2022年高校大数据挑战赛A题工业机械设备故障预测求解全过程论文及程序
2022年高校大数据挑战赛
A题 工业机械设备故障预测
原题再现:
制造业是国民经济的主体,近十年来,嫦娥探月、祝融探火、北斗组网,一大批重大标志性创新成果引领中国制造业不断攀上新高度。作为制造业的核心,机械设备在工业生产的各个环节都扮演着不可或缺的重要角色。但是,在机械设备运转过程中会产生不可避免的磨损、老化等问题,随着损耗的增加,会导致各种故障的发生,影响生产质量和效率。
实际生产中,若能根据机械设备的使用情况,提前预测潜在的故障风险,精准地进行检修维护,维持机械设备稳定运转,不但能够确保整体工业环境运行具备稳定性,也能切实帮助企业提高经济效益。
某企业机械设备的使用情况及故障发生情况数据见“train data.xlsx”,用于设备故障预测及故障主要相关因素的探究。数据包含 9000 行,每一行数据记录了机械设备对应的运转及故障发生情况记录。因机械设备在使用环境以及工作强度上存在较大差异,其所需的维护频率和检修问题也通常有所不同。
数据提供了实际生产中常见的机械设备使用环境和工作强度等指标,包含不同设备所处厂房的室温(单位为开尔文K),其工作时的机器温度(单位为开尔文K)、转速(单位为每分钟的旋转次数rpm)、扭矩(单位为牛米Nm)及机器运转时长(单位为分钟min)。除此之外,还提供了机械设备的统一规范代码、质量等级及在该企业中的机器编号,其中质量等级分为高、中、低(H\M\L)三个等级。对于机械设备的故障情况,数据提供了两列数据描述——“是否发生故障” 和“具体故障类别”。其中“是否发生故障”取值为 0/1,0 代表设备正常运转,1 代表设备发生故障;“具体故障类别”包含 6 种情况,分别是NORMAL、TWF、HDF、PWF、OSF、RNF,其中,NORMAL代表设别正常运转(与是否发生故障”为 0相对应),其余代码代表的是发生故障的类别,包含 5 种,其中TWF代表磨损故障,HDF代表散热故障,PWF代表电力故障,OSF代表过载故障,RNF代表其他故障。
基于赛题提供的数据,自主查阅资料,选择合适的方法完成如下任务:
任务 1:观察数据“train data.xlsx”,自主进行数据预处理,选择合适的指标用于机械设备故障的预测并说明原因。
任务 2:设计开发模型用于判别机械设备是否发生故障,自主选取评价方式和评价指标评估模型表现。
任 务 3 : 设 计 开 发 模 型 用 于 判 别 机 械 设 备 发 生 故 障 的 具 体 类 别(TWF/HDF/PWF/OSF/RNF),自主选取评价方式和评价指标评估模型表现。
任务 4:利用任务 2 和任务 3 开发的模型预测“forecast.xlsx”中是否发生故障以及故障类别。数据“forecast.xlsx”。与数据“train data.xlsx”格式类似,要求在“forecast.xlsx”第 8 列说明设备是否发生故障(0 或 1),在第 9 列标识出具体的故障类型(TWF/HDF/PWF/OSF/RNF)。
任务 5:探究每类故障(TWF/HDF/PWF/OSF/RNF)的主要成因,找出与其相关的特征属性,进行量化分析,挖掘可能存在的模式/规则。
补充说明:
1. 开发语言不限,推荐使用python 3.7 及以上版本或Java 8 进行开发。
2.允许使用公开模型/开源代码,但需要在文档中注明出处。
3.除论文报告外,还需提供完整的程序代码、运行说明(包括依赖包、版本号)、预测结果文件“forecast.xlsx”及其他必要的佐证材料,以压缩包的形式提交。注意:forecast.xlsx不要改名,便于评审专家检测。
4.提交的支撑材料不得超过 20Mb
整体求解过程概述(摘要)
在工业生产中,机械设备是否稳定工作密切决定着产品的生产效率和企业的经济效益,对其故障进行诊断与预测并及时进行维护更换是至关重要的问题。本文通过选取影响设备故障的指标,建立预测机器是否故障及其具体故障类型的模型,并实现对各影响因素的量化分析,挖掘五类故障的潜在的内部机理。
针对任务一,首先以数据中唯一的统一规范代码为作为机器标识。将机器三个质量等级、五种故障类型重新编码数字化。剔除发生故障的机器中存在的两组 Normal 类型数据是异常值。随后对指标变量进行相关性分析,得到机器温度与室温相关系数为0.86,因此引入二者做差的新变量温差。再根据转速扭矩的电机学公式,得到功率指标。经过正态检验后对以上八个指标与是否发生故障进行单因素方差检验,得到全部方差分析结果 P 值均<0.1,说明统计结果存在较为显著的差异。因此,选取三个质量等级、温差、转速、扭矩、功率和使用时长八个指标用于后续机械设备故障的预测。
针对任务二,首先建立朴素贝叶斯判别模型,但由于数据样本分布不均衡的特征,因此选取基于决策树学习器的 CatBoost、XGBoost 以及随机森林算法分别建立模型,通过混淆矩阵并考虑指标的稳定性和解释性,本文选择 F1 Score 值、AUC 值以及描述实际分类与预测分类相关系数的 MCC 值作为判别模型的评价指标,得到随机森林模型的分类效果最好,其 MCC 值为 0.96,使用该模型用于后续是否发生故障的预测。
