服务端开发之Java备战秋招面试篇5
努力了那么多年,回头一望,几乎全是漫长的挫折和煎熬。对于大多数人的一生来说,顺风顺水只是偶尔,挫折、不堪、焦虑和迷茫才是主旋律。我们登上并非我们所选择的舞台,演出并非我们所选择的剧本。继续加油吧!
目录
1.ArrayList与LinkedList区别, 应用场景?
2.LinkedList是单链表还是双链表?Linkedlist查找第二个和倒数第二个效率一样吗?为什么?
3.线程启动方式有哪些,区别是什么?
4. 除了加锁如何实现线程安全 ?
5.volatile加锁么?什么是自旋?什么是CPU空转?
6.进程和线程区别? 通信过程中区别?
7.Java的基本数据类型?常量池有哪些?在哪里?
8.TreadLoacl解释一下,为什么会内存泄露?如何避免内存泄漏?
9.HashMap和hashTable的区别?
10.HashMap得扩容机制?
11.ArrayList得扩容机制?
12.spring如何开开启一个事务?
13.BIO,NIO,AIO模型解释一下?NIO的三大组件?
14.讲一下聚簇索引和非聚簇索引区别?
15.如何开启一个线程?调用start和run方法有什么不同?
16.InnodB和myiasm的区别?
17.数据库隔离级别?MySQL和Oracle默认得隔离级别?
18.AOP解释一下?
19.CAS介绍一下?Syschronized?ReentrantLock?Lock?Synchronized锁升级?
20.算法题:二叉树的先序,中序,后序遍历
1.ArrayList与LinkedList区别, 应用场景?
通常情况下,ArrayList和LinkedList的区别有以下几点:
1. 数据结构:ArrayList是实现了基于动态数组的数据结构,而LinkedList是基于链表的数据结构; 2. 随机访问:对于随机访问get和set,ArrayList要优于LinkedList,因为LinkedList要移动指针;
3. 添加删除操作:对于添加和删除操作add和remove,一般大家都会说LinkedList要比ArrayList快,因为ArrayList要移动数据。但是实际情况并非这样,对于添加或删除,LinkedList和ArrayList并不能明确说明谁快谁慢,当数据量较大时,大约在容量的1/10处开始,LinkedList的效率就开始没有ArrayList效率高了,特别到一半以及后半的位置插入时,LinkedList效率明显要低于ArrayList,而且数据量越大,越明显;
应用场景:
(1)如果应用程序对数据有较多的随机访问,ArrayList对象要优于LinkedList对象;
( 2 ) 如果应用程序有更多的插入或者删除操作,较少的随机访问,LinkedList对象要优于ArrayList对象;
(3)不过ArrayList的插入,删除操作也不一定比LinkedList慢。
2.LinkedList是单链表还是双链表?Linkedlist查找第二个和倒数第二个效率一样吗?为什么?
Linkedlist,双向链表,优点,增加删除,用时间很短,但是因为没有索引,对索引的操作,比较麻烦,只能循环遍历,但是每次循环的时候,都会先判断一下,这个索引位于链表的前部分还是后部分,每次都会遍历链表的一半 ,而不是全部遍历。
双向链表,都有一个previous和next, 链表最开始的部分都有一个fiest和last 指向第一个元素,和最后一个元素。增加和删除的时候,只需要更改一个previous和next,就可以实现增加和删除,所以说,LinkedList对于数据的删除和增加相当的方便。
按道理来说,Linkedlist查找第二个和倒数第二个效率一样,因为双向链表可以两个方向遍历。
3.线程启动方式有哪些,区别是什么?
1.继承Thread类,并复写run方法,创建该类对象,调用start方法开启线程。
2.实现Runnable接口,复写run方法,创建Thread类对象,将Runnable子类对象传递给Thread类对象。调用start方法开启线程。
3.创建FutureTask对象,创建Callable子类对象,复写call(相当于run)方法,将其传递给FutureTask对象(相当于一个Runnable)。
创建Thread类对象,将FutureTask对象传递给Thread对象。调用start方法开启线程。这种方式可以获得线程执行完之后的返回值。
4. 除了加锁如何实现线程安全 ?
使用线程安全的类,本质上还是加锁。
在性能和安全性之前取得一个平衡,所以引出一个无锁并发的概念,当然,本质上来讲,就是扯犊子,保持原子性肯定是需要加锁的。
第一种方法,通过自旋锁,线程在没有抢占锁的情况下,先自旋指定的次数去获得锁。
第二种方法是乐观锁,给每个数据增加一个版本号,一旦数据发生变化,则去修改这个版本号。
第三种就是尽量在业务中减少共享对象的使用,实现隔离减少并发。
第四种就是使用Threadlocal创建共享变量的副本。
5.volatile加锁么?什么是自旋?什么是CPU空转?
volatile不需要加锁,比synchronized更轻便,不会阻塞线程,volatile能保证可见性和有序性但不能保证多线程下的原子性。volatile只能保证受限的原子性。通过对volatile修饰的变量的读写操作前后加上各种特定的内存屏障来禁止指令重排序来保证有序性。可见性:变量被volatile修饰,java内存模型能确保所有的线程看到的这个变量的值是一致的。
自旋:就是自己在这里不停地循环,直到目标达成,CAS算法就是一种自旋锁机制,不会导致线程阻塞,获取不到锁,就不停地自旋尝试加锁。
cpu空转: 如果CAS失败,会一直进行尝试,如果CAS长时间一直不成功,不释放CPU,可能会给CPU带来很大的开销。(CPU空转问题)(锁饥饿)
6.进程和线程区别? 通信过程中区别?
进程与线程的区别总结:
本质区别:进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位。
包含关系:一个进程至少有一个线程,线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
资源开销:每个进程都有独立的地址空间,进程之间的切换会有较大的开销;线程可以看做轻量级的进程,同一个进程内的线程共享进程的地址空间,每个线程都有自己独立的运行栈和程序计数器,线程之间切换的开销小。
影响关系:一个进程崩溃后,在保护模式下其他进程不会被影响,但是一个线程崩溃可能导致整个进程被操作系统杀掉,所以多进程要比多线程健壮。
进程间通信:
①管道
管道传输数据是单向的,如果想相互通信,我们需要创建两个管道才行,半双工。
②消息队列:
基本原理:A 进程要给 B 进程发送消息,A 进程把数据放在对应的消息队列后就可以正常返回了,B 进程需要的时候再去读取数据就可以了。
③共享内存:
共享内存解决了消息队列的读取和写⼊的过程会有发生用户态与内核态之间的消息拷贝的问题。
就是拿出⼀块虚拟地址空间来,映射到相同的物理内存中。这段共享内存由一个进程创建,但多个进程都可以访问。这样这个进程写⼊的东⻄,另外⼀个进程马上就能看到了,都不需要拷贝,提高了进程间通信的速度。
④信号量:
- 防止多进程竞争共享资源,造成的数据错乱,所以需要保护机制,使得共享的资源,在任意时刻只能被⼀个进程访问,信号量就实现了这⼀保护机制。
- 信号量其实是⼀个整型的计数器,主要用于实现进程间的互斥与同步,不是用于缓存进程间通信的数据。
⑤Socket:
那要想跨网络与不同主机上的进程之间通信,就需要 Socket 通信了。还可以在同主机上进程间通信。TCP和UDP。
线程间通信:
线程间的通信目的主要是用于线程同步。所以线程没有像进程通信中的用于数据交换的通信机制。
同一进程的不同线程共享同一份内存区域,所以线程之间可以方便、快速地共享信息。只需要将数据复制到共享(全局或堆)变量中即可。但是需要避免出现多个线程试图同时修改同一份信息。
1、互斥锁
在访问共享资源前进行加锁,在访问完成后释放互斥锁。加锁后其他想访问此资源的线程会进入阻塞,直到当前线程释放互斥锁。注意防止死锁。
2、读写锁
一次只有一个线程可以占有写模式的读写锁,但是多个线程可以同时占有读模式的读写锁。
