Cypher中的聚合
- 深解Cypher中的聚合
- 值或计数的聚合要么从查询返回,要么用作多步查询下一部分的输入。
- 查看数据模型
- CALL db.schema.visualization()
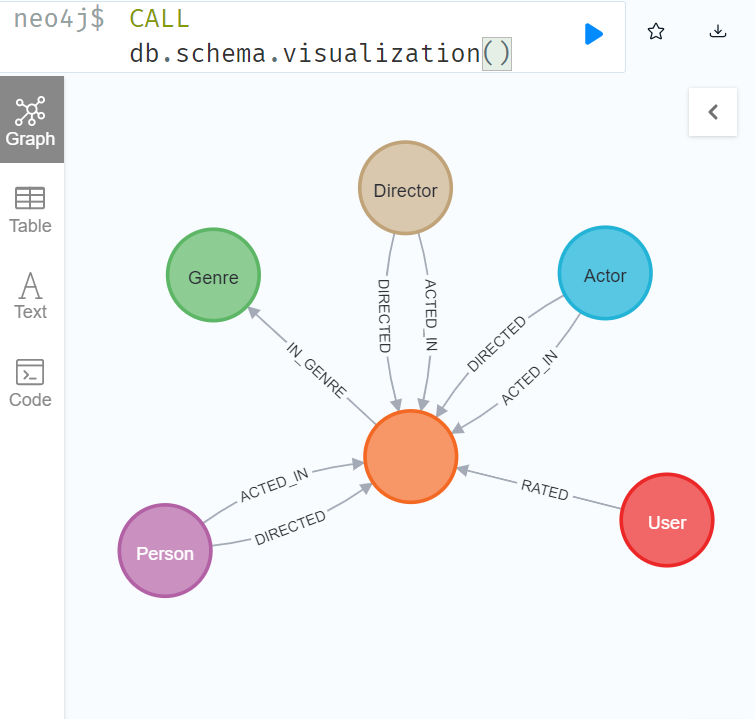
- CALL db.schema.visualization()
- 查看图中节点的属性类型
- CALL db.schema.notetypeproperties()
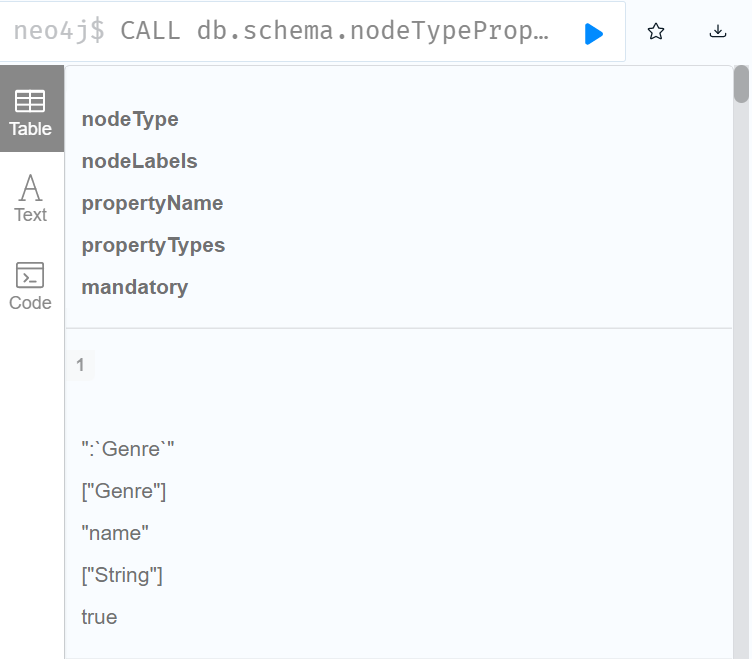
- CALL db.schema.notetypeproperties()
- 查看图中关系的属性类型
- CALL db.schema.reltypeproperties()
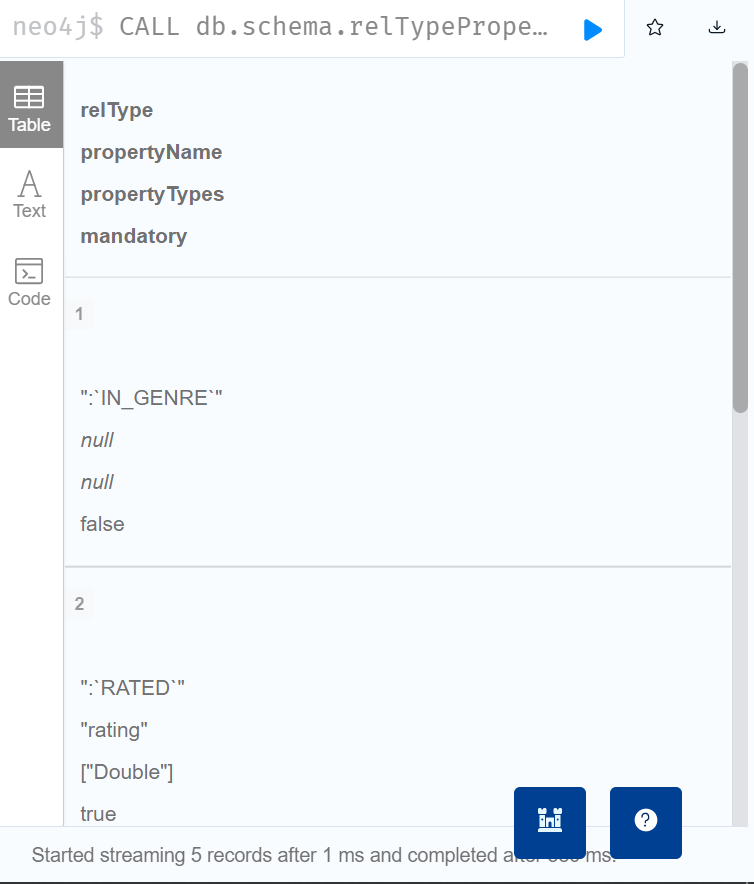
- CALL db.schema.reltypeproperties()
- Cypher中的聚合
- 列表
- 列表是包含元素的数组。列表中的元素不必都是同一类型。
- 使用 [ ]
- MATCH (m:Movie) RETURN [m.title, m.released, date().year - date(m.released).year + 1 ]
- 使用 collect()
- MATCH (a:Actor)--(m:Movie) WITH a,collect(m.title) AS Movies RETURN a.name AS Actor,Movies LIMIT 10
- 工作原理
- 返回一个元素列表。可以 collect() 在查询期间随时使用创建列表。在查询期间创建列表时,会发生聚合。
- 在聚合期间,图形引擎通常根据行中的某个值对数据进行分组。(非聚合值是分组键)
- Examples
- 多个MATCH
- PROFIL EMATCH (m:Movie {title:'Jupiter Ascending'}) MATCH (d:Person)-[:DIRECTED]->(m) MATCH (a:Person)-[:ACTED_IN]->(m) RETURN m.title AS Title, collect(DISTINCT a.name) AS Actors,collect(DISTINCT d.name) AS Directors
- 优化
- PROFILE MATCH (m:Movie {title:'Jupiter Ascending'}) MATCH (d:Person)-[:DIRECTED]->(m) WITH m, collect (d.name) AS Directors MATCH (a:Person)-[:ACTED_IN]->(m) RETURN m.title AS Title, collect(a.name) AS Actors, Directors
- 类似传统SQL将每部分添加查询条件得到最终结果
- 优化
- PROFIL EMATCH (m:Movie {title:'Jupiter Ascending'}) MATCH (d:Person)-[:DIRECTED]->(m) MATCH (a:Person)-[:ACTED_IN]->(m) RETURN m.title AS Title, collect(DISTINCT a.name) AS Actors,collect(DISTINCT d.name) AS Directors
- 单个MATCH
- PROFILE MATCH (d:Person)-[:DIRECTED]->(m:Movie {title:'Jupiter Ascending'})<-[:ACTED_IN]-(a:Person) RETURN m.title AS Title, collect(DISTINCT a.name) AS Actors,collect(DISTINCT d.name) AS Directors
