Redis源码---有序集合为何能同时支持点查询和范围查询
目录
前言
Sorted Set 基本结构
跳表的设计与实现
跳表数据结构
跳表结点查询
跳表结点层数设置
哈希表和跳表的组合使用
-
前言
- 有序集合(Sorted Set)是 Redis 中一种重要的数据类型,它本身是集合类型,同时也可以支持集合中的元素带有权重,并按权重排序
- 为什么 Sorted Set 能同时提供以下两种操作接口,以及它们的复杂度分别是 O(logN)+M 和 O(1) 呢?
- ZRANGEBYSCORE:按照元素权重返回一个范围内的元素
- ZSCORE:返回某个元素的权重值
- 实际上,这个问题背后的本质是:为什么 Sorted Set 既能支持高效的范围查询,同时还能以O(1) 复杂度获取元素权重值?
- 这其实就和 Sorted Set 底层的设计实现有关了
- Sorted Set 能支持范围查询,这是因为它的核心数据结构设计采用了跳表
- 而它又能以常数复杂度获取元素权重,这是因为它同时采用了哈希表进行索引
- 那么,Sorted Set 是如何把这两种数据结构结合在一起的?它们又是如何进行协作的呢?
-
Sorted Set 基本结构
- 要想了解 Sorted Set 的结构,就需要阅读它的代码文件
- 这里需要注意的是,在 Redis 源码中,Sorted Set 的代码文件和其他数据类型不太一样,它并不像哈希表的 dict.c/dict.h,或是压缩列表的 ziplist.c/ziplist.h,具有专门的数据结构实现和定义文件
- Sorted Set 的实现代码在t_zset.c文件中,包括 Sorted Set 的各种操作实现
- 同时 SortedSet 相关的结构定义在server.h文件中
- 如果想要了解学习 Sorted Set 的模块和操作,注意要从 t_zset.c 和 server.h 这两个文件中查找
- 在知道了 Sorted Set 所在的代码文件之后,可以先来看下它的结构定义
- Sorted Set 结构体的名称为 zset,其中包含了两个成员,分别是哈希表 dict 和跳表 zsl,如下所示:

- Sorted Set 这种同时采用跳表和哈希表两个索引结构的设计思想,是非常值得学习的
- 因为这种设计思想充分利用了跳表高效支持范围查询(如ZRANGEBYSCORE 操作),以及哈希表高效支持单点查询(如 ZSCORE 操作)的特征
- 这样一来,就可以在一个数据结构中,同时高效支持范围查询和单点查询,这是单一索引结构比较难达到的效果
- 不过,既然 Sorted Set 采用了跳表和哈希表两种索引结构来组织数据,在实现 Sorted Set 时就会面临以下两个问题:
- 跳表或是哈希表中,各自保存了什么样的数据?
- 跳表和哈希表保存的数据是如何保持一致的?
-
跳表的设计与实现
- 首先来了解下什么是跳表(skiplist)
- 跳表其实是一种多层的有序链表
- 为了便于说明,把跳表中的层次从低到高排个序,最底下一层称为 level0,依次往上是 level1、level2 等
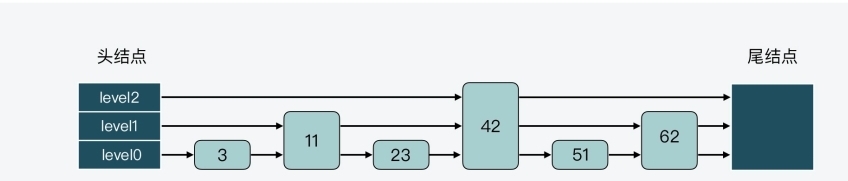
- 下图展示的是一个 3 层的跳表
- 其中,头结点中包含了三个指针,分别作为 leve0 到 level2上的头指针
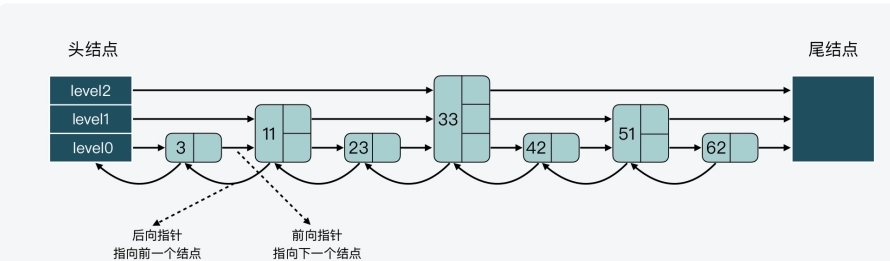
- 可以看到,在 level 0 上一共有 7 个结点,分别是 3、11、23、33、42、51、62
- 这些结点会通过指针连接起来,同时头结点中的 level0 指针会指向结点 3
- 然后,在这 7 个结点中,结点 11、33 和 51 又都包含了一个指针,同样也依次连接起来,且头结点的 level 1 指针会指向结点 11
- 这样一来,这 3 个结点就组成了 level 1 上的所有结点
- 最后,结点 33 中还包含了一个指针,这个指针会指向尾结点,同时,头结点的 level 2 指针会指向结点 33,这就形成了 level 2,只不过 level 2 上只有 1 个结点 33
- 在对跳表有了直观印象后,再来看看跳表实现的具体数据结构
-
跳表数据结构
- 先来看下跳表结点的结构定义,如下所示

