kafka3.6.0部署
部署zk
https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.9.1/apache-zookeeper-3.9.1.tar.gz
tar -xf apache-zookeeper-3.9.1.tar.gz -C /apps
cd /apps/ && ln -s apache-zookeeper-3.9.1 zookeeper
修改配置```bash
grep -vE '^$|^#' conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/apps/zookeeper/data
clientPort=2181
autopurge.snapRetainCount=3
autopurge.purgeInterval=24
server.1=192.168.1.60:2888:3888 #server.后面数字不要一样
server.2=192.168.1.61:2888:3888
server.3=192.168.1.62:2888:3888root@ubuntu20:/apps/zookeeper/bin# cat /etc/profile.d/zk.sh
#!/bin/bash
export PATH=/apps/zookeeper/bin/:$PATH
mkdir /data
root@ubuntu20:/apps/zookeeper# echo 3 > data/myid
拷贝到其他节点并修改myid
配置环境变量
root@ubuntu20:/apps/zookeeper/bin# source /etc/profile.d/zk.sh
scp /etc/profile.d/zk.sh 192.168.1.62:/etc/profile.d
scp /etc/profile.d/zk.sh 192.168.1.61:/etc/profile.d
source /etc/profile.d/zk.sh
启动zk
zkServer.sh start
查看状态
root@ubuntu20:/apps/zookeeper# zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /apps/zookeeper/bin/…/conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
访问zk
zkCli.sh -server 192.168.1.60:2181
部署kafka集群
192.168.1.60
192.168.1.61
192.168.1.62
下载解压
修改 配置文件root@ubuntu20:/apps/kafka/config# cat server.properties
broker.id=62 #每个节点不要一样
listeners=PLAINTEXT://192.168.1.62:9092 #监听的地址:配置为本机ip ,注意格式
zookeeper.connect=192.168.1.60:2181,192.168.1.61:2181,192.168.1.62:2181 #修改配置zk的地址所有节点配置环境变量
cat /etc/profile.d/kafka.sh
#!/bin/bash
export KAFKA_HOME=/apps/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile.d/kafka.sh
root@ubuntu20:/apps/kafka/config# scp /etc/profile.d/kafka.sh 192.168.1.62:/etc/profile.d/
启动
kafka-server-start.sh -daemon /apps/kafka/config/server.properties
查看端口
vi /lib/systemd/system/kafka.service
[Unit]
Description=Apache Kafka
After=network.target[Service]
Type=simple
#Environment=JAVA_HOME=/data/server/java
PIDFile=/apps/kafka/kafka.pid
ExecStart=/apps/kafka/bin/kafka-server-start.sh /apps/kafka/config/server.properties
ExecStop=/bin/kill -TERM ${MAINPID}
Restart=always
RestartSec=20[Install]
WantedBy=multi-user.target创建topic
root@ubuntu20:/apps/kafka/data# kafka-topics.sh --create --topic wang --bootstrap-server 192.168.1.60:9092 --partitions 3 --replication-factor 2
Created topic wang.
查看topic
kafka-topics.sh --bootstrap-server 192.168.1.60:9092 --list
查看topic详细信息
root@ubuntu20:/apps/kafka# kafka-topics.sh --bootstrap-server 192.168.1.60:9092 --topic luo --describe
Topic: luo TopicId: 3Gm_DopHQb-HgvLih6WuiQ PartitionCount: 1 ReplicationFactor: 1 Configs: Topic: luo Partition: 0 Leader: 60 Replicas: 60 Isr: 60root@ubuntu20:/apps/kafka# kafka-topics.sh --bootstrap-server 192.168.1.60:9092 --topic wang --describe
Topic: wang TopicId: eZ7lTktaQ1mVarYE-Q_K1A PartitionCount: 3 ReplicationFactor: 2 Configs: Topic: wang Partition: 0 Leader: 61 Replicas: 61,60 Isr: 61,60Topic: wang Partition: 1 Leader: 60 Replicas: 60,62 Isr: 60,62Topic: wang Partition: 2 Leader: 62 Replicas: 62,61 Isr: 62,61读写都在leader节点上
启动生产者
kafka-console-producer.sh --topic luo --bootstrap-server 192.168.1.60:9092
该命令的目的是启动一个 Kafka 生产者,将消息发送到 luo 主题,并使用 192.168.1.60:9092 作为 Kafka 集群的地址。
启动消费者 --from-beginning 从头开始拿数据
kafka-console-consumer.sh --topic luo --from-beginning --bootstrap-server 192.168.1.60:9092
修改分区数为5
kafka-topics.sh --bootstrap-server 192.168.1.60:9092 --topic wang --alter --partitions 5