当读写锁是写加锁状态时,在这个锁被解锁之前,所有试图对这个锁加锁的线程都会被阻塞。
当读写锁在读加锁状态时,所有试图以读模式对它进行加锁的线程都可以得到访问权,但是任何希望以写模式对此锁进行加锁的线程都会阻塞,直到所有的线程释放它们的读锁为止。
3、条件变量
互斥量用于上锁,条件变量则用于等待,并且条件变量总是需要与互斥锁一起使用,运行线程以无竞争的方式等待特定的条件发生。
条件变量本身是由互斥量保护的,线程在改变条件变量之前必须首先加互斥锁。(某共享数据达到某值的时候,唤醒等待这个共享数据的线程)
4、信号量
使用线程的信号量可以高效地完成基于线程的资源计数。信号量实际上是一个非负的整数计数器,用来实现对公共资源的控制。
在公共资源增加的时候,信号量就增加;公共资源减少的时候,信号量就减少;只有当信号量的值大于0的时候,才能访问信号量所代表的公共资源。
7.Java的基本数据类型?常量池有哪些?在哪里?
Java中有8种基本数据类型,分别为:
6种数字类型 :byte、short、int、long、float、double
1种字符类型:char
1种布尔型:boolean
字符串常量池(String Constant Pool)
class常量池(Class Constant Pool)
运行时常量池(Runtime Constant Pool)
Java6及之前,常量池是存放在方法区(永久代)中的。
Java7,将常量池是存放到了堆中。
Java8之后,取消了整个永久代区域,取而代之的是元空间。运行时常量池和静态常量池存放在元空间中,而字符串常量池依然存放在堆中。
8.TreadLoacl解释一下,为什么会内存泄露?如何避免内存泄漏?
多个线程访问同一个共享变量时,如果不做同步控制,往往会出现「数据不一致」的问题,通常会使用synchronized关键字加锁来解决,ThreadLocal则换了一个思路。
ThreadLocal本身并不存储值,它依赖于Thread类中的ThreadLocalMap,当调用set(T value)时,ThreadLocal将自身作为Key,值作为Value存储到Thread类中的ThreadLocalMap中,这就相当于所有线程读写的都是自身的一个私有副本,线程之间的数据是隔离的,互不影响,也就不存在线程安全问题了。
Entry将ThreadLocal作为Key,值作为value保存,它继承自WeakReference,注意构造函数里的第一行代码super(k),这意味着ThreadLocal对象是一个「弱引用」。综上所述,由于ThreadLocal对象是弱引用,如果外部没有强引用指向它,它就会被GC回收,导致Entry的Key为null,如果这时value外部也没有强引用指向它,那么value就永远也访问不到了,按理也应该被GC回收,但是由于Entry对象还在强引用value,导致value无法被回收,这时「内存泄漏」就发生了,value成了一个永远也无法被访问,但是又无法被回收的对象。
如何避免内存泄漏?
使用ThreadLocal时,一般建议将其声明为static final的,避免频繁创建ThreadLocal实例。
尽量避免存储大对象,如果非要存,那么尽量在访问完成后及时调用remove()删除掉。
9.HashMap和hashTable的区别?
1.HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key),由于非线程安全,在只有一个线程访问的情况下,效率要高于Hashtable。
2.HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。
HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。
3.Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface的一个实现。
4.最大的不同是,Hashtable的方法是Synchronize的,而HashMap不是,在多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap就必须为之提供同步。
10.HashMap得扩容机制?
HashMap的底层有数组 + 链表(红黑树)组成,数组的大小可以在构造方法时设置,默认大小为16,数组中每一个元素就是一个链表,jdk7之前链表中的元素采用头插法插入元素,jdk8之后采用尾插法插入元素,由于插入的元素越来越多,查找效率就变低了,所以满足某种条件时,链表会转换成红黑树。随着元素的增加,HashMap的数组会频繁扩容,如果构造时不赋予加载因子默认值,那么负载因子默认值为0.75,数组扩容的情况如下:
1:当添加某个元素后,数组的总的添加元素数大于了 数组长度 * 0.75(默认,也可自己设定),数组长度扩容为两倍。(如开始创建HashMap集合后,数组长度为16,临界值为16 * 0.75 = 12,当加入元素后元素个数超过12,数组长度扩容为32,临界值变为24)
2:在没有红黑树的条件下,添加元素后数组中某个链表的长度超过了8,数组会扩容为两倍.(如开始创建HashMAp集合后,假设添加的元素都在一个链表中,当链表中元素为8时,再在链表中添加一个元素,此时若数组中不存在红黑树,则数组会扩容为两倍变成32,假设此时链表元素排列不变,再在该链表中添加一个元素,数组长度再扩容两倍,变为64,假设此时链表元素排列还是不变,则此时链表中存在10个元素,这是HashMap链表元素数存在的最大值,此时,再加入元素,满足了链表树化的两个条件(1:数组长度达到64, 2:该链表长度达到了8),该链表会转换为红黑树
11.ArrayList得扩容机制?
ArrayList的底层是一个动态数组,ArrayList首先会对传进来的初始化参数initalCapacity进行判断
- 如果参数等于0,则将数组初始化为一个空数组,
- 如果不等于0,将数组初始化为一个容量为10的数组。
扩容时机
当数组的大小大于初始容量的时候(比如初始为10,当添加第11个元素的时候),就会进行扩容,新的容量为旧的容量的1.5倍。
扩容方式
扩容的时候,会以新的容量建一个原数组的拷贝,修改原数组,指向这个新数组,原数组被抛弃,会被GC回收。
12.spring如何开开启一个事务?
注解声明式事务
通过注解的方式使用 Spring 事务管理,首先需要开启这个功能,有两种方式。
- Spring XML 配置文件中配置
<tx:annotation-driven/>。 - Spring 配置类上添加
@EnableTransactionManagement注解。
开启注解后还需要在 Spring 中配置 TransactionManager 作为 bean,通常使用的实现为 DataSourceTransactionManager,如果引入了 spring-boot-starter-jdbc,则无需显式配置 TransactionManager,而只需要配置一个 Datasource 即可。
开启注解支持后需要在 Spring Bean 的类或方法上使用 @Transactional 注解。
13.BIO,NIO,AIO模型解释一下?NIO的三大组件?
Java共支持3种网络编程的I/O模型:BIO、NIO、AIO
BIO:
同步并阻塞(传统阻塞型),服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,可以通过线程池机制改善(实现多个客户连接服务器)。
BIO编程流程的梳理:
- 服务器端启动一个ServerSocket,注册端口,调用accpet方法监听客户端的Socket连接
- 客户端启动Socket对服务器进行通信,默认情况下服务器端需要对每个客户建立一个线程与之通讯
NIO:
同步非阻塞,服务器实现模式为一个线程处理多个请求(连接),即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求就进行处理。
- NIO有三大核心部分:Channel(通道)、Buffer(缓冲区)、Selector(选择器)
