【C++】哈希
哈希
- 一、unordered系列关联式容器
- 二、哈希原理
- 2.1 哈希映射
- 2.2 哈希冲突
- 2.2.1 闭散列—开放地址法
- 2.2.2 代码实现
- 2.2.3 开散列—拉链法
- 2.2.4 代码实现
- 三、哈希封装unordered_map/unordered_set
- 3.1 基本框架
- 3.2 迭代器实现
- 3.2.3 operator*和operator->和operator!=
- 3.2.4 operator++与构造函数
- 3.2.5 begin()和end()
- 3.2.6 operator[]
- 3.2.7 const迭代器问题
- 四、哈希源码
一、unordered系列关联式容器
map和set的底层是用红黑树实现的,在最差的情况下也能在高度次查询到节点。但是当节点数量非常多的时候,效率并不理想,所以C++11引入了unorderedmap与unorderedset,能极快的查找到元素节点,但是它们的底层不是用搜索树实现的,所以不能保证有序。
二、哈希原理
2.1 哈希映射
红黑树我们需要进行比较查找才能找到对应节点。而进过哈希映射函数,让key值跟存储位置建立映射关系,那么在查找时通过该函数可以很快找到该元素。
像计数排序就可以看作一个简单的哈希映射,叫做直接定址法,但是得范围集中才行。
如果范围不集中,就可以用除留余数法,我们可以用元素的值去模上容器的大小。这样所有的元素就一定能存入表中。
2.2 哈希冲突
上面的除留余数法可能会导致两个元素要存储在同一个位置。我们把这种情况称为哈希冲突。而解决哈希冲突的方法有两种
2.2.1 闭散列—开放地址法
闭散列的大致方法就是:当映射的地方已经有值了,那么就按规律找其他位置。而查找空位的方法又分为线性探测和二次探测。
【线性探测】
插入:
用除留余数法求出key值的关键码,并将它放到对应的位置上。如果该位置已经存在数据被占用了,那么继续寻找下一个位置,也就是+1的位置,如果+1的位置已经有数据,那么继续+1,直到寻找到下一个空位置为止。
查找:
查找就是取余后往后探索,知道找到空位置就停止,这里要注意如果删除了一个数据,而要查找的元素在删除位置的后边,就会在删除的地方停下来,导致本来存在的元素查找不到。
解决这种情况的方式:
可以再设置一种状态(枚举),将数组中每个数据的状态记录一下,所以就有了存在,空和删除这三种状态。删除的位置状态时删除,查找的时候不会停下。
这里要注意有一种情况是整个闭散列全部都存在或者为删除状态(边插入边删除不会扩容),所以最多循环一圈。
负载因子:
表中的有效数据个数/表的大小,载荷因子不能超过1。为了减小冲突,一般到0.7就会扩容。
字符串哈希:
这里要注意如果key是字符串就不能使用除法取余,所以我们需要一个仿函数把字符串转换成数字。
【二次探测】
我们知道线性探测如果发生了冲突并且冲突连在一起就会引起数据堆积,导致搜索效率降低,为了解决这种情况,就有了二次探测。
二次探测的方法就是以i的2次方去进行探测,如果要找的位置Idx被占,下次找Idx + 1^2,如果再次被占,则找Idx + 2^2,以此类推。
2.2.2 代码实现
// 状态
enum Sta
{EXIST,DELETE,EMPTY,
};// 数据类型
template <class K, class V>
struct HashData
{pair<K, V> _kv;Sta _state = EMPTY;
};template <class K>
struct HashKey
{size_t operator()(const K& key){return (size_t)key;}
};// 字符串哈希
template <>
struct HashKey<string>
{size_t operator()(const string& key){size_t ans = 0;for (int i = 0; i < key.size(); i++){ans *= 131;ans += i;}return ans;}
};// 哈希表结构
template <class K, class V, class GetKey = HashKey<K>>
class HashTable
{typedef HashData<K, V> data;
public:HashTable(): _n(0){_tables.resize(7);}bool insert(const pair<K, V>& kv){// 重复if (find(kv.first)) return false;// 负载因子size_t load = _n * 10 / _tables.size();if (load >= 10){// 出作用域后销毁HashTable<K, V> newhash;newhash._tables.resize(2 * _tables.size());for (auto& e : _tables){if (e._state == EXIST){newhash.insert(e._kv);}}_tables.swap(newhash._tables);}GetKey Get;size_t hashI = Get(kv.first) % _tables.size();while (_tables[hashI]._state == EXIST){++hashI;hashI %= _tables.size();}_tables[hashI]._kv = kv;_tables[hashI]._state = EXIST;++_n;return true;}data* find(const K& key){GetKey Get;size_t hashI = Get(key) % _tables.size();size_t startI = hashI;// 最多循环一圈while (_tables[hashI]._state != EMPTY){if (_tables[hashI]._state == EXIST&& _tables[hashI]._kv.first == key){return &_tables[hashI];}++hashI;hashI %= _tables.size();if (hashI == startI) break;}return nullptr;}bool erase(const K& key){data* node = find(key);if (node){node->_state = DELETE;return true;}return false;}
private:vector<data> _tables;size_t _n;// 有效数据个数
};
2.2.3 开散列—拉链法
闭散列解决哈希冲突的办法就是抢占别人的位置,而开散列不一样,冲突的元素可以一起在同一个位置。
首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
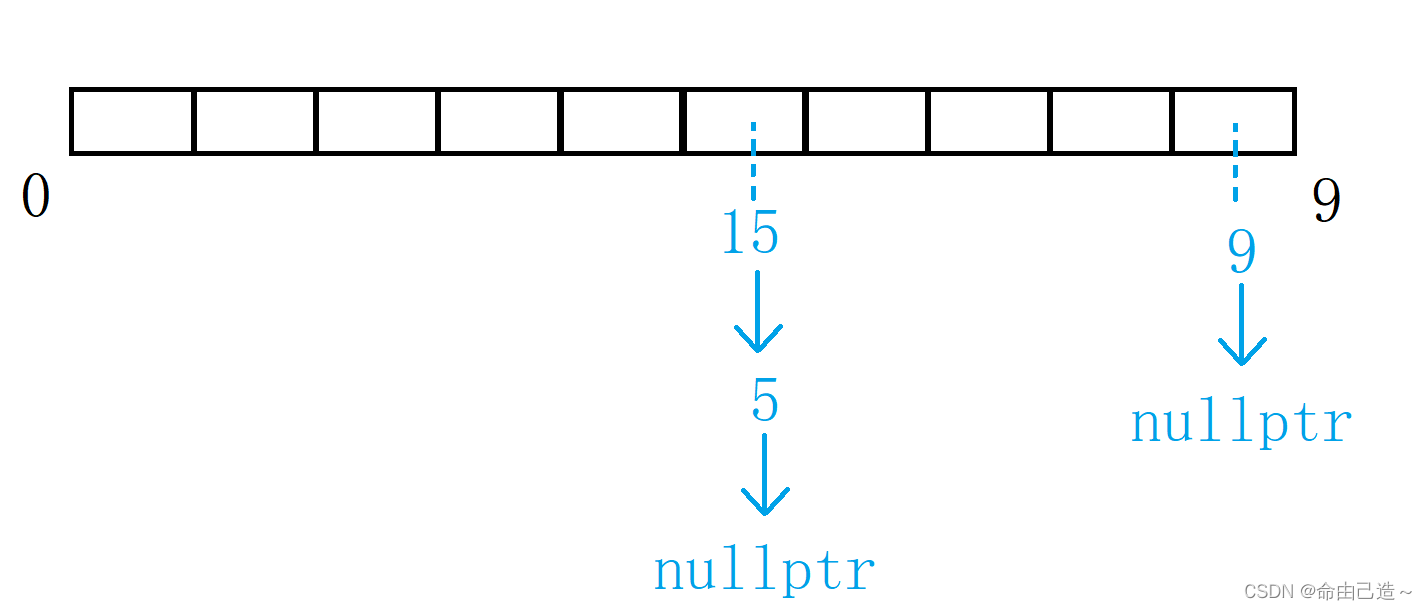
【增容】
随着插入的数量增加,可能导致一个桶的节点数目非常多,为了应对这种情况,在一定情况下需要增容。一般当负载因子为1的时候扩容。
2.2.4 代码实现
template <class K, class V>
struct HashNode
{HashNode(const pair<K, V> kv): _kv(kv), _next(nullptr){}pair<K, V> _kv;HashNode<K, V>* _next;
};template <class K, class V, class GetKey = HashKey<K>>
class HashTable
{typedef HashNode<K, V> Node;
public:HashTable(): _n(0){_tables.resize(10);}~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}bool insert(const pair<K, V>& kv){// 重复if (find(kv.first))return false;// 负载因子为1扩容if (_tables.size() == _n){vector<Node*> newtable;newtable.resize(2 * _n);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t idx = GetKey()(cur->_kv.first) % newtable.size();cur->_next = newtable[idx];newtable[idx] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtable);}GetKey Get;size_t hashI = GetKey()(kv.first) % _tables.size();Node* newnode = new Node(kv);newnode->_next = _tables[hashI];_tables[hashI] = newnode;++_n;return true;}Node* find(const K& key){size_t idx = GetKey()(key) % _tables.size();Node* cur = _tables[idx];while (cur){if (cur->_kv.first == key)return cur;elsecur = cur->_next;}return nullptr;}bool erase(const K& key){size_t idx = GetKey()(key) % _tables.size();Node* cur = _tables[idx];Node* pre = nullptr;while (cur){if (cur->_kv.first == key){if (pre = nullptr){_tables[i] = nullptr;}else{pre->_next = cur->_next;}delete cur;--_n;return true;}else{pre = cur;cur = cur->_next;}}return false;}
