C++ 系列 第四篇 C++ 数据类型上篇—基本类型
系列文章
C++ 系列 前篇 为什么学习C++ 及学习计划-CSDN博客
C++ 系列 第一篇 开发环境搭建(WSL 方向)-CSDN博客
C++ 系列 第二篇 你真的了解C++吗?本篇带你走进C++的世界-CSDN博客
C++ 系列 第三篇 C++程序的基本结构-CSDN博客
前言
面向对象编程(OOP)的本质就是设计并扩展自己的数据类型。设计自己的数据类型就是让类型与数据匹配。如果正确做到了这一点,将会发现以后使用数据时会容易得多。然而,在创建自己的类型之前,必须了解并理解 C++内置的类型,因为这些类型是创建自己类型的基本组件。
内置的 C++类型分两组:基本类型和复合类型。本章将介绍基本类型,即整数和浮点数。基础类型只有两种类型,但 C++知道,没有任何一种整型和浮点型能够满足所有的编程要求,因此对于这两种数据,它提供了多种变体,本章会分别进行介绍。而复合类型,包括数组、字符串、指针和结构,我们会在后续讲到。
整形
一句话概括:整型(Integer)是一种数据类型,用于表示整数值。
我们都知道整数是没有小数部分的数字,如 1、100、-100 和 0。整数有很多,如果将无限大的整数看作很大,则不可能用有限的计算机内存来表示所有的整数。因此,程序语言中的整形类型也只能是表示所有整数的子集,即部分整数范围,C++基本延续了C的类型设计, 提供好几种整数类型,这样使用者能够根据程序的具体要求选择最合适的整型。
不同整型使用不同的内存量来存储整数。使用的内存量越大,可以表示的整数值范围也越大。另外,有的类型(符号类型)可表示正值和负值,而有的类型(无符号类型)不能表示负值。
C++的基本整型(按宽度递增的顺序排列)分别是char、short、int、long 和C++11 新增的 long long,其中每种类型都有符号版本和无符号版本,因此总共有 10 种类型可供选择。
1、整型宽度
不同系统上,同样的整形类型表达范围可能不一样,比如同样都是int, 有的系统 表示范围 只有-2^15 到 2^15 - 1(2字节宽度), 而有的系统表示范围-2^31到 2^31 - 1 (4字节宽度)。但是对整形类型 有 统一的最小约束:
1)short 至少 16 位
2)int 至少与 short 一样长
3)long 至少 32 位,且至少与 int 一样长
4) long long 至少 64 位,且至少与 long 一样长
2、整型宽度计算
同C 一样,C++ 中也可以 使用sizeof 获取 类型 或 类型定义的变量(如 int a,a就是一个变量)的宽度,语法同C 中也完全一样, 可以 “sizeof(类型)” 或者 “sizeof 变量” 或者 “sizeof(变量)”。
但是有一个需要注意的是,sizeof 出来的是 “字节”的个数,不同系统可能 表达字节 宽度(有多少位)也不一样,比如有的用16位表示一个字节,有的用8位表示一个字节。不过这些基本不用关心,起码这么多年我是没碰到过,现代大部分的系统还是8位字节表示法。
3、整形类型选择
C++提供了这么多整型类型,应使用哪种类型呢? 通常,int 被设置为对目标计算机而言最为“自然”的长度。自然长度(naturalsize)指的是计算机处理起来效率最高的长度。如果没有非常有说服力的理由来选择其他类型,则应使用int。现在来看看可能使用其他类型的原因。
1)如果变量表示的值不可能为负,如文档中的字数,则可以使用无符号类型,这样变量可以表示更大的值,并且含义更准确。
2)如果出于节省内存的考虑,并且所要存储的数据,使用short 或者 无符号的short 可以支撑,那就选择short 。以经验来看,只有大型整型数组时,才有必要考虑更小尺寸的整型类型。
4、整型的字面值
整型字面值(常量)是显式地书写的常量,如 100 或 1000。与 C 相同,C++能够以三种不同的计数方式来书写整数:基数为10 (int a = 10)、基数为8(int a = 012)和基数为16(int a = 0x0A)。C++使用前一(两)位来标识数字常量的基数。如果第一位为1~9,则基数为 10(十进制);所以10是以 10 为基数的。如果第一位是 0,第二位为 1~7,则基数为 8(八进制) ;因此 012 的基数是8,它相当于十进制数10。如果前两位为0x或0X,则基数为16(十六进制);因此0x0A的计数是16,它相当于十进制数10。
5、如何确定整型常量的类型
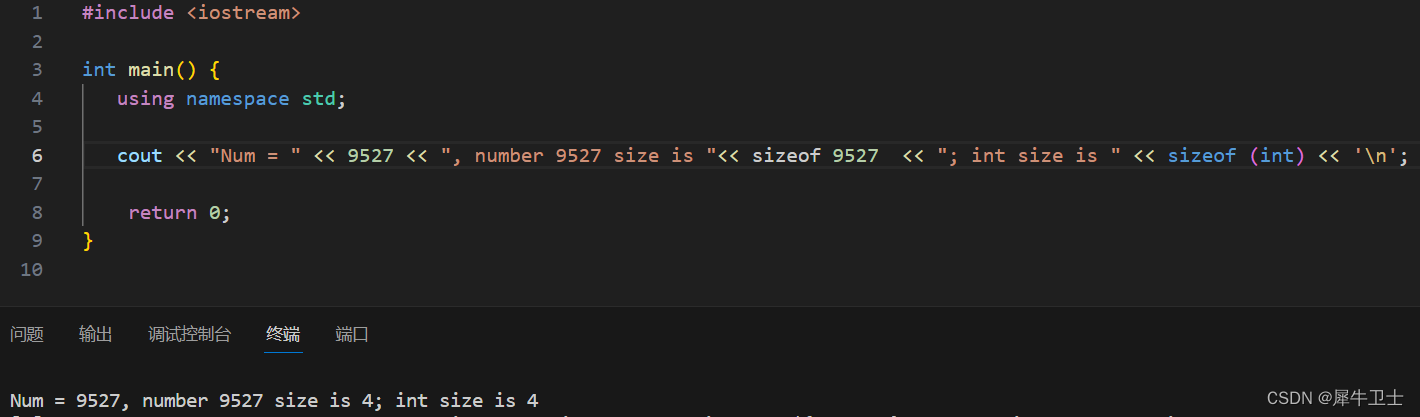
cout << "Num = " << 9527<< '\n' ; 该程序将把 9527 存储为 int、long 还是其他整型呢?
答案是,如下执行结果所示,除非有理由存储为其他类型(如使用了特殊的后缀来表示特定的类型,或者值太大,不能存储为 int),否则 C++将整型常量存储为int类型。