针对任务三,在前面任务基础上,继续使用上述四个分类模型,对 train.xlsx 数据集按照五种故障类型划分五次,每次以一种故障类型样本作为正例,所有其他类作为反例来训练四个模型。并仍然使用任务二的三个指标,评价发现随机森林模型最优,且四个模型对于 TWF 和 RNF 故障类型的判别 MCC 值均为 0 或十分接近 0,认为这两种故障类型使用模型的预测效果与随机预测的结果不相上下。
针对任务四,使用任务三建立的模型,以 train.xlsx 为训练集,forecast.xlsx 为预测集,得到机器所属的 HDF、PWF、OSF 以及 Normal 类型。并由于 TWF 和 RNF 两种故障类型的特殊性,根据两种类型在 train.xlsx 中所占的比例,对预测集数据中的数据进行分析计算,估计预测集数据中存在 4 台或 5 台发生 TWF 的机器以及 0 个或 1个发生 RNF 的机器。
针对任务五,本文首先通过箱型图对数据可视化,对于 5 种故障类型中个别指标离群的数据进行去除,并得到其分布情况。随后通过 Shapley 值分别计算对 5 种故障类型特征边际贡献最大的一个或几个特征,结合根据目标变量的分布情况计算出的基值,最终得出五种故障类型的成因及其存在的规则。
最后,对模型的优缺点进行了评价,并提出了改进方法与推广,除了机械故障的预测维护方面,对医疗疾病诊断、电力网络故障预测等领域也提出了一定的参考。
模型假设:
1. 除了题目所给的指标,其他指标对机器是否发生故障及故障类型没有影响。
2. 不考虑同一台机器发生多种类型故障的情况。
3. 数据预处理后 train data.xlsx 中每台机器是否发生故障与具体故障类别均正确无误。
问题分析:
任务一的分析
任务一首先要求对数据进行预处理,由于针对不同的统一规范代码机器的存在相同的编号,因此以统一规范代码为机器 id。由于机器三个质量等级是离散、无序的定类变量,因此对它们进行重新编码数字化。删除两组发生故障的机器中的 Normal 类型数据。随后对全部指标变量进行相关性分析,由于机器温度和室温具有较强的相关性,因此对机器温度和室温做差,引入新变量温差。再根据电机学公式,对转速和扭矩及常数相乘,得到功率指标。再对这些指标与是否发生故障进行单因素方差分析,选取通过显著性的指标进行后续预测。
任务二的分析
任务二要求建立模型判别机械设备是否发生故障,首先考虑通过朴素贝叶斯建立判别函数模型,由于数据样本量足够,因此考虑集成学习算法,提升基础学习算法的性能,选取了基于决策树学习器的 CatBoost、XGBoost 以及随机森林算法,分别建立模型,并通过混淆矩阵进一步得到模型的评价指标,考虑指标的解释性,本文选择对训练数据处理后得到的权衡精确率与召回率的 F1 Score 值、衡量二分类模型精度的AUC 值以及描述实际分类与预测分类之间的相关系数 MCC 值作为判别模型的评价指标,并对模型进一步分析。
任务三的分析
任务三要求建立模型判别机械设备发生故障的具体类别。首先在任务一、任务二的基础上,使用朴素贝叶斯、CatBoost、XGBoost 以及随机森林算法分类模型,对数据集按照五种故障类型划分五次,每次都以其中一种具体的故障类型样本作为正例,所有其他类的样例作为反例来训练四个模型。并仍然使用 F1 Score、AUC、MCC 三个指标对模型进行评价。
任务四的分析
任务四在任务二和任务三所建立的判别模型预测“forecast.xlsx”中的机器是否发生故障并标识出具体的故障类型。由于在任务二和任务三中已经得到基于决策树学习器的 CatBoost、XGBoost 以及随机森林算法训练好的模型,且通过比较检验认为随机森林模型最适用于样本不均衡的数据,因此选用随机森林模型,以 train.xlsx 为训练集,forecast.xlsx 为预测集对机器是否发生故障并标识出具体的故障类型进行预测,最终比较检验预测集中的预测结果。
任务五的分析
任务五要求分析五类故障的具体成因,首先通过计算 Shapley 值得到每个特征对5 种故障类型 TWF/HDF/PWF/OSF/RNF 的边际贡献,并筛选出对各类故障具有显著影响的特征属性。利用统计分析的方法对各类故障进行特征属性的量化分析,并挖掘每类故障中的可能存在的模式或者机制。
模型的建立与求解整体论文缩略图


全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:
部分程序如下:
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score, recall_score, roc_auc_score,
accuracy_score, roc_curve, auc
import csv, os
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
listTrainData = [[] for i in range(8998)]
listTestData = [[] for i in range(1000)]
Y = []
rowTrain = csv.reader(open(os.path.join(os.path.dirname(__file__),
"train_data.csv"), "r", encoding="UTF-8"))
n_row = 0
