition:0 Leader:0
Replicas:0,2,1 Isr:0,2,1
从上面的输出,我们可以得出结论,第一行给出所有分区的摘要,显示主题名称,分区数量和我们已经选择的复制因子。 在第二行中,每个节点将是分区的随机选择部分的领导者。
在我们的例子中,我们看到我们的第一个 broker(with broker.id 0)是领导者。 然后 Replicas:0,2,1 意味着所有代理复制主题最后 Isr 是 in-sync 副本的集合。 那么,这是副本的子集,当前活着并被领导者赶上。
启动生产者以发送消息
此过程保持与单代理设置中相同。
示例
bin/kafka-console-producer.sh --broker-list localhost:9092
--topic Multibrokerapplication
输出
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Multibrokerapplication
[2016-01-20 19:27:21,045] WARN Property topic is not valid (kafka.utils.Verifia-bleProperties)
This is single node-multi broker demo
This is the second message
启动消费者以接收消息
此过程保持与单代理设置中所示的相同。
示例
bin/kafka-console-consumer.sh
--zookeeper localhost:2181
—topic Multibrokerapplica-tion
--from-beginning
输出
bin/kafka-console-consumer.sh
--zookeeper localhost:2181
—topic Multibrokerapplica-tion —from-beginning
This is single node-multi broker demo
This is the second message
修改主题
您已经了解如何在 Kafka Cluster 中创建主题。 现在让我们使用以下命令修改已创建的主题
语法
bin/kafka-topics.sh
—zookeeper localhost:2181
--alter
--topic topic_name
--parti-tions count
示例
We have already created a topic “Hello-Kafka" with single partition count and one replica factor.
Now using “alter" command we have changed the partition count.
bin/kafka-topics.sh
--zookeeper localhost:2181
--alter
--topic Hello-kafka
--parti-tions 2
输出
WARNING: If partitions are increased for a topic that has a key,
the partition logic or ordering of the messages will be affected
Adding partitions succeeded!
删除主题
要删除主题,可以使用以下语法。
语法
bin/kafka-topics.sh
--zookeeper localhost:2181
--delete
--topic topic_name
示例
bin/kafka-topics.sh
--zookeeper localhost:2181
--delete
--topic Hello-kafka
输出
> Topic Hello-kafka marked for deletion
注意 - 如果 delete.topic.enable 未设置为 true,则此操作不会产生任何影响
Apache Kafka 简单生产者示例
让我们使用Java客户端创建一个用于发布和使用消息的应用程序。 Kafka生产者客户端包括以下API。
KafkaProducer API
让我们了解本节中最重要的一组Kafka生产者API。 KafkaProducer API的中心部分是 KafkaProducer 类。 KafkaProducer类提供了一个选项,用于将其构造函数中的Kafka代理连接到以下方法。
- KafkaProducer类提供send方法以异步方式将消息发送到主题。 send()的签名如下
producer.send(new ProducerRecord<byte[],byte[]>(topic,
partition, key1, value1) , callback);
-
ProducerRecord - 生产者管理等待发送的记录的缓冲区。
-
回调 - 当服务器确认记录时执行的用户提供的回调(null表示无回调)。
-
KafkaProducer类提供了一个flush方法,以确保所有先前发送的消息都已实际完成。 flush方法的语法如下 -
public void flush()
- KafkaProducer类提供了partitionFor方法,这有助于获取给定主题的分区元数据。 这可以用于自定义分区。 这种方法的签名如下 -
public Map metrics()
它返回由生产者维护的内部度量的映射。
- public void close() - KafkaProducer类提供关闭方法块,直到所有先前发送的请求完成。
生产者API
生产者API的中心部分是生产者类。 生产者类提供了一个选项,通过以下方法在其构造函数中连接Kafka代理。
生产者类
生产者类提供send方法以使用以下签名向单个或多个主题发送消息。
public void send(KeyedMessaget<k,v> message)
- sends the data to a single topic,par-titioned by key using either sync or async producer.
public void send(List<KeyedMessage<k,v>>messages)
- sends data to multiple topics.
Properties prop = new Properties();
prop.put(producer.type,"async")
ProducerConfig config = new ProducerConfig(prop);
有两种类型的生产者 - 同步和异步。
相同的API配置也适用于同步生产者。 它们之间的区别是同步生成器直接发送消息,但在后台发送消息。 当您想要更高的吞吐量时,异步生产者是首选。 在以前的版本,如0.8,一个异步生产者没有回调send()注册错误处理程序。 这仅在当前版本0.9中可用。
public void close()
生产者类提供关闭方法以关闭与所有Kafka代理的生产者池连接。
配置设置
下表列出了Producer API的主要配置设置,以便更好地理解 -
| S.No | 配置设置和说明 |
|---|---|
| 1 | client.id 标识生产者应用程序 |
| 2 | producer.type 同步或异步 |
| 3 | acks acks配置控制生产者请求下的标准是完全的。 |
| 4 | 重试 如果生产者请求失败,则使用特定值自动重试。 |
| 5 | bootstrapping代理列表。 |
| 6 | linger.ms 如果你想减少请求的数量,你可以将linger.ms设置为大于某个值的东西。 |
| 7 | key.serializer 序列化器接口的键。 |
| 8 | value.serializer 值。 |
| 9 | batch.size 缓冲区大小。 |
| 10 | buffer.memory 控制生产者可用于缓冲的存储器的总量。 |
ProducerRecord API
ProducerRecord是发送到Kafka cluster.ProducerRecord类构造函数的键/值对,用于使用以下签名创建具有分区,键和值对的记录。
public ProducerRecord (string topic, int partition, k key, v value)
-
主题 - 将附加到记录的用户定义的主题名称。
-
分区 - 分区计数。
-
键 - 将包含在记录中的键。
-
值 - 记录内容。
public ProducerRecord (string topic, k key, v value)
ProducerRecord类构造函数用于创建带有键,值对和无分区的记录。
-
主题 - 创建主题以分配记录。
-
键 - 记录的键。
-
值 - 记录内容。
public ProducerRecord (string topic, v value)
ProducerRecord类创建一个没有分区和键的记录。
-
主题 - 创建主题。
-
值 - 记录内容。
ProducerRecord类方法列在下表中 -
| S.No | 类方法和描述 |
|---|---|
| 1 | public string topic() 主题将附加到记录。 |
| 2 | public K key() 将包括在记录中的键。 如果没有这样的键,null将在这里重新打开。 |
| 3 | public V value() 记录内容。 |
| 4 | partition() 记录的分区计数 |
SimpleProducer应用程序
在创建应用程序之前,首先启动ZooKeeper和Kafka代理,然后使用create topic命令在Kafka代理中创建自己的主题。 之后,创建一个名为 Sim-pleProducer.java 的java类,然后键入以下代码。
//import util.properties packages
import java.util.Properties;//import simple producer packages
import org.apache.kafka.clients.producer.Producer;//import KafkaProducer packages
import org.apache.kafka.clients.producer.KafkaProducer;//import ProducerRecord packages
import org.apache.kafka.clients.producer.ProducerRecord;//Create java class named “SimpleProducer"
public class SimpleProducer {public static void main(String[] args) throws Exception{// Check arguments length valueif(args.length == 0){System.out.println("Enter topic name");return;}//Assign topicName to string variableString topicName = args[0].toString();// create instance for properties to access producer configs Properties props = new Properties();//Assign localhost idprops.put("bootstrap.servers", “localhost:9092");//Set acknowledgements for producer requests. props.put("acks", “all");//If the request fails, the producer can automatically retry,props.put("retries", 0);//Specify buffer size in configprops.put("batch.size", 16384);//Reduce the no of requests less than 0 props.put("linger.ms", 1);//The buffer.memory controls the total amount of memory available to the producer for buffering. props.put("buffer.memory", 33554432);props.put("key.serializer", "org.apache.kafka.common.serializa-tion.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serializa-tion.StringSerializer");Producer<String, String> producer = new KafkaProducer<String, String>(props);for(int i = 0; i < 10; i++)producer.send(new ProducerRecord<String, String>(topicName, Integer.toString(i), Integer.toString(i)));System.out.println(“Message sent successfully");producer.close();}