- 多个MATCH
- 收集节点
- MATCH (m:Movie) UNWIND m.languages AS language WITH language, collect(m) AS movies MERGE (l:Language {name:language}) WITH l, movies UNWIND movies AS m WITH l,mMERGE (l)<-[:SPEAKS]-(m)
- 以作为 language 分组键,收集节点
- 使用 nodes() 返回路径中的节点列表。
- MATCH path = (p:Person {name: 'Elvis Presley'})-[*4]-(a:Actor) WITH nodes(path) AS n UNWIND n AS x WITH x WHERE x:Movie RETURN DISTINCT x.title
- 收集关系
- MATCH (u:User {name: "Misty Williams"})-[x]->() WITH collect(x) AS ratings UNWIND ratings AS r WITH r WHERE r.rating <= 1 RETURN r.rating AS Rating, endNode(r).title AS Title
- 使用 endNode() 返回关系末尾的节点。
- 与子查询
- PROFILE MATCH (m:Movie)<-[:ACTED_IN]-(p:Person) WITH m, collect(p.name) AS Actors WHERE size(Actors) <= 3 RETURN m.title AS Movie, Actors
- 查询重写
- PROFILE CALL { MATCH (m:Movie)<-[:ACTED_IN]-(p:Person) WITH m , collect(p.name) as Actors WHERE size(Actors)<= 3 RETURN m.title as Movie, Actors } RETURN Movie, Actors
- 使用 count()
- 可以在查询处理期间对属性、节点、关系、路径或行进行计数。
- MATCH (a:Person)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(d:Person) RETURN a.name AS ActorName,d.name AS DirectorName,count(*) AS NumMovies, collect(m.title) AS Movies ORDER BY NumMovies DESC
- 在属性值上使用
- MATCH (p:Person) RETURN count(p) , count(p.born),count(p.name)
- 此查询看到 born 的计数与其它不同,说明节点中无 born 属性
- MATCH (p:Person) RETURN count(p) , count(p.born),count(p.name)
- 作为过滤查询的子句
- MATCH (a:Person)-[:ACTED_IN]->(m:Movie) WITH a, count(*) AS NumMovies, collect(m.title) AS Movies WHERE NumMovies = 2 RETURN a.name AS Actor,Movies
- 计算节点数