Java NIO的非阻塞模式,使一个线程从某通道发送请求或者读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。非阻塞写也是如此,一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。
AIO:
异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由操作系统先完成了再通知服务器应用去启动线程进行处理,一般适用于连接数较多且连接时间较长的应用。
14.讲一下聚簇索引和非聚簇索引区别?
在 MySQL 默认引擎 InnoDB 中,索引大致可分为两类:聚簇索引和非聚簇索引。
聚簇索引(Clustered Index)一张表中只能有一个,一般指的是主键索引(如果存在主键索引的话),聚簇索引也被称之为聚集索引。索引的叶节点就是数据节点。将索引和表数据放到同一个节点中,索引结构的叶子节点存放数据,找到了索引,即找到了数据
非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。索引存储和数据存储分离,索引结构的叶子节点指向数据的位置。通过索引找到位置,再通过位置找到数据,这个过程叫做回表查询。一个表可以有多个非聚簇索引。非聚簇索引也成为辅助索引。
聚集索引表数据按照索引的顺序来存储的,也就是说索引项的顺序与表中记录的物理顺序一致。
非聚集索引。表数据存储顺序与索引顺序无关。
15.如何开启一个线程?调用start和run方法有什么不同?
1)继承Thread类,并重写run()方法
2)实现Runnable接口并重写run()方法
3)实现Callable接口并重写call()方法
启动一个线程是调用start()方法,使线程就绪状态,以后可以被调度为运行状态,一个线程必须关联一些具体的执行代码,run()方法是该线程所关联的执行代码。
16.InnodB和myiasm的区别?
1.InnoDB 支持事务,MyISAM 不支持。对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务;
2. InnoDB 支持外键,而 MyISAM 不支持。对一个包含外键的InnoDB表转为MYISAM会失败; (外键现在用的也不多,因为它关联性太强,如果要删除一个表,会因为有外键的关联而导致删除失败。通常是通过 table a = table b on a.id = b.id 这种两表关联的方式来间接替代外键作用 )
3.InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的;MyISAM是非聚集索引,它也是使用B+Tree作为索引结构,但是索引和数据文件是分离的,索引保存的是数据文件的指针。
4.InnoDB 必须要有主键,MyISAM可以没有主键;InnoDB 如果我们没有明确去指定创建主键索引。它会帮我们隐藏的生成一个 6 byte 的 int 型的索引作为主键索引。
5. InnoDB支持表级锁、行级锁,默认为行级锁;而 MyISAM 仅支持表级锁。InnoDB 的行锁是实现在索引上的,而不是锁在物理行上。如果访问未命中索引,也是无法使用行锁,将会退化为表锁.
17.数据库隔离级别?MySQL和Oracle默认得隔离级别?
MySQL支持四种事务隔离级别,默认的事务隔离级别为repeatable read,Oracle数据库默认的隔离级别是read committed。
四种隔离级别分别为读未提交,读已提交,可重复读, 序列化/串行化。其中,读未提交是最低的隔离级别,序列化隔离级别最高。
1.读未提交(read uncommitted):没有提交就读取到了。
2.读已提交(read committed):已经提交的才能读取。
3.可重复读(repeatable read):事务结束之前。永远读取不到真实数据,提交了也读取不到,读取的永远都是最初的数据,即假象。
4.序列化(serializable):表示事务排队,不能并发,每次读取的都是最真实的数据。
同时运行多个事务,当这些事务访问数据库中相同的数据时,如果没有采取必要的隔离机制,就会导致各种并发问题。
1-脏读:对于两个事务T1和T2,T1读取了已经被T2更新但还没有提交的字段,之后,若T2回滚,则T1读取的数据就是临时且无效的。
2-不可重复读:对于两个事务T1和T2,T1读取了该字段,但是T2更新了该字段,T1再次读取这个字段,值就不同了。
3-幻读:对于两个事务T1和T2,T1从表中读取了一些字段,T2在表中插入了一些新的行,T1再次读取该表发现多几行。
read uncommitted:可以出现脏读,幻读,不可重复读。
read committed:避免脏读,出现幻读和不可重复读。
repeatable read:避免脏读和不可重复读,出现幻读。
serializable:避免脏读,幻读,不可重复读。
18.AOP解释一下?
AOP(Aspect Oriented Programming):面向切面编程,一种编程范式,隶属于软件工程范畴,指导开发者如何组织程序结构,AOP弥补了OOP的不足,基于OOP基础之上进行横向开发。其实重复的这一部分代码可以进行抽取,简化了我们的开发 。运行的时候需要将其中抽取出来的共性功能代码放回去,形成一个完整的代码,从而使程序正常运行,这样的一种开发模式被称为AOP。
Joinpoint(连接点):我们平常所写的普通方法在AOP中就是连接点
Pointcut(切入点):挖掉共性功能剩余下来的方法.
Advice(通知):抽取出来的共性功能就是通知,最终回以一个方法的形式呈现
Aspect(切面):共性功能与切入点之间的存在的位置对应关系
Target(目标对象):挖掉功能的方法对应的类所产生的对象,这种对象是无法直接完成最终工作的.
Weaving(织入):是一个将挖掉的功能进行回填的一个动态过程。
Proxy(代理):目标对象是无法直接完成工作的,需要对其进行功能回填,通过创建的代理对象实现。
Introduction(引入/引介):就是对原始对象无中生有的添加成员变量或成员方法
19.CAS介绍一下?Syschronized?ReentrantLock?Lock?Synchronized锁升级?
CAS是实现乐观锁的一种方式,即compare and swap(比较与交换),涉及三个操作数:
需要读写的内存值 V,进行比较的值 A,拟写入的新值 B
会先把要原值A查询出来,然后只有当V=A时才会去写入新值B,如果不相等则说明原值已被别的线程修改过了,就会去不断自旋重试再次修改值
CAS存在的问题:ABA问题,CPU开销大,只能保证一个共享变量的原子操作
CAS使用场景,读多写少,对于资源竞争较少(线程冲突较轻)的情况
- 此时如果使用synchronized,那么用户态、内核态的频繁切换会耗费很多资源;
- CAS自旋几率小,性能更高。
Synchronized是悲观锁的一种,使用场景,写冲突多,线程冲突严重,强一致性的场景,此时CAS自旋概率大,会浪费更多CPU资源。synchronized是JVM的内置锁,内部通过监视器锁实现,基于monitorenter和monitorexit实现代码块同步,每个同步对象都有一个自己的监视器锁,需要判断对象能否拿到监视器锁,如果拿到监视器锁,才能进入同步块执行同步逻辑,否则需要进入同步队列等待。
ReentrantLock使用场景:
synchronized的锁升级是不可逆的。如果是一个打车软件,那过了打车高峰期,还是重量级锁,就会降低效率;此时如果用Reentratlock就比较好。
可重入锁的概念:自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都是自增1,所以要等到锁的计数器下降为0时才能释放锁。
ReentrantLock使用起来比较灵活,但是必须有释放锁的配合动作
ReentrantLock必须手动获取与释放锁,而synchronized不需要手动释放和开启锁
ReentrantLock只适用于代码块锁,而synchronized可以修饰类、方法、变量等
两者的锁机制其实也是不一样的。ReentrantLock底层调用的是Unsafe的park方法加锁synchronized操作的应该是对象头中mark word