private:vector<Node*> _tables;size_t _n = 0;
};
三、哈希封装unordered_map/unordered_set
3.1 基本框架
这里的封装跟红黑树的类似,我们需要改变一下节点的结构,不管传入的是key还是pair,都用模板参数T接收。
template <class T>
struct HashNode
{HashNode(const T& data): _data(data), _next(nullptr){}T _data;HashNode<T>* _next;
};
根据前面红黑树的封装可以知道传入的时候第一个参数主要用来查找和删除,第二个参数决定节点是什么类型。
代码如下:
// unordered_Set.h
template <class K, class Hash = HashKey<K>>
class unordered_set
{struct SetKeyOfT{const K& operator()(const K& key){return key;}};
public:
bool insert(const K& key)
{return _ht.insert(key);
}
private:hashbucket::HashTable<K, K, Hash, SetKeyOfT> _ht;
};// unordered_Map.h
template <class K, class V, class Hash = HashKey<K>>
class unordered_map
{struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};
public:bool insert(const T& data){return _ht.insert(data);}
private:hashbucket::HashTable<K, pair<K, V>, Hash, MapKeyOfT> _ht;
};
3.2 迭代器实现
3.2.3 operator*和operator->和operator!=
解引用operator*是将一个指针指向的内容取出来,它返回的是哈希节点的数据。operator->是将指针指向内容的地址取出来,也就是节点指向数据的地址。
T& operator*()
{return _node->_data;
}T* operator->()
{return &_node->_data;
}bool operator!=(const self& it) const
{return _node != it._node;
}
3.2.4 operator++与构造函数
如果这个桶没有走完,那么直接遍历当前迭代器指向节点的下一个节点。如果这个桶走完了,要遍历下一个桶。但是既然要遍历,那么一定需要_tables的大小,而_tables又是一个私有成员,随意我们可以用友元类来访问。
template<class K, class T, class GetKey, class KeyOfT>
friend struct HashIterator;// 迭代器需要访问私有
而且我们还需要_tables,所以在构造迭代器的时候要传进来个_tables的指针。
HashIterator(HT* ht, Node* node)// 传递指针: _node(node), _ht(ht)
{}
operator++代码如下:
self& operator++()
{if (_node->_next){_node = _node->_next;}else{// 找下一个桶KeyOfT kot;Hash hash;size_t idx = hash(kot(_node->_data)) % _ht->_tables.size();idx++;while (idx < _ht->_tables.size()){if (_ht->_tables[idx] != nullptr){_node = _ht->_tables[idx];break;}else{idx++;}}if (idx == _ht->_tables.size()){_node = nullptr;}}return *this;
}
3.2.5 begin()和end()
begin就是找到_tables表的第一个不为空的桶的头节点,如果找到了,返回第一个位置的迭代器,因为迭代器的构造需要节点指针和哈希表的指针,那么哈希表的指针是什么呢?哈希表的指针就是this,this代表了整个哈希表的指针。将this指针传给迭代器的构造,那么我们就能取到_table。
而end就是最后一个节点的下一个地址,也就是nullptr。
template <class K, class T, class GetKey, class KeyOfT>
class HashTable
{typedef HashNode<T> Node;template<class K, class T, class GetKey, class KeyOfT>friend struct HashIterator;// 迭代器需要访问私有
public:typedef HashIterator<K, T, GetKey, KeyOfT> iterator;iterator begin(){for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]){return iterator(this, _tables[i]);}}return iterator(this, nullptr);}iterator end(){return iterator(this, nullptr);}
};
3.2.6 operator[]
[]在前面的红黑树的封装也出现过,operator[]只有map中有,因为operator[]可以对插入的值进行增加,查找。如果该值第一次出现,那么operator[]充当的是插入,如果该值第二次出现,那么operator[]就充当的是修改。
既然是对是否成功插入做判断,那么insert和find都要做出修改。
// unordered_Map.h
V& operator[](const K& key)
{pair<iterator, bool> ret = _ht.insert(make_pair(key, V()));return ret.first->second;
}// HashTable.h
pair<iterator, bool> insert(const T& data)
{// 重复iterator it = find(KeyOfT()(data));if (it != end()){return make_pair(it, false);}// 负载因子为1扩容if (_tables.size() == _n){vector<Node*> newtable;newtable.resize(2 * _n);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t idx = GetKey()(KeyOfT()(data)) % newtable.size();cur->_next = newtable[idx];newtable[idx] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtable);}size_t hashI = GetKey()(KeyOfT()(data)) % _tables.size();Node* newnode = new Node(data);newnode->_next = _tables[hashI];_tables[hashI] = newnode;++_n;return make_pair(iterator(this, newnode), true);
}iterator find(const K& key)
{size_t idx = GetKey()(key) % _tables.size();Node* cur = _tables[idx];while (cur){if (KeyOfT()(cur->_data) == key)return iterator(this, cur);elsecur = cur->_next;}return end();
}bool erase(const K& key)