后缀是放在数字常量后面的字母,用于表示类型。整数后面的 l 或 L 后缀表示该整数为 long 常量,u或U后缀表示unsigned int 常量,ul(可以采用任何一种顺序,大写小写均可)表示unsigned long 常量(由于小写L 看上去像1,因此应使用大写 L 作后缀),C++11 引入了 long long ,所以可以有 LL 、ll 、ULL、ull 的后缀。
各位要是有 C 编程经验的,是否碰到过 " long变量 & 1 << 33 " 结果不正确的时候 ,正确写法应该是 " long变量 & 1UL << 33 ",这里就不展开叙述了。
6、特殊类型 char
顾名思义,char 类型是专为存储字符(如字母和数字)而设计的。现在,存储数字对于计算机来说算不了什么,但存储字母则是另一回事。编程语言通过使用字母的数值编码解决了这个问题。因此,char 类型是另一种整型。它足够长,能够表示目标计算机系统中的所有基本符号--所有的字母、数字、标点符号等。实际上,很多系统支持的字符都不超过 128 个,因此用一个字节就可以表示所有的符号。虽然char 最常被用来处理字符,但也可以将它用做比 short更小的整型。
C++ char 的一些注意点
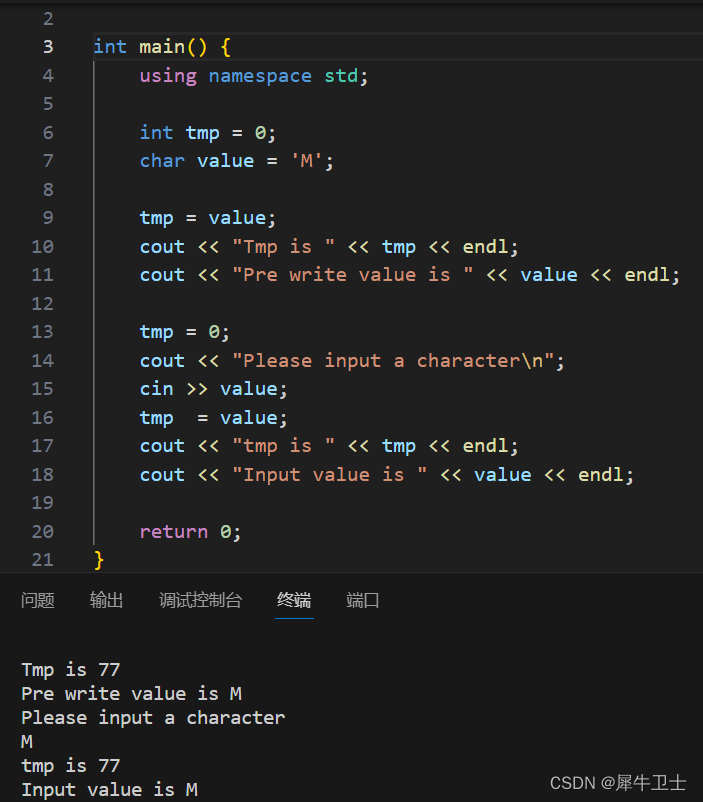
1)不管什么类型其实在计算器内存里存储的都是数值,char vlaue = 'M' 只是让使用代码的人便于理解、查看代码
2)使用C++的库iostream 输入输出字符 ,该库会自动识别数据类型转换输入和输出,C语言则靠格式占位符如 "printf("%d\n", ch);" 来决定是输出字符 字面值 还是字符的值。
如下小示例,可以看到 value 初始化成了字符'M',直接打印输出为'M', 但其实把该字符变量值 赋值给一个int 类型变量,输出int 类型的就是对应的ascii 码值;同理使用cin 输入一个字符'M', 然后再输出,还是'M',但是赋值给int 类型变量后,直接输出 int 类型变量,输出就是值了,这个小代码充分说明了C++ 的iostream 对象中的 cout 、cin 等方法是会根据变量类型进行自动格式化输出的
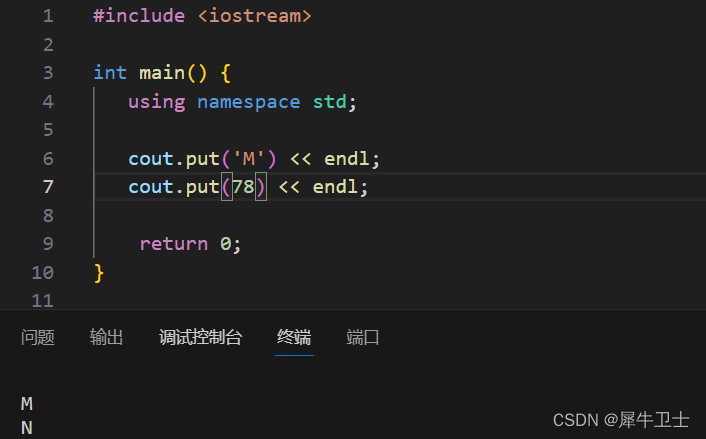
3)字符输出除了使用cout外, 还可以使用cout.put('M'); 或者cout.put(78); 方式进行输出,但是注意该方式只能输出字符,不能输出字符串。 C 语言中也有对应的函数,如 putc() 函数。
4)同C语言一样,如果碰到不可打印的字符,则使用转义,如换行符'\n'。转义符同正常字符一样的使用方式,如果是单独输出一个转义符,使用单引号进行包含,如果再字符串里同其他字符一起被输出,则被双引号包含。
5)C++有基本的源字符集,即可用来编写源代码的字符集。它由标准美国键盘上的字符(大写和小写)和数字、C 语言中使用的符号(如{和=}以及其他一些字符(如换行符和空格)组成。还有一个基本的执行字符集,它包括在程序执行期间可处理的字符(如可从文件中读取或显示到屏幕上的字符)。它增加了一些字符,如退格和振铃。
C++标准还允许实现提供扩展源字符集和扩展执行字符集。C++有一种表示这种特殊字符的机制,它独立于任何特定的键盘,使用的是通用字符名(universal character name)。通用字符名的用法类似于转义序列。通用字符名可以以\u 或\U 打头。\u 后面是 4 个字符(如\u0001),\U后面则是 8 个字符(如\U00000001)。这些字符表示的是字符的ISO 10646 码点,这个知道有这么回事就行,后续用到了再细了解即可。
6)char 的符号特性,与int不同的是,char 在默认情况下既不是没有符号,也不是有符号。是否有符号由编译器实现决定,这样编译器开发人员可以最大限度的将这种类型与硬件属性匹配起来。如果char有某种特定的行为对开发来说非常重要,则可以显示的设置为signed char 或者 unsigned char。单现代大部分编译器char 就是无符号型的。
7)wchar_t
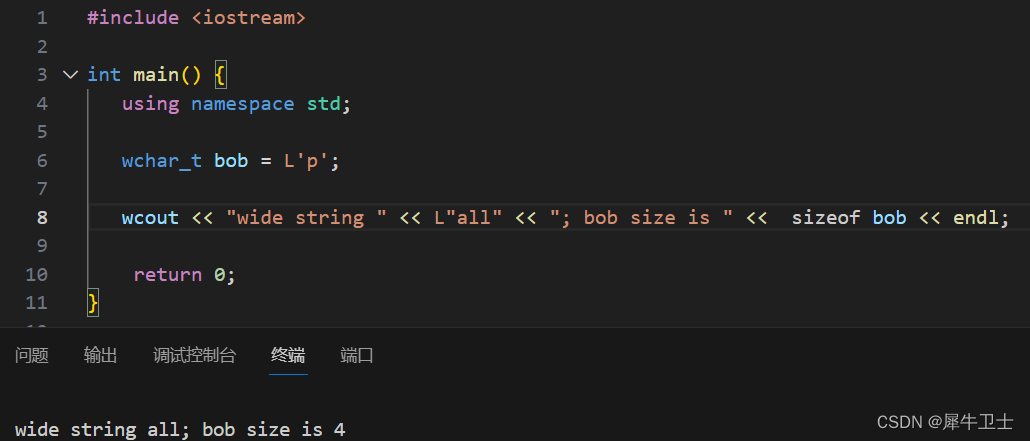
程序需要处理的字符集可能无法用一个 8 位的字节表示,如日文汉字系统。对于这种情况,C++的处理方式有两种。首先,如果大型字符集是实现的基本字符集,则编译器厂商可以将char定义为一个16位的字节或更长的字节。其次,一种实现可以同时支持一个小型基本字符集和一个较大的扩展字符集。8 位char 可以表示基本字符集,另一种类型wchart(宽字符类型)可以表示扩展字符集。wchar_t 类型是一种整数类型,它有足够的空间,可以表示系统使用的最大扩展字符集。这种类型与另一种整型(底层类型)的长度和符号属性相同。对底层类型的选择取决于实现,因此在一个系统中,它可能是unsigned short,而在另一个系统中,则可能是int。cin 和 cout 将输入和输出看作是char 流,因此不适于用来处理 wchar_t 类型。iostream 头文件的最新版本提供了作用相似的工具--wcin 和 wcout,可用于处理 wchar_t 流。