删除topic
kafka-topics.sh --delete --bootstrap-server=192.168.1.60:9092 --topic test
kafka依赖zk提供元数据储存
分区:
副本:
kafka-producer-perf-test.sh --topic test --num-records 10000000 --throughput -1 --record-size 1024 --producer-props bootstrap.servers=192.168.1.60:9092 acks=-1 linger.ms=2000 compression.type=lz432532 records sent, 6499.9 records/sec (6.35 MB/sec), 1536.5 ms avg latency, 2338.0 ms max latency.
32532 records sent:发送了 32532 条消息。
6499.9 records/sec:平均每秒发送了 6499.9 条消息。
(6.35 MB/sec):发送速度为每秒 6.35 MB 的数据量。
1536.5 ms avg latency:平均延迟为 1536.5 毫秒,这表示从消息发送到确认接收所需的平均时间。
2338.0 ms max latency:最大延迟为 2338.0 毫秒,这表示消息发送到确认接收期间的最长时间。
消费者组案列
启动生产者
kafka-console-producer.sh --topic oldboy --broker-list 192.168.1.60:9092
基于配置文件启动消费者
root@kafka01:~# kafka-console-consumer.sh --bootstrap-server 192.168.1.60:9092 --topic oldboy --consumer.config /apps/kafka/config/consumer.properties
ll
.dd
基于命令行启动消费者
root@kafka01:~# kafka-console-consumer.sh --bootstrap-server 192.168.1.60:9092 --topic oldboy --consumer-property group.id=luohuiwen
上面的案例启动了1个生产者,2个消费者。但同一时刻只有一个消费者接收到生产者的消息,不可能2个消费者同时接收到生产者发送的消息哟~
kafka高效读写数据的底层原理:顺序写磁盘 零拷贝技术 异步刷盘
堆内存调整
root@kafka01:/apps/kafka/bin# grep export kafka-server-start.sh export KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:$base_dir/../config/log4j.properties"# export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" #修改此行就行# export KAFKA_HEAP_OPTS="-Xmx256M -Xms256M"export KAFKA_HEAP_OPTS="-server -Xmx256M -Xms256M -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads
=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
添加修改端口 这个是jmx的端口,后面的监控要用到