- MATCH (p:Person {name: 'Elvis Presley'})-[]-(m:Movie)-[]-(a:Actor) RETURN count(*), count(m), count (a)
- 可以在查询处理期间对属性、节点、关系、路径或行进行计数。
- 使用模式理解
- 模式理解的行为类似于使用 OPTIONAL MATCH,并且对于这个特定的查询,经过的时间减少了。
- 原
- PROFILE MATCH(m:Movie) WHERE m.year = 2015 OPTIONAL MATCH (a:Person)-[:ACTED_IN]-(m) WITH m, collect(DISTINCT a.name) AS Actors OPTIONAL MATCH (m)-[:DIRECTED]-(d:Person) RETURN m.title AS Movie, Actors, collect (DISTINCT d.name) AS Directors
- 模式
- PROFILE MATCH (m:Movie) WHERE m.year = 2015 RETURN m.title AS Movie,[(dir:Person)-[:DIRECTED]->(m) | dir.name] AS Directors,[(actor:Person)-[:ACTED_IN]->(m) | actor.name] AS Actors
- 原
- 模式理解条件的过滤
- MATCH (a:Person {name: 'Tom Hanks'}) RETURN [(a)--(b:Movie) WHERE b.title CONTAINS "Toy" | b.title ]AS Movies
- 返回的列表添加更多属性(相当于Oracle中的合并列)
- 相当于不重复属性的collect(),注:模式理解下的属性可能为0,所有用size()定义
- MATCH (a:Actor)-[:ACTED_IN]->(m:Movie) WHERE 2000 <= m.year <= 2005 AND a.born.year >= 1980 RETURN a.name AS Actor, a.born AS Born,collect(DISTINCT m.title) AS Movies ORDER BY Actor
- MATCH (a:Actor) WHERE a.born.year >= 1980 WITH a, [(a)-[:ACTED_IN]->(m:Movie) WHERE 2000 <= m.year <= 2005 | m.title] AS Movies WHERE size(Movies) > 0 RETURN a.name as Actor, a.born as Born, Movies
- MATCH (a:Person {name: 'Tom Hanks'}) RETURN [(a)--(b:Movie) WHERE b.title CONTAINS "Toy" | b.title + ": " + b.year] AS Movies
- 相当于不重复属性的collect(),注:模式理解下的属性可能为0,所有用size()定义
- 模式理解的行为类似于使用 OPTIONAL MATCH,并且对于这个特定的查询,经过的时间减少了。
- 列表
相关文章:
Cypher中的聚合
深解Cypher中的聚合 值或计数的聚合要么从查询返回,要么用作多步查询下一部分的输入。查看数据模型 CALL db.schema.visualization() 查看图中节点的属性类型 CALL db.schema.notetypeproperties() 查看图中关系的属性类型 CALL db.schema.reltypeproperties() C…...