}
编译 - 可以使用以下命令编译应用程序。
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*" *.java
执行 - 可以使用以下命令执行应用程序。
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*":. SimpleProducer <topic-name>
输出
Message sent successfully
To check the above output open new terminal and type Consumer CLI command to receive messages.
>> bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic <topic-name> —from-beginning
1
2
3
4
5
6
7
8
9
10
简单消费者示例
到目前为止,我们已经创建了一个发送消息到Kafka集群的生产者。 现在让我们创建一个消费者来消费Kafka集群的消息。 KafkaConsumer API用于消费来自Kafka集群的消息。 KafkaConsumer类的构造函数定义如下。
public KafkaConsumer(java.util.Map<java.lang.String,java.lang.Object> configs)
configs - 返回消费者配置的地图。
KafkaConsumer类具有下表中列出的以下重要方法。
| S.No | 方法和说明 |
|---|---|
| 1 | public java.util.Set< TopicPar- tition> assignment()获取由用户当前分配的分区集。 |
| 2 | public string subscription()订阅给定的主题列表以获取动态签名的分区。 |
| 3 | public void sub-scribe(java.util.List< java.lang.String> topics,ConsumerRe-balanceListener listener)订阅给定的主题列表以获取动态签名的分区。 |
| 4 | public void unsubscribe()从给定的分区列表中取消订阅主题。 |
| 5 | public void sub-scribe(java.util.List< java.lang.String> topics)订阅给定的主题列表以获取动态签名的分区。 如果给定的主题列表为空,则将其视为与unsubscribe()相同。 |
| 6 | public void sub-scribe(java.util.regex.Pattern pattern,ConsumerRebalanceLis-tener listener)参数模式以正则表达式的格式引用预订模式,而侦听器参数从预订模式获取通知。 |
| 7 | public void as-sign(java.util.List< TopicPartion> partitions)向客户手动分配分区列表。 |
| 8 | poll()使用预订/分配API之一获取指定的主题或分区的数据。 如果在轮询数据之前未预订主题,这将返回错误。 |
| 9 | public void commitSync()提交对主题和分区的所有子编制列表的最后一次poll()返回的提交偏移量。 相同的操作应用于commitAsyn()。 |
| 10 | public void seek(TopicPartition partition,long offset)获取消费者将在下一个poll()方法中使用的当前偏移值。 |
| 11 | public void resume()恢复暂停的分区。 |
| 12 | public void wakeup()唤醒消费者。 |
ConsumerRecord API
ConsumerRecord API用于从Kafka集群接收记录。 此API由主题名称,分区号(从中接收记录)和指向Kafka分区中的记录的偏移量组成。 ConsumerRecord类用于创建具有特定主题名称,分区计数和< key,value>的消费者记录。 对。 它有以下签名。
public ConsumerRecord(string topic,int partition, long offset,K key, V value)
-
主题 - 从Kafka集群接收的使用者记录的主题名称。
-
分区 - 主题的分区。
-
键 - 记录的键,如果没有键存在null将被返回。
-
值 - 记录内容。
ConsumerRecords API
ConsumerRecords API充当ConsumerRecord的容器。 此API用于保存特定主题的每个分区的ConsumerRecord列表。 它的构造器定义如下。
public ConsumerRecords(java.util.Map<TopicPartition,java.util.List
<Consumer-Record>K,V>>> records)
-
TopicPartition - 返回特定主题的分区地图。
-
记录 - ConsumerRecord的返回列表。
ConsumerRecords类定义了以下方法。
| S.No | 方法和描述 |
|---|---|
| 1 | public int count()所有主题的记录数。 |
| 2 | public Set partitions()在此记录集中具有数据的分区集(如果没有返回数据,则该集为空)。 |
| 3 | public Iterator iterator()迭代器使您可以循环访问集合,获取或重新移动元素。 |
| 4 | public List records()获取给定分区的记录列表。 |
配置设置
Consumer客户端API主配置设置的配置设置如下所示 -
| S.No | 设置和说明 |
|---|---|
| 1 | 引导代理列表。 |
| 2 | group.id将单个消费者分配给组。 |
| 3 | enable.auto.commit如果值为true,则为偏移启用自动落实,否则不提交。 |
| 4 | auto.commit.interval.ms返回更新的消耗偏移量写入ZooKeeper的频率。 |
| 5 | session.timeout.ms表示Kafka在放弃和继续消费消息之前等待ZooKeeper响应请求(读取或写入)多少毫秒。 |
SimpleConsumer应用程序
生产者应用程序步骤在此保持不变。 首先,启动你的ZooKeeper和Kafka代理。 然后使用名为 SimpleCon-sumer.java 的Java类创建一个 SimpleConsumer 应用程序,并键入以下代码。
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;public class SimpleConsumer {public static void main(String[] args) throws Exception {if(args.length == 0){System.out.println("Enter topic name");return;}//Kafka consumer configuration settingsString topicName = args[0].toString();Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", "test");props.put("enable.auto.commit", "true");props.put("auto.commit.interval.ms", "1000");props.put("session.timeout.ms", "30000");props.put("key.deserializer", "org.apache.kafka.common.serializa-tion.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serializa-tion.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);//Kafka Consumer subscribes list of topics here.consumer.subscribe(Arrays.asList(topicName))//print the topic nameSystem.out.println("Subscribed to topic " + topicName);int i = 0;while (true) {ConsumerRecords<String, String> records = con-sumer.poll(100);for (ConsumerRecord<String, String> record : records)// print the offset,key and value for the consumer records.System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value());}}
}
编译 - 可以使用以下命令编译应用程序。
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*" *.java
执行 - 可以使用以下命令执行应用程序
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*":. SimpleConsumer <topic-name>
输入 - 打开生成器CLI并向主题发送一些消息。 你可以把smple输入为’Hello Consumer’。
输出 - 以下是输出。
Subscribed to topic Hello-Kafka
offset = 3, key = null, value = Hello Consumer
Apache Kafka 消费者组示例
消费群是多线程或多机器的Apache Kafka主题。
消费者群体
消费者可以使用相同的 group.id 加入群组
一个组的最大并行度是组中的消费者数量←不是分区。
Kafka将主题的分区分配给组中的使用者,以便每个分区仅由组中的一个使用者使用。
Kafka保证消息只能被组中的一个消费者读取。
消费者可以按照消息存储在日志中的顺序查看消息。
重新平衡消费者
添加更多进程/线程将导致Kafka重新平衡。 如果任何消费者或代理无法向ZooKeeper发送心跳,则可以通过Kafka集群重新配置。 在此重新平衡期间,Kafka将分配可用分区到可用线程,可能将分区移动到另一个进程。
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;public class ConsumerGroup {public static void main(String[] args) throws Exception {if(args.length < 2){System.out.println("Usage: consumer <topic> <groupname>");return;}String topic = args[0].toString();String group = args[1].toString();Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", group);props.put("enable.auto.commit", "true");props.put("auto.commit.interval.ms", "1000");props.put("session.timeout.ms", "30000");props.put("key.deserializer", "org.apache.kafka.common.serializa-tion.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serializa-tion.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);consumer.subscribe(Arrays.asList(topic));System.out.println("Subscribed to topic " + topic);int i = 0;while (true) {ConsumerRecords<String, String> records = con-sumer.poll(100);for (ConsumerRecord<String, String> record : records)System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value());} }