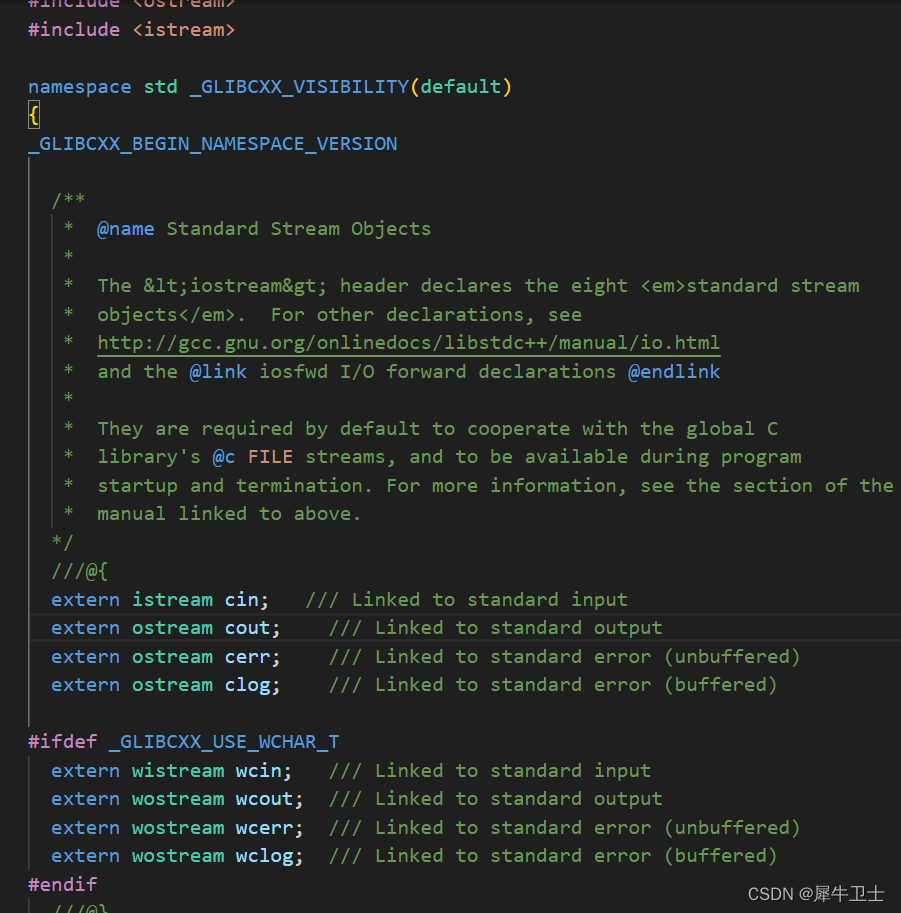
另外,可以通过加上前缀 L 来指示宽字符常量和宽字符串。 如下可以看到在我的环境宽字符是int型的。
8)char16_t 和char32_t
C++11 新增了这两种类型,随着编程人员日益熟悉 Unicode,类型wchar_t 显然不再能够满足需求。事实上,在计算机系统上进行字符和字符串编码时,仅使用 Unicode 码点并不够。具体地说,进行字符串编码时,如果有特定长度和符号特征的类型,将很有帮助,而类型wchar_t的长度和符号特征随实现而已。因此,C++11新增了类型char16_t和char32_t,其中前者是无符号的,长 16 位,而后者也是无符号的,但长 32 位。
C++11 使用前缀u表示char16_t 字符常量和字符串常量,如u'C'和u"be good";并使用前缀U表示char32_t常量,如 U'R'和U"dirtyrat"。类型char16_t 与/u00F6 形式的通用字符名匹配,而类型char32_t 与/U0000222B 形式的通用字符名匹配。与wchar_t 一样,char16_t 和 char32_t 也都有底层类型-一种内置的整型,但底层类型是随系统的。
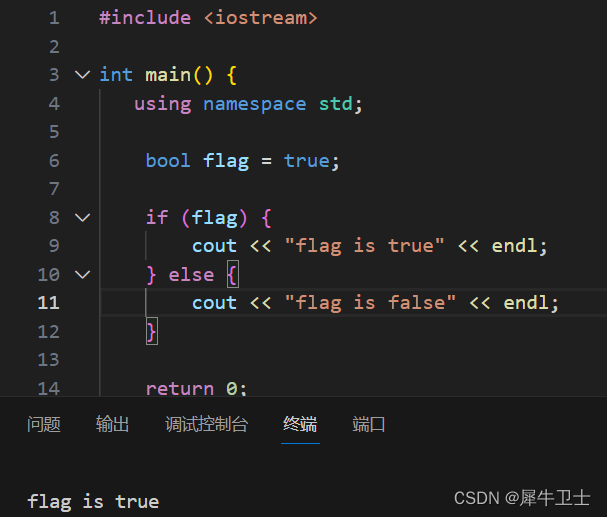
7、bool 类型
C++ 和 C 语言将非零值解释为 true,将零解释为 false。可以使用bool类型来表示真和假,它们分别用预定义的字面值true 和false表示 。
浮点数
浮点数是 C++的第二组基本类型。浮点数能够表示带小数部分的数字,如 521.1314,它们提供的值范围也更大,如果数字很大,无法表示为 long类型,如人体的细菌数(估计超过100兆),则可以使用浮点类型来表示。
计算机将诸如1314.521 这样的浮点数分成两部分存储。一部分表示值,另一部分用于对值进行放大或缩小。下面打个比方。对于数字34.1245 和34124.5,它们除了小数点的位置不同外,其他都是相同的。可以把第一个数表示为0.341245(基准值)和100(缩放因子),而将第二个数表示为0.341245(基准值相同)和 10000(缩放因子更大)。缩放因子的作用是移动小数点的位置,术语浮点因此而得名。C++内部表示浮点数的方法与此相同,只不过它基于的是二进制数,因此缩放因子是2 的幂,不是 10 的幂。
浮点数的书写格式
C++有两种书写浮点数的方式。
第一种是使用常用的标准小数点表示法:12.34 。
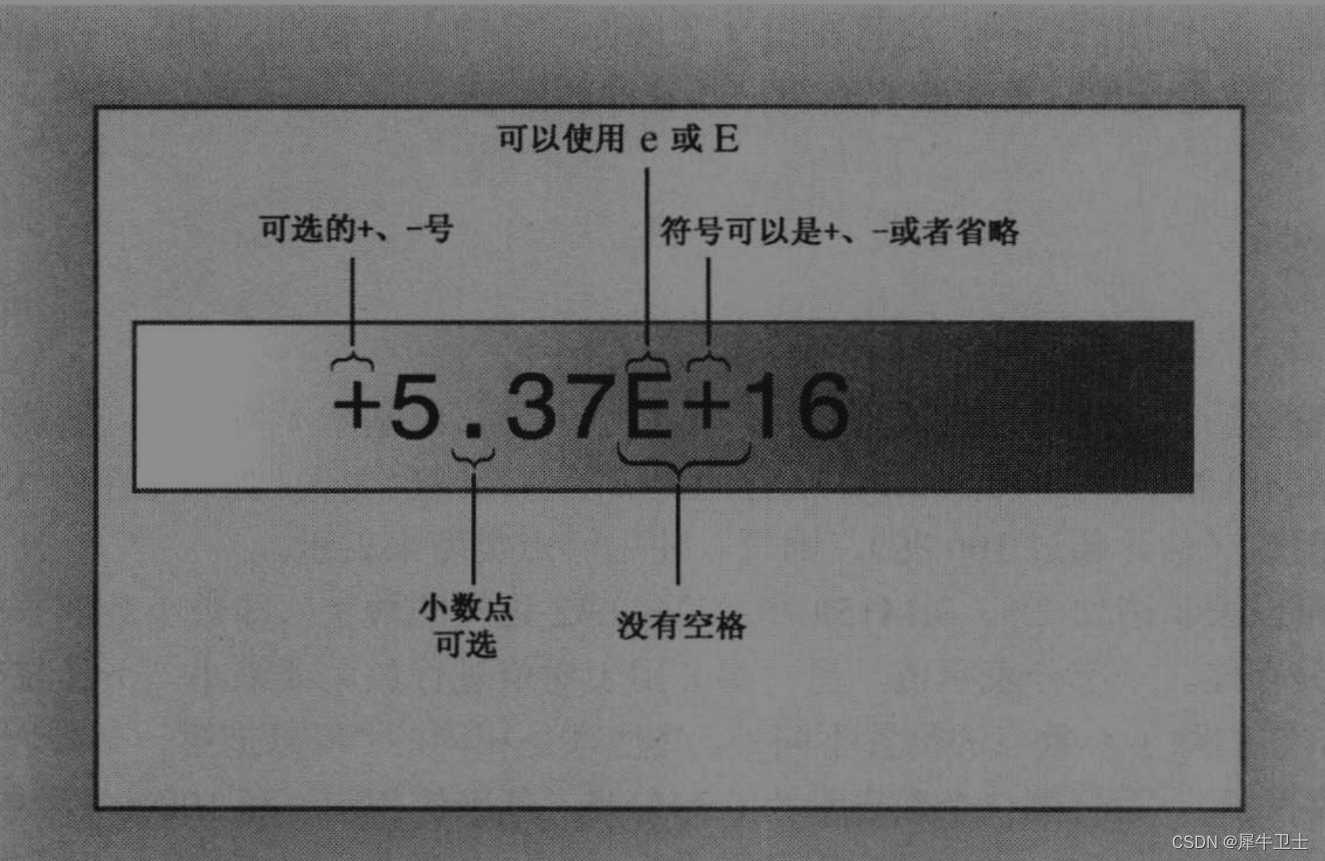
第二种表示浮点值的方法叫E表示法,其外观是像这样的:3.45E6,这指的是3.45 与 1000000 相乘的结果;E6 指的是 10 的 6 次方,即 1 后面 6 个 0。因此,3.45E6 表示的是 3450000,6 被称为指数,3.45被称为尾数。
E表示法最适合于非常大和非常小的数。E 表示法确保数字以浮点格式存储,即使没有小数点。注意,既可以使用 E 也可以使用e,指数可以是正数也可以是负数 。
浮点类型
和ANSI C 一样,C++也有 3 种浮点类型:float、double 和 long double。
这些类型是按它们可以表示的有效数位和允许的指数最小范围来描述的。有效位是数字中有意义的位。例如,山脉的高度为14179 英尺,该数字使用了 5 个有效位,指出了最接近的英尺数。然而,将Shasta 山脉的高度写成约14000 英尺时,有效位数为2 位,因为结果经过四舍五入精确到了千位。在这种情况下,其余的3位只不过是占位符而已。有效位数不依赖于小数点的位置。例如,可以将高度写成14.162千英尺。这样仍有 5个有效位,因为这个值精确到了第 5位。
事实上,C和C++对于有效位数的要求是,float 至少 32 位,double 至少48位,且不少于float,long double至少和 double 一样多。这三种类型的有效位数可以一样多。然而,通常,float 为 32 位 (4个8位字节),double 为 64 位,long double 为 80、96 或128 位。另外,这 3 种类型的指数范围至少是-37到37.可以从头文件cfloat 或 float.h中找到系统的限制。(cfloat 是 C 语言的float.h 文件的C++版本。)