- 首先,因为 Sorted Set 中既要保存元素,也要保存元素的权重,所以对应到跳表结点的结构定义中,就对应了 sds 类型的变量 ele,以及 double 类型的变量 score
- 此外,为了便于从跳表的尾结点进行倒序查找,每个跳表结点中还保存了一个后向指针(*backward),指向该结点的前一个结点
- 然后,因为跳表是一个多层的有序链表,每一层也是由多个结点通过指针连接起来的
- 因此在跳表结点的结构定义中,还包含了一个 zskiplistLevel 结构体类型的 level 数组
- level 数组中的每一个元素对应了一个 zskiplistLevel 结构体,也对应了跳表的一层
- 而zskiplistLevel 结构体定义了一个指向下一结点的前向指针(*forward),这就使得结点可以在某一层上和后续结点连接起来
- 同时,zskiplistLevel 结构体中还定义了跨度,这是用来记录结点在某一层上的*forward指针和该指针指向的结点之间,跨越了 level0 上的几个结点
- 来看下面这张图,其中就展示了 33 结点的 level 数组和跨度情况
- 可以看到,33 结点的level 数组有三个元素,分别对应了三层 level 上的指针
- 此外,在 level 数组中,level 2、level1 和 level 0 的跨度 span 值依次是 3、2、1
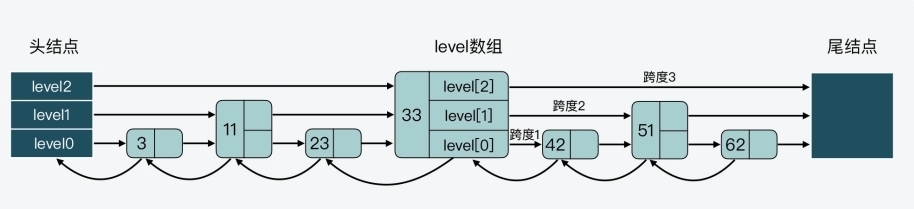
- 最后,因为跳表中的结点都是按序排列的,所以,对于跳表中的某个结点,可以把从头结点到该结点的查询路径上,各个结点在所查询层次上的*forward指针跨度,做一个累加
- 这个累加值就可以用来计算该结点在整个跳表中的顺序
- 另外这个结构特点还可以用来实现Sorted Set 的 rank 操作,比如 ZRANK、ZREVRANK 等
- 了解了跳表结点的定义后,可以来看看跳表的定义
- 在跳表的结构中,定义了跳表的头结点和尾结点、跳表的长度,以及跳表的最大层数,如下所示