}
Consumer客户端API主配置设置的配置设置如下所示
| S.No | 设置和说明 |
|---|---|
| 1 | 引导代理列表。 |
| 2 | group.id将单个消费者分配给组。 |
| 3 | enable.auto.commit如果值为true,则为偏移启用自动落实,否则不提交。 |
| 4 | auto.commit.interval.ms返回更新的消耗偏移量写入ZooKeeper的频率。 |
| 5 | session.timeout.ms表示Kafka在放弃和继续消费消息之前等待ZooKeeper响应请求(读取或写入)多少毫秒。 |
编译
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*" ConsumerGroup.java
执行
>>java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-group
>>java -cp "/home/bala/Workspace/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-group
在这里,我们为两个消费者创建了一个示例组名称为 my-group 。 同样,您可以在组中创建您的组和消费者数量。
输入
打开生产者CLI并发送一些消息 -
Test consumer group 01
Test consumer group 02
第一个过程的输出
Subscribed to topic Hello-kafka
offset = 3, key = null, value = Test consumer group 01
第二个过程的输出
Subscribed to topic Hello-kafka
offset = 3, key = null, value = Test consumer group 02
希望你能通过使用Java客户端演示了解SimpleConsumer和ConsumerGroup。
现在,您了解如何使用Java客户端发送和接收消息。 让我们在下一章继续Kafka与大数据技术的集成。
Apache Kafka 整合 Storm
在本章中,我们将学习如何将Kafka与Apache Storm集成。
关于Storm
Storm最初由Nathan Marz和BackType的团队创建。 在短时间内,Apache Storm成为分布式实时处理系统的标准,允许您处理大量数据。 Storm是非常快的,并且一个基准时钟为每个节点每秒处理超过一百万个元组。 Apache Storm持续运行,从配置的源(Spouts)消耗数据,并将数据传递到处理管道(Bolts)。 联合,Spouts和Bolt构成一个拓扑。
与Storm集成
Kafka和Storm自然互补,它们强大的合作能够实现快速移动的大数据的实时流分析。 Kafka和Storm集成是为了使开发人员更容易地从Storm拓扑获取和发布数据流。
概念流
Spouts是流的源。 例如,一个喷头可以从Kafka Topic读取元组并将它们作为流发送。 Bolt消耗输入流,处理并可能发射新的流。 Bolt可以从运行函数,过滤元组,执行流聚合,流连接,与数据库交谈等等做任何事情。 Storm拓扑中的每个节点并行执行。 拓扑无限运行,直到终止它。 Storm将自动重新分配任何失败的任务。 此外,Storm保证没有数据丢失,即使机器停机和消息被丢弃。
让我们详细了解Kafka-Storm集成API。 有三个主要类集成Kafka与Storm。 他们如下 -
BrokerHosts - ZkHosts & StaticHosts
BrokerHosts是一个接口,ZkHosts和StaticHosts是它的两个主要实现。 ZkHosts用于通过在ZooKeeper中维护细节来动态跟踪Kafka代理,而StaticHosts用于手动/静态设置Kafka代理及其详细信息。 ZkHosts是访问Kafka代理的简单快捷的方式。
ZkHosts的签名如下 -
public ZkHosts(String brokerZkStr, String brokerZkPath)
public ZkHosts(String brokerZkStr)
其中brokerZkStr是ZooKeeper主机,brokerZkPath是ZooKeeper路径以维护Kafka代理详细信息。
KafkaConfig API
此API用于定义Kafka集群的配置设置。 Kafka Con-fig的签名定义如下
public KafkaConfig(BrokerHosts hosts, string topic)
主机 - BrokerHosts可以是ZkHosts / StaticHosts。
主题 - 主题名称。
SpoutConfig API
Spoutconfig是KafkaConfig的扩展,支持额外的ZooKeeper信息。
public SpoutConfig(BrokerHosts hosts, string topic, string zkRoot, string id)
-
主机 - BrokerHosts可以是BrokerHosts接口的任何实现
-
主题 - 主题名称。
-
zkRoot - ZooKeeper根路径。
-
id - spouts存储在Zookeeper中消耗的偏移量的状态。 ID应该唯一标识您的喷嘴。
SchemeAsMultiScheme
SchemeAsMultiScheme是一个接口,用于指示如何将从Kafka中消耗的ByteBuffer转换为风暴元组。 它源自MultiScheme并接受Scheme类的实现。 有很多Scheme类的实现,一个这样的实现是StringScheme,它将字节解析为一个简单的字符串。 它还控制输出字段的命名。 签名定义如下。
public SchemeAsMultiScheme(Scheme scheme)
- 方案 - 从kafka消耗的字节缓冲区。
KafkaSpout API
KafkaSpout是我们的spout实现,它将与Storm集成。 它从kafka主题获取消息,并将其作为元组发送到Storm生态系统。 KafkaSpout从SpoutConfig获取其配置详细信息。
下面是一个创建一个简单的Kafka喷水嘴的示例代码。
// ZooKeeper connection string
BrokerHosts hosts = new ZkHosts(zkConnString);//Creating SpoutConfig Object
SpoutConfig spoutConfig = new SpoutConfig(hosts, topicName, "/" + topicName UUID.randomUUID().toString());//convert the ByteBuffer to String.
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());//Assign SpoutConfig to KafkaSpout.
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);
创建Bolt
Bolt是一个使用元组作为输入,处理元组,并产生新的元组作为输出的组件。 Bolt将实现IRichBolt接口。 在此程序中,使用两个Bolt类WordSplitter-Bolt和WordCounterBolt来执行操作。
IRichBolt接口有以下方法 -
-
准备 - 为Bolt提供要执行的环境。 执行器将运行此方法来初始化喷头。
-
执行 - 处理单个元组的输入。
-
清理 - 当Bolt要关闭时调用。
-
declareOutputFields - 声明元组的输出模式。
让我们创建SplitBolt.java,它实现逻辑分割一个句子到词和CountBolt.java,它实现逻辑分离独特的单词和计数其出现。
SplitBolt.java
import java.util.Map;import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;public class SplitBolt implements IRichBolt {private OutputCollector collector;@Overridepublic void prepare(Map stormConf, TopologyContext context,OutputCollector collector) {this.collector = collector;}@Overridepublic void execute(Tuple input) {String sentence = input.getString(0);String[] words = sentence.split(" ");for(String word: words) {word = word.trim();if(!word.isEmpty()) {word = word.toLowerCase();collector.emit(new Values(word));}}collector.ack(input);}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {declarer.declare(new Fields("word"));}@Overridepublic void cleanup() {}@Overridepublic Map<String, Object> getComponentConfiguration() {return null;}}
CountBolt.java
import java.util.Map;
import java.util.HashMap;import backtype.storm.tuple.Tuple;
import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;public class CountBolt implements IRichBolt{Map<String, Integer> counters;private OutputCollector collector;@Overridepublic void prepare(Map stormConf, TopologyContext context,OutputCollector collector) {this.counters = new HashMap<String, Integer>();this.collector = collector;}@Overridepublic void execute(Tuple input) {String str = input.getString(0);if(!counters.containsKey(str)){counters.put(str, 1);}else {Integer c = counters.get(str) +1;counters.put(str, c);}collector.ack(input);}@Overridepublic void cleanup() {for(Map.Entry<String, Integer> entry:counters.entrySet()){System.out.println(entry.getKey()+" : " + entry.getValue());}}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {}@Overridepublic Map<String, Object> getComponentConfiguration() {return null;}
}
提交拓扑
Storm拓扑基本上是一个Thrift结构。 TopologyBuilder类提供了简单而容易的方法来创建复杂的拓扑。 TopologyBuilder类具有设置spout(setSpout)和设置bolt(setBolt)的方法。 最后,TopologyBuilder有createTopology来创建to-pology。 shuffleGrouping和fieldsGrouping方法有助于为喷头和Bolt设置流分组。
本地集群 - 为了开发目的,我们可以使用 LocalCluster 对象创建本地集群,然后使用 LocalCluster的 submitTopology 类。
KafkaStormSample.java
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;import java.util.ArrayList;
import java.util.List;
import java.util.UUID;import backtype.storm.spout.SchemeAsMultiScheme;
import storm.kafka.trident.GlobalPartitionInformation;