锁升级过程:由无锁->偏向锁->轻量级锁->重量级锁。偏向锁:只有一个线程进入临界区访问同步块。轻量级锁:多线程竞争不激烈,同步块执行响应快。重量级锁:多线程竞争,同步块执行时间较长。
1 无锁
当一个对象被创建之后,还没有线程进入,这个时候对象处于无锁状态,其Mark Word中的信息如上表所示。
2 偏向锁
当锁处于无锁状态时,有一个线程A访问同步块并获取锁时,会在对象头和栈帧中的锁记录记录线程ID,以后该线程在进入和退出同步块时不需要进行CAS操作来进行加锁和解锁,只需要简单的测试一下啊对象头中的线程ID和当前线程是否一致。
3 轻量级锁
在偏向锁的基础上,又有另外一个线程B进来,这时判断对象头中存储的线程A的ID和线程B不一致,就会使用CAS竞争锁,并且升级为轻量级锁,会在线程栈中创建一个锁记录(lock Record),将Mark Word复制到锁记录中,然后线程尝试使用CAS将对象头的Mark Word替换成指向锁记录的指针,如果成功,则当前线程获得锁;失败,表示其他线程竞争锁,当前线程便尝试CAS来获取锁。
4 重量级锁
当线程没有获得轻量级锁时,线程会CAS自旋来获取锁,当一个线程自旋10次之后,仍然未获得锁,那么就会升级成为重量级锁。 成为重量级锁之后,线程会进入阻塞队列(EntryList),线程不再自旋获取锁,而是由CPU进行调度,线程串行执行。
20.算法题:二叉树的先序,中序,后序遍历
先将先序遍历结果存到集合里面,先序遍历递归注意递归出口,最后从集合李取元素存到数组。
先序遍历题目:二叉树的前序遍历_牛客题霸_牛客网
import java.util.*;/** public class TreeNode {* int val = 0;* TreeNode left = null;* TreeNode right = null;* public TreeNode(int val) {* this.val = val;* }* }*/public class Solution {/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可** * @param root TreeNode类 * @return int整型一维数组*/public static void preOrder(TreeNode root, ArrayList<Integer> arrayList){if(root == null){ //递归出口return ;}arrayList.add(root.val) ;preOrder(root.left,arrayList) ;preOrder(root.right,arrayList) ;}public int[] preorderTraversal (TreeNode root) {// write code hereArrayList<Integer> arrayList = new ArrayList<> () ;preOrder(root, arrayList) ;int [] ans = new int [arrayList.size()] ;for(int i=0; i<ans.length; i++){ans[i] = arrayList.get(i) ;}return ans ;}}中序遍历题目:二叉树的中序遍历_牛客题霸_牛客网
import java.util.*;/** public class TreeNode {* int val = 0;* TreeNode left = null;* TreeNode right = null;* public TreeNode(int val) {* this.val = val;* }* }*/public class Solution {/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可** * @param root TreeNode类 * @return int整型一维数组*/public int[] inorderTraversal (TreeNode root) {// write code hereArrayList<Integer> arraylist = new ArrayList<>() ;inOrder(root, arraylist) ;int [] ans = new int [arraylist.size()] ;for(int i=0; i<ans.length; i++){ans[i] = arraylist.get(i) ;}return ans ;}public static void inOrder(TreeNode root, ArrayList<Integer> arraylist){if(root == null){return ;}inOrder(root.left,arraylist) ;arraylist.add(root.val) ;inOrder(root.right,arraylist) ;}
}后序遍历题目:二叉树的后序遍历_牛客题霸_牛客网
import java.util.*;/** public class TreeNode {* int val = 0;* TreeNode left = null;* TreeNode right = null;* public TreeNode(int val) {* this.val = val;* }* }*/public class Solution {/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可** * @param root TreeNode类 * @return int整型一维数组*/public int[] postorderTraversal (TreeNode root) {// write code hereArrayList<Integer> arraylist = new ArrayList<>() ;postOrder(root, arraylist) ;int [] ans = new int [arraylist.size()] ;for(int i=0; i<ans.length; i++){ans[i] = arraylist.get(i) ;}return ans ;}public void postOrder(TreeNode root, ArrayList<Integer> arraylist){if(root == null){return ;}postOrder(root.left,arraylist) ;postOrder(root.right,arraylist) ;arraylist.add(root.val) ;}
}相关文章:
服务端开发之Java备战秋招面试篇5
努力了那么多年,回头一望,几乎全是漫长的挫折和煎熬。对于大多数人的一生来说,顺风顺水只是偶尔,挫折、不堪、焦虑和迷茫才是主旋律。我们登上并非我们所选择的舞台,演出并非我们所选择的剧本。继续加油吧! 目录 1.ArrayList与LinkedList区别, 应用场景…...