- 因为跳表的每个结点都是通过指针连接起来的,所以在使用跳表时,只需要从跳表结构体中获得头结点或尾结点,就可以通过结点指针访问到跳表中的各个结点
- 当在 Sorted Set 中查找元素时,就对应到了 Redis 在跳表中查找结点
- 而此时,查询代码是否需要像查询常规链表那样,逐一顺序查询比较链表中的每个结点呢?
- 其实是不用的,因为这里的查询代码,可以使用跳表结点中的 level 数组来加速查询
-
跳表结点查询
- 事实上,当查询一个结点时,跳表会先从头结点的最高层开始,查找下一个结点
- 而由于跳表结点同时保存了元素和权重,所以跳表在比较结点时,相应地有两个判断条件:
- 当查找到的结点保存的元素权重,比要查找的权重小时,跳表就会继续访问该层上的下一个结点
- 当查找到的结点保存的元素权重,等于要查找的权重时,跳表会再检查该结点保存的SDS类型数据,是否比要查找的 SDS 数据小
- 如果结点数据小于要查找的数据时,跳表仍然会继续访问该层上的下一个结点
- 但是,当上述两个条件都不满足时,跳表就会用到当前查找到的结点的 level 数组
- 跳表会使用当前结点 level 数组里的下一层指针,然后沿着下一层指针继续查找,这就相当于跳到了下一层接着查找
- 这部分的代码逻辑如下所示,因为在跳表中进行查找、插入、更新或删除操作时,都需要用到查询的功能,可以重点了解下

-
跳表结点层数设置
- 这样一来,有了 level 数组之后,一个跳表结点就可以在多层上被访问到了
- 而一个结点的level 数组的层数也就决定了,该结点可以在几层上被访问到
- 所以,当要决定结点层数时,实际上是要决定 level 数组具体有几层
- 一种设计方法是,让每一层上的结点数约是下一层上结点数的一半,就像下面这张图展示的
- 第 0 层上的结点数是 7,第 1 层上的结点数是 3,约是第 0 层上结点数的一半
- 而第 2 层上的结点就 33 一个,约是第 1 层结点数的一半
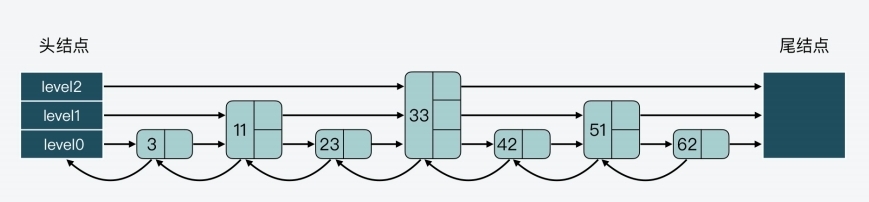
- 这种设计方法带来的好处是,当跳表从最高层开始进行查找时,由于每一层结点数都约是下一层结点数的一半,这种查找过程就类似于二分查找,查找复杂度可以降低到 O(logN)
- 但这种设计方法也会带来负面影响,那就是为了维持相邻两层上结点数的比例为 2:1,一旦有新的结点插入或是有结点被删除,那么插入或删除处的结点,及其后续结点的层数都需要进行调整,而这样就带来了额外的开销
- 先来举个例子,看下不维持结点数比例的影响,这样虽然可以不调整层数,但是会增加查询复杂度
- 首先,假设当前跳表有 3 个结点,其数值分别是 3、11、23,如下图所示
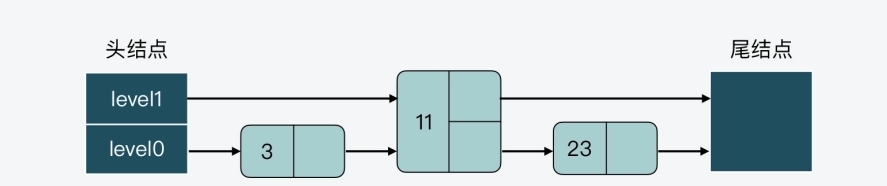
- 接着,假设现在要插入一个结点 15,如果不调整其他结点的层数,而是直接插入结点 15的话,那么插入后,跳表 level 0 和 level 1 两层上的结点数比例就变成了为 4:1,如下图所示