import storm.kafka.ZkHosts;
import storm.kafka.Broker;
import storm.kafka.StaticHosts;
import storm.kafka.BrokerHosts;
import storm.kafka.SpoutConfig;
import storm.kafka.KafkaConfig;
import storm.kafka.KafkaSpout;
import storm.kafka.StringScheme;public class KafkaStormSample {public static void main(String[] args) throws Exception{Config config = new Config();config.setDebug(true);config.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1);String zkConnString = "localhost:2181";String topic = "my-first-topic";BrokerHosts hosts = new ZkHosts(zkConnString);SpoutConfig kafkaSpoutConfig = new SpoutConfig (hosts, topic, "/" + topic, UUID.randomUUID().toString());kafkaSpoutConfig.bufferSizeBytes = 1024 * 1024 * 4;kafkaSpoutConfig.fetchSizeBytes = 1024 * 1024 * 4;kafkaSpoutConfig.forceFromStart = true;kafkaSpoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());TopologyBuilder builder = new TopologyBuilder();builder.setSpout("kafka-spout", new KafkaSpout(kafkaSpoutCon-fig));builder.setBolt("word-spitter", new SplitBolt()).shuffleGroup-ing("kafka-spout");builder.setBolt("word-counter", new CountBolt()).shuffleGroup-ing("word-spitter");LocalCluster cluster = new LocalCluster();cluster.submitTopology("KafkaStormSample", config, builder.create-Topology());Thread.sleep(10000);cluster.shutdown();}
}
在移动编译之前,Kakfa-Storm集成需要策展人ZooKeeper客户端java库。 策展人版本2.9.1支持Apache Storm 0.9.5版(我们在本教程中使用)。 下载下面指定的jar文件并将其放在java类路径中。
- curator-client-2.9.1.jar
- curator-framework-2.9.1.jar
在包括依赖文件之后,使用以下命令编译程序,
javac -cp “/path/to/Kafka/apache-storm-0.9.5/lib/*” *.java
执行
启动Kafka Producer CLI(在上一章节中解释),创建一个名为 my-first-topic 的新主题,并提供一些样本消息,如下所示 -
hello
kafka
storm
spark
test message
another test message
现在使用以下命令执行应用程序 -
java -cp “/path/to/Kafka/apache-storm-0.9.5/lib/*":. KafkaStormSample
此应用程序的示例输出如下所示 -
storm : 1
test : 2
spark : 1
another : 1
kafka : 1
hello : 1
message : 2
Apache Kafka 与Spark的集成
在本章中,我们将讨论如何将Apache Kafka与Spark Streaming API集成。
关于Spark
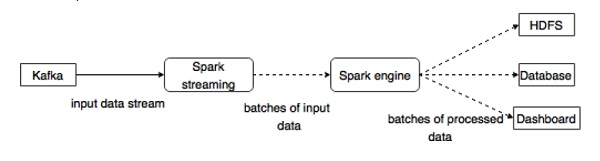
Spark Streaming API支持实时数据流的可扩展,高吞吐量,容错流处理。 数据可以从诸如Kafka,Flume,Twitter等许多源中提取,并且可以使用复杂的算法来处理,例如地图,缩小,连接和窗口等高级功能。 最后,处理的数据可以推送到文件系统,数据库和活动仪表板。 弹性分布式数据集(RDD)是Spark的基本数据结构。 它是一个不可变的分布式对象集合。 RDD中的每个数据集划分为逻辑分区,可以在集群的不同节点上计算。
与Spark集成
Kafka是Spark流式传输的潜在消息传递和集成平台。 Kafka充当实时数据流的中心枢纽,并使用Spark Streaming中的复杂算法进行处理。 一旦数据被处理,Spark Streaming可以将结果发布到另一个Kafka主题或存储在HDFS,数据库或仪表板中。 下图描述了概念流程。
现在,让我们详细了解Kafka-Spark API。
SparkConf API
它表示Spark应用程序的配置。 用于将各种Spark参数设置为键值对。
SparkConf 类有以下方法 -
-
set(string key,string value) - 设置配置变量。
-
remove(string key) - 从配置中移除密钥。
-
setAppName(string name) - 设置应用程序的应用程序名称。
-
get(string key) - get key
StreamingContext API
这是Spark功能的主要入口点。 SparkContext表示到Spark集群的连接,可用于在集群上创建RDD,累加器和广播变量。 签名的定义如下所示。
public StreamingContext(String master, String appName, Duration batchDuration, String sparkHome, scala.collection.Seq<String> jars, scala.collection.Map<String,String> environment)
-
主 - 要连接的群集网址(例如mesos:// host:port,spark:// host:port,local [4])。
-
appName - 作业的名称,以显示在集群Web UI上
-
batchDuration - 流式数据将被分成批次的时间间隔
public StreamingContext(SparkConf conf, Duration batchDuration)
通过提供新的SparkContext所需的配置创建StreamingContext。
-
conf - Spark参数
-
batchDuration - 流式数据将被分成批次的时间间隔
KafkaUtils API
KafkaUtils API用于将Kafka集群连接到Spark流。 此API具有如下定义的显着方法 createStream 。
public static ReceiverInputDStream<scala.Tuple2<String,String>> createStream(StreamingContext ssc, String zkQuorum, String groupId,scala.collection.immutable.Map<String,Object> topics, StorageLevel storageLevel)
上面显示的方法用于创建从Kafka Brokers提取消息的输入流。
-
ssc - StreamingContext对象。
-
zkQuorum - Zookeeper quorum。
-
groupId - 此消费者的组ID。
-
主题 - 返回要消费的主题的地图。
-
storageLevel - 用于存储接收的对象的存储级别。
KafkaUtils API有另一个方法createDirectStream,用于创建一个输入流,直接从Kafka Brokers拉取消息,而不使用任何接收器。 这个流可以保证来自Kafka的每个消息都包含在转换中一次。
示例应用程序在Scala中完成。 要编译应用程序,请下载并安装 sbt ,scala构建工具(类似于maven)。 主要应用程序代码如下所示。
import java.util.HashMapimport org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, Produc-erRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._object KafkaWordCount {def main(args: Array[String]) {if (args.length < 4) {System.err.println("Usage: KafkaWordCount <zkQuorum><group> <topics> <numThreads>")System.exit(1)}val Array(zkQuorum, group, topics, numThreads) = argsval sparkConf = new SparkConf().setAppName("KafkaWordCount")val ssc = new StreamingContext(sparkConf, Seconds(2))ssc.checkpoint("checkpoint")val topicMap = topics.split(",").map((_, numThreads.toInt)).toMapval lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)val words = lines.flatMap(_.split(" "))val wordCounts = words.map(x => (x, 1L)).reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2)wordCounts.print()ssc.start()ssc.awaitTermination()}
}
构建脚本
spark-kafka集成取决于Spark,Spark流和Spark与Kafka的集成jar。 创建一个新文件 build.sbt ,并指定应用程序详细信息及其依赖关系。 在编译和打包应用程序时, sbt 将下载所需的jar。
name := "Spark Kafka Project"
version := "1.0"
scalaVersion := "2.10.5"libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming" % "1.6.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka" % "1.6.0"
编译/包装
运行以下命令以编译和打包应用程序的jar文件。 我们需要将jar文件提交到spark控制台以运行应用程序。
sbt package
提交到Spark
启动Kafka Producer CLI(在上一章中解释),创建一个名为 my-first-topic 的新主题,并提供一些样本消息,如下所示。
Another spark test message
运行以下命令将应用程序提交到spark控制台。
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-streaming
-kafka_2.10:1.6.0 --class "KafkaWordCount" --master local[4] target/scala-2.10/spark
-kafka-project_2.10-1.0.jar localhost:2181 <group name> <topic name> <number of threads>
此应用程序的示例输出如下所示。
spark console messages ..
(Test,1)
(spark,1)
(another,1)
(message,1)
spark console message ..
Apache Kafka 实时应用程序(Twitter)
让我们分析一个实时应用程序,以获取最新的Twitter Feed和其标签。 早些时候,我们已经看到了Storm和Spark与Kafka的集成。 在这两种情况下,我们创建了一个Kafka生产者(使用cli)向Kafka生态系统发送消息。 然后,storm和spark集成通过使用Kafka消费者读取消息,并将其分别注入到storm和spark生态系统中。 因此,实际上我们需要创建一个Kafka Producer,