部署
安装数据库创建数据库授权
下载https://github.com/smartloli/kafka-eagle-bin/archive/v3.0.1.tar.gz
解压修改配置
efak.zk.cluster.alias=cluster1,cluster2
cluster1.zk.list=192.168.1.60:2181,192.168.1.61:2181,192.168.1.62:2181 #填写kafka地址efak.url=jdbc:mysql://127.0.0.1:3306/oldboyedu_kafka? useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull #oldboyedu_kafka 创建的数据库
efak.username=kafka #数据库授权用户
efak.password=123456
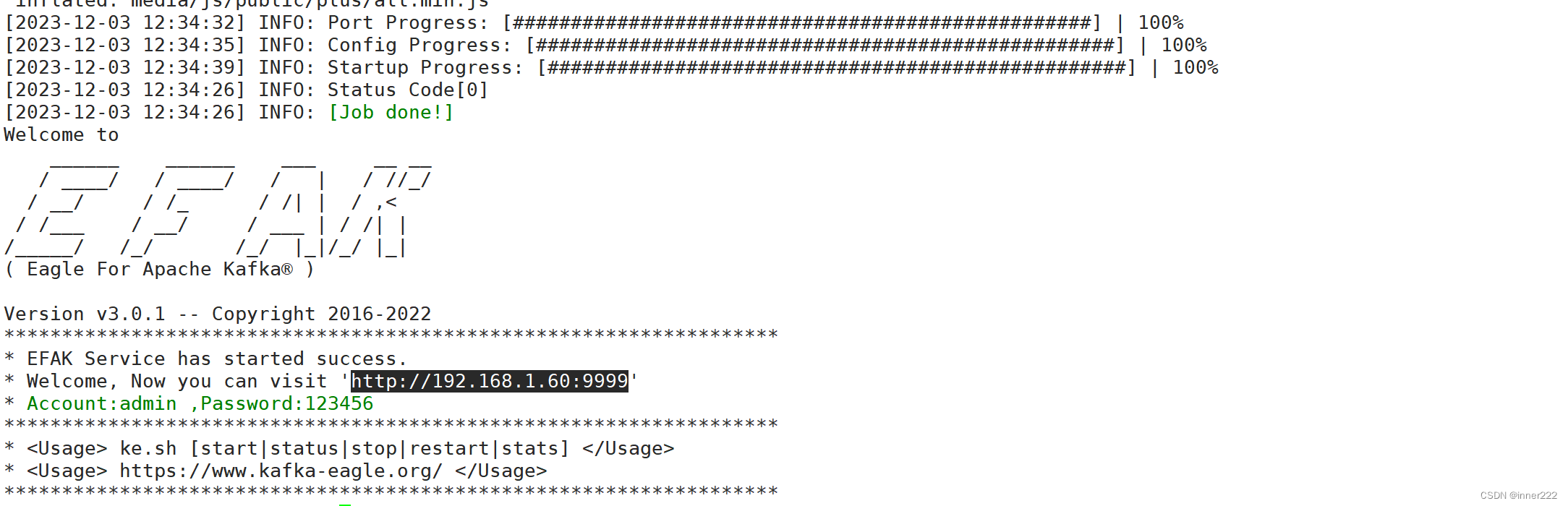
访问
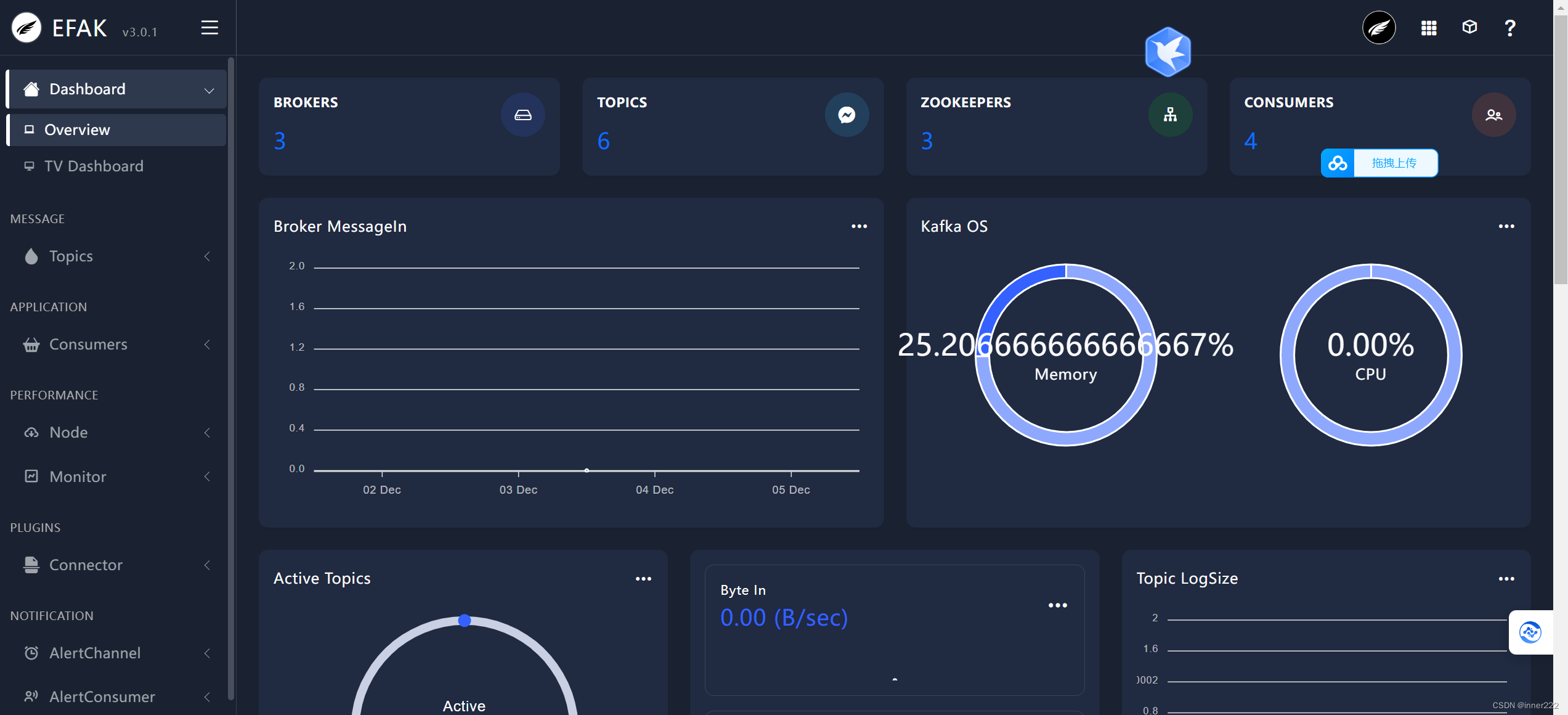
压力测试
kafka-consumer-perf-test.sh --broker-list 192.168.1.60:9092,192.168.1.61:9092,192.168.1.62:9092 --topic luohuiwen --messages 100000000 --fetch-size 1048576 --threads 10
告警
谁创建了topic就发生通知
调优
1.硬件架构选择
cpu:建议选择核心数多的优于主bi,
内存
磁盘
网卡
加大文件描述符
内核优化
export KAFKA_HEAP_OPTS="-server -Xmx256M -Xms256M -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads
=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="8888"
-server -Xmx256M
-Xms256M
-XX:PermSize=128m
-XX:+UseG1GC 表示让jvm使用G1垃圾收集器
-XX:MaxGCPauseMillis=200 设置每次年轻代垃圾回收的最长时间为200ms,如果时间无法满足,jvm会自动调整年轻代大小,以满足此值
-XX:ParallelGCThreads=8 设置并行垃圾回收的线程数,此值可以设置与机器处理数相等
-XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
该参数可以指定当整个堆使用率到达多少时,触发并标记周期的执行。默认值是45,即当堆的使用45%,执行并标记周期,该值一旦设置,始终不会被G1修改
broken调优
auto.create.topics.enable=false #是否允许自动创建topic
log.retention.hours=168 # 日志保留时间
相关文章:
kafka3.6.0部署
部署zk https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.9.1/apache-zookeeper-3.9.1.tar.gz tar -xf apache-zookeeper-3.9.1.tar.gz -C /apps cd /apps/ && ln -s apache-zookeeper-3.9.1 zookeeper 修改配置bash grep -vE ^$|^# conf/zo…...
,增强为真实批量插入)
MybatisPlus批量插入(伪批量),增强为真实批量插入
项目基于优秀开源项目:若依 项目背景:项目中牵扯到数据批量导入,为提高性能,先考虑将MybatisPlus伪批量插入增强为真实批量插入 MybatisPlus源码: MybatisPlus支持批量插入,但是跟踪源码发现底层是将批量…...