{size_t idx = GetKey()(KeyOfT()(key)) % _tables.size();Node* cur = _tables[idx];Node* pre = nullptr;while (cur){if (cur->_data == key){if (pre = nullptr){_tables[idx] = nullptr;}else{pre->_next = cur->_next;}delete cur;--_n;return true;}else{pre = cur;cur = cur->_next;}}return false;
}
3.2.7 const迭代器问题
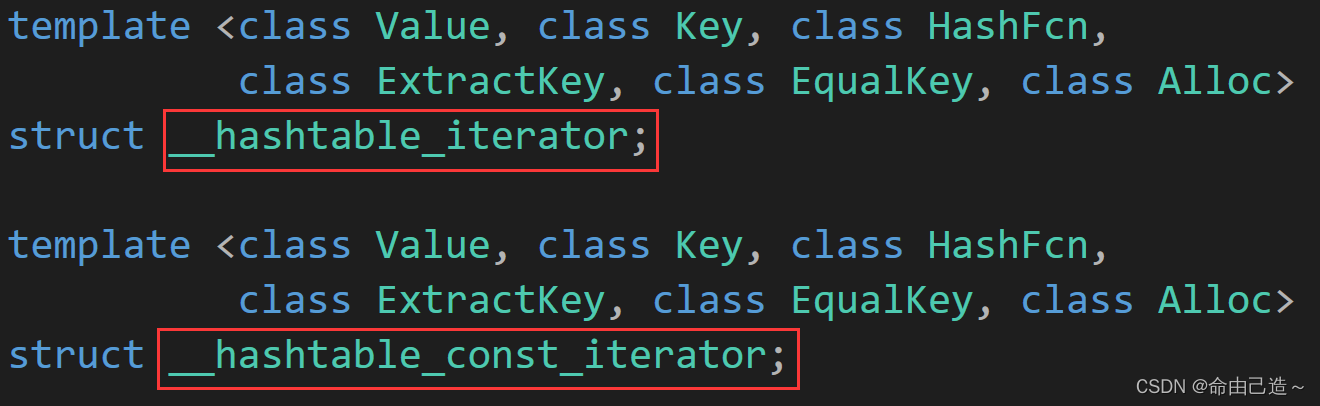
在stl源码中可以看到并没有用以前的方法使用:
typedef _list_iterator<T, T&, T*> iterator;
typedef _list_iterator<T, const T&, const T*> const_iterator;
原因是如果使用const版本传递,那么_tables使用[]返回的就是const。而用const迭代器去构造 HT* _ht; Node* _node;就会导致权限放大,无法构造。但是如果改成 const HT* _ht; const Node* _node;,又会导致[]不能修改的问题。
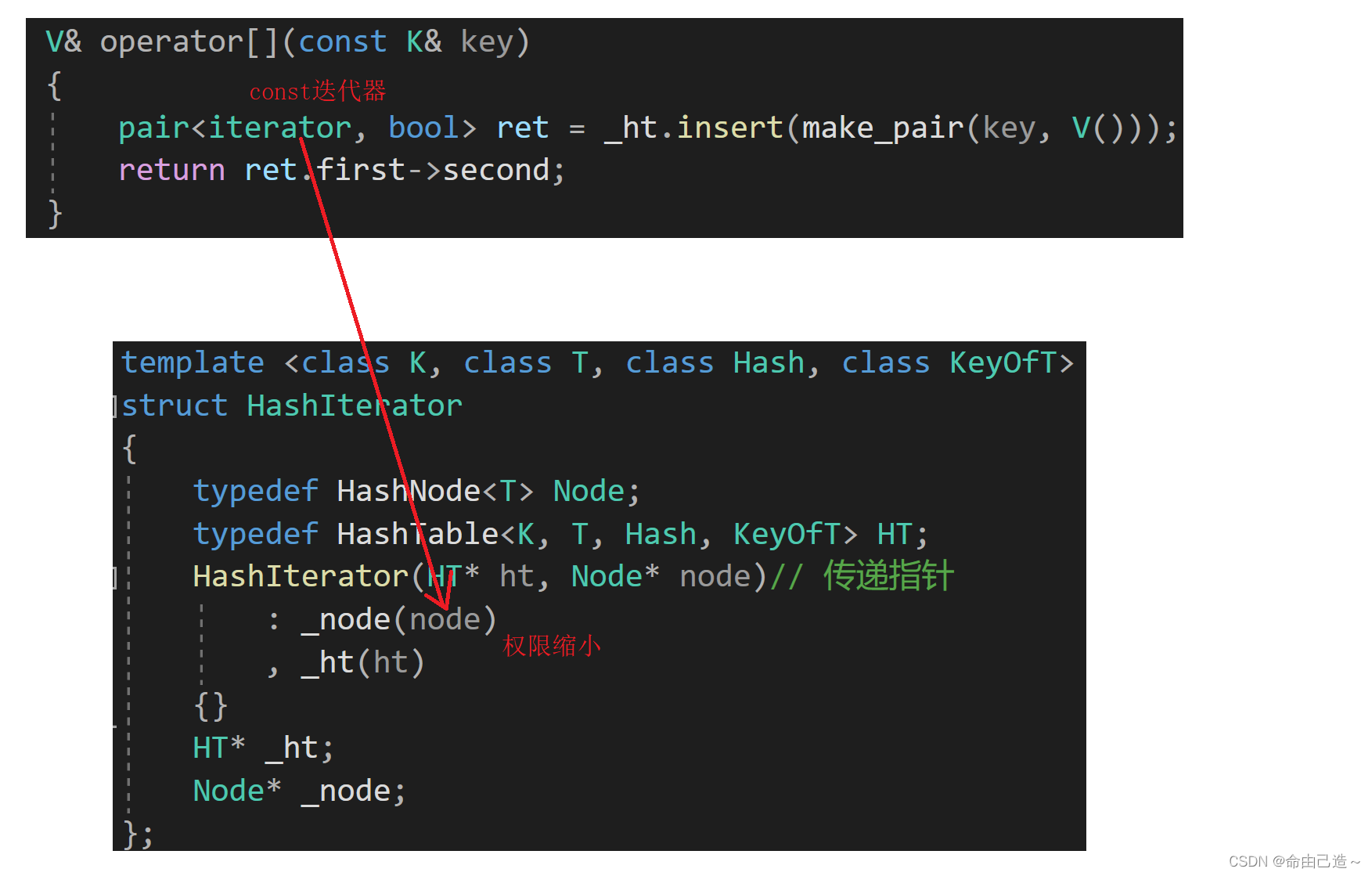
所以我们需要再写一个const版本迭代器:
template <class K, class T, class Hash, class KeyOfT>
struct ConstHashIterator
{typedef HashNode<T> Node;typedef ConstHashIterator<K, T, Hash, KeyOfT> self;typedef HashTable<K, T, Hash, KeyOfT> HT;ConstHashIterator(const HT* ht, const Node* node)// 传递指针: _node(node), _ht(ht){}const T& operator*() const{return _node->_data;}const T* operator->() const{return &_node->_data;}bool operator!=(const self& it) const{return _node != it._node;}self& operator++(){if (_node->_next){_node = _node->_next;}else{// 找下一个桶KeyOfT kot;Hash hash;size_t idx = hash(kot(_node->_data)) % _ht->_tables.size();idx++;while (idx < _ht->_tables.size()){if (_ht->_tables[idx] != nullptr){_node = _ht->_tables[idx];break;}else{idx++;}}if (idx == _ht->_tables.size()){_node = nullptr;}}return *this;}const HT* _ht;const Node* _node;
};
往HashTable写入友元类:
template <class K, class T, class Hash, class KeyOfT>
friend struct ConstHashIterator;
添加cbegin()与cend()。
// unordered_Set.h
typedef typename hashbucket::HashTable<K, K, Hash, SetKeyOfT>::const_iterator const_iterator;const_iterator cbegin()
{return _ht.cbegin();
}const_iterator cend()
{return _ht.cend();
}//unordered_Map.h
typedef typename hashbucket::HashTable<K, pair<K, V>, Hash, MapKeyOfT>::const_iterator const_iterator;const_iterator cbegin()
{return _ht.cbegin();
}const_iterator cend()
{return _ht.cend();
}
四、哈希源码
unordered_set.h:
#pragma once
#include "HashTable.h"namespace yyh
{template <class K, class Hash = HashKey<K>>class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:typedef typename hashbucket::HashTable<K, K, Hash, SetKeyOfT>::iterator iterator;typedef typename hashbucket::HashTable<K, K, Hash, SetKeyOfT>::const_iterator const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}const_iterator cbegin(){return _ht.cbegin();}const_iterator cend(){return _ht.cend();}pair<iterator, bool> insert(const K& key){return _ht.insert(key);}bool find(const K& key){return _ht.find(key);}bool erase(const K& key){return _ht.erase(key);}private:hashbucket::HashTable<K, K, Hash, SetKeyOfT> _ht;};
}
unordered_map.h:
#pragma once
#include "HashTable.h"namespace yyh
{template <class K, class V, class Hash = HashKey<K>>class unordered_map{struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:typedef typename hashbucket::HashTable<K, pair<K, V>, Hash, MapKeyOfT>::iterator iterator;typedef typename hashbucket::HashTable<K, pair<K, V>, Hash, MapKeyOfT>::const_iterator const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}const_iterator cbegin(){return _ht.cbegin();}const_iterator cend(){return _ht.cend();}pair<iterator, bool> insert(const pair<K, V>& kv){return _ht.insert(kv);}bool find(const K& key){return _ht.find(key);}bool erase(const K& key){return _ht.erase(key);}V& operator[](const K& key){pair<iterator, bool> ret = _ht.insert(make_pair(key, V()));return ret.first->second;}private:hashbucket::HashTable<K, pair<K, V>, Hash, MapKeyOfT> _ht;};
}
HashTable.h:
#pragma once#include <iostream>
#include <vector>
#include <string>
using namespace std;template <class K>
struct HashKey
{size_t operator()(const K& key){return (size_t)key;}
};// 字符串哈希
template <>
struct HashKey<string>
{size_t operator()(const string& key){size_t ans = 0;for (size_t i = 0; i < key.size(); i++){ans *= 131;ans += i;}return ans;}
};namespace hashbucket