- 使用“Twitter Streaming API"阅读Twitter Feed,
- 处理Feeds,
- 提取HashTags
- 发送到Kafka。
一旦Kafka接收到 HashTags ,Storm / Spark集成接收到该信息并将其发送到Storm / Spark生态系统。
Twitter Streaming API
“Twitter Streaming API"可以使用任何编程语言访问。 “twitter4j"是一个开源的非官方Java库,它提供了一个基于Java的模块,可以轻松访问“Twitter Streaming API"。 “twitter4j"提供了一个基于监听器的框架来访问tweet。 要访问“Twitter Streaming API",我们需要登录Twitter开发者帐户,并应获取以下 OAuth 身份验证详细信息。
- Customerkey
- CustomerSecret
- AccessToken
- AccessTookenSecret
创建开发人员帐户后,下载“twitter4j"jar文件并将其放置在java类路径中。
完整的Twitter Kafka生产者编码(KafkaTwitterProducer.java)如下所列 -
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.LinkedBlockingQueue;import twitter4j.*;
import twitter4j.conf.*;import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;public class KafkaTwitterProducer {public static void main(String[] args) throws Exception {LinkedBlockingQueue<Status> queue = new LinkedBlockingQueue<Sta-tus>(1000);if(args.length < 5){System.out.println("Usage: KafkaTwitterProducer <twitter-consumer-key><twitter-consumer-secret> <twitter-access-token><twitter-access-token-secret><topic-name> <twitter-search-keywords>");return;}String consumerKey = args[0].toString();String consumerSecret = args[1].toString();String accessToken = args[2].toString();String accessTokenSecret = args[3].toString();String topicName = args[4].toString();String[] arguments = args.clone();String[] keyWords = Arrays.copyOfRange(arguments, 5, arguments.length);ConfigurationBuilder cb = new ConfigurationBuilder();cb.setDebugEnabled(true).setOAuthConsumerKey(consumerKey).setOAuthConsumerSecret(consumerSecret).setOAuthAccessToken(accessToken).setOAuthAccessTokenSecret(accessTokenSecret);TwitterStream twitterStream = new TwitterStreamFactory(cb.build()).get-Instance();StatusListener listener = new StatusListener() {@Overridepublic void onStatus(Status status) { queue.offer(status);// System.out.println("@" + status.getUser().getScreenName() + " - " + status.getText());// System.out.println("@" + status.getUser().getScreen-Name());/*for(URLEntity urle : status.getURLEntities()) {System.out.println(urle.getDisplayURL());}*//*for(HashtagEntity hashtage : status.getHashtagEntities()) {System.out.println(hashtage.getText());}*/}@Overridepublic void onDeletionNotice(StatusDeletionNotice statusDeletion-Notice) {// System.out.println("Got a status deletion notice id:" + statusDeletionNotice.getStatusId());}@Overridepublic void onTrackLimitationNotice(int numberOfLimitedStatuses) {// System.out.println("Got track limitation notice:" + num-berOfLimitedStatuses);}@Overridepublic void onScrubGeo(long userId, long upToStatusId) {// System.out.println("Got scrub_geo event userId:" + userId + "upToStatusId:" + upToStatusId);} @Overridepublic void onStallWarning(StallWarning warning) {// System.out.println("Got stall warning:" + warning);}@Overridepublic void onException(Exception ex) {ex.printStackTrace();}};twitterStream.addListener(listener);FilterQuery query = new FilterQuery().track(keyWords);twitterStream.filter(query);Thread.sleep(5000);//Add Kafka producer config settingsProperties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("acks", "all");props.put("retries", 0);props.put("batch.size", 16384);props.put("linger.ms", 1);props.put("buffer.memory", 33554432);props.put("key.serializer", "org.apache.kafka.common.serializa-tion.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serializa-tion.StringSerializer");Producer<String, String> producer = new KafkaProducer<String, String>(props);int i = 0;int j = 0;while(i < 10) {Status ret = queue.poll();if (ret == null) {Thread.sleep(100);i++;}else {for(HashtagEntity hashtage : ret.getHashtagEntities()) {System.out.println("Hashtag: " + hashtage.getText());producer.send(new ProducerRecord<String, String>(top-icName, Integer.toString(j++), hashtage.getText()));}}}producer.close();Thread.sleep(5000);twitterStream.shutdown();}
}
汇编
使用以下命令编译应用程序 -
javac -cp "/path/to/kafka/libs/*":"/path/to/twitter4j/lib/*":. KafkaTwitterProducer.java
执行
打开两个控制台。 在一个控制台中运行上面编译的应用程序,如下所示。
java -cp “/path/to/kafka/libs/*":"/path/to/twitter4j/lib/*":
. KafkaTwitterProducer <twitter-consumer-key>
<twitter-consumer-secret>
<twitter-access-token>
<twitter-ac-cess-token-secret>
my-first-topic food
在另一个窗口中运行前一章中解释的Spark / Storm应用程序中的任何一个。 主要要注意的是,在这两种情况下使用的主题应该是相同的。 在这里,我们使用“我的第一主题"作为主题名称。
输出
此应用程序的输出将取决于关键字和Twitter的当前Feed。 下面指定样本输出(集成storm)。
. . .
food : 1
foodie : 2
burger : 1
. . .
Apache Kafka 工具
Kafka在“org.apache.kafka.tools。"下打包的工具。 工具分为系统工具和复制工具。
系统工具
可以使用运行类脚本从命令行运行系统工具。 语法如下 -
bin/kafka-run-class.sh package.class - - options
下面提到一些系统工具 -
-
Kafka迁移工具 - 此工具用于将代理从一个版本迁移到另一个版本。
-
Mirror Maker - 此工具用于向另一个Kafka集群提供镜像。
-
消费者偏移检查器 - 此工具显示指定的主题和使用者组的消费者组,主题,分区,偏移量,日志大小,所有者。
复制工具
Kafka复制是一个高级设计工具。 添加复制工具的目的是为了更强的耐用性和更高的可用性。 下面提到一些复制工具 -
-
创建主题工具 - 这将创建一个带有默认分区数,复制因子的主题,并使用Kafka的默认方案进行副本分配。
-
列表主题工具 - 此工具列出了指定主题列表的信息。 如果命令行中没有提供主题,该工具将查询Zookeeper以获取所有主题并列出它们的信息。 工具显示的字段是主题名称,分区,leader,replicas,isr。
-
添加分区工具 - 创建主题,必须指定主题的分区数。 稍后,当主题的卷将增加时,可能需要用于主题的更多分区。 此工具有助于为特定主题添加更多分区,还允许手动复制分配已添加的分区。
Apache Kafka 应用
Kafka支持许多当今最好的工业应用。 我们将在本章中简要介绍Kafka最为显着的应用。
Twitter是一种在线社交网络服务,提供发送和接收用户推文的平台。 注册用户可以阅读和发布tweet,但未注册的用户只能阅读tweets。 Twitter使用Storm-Kafka作为其流处理基础架构的一部分。
Apache Kafka在LinkedIn中用于活动流数据和操作度量。 Kafka消息系统帮助LinkedIn的各种产品,如LinkedIn Newsfeed,LinkedIn今天的在线消息消费,以及离线分析系统,如Hadoop。 Kafka的强耐久性也是与LinkedIn相关的关键因素之一。
Netflix
Netflix是美国跨国公司的按需流媒体提供商。 Netflix使用Kafka进行实时监控和事件处理。
Mozilla
Mozilla是一个自由软件社区,由Netscape成员于1998年创建。 Kafka很快将更换Mozilla当前生产系统的一部分,以从最终用户的浏览器收集性能和使用数据,如遥测,测试试验等项目。
Oracle
Oracle通过其名为OSB(Oracle Service Bus)的Enterprise Service Bus产品提供与Kafka的本地连接,该产品允许开发人员利用OSB内置中介功能实现分阶段的数据管道。
相关文章:
【消息中间件】Apache Kafka 教程
文章目录Apache Kafka 概述什么是消息系统?点对点消息系统发布 - 订阅消息系统什么是Kafka?好处用例需要KafkaApache Kafka 基础(一)消息系统1、点对点的消息系统2、发布-订阅消息系统(二)Apache Kafka 简介…...