有趣的 Kotlin 0x11: joinToString,你真的了解嘛?
前言 之前使用 joinToString 函数也就是用逗号连接集合元素形成字符串,也没有细看它的参数,但是今天和 ChatGPT 聊天时,发现它给我输出了诸多内容。 joinToString joinToString()是Kotlin中一个非常有用的函数,它可以将集合的元…...
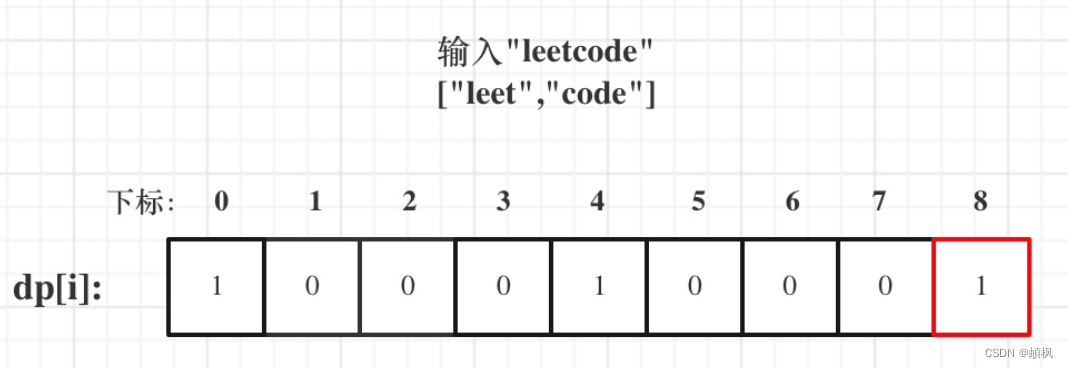
代码随想录算法训练营day46 | 动态规划之背包问题 139.单词拆分
day46139.单词拆分1.确定dp数组以及下标的含义2.确定递推公式3.dp数组如何初始化4.确定遍历顺序5.举例推导dp[i]139.单词拆分 题目链接 解题思路:单词就是物品,字符串s就是背包,单词能否组成字符串s,就是问物品能不能把背包装满。…...