- 而假设持续插入多个结点,但是仍然不调整其他结点的层数,这样一来,level0 上的结点数就会越来越多,如下图所示

- 相应的,如果要查找大于 11 的结点,就需要在 level 0 的结点中依次顺序查找,复杂度就是 O(N) 了
- 所以,为了降低查询复杂度,就需要维持相邻层结点数间的关系
- 再来看下维持相邻层结点数为 2:1 时的影响
- 比如,可以把结点 23 的 level 数组中增加一层指针,如下图所示
- 这样一来,level 0 和 level 1 上的结点数就维持在了 2:1
- 但相应的代价就是,需要给 level 数组重新分配空间,以便增加一层指针

- 类似的,如果要在有 7 个结点的跳表中删除结点 33,那么结点 33 后面的所有结点都要进行调整:

- 调整后的跳表如下图所示
- 可以看到,结点 42 和 62 都要新增 level 数组空间,这样能分别保存 3 层的指针和 2 层的指针,而结点 51 的 level 数组则需要减少一层
- 也就是说,这样的调整会带来额外的操作开销
- 因此,为了避免上述问题,跳表在创建结点时,采用的是另一种设计方法,即随机生成每个结点的层数
- 此时,相邻两层链表上的结点数并不需要维持在严格的 2:1 关系
- 这样一来,当新插入一个结点时,只需要修改前后结点的指针,而其他结点的层数就不需要随之改变了,这就降低了插入操作的复杂度
- 在 Redis 源码中,跳表结点层数是由 zslRandomLevel 函数决定
- zslRandomLevel 函数会把层数初始化为 1,这也是结点的最小层数
- 然后,该函数会生成随机数,如果随机数的值小于 ZSKIPLIST_P(指跳表结点增加层数的概率,值为 0.25),那么层数就增加 1 层
- 因为随机数取值到[0,0.25) 范围内的概率不超过 25%,所以这也就表明了,每增加一层的概率不超过25%
- 下面的代码展示了 zslRandomLevel 函数的执行逻辑,可以看下

- 现在就了解了跳表的基本结构、查询方式和结点层数设置方法
- 那么下面接着来学习下,Sorted Set 中是如何将跳表和哈希表组合起来使用的,以及是如何保持这两个索引结构中的数据是一致的
-
哈希表和跳表的组合使用
- 其实,哈希表和跳表的组合使用并不复杂
- 首先,从刚才介绍的 Sorted Set 结构体中可以看到,Sorted Set 中已经同时包含了这两种索引结构,这就是组合使用两者的第一步
- 然后,还可以在 Sorted Set 的创建代码(t_zset.c文件)中,进一步看到跳表和哈希表被相继创建
- 当创建一个 zset 时,代码中会相继调用 dictCreate 函数创建 zset 中的哈希表,以及调用 zslCreate 函数创建跳表,如下所示

- 这样,在 Sorted Set 中同时有了这两个索引结构以后,接下来要想组合使用它们,就需要保持这两个索引结构中的数据一致了
- 简单来说,这就需要在往跳表中插入数据时,同时也向哈希表中插入数据
- 而这种保持两个索引结构一致的做法其实也不难,当往 Sorted Set 中插入数据时,zsetAdd函数就会被调用
- 所以,可以通过阅读 Sorted Set 的元素添加函数 zsetAdd 了解到
- 下面就来分析一下 zsetAdd 函数的执行过程
- 首先,zsetAdd 函数会判定 Sorted Set 采用的是 ziplist 还是 skiplist 的编码方式
- 注意,在不同编码方式下,zsetAdd 函数的执行逻辑也有所区别
- 这一讲重点关注的是skiplist 的编码方式,所以接下来,就主要来看看当采用 skiplist 编码方式时,zsetAdd函数的逻辑是什么样的
- zsetAdd 函数会先使用哈希表的 dictFind 函数,查找要插入的元素是否存在
- 如果不存在,就直接调用跳表元素插入函数 zslInsert 和哈希表元素插入函数 dictAdd,将新元素分别插入到跳表和哈希表中
- 这里需要注意的是,Redis 并没有把哈希表的操作嵌入到跳表本身的操作函数中,而是在zsetAdd 函数中依次执行以上两个函数
- 这样设计的好处是保持了跳表和哈希表两者操作的独立性
- 然后,如果 zsetAdd 函数通过 dictFind 函数发现要插入的元素已经存在,那么 zsetAdd 函数会判断是否要增加元素的权重值
- 如果权重值发生了变化,zsetAdd 函数就会调用 zslUpdateScore 函数,更新跳表中的元素权重值
- 紧接着,zsetAdd 函数会把哈希表中该元素(对应哈希表中的 key)的 value 指向跳表结点中的权重值,这样一来,哈希表中元素的权重值就可以保持最新值了
- 下面的代码显示了 zsetAdd 函数的执行流程,可以看下