浮点常量
在程序中书写浮点常量的时候,程序将把它存储为哪种浮点类型呢?在默认情况下,像8.24 和2.4E8这样的浮点常量都属于double 类型。如果希望常量为float 类型,请使用f或F后缀。对于 long double 类型,可使用l或 L 后缀(由于l看起来像数字1,因此 L 是更好的选择)。
浮点数优缺点
与整数相比,浮点数有两大优点。首先,它们可以表示整数之间的值。其次,由于有缩放因子,它们可以表示的范围大得多。
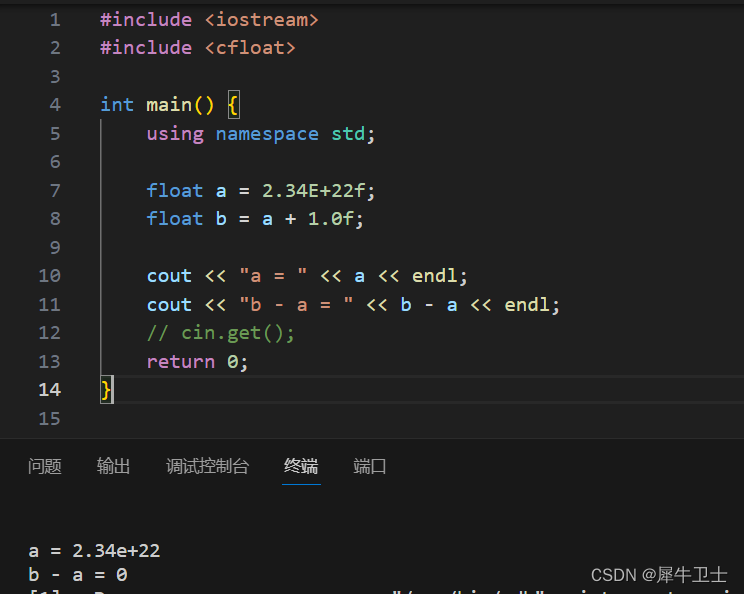
缺点是浮点运算的速度通常比整数运算慢,且精度将降低 ,如下就是一个精度降低的例子。该程序将数字加1,然后减去原来的数字。结果应该为 1。但结果是0,问题在于,2.34E+22 是一个小数点左边有 23 位的数字。加上1,就是在第23 位加 1。但float 类型只能表示数字中的前 6 位或前 7 位,因此修改第 23位对这个值不会有任何影响。
扩展小知识: 6位或者7位 是怎么来的呢?
浮点数的表示方式是使用 32 位(4 字节)来存储。其中,1 位用于表示符号位,8 位用于表示指数部分,剩下的 23 位用于表示尾数部分。有效数字是指一个数中能够表达出来并且对结果有影响的数字的个数。在浮点数表示中,尾数部分有 23 位,意味着可以表示的尾数的精度为 23 位。(2的23次方 是8388608,十进制的7位 )
总结:
C++的基本类型分为两组:一组由存储为整数的值组成,另一组由存储为浮点格式的值组成。
整型之间通过存储值时使用的内存量及有无符号来区分。
整型从最小到最大依次是:bool、char、signed charunsigned char、short、unsigned short、int、unsigned intlong、unsigned long 以及C++11新增的long long和unsigned long long。还有一种 wchar_t 类型,它在这个序列中的位置取决于实现。C++11 新增了类型char16_t 和char32_t,它们的宽度足以分别存储16 和 32 位的字符编码。
C++确保了 char 足够大,能够存储系统基本字符集中的任何成员,而wchar_t 则可以存储系统扩展字符集中的任意成员,short 至少为 16位,而 int 至少与 short 一样长,long 至少为 32 位,且至少和 int 一样长。确切的长度取决于实现。字符通过其数值编码来表示。I/O系统决定了编码是被解释为字符还是数字。
浮点类型可以表示小数值以及比整型能够表示的值大得多的值。3 种浮点类型分别是 float、double 和long double.C++确保 float 不比 double 长,而 double 不比 long double 长。通常,float 使用 32 位内存,double使用64 位,long double 使用80到128 位。
通过提供各种长度不同、有符号或无符号的类型,C++使程序员能够根据特定的数据要求选择合适的类型。
相关文章:
C++ 系列 第四篇 C++ 数据类型上篇—基本类型
系列文章 C 系列 前篇 为什么学习C 及学习计划-CSDN博客 C 系列 第一篇 开发环境搭建(WSL 方向)-CSDN博客 C 系列 第二篇 你真的了解C吗?本篇带你走进C的世界-CSDN博客 C 系列 第三篇 C程序的基本结构-CSDN博客 前言 面向对象编程(OOP)的…...
C++ 指针详解
目录 一、指针概述 指针的定义 指针的大小 指针的解引用 野指针 指针未初始化 指针越界访问 指针运算 二级指针 指针与数组 二、字符指针 三、指针数组 四、数组指针 函数指针 函数指针数组 指向函数指针数组的指针 回调函数 指针与数组 一维数组 字符数组…...