DPDK中的无锁共享数据结构
目录背景解决方法共享内存无锁操作新/老共享数据结构rte_ringrefcnt延迟释放方法1:读的线程来释放方法2:释放线程等到读线程轮询一轮参考背景 dpvs多线程,如何做到节约内存、高性能之间的均衡。 解决方法 共享内存 多线程共享内存&#x…...
【使用两个栈实现队列】
文章目录一、栈和队列的基本特点二、基本接口函数的实现1.栈的接口2.创建队列骨架3.入队操作4.取出队列元素5.返回队首元素6.判断队列是否为空7.销毁队列总结一、栈和队列的基本特点 栈的特点是后进先出,而队列的特点是先进先出。 使用两个栈实现队列,必…...
web,h5海康视频接入监控视频流记录一
项目需求,web端实现海康监控视频对接接入,需实现实时预览,云台功能,回放功能。 web端要播放视频,有三种方式,一种是装浏览器装插件,一种是装客户端exe,还有就是无插件了。浏览器装插…...

做毕业设计,前端部分你需要掌握的6个核心技能
其实前端新手如果想要自己实现一套毕业设计项目并非简单的事,因为之前很多人一直还停留在知识点的阶段,而且管理系统和C端网站都需要开发,但现在需要点连成线了。所以在启动项目开发之前呢,针对前端部分,我列举一些非常…...
--EventLoop and thread model)
Read book Netty in action(Chapter VIII)--EventLoop and thread model
前言 简单地说,线程模型指定了操作系统、编程语言、框架或者应用程序的上下文中的线程管理的关键方面。显而易见地,如何以及何时创建线程将对应用程序代码的执行产生显著的影响,因此开发人员需要理解与不同模型相关的权衡。无论是他们自己选…...
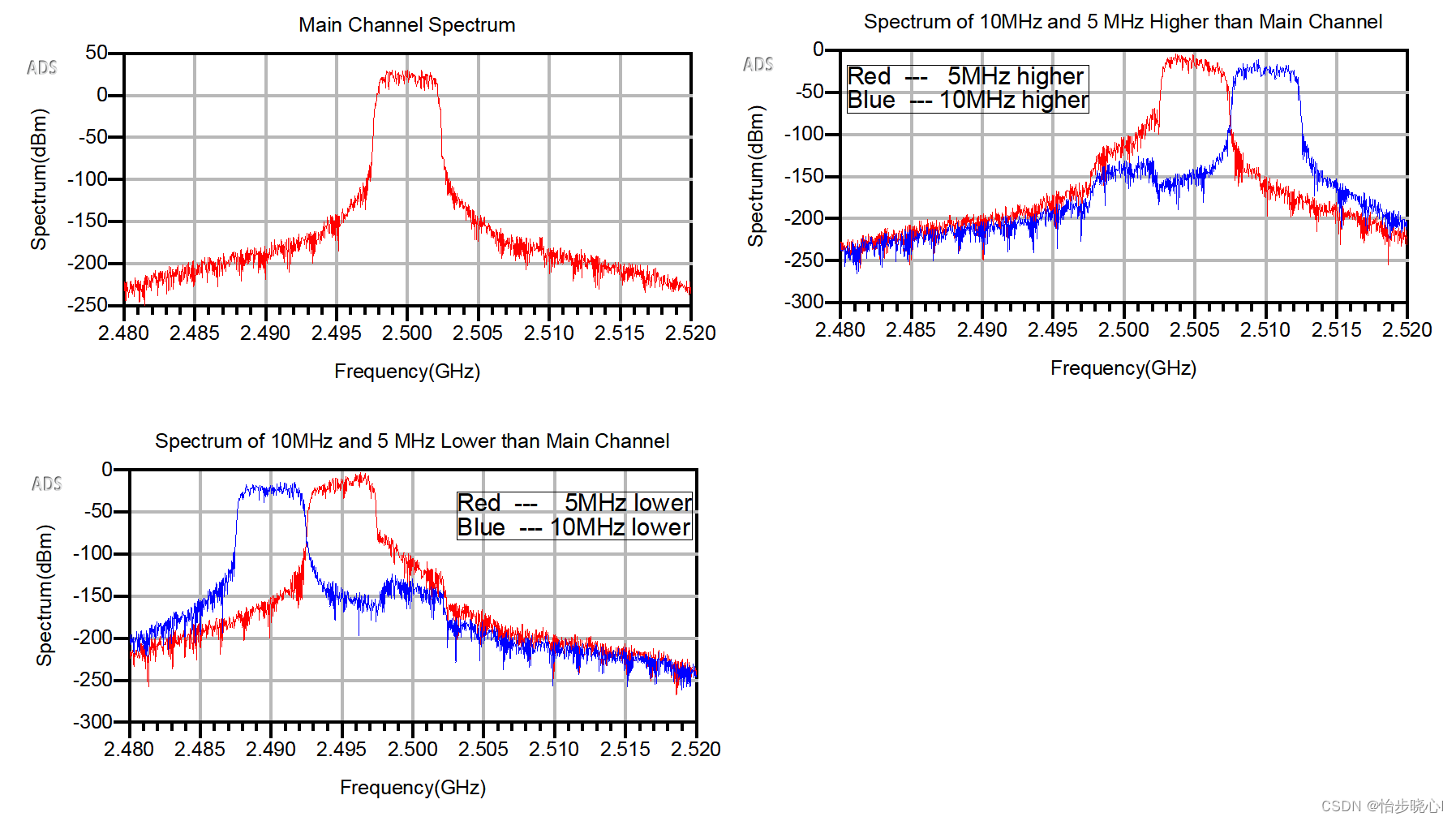
番外11:使用ADS对射频功率放大器进行非线性测试3(使用带宽5MHz的WCDMA信号进行ACLR测试)
番外11:使用ADS对射频功率放大器进行非线性测试3(使用带宽5MHz的WCDMA信号进行ACLR测试) 其他测试: 番外9:使用ADS对射频功率放大器进行非线性测试1(以IMD3测试为例) 番外10:使用AD…...