- 总之可以记住的是,Sorted Set 先是通过在它的数据结构中同时定义了跳表和哈希表,来实现同时使用这两种索引结构
- 然后,Sorted Set 在执行数据插入或是数据更新的过程中,会依次在跳表和哈希表中插入或更新相应的数据,从而保证了跳表和哈希表中记录的信息一致
- 这样一来,Sorted Set 既可以使用跳表支持数据的范围查询,还能使用哈希表支持根据元素直接查询它的权重
相关文章:
Redis源码---有序集合为何能同时支持点查询和范围查询
目录 前言 Sorted Set 基本结构 跳表的设计与实现 跳表数据结构 跳表结点查询 跳表结点层数设置 哈希表和跳表的组合使用 前言 有序集合(Sorted Set)是 Redis 中一种重要的数据类型,它本身是集合类型,同时也可以支持集合中…...
从计费出账加速的设计谈周期性业务的优化思考
1号恐惧症 你有没有这样的做IT的朋友?年纪轻轻,就头发花白或者秃顶,然后每个月周期性的精神不振,一到月底,就有明显的焦虑。如果有,他可能就是运营商行业做计费运营的,请对他好点,特…...

垃圾回收的概念与算法(第四章)
《实战Java虚拟机:JVM故障诊断与性能优化 (第2版)》 第4章 垃圾回收的概念与算法 目标: 了解什么是垃圾回收学习几种常用的垃圾回收算法掌握可触及性的概念理解 Stop-The-World(STW) 4.1. 认识垃圾回收 - 内存管理清洁工 垃圾…...

让您的客户了解您的制造过程“VR云看厂实时数字化展示”
一、工厂云考察,成为市场热点虚拟现实(VR)全景技术问世已久,但由于应用范围较为狭窄,一直未得到广泛应用。国外客户无法亲自到访,从而导致考察难、产品取样难等问题,特别是对于大型制造企业来说…...

CV——day80 读论文:DLT-Net:可行驶区域、车道线和交通对象的联合检测
DLT-Net:可行驶区域、车道线和交通对象的联合检测I. INTRODUCTIONII. ANALYSIS OF PERCEPTIONIV. DLT-NETA. EncoderB. Decoder1) Drivable Area Branch(可行驶区域分支)2) Context Tensor(上下文张量)3) Lane Line Branch(车道线分支)4) Traffic Object Branch(目标检测对象分…...
工具篇4.5数据可视化工具大全
1.1 Flourish 数据可视化不仅是一项技术,也是一门艺术。当然,数据可视化的工具也非常多,仅 Python 就有 matplotlib、plotly、seaborn、bokeh 等多种可视化库,我们可以根据自己的需要进行选择。但不是所有的人都擅长写代码完成数…...
)
京东前端二面常考手写面试题(必备)
实现发布-订阅模式 class EventCenter{// 1. 定义事件容器,用来装事件数组let handlers {}// 2. 添加事件方法,参数:事件名 事件方法addEventListener(type, handler) {// 创建新数组容器if (!this.handlers[type]) {this.handlers[type] …...
如何用AST还原某音的JSVMP
1. 什么是JSVMP vmp简单来说就是将一些高级语言的代码通过自己实现的编译器进行编译得到字节码,这样就可以更有效的保护原有代码,而jsvmp自然就是对JS代码的编译保护,具体的可以看看H5应用加固防破解-JS虚拟机保护方案。 如何区分是不是jsv…...