.locked、locked1勒索病毒的最新威胁:如何恢复您的数据?
导言: 网络安全问题变得愈加严峻。.locked、locked1勒索病毒是近期备受关注的一种恶意软件,给用户的数据带来了巨大威胁。本文将深入探讨.locked、locked1勒索病毒的特征,探讨如何有效恢复被其加密的数据,并提供一些建议…...
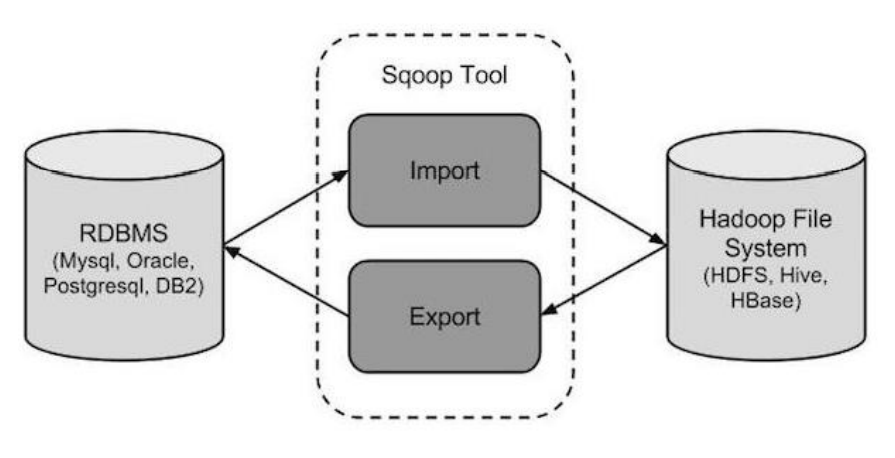
Apache Sqoop使用
1. Sqoop介绍 Apache Sqoop 是在 Hadoop 生态体系和 RDBMS 体系之间传送数据的一种工具。 Sqoop 工作机制是将导入或导出命令翻译成 mapreduce 程序来实现。在翻译出的 mapreduce 中主要是对 inputformat 和 outputformat 进行定制。 Hadoop 生态系统包括:HDFS、Hi…...