{template <class T>struct HashNode{HashNode(const T& data): _data(data), _next(nullptr){}T _data;HashNode<T>* _next;};// 前置声明template <class K, class T, class Hash, class KeyOfT>class HashTable;template <class K, class T, class Hash, class KeyOfT>struct HashIterator{typedef HashNode<T> Node;typedef HashIterator<K, T, Hash, KeyOfT> self;typedef HashTable<K, T, Hash, KeyOfT> HT;HashIterator(HT* ht, Node* node)// 传递指针: _node(node), _ht(ht){}T& operator*(){return _node->_data;}T* operator->(){return &_node->_data;}bool operator!=(const self& it) const{return _node != it._node;}self& operator++(){if (_node->_next){_node = _node->_next;}else{// 找下一个桶KeyOfT kot;Hash hash;size_t idx = hash(kot(_node->_data)) % _ht->_tables.size();idx++;while (idx < _ht->_tables.size()){if (_ht->_tables[idx] != nullptr){_node = _ht->_tables[idx];break;}else{idx++;}}if (idx == _ht->_tables.size()){_node = nullptr;}}return *this;}HT* _ht;Node* _node;};template <class K, class T, class Hash, class KeyOfT>struct ConstHashIterator{typedef HashNode<T> Node;typedef ConstHashIterator<K, T, Hash, KeyOfT> self;typedef HashTable<K, T, Hash, KeyOfT> HT;ConstHashIterator(const HT* ht, const Node* node)// 传递指针: _node(node), _ht(ht){}const T& operator*() const{return _node->_data;}const T* operator->() const{return &_node->_data;}bool operator!=(const self& it) const{return _node != it._node;}self& operator++(){if (_node->_next){_node = _node->_next;}else{// 找下一个桶KeyOfT kot;Hash hash;size_t idx = hash(kot(_node->_data)) % _ht->_tables.size();idx++;while (idx < _ht->_tables.size()){if (_ht->_tables[idx] != nullptr){_node = _ht->_tables[idx];break;}else{idx++;}}if (idx == _ht->_tables.size()){_node = nullptr;}}return *this;}const HT* _ht;const Node* _node;};template <class K, class T, class GetKey, class KeyOfT>class HashTable{typedef HashNode<T> Node;template<class K, class T, class GetKey, class KeyOfT>friend struct HashIterator;// 迭代器需要访问私有template <class K, class T, class Hash, class KeyOfT>friend struct ConstHashIterator;public:typedef HashIterator<K, T, GetKey, KeyOfT> iterator;typedef ConstHashIterator<K, T, GetKey, KeyOfT> const_iterator;iterator begin(){for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]){return iterator(this, _tables[i]);}}return iterator(this, nullptr);}iterator end(){return iterator(this, nullptr);}const_iterator cbegin(){for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]){return const_iterator(this, _tables[i]);}}return const_iterator(this, nullptr);}const_iterator cend(){return const_iterator(this, nullptr);}HashTable(): _n(0){_tables.resize(10);}~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}pair<iterator, bool> insert(const T& data){// 重复iterator it = find(KeyOfT()(data));if (it != end()){return make_pair(it, false);}// 负载因子为1扩容if (_tables.size() == _n){vector<Node*> newtable;newtable.resize(2 * _n);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t idx = GetKey()(KeyOfT()(data)) % newtable.size();cur->_next = newtable[idx];newtable[idx] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtable);}size_t hashI = GetKey()(KeyOfT()(data)) % _tables.size();Node* newnode = new Node(data);newnode->_next = _tables[hashI];_tables[hashI] = newnode;++_n;return make_pair(iterator(this, newnode), true);}iterator find(const K& key){size_t idx = GetKey()(key) % _tables.size();Node* cur = _tables[idx];while (cur){if (KeyOfT()(cur->_data) == key)return iterator(this, cur);elsecur = cur->_next;}return end();}bool erase(const K& key){size_t idx = GetKey()(KeyOfT()(key)) % _tables.size();Node* cur = _tables[idx];Node* pre = nullptr;while (cur){if (cur->_data == key){if (pre = nullptr){_tables[idx] = nullptr;}else{pre->_next = cur->_next;}delete cur;--_n;return true;}else{pre = cur;cur = cur->_next;}}return false;}private:vector<Node*> _tables;size_t _n = 0;};
}相关文章:
【C++】哈希
哈希一、unordered系列关联式容器二、哈希原理2.1 哈希映射2.2 哈希冲突2.2.1 闭散列—开放地址法2.2.2 代码实现2.2.3 开散列—拉链法2.2.4 代码实现三、哈希封装unordered_map/unordered_set3.1 基本框架3.2 迭代器实现3.2.3 operator*和operator->和operator!3.2.4 opera…...
「TCG 规范解读」PC 平台相关规范(3)
可信计算组织(Ttrusted Computing Group,TCG)是一个非盈利的工业标准组织,它的宗旨是加强在相异计算机平台上的计算环境的安全性。TCG于2003年春成立,并采纳了由可信计算平台联盟(the Trusted Computing Platform Alli…...
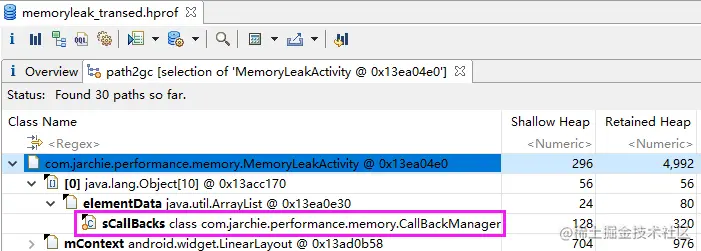
这篇教你搞定Android内存优化分析总结
一、内存优化概念1.1 为什么要做内存优化?内存优化一直是一个很重要但却缺乏关注的点,内存作为程序运行最重要的资源之一,需要运行过程中做到合理的资源分配与回收,不合理的内存占用轻则使得用户应用程序运行卡顿、ANR、黑屏&…...