ARM基础
文章目录1.ARM成长史1.1 ARM发展的里程碑11.2 ARM发展的里程碑21.3 ARM发展的里程碑31.4 ARM发展的里程碑42.ARM的商业模式和生态系统3.先搞清楚各种版本号3.1 ARM 的型号命名问题3.2 ARM 的几种版本号3.3 ARM型号的发展历程4.SoC和CPU的区别 & 外设概念的引入4.1 SoC和CPU…...

Python排序 -- 内附蓝桥题:错误票据,奖学金
排序 ~~不定时更新🎃,上次更新:2023/02/28 🗡常用函数(方法) 1. list.sort() --> sort 是 list 的方法,会直接修改 list 举个栗子🌰 li [2,3,1,5,4] li.sort() print(li) …...

容器化部署是什么意思?有什么优势?
多小伙伴不知道容器化部署是什么意思?不知道容器化部署有什么优势?今天我们就来一起看看。 容器化部署是什么意思? 容器化部署是指将软件代码和所需的所有组件(例如库、框架和其他依赖项)打包在一起,让它…...

1.设计模式简介
一、设计模式的目的 1. 代码重用性 2. 可读性 3. 可扩展性 4. 可靠性 5. 高内聚,低耦合 二、设计模式七大原则 1. 单一职责原则 1)降低类的复杂度,一个类只负责一项职责 2)提高类的可读性,可维护性 3&#x…...