【UGUI】实现UGUI背包系统的六个主要交互功能
在这篇教程中,我们将详细介绍如何在Unity中实现一个背包系统的六个主要功能:添加物品、删除物品、查看物品信息、排序物品、搜索物品和使用物品。让我们开始吧! 一、添加物品 首先,我们需要创建一个方法来添加新的物品到背包中。…...
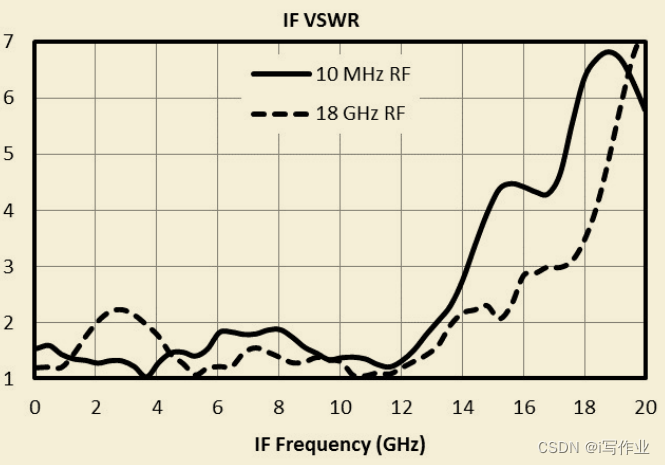
电压驻波比
电压驻波比 关于IF端口的电压驻波比 一个信号变频后,从中频端口输出,它的输出跟输入是互异的。这个电压柱波比反映了它输出的能量有多少可以真正的输送到后端连接的器件或者设备。...