【零基础入门Python】Python If Else流程控制
✍面向读者:所有人 ✍所属专栏:零基础入门Pythonhttps://blog.csdn.net/arthas777/category_12455877.html Python if语句 Python if语句的流程图 Python if语句示例 Python If-Else Statement Python if else语句的流程图 使用Python if-else语句 …...

新手零基础学习彩铅画,彩铅快速入门教程合集
一、教程描述 画画是很美好的一件事情,你可以把你想到的,或者看到的都画下来,照相机可以拍下任何你看到的,但是你想到的任何事物,只能通过绘画的方式来表达。本套教程是非常不错的,彩铅的小视频教程&#…...

线程池的拒绝策略
文章目录 线程池的拒绝策略AbortPolicy拒绝策略:CallerRunsPolicy拒绝策略:DiscardOldestPolicy拒绝策略:DiscardPolicy拒绝策略: 线程池的拒绝策略 若在线程池当中的核心线程数已被用完且阻塞队列已排满,则此时线程池…...
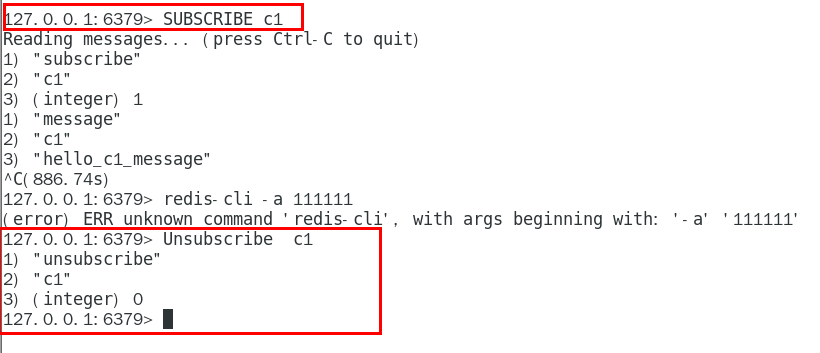
Redis7--基础篇5(管道、发布订阅)
管道是什么 管道(pipeline)可以一次性发送多条命令给服务端,服务端依次处理完完毕后,通过一条响应一次性将结果返回,通过减少客户端与redis的通信次数来实现降低往返延时时间。pipeline实现的原理是队列,先进先出特性就保证数据的…...
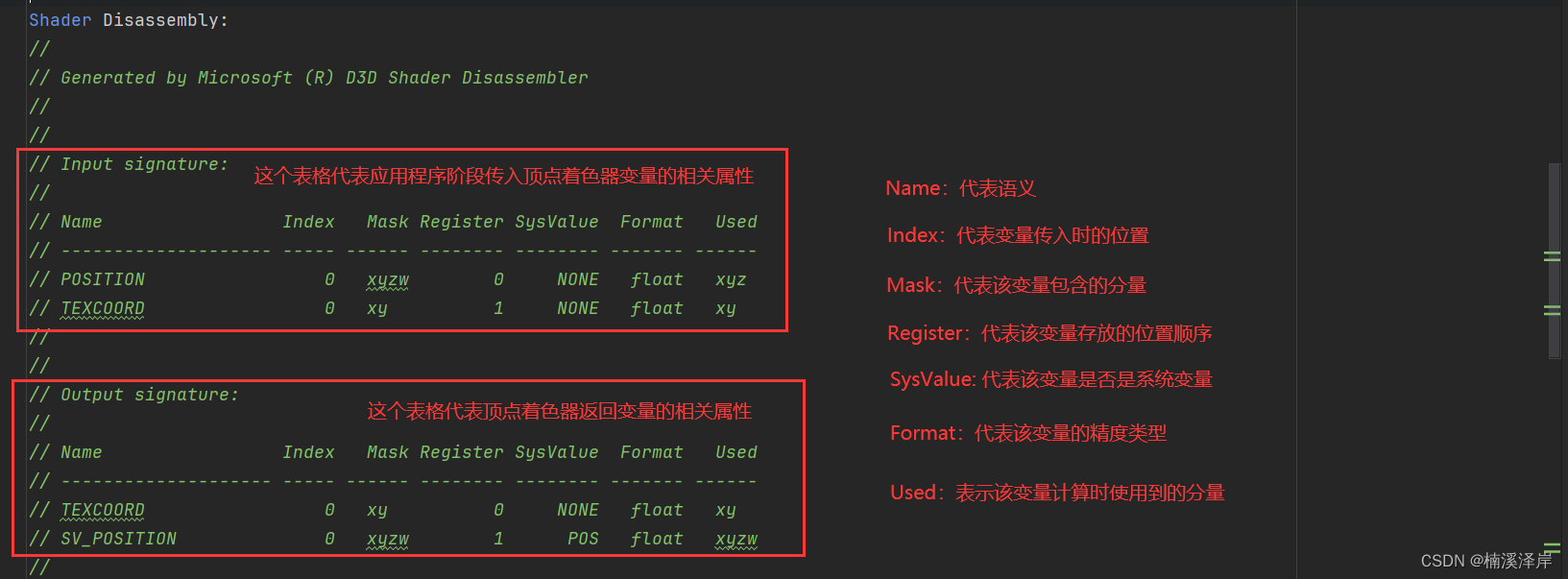
Unity中Shader指令优化(编译后指令解析)
文章目录 前言一、我们先创建一个简单的Shader二、编译这个Shader,并且打开1、编译后注意事项2、编译平台 和 编译指令数3、顶点着色器用到的信息4、顶点着色器计算的核心部分5、片元着色器用到的信息6、片元着色器核心部分 前言 我们先读懂Shader编译后代码&#…...
单个 Zip 文件体积超过 40GB
单个 Zip 文件体积超过 40GB WinRAR 平时用的多,不过有时候为了更好的通用性,也常常用到 zip 格式.查了一下资料,说是 zip 单个文件的体积不能超过 4GB. 自己动手试了下,用 WinRAR 创建出来的 zip 文件,大小可以超过 40GB, 如下图 为了压缩速度快,压缩方式用的是 “存储” Wi…...

pandas 基础操作3
数据删减 虽然我们可以通过数据选择方法从一个完整的数据集中拿到我们需要的数据,但有的时候直接删除不需要的数据更加简单直接。Pandas 中,以 .drop 开头的方法都与数据删减有关。 DataFrame.drop 可以直接去掉数据集中指定的列和行。一般在使用时&am…...
开发知识点-Maven包管理工具
Maven包管理工具 SpringBootSpringSecuritydubbo图书电商后台实战-环境设置(JDK8, STS, Maven, Spring IO, Springboot)点餐小程序Java版本的选择和maven仓库的配置视频管理系统&&使用maven-tomcat7插件运行web工程SpringTool suite——maven项目…...

104. 二叉树的最大深度
104. 二叉树的最大深度 /*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val val; }* TreeNode(int val, TreeNode left, TreeNode right…...