概率论与数理统计期末小题狂练 11-12两套,12-13-1
11-12第一学期A1 略。2 X服从正态分布N(0,1),X^2服从卡方分布。又考查了卡方分布均值和方差公式。一开始如果对本题无从下手,大概是没看出来是什么分布。3 第二小空本身也可以作为一个结论。4 考查切比雪夫不等式&…...

golang对字符串的处理操作 如何正确理解 rune byte和string
fmt.Printf相关参数介绍 先来看代码的演示 package mainimport ("fmt""unicode/utf8" )func main() {s:"我爱中国人haha!"fmt.Println(len(s))//20个字节 一个中文三个字节 1541fmt.Print("\n echo byte \n")for k,v: range []byte(…...
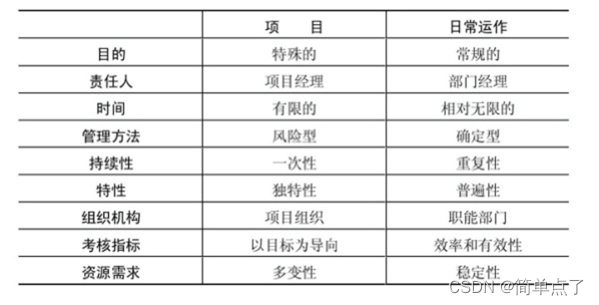
软件项目管理简答题复习(1)
1.项目:创造唯一的产品,唯一的服务临时性的努力 2.项目特征:不可见性,复杂性,一致性,变更性,特殊性 3.项目和日常活动的区别? 项目具有特殊性,负责人是项目经理&#…...
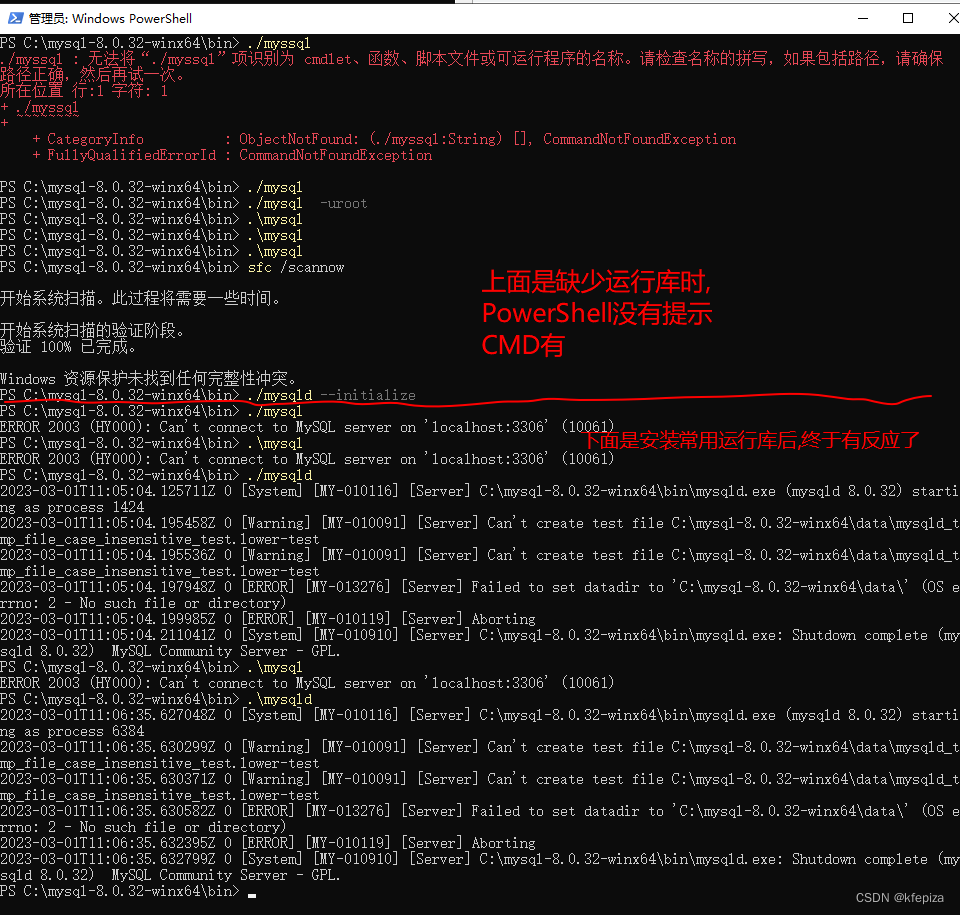
云Windows Server 2022 Datacenter 安装MySQL8解压缩版 mysql-8.0.32-winx64 230301记录
MySQL Community Downloads MySQL社区版压缩包下载地址 https://dev.mysql.com/downloads/mysql/ 解压到了C盘 没打算设置环境变量 右键点击开始 或 winx 以管理员身份打开 PowerShell 进入到安装目录下的 bin 目录 可以输入cd 后, 拖动 bin 文件夹到控制台&…...

如何使用BeaconEye监控CobaltStrike的Beacon
关于BeaconEye BeaconEye是一款针对CobaltStrike的安全工具,该工具可以扫描正在运行的主动CobaltStrike Beacon。当BeaconEye扫描到了正在运行Beacon的进程之后,BeaconEye将会监控每一个进程以查看C2活动。 工作机制 BeaconEye将会扫描活动进程或Mini…...
STM32开发(17)----CubeMX配置CRC
CubeMX配置CRC前言一、什么是CRC?二、实验过程1.STM32CubeMX配置2.代码实现重载printf3.实验结果总结前言 本章介绍使用STM32CubeMX对CRC进行配置的方法,CRC的目的是保证数据的完整性,所有的STM32芯片都内置了一个硬件的CRC计算模块…...
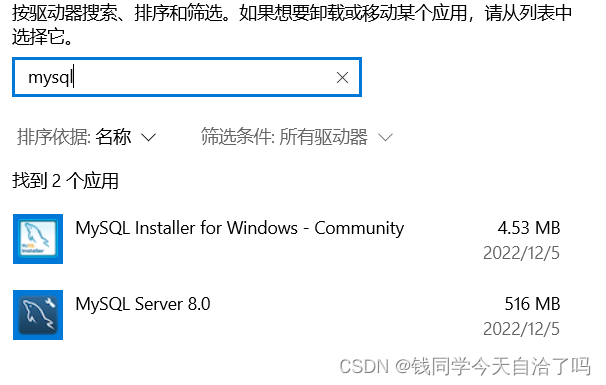
【MySQL】基础操作:登录、访问、退出和卸载
一、MySQL简介 MySQL数据库最初是由瑞典MySQL AB公司开发,2008年1月16号被Sun公司收购。2009年,SUN又被Oracle收购。MySQL是目前IT行业最流行的开放源代码的数据库管理系统,同时它也是一个支持多线程、高并发、多用户的关系型数据库管理系统。…...
)
【算法经典题集】递推(持续更新~~~)
😽PREFACE🎁欢迎各位→点赞👍 收藏⭐ 评论📝📢系列专栏:算法经典题集🔊本专栏涉及到的知识点或者题目是算法专栏的补充与应用💪种一棵树最好是十年前其次是现在递推简单的斐波那契…...

mysql兼容性验证
MySQL是一个关系型数据库管理系统。 一、安装启动 安装mysql相关软件包 yum install mysql-server 启动mysql服务 systemctl start mysqld systemctl status mysqld mysql数据库启动失败问题汇总: <问题1>、start mysqld显示失败,如下所示&…...

C++回顾(五)—— 构造函数和析构函数
5.1 构造和析构 5.1.1 构造函数 (1)定义 1)C中的类可以定义与类名相同的特殊成员函数,这种与类名相同的成员函数叫做构造函数;2)构造函数在定义时可以有参数;3)没有任何返回类型的…...