for r in rowTrain:if n_row != 0:for i in range(0, 8):listTrainData[n_row - 1].append(float(r[i]))Y.append(float(r[13]))n_row += 1
rowTrain = csv.reader(open(os.path.join(os.path.dirname(__file__),
"forecast.csv"), "r", encoding="UTF-8"))
n_row = 0
for r in rowTrain:if n_row != 0:for i in range(0, 8):listTestData[n_row - 1].append(float(r[i]))n_row += 1
Xtrain, Xtest, Ytrain, Ytest = train_test_split(listTrainData, Y,
test_size=0.3) # 数据划分
clf = DecisionTreeClassifier(random_state=0) # 决策树实例化
rfc = RandomForestClassifier(random_state=0) # 随机森林实例化
# 训练苏数据集
rfc = rfc.fit(Xtrain, Ytrain)
predicted = rfc.predict(listTrainData) # 测试样本预测
f1_score = f1_score(Y, predicted)
roc_socre = roc_auc_score(Y, predicted)
score_r = rfc.score(Xtest, Ytest)
forecast = rfc.predict(listTestData)
pdResult = pd.DataFrame(forecast)
pdResult.to_csv(os.path.join(os.path.dirname(__file__),
"Output/Predict.csv"))
print(f1_score)
print(roc_socre)
print("randon forest:{}".format(score_r))
importances = rfc.feature_importances_
indices = np.argsort(importances)[::-1]
feat_labels = ["L", "M", "H", "机器温度-室温", "转速(rpm)", "扭矩(Nm)",
"功率(kW)", "使用时长(min)"]
for f in range(np.array(Xtrain).shape[1]):print("%2d) %-*s %f" % (f + 1, 30, feat_labels[indices[f]],
importances[indices[f]]))
import xlrd
import numpy as np
import time
start = time.time()
workbook = xlrd.open_workbook(r'train_data.xlsx')
# 根据下标获取 sheet 名称
sheet_name = workbook.sheet_names()[0]
print(sheet_name)
sheetData = workbook.sheet_by_name(sheet_name)
cols = []
cols.append(np.array(sheetData.col_values(1))) # 第一列
cols.append(np.array(sheetData.col_values(2))) # 第一列
cols.append(np.array(sheetData.col_values(3))) # 第一列
cols.append(np.array(sheetData.col_values(4))) # 第一列
cols.append(np.array(sheetData.col_values(5))) # 第一列
cols.append(np.array(sheetData.col_values(6))) # 第一列
cols.append(np.array(sheetData.col_values(7))) # 第一列
cols.append(np.array(sheetData.col_values(8))) # 第一列
X = np.array(cols).T
print(X.shape)
y = np.array(sheetData.col_values(10)) # 9 是是否发生故障,10 是 HDF,11 是
OSF,12 是 PDF,13 是 RNF,14 是 TWF
print(y.shape)
# ================基于 XGBoost 原生接口的分类=============
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 准确率
# 加载样本数据集
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=1234565) # 数据集分割