JAVA毕业设计113—基于Java+Springboot+Vue的体育馆预约系统(源代码+数据库+12000字论文)
基于JavaSpringbootVue的体育馆预约系统(源代码数据库12000字论文)113 一、系统介绍 本项目前后端分离,本系统分为管理员、用户两种角色 用户角色包含以下功能: 注册、登录、场地(查看/预订/收藏/退订)、在线论坛、公告查看、我的预订管理、我的收藏…...
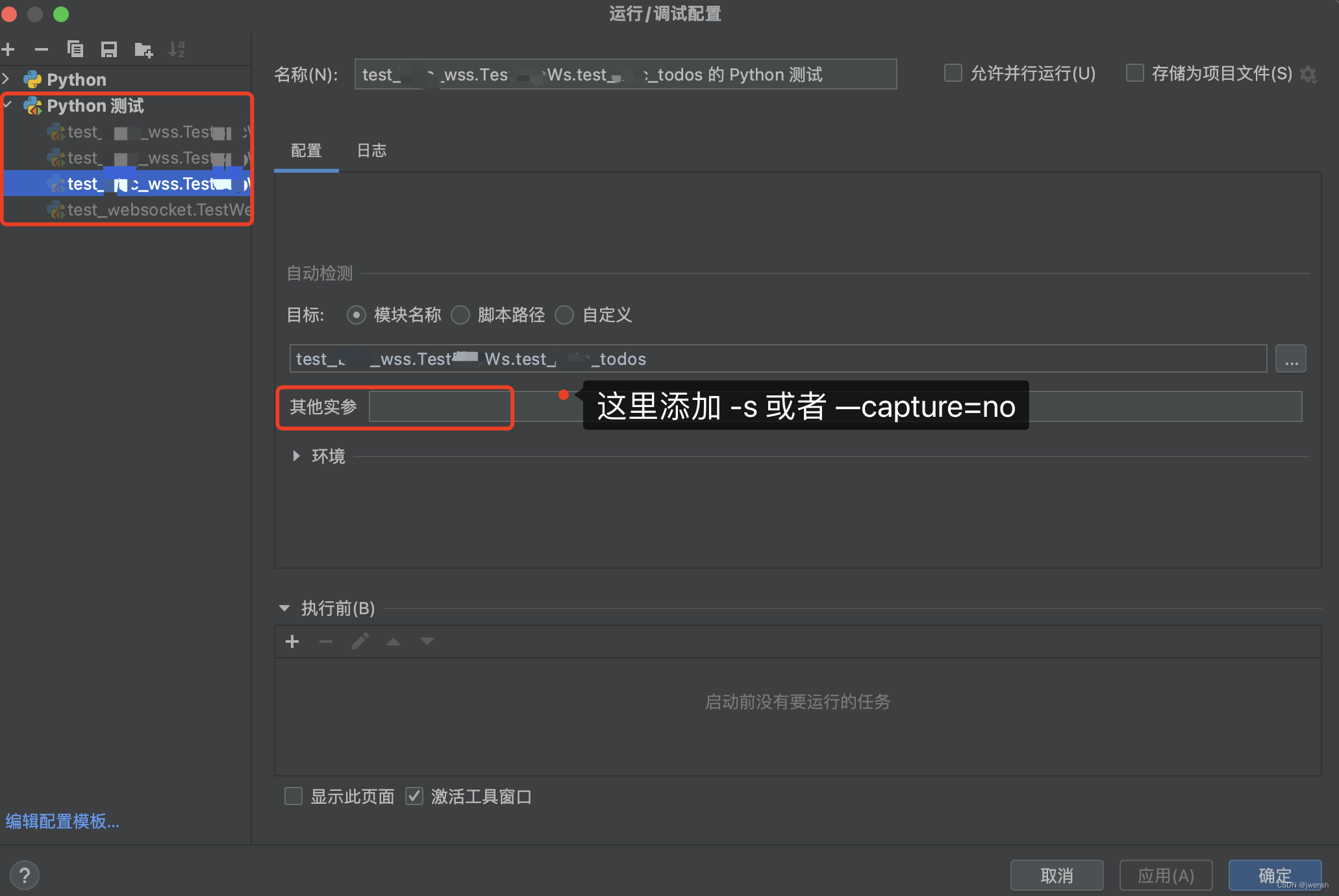
【自动化测试】pytest 用例执行中print日志实时输出
author: jwensh date: 20231130 pycharm 中 pytest 用例执行中 print 日志 standout 实时命令行输出 使用场景 在进行 websocket 接口进行测试的时候,希望有一个 case 是一直执行并接受接口返回的数据 def on_message(ws, message):message json.loads(message)…...

【深度学习】KMeans中自动K值的确认方法
1 前言 聚类常用于数据探索或挖掘前期,在没有做先验经验的背景下做的探索性分析,也适用于样本量较大情况下的数据预处理等方面工作。例如针对企业整体用户特征,在未得到相关知识或经验之前先根据数据本身特点进行用户分群,然后再…...