嵌入式学习笔记——概述
嵌入式系统概述前言“嵌入式系统”概念1.是个啥?2.可以干啥?3.有哪些入坑方向?4.入坑后可以有多少薪资?单片机1.什么是单片机?2.架构简介3.基于ARM架构的单片机结构简介总结前言 断更很长时间了,写博客确实…...
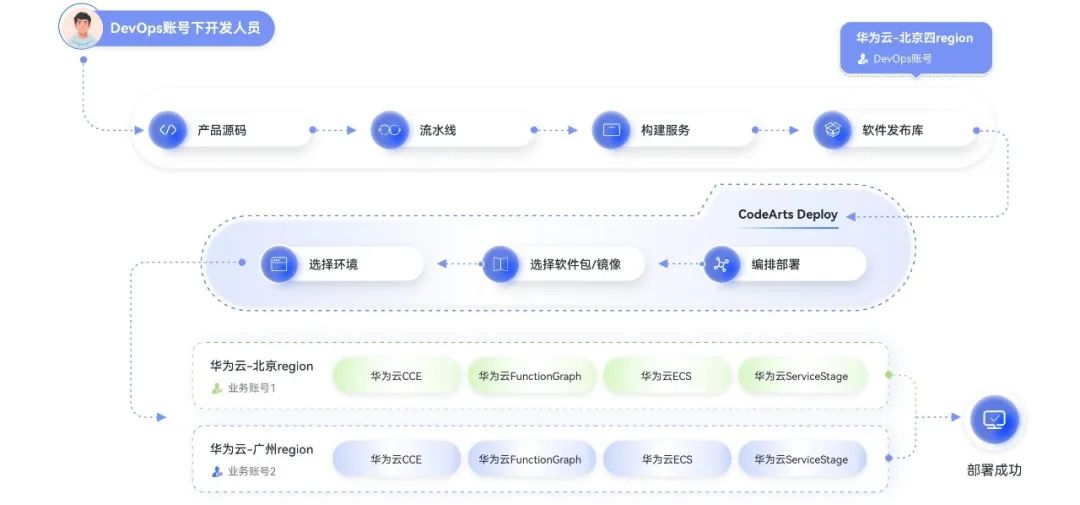
化繁为简高效部署 华为云发布部署服务CodeArts Deploy
随着互联网、数字化的发展,公司机构与各类企业往往需要进行大量频繁的软件部署,部署设备类型多样,如:本地机器、云上裸金属服务器、云上虚拟机与容器等。面对多种部署模式、分布式复杂运行环境,如何用最短时间、高质…...

注意力机制详解系列(四):混合注意力机制
👨💻作者简介: 大数据专业硕士在读,CSDN人工智能领域博客专家,阿里云专家博主,专注大数据与人工智能知识分享。 🎉专栏推荐: 目前在写CV方向专栏,更新不限于目标检测、OCR、图像分类、图像分割等方向,目前活动仅19.9,虽然付费但会长期更新,感兴趣的小伙伴可以…...