图注意网络GAT理解及Pytorch代码实现【PyGAT代码详细注释】
文章目录GAT代码实现【PyGAT】GraphAttentionLayer【一个图注意力层实现】用上面实现的单层网络测试加入Multi-head机制的GAT对数据集Cora的处理csr_matrix()处理稀疏矩阵encode_onehot()对label编号build graph邻接矩阵构造GAT的推广GAT 题:Graph Attention Netwo…...

项目成本管理中的常见误区及解决方案
做过项目的人都明白,项目实施时间一般很长,在实施期间总有很多项目结果不尽人意的问题。要使一个项目取得成功,就要结合很多因素一起才能作用,其中做好项目成本的管理就是最重要的步骤之一,下面列出了常见的项目成本管…...

墨天轮2022年度数据库获奖名单
2022年,国家相继从高位部署、省级试点布局、地市重点深入三个维度,颁布了多项中国数据库行业发展的利好政策。但是我们也能清晰地看到,中国数据库行业发展之路道阻且长,而道路上的“拦路虎”之一则是生态。中国数据库的发展需要多…...
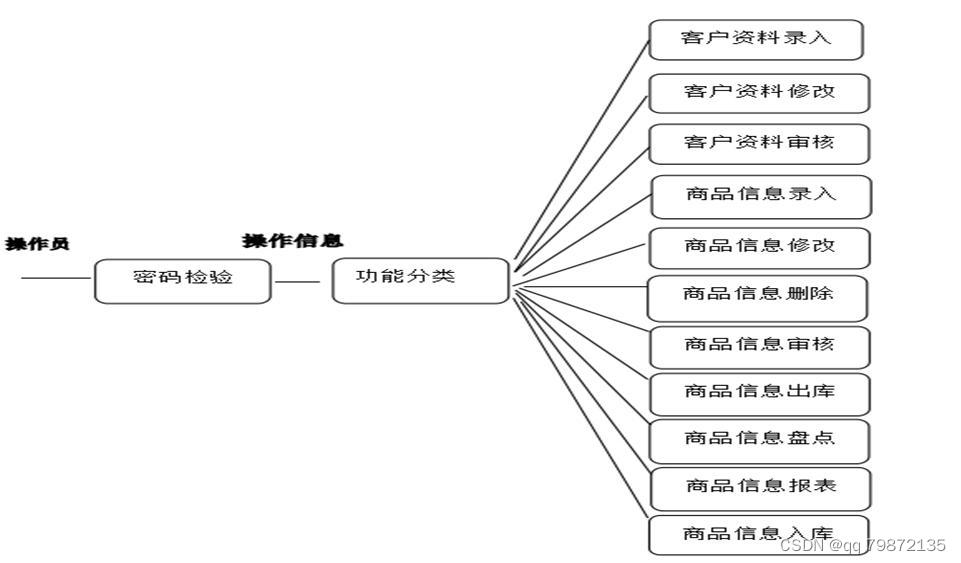
仓储调度|库存管理系统
技术:Java、JSP等摘要:随着电子商务技术和网络技术的快速发展,现代物流技术也在不断进步。物流技术是指与物流要素活动有关的所有专业技术的总称,包括各种操作方法、管理技能等,物流业采用某些现代信息技术方面的成功经…...

Canvas入门-01
导读: 读完全文需要2min。通过这篇文章,你可以了解到以下内容: Canvas标签基本属性如何使用Canvas画矩形、圆形、线条、曲线、笑脸😊 如果你曾经了解过Canvas,可以对照目录回忆一下能否回答上来 毕竟带着问题学习最有效…...