# 算法参数
params = {'booster': 'gbtree','objective': 'multi:softmax','num_class': 3,'gamma': 0.1,'max_depth': 6,'lambda': 2,'subsample': 0.7,'colsample_bytree': 0.7,'min_child_weight': 3,'silent': 1,'eta': 0.1,'seed': 1000,'nthread': 4,
}
plst = list(params.items())
dtrain = xgb.DMatrix(X_train, y_train) # 生成数据集格式
num_rounds = 500
model = xgb.train(plst, dtrain, num_rounds) # xgboost 模型训练
# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
y_pred = model.predict(dtest)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("accuarcy: %.2f%%" % (accuracy * 100.0))
# 显示重要特征
plot_importance(model)
plt.show()
from sklearn import metrics
print('AUC: %.4f' % metrics.roc_auc_score(y_test, y_pred))
print('ACC: %.4f' % metrics.accuracy_score(y_test, y_pred))
print('Recall: %.4f' % metrics.recall_score(y_test, y_pred))
print('F1-score: %.4f' % metrics.f1_score(y_test, y_pred))
print('Precesion: %.4f' % metrics.precision_score(y_test, y_pred))
from sklearn import metrics
print('matthews_corrcoef: %.4f' % metrics.matthews_corrcoef(y_test,
y_pred))
metrics.confusion_matrix(y_test, y_pred)
workbook = xlrd.open_workbook(r'forecast.xlsx')
# 根据下标获取 sheet 名称
sheet_name = workbook.sheet_names()[0]
print(sheet_name)
sheetData = workbook.sheet_by_name(sheet_name)
cols = []
cols.append(np.array(sheetData.col_values(2))) # 第一列
cols.append(np.array(sheetData.col_values(3))) # 第一列
cols.append(np.array(sheetData.col_values(4))) # 第一列
cols.append(np.array(sheetData.col_values(5))) # 第一列
cols.append(np.array(sheetData.col_values(6))) # 第一列
cols.append(np.array(sheetData.col_values(7))) # 第一列
cols.append(np.array(sheetData.col_values(8))) # 第一列
cols.append(np.array(sheetData.col_values(9))) # 第一列
X = np.array(cols).T
print(X.shape)
# 对预测集进行预测
dtest = xgb.DMatrix(X)
y_pred = model.predict(dtest)
import xlwt
book = xlwt.Workbook(encoding='utf-8', style_compression=0)
sheet = book.add_sheet('预测结果', cell_overwrite_ok=True)
for i in range(len(y_pred)):sheet.write(i, 0, str(y_pred[i]))
savepath = 'C:/Users/Desktop/A题/excel 表格.xls'
book.save(savepath)
全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
相关文章:
2022年高校大数据挑战赛A题工业机械设备故障预测求解全过程论文及程序
2022年高校大数据挑战赛 A题 工业机械设备故障预测 原题再现: 制造业是国民经济的主体,近十年来,嫦娥探月、祝融探火、北斗组网,一大批重大标志性创新成果引领中国制造业不断攀上新高度。作为制造业的核心,机械设备在…...