【蓝桥杯试题】 递归实现指数型枚举例题
💃🏼 本人简介:男 👶🏼 年龄:18 🤞 作者:那就叫我亮亮叭 📕 专栏:蓝桥杯试题 文章目录1. 题目描述2. 思路解释2.1 时间复杂度2.2 递归3. 代码展示最后&#x…...
【用Group整理目录结构 Objective-C语言】
一、接下来,我们看另外一个知识点,怎么用Group把这一堆乱七八糟的文件给它整理一下,也算是封装一下吧, 1.这一堆杂乱无章的文件: 那么,哪些类是属于模型呢,哪些类是属于视图呢,哪些类是属于控制器呢, 我们接下来通过Group的方式,来给它们分一下类, 这样看起来就好…...
JavaScript高级程序设计读书分享之8章——8.1理解对象
JavaScript高级程序设计(第4版)读书分享笔记记录 适用于刚入门前端的同志 创建自定义对象的通常方式是创建 Object 的一个新实例,然后再给它添加属性和方法。 let person new Object() person.name Tom person.age 18 person.sayName function(){//示 this.name…...
代码随想录算法训练营第四十天 | 343. 整数拆分,96.不同的二叉搜索树
一、参考资料整数拆分https://programmercarl.com/0343.%E6%95%B4%E6%95%B0%E6%8B%86%E5%88%86.html 视频讲解:https://www.bilibili.com/video/BV1Mg411q7YJ不同的二叉搜索树https://programmercarl.com/0096.%E4%B8%8D%E5%90%8C%E7%9A%84%E4%BA%8C%E5%8F%89%E6%90…...

数据结构与算法系列之顺序表的实现
这里写目录标题顺序表的优缺点:注意事项test.c(动态顺序表)SeqList.hSeqList.c各接口函数功能详解void SLInit(SL* ps);//定义void SLDestory(SL* ps);void SLPrint(SL* ps);void SLPushBack(SL* ps ,SLDataType * x );void SLPopBack(SL* ps…...

基于Linux_ARM板的驱动烧写及连接、挂载详细过程(附带驱动程序)
文章目录前言一、搭建nfs服务二、ARM板的硬件连接三、putty连接四、挂载共享文件夹五、烧写驱动程序六、驱动程序示例前言 本文操作环境:Ubuntu14.04、GEC6818 这里为似懂非懂的朋友简单叙述该文章的具体操作由来,我们的主要目的是将写好的驱动程序烧进…...

python-爬虫-字体加密
直接点 某8网 https://*****.b*b.h*****y*8*.com/ 具体网址格式就是这样的但是为了安全起见,我就这样打码了. 抛出问题 我们看到这个号码是在页面上正常显示的 F12 又是这样就比较麻烦,不能直接获取.用requests库也是获取不到正常想要的 源码的,因为字体加密了. 查看页面源代码…...

计算机组成原理4小时速成5:输入输出系统,io设备与cpu的链接方式,控制方式,io设备,io接口,并行串行总线
计算机组成原理4小时速成5:输入输出系统,io设备与cpu的链接方式,控制方式,io设备,io接口,并行串行总线 2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,…...

安全狗受聘成为福州网信办网络安全技术支撑单位
近日,福州市委网信办召开了2022年度网络安全技术支撑单位总结表彰大会。 作为国内云原生安全领导厂商,安全狗也出席了此次活动。 据悉,会议主要对2022年度优秀支撑单位进行表彰,并为2023年度支撑单位举行授牌仪式。 本次遴选工…...

RV1126 在Ubuntu18.04开发环境搭建
1:安装软件终端下输入安装命名:sudo apt install openssh-serversudo apt install android-tools-adbsudo apt install vim net-tools gitsudo apt install cmakesudo apt install treesudo apt install minicomsudo apt install gawksudo apt install bisonsudo ap…...
?)
如何在 C++ 中调用 python 解析器来执行 python 代码(一)?
实现 Python UDF 中的一步就是学习如何在 C 语言中调用 python 解析器。本文根据 Python 官方文档做了一次实验,记录如下: 1. 安装依赖包 $sudo yum install python3-devel.x86_642. 使用 python-config 来生成编译选项 $python3.6-config --cflags -…...