Makefiles学习1
初识"Makefiles" 创建一个 “Makefile” 文件 touch Makefile“touch” 用于修改文件或者目录的时间属性,包括访问时间和修改时间,若文件不存在,则重新建立一个新的文件。这里有两个需要我们注意的: 进入并编辑"…...
日志框架以及如何使用LogBack记录程序
使用日志框架可以记录一个程序运行的过程和详情,同时便捷地存储到文件里面,并且性能和灵活性都比较好。日志的体系结构包括两类日志规范接口:Commons Logging,简称:JCL;Simple Logging Facade for Java&…...
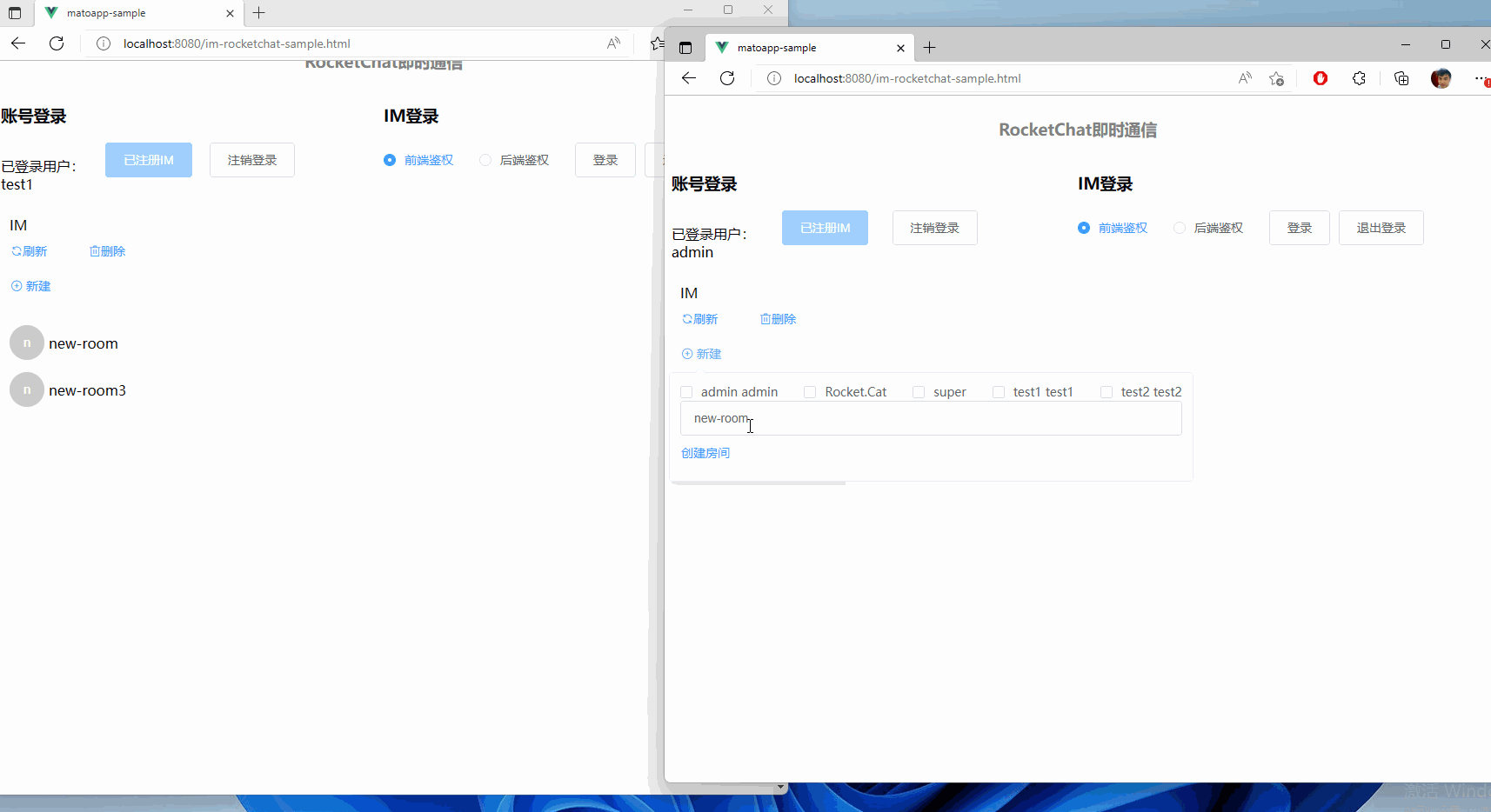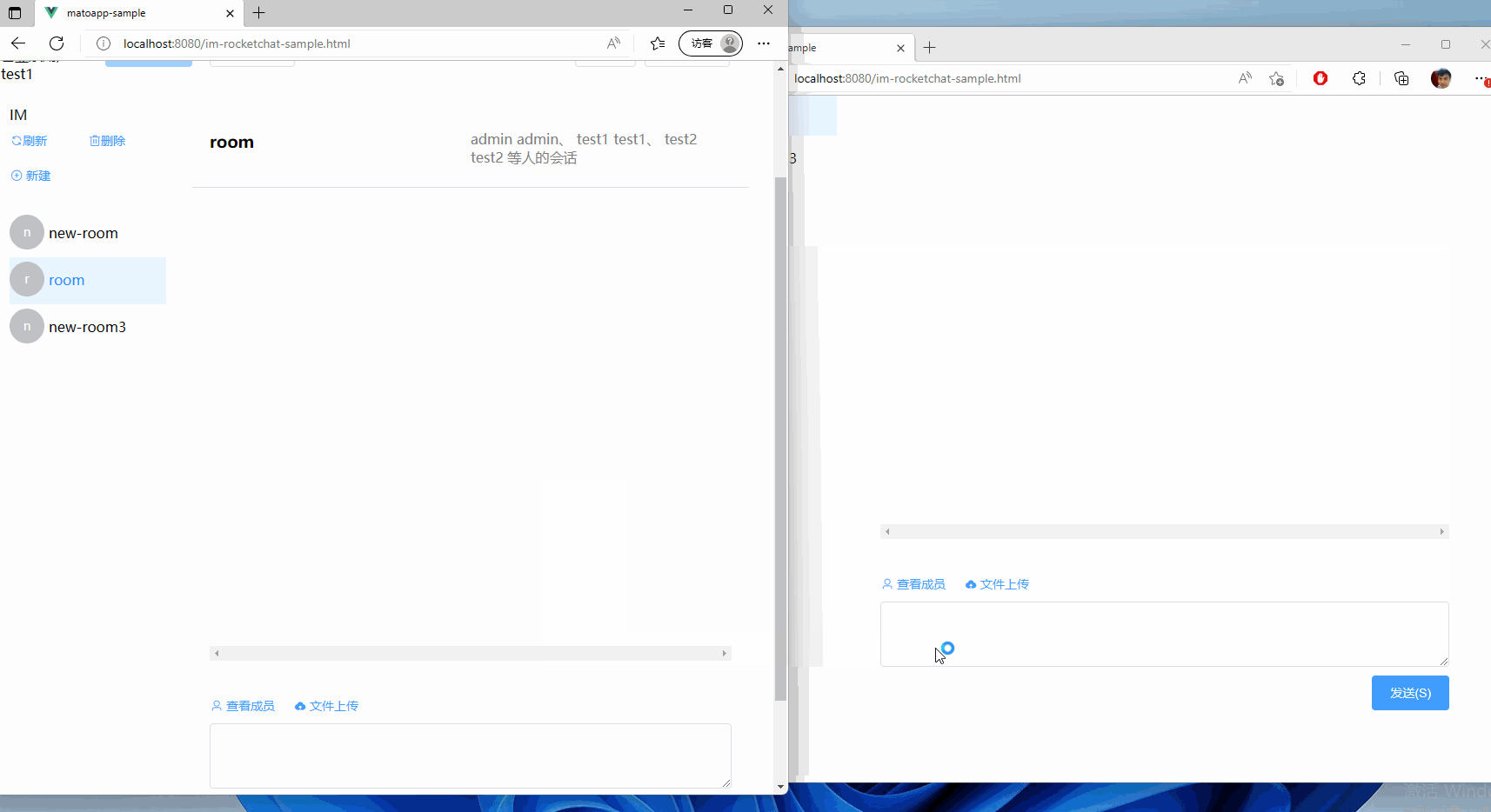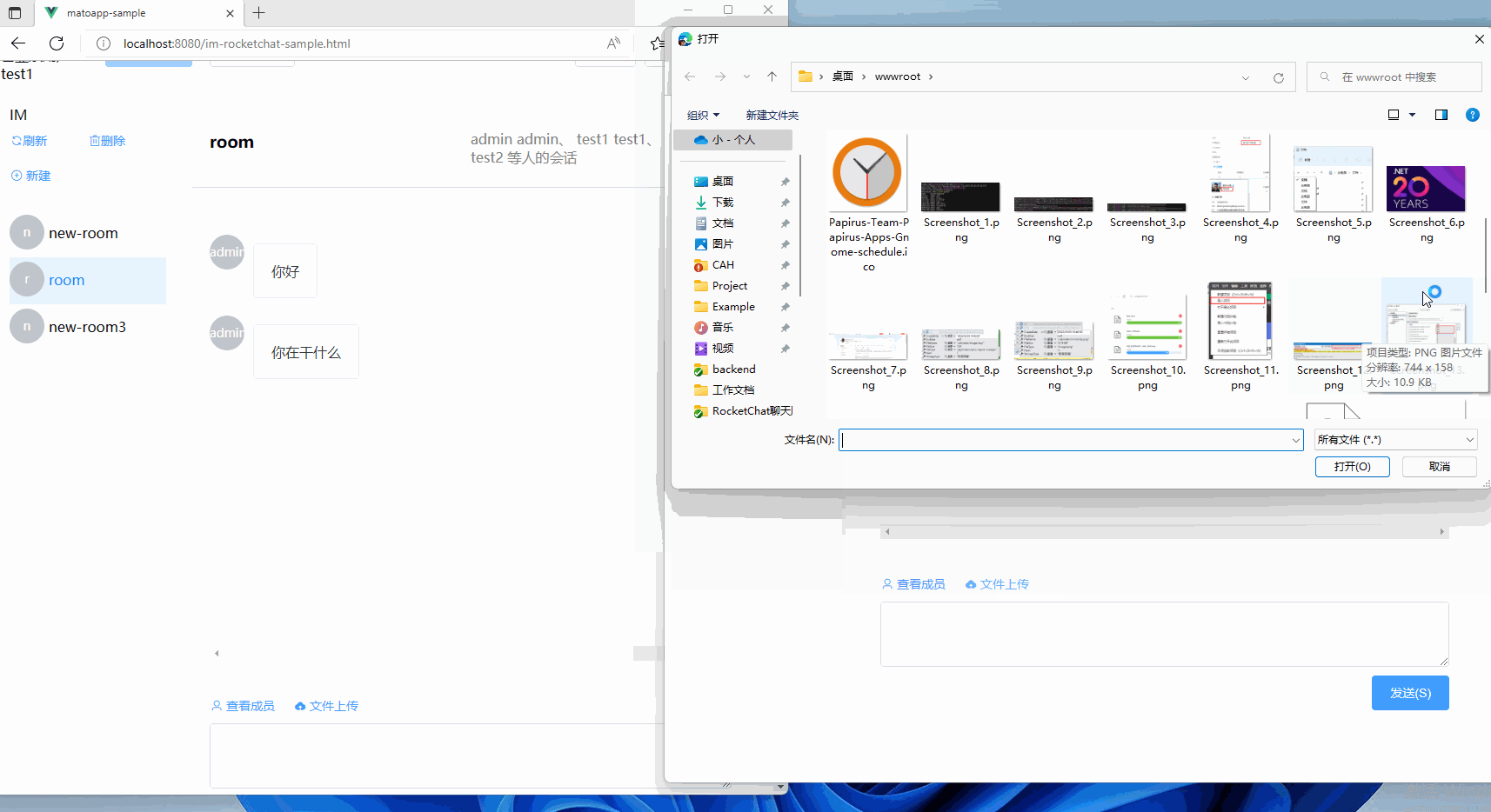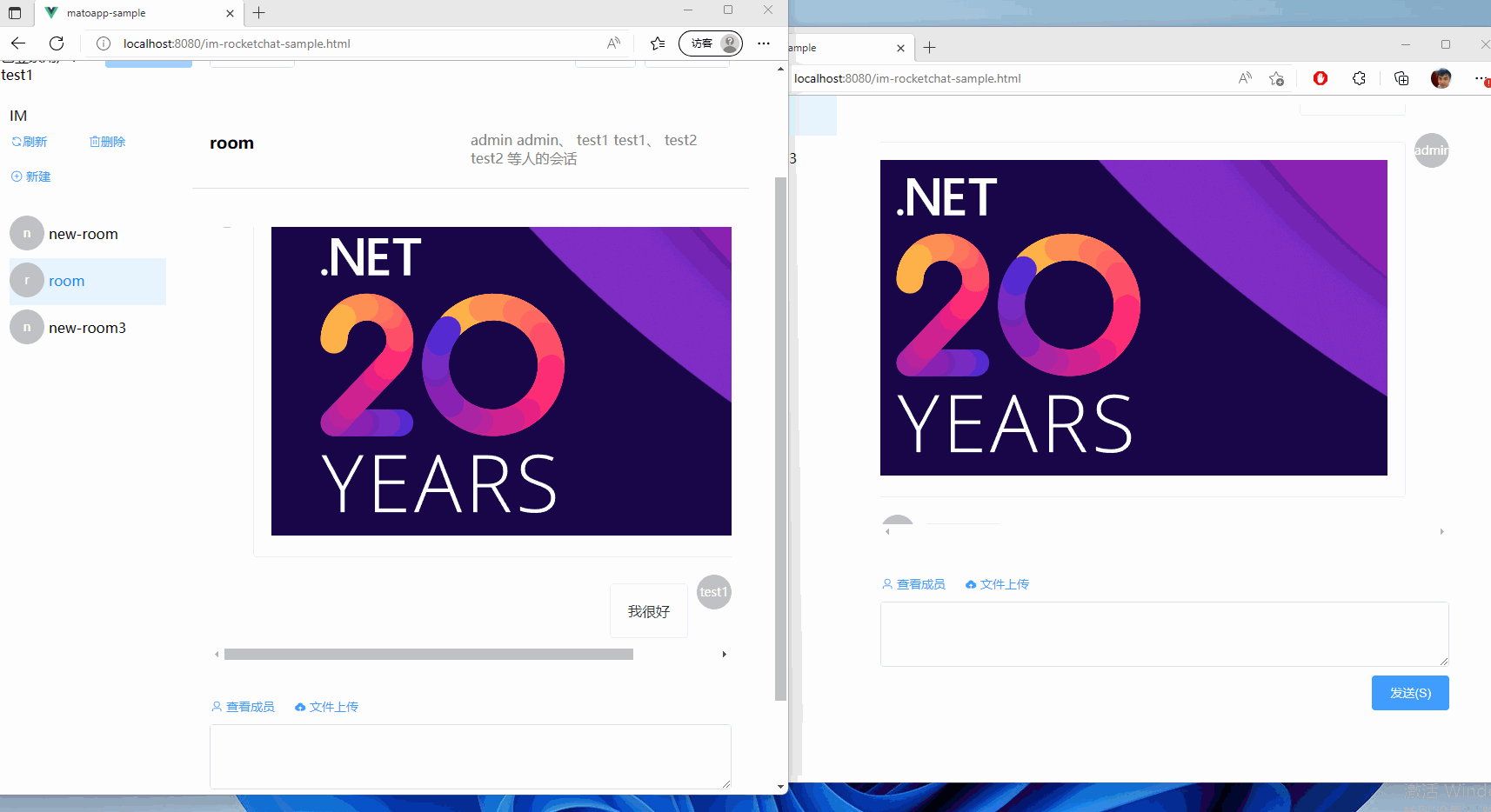