【算法题解】实现一个包含“正负数和括号”的基本计算器
这是一道 困难 题。 题目来自:leetcode 题目 给你一个字符串表达式 s ,请你实现一个基本计算器来计算并返回它的值。 注意: 不允许使用任何将字符串作为数学表达式计算的内置函数,比如 eval() 。 提示: s 由数字、‘’、‘-’…...

网站服务器如何防护攻击?网站服务器被挂马如何检测
网站服务器是指安装在互联网上的服务器,主要用于提供网站服务。由于网站服务器的重要性,它也是攻击者的活动焦点,因此如何防护攻击就显得尤为重要。本文将分析网站服务器是如何被攻击的以及如何防护攻击。 网站服务器是怎么被攻击的? 网站…...

JavaSE16-面向对象-接口
文章目录一、概念二、格式1.使用interface来定义接口2.implements实现接口三、接口中的成员1.常用成员2.新增成员(不重要)2.1 默认方法2.2 静态方法2.3 私有方法四、继承关系 & 实现关系五、抽象类和接口的使用区别一、概念 接口就是规范\规则&…...

安卓设备蓝牙键盘快捷键
安卓设备蓝牙键盘快捷键前言注意鼠标按键系统快捷键桌面快捷键输入法快捷键其它快捷键旧快捷键(已失效)前言 安卓设备可以通过蓝牙或有线外接键盘,值得一提的是,安卓平板连接蓝牙键盘和蓝牙鼠标是一个不错的组合。本文以鸿蒙3.0平…...

Puppeteer项目结构梳理
最近接触了一个个人感觉很奈斯的项目,故记录思路如下: puppeteer项目梳理: 入口文件 run.js 入口命令 node run.js YourConfig.json 1、我们可以在自己的config.json里面设置好 ①、登录的用户名密码;aws或其它服务器的access等id,accessKey…...

(02)Unity HDRP Volume 详解
1.概述这篇文章主要针对HDRP中的Volume和Volume Post-processing进行解释,针对于各个组件只能进行部分参数的解释,具体的信息可参考官方资料,这里只是对官方文档的图片效果补充以及笔者自己的理解。看到这里进入正文,请确保你的Un…...