操作系统权限提升(二十三)之Linux提权-通配符(ws)提权
系列文章 操作系统权限提升(十八)之Linux提权-内核提权 操作系统权限提升(十九)之Linux提权-SUID提权 操作系统权限提升(二十)之Linux提权-计划任务提权 操作系统权限提升(二十一)之Linux提权-环境变量劫持提权 操作系统权限提升(二十二)之Linux提权-SUDO滥用提权 利用通配符…...

小说下载器终极指南:一站式解决100+网站小说保存难题
小说下载器终极指南:一站式解决100网站小说保存难题 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾因小说突然下架、网站404或网络中…...
:揭秘那个让虚拟世界“有重量感“的阴影魔法)
环境光遮蔽(Ambient Occlusion):揭秘那个让虚拟世界“有重量感“的阴影魔法
一、一个让我"开窍"的老木匠故事 我有个朋友是传统家具的修复师,他给我讲过一个让我至今难忘的故事。他说他刚入行时跟着一位 70 多岁的老木匠师父学习——师父让他做的第一件事不是雕花、不是榫卯——而是"看阴影"——这个看似奇怪的训练改变了…...
)
Claude端到端测试设计:从零搭建可审计、可回放、可量化的AI服务测试流水线(含开源Schema校验工具)
更多请点击: https://codechina.net 第一章:Claude端到端测试设计 端到端测试是验证Claude模型在真实用户交互链路中行为一致性的关键手段。它覆盖从原始提示输入、上下文管理、流式响应生成,到输出解析与业务校验的全路径,确保模…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...

树莓派工业GPIO接口板:电气隔离与电平转换实战指南
1. 项目概述:为什么需要一块工业级GPIO接口板?如果你用树莓派做过一些硬件项目,尤其是涉及到控制继电器、电机或者连接工业设备(比如PLC、变频器)时,大概率踩过这样的坑:直接用树莓派的GPIO引脚…...

量子机器学习与傅里叶分析:革新期权定价的混合计算范式
1. 项目概述:当量子机器学习遇见金融定价在金融工程的核心地带,期权定价一直是个计算密集型的硬骨头。传统的蒙特卡洛模拟虽然通用,但为了达到足够的精度,动辄需要百万甚至千万次的路径模拟,计算成本高昂。近年来&…...

别再把大模型当搜索框了:一文讲透 LLM 的基本原理、能力边界与局限性
写在前面很多人把大语言模型当成“会聊天的搜索引擎”,结果一上线就遇到幻觉、口径不稳、上下文丢失、成本失控。真正理解 LLM,要先抓住一句话:它是基于 Transformer 的概率生成模型,核心能力来自海量预训练、上下文学习与后训练对…...

昇腾NPU模型服务化——从离线模型到高可用推理服务
模型训练完只是第一步。真正产生业务价值的是把模型部署成724小时在线服务——毫秒级延迟、支持动态Batching、能扛住流量洪峰,且具备高可用性。 这篇将手把手教你基于昇腾NPU构建生产级模型推理服务,涵盖框架选型、服务化架构、动态Batching优化、热加载…...

基于STM32WL与LoRaWAN的远程空气质量监测系统全栈开发实践
1. 项目概述:构建一个远程空气质量监测系统最近在做一个挺有意思的玩意儿:一个能自己找地方待着、靠太阳能供电,然后把周围空气数据悄无声息传回来的远程监测终端。核心想法很简单,就是想知道某个犄角旮旯,比如工厂周边…...

基于Jetson Nano与JNEEG Shield的脑电信号采集与边缘AI处理实战
1. 项目概述:低成本脑机接口的硬件基石 如果你对脑机接口、生物信号处理或者边缘AI应用感兴趣,但又苦于专业设备动辄数万甚至数十万的高昂门槛,那么JNEEG Shield的出现,可能会为你打开一扇新的大门。这是一个专为NVIDIA Jetson Na…...