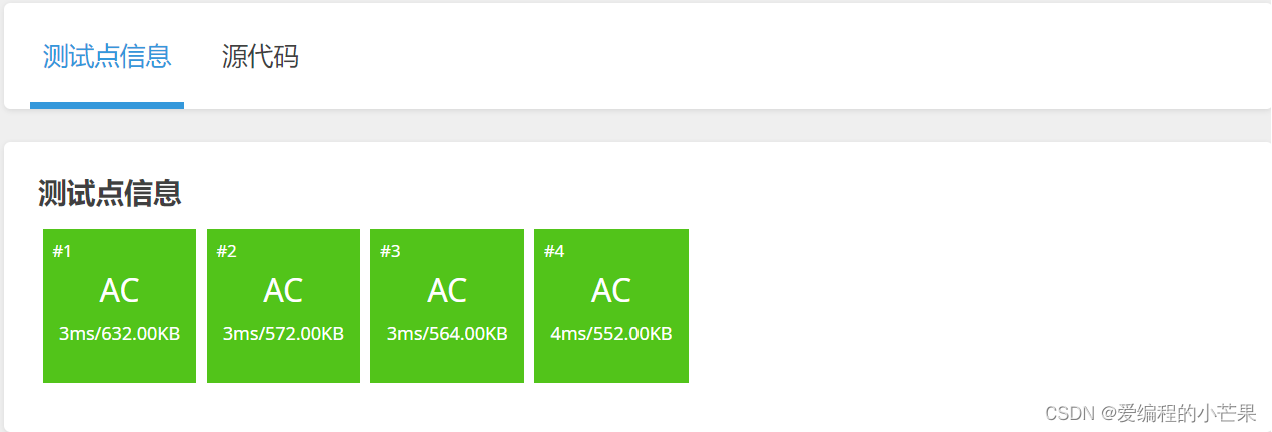
洛谷 P1998 阶乘之和 C++代码
前言 今天我们来做洛谷上的一道题目。 网址:[NOIP1998 普及组] 阶乘之和 - 洛谷 西江月夜行黄沙道中 【宋】 辛弃疾 明月别枝惊鹊,清风半夜鸣蝉。稻花香里说丰年,听取WA声一片。 七八个星天外,两三点雨山前。旧时茅店社林边&…...