Linux libpqxx 库安装及使用
记录一下linux安装 libpqxx遇到的一些问题 1.准备安装包: 1.准备安装包,以libpqxx-4.0.1.tar.gz为例子 链接如下:https://launchpad.net/libpqxx/milestone/4.0.1 2.上传并安装 上传到安装目录并安装,我是放到/use/local下面 c…...

如何使用COM-Hunter检测持久化COM劫持漏洞
关于COM-Hunter COM- Hunter是一款针对持久化COM劫持漏洞的安全检测工具,该工具基于C#语言开发,可以帮助广大研究人员通过持久化COM劫持技术来检测目标应用程序的安全性。 关于COM劫持 微软在Windows 3.11中引入了(Component Object Model, COM)&…...

Cartesi 举办的2023 黑客马拉松
Cartesi 是具有 Linux 运行时的特定于应用程序的Rollups执行层。Cartesi 的特定应用程序 Optimistic Rollup 框架使区块链堆栈足够强大,开发人员可以构建计算密集型和以前不可能的去中心化实例。Cartesi 的 RISC-V 虚拟机支持 Linux 运行时环境,允许像你…...

架构篇--代码质量手册
目前团队缺少SA(研发经理)的角色,大家代码写的有点随意,老板让我写一份开发手册。嗯!!!当时我稍微纠结了一下,感觉这个似乎不是我的工作范畴,但是本着"我就是块砖&a…...
那些年用过的IDEA插件
今天和大家分享一下经常使用的IDEA的插件,希望有所帮助。一、IDEA插件CodeGlance2显示代码缩略图插件,方便查看代码。Lombok用于编译期间自动生成getter、setter、构造、toString等方法,简化代码。Mybatis Builder或MybatisXMapper接口和xml双…...
python+requests实现接口自动化测试
这两天一直在找直接用python做接口自动化的方法,在网上也搜了一些博客参考,今天自己动手试了一下。 一、整体结构 上图是项目的目录结构,下面主要介绍下每个目录的作用。 Common:公共方法:主要放置公共的操作的类,比如数据库sqlhe…...

rtthread 线程
创建动态线程最简单代码 #include <rtthread.h>//包含头文件static rt_thread_t thread1 RT_NULL; //创建线程控制块指针,指向空static void thread1_entry(void *parameter)//线程入口(干什么) {rt_kprintf("do something"…...

伯恩光学再成被执行人:多次因劳动纠纷被起诉,曾冲刺港交所上市
近日,贝多财经从天眼查APP了解到,伯恩光学(深圳)有限公司(下称“伯恩光学”)因《伯恩光学(深圳)有限公司与温*燕劳动合同纠纷的案件》一事,被广东省深圳市龙岗区人民法院…...

mysql基础操作2
通配符_:一个任意字符,like ‘张_’%:任意长度的字符串,like ‘co%’,‘%co’,‘%co%’【】:括号中所指定范围内的一个字符,like ‘9W0【1-2】’【^】:不在括号中所指定范…...