github问题解决(持续更新中)
1、ssh: connect to host github.com port 22: Connection refused 从.ssh文件夹中新建文件名为config,内容为: Host github.com Hostname ssh.github.com Port 4432、解决 git 多用户提交切换问题 使用系统命令ssh创建rsa公私秘钥 C:\Users\fyp01&g…...
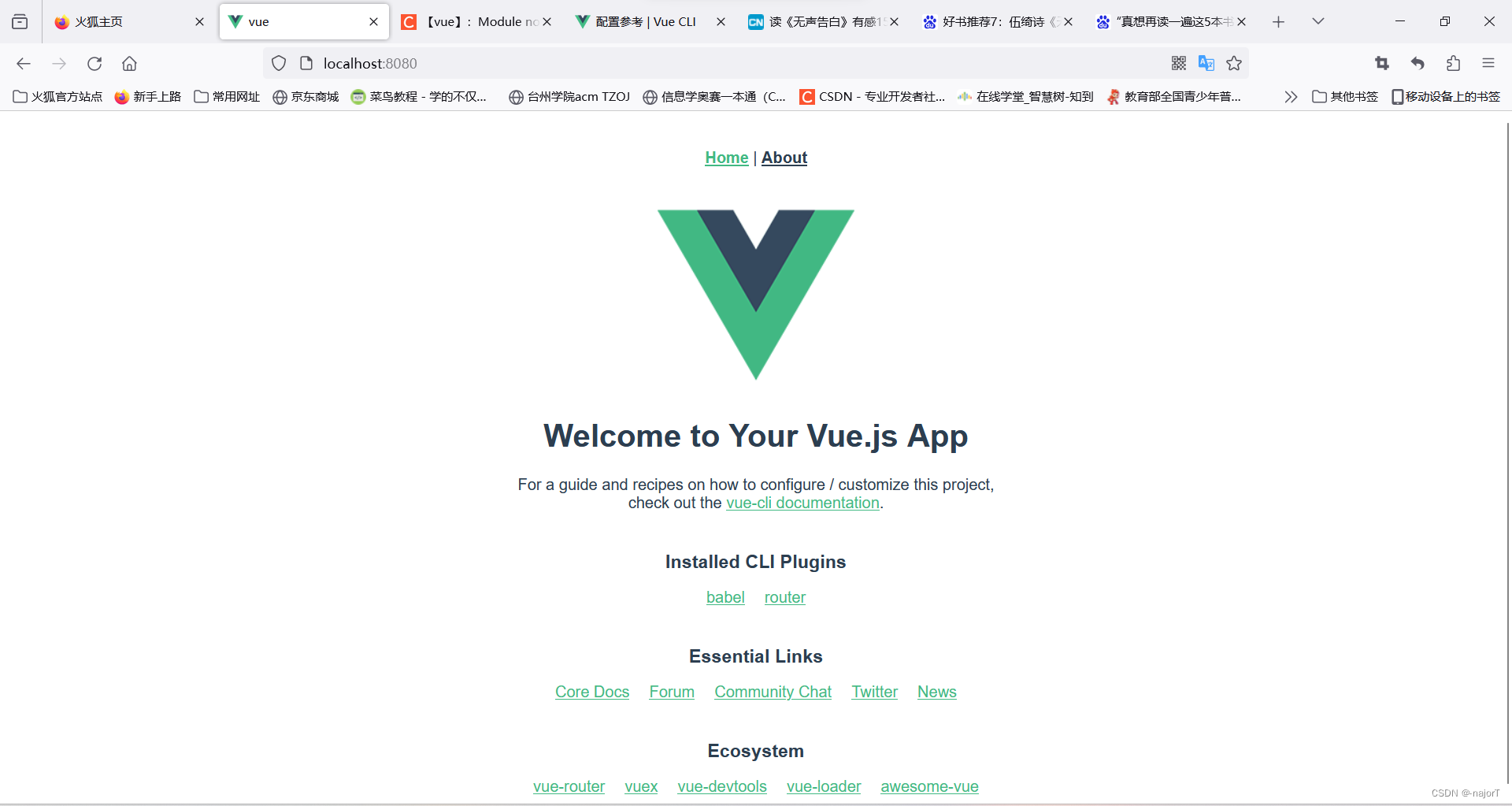
如何创建一个vue工程
1.打开vue安装网址:安装 | Vue CLI (vuejs.org) 2.创建一个项目文件夹 3.复制地址 4.打开cmd,进入这个地址 5.复制粘贴vue网页的安装命令 npm install -g vue/cli 6.创建vue工程 vue create vue这里可以通过上下键来进行选择。选最后一个选项按回车。 …...
50 代码审计-PHP无框架项目SQL注入挖掘技巧
目录 演示案例:简易SQL注入代码段分析挖掘思路QQ业务图标点亮系统挖掘-数据库监控追踪74CMS人才招聘系统挖掘-2次注入应用功能(自带转义)苹果CMS影视建站系统挖掘-数据库监控追踪(自带过滤) 技巧分析:总结: demo段指的是代码段,先…...