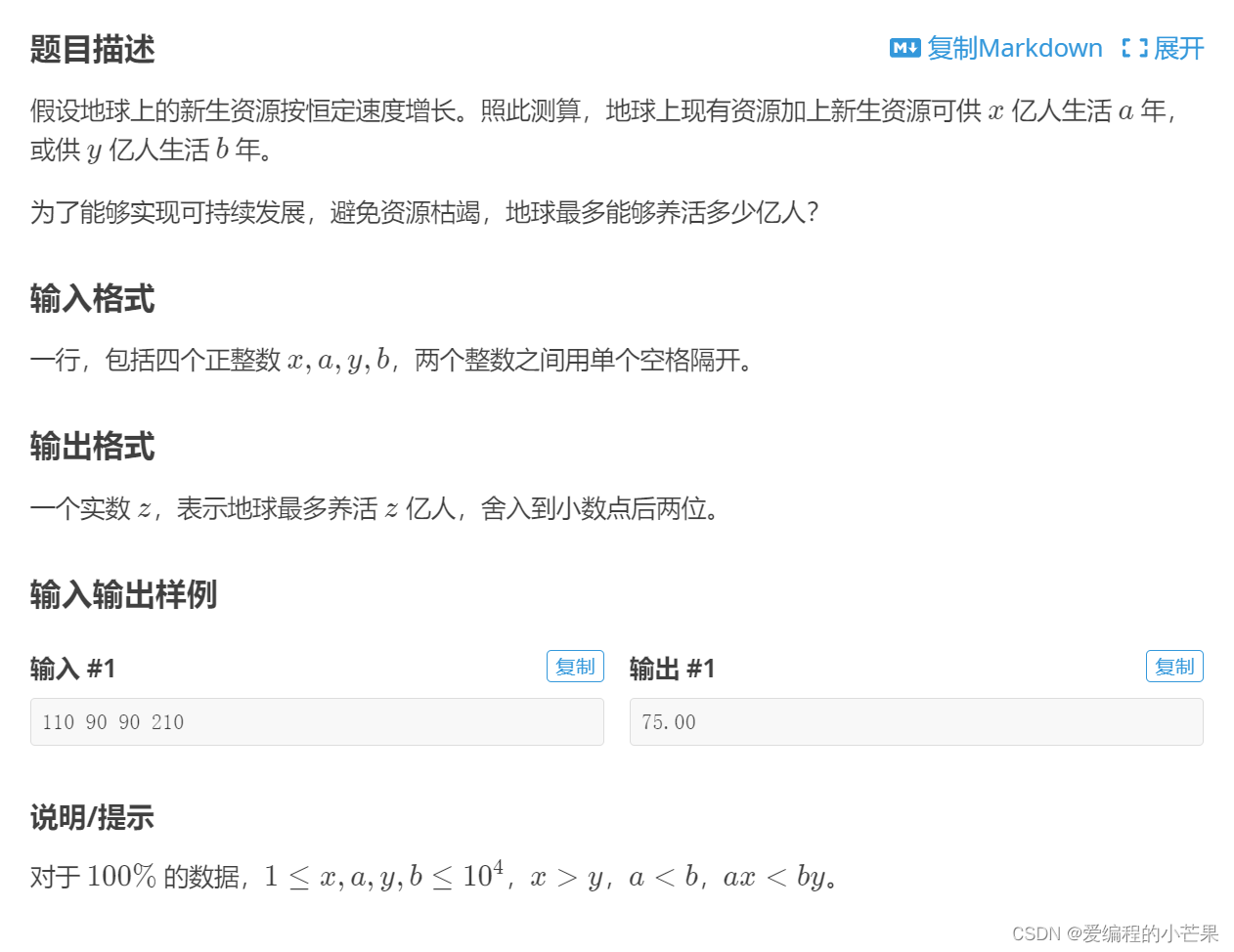
洛谷 B2006 地球人口承载力估计 C++代码
目录 前言 思路点拨 AC代码 结尾 前言 今天我们来做洛谷上的一道题目。 网址:地球人口承载力估计 - 洛谷 题目: 思路点拨 经典牛吃草问题。 解设一个人一年吃一份草。 则x*a-y*b为会多出的草,为什么会多呢?是因为每年都有…...

少走弯路:OpenCV、insightface 等多方案人脸推理和识别
脑壳有包又花时间折腾了一下,其实之前也折腾过,主要是新看了一个方法 在下图中查找脸部 第一种方案: 使用了opencv 的cv2.FaceDetectorYN. ,完整代码如下: import numpy as np import cv2imgcv2.imread("00000…...

github代码连接vercel 建立一个公用网站
Deploying to the Cloud using Vercel 前置任务 建立一个基于flask的web app代码库并上传至github repo Vercel用途 vercel有点像一个免费的cloud server,帮助你将flask框架下的程序运行在云端。可以public访问。 deploy流程 在主文件夹中建立requirements.tx…...

使用pandas将字符串格式数据转换为单独的行
有时在处理数据时,可能会遇到这样的情况,即数据框中的整个字符串条目需要拆分到不同的行中。这可能是一项具有挑战性的任务,特别是当数据庞大而复杂时。尽管如此,一个名为pandas的Python库提供了各种函数,使用这些函数…...