指针的进阶【下篇】
文章目录📀8.指向函数指针数组的指针📀9.回调函数📀8.指向函数指针数组的指针 🌰请看代码与注释👇 int Add(int x, int y) {return x y; } int Sub(int x, int y) {return x - y; } int main() {int (*pf)(int, int…...
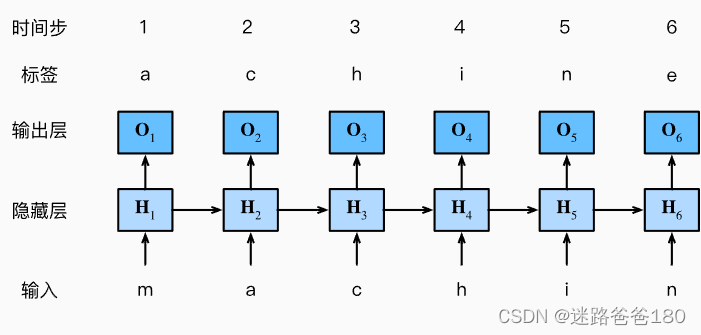
不同序列模型的输入和输出总结
不同序列模型的输入和输出总结 文章目录不同序列模型的输入和输出总结RNNLSTMGRURNN RNN 是迭代输出: 输入第一个 -> 输出第二个, 输入第二个 -> 输出第三个, 输出倒数第二个 -> 输出最后一个。 LSTM LSTM 也是迭代输出ÿ…...

【nginx】深入解析net::ERR_CONTENT_LENGTH_MISMATCH 200:权限配置与日志排查实战
1. 错误现象与初步诊断 当你用浏览器访问Nginx托管的网站时,突然看到控制台报错net::ERR_CONTENT_LENGTH_MISMATCH 200,但页面居然还能正常显示部分内容,这种情况是不是很诡异?我第一次遇到时也是一头雾水。这个错误表面看是内容长…...

2000-2024年县域就业人数乡村从业人员数数据
数据介绍 国家统计局统计,乡村从业人员数量庞大,且随着农业现代化和农村经济的发展,乡村从业人员的结构也在发生变化。农林牧渔业从业人员数量有所减少,而农村电商、乡村旅游等新兴产业的从业人员数量在增加。 数据名称…...

Qwen3-VL-8B在.NET生态中的集成:开发C#桌面端图像分析应用
Qwen3-VL-8B在.NET生态中的集成:开发C#桌面端图像分析应用 最近在帮一个做电商的朋友处理商品图片,他每天要手动整理上百张图片的信息,比如识别商品类别、提取价格标签、统计库存表格,忙得焦头烂额。我就在想,能不能用…...

沃虎电子|千兆网络变压器选型实战:从PoE等级到PHY匹配,一站式解决工程师的三大难题
在工业以太网、安防监控、光伏储能、无线AP等场景全面爆发的今天,千兆网络变压器已成为硬件设计中不可或缺的关键一环。然而,选型过程中的“隐形陷阱”——PoE供电不稳、封装温度错配、PHY芯片接法错误——却频频导致设备掉电、通信故障甚至批量召回。 …...

SEO关键词优化和广告投放的关系是什么
SEO关键词优化和广告投放的关系是什么 在当今数字营销的世界里,SEO关键词优化和广告投放是两个不可或缺的组成部分。它们之间的关系不仅仅是独立存在,而是相辅相成,共同为企业的网络营销目标提供支持。本文将详细探讨SEO关键词优化和广告投放…...

康奈尔大学 AlScN/GaN 异质结构研究“单通道和多通道 AlScN 势垒”
康奈尔大学的研究团队声称,利用铝钪氮(AlScN)势垒开发的氮化镓(GaN)单通道和多通道异质结构,实现了迄今为止最低的薄层电阻(Sheet Resistance)。这项工作旨在推动下一代高速、高功率…...

Linux线程创建机制与多线程编程实践
1. Linux线程创建机制解析在Linux系统中,线程创建是一个内核态与用户态协同工作的过程。与进程不同,线程不是完全由内核实现的机制,而是通过glibc库函数与内核系统调用的配合完成的。理解线程创建机制对开发高性能多线程程序至关重要。线程与…...
)
企业网络架构设计:如何选择核心交换机、汇聚交换机和接入交换机(含真实案例)
企业网络架构设计实战:核心层、汇聚层与接入层交换机选型指南 当一家200人规模的制造企业决定升级网络基础设施时,IT负责人发现市场上交换机的型号多达上千种,价格从几百元到几十万元不等。核心交换机是否必须选用思科Catalyst 9500系列&…...
)
别再死记硬背公式!用Python可视化理解数字基带信号功率谱(含代码)
用Python动态解析数字基带信号功率谱:从公式到视觉直觉的跨越 通信原理课程中那些晦涩的公式是否曾让你望而生畏?特别是当教授在黑板上推导数字基带信号功率谱密度时,那一连串的δ函数和Sa函数让人头晕目眩。本文将通过Python代码实现一个交互…...

基于Matlab/Simulink的直流调速系统PI控制器设计与抗扰性能仿真分析
1. 直流调速系统与PI控制基础 直流电机调速系统在工业自动化领域应用广泛,从机床主轴控制到电动汽车驱动都离不开它。我第一次接触这个课题是在研究生实验室,当时用老旧的直流电机做实验,手忙脚乱调参数的样子至今记忆犹新。传统调速系统最让…...