运算符优先级
醋坛酸味罐,位落跳福豆 醋:初等运算符: () [] -> . 坛:单目运算符: - ~ – * & ! sizeof 右结合 酸:算术运算符: - * / % 味:位移运算符:>> << …...
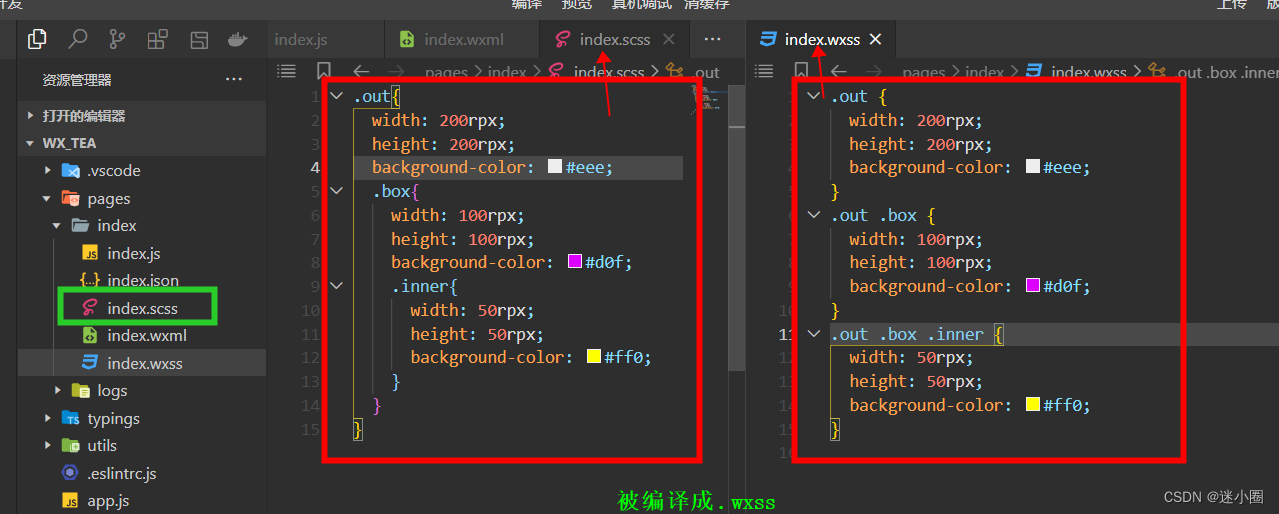
微信小程序使用scss编译wxss文件的配置步骤
文章目录1、在 vscode 中搜索 easysass 插件并安装2、在微信开发工具中导入安装的easysass插件3、修改 spook.easysass-0.0.6/package.json 文件中的配置4、重启开发者工具,就可用使用了微信小程序开发者工具集成了 vscode 编辑器,可以使用 vscode 中众多…...

一步一步教你如何使用 Visual Studio Code 编译一段 C# 代码
以下是一步一步教你如何使用 Visual Studio Code 编写使用 C# 语言输出当前日期和时间的代码: 1、下载并安装 .NET SDK。您可以从 Microsoft 官网下载并安装它。 2、打开 Visual Studio Code,并安装 C# 扩展。您可以在 Visual Studio Code 中通过扩展菜…...

vue-cli中的环境变量注意点
在客户端侧代码中使用环境变量只有以 VUE_APP_ 开头的变量会被 webpack.DefinePlugin 静态嵌入到客户端侧的包中。你可以在应用的代码中这样访问它们:console.log(process.env.VUE_APP_SECRET)在构建过程中,process.env.VUE_APP_SECRET 将会被相应的值所…...

2.3数据类型
文章目录1. 命名规则2.字符3.数字4.日期5.图片1. 命名规则 字段名必须以字母开头,尽量不要使用拼音长度不能超过30个字符(不同数据库,不同版本会有不同)不能使用SQL的保留字,如where,order,group只能使用如下字符a-z、…...
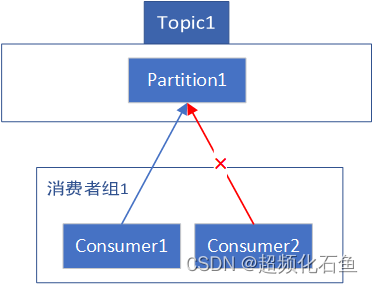
Kafka基本概念
什么是Kafka Kafka是一个消息系统。它可以集中收集生产者的消息,并由消费者按需获取。在Kafka中,也将消息称为日志(log)。 一个系统,若仅有一类或者少量的消息,可直接进行发送和接收。 随着业务量日益复杂,消息的种类…...