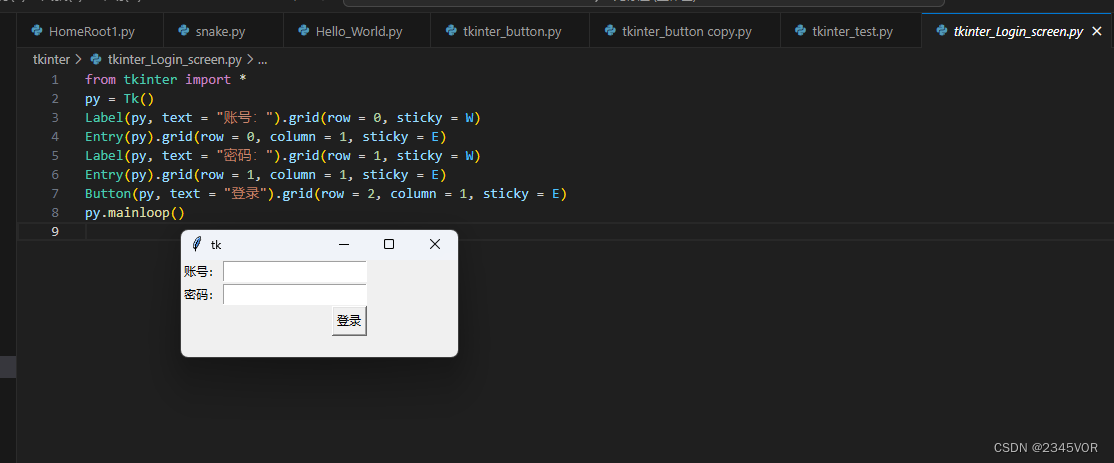
【Tkinter 入门教程】
【Tkinter 入门教程】 1. Tkinter库的简介:1.1 GUI编程1.2 Tkinter的定位 2. Hello word! 程序起飞2.1 第⼀个程序2.2 字体颜色主题 3. 组件讲解3.1 tkinter 的核⼼组件3.2 组件的使⽤3.3 标签Label3.3.1 标签显示内容3.3.2 多标签的应⽤程序3.3.3 总结 3.4 按钮but…...

深入理解Java中继承的高级使用方案
摘要: 继承是Java中的一项强大的特性,它允许子类从父类中继承属性和方法。然而,继承的高级使用方案涉及更复杂的概念和技术,可以帮助开发人员构建更加灵活、可维护和可扩展的代码。本文将深入探讨Java中继承的高级用法,…...
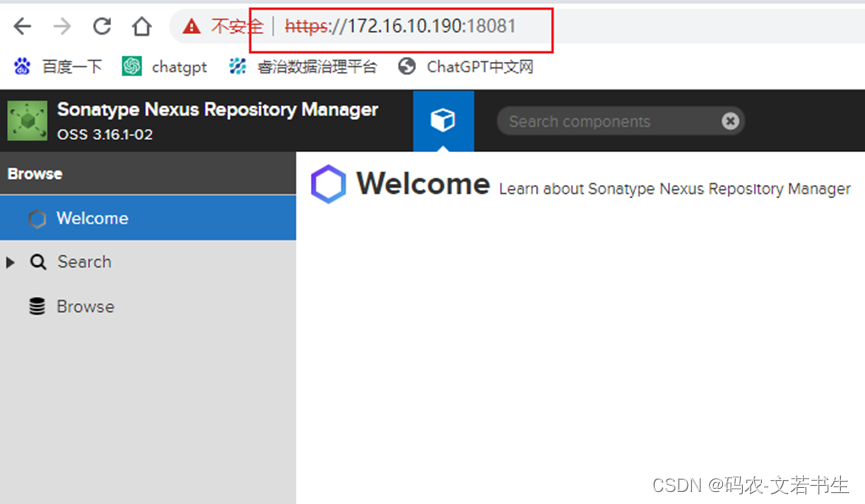
nexus私服开启HTTPS
maven3.8.1以上不允许使用HTTP服务的仓库地址,如果自己搭建的私服需要升级为HTTPS或做一些设置,如果要升级HTTPS服务有两种方式:1、使用Nginx开启HTTPS并反向代理nexus;2、直接在nexus开启HTTPS。这里介绍第二种方式 1、在ssl目录…...