Open3D 最小二乘拟合二维直线(直接求解法)
目录 一、算法原理二、代码实现三、结果展示本文由CSDN点云侠原创,原文链接。爬虫网站自重。 一、算法原理 平面直线的表达式为: y = k x + b...
)
面试题目总结(二)
1. IoC 和 AOP 的区别 控制反转(Ioc) 和面向切面编程(AOP) 是两个不同的概念,它们在软件设计中有着不同的应用和目的。 IoC 是一种基于对象组合的编程模式,通过将对象的创建、依赖关系和生命周期等管理权交给外部容器或框架来实现程序间的解耦。IoC 的…...

TrustZone概述
目录 一、概述 1.1 在开始之前 二、什么是TrustZone? 2.1 Armv8-M的TrustZone 2.2 Armv9-A Realm Management Ext...

[go 面试] Go Kit中读取原始HTTP请求体的方法
关注公众号【爱发白日梦的后端】分享技术干货、读书笔记、开源项目、实战经验、高效开发工具等,您的关注将是我的更新动力! 在Go Kit中,如果你想读取未序列化的HTTP请求体,可以使用标准的net/http包来实现。以下是一个示例,演示了如何完成这个任务: package mainimport …...

小程序如何刷新当前页面?
在小程序中,刷新当前页面通常有两种方法: 使用 wx.navigateBack 方法: wx.navigateBack({delta: 1 }) 这将返回上一页,并刷新页面。你可以通过调整 delta 参数来控制返回的页面数。例如,如果你想要返回到两页之前的页…...

ChatGPT使用路径:从新手到专家的指南
原文&精华文章&转载注明:ChatGPT与日本首相交流核废水事件-精准Prompt... hello,我是小索奇,有任何问题或者需要帮助的都可以在这里找到我或者留言哈 一、初识ChatGPT 什么是ChatGPT? ChatGPT是一种大型语言模型&…...
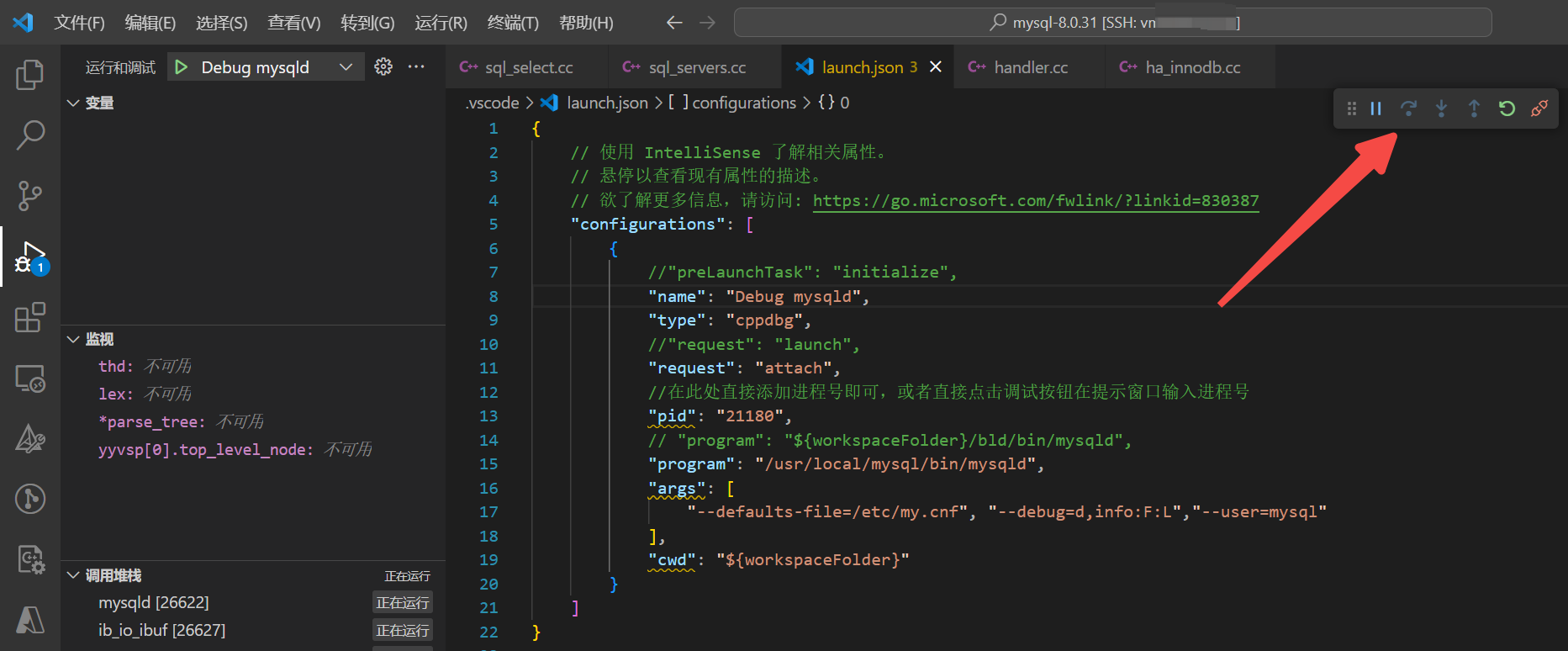
VsCode 调试 MySQL 源码
1. 启动 MySQL 2. 查看 MySQL 进程号 [root ~]# ps -ef | grep mysqld root 21479 1 0 Nov01 ? 00:00:00 /bin/sh /usr/local/mysql/bin/mysqld_safe --datadir/usr/local/mysql/data --pid-file/usr/local/mysql/data/mysqld.pid root 26622 21479 0 …...

Mysql中的正经行锁、间隙锁和临键锁
行锁、间隙锁和临键锁是数据库中的三种不同类型的锁,三者都属于行锁,第一个一般叫他正经的行锁(《Mysql是怎样运行的》一书中的说法)。 行锁(Row Lock):行锁是指对数据表中的某一行进行的锁定操…...