使用QueryBuilders、NativeSearchQuery实现复杂查询
使用QueryBuilders、NativeSearchQuery实现复杂查询 本文继续前面文章《ElasticSearch系列(二)springboot中集成使用ElasticSearch的Demo》,在前文中,我们介绍了使用springdata做一些简单查询,但是要实现一些高级的组…...

taobao.open.account.update( Open Account数据更新 )
¥开放平台免费API不需用户授权 Open Account数据更新 公共参数 请求地址: HTTP地址 http://gw.api.taobao.com/router/rest 公共请求参数: 公共响应参数: 响应参数 点击获取key和secret 请求示例 TaobaoClient client new DefaultTaobaoClient(url, appkey, sec…...
PT100铂电阻温度传感器
PT100温度传感器又叫做铂热电阻。 热电阻是中低温区﹡常用的一种温度检测器。它的主要特点是测量精度高,性能稳定。其中铂热电阻的测量精确度是﹡高的,它不仅广泛应用于工业测温,而且被制成标准的基准仪。金属热…...

蓝桥杯-本质上升序列
没有白走的路,每一步都算数🎈🎈🎈 题目描述: 小蓝特别喜欢单调递增的事物 在一个字符串中如果取出若干个字符,按照在原来字符串中的顺序排列在一起,组成的新的字符串如果是单调递增的…...

synchronized锁重入验证
文章目录synchronized锁重入验证1. 可重入锁2. synchronized锁重入2.1 本类同步方法内部调用本类其它同步方法2.2 子类同步方法内部调用父类的同步方法2.3 A类的同步方法内部调用B类的同步方法3. synchronized修饰方法写法synchronized锁重入验证 1. 可重入锁 可重入锁&#…...

超简单的计数排序!!
假设给定混乱数据为:3,0,1,3,6,5,4,2,1,9。 下面我们将通过使用计数排序的思想来完成对上面数据的排序。(先不谈负数) 计数排序 该排序的思路和它的名字一样…...

发现新大陆——原来软件开发根本不需要会编码(看我10分钟应用上线)
目录 一、前言 二、官网基础功能及搭建 三、体验过程 01、连接数据源 02、设计表单 03、流程设计 04、图表呈现 05、组织架构设置 五、效率评价 六、小结 一、前言 众所周知,每家公司在发展过程中都需要构建大量的内部系统, 如运营使用的用户…...

【Leedcode】栈和队列必备的面试题(第二期)
【Leedcode】栈和队列必备的面试题(第二期) 文章目录【Leedcode】栈和队列必备的面试题(第二期)一、题目(用两个队列实现栈)二、思路图解1.定义两个队列2.初始化两个队列3.往两个队列中放入数据4.两个队列出…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

UE5 学习系列(三)创建和移动物体
这篇博客是该系列的第三篇,是在之前两篇博客的基础上展开,主要介绍如何在操作界面中创建和拖动物体,这篇博客跟随的视频链接如下: B 站视频:s03-创建和移动物体 如果你不打算开之前的博客并且对UE5 比较熟的话按照以…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...

在Mathematica中实现Newton-Raphson迭代的收敛时间算法(一般三次多项式)
考察一般的三次多项式,以r为参数: p[z_, r_] : z^3 (r - 1) z - r; roots[r_] : z /. Solve[p[z, r] 0, z]; 此多项式的根为: 尽管看起来这个多项式是特殊的,其实一般的三次多项式都是可以通过线性变换化为这个形式…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...
实现跳一跳小游戏)
鸿蒙(HarmonyOS5)实现跳一跳小游戏
下面我将介绍如何使用鸿蒙的ArkUI框架,实现一个简单的跳一跳小游戏。 1. 项目结构 src/main/ets/ ├── MainAbility │ ├── pages │ │ ├── Index.ets // 主页面 │ │ └── GamePage.ets // 游戏页面 │ └── model │ …...