集成RocketChat至现有的.Net项目中,为ChatGPT铺路
文章目录前言项目搭建后端前端代理账号鉴权方式介绍登录校验模块前端鉴权方式后端鉴权方式登录委托使用登录委托处理聊天消息前端鉴权方式后端校验方式项目地址前言 今天我们来聊一聊一个Paas的方案,如何集成到一个既有的项目中。 以其中一个需求为例子:…...
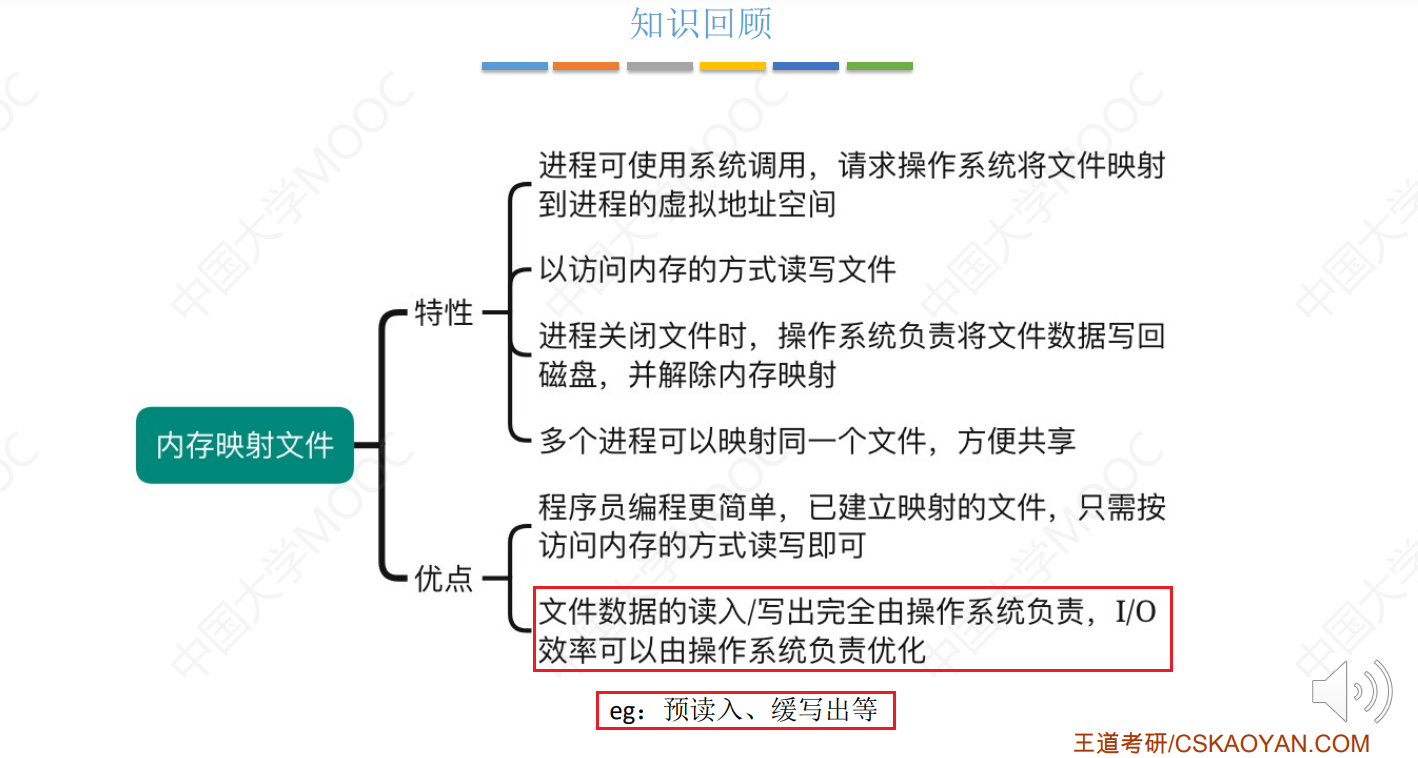
王道操作系统课代表 - 考研计算机 第三章 内存管理 究极精华总结笔记
本篇博客是考研期间学习王道课程 传送门 的笔记,以及一整年里对 操作系统 知识点的理解的总结。希望对新一届的计算机考研人提供帮助!!! 关于对 “内存管理” 章节知识点总结的十分全面,涵括了《操作系统》课程里的全部…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...