融合CFPNet的EVC-Block改进YOLO的太阳能电池板缺陷检测系统
1.研究背景与意义 项目参考AAAI Association for the Advancement of Artificial Intelligence 研究背景与意义 随着太阳能电池板的广泛应用,对其质量和性能的要求也越来越高。然而,由于生产过程中的各种因素,太阳能电池板上可能存在各种缺…...

传媒行业CRM:打造高效客户管理,提升品牌影响力
传媒行业充满竞争和变化,传媒企业面临着客户管理不透明、业务流程混乱、销售数据分析不足,无法优化营销策略和运营管理等问题。CRM系统是企业实现数智化管理的神器,可以有效解决这些问题。下面说说,传媒行业CRM系统推荐。 1、建立…...
基于深度学习的肺炎CT图像检测诊断系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、系统四. 总结 一项目简介 深度学习在肺炎CT图像检测诊断方面具有广泛的应用前景。以下是关于肺炎CT图像检测诊断系统的介绍: 任务…...

YOLOv8改进 | 2023 | SCConv空间和通道重构卷积(精细化检测,又轻量又提点)
一、本文介绍 本文给大家带来的改进内容是SCConv,即空间和通道重构卷积,是一种发布于2023.9月份的一个新的改进机制。它的核心创新在于能够同时处理图像的空间(形状、结构)和通道(色彩、深度)信息…...
)
Python 全栈体系【四阶】(一)
四阶:机器学习 - 深度学习 第一章 numpy 一、numpy 概述 Numerical Python,数值的 Python,补充了 Python 语言所欠缺的数值计算能力。 Numpy 是其它数据分析及机器学习库的底层库。 Numpy 完全标准 C 语言实现,运行效率充分优…...

Git【成神路】
目录 1.为啥要学git啊?😕😕😕 2.版本控制软件的基本功能 🤞🤞🤞 3.集中式版本控制 🤶🤶🤶 4.分布式版本控制😎😎😎 …...

文件操作详解
文件操作详解 一:文件相关概念1:问什么使用文件2:什么是文件???2.1:程序文件2.2数据文件 二:文件的打开和关闭1:流的定义2:标准流3:文件指针 一&a…...
模块 A:web理论测试
模块 A:理论测试 任务一:单选题 1.为 EMP 表的 namesalary 字段创建名为 emp name salary idx 的校复习接课 name 字段升序, salary 字段降序的复合索引的 SQL 语句是? B A: CREATEINDEX emp name salary idx ON EMP(namesalary) B: …...
git rebase冲突说明(base\remote\local概念说明)
主线日志及修改 $ git log master -p commit 31213fad6150b9899c7e6b27b245aaa69d2fdcff (master) Author: Date: Tue Nov 28 10:19:53 2023 08004diff --git a/123.txt b/123.txt index 294d779..a712711 100644 --- a/123.txtb/123.txt-1,3 1,4 123 4^Mcommit a77b518156…...

函数式接口的妙用,让异步执行更简单
你是否曾经遇到过在SpringBoot中Async注解无法正常工作的问题?今天,我们用函数式接口来解决这个问题。 一、什么是函数式接口? 函数式接口(Functional Interface)是 Java 8 中引入的一个概念,是指只包含一…...

读书笔记:《More Effective C++》
More Effective C Basics reference & pointer reference 必定有值,pointer 可以为空reference 声明时必须定义,必须初始化reference 无需测试有效性,pointer 必须测试是否为 nullreference 可以更改指向对象的值,但是无法…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...