最强AI之风袭来,你爱了吗?
2017年,柯洁同阿尔法狗人机大战,AlphaGo以3比0大获全胜,一代英才泪洒当场...... 2019年,换脸哥视频“杨幂换朱茵”轰动全网,时至今日AI换脸仍热度只增不减; 2022年,ChatGPT一经发布便轰动全球&a…...

时间序列预测实战(二十三)进阶版LSTM多元和单元预测(课程设计毕业设计首选)
一、本文介绍 本篇文章给大家带来的是利用我个人编写的架构进行LSTM模型进行时间序列建模(专门为了时间序列领域新人编写的架构,简单且不同于市面上大家用GPT写的代码),包括结果可视化、支持单元预测、多元预测、模型拟合效果检测…...
Python之Appium 2自动化测试(Android篇)
一、环境搭建及准备工作 1、Appium 2 环境搭建 请参考另一篇文章: Windows系统搭建Appium 2 和 Appium Inspector 环境 2、安装 Appium-Python-Client,版本要求3.0及以上 pip install Appium-Python-ClientVersion: 3.1.03、手机连接电脑,并在dos窗口…...
-ipcz-分层、和mojo的关系以及handle)
chromium通信系统-ipcz系统(四)-ipcz-分层、和mojo的关系以及handle
在只有mojo的情况下, 进程间通信都是靠unix 域套接字来完成了,由于这种方式比较低效,并且不够灵活,后来引入了ipcz。 但是系统中基本上使用mojo做进程间通信,想要一步到位迁移到ipcz系统是比较困难的。 所以chrome团队…...

推荐一些研发人员经常用到的免费API接口
快递物流订阅与推送(含物流轨迹):【物流订阅与推送、H5物流轨迹、单号识别】支持单号的订阅与推送,订阅国内物流信息,当信息有变化时,推送到您的回调地址。地图轨迹支持在地图中展示包裹运输轨迹。包括顺丰…...

高薪资是跳出来的,好工作是面出来的~
听人劝、吃饱饭,奉劝各位小伙伴,不要订阅该文所属专栏。 如需要项目实战或者是体系化资源,文末名片加V! 作者:哈哥撩编程,工作十余年, 从事过全栈研发、产品经理等工作,目前在公司担任研发部门CTO。荣誉:2022年度博客之星Top4、2023年度超级个体得主、谷歌与亚马逊开发…...

硬件对齐的稀疏注意力机制:原理、优化与实践
1. 硬件对齐的稀疏注意力机制概述在自然语言处理领域,Transformer架构已成为主流,但其核心组件——注意力机制的计算复杂度随序列长度呈平方级增长,这成为处理长文本的主要瓶颈。传统全注意力(Full Attention)需要计算每个查询(Query)与所有键…...

谷歌首次阻止AI驱动的零日漏洞攻击,黑客利用AI找漏洞手段曝光
AI零日漏洞攻击计划浮出水面谷歌威胁情报小组(GTIG)的报告显示,“知名网络犯罪威胁行为者”正谋划利用人工智能开发的零日漏洞发动“大规模利用事件”。其目标是绕过一款未具名的“开源、基于网络的系统管理工具”的双因素认证。目前谷歌已成…...

WordPress AI内容创作栈:基于Claude API的自动化写作与运维实践
1. 项目概述:一个为WordPress量身定制的AI内容创作栈最近在折腾一个内容站,发现内容创作和日常运维的重复性工作实在太多了。从构思文章大纲、撰写初稿,到批量处理图片、优化SEO元数据,再到回复评论、生成周报,这些工作…...

惠普OMEN游戏本性能优化终极指南:如何用开源工具彻底释放硬件潜力
惠普OMEN游戏本性能优化终极指南:如何用开源工具彻底释放硬件潜力 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为惠普OMEN游戏本官方软…...

终极指南:如何免费使用Umi-OCR实现高效离线文字识别
终极指南:如何免费使用Umi-OCR实现高效离线文字识别 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库…...

AI技能开发脚手架:从零构建大模型应用的标准化起点
1. 项目概述:一个为AI技能开发量身定制的脚手架如果你正在或打算开发一个基于大语言模型的AI技能(Skill),无论是想集成到ChatGPT的GPTs里,还是想构建一个独立的AI Agent,那么你大概率会遇到一个共同的起点问…...

Amphenol ICC RJE1Y33A53162401网线组件解析与替代思路
在工业通信、服务器互联以及智能设备网络连接场景中,RJ45类线束组件一直是不可忽视的重要组成部分。近期不少工程师在项目选型时关注到 Amphenol ICC 推出的 RJE1Y33A53162401 线束组件。本文就围绕这款型号,从产品特点、应用方向、选型思路以及兼容替代…...

ARM GIC中断控制器架构与关键寄存器详解
1. ARM GIC中断控制器架构概述ARM通用中断控制器(GIC)是现代ARM处理器中负责中断管理的核心组件,它实现了复杂的中断分发和处理机制。GIC架构从v2版本发展到现在的v4版本,功能不断增强,支持多核处理、虚拟化扩展和安全隔离等高级特性。GIC主要…...

ElevenLabs账号被限频?紧急修复手册:3分钟绕过Rate Limit限制,解锁Pro级语音并发权限
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs超写实语音生成教程 ElevenLabs 是当前业界领先的 AI 语音合成平台,其模型在语调自然度、情感表达力与跨语言一致性方面表现卓越。本章将指导你完成从 API 接入到高质量语音生成的…...

社交媒体运营实战指南:从算法逻辑到内容变现的完整技能树
1. 项目概述:社交媒体技能库的构建与价值在信息爆炸的今天,社交媒体早已不是简单的“发发状态、看看朋友”的平台。无论是个人品牌塑造、产品推广、内容创作,还是求职招聘、行业洞察,社交媒体都扮演着至关重要的角色。然而&#x…...