基于Spring、SpringMVC、MyBatis的企业博客网站
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于Spring、SpringMVC、MyBatis的企业博…...
spring日志输出到elasticsearch
1.maven <!--日志elasticsearch--><dependency><groupId>com.agido</groupId><artifactId>logback-elasticsearch-appender</artifactId><version>3.0.8</version></dependency><dependency><groupId>net.l…...

谷歌 Gemini 模型发布计划推迟:无法可靠处理部分非英语沟通
本心、输入输出、结果 文章目录 谷歌 Gemini 模型发布计划推迟:无法可靠处理部分非英语沟通前言由谷歌 CEO 桑达尔・皮查伊做出决策从一开始,Gemini 的目标就是多模态、高效集成工具、API花有重开日,人无再少年实践是检验真理的唯一标准 谷歌…...

从DeepFM源码到业务落地:Normalized Gini Coefficient在CTR预估中的实战调优指南
从DeepFM源码到业务落地:Normalized Gini Coefficient在CTR预估中的实战调优指南 当你在TensorFlow-DeepFM的源码中第一次看到Normalized Gini Coefficient这个评估指标时,是否和我一样产生过疑惑——为什么不用常见的AUC或LogLoss?这个问题困…...

Axmol 2.11.0 LTS发布:聚焦稳定性与开发者体验的跨平台引擎升级
1. Axmol 2.11.0 LTS版本的核心价值 对于跨平台游戏开发者来说,选择一个稳定可靠的引擎版本往往比追求新功能更重要。Axmol 2.11.0作为长期支持(LTS)版本,正是瞄准了这个核心需求。我在实际项目中使用过多个版本的Axmol引擎&#…...

Trae智能体实战:手把手教你搭建一个会写技术博客的刷题助手
Trae智能体实战:手把手教你搭建一个会写技术博客的刷题助手 在技术社区持续输出高质量内容,已经成为开发者建立个人品牌的重要方式。但很多程序员面临一个现实困境:刷题已经耗费大量精力,哪还有时间整理解题思路并写成技术博客&am…...

Unity Mod加载效率提升解决方案:MelonLoader从安装到精通的全方位指南
Unity Mod加载效率提升解决方案:MelonLoader从安装到精通的全方位指南 【免费下载链接】MelonLoader The Worlds First Universal Mod Loader for Unity Games compatible with both Il2Cpp and Mono 项目地址: https://gitcode.com/gh_mirrors/me/MelonLoader …...

OpenTSDB查询语言完全指南:从基础查询到高级聚合操作
OpenTSDB查询语言完全指南:从基础查询到高级聚合操作 【免费下载链接】opentsdb A scalable, distributed Time Series Database. 项目地址: https://gitcode.com/gh_mirrors/op/opentsdb OpenTSDB是一个可扩展的分布式时间序列数据库,专为处理大…...

SecGPT-14B应用场景:DevSecOps流水线中嵌入安全问答节点实现CI/CD风险拦截
SecGPT-14B应用场景:DevSecOps流水线中嵌入安全问答节点实现CI/CD风险拦截 1. 安全自动化新范式 现代软件开发流程中,安全防护往往成为效率的"绊脚石"。传统安全审查需要人工介入,导致CI/CD流水线频繁中断。SecGPT-14B的出现为这…...
)
DeepSeek LeetCode 1425.带限制的子序列和 public int constrainedSubsetSum(int[] nums, int k)
以下是 LeetCode 1425「带限制的子序列和」的 Java 解法,使用动态规划 单调队列实现,时间复杂度 O(n),空间复杂度 O(n)。java public int constrainedSubsetSum(int[] nums, int k) {int n nums.length;int[] dp new int[n]; // …...

OFA-VE效果集:天文星图与观测记录文本逻辑一致性AI核查
OFA-VE效果集:天文星图与观测记录文本逻辑一致性AI核查 1. 引言:当AI遇见星空 想象一下,你是一位天文爱好者,或者是一位科研工作者。你手头有一张刚刚拍摄的深空星图,旁边还附带着一段观测记录的文字描述。你可能会问…...

别死记硬背DP了!用‘斐波那契数列’和‘兔子繁殖’故事,真正理解重叠子问题与最优子结构
从兔子繁殖到算法竞赛:用生活故事拆解动态规划的核心思想 第一次接触动态规划(DP)时,很多人的反应都是"这太抽象了"。教科书上充斥着"最优子结构"、"重叠子问题"等专业术语,让人望而生畏…...

Adaptive Wing Loss在热力图回归中的优化策略与实践
1. 热力图回归与Adaptive Wing Loss基础认知 第一次接触热力图回归这个概念时,我盯着屏幕上的高斯分布图发了半小时呆。这种用"软标注"替代硬坐标的方法,就像是用毛笔代替钢笔作画——不再追求像素级的绝对精确,而是通过模糊的色块…...