拒绝B站邀约,从月薪3k到年薪47W,我的经验值得每一个测试人借鉴
有时候,大佬们总是会特立独行。因为像我这样的常人总是想不通,究竟是怎样的情境,连B站这样的大厂面试都可以推掉? 缘起一通电话,踏出了改变人生轨迹的第一步 我是小瑾,今年28岁,2016年毕业于陕…...

分享一种实用redis原子锁的方式
1. setnx(lockkey, 当前时间过期超时时间) ,如果返回1,则获取锁成功;如果返回0则没有获取到锁,转向2。2. get(lockkey)获取值oldExpireTime ,并将这个value值与当前的系统时间进行比较,如果小于当前系统时间…...
)
【华为OD机试】 字符串解密(C++ Java JavaScript Python)
题目描述 给定两个字符串string1和string2。 string1是一个被加扰的字符串。 string1由小写英文字母(’a’’z’)和数字字符(’0’’9’)组成,而加扰字符串由’0’’9’、’a’’f’组成。 string1里面可能包含0个或多个加扰子串,剩下可能有0个或多个有效子串,这些有…...
金三银四,助力你的大厂梦,2023年软件测试经典面试真题(1)(共3篇)
前言 金三银四即将到来,相信很多小伙伴要面临面试,一直想着说分享一些软件测试的面试题,这段时间做了一些收集和整理,下面共有三篇经典面试题,大家可以试着做一下,答案附在后面,希望能帮助到大…...

假如面试官要你手写一个promise
promise 在开发中,经常需要用到promise,promise具有很多特性,这一次将对promise特性进行总结,并从零写一个promise。 步骤一 Promise特点 1,创建时需要传递一个函数,否则会报错2,会给传入的函…...

【leetcode】寻找重复数
题目链接:寻找重复数https://leetcode.cn/problems/find-the-duplicate-number/ 方法一:快慢指针 因为只有一个数字是重复的,且一个数字正好对应一个唯一的下标,所以可以将数组抽象为一个链表,假定数组为{1,2,3,4,5,…...

LeetCode 1247. Minimum Swaps to Make Strings Equal【数学,贪心,字符串】
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

pid控制加热算法,附代码仓库
1、该项目层次化结构清晰,代码框架耦合度低,可复用性、可移植性强。 2、功能代码与底层硬件无直接关联,无需更改上层应用逻辑,只需更改接口文件,即可移植到不同的硬件平台; 3、使用lwrb开源组件、pid开源算…...

一文看懂预训练和自训练模型
说到预训练模型,不得不提迁移学习了,由于很多数据不是标签数据,人工标注非常耗时,神经网络在很多场景下受到了限制。但是迁移学习和自学习的出现,在一定程度上缓解甚至解决了这个问题。我们可以在标签丰富的场景下进行…...

Vest框架性能优化:10个技巧提升验证效率
Vest框架性能优化:10个技巧提升验证效率 【免费下载链接】vest Vest ✅ Declarative validations framework 项目地址: https://gitcode.com/gh_mirrors/ve/vest Vest是一个声明式验证框架,能够帮助开发者轻松构建高效的表单验证逻辑。随着应用规…...

30秒React实用工具函数大全:10个必备开发技巧
30秒React实用工具函数大全:10个必备开发技巧 【免费下载链接】30-seconds-of-react Short React code snippets for all your development needs 项目地址: https://gitcode.com/gh_mirrors/30/30-seconds-of-react 30-seconds-of-react是一个专注于提供简短…...

终极Windows优化指南:用Win11Debloat一键告别系统卡顿和隐私泄露
终极Windows优化指南:用Win11Debloat一键告别系统卡顿和隐私泄露 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declut…...

cv_resnet18_ocr-detection进阶玩法:导出ONNX模型跨平台使用
cv_resnet18_ocr-detection进阶玩法:导出ONNX模型跨平台使用 1. 为什么需要导出ONNX模型 当你已经熟悉了cv_resnet18_ocr-detection的基本使用后,可能会遇到这样的需求:想把模型部署到手机APP上,或者集成到C项目中,又…...

Go Context 控制流的正确使用方式
Go语言中的Context是控制并发流程的重要工具,它不仅能传递请求范围的数据,还能优雅地处理超时、取消等场景。正确使用Context可以避免资源泄漏、提升程序健壮性,但错误的使用方式可能导致难以排查的问题。本文将深入探讨Context的核心使用原则…...

hyn/multi-tenant性能优化技巧:缓存策略与连接管理
hyn/multi-tenant性能优化技巧:缓存策略与连接管理 【免费下载链接】multi-tenant Run multiple websites using the same Laravel installation while keeping tenant specific data separated for fully independent multi-domain setups, previously github.com/…...

10.1软件工程概述-CMM-软件过程模型-逆向工程
一、软件工程基础知识 00:00 1. 软件工程概述 03:10 考试重要性:本章节每年考察12-15分,涉及选择题、案例和论文三种题型,重要性仅次于系统架构设计。内容特点:新版教材对概念定义改动较大,但…...
方法:一个被低估的‘对象侦探’,5分钟搞懂它的正确用法和常见误区)
JavaScript WeakSet的has()方法:一个被低估的‘对象侦探’,5分钟搞懂它的正确用法和常见误区
JavaScript WeakSet的has()方法:一个被低估的‘对象侦探’,5分钟搞懂它的正确用法和常见误区 想象一下,你有一个只认人脸不认名字的侦探朋友。无论你如何描述一个人的特征,他只会摇头说:"除非让我亲眼看到这个人&…...

如何实现AI到PSD的无损转换?告别矢量信息丢失的终极方案
如何实现AI到PSD的无损转换?告别矢量信息丢失的终极方案 【免费下载链接】ai-to-psd A script for prepare export of vector objects from Adobe Illustrator to Photoshop 项目地址: https://gitcode.com/gh_mirrors/ai/ai-to-psd 你是否曾经因为Adobe Ill…...

Qwen3-0.6B-FP8部署教程:利用vLLM提升推理速度,Chainlit美化交互
Qwen3-0.6B-FP8部署教程:利用vLLM提升推理速度,Chainlit美化交互 1. 环境准备与快速部署 1.1 硬件与系统要求 显卡:NVIDIA GPU(RTX 3060 6GB起步,推荐RTX 4090/3090)驱动:NVIDIA Driver ≥ 5…...